ANALISA PERBANDINGAN ALGORITMA SVM, NAIVE BAYES, DAN
DECISION TREE DALAM MENGKLASIFIKASIKAN SERANGAN (ATTACKS)
PADA SISTEM PENDETEKSI INTRUSI
Dwi WidiastutiJurusan Sistem Informasi, Universitas Gunadarma
ABSTRAK
Prediksi serangan (attacks) merupakan tindakan yang diperlukan oleh sebuah sistem pendeteksi intrusi sebagai langkah awal atau antisipasi jika terjadi serangan. Banyak metode yang bisa dilakukan untuk prediksi jenis serangan. Salah satu metode yang digunakan adalah teknik data mining. Tapi tidak semua algoritma data mining memiliki kinerja yang baik dalam mengklasifikasi jenis serangan. Oleh karena itu penelitian ini akan mencoba membandingkan beberapa algoritma.
Ada 41 atribut/variable yang digunakan untuk mengklasifikasikan jenis serangan. Dari sekian banyak jenis serangan yang terjadi, maka dikelompokkan kedalam empat kelas, yang mana dikategorikan berdasarkan tujuan akhir yang dicapai oleh suatu serangan. Kategori tersebut antara lain : Probe, DoS, U2R, dan R2L. Dan untuk data set yang dipakai adalah data set dari KDD Cup 1999, dimana data set ini merupakan data yang direferensikan untuk penelitian kasus IDS.
Perbandingan algoritma akan dilihat berdasarkan nilai correctly classified instance, incorrectly classified, kappa statistic, true positif, false positif, dan confusion matrix. Dalam penelitian ini, algoritma yang dibandingkan adalah algoritma SVM, decision tree, dan naive bayes. Dengan menggunakan alat bantu WEKA (Waikato Environment for Knowledge Analysis) versi 3.4.13, dapat disimpulkan algoritma yang memiliki kinerja yang lebih unggul adalah decision tree.
Kata Kunci : Attacks, Decision Tree, IDS, Klasifikasi, Naive Bayes, Serangan, SVM, WEKA.
1. PENDAHULUAN
Berdasarkan dari penelitian yang dilakukan oleh Srinivas Mukkamala dan Andrew H. Sung (2003) menyatakan bahwa kinerja algoritma SVM lebih baik jika dibandingkan dengan ANN dalam hal solusi yang dicapai untuk kasus pengklasifikasian IDS. Menurut penelitian Budi Santosa (2007), SVM menemukan solusi berupa global optimum, mencapai solusi yang sama untuk setiap running, sedangkan ANN menemukan solusi yang local optimal, solusi dari setiap training yang selalu berbeda. Algoritma SVM terutama teknik SMO (Sequential Minimal Optimization) juga merupakan algoritma paling popular dalam teknik klasifikasi maupun regresi.
Dari penelitian yang dilakukan oleh Mrutyunjaya Panda dan Mana R. Patra (2007) menyatakan bahwa kinerja algoritma Bayesian lebih efisien dalam mengklasifikasikan Network IDS (NIDS) dibandingkan ANN. Teknik algoritma Bayesian yang digunakan adalah klasifikasi Naïve Bayes, metode klasifikasi Naïve Bayes yang sering disebut sebagai Naïve Bayes Classifier
(NBC) dimana teknik ini dikenal sebagai teknik yang paling baik dalam hal waktu komputasi dibandingkan teknik algoritma data mining lainnya.
Sedangkan menurut penelitian yang dilakukan oleh Bloedorn (2002) algoritma yang paling tepat dalam memgklasifikasikan kasus-kasus IDS adalah algoritma Decision Tree yang difokuskan pada model C4.5 (yang kini telah dimodifikasi menjadi model J48). Model ini mudah untuk diimplementasikan dan telah juga memiliki kinerja yang baik dalam memprediksi dan mengklasifikasikan kasus-kasus IDS.
Sehingga muncul pertanyaan “Bagaimana tingkat akurasi antara model yang dihasilkan oleh algoritma SVM, Bayesian, ataupun Decision Tree dalam memprediksi kasus-kasus IDS?”
Pada penelitian ini digunakan data offline sebanyak 5092 record, dimana data yang diteliti berasal dari data set KDD 1999. Data set yang digunakan terdiri dari 41 atribut data (variabel) berdasarkan penelitian Charles Elkan (2000). Menurut penelitian Mukkamala dan Andrew H. Sung (2003) kasus-kasus IDS diklasifikasikan menjadi empat kelas yakni : Denial-of Service (DoS), Probing/Surveillance, User-to-Root (U2R), dan Remote-to-Local (R2L).
tujuan dari penelitian ini adalah membandingkan tingkat akurasi yang dihasilkan oleh teknik/model data mining yaitu algoritma SVM, Bayesian, ataupun Decision Tree dalam memprediksi kasus-kasus pada IDS.
2. TINJAUAN PUSTAKA
Kemajuan dalam pengumpulan data dan teknologi penyimpanan yang cepat memungkinkan organisasi menghimpun jumlah data yang sangat luas. Alat dan teknik analisis data yang tradisional tidak dapat digunakan untuk mengektrak informasi dari data yang sangat besar. Untuk itu diperlukan suatu metoda baru yang dapat menjawab kebutuhan tersebut. Data mining merupakan teknologi yang menggabungkan metoda analisis tradisional dengan algoritma yang canggih untuk memproses data dengan volume besar. Tiga algoritma yang digunakan dalam penelitian ini akan dijelaskan sebagai berikut :
1. Support Vector Machine
Support Vector Machine (SVM) adalah sistem pembelajaran yang pengklasifikasiannya menggunakan ruang hipotesis berupa fungsi-fungsi linear dalam sebuah ruang fitur (feature space) berdimensi tinggi, dilatih dengan algoritma pembelajaran yang didasarkan pada teori optimasi dengan mengimplementasikan learning bias yang berasal dari teori pembelajaran statistik (Nello Christianini dan John S. Taylor, 2000).
Dalam konsep SVM berusaha menemukan fungsi pemisah (hyperplane) terbaik diantara fungsi yang tidak terbatas jumlahnya. Hyperplane pemisah terbaik antara kedua kelas dapat
ditemukan dengan mengukur margin hyperplane tersebut dan mencari titik maksimalnya. Pada gambar 2.2 dapat dilihat margin adalah jarak antara hyperplane tersebut dengan fungsi terdekat dari masing-masing kelas. Adapun data yang berada pada bidang pembatas disebut support vector. Secara matematika, konsep dasar SVM yaitu :
min
2
1
|w|2
s.t yi(xi.w+b)-1
0dimana
(
x
i.
w
b
)
1
untuk kelas 1, dan(
x
i.
w
b
)
1
untuk kelas 2,x
i adalah data set,y
iadalah output dari data
x
i, dan w, b adalah parameter yang dicari nilainya. Formulasi optimasi SVM untuk kasus klasifikasi dua kelas dibedakan menjadi klasifikasi linear dan non-linear.2. Decision Tree
Decision tree adalah algoritma yang paling banyak digunakan untuk masalah pengklasifikasian. Sebuah decision tree terdiri dari beberapa simpul yaitu tree’s roo, internal nod dan leafs. Konsep entropi digunakan untuk penentuan pada atribut mana sebuah pohon akan terbagi (split). Semakin tinggi entropy sebuah sampel, semakin tidak murni sampel tersebut. Rumus yang digunakan untuk menghitung entropy sampel S adalah sebagai berikut :
(1)
Dimana p1, p2, ...., pn masing-masing menyatakan proposi kelas 1, kelas 2, ..., kelas n dalam
output.
3. Naïve Bayes
Klasifikasi Bayesian adalah klasifikasi statistik yang bisa memprediksi probabilitas sebuah class. Klasifikasi Bayesian ini dihitung berdasarkan Teorema Bayes berikut ini :
(2)
Berdasarkan rumus di atas kejadian H merepresentasikan sebuah kelas dan X merepresentasikan sebuah atribut. P(H) disebut prior probability H, contoh dalam kasus ini adalah probabilitas kelas yang mendeklarasikan normal. P(X) merupakan prior probability X, contoh untuk probabilitas sebuah atribut protocol_type. P(H|X) adalah posterior probability yang merefleksikan probabilitas munculnya kelas normal terhadap data atribut protocol_type. P(X|H) menunjukkan kemungkinan munculnya prediktor X (protocol_type) pada kelas normal. Dan begitu juga seterusnya untuk proses menghitung probabilitas ke-empat kelas lainnya.
3. METODE PENELITIAN
Penelitian dilakukan terhadap data set yang diperoleh dari KDD 1999 sebanyak 5092 record dan dikelompokkan menjadi lima kelas.
Klasifikasi dilakukan dengan menerapkan algoritma algoritma SVM (menggunakan teknik SMO), Bayesian (menggunakan teknik NBC), dan Decision Tree (menggunakan teknik J48) yang telah tersedia pada tools data mining yakni WEKA 3.4.13.
4. HASIL DAN PEMBAHASAN
Berdasarkan penelitian Charles Elkan (2000), data log file sebelum menjadi data set dieksrak sedemikian rupa dengan menggunakan 41 variable/atribut yang dianggap berpengaruh pada sistem pendeteksi intrusi dan merupakan variable yang cukup efektif untuk menghitung performa algoritma.
Pada data set tersebut terdapat 24 jenis serangan, antara lain: back, buffer_overflow, ftp_write, guess_passwd, imap, ipsweep, land, loadmodule, multihop, neptune, nmap, normal, perl, phf, pod, portsweep, rootkit, satan, smurf, spy, teardrop, warezclient, warezmaster. Data set penelitian ini (5092 record) serangan-serangan tersebut diklasifikasikan berdasarkan sasaran dan tujuan serangan menjadi lima kelas kategori, yakni : DoS, Probe, U2R, dan U2L, dan Normal (Mrutyunjaya Panda dan Mana R. Patra, 2007)
Dari data yang tersedia, diolah menggunakan Microsoft Excel di konversi menjadi format csv yang kemudian diubah menjadi format file yang dikenali oleh WEKA yaitu arff. Data dengan
Mempersiapkan data yang telah diekstraksi
menjadi data set berdasarkan 41 variable
yang telah diteliti
Data set disimpan dalam format *csv Format file dikonversi ke *arff Menggunakan data dengan format arff pada
WEKA untuk dianalisis Menggunakan Modul classify dengan algoritma SVM, decision tree
dan naïve bayes Menggunakan hasil output untuk perbandingan ketiga algoritma Mulai Selesai
format file arff diproses menggunakan modul-modul yang ada di WEKA. Hasil pemrosesan data diringkas dalam bentuk tabel sebagai berikut :
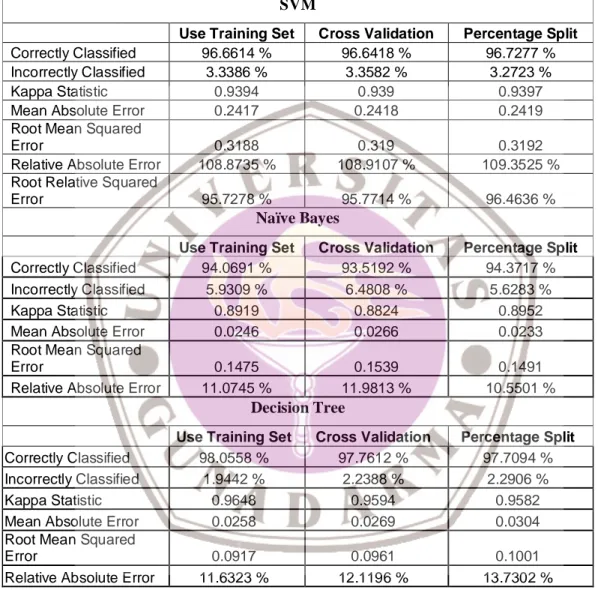
Tabel 1. Perbandingan SVM, Naïve Bayes, dan Decision Tree Pada Data Numerik
SVM
Use Training Set Cross Validation Percentage Split Correctly Classified 96.6614 % 96.6418 % 96.7277 % Incorrectly Classified 3.3386 % 3.3582 % 3.2723 %
Kappa Statistic 0.9394 0.939 0.9397
Mean Absolute Error 0.2417 0.2418 0.2419
Root Mean Squared
Error 0.3188 0.319 0.3192
Relative Absolute Error 108.8735 % 108.9107 % 109.3525 % Root Relative Squared
Error 95.7278 % 95.7714 % 96.4636 %
Naïve Bayes
Use Training Set Cross Validation Percentage Split Correctly Classified 94.0691 % 93.5192 % 94.3717 % Incorrectly Classified 5.9309 % 6.4808 % 5.6283 %
Kappa Statistic 0.8919 0.8824 0.8952
Mean Absolute Error 0.0246 0.0266 0.0233
Root Mean Squared
Error 0.1475 0.1539 0.1491
Relative Absolute Error 11.0745 % 11.9813 % 10.5501 %
Decision Tree
Use Training Set Cross Validation Percentage Split Correctly Classified 98.0558 % 97.7612 % 97.7094 % Incorrectly Classified 1.9442 % 2.2388 % 2.2906 %
Kappa Statistic 0.9648 0.9594 0.9582
Mean Absolute Error 0.0258 0.0269 0.0304
Root Mean Squared
Error 0.0917 0.0961 0.1001
Relative Absolute Error 11.6323 % 12.1196 % 13.7302 %
Dari tabel di atas bisa disimpulkan, secara keseluruhan algoritma Decision Tree merupakan teknik yang paling sederhana dalam mengelompokkan kasus IDS dan memiliki kecenderungan tingkat akurasi yang tinggi. Akan tetapi algoritma NBC merupakan algoritma yang paling baik dalam hal waktu komputasi (waktu yang dibutuhkan untuk membangun sebuah model), terlihat dari perbandingan tabel 2.
Tabel 4.6 Hasil Perbandingan Waktu Komputasi Algoritma (Satuan : second ) SVM (SMO) Bayesian (Naïve Bayes) Decision Tree (J48)
Use Training Set 182.97 0.58 1.83
Cross Validation 170.61 0.42 1.99
5. PENUTUP
Perbandingan algoritma dengan menggunakan WEKA 3.4.13 dapat dilihat dari beberapa nilai yang dihasilkan antara lain correctly classified instance, incorrectly classified, kappa statistic, mean absolute error, root mean squared error, relative absolute error, root relative squared error. Selain nilai-nilai tersebut, confusion matrix yang dihasilkan dapat diketahui jumlah false positive dan false negative sehingga dapat dihitung performa masing algoritma untuk masing-masing kelas.
Secara keseluruhan, kinerja algoritma decision tree lebih baik dibandingkan dengan algoritma SVM dan NBC. Ada beberapa factor yang menjadikan algoritma decision tree lebih baik dibandingkan yang lainnya, salah satunya kemampuannya yang secara sederhana (simple) mendefinisikan dan mengklasifikasikan masing-masing atribut ke setiap kelas. Namun tidak untuk waktu komputasi (running time), untuk membangun sebuah model algoritma yang tercepat dari ketiga algoritma tersebut adalah naïve bayes. Untuk membangun atau menambahkan teknik yang baik pada system IDS maka teknik algoritma yang dianjurkan adalah Decision Tree.
Pengukuran kinerja sebuah algoritma data mining dapat dilakukan berdasarkan beberapa kriteria antar lain akurasi, kecepatan komputasi, robustness, skalabilitas dan interpretabilitas. Penelitian ini baru menggunakan satu kriteria yaitu berdasarkan akurasi. Akan lebih baik jika semua kriteria diuji coba agar algoritma yang diteliti lebih teruji kinerjanya.
Akurasi sebuah algoritma bisa ditingkatkan dengan menggunakan beberapa teknik antara lain teknik bagging dan boosting. Penelitian ini juga belum menggunakan kedua teknik tersebut untuk meningkatkan akurasi karena penelitian ini hanya terbatas pada perbandingan algoritma SVM, decision tree dan naïve bayes.
Penelitian ini juga menggunakan data sampel yang cukup terbatas yaitu 5092 record log file, ini dikarenakan keterbatasan source baik itu memory maupun processor yang digunakan. Untuk mengestimasi akurasi sebuah algoritma akan lebih baik jika jumlah data sampel yang digunakan mendekati populasi yang ada. Diharapkan pada penelitian selanjutnya, record yang digunakan lebih banyak karena semakin banyak record yang dilatih maka kemungkinan untuk menemukan pola diluar perkiraan (new attacks) akan ditemukan diluar pola yang ada. Sehingga algoritma dapat diuji ketelitiannya terhadap klasifikasi jenis serangan baru. Dan untuk requirement hardware akan lebih baik didukung dengan source dengan high performance
.
6. DAFTAR PUSTAKA
Bloedorn, Eric, et al. 2002. Data Mining for Network Intrusion Detection: How to Get Started. Jurnal. Massachusetts: The Mitre Corporation. USA.
Budi, Santosa. 2007. Data Mining, Teknik Pemanfaatan Data untuk Keperluan Bisnis. Graha Ilmu. Yogyakarta.
Christianini, Nello, dan Jhon S. Taylor. 2000. An Introduction to Support Vector Machines and Other Kernel-based Learning Methods. Jurnal. Cambridge University Press. Australia.
Christianini, Nello. 2001. Support Vector and Kernel Machines. Tutorial. ICML.
Dunham, H. Margareth. 2002. Data Mining: Introductory and Advanced. Tutorial. Prentice Hall.
Fayyad, U., Piatetsky-Shapiro, dan G. Smyth. 1996. From Data Mining to Knowledge Discovery in Databases. Jurnal. AAAI and The MIT Pres, 37-53.
Han, J. dan M. Kamber. 2001. Data Mining: Concepts and Techniques. Tutorial. Morgan Kaufman Publisher. San Francisco.
Haridas, Mandar. 2007. Step By Step Tutorial for Weka.
http://people.cis.ksu.edu/~hankley/d764/tut07/Haridas_DM.pdf. Tanggal akses 26 Juni 2008.
Ian H, Witten., dan Eibe Frank. 2005. Data Mining, Practical Machine Learning Tools and Techniques, Second Edition. Morgan Kaufmann Publisher. San Francisco.
Iko, Pramudiono. 2003. Pengantar Data Mining: Menambang Permata Pengetahuan di Gunung Data. http://ilmukomputer.com. Tanggal akses 07 Mei 2008.
Larose, Daniel. T. 2005. Discovering Knowledge In Data, an Introduction to Data Mining. Wiley Interscience. New Jersey.
Kamber, Michelin., Jiawei Han. 2006. Data Mining Concepts and Techniques, Second Edition. Morgan Kaufman Publisher. San Francisco.
Krisantus, Sembiring. 2007. Penerapan Teknik Support Vector Machine untuk Pendeteksi Intrusi pada Jaringan. Jurnal. Teknik Informatika, ITB. Bandung.
Mukkamala, Srinivas. dan Andrew H. Sung. 2003. Feature Selection for Intrusion Detection Using Neural Networks and Support Vector Machines. Jurnal. Department of Computer Science, MIT. USA.
Osuna, Edgar E., et al. 1997. Support Vector Machine: Training and Applications. Jurnal. Department of Computer Science, MIT. USA.
Panda, Mrutyunjaya. And Mana R. PATRA. 2007. Network Intrusión Detection Using Naive Bayes. Jornal. Department of Computer Science, Behampur University. India.
Sinclair, C., L. Pierce, dan Matzner S. 2000. An Application of Mechine Learning to Network Intrusion Detection Detection. Applied Research Laboratory Technical Report No.859, The University of Texas. Austin.
Suryani, Alifah. 2004. Ekstraksi Ciri Signifikan Pada Analisa Forensik Jaringan Menggunakan Teknik Intelegensia Buatan. Tesis. Teknologi Informasi, ITB. Bandung.
Tan P. N., Steinbach M., dan Kumar V. 2006. Introduction to Data Mining. Tutorial. Addison Wesley.
Turban, Efraim., Jay E. Aronson, dan Ting Peng Liang. 2005. Decision Support System and Intelligent Systems (Sistem Pendukung Keputusan dan Sistem Cerdas). Edisi 7 Jilid 1, Andi Offset. Yogyakarta.