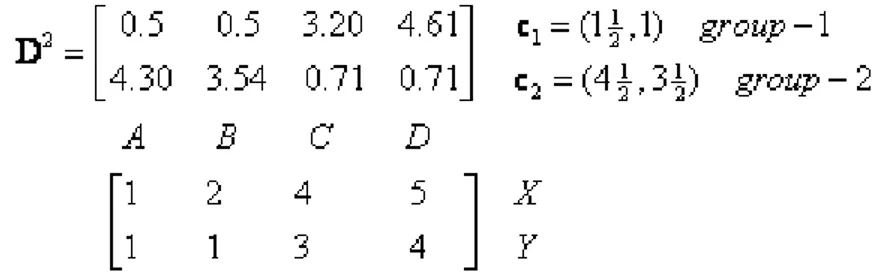ANALISIS MULTIVARIAT
ANALISIS CLUSTER DENGAN METODE K-MEANS
(TEORI DAN CONTOH STUDY KASUS)
Oleh :Rizka Fauzia 1311 100 126
Dosen Pengampu:
Santi Wulan Purnami S.Si., M.Si.
PROGRAM STUDI SARJANA JURUSAN STATISTIKA FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT TEKNOLOGI SEPULUH NOPEMBER SURABAYA 2014
1. CLUSTERING
PendahuluanClustering adalah suatu metode pengelompokan berdasarkan ukuran kedekatan(kemiripan).Clustering beda dengan group, kalau group berarti kelompok yang sama,kondisinya kalau tidak ya pasti bukan kelompoknya.Tetapi kalau cluster tidak harus sama akan tetapi pengelompokannya berdasarkan pada kedekatan dari suatu karakteristik sample yang ada, salah satunya dengan menggunakan rumus jarak ecluidean.Aplikasinya cluster ini sangat banyak, karena hamper dalam mengidentifikasi permasalahan atau pengambilan keputusan selalu tidak sama persis akan tetapi cenderung memiliki kemiripan saja.
Manfaat
Identifikasi obyek (Recognition) :
Dalam bidang mage Processing , Computer Vision atau robot vision
Decission Support System dan data mining
Segmentasi pasar, pemetaan wilayah, Manajemen marketing dll.
Prinsip dasar :
Similarity Measures (ukuran kedekatan)
Distances dan Similarity Coeficients untuk beberapa sepasang dari item Ecluidean Distance: 2 2 2 2 2 1 1 ) ( ) ... ( ) ( ) , (x y x y x y xp yp d Atau : 2 / 1 2 1 | | ) , (
i p i i y x y x d2. TINJAUAN PUSTAKA
2.1 Analisis Kelompok (Cluster Analisis)Analisis kelompok (Cluster analiysis) merupakan sebuah metode analisis untuk mengelompokan objek-objek pengamatan menjadi beberapa kelompok sehingga akan diperoleh kelompok dimana objek-objek dalam satu kelompok mempunyai banyak persamaan sedangkan dengan anggota kelompok yang lain mempunyai banyak perbedaan (Johnson dan Wichern, 2007). Prosedur pengelompokan pada dasarnya ada dua, yaitu pengelompokan dengan prosedur hierarki dan tak berhierarki. Pada penelitian ini metode yang dipakai adalah prosedur hierarki karena jumlah kelompok yang akan dibentuk belum ditentukan.
2.2 Analisis Cluster Hierarki
Pada metode ini terdapat n objek dan k kelompok, tetapi kelompok yang akan terbentuk tidak ditentukan terlebih dahulu. Pembentukan kelompok dilakukan dengan pemotongan dendogram yang dihasilkan dari analisis. Dalam pembentukan kelompok ditentukan jarak antara dua objek yang nantinya digabungkan menjadi satu.Single
Linkage Method, Complete Linkage Method, Average Linkage Method, dan Ward`s Method merupakan merupakan metode hirarki, bagian dari metode agglomerative yang
memiliki ukuran kemiripan yang berbeda saat pengklasteran. Single Linkage Method pengelompokannya didasarkan pada jarak terdekat antar cluster, Complete Linkage
Method pengelompokannya didasarkan pada jarak terjauh antar cluster, Average Linkage Method pengelompokannya didasarkan pada jarak rata-rata antar cluster, sedangkan Ward`s Method pengklasteran didasarkan pada error sum of square (ESS) yang minimum
(Johnson dan Wichern, 2007). Beberapa macam jarak yang biasa dipakai di dalam analisis cluster adalah sebagai berikut.
Tabel 2.1 Macam-Macam Jarak yang Digunakan
No. Jarak Formula 1. Euclidean
2. Manhattan
3. Pearson
2.3 Analisis Cluster Nonhirarki
Metode cluster nonhirarki diawali dengan proses penentuan jumlah cluster terlebih dahulu. Secara umum metode ini meminimumkan fungsi objektif atau kriteria optimal sehingga dapat mengatasi masalah optimasi untuk memenuhi kriteria optimal. Berdasarkan karakteristik datanya metode non-hirarki dibagi menjadi beberapa model, yaitu partitioning clustering, overlapping clustering dan model hybrid. Partitioning
clustering merupakan metode rekontruktif yang berusaha meminimumkan fungsi
objektif. Contoh dari partitioning clustering antara lain algoritma K-Means clustering dan Analisis Residual. Overlappingclustering biasanya digunakan ketika sejumlah data mengalami tumpang tindih (overlap) sehingga setiap data termasuk ke dalam beberapa
cluster. Contoh dari overlapping clustering antara lain Fuzzy C-Means, Fuzzy Substractiveclustering dan Gaussian Mixture Model. Sedangkan model hybrid yaitu suatu
metode clustering dimana metode tersebut menggabungkan karakteristik dari partitioning, overlapping, dan hirarki. (Johnson dan Wichern, 2007)
3. METODE K-MEANS
Metode K-Means pertama diperkenalkan oleh James B MacQueen pada tahun 1967 dalam proceeding of the 5th berkeley symposium on Mathematical Statistic and
Probability. Dasar pengelompokkan dalam metode ini adalah menempatkan objek
berdasarkan rata-rata cluster terdekat. Oleh karena itu, metode ini bertujuan untuk meminimumkan error akibat partisi n objek ke dalam k cluster. Error partisi disebut sebagai fungsi objektif.
Misalkan X = {Xi}, i = 1,2, ...,n merupakan titik-titik dalam ruang berdimensi n
(Rn) dan titik tersebut dikelompokkan ke dalam i cluster, C
i, i = 1,2, ..., k. Misalkan ci
centroid dari cluster ci sehingga jumlah kuadrat antara ci dan titik di dalam cluster yaitu
xi, didefinisikan sebagai berikut.
( )2
)
(ck xi ci ci xi
J (2.4)
Prinsip dasar metode K-Means adalah meminimumkan jumlah kuadrat error dari seluruh i cluster adalah sebagai berikut.
k i xi ci xi ci SSE 1 2 ) ( (2.5) (Hair dkk, 2010) 2.3.1 Komponen K-MeansAlgoritma K-Means memerlukan 3 komponen adalah sebagai berikut (Hair dkk, 2010).
1. Jumlah Cluster K
K-Means merupakan bagian dari metode non-hirarki sehingga dalam metode ini
jumlah K harus ditentukan terlebih dahulu. Jumlah cluster dapat ditentukan melalui pendekatan metode hirarki. Namun perlu diperhatikan bahwa tidak terdapat aturan khusus dalam menentukan jumlah cluster K, terkadang jumlah cluster yang diinginkan tergantung pada subjektif seseorang.
2. Cluster Awal
Cluster awal yang dipilih berkaitan dengan penentuan pusat cluster awal (centroid
awal). Oleh karena adanya pemilihan cluster awal yang berbeda ini maka kemungkinan besar solusi cluster yang dihasil akan berbeda pula.
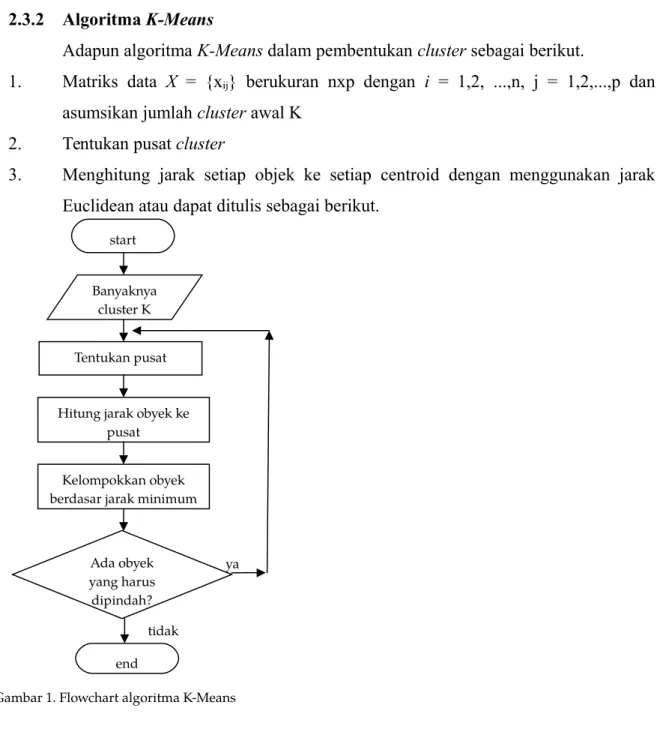
start Banyaknya
cluster K Tentukan pusat Hitung jarak obyek ke
pusat Kelompokkan obyek berdasar jarak minimum
Ada obyek yang harus dipindah? ya tidak end
Gambar 1. Flowchart algoritma K-Means
3. Ukuran Jarak
Dalam hal ini, ukuran jarak digunakan untuk menentukan observasi ke dalam
cluster berdasarkan centroid terdekat. Ukuran jarak yang digunakan dalam metode K-Means adalah jarak Euclidean.
2.3.2 Algoritma K-Means
Adapun algoritma K-Means dalam pembentukan cluster sebagai berikut.
1. Matriks data X = {xij} berukuran nxp dengan i = 1,2, ...,n, j = 1,2,...,p dan
asumsikan jumlah cluster awal K 2. Tentukan pusat cluster
3. Menghitung jarak setiap objek ke setiap centroid dengan menggunakan jarak Euclidean atau dapat ditulis sebagai berikut.
2 ) ( ) , (xi ci xi ci d (2.6)
4. Setiap objek disusun ke centroid terdekat dan kumpulan objek tersebut akan membentuk cluster.
5. Menentukan centroid baru dari cluster yang baru terbentuk, dimana centroid baru itu diperoleh dari rata-rata setiap objek yang terlatak pada cluster yang sama. 6. Mengulang langkah 3, jika centroid awal dan baru tidak sama.
(Hair dkk, 2010) Gambar 1 berikut menunjukkan diagram alir dari algoritma K-Means.
4. CONTOH PENGHITUNGAN DENGAN METODE K-MEANS
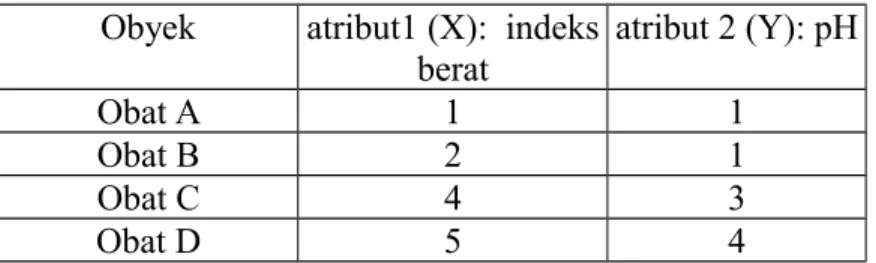
Tabel 4.1 Daftar obyek yang akan diolah dalam clustering Obyek atribut1 (X): indeks
berat atribut 2 (Y): pH Obat A 1 1 Obat B 2 1 Obat C 4 3 Obat D 5 4
2. Menghitung jarak obyek ke centroid dengan menggunakan rumus jarak Euclid.
Misalnya jarak obyek pupuk C=(4,3) ke centroid pertama adalah
dan jaraknya dengan centroid kedua adalah
.
Hasil perhitungan jarak ini disimpan dalam bentuk matriks k x n, dengan k banyaknya cluster dan n banyak obyek. Setiap kolom dalam matriks tersebut menunjukkan obyek sedangkan baris pertama menunjukkan jarak ke centroid pertama, baris kedua menunjukkan jarak ke centroid kedua. Matriks jarak setelah iterasi ke-0 adalah sebagai berikut:
3. Clustering obyek : Memasukkan setiap obyek ke dalam cluster (grup) berdasarkan jarak minimumnya. Jadi obat A dimasukkan ke grup 1, dan obat B, C dan D dimasukkan ke grup 2. Keanggotaan obyek ke dalam grup dinyatakan dengan matrik, elemen dari matriks bernilai 1 jika sebuah obyek menjadi anggota grup.
4. Iterasi-1, menetukan centroid : Berdasarkan anggota masing-masing grup, selanjutnya ditentukan centroid baru. Grup 1 hanya berisi 1 obyek, sehingga centroidnya tetap
. Grup 2 mempunyai 3 anggota, sehingga centroidnya ditentukan berdasarkan
rata-rata koordinat ketiga anggota tersebut: .
5. Iterasi-1, menghitung jarak obyek ke centroid: selanjutnya, jarak antara centroid baru dengan seluruh obyek dalam grup dihitung kembali sehingga diperoleh matriks jarak sebagai berikut:
6. Iterasi-1, clustering obyek: langkah ke-3 diulang kembali, menentukan keanggotaan grup berdasarkan jaraknya. Berdasarkan matriks jarak yang baru, maka obat B harus dipindah ke grup 2.
7. Iterasi-2, menentukan centroid: langkah ke-4 diulang kembali untuk menentukan centroid baru berdasarkan keanggotaan grup yang baru. Grup 1 dan grup 2 masing-masing mempunyai 2 anggota, sehingga centroidnya menjadi
dan
8. Iterasi-2, menghitung jarak obyek ke centroid : ulangi langkah ke-2, sehingga diperoleh matriks jarak sebagai berikut:
9. Iterasi-2, clustering obyek: mengelompokkan tiap-tiap obyek berdasarkan jarak minimumnya, diperoleh:
Hasil pengelompokkan pada iterasi terakhir dibandingkan dengan hasil sebelumnya, diperoleh . Hasil ini menunjukkan bahwa tidak ada lagi obyek yang berpindah grup, dan algoritma telah stabil. Hasil akhir clustering ditunjukkan dalam Tabel 2.
Tabel 4.2 Hasil clustering Obyek atribut1 (X): indeks
berat
atribut 2 (Y): pH Grup hasil
Obat A 1 1 1
Obat B 2 1 1
Obat C 4 3 2
Obat D 5 4 2
Kelebihan dan Kelemahan algoritma K-means
Algoritma K-means dinilai cukup efisien, yang ditunjukkan dengan kompleksitasnya O(tkn), dengan catatan n adalah banyaknya obyek data, k adalah jumlah cluster yang dibentuk, dan t banyaknya iterasi. Biasanya, nilai k dan t jauh lebih kecil daripada nilai n. Selain itu, dalam iterasinya, algoritma ini akan berhenti dalam kondisi optimum lokal.
Hal yang dianggap sebagai kelemahan algoritma ini adalah adanya keharusan menetukan banyaknya cluster yang akan dibentuk, hanya dapat digunakan dalam data yang mean-nya dapat ditentukan, dan tidak mampu menangani data yang mempunyai
penyimpangan-penyimpangan (noisy data dan outlier). Beberapa kelemahan algoritma K-means adalah: (1) sangat bergantung pada pemilihan nilai awal centroid, (2) tidak jelas berapa banyak cluster k yang terbaik, (3) hanya bekerja pada atribut numerik.
Similarity dan Dissimilarity
Memperhatikan input dalam algoritma K-Means, dapat dikatakan bahwa algoritma ini hanya mengolah data kuantitatif. Algoritma K-means hanya dapat mengolah atribut numerik.
Sebuah basis data, tidak mungkin hanya berisi satu macam type data saja, akan tetapi beragam type. Sebuah basis data dapat berisi data-data dengan type sebagai berikut: symmetric binary, asymmetric binary, nominal, ordinal, interval dan ratio.
Berbagai macam atribut dalam basis data yang berbeda type harus diolah terlebih dahulu menjadi data numerik, sehingga dapat diberlakukan algoritma K-means dalam pembentukan clusternya. Pengukuran similarity dan dissimilarity dapat digunakan untuk pengolahan data tersebut
Atribut yang berbeda tipe sama artinya dengan adanya ketidaksamaan (dissimilarity) antar atribut tersebut. Ketidaksamaan (dissimilarity) antara dua obyek dapat diukur dengan menghitung jarak antar obyek berdasarkan beberapa sifatnya. Hubungan dissimilarity antara 2 buah data obyek a=(a1,a2,……,ap) dan b=(b1,b2, ….,bp) dapat dinyatakan dengan pengukuran jarak antara 2 obyek tersebut. Beberapa sifat jarak (dissimilarity) adalah sebagai berikut d(a, b) 0 , jarak kedua obyek selalu positif atau nol,
d(a, a) = 0, jarak terhadap diri sendiri adalah nol, d(a, b) = d(b, a) , jarak kedua obyek adalah simetri,
d(a, b) d(a, c) + d(c, b), jarak memenuhi ketidaksamaan segitiga.
Misalkan dissimilarity antara obyek i dan obyek j dinyatakan dengan dij dan
similarity dinyatakan dengan sij. Hubungan antara relationship dissimilarity dengan
similarity dinyatakan dengan sij.=1- dij, dengan similarity terbatas pada 0 dan 1 ([5]). Jika
similarity bernilai satu (benar-benar sama), maka dissimilarity nol, dan jika similarity
dissimilarity dari setiap variabel, maka seluruh hasil dikumpulkan menjadi sebuah indeks similarity (atau dissimilarity) antara dua obyek ([5]). Selanjutnya hasil tersebut dapat
diolah menjadi obyek-obyek yang akan dikelompokkan dalam cluster-cluster oleh algoritma K-means.
ANALISIS CLUSTER NON-HIERARKI K-MEANS CLUSTERING
STUDI KASUS FAKTOR PERCERAIAN DI KABUPATEN/KOTA
DI JAWA TIMUR DENGAN BANTUAN SPSS
Variabel penelitian yang digunakan dalam praktikum ini dengan menggunakan data pengelompokan kabupaten / kota di jawa timur berdasarkan faktor-faktor penyebab perceraian tahun 2010 adalah sebagai berikut.
Variabel Penelitian untuk Metode Analisis Cluster
Variabel Penjelasan
X1
(Moral)
Persentase penyebab utama perceraian karena moral per kabupaten/kota. Variabel ini diukur berdasarkan rasio jumlah perceraian karena poligami tidak sehat, krisis akhlak, dan cemburu terhadap total perceraian pada kabupaten/kota.
X2
(Meninggalkan Kewajiban)
Persentase penyebab utama perceraian karena meninggalkan kewajiban per kabupaten/kota. Variabel ini diukur ber-dasarkan rasio jumlah perceraian karena kawin paksa, ekonomi, dan tidak tanggung jawab terhadap total perceraian pada kabupaten/kota. X3
(Kawin Dibawah Umur)
Persentase penyebab utama perceraian karena kawin di bawah umur per kabupaten/kota. Variabel ini diukur berdasarkan rasio jumlah perceraian karena kawin dibawah umur terhadap total perceraian pada kabupaten/kota.
X4
(Penganiayaan)
Persentase penyebab utama perceraian karena penganiayaan per kabupaten/kota. Variabel ini diukur berdasarkan rasio jumlah perceraian karena kekejaman mental dan kekejaman fisik terhadap total perceraian pada kabupaten/kota.
X5
(Dihukum)
Persentase penyebab utama perceraian karena dihukum per kabupaten/kota. Variabel ini diukur berdasarkan rasio jumlah perceraian karena dihukum terhadap total perceraian pada kabupaten/kota.
X6
(Cacat Biologis)
Persentase penyebab utama perceraian karena cacat biologis per kabupaten/kota. Variabel ini diukur berdasarkan rasio jumlah perceraian karena cacat biologis terhadap total perceraian pada kabupaten/kota.
X7
(Sering Berselisih)
Persentase penyebab utama perceraian karena terus menerus berselisih per kabupaten/kota. Variabel ini diukur ber-dasarkan rasio jumlah perceraian karena politis, gangguan pihak ketiga, tidak ada keharmonisan terhadap total per-ceraian pada kabupaten/kota.
Karena jumlah data Kabupaten/Kota di Jawa Timur berdasarkan faktor perceraian banyak maka, berdasarkan teori akan lebih efisien jika menggunakan analisis cluster non-hierarki dengan metode K-Means. Hasil analisis yang diperoleh adalah sebagai berikut.
4.1 Pengelompokan Kabupaten/Kota dengan Menggunakan 2 cluster
Dengam menggunakan analisis cluster non-herarki dapat ditemtukan jumalh
cluster yang akan digunakan. Alternatif pertama yakni dengan menggunakan 2 cluster
didapatkan hasil pengelompokan sebagai berikut.
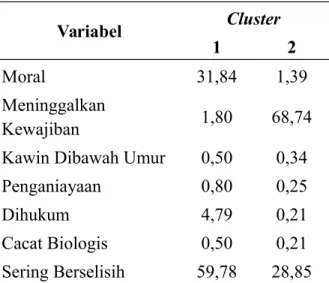
Tabel 4.3Jarak Pusat dengan 2 Cluster
Variabel Cluster
1 2
Moral 31,84 1,39 Meninggalkan
Kewajiban 1,80 68,74 Kawin Dibawah Umur 0,50 0,34 Penganiayaan 0,80 0,25 Dihukum 4,79 0,21 Cacat Biologis 0,50 0,21 Sering Berselisih 59,78 28,85
Berdasarkan Tabel 4.3, dapat diketahui jarak pusat yang dihasilkan sebelum dilakukan iterasi. Untuk cluster pertama, pada variabel (moral) didapatkan jarak
pusatsebesar 31,84. Untuk variabel meninggalkan kewajiban) didaptakan jarak pusat
sebesar 1,80. Pada variabel (kawin dibawah umur) didapatkan jarak pusatsebesar 0,50.
Pada variabel (penganiayaan didapatkan jarak pusatsebesar 0,80. Pada variabel
(dihukum) didapatkan jarak pusatsebesar 4,79. Pada variabel (cacat biologis)
didapatkan jarak pusatsebesar 0,50. Pada variabel (sering berselisish) didapatkan jarak
pusatsebesar 59,78. Untuk cluster kedua, pada variabel (moral) didapatkan jarak
sebesar 68,74. Pada variabel (kawin dibawah umur) didapatkan jarak pusatsebesar
0,34. Pada variabel (penganiayaan) didapatkan jarak pusatsebesar 0,25. Pada variabel
(dihukum) didapatkan jarak pusatsebesar 0,21. Pada variabel (cacat biologis)
didapatkan jarak pusatsebesar 0,21. Pada variabel (sering berselisish) didapatkan jarak pusatsebesar 28,85.
Untuk mendeteksi berapa kali proses iterasi yang dilakukan dalam proses
clustering dari 37 kasus yang diteliti pada 7 variabel di atas, dapat dilihat jumlah iterasi
yang dihasilkan adalah sebagai berikut.
Tabel 4.4 Jumlah Iterasi untuk 2 Cluster
Iterasi
Perubahan Jarak Pusat
Cluster 1 2 1 30,158 23,995 2 1,898 0,753 3 1,623 0,624 4 1,365 0,657 5 1,273 0,667 6 0,000 0,000
Berdasarkan Tabel 4.4 di atas dapat menjelaskan bahwa proses clustering yang dilakukan pada data faktor perceraian di Provinsi Jawa Timur pada Tahun 2010 melalui 6 tahapan iterasi untuk mendapatkan cluster yang tepat. Iterasi pertama menghasilkan
cluster pusat 1 sebesar 30,158 dan cluster pusat 2 adalah sebesar 223,995. Iterasi kedua
menghasilkan cluster pusat 1 sebesar 1,898 dan cluster pusat 2 adalah sebesar 0,753. Iterasi ketiga menghasilkan cluster pusat 1 sebesar 1,623 dan cluster pusat 2 adalah sebesar 0,753. Iterasi keempat menghasilkan cluster pusat 1 sebesar 1,365 dan cluster pusat 2 adalah sebesar 0,657. Iterasi kelima menghasilkan cluster pusat 1 sebesar 1,273 dan cluster pusat 2 adalah sebesar 0,667. Sedangkan, pada iterasi keenam menghasilkan
Hasil akhir dari proses clustering dengan menggunakan 2 clustersetelah dilakukan iterasi adalah sebagai berikut.
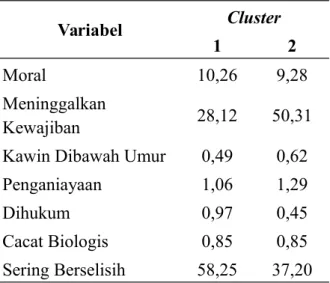
Tabel 4.5Final Centersdengan 2 cluster
Variabel Cluster
1 2
Moral 10,26 9,28 Meninggalkan
Kewajiban 28,12 50,31 Kawin Dibawah Umur 0,49 0,62 Penganiayaan 1,06 1,29 Dihukum 0,97 0,45 Cacat Biologis 0,85 0,85 Sering Berselisih 58,25 37,20
Berdasarkan Tabel 4.5, dapat diketahui final jarak pusat clustering yang dihasilkan setelah dilakukan iterasi. Untuk cluster pertama, pada variabel (moral)
didapatkan jarak pusatsebesar 10,26. Untuk variabel meninggalkan kewajiban)
didaptakan jarak pusat sebesar 28,12. Pada variabel (kawin dibawah umur) didapatkan
jarak pusatsebesar 0,49. Pada variabel (penganiayaan didapatkan jarak pusatsebesar
1,06. Pada variabel (dihukum) didapatkan jarak pusatsebesar 0,97. Pada variabel
(cacat biologis) didapatkan jarak pusatsebesar 0,85. Pada variabel (sering berselisish)
didapatkan jarak pusatsebesar 58,25. Untuk cluster kedua, pada variabel (moral)
didapatkan jarak pusatsebesar 9,28. Untuk variabel meninggalkan kewajiban)
didaptakan jarak pusat sebesar 50,31. Pada variabel (kawin dibawah umur) didapatkan
jarak pusatsebesar 0,62. Pada variabel (penganiayaan) didapatkan jarak pusatsebesar
1,29. Pada variabel (dihukum) didapatkan jarak pusatsebesar 0,45. Pada variabel
didapatkan jarak pusatsebesar 37,20. Jarak antara jarak pusat final terdekat berdasarkan (Lampiran 3.) adalah sebesar 30,611.
Berikut ini merupakan hasil pngelompokkan Kabupaten/Kota di Jawa Timur berdasarkan faktor penyebab perceraian pada tahun 2010.
Tabel 4.6 Hasil Pengelompokkan 2 cluster
Cluster Anggota Total
Cluster
1
Bangil, Bangkalan, Kraksaan, Magetan, Malang (Kab), Malang (Kota), Pamekasan, Pasuruan, Probolinggo, Sampang, Situbondo, Surabaya
12 Anggota
Cluster
2
Banyuwangi, Bawean, Blitar, Bojonegoro, Bondowoso, Gresik, Jember, Jombang, Kangean, Kediri (Kab), Kediri (Kota), Lamongan, Lumajang, Madiun (Kab), Madiun (Kota), Mojokerto, Nganjuk, Ngawi, Pacitan, Ponorogo, Sidoarjo, Sumenep, Trenggalek, Tuban, Tulungagung
25 Anggota
Berdasarkan Taebl 4.6,dapat diketahui bahwa anggota cluster 1 adalah Bangil, Bangkalan, Kraksaan, Magetan, Malang (Kab), Malang (Kota), Pamekasan, Pasuruan, Probolinggo, Sampang, Situbondo, Surabaya. Sedangkan anggota cluster 2 adalah Banyuwangi, Bawean, Blitar, Bojonegoro, Bondowoso, Gresik, Jember, Jombang, Kangean, Kediri (Kab), Kediri (Kota), Lamongan, Lumajang, Madiun (Kab), Madiun (Kota), Mojokerto, Nganjuk, Ngawi, Pacitan, Ponorogo, Sidoarjo, Sumenep, Trenggalek, Tuban, Tulungagung.
Analisis berikutnya merupakan analisis of variance (ANOVA) pada cluster 1 dan 2 yang bertujuan untuk mengetahui apakan variabel yang digunakan berkontribusi terhadap pembentukan cluster. Jika didapatkan p-value untuk masing-masing variabel kurang dari α=0,05 maka dapat dikatakan variabel tersebut signifikan atau berkontribusi terhadap pembentukan cluster. Hasil analisis keragaman pada 2 cluster adalah sebagai berikut.
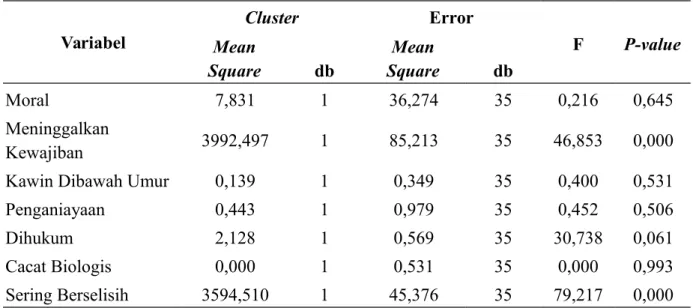
Tabel 4.7Analisis Keragaman (ANOVA) dengan 2 Cluster Variabel Cluster Error F P-value Mean Square db Mean Square db Moral 7,831 1 36,274 35 0,216 0,645 Meninggalkan Kewajiban 3992,497 1 85,213 35 46,853 0,000 Kawin Dibawah Umur 0,139 1 0,349 35 0,400 0,531 Penganiayaan 0,443 1 0,979 35 0,452 0,506 Dihukum 2,128 1 0,569 35 30,738 0,061 Cacat Biologis 0,000 1 0,531 35 0,000 0,993 Sering Berselisih 3594,510 1 45,376 35 79,217 0,000
Berdasarkan Tabel 4.7, dapat diketahuiuntuk variabel (moral), (kawin dibawah
umur), (penganiayaan), (dihukum), dan (cacat biologis) didapatkan p-value masing-masing sebesar 0,645; 0,531; 0,506; 0,061; 0,993 yang lebih besar dibandingkan α=0,05. Sehingga dapat disimpulkan variabel , , , dan tidak signifikan atau tidak berkontribusi terhadap pembentukan cluster. Sedangkan untuk variabel (meninggalkan kewajiban) dan (sering berselisih) menghasilkan p-value masing-masing sebesar 0,000 yang lebih kecil dibandingkan α=0,05. Sehingga dapat disimpulkan variabel dan signifikan atau berkontribusi terhadap pembentukan cluster.