Tugas Kelompok
KRIPTOGRAFIDosen : Dr. rer. Nat. A. Benny Mutiara
JARINGAN NEURAL YANG SALING BERINTERAKSI
Oleh :
Arie Sriyono NPM : 92304072
Ivan Maurits NPM : 92304078
Priyo Sarjono Wibowo NPM : 92304083
Rudi Permana NPM : 92304085
PROGRAM PASCA SARJANA PERANGKAT LUNAK SISTEM INFORMASI MAGISTER MANAGEMEN SISTEM INFORMASI
JARINGAN NEURAL YANG SALING BERINTERAKSI
1.Pendahuluan
Jaringan neural belajar dari contoh. Konsep ini telah secara ekstensif dipelajari dengan menggunakan model dan metoda dari ilmu fisika statistik. Khususnya skenario jaringan feedforward dilatih dengan contoh yang dihasilkan oleh suatu jaringan yang berbeda.
Jaringan feedforward menggolongkan data dimensional tinggi, di kasus yang paling sederhana keluaran tunggal bit (1/0, wrong/correct, yes/no). Jaringan ini adalah algoritma yang adaptip, parameter mereka(pembobotan synaptic) mengadaptasikan persis sama satuan contoh pelatihan, dalam kasus ini satu set input/output pasangan. Setelah tahap pelatihan, jaringan sudah mencapai beberapa pengetahuan tentang aturan dari contoh itu, jaringan dapat menggolongkan vektor masukan yang tidak pernah telah dilihat sebelumnya, sehingga diakatakan dapat mengheneralisasi.
Beberapa model matematika yang dipelajari sebelum contoh pelatihan digunakan, dihasilkan oleh suatu jaringan neural yang berbeda, yang disebut sebagai “guru”. Pelatihan on-line berarti “siswa”, pada masing-masing langkah pelatihan, menerima suatu contoh yang baru dari jaringan guru. Masing-masing contoh digunakan hanya sekali ketika untuk pelatihan. Dalam hal ini pelatihan mungkin digunakan sebagai dinamika dari jaringan neural yang saling berinteraksi: Sebuah jaringan guru mengirimkan isyarat (contoh) kepada jaringan siswa yang kemudian secara berurut mengubah pembobotannya menurut pesan yang diterima.
Metoda matematis telah dikembangkan untuk mengkalkulasi kekayaan dari dinamika dari jaringan yang saling berinteraksi. Di batas dari jaringan besar seseorang dapat menguraikan sistem oleh suatu penyamaan diferensial untuk beberapa “parameter benahan” yang menentukan, sebagai contoh, generalisasi kesalahan sebagai fungsi dari jumlah contoh pelatihan.
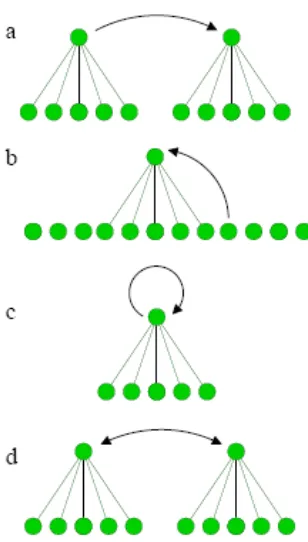
Gambar 1: Macam yang berbeda tentang interaksi membahas di tulisan ini: (a) guru statis melawan siswa yang adaptip, (b) generasi gugus berkala dan ramalan, (c)self-interaction, ( d) pelajaran timbal balik
Ketika suatu jaringan dilatih menggunakan keluarannya sendiri, maka jaringan tersebut saling berinteraksi dengan sendiri. Skenario itu mempunyai implikasi dalam teori dari algoritma ramalan, yang dibahas pada bagian 5. Ketika suatu sistem dari jaringan dilatih ke keputusan minoritasnya, maka diperlakukan sebagai sebagai suatu model untuk kompetisi dalam pasar tertutup, yang dapat dilihat pada bagian 6. Pada bagian 7 akan ditunjukkan dua jaringan yang saling berinteraksi. Suatu peristiwa diamati yaitu sinkronisasi pelajaran timbal balik. Pada bagian 8 akan ditunjukkan, bagaimana peristiwa ini dapat digunakan dalam ilmu baca sandi yaitu generasi dari suatu kunci rahasia dalam suatu saluran publik.
2. Pelatihan on-line
Secara matematis jaringan neural yang paling sederhana adalah perseptron. Yang terdiri dari lapisan tunggal dari N pembobotan sinaptik w = ( w1, ..., wN). Untuk vektor masukan yang ditentukan x, maka bit keluaran adalah:
Permukaan keputusan dari suatu perseptron adalah berbentuk hyperplane N-Dimensional dengan ruang masukan w⋅x=0. Suatu perseptron juga mempunyai suatu keluaran berlanjut y dengan
...(2)
Suatu perseptron diperlakukan sebagai suatu unit dasar dari suatu jaringan yang lebih rumit seperti suatu jaringan attractor atau suatu jaringan yang berlapis-lapis. Sesungguhnya fungsi apapun dapat didekati oleh suatu jaringan berlapis jika banyaknya unit tersembunyi adalah cukup besar.
Perseptron mengenal dari contoh. Contoh adalah pasangan input/output
...(3)
Pelatihan on-line berarti pada masing-masing langkah waktu t pembobotan dari perseptron menyesuaikan persis sama benar dengan contoh yang baru, sebagai contoh adalah aturan :
……….(4)
F(z) = 1 disebut sebagai (sesuai dengan mekanisme biologi) Aturan Hebbian, setiap sinapsis wi
bereaksi terhadap aktivitas σ(t).xi(t) pada bagian akhirnya. F(z)= Θ(-z) disebut sebagai aturan
Rosenblatt dimana langkah pelatihan dilakukan bila terjadi kesalahan penggolongan contoh. Akhirnya, aturan Adatron F(z)=|z|Θ(-z) menjadi penting karena memberikan hasil yang baik untuk generalisasi. Untuk dua aturan pembelajaran, sebagai tambahan pada dua aktivitas neural akhir yang sinaptik, potensi postsynaptic menentukan kekuatan adaptasi sinaptik.
3. Generalisasi
Sekarang bila dipertimbangkan dua buah perseptron. Yang pertama disebut sebagai jaringan guru yang memproduksi satu set contoh. Jaringan menerima satu set x(t) vektor masukan yang acak dan mengahasilkan bit keluaran σ(t). Guru mempunyai pembobotan vektor tetap wT.
Setiap kali guru memproduksi suatu contoh baru, perseptron siswa dilatih berdasarkan contoh tersebut. Sebagai konsekuensi, bobot vektor dari wS(t) siswa tergantung dari waktu. Siswa mencoba
untuk mendekati guru, pada masing-masing langkah pelatihan t, bobot vektor bergerak ke arah guru. Dapat dilihat itu untuk masukan yang acak x, persamaan (4) memberi semacam cara berjalan acak dalam N-Dimensional ruang dengan suatu penyimpangan ke arah wT vektor guru.
Jarak antara siswa dan guru dapat diukur dengan overlaped
Kuantitas R menentukan sudut φ antara siswa dan pembobotan guru, R = cosφ . Ternyata bahwa dari tumpang-tindih generalisasi kesalahan dapat dihitung secara analitis. Kesalahan generalisasi adalah kemungkinan bahwa siswa memberi suatu jawaban untuk suatu masukan yang acak x yang berbeda dari guru .
Bila misalnya
…...(6)
Dengan unit masukan yang tak terbatas, N →∞, dinamika dari tumpang-tindih R(t) dapat dihitung secara analitis. Besar langkah pelatihan menurun dengan 1/N. Oleh karena itu dapat digambarkan suatu variabel α = t / N yang menjadi suatu variabel yang berlanjut, yang disebut sebagai waktu, dibatasi oleh besar N.
Waktunya ketergantungan dari R(α) diperoleh dengan perkalian (4) dengan wT dan wS dan dengan
melakukan rata-rata dua persamaan ini dengan vektor masukan acak x. Hal Ini dapat dilakukan karena w· x adalah variabel Gaussian.
Karena aturan Adatron didapatkan dengan persamaan diferensial
………..(7)
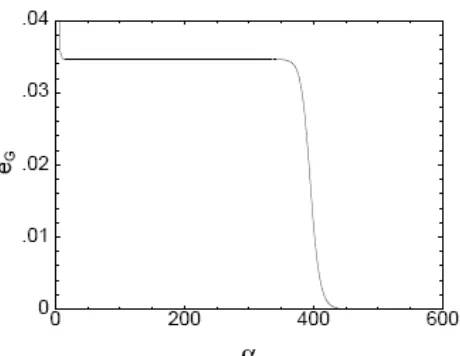
Generalisasi kesalahan yang dihitung oleh persamaan ini ditunjukkan pada gambar 2. Seandainya suatu jumlah contoh terbatas yang telah dipelajari, α = 0, error adalah 50%, seburuk tebakan acak. Jika banyaknya contoh pelatihan adalah ordo dari N, α > 0, jaringan siswa telah memperoleh beberapa tumpang-tindih terhadap guru. Dibatasi nilai α yang besar maka kesalahan berkurang menjadi nol, siswa telah memperoleh pengetahuan yang lengkap tentang parameter dari guru itu.
Gambar 3: Generalisasi kesalahan sebagai fungsi dari waktu, untuk suatu jaringan yang berlapis dengan dua unit yang tersembunyi
Degenerasi asymptotik dari generalisasi kesalahan tergantung dari aturan pembelajaran. Diketahui
untuk aturan Adatron 1
2 3 − ∝ α g
e . Sesungguhnya, ditunjukkan bahwa kesalahan tidak dapat
terdegenerasi lebih cepat dari 1
88
e . Tetapi dalam semua kasus siswa berhasil untuk mendekati guru ketika ordo mencapai ke N langkah. Ini termasuk ada ketika contoh disimpangkan oleh gangguan.
Pembelajaran dari contoh juga berlaku untuk jaringan yang lebih rumit. Di sini disampaikan pekerjaan pada spesialisasi mesin komisi.
Jaringan seperti itu adalah suatu jaringan yang berlapis-lapis dengan beberapa unit yang tersembunyi, serupa dengan gambar 8. Bit keluaran dari unit yang tersembunyi berlanjut dijumlahkan dan diambil sebagai keluaran dari jaringan itu. Jaringan guru dan siswa mempunyai suatu arsitektur yang serupa, dan langkah pembelajaran adalah gradien menurun kesalahan pelatihan, penyimpangan yang kwadratik antara keluaran guru dan siswa.
Generalisasi kesalahan ditunjukkan di pada gambar 3. Untuk jumlah kecil contoh, penurunan terjadi dengan cepat dan kemudian mendatar lalu untuk jumlah contoh besar berkurang menjadi nol.
Gerakan dari jaringan siswa dapat dinyatakan oleh tumpang-tindih antara anggota yang berkesesuaian dari dua mesin. Guru seperti halnya siswa terdiri dari dua vektor pembobotan, w1T/S
dan w2T/S.
Jarak antar guru dan siswa dapat digambarkan dari tumpang-tindih
Pada awalnya, semua vektor adalah acak, karenanya berfluktuasi dan semua tumpang-tindih adalah nol. Kemudian semua tumpang-tindih meningkat sesuai dengan pembelajaran. Tetapi pada bagian datar dari tumpang-tindih semua serupa, R1,1= R2,2= R1,2. Siswa telah mencapai beberapa pengetahuan, tetapi dalam keadaan yang simetris. Hanya jika siswa menerima informasi lebih jauh maka dapat berspesialisasi R1,1= R2,2 lebih besar dari R1,2.
Di awal proses dua anggota dari komisi siswa bertindak sebagai menjadi satu perseptron tunggal, tetapi kemudiannya mereka berspecialisi dan mengikuti mitra mereka di komisi guru sampai mereka mencapai pengetahuan yang lengkap untuk α→∞.
4. Ramalan gugus berkala dan generasi
Jaringan neural adalah algoritma ramalan yang sukses. Dengan memberikan urutan angka-angka, suatu jaringan neural dapat dilatih dalam urutan ini dengan bergerak di atas urutan, seperti ditunjukkan pada gambar.4. Urutan ini dapat diproduksi oleh jaringan lain, yang disebut sebagai guru, dengan membangkitan suatu nomor baru sebagai suatu komponen masukan di langkah berikutnya. Karenanya dipunyai semacam jaringan baru yang saling berinteraksi:
Guru dengan vektor pembobotan yang statis adalah generator bit atau urutan. Siswa mengadaptasikan pembobotan pada urutan yang dihasilkan oleh guru.
Gambar 4: Generasi gugus berkala dan ramalan oleh suatu perceptron
Pada prinsipnya, hal ini adalah skenario yang telah diuraikan di bagian yang sebelumnya. Di sini yang menjadi perbedaan adalah bahwa pola empunyai korelasi, masukan tidaklah acak tetapi digenerasikan dari keluaran guru.
Jika suatu jaringan neural tidak bisa menghasilkan urutan angka-angka yang ditentukan, maka jaringa tersebut tidak bisa meramalkan dengan kesalahan nol. Ini situnjukan dari beberapa hasil investatigasi pembuatan gugus berkala dengan jaringan neural. Sekalipun urutan telah dihasilkan oleh suatu (yang tak dikenal) jaringan neural (guru), suatu jaringan yang berbeda (siswa) dapat mencoba untuk belajar dan untuk meramalkan urutan ini.
Pada konteks ini ada dua pertanyaan yang cukup menarik:
1. Ketika seorang jaringan siswa dengan arsitektur yang serupa dengan guru dilatih, bagaimana cara tumpang-tindih antara siswa dan guru dikembangkan dengan menggunakan banyaknya contoh pelatihan( jendela dari urutan)?
2. Setelah jaringan siswa telah dilatih dari bagian urutan, seberapa baik dapat meramalkan urutan beberapa langkah ke depan?
Baru - baru ini pertanyaan ini telah diselidiki secara numerik untuk perseptron yang sederhana, persamaan (1,2). Pertimbangkan perseptron guru dengan wT pembobotan vektor yang
membangkitkan urutan S0, S1, S2,..., St….. Urutan ini mengikuti persamaan sebagai berikut :
...(9)
di mana f(x) adalah fungsi perpindahan. Telah ditunjukkan bahwa suatu perseptron dapat menghasilkan urutan yang sederhana sampai urutan yang kompleks.
Jika f(x) adalah monoton, sebagai contoh f(x)= tanh(βx), kemudian secara umum diperoleh urutan yang quasiperiodik. Sesungguhnya, urutan secara esensial dihasilkan oleh satu komponen Fourier dari bobot vektor wTi. Jika fungsi perpindahan tidak monoton, sebagai contoh f(x)= sin(βx), maka
urutan menjadi kacau, tergantung dari parameter model. Karena kedua kasus, pembelajaran dan ramalan telah diselidiki.
Jika suatu urutan yang quasi periodik dipelajari on-line, menggunakan gradien menurun untuk memperbaharui bobot,
...(10)
Maka terjadi dua timbangan waktu ( waktu α berarti banyaknya langkah pelatihan yang dibagi oleh N):
1. Suatu skala pendek dimana tumpang-tindih R(α) antara guru dan siswa secara cepat meningkat ke sebuah yang masih jauh dari nilai R= 1, nilai persetujuan yang sempurna. 2. Suatu skala panjang dimana tumpang-tindih R(α) meningkat dengan perlahan. Simulasi
numerik sampai dengan 106N langkah pelatihan menghasilkan suatu tumpang-tindih yang
adalah dekat tetapi masih berbeda dari nilai R= 1.
Walaupun ada suatu dalil matematis untuk optimisasi stokastik untuk menjamin pemusatan sukses yang sempurna, algoritma on–line tidak bisa memperoleh banyak informasi tentang jaringan guru, sedikitnya selama beberapa periode pelatihan.
Hal Ini sepenuhnya berbeda untuk suatu gugus berkala kacau yang dihasilkan oleh jaringan guru dengan f(x)= sin(x). Ternyata bahwa rangkaian kacau akan nampak seperti yang rangkaian acak : setelah batas tertentu jumlah langkah pelatihan dari ordo dari N tumpang-tindih dengan cepat berelaxsasi secara exponen untuk menyempurnakan persetujuan antara guru dan siswa.
Dari pelatihan perseptron dengan sejumlah contoh dari ordo dari N diperoleh dua kasus: Karena suatu urutan berkala quasi periodik siswa belum memperoleh banyak informasi tentang guru, untuk suatu urutan yang kacau student’s bobot vektor mendekati dengan yang dipunyai guru. Satu sisa pertanyaan yang penting adalah seberapa baik dapat siswa meramalkan waktunya rangkaian?
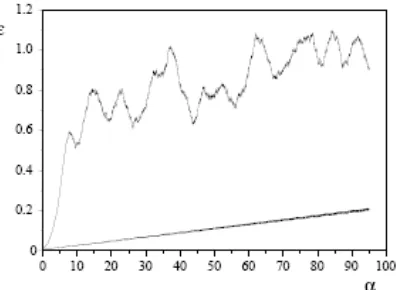
meramalkannya dengan baik sekali. Kesalahan meningkat secara linier seiring dengan ukuran dari interval , walaupun telah diramalkan 10N langkah ke depan dihasilkan suatu kesalahan sekitar 10% dari total cakupan yang mungkin. Di sisi lain, siswa yang dilatih dengan urutan yang kacau tidak bisa membuat ramalan. Terjadi peningkatan kesalahan ramalan secara exponensial seiring dengan waktu; terjadi langsung setelah beberapa langkah tanggapan pada tebakan acak, eg ≈ 1.
Penjelasannya adalah bahwa suatu perubahan yang kecil sekali di parameter dari suatu peta yang kacau mempengaruhi perubahan pada syarat awal, yakni, suatu pertumbuhan yang bersifat exponen dari antara bagian asli dan bagian yang diganggu.
Gambar 5: Kesalahan ramalan sebagai fungsi dari langkah waktu kei depan, untuk suatu kala quasi periodik (bagian bawah) dan kacau (bagian atas) rangkaian
Secara ringkas ditemukan sebuah counterintuitive dari hasil tersebut:
1. Suatu jaringan yang dilatih urutan quasiperiodik tidak memperoleh banyak informasi tentang jaringan guru yang menghasilkan urutan. Tetapi jaringan dapat meramalkan urutan ini dari ordo dari N langkah ke depan
2. Suatu jaringan yang dilatih dengan suatu urutan yang kacau memperoleh hampir secara lengkap pengetahuan tentang jaringan guru. Tetapi jaringan ini tidak bisa membuat ramalan yang beralsan untuk jangka panjang dari urutan.
Ini akan menarik untuk menemukan apakah hasil ini juga terjadi untuk algoritma ramalan yang lain, seperti halnya jaringan yang berlapis.
5. Self-Interaction
Dalam bagian sebelumnya gugus berkala telah dihasilkan oleh jaringan guru yang statis.Sekarang dipertimbangkan suatu jaringan yang berubah pembobotan sinaptiknya ketika sedang membangkitkan urutan bit . Guru berinteraksi dengan dirinya sendiri. Motivasi dari penyelidikan ini berasal dari masalah berikut:
Pertimbangan beberapa algoritma ramalan yang sewenang-wenang. Mungkin berisi semua pengetahuan dari manusia, banyak tenaga ahli telah mengembangkan itu. Sekarang ada urutan bit S1, S2,... dan algoritma telah dilatih dengan t bit pertama S1,..., St.
Dapatkah algoritma tersebut meramalkan St+1 bit yang berikutnya? Apakah kesalahan ramalan, suatu t interval besar dirata-ratakan , kurang dari 50%?
Jika urutan bit adalah acak, maka tiap-tiap algoritma akan memberi suatu kesalahan ramalan dari 50%. Tetapi jika ada beberapa korelasi di urutan maka suatu algoritma yang pandai bisa mengurangi kesalahan ini. Sesungguhnya, untuk algoritma paling kuat pun akan tergoda untuk katakan untuk urutan apapun lebih baik daripada 50% kesalahan. Bagaimanapun, ini adalah tidak benar. Untuk melihat ini [hanya;baru saja] menghasilkan suatu urutan S1, S2, S3,... penggunaan algoritma berikut:
Sekarang, jika algoritma yang sama dilatih urutan ini, bit yang diramalkan akan mengandung 100% kesalahan. Karenanya tidak ada mesin ramalan yang umum; untuk berhasil algoritma terpaksa membutuhkan beberapa pre-knowledge tentang kelas dari permasalahan itu.
Perseptron Boolean adalah suatu algoritma ramalan yang sangat sederhana untuk urutan bit, khususnya dengan algoritma on–line pelatihan Hebbian. Apa yang terlihat dari urutan bit seperti bila perseptron gagal dengan sepenuhnya?
Berikut ini, diambil nilai yang negatif :
...(11) dan kemudian melatih jaringan dengan bit baru ini:
...(12)
Perseptron dilatih dengan nilai kebalikan(=negatif) tentang dari ramalannya sendiri.
Permulaan dari keadaan awal yang acak S1,..., SN dan pembobotan w, prosedur ini menghasilkan suatu urutan dari bit S1, S2,... St,... dan vektor w,w(1),w(2),..w(t),... juga. Dengan memberikan urutan dan statusawal yang sama, perseptron yang telah dilatih .akan menghasilkan suatu kesalahan ramalan 100%.
Ternyata bahwa algoritma sederhana ini menghasilkan suatu urutan bit agak kompleks yang mirip dengan urutan acak. Hingga batas tertentu waktu yang temporer, vektor bobot w(t) nampak melaksanakan cara berjalan acak pada suatu N–Dimensional hypersphere. Urutan bit bersiklus dengan rata-rata panjang L berskala exponensial dengan N,
...(13)
Definisikan St+i sebagai kebalikan dari ramalan dari algoritma ini yang telah dilatih pada
fungsi autokorelasi dari urutan menunjukkan kekayaan yang kompleks: Itu mendekati nol sampai ke N, berosilasi antara N dan 3N dan menyerupai noise yang acak untuk jarak yang lebih besar. Entropy nya lebih kecil dibanding yang adalah suatu urutan acak karena frekuensi dari beberapa pola ditindas. Tentu saja hasl tersebut tidaklah acak karenakesalahan ramalan adalah 100% bukannya 50% untuk suatu urutan bit yang acak.
Ketika suatu perceptron kedua (= siswa) dengan wS status awal yang berbeda dilatih urutan yang
anti-predictable seperti dihasilkan oleh persamaan (11) dapat melaksanakan sedikit lebih baik daripada guru: Kesalahan ramalan turun ke sekitar 78% tetapi itu masih lebih besar dari 50% untuk tebakan yang acak. Berhubungan dengan Ini, siswa memperoleh pengetahuan tentang guru: sudut antara kedua bobot vektor terrelaksasi ke sekitar 45 derajat. Karenanya urutan yang antipredictable yang kompleks masih berisi informasi cukup untuk siswa untuk mengikuti guru yang time dependent.
6. Agen bersaing pada pasar tertutup
Baru saja dipertimbangkan suatu jaringan saling berinteraksi dengan dirinya sendiri. Sekarang model ini diperluas menjadi sebuah sistem dari banyak jaringan saling berinteraksi dengan keputusan yang minoritas dari semua anggota. Bagian ini dimotivasi oleh permasalahan dalam econophysics.
Baru-baru ini suatu model matematika dari ekonomi menerima banyak perhatian di masyarakat dari ilmu fisika statistik. Suatu model yang sederhana dari suatu pasar yang tertutup: Ada agen K yang harus membuat suatu keputusan biner σ(t)∈{+1,−1} pada langkah waktu. Semua agen [siapa] yang termasuk golongan keuntungan minoritas mendapatkan satu poin, mayoritas harus membayar satu poin yang (kasir selalu menang). Kerugian global :
………(14)
Jika agen sebelum membuat suatu keputusan yang baru, mudah untuk meminimasi G:( K - 1)/2 agen harus memilih + 1, kemudian G= 1. Bagaimanapun, ini adalah bukan aturan permainannya; agen tidaklah diijinkan untuk membuat kontrak, dan komunikasihanya disampaikan lewat penjumlahan yang global tentang keputusan. Masing-Masing agen mengetahui hanya sejarah dari keputusan yang minoritas, S1, S2, S3,..., tetapi jika tidak punya informasi. Dapatkah agen temukan suatu algoritma untuk memaksimalkan laba?
Jika masing-masing agen membuat suatu keputusan yang acak, kemudian (G2)= K. Ini hal yang
mungkin, tetapi tidak sepele, untuk menemukan algoritma yang lebih baik daripada algoritma acak.
Di sini digunakan suatu perseptron untuk masing-masing agen dalam membuat suatu keputusan berdasarkan dengan masa lalu N langkah S = ( St-N,..., St-1) dari keputusan yang minoritas.
Keputusan dari w(t ) agen ditulis dengan
Setelah bit St dari minoritas telah ditentukan, masing-masing perseptron dilatih contoh baru (S, St),
……….. ( 16)
Masalah ini bisa dipecahkan secara analitis]. Rata-rata kerugian global untuk η→0ditulis dengan
……..( 17)
Karenanya, untuk pembelajaran yang cukup kecil, sistem dari jaringan neural saling berinteraksi lebih baik daripada keputusan acak. Kooperasi yang sukses muncul dari suatu kolam adaptip perseptron.
7. Sinkronisasi pelajaran timbal balik
Sebelumnya, sudah mempertimbangkan suatu kolam dari beberapa jaringan neural yang saling berinteraksi melalui keputusan minoritas mereka. Sekarang dipelajari interaksi dari dua neural jaringan. Bertentangan dengan kasus teacher/student, sekarang kedua jaringan adalah adaptip, masing-masing jaringan belajar bit keluaran mitranya.
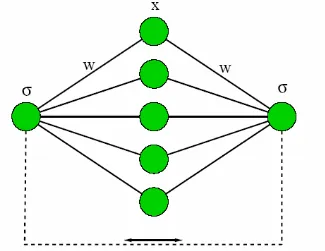
Gambar 6: Dua perceptrons dilatih oleh keluaran timbal balik bit
Pertimbangkan model di mana ada dua perseptron A dan B menerima suatu vektor masukan acak umum x dan berubah pembobotan w menurut bit timbal balik mereka, seperti ditampilkan pada gambar 6. Bit keluaran dari perceptron yang tunggal mempunyai persamaan
x adalah suatu N-Dimensional vektor masukan dengan komponen yang berasal dari Gaussian/Gauss dengan rata - rata 0 dan varian 1. w adalah suatu N-Dimensional pembobotan vektor dengan komponen berlanjut ternormalisasi,
w· w= 1 ...(19)
Status awal adalah suatu pilihan acak dari komponen wiA/B i, i= 1, ..., N untuk dua bobot vektor wA
dan wB. Pada masing-masing langkah pelatihan vektor masukan umum yang acak diperkenalkan
pada dua jaringan yang menghasilkan dua bit keluaran σA dan σB. Sekarang bobot vektor
diperbaharui oleh aturan pembelajaran Rosenblatt:
………..(20)
Θ(x) adalah fungsi langkah. Karenanya, hanya jika kedua perseptron tidak sependapat untuk suatu langkah pelatihan maka maka ditunjukkandengan sebuah laju pembelajaran η. Pada setiap langkah, dua bobot vektor berat/beban harus dinormalisasi.
Pada batas N →∞, tumpang-tindih adalah
...(21)
telah dihitung secara analitis. Banyaknya langkah-langkah pelatihan t adalah terskala dengan α= t/N, dan R(α) dengan mengikuti persamaan
...(22)
dengan α adalah sudut antara kedua bobot vektor wA dan wB, yaitu. R= cos φ
Persamaan ini mempunyai titik tetap R= 1, R= -1, dan
...(23)
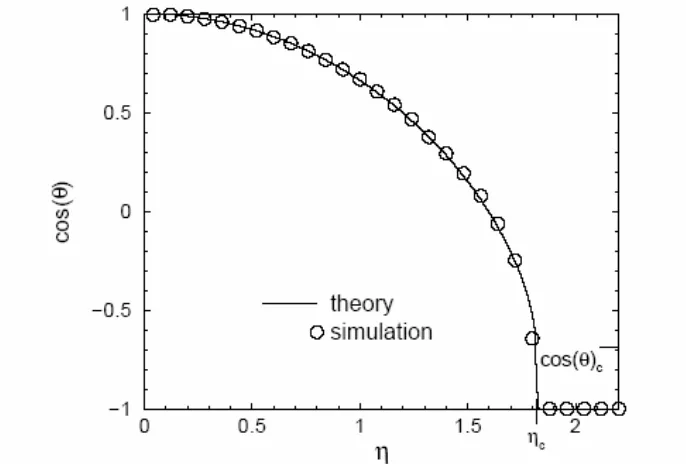
Gambar.7 menunjukkan titik tetap yang menarik dari (22) sebagai fungsi dari laju pembelajaran η Untuk nilai kecil dari η, dua jaringan berelaksasi pada status persetujuan yang timbal balik, R→1 dan η→0. Dengan terus meningkat laju pembelajaran sudut antara kedua bobot vektor meningkat sampai ke nilai Ф= 133˚ untuk
Di atas laju kritis ηc jaringan terelaksasi ke status ketidaksepahaman lengkap, Ф=180˚,R=-1.Dua
bobot vektor akan antisejajar untuk satu sama lain, bila wA=-wB.
Sebagai konsekuensi, solusi analitik menunjukkan, yang didukung oleh simulasi numerik untuk N= 100, bahwa dua jaringan neural dapat bersinkronisasi satu sama lain dengan pelajaran timbal balik. Kedua jaringan dilatih oleh contoh yang dihasilkan oleh mitra mereka dan akhirnya memperoleh suatu kelurusan antisejajar. Bahkan setelah sinkronisasi aringan terus bergerak, pergerakannya berjalan acak pada suatu N-Dimensional hypersphere yang memproduksi suatu urutan bit yang agak kompleks dari bit keluaran σA= -σB. Sesungguhnya, setelah sistem bersinkronisasi, serupa dengan
jaringan tunggal yang mepelajari kebalikan bit keluaran yang dibahas pada bagian 5.
Gambar 7. Akhir Tumpang-Tindih R antar dua perseptron sebagai fungsi laju pembelajaran η. Pada kurva diatas laju kritis ηc , jaringan tergantung waktu tersinkronisasi.
8. Kriptografi
Dalam bidang ilmu kriptografi, yang mertarik adalah metoda untuk memancarkan pesan rahasia antar dua mitra A dan B. Lawan E yang bisa mendengarkan komunikasi harus tidak mampu memulihkan pesan rahasia itu.
Sebelum1976, semua metoda yang kryptografi harus lebih dulu bersandar pada kunci rahasia untuk encryption yang telah dipancarkan antar A dan B pada suatu saluran rahasia yang tidak dapat diakses lawan. Kunci rahasia umum seperti itu dapat digunakan, sebagai contoh, sebagai benih untuk suatu generator bit acak dengan mana urutan bit dari pesan ditambahkan (modulo 2).
Baru-baru ini, telah ditunjukkan bagaimana jaringan neural yang saling berinteraksi dapat menghasilkan suatu kunci rahasia umum dengan pertukaran bit melewati suatu saluran publik dan dengan belajar dari masing-masing network.
Di bagian yang sebelumnya terelihat bahwa bobot vektor dari dua perseptron belajar dari masing-masing jaringan dapat bersinkronisasi. Gagasan baru adalah untuk menggunakan pembobotan umum wA =-wB sebagai kunci encryption. Tetapi dua permasalahan harus masih dipecahkan:
(i) Dapatkah suatu peninjau yang eksternal, merekam pertukaran dari bit, mengkalkulasi nilai akhir wA(t), (ii) mengerjakan peristiwa ini ada untuk pembobotan yang terpisah? Poin (i)adalah penting bagi kriptografi, yang akan jadi dibahas lebih lanjut pada bagian bawah. Poin(ii) adalah penting untuk solusi praktis karena komunikasi pada umumnya didasarkan pada urutan bit. Yang akan diselidiki sebagai berikut.
Sinkhonisasi terjadi untuk bobot yang ternormalisasi, sedangkan yang tidak, tidak bersinkronisasi. Oleh karena itu, untuk bobot yang terpisah, diperkenalkan suatu pembatasan pada ruang yang mungkin dari vektor dan membatasi wA/B komponen pada nilai 2L+1 nilai yang berbeda,
…………..( 25)
Dalam rangka memperoleh sinkronisasi paralel persis sama benar– sebagai ganti suatu bentuk antisejajar– dinyatakan wA= wB, aturan belajar dimodifikasi:
...( 26)
Sekarang komponen dari vektor masukan acak x biner dengan xi∈ {+1,-1}. Jika dua jaringan
menghasilkan suatu bit keluaran yang serupa σA= σB, kemudian pembobotan pindah satu langkah
dengan arah dari -xiσA. Tetapi bobot tersebut harus berada pada interval karena itu bila ada
komponen pindah dari interval ini, maka diundurkan kembali pada batas wi = ± L.
Setiap komponen dari vektor bobot berjalan acak pada batas. Dua bersesuaian degan komponen wAi dan wBi menerima nomor acak ± 1. Setelah setiap pukulan pada batas dengan jarak | wAi-wBi|
dikurangi sampai mencapai nol. Selama dua perseptron N-Dimensional bobot spasi dipunyai dua ansambel dari N acak internal {-L, ..., L}. Jika kita melalaikan isyarat global σA=σB seperti halnya
penyimpangan σA, diharapkan setelah beberapa skala waktu karakteristik τ=O(L2) kemungkinan dari
dua cara berjalan acak pada status menyimpang menurun
... (27)
Karenanya total waktu sinkronisasi harus diberi oleh N· P(t)= 1 dengan
Sesungguhnya, simulasi untuk N= 100 menunjukkan bahwa dua perseptrons dengan L= 3 tersinkronisasi pada sekitar 100 langkah waktu dan waktu sinkronisasi meningkat secara logaritmis dengan N. Bagaimanapun, simulasi juga menunjukkan bahwa suatu lawan, merekam urutan dari (σA, σB, x)t dapat bersinkronisasi juga. Oleh karena itu, perseptron tunggal tidak dapat mengenerasi
suatu kunci rahasia.
Sesungguhnya, perseptron tunggal memancarkan terlalu banyak informasi. Lawan, yang mengetahui satuan input/output pasangan, dapat memperoleh bobot dari dua mitra setelah sinkronisasi. Oleh karena itu, harus dilajkukan penyembunyian banyak informasi, sehingga lawan tidak bisa mengkalkulasi bobot tersebut, tetapi di sisi lain harus dapat memancarkan informasi yang cukup sehingga dua mitra dapat bersinkronisasi.
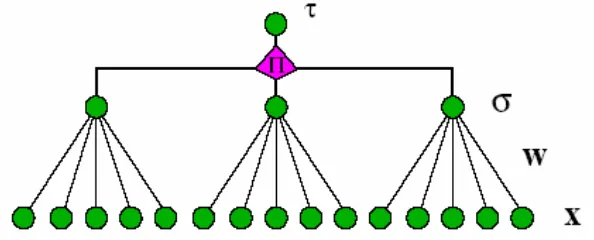
Sesungguhnya, telah ditunjukkan bahwa jaringan berlapis dengan unit tersembunyi mungkin cocok untuk suatu tugas seperti itu. Dengan tepat, dapat dilihat pada mesin pariti dengan tiga unit yang tersembunyi seperti ditunjukkan pada gambar 8
Gambar 8: Mesin kesamaan dengan tiga unit yang tersembunyi.
Setiap unit yang tersembunyi adalah suatu perseptron dengan bobot diskret. Bit keluaran τ dari total jaringan adalah produk dari tiga bit dari unit yang tersembunyi
…………..( 29)
Pada masing-masing langkah pelatihan dua mesin A dan B menerima vektor masukan serupa, x1, x2, x3. Algoritma pelatihan adalah: Hanya jika dua bit keluaran adalah serupa, τ A= τ B, bobot dapat
diubah. Dalam hal ini, hanya unit tersembunyi σi yang identik dengan τ mengubah bobotnya yang
menggunakan aturan Hebbian
………..( 30)
Sebagai contoh, jika τA=τB= 1 ada empat bentuk wujud yang mungkin dari unit tersembunyi pada
setiap jaringan:
Di kasus yang pertama, adalah semua tiga wi,w2,w3 bobot vektor diubah, dalam semua tiga kasus
lain hanya satu vektor bobot diubah. Mitra seperti halnya lawan tidak mengetahui salah satu vektor bobot diperbaharui.
Mitra A dan B bereaksi kepada perhentian timbal balik mereka dan isyarat gerak τA dan τB,
sedangkan lawan hanya dapat menerima isyarat ini tetapi tidak mempengaruhi mitra dengan bit keluaranya. Ini adalah mekanisme penting yang mengijinkan sinkronisasi tetapi melarang pembelajaran. Baik dengan cara numerik maupun analitis, kalkulasi dari proses dinamis menunjukkan bahwa mitra dapat bersinkronisasi dalam waktu singkat sedangkan lawan terpaksa membutuhkan waktu yang lebih panjang untuk mengunci mitra.
Pengamatan ini menjaga suatu peninjau yang menggunakan algoritma yang sama seperti dua mitra A dan B. Perlu diingat bahwa peninjau mengetahui 1. algoritma dari A dan B, 2. vektor masukan, x1, x2, x3 pada masing-masing langkah waktu dan 3. bit keluaran τA dan τB pada masing-masing
langkah waktu. Meskipun demikian, tidak akan berhasil bersinkronisasi dengan A dan B dalam periode komunikasi.
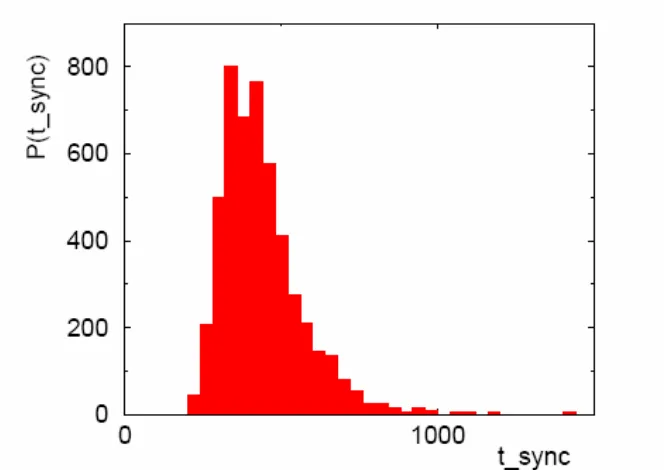
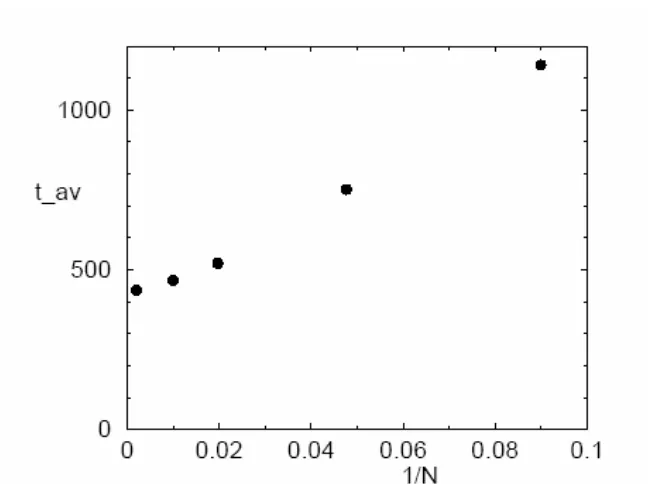
Untuk setiap run dua mitra menarik bobot awal acak dan karena vektor masukan acak, diperoleh suatu distribusi dari sinkronisasi seperti ditunjukkan pada gambar 9. untuk N= 100 dan L= 3. Rata-rata nilai dari distribusi ini dinyatakan sebagai sebagai suatu fungsi dari ukuran sistem N pada gambar 10
Gambar 10: Rata-rata waktu sinkronisasi sebagai fungsi dari ukuran sistem kebalikan.
Gambar 11: Distribusi dari perbandingan dari waktu sinkronisasi antar jaringan A dan B terhadap pembelajaran waktu dari suatu penyerang E.
Bahkan suatu jaringan dengan besar tidak terbatas hanya membutuhkan suatu jumlah bit terbatas yang ditukar- sekitar 400 dalam hal ini - untuk sinkronisasi.
pernah melewati nilai r = 0.1, dan rata-rata waktu pembrlajaran akan berbuat 50000 langkah waktu, lebih besar dari waktu sinkronisasi. Karenanya, dua mitra dapat mengambil pembobotan wAi(t)= wB i
(t) pada langkah waktu t di mana sinkronisasi paling mungkin terjadi sebagai kunci rahasia umum. Sinkronisasi jaringan neural dapat digunakan sebagai sebagai suatu protokol pertukaran kunci melewati saluran publik.
Hingga kini tidak jelas, apakah lebih serangan tingkat lanjut akan akhirnya memecahkan protokol pertukaran ini. Di sisi lain, ada beberapa perluasan yang mungkin dari mekanisme sinkronisasi di mana perkerjaan mentracking akan lebih sulit,
9. Kesimpulan
Dinamika dari jaringan neural yang saling berinteraksi telah dipelajari dalam konteks suatu model yang sederhana: perceptron dan perluasannya. Dinamika dari model ini dapat dihitung secara analitis; bersifat makroskopik dapat diuraikan dengan persamaan diferensial untuk beberapa parameter benahan.
Beberapa macam dari proses interaksi telah dipelajari. Dalam semua kasus jaringan dilatih oleh satu set yang contoh dihasilkan oleh jaringan yang berbeda. Ini adalah jaringan yang saling berhubungan. Beberapa jaringan membangitkan pasangan dari data masukan dimensional tinggi dan suatu isyarat keluaran bersesuaian dan memancarkan informasi ini kepada jaringan yang lain. Jaringan yang menerima informasi ini mengadaptasikan parameter mereka (bobot sinaptik mereka) pada masing-masing contoh. Yang menjadi pertanyaan adalah cakupan luasan informasi pertukaran jaringan yang saling mendekati satu sama lain pada ruang sinaptik dimensional tinggi.
Skenario Teacher/Student dari suatu jaringan statis yang membangkitkan contoh sebagai tambahan terhadap suatu jaringan adaptip yang dilatih dengan contoh ini adalah kasus yang kebanyakan dipelajari. Yang menjadi pertanyaan adalah berapa baikkah siswa belajar aturan yang memproduksi contoh tersebut, bagaimana mungkin digeneralisasi? Solusi analitik untuk perseptron menunjukkan banyaknya contoh pelatihan harus dicapai dari jumlah neurons untuk mencapai generalisasi. Karena memberi isyarat kepada seseorang, algoritma pelatihan optimal generalisasi kesalahan tidak membusuk lebih cepat dari kebalikan dari waktu pelatihan.
Jika kedua jaringan guru dan siswa lebih kompleks kemudian gejala yang baru diamati. Sebagai contoh, untuk suatu spesialisasi mesin komisi terjadi: Untuk menyingkat siswa berelaksasi cepat persis sama benar bentuk wujud di mana telah mencapai generalisasi tetapi masih dalam status yang simetris, bertindak seperti suatu perseptron sederhana.Hanya jika banyaknya contoh ditingkatkan pada nilai sangat besar, jaringan siswa dapat lepas dari bentuk konfigurasi ini dan masing-masing anggota dari komisi berspesialisasi bersesuaian dengan anggota di jaringan guru.
Jaringan guru yang statis dapat juga menghasilkan suatu gugus berkala untuk jaringan siswa terlatih. Sebagai tambahan terhadap tumpang-tindih antara guru dan parameter siswa, adanya ketertarikan akan kemampuan ramalan dari siswa setelah periode interaksi. Ternyata belajar dan ramalan tidaklah perlu dihubungkan. Ditemukan bahwa perseptron baik sekali belajar suatu urutan yang kacau tetapi tidak bisa meramal. Di sisi lain, urutan quasiperiodic sukar untuk mempelajari pembootan guru tetapi dengan mudah untuk meramalkan urutan bersesuaian.
Suatu pertanyaan umum tentang properti dari algoritma ramalan memimpin ke arah suatu perseptron saling berinteraksi dengan dirinya sendiri. Hal tersebut menghasilkan suatu gugus berkala agak kompleks yang menghasilkan 100% kesalahan ramalan jika perseptron yang sama dilatih urutan ini. Tetapi sekalipun suatu perseptron yang berbeda mengarahkan urutan ini, dan dapat mencapai beberapa pengetahuan tentang guru, tetapi kesalahan ramalannya lebih besar dari 50%.
Suatu masyarakat dari jaringan neural dapat menukar informasi dan tahu dari satu sama lain. Ditunjukkan dengan bagaimana skenario seperti itu dapat didorong kearah kooperasi yang sukses di permainan minoritas – suatu model untuk bersaing agen pasar yang tertutup.
Jika dua jaringan sedang menukarkan informasi dan belajar dari masing-masing, mereka dapat bersinkronisasi. Itu berarti, setelah beberapa waktu pelatihan mereka berelaksasi persis sama benar dalam bentuk wujud dengan waktu yang serupa dengan pembobotan sinaptik (sampai ke suatu tanda yang umum). Dua jaringan tetap berdifusi pada suatu hypersphere dimensional tinggi, tetapi dengan bobot yang serupa. Jaringan neural dapat bersinkronisasi dalam pelajaran timbal balik.
Peristiwa yang baru ini dapat diberlakukan bagi kriptografi. Ditunjukkan dengan bagaimana jaringan yang berlapis dengan hingga batas tertentu bersinkronisasi bobot diskret setelah ratusan langkah interaksi. Bagaimanapun, sepertiga jaringan yang merekam pertukaran dari contoh tidak bersinkronisasi, sedikitnya selama suatu jangka waktu pendek. Pelajaran oleh pelajaran timbal balik cepat, tetapi belajar dan dengan mendengarkan adalah sangat lambat. Karenanya dua mitra dapat bermufakat untuk suatu rahasia yang umum melewati suatu saluran publik. Peninjau yang mengetahui semua detil dari algoritma dan mengetahui semua contoh pelatihan tidak bisa mengkalkulasi kunci yang rahasia itu. Ini adalah kunci publik yang pertama yang tidak didasarkan pada teori nomor. Riset masa depan akan menunjukkan bagaimana baik algoritma yang baru ini– yang didasarkan pada pelajaran timbal balik tentang jaringan neural.
Sinkhronisasi dari jaringan neural adalah suatu pokok yang aktip tentang riset dalam neurobiologi. Hingga kini adalah belum jelas bagaimana sinkronisasi dikembangkan dan apa fungsinya. Di sini kalkulasi model menunjuk suatu arah yang baru: Dua atau beberapa jaringan biologi dapat mencapai suatu status bergantung waktu umum dengan informasi pelajaran menukar antara mitra aktif. Jaringan yang lain menerima yang sama informasi tanpa menjadi mampu mempengaruhi mitra, tidak bisa mengunci dalam waktu umum. Karenanya bahkan secara penuh jaringan dihubungkan, bagian-bagian itu dapat bersinkronisasi oleh pelajaran timbal balik, pada waktu yang sama menyaring status synchronisasi mereka dari pembelajaran hanya dengan mendengarkan.
Secara ringkas, ini adalah usaha pertama untuk mengembangkan suatu teori dari jaringan neural yang saling berinteraksi. Beberapa gejala telah ditemukan dari model sederhana seperti perseptron atau mesin pariti. Gejala ini bukan dimasukkan ke dalam model dari awal dan tidak pula jelas nyata; mereka adalah suatu hasil dari perilaku kerjasama dari pembobotan sinaptik dan hanya dapat dipahami dari kalkulasi numerik dan analitis.