1 BAB I
PENDAHULUAN
1.9 Latar Belakang
Salah satu tujuan pembangunan nasional adalah meningkat kinerja perekonomian
agar mampu menciptakan lapangan kerja dan menata kehidupan yang layak bagi
seluruh rakyat yang pada gilirannya akan meujudkan kesejahteraan penduduk
Indonesia. Salah satu sasaran pembangunan nasional adalah menurunkan tingkat
kemiskinan. Kemiskinan merupakan salah satu penyakit dalam ekonomi, sehingga
harus disembuhkan atau paling tidak dikurangi. Permasalahan kemiskinan
memang merupakan permasalahan yang kompleks dan bersifat multidimensional.
Oleh karena itu, upaya pengentasan kemiskinan harus dilakukan secara
komprehensif, mencakup berbagai aspek kehidupan masyarakat, dan dilaksanakan
secara terpadu.
Data kemiskinan yang baik digunakan untuk mengevaluasi kebijakan
pemerintah terhadap kemiskinan, membandingkan kemiskinan antar waktu dan
daerah, serta menentukan target penduduk miskin dengan tujuan untuk
memperbaiki kualitas hidup mereka. Secara umum kemiskinan didefinisikan
sebagai kondisi dimana seseorang atau sekelompok orang tidak mampu memenuhi
hak-hak dasarnya untuk mempertahankan dan mengembangkan kehidupan yang
bermatabat. Definisi yang sangat luas ini menunjukkan bahwa kemiskinan
merupakan masalah multi dimensional, sehingga tidak mudah untuk mengukur
kemisikinan dan perlu kesepakatan pendekatan pengukuran yang dipakai (BPS &
World Bank).
Dipandang dari sudut ekonomi, kemiskinan dapat dilihat dari beberapa
sisi, yaitu : secara makro, kemiskinan muncul karena adanya ketidaksamaan pola
kepemilikan distribusi yang timpang. Penduduk miskin memiliki sumberdaya
terbatas dan kualitasnya rendah; Kemiskinan muncul sumberdaya manusia yang
rendah berarti produktivitasnya rendah, yang pada gilirannya upahnya rendah.
Rendahnya kualitas sumberdaya manusia ini karena rendahnya tingkat
keturunan; Kemiskinan muncul akibat pebedaan akses dalam modal; Di daerah
perkotaan, derasnya arus migran masuk juga member dampak terhadap semakin
banyaknya penduduk dalam kategori miskin. Prilaku para migran dalam
kehidupan kota yang sedemikian rupa, yakni pengeluaran yang
serendah-rendahnya di daerah tujuan (kota) agar dapat menabung untuk dapat menabung
untuk dapat dibawa pulang ketika mereka mudik ke kampung halaman (daerah
asal). Para migran memanfaatkan hanya sebagian kecil pendapatannya mereka
untuk penegluaran di daerah tujuan, disamping mmang sebagian besar dari
mereka berendapatan rendah karena kualitas sumberdaya manusianya juga rendah.
Untuk menanggulangi masalah kemiskinan harus dipilih strategi yang
dapat memperkuat peran dan posisi perekonomian rakyat dalam perekonoimian
nasional, sehingga terjadi perubahan struktural yang meliputi pengalokasian
sumber daya, penguatan kelembagaan, pemberdayaan sumber daya manusia.
Program yang dipilih harus berpihak dan memberdayakan masyarakat melalui
pembangunan ekonomi dan peningkatan perekonomian rakyat. Program ini harus
diwujudkan dalam langkah-langkah strategis yang diarahkan secara langsung pada
perluasan akses masyarakat miskin kepada sumber daya pembangunan dan
menciptakan peluang bagi masyarakat paling bawah untuk berpartisipasi dalam
proses pembangunan, sehingga mereka mampu mengatasi kondisi
keterbelakangannya. Selain itu upaya penanggulangan kemiskinan harus
senantiasa didasarkan pada penentuan garis kemiskinan yang tepat dan pada
pemahaman yang jelas mengenai sebab-sebab timbulnya persoalan itu (Gunawan
Sumodiningrat; 1998).
Dari uraian diatas serta pemikiran diatas, maka penulis merasa terdorong
untuk mendalami dan meneliti tentang “Analisis Pengaruh Luas Wilayah,
Kepadatan Penduduk, Tingkat Pengangguran dan Tingkat Pendidikan
Terhadap Jumlah Penduduk Miskin Provinsi Sumatera Utara Tahun 2013”.
1.10 Rumusan masalah
Dari uraian latar belakang, penulis merumuskan masalah sebagai berikut:
Bagaimana pengaruh luas wilayah, kepadatan penduduk, tingkat pengangguran,
1.11 Batasan Masalah
Untuk lebih mempermudah dan agar lebih terarah, maka penulis membatasi ruang
lingkup permasalahannya, yaitu :
1. Banyaknya variabel yang diteliti ada 4 yaitu : Luas wilayah, kepadatan
penduduk, tingkat pengangguran dan tingkat pendidikan.
2. Populasi yang diambil dibatasi pada Provinsi Sumatera Utara pada Tahun
2013.
1.12 Tujuan Penelitian
Tujuan dari penelitian adalah umtuk menganalisis pengarruh luas wilayah,
kepadatan penduduk, tingkat pengangguran dan tingkat pendidikan terhadap
jumlah penduduk miskin Provinsi Sumatera Utara.
1.13 Manfaat Penelitian
Adapun manfaat dari penelitian adalah:
1. Sebagai bahan masukan atau bahan pertimbangan bagi pemerintah dalam
mengambil keputusan atau mentapkan kebjakan tentang pengentasan
kemiskinan Sumatera Utara.
2. Semakin banyaknya penelitian akan semakin terbuk informasi dan cara-cara
yang efektif dalam menanggulangi masalah kemiskinan di Sumatera Utara.
3. Dapat dijadikan kerangka peniaian kearah pembangunan dalam memcahkan
masalah kemiskinan di Sumatera Utara.
1.14 Tinjauan Pustaka
Dalam ilmu statistika, teknik yang umum digunakan untuk menganalisis
hubungan antara dua atau lebih variabel adalah analisis regresi. Model matematis
dalam menjelaskan hubungan antara variabel dalam analisis regresi menggunakan
persamaan regresi.
Prinsip dasar yang harus dipenuhi dalam membangun suatu persamaan
mempunyai hubungan sebab akibat, baik yang didasarkan pada teori, hasil
penelitian sebelumnya, ataupun yang berdasarkan pada penjelasan logis tertentu.
Bentuk hubungan antar variabel dapat searah atau berlawanan arah. Hubungan
antara variabel searah artinya perubahan nilai yang satu dengan yang lainnya
searah. Hubungan antara variabel berlawanan arah artinya perubahan nilai yang
satu dengan yang lainnya adalah berlawanan arah.
Analisis korelasi adalah alat statistik yang dapat digunakan untuk
mengetahui derajat hubungan linier antara satu variabel dengan variabel lain.
Koefisien determinasi adalah salah satu nilai statistik yang dapat digunakan untuk
mengetahui apakah ada hubungan pengaruh antar variabel.
Pengetahuan tentang koefisien regresi bertujuan untuk memastikan apakah
variabel independen yang terdapat dalam persamaan tersebut secara individu
berpengaruh terhadap variabel dependen. Caranya adalah dengan melakukan
pengujian terhadap koefisien regresi setiap variabel independen. Semakin
mendekati nol besarnya koefisien determinasi suatu persamaan, semakin kecil
pula pengaruh semua variabel independen terhadap nilai variabel dependen
( Algifari, 2002; 45).
Regresi ganda berguna untuk mendapatkan pengaruh dua variabel
kriterium atau untuk mencari hubungan fungsional dua predictor atau lebih
dengan variabel kriteriumnya atau untuk meramalkan dua variabel prediktor atau
lebih terhadap kriteriumnya ( Usman dkk, 1995; 241). Studi yang membahas
derajat hubungan antara variabel- variabel dikenal dengan nama analisis korelasi.
Ukuran yang dipakai untuk mengetahui derajat hubungan, terutama data
kuantitatif dinamakan koefisien korelasi ( Sudjana, 2001; 367).
Rumus yang saya gunakan adalah rumus Penduga sebagai berikut :
Ŷ = �� + ���� + ���� + ���� + … + �� �� ; n=1,2,3,…(1.1)
Dimana :
Ŷ = Nilai estimasi Y
�� = Nilai Y pada perpotongn antara garis linier dengan sumbu vertikal Y
�� = Nilai variabel independen ��
Dari rumus diatas jika dimasukan ke variabel yang digunakan dapat diperoleh
Untuk rumus diatas, dapat diselesaikan dengan empat persamaan dengan
empat variabel yang terbentuk:
∑
∑
∑
∑
1.15 Pengujian Kriteria Statistik
Gujarati (1995) menyatakan bahwa uji signifikan merupakan prosedur yang
digunakan untuk menguji kebenaran atau kesehatan dari hasil hipotesis nol dari
sampel. Ide dasar yang melatarbelakangi pengujian signifikansi adalah uji statistik
(estimator) dari distribusi sampel dari suatu statistik dibawah hipotesis nol.
Keputusan untuk mengolah Ho dibuat berdasarkan nilai uji statistic yang
1.15.1 Kesalahan Standard Estimasi
Untuk mengetahui ketepatan persamaan estimasi dapat digunakan kesalahan
standar estimasi (standard error of estimate). Besarnya kesalahan standar estimasi
menunjukkan ketepatan persamaan estimasi untuk menjelaskan nilai variabel
tidak bebas yang sesungguhnya. Semakin kecil nilai kesalahan standar estimasi,
makin tinggi ketepatan persamaan estimasi yang dihasilkan untuk menjelaskan
nilai variable tidak bebas sesungguhnya. Sebaliknya, semakin besar nilai
kesalahan standar estimasi, makin rendah ketepatan persamaan estimasi yang
dihasilkan untuk menjelaskan nilai variable tidak bebas sesungguhnya ( Algifari,
2000). Kesalahan standar estimasi dapat ditentukan dengan rumus :
��,1,2,…,� =� ∑ ��
��2
� − � −1
dimana:
Yi = nilai data sebenarnya
Ŷ = nilai taksiran
1.15.2 Uji F-Statistik
Uji statistik ini adalah pengujian yang bertujuan untuk mengetahui seberapa besar
pengaruh koefisien regresi secara bersama-sama terhadap variabel dependen.
Adapun langkah-langkah dalam pengujian uji F-statistik adalah sebagai berikut:
1. Menentukan formulasi hipotesis
2. Mencari nilai Ftabel dari Tabel Distribusi F
Dengan taraf nyata α = 0,05 dan nilai Ftabel dengan dk pembilang (v1) = k = 4 dan dk penyebut (v2) = n – k – 1 = 33 – 4 – 1 = 28, maka di peroleh
��1;�2(�) = �4;28(0,05)= 2,048
3. Menentukan kriteria pengujian �0 diterima bila �ℎ����� <������
�0 ditolak bila �ℎ����� ≥ ������
4. Menentukan nilai statistik Fhitung
Untuk menguji model regresi yang telah terbentuk, maka diperlukan
nilai-nilai y, x1, x2 dan x3 dengan rumus :
y= −Y Y x2 = X2−Y x4 = X4 −Y
1 1
x = X −Y x3 =X3−Y
1.15.3 Koefisien Determinasi
Menguji keberartian regresi linear berganda dimaksudkan untuk meyakinkan
apakah regresi yang didapat berdasarkan penelitian ada artinya bila dipakai untuk
membuat kesimpulan mengenai sejumlah peubah yang dipelajari.( Usman,
Husaini, dan R. Purnomo Setiady Akbar, 1995).
Hipotesa :
H0 : Tidak terdapat hubungan fungsional yang signifikan antara semua
faktor yang mempengaruhi terhadap faktor yang dipengaruhi.
H1 : Terdapat hubungan fungsional yang signifikan antara semua faktor
yang mempengaruhi terhadap faktor yang dipengaruhi.
Koefisien determinasi yang dinyatakan dengan R2 untuk pengujian regresi
linear berganda yang mencakup lebih dari dua variabel adalah untuk mengetahui
proporsi keragaman total dalam variabel terikat (Y) yang dapat dijelaskan atau
diterangkan oleh variabel–variabel bebas (X) yang ada dalam model persamaan
regresi linear berganda secara bersama–sama. Maka R2 akan ditentukan dengan
rumus, yaitu:
�2 =�����
∑ ��2
Dimana:
JKreg = Jumlah Kuadrat Regresi
Harga R2 yang diperoleh sesuai dengan variansi yang dijelaskan masing –
masing variabel yang tinggal dalam regresi. Hal ini mengakibatkan variasi yang
dijelaskan penduga yang disebabkan oleh variabel yang berpengaruh saja (yang
1.15.4 Koefisien Korelasi
Analisa korelasi adalah alat statistik yang dapat digunakan untuk mengetahui
derajat hubungan linier antara satu variabel dengan variabel lain. Ukuran yang
dipakai untuk mengetahui derajat hubungan, terutama data kuantitatif dinamakan
koefisien korelasi. Untuk menghitung koefisien korelasi (r) antara dua variabel
dapat digunakan rumus:
��� = � ∑ ����� −
(∑ ���)(∑ ��)
�{� ∑ ���2 −(∑ ���)2}{� ∑ �
�2−(∑ ��)2}
Dimana:
ryx = Koefisien korelasi antara Y dan X
Xki = Variabel bebas
Yi = Variabel terikat
Nilai r selalu terletak antara -1 dan 1, sehingga nilai r tersebut dapat ditulis
-1≤ r ≤+1. Untuk r = +1, berarti ada korelasi positif sempurna antara X dan Y,
sebaliknya jika r = -1, berarti korelasi negatif sempurna antara X dan Y,
sedangkan r = 0, berarti tidak ada korelasi antara X dan Y.
Jika kenaikan didalam suatu variabel diikuti dengan kenaikan didalam
variabel lain, maka dapat dikatakan bahwa kedua variabel tersebut mempunyai
korelasi yang positif. Tetapi jika kenaikan didalam suatu variabel diikuti oleh
penurunan didalam variabel lain, maka dapat dikatakan bahwa variabel tersebut
mempunyai korelasi yang negatif. Dan jika tidak ada perubahan pada variabel
walaupun variabel lainnya berubah maka dikatakan bahwa kedua variabel tersebut
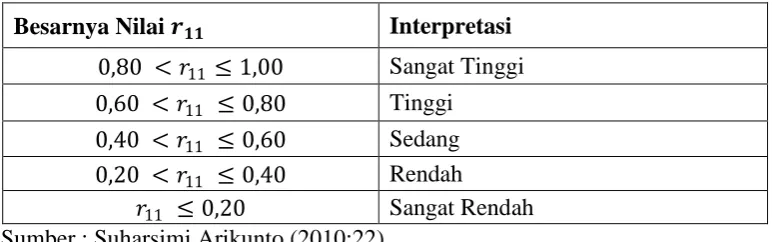
tidak mempunyai hubungan. Interpretasi harga r akan disajikan dalam tabel
berikut:
Tabel 1.1 Interpretasi Koefisien Korelasi
Besarnya Nilai ��� Interpretasi
0,80 <�11 ≤ 1,00 Sangat Tinggi
0,60 <�11 ≤ 0,80 Tinggi
0,40 <�11 ≤ 0,60 Sedang 0,20 <�11 ≤ 0,40 Rendah
�11 ≤ 0,20 Sangat Rendah
Keterangan:
r = koefisien korelasi
+ = menunjukkan korelasi positif
− = menunjukkan korelasi negatif
0 = menunjukkan tidak adanya korelasi (korelasi nihil)
Hubungan antara variabel dapat dikelompokkan menjadi tiga jenis:
1. Korelasi Positif
Terjadinya korelasi positif apabila perubahan antara variabel yang satu diikuti
oleh variabel lainnya dengan arah yang sama (berbanding lurus). Artinya
variabel yang satu meningkat, maka akan diikuti peningkatan variabel lainnya.
2. Korelasi Negatif
Terjadinya korelasi negatif apabila perubahan antara variabel yang satu diikuti
oleh variabel lainnya dengan arah yang berlawanan (berbanding terbalik).
Artinya apabila variabel yang satu meningkat, maka akan diikuti penurunan
variabel lainnya.
3. Korelasi Nihil
Korelasi nihil artinya tidak adanya korelasi antara variabel.
Dalam hal ini penulis menggunakan empat variabel dalam penelitiannya,
untuk hubungan empat variabel dapat dihitung dengan menggunakan rumus
sebagai berikut:
a. Koefisien Korelasi antara Y dan X1
���1 =
� ∑ �1�1−(∑ �1)(∑ �)
�{� ∑ �12−(∑ �1)2}{� ∑ �2 −(∑ �)2}
b. Koefisien Korelasi antara Y dan X2
���2 =
� ∑ �2�1−(∑ �2)(∑ �)
�{� ∑ �22 −(∑ �2)2}{� ∑ �2−(∑ �)2}
c. Koefisien Korelasi antara Y dan X3
���3 =
� ∑ �3�1−(∑ �3)(∑ �)
�{� ∑ �32 −(∑ �3)2}{� ∑ �2−(∑ �)2}
d. Koefisien Korelasi antara Y dan X4
���4 =
� ∑ �4�1−(∑ �4)(∑ �)
e. Koefisien Korelasi antara X1 dan X2
�12 =
� ∑ �1�2−(∑ �1)(∑ �2)
�{� ∑ �12−(∑ �1)2}{� ∑ �22−(∑ �2)2}
f. Koefisien Korelasi antara X1 dan X3
�13 =
� ∑ �1�3−(∑ �1)(∑ �3)
�{� ∑ �12−(∑ �1)2}{� ∑ �32−(∑ �3)2}
g. Koefisien Korelasi antara X1 dan X4
�14 =
� ∑ �1�4−(∑ �1)(∑ �4)
�{� ∑ �12−(∑ �1)2}{� ∑ �
42−(∑ �4)2}
h. Koefisien Korelasi antara X2 dan X3
�23 =
� ∑ �2�3−(∑ �2)(∑ �3)
�{� ∑ �22−(∑ �2)2}{� ∑ �32−(∑ �3)2}
i. Koefisien Korelasi antara X2 dan X4
�24 =
� ∑ �2�4−(∑ �2)(∑ �4)
�{� ∑ �22−(∑ �2)2}{� ∑ �
42−(∑ �4)2}
j. Koefisien Korelasi antara X3 dan X4
�34 =
� ∑ �3�4−(∑ �3)(∑ �4)
�{� ∑ �32−(∑ �3)2}{� ∑ �42−(∑ �4)2}
1.15.5 Uji t- Statistik
Uji t-statistik merupakan suatu pengujian secara parsial yang bertujuan untuk
mengetahui apakah masing-masing koefisien regresi signifikan atau tidak
terhadap variabel dependen dengan menganggap variabel lainnya konstan.
Adapun langkah-langkahnya adalah:
1. Menentukan formulasi hipotesis
2. Mencari nilai ttabel dari Tabel Distribusi t
3. Menentukan kriteria pengujian �0 diterima bila �ℎ����� <������
�0 ditolak bila �ℎ����� ≥ ������
4. Menentukan nilai statistik thitung
��1= �
��2.12 …�
(∑ �12)(1− ��2.12)
Selanjutnya hitung statistik :
�ℎ����� =��1 �1
5. Kesimpulan
1.15.6 Uji Penyimpangan Asumsi Klasik
1.15.6.1 Uji Multikolinieritas
Uji multikolinieritas dilakukan untuk menguji apakah pada model regresi
ditemukan adanya korelasi antar variabel bebas, model regresi yang baik tidak ada
korelasi yang tinggi diantara variabel-variabel independennya. Model regresi yang
baik seharusnya tidak terjadi korelasi diantara variabel independent. Pengujian
ada tidaknya gejala multikolinieritas dilakukan dengan memperhatikan nilai
matriks korelasi yang dihasilkan pada saat pengolahan data serta nilai VIF
(Variance Inflation Factor) dan toleransinya. Apabila nilai matrik korelasi tidak
ada yang lebih besar dari 0,5 maka dapat dikatakan data yang akan dianalisis
bebas dari multikolinieritas. Kemudian apabila nilai VIF berada dibawah 10 dan
nilai toleransi mendekati 1, maka diambil kesimpulan bahwa model regresi
tersebut tidak terdapat multikolinieritas (Singgih Santoso, 2000).
1.15.6.2 Uji Heteroskedastisitas
Uji Heteroskedastisitas bertujuan untuk menguji apakah dalam model regresi
terjadi ketidaksamaan varians dari residual satu pengamatan ke pengamatan yang
lain tetap, maka disebut homoskedastitas dan jika berbeda disebut
Heteroskedastisitas.
Untuk menguji heteroskedastisitas digunakan uji Glesjer SPSS. Uji ini
pada dasarnya bertujuan untuk menguji apakah dalam model regresi terjadi
ketidaksamaan variance dari residual satu pengamatan ke pengamatan yang lain.
Jika variance dari residual satu pengamatan ke pengamatan lain tetap, maka
yang baik seharusnya tidak terjadi heteroskedastisitas. Dasar pengambilan
keputusan pada Uji Heteroskedastisitas yakni:
• Jika nilai signifikansi lebih besar dari 0,05, kesimpulannya adalah tidak terjadi heteroskedastisitas.
• Jika nilai nilai signifikansi lebih kecil dari 0,05, kesimpulannya adalah terjadi heteroskedastisitas.
1.15.6.3 Uji Normalitas
Uji Normalitas bertujuan untuk menguji apakah dalam model regresi variabel
bebas keduanya mempunyai distribusi normal ataukah tidak. Model regresi yang
baik adalah memiliki distribusi data normal atau dilakukan dengan uji kolmogrov
smirnov.
Untuk menguji normalitas data dapat digunakan dengan uji kolmogrov
smirnov dengan melihat data residualnya. Uji kolmogrov smirnov dihitung
dengan bantuan SPSS. Dasar pengambilan keputusan dalam uji normalitas yakni :
jika nilai signifikansi lebih besar dari 0,05 maka data tersebut berdistribusi
normal. Sebaliknya, jika nilai signifikansi lebih lebih dari 0,05 maka data tersebut
tidak berdistribusi normal.
1.16 Metode Penelitian
Metode penelitian adalah salah satu cara yang terdiri dari langkah – langkah atau
urutan kegiatan yang berfungsi sebagai pedoman umum yang digunakan untuk
melaksanakan penelitian sehingga apa yang menjadi tujuan dari penelitian itu
dapat terwujud. Dalam penelitian ini dilakukan beberapa langkah untuk
menyelesaikan penelitian antara lain :
1. Pengambilan data sekunder yaitu data yang diolah diperoleh dari kantor Badan
Pusat Statistik Provinsi Sumatera Utara.
2. Pengolahan Data
Dalam penelitian ini dilakukan beberapa langkah untuk menyelesaikan
penelitian antara lain:
a. Menentukan apa saja yang menjadi variabel bebas (X) dan variabel terikat
b. Mencari persamaan regresi antara variabel (X) dan (Y) dengan
menggunakan rumus yang telah diperoleh dari buku literature.
3. Menguji tingkat signifikasi pengaruh setiap variabel dengan Uji F, Uji t dan
Koefisien Korelasi dan koefisien Determinasi, serta melalui uji asumsi klasik.