PENDEKATAN CROSS ENTROPY-GENETIC ALGORITHM UNTUK
PERMASALAHAN PENJADWALAN JOB SHOP TANPA WAKTU TUNGGU PADA BANYAK MESIN
Muhammad Arif Budiman
Jurusan Teknik Industri, Fakultas Teknologi Industri, Institut Teknologi Sepuluh Nopember Surabaya
[email protected] ABSTRAK
Permasalahan penjadwalan job shop tanpa waktu tunggu (no-wait job-shop scheduling
– NWJSS) merupakan salah satu permasalahan penjadwalan klasik yang dapat ditemui pada perusahaan-perusahaan pengecoran logam, plastik, dan makanan, dengan operasi tidak diizinkan menunggu. Beberapa metode penyelesaian permasalahan tersebut telah dikembangkan baik dengan pendekatan eksak maupun heuristik/metaheuristik. Cross entropy
sebagai salah satu metode metaheuristik yang relatif baru dapat menjadi alternatif metode untuk mendapatkan pendekatan penyelesaian permasalahan tersebut. Metode ini sudah diaplikasikan pada permasalahan optimasi kombinatorial, optimasi multi ekstermal, serta rare event simulation, dengan hasil penyelesaian yang cukup optimal dengan waktu yang relatif singkat. Penelitian ini mengimplementasikan metode cross entropy yang dihibridasi dengan algoritma genetika (cross entropy – genetic algorithm/CEGA) dalam permasalahan
m-machines NWJSS, serta membandingkan kelebihan dan kekurangan antara metode CEGA
tersebut dengan metode lain pada permasalahan yang sama. Hasil yang diharapkan dari penelitian ini adalah pengembangan algoritma CEGA pada permasalahan NWJSS, untuk mendapatkan hasil makespan yang lebih baik.
I. PENGANTAR
Permasalahan NWJSS merupakan permasalahan yang tergolong non-polynomial hard
(NP-Hard), terutama pada permasalahan banyak mesin (m-machines NWJSS) (Pan, 2009). Pada permasalahan job shop secara umum, urutan pengerjaan operasi pada masing-masing job
tidak sama, sehingga ketidak-tepatan penjadwalan dapat mengakibatkan bertambahnya waktu penyelesaian keseluruhan job (makespan). Selain itu, batasan no-wait (tanpa waktu tunggu) – misalnya pada beberapa perusahaan pengecoran logam, plastik, dan makanan – membuat permasalahan tersebut menjadi lebih rumit, di mana ketidak-tepatan penjadwalan dapat mengakibatkan mundurnya makespan yang lebih signifikan. Hal ini karena keberlangsungan operasi kerja dalam satu job harus dijaga untuk menghindari pengerjaan ulang operasi (operation rework) maupun pengerjaan ulang job kembali dari operasi permulaan (jobredo).
Beberapa penelitian untuk mendapatkan penyelesaian permasalahan NWJSS tersebut telah dilakukan, misalnya dengan menggunakan Genetic Algorithm-Simulated Annealing
(Schuster, 2003) dan Tabu Search Hibrida (Bożejko, 2009). Beberapa dari metode tersebut mendapatkan hasil makespan yang kurang optimal, namun ada pula yang mendapatkan hasil
makespan yang optimal namun dengan waktu komputasi yang relatif lama.
Metode cross entropy sebagai salah satu metode metaheuristik yang relatif baru telah digunakan dalam beberapa permasalahan optimasi kombinatorial, optimasi kontinu, optimasi
noisy, dan rare event simulation (Rubinstein, 2004). Pada beberapa permasalahan, metode ini dapat menghasilkan penyelesaian yang cukup optimal dengan perbandingan waktu penghitungan yang relatif lebih singkat, misalnya pada permasalahan Support Vector Machine
(Widyarini, 2009). Penelitian ini akan melakukan suatu pengembangan algoritma dengan pendekatan cross entropy yang dihibridasi dengan algoritma genetika (untuk selanjutnya dinamakan cross entropy-genetic algorithm atau CEGA) untuk menyelesaikan permasalahan
NWJSS. Penggunaan pendekatan cross entropy-genetic algorithm untuk mengembangkan algoritma dalam menyelesaikan permasalahan NWJSS diharapkan menjadi alternatif untuk menghasilkan jadwal dengan makespan yang optimal.
II. MODEL PERMASALAHAN
Merujuk pada definisi Graham dkk. pada penelitian Schuster (2003), permasalahan
NWJSS secara umum adalah sebagai berikut:
Terdapat seperangkat mesin M = {1, 2, …, m} yang akan digunakan untuk mengerjakan seperangkat job J = {1, 2, …, n}. Untuk setiap job ke-i ∈J, diberikan urutan-urutan pengerjaan sebanyak k operasi O = {O(i,1), O(i,2), …, O(i,j)} yang merupakan detail dari
pengerjaan semua job ke-i. Masing-masing operasi tersebut memiliki (m(i,j), w(i,j)) ∈ M×ℕ,
yang menunjukkan bahwa operasi o(i,j) dikerjakan pada mesin m(i,j) dengan waktu operasi
w(i,j).
Sedangkan merujuk pada model yang diusulkan Brizuela pada penelitian Pan (2009), permasalahan NWJSS dengan minimasi makespan dapat dimodelkan dalam bentuk pemrograman integer sebagai berikut:
Simbol yang digunakan
Ji Job ke-i
Mk Mesin ke-k
Oik Operasi job ke-i yang dijalankan di mesin ke-k
O(i,j) Operasi ke-j pada job ke-i
Ni Banyaknya operasi pada job ke-i Parameter permasalahan
M Bilangan positif sembarang yang sangat besar
n Banyaknya job
m Banyaknya mesin pada lantai produksi
wik Waktu proses job ke-i pada mesin ke-k
r(i,j,k) Biner pemroses, bernilai 1 jika O(i,j) diproses di Mk, bernilai 0 jika tidak Peubah keputusan
Cmax Waktu penyelesaian maksimal tercepat (makespan)
sik Waktu mulai tercepat job ke-i pada mesin ke-k
Z(i,i’,k) Biner pendahulu, bernilai 1 jika job ke-i mendahului job ke-i’ pada mesin ke-k, bernilai 0 jika tidak
Model permasalahan Minimize Cmax Subject to (7) (8) (9) (10) (11) dengan i∊ {1,2,...,n}; j∊ {1,2,...,Ni-1}; k∊ {1,2,...,m};
Persamaan (7) memberi batasan bahwa mesin ke-k akan memulai O(i,j+1) sesaat setelah O(i,j) sudah selesai (untuk meyakinkan bahwa batasan tanpa tunggu terpenuhi). Persamaan (8) dan (9) memberi batasan bahwa hanya ada satu job yang diproses dalam satu mesin pada satu waktu. Keduanya secara bersama-sama dipakai untuk meyakinkan bahwa hanya satu persamaan yang akan berdampak, terkait dengan nilai biner Z(i,i’,k). Persamaan (10) digunakan untuk meminimalkan Cmax terkait dengan fungsi tujuan. Sedangkan persamaan (11) digunakan untuk meyakinkan bahwa nilai Cmaxdan sik tak negatif.
III. ALGORITMA YANG DIUSULKAN
Dalam penelitian ini, metode yang diusulkan yakni metode cross entropy yang dihibridasi dengan algoritma genetika (untuk selanjutnya dinamakan Cross Entropy-Genetic Algorithm/ CEGA). Kaidah cross entropy digunakan sebagai kaidah dasar dalam algoritma, sedangkan kaidah algoritma genetika hanya terbatas penggunaannya pada proses pembangkitan sampel.
Metode cross entropy sendiri diilhami oleh sebuah konsep pada teori informasi modern, yakni konsep jarak Kullback-Leibler atau yang dikenal juga dengan nama yang sama: konsep jarak cross entropy (Rubinstein, 2004). Konsep ini dikembangkan oleh Solomon Kullback dan Richard Leibler, untuk mengukur perbedaan selisih jarak antara sebuah distribusi referensi ideal p dengan distribusi teraplikasi q. Sedangkan metode algoritma genetika sendiri diilhamii dari proses evolusi biologis yang terjadi di alam, yang meliputi unsur-unsur pewarisan gen, seleksi alam, pindah silang/rekombinasi, dan mutasi.
Secara umum alur algoritma CEGA yang digunakan sebagai metode penyelesaian permasalahan NWJSS ini adalah sebagai berikut:
Gambar 1 Diagram Alir Algoritma CEGA
Mulai Pendefinisian input dan output Penentuan nilai parameter inisial Pembangkitan sampel awal Penghitungan makespan masing-masing jadwal
Pemilihan sampel elite
Pembaharuan parameter pindah silang dan parameter
mutasi Apakah sudah memenuhi syarat pemberhentian? Penampilan hasil Selesai Ya Tidak Pembobotan sampel elite Penghitungan Nilai Linear Fitness Ranking Pindah Silang Mutasi Penentuan Induk
Penjelasan dari alur di atas adalah sebagai berikut: 1. Pendefinisian Input dan Output
Pada langkah ini ditentukan input apa saja yang akan diproses pada algoritma dan output
apa saja yang akan ditampilkan sebagai hasil dari proses. Adapun pada penelitian ini, mengingat permasalahan yang diteliti adalah permasalahan NWJSS dan metode yang digunakan adalah cross entropy yang dihibridasi dengan algoritma genetika, maka input
dan output-nya adalah sebagai berikut: Input:
Matriks rute mesin (R(j,k); dengan j menyatakan nomor job dan k menyatakan nomor urutan operasi)
Matriks waktu proses (W(j,k))
Jumlah sampel pembangkitan (N)
Parameter kejarangan (ρ)
Koefisien penghalusan (α)
Parameter pindah silang/crossover rate (Pps) inisial
Toleransi pemberhentian (β)
Output:
Timetable jadwal optimal (waktu mulai dan waktu selesai masing-masing operasi)
Nilai makespan jadwal optimal (Cmax)
Waktu komputasi (T)
Jumlah iterasi (iterasi) 2. Penentuan Nilai Parameter Inisial
Parameter-parameter yang dimasukkan sebagai input, yakni N, ρ , α, Pps inisial, dan β, ditentukan sebagai tolok ukur performansi output yang dihasilkan. Dengan nilai parameter yang berbeda pastinya akan didapatkan hasil yang berbeda.
Adapun aturan untuk pemberian parameter tersebut di atas adalah sebagai berikut:
Untuk jumlah sampel pembangkitan N, tidak ada aturan khusus terkait dengan penentuan jumlah sampel pada optimasi kombinatorial, namun semakin besar jumlah job pastinya semakin besar sampel yang harusnya diambil. Pada algoritma digunakan jumlah sampel default sama dengan jumlah job pangkat tiga (n3). Untuk parameter kejarangan ρ, biasanya digunakan nilai 1% - 10% (Kroese,
2009). Pada algoritma digunakan nilai default 2%
Untuk koefisien penghalusan α, nilainya berada antara 0 – 1, namun secara empiris nilai 0,4 - 0,9 merupakan nilai yang paling optimal (de Boer, 2003). Pada algoritma digunakan nilai default 0,8
Untuk parameter pindah silang (Pps) inisial digunakan nilai 1 sebagai nilai default Untuk toleransi pemberhentian β, nilainya mendekati 0 ( ). Pada
algoritma digunakan nilai default 0,001 3. Pembangkitan Sampel
Sampel yang dibangkitkan di sini adalah merupakan urutan prioritas job yang terlebih dahulu dijadwalkan. Pembangkitan sampel inisial (iterasi=1) dilakukan dengan menggunakan teknik acak penuh (fully randomized), sedangkan pada pembangkitan sampel setelahnya (iterasi>1) dilakukan dengan menggunakan kaidah algoritma genetika, yakni pindah silang dan mutasi, dengan alur sebagai berikut:
a) Pembobotan sampel elite
Pembobotan ini diperlukan untuk tahap pemilihan induk pertama, di mana induk pertama akan dipilih dari sampel elite dengan mempertimbangkan bobot dari masing-masing urutan pada sampel elite. Adapun aturan pembobotan yang digunakan yakni, jika makespan yang dihasilkan oleh urutan lebih baik daripada
makespan terbaik yang pernah dikunjungi pada iterasi sebelumnya, maka bobot yang diberikan adalah senilai banyaknya sampel elite, selebihnya hanya diberi bobot 1.
b) Penghitungan linear fitness ranking
Linear fitness ranking (LFR) dihitung dari perbandingan nilai kesesuaian (fitness) semua sampel yang telah dibangkitkan pada iterasi sebelumnya. Nilai LFR adalah sebesar LFR(I(N-i+1))=Fmax-(Fmax-Fmin)((i-1)/(N-1))
Dengan i merupakan nilai yang berkisar antara 1 sampai dengan jumlah sampel (N), serta I menunjukkan indeks job pada matriks sampel.
c) Pemilihan induk
Pemilihan induk dilakukan dengan menggunakan mekanisme roda roulette
(roulette wheel selection), di mana bobot yang lebih besar akan mendapatkan peluang yang lebih tinggi untuk terpilih sebagai induk. Induk pertama dipilih dari sampel elite dengan pembobotan yang sudah ditentukan sebelumnya, sedangkan induk kedua dipilih dari sampel pada iterasi sebelumnya dengan pembobotan dari nilai linearfitness ranking.
d) Pindah silang
Pindah silang dilakukan dengan menggunakan teknik order crossover dua titik, di mana pemilihan dua titik tersebut dilakukan secara acak pada kedua induk. Hasil anakan yang didapat mempunyai segmen yang sama di antara dua titik tersebut sebagaimana induknya, namun segmen yang lain dijaga urutannya sesuai dengan induk yang lain dari masing-masing anakan.
e) Mutasi
Mutasi dilakukan dengan menggunakan metode swapping mutation, di mana mutasi dilakukan dengan mempertukarkan job yang termutasi dengan job lain pada anakan yang sama.
4. Penghitungan Makespan
Penghitungan nilai makespan ini dilakukan dengan menggunakan metode timetabling
geser sederhana (simple shift timetabling) yang diadaptasi dari metode geser dari Zhu dkk. (2009). Langkah-langkahnya sebagai berikut:
a) Jadwalkan job urutan priotitas pertama mulai t = 0
b) Jadwalkan job urutan prioritas selanjutnya mulai t=0, kemudian cek apakah terjadi
overload pada mesin. Jika ya, maka geser job ke kanan sampai tidak terdapat
overload
c) Ulangi langkah b) hingga seluruh job terjadwalkan 5. Pemilihan Sampel Elite
Sampel elite dipilih sebanyak ⌈ρ N⌉ dari jumlah sampel yang dibangkitkan berdasarkan nilai makespan-nya. Sebelum langkah ini dilakukan, terlebih dahulu makespan yang didapatkan dari semua sampel diurutkan dari yang terkecil hingga yang terbesar.
6. Pembaharuan Parameter Pindah Silang dan Parameter Mutasi
Pembaharuan parameter dilakukan dengan menggunakan perbandingan antara rata-rata
makespan pada sampel elite dengan 2 kali nilai makespan terbaik pada tiap iterasi. Nilai perbandingan tersebut didefinisikan sebagai u. Parameter pindah silang kemudian diperbaharui dengan menggunakan rumus Pi=(1-α)u+Pi-1 Sedangkan parameter mutasi nilainya didefinisikan sebagai ½ dari nilai parameter pindah silang
7. Pengecekan terhadap Syarat Pemberhentian
Syarat pemberhentian pada penelitian ini adalah bahwa selisih antara parameter pindah silang hasil pembaharuan dengan parameter pindah silang sebelumnya lebih kecil dari β. Jika syarat pemberhentian ini terpenuhi, maka hentikan iterasi dan lanjutkan ke langkah berikutnya. Jika tidak, maka ulangi kembali iterasi mulai langkah keempat.
8. Penampilan Hasil
Hasil yang ditampilkan dari algoritma ini adalah berupa output-output yang sudah didefinisikan sebelumnya.
IV. PENGUJIAN ALGORITMA
Pengujian algoritma dilakukan dengan membuat kode program algoritma pada
software Matlab). Kode ini kemudian dijalankan sebanyak 30 kali pengulangan, dengan menggunakan spesifikasi komputer Intel Core 2 Duo 1,66 GHz, RAM 1 GB, serta menggunakan software Matlab seri 6.5. Sedangkan data yang digunakan sebagai data uji adalah set data kasus pada ORLibrary yakni data kasus dengan kode Ft06, Ft10, La01-La25, serta Orb01-Orb06 dan Orb08-Orb10.
Adapun hasil dari pengujian adalah sebagai berikut:
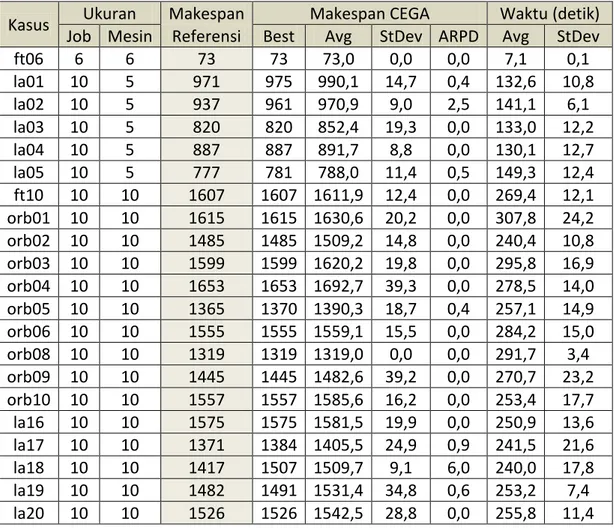
Tabel 1 Statistik Hasil Pengujian Algoritma CEGA untuk Kasus Ukuran Kecil
Kasus Ukuran Makespan Makespan CEGA Waktu (detik)
Job Mesin Referensi Best Avg StDev ARPD Avg StDev
ft06 6 6 73 73 73,0 0,0 0,0 7,1 0,1 la01 10 5 971 975 990,1 14,7 0,4 132,6 10,8 la02 10 5 937 961 970,9 9,0 2,5 141,1 6,1 la03 10 5 820 820 852,4 19,3 0,0 133,0 12,2 la04 10 5 887 887 891,7 8,8 0,0 130,1 12,7 la05 10 5 777 781 788,0 11,4 0,5 149,3 12,4 ft10 10 10 1607 1607 1611,9 12,4 0,0 269,4 12,1 orb01 10 10 1615 1615 1630,6 20,2 0,0 307,8 24,2 orb02 10 10 1485 1485 1509,2 14,8 0,0 240,4 10,8 orb03 10 10 1599 1599 1620,2 19,8 0,0 295,8 16,9 orb04 10 10 1653 1653 1692,7 39,3 0,0 278,5 14,0 orb05 10 10 1365 1370 1390,3 18,7 0,4 257,1 14,9 orb06 10 10 1555 1555 1559,1 15,5 0,0 284,2 15,0 orb08 10 10 1319 1319 1319,0 0,0 0,0 291,7 3,4 orb09 10 10 1445 1445 1482,6 39,2 0,0 270,7 23,2 orb10 10 10 1557 1557 1585,6 16,2 0,0 253,4 17,7 la16 10 10 1575 1575 1581,5 19,9 0,0 250,9 13,6 la17 10 10 1371 1384 1405,5 24,9 0,9 241,5 21,6 la18 10 10 1417 1507 1509,7 9,1 6,0 240,0 17,8 la19 10 10 1482 1491 1531,4 34,8 0,6 253,2 7,4 la20 10 10 1526 1526 1542,5 28,8 0,0 255,8 11,4
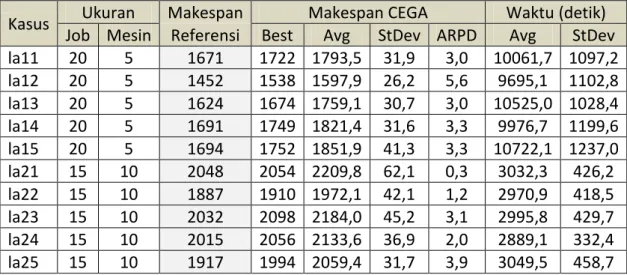
Tabel 2 Statistik Hasil Pengujian Algoritma CEGA untuk Kasus Ukuran Besar
Kasus Ukuran Makespan Makespan CEGA Waktu (detik)
Job Mesin Referensi Best Avg StDev ARPD Avg StDev
la06 15 5 1248 1304 1342,0 24,3 4,3 1635,8 236,9
la07 15 5 1172 1221 1265,7 23,9 4,0 1670,1 205,8
la08 15 5 1244 1274 1323,8 23,2 2,4 1626,9 187,2
la09 15 5 1358 1382 1443,1 21,2 1,7 1745,9 202,6
Kasus Ukuran Makespan Makespan CEGA Waktu (detik) Job Mesin Referensi Best Avg StDev ARPD Avg StDev la11 20 5 1671 1722 1793,5 31,9 3,0 10061,7 1097,2 la12 20 5 1452 1538 1597,9 26,2 5,6 9695,1 1102,8 la13 20 5 1624 1674 1759,1 30,7 3,0 10525,0 1028,4 la14 20 5 1691 1749 1821,4 31,6 3,3 9976,7 1199,6 la15 20 5 1694 1752 1851,9 41,3 3,3 10722,1 1237,0 la21 15 10 2048 2054 2209,8 62,1 0,3 3032,3 426,2 la22 15 10 1887 1910 1972,1 42,1 1,2 2970,9 418,5 la23 15 10 2032 2098 2184,0 45,2 3,1 2995,8 429,7 la24 15 10 2015 2056 2133,6 36,9 2,0 2889,1 332,4 la25 15 10 1917 1994 2059,4 31,7 3,9 3049,5 458,7
Dari hasil pengujian algoritma yang telah dilakukan, dapat diketahui bahwa performansi dari CEGA relatif baik, terutama pada kode kasus yang berukuran kecil. Hal ini dapat dilihat dari sebagian besar nilai ARPD pada kasus yang berukuran kecil bernilai 0,0 dan hampir seluruhnya bernilai di bawah 1,0 (kecuali pada La02 dan La18), yang berarti nilai
makespan terbaik yang didapat oleh CEGA pada tersebut relatif hampir sama dengan nilai optimal yang didapatkan dari hasil penghitungan dengan branch and bound. Bahkan pada kode kasus Ft06 dan Orb08, algoritma ini menghasilkan nilai ARPD 0,0 sekaligus nilai simpangan bakunya 0,0, yang berarti hasil yang didapatkan pada 30 kali pengulangan adalah seragam sama dengan nilai optimalnya.
Sedangkan pada kasus berukuran besar, performansi algoritma CEGA cenderung menurun, dapat dilihat dari nilai ARPD-nya yang cenderung di atas 1,0. Hal ini dapat dimaklumi, mengingat jumlah ruang pencarian yang semakin besar dan meningkat secara faktorial, yang tidak diimbangi dengan peningkatan jumlah sampel pencarian. Untuk peningkatan ukuran dari 10 job menjadi 15 job saja, terjadi peningkatan ruang pencarian dari 10! menjadi 15! atau sebanyak 15x14x13x12x11=360360 kali lipat dari semula. Peningkatan tersebut tentunya tidak dapat serta-merta diikuti dengan peningkatan jumlah sampel, mengingat pertimbangan waktu komputasi yang akan juga meningkat secara drastis. Namun demikian, dengan menggunakan jumlah sampel n3, performansi yang ditunjukkan boleh dibilang masih dalam nilai yang cukup bagus, ditunjukkan dengan terdapatnya nilai ARPD di bawah 1,0 (yakni pada La10 dan La21) dan sebagian besar nilai ARPD masih di bawah nilai galat baku yakni 5,0 (kecuali La12).
Gambar 2 Grafik Waktu Komputasi Berdasarkan Ukuran Job
0 2000 4000 6000 8000 10000 12000 0 5 10 15 20 25 W ak tu K om pu ta si (D e ti k) Ukuran Job Rata-rata Simpangan Baku
Apabila ditinjau secara keseluruhan dari nilai rata-rata dan simpangan baku makespan
dari pengulangan yang dilakukan, nilai rata-rata yang didapatkan cenderung mendekati nilai
makespan referensinya, sedangkan nilai simpangan bakunya cenderung besar (cenderung bernilai lebih besar dari 10,0, kecuali pada beberapa kasus). Hal itu berarti algoritma ini cenderung menghasilkan nilai makespan yang tidak seragam pada masing-masing pengulangannya, namun dengan probabilitas mendapatkan hasil yang terbaik relatif lebih besar. Performansi yang seperti ini dirasakan sudah cukup baik, mengingat hasil tersebut menunjukkan adanya upaya untuk tidak terjebak pada satu nilai penyelesaian saja (dalam hal ini optimal setempat). Namun tentunya, algoritma perlu lebih dioptimalkan kembali agar nilai simpangan baku yang besar itu bisa diperkecil, dengan nilai rata-rata yang lebih baik atau, paling tidak, sama (yang berarti nilai makespan yang didapatkan pada tiap pengulangan akan lebih seragam namun dengan tetap cenderung mendekati nilai terbaik referensinya).
Walaupun algoritma ini menghasilkan nilai makespan yang secara keseluruhan lebih baik, namun waktu yang digunakan untuk melakukan perhitungan relatif lama dan bertambah secara signifikan pada setiap penambahan job. Hal tersebut dapat dilihat pada grafik yang ditampilkan pada Gambar 2, di mana nilai rata-rata waktu yang dibutuhkan oleh algoritma untuk setiap penambahan job akan meningkat dengan drastis, diikuti pula dengan peningkatan nilai simpangan bakunya. Ini diduga disebabkan oleh proses timetabling untuk menghitung fungsi tujuan yang relatif memakan waktu. Seperti yang sudah dijelaskan pada bab sebelumnya bahwa mekanisme timetabling geser sederhana yang digunakan mengharuskan pengecekan terhadap adanya overload pada mesin untuk setiap penjadwalan job baru. Setiap kali terjadi overload pengerjaan operasi pada job yang akan dijadwalkan maka job yang akan dijadwalkan harus digeser sejauh nilai waktu mesin yang bersangkutan overload. Jika setelah digeser, mesin yang lain overload maka dilakukan lagi penggeseran, hingga semua mesin tidak ada yang mengalami overload pengerjaan operasi. Ini tentunya memakan waktu komputasi yang cukup lama, terutama apabila ukuran job yang harus dijadwalkan semakin banyak. Selain itu juga, penggunaan spesifikasi komputer dan spesifikasi software juga berpengaruh terhadap kecepatan penghitungan dari algoritma tersebut.
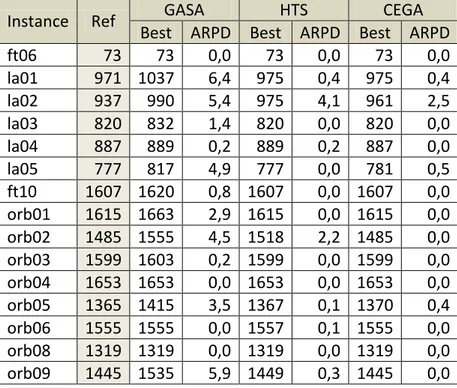
Kemudian, apabila dibandingkan dengan algoritma-algoritma lain yakni Genetic Algorithm-Simulated Annealing (Schuster, 2003) dan Hybrid Tabu Search (Bożejko, 2009), performansi CEGA dapat ditunjukkan pada Tabel 3 dan Tabel 4.
Tabel 3 Perbandingan Makespan GASA, HTS, dan CEGA pada Kasus Ukuran Kecil
Instance Ref GASA HTS CEGA
Best ARPD Best ARPD Best ARPD
ft06 73 73 0,0 73 0,0 73 0,0 la01 971 1037 6,4 975 0,4 975 0,4 la02 937 990 5,4 975 4,1 961 2,5 la03 820 832 1,4 820 0,0 820 0,0 la04 887 889 0,2 889 0,2 887 0,0 la05 777 817 4,9 777 0,0 781 0,5 ft10 1607 1620 0,8 1607 0,0 1607 0,0 orb01 1615 1663 2,9 1615 0,0 1615 0,0 orb02 1485 1555 4,5 1518 2,2 1485 0,0 orb03 1599 1603 0,2 1599 0,0 1599 0,0 orb04 1653 1653 0,0 1653 0,0 1653 0,0 orb05 1365 1415 3,5 1367 0,1 1370 0,4 orb06 1555 1555 0,0 1557 0,1 1555 0,0 orb08 1319 1319 0,0 1319 0,0 1319 0,0 orb09 1445 1535 5,9 1449 0,3 1445 0,0
Instance Ref GASA HTS CEGA Best ARPD Best ARPD Best ARPD orb10 1557 1618 3,8 1571 0,9 1557 0,0 la16 1575 1637 3,8 1575 0,0 1575 0,0 la17 1371 1430 4,1 1384 0,9 1384 0,9 la18 1417 1555 8,9 1417 0,0 1507 6,0 la19 1482 1610 8,0 1491 0,6 1491 0,6 la20 1526 1693 9,9 1526 0,0 1526 0,0 Rata-rata 3,5 0,5 0,5
Tabel 4 Perbandingan Makespan GASA, HTS, dan CEGA pada Kasus Ukuran Besar
Kasus Ref GASA HTS CEGA
Best ARPD Best ARPD Best ARPD la06 1248 1339 6,8 1248 0,0 1304 4,3 la07 1172 1240 5,5 1172 0,0 1221 4,0 la08 1244 1296 4,0 1298 4,2 1274 2,4 la09 1358 1447 6,2 1415 4,0 1382 1,7 la10 1287 1338 3,8 1345 4,3 1299 0,9 la11 1671 1825 8,4 1704 1,9 1722 3,0 la12 1452 1631 11,0 1500 3,2 1538 5,6 la13 1624 1766 8,0 1696 4,2 1674 3,0 la14 1691 1805 6,3 1722 1,8 1749 3,3 la15 1694 1829 7,4 1747 3,0 1752 3,3 la21 2048 2182 6,1 2191 6,5 2054 0,3 la22 1887 1965 4,0 1922 1,8 1910 1,2 la23 2032 2193 7,3 2126 4,4 2098 3,1 la24 2015 2150 6,3 2132 5,5 2056 2,0 la25 1917 2034 5,8 2020 5,1 1994 3,9 Rata-rata 6,5 3,3 2,8
Dari hasil perbandingan tersebut dapat dilihat bahwa tingkat performansi CEGA
berdasarkan makespan terbaik yang didapat ternyata jauh lebih baik jika dibandingkan dengan GASA, ditandai dengan selisih nilai rata-rata ARPD antara CEGA dan GASA yang sangat besar, serta nilai makespan yang didapat pada masing-masing kasus di mana CEGA
unggul secara mutlak.
Sedangkan jika dibandingkan dengan HTS, performansinya relatif sama namun CEGA
sedikit lebih baik. Hal ini dapat dilihat dari selisih nilai rata-rata ARPD, di mana pada kasus berukuran kecil ARPD bernilai 0 sehingga dapat dianggap tidak signifikan. Sedangkan untuk kasus berukuran besar, nilai ARPD-nya hanya berselisih 0,5. Selain itu, nilai makespan yang didapatkan oleh CEGA tidak unggul secara mutlak dibandingkan dengan HTS, terlihat dari beberapa nilai makespan terbaik HTS yang lebih unggul dibandingkan dengan CEGA, misalnya pada La06 dan La07.
V. KESIMPULAN
Dari hasil analisis dan interpretasi hasil pengujian serta perbandingan hasil ekseprimen dengan metode lain, dapat ditarik kesimpulan bahwa metode CEGA dapat digunakan sebagai metode alternatif penyelesaian permasalahan NWJSS, dan dapat diaplikasikan kegunaannya pada perusahaan-perusahaan dengan karakteristik NWJSS. Ini mengingat performansi yang
didapatkan dari algoritma ini relatif baik, terutama pada kasus NWJSS berukuran kecil, walaupun performansinya semakin menurun seiring dengan bertambahnya ukuran kasus.
Diharapkan pada penelitian-penelitian selanjutnya, ada upaya untuk melakukan modifikasi lanjutan bagi algoritma CEGA bagi permasalahan NWJSS agar dapat meningkatkan performansinya untuk ukuran populasi yang besar. Selain itu, penggunaan algoritma ini pada permasalahan yang lain juga dianjurkan.
DAFTAR RUJUKAN
Baker, Kenneth R. 1974. Introduction to Sequencing and Scheduling. New York: John Wiley & Sons, Inc.
Beasley, J. E., 1990. OR-Library: Distributing Test Problems by Electronic Mail. Journal of the Operational Research Society 41: 1069 – 1072.
Boubezoul, Abderrahmane; Paris, Sébastien; dan Ouladsine, Mustapha. 2008. Application of
the Cross Entropy Method to the GLVQ Algorithm. Pattern Recognition 41: 3173
– 3178
Bożejko, Wojciech dan Makuchowski, Mariusz. 2009. A Fast Hybrid Tabu Search Algorithm for the No-Wait Job Shop Problem. Computers & Industrial Engineering 56: 1502–1509
Caserta, M.; Rico, E. Quiñonez; dan Uribe, A. Márquez. 2008. A Cross Entropy Algorithm for the Knapsack Problem with Setups. Computers & Operations Research 35: 241 – 252
de Boer, Pieter-Tjerk; Kroese, Dirk P.; Mannor, Shie; dan Rubinstein, Reuven Y. 2003. A
Tutorial on the Cross-Entropy Method. Haifa: Department of Industrial
Engineering, Technion – Israel Institute of Technology
Dewi, Dian Retno Sari. Pengembangan Algoritma Penjadualan Produksi Job Shop untuk Meminimumkan Total Biaya Earliness dan Tardiness. Jurnal Ilmiah Teknik Industri 4 no. 2: 57 – 65
Ganduri, Chandrasekhar V. 2004. Rule Driven Job-Shop Scheduling Derived from Neural Networks Through Extraction. Department of Industrial and Manufacturing Systems Engineering, Ohio University
Kroese, Dirk P. 2009. Cross-Entropy Method. Brisbane: Mathematics Department, University of Queensland
Liaw, Ching-Fang. 2008. An Efficient Simple Metaheuristic for Minimizing The Makespan in Two-Machine No-Wait Job Shops. Computer & Operations Research 35: 3276 – 3283
Mascis, Alessandro, dan Pacciarelli, Dario. 2002. Discrete Optimization: Job-Shop
Scheduling with Blocking and No-Wait Constraints. European Journal of
Operational Research 143: 498 – 517
Pan, Jason Chao-Hsien, dan Huang, Han-Chiang. 2009. A Hybrid Genetic Algorithm for
No-Wait Job Shop Scheduling Problems. Expert Systems with Application 36: 5800 –
5806
Rera, Gladiez Florista. 2010. Penerapan Metode Cross Entropy dalam Penyelesaian
Capacitated Vehicle Routing Problem – Studi Kasus: Distribusi Koran Jawa Pos
Surabaya. Surabaya: Institut Teknologi Sepuluh Nopember
Rubinstein, Reuven Y., dan Kroese, Dirk P. 2004. The Cross-Entropy Method: A Unified Approach to Combinatorial Optimization, Monte-Carlo Simulation, and Machine
Learning. New York: Springer Science+Business Media, Inc.
Schuster, Christoph J. dan Framinan, Jose M. 2003. Approximative Procedures for No-Wait Job Shop Scheduling. Operations Research Letters 31: 308 – 318
Widyarini, Tiananda. 2009. Aplikasi Metode Cross Entropy untuk Support Vector Machines. Surabaya: Institut Teknologi Sepuluh Nopember
Waterloo Manufacturing Software. Job Shop Scheduling. http://www.waterloo-software.com/planning-and-scheduling/job-shop-scheduling.html. Diakses pada 24 Februari 2010
Wikipedia. Cross Entropy Method. http://en.wikipedia.org/wiki/Cross_Entropy_Method. Diakses pada 19 Februari 2010
_________. Crossover (Genetic Algorithm). http://en.wikipedia.org/wiki/Crossover_ (Genetic_Algorithm). Diakses pada 18 Juni 2010
_________. Genetic Algorithm. http://en.wikipedia.org/wiki/ Genetic_Algorithm. Diakses pada 18 Juni 2010
_________. Kullback-Leibler Divergence. http://en.wikipedia.org/wiki/Kullback-Leibler_ Divergence. Diakses pada 19 Februari 2010
_________. Mutation (Genetic Algorithm). http://en.wikipedia.org/wiki/Mutation_ (Genetic_Algorithm). Diakses pada 18 Juni 2010
_________. Selection (Genetic Algorithm). http://en.wikipedia.org/wiki/Selection_ (Genetic_Algorithm). Diakses pada 18 Juni 2010
Zhu, Jie; Li, Xiaoping; dan Wang, Qian. 2009. Complete Local Search with Limited Memory
Algorithm for No-Wait Job Shops to Minimize Makespan. European Journal of