BAB 2
LANDASAN TEORI
2.1Citra Digital
Citra adalah suatu representasi, kemiripan atau imitasi dari suatu objek atau benda, misal: foto seseorang mewakili entitas dirinya sendiri di depan kamera. Sedangkan citra digital adalah citra yang disimpan dalam format digital (dalam bentuk file) yang dapat diolah oleh komputer. Jenis citra lain jika akan diolah dengan komputer harus diubah dulu menjadi citra digital.
Sebuah citra digital dapat diwakili oleh sebuah matriks yang terdiri dari M kolom dan N baris, dimana perpotongan antara kolom dan baris disebut piksel, yaitu elemen terkecil dari sebuah citra. Piksel mempunyai dua parameter, yaitu koordinat dan intensitas atau warna. Nilai yang terdapat pada koordinat (x,y) adalah f(x,y), yaitu besar intensitas dari piksel di titik itu. Oleh sebab itu, sebuah citra digital dapat ditulis dalam bentuk matriks berikut [7]:
f(x,y)=�
2.2Jenis Citra Digital
Nilai suatu piksel memiliki nilai rentang tertentu, dari nilai minimum sampai nilai maksimum.Jangkauan yang digunakan berbeda-beda tergantung dari jenis warnanya.Namun, secara umum jangkauannya adalah 0 – 255.Berikut adalah jenis-jenis citra berdasarkan nilai pikselnya.
2.2.1 Citra Biner
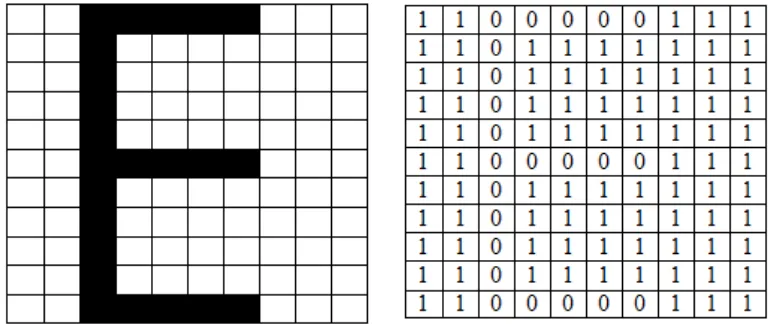
Citra biner adalah citra digital yang hanya memiliki dua kemungkinan nilai piksel yaitu hitam dan putih. Nilai 0 mewakili warna hitam dan nilai 1 mewakili warna putih. Citra biner disebut juga dengan citra B&W (black & white)atau citra monokrom. Oleh karena itu, hanya dibutuhkan 1 bit untuk mewakili nilai setiap piksel dari citra biner. Contoh citra biner dapat di lihat pada gambar 2.1.
Gambar 2.1 Contoh Citra Biner Berukuran 10 x 11 piksel dan Representasinya dalam data digital
2.2.2 Citra Grayscale
araskeabuan karena warna abu-abu diantara warna minimum (hitam) dan warna maksimum (putih). Pada umumnya citra grayscale memiliki kedalaman piksel 4 bit dan 8 bit. Citra dengan 4 bit memiliki 24 = 16 kemungkinan warna, yaitu 0 (minimal) 15 (maksimal). Sementara citra dengan 8 bit memiliki 28 = 256 warna, yaitu 0 (minimal) hingga 255 (maksimal). Contoh citra grayscale dapat di lihat pada gambar 2.2.
Gambar 2.2 Contoh Citra Grayscale skala keabuan 8 bit
2.2.3 Citra Warna
Gambar 2.3 Contoh Citra Warna
2.3Kompresi Citra
Kompresi citra adalah proses pemampatan citra yang bertujuan untuk mengurangi duplikasi data pada citra sehingga memory yang digunakan untuk merepresentasikan citra menjadi lebih sedikit daripada representasi citra semula.
Rasio citra kompresi adalah ukuran persentase citra yang telah berhasil dimampatkan. Secara matematis rasio pemampatan data ditulis sebagai berikut [7]:
R = 100% - (K1/Ko) x 100 %
Dimana:
R adalah rasio kompresi. Ko adalah Ukuran file asli.
K1 adalah Ukuran file terkompresi.
1. Metode lossless
Merupakan kompresi citra dimana hasil dekompresi dari citra yang terkompresi sama dengan citra aslinya, tidak ada informasi yang hilang. Sayangnya, untuk ratio kompresi citra metode ini sangat rendah. secara umum teknik lossless digunakan untuk penerapan aplikasi yang memerlukan kompresi tanpa cacat, seperti pada aplikasi radiografi, kompresi citra hasil diagnose medis atau gambar satelit, di mana kehilangan gambar sekeil apa pun akan menyebabkan hasil yang tidak diharapkan. Contoh metode ini adalah Shannon-Fano Coding, Huffman Coding, Arithmetic Coding, Run Length Encodingdan lain sebagainya.
2. Metode lossy
Merupakan kompresi citra dimana hasil dekompresi dari citra yang terkompresi tidak sama dengan citra aslinya, artinya bahwa ada informasi yang hilang, tetapi masih bias ditolerir oleh persepsi mata. Metode ini menghasilkan ratio kompresi yang lebih tinggi dari pada metode lossless. Contohnya adalah color reduction, chroma subsampling, dan transform coding, seperti transformasi Fourier, Wavelet
dll.
2.4Dekompresi
Sebuah citra yang sudah dikompres tentunya harus dapat dikembalikan lagi kebentuk aslinya, prinsip ini dinamakan dekompresi. Untuk dapat merubah citra yang terkompres diperlukan cara yang berbeda seperti pada waktu proses kompres dilaksanakan. Jadi pada saat dekompres catatan header yang berupa byte-byte tersebut terdapat catatan isi mengenai isi dari file tersebut.
Kompresi Dekompresi
Ukuran Citra Asli Ukuran Citra Hasil Kompresi Gambar 2.4 Alur kompresi-dekompresi citra
2.5 Run Length Encoding (RLE)
Berbeda dengan teknik-teknik yang bekerja berdasarkan karakter per karakter, teknik run length ini bekerja berdasarkan sederetan karakter yang berurutan. Run Length
Encoding adalah suatu metode kompresi data yang bersifat lossless.Metode ini
mungkin merupakan metode yang paling mudah untuk dipahami dan diterapkan.Run Length Encoding (RLE) adalah metode kompresi yang sangat mendasar. Metode
kompresi ini sangat sederhana, yaitu hanya memindahkan pengulangan byte yang sama berturut-turut (secara terus menerus) [2].
Sebagai contoh adalah sebuah data angka numerik “122221113113444” akan di-encode dengan metode RLE maka hasilnya adalah sebagai berikut.
(1,1)(2,4)(1,3)(3,1)(1,2),(3,1)(4,3)
Hasil pengkodean adalah:
11241331123143, semuanya = 14 byte.
Ukuran citra sebelum dikompresi = 15 x 8 bit = 120 bit. Ukuran citra sesudah dikompresi = 14 x 8 bit = 112 bit.
�100%−112
120𝑥𝑥 100 % �= 6.66 %, artinya 6.66 % dari citra semula telah dikompresi.
2.6Metode Huffman
Metode Huffman adalah metode pengkodean yang telah banyak diterapkan untuk aplikasi kompresi citra. Seperti metode Shannon Fano, metode Huffman juga membentuk pohon atas dasar probabilitas setiap simbol, namun teknik pembentukan pohonnya berbeda.
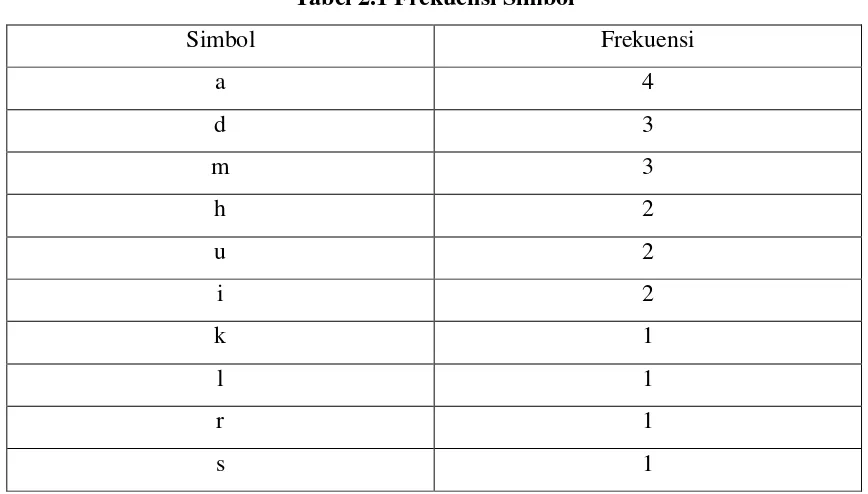
1. Data dianalisis dahulu dengan cara membuat table frekuensi kemunculan setiap simbol ASCII, table frekuensi tersebut memiliki atribut berupa simbol ASCII dan frekuensi.
2. Dua data yang memiliki frekuensi kemunculan paling kecil dipilih sebagai simpul pertama pada pohon Huffman.
3. dari dua simpul ini dibuat simpul induk yang mencatat jumlah frekuensi dua simpul pertama.
4. Kemudian dua simpul tersebut dihapus dari table digantikan oleh simpul induk tadi. Simpul ini kemudian dijadikan acuan untuk membentuk pohon.
5. Langkah 3-5 dilakukan dengan berulang-ulang hingga isi table tinggal satu saja. Data inilah yang akan menjadi simpul bebas atau simpul akar.
6. Setiap simpul yang terletak pada cabang kiri (simpul dengan frekuensi lebih besar) diberi nilai 0 dan simpul yang terletak pada cabang kanan (simpul dengan frekuensi lebih kecil) diberi nilai 1.
7. Pembacaan dilakukan dari simpul akar kearah simpul daun dengan memperhatikan nilai setiap cabang.
Berikut adalah contoh implementasi metode Huffman yang telah dipaparkan di atas. Kata yang ingin dikompresi : muhammadsaidalkhudri
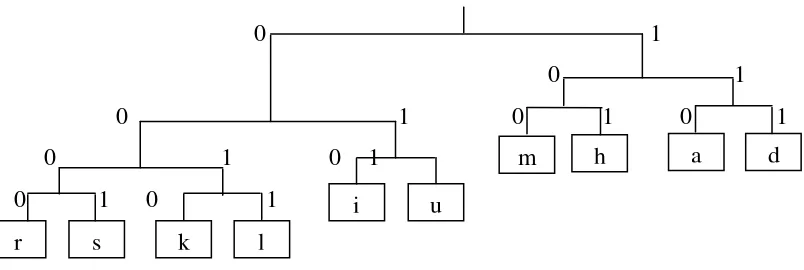
Proses pembentukan pohon Huffman dimulai dari menggabung simbol “s” dan “r” (dua simbol terbawah) dengan frekuensi berjumlah 2. Gabungan 2 simbol tersebut (“sr”) dipakai sebagai acuan untuk bergerak ke atas. Karena simbol “l” frekuensinya masih lebih kecil dari simbol “sr”, maka simbol “l” digabung dengan simbol di atasnya (“k”) menghasilkan simbol “lk”. Gabungan tersebut menghasilkan freuensi berjumlah 2. Simbol “sr” dan “lk” membentuk pohon Huffman dengan total frekuensi berjumlah 4. Proses pergerakan ke atas kemudian dilanjutkan sehingga dihasilkan pohon Huffman.
Pohon Huffman pada Gambar 2 dibentuk atas dasar simbol yang memiliki frekuensi lebih tinggi dikodekan dengan nilai “0” dan yang lebih rendah dengan nilai “1”.
Gambar 2.5 Pohon Huffman dari kata “muhammadsaidalkhudri”
Berdasarkan Gambar 2.5 di atas, maka setiap simbol dapat dikodekan seperti ditunjukkan pada Tabel 2:
Tabel 2.2 Hasil Proses Pengkodean Huffman
Simbol Frekuensi Kode Jumlah Bit
u 2 011 3 6
i 2 010 3 6
k 1 0010 4 4
l 1 0011 4 4
r 1 0000 4 4
s 1 0001 4 4
Total 20 64 bit