DETEKSI KOMENTAR SPAM PADA MEDIA SOSIAL INSTAGRAM MENGGUNAKAN METODE NAÏVE BAYES
REPOSITORY
Oleh:
SELA ANDRIANI NIM. 1403111751
PROGRAM STUDI SISTEM INFORMASI JURUSAN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS RIAU
PEKANBARU
2019
DETEKSI KOMENTAR SPAM PADA MEDIA SOSIAL INSTAGRAM MENGGUNAKAN METODE NAÏVE BAYES
Sela Andriani, Roni Salambue
Mahasiswa Program Studi S1 Sistem Informasi Jurusan Ilmu Komputer
Fakultas Matematika dan Ilmu Pengetahuan Alam Kampus Bina Widya Pekanbaru, 28293, Indonesia
[email protected] ABSTRACT
Text Mining is the process of finding new information or trends that were previously not revealed by processing and analyzing large amounts of data. In this thesis text mining is used to classify comments on Instagram social media. This technique aims to distinguish spam and not spam comments. One of the algorithms used in the classification is Naïve Bayes Classifier (NBC). In the NBC method, there are two stages, they are Training stage and the Testing Phase. Before the classification is done first the data will go through the Preprocessing stage, in which there are casefolding, stopcharacter removal, stopword, stemming and weighting. Evaluation to measure accuracy using Confussion Matrix which produces 93% Accuracy, 92% Precision, Recall 93.87% and Error Rate 7%.
Keywords: Instagram, Spam Comments, Naïve Bayes Classifier, Text Mining.
ABSTRAK
Text Mining adalah proses penemuan akan informasi atau trend baru yang sebelumnya tidak terungkap dengan memproses dan menganalisa data dalam jumlah besar. Dalam skripsi ini text mining digunakan untuk mengklasifikasi komentar pada media sosial Instagram. Teknik ini bertujuan untuk membedakan komentar spam dan not spam. Salah satu algoritma yang digunakan dalam klasifikasi adalah Naïve Bayes Classifier (NBC).
Pada metode NBC dilakukan dua tahap yaitu tahap Pelatihan dan Tahap Pengujian.
Sebelum dilakukan klasifikasi terlebih dahulu data akan melalui tahap Preprocessing, yang didalamnnya terdapat casefolding, stopcharacter removal, stopword, stemming dan pembobotan. evaluasi untuk mengukur akurasi menggunkan Confussion Matrix yang menghasilkan Akurasi 93 %, Presisi 92%, Recall 93.87% dan Error Rate 7%.
Kata kunci: Instagram, Komentar Spam, Naïve Bayes Classifier, Text Mining.
PENDAHULUAN
Pada era teknologi ini telah hadir berbagai macam aplikasi media sosial, salah satunya adalah Instagram. Instagram merupakan salah satu aplikasi media sosial berbasis web dan mobile yang khusus digunakan untuk mengunggah gambar atau foto (Chrismanto & Lukito, 2017).
Instagram memiliki jumlah pengguna aktif bulanan di Indonesia mencapai 53 juta (Pertiwi, 2018). Hal ini menjadikan media sosial ini sangat terkenal dan disukai para penggunanya. Instagram merupakan situs media sosial yang semakin banyak digunakan terutama oleh para artis atau aktor Indonesia. Permasalahannya, Instagram ternyata memiliki banyak sekali komentar spam pada status-status para publik figur, terutama artis atau aktor yang memiliki follower sangat banyak. Komentar spam tersebut bisa berupa tulisan yang tidak berhubungan sama sekali dengan status yang dibagikan, komentar jualan, endorse, bahkan link ke suatu website berbahaya. Semakin terkenal suatu artis atau aktor, semakin banyak followers-nya, maka semakin banyak pula mendapat komentar spam (Chrismanto & Lukito, 2017).
Pada penelitian ini dikembangkan sistem pendeteksian komentar spam pada media sosial Instagram berbasis web. Algoritma yang digunakan untuk klasifikasi yaitu Naïve Bayes Classifier (NBC). NBC adalah metode klasifikasi sederhana tetapi memiliki akurasi serta performansi yang tinggi dalam pengklasifikasian teks (Routray, et al, 2013).
METODE PENELITIAN
a. Teknik Pengumpulan Data
Data yang diambil adalah komentar dalam Bahasa Indonesia, yaitu komentar dari post terbaru pada akun instagram dengan jumlah followers terbanyak di Indonesia, yaitu
@ayutingting92 dengan jumlah followers 25,4 juta pada 03 Oktober 2018 (Sripoku, 2018).
b. Peralatan yang Digunakan
Peralatan yang digunakan dalam penelitian ini terbagi menjadi 2 kategori, yaitu hardware dan software. Peralatan hardware dapat dilihat pada Tabel 1 dan software pada Tabel 2.
Tabel 1. Hardware yang digunakan
No Nama Alat dan Bahan Fungsi Keterangan
1 Laptop Perangkat untuk
pengolahan data dan pembuatan sistem
Lenovo Intel Core i3-3110M
2 Printer Mencetak Laporan
Penelitian
CANNON PIXMA IP2770
Tabel 2. Software yang digunakan
No Nama Alat dan Bahan Fungsi Keterangan
1 StarUML Software Pembuatan
Diagram UML
Versi 3.0.2 2 Sublime Text Text editor penulisan
bahasa PHP
Versi 3.1.1 3 XAMPP Web Server yang terdiri atas
Apache Server, MySQL Database, dan bahasa PHP
Versi 3.2.2
4 Mendeley Pembuatan daftar pustaka Versi 1.19.2 c. Langkah-langkah Penelitian
1. Pembobotan
Proses pembobotan menggunakan term frequency (TF). Konsep TF yang diambil adalah Raw term frequency. Nilai tf sebuah term diperoleh berdasarkan jumlah kemunculan term tersebut dalam dokumen, apabila term muncul sebanyak lima kali dalam suatu dokumen, maka nilai tf term adalah 5.
2. Metode Naïve Bayes Classifier
Naïve Bayes Classifier (NBC) adalah teknik pembelajaran mesin yang berbasis probabilistik. NBC dipilih karna merupakan metode yang sederhana tetapi memiliki akurasi serta performansi yang tinggi dalam pengklasifikasian teks (Routray, et al, 2013).
3. Confusion Matrix
Confusion matrix merupakan alat yang berguna untuk menganalisis seberapa baik classifier mengenali tuple dari kelas yang berbeda. True Positive (TP) dan True Negative (TN) memberikan informasi ketika classifier benar, sedangkan False Positive (FP) dan False Negative (FN) memberikan informasi ketika classifier salah (Sujatmoko, Waworundeng and Wahyudi, 2015).
Berdasarkan nilai True Negative (TN), False Positive (FP), False Negative (FN), dan True Positive (TP) dapat diperoleh nilai accuracy, Clssification error dan recall.
Nilai accuracy menggambarkan seberapa akurat sistem dapat mengklasifikasikan data secara benar. Nilai Clssification error adalah persentase classifier melakukan kesalahan prediksi. Nilai recall adalah persentase dari data kategori spam yang terklasifikasikan dengan benar oleh sistem.
HASIL DAN PEMBAHASAN
a. Desain dan Pengembangan Sistem
Pengembangan atau pembuatan sistem deteksi komentar spam berbasis web.
Aplikasi ini dikembangkan dengan bahasa pemrograman PHP dan database MySQL.
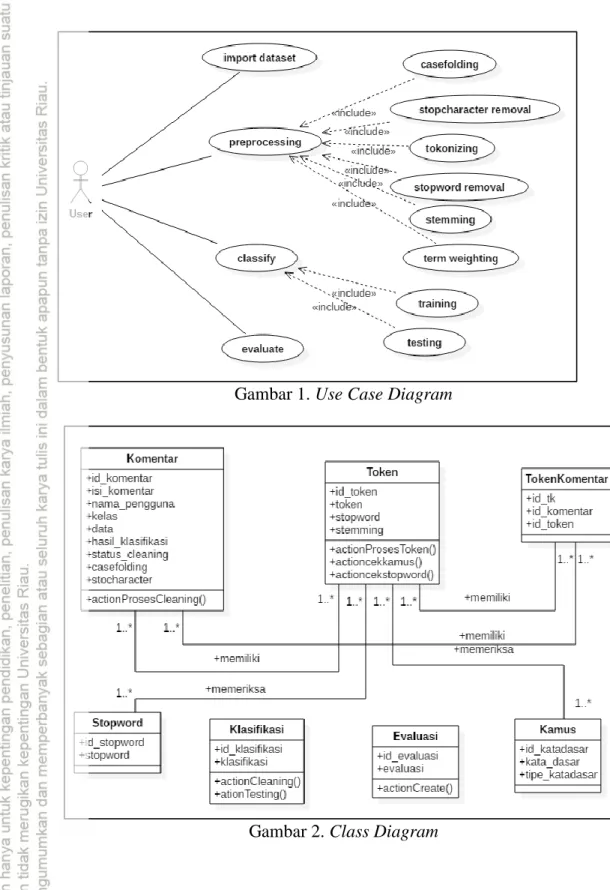
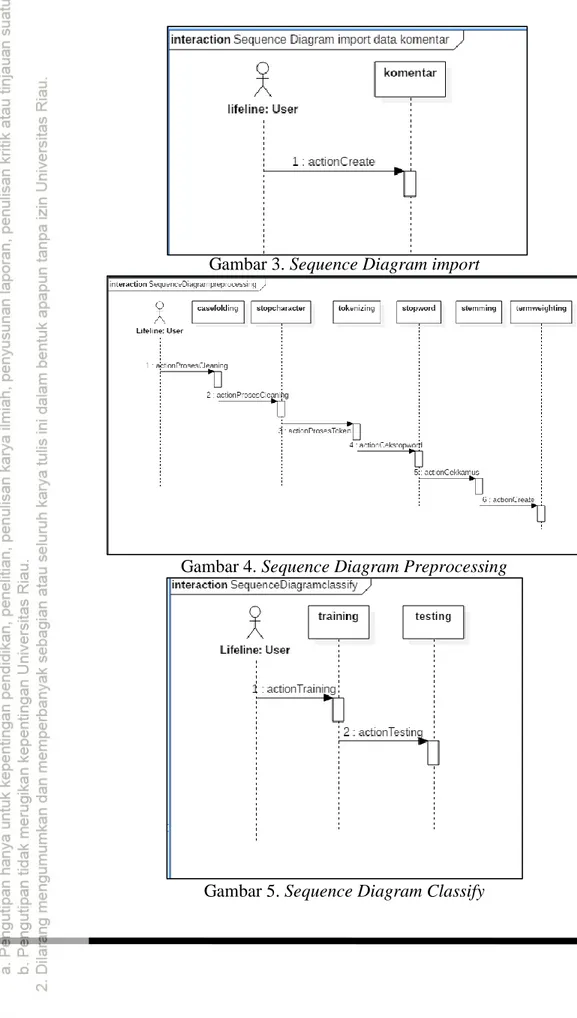
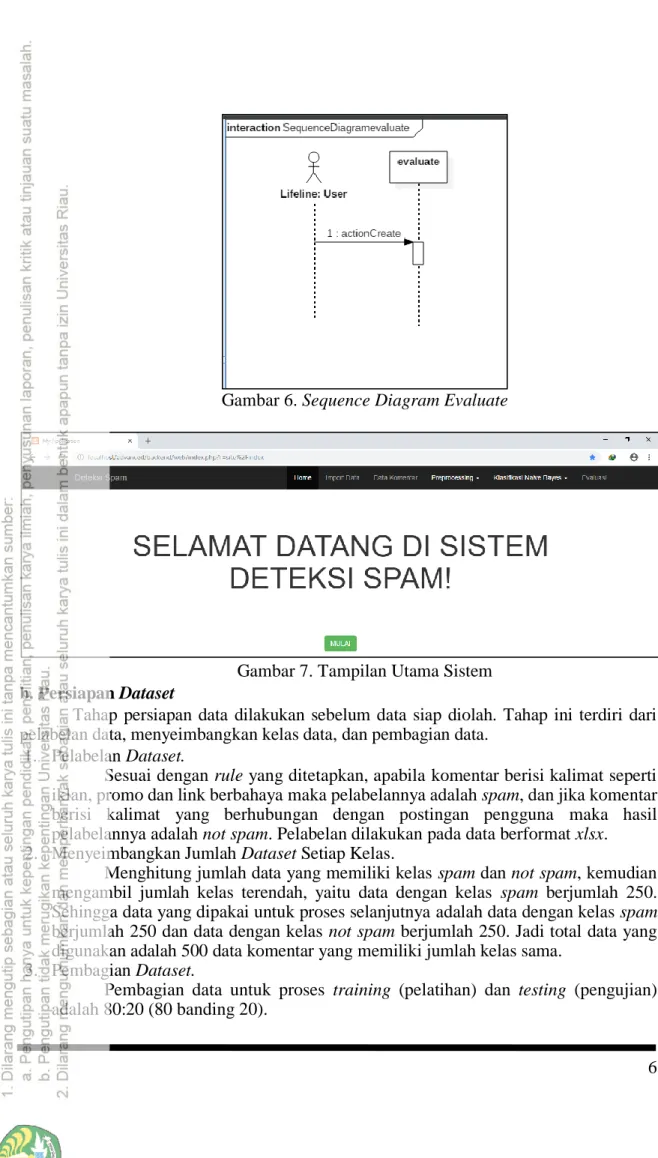
Aplikasi ini terdiri dari 4 fungsi utama, yaitu import data, preprocessing data, klasifikasi dan evaluasi. Desain sistem menggunakan UML yang dapat dilihat pada gambar 1 sampai Gambar 6 dan tampilan halaman utama sistem dapat dilihat pada Gambar 7.
Gambar 1. Use Case Diagram
Gambar 2. Class Diagram
Gambar 3. Sequence Diagram import
Gambar 4. Sequence Diagram Preprocessing
Gambar 5. Sequence Diagram Classify
Gambar 6. Sequence Diagram Evaluate
Gambar 7. Tampilan Utama Sistem
b. Persiapan Dataset
Tahap persiapan data dilakukan sebelum data siap diolah. Tahap ini terdiri dari pelabelan data, menyeimbangkan kelas data, dan pembagian data.
1. Pelabelan Dataset.
Sesuai dengan rule yang ditetapkan, apabila komentar berisi kalimat seperti iklan, promo dan link berbahaya maka pelabelannya adalah spam, dan jika komentar berisi kalimat yang berhubungan dengan postingan pengguna maka hasil pelabelannya adalah not spam. Pelabelan dilakukan pada data berformat xlsx.
2. Menyeimbangkan Jumlah Dataset Setiap Kelas.
Menghitung jumlah data yang memiliki kelas spam dan not spam, kemudian mengambil jumlah kelas terendah, yaitu data dengan kelas spam berjumlah 250.
Sehingga data yang dipakai untuk proses selanjutnya adalah data dengan kelas spam berjumlah 250 dan data dengan kelas not spam berjumlah 250. Jadi total data yang digunakan adalah 500 data komentar yang memiliki jumlah kelas sama.
3. Pembagian Dataset.
Pembagian data untuk proses training (pelatihan) dan testing (pengujian) adalah 80:20 (80 banding 20).
c. Import Dataset
Melalukan import dataset yang telah disiapkan dalam format xlsx ke dalam database MySQL menggunakan sistem deteksi komentar spam berbasis web untuk melakukan langkah selanjutnya, yaitu preprocessing data.
d. Preprocessing Data
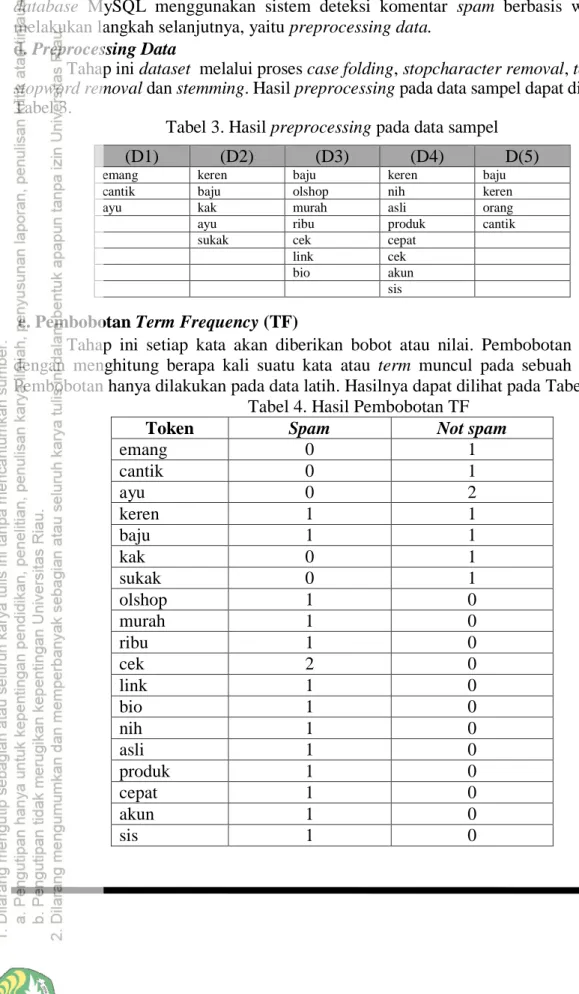
Tahap ini dataset melalui proses case folding, stopcharacter removal, tokenizing, stopword removal dan stemming. Hasil preprocessing pada data sampel dapat dilihat pada Tabel 3.
Tabel 3. Hasil preprocessing pada data sampel
e. Pembobotan Term Frequency (TF)
Tahap ini setiap kata akan diberikan bobot atau nilai. Pembobotan dilakukan dengan menghitung berapa kali suatu kata atau term muncul pada sebuah dokumen.
Pembobotan hanya dilakukan pada data latih. Hasilnya dapat dilihat pada Tabel 4.
Tabel 4. Hasil Pembobotan TF
Token Spam Not spam
emang 0 1
cantik 0 1
ayu 0 2
keren 1 1
baju 1 1
kak 0 1
sukak 0 1
olshop 1 0
murah 1 0
ribu 1 0
cek 2 0
link 1 0
bio 1 0
nih 1 0
asli 1 0
produk 1 0
cepat 1 0
akun 1 0
sis 1 0
(D1) (D2) (D3) (D4) D(5)
emang keren baju keren baju
cantik baju olshop nih keren
ayu kak murah asli orang
ayu ribu produk cantik
sukak cek cepat
link cek
bio akun
sis
f. Klasifikasi Naïve Bayes Classifier
Tahap ini algoritma klasifikasi Naïve Bayes akan melakukan pembelajaran menggunakan data latih dan melakukan pengujian terhadap data uji. Ada beberapa langkah yang dilakukan yaitu sebagai berikut:
1. Tahap Training
Hitung probabilitas dari setiap kategori menggunakan persamaan sebagai berikut :
𝑃(𝑉
𝑗) =
|𝑑𝑜𝑐𝑠 𝑗||𝑐𝑜𝑛𝑡𝑜ℎ| ... (1) Keterangan :
Vj : Kelas komentar, yaitu kelas spam dan not spam P(Vj) : Probabilitas dari Vj
|docs j| : Jumlah dokumen setiap kelas j
|contoh| : Jumlah dokumen dari semua kelas
Menghitung probabilitas dari setiap term dari semua dokumen dengan menggunakanpersamaan sebagai berikut :
𝑃(𝑊𝑘 | 𝑉𝑗) = 𝑛𝑘+1
𝑛+|𝑣𝑜𝑐𝑎𝑏𝑢𝑙𝑎𝑟𝑦| ... (2) Keterangan:
Wk : Kata yang muncul dalam doukumen
Vj : Kelas komentar, yaitu kelas spam dan not spam
nk : Frekuensi munculnya kata wk dalam dokumen yang berkategori vj n : Banyaknya seluruh kata dalam dokumen berkategori vj
|vocabulary| : Banyaknya kata dalam contoh pelatihan.
Tabel 5. Penghitungan Probabilitas Kata Data Latih
Dokumen Kelas Sentimen
Spam Not Spam
emang 0+1
15+19
=
134
1+1 8+19
=
227
cantik 0+1
15+19
=
134
1+1 8+19
=
227
Ayu 0+1
15+19
=
134
2+1 8+19
=
327
keren 1+1
15+19
=
234
1+1 8+19
=
227
Baju 1+1
15+19
=
234
1+1 8+19
=
227
kakv 0+1
15+19
=
134
1+1 8+19
=
227
sukak 0+1
15+19
=
134
1+1 8+19
=
227
olshop 1+1
15+19
=
234
0+1 8+19
=
127
murah 1+1
15+19
=
234
0+1 8+19
=
127
ribu 1+1
15+19
=
234
0+1 8+19
=
127
cek 2+1
15+19
=
334
0+1 8+19
=
127
link 0+1
15+19
=
134
1+1 8+19
=
227
bio 1+1
15+19
=
234
0+1 8+19
=
127
nih 1+1
15+19
=
234
0+1 8+19
=
127
asli 1+1
15+19
=
234
0+1 8+19
=
127
produk 1+1
15+19
=
230
0+1 8+19
=
127
cepat 1+1
15+19
=
234
0+1 8+19
=
127
akun 1+1
15+19
=
234
0+1 8+19
=
127
sis 1+1
15+19
=
234
0+1 8+19
=
127
2. Tahap Testing
Menghitung Probabilitas Data Uji menggunakan persamaan 2.
Tabel 6. Penghitungan Probabilitas Kata Data Uji
Dokumen Kelas Sentimen
Spam Not Spam
baju 1+1
15+19
=
234
0+1 8+19
=
127
keren 1+1
15+19
=
234
1+1 8+19
=
227
orang 0+1
8+19
=
127
0+1 8+19
=
127
cantik 0+1
15+19
=
134
1+1 8+19
=
2 Penghitungan VMAP Data Uji. 27
Menentukan probabilitas tertinggi dari masing-masing kelas berdasarkan proses pelatihan. Nilai probabilitas kelas maksimum adalah kelas terpilih hasil klasifikasi. VMAP dihitung berdasarkan hasil pada Tabel 6 menggunakan Persamaan sebagai berikut:
𝑉𝑀𝐴𝑃 = 𝑃(𝑥1|𝑉𝑗)𝑃(𝑉𝑗) ... (2) Keterangan:
VMAP : Probabilitas dokumen yang diuji P(xi|Vj) : Probabilitas xi pada kelas Vj P(Vj) : Probabilitas dari Vj
𝑝(𝑡𝑒𝑠𝑡𝑖𝑛𝑔|𝑠𝑝𝑎𝑚) = 𝑝(𝑠𝑝𝑎𝑚) × 𝑝(𝑏𝑎𝑗𝑢|𝑠𝑝𝑎𝑚) × 𝑝(𝑘𝑒𝑟𝑒𝑛|𝑠𝑝𝑎𝑚) × 𝑝(𝑜𝑟𝑎𝑛𝑔|𝑠𝑝𝑎𝑚) × 𝑝(𝑐𝑎𝑛𝑡𝑖𝑘|𝑠𝑝𝑎𝑚)
𝑝(𝑡𝑒𝑠𝑡𝑖𝑛𝑔|𝑠𝑝𝑎𝑚) =2
4× (0.0588235294) × (0.0588235294) × (0.0294117647) × (0.0294117647)
=1.496629590163× 10-6
𝑝(𝑡𝑒𝑠𝑡𝑖𝑛𝑔|𝑛𝑜𝑡 𝑠𝑝𝑎𝑚) = 𝑝(𝑛𝑜𝑡 𝑠𝑝𝑎𝑚) × 𝑝(𝑏𝑎𝑗𝑢|𝑛𝑜𝑡 𝑠𝑝𝑎𝑚) × 𝑝(𝑘𝑒𝑟𝑒𝑛|𝑛𝑜𝑡 𝑠𝑝𝑎𝑚) × 𝑝(𝑜𝑟𝑎𝑛𝑔|𝑛𝑜𝑡 𝑠𝑝𝑎𝑚)
× 𝑝(𝑐𝑎𝑛𝑡𝑖𝑘|𝑛𝑜𝑡 𝑠𝑝𝑎𝑚) 𝑝(𝑡𝑒𝑠𝑡𝑖𝑛𝑔|𝑛𝑜𝑡 𝑠𝑝𝑎𝑚) =2
4× ( 0.0740740740) × ( 0.0740740740) × (0.037037037) × (0.0740740740)
= 7.5267056926357× 10-6
Berdasarkan penghitungan diatas, nilai probabilitas tertinggi terdapat pada probabilitas Not spam, sehingga komentar tersebut diklasifikasikan ke dalam kelas Not spam.
g. Evaluasi menggunakan Confusion Matrix
Melakukan evaluasi penghitungan akurasi metode menggunakan confusion matrix. Pembagian dataset dalam penelitian ini adalah 80% data latih terdiri dari 400 komentar dan 20% data uji terdiri dari 100 komentar, hasilnya dapat dilihat pada Tabel 7.
Tabel 7. Confusion Matrix Pengujian Kelas Sebenarnya Kelas Prediksi Metode
Spam Not Spam
Spam 46 (TP) 4 (FN)
Not Spam 3 (FP) 47 (TN)
Berdasarkan Tabel 7, nilai akurasi dapat dihitung sebagai berikut:
Akurasi = 𝑇𝑃+𝑇𝑁
𝑇𝑃+𝐹𝑁+𝐹𝑃+𝑇𝑁
𝑥
100% = 93100
𝑥
100% = 93%KESIMPULAN
Berdasarkan hasil penelitian ini dapat disimpulkan beberapa hal, yaitu sebagai berikut:
1. Sistem yang dibuat mampu melakukan pendeteksian spam secara otomatis
2. Penelitian ini sudah berhasil mengimplementasikan algoritma Naïve Bayes pada studi kasus deteksi komentar spam menggunakan data komentar Instagram berbahasa Indonesia.
3. Untuk Akurasi dapat dilihat pada Waktu eksekusi program untuk fungsi impor data adalah 3.2901763916016 ×10-5 microsecond, casefolding dan stopcharacter 4.1961669921875 ×10-5 microsecond, tokenisasi, stopword, stemming dan pembobotan 9.8228454589844 ×10-5 microsecond, training 2.6941299438477 ×10-5 microsecond, testing 3.7908554073148 ×10-5 microsecond dan evaluasi 4.3153762817383 ×10-5 microsecond.
4. Penelitian ini telah menguji kemampuan algoritma klasifikasi Naive Bayes dan diperoleh akurasi sebesar 93%, presisi 92%, recall 93.87% dan classification error 7% dari metode.
UCAPAN TERIMA KASIH
Penulis mengucapkan terima kasih kepada bapak Roni Salambue, S.Kom., M.Si.
yang telah membimbing, memotivasi serta membantu penelitian dan penulisan karya ilmiah ini.
DAFTAR PUSTAKA
Chrismanto, A. R. and Lukito, Y. 2017. ‘Deteksi Komentar Spam Bahasa Indonesia pada Instagram Menggunakan Naive Bayes’, Ultimatics, IX(June), p. 50.
Pertiwi, W. K. 2018. ‘Riset Ungkap Pola Pemakaian Medsos Orang Indonesia’. Available at: https://tekno.kompas.com/read/2018/03/01/10340027/riset-ungkap-pola- pemakaian-medsos-orang-indonesia.
Routray, P., Kumar Swain, C. and Prava Mishra, S. (2013) ‘A Survey on Sentiment Analysis’, International Journal of Computer Applications, 76(10), pp. 975–8887.
doi: 10.5120/13280-0527.
Sripoku .2018. ‘5 Artis Followers Instagram Terbanyak’. Palembang: Tribun News.
Available at: http://palembang.tribunnews.com/2018/08/02/data-terbaru-5-artis- followers-instagram-terbanyak.
Sujatmoko, A. S. R., Waworundeng, J. and Wahyudi, A. K. (2015) ‘Rancang Bangun Detektor Asap Rokok Menggunakan SMS Gateway Untuk Asrama Crystal di Universitas Klabat’, Konferensi Nasional Sistem & Informatika 2015 STMIK STIKOM Bali, 9 – 10 Oktober 2015, pp. 460–465.