Materi Pembelajaran: statistik non parametrik, uji chi kuadrat, koefisien
Spearman RankAlokasi WaktU2 x tatap muka perkuliahan (@ 3 x 50
menit)
MODUL 6
STATISTIK NON
PAREMETRIK
STANDAR KOMPETENSI
Mampu menerapkan konsep statistik dalam aplikasi bisnis. KOMPETENSI DASAR
Memahami statistik non parametrik, uji chi kuadrat dan koefisien spearman rank. INDIKATOR
Kognitif
a. Mahasiswa dapat menjelaskan statistik non parametrik. b. Mahasiswa dapat menghitung uji chi kuadrat.
c. Mahasiswa dapat menghitung koefisien Spearman Rank. d. Mahasiswa dapat menganalisa statistik non parametrik. e. Mahasiswa dapat menganalisa uji chi kuadrat.
f. Mahasiswa dapat menganalisa koefisien Spearman Rank. Psikomotor
a. Mahasiswa dapat menjelaskan statistik non parametrik secara lisan di depan kelas.
b. Mahasiswa dapat menghitung uji chi kuadrat secara tertulis di depan kelas.
c. Mahasiswa dapat menghitung koefisien Spearman Rank secara tertulis di depan kelas.
d. Mahasiswa dapat menganalisa statistik non parametrik secara tertulis di depan kelas.
e. Mahasiswa dapat menganalisa uji chi kuadrat secara tertulis di depan kelas.
f. Mahasiswa dapat menganalisa koefisien Spearman Rank secara tertulis di depan kelas.
Afektif
a. Mengembangkan perilaku karakter, meliputi: jujur, peduli, dan tanggung-jawab.
b. Mengembangkan keterampilan sosial, meliputi: menjadi pendengar yang baik, berpendapat, dan bertanya.
Materi Pembelajaran
statistik non parametrik, uji chi kuadrat, koefisien Spearman Rank Alokasi Waktu
2 x tatap muka perkuliahan (@ 3 x 50 menit) Model Pembelajaran
Model: Pembelajaran langsung Metode
URAIAN MATERI
1.1. Pengujian Statistik NonParametrik
tatistik terbagi menjadi dua bagian yaitu statistik deskriptif dan statistik Inferensia/ Induktif. Inferensia/ Induktif terbagi menjadi du bagian yaitu Statistik Parametri dan statistik nonparametrik. Pada bahasan ini kita akan membahas tentang statistik nonparametrik.
Statistik NONPARAMETRIK adalah analisis yang tidak menggunakan parameter-parameter dan tidak mensyaratkan data harus berdistribusi normal. Pada analisis statistik parametrik menggunakan parameter-parameter seperti mean, deviasi standar, variansi.
Statistik NONPARAMETRIK digunakan untuk menganalisis data yang bersekala nominal dan ordinal dari populasi yang bebas distribusi (tidak harus berdistribusi normal). Dalam banyak hal terkadang ditemui permasalahan, yaitu tidak semua data yang dianalisa berskala nominal dan ordinal, tetapi merupakan campuran antara ordial dan rasio, atau nominal dan ordinal atau rasio. Dalam hal ini maka yang diapai sebagai acuan adalah derajad data yang lebih rendah. Misalnya akan danalisa korelasi antara data ordinal dan data rasio, maka metode yang dipergunakan adalah data yang derajad lebih rendah yaitu data ordinal, dan metode yang dipilih adalah non parametrik.
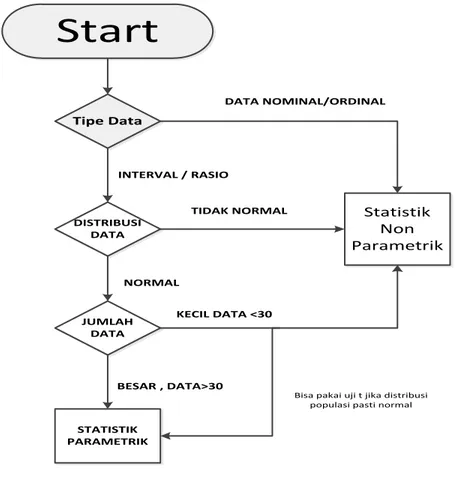
Sebagai gambaran dalam mengambil keputusan, metode apakah yang akan dipergunakan, berikut ini dibuatkan gambar diagram sebagai pedoman dalam penggunaan statistik non parametrik.
Start
Tipe Data Statistik Non Parametrik DATA NOMINAL/ORDINAL DISTRIBUSI DATA INTERVAL / RASIO TIDAK NORMAL NORMAL JUMLAH DATA STATISTIK PARAMETRIK KECIL DATA <30 BESAR , DATA>30Bisa pakai uji t jika distribusi populasi pasti normal
Gambar 5.1. Penggunaan Metode Non Parametrik
Sumber: singgih santoso 2004, hal 7
Gambar 6.1 Jenis-jenis Statistik Sumber Sugiyono, 2007:23
Sehingga Metode analisis NONPARAMETRIK menjadi metode analisis alternatif apabila salah satu atau keseluruhan persyaratan pada analisis parametrik tidak
Statistik
Inferensia
NonParametrik
Parametrik
Deskriptif
terpenuhi, misalnya normalitas data, atau tidak terpenuhinya asumsi-asumsi tertentu. pada bab ini akan dibahas dua metode analisis non parametrik yaitu :
1. Analisis Chi Square 2. Korelasi Rank Spearman
Soal Latihan :
1. Dalam Statistik inferensial dikenal dengan statistik Non Parametrik, jelaskan dengan singkat apakah yang dimaksud dengan statistik non parametrik dan berikan penjelasan mengapa seseorang menggunakan metode statistik non parametrik?
2. Dalam sebuah penelitian di dalam sebuah perusahaan, seorang peneliti mengambil berbagai data untuk bahan penelitiannya. diantara data yang diambil adalah sebagai berikut:
a. Data hasil Test Masuk b. Data Pendidikan terakhir c. Data Umur
d. Data status Pernikahan e. Data Motivasi Kerja
f. Data Prestasi Kerja g. Data Kehadiran
h. Data Pendapatan Perusahaan i. Data Beban Pengeluaran
Perusahaan
Berdasarkan data-data diatas, jika akan menggunakan metode statistik non parametri data manakah yang dapat dipergunakan? dan jelaskan mengapa dipilh data tersebut?
Tugas:
Membuat kelompok dengan jumlah antara 5 s/d 10 mahasiswa, dan indentifikasikan bersama sekelompokmu 10 data yang dapat dipergunakan untuk uji nonparametrik? dan berikan penjelasan megapa data tersebut dipergunakan?
1.2. CHI SQUARE ANALISIS (GOODNESS OF FIT TEST)
Chi kuadrat (X2; baca "kai kuadrat") atau sering disebut dengan goodness of fit test. Merupakan alat uji statistik yang digunakan untuk menguji hipotesis bila dalam populasi terdiri atas dua atau lebih kelas bila data berbentuk nominal dan sampelnya besar.
Chi Square adalah analisis untuk mengetahui apakah distribusi data seragam atau tidak, Uji ini juga disebut uji keselarasan atau goodness of fit test. Chi kuadrat merupakan salah satu teknik statistik yang memudahkan peneliti menilai kemungkinan memperoleh perbedaan frekuensi yang nyata (yang diobservasi) dengan frekuensi yang diharapkan dalam kategori-kategori tertentu akibat dari kesalahan sampling.
Persamaan untuk menghitung nilai chi kuadrat adalah sebagai berikut:
∑
dimana,
X2 = Chi Kuadrat
fo = Frekuensi sampel (frekuensi yang diperoleh dari hasil observasi sampel fh = Frekuensi harapan (frekuensi yang diharapkan dalam sampel sebagai
pencerminan frekuensi yang diharapkan dalam populasi).
Chi Kuadrat dapat digunakan untuk menguji hipotesis deskriptif satu sampel atau satu variabel, yang terdiri atas dua kategori atau lebih. selain itu dapat digunakan untuk menguji hipotesis komparatif 2 sampel atau 2 variabel yang berskala nominal. Pada modul ini pembahasan dan perhitungan menggunakan tiga metode yaitu,
1. Metode menghitung nilai chi square dengan persamaan chi square 2. Metode perhitungan SPSS dengan tabel Frekuensi
Contoh 1 : Data dalam Tabel frekuensi
Chi kuadrat untuk mengetahui apakah terdapat perbedaan suara yang signifikan diantara calon pada pemilihan Gubernur BEM fakultas Ekonomi Universitas Narotama periode tahun 2012 s/d 2014. terdapat tiga calon Gubernur Fakultas Ekonomi dengan perolehan suara sebagai berikut:
No Nama Calon Jumlah Suara
1 David 85 2 Eko 40 3 Setyo 35 4 Venda 65 Sumber Data: Penyelesaian : 1. Persamaan :
∑
2. Mencari fh = Frekuensi harapan
maka fh = 56.25
3. Mencari chi kuadrat
untuk memudahkan pembayaran digunakan tabel penolong :
CALON fo fh fo-fh (fo-fh)2
David 85 56.25 28.75 826.5625 14.69444 Setyo 40 56.25 (16.25) 264.0625 4.694444 Eko 35 56.25 (21.25) 451.5625 8.027778 Venda 65 56.25 8.75 76.5625 1.361111 Total 225 28.7778
dengan tabel penolong diatas maka didapatkan nilai untuk chi kuadrat (x2) adalah sebesar 28,78
4. Mencari Chi Kuadrat tabel
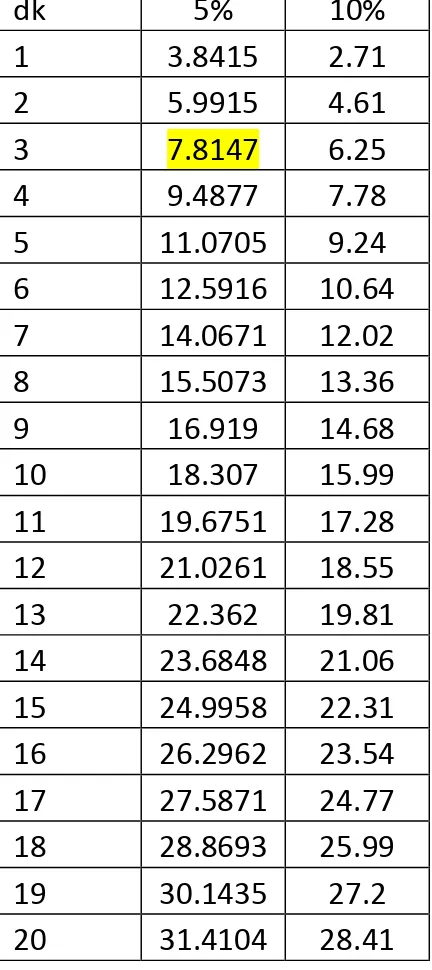
dari data diatas diketahui bahwa jumlah calon = 5 dan jumlah variabel =2 maka dk untuk data tersebut adalah :
dengan menggunakan alfa = 5% (0,05) , didapatkan Chi kuadrat tabel (X2 tabel ) adalah 7.8147
Tabel Chi Kuadrat , untuk alfa 5% dan alfa 10%
5. Pengambilan Keputusan
Cara pengambilan keputusan adalah
1. Jika X2 hitung > X2 tabel, maka terjadi perbedaan perolehan suara 2. Jika X2 hitung < X2 tabel, maka tidak ada perbedaan perolehan suara
dk 5% 10% 1 3.8415 2.71 2 5.9915 4.61 3 7.8147 6.25 4 9.4877 7.78 5 11.0705 9.24 6 12.5916 10.64 7 14.0671 12.02 8 15.5073 13.36 9 16.919 14.68 10 18.307 15.99 11 19.6751 17.28 12 21.0261 18.55 13 22.362 19.81 14 23.6848 21.06 15 24.9958 22.31 16 26.2962 23.54 17 27.5871 24.77 18 28.8693 25.99 19 30.1435 27.2 20 31.4104 28.41
3. berdasarkan hasil diatas maka Jika X2 hitung > X2 tabel, yaitu 28,78 > 7.8147, maka dapat diambil kesimpulan bahwa terdapat perbedaan yang signifikan dalam perolehan suara kelima calo tersebut diatas
Perhitungan dengan SPSS Langkah langkah
1. Buka data view pada SPSS
2. Masukan data perolehan suara diatas pada sheet data view 3. Berikan identitas variabel pada variabel view
4. Proses Weight Cases pada variabel calon, dimaksudkan bahwa agar nilai dari nama calon mengacu pada jumlah suara.
a. Buka menu Data pilih Weight Cases , pada weight cases by, pilih variabel Jumlah , pilih Ok
5. Proses Uji Chi Kuadrat
a. Pada menu Data view, pilih menu Analize b. Pilih variabel Nama Calon
c. Abaikan yang lainnya dan d. pilih Ok
Tampilan Hasil SPSS
NamaCalon
Observed N Expected N Residual
david 85 56.3 28.8
setyo 40 56.3 -16.3
eko 35 56.3 -21.3
venda 65 56.3 8.8
Test Statistics NamaCalon Chi-square 28.778a
df 3
Asymp. Sig. .000 a. 0 cells (.0%) have expected frequencies less than 5. The minimum expected cell frequency is 56.3.
berdasarkan hasil di atas, dapat diketahui bahwa hasil kedua perhitungan adalah mendekati sama, yaitu 28,78 dan 28,778.
Contoh 2 : Data dalam Tabel Data
Sebagaimana dalam contoh 1, jika data belum diolah dalam bentuk tabel frekuensi, maka Untuk Data yang belum diolah dalam bentuk tabel Frekuensi, masih dalam bentuk tabel data. Langkah yang dilakukan adalah sebagai berikut:
Langkah langkah
1. Buka data view pada SPSS
2. Masukan data perolehan suara diatas pada sheet data view
Pada variabel view, pada value diisi dengan nilai nama calon.yaitu 1 untuk david,2 untuk eko, dst
Berikan identitas value variabel pada variabel view, 1= david
2 = Setyo 3 = Eko 4 = Venda
3. Proses Uji Chi Kuadrat
a. Pada menu Data view, pilih menu Analize b. pilih Non Parametric Test
c. Pilih Legacy Dialog
d. Pilih Chi square ... Tampil dialog Box uji chi square e. pada Test Variable Test Pilih Data Calon
a. Abaikan yang lainnya dan f. pilih Ok
g. OutPut adalah sebagai berikut:
Calon
Observed N Expected N Residual
David 85 56.3 28.8 Setyo 40 56.3 -16.3 Eko 35 56.3 -21.3 Venda 65 56.3 8.8 Total 225 Test Statistics Calon Chi-square 28.778a zZ mmmzmM<> 0020zzxsdcyd dsyfgf fddff df 3 Asymp. Sig. .000
Dari hasil diatas data diketahui bahwa hasil metode pertama dan metode yang kedua adalah sama.
Kesimpulan:
1. Perhitungan nilai Chi square dengan tiga metode yaitu Metode menghitung nilai chi square dengan persamaan chi square, Metode perhitungan SPSS dengan tabel Frekuensi dan Metode peritungan SPSS dengan tabel data mendapatakan hasil yang sama yaitu 28, 778, atau 28,78.
2. Nila chi tabel pada alfa 5% atau 0,05 adalah sebesar 7.8147, yang berarti bahwa perolehan suara calon Gubernur BEM Universitas Narotama adalah berbeda secara signifikan untuk 4 calon
Soal dan Tugas
1. Uji Chi Square sering disebut juga dengan goodness of fit test, jelaskanlah hubungan istilah tersebut dengan frekuensi harapan (fh) dari sebuah sampel penelitian?
2. Seseorang yang akan melukakan uji Chi Square, melakukan beberapa tahapan yaitu :
a. Mengumpulkan data b. Membuat Tabel Data c. Membuat Tabel Frekuensi d. Menghitung Frekuensi Harapan e. Menghitung Chi Kuadrat f. Menghitung Chi Tabel g. Membuat Analisa Keputusan
Dari uraian diatas, jika seseorang akan menghitung dengan menggunakan persamaan, langkah apakah yang belum disebutkan? dan uraiakanlah langkah untuk mencari Chi tabel?
3. Tugas, Carilah data tentang kesukaan teman-temanmu mahasiswa sebanyak 35 data dan buatlah perhitungan dan analisa uji chi kuadratnya?
Referensi :
1. Nanang Martono, 2010, Statistik Sosial Teori dan aplikasi Program SPSS, Yogyakarta, Gava Media
2. Singgih Santoso, 2004, Buku Latihan SPSS Statistik non Parametrik. Jakata: PT Gramedia
Lampiran
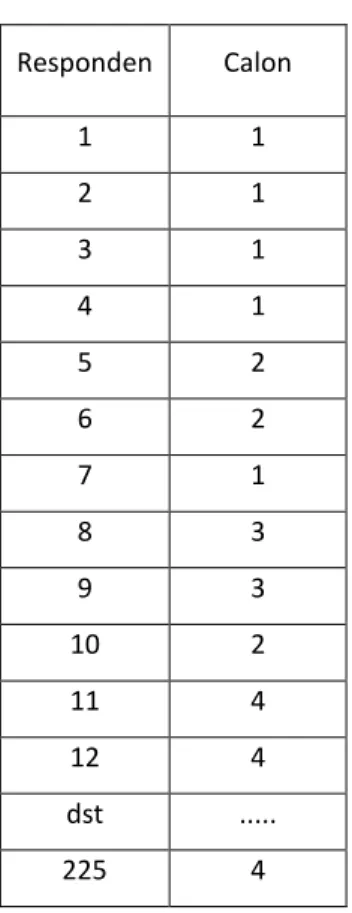
Tabel Data untuk SPSS
Responden Calon 1 1 2 1 3 1 4 1 5 2 6 2 7 1 8 3 9 3 10 2 11 4 12 4 dst ... 225 4
dimana pada kolom data calon, nilai 1,2,3,4 adalah nilai kode untuk masing-masing calon yaitu,
1= david 2 = Setyo 3 = Eko 4 = Venda
Langkah ke 1, Input data ke data sheets SPSS
Langkah ke 3, Uji Chi Square
Output/ Hasil Uji Chi square SPSS Calon
Observed N Expected N Residual
David 85 56.3 28.8 Setyo 40 56.3 -16.3 Eko 35 56.3 -21.3 Venda 65 56.3 8.8 Total 225 Test Statistics Calon Chi-square 28.778a df 3 Asymp. Sig. .000 a. 0 cells (.0%) have expected frequencies less than 5. The minimum expected cell frequency is 56.3.
1.4. KORELASI RANK SPEARMAN
eori Korelasi ini dikemukakan oleh Carl Spearman. Nilai korelasi ini disimbolkan dengan " " (dibaca: rho) atau dengan simbul rs. Korelasi Spearman digunakan pada
data yang berskala ordinal semuanya atau sebagian data adalah ordinal. untuk itu sebelum dilakukan pengolahan data, data yang akan dianalisis perlu disusun dalam bentuk ranking. Sehingga Korelasi Spearman merupakan alat uji statistik yang digunakan untuk menguji hipotesis asosiatif dua variabel bila datanya berskala ordinal (ranking).
Pada pengukuran korelasi untuk dua data yang nominal, bisa dengan metode Cramer, Lambda dan sebagainya. Namun jika data yang yang diteliti tidak semuanya nominal, maka penggunaan metode-metode tersebut tidaklah tepat. Untuk data dengan tipe Ordinal yaitu data mempunyai urutan atau rangking, seperti sikap suka, Cukup Suka. Tidak Suka, peringkat 1,2,3 dst), ukuran korelasi yang digunakan bisa berupa Korelasi Spearman, Kendall, Somers, Gamma dan sebagainya.
Pada suatu kasus, jika salah satu satu variabel mempunyai tipe ordinal dan yan lainnya data Rasio, maka diambil penggunaan metode dengan data yang lebih rendah derajatnya, pada kasus ini maka yang digunakan adalah korelasi Spearman. Hal ini sama jika akan dilakukan uji korelasi antara variabel bertipe nominal dengan ordinal, maka akan dipakai ukuran korelasi nominal, yaitu menggunakan uji korelasi Cramer, Lambda dan lainnya.
Nilai Korelasi Spearman berada di antara -1 < < 1. Bila nilai = 0, berarti tidak ada korelasi atau tidak ada hubungan antara variabel independen dan dependen. Nilai = +1 berarti terdapat hubungan yang positif antara variabel independen dan dependen. Nilai = -1 berarti terdapat hubungan yang negatif antara variabel independen dan dependen. Dengan kata lain, tanda "+" dan "-" menunjukkan arah hubungan di antara variabel yang sedang dioperasionalkan.
Uji signifikansi Spearman menggunakan Uji Z karena distribusinya mendekati distribusi normal. Kekuatan hubungan antar variabel ditunjukkan melalui nilai korelasi. Berikut adalah tabel nilai korelasi beserta makna nilai tersebut:
Tabel , Makna Nilai Korelasi Spearman
Nilai Makna
0,00-0,19 Sangat rendah / sangat lemah
0,20-0,39 Rendah / lemah
0,40-0,59 Sedang
0,60-0,79 Tinggi / kuat
0,80-1,00 Sangat tinggi/sangat kuat
Sumber: nanang martono 2010, 225
Menghitung Korelasi Rank Spearman
Persamaan 01: untuk nilai skor data tidak ada yang sama
∑
Persamaan 2, untuk data yang skornya ada yang sama (ties)
∑ ∑ ∑ √∑ ∑ dan ∑ ∑ ∑ ∑ ∑ ∑ dimana:
: nilai korelasi rank spearman.
di : selisih ranking data ke i n : jumlah sampel.t : jumlah data yang sama
Menentukan kriteria pengujian:
Bila hitung > tabel, maka H1 diterima.
Bila hitung < tabel, maka H0 diterima.
Melakukan uji signifikansi menggunakan uji Z:
(√
⁄
)
Mengambil kesimpulan:
Bila Z hitung > Z tabel, maka hubungan x dan y adalah signifikan. Bila Z hitung < Z tabel, maka hubungan x dan y adalah tidak signifikan.
Contoh:
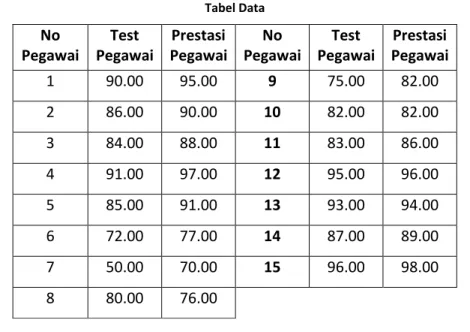
Pada contoh kasus berikut ini mengg unakan kombinasi antara data ordinal dan data rasio. Diadakan penelitian hubungan antara skor Test, Prestasi Kerja, dan absensi pegawai sebuah perusahaan. digunakan metode rank spearman untuk mengukur hubungan antara variabel tersebut: Data hasil penelitian sebagaimana berikut ini:
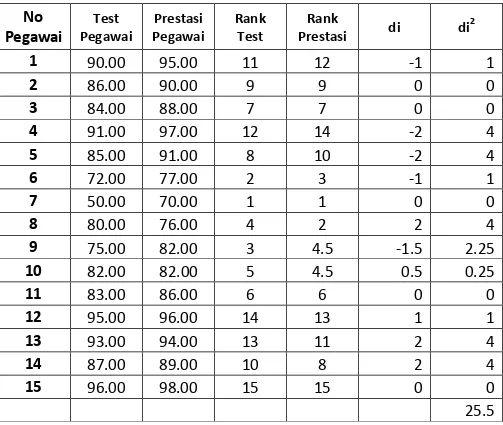
Tabel Data No Pegawai Test Pegawai Prestasi Pegawai No Pegawai Test Pegawai Prestasi Pegawai 1 90.00 95.00 9 75.00 82.00 2 86.00 90.00 10 82.00 82.00 3 84.00 88.00 11 83.00 86.00 4 91.00 97.00 12 95.00 96.00 5 85.00 91.00 13 93.00 94.00 6 72.00 77.00 14 87.00 89.00 7 50.00 70.00 15 96.00 98.00 8 80.00 76.00 Penyelesaian: 1.Uraian Data
Pada kasus ini jenis data yang dipergunakan adalah kombinasi antara data ordinal dan data rasio yaitu :
Variabel Jenis Data
Test Ordinal
Prestasi Kerja Ordinal
Absensi Rasio
Variabel Test, Prestasi dan Motivasi adalah data ordinal, dengan penilaian skor 100, skor 0 , sangat jelek dan skor 100 sangat bagus. Dalam data ordinal perbedaan skor adalah perbedaan peringkat, bukan suatu penambahan atau kelipatan jumlah. Sebagai contoh, jika prestasi kerja pekerja ke 1 mempunyai skor 30 dan prestasi pekerja ke 2 mempunyai skor 60, maka tidak bisa dikatakan pekerja 2 berprestasi dua kali lebih bagus dari pekerja ke 1, tetapi dapat dikatakan bahwa pekerja 2 lebih bagus prestasinya dibandingkan pekerja 1. Data variabel Absen adalah data rasio, yang berarti bahwa angka 4 berarti seorang pekerja benar-benar 4 kali tidak masuk bekerja dalam sebulan.
2. Persamaan , digunakan persamaan adalah
∑
dimana :
rs : Korelasi rank spearman di : selisih ranking data ke i n : jumlah data
3. Hubungan antara Test dan Prestasi Kerja Pegawai Tabel Pembantu
berdasrkan persamaan diatas, maka untuk memudahkan perhitungan maka dibuatkan tabel pembantu sebagai berikut:
Tabel Pembantu: No Pegawai Test Pegawai Prestasi Pegawai Rank Test Rank Prestasi di di 2 1 90.00 95.00 11 12 -1 1 2 86.00 90.00 9 9 0 0 3 84.00 88.00 7 7 0 0 4 91.00 97.00 12 14 -2 4 5 85.00 91.00 8 10 -2 4 6 72.00 77.00 2 3 -1 1 7 50.00 70.00 1 1 0 0 8 80.00 76.00 4 2 2 4 9 75.00 82.00 3 4.5 -1.5 2.25 10 82.00 82.00 5 4.5 0.5 0.25 11 83.00 86.00 6 6 0 0 12 95.00 96.00 14 13 1 1 13 93.00 94.00 13 11 2 4 14 87.00 89.00 10 8 2 4 15 96.00 98.00 15 15 0 0 25.5
Rangking Data untuk Test mempunyai mulai dari 1 s/d 11, dan tidak ada skor yang nilainya sama.
Rangking Data untuk Prestasi mempunyai mulai dari 1 s/d 11, tetapi ada skor yang nilainya sama yaitu skor 75 ada 2 buah, maka rangking yang diberikan adalah (4+5)/2 = 4,5.
Penyelesaian persamaan : dari persamaan diatas,
∑
diketahui bahwa, n = 15,
∑
maka
∑
=
jadi korelasi antara test pegawai dan prestasi kerja pegawai adalah sebesar
Perbandingan Hasil SPSS Correlations Test Prestasi Kerja Spearman's rho Test Correlation
Coefficient 1.000 .954** Sig. (2-tailed) . .000 N 15 15 Prestasi Kerja Correlation Coefficient .954** 1.000 Sig. (2-tailed) .000 . N 15 15
**. Correlation is significant at the 0.01 level (2-tailed).
coba perhatikan bahwa hasil perhitungan point 3 hasilnya sama dengan hasil Uji SPSS, rs = 0,954
Uji Penafsiran Keeratan Hubungan
Uji sigifikansi, digunakan untuk manafsir keeratan korelasi antara Test dan Prestasi Kerja. pengujian dilakukan dengan dilakukan dengan uji Z.
Dasar pengambilan keputusan:
Dengan membandingkan z hitung dengan z tabel: Jika z hitung < z tabel, maka Ho diterima
Jika z hitung > z tabel. maka Ho ditolak ■
Dengan melihat angka probabilitas. dengan ketentuan: Probabilitas > 0.05 maka Ho diterima
Probabilitas < 0.05 maka Ho ditolak Keputusan:
• Dengan membandingkan / hitung dengan z label:
NB: Untuk n (jumlah sampel) di atas 10. bisa menggunakan uji z. Mencari z hitung:
√
dengan r = 0,954 dan n = 15. didapat z hitung:
√ √
maka Z hitung adalah Mencari z tabel:
Dengan tingkat kepercayaan 95% dan tingkat signifikansi 5% (ini adalah standar dari SPSS),
Uji dua sisi, Oleh karena dua sisi. maka tingkat signifikansi 5% juga dibagi 2.
menghasilkan 2,5%.
Luas kurva tabel Z adalah luasan Komulatif, maka luas kurva 50% -2,5%= 47.5%. Didalam tabel luasan adalah 47,5% + 50% = 97,5% atau 0,975 , maka Dari tabel z untuk luasan 0,975 didapat z tabel 1.96. (sisi sebelah kiri 1,9 dan kolom atas 0,06 maka menjadi 1,96
Kesimpulan:
Dari uraian dan perhitungan diatas didapatkan hasil sebagai berikut:
1. Koefisien korelasi rs = 0.954 , bahwa korelasi dua variabel adalah sangat kuat
2. Nilai Zhitung = > dari Zi tabel 1,96, maka H0 ditolak, bahwa terdapat hubungan yang nyata antara test pegawai dan prestasi kerja pegawai, artinya bahwa jika test pegawai baik maka prestasi kerja pegawai tersebut cenderung baik, dan juga sebaliknya.
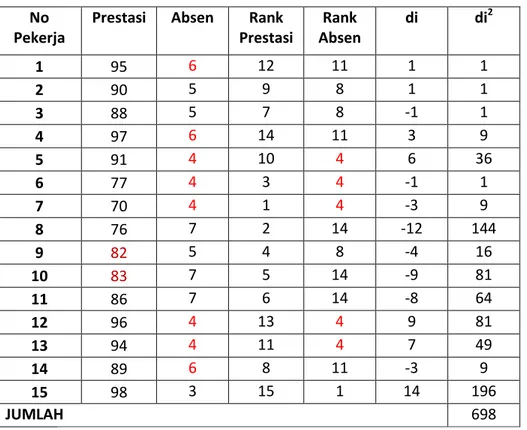
4. Hubungan antara Prestasi Pegawai dan Absen Pegawai
Dalam hal ini permasalahan yang dihadapi adalah ntuk mengetahui apakah ada hubungan yang signifikan antara prestasi kerja pegawi dan tingkat kehadirannya. Dugaannya adalah bahwa pegawi yang prestasinya tinggi maka kehadirannya bagus, atau dengan kata lain bahwa hubungan prestasi dan absen pegawai adalah hubungan negatif.
Persamaan :
∑
∑
∑
√∑
∑
dan∑
∑
∑
∑
∑ ∑
Tabel Pembantu : No
Pekerja
Prestasi Absen Rank Prestasi Rank Absen di di2 1 95 6 12 11 1 1 2 90 5 9 8 1 1 3 88 5 7 8 -1 1 4 97 6 14 11 3 9 5 91 4 10 4 6 36 6 77 4 3 4 -1 1 7 70 4 1 4 -3 9 8 76 7 2 14 -12 144 9 82 5 4 8 -4 16 10 83 7 5 14 -9 81 11 86 7 6 14 -8 64 12 96 4 13 4 9 81 13 94 4 11 4 7 49 14 89 6 8 11 -3 9 15 98 3 15 1 14 196 JUMLAH 698 Penyelesaian: Menghitung Tx/Ty
dalam menghitung TX/Ty yang perlu dilakukan adalah mencari rangking yang sama pada masing-masing variabel:
Variabel Prestasi : tidak ada rangking yang sama Tx=0
Variabel Absen : terdapat beberapa data yang rangking nya sama ranking 4 ada 5 , maka t =5
ranking 5 ada 3 , maka t =3 ranking 6 ada 3 , maka t =3 ranking 7 ada 3 , maka t =3 Menghitung Ty
Menghitung ∑ dan ∑ ∑ ∑ ∑ ∑ = 280 Menghitung ∑ ∑ ∑
dengan menggunakan hasil sebelumnya maka
∑
Menghitung Korelasi Rang Spearman
∑ ∑ ∑ √∑ ∑ √∑
Hasil perhitungan SPSS
Correlations
Prestasi Kerja Absen Spearman's rho Prestasi Kerja Correlation Coefficient 1.000 -.283
Sig. (2-tailed) . .306
N 15 15
Absen Correlation Coefficient -.283 1.000
Sig. (2-tailed) .306 .
N 15 15
dari kedua cara perhitungan tersebut didapatkan bahwa korelasi yang diperoleh adalah sama.
Uji Penafsiran Keeratan Hubungan
Uji sigifikansi, digunakan untuk manafsir keeratan korelasi antara Prestasi Kerja dan Absen Pegawai . pengujian dilakukan dengan dilakukan dengan uji Z.
Dasar pengambilan keputusan:
Dengan membandingkan z hitung dengan z tabel: Jika z hitung < z tabel, maka Ho diterima
Jika z hitung > z tabel. maka Ho ditolak ■
Dengan melihat angka probabilitas. dengan ketentuan: Probabilitas > 0.05 maka Ho diterima
Probabilitas < 0.05 maka Ho ditolak Keputusan:
• Dengan membandingkan / hitung dengan z label:
Mencari z hitung:
√
dengan r = 0,954 dan n = 15. didapat z hitung:
√ √
maka Z hitung adalah
Mencari z tabel:
Dengan tingkat kepercayaan 95% dan tingkat signifikansi 5% (ini adalah standar dari SPSS),
Uji dua sisi, Oleh karena dua sisi. maka tingkat signifikansi 5% juga dibagi 2. menghasilkan 2,5%.
Luas kurva tabel Z adalah luasan Komulatif, maka luas kurva 50% -2,5%= 47.5%. Didalam tabel luasan adalah 47,5% + 50% = 97,5% atau 0,975 , maka Dari tabel z untuk luasan 0,975 didapat z tabel 1.96. (sisi sebelah kiri 1,9 dan kolom atas 0,06 maka menjadi 1,96, Z tabel adalah = 1,96
Kesimpulan:
Dari uraian dan perhitungan diatas didapatkan hasil sebagai berikut:
1. Koefisien korelasi rs = -.283, bahwa korelasi dua variabel adalah sangat lemah
2. Nilai Zhitung = dari Z tabel 1,96, maka H0 diterima bahwa tidak terdapat hubungan yang nyata antara Prestasi pegawai dan absen pegawai, artinya bahwa jika prestasi kerja pegawai tersebut tidak cenderung absennya buruk, dan juga sebaliknya.
DAFTAR PUSTAKA
Arikunto, Suharsimi. 1996. Statistik Untuk Penelitian. Jakarta: Rineka Cipta. Dajan, Anto. 2000. Pengantar Metode Statistik. Cetakan Ke-16, Jakarta: LP3ES. Heryanto, N. 2003. Statistik. Bandung: Pustaka Setia.
Levin, dkk. 1991. Statistics for Managemen. New Jersey: Prentice Hall, 1991 Murdan. 2003. Statistik Pendidikan. Jakarta: Global Pustaka.
Rasyid, Harun A. 2000. Statistik. UNIVERSITAS PADJAJARAN, BANDUNG. Sugiarto. 2002. Metode Statistik. Jakarta: Gramedia.
Walpole, Ronald E. 1992. PengantarStatistik. edisi terjemahan. Jakata: PT Gramedia. Singgih Santoso, 2004, Buku Latihan SPSS Statistik non Parametrik. Jakata: PT Gramedia
LKM: Statistik Non-Parametrik
Nama Mahasiswa :
NIM :
Jawablah pertanyaan di bawah ini dengan sebaik-baiknya!
Buatlah data nilai mata kuliah statistik kelas masing-masing mempunyai 20 mahasiswa dengan rentang 6 sampai dengan 9.
a. Analisa data yang telah Anda buat dengan uji chi kuadrat! Jelaskan kesimpulan yang Anda peroleh!
b. Hitunglah koefisien Spearman Rank data yang telah Anda buat! Jelaskan kesimpulan yang Anda peroleh!
LP: Kognitif
Nama Mahasiswa :
NIM :
Jawablah pertanyaan-pertanyaan berikut ini dengan singkat dan benar! 1. Jelaskan konsep statistik non parametrik!
2. Berdasarkan data di handout/buku modul 5
a. Hitunglah dan analisa data tersebut dengan uji chi kuadrat! b. Hitunglah dan analisa koefisien spearman rank dari data tersebut!
LP: Psikomotorik
Jawablah secara lisan di depan kelas:
1. Jelaskan konsep statistik non parametrik! Demonstrasikan di depan kelas:
1. Berdasarkan data di modul 5
a. Hitunglah dan analisa data tersebut dengan uji chi kuadrat! b. Hitunglah dan analisa koefisien spearman rank dari data tersebut!
Lembar Penilaian
Nama Mahasiswa :
NIM :
No. Aspek yang dinilai Skor
4 3 2 1 1. Kebenaran uraian 2. Kejelasan bahasa 3. Keseriusan 4. Improvisasi Total skor Catatan:
LP: Pengamatan Perilaku Berkarakter
Petunjuk:
Amati untuk setiap perilaku berkarakter berikut ini selama perkuliahan berlangsung.
Nama Mahasiswa :
NIM :
No. Rincian Tugas Kinerja (RTK) Penilaian
4 3 2 1
1. Jujur 2. Peduli
3. Tanggungjawab
Catatan:
Skor 4: sangat baik; Skor 3: baik; Skor 2: cukup; Skor 1: kurang.
LP: Pengamatan Keterampilan Sosial
Petunjuk:
Amati untuk setiap keterampilan sosial yang dilakukan mahasiswa selama perkuliahan berlangsung.
Nama Mahasiswa :
NIM :
No. Rincian Tugas Kinerja (RTK) Penilaian
4 3 2 1
1. Menjadi pendengar yang baik 2. Berpendapat
3. Bertanya
Catatan:
Skor 4: sangat baik; Skor 3: baik; Skor 2: cukup; Skor 1: kurang.
LAMPIRAN: Tabel Z Z Z_0.0 Z_0.01 Z_0.02 Z_0.03 Z_0.04 Z_0.05 Z_0.06 Z_0.07 Z_0.08 Z_0.09 0,0 0.5 0.504 0.508 0.512 0.516 0.5199 0.5239 0.5279 0.5319 0.5359 0.1 0.5398 0.5438 0.5478 0.5517 0.5557 0.5596 0.5636 0.5675 0.5714 0.5753 0.2 0.5793 0.5832 0.5871 0.591 0.5948 0.5987 0.6026 0.6064 0.6103 0.6141 0.3 0.6179 0.6217 0.6255 0.6293 0.6331 0.6368 0.6406 0.6443 0.648 0.6517 0.4 0.6554 0.6591 0.6628 0.6664 0.67 0.6736 0.6772 0.6808 0.6844 0.6879 0.5 0.6915 0.695 0.6985 0.7019 0.7054 0.7088 0.7123 0.7157 0.719 0.7224 0.6 0.7257 0.7291 0.7324 0.7357 0.7389 0.7422 0.7454 0.7486 0.7517 0.7549 0.7 0.758 0.7611 0.7642 0.7673 0.7704 0.7734 0.7764 0.7794 0.7823 0.7852 0.8 0.7881 0.791 0.7939 0.7967 0.7995 0.8023 0.8051 0.8078 0.8106 0.8133 0.9 0.8159 0.8186 0.8212 0.8238 0.8264 0.8289 0.8315 0.834 0.8365 0.8389 1 0.8413 0.8438 0.8461 0.8485 0.8508 0.8531 0.8554 0.8577 0.8599 0.8621 1.1 0.8643 0.8665 0.8686 0.8708 0.8729 0.8749 0.877 0.879 0.881 0.883 1.2 0.8849 0.8869 0.8888 0.8907 0.8925 0.8944 0.8962 0.898 0.8997 0.9015 1.3 0.9032 0.9049 0.9066 0.9082 0.9099 0.9115 0.9131 0.9147 0.9162 0.9177 1.4 0.9192 0.9207 0.9222 0.9236 0.9251 0.9265 0.9279 0.9292 0.9306 0.9319 1.5 0.9332 0.9345 0.9357 0.937 0.9382 0.9394 0.9406 0.9418 0.9429 0.9441 1.6 0.9452 0.9463 0.9474 0.9484 0.9495 0.9505 0.9515 0.9525 0.9535 0.9545 1.7 0.9554 0.9564 0.9573 0.9582 0.9591 0.9599 0.9608 0.9616 0.9625 0.9633 1.8 0.9641 0.9649 0.9656 0.9664 0.9671 0.9678 0.9686 0.9693 0.9699 0.9706
Z Z_0.0 Z_0.01 Z_0.02 Z_0.03 Z_0.04 Z_0.05 Z_0.06 Z_0.07 Z_0.08 Z_0.09 1.9 0.9713 0.9719 0.9726 0.9732 0.9738 0.9744 0.975 0.9756 0.9761 0.9767 2 0.9772 0.9778 0.9783 0.9788 0.9793 0.9798 0.9803 0.9808 0.9812 0.9817 2.1 0.9821 0.9826 0.983 0.9834 0.9838 0.9842 0.9846 0.985 0.9854 0.9857 2.2 0.9861 0.9864 0.9868 0.9871 0.9875 0.9878 0.9881 0.9884 0.9887 0.989 2.3 0.9893 0.9896 0.9898 0.9901 0.9904 0.9906 0.9909 0.9911 0.9913 0.9916 2.4 0.9918 0.992 0.9922 0.9925 0.9927 0.9929 0.9931 0.9932 0.9934 0.9936 2.5 0.9938 0.994 0.9941 0.9943 0.9945 0.9946 0.9948 0.9949 0.9951 0.9952 2.6 0.9953 0.9955 0.9956 0.9957 0.9959 0.996 0.9961 0.9962 0.9963 0.9964 2.7 0.9965 0.9966 0.9967 0.9968 0.9969 0.997 0.9971 0.9972 0.9973 0.9974