BAB 2
TINJAUAN PUSTAKA
Setelah membaca bab ini maka pembaca akan memahami pengertian tentang
kompresi, pengolahan citra, kompresi data, Teknik kompresi, Kompresi citra.
2.1
Defenisi Data
Data adalah keterangan yang benar dan nyata atau dengan kata lain adalah catatan atas
kumpulan fakta yang mendeskripsikan simbol, grafik, gambar, kata, angka, huruf,
objek ataupun kondisi. Data merupakan bentuk jamak dari
datum, berasal dari bahasa
latin yang artinya “sesuatu yang diberikan”. Data terkadang dipandang sebagai bentuk
Data merupakan salah satu hal utama yang dikaji dalam masalah teknologi informasi.
Penggunaan dan pemanfaatan data sudah mencakup banyak aspek. Berikut adalah
pembahasan definisi data berdasarkan berbagai sumber. Data menggambarkan sebuah
representasi fakta yang tersusun secara terstruktur. Selain deskripsi dari sebuah fakta,
data dapat pula merepresentasikan suatu objek sebaga
imana bahwa “Data adalah nilai
yang merepresentasikan deskripsi dari suatu objek atau kejadian (
event) “
Dengan demikian dapat dijelaskan kembali bahwa data merupakan suatu objek,
kejadian, atau fakta yang terdokumentasikan dengan memiliki modifikasi terstruktur
untuk suatu atau beberapa entitas (Sarifah, 2010).
2.2
Text File
Text file
(disebut juga dengan
flat file) adalah salah satu jenis
filekomputer yang
tersusun dalam suatu urutan baris (Text File). Data teks biasanya diwakili oleh 8
bit kode
ASCII(atau
EBCDIC). Akhir dari sebuah
fileteks sering ditandai dengan
penempatan satu atau lebih karakter
–
karakter khusus yang dikenal dengan tanda
end-of-file
setelah baris terakhir di suatu
fileteks.
Fileteks biasanya mempunyai
jenis
MIME(
Multipurpose Internet Mail Extension) "
text/plain", biasanya sebagai
informasi tambahan yang menandakan suatu pengkodean. pada sistem operasi
Windows
, suatu
filedikenal sebagai suatu
fileteks jika memiliki
extentionmisalnya
txt, rtf, docdan lain
–
lain (Sarifah, 2010).
2.3
Teknik Kompresi
Kompresi mempunyai bermacam-macam jenis kompresi antara lain adalah
sebagai berikut:
2.3.1
Lossless CompressionAlgoritma pengkompresi ini dapat mengembalikan data yang sudah dikompresi sama
atau sesuai dengan data asli (data sebelum dikompresi). Contoh algoritma ini dapat
ditemukan pada pengkompresian teks (Nurjaman, 2011).
Prinsip dasar eksploitasi data statistik citra:
a. Menghasilkan citra hasil kompresi yang tepat sama dengan citra semula.
b. Dalam proses kompresinya, tidak ada informasi yang hilang.
c. Rasio kompresi sangat rendah / terbatas.
Algoritma kompresi
losslessdibagi dalam dua kategori, yaitu
1.
Dictionary-based TechniqueMenghasilkan file kompresi yang berisi
fixed-length code(12
–
16
bits) yang
merepresentasikan
sequence bytes fileasli, misalnya
Run-Length Encodingdan
LZW
encoding.2.
Variable Length CodingMerepresentasikan karakter yang sering muncul dalam
bityang lebih kecil,
misalnya
Dynamic Markov Compression, Huffman Coding. Contoh format
filedengan kompresi
lossless: GIF, PCX, BMP, TIFF, TRG, PGM.
2.3.2
Lossy CompressionAlgoritma pengkompresi ini bersifat terbalik dengan algoritma
losslesskarena
tidak
dapat mengembalikan data yang sudah dikompresi sesuai atau sama dengan data asli
(data sebelum dikompresi). Contoh algoritma ini misalnya pada pengkompresian
gambar, suara dan video (Nurjaman, 2011).
Prinsip atau ciri-ciri umum pada
lossy compressionadalah:
1.
Menghasilkan citra hasil kompresi yang hampir sama dengan citra semula. Dalam
proses kompresinya, ada informasi yang hilang namun dalam batas toleransi
tertentu.
2.
Rasio kompresi tinggi.
3.
Contoh aplikasi: transmisi citra pada
bandwidthsaluran komunikasi terbatas.
4.
Algoritma kompresi
lossytelah banyak dikembangkan, diantaranya menggunakan
kuantisasi,
fraktal,
wavelet, dll.
5.
Contoh format
filedengan kompresi
lossy: JPEG, MPEG.
2.4
Kompresi Data
Pemampatan merupakan salah satu dari bidang teori informasi yang bertujuan untuk
menghilangkan redudansi dari sumber. Pemampatan bermanfaat dalam membantu
mengurangi konsumsi sumber daya yang mahal, seperti ruang hard disk atau
pemindahan data melalui internet (Razi, 2009).
Data dan informasi adalah dua hal yang berbeda. Pada data terkandung suatu
informasi. Namun tidah semua bagian data terkait dengan informasi tersebut atau
pada suatu data terdapat bagian-bagian data yang berulang untuk mewakili informasi
yang sama. Bagian data yang tidak terkait atau bagian data yang berulang tersebut
disebut dengan data berlebihan (
redundancy data). Tujuan daripada kompresi data
tiada lain adalah untuk mengurangi data berlebihan tersebut sehingga ukuran data
menjadi lebih kecil dan lebih ringan dalam proses transmisi (Putra, 2010).
Kompresi citra (
image compression) adalah proses untuk meminimalisasi
jumlah
bityang merepresentasikan suatu citra sehingga ukuran data citra menjadi
lebih kecil. Pengiriman data hasil kompresi dapat dilakukan jika pihak pengirim yang
melakukan kompresi dan pihak penerima memiliki aturan yang sama dalam hal
kompresi data. Pihak pengirim harus menggunakan algoritma kompresi data yang
sudah baku dan pihak penerima juga menggunakan teknik dekompresi data yang
sama dengan pengirim sehingga data yang diterima dapat dibaca kembali dengan
benar. Kompresi data menjadi sangat penting karena memperkecil kebutuhan
penyimpanan data, mempercepat pengiriman data, memperkecil kebutuhan
bandwidth
(Taryani, 2008).
Dalam teknik kompresi data, redundansi dari data menjadi masalah utama.
Kompresi data ditujukan untuk mereduksi penyimpanan data yang redundan atau
dalam istilah lain kompresi citra digital dilakukan untuk dengan cara meminimalkan
jumlah bit yang diperlukan untuk merepresentasikan suatu data citra, namun
seringkali kualitas gambar yang dihasilkan jauh lebih buruk dari aslinya karena
keinginan kita untuk memperoleh rasio kompresi yang tinggi.
Secara mendasar standar teknik kompresi gambar memiliki 2 teknik kompresi
yaitu teknik kompresi secara
lossydan
lossles. Untuk teknik kompresi secara
lossyada sebagian dari informasi yang hilang dalam gambar tersebut sehingga jika
dilakuakan proses
editakan susah dilakukan. Sedangkan teknik kompresi secara
Secara umum proses kompresi dan dekompresi dapat diliha pada gambar di bawah
ini:
Data Asli
Data Hasil
Kompresi
Kompresi
Dekompresi
Ukurn Data Hasil Ukuran Data Hasil Kompresi
Gambar 2.1 Alur Kompresi-Dekompresi Data (Sarifah, 2010).
2.5
Kompresi Citra
Kriteria yang digunakan untuk mengukur pemampatan citra adalah:
1.
Waktu kompresi dan waktu dekompresi
Proses kompresi merupakan proses pengodekan citra (
encode) sehingga diperoleh
citra dengan representasi kebutuhan memori yang minimum.
2.
Kebutuhan memori
Metode kompresi yang baik adalah metode kompresi yang mampu mengompresi
file citra menjadi file yang berukuran paling minimal.
3.
Kualitas pemapatan (
fidelity)
Metode kompresi yang baik adalah metode kompresi yang mampu
mengendalikan citra hasil kompresi menjadi citra semula tanpa kehilangan
informasi apa pun.
4.
Format keluaran
Format citra hasil pemapatan yang baik adalah yang cocok dengan kebbutuhan
pengiriman dan penyimpanan data (Sutoyo,
et al. 2009).
2.6
Metode Kompresi Data
Organisasi
–
organisasi yang mengoperasikan jaringan komputer sering kali
mengharapkan dapat menekan biaya pengiriman data. Biaya pengiriman itu sangat
tergantung dengan banyaknya
bytedata yang dikirimkan. Oleh karena itu, dengan
melakukan kompresi terhadap data, akan dapat menghemat biaya pengiriman.
Istilah kompresi tersebut diterjemahkan dari kata bahasa Inggris “
compression”
pemampatan sesuatu yang berukuran besar sehingga menjadi kecil. Dengan
demikian, kompresi data berarti proses untuk pemampatan data agar ukurannya
menjadi lebih kecil.
Pemampatan ukuran berkas melalui proses kompresi hanya diperlukan sewaktu
berkas tersebut akan disimpan dan atau dikirim melalui media transmisi atau
telekomunikasi. Apabila berkas tersebut akan ditampilkan lagi pada layar monitor,
maka data yang terkompresi tersebut harus dikembalikan pada format semula agar
dapat dibaca kembali. Proses mengembalikan berkas yang dimampatkan ke bentuk
awal inilah yang disebut dekompresi.
Satuan yang cukup penting dalam kompresi data adalah
compression ratioyang
menggambarkan seberapa besar ukuran data setelah melewati proses kompresi
dibandingkan dengan ukuran berkas yang asli.
Beberapa teknik kompresi data yang telah banyak digunakan adalah
Bit Mapping,
Half byte packing
,
Huffman,
Arithmatic Encoding,
Run Length Encoding(Santi,
2010).
2.7
Dekompresi Data
Sebuah data yang sudah dikompres tentunya harus dapat dikembalikan lagi
kebentuk aslinya, prinsip ini dinamakan dekompresi. Untuk dapat merubah data
yang terkompres diperlukan cara yang berbeda seperti pada waktu proses kompres
dilaksanakan. Jadi pada saat dekompres terdapat catatan
headeryang berupa
byte-byte
yang berisi catatan mengenai isi dari
filetersebut.
Catatan
headerakan menuliskan kembali mengenai isi dari
filetersebut, jadi isi
dari
filesudah tertulis oleh catatan
headersehingga hanya tinggal menuliskan
kembali pada saat proses dekompres. Proses dekompres dikatakan sempurna
apabila file kembali kebentuk aslinya (Santi, 2010).
2.8
Dynamic Markov Compressionsebelumnya, dan beralih ke salah satu dari dua
statelain tergantung pada apakah bit
inputan adalah 1 atau 0. Algoritma ini dimulai dengan mesin kecil (mungkin
sesederhana hanya satu
state) dan menambahkan
statesitu didasarkan pada input.
Dengan demikian adaptif. Segera setelah
statebaru ditambahkan ke mesin,maka
akan dimulai perhitungan
bitdan menggunakannya untuk menghitung probabilitas
untuk 0 dan 1. Bahkan dalam bentuk yang sederhana, mesin bisa tumbuh sangat
besar dan dengan cepat mengisi seluruh memori yang tersedia. Salah satu
keuntungan menggunakan data biner adalah encoder aritmatika dapat dibuat sangat
efisien jika ia harus menggunakan hanya dengan dua symbol (Salomon, 2004).
Algoritma DMC adalah algoritma yang memanfaatkan teknik pemodelan yang
didasarkan pada model
finite-state (proses Markov). Algoritma ini dikembangkan
oleh Gordon Cormack dan Horspool Nigel. Algoritma DMC menggunakan
predictive arithmetic coding
yang mirip dengan PPM (
Prediction by Partian Matching) sehingga memungkinkan kemampuan kompresi file yang tinggi (Taryani,
2008).
DMC membuat probabilitas dari karakter biner berikutnya dengan
menggunakan pemodelan
finite-state, dengan model awal berupa mesin FSA dengan
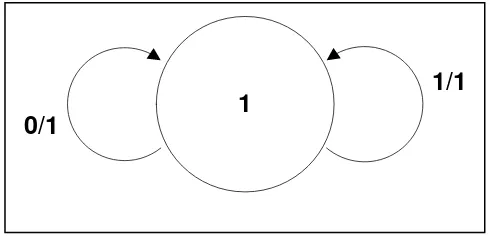
transisi 0/1 dan 1/1, seperti ditunjukkan pada Gambar 2.2. DMC merupakan teknik
kompresi yang adaptif, karena struktur mesin
finite-stateberubah seiring dengan
pemrosesan
file. Kemampuan kompresinya tergolong amat baik, meskipun waktu
komputasi yang dibutuhkan lebih besar dibandingkan metode lain
1
1/1
0/1
Gambar 2.2 Model Awal DMC (Taryani, 2008).
transisi yang keluar dari
state1 diberi label 0/5, artinya bit 0 di
state1 terjadi
sebanyak 5 kali.
1
3 2
4 0/5
1/2
1/1
1/2 1/4
0/3 0/3
0/2
Gambar 2.3 Sebuah Model yang Diciptakan Oleh Metode DMC (Taryani, 2008).
Secara umum, transisi ditandai dengan 0/
patau 1/
qdimana
pdan
qmenunjukkan jumlah transisi dari
statedengan input 0 atau 1. Nilai probabilitas
bahwa input selanjutnya bernilai 0 adalah
p/(
p+
q) dan input selanjutnya bernilai 1
adalah
q/(
p+
q). Lalu bila
bitsesudahnya ternyata bernilai 0, jumlah
bit0 di
transisi
sekarang ditambah satu menjadi
p+1. Begitu pula bila
bitsesudahnya
ternyata
bernilai 1, jumlah
bit1 di transisi sekarang ditambah satu menjadi
q+1.
Jika frekuensi transisi dari suatu
state tke
statesebelumnya, yaitu
state u,
sangat tinggi, maka
sta te tdapat di-
cloning. Ambang batas nilai
cloningharus
disetujui oleh
encoderdan
decoder. State yang di-
cloningdiberi simbol
t’. Atur
an
cloning
adalah sebagai berikut :
a. Semua transisi dari
sta te udikirim ke
state t’. Semua transisi dari
statelain ke
statet tidak berubah.
b. Jumlah transisi yang keluar dari
t’ harus mempunyai rasio yang sama (antara 0 dan
1) dengan jumlah transisi yang keluar dari
t.
d. dengan jumlah transisi yang masuk.
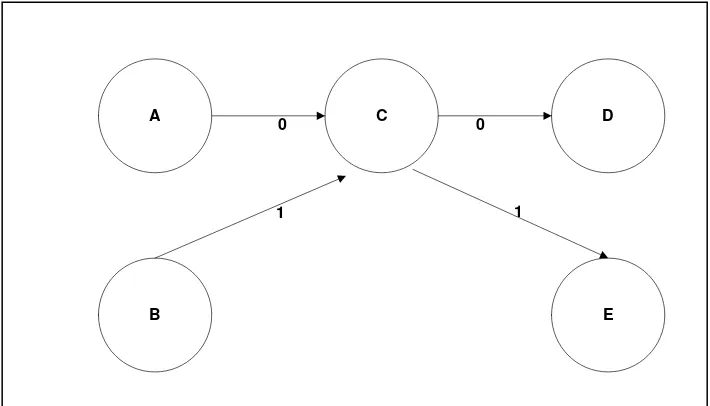
A C D
B E
0 0
1 1
a.
Sebelum
CloningA C D
B E
0 0
1
1
C
1 0