ALGORITMA
DECISION TREE-J48, K-NEAREST,
DAN
ZERO-R
PADA KINERJA AKADEMIK
Nurfaizah
1)Mohammad Imron
2)Linda Perdanawanti
3)1),2),3)
Sistem Informasi, STMIK AMIKOM Purwokerto
Jl. Letjend. Pol. Sumarto, Purwokerto, Indonesia
e-mail: 1)[email protected], 2) [email protected], 3) [email protected]
ABSTRACT
The student's academic performance becomes one of the benchmarks of the quality of Higher Education, in this study to know the students who have poor academic performance in the learning process in order to be known. One solution that researchers do is to detect the timeliness of graduation students with data mining techniques in order to note the problems that occur in the students.
The purpose of this study compared decision-j48, k-nearest neighbor, and zero-r algorithms with a combination of CFS to measure the best accuracy of each algorithm for the evaluation of student academic performance. From the result of comparison obtained from testing decision algorithm j48, k-nearest neighbor, and zero-r with combination of CFS can be known result of comparation from each experiment. From the same dataset, the use of feature selection turns out to have better results from the decision tree-j48 and zero-r algorithms with 86.38% accuracy value while the feature selection has an accuracy of 87.88%, while from the test result with k- Nearest neighbor has the highest accuracy value without selection or with feature selection that is with accuracy 89.04%.
Key words
Student academic performance, Decision Tree-J48, K-Nearest, Zero-R, CFS
1. Pendahuluan
Sebagai lembaga pendidikan, STMIK AMIKOM Purwokerto tentunya mengharapkan regenerasi yang berkualitas dan dapat bersaing dengan Perguruan Tinggi lainnya. Sehingga kualitas dari Perguruan Tinggi selain dilihat dari rata-rata masa lulusnya mendapatkan pekerjaan juga dapat dilihat dari rata-rata masa studi dari mahasiswanya.
Sehingga Perguruan Tinggi kini dituntut untuk memiliki keunggulan dalam bersaing dengan memanfaatkan semua sumber daya yang dimiliki, sesuai dengan buku pedoman akademik STMIK AMIKOM Purwokerto tahun 2011/2012, pada Bab I dengan pengertian umum Pasal 1 ayat (2) disebutkan bahwa: Program Sarjana (S-1) reguler adalah program pendidikan akademik setelah pendidikan menengah yang memiliki beban studi sekurang-kurangnya 144 sks dan sebanyak-banyaknya 160 sks yang dijadwalkan untuk 8 semester dan dapat ditempuh dalam waktu kurang dari 8 semester, paling lama 12 semester [1].
Untuk mengolah data yang begitu besar dan kompleks maka dibutuhkan proses penggalian data atau dikenal dengan istilah data mining. Tingkat kelulusan mahasiswa tepat waktu sangat penting dibahas, dikarenakan berpengaruh terhadap kualitas suatu Perguruan Tinggi [2]. Data Mining juga didefinisikan sebagai rangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual [3].
Beberapa penelitian terkait dengan topik penelitian yang pernah dilakukan [4] monitoring dan evaluasi kinerja akademik mahasiswa menggunakan teknik data mining. [5] evaluasi kinerja akademik mahasiswa menggunakan algoritma naive bayes, dan [6] prediksi kinerja mahasiswa menggunakan algoritma klasifikasi data mining dengan menggunakan algoritma decision tree classifier, neural network,dan nearest neighbor.
Tujuan dari penelitian ini adalah untuk mendapatkan hasil komparasi metode klasifikasi DC Tree-J48, K-Nearest Neighbor, dan Zero-R berbasis CFS untuk mengevaluasi kinerja akademik mahasiswa, serta membangun sebuah sistem pendukung keputusan.
2. Landasan Teori
2.1 Data Mining
Penambangan data (data mining) adalah serangkaian proses untuk menggali nilai tambah dari sekumpulan data berupa pengetahuan yang selama ini tersembunyi dibalik data atau tidak diketahui secara manual [3].
Data Mining adalah suatu teknik menggali informasi berharga yang terpendam atau tersembunyi pada suatu koleksi data (database) yang sangat besar sehingga ditemukan suatu pola yang menarik yang sebelumnya tidak diketahui. Data Mining sendiri berarti usaha untuk mendapatkan sedikit barang berharga dari sejumlah besar material dasar, dimana data mining memiliki akar yang panjang dari bidang ilmu seperti kecerdasan buatan (artificial intelligent), machine learning, statistik dan database [7].
Masalah-masalah yang sesuai untuk diselesaikan dengan teknik data mining dapat dirincikan dengan [8]:
1. Memerlukan keputusan yang bersifat knowledge-based
2. Mempunyai lingkungan yang berubah
3. Metode yang ada sekarang bersifat sub-optimal 4. Tersedia data yang bisa diakses, cukup dan relevan 5. Memberikan keuntungan yang tinggi jika keputusan
yang diambil tepat.
2.2 Klasifikasi
Klasifikasi adalah proses penemuan model atau fungsi yang menggambarkan dan membedakan kelas data atau konsep yang bertujuan agar bisa digunakan untuk memprediksi kelas dari objek yang label kelasnya tidak diketahui [9]. Klasifikasi data terdiri dari 2 langkah proses, yang Pertama adalah learning (fase training), dimana algoritma klasifikasi dibuat untuk menganalisa data training, lalu direprestasikan dalam bentuk rule klasifikasi. Proses yang Kedua adalah klasifikasi, dimana data tes digunakan untuk memprediksi atau memperkirakan akurasi dari rule klasifikasi [9].
2.3 Algoritma Decision Tree J48
Decision Tree J48 merupakan implementasi algoritma C4.5 (berbasis Java) pada Weka [10]. Algoritma C4.5 digunakan untuk pemisah obyek [11]. Tree atau pohon keputusan banyak dikenal sebagai bagian dari Graph, yang termasuk dalam irisan bidang ilmu otomata dan teori bahasa serta matematika diskrit. Tree sendiri merupakan graf tak-berarah yang terhubung, serta tidak mengandung sirkuit [12].
Secara umum algoritma C4.5 untuk membangun pohon keputusan adalah sebagai berikut [13]:
1. Pilih atribut sebagai akar 2. Buat cabang untuk tiap-tiap nilai 3. Bagi kasus dalam cabang
4. Ulangi proses untuksetiap cabang sampai semua kasus pada cabang memiliki kelas yang sama. Untuk memilih atribut sebagai akar, didasarkan pada nilai gain tertinggi dari atribut-atribut yang ada. Untuk menghitung gain digunakan persamaan sebagai berikut:
………….(1) Keterangan:
S = himpunan kasus A = atribut
n = jumlah partisi atribut A |Si| = jumlah kasus pada partisi ke-i |S| = jumlah kasus dalam S
Rumus dasar dari entropy tersebut adalah sebagai berikut: .………….(2) Keterangan: S = himpunan kasus A = fitur n = jumlah partisi S
pi = proporsi dari Si terhadap S
2.4 Algoritma K-Nearest Neighbor
Algoritma k-nearest neighbor merupakan sebuah metode untuk melakukan klasifikasi terhadap obyek baru berdasarkan (k) tetangga terdekatnya [14]. KKN termasuk algoritma supervised learning, dimana hasil query instance yang baru, diklasifikasikan berdasarkan mayoritas dari kategori pada KNN. Kleas yang paling banyak muncul yang akan menjadi kelas hasil klasifikasi [14]. Algoritma k-nearest neighbor merupakan metode klasifikasi yang mengelompokkan data baru berdasarkan jarak data baru itu kebeberapa data atau tetangga (neighbor) terdekat. Teknik knn dengan melakukan langkah-langkah yaitu, mulai input : data training, label, data training, dan data testing.
2.5 Algoritma Zero-R
Algoritma Zero-R secara sederhana memprediksi mayoritas kelas dalam training data [3], meskipun algoritma Zero-R memiliki sedikit akal untuk digunakan sebagai prediktor, algoritma Zero-R bermanfaat untuk
menentukan performance dasar sebagai benchmark untuk skema pembelajaran yang lain.
2.6 Seleksi Fitur
Metode pemilihan fitur yang digunakan adalah correlation based feature selection (CFS) subset evaluation [15]. Metode CFS subset evaluation memilih fitur terbaik dari fitur yang ada. Dengan kata lain ada fitur yang harus dibuang karena memiliki nilai korelasi yang rendah terhadap hasil prediksi kategori. Sebagai inti dalam CFS adalah teknik heuristic untuk mengevaluasi nilai atau harga subset fitur [13]. Teknik ini mempertimbangkan kegunaan fitur individual bagi prakiraan label kelas dengan level interkorelasi di antara fitur-fitur. Fitur secara individual menguji mana ukuran yang berkaitan dengan variable yang diamati (sebagai kelas target).
Sebagai inti dalam CFS adalah teknik heuristic untuk mengevaluasi nilai atau harga subset fitur [14]. Teknik ini mempertimbangkan kegunaan fitur individual bagi prakiraan label kelas dengan level interkorelasi di antara fitur-fitur. Fitur secara individual menguji mana ukuran yang berkaitan dengan variable yang diamati (sebagai kelas target). Persamaan berikut adalah formalisasi nilai harga heuristic yang dimaksud:
………….(3) Dimana Merits merupakan harga heuristic subset fitur S yang berisi k fitur rcf yang merupakan rata-rata korelasi fitur-kelas, rff adalah rata-rata interkorelasi fitur ke fitur. Pada kenyataannya semua variable distandardisasi sesuai rumus korelasi Pearson. Numerator dianggap telah dipahami sebagai indikasi bagaimana sifat prediksi suatu fitur kelompok, sedangkan denominator menunjukkan bagaimana redundansi data antara fitur.
3. Metode Penelitian
Penelitian ini didesain dengan merujuk pada model CRISP-DM (Cross-Industry Satndard Process for Data Mining). Dimana penelitian ini melakukan pengujian tingkat akurasi terbaik antara algoritma J48, KNN, dan Zero-R Kombinasi CFS. Data eksperimen diambil dari data mahasiswa STMIK AMIKOM Purwokerto.
3.1 Metode Analisis Data
Metode analisis data dalam penelitian ini mengacu pada tahapan proses CRISP-DM, yang merupakan suatu
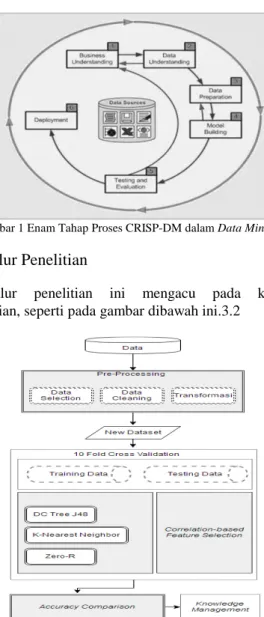
konsorsium perusahaan yang didirikan oleh Komisi Eropa pada tahun 1996 dan telah ditetapkan sebagai proses standar dala data mining yang dapat diaplikasikan diberbagai sektor industri. Gambar 3.1 menjelaskan tentang siklus hidup pengembangan data mining yang telah ditetapkan dalam CRISP-DM.
Menurut Larose, data mining memeliki enam fase CRISP-DM ( Cross Industry Standard Process for Data Mining ) [18].
a. Fase Pemahaman Bisnis (Business Understanding Phase)
b. Fase Pemahaman Data (Data Understanding Phase ) c. Fase Pengolahan Data (Data Preparation Phase ) d. Fase Pemodelan (Modeling Phase )
e. Fase Evaluasi (Evaluation Phase ) f. Fase Penyebaran (Deployme nt Phase)
Gambar 1 Enam Tahap Proses CRISP-DM dalam Data Mining[16]
3.2 Alur Penelitian
Alur penelitian ini mengacu pada kerangka penelitian, seperti pada gambar dibawah ini.3.2
4. Hasil dan Pembahasan
4.1 Penentuan Dataset Mahasiswa
Pada penelitian ini peneliti mengkaji dan melakukan proses klasifikasi penentuan dataset yang disimpan dalam format excel, seperti terlihat pada gambar dibawah ini:
Gambar 3 Dataset setelah Pembersihan Atribut
Setelah melewati tahap pembersihan dan integrasi data, dataset yang dihasilkanpun tidak langsung dapat digunakan karena masih terdapat beberapa data yang memiliki tipe data yang inkonsisten sehingga perlu dilakukan beberapa perubahan tipe data. Tahap ini dilakukan dalam tahap transformasi data.
4.2 Transformasi Data
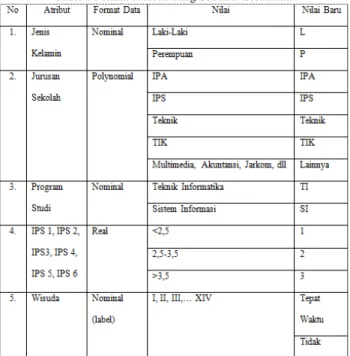
Pada tahap ini dilakukan perubahan tipe data pada atribut jenis kelamin, program studi, dan IP. Format dataset yang akan digunakan sebagai sumber data pemodelan klasifikasi adalah sebagai berikut:
Tabel 1 Format Atribut Yang Sudah Disesuaikan
Setelah atribut disesuaikan melalui tahap transformasi data dapat terlihat tabel keterangan atribut yang menjelaskan masing-masing atribut yang akan digunakan sebagai atribut dataset dibawah ini:
Tabel 2 Dataset Setelah Penyesuain Atribut
Data yang digunakan berasal dari data mahasiswa, data nilai mahasiswa dan data kelulusan mahasiswa tahun angkatan 2010 - 2012 dengan jumlah total 2.189 record. Dataset setelah pembersihan data yaitu data training sebanyak 667 record yang merupakan data mahasiswa tahun 2010 - 2011 yang lulus tepat waktu dan tidak tepat waktu, kemudian data testing 867 record yang merupakan data mahasiswa tahun 2010 – 2012 yang belum lulus.
Setelah melewati tahap pembersihan dan integrasi data, dataset yang dihasilkan pun tidak langsung dapat digunakan karena masih terdapat beberapa data yang memiliki tipe data yang inkonsisten sehingga perlu dilakukan beberapa perubahan tipe data. Tahap ini dilakukan dalam tahap transformasi data.
Setelah dilakukan proses transformasi data, langkah terakhir dari preprocessing data adalah mengubah dataset dari file excel menjadi format CSV atau ARFF agar dapat dikenali sebagai sumber data pada WEKA. Namun sebelum disimpan menjadi format file ARFF, diketahui bahwa dataset yang ada masih merupakan dataset asli yang masih tercampur sehingga perlu dilakukan pembagian dataset menjadi 2 yaitu data yang akan digunakan sebagai data sampel (data training) dan data yang akan digunakan sebagai data uji/prediksi (data testing).
4.3 Pengujian Algoritma
Pada tahap ini bertujuan untuk mengetahui akurasi dari algoritma Decision Tree J48, k-nn, dan Zero-R dalam mengklasifikasikan data ke dalam kelas yang telah ditentukan untuk mengetahui nilai akurasi dari masing-masing algoritma yang diujikan berdasarkan dataset yang telah ditentukan.
4.3.1 Algoritma Decision Tree J48
Dari hasil pengujian dengan menggunakan algoritma DC Tree J48 yang telah dilakukan terhadap dataset, dengan menunjukkan hasil evaluasi tingkat akurasi klasifikasi algoritma DC Tree J48 yang memiliki nilai akurasi sebesar 86.38%, tingkat akurasi dari tabel tersebut diperoleh dari hasil perhitungan confusion matrix, yaitu:
Akurasi (%) =
Akurasi (%) = = = 86,38 %
4.3.2 Algoritma K-Nearest Neighbor
Sedangkan dari hasil pengujian dengan menggunakan algoritma K-NN yang telah dilakukan memiliki nilai akurasi paling tinggi yaitu sebesar 89.04%, tingkat akurasi dari tabel tersebut diperoleh dari hasil perhitungan confusion matrix, yaitu:
Akurasi (%) =
Akurasi (%) =
= = 89,04%
4.3.3 Algoritma Zero-R
Dan pengujian berikutnya dengan menggunakan algoritma Zero-R, dari hasil pengujian tersebut untuk memiliki nilai akurasi sebesar 86.38%, dan tingkat akurasi dari tabel tersebut diperoleh dari hasil perhitungan confusion matrix, yaitu:
Akurasi (%) =
Akurasi (%) =
= = 86,38% 4.3.4 Seleksi Atribut
Sedangkan dengan pengujian seleksi atribut dari tiga algoritma diatas dengan menggunakan 7 atribut yang telah diseleksi memiliki nilai akurasi sebesar 87,88%. Dari hasil pengujian dapat disimpulkan bahwa seleksi atribut lebih unggul dari dua algoritma J48 dan Zero-R, dibandingkan
dengan algoritma K-NN yang memilki nilai akurasi lebih baik tanpa seleksi atribut ataupun dengan seleksi atribut.
4.4 Analisis Hasil
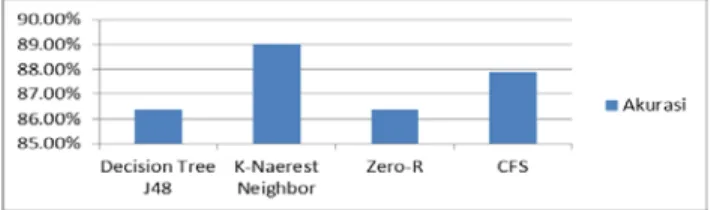
Dari hasil pengujian dapat diketahui setiap percoban dari algoritma decision tree j48, k-nn, dan zero-r dengan kombinasi seleksi atribut, sehingga dapat diketahui hasil dari komparasi setiap percobaan. Percobaan dilakukan untuk mengetahui tingkat akurasi dari 3 algoritma yang telah dilakukan dengan kombinasi seleksi atribut.
Tabel 3 Hasil Komparasi Algoritma Decision Tree J48, K-Naerest
Neighbor, dan Zero-R dengan kombinasi CFS.
Metode Akurasi
Decision Tree J48 86,38 %
K-Naerest Neighbor 89,04%
Zero-R 86,38%
CFS 87,88%
Penambahan seleksi atribut menghasilkan tingkat akurasi yang lebih baik dari kedua algoritma decision tree j48 dan Zero-R yang memilki nilai akurasi hampir sama yaitu 86,38%, sedangkan dengan seleksi atribut sendiri memiliki nilai akurasi lebih baik dibandingkan kedua akurasi diatas yaitu sebesar 87,88%. Dan dari hasil komparasi algoritma diatas yang lebih baik menggunakan algoritma K-Naerest Neighbor baik dengan seleksi atribut ataupun tidak dengan seleksi atribut memilki nilai akurasi lebih baik yaitu sebesar 89,04%.
Gambar 4 Grafik Hasil Komparasi Algoritma Decision Tree J48, K-Naerest Neighbor, dan Zero-R dengan kombinasi CFS
5. Kesimpulan
Berdasarkan hasil implementasi algoritma Decision Tree J48, K-Naerest Neighbor, dan Zero-R dengan kombinasi CFS pada kasus kinerja akademik mahasiswa dapat diambil beberapa kesimpulan sebagai berikut: 1. Dengan dataset yang sama, penggunaan seleksi fitur
pada algoritma Decision Tree J48, K-Naerest Neighbor, dan Zero-R, pada kasus kinerja akademik mahasiswa lebih baik dibandingkan algoritma decision tree j48 dan zero-r, dimana algoritma tersebut hanya memilki nilai akurasi 86,38% dibandingan dengan menggunakan seleksi fitur yaitu 87,88%. Sedangkan
untuk algoritma K-Naerest Neighbor lebih baik dengan seleksi atribut ataupun tidak memiliki nilai akurasi lebih tinggi yaitu 89,04%.
2. Penentuan data training pada pengujian tersebut memiliki pengaruh terhadap hasil pengujian, dimana pola data training tersebut dijadikan rule untuk menentukan class pada data testing. Dari hasil pengujian bahwa data akademik setiap angkatan memiliki pola yang berbeda-beda yang ditunjukan oleh tingkat akurasi dari setiap data testing yang diujicoba. 3. Hasil dari komparasi yang telah diimplementasikan
bahwa algoritma K-Naerest Neighbor lebih baik dengan nilai akurasi nilai tertinggi sebesar 89,04%.
REFERENSI
[1] STMIK AMIKOM Purwokerto, Buku Panduan Akademik
Mahasiswa Tahun Ajaran 2012-2013. Purwokerto, Jawa Tengah: STMIK AMIKOM Purwokerto, 2012.
[2] Hastuti, Khafiizh. 2012. Analisis Komparasi Algoritma
Klasifikasi Data Mining untuk Prediksi Mahasiswa Non Aktif. Seminar Naisonal Informasi dan Komunikasi
Terapan 2012 (Semantik 2012) Semarang, 23 Juni 2012. [3] Han, J., & Kamber, M. (2006). Data Mining Concept and
Tehniques. San Fransisco: Morgan Kauffman. ISBN 13:
978-1-55860-901-3.
[4] Ogor, E.N. 2007. Student Academic Performance
Monitoring and Evaluation Using Data Mining Techniques. IEEE Computer Society.
[5] Nasution, dkk. 2015. Evaluasi Kinerja Akademik
Mahasiswa Menggunakan Algoritma Naïve Bayes (Studi
Kasus: Fasilkom Unilak). Jurnal Teknologi Informasi & Komunikasi Digital Zone, Volume 6, Nomor 2
[6] Kabakchieva, D. 2012. Student Performance Prediction by
Using Data Mining Classification Algorithms. IJCSMR.
Vol 1 Issue 4: 686-690.
[7] Witten, I. H., Frank, E., Hall, M. A., 2011, Data Mining:
Practical Machine Learning Tools and Techniques 3rd Edition, Morgan Kaufmann Publishers, San Fransisco.
[8] Herera, francisco, 2010. Data Mining and Soft
Computing, Dept. of Computer Science and A.I.
University of Granada, Spain.
[9] Tan, P.N., Steinbach, M., Kumar, V. (2006), Introduction
to Data Mining, 1st Ed, Pearson Education: Boston San
Fransisco New York.
[10] http://www.cs.waikato.ac.nz/ml/weka/documentation.html (diakses terakhir 18 Nopember 2013).
[11] W. Nor Haizan W. Mohamed, Mohd Najib Mohd Salleh, Abdul Halim Omar, “A Comparative Study of
Reduced Error Pruning Method in Decision Tree Algorithms”,IEEE International Conference on Control System, Computing and Engineering, 23 -Penang,
Malaysia , 25 Nov. 2012
[12] Munir, R. (2010). Matematika Diskrit. Bandung: Informatika Bandung.
[13] Kusrini dan Taufiq Lutfi, Emha. (2009). “Algoritma Data
Mining.” Yogyakarta: Andi.
[14] Hall, M.A.: Correlation-based feature selection for
discrete and numeric class machine learning. In Proceedings of the 17th Intl. Conf. Machine Learning
(2000) 359-366.
[15] Susanto & Suryadi. 2010. Pengantar Data Mining Menggali Pengetahuan dari Bongkahan Data.CV Andi Offset.Yogyakarta.
[16] Larose, Daniel T, Data Mining Methods and Models.
Hoboken New Jersey: Jhon iley & Sons, Inc, 2006
Nurfaizah, memperoleh gelar S.Kom dan M.Kom dari STMIK
AMIKOM Purwokerto dan STMIK AMIKOM Yogyakarta pada tahun 2011 dan 2014. Saat ini sebagai Staf Pengajar program studi Sistem Informasi STMIK AMIKOM Purwokerto.
Linda Perdanawanti, memperoleh gelar S.Kom dan M.Kom
dari STMIK AMIKOM Purwokerto dan STMIK AMIKOM Yogyakarta pada tahun 2010 dan 2013. Saat ini sebagai Staf Pengajar program studi Teknik Informatika STMIK AMIKOM Purwokerto.
Mohammad Imron, memperoleh gelar S.Kom dan M.Kom dari
STMIK AMIKOM Purwokerto dan Universitas Dian NuswantoroSemarang pada tahun 2010 dan 2016. Saat ini sebagai Staf Pengajar program studi Teknik Informatika STMIK AMIKOM Purwokerto.