BAB 2
LANDASAN TEORI
2.1 Intruksi Presiden No.2 Tahun 2001
Adapun Instruksi Presiden Republik Indonesia Nomor 2 Tahun 2001 mengenai Penggunaan Komputer dengan Aplikasi Komputer Berbahasa Indonesia adalah Bahwa kemampuan penguasaan, pengembangan dan pemanfaatan ilmu pengetahuan dan teknologi, khususnya teknologi informasi melalui komputer oleh masyarakat ataupun aparatur negara perlu ditingkatkan, akan tetapi adanya kendala aplikasi komputer dengan penggunaan bahasa-bahasa asing tanpa adanya pilihan untuk menggunakan aplikasi komputer berbahasa Indonesia. Menerapkan bahasa Indonesia dalam aplikasi komputer akan mempermudah pengguna komputer melaksanakan tugasnya, sekaligus sebagai
alternative pilihan penggunaan bahasa dalam penggunaan komputer.
Sehubungan dengan hal-hal tersebut dan dalam rangka meningkatkan kinerja aparatur negara dalam melaksanakan tugas dan fungsinya, dipandang perlu menetapkan Instruksi Presiden tentang Penggunaan Komputer dengan Aplikasi Komputer berbahasa Indonesia. Universitas Negeri yang dimana dinaungi oleh Menteri Riset dan Teknologi juga ikut serta dalam penyusunan dokumen-dokumen yang pemakaiannya dengan mengikut-sertakan instansi dan pihak lain terkait.
2.2 Senarai Padanan Istilah (SPI)
Tabel 2. 1 10 Contoh Istilah Asing yang telah di Indonesiakan untuk Bidang Komputer
Istilah Asing SPI (telah di Indonesiakan)
Cluster Gugur; Rumpun
Coding Pengodean
Copy Kopi
Cut Potong
Database Pangkalan Data; Basis Data
Download Unduh
Upload Unggah
Paste Pasta; Rekat
Transmission Transmisi
Window Jendela
2.3 Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH)
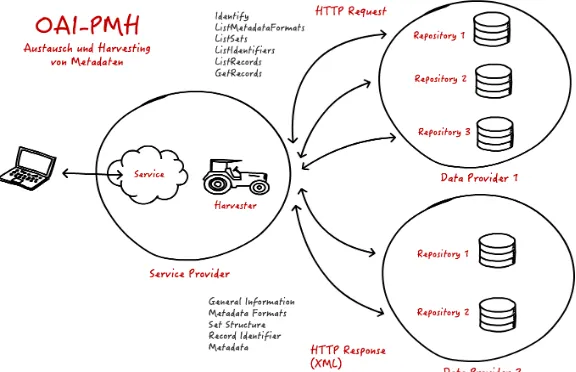
OAI-PMH menawarkan pilihan teknis sederhana untuk katalog dan layanan repositori untuk membuat metada mereka tersedia untuk layanan lainnya, berdasarkan pada HTTP (Hypertext Transfer Protocol) dan XML (Extensible Markup Language) standar, sehingga penemuan difasilitasi sumber daya didistribusikan. Metadata yang akan dipanen mungkin dalam format yang telah disepakati, meskipun tidak memenuhi syarat Dublin Core diperlukan oleh spesifikasi dalam rangka memberikan interprobabilitas tingkat dasar. Framework OAI membedakan antara penyedia data dan penyedia layanan. OAI-PMH memungkinkan penyedia data untuk membuat metadata mereka tersedia untuk dipanen oleh penyedia layanan, ini adalah proses pengumpulan, metadata dikumpulkan dari sejumlah repositori didistribusikan kedalam store gabungan. (Chua, et al. 2009). Proses request data pada OAI-PMH memiliki beberapa enam tipe yang berbeda yaitu :
Gambar 2. 1 Struktur Umum OAI-PMH (digiacademy, 2016)
2.4 Dublin Core
Dublin Core merupakan inisiatif untuk menciptakan sebuah "katalog kartu perpustakaan"
digital untuk Web. Dublin Core terdiri dari 15 metadata (data yang menjelaskan data)
elemen yang menawarkan diperluas katalogisasi informasi dan meningkatkan
pengindeksan dokumen untuk program mesin pencari.
Lima belas elemen metadata yang digunakan oleh Dublin Core adalah: Judul
(nama yang diberikan sumber daya), pencipta (orang atau organisasi yang bertanggung
jawab untuk konten yang), subjek (topik tertutup), deskripsi (garis tekstual konten),
penerbit ( mereka yang bertanggung jawab untuk membuat sumber daya yang tersedia),
kontributor (orang-orang yang ditambahkan ke konten), tanggal (ketika sumber daya
dibuat tersedia), jenis (kategori untuk konten), Format (bagaimana sumber daya yang
disajikan), identifier (numerik pengenal untuk konten seperti URL), sumber (dimana
isinya awalnya berasal dari), bahasa (dalam bahasa apa konten yang ditulis), hubungan
ke pemberitahuan hak cipta). Contoh format metadata Dublin core dapat dilihat pada
gambar 2.2.
<meta name="DC.Format" content="video/mpeg; 10 minutes"> <meta name="DC.Language" content="en” >
<meta name="DC.Publisher" content="publisher-name" > <meta name="DC.Title" content="HYP" >
<meta name="DC.Link" content="www.link.com" >
Gambar 2. 2 Contoh format metadata pada Dublin core (dc)
Dari contoh format metadata diatas dapat dilihat ada 5 attribute, antara lain : 1. DC.Format yang dimana atribut ini berisi format file.
2. DC.Language yang dimana atribut ini berisi format bahasa yang digunakan. 3. DC.Publisher yang dimana atribut ini berisi nama penerbit.
4. DC.Title yang dimana atribut ini berisi nama file.
5. DC.Link yang dimana atribut ini berisi link dimana file tersedia.
2.5 Text Preprocessing
Preprocessing adalah tahap yang penting dan kritikal dalam Text Mining, Natural Language Processing (NLP) dan Information Retrieval (IR). Tahap ini digunakan untuk menarik hal penting dan tidak sepele dan pengetahuan dari data teks yang tidak terstruktur. Information Retrieval(IR) pada dasarnya adalah masalah memutuskan infomasi dokumen mana yang dibutuhkan pengguna (Vairaprakash & Subbu, 2014).
Pada tahap ini, tindakan yang dilakukan adalah tokenizing yaitu proses penguraian
deskripsi yang semula berupa kalimat menjadi kata-kata kemudian menghilangkan
delimiter-delimiter seperti tanda koma (,), tanda titik (.), spasi dan karakter angka yang
dokumen. Stemming untuk mengubah kata berimbuhan menjadi kata dasar, algoritma stemming yang digunakan adalah algoritma stemming (Nazief Andriani, 1996).
2.6 String Matching
2.6.1 Pengertian String Matching
String matching adalah pencarian sebuah pattern pada sebuah teks (Rasool, Akhtar. dkk ,2012). String matching atau sering disebut juga pencocokan string adalah algoritma
untuk melakukan pencarian semua kemunculan string pendek yang
disebut pattern di string yang lebih panjang yang disebut teks.
Pencocokkan string merupakan permasalahan paling sederhana dari semua permasalahan string lainnya, dan dianggap sebagai bagian dari pemrosesan data, pengkompresian data, analisis leksikal, dan temu balik informasi. Teknik untuk menyelesaikan permasalahan pencocokkan string biasanya akan menghasilkan implikasi langsung ke aplikasi string lainnya.
2.6.2 Klasifikasi Algoritma String Matching
Algoritma string matching dapat diklasifikasikan menjadi tiga bagian menurut arah pencariannya (Charras, C. & Lecroq, T. 1997), yaitu:
1. From left to right
Dari arah yang paling alami, dari kiri ke kanan, yang merupakan arah untuk membaca. Algoritma yang termasuk dalam kategori ini adalah algoritma Brute Force,
algoritma Morris dan Pratt yang kemudian dikembangkan menjadi algoritma Knuth-Morris-Pratt.
2. From right to left
Dari arah kanan ke kiri, arah yang biasanya menghasilkan hasil terbaik secara partikal. Contoh algoritma ini adalah algoritma Boyer-Moore, yang kemudian banyak dikembangkan menjadi algoritma Tuned Boyer-Moore, algoritma Turbo Boyer-Moore,
3. In a specific order
Dari arah yang ditentukan secara spesifik oleh algoritma tersebut, arah ini menghasilkan hasil terbaik secara teoritis. Algoritma yang termasuk kategori ini adalah algoritma Colussi dan algoritma Crochemore-perrin.
2.6.3 Teknik Algoritma String Matching
Menurut Singla, N. & Garg, D. (2012), ada dua teknik utama dalam algoritma string matching, yaitu:
1. Exact string matching.
Exact string matching, merupakan pencocokan string secara tepat dengan susunan karakter dalam string yang dicocokkan memiliki jumlah maupun urutan karakter dalam string yang sama. Bagian algoritma ini bermanfaat jika pengguna ingin mencari string
dalam dokumen yang sama persis dengan string masukan. Beberapa algoritma exact string matching antara lain:
a. Knuth-Morris-Pratt
Metode ini mencari kehadiran sebuah kata dalam teks dengan melakukan observasi awal (preprocessing) dengan cara mengecek ulang kata sebelumnya. Algoritma ini melakukan pencocokan dari kiri ke kanan.
b. Boyer-Moore
Algoritma Boyer-Moore adalah algoritma string matching yang paling efisien dibandingkan algoritma string matching lainnya. Sebelum melakukan pencarian
string, algoritma melakukan proses terlebih dahulu pada pattern, bukan pada string
2. Approximate string matching atau Fuzzy string matching.
Fuzzy string matching merupakan pencocokan string secara samar, maksudnya pencocokan string dimana string yang dicocokkan memiliki kemiripan memiliki susunan karakter yang berbeda (mungkin jumlah atau urutannya), tetapi string tersebut memiliki kemiripan baik kemiripan tekstual/penulisan (approximate string matching) atau kemiripan ucapan (phonetic string matching).
2.7 Algoritma Boyer-Moore
Algoritma Boyer Moore diperkenalkan oleh Bob Boyer dan J.S. Moore pada tahun 1977. Pada Metode ini pencocokan kata dimulai dari karakter terakhir kata kunci menuju karakter awalnya. Jika terjadi perbedaan antara karakter terakhir kata kunci dengan kata yag dicocokkan, maka karakter-karakter dalam potongan kata yang dicocokkan tadi akan diperiksa satu per satu. Hal ini dimaksudkan untuk mendeteksi apakah ada karakter dalam potongan kata tersebut yang sama dengan karakter yang ada pada kata kunci.
Algoritma Boyer Moore termasuk algoritma string matching yang paling efisien dibandingkan algoritma-algoritma string matching lainnya. Karena sifatnya yang efisien, banyak dikembangkan algoritma string matching dengan bertumpu pada konsep
algoritma Boyer Moore, beberapa di antaranya adalah algoritma Turbo BM dan algoritma
Quick Search.
Algoritma Boyer Moore menggunakan metode pencocokan string dari kanan ke kiri yaitu men-scan karakter pattern dari kanan ke kiri dimulai dari karakter paling kanan. Algoritma Boyer Moore menggunakan dua fungsi shift yaitu good-suffix shift dan bad-character shift untuk mengambil langkah berikutnya setelah terjadi ketidakcocokan antara karakter pattern dan karakter teks yang dicocokkan (Dwi Purwoko, 2006).
2.7.1 Deskripsi kerja algoritma Boyer-Moore
Untuk menjelaskan konsep dari good-suffix shift dan bad-character shift diperlukan contoh kasus, seperti kasus ketidakcocokan ditengah pencocokan karakter pada teks dan
2.7.2 Good-suffix Shift
Konsep dari fungsi good-suffix shift adalah sebagai berikut:
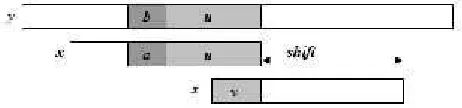
1. Good-suffix shift adalah pergeseran yang dibutuhkan dari x[i]=a kekarakter lain yang letaknya lebih kiri dari x[i] dan terletak di sebelah kiri segmen u. Kasus ini ditunjukkan pada Gambar 2.3
Gambar 2. 3 Good-suffix shift, u terjadi lagi didahului karakter c berbeda dari a
(Charras dan Lecroq, 1997)
2. Jika tidak ada segmen yang sama dengan u, maka dicari u yang merupakan suffix
terpanjang u. Kasus ini ditunjukkan pada Gambar 2.4
Gambar 2. 4 Good-suffix shift, hanya suffix dari u yang terjadi lagi di pattern x
(Charras dan Lecroq, 1997)
2.7.3 Bad-Character Shift
Berdasarkan contoh kasus di atas, bad-character adalah karakter pada teks yaitu y [i+j] yang tidak cocok dengan karakter pada pattern.
Konsep dari fungsi bad-character shift adalah sebagai berikut:
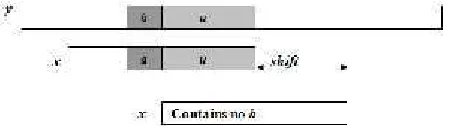
Gambar 2. 5Bad-character shift, b terdapat di pattern x (Charras dan Lecroq, 1997)
2. Jika bad-character y[i+j] tidak ada pada pattern sama sekali, maka pattern digeser ke kanan sejauh i. Kasus ini dit tunjukkan pada Gambar 2.6
Gambar 2. 6Bad-character shift, b tidak ada di pattern x (Charras dan Lecroq, 1997)
3. Jika bad-character y[i+j] terdapat pada pattern di posisi terkanan k yang lebih kanan
dari x[i] maka pattern seharusnya digeser sejauh i-k yang hasilnya negatif (pattern
digeser kembali ke kiri). Maka bila kasus ini terjadi. akan diabaikan.
Pada kasus ketidakcocokan di atas, algoritma akan membandingkan langkah yang diambil oleh fungsi good-suffix shift dan bad-character shift dimana langkah yang paling besar yang akan digunakan
2.8 Penelitian Terdahulu
Harvesting data untuk jurnal elektronik untuk paper Ekonomi dan Informatika yang menggunakan OAI-PMH sebagai tempat pengutipan metada yang dimana Czech University of Life Sciences Prague sebagai data provider juga pernah diteliti oleh Pavel, Jarolimek, Jiri dan Michal pada tahun 2011 dengan hasil pengoleksian data-data jurnal dengan hasil yang cukup baik.
Penelitian mengenai Algoritma Boyer-Moore telah banyak dilakukan, antara lain oleh
Sheshasayee dan Thailambal pada tahun 2015 yang melakukan perbandingan antara
algoritma Boyer-Moore, Knuth Moris Pratt dan Naïve String dalam text mining yang
diimplementasikan didalam Bahasa pemrograman Python untuk membandingkan waktu
eksekusi ketiga algoritma berdasarkan perbedaan panjang teks dan pola teks. Didapatkan
hasil pada percobaan panjang teks dengan parameter 182 dan 475, Boyer-Moore menjadi
algoritma dengan hasil kedua tercepat pada kedua parameter.
Selain itu, Pada tahun 2011, Yuan melakukan penelitian pada pengutipan informasi
Chinese dengan menggunakan Boyer-Moore dengan tujuan untuk meminimalkan waktu
untuk mencocokan string dan membandingkan. Hasil yang didapatkan dengan
menggunakan Boyer-Moore pada string “xiatianbaorefengshaobaoyuduobaofengyu” 5
kali waktu pencocokan dan 7 waktu perbandingan, dan dengan algoritma pada literatur
lain 4 kali waktu pencocokan dan 6 kali waktu perbandingan dan dengan algoritma
penelitian ini hanya 3 kali waktu pencocokan dan 5 kali waktu perbandingan.
Dalam penelitian yang dilakukan Jaiswal pada tahun 2014 menggunakan peningkatan
algoritma Boyer-Moore pada Multicore GPU untuk Network Security. Dilakukanlah
perbandingan dengan serial version dan multithreaded version pada CPU dan didapatkan
hasil 10 kali lebih cepat dibandingkan dengan versi CPU dan 9 kali lebih cepat