PENGELOMPOKKAN JENIS LAYANAN
KESEHATAN MASYARAKAT DAERAH DEMAK
MENGGUNKAAN ALGORITMA K-MEANS
CLASSIFICATION OF DEMAK REGIONAL PUBLIC
HEALTH SERVICES USING K-MEANS ALGORITHM
Ramadhanti Sukma P
1, Nova Rijati
2Fakultas Ilmu Komputer, Universitas Dian Nuswantoro Semarang
1e-mail : ramadhantisukma@gmail.com,
2novaola@yahoo.com
Abstrak
Implementasi data mining dapat memberikan informasi tentang daerah yang terjangkit penyakit dan jenis layanan yang digunakan oleh pasien dengan cepat, jelas, dan akurat dalam bentuk aplikasi. Data mining merupakan penemuan informasi baru dengan mencari pola dari sejumlah data dalam jumlah besar. Algoritma k-means adalah algoritma pengelompokkan yang dipilih untuk pengelolaan data sehingga informasi yang dibutuhkan dapat terpenuhi. Pada tahap clustering dengan menggunakan algoritma k-means dimulai dengan pembentukan cluster. Melalui data pasien rawat inap ini lalu dikelompokkan berdasarkan jenis layanannya. Dari hasil proses klustering menggunakan 200 data yang diperoleh dari tempat penelitian RSI Sultan Agung Semarang dengan lima kategori kluster maka didapatkan hasil dari sistem pengelompokkan penggunaaan jenis layanan yang paling banyak digunakan pasien yaitu, pada Kecamatan Sayung (C1) jenis layanan yang paling banyak digunakan pasien adalah JKN NON PBI, pada Kecamatan Karangtengah (C2) jenis layanan yang paling banyak digunakan pasien adalah JKN NON PBI, pada Kecamatan Mranggen (C3) jenis layanan yang paling banyak digunakan pasien adalah JKN PBI, pada Kecamatan Guntur (C4) jenis layanan yang paling banyak digunakan pasien adalah JKN PBI dan pada Kecamatan Karangawen (C5) jenis layanan yang paling banyak digunakan pasien adalah JKN PBI dan JKN NON PBI.
Kata Kunci: Data Mining, Rawat Inap, Clustering, K-Means Abstract
Implementation of data mining can provide information about the area that is infected and the types of services used by patients with fast, clear, and accurate information in the application form. Data mining is the discovery of new information by looking for patterns of a number of large amounts of data. Algorithm k-means clustering algorithm is selected for the management of data so that the information it needs can be met. At this stage of clustering algorithms using k-means starting with the formation of clusters. Through the data of hospitalized patients were then grouped by type of service. From the results of the clustering using the 200 data obtained from the study RSI Sultan Agung Semarang with five categories of clusters the results obtained from the system of grouping the use of the type of service most widely used patient is, at the District Sayung (C1) the type of service most widely used patient is JKN NON PBI, in the District Karangtengah (C2) the type of service most widely used patient is JKN NON PBI, in the District Mranggen (C3) the type of service most widely used patient is JKN PBI, in the District of Thunder (C4) the type of service most patient use is JKN PBI and the District
of Karangawen (C5) the type of service most widely used patient is JKN PBI and JKN NON PBI.
Keywords: Data Mining , Inpatient , Clustering , K -Means
1. PENDAHULUAN 1.1 Latar Belakang
Kebutuhan informasi di dalam kehidupan sehari-hari baik pendidikan, politik, budaya, sosial maupun kesehatan sudah menjadi kebutuhan pokok. Kebutuhan informasi menjadi maslaah ketika kebutuhan tersebut tidak dapat dirumuskan dengan baik sehingga tidak mewakili kebutuhan itu sendiri. Misalnya dalam dunia kesehatan terutama dalam lingkungan rumah sakit, kebutuhan informasi mengenai suatu penyakit atau pasien yang mengidap suatu penting sangatlah penting.
Rumah Sakit Islam Sultan Agung Semarang merupakan lembaga pelayanan kesehatan masyarakat di bawah naungan Yayasan Badan Wakaf Sultan Agung. RSI Sultan Agung Semarang terletak di jalan Raya Kaligawe Km.4 yang berdekatan dengan terminal Terboyo dan pusat pertumbuhan industri. RSI Sultan Agung Semarang dibangun pada tahun 1971, yang diresmikan sebagai rumah sakit umum pada tanggal 23 Oktober 1973 dengan SK dari Menkes No. 1/024/Yan Kes/1075 tertanggal 23 Oktober 1975 diresmikan sebagai rumah sakit tipe C (rumah sakit tipe Madya).
Melihat kondisi dengan ketersediaan data rekam medis yang begitu besar, tentunya pihak rumah sakit perlu mengetahui informasi tentang kunjungan pasien serta kecenderungan pasien berdasarkan alamat, jenis kelamin, umur, dan jenis layanan yang dapat dijadikan pendukung pengambilan keputusan bagi pihak rumah sakit dan dinas terkait. Untuk membantu dalam proses pencarian informasi dalam data yang besar maka teknik pemanfaatan data mining dapat membantu proses ini. Rekam Medis menurut Peraturan Menteri Kesehatan RI No.269/Menkes/PER/III/2008, rekam medis adalah berkas yang berisikan catatan dan dokumen tentang identitas pasien, pengobatan, tindakan dan pelayanan lain yang telah diberikan kepada pasien. Dari data rekam medis dapat diperoleh banyak informasi. Dengan kelengkapan informasi yang dimiliki dapat dijadikan sebuah pertimbangan bagi pihak rumah sakit untuk melakukan tindakan baik pencegahan maupun penanggulangan. Informasi-informasi ini bisa didapatkan dari pengolahan dan analisis data yang dimiliki. Berdasarkan latar belakang tersebut dibuatlah skripsi yang berjudul “Pengelompokkan Jenis Layanan Kesehatan Masyarakat Daerah Demak Menggunakan Algoritma K-Means”.
2. METODE PENELITIAN 2.1 Objek Penelitian
Penelitian ini dilaksanakan di Rumah Sakit Islam Sultan Agung Semarang. Dalam penelitian ini yang menjadi objek penelitian adalah data dari rekam medis yaitu data pasien rawat inap di triwulan pertama pada tahun 2016.
2.2 Sumber Data
Untuk mendapatkan data - data yang benar akurat dan relevan sebagai inputan bagi sistem. Adapun metode yang akan digunakan dalam tahap pengumpulan data antara lain :
a. Wawancara
Pada teknik ini digunakan untuk mendapatkan keterangan-keterangan tentang data rawat inap pasien rumah sakit pada rekam medis secara lisan yaitu dengan melakukan percakapan tanya jawab dengan narasumber dari pihak-pihak yang mengetahui bidang terkait dengan penelitian ini.
b. Studi pustaka
Adalah penelitian dengan mempelajari karangan ilmiah yang relevan dalam pembahasan ini dan buku – buku yang memiliki keterkaitan dengan masalah yang akan dibahas.
c. Observasi
Sumber data dan tujuan penyusunan penelitian ini untuk mendapatkan data yang benar-benar akurat dan relevan, maka dalam pengumpulan data penulis melakukan observasi untuk mendapatkan data-data dari bagian rekam medis tentang data pasien rawat inap pada triwulan pertama tahun 2016.
2.3 Teknik Dan Analisis Data
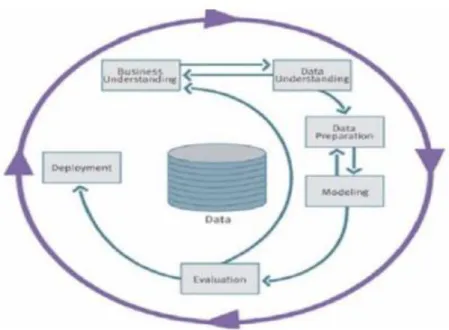
Proses analisis data mining pada penelitian ini menggunakan tahap CRISP-DM (Cross-Industry Standard Process for Data Mining) dengan enam fase CRISP-DM
.
2.3.1 Fase Pemahaman Bisnis
Fase ini adalah fase pertama dalam CRISP-DM yang merupakan patokan atau tujuan dilakukannya suatu penelitian. Penelitian ini dilakukan dengan tujuan untuk mengimplementasikan algoritma k-means pada data rawat inap pasien di Rumah Sakit Islam Sultan Agung Semarang, sehingga didapat informasi wilayah pasien berdasarkan jenis layanan kesehatannya secara lebih cepat dan akurat.
2.3.2 Fase Pemahaman Data
Fase pemahaman data yaitu menentukan data apa yang akan diambil dan diolah untuk mencapai tujuan yang telah ditentukan. Data yang menjadi training pada metode clustering dengan algoritma k-means adalah data pasien rawat inap triwulan pertama pada tahun 2016 Rumah Sakit Islam Sultan Agung Semarang. Dari survey yang dilakukan peneliti, didapatkan data bulan Januari adalah 200 data, jadi total data pasien yang didapat untuk training ini sebanyak 200 data.
2.3.3 Fase Pengolahan Data
Pada fase pengolahan data ini, data mentah yang didapat tidak semuanya dapat digunakan karena masih ada data yang mengandung missing value (keterangan tidak lengkap). Oleh karena itu, perlu dilakukan preprocessing yaitu cleaning data dan selection data. Cleaning data dan selection data merupakan tahap awal dari preprocessing data mining. Pembersihan ini dilakukan untuk membuang data yang mempunyai informasi tidak lengkap.
2.3.4 Fase Pemodelan
Pada fase pemodelan ini, memilih dan mengaplikasikan teknik pemodelan yang sesuai dengan kalibrasi aturan model untuk mengoptimalkan hasil. Perlu diperhatikan bahwa beberapa teknik mungkin telah digunakan pada permasalahan mining yang sama. Jika diperlukan proses dapat kembali ke fase pengolahan data untuk menjadikan data ke dalam bentuk yang sesuai dengan spesifikasi kebutuhan teknik data mining tertentu.
2.3.5 Fase Evaluasi
Pada fase ini bertujuan untuk mendapatkan hasil apakah model yang telah ditetapkan memenuhi tujuan pada fase awal, apakah terdapat permasalahan penting dari bisnis atau penelitian yang tidak tertangani dengan baik, serta mengambil keputusan yang berkaitan dengan pengunaan hasil dari data mining.
2.3.6 Fase Implementasi
Pada fase implementasi ini merupakan fase terakhir dari enam fase CRISP-DM. Dengan terbentuknya model tidak menandakan telah terselesainya suatu proyek. Contoh paling sederhana implementasi yaitu pembuatan laporan. Contoh kompleks dari implementasi adalah penerapan proses data mining secara paralel pada departemen lain.
2.4 Landasan Teori
2.4.1 Metode Clustering
Clustering adalah proses pengelompokan data ke dalam beberapa cluster atau kelompok sehingga data dalam satu cluster memiliki kemiripan yang minimum. [2]
Clustering merupakan metode segmentasi data yang telah diimplementasikan dalam berbagai bidang seperti prediksi dan analisis masalah bisnis segmentasi pasar, marketing, zonasi wilayah hingga identifikasi obyek dan pola dalam
bidang computer vision dan pengolahan citra. [2] Hasil dari penelitian ini menggunakan algoritma K-means
.
2.4.2 Algoritma K-Means
Algoritma K-means adalah salah satu metode clustering non hirarki yang berusaha mempartisi data yang ada ke dalam satu atau lebih cluster. Metode ini mempartisi data ke dalam cluster sehingga data yang memiliki karakteriktik yang sama dikelompokkan kedalam satu cluster yang sama dan data yang memiliki karakteriktik yang berbeda di kelompokkan ke dalam cluster yang lain [3]
3.1 Metode Pengujian Sistem 1. Halaman Home
Gambar 1 Halaman Home 2. Halaman Input Data Pasien
3. Halaman Input Kode Penyakit
Gambar 4 Halaman Input Kode Penyakit 4. Halaman Input Kode Layanan
Gambar 5 Halaman Input Kode Layanan 5. Halaman Clustering
3.2 Hasil Dan Pembahasan A. Hasil Penelitian
Pada hasil penelitian ini, terciptanya sistem untuk mengelompokkan data untuk memperoleh informasi. Sistem terdiri dari beberapa interface yaitu Home, Input Data Pasien, Input Kode Penyakit, Input Kode Layanan, Halaman Clustering. Setiap antar muka mempunyai fungsi yang berbeda. Pada implementasi program dan interface pengguna dapat memperoleh informasi berupa daerah pengguna jenis layanan sehingga pihak rumah sakit bisa bekerja sama dengan penyedia layanan untuk mempromosikan jenis layanan ke daerah tersebut dengan menggunakan algoritma k-means.
B. Pembahasan
Tahap clustering dengan menggunakan K-Means ini dimulai dengan pembentukan cluster ini dipilih secara random, penulis membentuk 5 cluster dari 20 data yang diambil dari dataset sebagai contoh.
Proses perhitungan cntroid awal dimulai dengan pemberian nama awal cluster dari cluster pertama sampai dengan cluster kelima secara random pada data hasil cleaning.
Tabel 4.1 Pusat Awal Cluster Data
Ke- Umur Layanan
Kode Penyakit Lama Dirawat 1 23 7 16 5 5 49 7 21 3 9 50 7 21 4 13 22 8 17 5 19 21 7 1 3
Selanjutnya dilakukan perhitungan untuk mendapatkan nilai centroid awal dengan menghitung rata-rata pada masing-masing cluster dengan membagi jumlah data yang didapatkan untuk setiap cluster dengan menggunakan mean (rata-rata) ini ditujukan agar setiap cluster memiliki anggota data pada iterasi pertama. Dengan rumus :
1. Tentukan jumlah cluster yang ingin dibentuk dan tetapkan pusat clusterk. 2. Menggunakan jarak euclidean kemudian hitung setiap data ke pusat
cluster.
√∑ (2.1)
3. Kelompokkan data ke dalam cluster dengan jarak yang paling pendek dengan persamaan
∑ √∑ (2.2)
4. Hitung pusat cluster yang baru menggunakan persamaan
∑ (2.3)
Dengan :
xij € Clusterke – k
5. Ulangi langkah dua sampai dengan empat sehingga sudah tidak ada lagi data yang berpindah ke kluster yang lain.
Perhitungan jarak data dengan centroid tiap cluster, selanjutnya akan ditampilkan dalam bentuk tabel di bawah ini.
Tabel 4.2 Hasil Perhitungan Awal cluster Data ke- C1 C2 C3 C4 C5 1 0 26,55184 27,47726 1,732051 15,26434 2 9,055385 17,9722 18,78829 10,14889 18,84144 3 11,22497 37,13489 38,11824 10,14889 19,26136 4 2,828427 28,23119 29,1719 1,732051 17,11724 5 26,55184 0 1,414214 27,38613 34,4093 6 5,09902 26,09598 27,03701 4,582576 20,22375 7 5,830952 29,06888 30,01666 4,582576 20,12461 8 7,071068 21,09502 22,02272 7,28011 21,2838 9 27,47726 1,414214 0 28,3196 35,24202 10 6,708204 30 31,01612 5,477226 20,09975 11 14 13,37909 14,17745 14,73092 25,19921 12 4,472136 29,10326 30,08322 3,605551 18,08314 13 1,732051 27,38613 28,3196 0 16,18641 14 9,165151 34,1321 35,08561 7,681146 20,12461 15 4,123106 26,11513 27,0555 3,162278 19,23538 16 4,242641 25,03997 26,01922 3,872983 19,26136 17 4,582576 30,59412 31,59114 4,242641 14,14214 18 15,26434 34,4093 35,24202 16,18641 0 19 15,26434 34,4093 35,24202 16,18641 0 20 7,874008 28,08914 29,1376 6,855655 22,02272
Iterasi pada clustering ini akan berhenti, jika anggota data cluster pada iterasi sebelumnya sama dengan anggota data cluster pada iterasi selanjutnya. Dari 20 dataset tersebut, untuk memperoleh nilai centroid yang sama terbentuklah 6 iterasi.
Tabel 4.3 Hasil Perhitungan Cluster Terakhir Data Ke C1 C2 C3 C4 C5 1 2,730696 9,614978 27,00926 5,503063 15,26434 2 9,784513 3,332837 18,37117 14,31306 18,84144 3 10,72645 20,11437 37,62313 6,140334 19,26136 4 1,826664 11,1017 28,69669 3,504811 17,11724 5 26,49409 17,29531 0,707107 30,98586 34,4093
6 2,607048 9,208029 26,56125 5,153998 20,22375 7 3,532237 12,14281 29,53811 2,06971 20,12461 8 5,810052 4,409966 21,55226 10,01417 21,2838 9 27,43969 18,16006 0,707107 31,97974 35,24202 10 4,704965 13,38386 30,5041 0,35171 20,09975 11 13,62779 4,409966 13,7659 18,14232 25,19921 12 3,045768 12,13787 29,58885 2,44616 18,08314 13 2,014125 10,3686 27,8478 4,582979 16,18641 14 7,993541 17,18627 34,60491 3,704551 20,12461 15 1,586411 9,149197 26,58007 5,196508 19,23538 16 2,043698 8,209007 25,5245 5,975257 19,26136 17 5,526002 13,95449 31,08858 2,474611 14,14214 18 17,87335 21,5204 34,82097 5,303178 0 19 17,87335 21,5204 34,82097 5,303178 0 20 5,41449 12,17653 28,60944 2,922961 22,02272
Dari hasil cluster diperoleh karakteristik masing-masing cluster. Karakteristik yang diperoleh dari 20 dataset diatas adalah :
1. Anggota C1 : data 1, 4, 6, 13, 15 dan 16 2. Anggota C2 : data 2, 8 dan 11
3. Anggota C3 : data 5 dan 9
4. Anggota C4 : data 3, 7, 10, 12, 14, 17 dan 20 5. Anggota C5 : data 18 dan 19
4. KESIMPULAN 4.1 Kesimpulan
Berdasarkan hasil analisis implementasi dan pengujian pada sistem clustering, maka dapat disimpulkan bahwa metode k-means berhasil dan dapat diterapkan untuk mengelompokkan jenis layanan yang digunakan oleh pasien yang berada pada daerah Demak. Dari hasil proses klustering menggunakan 200 data yang diperoleh dari tempat penelitian Rumah Sakit Islam Sultan Agung Semarang dengan lima kategori kluster maka didapatkan hasil dari sistem pengelompokkan penggunaaan jenis layanan yang paling banyak digunakan pasien yaitu, pada Kecamatan Sayung (C1) jenis layanan yang paling banyak digunakan pasien adalah JKN NON PBI, pada Kecamtan Karangtengah (C2) jenis layanan yang paling banyak digunakan pasien adalah JKN NON PBI, pada Kecamtan Mranggen (C3) jenis layanan yang paling banyak digunakan pasien adalah JKN PBI, pada Kecamtan Guntur (C4) jenis layanan yang paling banyak digunakan pasien adalah JKN PBI dan pada Kecamtan Karangawen (C5) jenis layanan yang paling banyak digunakan pasien adalah JKN PBI dan JKN NON PBI.
Hal ini menunjukkan bahwa metode k-means dapat diterapkan dalam proses pengelompokkan data pasien dan jenis layanan pasien berdasarkan data dari rekam medis RSI Sultan Agung Semarang.
5. SARAN 5.1 Saran
Dalam penelitian ini masih memiliki kekurangan yang dapat dikembangkan dan dapat diperbaiki dalam penelitian selanjutnya yang memiliki pembahasan sama, saran untuk penelitian berikutnya yaitu pada proses pengelompokkan metode k-means dapat menggunakan atribut lebih banyak agar hasil akurasi dapat ditingkatkan dan juga pada hasil dari proses klustering agar dapat ditambahkan urutan data ke berapa saja yang masuk dalam setiap kluster yang telah dibuat.
DAFTAR PUSTAKA
[1]
Novita Yuliani, “Analisis Keakuratan Kode Diagnosis Penyakit Commotio CerebriPasien Rawat Inap Berdasarkan ICD-10 Rekam Medik di Rumah Sakit Islam Klaten” ISSN : 2086-2628, 1 Februari 2010
[2]
Edy Irwansyah, Muhammad Faisal. (2015). “Advanced Clustering Teori danAplikasi”. DeePublish. Pp 1-2. ISBN 6022805007
[3]
Yudi Agusta (Phd: 2007), K-Means – Penerapan, Permasalahan, dan Metode Terkait . http://www.magenep.com[4]
Julianta, Feri., & Dominikus Juju. (2010). Data Mining – Meramalkan Bisnis Perusahaan.[5]
Kusrini., & Luthfi, Emha Taufiq. (2009). Algoritma Data Mining. Andi offset: Yogyakarta.[6]
Santosa, Budi. (2007). Data Mining Teknik Pemanfaatan Data Untuk Keperluan Bisnis. Graha Ilmu; Yogyakarta.[7]
Prasetyo, Eko. Data Mining “Mengolah Data Menjadi Informasi Menggunakan MATLAB”. Andi Offset : Yogyakarta.[8]
Larose, Daniel T. (2014). Discovering knowledge in data an introduction to Data Mining. A John Willey & Sons, Inc: United State.[9]
Nurfaizin. (2015). Implementasi Algoritma K-Means Untuk Mengetahui Wilayah Rentan Penyakit Menggunakan Data RL Rawat Inap RSUP Dr.Kariadi Semarang. Semarang : Universitas Dian Nuswantoro.[10]
Fitria Wahyu Putri. (2015). Analisis Data Rawat Inap Rumah Sakit Kota Semarang Untuk Mengetahui Daerah Endemi Penyakit Menggunakan Algoritma K-Means. Semarang : Universitas Dian Nuswantoro.[11]
Erga, Sari Aprina. (2015). Penerapan Algoritma K-Means untuk Menentukan Tingkat Kesehatan Bayi dan Balita Pada Kabupaten dan Kota di Jawa Tengah. Semarang : Universitas Dian Nuswantoro. KUALITAS PELAYANAN," vol. 3 no.1,2015.