ANALISIS SENTIMEN KOMENTAR MASYARAKAT JAKARTA TERHADAP PEMBATASAN SOSIAL BERSKALA
BESAR (PSBB) MENGGUNAKAN ALGORITMA K-MEANS DAN ALGORITMA LEVENSTHEIN DISTANCE
Skripsi
Oleh :
Mochamad Fadli NIM : 11140910000065
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA
2021 M / 1442 H
ANALISIS SENTIMEN KOMENTAR MASYARAKAT JAKARTA TERHADAP PEMBATASAN SOSIAL BERSKALA
BESAR (PSBB) MENGGUNAKAN ALGORITMA K-MEANS DAN ALGORITMA LEVENSTHEIN DISTANCE
Skripsi
Sebagai Salah Satu Syarat untuk Memperoleh Gelar Sarjana Komputer (S.Kom)
Oleh :
Mochamad Fadli NIM : 11140910000065
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS ISLAM NEGERI SYARIF HIDAYATULLAH JAKARTA
2021 M / 1442 H
LEMBAR PERSETUJUAN
ANALISIS SENTIMEN KOMENTAR MASYARAKAT JAKARTA TERHADAP PEMBATASAN SOSIAL BERSKALA
BESAR (PSBB) MENGGUNAKAN ALGORITMA K-MEANS DAN ALGORITMA LEVENSTHEIN DISTANCE
Skripsi
Sebagai Salah Satu Syarat untuk Memperoleh Gelar Sarjana Komputer (S.Kom)
Menyetujui, Pembimbing I
Siti Ummi Masruroh, M.Sc NIP. 198208232011012013
Pembimbing II
Hendra Bayu Suseno, M.Kom NIP. 198212112009121003
Mengetahui,
Ketua Prodi Teknik Informatika
Dr. Imam Marzuki Shofi, MT NIP. 197202052008011010
HALAMAN PENGESAHAN UJIAN
Skripsi yang berjudul “Analisis Sentimen Komentar Masyarakat Jakarta Terhadap Pembatasan Sosial Berskala Besar (PSBB) Menggunakan Algoritma K-Means Dan Algoritma Levensthein Distance” yang ditulis oleh Mochamad Fadli , NIM 11140910000065 telah diuji dan dinyatakan lulus dalam sidang munaqasyah Fakultas Sains dan Teknologi UIN Syarif Hidayatullah Jakarta pada 20 Mei 2021.
Skripsi ini telah diterima sebagai salah satu syarat memperoleh gelar Sarjana Komputer (S.Kom) pada program Studi Teknik Informatika.
Jakarta, 10 Agustus 2021 Tim Penguji
Penguji I
Anif Hanifa Setianingrum, M.Si NIDN: 0410116402
Penguji II
Saepul Aripiyanto, M.Kom NIP. 198909112020121007 Tim Pembimbing
Pembimbing I
Siti Ummi Masruroh, M.Sc NIP. 198208232011012013
Pembimbing II
Hendra Bayu Suseno, M.Kom NIP. 198212112009121003 Mengetahui,
Dekan FST
Ir. Nashrul Hakiem. S.Si. M.T. Ph.D NIP. 197106082005011005
Ketua Program Studi
Dr. Imam Marzuki Shofi, MT NIP. 197202052008011010
PERNYATAAN ORISINALITAS
Dengan ini saya menyatakan bahwa :
1. Skripsi ini merupakan hasil karya asli saya yang diajukan untuk memenuhi salah satu persyaratan memperoleh gelar strata 1 di UIN Syarif Hidayatullah Jakarta.
2. Semua sumber yang saya gunakan dalam penulisan ini telah saya cantumkan sesuai dengan ketentuan yang berlaku di UIN Syarif Hidayatullah Jakarta.
3. Jika di kemudian hari terbukti bahwa karya ini bukan hasil karya asli saya atau merupakan hasil jiplakan dari karya orang lain, maka saya bersedia menerima sanksi yang berlaku di UIN Syarif Hidayatullah Jakarta.
Jakarta, 10 Agustus 2021
HALAMAN PERNYATAAN PERSETUJUAN PUBLIKASI SKRIPSI
Sebagai civitas akademik UIN Syarif Hidayatullah Jakarta, saya yang bertandatangan dibawah ini:
Nama : Mochamad Fadli
NIM : 11140910000065
Program Studi : Teknik Informatika
Fakultas : Fakultas Sains dan Teknologi Jenis Karya : Skripsi
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Islam Negeri Syarif Hidayatullah Jakarta Hak Bebas Royalti Non Eksklusif (Non-exclusive Royalti Free Right) atas karya ilmiah saya yang berjudul: ANALISIS SENTIMEN KOMENTAR MASYARAKAT JAKARTA TERHADAP PEMBATASAN SOSIAL BERSKALA BESAR (PSBB) MENGGUNAKAN ALGORITMA K-MEANS DAN ALGORITMA LEVENSTHEIN DISTANCE
ANALISIS
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Non Eksklusif ini Universitas Islam Negeri Syarif Hidayatullah Jakarta berhak menyimpan, mengalihmedia/formatkan, mengelola dalam bentuk pangkalan data (database), merawat, dan mempublikasikan tugas akhir saya selama tetap mencantumkan nama saya sebagai penulis/pencipta dan sebagai pemilik Hak Cipta.
Demikian pernyataan ini saya buat dengan sebenarnya.
Dibuat di : Jakarta Pada tanggal : 10 Agustus 2021
Yang menyatakan
(Mochamad Fadli )
Nama : Mochamad Fadli Program Studi : Teknik Informatika
Judul : Analisis Sentimen Komentar Masyarakat Jakarta Terhadap Pembatasan Sosial Berskala Besar (PSBB) Menggunakan Algoritma K-Means dan Algoritma Levensthein Distance
ABSTRAK
Masyarakat tengah dihebohkan dengan pemberitaan mengenai virus corona atau virus yang mematikan. Indonesia telah melaksanakan masa tanggap darurat penanganan covid sejak awal Maret 2020, kemudian disusul modifikasi kebijakan karantina wilayah menjadi PSBB dimulai pada 10 April 2020 di Jakarta. Media sosial berkembang pesat sejalan dengan pertumbuhan dan kemudahan akses informasi yang didukung oleh kekuatan teknologi komunikasi.Analisis sentimen adalah sebuah proses untuk menentukan opini dari seseorang yang bisa di kategorikan sebagai sentiment positif, negatif, atau netral. Tidak setuju dengan adanya kebijakan psbb karena masyarakat banyak yang di phk, dan bantuan sosial tidak merata.ingin melihat sentimen masyarakat terhadap kebijakan pemerintah Jakarta terkait kebijakan pembatasan sosial berskala besar (psbb) dan melihat tingkat akurasi dari sistem analisis sentimen. Dalam pengumpulan data yang di gunakan oleh penulis dalam melakukan penelitian ini menggunakan metode pengumpulan data yaitu : Studi lapangan (observasi) dan studi Pustaka : url,studi literatur, dan jurnal Sentimen publik yang dicari terhadap kebijakan pemerintah terhadap pembatasan sosial berskala besar (psbb) yaitu positif dan negatif menggunakan Metode K-Means. Untuk menormalisasi kata menggunakan algoritma Levensthein Distance, dalam penguraian kata atau stemming kata menjadi kata baku, penulis menggunakan algoritma Nazief dan Andriani. Dalam fitur pembobotan kata, penulis menggunakan algoritma TF-IDF. Dalam perhitungan tingkat akurasi, penulis menggunakan Confusion Matrix.
Kata kunci : PSBB, Analisis Sentimen,Algoritma, K-Means, Levensthein Distance, Nazief dan Andriani
Daftar Pustaka : 22 Jurnal
Jumlah Halaman : VI BAB + xcv Halaman + 95 Halaman + 13 Gambar + 37 Tabel
Nama : Mochamad Fadli Program Studi : Teknik Informatika
Judul : Analisis Sentimen Komentar Masyarakat Jakarta Terhadap Pembatasan Sosial Berskala Besar (PSBB) Menggunakan Algoritma K-Means dan Algoritma Levensthein Distance
ABSTRACT
The public is being shocked by the news about the corona virus or a deadly virus.
Indonesia has implemented an emergency response period for handling Covid since early March 2020, followed by the modification of the regional quarantine policy to PSBB starting on April 10, 2020 in Jakarta. Social media is growing rapidly in line with the growth and ease of access to information supported by the power of communication technology. Sentiment analysis is a process to determine the opinion of someone who can be categorized as positive, negative, or neutral sentiment. Disagree with the PSBB policy because many people have been laid off, and social assistance is not evenly distributed. I want to see public sentiment towards the Jakarta government's policy regarding the large-scale social restriction policy (PSBB) and see the level of accuracy of the sentiment analysis system. In collecting the data used by the author in conducting this research, data collection methods are used, namely: Field studies (observations) and library studies: url, literature studies, and journals. positive and negative using the K- Means Clustering Method. To normalize words using the Levensthein Distance algorithm, in parsing words or stemming words into standard words, the author uses the Nazief and Andriani algorithm. In the word weighting feature, the writer uses the TF-IDF algorithm. In calculating the level of accuracy, the author uses the Confusion Matrix.
Keywords : PSBB, Analysis Sentiment, K-Means,
Levensthein Distance, Levensthein Distance, Nazief and Andriani
Number Of Reference : 22 Papers
Number Of Pages : VI Chapters + xcv Pages + 95 Pages + 13 Images + 37 Tables
KATA PENGANTAR
Puji syukur penulis panjatkan kepada Allah SWT, karena atas nikmat dan rahmat- Nya sehingga penulis dapat menyelesaikan skripsi ini. Penulisan skripsi ini dilakukan dalam rangka memenuhi salah satu syarat untuk mencapai gelar Sarjana Komputer Program Studi Teknik Informatika Fakultas Sains dan Teknologi Universitas Islam Negeri Syarif Hidayatullah Jakarta. Proses penyelesaian skripsi ini tidak lepas dari berbagai bantuan, dukungan, saran, dan kritik yang telah penulis dapatkan, oleh karena itu dalam kesempatan ini peneliti ingin mengucapkan terima kasih kepada:
1. Kedua Orang tua dan istri yang selalu mendoakan, dan mendukung penulis dalam mengerjakan skripsi.
2. Bapak Ir. Nashrul Hakiem. S.Si. M.T. Ph.D., selaku Dekan Fakultas Sains dan Teknologi.
3. Bapak Dr. Imam Marzuki Shofi, MT., selaku ketua Program Studi Teknik Informatika dan Bapak Andrew Fiade, M. Kom, selaku sekretaris Program Studi Teknik Informatika.
4. Ibu Siti Ummi Masruroh, M. Sc., selaku Dosen Pembimbing I dan Bapak Hendra Bayu Suseno, M. Kom, selaku Dosen Pembimbing II yang telah memberikan bimbingan, motivasi, dan arahan kepada penulis sehingga skripsi ini bisa selesai dengan baik.
5. Seluruh Dosen, Staf Karyawan Fakultas Sains dan Teknologi, khususnya Program Studi Teknik Informatika yang telah memberikan bantuan dan kerja sama sejak awal perkuliahan.
6. Kepada teman seperjuangan Teknik Informatika angkatan 2014, yang sudah membantu penulis dalam menyelesaikan skripsi ini, terima kasih atas dukungannya.
Jakarta, 10 Agustus 2021
Mochamad Fadli
DAFTAR ISI
LEMBAR PERSETUJUAN ... ii
HALAMAN PENGESAHAN UJIAN ... iii
PERNYATAAN ORISINALITAS ... iv
HALAMAN PERNYATAAN PERSETUJUAN PUBLIKASI SKRIPSI ... v
ABSTRAK ... vi
ABSTRACT ... vii
KATA PENGANTAR ... viii
DAFTAR ISI ... ix
DAFTAR GAMBAR ... xiii
DAFTAR TABEL ... xiv
BAB I ... 1
PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 3
1.3 Batasan Masalah ... 3
1.4 Tujuan Masalah ... 4
1.5 Manfaat Penelitian ... 5
1.5.1 Bagi Penulis ... 5
1.5.2 Bagi Universitas ... 5
1.5.3 Bagi Pemerintah ... 5
1.6 Metodologi Penelitian ... 5
1.6.1 Metode Pengumpulan Data ... 5
1.6.2 Metode Implementasi ... 6
1.7 Sistematika Penulisan ... 6
BAB II ... 8
LANDASAN TEORI ... 8
2.1 Analisis Sentimen ... 8
2.2 PSBB ... 8
2.3 Clustering ... 8
2.4 Algoritma ... 9
2.5 Text Mining ... 9
2.6 Pre-Processing ... 9
2.6.1 Case Folding ... 10
2.6.2 Tokenizing... 10
2.6.3 Stopword/Filtering ... 10
2.6.4 Stemming ... 10
2.7 Algoritma K-Means Clustering ... 10
2.7.1 Tahapan Algoritma K-Means Clustering ... 11
2.8 Algoritma Levensthein Distance ... 11
2.8.1 Alasan Menggunakan Algoritma Levensthein Distance ... 13
2.9 Algoritma Nazief dan Andriani ... 13
2.9.1 Tahapan Algoritma Nazief dan Andriani ... 13
2.9.2 Alasan Menggunakan Algoritma Nazief dan Andriani ... 15
2.10 Algoritma TF-IDF ... 15
2.11 Confusion Matrix ... 15
2.12 PHP... 16
2.13 MySQL ... 16
2.14 R-Programming ... 16
BAB III... 20
METODOLOGI PENELITIAN ... 20
3.1 Metode Pengumpulan Data ... 20
3.1.1 Studi Pustaka ... 20
3.1.2 Studi Lapangan ... 20
3.2 Metode Simulasi ... 20
3.2.1 Formulasi Masalah (Problem Formulation) ... 21
3.2.2 Model Pengkonsepan (Conceptual Model) ... 21
3.2.3 Data Masukan/Keluaran (Input/Output Data) ... 21
3.2.4 Pemodelan (Modelling) ... 22
3.2.5 Simulasi ... 22
3.2.6 Verifikasi dan Validasi (Verification and Validation)... 22
3.2.7 Eksperimentasi (Experimentation) ... 23
3.2.8 Analisis Keluaran (Output Analysis) ... 23
3.3 Kerangka Berfikir ... 23
BAB IV ... 25
IMPLEMENTASI, SIMULASI, DAN EKSPERIMEN ... 25
4.1 Formulasi Masalah (Problem Formulation) ... 25
4.2 Model Pengkonsepan (Conceptual Model) ... 25
4.2.1 Conceptual model pada text mining ... 25
4.2.2 Conceptual model pada data latih ... 31
4.2.3 Conceptual model sentimen dengan algoritma k-means ... 33
4.2.4 Conceptual Model Sentimen Algoritma K-Means dengan bantuan Algoritma Levensthein Distance ... 37
4.3 Data Masukan/Keluaran (Input/Output Data) ... 39
4.4 Pemodelan (Modelling)... 39
4.4.1 Kontruksi Sentimen pada Algoritma K-Means ... 39
4.4.2 Kontruksi Sentimen pada Algoritma K-Means dengna bantuan Algoritma Levensthein Distance ... 59
4.5 Simulasi (Simulation) ... 80
4.5.1 Tahap Pengujian Data Uji ... 81
4.6 Verifikasi dan Validasi (Verification and Validation) ... 83
4.7 Eksperimen (Experimentation) ... 83
4.8 Analisis Keluaran (Output Analysis) ... 83
BAB V ... 84
HASIL DAN PEMBAHASAN ... 84
5.1 Verifikasi dan Validasi (Varification and Validation) ... 84
5.2 Eksperimentasi (Experimentation) ... 84
5.3 Analisis Keluaran (Output Analysis) ... 84
5.3.1 Hasil Sentimen Algoritma K-Means dan Algoritma Levensthein Distance ... 85
5.3.2 Analisis Hasil Akurasi Algoritma K-Means ... 87
5.3.3 Analisis Hasil Akurasi Algoritma K-means dan Algoritma
Levensthein Distance... 88
BAB VI ... 90
PENUTUP ... 90
6.1 Kesimpulan... 90
6.2 Saran ... 90
DAFTAR PUSTAKA ... 91
DAFTAR GAMBAR
Gambar 3. 1 Kerangka Berfikir ... 24
Gambar 4. 1 Flowchart Tahapan Pre-Processing ... 26
Gambar 4. 2 Flowchart Case Folding ... 27
Gambar 4. 3 Flowchart Tokenization ... 27
Gambar 4. 4 Flowchart Levensthein Distance ... 28
Gambar 4. 5 Flowchart Stopword Removal ... 29
Gambar 4. 6 Flowchart Stemming Algoritma Nazief dan Andriani ... 30
Gambar 4. 7 Penentuan Sentimen Data Latih ... 31
Gambar 4. 8 Flowchart Proses Sentimen Skenario 1... 34
Gambar 4. 9 Flowchart Proses Algoritma K-Means... 36
Gambar 4. 10 Flowchart Proses Sentimen Skenario 2 ... 37
Gambar 4. 11 Hasil Akurasi dan Aplikasi skenario 1 ... 82
Gambar 4. 12 Hasil Akurasi dan Aplikasi skenario 2 ... 82
DAFTAR TABEL
Tabel 2. 1 Studi Literatur Sejenis ... 18
Tabel 4. 1 Contoh Proses Case Folding ... 32
Tabel 4. 2 Proses Tokenization ... 32
Tabel 4. 3 Contoh Proses Normalisasi Kata ... 32
Tabel 4. 4 Contoh Proses Stopword Removal ... 32
Tabel 4. 5 Contoh Proses Stemming ... 33
Tabel 4. 6 Dokumen data latih ... 40
Tabel 4. 7 Penentuan Sentimen Data Latih ... 41
Tabel 4. 8 Hasil Proses Case Folding ... 41
Tabel 4. 9 Hasil Proses Filtering ... 42
Tabel 4. 10 Melakukan Proses Tokenization ... 43
Tabel 4. 11 Hasil Proses Normalisasi Kata ... 44
Tabel 4. 12 Hasil Proses Stemming ... 45
Tabel 4. 13 Proses Filtering / Stopword ... 46
Tabel 4. 14 Hasil Perhitungan IDF Skenario 1 ... 49
Tabel 4. 15 Hasil Perhitungan bobot TF-IDF Skenario 2 ... 51
Tabel 4. 16 Perhitungan Euclidean Distance cluster 1 ... 54
Tabel 4. 17 Perhitungan Euclidean Distance Cluster 2 ... 54
Tabel 4. 18 Perhitungan kembali Euclidean Distance Cluster 1... 56
Tabel 4. 19 Perhitungan kembali Euclidean Distance cluster 2 ... 56
Tabel 4. 20 Dokumen data latih... 59
Tabel 4. 21 Penenetuan sentiment data latih ... 60
Tabel 4. 22 Hasil proses Case Folding ... 61
Tabel 4. 23 Proses hasil Filtering ... 61
Tabel 4. 24 Hasil proses tokenization ... 62
Tabel 4. 25 Hasil proses Normalisasi Kata ... 63
Tabel 4. 26 Hasil Proses Stemming ... 65
Tabel 4. 27 Hasil proses filtering/stopword ... 66
Tabel 4. 28 Perhitungan Matriks Levensthein Distance ... 68
Tabel 4. 29 Hasil Perhitungan IDF Skenario 2... 70
Tabel 4. 30 Hasil Perhitungan bobot TF-IDF Skenario 2 ... 72
Tabel 4. 31 Perhitungan Euclidean Distance cluster 1 skenario 2 ... 75
Tabel 4. 32 Perhitungan Euclidean Distance cluster 2 Skenario 2 ... 75
Tabel 4. 33 Perhitungan kembali Euclidean Distance cluster 1 ... 77
Tabel 4. 34 Perhitungan kembali Euclidean Distance Cluster 2... 77
Tabel 4. 35 Faktor Simulasi Penelitian ... 81
Tabel 5. 1 Hasil Sentimen dari Skenario Pada Data Uji ... 85
Tabel 5. 2 Hasil Pengujian Skenario 1 ... 87
Tabel 5. 3 Hasil Pengujian Skenario 2 ... 88
1 UIN Syarif Hidayatullah Jakarta
BAB I
PENDAHULUAN
1.1 Latar BelakangMasyarakat tengah dihebohkan dengan pemberitaan mengenai virus corona atau virus yang mematikan. Kelompok virus ini yang dapat menyebabkan penyakit pada burung dan mamalia, termasuk manusia.
Pada manusia Coronavirus menyebabkan infeksi saluran pernapasan yang umumnya ringan, seperti pilek, meskipun beberapa bentuk penyakit seperti; SARS, MERS, dan Covid-19 sifatnya lebih mematikan.
Pemerintah menerapkan Pembatasan Sosial Berskala Besar (PSBB) demi memutus mata rantai penyebaran virus corona. Meskipun banyak fasilitas umum yang ditutup, namun beberapa sector vital seperti fasilitas Kesehatan, pasar atau minimarket tetap buka selama PSBB. Masyarakat pun mendukung opsi tersebut karena dianggap mampu mencegah penularan penyakit namun tetap menjaga daya beli masyarakat.
(Nasruddin & Haq, 2020)
Indonesia telah melaksanakan masa tanggap darurat penanganan covid sejak awal Maret 2020, kemudian disusul modifikasi kebijakan karantina wilayah menjadi PSBB dimulai pada 10 April 2020 di Jakarta.(Muhyiddin, 2020)
Media sosial berkembang pesat sejalan dengan pertumbuhan dan kemudahan akses informasi yang didukung oleh kekuatan teknologi komunikasi. Media sosial memiliki pengguna aktif sebesar 79 juta.
Indonesia merupakan salah satu negara teraktif di media sosial (Global Media Statistics, 2016). Pola penyebaran pesan yang cenderung bebas
memiliki maksud agar segera diketahui publik menjadi tujuan dari pengguna media sosial, maka tidak menjadi persoalan apakah informasi yang disebarkan itu akurat sesuai prinsip pemberitaan yang baik dan benar. (Susanto, 2017)
Analisis sentimen adalah sebuah proses untuk menentukan sentimen atau opini dari seseorang yang diwujudkan dalam bentuk teks dan bisa di kategorikan sebagai sentiment positif, negatif, atau netral.
Pengguna internet banyak menuliskan pengalaman, opini dan segala hal yang menjadi perhatian mereka. Ide dasar dari investigasi sentiment adalah untuk mendeteksi popularitas teks dokumen atau kalimat pendek dan mengklasifikasikannya dalam premis ini. (Arief & Imanuel, 2019)
Pada penelitian sebelumnya yang berkaitan dengan analisis sentiment yaitu “Implementasi Algoritma K-Means Clustering Pada Analisis Sentimen Keluhan Pengguna Indosat”. Pada penelitian ini, peneliti mengambil sebanyak 1000 data yang dikelompokan menjadi lima cluster yaitu cinta, marah, sedih, senang, dan takut. Implementasi metode K-Means pada penelitian tersebut menghasilkan akurasi sebanyak 76,3%. Peneliti melakukan pre-processing data terlebih dahulu seperti Case Folding, Tokenizing, Filtering, Stopword, dan Stemming.
Kemudian, melakukan pembobotan kata menggunakan algoritma TF- IDF. Tahap terakhir untuk pengambilan sentimennya hanya menggunakan algoritma k-means clustering. (Saputra & Arianty, 2019)
Pada penelitian selanjutnya yaitu “Analisis Sentimen Pengguna Twitter Terhadap Polemik Persepakbolaan Indonesia Menggunakan Pembobotan kata TF-IDF dan K-Nearest Neighbor”. Data yang digunakan dalam penelitian ini sejumlah 2000 data tweet yang akan dilakukan pembobotan kata dengan TF-IDF dan diklasifikasi menggunakan K-Nearest Neighbor yang menghasilkan nilai akurasi sebesar 80,6%. (Septian, Fahrudin, & Nugroho, 2019)
Pada penelitian selanjutnya yaitu “Analisis Sentimen Pada Ulasan Aplikasi Mobile Menggunakan Naïve Bayes dan Normalisasi Kata Berbasis Levensthein Distance (Studi Kasus Aplikasi BCA Mobile)”.
Penelitian ini menggunakan normalisasi kata berbasis Levenshtein Distance. Berdasarkan pengujian, nilai akurasi tertinggi terdapat pada perbandingan data latih 70% dan data uji 30%. Hasil akurasi tertinggi dari pengujian menggunakan nilai edit <=2 adalah 100%, nilai edit tertinggi kedua didapat pada nilai edit <=1 dengan akurasi 96,4%, sedangkan nilai edit dengan akurasi terendah diperoleh pada nilai edit
<=4 dan <=5 dengan akurasi 66,6%. (Gunawan, Fauzi, & Adikara, 2017) Berdasarkan permasalahan yang ada dilatar belakang di atas, penulis bermaksud untuk melakukan penelitian dengan topik “Analisis Sentimen Komentar Masyarakat Jakarta Terhadap Pembatasan Sosial Berskala Besar (PSBB ) Menggunakan Algoritma K-Means”.
1.2 Rumusan Masalah
Berdasarkan latar belakang di atas, maka penulis merumuskan masalah bagaimana analisis sentimen komentar masyarakat jakarta terhadap pembatasan sosial berskala besar (psbb) menggunakan algoritma K-Means dan kombinasi algoritma K-Means dengan algoritma Levensthein Distance serta tingkat akurasinya?
1.3 Batasan Masalah
Batasan-batasan masalah dalam penelitian ini adalah sebagai berikut:
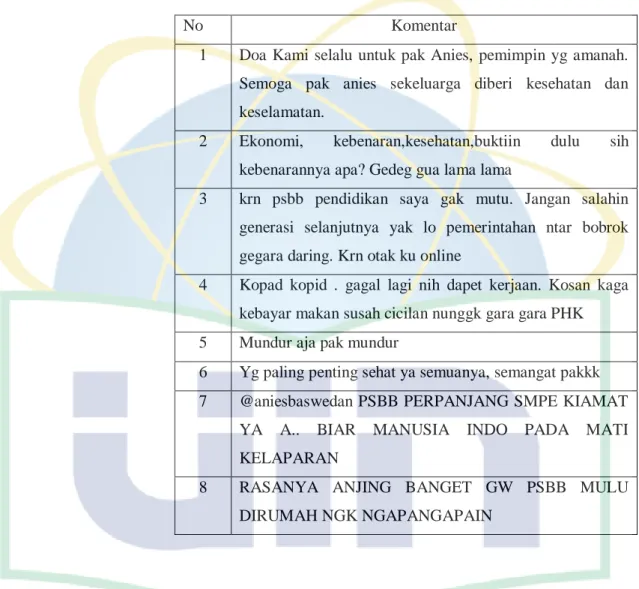
1. Tidak setuju dengan adanya kebijakan psbb karena masyarakat banyak yang di phk, gaji bulanan di potong dan bantuan sosial tidak merata.
2. Sentimen publik yang dicari terhadap kebijakan pemerintah terhadap pembatasan sosial berskala besar (psbb) yaitu positif dan negatif menggunakan Metode Clustering K-Means.
3. Untuk menormalisasi kata menggunakan algoritma Levensthein Distance.
4. Dalam penggunaan algoritma K-Means, penulis menggunakan k=2.
5. Dalam pengumpulan data secara manual dari komentar Instagram menggunakan Bahasa Pemrograman R.
6. Data yang didapatkan dan digunakan yaitu sebanyak 200 komentar.
7. Data latih yang digunakan yaitu 150 komentar.
8. Data uji yang digunakan yaitu 50 komentar.
9. Dalam penguraian kata atau stemming kata menjadi kata baku, penulis menggunakan algoritma Nazief dan Andriani.
10. Dalam fitur pembobotan kata, penulis menggunakan algoritma TF- IDF.
11. Dalam perhitungan tingkat akurasi, penulis menggunakan Confusion Matrix.
12. Penulis menggunakan Bahasa Pemrograman PHP dan MySQL sebagai database.
13. Metode implementasi yang digunakan yaitu metode simulasi.
1.4 Tujuan Masalah
Adapun tujuan yang akan dicapai dalam penelitian ini adalah ingin melihat sentimen masyarakat terhadap kebijakan pemerintah Jakarta terkait kebijakan pembatasan sosial berskala besar (psbb) dan melihat tingkat akurasi dari sistem analisis sentimen.
1.5 Manfaat Penelitian
Adapun manfaat yang didapat dari penelitian ini adalah:
1.5.1 Bagi Penulis
a) Dapat menerapkan ilmu yang didapat selama masa perkuliahan khususnya dalam pengimplementasian algoritma pada suatu system.
b) Sebagai salah satu persyaratan untuk meraih gelar sarjana S1 Teknik Informatika UIN Syarif Hidayatullah Jakarta.
1.5.2 Bagi Universitas
a) Mengukur tingkat kemampuan mahasiswa akan ilmu yang telah didapatkan selama masa perkuliahan.
b) Menjadi bahan tolak ukur evaluasi kedepannya.
1.5.3 Bagi Pemerintah
a) Sebagai bahan pertimbangan untuk kedepannya dari hasil penelitian yang telah dilakukan.
b) Membantu mengevaluasi kebijakan yang telah ditetapkan 1.6 Metodologi Penelitian
Dalam pengumpulan data yang digunakan oleh penulis dalam melakukan penelitian ini menjadi 2 metode, yaitu metode pengumpulan data dan metode pengembangan sistem. Berikut penjelasannya:
1.6.1 Metode Pengumpulan Data
Dalam pengumpulan data yang di gunakan oleh penulis dalam melakukan penelitian ini menggunakan 3 metode pengumpulan data, yaitu:
a. Studi lapangan : observasi
b. Studi Pustaka : url,studi literatur, dan jurnal
1.6.2 Metode Implementasi
Pada penelitian ini, penulis melakukan implementasi penelitian dengan menggunakan metode Simulasi. Adapun langkah-langkah yang dilakukan di dalam metode simulasi ini, yaitu:
a) Formulasi Masalah (Problem Formulation) b) Model Pengkonsepan (Conceptual Model) c) Data Masukan/Keluaran (Input/Output Data) d) Pemodelan (Modelling)
e) Simulasi (Simulation)
f) Verifikasi dan Validasi (Verification and Validation) g) Eksperimentasi (Experimentation)
h) Analisis Keluaran (Output Analysis) 1.7 Sistematika Penulisan
Untuk memudahkan dalam penulisan laporan tugas akhir ini, penulis menyusunnya ke dalam beberapa bagian. Setiap babnya terdiri dari beberapa sub bab tersendiri. Dimana bab tersebut secara keseluruhan saling berkaitan satu sama lain. Berikut penjelasan singkat dari masing- masing bab:
BAB 1 PENDAHULUAN
Pada bab ini peneliti menjelaskan terkait latar belakang dari dari sebuah permasalahan yang diangkat, tujuan penelitian, manfaat penelitian, rumusan masalah, batasan masalah, metodologi penelitian, dan sistematika penulisan pada tugas skripsi ini.
BAB 2 LANDASAN TEORI
Pada bab ini peneliti menjelaskan tentang materi-materi apa saja yang dipakai untuk dijadikan dasar penelitian yang sedang dilakukan.
BAB 3 METODE PENELITIAN
Pada bab ini peneliti menjelaskan tentang metode penelitian apa yang dipakai untuk mendapatkan data dan metode untuk pengembangan sistem yang telah dibuat serta kerangka berpikir pembuatan tugas akhir ini.
BAB 4 IMPLEMENTASI, SIMULASI, DAN EKSPERIMEN
Pada bab ini menjelaskan tentang implementasi dari metode yang telah digunakan untuk perancangan membangun sebuah sistem dan tahapan proses menganalisa simulasi.
BAB 5 HASIL DAN PEMBAHASAN
Pada bab ini peneliti membahas tentang hasil yang telah didapat dari proses simulasi yang telah dilakukan pada bab sebelumnya.
BAB 6 PENUTUP
Pada bab ini peneliti menjelaskan tentang kesimpulan dari hasil yang telah didapat dan menjawab semua pokok permasalahan yang dirancang serta saran-saran yang digunakan untuk penelitian lebih lanjut.
BAB II
LANDASAN TEORI
2.1 Analisis SentimenAnalisis sentimen adalah sebuah proses untuk menentukan sentimen atau opini dari seseorang yang diwujudkan dalam bentuk teks dan bisa di kategorikan sebagai sentiment positif, negatif, atau netral.
Pengguna internet banyak menuliskan pengalaman, opini dan segala hal yang menjadi perhatian mereka. Ide dasar dari investigasi sentiment adalah untuk mendeteksi popularitas teks dokumen atau kalimat pendek dan mengklasifikasikannya dalam premis ini. (Arief & Imanuel, 2019) 2.2 PSBB
Pemerintah menerapkan Pembatasan sosial Berskala Besar (PSBB) demi memutus mata rantai penyebaran virus corona. Meskipun banyak fasilitas umum yang ditutup, namun beberapa sector vitar seperti fasilitas kesehatan, pasar atau minimarket tetap buka selama PSBB. Masyarakat pun mendukung opsi tersebut karena dianggap mampu mencegah
Langkah PSBB lebih tepat jika dibandingkan dengan Lockdown, karena masyarakat sama sekali tidak diperbolehkan untuk keluar rumah segala transportasi mulai dari mobil, motor, kereta apim hingga pesawat pun tidak dapat beroperasi, dan bahkan aktivitas perkantoran bias dihentikan semuanya jika terjadi Lockdown, maka dari itu langkap PSBB jauh lebih baik diterapkan. (Nasruddin & Haq, 2020)
2.3 Clustering
Clustering merupakan salah satu metode data mining yang bersifat tanpa arahan (unsupervised) dan suatu metode untuk mencari dan mengelompokan data yang memiliki kemiripan karakteristik antara satu data dengan data lain. Pada clustering ini terdapat beberapa algoritma pengelompokan data secara mudah. Salah satunya adalah Algoritma K- Meanas yang merupakan metode analisis kelompok yang mengarah pada
partisisan N objek pengamatan kedalam K kelompok, dimana setiap objek pengamatan sebuah kelompok data dengan mean (rata-rata) terdekat. (Nur, Zarlis, & Nasution, 2017)
2.4 Algoritma
Algoritma adalah metode efektif yang diekspresikan sebagai rangkaian terbatas. Algoritma juga merupakan kumpulan perintah untuk menyelesaikan suatu masalah. Perintah ini dapat di terjemahkan secara bertahap dari awal hingga akhir. Masalah tersebut dapat berupa apa saja, dengan syarat untuk setiap permasalahan memiliki kriteria kondisi awal yang harus dipenuhi sebelum menjalankan sebuah algoritma. Algoritma juga memiliki pengulangan proses (iterasi) dan juga memiliki keputusan hingga keputusan selesai. Secara informal, algoritma yang dapat menyelesaikan permasalahan dalam waktu yang relative singkat memiliki tingkat kompleksitas yang rendah, sementara untuk algoritma yang menyelesaikan permasalahan dalam waktu yang lebih lama memiliki tingkat kompleksitas yang lebih tinggi pula. (Maulana, 2017)
2.5 Text Mining
Pengolahan dan pengambilan informasi dari sebuah data tekstual merupakan permasalahan yang tidak dapat diselesaikan dengan menggunakan teknik Data Mining. Diperlukan beberapa tahapan proses tambahan agar data tekstual yang memiliki format tidak teratur dapat dilakukan pengolahan dan pengambilan informasi, tahapan proses tersebut dikenal dengan Text Mining. (Indraloka & Santosa, 2017)
2.6 Pre-Processing
Dalam penelitian ini di terapkan text preprocessing untuk data yang akan digunakan dalam proses analisa sentiment, dimana data yang kita proses akan kita ambil informasi yang terkandung didalamnya. Dalam hal sentiment penulisannya yaitu negatif atau positif. Guna memudahkan dalam mengelola data maka data perlu kita berikan analisa sentiment
secara manual dengan membaca maksud dari kalimat yang ada dalam sentiment tersebut, sehingga dapat diberikan penilaian bahwa sentiment tersebut merupakan sentiment negatif atau positif. (H, 2015)
2.6.1 Case Folding
Pada proses case folding,semua huruf pada tiap tweet dirubah menjadi huruf kecil, karakter yang dianggap tidak valid seperti angka dan tanda baca dihilangkan. (Indraloka & Santosa, 2017)
2.6.2 Tokenizing
Tokenization merupakan tahapan penguraian string teks menjadi term atau kata. Tujuan dari Tokenization yaitu memisahkan kata-kata dalam sebuah paragraph, kalimat atau halaman kedalam kata tunggal. (Najjichah, Syukur, & Subagyo, 2019)
2.6.3 Stopword/Filtering
Stop removal, merupakan tahapan penghapusan kata-kata yang tidak relevan dalam penentuan topik sebuah dokumen dan yang sering muncul pada dokumen, misalnya ‘dan’, ‘atau,
‘sebuah’, ‘adalah’, pada dokumen berbahasa Indonesia.
(Najjichah, Syukur, & Subagyo, 2019) 2.6.4 Stemming
Stemming merupakan tahapan pengubahan suatu kata menjadi akar katanya dengan menghilangkan imbuhan awal atau akhir pada kata tersebuat. (Najjichah, Syukur, & Subagyo, 2019) 2.7 Algoritma K-Means Clustering
K-Means yaitu salah satu dari metode pengelompokan data nonhierarki (sekatan) yang dapat mempartisi data kedalam bentuk dua kelompok ataupun lebih. Metoda tersebut akan mempartisi data kedalam suatu kelompok dimana data yang berkarakteristik sama akan
dimasukkan kedalam satu kelompok sama sedangkan data yang memiliki karakteristik yang berbeda akan dikelompokan kedalam kelompok lainnya. Tujuan dari pengelompokan yaitu untuk meminimalkan dari fungsi objektif yang diset dalam proses pengelompokan, pada umumnya akan berusaha meminimalkan variasi didalam suatu kelompok dan memaksimalkan variasi antar kelompok.
Algoritma K-Means merupakan salah satu dari algoritma yang banyak digunakan dalam pengelompokan karena kesederhanaan dan efisiensi [9] dan diakui sebagai salah satu dari 10 algoritma data mining teratas oleh IEEE. (Gustientiedina, Adiya, & Desnelita, 2019)
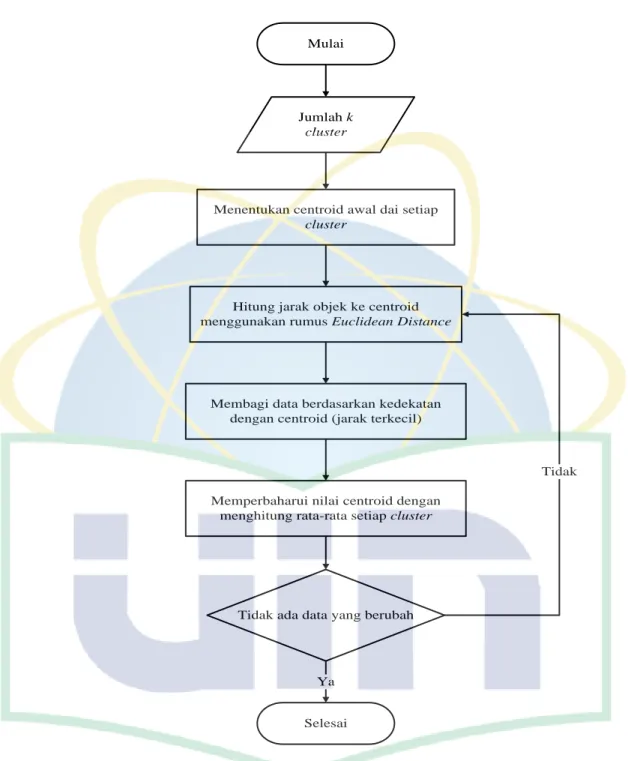
2.7.1 Tahapan Algoritma K-Means Clustering
Dalam menggunakan algoritma k-means akan melakukan pengulangan tahapan hingga terjadi kestabilan. Adapun tahapannya sebagai berikut.
1. Menentukan jumlah cluster dan menentukan koordinat titik tengah cluster. Penentuannya berdasarkan frekuensi kurang, frekuensi sedang dan frekuensi tinggi secara acak.
2. Penentuan nilai dari cluster untuk dijadikan acuan dalam melakukan perhitungan dan perhitungan jarak mengacu pada rumus euclidean.
3. Dilakukan pengelompokkan centroid sesuai dengan hasil dari jarak antar centroid tersebut. Hasilnya digunakan untuk penentuan kelompok clustering. (Asroni, Fitri, & Prasetyo, 2018)
2.8 Algoritma Levensthein Distance
Levenshtein Distance adalah sebuah matriks string yang digunakan untuk mengukur jarak perbedaan (distance) antara dua buah string.
Algoritma ini menghitung angka terendah dari operasi edit yang dibutuhkan untuk mengubah satu string untuk menuju ke string yang lain.
Cara yang paling umum adalah dengan menghitung ini dengan pendekatan pemrograman dinamis sebagai berikut:
1. Sebuah matriks diinisialisasin untuk perhitungan dalam (m, n) Levenshtein.
2. distance antara karakter pada posisi m dengan karakter lain pada posisi n.
3. Matriks tersebut kemudian diisi dari kiri atas hingga kanan bawah.
4. Masing-masing huruf kemudian berpindah secara horizontal atau vertical untuk menambahkan atau menghapus sesuai dengan kebutuhan.
5. Nilai yang dibutuhkan biasanya akan diset sebagai 1 untuk setiap operasi.
6. Perpindahan diagonal dapat bernilai 1 jika dua karakter dalam baris dan kolom tidak sama dan bernilai 1 jika keduanya sama. Setiap sel selalui mengurangi nilai secara lokal.
7. Dengan jalan ini nilai yang ada di bagian kanan bawah adalah jarak Levenshtein distance antara kedua kata. (Firdausillah & Arieansyah, 2019)
2.8.1 Alasan Menggunakan Algoritma Levensthein Distance
Karena pada algoritma levensthein distance terdapat 3 macam operasi utama yang dilakukan, yaitu :
a. Operasi penambahan karakter yaitu operasi yang digunakan untuk menambahkan karakter ke dalam string. Contoh pada penulisan string “kern” maka diubah menjadi string “keren” dengan menambahkan karakter ‘e’.
b. Operasi pengubahan karakter yaitu operasi yang digunakan untuk mengubah karakter dengan cara menukar sebuah karakter dengan karakter lain. Contoh pada penulisan string
“hidsp” diubah menjadi string “hidup” dengan mengubah karakter ‘S’ menjadi karakter ‘U’.
c. Operasi penghapusan karakter yaitu operasi yang digunakan untuk menghapus suatu karakter pada string. Contoh pada penulisan string “hebatt” diubah menjadi string “hebat”
dengan menghilangkan salah satu karakter ‘T’.
2.9 Algoritma Nazief dan Andriani
Algoritma Nazief & Adriani dikembangkan pertama kali oleh Bobby Nazief dan Mirna Adriani. Algoritma ini berdasarkan pada aturan morfologi bahasa Indonesia yang mengelompokkan imbuhan, yaitu imbuhan yang diperbolehkan atau imbuhan yang tidak diperbolehkan.
Pengelompokan ini termasuk imbuhan di depan (awalan), imbuhan dibelakang (akhiran), imbuhan di tengah (sisipan) dan kombinasi imbuhan awalan dan akhiran (konfiks).
2.9.1 Tahapan Algoritma Nazief dan Andriani
Algoritma Nazief & Adriani yang dibuat oleh Bobby Nazief dan Mirna Adriani ini memiliki tahap-tahap sebagai berikut [5]:
1. Pertama cari kata yang akan distemming dalam kamus kata dasar. Jika ditemukan maka diasumsikan kata adalah root word. Maka algoritma berhenti.
2. Inflection Suffixes (“-lah”, “-kah”, “-ku”, “-mu”, atau “-nya”) dibuang. Jika berupa particles (“-lah”, “-kah”, “-tah” atau “- pun”) maka langkah ini diulangi lagi untuk menghapus Possesive Pronouns (“-ku”, “-mu”, atau “-nya”), jika ada.
3. Hapus Derivation Suffixes (“-i”, “-an” atau “-kan”). Jika kata ditemukan di kamus, maka algoritma berhenti. Jika tidak maka ke langkah 3a.
a) Jika “-an” telah dihapus dan huruf terakhir dari kata tersebut adalah “- k”, maka “-k” juga ikut dihapus. Jika kata tersebut ditemukan dalam kamus maka algoritma berhenti. Jika tidak ditemukan maka lakukan langkah 3b.
b) Akhiran yang dihapus (“-i”, “-an” atau “-kan”) dikembalikan, lanjut ke langkah 4.
4. Hapus Derivation Prefix. Jika pada langkah 3 ada sufiks yang dihapus maka pergi ke langkah 4a, jika tidak pergi ke langkah 4b.
a) Periksa tabel kombinasi awalanakhiran yang tidak diijinkan. Jika ditemukan maka algoritma berhenti, jika tidak pergi ke langkah 4b.
b) For i = 1 to 3, tentukan tipe awalan kemudian hapus awalan. Jika root word belum juga ditemukan lakukan langkah 5, jika sudah maka algoritma berhenti. Catatan:
jika awalan kedua sama dengan awalan pertama algoritma berhenti.
5. Melakukan Recoding. 6) Jika semua langkah telah selesai tetapi tidak juga berhasil maka kata awal diasumsikan sebagai root word. Proses selesai. Kelebihan pada algoritma ini adalah memperhatikan kemungkinan adanya partikel- partikel yang mungkin mengikuti suatu kata berimbuhan.
Selain itu algoritma ini menggunakan kamus kata dasar dan mendukung recoding, yakni penyusunan kembali kata-kata
yang mengalami proses stemming berlebih. (Wirayasa, Wirawan, & Pradnyana, 2019)
2.9.2 Alasan Menggunakan Algoritma Nazief dan Andriani
Karena algoritma Nazief dan Adriani yaitu algoritma terbaik dalam proses stemming dan terdapat penambahan aturan- aturan untuk reduplikasi, penambahan aturan untuk awalan dan akhiran dalam meningkatkan presisi dari setiap kata yang distemming.
2.10 Algoritma TF-IDF
Algoritma TF-IDF (Term Frequency – inverse Document Frequency) adalah salah satu algoritma yang digunakan untuk menganalisa hubungan antara sebuah kalimat dengan sekumpulan dokumen dan metode untuk menghitung bobot setiap kata yang paling umum di gunakan. Rumus untuk TF-IDF yaitu:
Keterangan:
a. tf = banyaknya kata yang dicari pada sebuah dokumen
b. max (tf) = jumlah kemunculan terbanyak term pada dokumen yang sama.
c. nilai D = total dokumen
d. df (t) = jumlah dokumen yang mengandung term t.
e. IDF = Inversed Document Frequency ( log2 (D/df)) f. d = dokumen ke-d
g. t = kata ke-t dari kata kunci
h. W = bobot dokumen ke-d terhadap kata ke-t. (Utomo, Manaar, Khaira, & Suratno, 2019)
2.11 Confusion Matrix
Confusion matrix adalah suatu metode yang biasanya digunakan untuk melakukan perhitungan akurasi pada konsep data mining.Confusion matrix digambarkan dengan tabel yang menyatakan
jumlah data uji yang benar diklasifikasikan dan jumlah data uji yang salah diklasifikasikan. (Rahman, Darmawidjadja, & Alamsah, 2017) 2.12 PHP
PHP adalah salah satu bahasa pemrograman open source yang sangat cocok atau dikhususkan untuk pengembangan web dan dapat ditanamkan pada sebuah skripsi HTML. Bahasa PHP dapat dikatakan menggambarkan beberapa bahasa pemrograman seperti C, Java, dan Perl serta mudah untuk dipelajari. PHP merupakan bahasa scripting server – side, dimana pemrosesan datanya dilakukan pada sisi server.
Sederhananya, serverlah yang akan menerjemahkan skrip program, baru kemudian hasilnya akan dikirim kepada client yang melakukan permintaan. (Firman, F.Wowor, & Najoan, 2016)
2.13 MySQL
MySQL merupakan software database open source yang paling populer di dunia. MySQL menjadi pilihan utama bagi banyak pengembang software dan aplikasi hal ini dikarenakan kelebihan MySQL diantaranya sintaksnya yang mudah dipahami, didukung program- program umum seperti C, C++, Java, PHP, Pyton. Pengguna MySQL tidak hanya sebatas pengguna perseorangan maupun perusahaan kecil, namun perusahaan seperti Yahoo!, Google, Nokia, Youtube, Wordpress juga menggunakan DBMS MySQL. (Warman & Ramdaniansyah, 2018) 2.14 R-Programming
Software R dan paket Knitr menawarkan kemudahan untuk RR karena data dan kode dapat tersedia dengan mudah. Langkah pembuatan RR adalah pembuatan file .rmd, penyesuaian meta data, penulisan (chunk), dan rendering. Penerapan teks-kode, teks-tabel, dan teks-gambar pada sebuah contoh kasus artikel dengan RStudio, software R dan paket Knitr memberikan keuntungan yaitu penyesuaian hasil dan pengecekan yang lebih menghemat waktu jika terjadi perubahan data, cross reference yang mudah memanfaatkan data dan kode yang telah tersedia.
Pengadopsian reproducible research (data dank ode tersedia) menjadi penting bagi seorang peneliti agar kontribusi terhadap keilmuan lebih efektif. (Budiaji, 2019)
Tabel 2. 1 Studi Literatur Sejenis
Penulis & Tahun Taufik dkk (2018) Atika Rahmawati dkk (2017)
Arrofi Reza Satria dkk (2020)
A Sidang Amirul Haj dkk (2019)
Peneliti Penulis
Judul Analisis Sentimen
Terhadap Tokoh Publik Menggunakan Algoritma Support Vector Machine (SVM)
Analisis Sentimen publik pada media sosial Twitter terhadap pelaksanaan pilkada serentak menggunakan Algoritma Support Vector Machine
Analisis Sentimen Ulasan
Aplikasi Mobile
menggunakan Algoritma Gabungan Naïve Bayes dan C4.5 berbasis Normalisasi Kata Levenshtein Distance
Analisis Sentimen Kinerja KPU Pemilu 2019 Menggunakan Algoritma
K-Means Dengan
Algoritma Confix Stripping Stemmer
Analisis komentar masyarakat Jakarta terhadap kebijakan pembatasan sosial
berskala besar
menggunakan Algoritma K-Means dan Algoritma Levenshtein Distance
Data yang di ambil Dari twitter dengan
kata kunci
@temanAhok dan
“Ahok”
Twitter dengan
mendaftarkan akun untuk mengakses API Twitter
Data kometar aplikasi di playstore di ambil dengan Appbot
Komentar facebook Komentar Instagram
Algoritma Support Vector
Machine (SVM)
Support Vector Machine dan K-Means
Naïve Bayes, C4.5 dan Levensthein Distance
K-Means,Levesnthein, SVM,Confix Stripping
K-Means,Levensthein, Nazief dan Andriani
Stemmer, Naïve Bayes Nilai k k = 2 (Positif &
Negatif)
k = 2 (Positif & Negatif) k = 3 (Positif, Negatif &
Mixed)
k = 2 (Positif & Negatif) k = 2 (Positif & Negatif)
Data yang di gunakan
Data tweet sebanyak 630 data
3000 data 1300 data 200 data 150 data latih dan 50 data
uji
Stemming - - - Confix Stipping Stemer Algoritma Nazief dan
Andriani
Pembobotan kata TF-IDF - - TF-IDF TF-IDF
Normalisasi kata - - Levensthein Distance Levensthein Distane Levensthein Distance
Tools / Aplikasi - Pemrograma Java - PHP & MySQL R Programing,PHP &
MySQL Tahap pengujian dilakukan 1 kali. Pengujian dilakukan
sebanyak 2 kali.
Pengujian di lakukan sebanyak 4x .
Pengujian Dilakukan sebanyak 2 kali.
Pengujian Dilakukan sebanyak 2 kali.
BAB III
METODOLOGI PENELITIAN
3.1 Metode Pengumpulan DataPada penelitian ini penulis mengumpulkan data dan informasi yang dapat menunjang proses dalam penelitian dimana proses pengumpulan datanya sebagai berikut.
3.1.1 Studi Pustaka
Pada tahap pengumpulan data dengan studi pustaka ini penulis melakukan pengumpulan teori-teori yang berkaitan dengan penulisan skripsi sebagai bahan untuk melengkapi penelitian ini. Sumber teori berasal dari buku referensi, hasil penelitian (jurnal dan skripsi) dan artikel-artikel yang berkaitan dengan penelitian. Selain itu juga penulis juga mengunjungi beberapa situs-situs terkait aplikasi Clustering, text mining, preprocessing, algoritma k-means clustering, algoritma levenstein distance, algoritma nazief dan andriani, algoritma TF- IDF.
3.1.2 Studi Lapangan
Observasi mengambil data melalui Media Sosial secara manual yaitu komentar masyarakat Jakarta terhadap Pembatasan Sosial Berskala Besar (PSBB).
3.2 Metode Simulasi
Metode Simulasi ini digunakan untuk melihat hasil sentimen masyarakat dari objek yang diteliti yaitu komentar masyarakat Jakarta terhadap Pembatasan Sosial Berskala Besar (PSBB) dengan menggunakan algoritma k-means clustering dan algoritma levensthein distance sebagai normalisasi kata. Pada metode simulasi ini meliputi beberapa langkah atau tahap yang akan dilakukan yaitu:
3.2.1 Formulasi Masalah (Problem Formulation)
Tahap formulasi masalah merupakan langkah awal dalam perancangan pada model merode simulasi. Formulasi masalah merupakan suatu kegiatan untuk melakukan identifikasi masalah berdasarkan hasil penelitian sebelumnya. Dalam tahap formulasi masalah ini peneliti merumuskan sebuah masalah yaitu mengimplementasikan kombinasi algoritma k-means clustering dan algoritma levensthein distance dalam menganalisis sentimen komentar masyarakat Jakarta terhadap Pembatasan Sosial Berskala Besar (PSBB).
3.2.2 Model Pengkonsepan (Conceptual Model)
Pada tahapan ini peneliti membuat model konsep yang akan dilakukan yaitu membahasa keseluruhan penelitian ini. Konsep pertama membuat kosep pada proses text mining yang ingin digunakan. Kedua, dengan mengidentifikasikan input pada penelitian ini, yaitu komentar masyarakat Jakarta terhadap Pembatasan Sosial Berskala Besar (PSBB) dari akun instagram
@jktinfo dan @aniesbaswedan, kemudian komentar yang telah dikumpulkan kemudian diolah dan diproses secara manual untuk pelabelan terhadap data latih. Ketiga, membuat konsep untuk tahap uji pada skenario 1 yaitu dengan melihat hasil sentimen dan tingkat akurasi menggunakan algoritma k-means saja. Keempat, tahap uji pada skenario 2 yaitu melihat hasil sentimen dan tingkat akurasi menggunakan kombinasi algoritma K-Means dan dibantu algoritma Levensthein Distance sebagai normalisasi kata pada tahap pre-processing.
3.2.3 Data Masukan/Keluaran (Input/Output Data)
Data masukan seperti kamus kata dasar, kamus stopword, kamus untuk levensthein, dan data komentar yang didapat dari Instagram dijadikan input pada penelitian ini dalam aplikasi
berbasis PHP. Data yang diambil sebanyak 200 komentar. Data terdiri dari 150 komentar dijadikan data latih dan 50 komentar dijadikan data uji. Data pada aplikasi ini diolah menggunakan algoritma K-Means dan algoritma Levensthein Distance untuk menghasilkan output berupa hasil sentimen akhir dan tingkat akurasi dari skenario 1 dan skenario 2.
3.2.4 Pemodelan (Modelling)
Pada tahapan ini peneliti menentukan model skenario yang akan digunakan. Pada tahap ini penulis melakukan pemodelan dalam membuat rancangan sistem yang akan dibuat secara manual.
Pemodelan atau skenario yang dibuat yaitu skenario kombinasi antara algoritma K-Means dan algoritma Levensthein Distance dan skenario tanpa menggunakan algoritma Levensthein Distance (hanya menggunakan algoritma K-Means saja).
3.2.5 Simulasi
Pada tahapan ini, sistem akan dijalankan untuk mensimulasikan kinerja masing-masing algoritma suseai dengan konsep dan skenario yang telah ditentukan sebelumnya. Simulasi yang akan dilakukan adalah dengan melakukan input dataset latih dan uji. Melakukan pelabelan terhadap data latih secara manual untuk dikelompokkan sentimennya, melakukan pelatihan terhadap data latih dan melakukan clustering data uji. Hasil simulasi berupa perbandingan akurasi dari algoritma yang dijadikan,penelitian, kemudian akan dicatat dan kemudian dilakukan tahap verifikasi.
3.2.6 Verifikasi dan Validasi (Verification and Validation)
Pada tahapan ini peneliti mealukan verifikasi dan validasi dari tahapan sebelumnya. Pada tahap verifikasi dilakukan untuk memastikan adanya kesalahan atau tidak yang terjadi dalam beberapa tahapan atau proses simulasi. Sedangkan tahapan
validasi yang dilakukan untuk memastikan kesesuaian proses simulasi yang dibuat berdasarkan model pengkonsepan dengan formulasi masalah yang dibuat.
Pada intinya, verifikasi dan validasi bertujuan untuk menyakinkan hasil dari aplikasi sentimen ini sesuai dengan yang dikonsepkan sebelumnya
3.2.7 Eksperimentasi (Experimentation)
Pada tahapan ini peneliti melakukan eksperimen sesuai dengan model skenario yang dibuat pada saat tahap pemodelan.
Ekperimen disini bertujuan untuk mengevaluasi hasil simulasi aplikasi.
3.2.8 Analisis Keluaran (Output Analysis)
Tahapan analisis keluaran adalah tahapan simulasi yang paling terakhir. Peneliti melakukan analisa terhadap output-output berdasarkan skenario yang sudah dilakukan yaitu menghitung tingkat akurasi dari algoritma yang dijadikan penelitian.
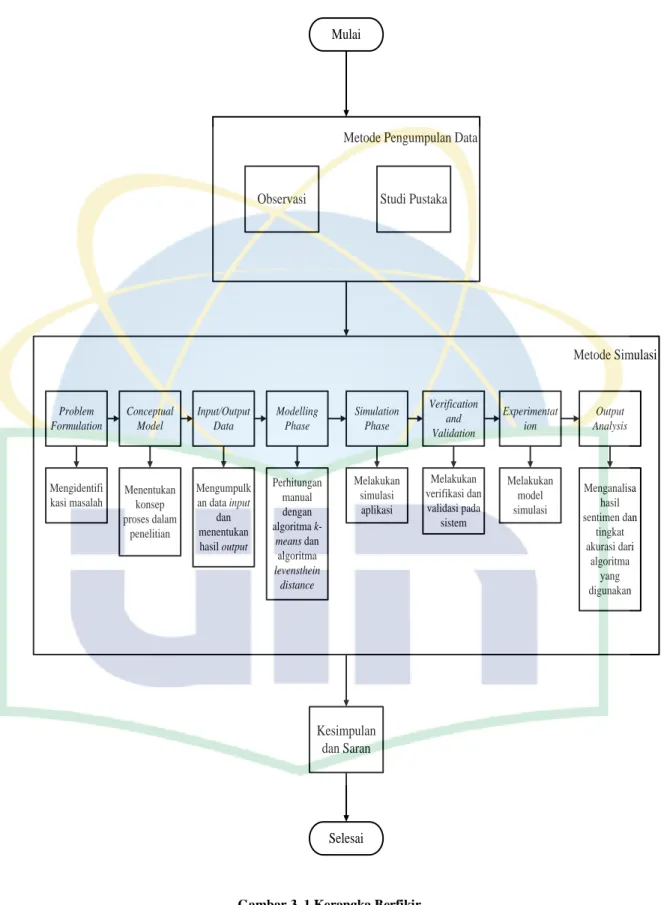
3.3 Kerangka Berfikir
Berfikir merupakan suatu alur diagram yang menjelaskan proses berjalannya sebuah penelitian. Dalam penelitian ini, penulis mengacu pada alur penelitian sebagai berikut:
Mulai
Metode Pengumpulan Data
Observasi Studi Pustaka
Metode Simulasi
Problem Formulation
Conceptual Model
Input/Output Data
Modelling Phase
Simulation Phase
Verification and Validation
Experimentat ion
Output Analysis
Kesimpulan dan Saran
Selesai Mengidentifi
kasi masalah
Menentukan konsep proses dalam
penelitian
Mengumpulk an data input
dan menentukan hasil output
Perhitungan manual dengan algoritma k-
means dan algoritma levensthein
distance
Melakukan simulasi aplikasi
Melakukan verifikasi dan validasi pada
sistem
Melakukan model simulasi
Menganalisa hasil sentimen dan
tingkat akurasi dari
algoritma yang digunakan
Gambar 3. 1 Kerangka Berfikir
BAB IV
IMPLEMENTASI, SIMULASI, DAN EKSPERIMEN
4.1 Formulasi Masalah (Problem Formulation)Pada tahap awal dimetode simulasi ini yaitu formulasi masalah, penulis melakukan identifikasi masalah berdasarkan hasi penelitian sebelumnya. Alhasil pada penelitian ini, penulis memformulasikan masalah penelitian pada kombinasi algoritma k-means dan algoritma normalisasi kata yaitu levensthein distance untuk dilakukan kombinasi terhadap kedua algoritma tersebut. Dengan hasil akhirnya yaitu sentiment masyarakat terhadap virus corona dan tingkat akurasi dari algoritma tersebut.
Data yang digunakan pada penelitian ini adalah komentar masyarakat terhadap pembatasan sosial berskala besar (psbb) yang diambil dari Instagram.
4.2 Model Pengkonsepan (Conceptual Model)
Pada tahap pemodelan konsep ini berkaitan dengan eksekusi dari sistem yang peneliti bangun, dari mulai masukan, proses, dan keluaran sistem tersebut. Berdasarkan tahap conceptual model pada sub bab 3.2.2, berikut ini merupakan alur keseluruhan dari sistem yang dibagun oleh peneliti.
4.2.1 Conceptual model pada text mining
Dalam penelitian saat ini, pemodelan pada text mining berkaitan dengan tahapan pre-processing teks. Tahapan pre- processing dilakukan dengan membuat fungsi sendiri dalam pengkodean menggunakan bahasa pemrograman PHP. Pre- processing ini dilakukan dengan tujuan:
1. Menghilangkan kata-kata yang mengganggu proses sentimen, seperti url atau link, hastag pada komentar, angka-angka, maupun tanda baca.
2. Menyeragamkan bentuk kata menjadi kata dasar sesuai dengan KBBI.
3. Mengurangi kata yang tidak digunakan atau tidak berpengaruh terhadap penentuan sentimen, seperti aku, kamu, dia, kita, dll.
Adapun tambahan proses yang dilakukan pada penelitian ini sekaligus pembeda dari penelitian yang sebelum-sebelumnya di tahapan pre-processing ini yaitu proses normalisasi kata menggunakan algoritma levensthein distance, berikut tahap-tahap pre-processing pada penelitian saati ini meliputi proses-proses seperti yang digambarkan pada flow di bawah ini:
Teks
dokumen Case folding Tokenization Normalisasi kata
Stopword removal Stemming
Gambar 4. 1 Flowchart Tahapan Pre-Processing
Berikut penjelasan dari tahapan pre-processing:
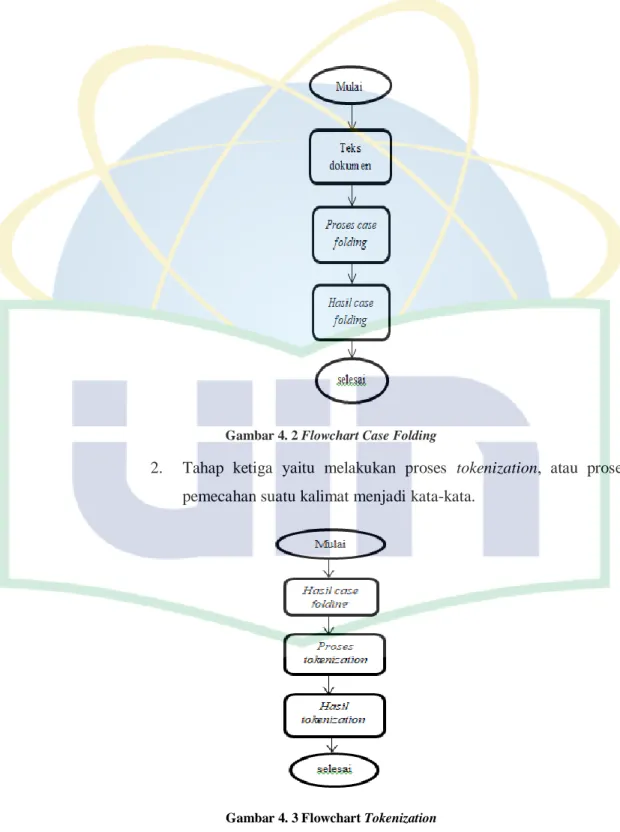
1. Tahap awal di pre-processing yaitu proses case folding atau merubah semua kata menjadi huruf kecil semu
Gambar 4. 2 Flowchart Case Folding
2. Tahap ketiga yaitu melakukan proses tokenization, atau proses pemecahan suatu kalimat menjadi kata-kata.
Gambar 4. 3 Flowchart Tokenization
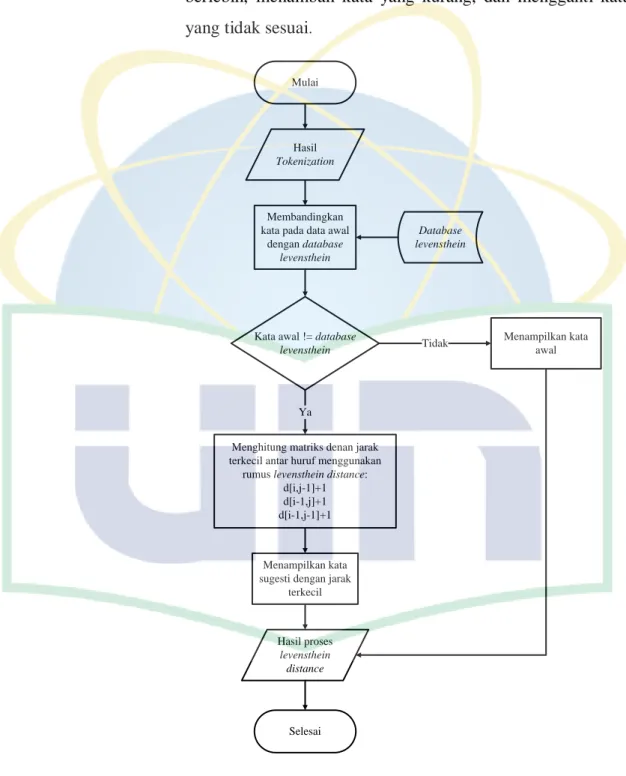
3. Proses selanjutnya yaitu melakukan proses menormalisasikan sebuah kata yang salah atau typo menggunakan algoritma levensthein distance dengan cara menghapus kata yang berlebih, menambah kata yang kurang, dan mengganti kata yang tidak sesuai.
Mulai
Hasil Tokenization
Membandingkan kata pada data awal
dengan database levensthein
Database levensthein
Kata awal != database levensthein
Menghitung matriks denan jarak terkecil antar huruf menggunakan
rumus levensthein distance:
d[i,j-1]+1 d[i-1,j]+1 d[i-1,j-1]+1
Hasil proses levensthein distance Menampilkan kata sugesti dengan jarak
terkecil
Menampilkan kata awal
Selesai Ya
Tidak
Gambar 4. 4 Flowchart Levensthein Distance
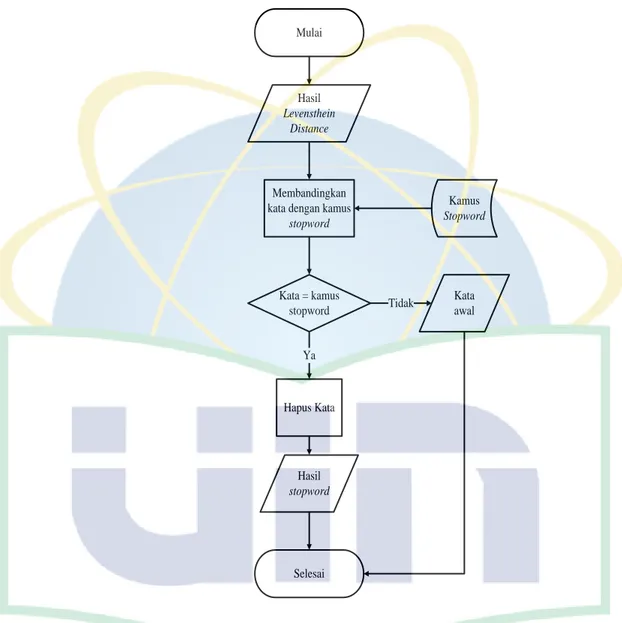
4. Selanjutnya melaukan proses stopword removal atau proses penghapusan kata-kata yang dianggap tidak penting, seperti dia, aku, kamu, pada, dan lainnya.
Mulai
Hasil Levensthein
Distance
Membandingkan kata dengan kamus
stopword
Kamus Stopword
Kata = kamus stopword
Hapus Kata
Kata awal
Selesai Hasil stopword
Tidak
Ya
Gambar 4. 5 Flowchart Stopword Removal
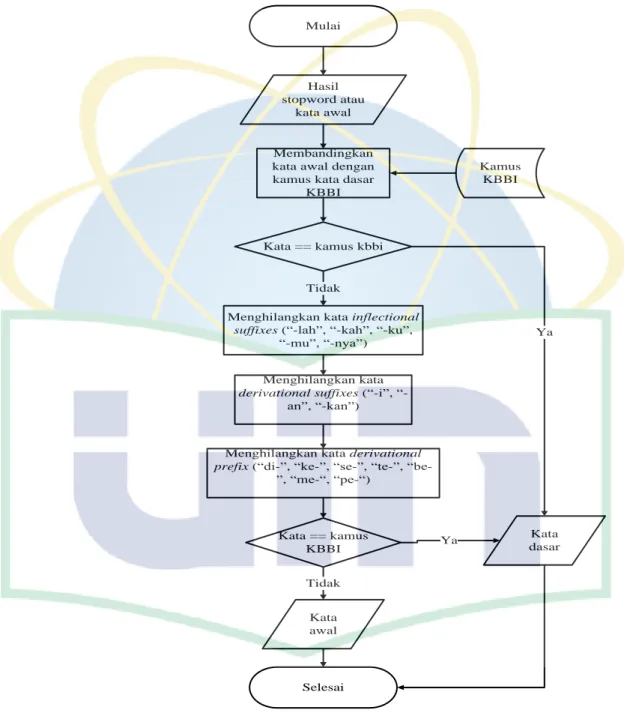
5. Tahap terakhir di pre-processing yaitu proses stemming atau merubah kata-kata imbuhan menjadi kata dasar sesuai KBBI menggunalan algoritma Nazief dan Adriani.
Mulai
Hasil stopword atau
kata awal
Membandingkan kata awal dengan kamus kata dasar
KBBI
Kata == kamus kbbi
Menghilangkan kata inflectional suffixes (“-lah”, “-kah”, “-ku”,
“-mu”, “-nya”)
Menghilangkan kata derivational suffixes (“-i”, “-
an”, “-kan”)
Menghilangkan kata derivational prefix (“di-”, “ke-”, “se-”, “te-”, “be-
”, “me-“, “pe-“)
Kata == kamus KBBI
Kata awal
Selesai
Kata dasar Kamus
KBBI
Tidak
Ya
Tidak
Ya
Gambar 4. 6 Flowchart Stemming Algoritma Nazief dan Andriani
4.2.2 Conceptual model pada data latih
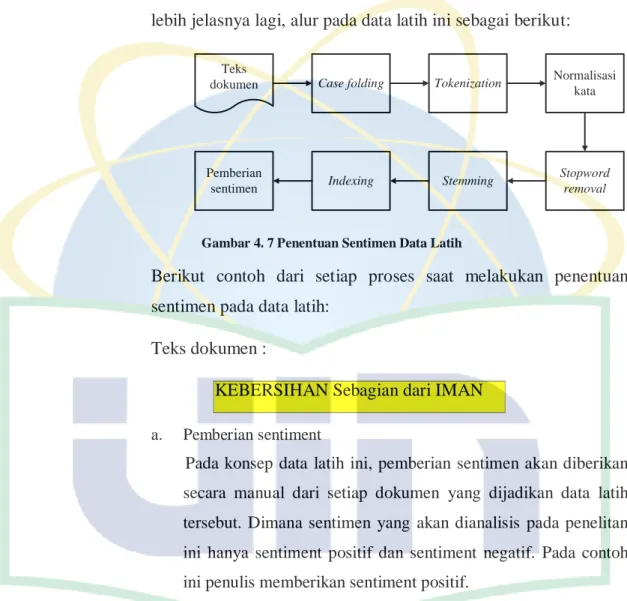
Konsep penentuan sentimen data latih pada penelitian ini dilakukan secara manual. Setelah diberikan sentimen pada setiap dokumen data latih, akan dilakukan proses pre-processing. Untuk lebih jelasnya lagi, alur pada data latih ini sebagai berikut:
Teks
dokumen Case folding Tokenization Normalisasi kata
Stopword removal Stemming
Indexing Pemberian
sentimen
Gambar 4. 7 Penentuan Sentimen Data Latih
Berikut contoh dari setiap proses saat melakukan penentuan sentimen pada data latih:
Teks dokumen :
KEBERSIHAN Sebagian dari IMAN a. Pemberian sentiment
Pada konsep data latih ini, pemberian sentimen akan diberikan secara manual dari setiap dokumen yang dijadikan data latih tersebut. Dimana sentimen yang akan dianalisis pada penelitan ini hanya sentiment positif dan sentiment negatif. Pada contoh ini penulis memberikan sentiment positif.
b. Case folding
Tabel 4. 1 Contoh Proses Case Folding
Teks dokumen Proses case folding KEBRSIHAN Sebagian dari kebrsihan sebagian dari
IMAN !!! iman !!!
c. Tokenization
Tabel 4. 2 Proses Tokenization
d. Normalisasi kata (menggunakan algoritma levensthein distance)
Tabel 4. 3 Contoh Proses Normalisasi Kata
Hasil tokenization Proses normalisasi
| kebrsihan | sebagian | dari | | kebersihan | sebagian | dari
iman | | iman |
e. Stopword removal
Tabel 4. 4 Contoh Proses Stopword Removal
Hasil normalisasi Proses stopword removal
| kebersihan | sebagian | dari | | kebersihan | iman | iman |
Hasil filtering Proses tokenization Kebersihan Sebagian dari
iman
| kebersihan | sebgaian | dari
| iman |
f. Stemming
Tabel 4. 5 Contoh Proses Stemming
g. Indexing
Pada tahap ini, dilakukan proses pengindeksan pada hasil pre-processing dan sentiment dari setiap dokumen. Pada inverted index akan tersimpan informasi berupa id dokumen, komentar, hasil pre-processing dan hasil sentimen.
4.2.3 Conceptual model sentimen dengan algoritma k-means
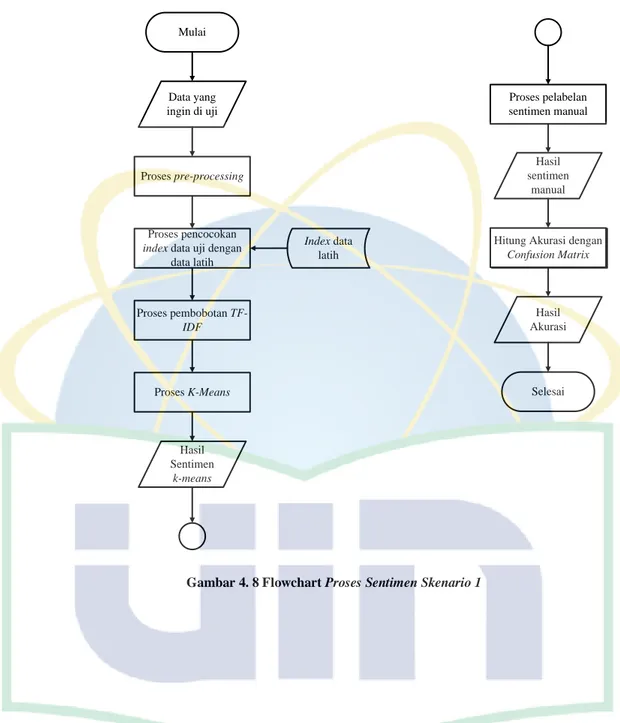
Skenario pertama pada penelitian ini secara alur dari analisa sentimen dengan menggunakan algoritma k-means tanpa bantuan algoritma levensthein distance sebagai algoritma normalisasi kata dapat dijelaskan pada gambar dibawah ini:
Hasil stopword removal
Proses stemming
| kebersihan | iman | | bersih | iman |
Mulai
Data yang ingin di uji
Proses pre-processing
Proses pencocokan index data uji dengan
data latih
Proses pembobotan TF- IDF
Index data latih
Proses K-Means
Hasil Sentimen
k-means
Selesai Proses pelabelan sentimen manual
Hasil sentimen
manual
Proses pre-processing Hitung Akurasi dengan
Confusion Matrix
Hasil Akurasi
Gambar 4. 8 Flowchart Proses Sentimen Skenario 1
Berikut penjelasan dari setiap proses saat melakukan penentuan sentimen menggunakan k-means:
1) Mengumpulkan data yang ingin di uji
2) Melakukan proses pre-processing tanpa bantuan algoritma levensthein distance sebagai algoritma normalisasi kata pada data uji
3) Hasil index dari pre-processing pada data uji, dicari yang cocok atau yang sama pada index data latih. Kemudian ambil kalimat yang terdapat index yang cocok atau sama itu untuk ke tahap selanjutnya.
4) Lakukan pembobotan kata pada index yang ada pada kalimat yang sudah diambil ditahap sebelumnya dan data ujinya menggunakan algoritma tf-idf dan diambil nilai total weightingnya untuk diproses ditahap selanjutnya.
5) Dari nilai total weighting yang sudah didapat dari proses tf-idf akan diproses menggunakan algoritma k-means untuk menentukan sentimennya. Alur dari algoritma k-means dapat digambarkan seperti berikut:
Mulai
Jumlah k cluster
Menentukan centroid awal dai setiap cluster
Hitung jarak objek ke centroid menggunakan rumus Euclidean Distance
Membagi data berdasarkan kedekatan dengan centroid (jarak terkecil)
Tidak ada data yang berubah
Selesai
Memperbaharui nilai centroid dengan menghitung rata-rata setiap cluster
Tidak
Ya
Gambar 4. 9 Flowchart Proses Algoritma K-Means
6) Menentukan pelabelan sentimen secara manual terhadap data uji sebagai perbandingan pada tahap akhir nanti.
7) Hitung akurasi dari perbandingan yang sudah dilakukan sebelumnya antara sentimen yang dihasilkan dari algoritma k- means dan sentimen dari pelabelan manual menggunakan rumus confusion matrix. Kalau sentimen yang dihasilkan keduanya sama maka akurasinya baik, dan sebaliknya kalau sentimen yang dihasilkan keduanya berbeda maka akurasi tidak baik.
8) Mendapatkan nilai akurasi dari scenario pertama.
4.2.4 Conceptual Model Sentimen Algoritma K-Means dengan bantuan Algoritma Levensthein Distance
Skenario kedua pada penelitian ini secara alur dari analisa sentimen dengan menggunakan algoritma k-means dan bantuan algoritma levensthein distance sebagai algoritma normalisasi kata dapat dijelaskan pada gambar dibawah ini:
Mulai
Data yang ingin di uji
Proses pre-processing with Levensthein
Proses pencocokan index data uji dengan
data latih
Proses pembobotan TF- IDF
Index data latih
Proses K-Means
Hasil Sentimen
k-means
Selesai Proses pelabelan sentimen manual
Hasil sentimen
manual
Proses pre-processing Hitung Akurasi dengan
Confusion Matrix
Hasil Akurasi
Gambar 4. 10 Flowchart Proses Sentimen Skenario 2