i
BERBAHASA INDONESIA MENGGUNAKAN STRUKTUR DATA
INVERTED INDEX DENGAN METODE PEMBOBOTAN TF-IDF
BERBASIS ORDBMS
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh:
Justina Septiani Wulandari
NIM : 085314031
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
PAPERS USING INVERTED INDEX DATA STRUCTURE WITH TF-IDF
WEIGHTING METHOD BASED ON ORDBMS
THESIS
Presented as Partial Fullfilment of the Requirements
To Obtain the Computer Bachelor Degree
In Informatics Engineering
By:
Justina Septiani Wulandari
Student Number : 085314031
INFORMATICS ENGINEERING STUDY PROGRAM
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
v
Penulis menyatakan dengan sesungguhnya bahwa skripsi yang ditulis ini
tidak memuat karya atau bagian karya orang lain, kecuali yang telah disebutkan
dalam kutipan dan daftar pustaka, sebagaimana layaknya sebuah karya ilmiah.
Yogyakarta, 13 Februari 2013
Penulis,
vi
LULUS ITU PILIHAN..
MAU CEPAT ATAU LAMBAT SEMUA DITENTUKAN OLEH DIRI
SENDIRI..
CINTAILAH SKRIPSI SEPERTI MENCINTAI PACARMU, MAKA
SKRIPSI AKAN LEBIH MUDAH UNTUK DITAKLUKAN..
JUST FOCUS AND SAY “I CAN DO IT!!”
vii
HALAMAN PERSEMBAHAN
Kupersembahkan skripsi ini kepada:
Tuhan Yesus Kristus dan Bunda-Nya atas lindungan dan kasih-Nya
ε(˘ʃƪ˘)зKeluargaku Mama Anastasia. W, Bapak FX. Suwarli, Adik F. Desylita. C,
Bulik T. Suwarni, Romo Paulus Sarmono, SCJ atas dukungan, kasih, doa
dan materi sehingga aku bisa menyelesaikan skripsiku (
ɔ
˘
⌣
˘)˘
⌣
˘ c)
Kekasih hati AG. Hari Jati Nugraha, S.T yang mau menjadi tempat
sharing, memberikan masukkan dan kritik, memberikan support dalam
penyelesaian skripsiku, menjadi alarm pengingat untuk cepat lulus, waktu
dan cutinya utk menemani saat ujian
(˘
⌣
˘)
ε
˘`)
beserta keluarganya
yang memberikan doa serta dukungan
Sahabat-sahabatku yang selalu mau membantu, memberikan semangat
dan kritik:
~@rezaEmde yang menjadi teman seperjuangan dalam penyelesaian
skripsi dan seminar nasional ReTII~ (*
^
□
^
)
八
(
^
□
^
*)
~Friends Photography crew: @petrav69, @puutripuut, @iamdewangga,
@SuryaAtmajaDB, @DeviiSinaga, @rosadell, @eesyyyyyy, Ndul,
@nezines22 yang memberikan pengalaman yang sangat berharga bekerja
sama, profesional, dan mendapatkan hal baru
\
(^o^)
/
~Kos Pak Kuat: @xtina_itha, @Little_Lan91, @yuliachann yang
menjadi teman seperjuangan dalam menyelesaikan skripsi~
╭
(
′
▽
`)
~@xvienz yang membantu dalam menggunakan sistem operasi open
source dan sharing skripsiku~
(˘
-
˘)
ง
~@bebh_beth, @endra_prasetya, @virtualservers, @gadissssssss,
@frendars, @batistagempil, @fidisiledif, @roysyahputra,
@cellathiodore, @stmita, @exseminaris2007~
( ▽ )
~Teman-teman Laskar TI 2008, SaOS atas persahabatannya~ (
ʃƪ
˘˘
ﻬ
)
Teman-teman yang sedang menyelesaikan skripsi, tetap semangat YOU
CAN DO IT!!
ƪ
(
٥
`
▽
´
٥
)
ʃ
viii
Setiap tahun makalah ilmiah berbahasa Indonesia semakin bertambah
banyak sehingga diperlukan sistem pemerolehan informasi untuk mencari
dokumen yang relevan. Sebagian besar sistem pemerolehan informasi dan web
pencarian menerapkan
inverted index yang terbukti efisien dalam menjawab
query. Pada penelitian sebelumnya, penggunaan
inverted index
pada
database
menawarkan beberapa keuntungan dan implementasi
inverted index dengan
Bahasa Indonesia menggunakan ORDBMS memiliki waktu akses yang lebih baik
dibandingkan menggunakan RDBMS.
Dari latar belakang tersebut, diimplementasikan sebuah pencarian makalah
ilmiah berbahasa Indonesia berdasarkan seluruh isi teks dalam dokumen
menggunakan struktur data
inverted index pada ORDBMS dengan metode
pembobotan TF-IDF (Savoy) dan
stemming menggunakan algoritma Nazief &
Adriani. Sistem ini dikembangkan menggunakan bahasa pemrograman Java,
ORDBMS pada Oracle 11g R2 Enterprise Edition dan Netbeans.
Percobaan ini menggunakan
corpus 281 dokumen makalah ilmiah
berbahasa Indonesia yang berisikan 25737 term. Waktu yang dibutuhkan untuk
proses pencarian pada operasi AND dengan 1 sampai 2 kata kunci kurang dari 0,1
detik, 3 kata kunci kurang dari 0,4 detik, dan 4 kata kunci kurang dari 1 detik.
Sedangkan, pada hasil perhitungan
recall precision pada 11 titik sistem dapat
menghasilkan nilai yang baik meskipun terdapat beberapa kelemahan yang
ditemukan.
ix
Every year, Indonesian scientific papers are multiplying so it required
information retrieval system to find relevant documents. Most of the information
retrieval system and web search implement inverted index which proven efficient
in answering queries. In previous research, the use of inverted index on database
offers several advantages and implementation of inverted index by using
Indonesian languages on ORDBMS had better access time than using RDBMS.
From these background, searching scientific paper with Indonesian
language was implemented scientific paper searching, the entire contents of the
text in a document using the inverted index data structure on ORDBMS with
TF-IDF weighting method (Savoy) and stemming algorithm Nazief & Adriani. The
system was developed using the Java programming language, ORDBMS Oracle
11g R2 Enterprise Edition and Netbeans.
This experiment uses corpus 281 Indonesian scientific papers documents
that contains 25,737 terms. The time needed to process a search on the AND
operation with 1 to 2 keywords less than 0.1 seconds, 3 keywords less than 0.4
seconds, and 4 keywords less than 1 second. Meanwhile, result on the 11-point
recall precision computation system can produce a good value despite some
weaknesses were found.
x
PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan dibawah ini, saya mahasiswa Universitas Sanata Dharma:
Nama
: Justina Septiani Wulandari
NIM
: 085314031
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan
Universitas Sanata Dharma karya ilmiah yang berjudul:
SISTEM PEMEROLEHAN INFORMASI MAKALAH ILMIAH
BERBAHASA INDONESIA MENGGUNAKAN STRUKTUR DATA
INVERTED INDEX MENGGUNAKAN METODE PEMBOBOTAN TF-IDF
BERBASIS ORDBMS
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan
kepada Perpustakaan Universitas Sanata Dharma hak untuk menyimpan,
mengalihkan dalam bentuk media lain, mengelolanya dalam bentuk pangkalan
data mendistribusikan secara terbatas, dan mempublikasikannya di Internet atau
media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya
maupun memberikan royalti kepada saya selama tetap mencantumkan nama saya
sebagai penulis.
Demikian pernyataan ini yang saya buat dengan sebenarnya.
Dibuat di Yogyakarta,
Pada tanggal: 13 Februari 2013
Yang menyatakan,
xi
Puji dan saya panjatkan kepada Tuhan Yesus Kristus atas kasih dan
lindungan-Nya sehingga saya dapat menyelesaikan tugas akhir ini.
Dalam penyelesaian tugas akhir ini ada begitu banyak pihak yang telah
memberikan bantuan dan perhatian dengan caranya masing-masing sehingga
tugas akhir ini dapat diselesaikan. Oleh karena itu saya mengucapkan terimakasih
kepada :
1.
Ibu Paulina Heruningsih Prima Rosa, S.Si., M.Sc., selaku dekan Fakultas
Sains dan Teknologi Universitas Sanata Dharma.
2.
Ibu Ridowati Gunawan, S.Kom., M.T., selaku ketua jurusan Teknik
Informatika Universitas Sanata Dharma.
3.
Bapak JB. Budi Darmawan, S.T., M.Sc., selaku dosen pembimbing TA yang
selalu membimbing dan memberikan banyak masukkan.
4.
Ibu Sri Hartati Wijono, S.Si., M.Kom. dan Bapak Puspaningtyas Sanjoyo
Adi, S.T., M.T. selaku penguji TA, atas saran dan kritik yang diberikan untuk
menunjang Tugas Akhir ini.
5.
Kedua orang tua FX. Suwarli dan Anastasia. W, adik Fabiola Desylita. C,
Bulik T. Suwarni, dan kekasih AG. Hari Jati Nugraha, S.T yang selalu
memberi dukungan, kasih sayang, semangat, dan masukkan dalam proses
pengerjaan tugas akhir ini.
xii
dukungan dan persahabatannya.
8.
Semua pihak yang telah membantu penulis baik secara langsung maupun
tidak langsung, yang tidak dapat disebutkan satu persatu.
Saya menyadari masih banyak kekurangan yang terdapat pada laporan ini.
Saran dan kritik selalu saya harapkan dari pembaca untuk perbaikan
–
perbaikan di
masa yang akan datang.
Akhir kata, saya berharap tulisan ini dapat bermanfaat bagi kemajuan dan
perkembangan ilmu pengetahuan dan berbagai pihak pengguna pada umumnya.
Yogyakarta, 13 Februari 2013
xiii
HALAMAN JUDUL BAHASA INDONESIA ... i
HALAMAN JUDUL BAHASA INGGRIS ... ii
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ... iv
PERNYATAAN KEASLIAN KARYA ... v
HALAMAN MOTO ... vi
HALAMAN PERSEMBAHAN ... vii
ABSTRAKSI ... viii
ABSTRACT ... ix
LEMBAR PERNYATAAN PERSETUJUAN ... x
KATA PENGANTAR ... xi
DAFTAR ISI ... xiii
DAFTAR TABEL ... xvii
DAFTAR GAMBAR ... xix
DAFTAR LISTING ... xxii
BAB I PENDAHULUAN ... 1
1.1
Latar Belakang Masalah... 1
1.2
Rumusan Masalah ... 2
1.3
Tujuan ... 2
1.4
Batasan Masalah ... 3
1.5
Metodologi Penelitian ... 3
1.6
Sistematika Penulisan ... 4
BAB II LANDASAN TEORI ... 5
2.1
Pemerolehan Informasi ... 5
2.1.1
Konsep Pemerolehan Informasi ... 5
2.1.2
Logical View Dokumen ... 5
2.1.4
Inverted Index... 11
xiv
2.2
Object Oriented Conceptual Model ... 14
2.2.1
Relasi Asosiasi ... 15
2.2.2
Relasi Agregrasi ... 15
2.3
Object Relational Database Management System ... 16
2.3.1
Konsep Object Relational Database Management System ... 16
2.4
Implementasi
Existence-Dependent Aggregation
menggunakan Teknik
Nesting ... 19
2.5
Penggunaan DBMS untuk Pemerolehan Informasi ... 19
BAB III ANALISA DAN PERANCANGAN SISTEM ... 22
3.1
Gambaran Sistem yang Dikembangkan ... 22
3.1.1
Gambaran Proses pada Sistem ... 23
3.1.1.1
Alur Kerja Proses Indexing ... 23
3.2
Analisa Kebutuhan ... 31
3.3
Perancangan Sistem ... 31
3.3.1
Diagram Use Case ... 31
3.3.2
Narasi Use Case ... 32
3.3.2.1
Login ... 32
3.3.2.2
Menambahkan Dokumen Makalah ... 34
3.3.2.3
Mengubah Data Dokumen Makalah ... 36
3.3.2.4
Logout ... 37
3.3.2.5
Mencari Dokumen Makalah ... 38
3.3.3
Data Flow Diagram (DFD) ... 39
3.3.3.1
Diagram Context ... 40
3.3.3.2
Diagram Berjenjang ... 40
3.3.3.3
DFD Level 0 ... 41
3.3.3.4
DFD Level 1 Proses 1 ... 42
3.3.3.5
DFD Level 1 Proses 2 ... 42
3.3.3.6
DFD Level 1 Proses 3 ... 43
3.3.3.7
DFD Level 1 Proses 4 ... 43
xv
3.4
Perancangan Database ... 45
3.4.1
Conceptual Database Design ... 45
3.4.2
Logical Database Design ... 48
3.4.3
Physical Database Design ... 48
3.4.4
Proses Query pada ORDBMS ... 54
3.5
Perancangan Antarmuka (Interface) ... 55
3.5.1
Desain Halaman Login Administrator ... 55
3.5.2
Desain Halaman Beranda Administrator ... 56
3.5.3
Desain Halaman Tambah Makalah ... 57
3.5.4
Desain Halaman Edit Makalah ... 57
3.5.5
Desain Halaman Pencarian ... 59
3.5.6
Desain Halaman Hasil Pencarian ... 59
BAB IV IMPLEMENTASI ... 61
4.1
Spesifikasi Software dan Hardware yang Digunakan... 61
4.1.1
Spesifikasi Software ... 61
4.1.2
Spesifikasi Hardware ... 61
4.2
Implementasi Basis Data ... 62
4.3
Koneksi dari Java ke Oracle ... 74
4.4
Implementasi Struktur Data Inverted Index ... 74
4.5
Pembuatan Antarmuka (Interface) ... 76
4.5.1
Halaman Login ... 76
4.5.2
Halaman Beranda Administrator ... 76
4.5.3
Halaman Tambah Makalah ... 77
4.5.5
Halaman Edit Makalah ... 88
4.5.6
Halaman Pencarian ... 89
4.5.7
Halaman Hasil Pencarian ... 96
BAB V ANALISA HASIL ... 97
5.1
Analisa Hasil Program ... 97
5.1.2
Analisa Uji Coba Pengguna ... 97
xvi
5.2.1
Kelebihan Sistem ... 119
5.2.2
Kelemahan Sistem ... 120
BAB VI KESIMPULAN DAN SARAN ... 121
6.1
Kesimpulan... 121
6.2
Saran ... 122
DAFTAR PUSTAKA ... 124
xvii
Tabel 2.1. Kombinasi Awalan Akhiran Yang Tidak Diijinkan ... 8
Tabel 2.2. Cara menentukan tipe awalan untuk
Kata yang diawali dengan “te
-
”
... 8
Tabel 2.3. Jenis Awalan Berdasarkan Tipe Awalannya... 9
Tabel 3.1. Tabel Analisa Kebutuhan ... 31
Tabel 3.2. Narasi Use Case Login ... 32
Tabel 3.3.Narasi Use Case Menambah Dokumen Makalah ... 34
Tabel 3.4.Narasi Use Case Mengubah Data Dokumen Makalah ... 36
Tabel 3.5. Narasi Use Case Logout ... 37
Tabel 3.6. Narasi Use Case Mencari Dokumen Makalah ... 38
Tabel 3.7. Tabel Status ... 49
Tabel 3.8. Tabel Documents ... 49
Tabel 3.9. Tabel Posting ... 50
Tabel 3.10. Tabel Terms... 50
Tabel 3.11. Tabel Posting_Stopword ... 51
Tabel 3.12. Tabel Stopwords ... 51
Tabel 3.13. Tabel Dictionary ... 51
Tabel 3.14. Tabel Administrator... 52
Tabel 3.15. Tabel Sourceterm ... 52
Tabel 3.16. Tabel Jurnal ... 53
Tabel 3.17. Tabel Term ... 53
Tabel 4.1. Tabel Status ... 64
Tabel 4.2. Tabel Documents ... 64
Tabel 4.3. Tabel Posting... 65
Tabel 4.4. Tabel Terms ... 66
Tabel 4.5. Tabel Posting_stopword ... 67
Tabel 4.6. Tabel Stopwords ... 68
Tabel 4.7. Tabel Dictionary ... 69
Tabel 4.8. Tabel Administrator ... 69
xviii
Tabel 4.11. Tabel Term ... 72
Tabel 5.1. Hasil operasi AND sebelum dijumlahkan nilai bobotnya ... 102
Tabel 5.2. Hasil operasi AND setelah dijumlahkan nilai bobotnya ... 102
Tabel 5.3. Urutan dokumen untuk kata kunci “jaringan syaraf tiruan”
... 103
Tabel 5.4. Seluruh dokumen yang relevan berdasarkan responden untuk kata
kunci “jaringan syaraf tiruan”
... 103
Tabel 5.5. Nilai recall dan precision
untuk kata kunci “jaringan syaraf tiruan”
. 104
Tabel 5.6. Perhitungan interpolasi untuk kata kunci “jaringan syaraf tiruan”
.... 105
Tabel 5.7. Seluruh dokumen yang relevan berdasarkan responden untuk kata
kunci “
data mining
asosiasi”
... 106
Tabel 5.8. Nilai recall dan precision
untuk kata kunci “
data mining
asosiasi”
.. 106
Tabel 5.9. Perhitungan
interpolasi untuk kata kunci “
data mining
asosiasi”
... 107
Tabel 5.10. Seluruh dokumen yang relevan berdasarkan responden untuk kata
ku
nci “
cube
”
... 109
Tabel 5.11. Nilai recall dan precision
untuk kata kunci “
cube
”
... 109
Tabel 5.12. Perhitungan interpolasi untuk kata kunci “
cube
”
... 110
Tabel 5.13. Seluruh dokumen yang relevan berdasarkan responden untuk kata
kunci “
hardisk
”
... 111
Tabel 5.14. Nilai recall dan precision
untuk kata kunci “
hardisk
”
... 112
Tabel 5.15. Perhitungan interpolasi untuk kata kunci “
hardisk
”
... 112
Tabel 5.16. Seluruh dokumen yang relevan berdasarkan responden untuk kata
kunci “
wireless network
”
... 113
Tabel 5.17. Nilai recall dan precision
untuk kata kunci “
wireless network
”
... 114
xix
Gambar 2.1. Operasi teks logical view dari sebuah dokumen: dari full text menjadi
sebuah set indeks term. (Baeza-Yates, 1999) ... 6
Gambar 2.2. Proses pemerolehan informasi (Baeza-Yates, 1999) ... 11
Gambar 2.3. Representasi Inverted Index (Manning, 2009) ... 12
Gambar 2.4.
Pemotongan
posting list untuk
query Brutus AND Calpuria
(Manning, 2009) ... 12
Gambar 2.5. Object (Pardede, 2006) ... 14
Gambar 2.6. Contoh relasi agregrasi (Pardede, 2006) ... 15
Gambar 2.7. Contoh relasi agregrasi existence-dependent (Pardede, 2006) ... 16
Gambar 2.8. Contoh relasi agregrasi existence-independent (Pardede, 2006) ... 16
Gambar 2.9. Object type dan contoh object type (Oracle, 2008) ... 17
Gambar 3.1. Gambaran sistem yang dikembangkan ... 23
Gambar 3.2.
Flowchart proses
indexing untuk menyimpan ke
database text
RDBMS ... 24
Gambar 3.3.
Flowchart
pada
stored procedure insert_term pada
database text
RDBMS ... 25
Gambar 3.4.
Flowchart
pembentukan
inverted index
dari
database text
RDBMS
ke database index ready ORDBMS... 26
Gambar 3.5.
Flowchart stored procedure insert_term_ordbms pada
database
index ready ORDBMS ... 27
Gambar 3.6. Flowchart untuk proses searching ... 28
Gambar 3.7. Flowchart untuk operasi AND ... 29
Gambar 3.8. Flowchart penghitungan waktu akses query ... 30
Gambar 3.9. Use Case... 32
Gambar 3.10. Diagram Context ... 40
Gambar 3.11. Diagram berjenjang ... 40
Gambar 3.12. DFD level 0 ... 41
Gambar 3.13. DFD level 1 proses 1... 42
xx
Gambar 3.16. DFD level 1 proses 4... 43
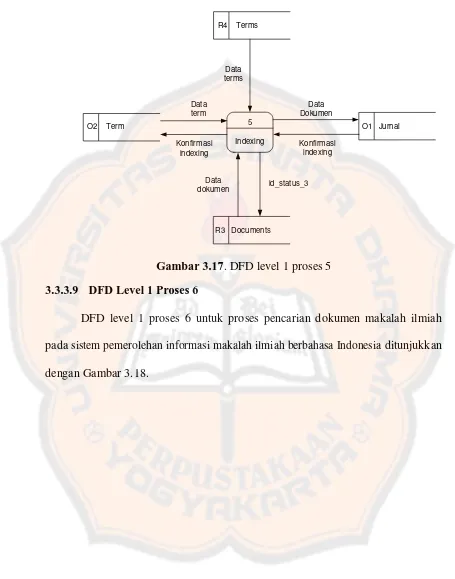
Gambar 3.17. DFD level 1 proses 5... 44
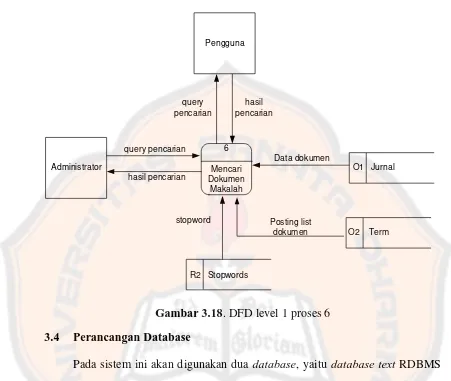
Gambar 3.18. DFD level 1 proses 6... 45
Gambar 3.19. Diagram ER pada database text RDBMS ... 46
Gambar 3.20. Struktur data inverted index klasik ... 46
Gambar 3.21. Gambaran nested table pada database index ready ORDBMS... 47
Gambar 3.22. Rancangan database index ready ORDBMS dalam bentuk diagram
kelas ... 48
Gambar 3.23. Hubungan relasi antar tabel pada database teks RDBMS ... 48
Gambar 3.24. Desain halaman login administrator ... 56
Gambar 3.25. Desain halaman beranda administrator ... 56
Gambar 3.26. Desain halaman tambah makalah ... 57
Gambar 3.27. Desain halaman edit makalah ... 58
Gambar 3.28. Desain halaman form edit makalah ... 58
Gambar 3.29. Desain halaman pencarian ... 59
Gambar 3.30. Desain halaman hasil pencarian ... 60
Gambar 4.1. Database text RDBMS pada sistem pemerolehan informasi makalah
ilmiah berbahasa Indonesia ... 63
Gambar 4.2. Database index ready ORDBMS pada sistem pemerolehan informasi
makalah berbahasa Indonesia ... 63
Gambar 4.3. Implementasi struktur data
inverted index
pada tabel posting dalam
database text RDBMS ... 75
Gambar 4.4. Implementasi struktur data
inverted index
pada tabel
term dalam
database index ready ORDBMS ... 75
Gambar 4.5. Halaman login ... 76
Gambar 4.6. Halaman beranda administrator ... 77
Gambar 4.7. Halaman tambah makalah ... 78
Gambar 4.8. Halaman edit data makalah ... 88
Gambar 4.9. Form edit data makalah... 89
xxi
Gambar 5.1. Output perintah SQL untuk kata jaring ... 98
Gambar 5.2. Output perintah SQL untuk kata syaraf ... 101
Gambar 5.3. Output perintah SQL untuk kata tiru ... 101
Gambar 5.4. Grafik interpolasi untuk kata kunci pencarian “jar
ingan
syaraf tiruan”
... 105
Gambar
5.5.
Grafik
interpolasi
untuk
kata
kunci
pencarian
“
data mining
asosiasi”
... 108
Gambar 5.6. Grafik interpolasi untuk kata kunci pencarian “
cube
”
... 110
Gambar 5.7. Grafik interpolasi untuk kata kunci pencarian “
hardisk
”
... 113
xxii
Listing 2.1. Perintah SQL umum untuk membuat object Type ... 17
Listing 3.1. Type untuk object type JurnalType ... 54
Listing 3.2. Type untuk object type PostingListType ... 54
Listing 3.3. Type untuk object type PostingListNestedType ... 54
Listing 3.4. Type untuk object type termType ... 55
Listing 3.5. Create tabel jurnal ... 55
Listing 3.6. Create tabel term ... 55
Listing 4.1. Create tabel status ... 64
Listing 4.2. Create tabel documents ... 65
Listing 4.3. Create tabel posting ... 66
Listing 4.4. Create tabel terms ... 67
Listing 4.5. Create tabel posting_stopword ... 67
Listing 4.6. Create tabel stopwords ... 68
Listing 4.7. Create tabel dictionary ... 69
Listing 4.8. Create tabel administrator ... 70
Listing 4.9. Create tabel sourceterm ... 70
Listing 4.10. Type untuk object type JurnalType... 71
Listing 4.11. Create tabel jurnal ... 72
Listing 4.12. Type untuk object type termType ... 73
Listing 4.13. Type untuk object type PostingListType ... 73
Listing 4.14. Create tabel term ... 73
Listing 4.15. JDBCURL untuk koneksi dari Java ke Oracle ... 74
Listing 4.16. Method getConnection ... 74
Listing 4.17. Perintah SQL untuk menampilkan struktur data
inverted index pada
database text RDBMS untuk kata syaraf ... 75
Listing 4.18. Perintah SQL untuk menampilkan struktur data
inverted index pada
database index ready ORDBMS ... 75
xxiii
stemmed word pada tabel terms database teks RDBMS ... 80
Listing 4.21.
Stored procedure
insert_sourceterm untuk menambahkan
original
word pada tabel source term database teks RDBMS ... 81
Listing 4.22. Stored procedure
counting_dfk_nidfk untuk menghitung nilai dfk
dan nidfk ... 82
Listing 4.23. Stored procedure counting_w untuk menghitung nilai ntfik dan w 83
Listing 4.24.
Method untuk penjadwalan
update
database index ready
ORDBMS ... 83
Listing 4.25. Method untuk memanggil method update dan
create inverted index
pada database index ready ORDBMS ... 84
Listing 4.26.
Method untuk
update inverted index pada
database index ready
ORDBMS ... 85
Listing 4.27.
Method
untuk
create inverted index
pada
database index ready
ORDBMS ... 85
Listing 4.28.
Stored procedure update_term_ordbms untuk update inverted index
pada database index ready ORDBMS ... 86
Listing 4.29.
Stored procedure insert_term_ordbms untuk
create inverted index
pada database index ready ORDBMS ... 87
Listing 4.30. Method searching untuk pencarian ... 90
Listing 4.31. Method singlesearch untuk pencarian dengan 1 kata kunci ... 91
Listing 4.32. Method AND untuk operasi pencarian AND ... 92
Listing 4.33. Listing untuk penghitungan waktu akses query ... 95
Listing 5.1. Perintah SQL untuk kata “jaring”
... 98
Listing 5.2. Perintah SQL untuk kata “syaraf”
... 100
1
BAB I
PENDAHULUAN
1.1
Latar Belakang Masalah
Kemajuan dunia pendidikan maupun riset dibidang teknologi cukuplah
pesat, khususnya teknologi informasi yang dapat dilihat dari banyak bermunculan
makalah penelitian. Setiap tahun makalah ilmiah akan bertambah banyak seiiring
dengan banyaknya orang yang melakukan penelitian. Pencari makalah pun ingin
menemukan makalah yang sesuai dengan kebutuhannya. Penyaringan makalah
secara manual dilakukan dengan membaca makalah yang kemudian
diklasifikasikan
dengan
kesesuaian
makalah
yang
diinginkan.
Untuk
mempermudah pencari makalah, maka diperlukan sistem pemerolehan informasi
untuk mencari dokumen makalah yang relevan.
Sebagian besar sistem pemerolehan informasi dan web pencarian
menerapkan
inverted index yang terbukti efisien dalam menjawab query
(Baeza-Yates, 1999). Penggunaan
inverted index pada DBMS (Database Management
System) menawarkan beberapa kelebihan dan kekurangannya (Papadakos P,
2008). Implementasi
inverted
index dengan Bahasa Indonesia pada ORDBMS
(Object Relational Database Management System) memiliki waktu akses yang
lebih baik dibanding menggunakan RDBMS (Relational Database Management
System) (Darmawan, 2012). Proses pembentukan indeks menggunakan rumus
(Hasibuan, 2001). Penggunaan indeks tersebut sudah pernah diterapkan pada
dokumen berbahasa Indonesia dan dapat menghasilkan dokumen pemerolehan
informasi (information retrieval) yang sesuai (Hasibuan, 2001). Penerapan
struktur data
inverted index
di ORDBMS
dapat menggunakan
collection yang
struktur datanya mirip dengan struktur data
inverted index klasik (Darmawan,
2012).
Aplikasi yang dikembangkan adalah sistem pemerolehan informasi makalah
ilmiah menggunakan struktur data
inverted index berbasis ORDBMS dengan
metode pembobotan TF-IDF.
1.2
Rumusan Masalah
Rumusan masalah tugas akhir ini adalah:
1.
Bagaimana mengimplementasikan sistem pemerolehan informasi untuk
pencarian dokumen makalah ilmiah berbahasa Indonesia?
2.
Bagaimana keakuratan pencarian dokumen makalah ilmiah berbahasa
Indonesia menggunakan
full
text dari
file pdf
dokumen makalah dengan
metode pembobotan Savoy dan stemming bahasa Indonesia?
3.
Bagaimana unjuk kerja penggunaan struktur data
inverted index berbasis
ORDBMS dengan metode pembobotan TF-IDF?
1.3
Tujuan
1.4 Batasan Masalah
Batasan masalah tugas akhir ini adalah :
1.
Sistem pemerolehan informasi ini hanya untuk pencarian dalam Bahasa
Indonesia.
2.
Koleksi dokumen yang disediakan adalah makalah ilmiah berbahasa
Indonesia dengan jumlah 281 dokumen.
3.
Kamus Bahasa Indonesia yang disediakan adalah 3278 kata.
4.
Jumlah stopword (kata buang) yang disediakan adalah 395 kata.
1.5 Metodologi Penelitian
Dalam pembuatan tugas akhir ini dilakukan tahap-tahap sebagai berikut:
1.
Studi pustaka penerapan pemerolehan informasi untuk menjawab
query
dalam ORDBMS menggunakan pembobotan TF-IDF dengan model
pemerolehan boolean AND.
2.
Analisa dan perancangan sistem. Melakukan analisis terhadap masalah dan
kebutuhan sistem yang akan dibangun. Kemudian, membuat perancangan
sistem.
3.
Pengumpulan dokumen-dokumen makalah ilmiah berbahasa Indonesia
sebagai corpus.
4.
Implementasi penerapan struktur data
inverted index dalam ORDBMS
dengan metode pembobotan TF-IDF menggunakan rumus Savoy.
5.
Pengujian dan analisa sistem.
1.6 Sistematika Penulisan
BAB I : PENDAHULUAN
Bab ini berisikan pendahuluan yang terdiri dari latar belakang, rumusan
masalah, tujuan, batasan masalah, metodologi penelitian, dan sistematika
penulisan
BAB II : LANDASAN TEORI
Bab ini berisikan konsep dasar sistem pemerolehan informasi (information
retrieval system), pembobotan TF-IDF, evaluasi sistem pemerolehan
informasi, algoritma stemming, konsep basis data relasional obyek.
BAB III : ANALISA DAN PERANCANGAN SISTEM
Bab ini berisikan analisis kebutuhan sistem dan rancangan database.
BAB IV : IMPLEMENTASI
Bab ini berisikan penjelasan dan fungsi sistem pemerolehan informasi
makalah ilmiah berbahasa Indonesia.
BAB V : ANALISA HASIL
Bab ini berisikan analisis hasil pengujian sistem.
BAB VI : KESIMPULAN DAN SARAN
Bab ini berisikan kesimpulan dan saran dari pembuatan sistem pencarian
makalah ilmiah berbahasa Indonesia.
5
BAB II
LANDASAN TEORI
2.1
Pemerolehan Informasi
2.1.1
Konsep Pemerolehan Informasi
Pemerolehan informasi adalah proses menemukan dokumen (berisikan
teks) yang tidak terstruktur untuk memenuhi kebutuhan informasi dari koleksi
yang besar (Manning, 2009).
2.1.2
Logical View Dokumen
Dokumen dalam koleksi sering dipresentasikan melalui
term
indeks atau
keyword.
Keyword tersebut dapat diekstraksi langsung dari teks dokumen atau
ditentukan secara manual (dibuat oleh spesialis seperti banyak dilakukan pada
bidang information science). Term indeks ini menyediakan suatu logical view dari
dokumen. Komputer modern memungkinkan representasi suatu dokumen dengan
menggunakan seluruh teks yang terdapat dalam dokumen tersebut. Dalam hal ini,
sistem pemerolehan informasi disebut mengadopsi
full
text logical view dari
dokumen. Jika koleksi dokumen sangat besar, maka komputer modern akan
mengurangi jumlah
term
indeks melalui proses penghapusan
stopwords,
stemming, dan indentifikasi noun groups (menghilangkan adjectives, adverbs, dan
verbs). Proses tersebut disebut text operation (operasi teks) yang akan mengurangi
kompleksitas dari representasi dokumen dan mengubah
logical view dari
full text
menjadi term indeks. Gambar 2.1 mengilustrasikan beberapa
intermediate logical
view yang akan digunakan oleh suatu sistem pemerolehan informasi
Gambar 2.1.
Operasi teks logical view dari sebuah dokumen: dari full text
menjadi sebuah set indeks term. (Baeza-Yates, 1999)
Penghapusan
stopword
adalah proses penghilangan kata-kata yang tidak
digunakan (kata buang). Contoh
stopwords pada Bahasa Indonesia adalah tetapi,
dan, atau, itu, yang (Hasibuan, 2001).
2.1.2.1
Stemming
Stemming
adalah merupakan proses mengubah kata-kata yang terdapat
dalam suatu dokumen dalam bentuk kata dasar (rootword) (Agusta, 2009).
Algoritma
stemming pada teks berbahasa Indonesia menggunakan
Algoritma Nazief & Adriani. Tahap-tahap pada Algoritma Nazief & Adriani
adalah sebagai berikut (Agusta, 2009):
1.
Cari kata yang akan di-stem dalam kamus. Jika ditemukan maka diasumsikan
bahwa kata tesebut adalah root word. Maka algoritma berhenti.
2.
Inflection Suffixes
(“
-
lah”, “
-
kah”, “
-
ku”, “
-
mu”, atau “
-
nya”) dibuang. Jika
berupa
particles
(“
-
lah”, “
-
kah”, “
-
tah” atau “
-
pun”) maka langkah ini
diulangi lagi untuk menghapus
Possesive Pronouns
(“
-
ku”, “
-
mu”, atau “
3.
Hapus
Derivation Suffixes
(“
-
i”, “
-
an” atau “
-
kan”). Jika kata ditemukan di
kamus, maka algoritma berhenti. Jika tidak maka ke langkah 3a
a.
Jika “
-
an” telah dihapus dan huruf terakhir dari kata tersebut adalah “
-
k”,
maka “
-
k” juga ikut dihapus.
Jika kata tersebut ditemukan dalam kamus
maka algoritma berhenti. Jika tidak ditemukan maka lakukan langkah 3b.
b.
Akhiran yang dihapus (“
-
i”, “
-
an” atau “
-
kan”) dikembalikan, lanjut ke
langkah 4.
4.
Hapus
Derivation Prefix. Jika pada langkah 3 ada
sufiks yang dihapus maka
pergi ke langkah 4a, jika tidak pergi ke langkah 4b.
a.
Periksa tabel kombinasi awalan-akhiran yang tidak diijinkan (
Tabel 2.1
).
Jika ditemukan maka algoritma berhenti, jika tidak pergi ke langkah 4b.
b.
For i = 1 to 3, tentukan tipe awalan kemudian hapus awalan. Jika
root
word belum juga ditemukan lakukan langkah 5, jika sudah maka algoritma
berhenti. Catatan: jika awalan kedua sama dengan awalan pertama
algoritma berhenti.
5.
Melakukan Recoding.
6.
Jika semua langkah telah selesai tetapi tidak juga berhasil maka kata awal
diasumsikan sebagai root word. Proses selesai.
Tipe awalan ditentukan melalui langkah-langkah berikut:
1.
Jika awalannya adalah: “di
-
”, “ke
-
”, atau “se
-
” maka tipe awalannya secara
berturut-
turut adalah “di
-
”, “ke
-
”, atau “se
-
”.
2.
Jika awalannya adalah “te
-
”, “me
-
”, “be
-
”, atau “pe
-
” maka dibutuhkan
3.
Jika dua karakter pertama bukan “di
-
”, “ke
-
”, “se
-
”,
“te
-
”, “be
-
”, “me”, atau
“pe
-
” maka berhenti.
4.
Jika tipe awalan adalah “none” maka berhenti. Jika tipe awalan adalah bukan
“none” maka awalan dapat dilihat pada
Tabel 2.2
. Hapus awalan jika
ditemukan.
Tabel 2.1.
Kombinasi Awalan Akhiran Yang Tidak Diijinkan
Awalan
Akhiran yang tidak diijinkan
be-
-i
di-
-an
ke-
-i, -kan
me-
-an
se-
-i, -kan
Tabel 2.2.
Cara
menentukan tipe awalan untuk Kata yang diawali dengan “te
-
”
Following Characters
Tipe
Awalan
Set 1
Set 2
Set 3
Set 4
“
-
r”
“
-
r”
-
-
none
“
-
r”
vowel
-
-
ter-luluh
“
-
r”
not (vowel or “
-
r”)
“
-
er”
vowel
ter
“
-
r”
not (vowel or “
-
r”)
“
-
er”
not vowel
ter-
“
-
r”
not (vowel or “
-
r”)
not “
-
er”
-
ter
not (vowel or “
-
r”)
“
-
er”
vowel
-
none
Tabel 2.3.
Jenis Awalan Berdasarkan Tipe Awalannya
Tipe Awalan Awalan yang harus dihapus
di-
di-
ke-
ke-
se-
se-
te-
te-
ter-
ter-
ter-luluh
ter
Untuk mengatasi keterbatasan pada algoritma di atas, maka ditambahkan
aturan-aturan dibawah ini:
1.
Aturan untuk reduplikasi.
-
Jika kedua kata yang dihubungkan oleh kata penghubung adalah kata yang
sama maka
root word
adalah bentuk tunggalnya, contoh : “buku
-
buku”
root
word-
nya adalah “buku”.
-
Kata lain, misalnya “bolak
-
balik”, “berbalas
-
balasan, dan ”seolah
-
olah”.
Untuk mendapatkan
root word-nya, kedua kata diartikan secara terpisah.
Jika keduanya memiliki
root word yang sama maka diubah menjadi bentuk
tunggal, contoh: kata “berbalas
-
balasan”, “berbalas” dan “balasan” memiliki
root word
yang sama yaitu “balas”, maka
root word
“berbalas
-
balasan”
adalah “balas”. Sebaliknya, pada kata “bolak
-
balik”, “bolak” dan “balik”
-
Untuk tipe awalan “mem
-
“, kata yang diawali dengan awalan “memp
-
”
memiliki tipe awalan “mem
-
”.
-
Tipe awalan “meng
-
“, kata yang diawali dengan awalan “mengk
-
” memiliki
tipe awalan “meng
-
2.1.3
Proses Pemerolehan Informasi
Proses pemerolehan informasi
terdapat beberapa tahap. Pertama-tama,
sebelum proses pemerolehan informasi dimulai, diperlukan pendefinisian
database teks. Hal ini dilakukan dengan melakukan identifikasi terhadap
dokumen-dokumen yang akan digunakan, operasi yang akan dilakukan terhadap
teks, dan model teks (struktur teks dan elemen mana saja dari teks yang dapat
dilakukan proses pemerolehan informasi). Operasi teks (text operations)
mentransformasikan dokumen asal menjadi
logical view
dokumen tersebut.
Setelah
logical view
dokumen diperoleh, dibuatlah
term
indeks pada
database
untuk mempercepat proses pencarian terhadap jumlah data yang besar. Struktur
indeks yang paling banyak digunakan adalah
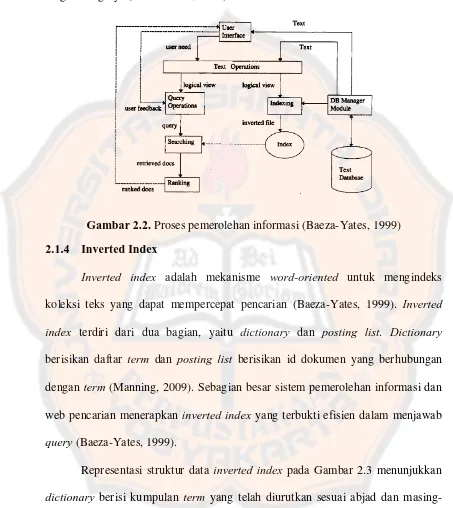
inverted file seperti pada Gambar
2.2. Database dokumen telah diindeks, maka proses pemerolehan informasi dapat
dimulai. Pengguna menentukan kebutuhannya yang kemudian ditransformasikan
oleh operasi teks yang sama digunakan pada koleksi dokumen.
Query kemudian
ditransformasi untuk mendapatkan dokumen pemerolehan informasi. Struktur
indeks
dibuat sebelumnya agar dapat mempercepat pemrosesan
query
(Baeza-Yates, 1999).
memeriksa kumpulan dokumen peringkat untuk mendapatkan informasi yang
berguna baginya (Baeza-Yates, 1999).
Gambar 2.2.
Proses pemerolehan informasi (Baeza-Yates, 1999)
2.1.4
Inverted Index
Inverted index adalah mekanisme
word-oriented untuk mengindeks
koleksi teks yang dapat mempercepat pencarian (Baeza-Yates, 1999).
Inverted
index
terdiri dari dua bagian, yaitu
dictionary
dan
posting list.
Dictionary
berisikan daftar
term dan
posting list
berisikan id dokumen yang berhubungan
dengan term (Manning, 2009). Sebagian besar sistem pemerolehan informasi dan
web pencarian menerapkan
inverted index yang terbukti efisien dalam menjawab
query (Baeza-Yates, 1999).
Gambar 2.3
.
Representasi
Inverted Index (Manning, 2009)
Inverted index pada Gambar 2.3, dapat dilakukan operasi
boolean dasar
untuk
query
Brutus AND Calpuria dengan langkah-langkah sebagai berikut
(Manning, 2009):
1.
Temukan Brutus di dictionary.
2.
Retrieve posting dari Brutus.
3.
Temukan Calpuria di dictionary.
4.
Retrieve posting dari Calpuria.
5.
Mengambil dokumen-dokumen yang terdapat pada kedua posting list dengan
melakukan pemotongan pada daftar posting list, seperti pada Gambar 2.4.
Gambar 2.4
.
Pemotongan posting list untuk query Brutus AND Calpuria
(Manning, 2009)
2.1.5
Metode Pembobotan TF-IDF
Teknik pembobotan Savoy (1993) adalah sebagai berikut (Hasibuan, 2001):
W
ik= ntf
ik* nidf
k,
dimana ntf
ik=
dan nidf
k=
ij j ik
tf
Max
tf
n dfn k
log log
Dimana :
W
ikadalah bobot istilah k pada dokumen i.
tf
ikmerupakan frekuensi dari istilah k dalam dokumen i.
n adalah jumlah dokumen dalam kumpulan dokumen.
df
kadalah jumlah dokumen yang mengandung istilah k.
Max
jtf
ijadalah frekuensi istilah terbesar pada satu dokumen.
Wd= bobot sebuah dokumen
Pada teknik pembobotan ini, bobot istilah dinormalisasi. Dalam
menentukan bobot suatu istilah tidak hanya berdasarkan frekuensi
term, tetapi
juga berdasarkan frekuensi terbesar pada dokumen bersangkutan. Hal ini untuk
menentukan posisi relatif bobot dari
term dibanding dengan
term-term
lain di
dokumen yang sama. Selain itu teknik ini juga memperhitungkan jumlah
dokumen yang mengandung
term bersangkutan dan jumlah dokumen. Hal ini
untuk menentukan posisi relatif bobot
term
bersangkutan pada suatu dokumen
dibandingkan dengan dokumen-dokumen lain yang memiliki
term
yang sama.
Sehingga jika sebuah
term
memiliki frekuensi yang sama pada dua dokumen
belum tentu memiliki bobot yang sama (Hasibuan, 2001).
2.1.6
Recall dan Precision
1.
Recall adalah perbandingan jumlah dokumen relevan yang di
retrieve
terhadap jumlah dokumen yang relevan.
=
�
�
2.
Precision adalah perbandingan jumlah dokumen relevan yang di
retrieve
terhadap jumlah dokumen yang ditemukembalikan.
=
�
�
Semakin tingginya nilai
recall, jumlah dokumen yang dicari semakin banyak.
Pada mesin pencari yang baik adalah semua hasil pencarian merupakan dokumen
yang relevan atau nilai recall dan precision adalah 1 (A.H, 2004).
2.2 Object Oriented Conceptual Model
Segmen dasar dari object oriented adalah object. Setiap object memiliki satu
atau lebih
unique attributes yang membedakan dari yang lain. Beberapa
object
juga dapat memiliki struktur yang sama yaitu atribut dan operasinya. Satu set
struktur atribut dan operasi yang berlaku untuk atribut-atribut disebut kelas.
Object
sering digambarkan dengan persegi panjang yang memiliki nama
object dan properti (atribut dan
method) (Pardede, 2006). Gambar 2.5
memberikan ilustrasi tentang object dan notasinya.
2.2.1 Relasi Asosiasi
Asosiasi adalah sebuah referensi dari satu
object ke
object lain yang
memberikan akses antar object-object dalam suatu sistem. Kardinalitas pada relasi
asosiasi adalah one-to-one, one-to-many, dan many-to-many (Pardede, 2006).
2.2.2 Relasi Agregrasi
Agregrasi berkaitan erat dengan asosiasi. Agregrasi adalah komposisi atau
“bagian
-
dari” relasi, di mana obyek komposit (seluruh) terdiri dari obyek
komponen lain (bagian). Sebagai contoh untuk relasi agregrasi antara PC secara
utuh dan bagian-bagiannya yang terdiri dari
hard disk, monitor,
keyboard, dan
CPU (Gambar 2.6) (Pardede, 2006).
Gambar 2.6
.
Contoh relasi agregrasi (Pardede, 2006)
Pada agregrasi terdapat dua jenis tipe, yaitu
exitence-dependent
dan
existence-independent. Kedua tipe tersebut bergantung antara seluruh
object dan
bagian
object
yang signifikan.
Gambar 2.7 menunjukkan contoh dari
existence-dependent. Sebagai contoh,
course outline object adalah enkapsulasi dari
beberapa bagian
object, yaitu
Course Objectives,
Course Contents, dan
Course
Schedule. Ketika seluruh object diakses, bagian dari objectnya dapat diidentifikasi
existence-dependent, penghapusan course outline akan menyebabkan penghapusan
course
outline tertentu dan semua elemen-elemennya (Pardede, 2006).
Gambar 2.7.
Contoh relasi agregrasi existence-dependent (Pardede, 2006)
Gambar 2.8 menunjukkan contoh dari
existence-independent. Sebagai
contoh, jika
travel document hilang,
ticket,
itenerary, dan
passport masih tetap
ada (Pardede, 2006).
Gambar 2.8
.
Contoh relasi agregrasi existence-independent (Pardede, 2006)
2.3 Object Relational Database Management System
2.3.1 Konsep Object Relational Database Management System
keunikan dari
record dengan mendefinisikan
primary key. Selain itu, ORDBMS
juga memungkinkan penggunaan
foreign key. Atribut
foreign key tabel merujuk
ke record tabel lain.
Pada ORDBMS terdapat beberapa fitur, yaitu :
1.
Object types dan user defined types
Object type adalah jenis tipe data (Oracle, 2008). Di Oracle, perintah untuk
membuat
object type
adalah “
create type
” yang kemudian digunakan untuk
membuat table dengan perintah “
create table
”.
Perintah SQL yang digunakan
untuk membuat object type dan table adalah sebagai berikut (Pardede, 2006):
Listing 2.1.
Perintah SQL umum untuk membuat object Type
Gambar 2.9 menunjukkan contoh dengan
object type, person_typ, dan dua
contoh object type (Oracle, 2008).
Gambar 2.9.
Object type dan contoh object type (Oracle, 2008)
CREATE [OR REPLACE] TYPE <object schema> AS OBJECT (attribute attribute type, ....,
2.
Collection Type
Salah satu fitur pada ORDBMS adalah
collection.
Collection digunakan
untuk menyimpan
multiple values dalam satu kolom dari sebuah tabel yang
menghasilkan nested table dimana sebuah kolom dalam sebuah tabel berisi tabel
lain (Conolly, 2005).
Nested table
adalah
unordered set dari elemen data yang
data typenya sama
dan memiliki sebuah kolom dari
object type. Jika kolom adalah sebuah
object
type, tabel juga dapat dilihat sebagai tabel
multi-column, dengan sebuah kolom
untuk setiap atribut dari object type (Conolly, 2005).
Pada Oracle semua data
nested table disimpan dalam satu tabel, yang terkait
dengan tabel terlampir atau object type (Pardede, 2006).
3.
Object Identifier
Dalam sistem berorienterasi obyek, OID adalah sistem yang dihasilkan dan
digunakan sebagai referensi untuk menunjuk suatu obyek tertentu. Implementasi
OID menggunakan perintah “
references
” untuk menyatakan
primary key
yang
diikuti table dan kolom yang dirujuk (Pardede, 2006).
4.
Relationships using Ref
Oracle menyediakan cara untuk merujuk suatu obyek dari obyek lain
menggunakan kata kunci ref. Teknik merujuk suatu obyek dapat digunakan untuk
2.4 Implementasi Existence-Dependent Aggregation menggunakan Teknik
Nesting
Implementasi agregasi pada Oracle menggunakan
nested table. Pada teknik
ini, bagian informasi berhubungan erat dengan informasi dari seluruh obyek yang
diimplementasikan sebagai
nested table. Hal ini memberlakukan tipe agregrasi
existence-dependent. Jika data dari seluruh obyek dihapus, semua yang terkait
dengan bagian obyek akan terhapus. Selain itu, data dalam
nested table diakses
melalui seluruh obyek. Oleh karena itu, teknik
nested table hanya cocok
diimplementasikan menggunakan existence-dependent (Pardede, 2006).
2.5
Penggunaan DBMS untuk Pemerolehan Informasi
Penggunaan DBMS (Database Management System) dalam pemerolehan
informasi mempunyai beberapa kelebihan dan kekurangan. Index dengan mudah
dapat diperluas dan menampung macam-macam tipe data (Papadakos, 2008).
Kelebihan menggunakan DBMS adalah sebagai berikut :
1.
Adanya kemungkinan untuk memperluas cangkupan index
Perluasan dilakukan dengan menambahkan kolom dan relasi (column
dan
relation).
2.
Proses pembentukan index
DBMS yang menangani
physical layer mengijinkan untuk tidak harus
membuat dan menggabungkan
partial indices untuk membuat index dari
sebuah korpus besar.
Menghapus entri yang menyangkut dokumen tertentu merupakan operasi
yang mahal di
inverted index. Dengan operasi DBMS dapat dilakukan lebih
efisien.
4.
Penggunaan single index
Sistem pemerolehan informasi klasik menggunakan index yang terpisah, yaitu
index untuk menjawab
query dan
index untuk
update.
Index baru akan
menggantikan
index yang pertama dibentuk. Dengan DBMS perbedaan dan
duplikasi tidak diperlukan, menggunakan
single index untuk proses
update
dan query tanpa harus menggunakan partial index.
5.
Penggunaan distributed query processing
Dengan kemajuan DBMS untuk
multicore dan sistem
cluster secara
menguntungkan sistem pemerolehan informasi. Sebagai contoh, PostgreSQL
dapat menggunakan lebih dari satu CPU/Core (untuk melakukan pengiriman
query).
Kekurangan DBMS adalah sebagai berikut :
1.
Penggunaan ruang penyimpanan yang tinggi
Kira-kira sebuah inverted index terdiri dari form (t, occ) dimana t adalah term,
sedangkan
occ adalah
occurrence
atau dokumen (d) dari kemunculan
t di
dalam
corpus. Kemunculannya bisa dari pengindentifikasian dokumen saja,
atau juga bobot
and/or dari
t dalam setiap dokumen. Kemunculan
term
menempati sebagian besar ruang
index dan untuk alasan ini penggunaan
special number encodings digunakan untuk mengurangi ruangan yang
lebih banyak dari sebuah
inverted index. Sebagai contoh,
entry (t, {d1,
d3,
d
5}). Di RDBMS akan direpresentasikan dengan 3
tuple [t,
d
1], [t,
d
3], [t, d
5]
yang akan memboroskan ruang penyimpanan.
2.
Lebih banyaknya operasi I/O
22
BAB III
ANALISA DAN PERANCANGAN SISTEM
3.1
Gambaran Sistem yang Dikembangkan
Text operation Dokumen
Koleksi
Text RDBMS Indexing
Ranking
Index Ready ORDBMS Query
Operations User Interface
Searching
Text
retrieved docs
ranked docs
Inverted file User need
Logical view
query
Logical view
Inverted file
Gambar 3.1.
Gambaran sistem yang dikembangkan
3.1.1
Gambaran Proses pada Sistem
Pada bagian berikut ini akan dijelaskan mengenai alur kerja proses-proses
yang terdapat pada gambaran sistem pemerolehan informasi makalah ilmiah
berbahasa Indonesia pada Gambar 3.1. Alur kerja proses ini akan dijelaskan
menggunakan flowchart.
3.1.1.1
Alur Kerja Proses Indexing
Mulai
Data koleksi
tokenizer
Pengecekan stopwords
stemming
Masih adakah kata atau term hasil dari stemming
Call store procedure insert_term
Hitung bobot Ya
Selesai Tidak
Gambar 3.2. Flowchart p
roses indexing untuk menyimpan ke database text
RDBMS
Proses penambahan term pada database text RDBMS menggunakan stored
procedure insert_term. Algoritma untuk proses pada stored procedure insert_term
Mulai
Gambar 3.3. Flowchart
pada stored procedure insert_term pada database text
RDBMS
Untuk mengisikan data-data dalam bentuk
inverted index pada
database
index ready ORDBMS akan dilakukan proses pengambilan data dari database text
insert_term_ordbms. Algoritma proses pembuatan
inverted index
pada
database
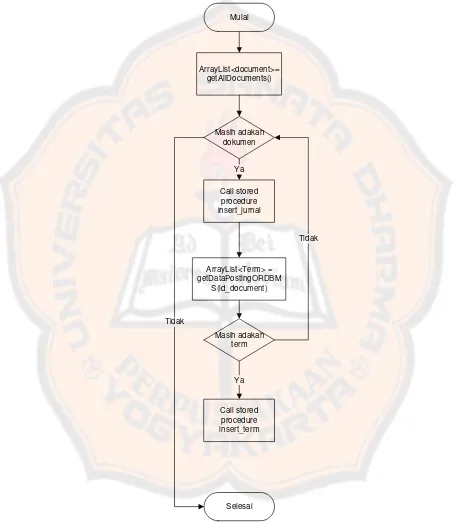
index ready ready ORDBMS ditunjukan pada flowchart Gambar 3.4.
Mulai
ArrayList<document>= getAllDocuments()
Masih adakah dokumen
Call stored procedure insert_jurnal
ArrayList<Term> = getDataPostingORDBM
S(id_document)
Call stored procedure insert_term
Ya
Selesai
Tidak
Tidak
Masih adakah term
Ya
Proses mengisikan
term pada
database index ready
ORDBMS
menggunakan
stored procedure insert_term_ordbms yang ditunjukkan pada pada
Gambar 3.5.
Mulai
Id_jurnal, term, nidfk,
dfk, tfk, ntfik, w
Cek apakah term sudah ada di tabel term
INSERT INTO TABLE (SELECT posting_term FROM term WHERE term =
p_term)
VALUES (p_tfik,0,0,(new_jurnal_id));
INSERT INTO term VALUES
(v_id,p_term,p_dfk,p_nidfk,PostingListNestedType( PostingListType(p_tfik,p_ntfik,p_w,new_jurnal_id))); Ya
Tidak
Selesai
Gambar 3.5. Flowchart stored procedure insert_term_ordbms
pada database
index ready ORDBMS
3.1.1.2
Alur Kerja Proses Searching
Mulai
Pada pencarian dengan menggunakan lebih dari 1 kata kunci akan
menggunakan operasi AND. Algoritma untuk proses pencarian dengan operasi
AND ditunjukkan pada flowchart Gambar 3.7.
Mulai
3.1.1.3
Alur Kerja Proses Penghitungan Waktu Akses Query
Proses penghitungan waktu akses
query digunakan untuk melihat lama
waktu
akses
query. Algoritma yang digunakan untuk melakukan penghitungan
waktu akses query ditunjukkan pada Gambar 3.8.
Mulai
Query dan pengguna menekan tombol cari
long start = System.currentTi
meMillis();
Proses pencarian Searching(Query)
long finish = System.currentTi
meMillis();
time = (long) ((finish - start)/
1000.0);
Waktu akses query
Selesai
3.2
Analisa Kebutuhan
Kebutuhan yang dibutuhkan oleh pengguna dari sistem pemerolehan
informasi makalah ilmiah berbahasa Indonesia adalah sebagai berikut:
Tabel 3.1.
Tabel Analisa Kebutuhan
Penguna Sistem
Kebutuhan
Administrator
1.
Dapat
melakukan
login
sebagai
administrator
2.
Menangani
manajemen
data
dokumen
makalah ilmiah berbahasa Indonesia
3.
Dapat melakukan pencarian
(searching)
dokumen
makalah
ilmiah
berbahasa
Indonesia sesuai kata kunci yang dimasukan
Pengguna
1.
Dapat melakukan pencarian
(searching)
dokumen
makalah
ilmiah
berbahasa
Indonesia sesuai kata kunci yang dimasukan
3.3
Perancangan Sistem
3.3.1
Diagram Use Case
sedangkan pengguna adalah aktor yang hanya dapat melakukan pencarian makalah
pada subsistem pencarian makalah ilmiah berbahasa Indonesia dengan mengetikan
keyword
yang diinginkan. Di bawah ini adalah perencangan diagram
use case
pada
sistem pemerolehan informasi
makalah ilmiah berbahasa Indonesia yang
ditunjukkan pada
Gambar 3.9
:
Subsistem Pencarian Makalah Ilmiah Berbahasa Indonesia
Subsistem Operasi Teks
Menambahkan dokumen makalah
Mengubah data
dokumen makalah Login
Mencari dokumen makalah
Logout
Administrator
Pengguna
<< dep
end on >>
<<depend on>>
<<depend on>>
Sistem Pemerolehan Informasi Makalah Ilmiah Berbahasa Indonesia