ANALISIS PERBANDINGAN ALGORITMA
DECISION TREE J48 DAN NAÏVE BAYES
DALAM MENGKLASIFIKASIKAN
POLA PENYAKIT
Frista Yulianora
Binus University, Jakarta, Indonesia, [email protected]
Muchammad Hasbi Latif
Binus University, Jakarta, Indonesia, [email protected]
Rika Jubel Febriana
Binus University, Jakarta, Indonesia, [email protected]
Abstract
RSAL DR. Mintohardjo Hospital is owned by Indonesian Marine Force. In this hospital is rich of
data but poor of knowledge. It is necessary to use data mining analysis. The purpose of this study is to conduct a comparison between J48 Decision Tree algorithm and Naïve Bayes algorithm to generate the better information to be applied in the process of outpatient care medical records of RSAL DR. Mintohardjo in the first quarter of 2012 in order to provide knowledge to the hospital or the Health Department Marine Force to be useful to society as one of its existing preventive measures such as counseling to prevent the disease developing in the region. The research methodology used for data collection is literature study and observation. The techniques used are classification and a method of Data Mining is the method of comparison, which comparing the J48 Decision Tree algorithm and Naive Bayes to classify patterns of disease. The conclusion after analyzing the Naïve Bayes algorithm is better at classifying diseases.
Keywords: Decision Tree J48, Naïve Bayes, Medical Record, Comparison
Abstrak
RSAL DR. Mintohardjo adalah Rumah Sakit yang dimiliki oleh Angakatan Laut Indonesia. Data pasien di rumah sakit sangat banyak tetapi miskin pengetahuan, untuk itu diperlukan analisis menggunakan data mining. Tujuan penelitian ini adalah melakukan perbandingan antara algoritma
Decision Tree J48 dan Naïve Bayes sehingga menghasilkan informasi algoritma yang lebih baik untuk
diterapkan dalam mengolah data rekam medis rawat jalan RSAL DR. Mintohardjo pada triwulan pertama tahun 2012 guna memberikan knowledge kepada rumah sakit atau pihak Dinas Kesehatan Angakatan Laut yang berguna bagi masyarakat sebagai salah satu tindakan preventif seperti ada nya penyuluhan untuk mencegah penyakit yang berkembang di suatu wilayah. Metodologi penelitian yang digunakan untuk pengumpulan data yaitu studi kepustakaan dan studi lapangan, teknik yang digunakan adalah klasifikasi dan metode Data Mining yang digunakan adalah metode perbandingan, yaitu membandingkan algoritma Decision Tree J48 dan Naive Bayes dalam mengklasifikasikan pola penyakit. Kesimpulan yang didapat setelah dilakukan proses analisa adalah Algoritma Naïve Bayes lebih baik dalam melakukan pengklasifikasian penyakit.
PENDAHULUAN
Rumah sakit merupakan suatu institusi atau organisasi kesehatan yang melalui tenaga medis profesional memberikan pelayanan kesehatan, asuhan keperawatan, diagnosis serta pengobatan penyakit yang di derita oleh pasien. Kegiatan operasional yang terjadi di rumah sakit dapat menghasilkan dan mengumpulkan banyak nya data rekam medis setiap hari Tumpukan data rekam medis digunakan untuk kebutuhan operasional, bahkan tidak jarang juga tumpukan data tersebut dibiarkan begitu saja sehingga menyebabkan data yang begitu banyak tidak mengandung pengetahuan atau sering disebut dengan “rich of data but poor of knowledge”.
Data rekam medis yang setiap hari selalu bertambah dapat digali untuk dijadikan informasi bagi pihak dinas kesehatan. Perkembangan teknologi yang demikian pesat menuntut banyak institusi pelayanan masyarakat untuk lebih mampu memberikan pelayanan yang berkualitas. Pengimplementasian teknologi informasi pun dilakukan di dalam organisasi kesehatan untuk menghasilkan informasi yang menjadi dasar dalam pengambilan keputusan serta meningkatkan efisiensi kerja dan pelayanan rumah sakit.
Dengan alasan diatas, maka dibuatlah skripsi dengan judul “ANALISIS PERBANDINGAN
ALGORITMA DECISION TREE J48 DAN NAIVE BAYES DALAM MENGKLASIFIKASIKAN POLA PENYAKIT”
METODE PENELITIAN
Metodologi yang akan digunakan dalam penelitian ini menggunakan dua metode, yaitu :
1. Metode Pengumpulan Data
• Studi Pustaka
Studi pustaka adalah teknik pengumpulan data dengan mengadakan studi penelaahan terhadap buku-buku, literatur-literatur, catatan-catatan, dan laporan-laporan yang ada hubungannya dengan masalah yang dipecahkan.
• Studi Lapangan
Melakukan survei, wawancara, dan observasi dengan mengunjungi langsung ke RSAL Dr. Mintohardjo untuk mendapatkan data dan informasi yang dibutuhkan dalam penulisan skripsi.
2. Instrumen Penelitian
• Tabel yang digunakan adalah tabel Rekam Medis Pasien, dengan jumlah record sebanyak 1985.
• Teknik yang digunakan adalah Classification, dengan melakukan perbandingan antara algoritma Naive Bayes dan Decision Tree J48.
HASIL DAN BAHASAN
Berikut adalah analisis dari perbandingan Algoritma Decision Tree J48 dan Naive Bayes dalam mengklasifikasikan pola penyakit
1. Arsitektur Data Mining
2. Perbandingan algoritma Decision Tree J48 dan Naive Bayes dalam mengklasifikasikan pola penyakit
Pemecahan suatu masalah tidak hanya dapat diselesaikan oleh satu metode. Penyelesaian masalah bisa diselesaikan dengan menggunakan beberapa metode dan logika yang berlainan. Membandingkan metode mana yang dapat dinilai baik dalam penyelesaian masalah dapat dilihat dari berbagai aspek. Diantaranya :
1. Tingkat Kepercayaan tinggi (realibility). Hasil yang diperoleh dari proses memiliki akurasi yang tinggi dan benar
2. Proses yang efisien yaitu proses harus diselesaikan secepat mungkin dan frekuensi kalkulasi yang sependek mungkin.
3. Bersifat general, maksudnya tidak hanya menyelesaikan satu kasus saja, tetapi kasus lain yang lebih general.
4. Bisa dikembangkan (expendable). Harus menjadi sesuatu yang dapat dikembangkan lebih jauh bedasarkan requirement yang ada.
5. Mudah dimengerti, Siapa saja yang melihat, orang itu akan dapat dengan mudah memahami algoritma tersebut. Karena jika sulit untuk dimengerti, maka akan suliit untuk dikelola.
6. Portabilitas yang tinggi (portability). Bisa dengan mudah diimplementasikan dimana saja.
7. Precise(tepat, benar, teliti). Setiap instruksi harus ditulis dengan baik dan tidak ada
keragu-raguan, dengan demikian setiap instruksi harus dinyatakan secara eksplisit dan tidak ada bagian yang dihilangkan karena user dianggap sudah mengerti.
Dari hal tersebut, dapat dilakukan perbandingan algoritma Decision Tree J48 dan Naïve
Bayes dari beberapa aspek yang bisa dibandingkan, seperti seberapa efektif algoritma tersebut dapat
mengelompokkan pola penyakit, tingkat keakuratan dan aspek lainnya. Berikut perbandingan Algoritma Decision Tree dan J48 naive bayes.
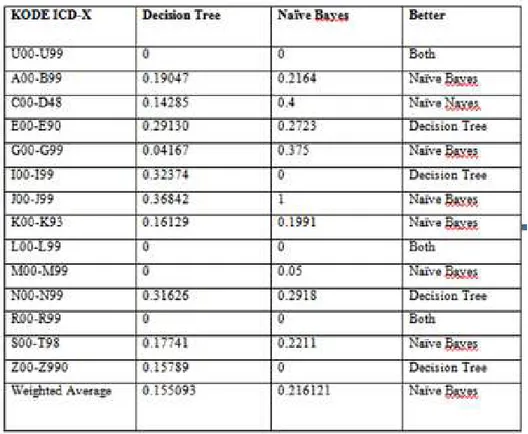
Tabel 1 Perbandingan Precision DT J48 dan Naïve Bayes
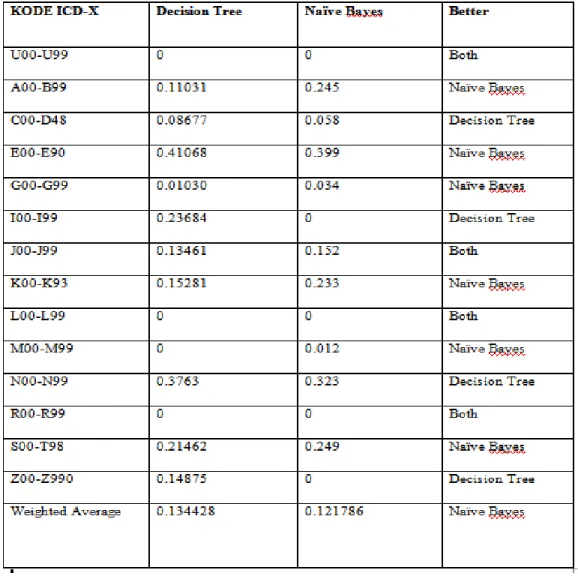
Tabel 3 Perbandingan F-Measure Decision Tree J48 dan Naïve Bayes
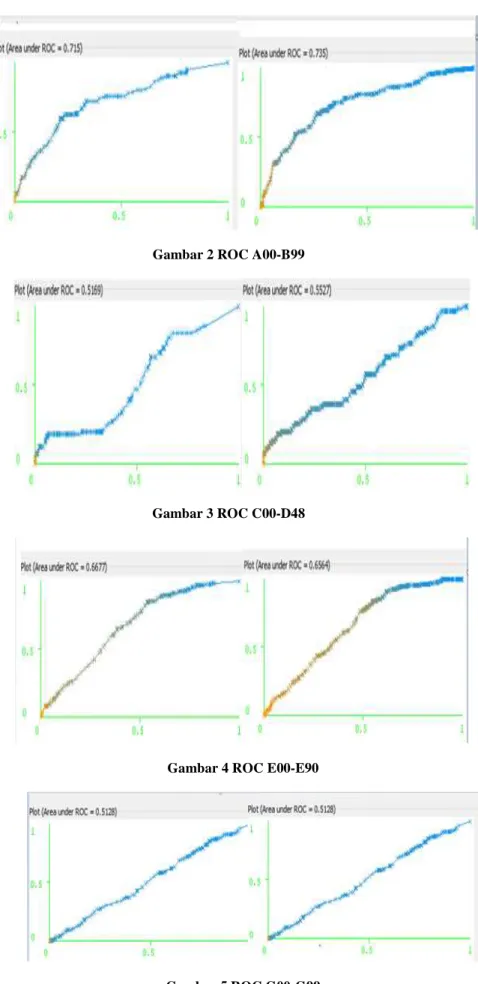
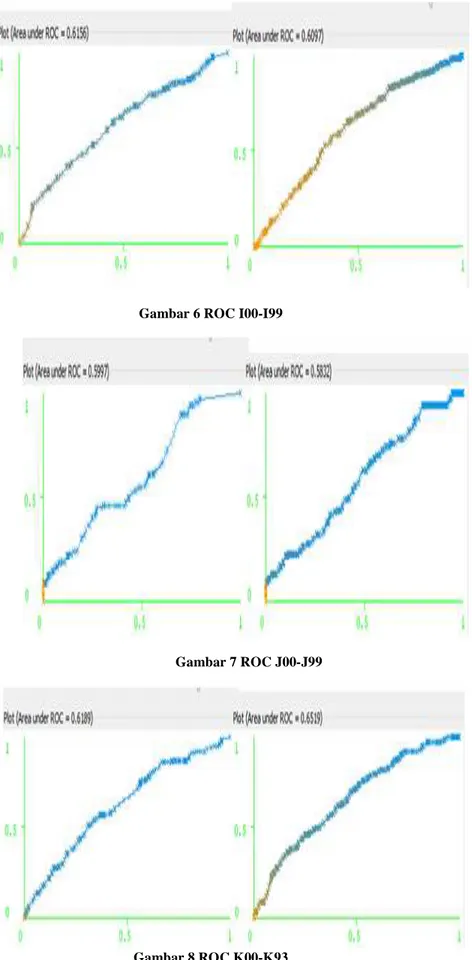
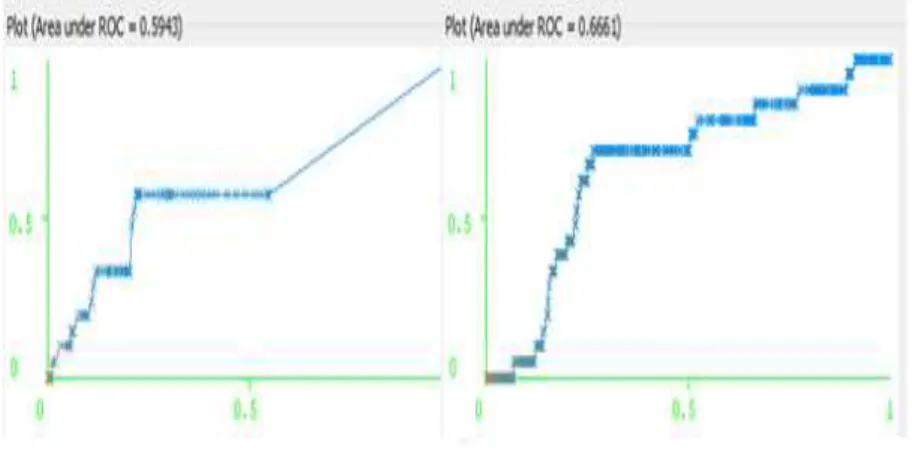
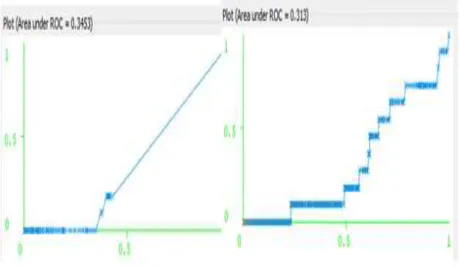
3. ROC AREA
Untuk menentukan kinerja identifikasi, ROC (Receiver Operating Characteristic) adalah analisis yang digunakan. Berdasarkan kurva yang dibentuk oleh ROC kesalahan dalam distribusi dapat diidentifikasi oleh algoritma dengan baik.
Gambar 2 ROC A00-B99
Gambar 3 ROC C00-D48
Gambar 4 ROC E00-E90
Gambar 6 ROC I00-I99
Gambar 7 ROC J00-J99
Gambar 9 ROC L00-L99
Gambar 10 ROC MOO-M99
Gambar 12 ROC R00-R99
Gambar 13 ROC S00-T98
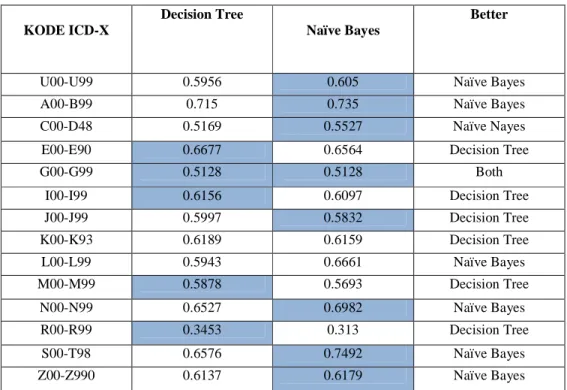
Tabel 4 Perbandingan Algoritma Decision Tree J48 dan Naïve Bayes
KODE ICD-X
Decision Tree
Naïve Bayes
Better
U00-U99 0.5956 0.605 Naïve Bayes A00-B99 0.715 0.735 Naïve Bayes C00-D48 0.5169 0.5527 Naïve Nayes E00-E90 0.6677 0.6564 Decision Tree G00-G99 0.5128 0.5128 Both
I00-I99 0.6156 0.6097 Decision Tree J00-J99 0.5997 0.5832 Decision Tree K00-K93 0.6189 0.6159 Decision Tree L00-L99 0.5943 0.6661 Naïve Bayes M00-M99 0.5878 0.5693 Decision Tree N00-N99 0.6527 0.6982 Naïve Bayes R00-R99 0.3453 0.313 Decision Tree S00-T98 0.6576 0.7492 Naïve Bayes Z00-Z990 0.6137 0.6179 Naïve Bayes
Dari data tabel diatas Algoritma naïve bayes lebih baik dalam melakukan pengklasifikasian penyakit. Algoritma Naïve Bayes lebih baik dalam mengklasifikasikan penyakit dengan kode U00-U99,A00-B99, C00-D48, L00-L99, N00-N99, S00-T98 dan Z00-Z99. Sedangkan Algoritma Decision Tree J48 hanya baik dalam mengklasifikasikan penyakit dengan kode E00-E90, I00-I99, J00-J99, K00-K93, M00-M99 dan R00-R99. Sedangkan pengklasifikasian penyakit dengan kode icdx G00-G99, kedua algoritma sama-sama dapat mengklasfikasikannya dengan nilai ROC area yang sama.
SIMPULAN DAN SARAN
SimpulanHasil dari penelitian yang telah dilakukan dapat diambil beberapa kesimpulan yaitu:
1. Perbandingan kedua algoritma ini menggunakan model pengujian yaitu cross validation. Hasil pengujian menggunakan cross validation yang dapat dilihat dari nilai correctly
classified.
2. Pola penyakit yang paling berkembang pada triwulan pertama tahun 2012 adalah penyakit dengan kode icdx E00-E90 dengan diagnosis penyakit Endokrin, Nutrisi, dan Gangguan Metabolik pada wilayah DKI Jakarta.
3. Cross Validation dengan hasil yang terbaik dari metode Naïve Bayes data pada 7-10 fold
adalah 29.8857 dan dari metode Decision Tree J48 pada 8 fold adalah 26.5143.
4. Pada algoritma Naive Bayes, memiliki nilai F-Measure lebih baik dengan 7 class kode ICDX dibandingkan dengan nilai F-Measure pada algoritma Decision Tree J48 dengan 4
class kode ICDX. Dapat dikatakan algoritma Naive Bayes menghasilkan kinerja yang lebih
baik dibandingkan algoritma Decision Tree J48.
5. Algoritma Naïve Bayes, memiliki nilai ROC area lebih baik dengan 7 class kode ICDX dibandingkan dengan nilai ROC area pada algoritma Decision Tree J48 dengan 6 class kode ICDX. Dapat dikatakan algoritma Naïve Bayes menghasilkan kinerja yang lebih baik dibandingkan algoritma Decision Tree J48.
Saran
Adapun saran yang dapat diberikan dari beberapa kesimpulan diatas adalah:
1. Penelitian ini menggunakan data triwulan pertama pada tahun 2012, maka untuk mencari pola penyakit tahunan diperlukan data lebih dari 12 bulan, agar hasil yang didapat lebih baik.
2. Penerapan feature selection untuk memilih fitur terbaik untuk meningkatkan akurasi. 3. Penelitian ini menggunakan kriteria yaitu berdasarkan akurasi. Akan lebih baik jika semua
kriteria diuji coba agar algoritma yang diteliti lebih teruji kinerjanya.
REFERENSI
Connolly, T. M., & Begg, C. E. (2010). Database System: A Practical Approach to Design,
Implementation and Management. Boston: Pearson.
Hall, J. A. (2011). Introduction to Accounting Information Systems. United States: South-Western Cangage Learning.
Han, J., Kamber, M., & Pei, J. (2011). Data Mining: Concepts and Techniques, 3rd Edition. USA: Morgan Kaufmann Publishers.
Hoffer, J. A., Ramesh, V., & Topi, H. (2012). Modern Database Management, 11th Edition. New Jersey: Prentice Hall, Pearson Education Inc.
Kimball, R., Ross, M., & Thornthwaite, W. (2010). The Kimball Group Reader : Relentlessly
Practical Tools for Data Warehousing and Business Intelligence. USA: Wiley Publishing
Inc.
Linoff, G. S., & Berry, M. J. (2011). Data Mining Techniques: For Marketing, Sales, and Customer
Relationship Management. Wiley Publishing. Inc: Indianapolis, Indiana.
MacLennan, J., Tang, Z., & Crivat, B. (2009). Data Mining with Microsoft SQL Server 2008. Indianapolis: Wiley Publishing Inc.
Mariscal, G., Marban, O., & Fernandez, C. (2010). A Survey of Data Mining and Knowledge Discovery Process Models and Methodologies. The Knowledge Engineering Review 25.2, 137-166.
Milovic, B., & Milovic, M. (2012). Prediction and Decision Making in Health Care using Data Mining. Kuwait Chapter of The Arabian Journal of Business and Management Review 1.12, 126-136.
Olson, D., & Shi, Y. (2013). Outlines and Highlights for Introduction Business Data Mining. USA: Cram101 Incorporated.
Science, D. C. (2005). Data Mining with Open Source Machine Learning Software in Java. Retrieved from WEKA The University of Waikato: http://www.cs.waikato.ac.nz/ml/weka/
Sharma, G., Bhargava, D. N., Bhargava, D. R., & Mathuria, M. (2013). Decision Tree Analysis on J48 Algorithm for Data Mining. International Journal of Advanced Research in Computer
Science and Software Engineering, 1114-1119.
Thomas, J. (2009). Medical Records and Issues in Negligence. Indian Journal of Urology 25.3, 384-388.
Turban, E., Aronson, J. E., Liang, T. P., & Sharda, R. E. (2011). Decision Support and Business
Intelligence Systems 9th edit. New Jersey: Prentice Hall.
Vercellis, C. (2009). Business Intelligence: Data Mining and Optimization for Decision Making. Chichester: Jon Wiley and Sons.
Wicaksana, I. M., & Widiartha, I. M. (2012). Penerapan Metode Ant Colony Optimization pada Metode K-Harmonic Means untuk Klasterisasi data. Jurnal Ilmu Komputer vol 5 no 1, 55-61. Witten, I. H., Frank, E., & Hall, M. A. (2011). Data Mining: Practical Machine Learning Tools and
Techniques, 3rd Edition. New Zealand: Universitas of Waikato.
RIWAYAT PENULIS
Frista Yulianora lahir di kota Jakarta pada tanggal 11 Juli 1992. Penulis menamatkan pendidikan S1
di Binus University dalam bidang Sistem Informasi pada tahun 2014.
Muchammad Hasbi Latif lahir di kota Jakarta pada tanggal 28 September 1992. Penulis
menamatkan pendidikan S1 di Binus University dalam bidang Sistem Informasi pada tahun 2014.
Rika Jubel Febriana lahir di kota Jakarta pada tanggal 5 Februari 1992. Penulis menamatkan