BAB II
LANDASAN TEORI
2.1 Film
Film adalah sebuah kesenian gabungan antara seni sastra, seni peran, seni musik, dan seni rupa[11]. Film alat berkomunikasi yang bersifat audio visual yang didalamnya terdapat pesan yang hendak diungkapkan oleh pembuat film[12].
Film juga merupakan sarana baru yang dipergunakan untuk menyalurkan suatu hiburan, serta menyajikan banyak alur peristiwa, drama ,musik, komedi, dan presentasi menarik lainnya kepada para masyarakat [11]. Film sendiri mampu mengirim pesan dengan banyak tujuan, mulai dari sekedar hiburan, pesan moral, pendidikan, informasi dan lain sebagainya.
2.2 Klasifikasi Teks
Klasifikasi teks merupakan sistem pemberian kategori pada tiap teks menurut isinya. Dapat dipakai untuk mengolah, menata, bahkan mengkategorikan hampir semua hal. Misalnya, artikel baru disusun menurut topik, percakapan dalam obrolan diatur menurut bahasa, penyebutan merek disusun berdasarkan sentimen, dan sebagainya.
Klasifikasi merupakan proses untuk menemukan fungsi dan model yang dapat menjelaskan serta membedakan konsep maupun kelas data, bertujuan agar dapat memperkirakan kelas dari suatu objek yang labelnya tidak diketahui[13].
Klasifikasi teks adalah pengelompokan dokumen atau teks ke dalam kelas-kelas yang mempunyai karateristik yang mirip atau sama[12].
Klasifikasi merupakan pengelompokkan suatu data ke dalam kelompok data yang telah ditentukan berdasarkan tingkat kemiripannya. Bertujuan untuk mempermudah penentuan dari seluruh dokumen dengan berbagai kategori tertentu[14].
2.3 Data Mining
merupakan alur yang didalamnya menggunakan metode statistik, artificial intelligence, matematika , dan learning machine untuk mengekstrak dan mengenali
informasi yang berguna dan pengetahuan yang ada pada kumpulan data besar[15]. Pada dasarnya, tujuan dari mining data yaitu agar mampu mendeteksi pola yang bersifat perulangan dan bernilai yang seringkali tertanam pada tumpukan data.
Mining data juga sering juga disebut dengan KDD (Knowledge Discovery in Database). Merupakan aktivitas yang merangkum pengumpulan, penggunaan dari history data agar dapat menemukan keteraturan, pola atau hubugan dalam kumpulan data yang berskala besar[15]. Proses KDD dapat dijelaskan sebagai berikut:
1. Data Selection
Merupakan kumpulan data yang diperlukan sebelum melakukan tahap penggalian informasi. Data yang telah terpilih akan dipakai dalam prosedur mining data, dan akan di save dalam sebuah file yang terpisah data awal.
2. Cleaning
Sebelum alur mining data dijalankan, penting dilakukan proses cleaning terhadap data yang menjadi acuan dari KDD. Alur cleaning berupa, menghilangkan data duplikat, mengecek data yang tidak konsisten, dan melakukan perbaikan kesalahan dalam data, seperti kesalahann pada pencetakan. Kemudian menjalankan proses enrichment, yaitu “memperkaya” data yang ada yang juga diperlukan dalam KDD,semisal data maupun informasi eksternal yang dibutuhkan.
3. Transformasi
Merupakan tahap transfomasi pada data yang belum memiliki entitas yang jelas ke dalam bentuk data yang valid untuk dilakukan data mining.
4. Data Mining
Meruakan tahap menemukan informasi yang menarik pada data yang dipilih dengan menggunakan metode tertentu. Teknik, method, atau algoritme dalam mining data akan sangat beragam. Penentuan method atau algoritme yang sesuai sangat bergantung pada tujuan dan alur KDD.
5. Interpretation / Evaluation
Tahap ini merupakan tahap terakhir yang dilakukan dengan urutan order atau keluaran dari proses data mining agar mudah dilakukan dan dipahami.
2.4 Text Preprocessing
Merupakan tahapan penyajian dokumen berupa fitur vektor, artinya teks tersebut harus merupkan kata tersendiri. Pada tahap ini, kata-kata stopwords pada dokumen dihapus dari dokumen, cleaning, dan stemming[16].
Text Preprocessing aadalah tahap dalam proses awal pembuatan teks menjadi data yang akan siap diolah. Sebuah teks tidak dapat diakses secara langsung oleh algoritme pencari, karena membutuhkan text preprocessing untuk mengubah teks menjadi numerik data. Tujuan dari pemrosesan awal atau preprocessing adalah untuk mempersiapkan text menjadi data yang siap diproses. Terdapat beberapa tahapan pembersihan dokumen seperti berikut[17]:
1. Case Folding
Case folding, yaitu tahapan pertama dari semua rangkaian preprocessing.
Dalam tahap ini semua huruf diubah ke dalam huruf kecil. Hanya huruf abjad yang terbaca. Karakter selain abjad akan dibersihkan dan dianggap delimiter[18].
2. Tokenizing
Pada proses ini, dokumen teks akan terbagi menjadi token atau kata. Dan akan dilakukan pembersihan karakter spesial dan tanda baca serta menyesuaikan tipe kapitalisasi pada teks[19].
3. Filtering
Filtering merupakan proses pengambilan kata inti dari dokumen, serta menghilangkan kata yang tidak diperlukan.
4. Stemming
Merupakan tahapan mencari dasar kata pada hasil filtering. ditahap ini akan dilakukan proses berbagai bentuk kata ke dalam perwakilan kata yang sama.
Pencarian kata dasar yaitu dengan cara menghilangkan semua imbuhan kata, baik berupa awalan, sisipan, ataupun akhiran[18].
2.5 TF-IDF
TF-IDF (Term Frequncy Inverse Document Frequency) adalah tahapan untuk memberi bobot pada keterkaitan suatu kata (term) dengan dokumen. Cara ini mengintegrasikan 2 konsep hitungan dalam hitugan bobot, frekuensi kemunculan kata
dalam dokumen tertentu dan inverse (kebalikan) frekuensi dokumen yang memuat kata tersebut[20]. Rumus TF dapat dilihat pada rumus persamaan 1:
𝑇𝐹(𝑖, 𝑗) = 0,5 + 0,5 𝑓(𝑖,𝑗)
max{𝑓(𝑤,𝑗):𝑤𝜖𝑗} (1)
tf(i,j) berupa term frekuensi kata i pada dokumen j dan f(i,j) merupakan jumlah frekuensi kata i pada dokumen j. sedangkan max{𝑓(𝑤, 𝑗): 𝑤𝜖𝑗} merupakan kemunculan kata paling banyak.
Sedangkan untuk menghitung IDF menggunakan rumus pada persamaan 2.
𝐼𝐷𝐹(𝑖, 𝑗) = log 𝑁
𝐷𝑓(𝑖,𝑗) (2)
idf(i,j) menggambarkan inverse dokumen frequency i dalam dokumen j, dan N menggambarkan banyaknya dokumen pada Df(i,j) sebagai banyaknya dokumen pada dokumen D yang berisi term i. Namun jika term tersebut tidak tampak maka akan mendapat nilai 0 dalam pembagian tersebut, sehingga perlu ditangani untuk mengubahnya menjadi 1 + 𝐷𝑓(𝑖, 𝑗).
Setelah itu akan melakukan perhitungan nilai pada TF-IDF yang dapat dijadikan sebagai pembobotan kata pada saat dilakukan pengelompokan data. Untuk menghitungan TF-IDF menggunakan rumus persamaan 3.
𝑇𝐹 − 𝐼𝐷𝐹(𝑖, 𝑗, 𝐷) = 𝑡𝑓(𝑖, 𝑗)𝑥𝑖𝑑𝑓(𝑖, 𝐷) (3)
2.6 Principal Component Analysis (PCA)
Algoritma Principal Component Analysis (PCA) adalah algoritma untuk mereduksi dimensi atau variabel dengan mengubah kumpulan dimensi yang saling berkorelasi menjadi dimensi yang tidak saling berkorelasi. Algoritma ini nantinya akan menghasilkan nilai yang disebut sebagai Principal Component (PC). Data PC tersebut adalah kombinasi linier dari nilai-nilai asli sebelum dilakukan reduksi[21]. Komponen utama diperoleh dengan memproyeksikan vektor ke dalam ruang yang ditentukan oleh vektor eigen[7].
Perhitungan algoritme PCA dapat dirumuskan sebagai berikut : 1) Menghitung covarian matrix :
𝑐 = 1
𝑛 = ∑𝑛𝑖=1𝑌𝑇𝑌 (4)
2) Mencari nilai eigen dan vektor eigen :
(𝜆𝐼 − 𝐴)𝑉 = 0 (5) 3) Compute Reduction Percentage :
𝑠𝑢𝑚𝜆 = 𝜆1+ 𝜆2+ 𝜆3 (6)
4) Principal Components :
𝑃𝐶 = 𝑌 × 𝑉 (7)
Banyaknya jumlah dari komponen utama atau component dapat ditentukan bersasarkan jumlah nilai eigen yang telah dipilih. Semisal hanya menginginkan satu komponent yang mengandung varians paling banyak, maka dapat memilih nilai eigen yang terbesar[7].
2.7 Naïve Bayes Classifier
Naïve Bayes Classifier merupakan metode yang memiliki dasar perhitungan matematis yang sangat kuat dan dalam efisiensi klasifikasi juga stabil. Metode ini juga salah satu method yang sering digunakan untuk mengkategorikan teks dengan frekuensi kata sebagai fitur. Dapat diambil kesimpulan bahwa fitur yang independen dapat dipastikan dalam algoritme klasifikasi menjadi lebih efektif[11].
Klasifikasi Naïve Bayes adalah suatu metode supervised document classification yang berarti dalam pengklasifikasian dibutuhkan data latih, mempunyai beberapa keunggulan yaitu sederhana, cepat, dan akurasi yang lumayan tinggi[8]. Perumpamaan Naïve Bayes dapat dirumuskan:
𝑃(𝐻|𝑋) =𝑃(𝑋|𝐻)𝑃(𝐻)
𝑃(𝑋) (8)
Ket:
X = data class yang belum diketahui
H = Hipotesa bahwa X adalah data dengan kelas/label
P(X|H) = Peluang data sampel X, bila diasumsikan hipotesa H benar P (H) = Peluang dari hipotesa H (likelihood)
P (X) = Peluang dari data sampel yang diamati (evidence)
2.8 Confusion Matrix
Evaluasi yang akan dilakukan dalam penelitian menggunakan confusion matrix, yaitu suatu metode yang digunakan untuk melakukan perhitungan nilai akurasi[7].
Confusion matrix berisikan informasi mengenai aktual dan prediksi yang diberikan oleh classifier[22]. Perumpamaan confusion matrix adalah sebagai berikut:
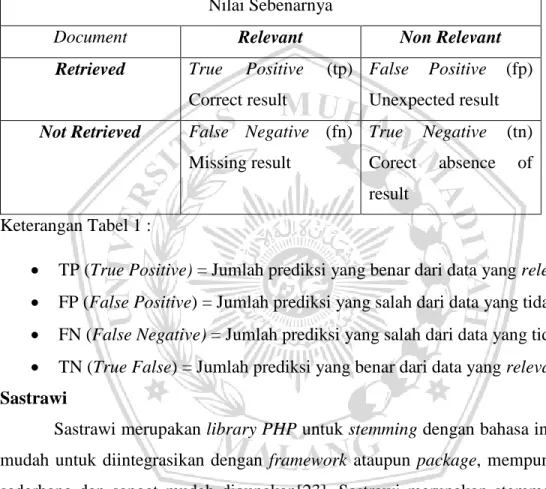
Tabel 1. Rumus confusion matrix Nilai Sebenarnya
Document Relevant Non Relevant
Retrieved True Positive (tp) Correct result
False Positive (fp) Unexpected result Not Retrieved False Negative (fn)
Missing result
True Negative (tn) Corect absence of result
Keterangan Tabel 1 :
TP (True Positive) = Jumlah prediksi yang benar dari data yang relevant.
FP (False Positive) = Jumlah prediksi yang salah dari data yang tidak relevant.
FN (False Negative) = Jumlah prediksi yang salah dari data yang tidak relevant.
TN (True False) = Jumlah prediksi yang benar dari data yang relevant 2.9 Sastrawi
Sastrawi merupakan library PHP untuk stemming dengan bahasa indonesia, yang mudah untuk diintegrasikan dengan framework ataupun package, mempunyai API yang sederhana dan sangat mudah digunakan[23]. Sastrawi merupakan stemmer yang sudah mengalami perbaikan dan merupakan yang terbaru, karena dibangun dari algoritma NA maka dari itu komputasinya tinggi dan bisa jadi lebih rendah dari NA original[24].
2.10 Python
Python adalah bahasa pemrograman yang bersifat open source. Python banyak digunakan karena bahasa ini memiliki banyak keunggulan terutama dalam pemrograman bebasis machine learning[25]. Merupakan bahasa program yang sangat mudah dibaca dan juga terstruktur, hal ini dikarenakan digunakannya sistem identasi. Python mempunyai
efisiensi yang tinggi untuk struktur data tingkat tinggi, pemrograman objek yang sederhana namun efektif dan dapat bekerja pada banyak platform.