Hadoop Framework 1. Pengantar
Saat ini, kita hidup di era big data, dimana data yang kita butuhkan untuk bekerja sehari-hari menyebabkan meningkatnya kemampuan pemrosesan dan penyimpanan suatu host tunggal. Big data membawa dua tantangan dasar : Cara menyimpan pekerjaan dengan ukuran data yang sangat besar, dan lebih penting, bagaimana untuk memahami data dan merubahnya menjadi persaingan yang mneguntungkan.
Hadoop memenuhi jurang pemisah pada pasar melalui penyediaan dan penyimpanan kemampuan komutasi melewati jumlah data yang substansi. Sistem terdistribusi hadoop menjadikan pendistribusian file sistem dan menawarkan cara untuk mensejajarkan dan mengeksekusi program pada mesin terkluster.
Hadoop adalah suatu platform yang menyediakan dua kemamapuan distribusi penyimpanan dan komputasi. Hadoop awalnya digunakan untuk memperbaiki persoalan skalabilitas yang terdapat pada nutch, suatu crawler sumber terbuka dan mesin pencari. Saat google menerbitkan artikel yang menjelaskan pendistribusian file sistem-nya yang baru, Google File System (GFS) dan Mapreduce, suatu kerangka kerja komputasi untuk pemrosesan paralel. Keberhasilan implementasi konsep pada paper ini pada Nutch menghasilkan pembagiannya menjadi dua projek yang terpisah, kedua yang menjadi Hadoop proyek kelas pertama apache.
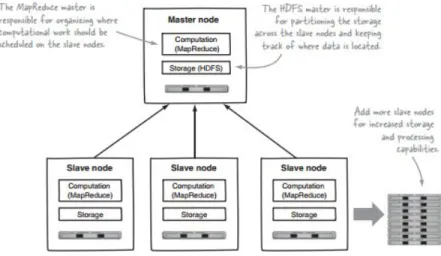
Hadoop yang sebenarnya yang ditujukan pada gambar 1.1 menerapkan arsitektur pendistribusian master slave yang terdiri dari Hadoop Distributed File System (HDFS) untuk penyimpanan dan mapreduce untk kemampuan komputasi. Ciri-ciri instrinsik hadoop adalah pemartisipasi data dan komputasi parallel pada dataset yang besar. Penyimpanan hadoop dan skala kemampuan komputasi dengan tambahan host pada haddop cluster, dan bisa menjangkau ukuran kapasitas dalam petabytes pada kluster dengan ribuan host.
2. Komponen Utama Hadoop
2.1 Hadoop Distributed File System (HDFS)
HDSF adalah komponen penyimpanan pada Hadoop. Hadoop pendistribusian file sistem dirancang setelah artikel Google File System. HDFS adalah pengoptimalan untk throuput yang tinggidan bekerja terbaik saat membaca dan menulis file besar (gigabytes dan lebih besar). Ketersediaan dan skalabilitas juga menjadi ciri-ciri kunci, memperleh bagian dari replikasi data dan toleransi kesalahan. Kluster hadoop memiliki nominal namenode tunggal ditambah datanode kluster, meskipun kelebihan opsi yang disediakan untuk hak namenode pada masa kritis. Setiap datanode menyediakan blok data melewati jaringan menggunakan blok protokol spesifik untuk HDFS. File sistem menggunakan socket TCP/IP untuk komunikasi. Klien menggunakan Prosedur pemanggilan jauh (RPC) untuk berkomunikasi antar satu dan lainnya.
HDFS menyimpan file besar menghubungi berbagai mesi. HDFS memperoleh kepercayaan melalui replikasi data melewati berbagai host, dan karena itu secara teoritis tidak memerlukan penyimpanan RAID pada host (tapi meningkatkan peforma I/O beberapa konfigurasi RAID tetap digunakan). Dengna nilai replikasi standar, data akan disimpan pada tiga node, dua pada rak yang sam dan satu pada rak yang berbeda. Data node bisa berkomunikasi dari satu kelainnya untuk menyeimbangkan data, unutk memudahkan penyalinan dan menjaga tingkat replikasi data. HDFS tidak sepenuhnya mematuhi POSIX, karena kebutuhan untuk file sistem POSIX berbeda dari tujuan untuk aplikasi hadoop.
HDFS menambahkan kemampuan ketersediaan tingkat tinggi yang dirilis pada versi 2.0 pada may 2012, membiarkan server utama metadata fail-over secara manual untuk backup. Projek juga mulai membangun fail-over otomatis. File sistem HDFS menyertakan namenode sekunder, yang ditujukan untuk namenode backup pada saat namenode primer offline. Faktanya, namenode sekunder secara teratur terhubung dengan namenode primer dan membangun informasi dari direktori namenode primer, yang mana sistem menyimpannya ke direktori lokal arau jauh. HDFS bisa di mount secara langung dengan file sistem di userspace (FUSE) virtual file sistem pada Linux dan beberapa sistem unix.
2.2 MapReduce
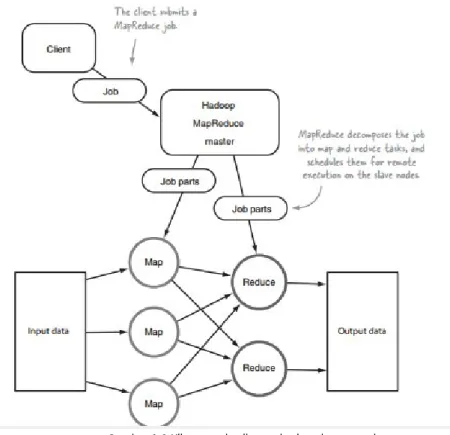
Mapreduce adalah model pemograman untuk ppemrosesan dan membangkitkan kumpulan data besar dengan paralel, algoritma terdisatribusi pada kluster. Konsep yang serupa memiliki pendekatan yang sering dijumpai ssejak 1995 dengan standar Message Passing Interface yang mengurangi dan menyebarkan operasi. Program mapreduce berisi Map() prosedur yang melakukan pemfilteran dan pemilihan dan reduce() prosedur yang mealukan ringkasan operasi. Permodelan ini terinspirasi melalui fungsi map dan reduce yang umum digunakan dalam pemograman fungsional, meskipun tujuan pada framework mapreduce tidak sama sebagaiman bentuk aslinya. Kontribusi kunci pada framework mapreduce sesungguhnya tidak pada fungsi map dan reduce tetapi perolehan skalabilitas dan toleransi kesalahan untuk bermacam aplikasi melalui pengoptimalan eksekusi suatu engine. Termasuk, implementasi mapreduce thread tunggal (termasuk MongoDB) biasanya tidak lebih cepat dari implementasi tradisional (non-mapreduce), perolehan papun pada
umunya hanya dilakukan dengan implementasi multi thread. Pennggunaan model ini hanya bermanfaat saat operasi pengoptimalan pendistribusian acak (yang mana mengurangi biaya komunikasi jaringan) dan fitur toleransi kesalahan pada mapreduce framwork juga ikut bermain.
Gambar 1.2 Klien memberikan pekerjaan ke mapreduce
2.3 YARN (Yet Another Resource Negotiator)
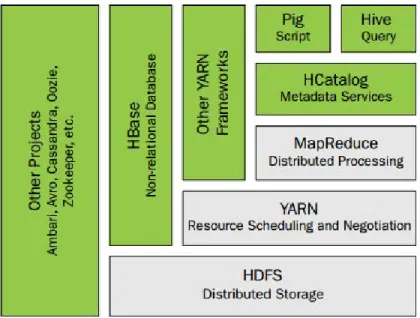
untuk yang sudah memahami hadoop versi 1 terdapat dua komponen yaitu hadoop Distributed File system (HDFS) dan integrasi engine mapreduce untuk pendistribusian proses. Hadoop YARN komponen baru untuk menggantikan Mapreduce pada versi 1. Penjadwalan dan manajemen sumber daya terpisah dari pemrosesan mapreduce. Sementara itu, hadoop versi 2 dengan YARN tetap menyediakan kemampuan penuh mapreduce dan kemampuan sebelumnya pada versi 1, dan juga membuka pintu untuk banyak framework aplikasi yang lain yang tidak berbasis pada pemrosesan mapreduce.
Akronim dari YARN sendiri adalah Yet another resource Negotiator yang memberikan deskripsi tentang kemampuan dari YARN. Pada dasarnya, YARN adalah sumber daya penjadwalan yang didisain untuk pekerjaan pada hadoop cluster yang sudah ada maupun yang baru. Penjadwalan yang terpisah mengizinkan pemanfaatan dan skalabilitas yang lebih baik pada suatu kluster, secara serempak menyediakan platform untuk aplikasi non-mapreduce yang lain untuk memperoleh keuntungan dari HDFS.
Gambar 1.3 penambahan YARN pada antarmuka umum untuk menjalankan pekerjaan non-mapreduce pada framework hadoop
2.4 Fitur-fitur tambahan pada Hadoop
Ambari : Pemantauan, manajemen dan penetapan hadoop kluster berbasis web termasuk mendukung untuk Hadoop HDFS, Hadoop mapreduce, Hive, Hcatalog, Hbase, Zookeeper, Oozie, Ping dan Sqoop. Ambari juga menyediakan papan tampilan untuk melihat kondisi kluster termasuk heatmap dan kemampuan untuk melihat aplikasi mapreduce, pig, hive secara visual
Chukwa : Sistem pengumpulan data untuk manajemen sistem terditribusi yang besar.
Hbase : pendistribusian basis data yang mendukung penyimpanan struktur data untuk tabel yang besar
Hive : Infrastruktur data warehouse yang menyediakan peringkasan data dan queri ad-hoc
Mahout : pustaka data mining dan machine learning
Pig : bahasa aliran data tingkat tinggi dan framework eksekusi untuk komputasi parallel
Spark : engine komputasi untuk hadoop data. Spark menyediakan model pemograman yang sederhana dan ekspresif yang mendukung banyak aplikasi termasuk ETL, Machine Learning, pemrosesan stream dan komputasi grafik
3. Teknologi yang Terkait 3.1 OpenMP
OpenMP (Open Multi Processing) adalah API (Application Programming Interface ) yang mendukung multi platform pemograman pembagian memori pada multiprocessing dalam c, c++ dan fortran, pada kebanyakan arsitektur prosesor dan
sistem operasi, termasuk Solaris, AIX, HP-UX, Linux, Mac OS-X dan Windows. OpenMP adalah implementasi multithreading, suatu metode pemrosesan parallel untuk master thread percabangan dengan nomor yang spesifik pada slave threads dan sistem membagi tugasnya. Thread berjalan secara bersamaan, dengan lingkungan runtime pengalokasian thread pada prosesor yang berbeda. Sesi kode yang berarti pengoperasian secara paralel dengan instruksi processor yang akan menyebabkan threads untuk berubah dari sesi setelah eksekusi.
3.2 MPI (Message Passing Interface)
MPI adalah bahasa independen protokol komunikasi untuk komputasi paralel. Mendukung mode kedua point-to-point dan komunikasi bersama. MPI tidak mendukung standar utama apapun, namun, menjadi standar de facto untuk komunikasi sepanjang proses pemodelan komputasi paralel yang berjalan pada sistem memori terdistribusi. sebenarnya pendistribusian memori superkomputer, termasuk kluster komputer menjalankan berbagai program. Prinsip dari model MPI-1 tidak memiliki konsep berbagi memori, dan MPI-2 hanya memiliki konsep membatasi distribusi pembagian memori. Meskipun demikian, program MPI secara umum membagi memori komputer. Walaupun, MPI berada pada layer 5 dan lebih tinggi pada model OSI layer, implemetasinya mencakup seluruh layer dengan socket dan TCP yang digunakan pada transport layer. Kebanyakan implementasi MPI terdiri dari kumpulan spesifik langsung terhubung dari C, C++, Fortran dan bahasa apapun yang dapat terhubung ke antarmuka dengan beberapa pustaka termasuk C#, Java atau python.
3.3 HPCC
HPCC (High-Performance Computing Cluster) atau juga dikenal DAS (Data Analytics Supercomputer) adalah komputasi intensif-data berbasis open-source yang dibangun oleh LexisNexis Risk Solution. Platform HPCC menggabungkan implementasi arsitektur perangkat lunak pada komputer kluster utama untuk menyediakan kinerja tinggi, pemrosesan data parallel untuk aplikasi big data. Platform HPCC termasuk sistem konfigurasi untuk mendukung pemrosesan batch data paralel dan kinerja tinggi queri aplikasi menggunakan file data terindeks. Arsitektur sistem HPCC termasuk dua perbedaan pemrosesan lingkungan kluster, yang mana masing-masing bisa untuk mengoptimalkan secara independen untk tujuan pemrosesan data parallel.
4. Manfaat Hadoop
Beberapa manfaat dalam implementasi hadoop daam sistem terdistribusi adalah Scalable
Hadoop adalah platform penyimpanan yang sangat scalable, karena dapat menyimpan dan mendistribusikan data set yang sangat besar di ratusan server murah yang beroperasi secara paralel. Tidak seperti sistem tradisional relasional database (RDBMS) yang tidak dapat skala untuk memproses data dalam jumlah besar, Hadoop memungkinkan bisnis untuk menjalankan aplikasi pada ribuan node yang melibatkan ribuan terabyte data.
Cost Effective
Hadoop juga menawarkan solusi penyimpanan yang efektif biaya untuk bisnis 'meledak set data. Masalah dengan sistem manajemen database relasional tradisional adalah bahwa hal itu sangat biaya mahal untuk skala untuk gelar tersebut untuk memproses volume besar seperti data. Dalam upaya untuk mengurangi biaya, banyak perusahaan di masa lalu akan memiliki data down-sampel dan mengklasifikasikan berdasarkan asumsi tertentu untuk mana data yang paling berharga. Data mentah akan dihapus, karena akan terlalu biaya terlalu tinggi untuk menjaga. Meskipun pendekatan ini mungkin telah bekerja dalam jangka pendek, ini berarti bahwa ketika prioritas bisnis berubah, kumpulan data mentah lengkap tidak tersedia, karena itu terlalu mahal untuk menyimpan. Hadoop, di sisi lain, dirancang sebagai arsitektur scale-out yang terjangkau dapat menyimpan semua data perusahaan untuk digunakan nanti. Penghematan biaya yang mengejutkan: bukan biaya ribuan hingga puluhan ribu pound per terabyte, Hadoop menawarkan komputasi dan penyimpanan kemampuan untuk ratusan pound per terabyte.
Flexibel
Hadoop memungkinkan bisnis untuk dengan mudah mengakses sumber data baru dan memanfaatkan berbagai jenis data (baik terstruktur dan tidak terstruktur) untuk menghasilkan nilai dari data tersebut. Ini berarti bisnis dapat menggunakan Hadoop untuk mendapatkan wawasan bisnis yang berharga dari sumber data seperti media sosial, percakapan email atau data clickstream. Selain itu, Hadoop dapat digunakan untuk berbagai keperluan, seperti pengolahan log, sistem rekomendasi, data pergudangan, analisis kampanye pasar dan deteksi penipuan.
Cepat
Metode penyimpanan yang unik Hadoop didasarkan pada sistem file terdistribusi yang pada dasarnya data yang 'peta' di mana pun ia berada pada sebuah cluster. Alat untuk pengolahan data sering pada server yang sama di mana data berada, sehingga lebih cepat pengolahan data. Jika Anda berurusan dengan volume besar data terstruktur, Hadoop mampu efisien proses terabyte data hanya dalam hitungan menit, dan petabyte dalam jam.
Referensi Situs web http://www.itproportal.com/2013/12/20/big-data-5-major-advantages-of-hadoop/ http://en.wikipedia.org/wiki/Message_Passing_Interface#Overview http://en.wikipedia.org/wiki/HPCC http://docs.hortonworks.com/HDPDocuments/Ambari- 1.6.1.0/bk_Monitoring_Hadoop_Book/bk_Monitoring_Hadoop_Book-20140715.pdf https://hadoop.apache.org/ Buku
Apache Hadoop Yarn, Arun C. Murthy, Addison-Wesley Hadoop beginner’s Guide, Garry Turkington, Packt Publising