BAB 2
LANDASAN TEORI
1.8 Defenisi Peramalan
Peramalan adalah suatu kegiatan yang meliputi pembuatan perencanaan di masa yang akan datang dengan menggunakan data masa lalu dan data masa sekarang, sehingga dapat membuat prediksi di masa yang akan datang. Dalam hal manajemen dan administrasi, perencanaan merupakan kebutuhan yang penting untuk dilakukan. Oleh karena itu dibutuhkan peramalan untuk menduga berbagai peristiwa yang akan terjadi di masa mendatang.
Dalam suatu instansi atau perusahaan ramalan sangat dibutuhkan untuk memberikan imformasi kepada pimpinan yang akan dijadikan sebagai dasar untuk membuat suatu keputusan dalam berbagai kegiatan, seperti penentuan kebijakan yang akan diambil, penjualan permintaan, persediaan keuangan dan sebagainya.
Sejak awal tahun 1960-an, semua tipe organisasi telah menunjukkan keinginan yang meningkat untuk mendapatkan ramalan dan menggunakan sumber daya peramalan secara lebih baik. Komitmen tentang peramalan telah tumbuh karena beberapa faktor:
Pertama, karena meningkatnya kompleksitas organisasi dan lingkungannya; hal ini menjadikan semakin sulit bagi pengambil keputusan untuk mempertimbangkan semua faktor secara memuaskan.
Kedua, dengan meningkatnya ukuran organisasi, maka bobot dan kepentingan suatu keputusan telah meningkat pula; lebih banyak keputusan yang memerlukan telaah peramalan khusus dan analisis yang lengkap.
Ketiga, lingkungan dari kebanyakan organisasi telah berubah dengan cepat. Keterkaitan yang harus dimengerti oleh organisasi selalu berubah-ubah dan peramalan memungkinkan bagi organisasi untuk mempelajari keterikatan yang baru secara lebih cepat.
Keempat, pengambilan keputusan telah semakin sistematis yang melibatkan justifikasi tindakan individu secara gamblang (eksplisit). Peramalan formal merupakan salah satu cara untuk mendukung tindakan yang akan diambil.
2.1.2 Pola Data
Pola data dapat dibedakan menjadi empat jenis siklis dan trend:
A. Pola horizontal (H)
Terjadi bilamana nilai data berfluktuasi di sekitar nilai rata- rata yang
konstan. (Deret seperti itu adalah “stasioner” terhadap nilai rata-ratanya).
Suatu produk yang penjualannya tidak meningkat atau menurun selama waktu tertentu termasuk jenis ini. Demikian pula suatu keadaan pengendalian kualitas yang menyangkut pengambilan contoh dari suatu proses produksi kontiniu yang secara teoritis tidak mengalami perubahan juga termasuk jenis ini.
Gambar 1.1 berikut menunjukkan suatu pola khas dari data horizontal atau stasioner seperti itu.
Y
waktu
Gambar 1.1 POLA DATA HORIZONTAL B. Pola musiman (S)
pemanas ruang. Semuanya menunjukkan jenis pola ini. Untuk pola musiman kuartalan, mungkin datanya serupa dengan gambar 1.2 berikut.
Y
Waktu
Gambar 1.2 POLA DATA MUSIMAN
C. Pola siklis (C) terjadi bilamana datanya dipengaruhi oleh fluktuasi ekonomi jangka panjang seperti yang berhubungan dengan siklus bisnis. Penjualan produk seperti mobil, baja, dan peralatan utama lainnya. Menunjukkan jenis pola ini seperti ditunjukkan pada gambar 1.3
Y
Waktu
D. Pola trend (T) terjadi bilamana terdapat kenaikan atau penurunan sekuler jangka panjang dalam data. Banyak penjualan perusahaan, produk bruto nasional (GNP) dan berbagai indicator bisnis ekonomi lainnya mengikuti suatu pola trend selama perubahannya sepanjang waktu. Gambar 1.4 menunjukkan salah satu pola trend seperti itu.
Y
Waktu
Gambar 1.4 POLA DATA TREND
2.1.3 Jenis Data
Data yang diperoleh dari suatu hasil observasi dapat diklarifikasikan menurut jenisnya berdasarkan kriteria berikut:
A. Data Primer dan Data Sekunder
Data sekunder merupakan data primer yang diperoleh pihak lain, atau telah diolah dan disajikan baik oleh pengumpul data primer atau pihak lain, pada umumnya disajikan dalam bentuk table atau diagram. Data sekunder pada umumnya digunakan peneliti untuk memberikan gambaran tambahan, gambaran pelengkap ataupun untuk diproses lebih lanjut.
B. Data Kualitatif dan Data Kuantitatif
Data kualitatif adalah data yang sifatnya hanya menggolongkan saja. Termasuk dalam klasifikasi data kualitatif adalah data yang berskala ukur normal atau ordinal. Sebagai contoh data kualitatif adlah jenis pekerjaan seseorang (supir, bisnisman, guru, dll), motivasi karyawan (bagus, jelek, sedang) dan jabatan di perusahaan (supervisor, manajer pemasaran, dll).
Data kuantitatif adalah data berbentuk angka. Yang termasuk dalam klasifikasi ini adalah data berskala ukur interval dan rasio. Sebagai contoh adalah keuntungan suatu perusahaan X (Rp.5 Miliar), kenaikan penjualan suatu perusahaan X (35%), dsb.
C. Data Internal dan Data Eksternal
Data eksternal menggambarkan keadaan di luar organisasi. Pada umumnya data ini didapat dari pihak lain dan digunakan sebagai pembanding.
D. Data Time Series dan Data Cross Section
Data time series atau data deret waktu merupakan data yang dikumpalkan dari beberapa tahapan waktu secara kronologis. Pada umumnya data ini merupakan kumpulan dari fenomena tertentu yang didapat dalam interval tertentu, misalnya waktu mingguan, bulanan atau tahunan.
Data cross section adalah data yang dikumpulkan pada waktu dan tempat tertentu saja. Data ini pada umumnya mencerminkan suatu fenomena dalam satu kurun waktu tertentu.
Dalam peramalan, data time series dan data cross section menempati posisi yang amat penting. Dalam penggunaannya, beberapa kasus melibatkan gabungan dari keduanya.
2.2 Bentuk Analisis Data Deret Waktu
Beberapa bentuk analisis data deret waktu dapat dikelompokkan ke dalam beberapa kategori:
Metode pemulusan dapat dilakukan dengan dua pendekatan yakni Metode Perataan (Average) dan Metode Pemulusan Eksponensial (Exponential Smoothing). Pada metode rataan bergerak dapat digunakan untuk memuluskan data deret deret waktu dengan berbagai metode perataan, diantaranya:
rata-rata bergerak sederhana rata-rata bergerak ganda
rata-rata bergerak dengan ordo lebih tinggi.
Untuk semua kasus dari metode tersebut, tujuannya adalah memanfaatkan data masa lalu untuk mengembangkan system peramalan pada periode mendatang.
Pada metode pemulusan eksponensial, pada dasarnya data masa lalu dimuluskan dengan cara melakukan pembobotan menurun secara eksponensial terhadap nilai pengamatan yang lebih tua. Atau nilai yang lebih baru diberikan bobot yang relatif lebih besar dibanding nilai pengamatan yang lebih lama. Beberapa jenis analisis data deret waktu yang masuk pada kategori pemulusan eksponensial, diantaranya:
pemulusan eksponensial tunggal
pemulusan eksponensial tunggal: pendekatan adaptif pemulusan eksponensial ganda: metode Brown metode pemulusan eksponensial ganda: metode Holt pemulusan eksponensial tripel: metode Winter.
pada metode rataan bergerak, metode pemulusan eksponensial juga dapat digunakan untuk meramalkan data beberapa periode ke depan.
b. Model ARIMA (Autoregressive Integrated Moving Average)
Seperti halnya pada metode analisis sebelumnya, model ARIMA dapat digunakan untuk analisis data deret waktu dan peramalan data. Pada model ARIMA diperlukan penetapan karakteristik data deret berkala seperti: stasioner, musiman dan sebagainya, yang memerlukan suatu pendekatan sistematis, dan akhirnya akan menolong untuk mendapatkan gambaran yang jelas mengenai model-model dasar yang akan ditangani. Hal utama yang mencirikan dari model ARIMA dalam menganalisis data deret waktu dibandingkan metode pemulusan adalah perlunya pemeriksaaan keacakan data dengan melihat koefisien autokorelasinya. Model ARIMA juga bisa digunakan untuk mengatasi masalah sifat keacakan, trend, musiman bahkan sifat siklis data-data deret waktu yang dianalisis.
c. Analisis Deret Berkala Multivariate
Model-model multivariate diantaranya: (1) model fungsi transfer, (2) model analisis intervensi, (3) fourier analysis, (4) analisis spectral dan (5) vector time series models.
2.3Beberapa Uji Yang Digunakan
Adapun beberapa uji yang digunakan pada peramalan antara lain:
a. Uji Kecukupan Sampel
Sebelum melakukan analisa terhadap data yang diperoleh, langkah awal yang harus dilakukan adalah pengujian terhadap anggota sampel. Hal ini dimaksudkan untuk mengetahui apakah data yang diperoleh dapat diterima sebagai sampel. Dengan tingkat keyakinan 95% (α = 0,05) rumus yang digunakan untuk menentukan jumlah anggota sampel adalah:
2
= Ukuran sampel yang dibutuhkan
Apabila < N , maka sampel percobaan dapat diterima sebagai sampel.
b. Uji Musiman
Untuk mengetahui adanya komponen musiman dilakukan uji musiman dengan hipotesa ujinya sebagai berikut:
= data tidak dipengaruhi musiman
= data dipengaruhi musiman
Untuk perhitungan digunakan notasi:
i k i
i y
n J
R 1
2
(2.2)
,
Sehingga diperoleh:
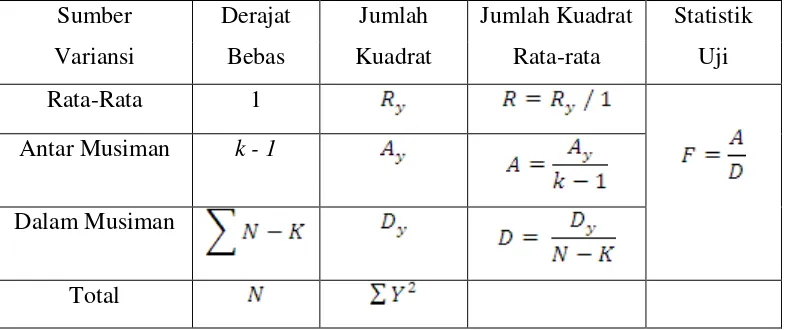
Tabel 2.1 Perhitungan ANAVA Uji Musiman
Sumber Derajat Jumlah Jumlah Kuadrat Statistik Variansi Bebas Kuadrat Rata-rata Uji Rata-Rata 1
Antar Musiman k - 1
Dalam Musiman
Total
Kriteria pengujian adalah:
Jika maka diterima (tidak dipengaruhi musiman)
jika maka ditolak (data dipengaruhi musiman)
c. Uji Trend
Tujuan dari uji trend adalah untuk melihat apakah ada pengaruh komponen trend terhadap data dengan hipotesis ujinya sebagai berikut:
= frekuensi naik dan turun dalam data adalah sama, artinya tidak ada trend
= frekuensi naik dan turun tidak sama, artinya dipengaruhi oleh trend
...(2.3) m
Z
dimana:
dengan:
m = frekuensi naik n = jumlah data
= frekuensi naik
= standart error antara naik dan turun
Kriteria pengujian adalah:
Dengan taraf signifikan , diterima jika dan
ditolak jika
2.4 Metode Pemulusan (Smoothing) Eksponensial
Kasus yang paling sederhana dari pemulusan (smoothing) eksponensial tunggal dapat digantikan dengan suatu nilai pendekatan (aproksimasi). Salah satu pengganti yang mungkin adalah nilai ramalan periode yang sebelumnya Ft. Dengan melakukan substitusi ini persamaan (2-2) menjadi:
1
Jika datanya stasioner pendekatan di atas merupakan pendekatan yang cukup baik, namun bila terdapat trend, metode eksponensial tunggal yang dijelaskan disini tidak cukup baik.
Dari persamaan (2.6) dapat dilihat bahwa ramalan ini (Ft+1) didasarkan atas
pembobotan observasi yang terakhir dengan suatu nilai bobot 1 N
dan pembobotan
nilai ramalan yang terakhir sebelumnya (Ft) dengan suatu bobot 1 1 N
. Karena N
merupakan suatu bilangan positif, 1 N
N tak terhingga) dan 1 (jika N = 1). Dengan mengganti 1
Ft+1 = Ramalan satu periode ke depan Xt = Data actual pada periode t Ft = Ramalan pada periode t
= Parameter pemulusan (0<α<1).
Persamaan ini merupakan bentuk umum yang digunakan dalam menghitung ramalan dengan metode pemulusan eksponensial. Metode ini banyak mengurangi masalah penyimpanan data, karena tidak perlu lagi menyimpan semua data historis atau sebagian daripadanya. Agaknya hanya observasi terakhir, ramalan terakhir, dan suatu nilai α yang harus disimpan.
Implikasi pemulusan ekponensial dapat dilihat dengan lebih baik bila persamaan (2.7) diperluas dengan mengganti F dengan komponennya sebagai berikut:
observasi masa lalu akan menjadi sebagai berikut:Bobot yang diberikan pada: n = 0,2 n = 0,4 n=0,6 n=0,8 eksponensial, dari sanalah nama pemulusan (smoothing) eksponensial muncul.
2.4.2 Pemulusan Eksponensial Tunggal: Pendekatan Adaptif
Dalam pemulusan ini, terdapat dua parameter yang bergerak dari nol sampai satu. Persamaan dasar untuk peramalan dengan metode pendekatan adaptif adalah serupa dengan persamaan (2.7) kecuali bahwa nilai α diganti dengan αt :
1 1
t t t t t
F X F ………..(2.8)
E M = Unsur kesalahan yang dihaluskan
& = Parameter antara 0 dan 1.
Metode pemulusan ini cocok digunakan untuk peramalan yang jenis datanya stasioner dan non-musiman.
2.4.3 Pemulusan (Smoothing) Eksponensial Ganda: Metode Linier Satu-Parameter
dari Brown
Pemulusan eksponensial linier satu-parameter dari Brown merupakan metode yang lebih disukai untuk data non-stasioner, terutama karena metode ini mempunyai satu parameter (dibanding dua parameter Holt). Berdasarkan pengalaman disarankan bahwa nilai optimal terletak dalam kisaran 0,1 dan 0,2 karena adanya himpunan pilihan α yang dipersempit ini, maka metode ini biasanya dipandang sebagai metode yang lebih mudah diterapkan (Spyros Makridakis, 1999).
S = nilai pemulusan eksponensial tunggal
"
t
S = nilai pemulusan eksponensial ganda
= parameter pemulusan eksponensial (0< <1)
, t t
a b = konstanta pemulusan
t m
F = hasil pemulusan untuk m periode ke depan.
2.4.4 Pemulusan (Smoothing) Eksponensial Ganda: Metode Dua-Parameter dari Holt
menggunakan dua konstanta, yakni (0<<1) & (0< <1). Bentuk umum dari pemulusan Holt adalah sebagai berikut:
1 1 1 1
t t t
S X S b ………….………..(2.17)
– 1
1
1t t t t
b S S b ...………(2.18)
t m t t
F S b m………...(2.19)
Dengan:
t
S = nilai pemulusan awal
t
b = konstanta pemulusan
t m
F = ramalan untuk m periode ke depan t
,
= parameter pemulusan yang bernilai antara 1 dan 0.
dikalikan dengan (1- ). Akibatnya persamaan (2.18) dipakai untuk meramalkan periode ke depan.
2.5 Masalah Nilai Awal
Jika data di masa lalu tidak ada, maka nilai-nilai berikut dapat dipakai:
a. Pemulusan eksponensial tunggal dengan tingkat respon yang adatif
1 1
F X
b. Pemulusan eksponensial linier dari Brown
" '
1 1 1
S S X
1 1
a X
2 1
4 3
1
2
X X X X
b
c. Pemulusan eksponensial dari Holt
1 1
S X
2 1
4 3
1
2
X X X X
b
Metodologi untuk menganalisis data deret berkala untuk memperlihatkan apakah data mengandung pola data trend dan musiman. Dalam hal ini digunakan:
1. Plot Data
Langkah pertama yang baik untuk menganalisis data deret berkala adalah dengan memplot data tersebut secara grafis.
2. Koefisien Autokorelasi
Koefisien autokorelasi digunakan untuk melihat apakah ada hubungan antara suatu data deret berkala dengan kelambatan waktu (time lag) k periode. Selain hal itu distribusi koefisien autokorelasi sangat membantu dalam melihat sifat pola yang terkandung dalam data apakah data berpola, trend, musiman ataupun
stasioner. Autokorelasi untuk lag waktu 1, 2, 3, …, k dapat dicari dan
dinotasikan rk (Spyros Makridakis, 1983), dengan menggunakan rumus sebagai berikut:
r = koefisien autokorelasi
t
t k
Y = data actual periode t dengan kelambatan (time lag) k Y = rata-rata data actual
Koefisien autokorelasi perlu diuji untuk menentukan apakah nilainya berbeda secara signifikan dari nol atau tidak, hal ini menunjukkan sifat pola data. Untuk melihat perbedaan yang signifikan ini, perlu dihitung kesalahan standar denga persamaan:
1 rk se
n
………..(2.21)
Dengan n adalah jumlah data, dan batas signifikan autokorelasinya adalah:
2 2
. rk k . rk
Z x se r Z x se
………...(2.22)
Apabila nilai koefisien autokorelasi pada beberapa time lag pertama secara berurutan berbeda secara signifikan dari nol, maka data menunjukkan pola trend, dan apabila nilai koefisien autokorelasi pada sepanjang time lag mempunyai jarak yang sistematis atau beraturan berbeda secara signifikan dari nol, maka data tersebut menunjukkan pola musiman.
2.7Ketepatan Peramalan
Nilai Tengah Kesalahan (Mean Error)
Nilai Tengah Kesalahan Absolut (Mean Absolute Error)
1
Jumlah Kuadrat Kesalahan Absolut (Sum Squared Error)
2
Deviasi Standar Kesalahan (Standard Deviation Error)
Nilai Tengah Kesalah Kuadrat ( Mean Squared Error)
2
Nilai Tengah Persentase Absolut (Mean Absolute Percentage Error)
Nilai Tengah Kesalahan Persentase (Mean Percentage Error)
Untuk melihat ketepatan peramalan digunakan kriteria Mean Squared Error (MSE) yang terkecil yang sekaligus merupakan kriteria paling baik, karena:
1. Usaha meminimalkan
etakan menambah kesulitan karena beberapa nilai et positif dan negatif sehingga terjadi kesalahan yang salingmeniadakan.
2. Usaha meminimalkan nilai absolut
et akan menambah kesulitan karena beberapa nilai et negatif dianggap positif, demikian juga untukmeminimasi absolut