6
BAB II
LANDASAN TEORI
2.1 Data Mining
Data mining mengacu pada proses ekstraksi atau “menggali” pengetahuan
dari sekumpulan data yang besar. Data mining mempunyai nama lain yang dikenal secara popular dengan sebutan Knowledge Discovery from Data (KDD). Proses Knowledge Discovery adalah sebagai berikut (Han,2006,pp 5-7) :
1. Data Cleaning
Berguna untuk menghilangkan noise dan data yang tidak konsisten
2. Data Integration
Dimana data yang berasal dari sumber data yang lebih dari satu dapat dikombinasikan.
3. Data Selection
Dimana data relevan terhadap tugas analisa yang didapat dari database.
4. Data Transformation
Dimana data diubah atau dikonsolidasi menjadi bentuk yang tepat untuk dilakukan mining dengan kesimpulan dan operasi aggregasi.
5. Data Mining
Proses dimana metode intelligent di terapkan untuk melakukan ekstraksi terhadap pola data.
6. Pattern Evaluation
Melakukan identifikasi terhadap pola data yang merepresentasikan
knowledge base didalam suatu ukuran.
7. Knowledge Presentation
Dimana visualisasi dan teknik representasi dari sebuah knowledge digunakan untuk knowledge dari user dimasa sekarang.
2.2 Proses Data Mining
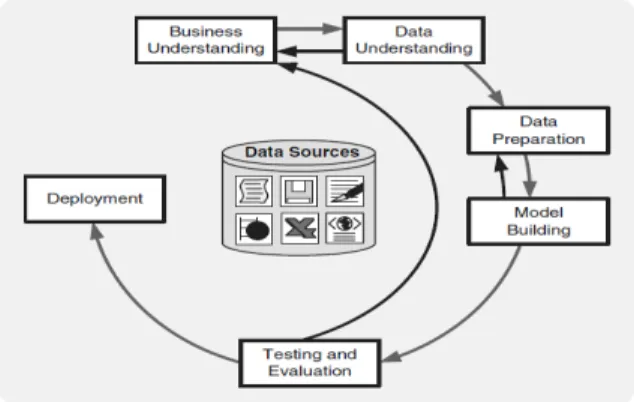
2.2.1 CRISP- DM
Model Cross- Industry Standard Process for Data Mining (CRISP-DM) banyak digunakan di berbagai industry (Olson,2008,pp 9-18). Model ini terdiri dari 6 tahap proses :
1. Business Understanding
Pada tahap ini pemahaman bisnis meliputi penentuan tujuan bisnis, menilai situasi saat ini, menetapkan tujuan dari data mining, dan mengembangkan rencana proyek.
2. Data understanding
Setelah tujuan bisnis dan rencana proyek dibuat, tahap ini akan mempertimbangkan tentangkebutuhan data. Langkah ini dapat mencakup pengumpulan awal data, deskripsi data, eksplorasi data, dan verifikasi dari kualitas data.Data eksplorasi seperti melihat ringkasan statistik dapat terjadi pada akhir fase ini. Model analisis cluster dapat diterapkan selama tahap ini, dengan maksud mengidentifikasi pola-pola dalam data.
3. Data preparation
Setelah sumber data yang tersedia diidentifikasi, data harus dipilih, dibersihkan, dibangun ke dalam bentuk yang diinginkan, dan di beri format.Pembersihan data (Data Cleaning) dan transformasi data dalam persiapan data pemodelan terjadi pada fase ini.Data eksplorasi pada kedalaman yang lebih besar dapat diterapkan selama fase ini, dan model tambahan digunakan, untuk menyediakan kesempatan untuk melihat pola yang didasarkan pada pemahaman bisnis.
4. Modeling
Tools untuk data miningseperti visualisasi (plotting data dan membangun
variabel-variabelyang berjalan dengan baik bersama-sama) yang berguna untuk analisisawal. Tools seperti induksi aturan umum dapat mengembangkan aturan asosiasi awal.Setelah pengertian tentang data didapatkan (seringkali melalui
pattern recognition yang dapat dilihat berdasarkan output dari model), model
lebih rinci sesuai dengan tipe data dapat diterapkan. Pembagian data menjadi
training set dan test set juga dibutuhkan untuk pemodelan.
5. Evaluation
Hasil dari model harus dievaluasi dalam konteks sasaran bisnisyang telah didirikan pada tahap pertama (Business Understanding). Hal ini akan mengarah pada identifikasi kebutuhan lainnya (terkadang melalui pattern recognition), atau kepada fase sebelumnya CRISP-DM. Mendapatkan pemahaman akan bisnis merupakan prosedur iterasi dalam data mining, di mana hasil dari berbagai visualisasi, statistik, dan alat kecerdasan buatan menunjukkan hubungan pengguna baru yang memberikan pemahaman yang lebih dalam operasi suatu organisasi.
6. Deployment
Data mining dapat digunakan untuk melakukan verifikasi yang dihasilkan dari hipotesis, atau untuk knowledge discovery (identifikasi tak terduga dan hubungan yang bermanfaat). Melalui knowledge discovery difase awal dari proses CRISP-DM, model dapat diperoleh yang kemudian dapat diterapkan pada operasi bisnis untuk berbagai tujuan, termasuk prediksi atau identifikasi situasi kunci. Model ini perlu dipantau untuk perubahan kondisi dari sebuah
operasi, karena apa mungkin benar hari ini mungkin tidak benar ditahun berikutnya. Bila perubahan signifikan memang terjadi, model harus diulang.
2.3 Strategi Data Mining
2.3.1 Supervised Learning
Supervised Learning membangun sebuah model dengan menggunakan
sebuah variabel, Langkah pertama sebuah algoritma akan menyediakan sebuah
training set data dimana mencakup nilai-nilai sebelum diklasifikasikan dari
variabel target selain prediktor. Langkah kedua yaitu untuk menguji bagaimana model data mining sementara pada tes data set. Dalam melakukan tes set, ketidaksepakatan data set, nilai-nilai sementara variabel target yang tersembunyi dari model sementara, kemudian melakukan klasifikasi menurut pola dan struktur itu kemudian dipelajari dari pelatihan yang ditetapkan.Manfaat dari klasifikasi kemudian dievaluasi dengan membandingkan terhadap nilai-nilai sebenarnya dari variabel target sementara model data mining kemudian disesuaikan untuk meminimalkan tingkat kesalahan pada tes ditetapkan.(Larose, 2005, pp 91-92).
Beberapa metode supervised yaitu decision trees, neural network,
2.3.2 Unsupervised Learning
Dalam metode unsupervised learning, tidak ada variabel target yang di identifikasi dengan demikian. Sebaliknya, algoritma pencarian data mining untuk pola dan struktur di antara semua variabel. Metode unsupervisedadalah
clustering.
2.4 Klasifikasi dan Prediksi
Klasifikasi adalah sebuah proses untuk mencari model atau fungsi yang menjelaskan dan membedakan kelas atau konsep dari data, dengan tujuan untuk menggunakan model dan melakukan prediksi dari kelas suatu objek dimana tidak diketahui label dari kelas tersebut. Model yang ada berasal dari analisis dari kumpulan training data (objek data dimana kelas dari label diketahui) (Han,2006,pp 24-26)
Derived model dapat direpresentasikan di berbagai macam bentuk, seperti
aturan klasifikasi (IF-THEN) ,decision trees, mathematical formula, atau neural
network. Decision tree adalah seperti flow chart tree structure, dimana setiap node
test dari nilai atribut, setiap cabang merepresentasikan output dari test dan daun pohon merepresentasikan kelas atau distribusi dari kelas.Neural network, ketika digunakan untuk klasifikasi adalah sebuah koleksi dari neuron like processing unit dengan weighted connections diantara unit. Banyak metode untuk melakukan konstruksi terhadap model klasifikasi, seperti naïve Bayesian classification,
2.4.1 Feature Selection
Pengertian feature selection menurut (Martin Seweel,2007) adalah sebuah proses yang bisaa digunakan pada machine learning dimana sekumpulan dari features yang dimiliki data digunakan untuk pembelajaran algoritma. Subset yang baik memiliki sedikitnya dimensi angka yang paling banyak berkontribusi untuk akurasi dan nantinya akan dibuangnya sisa dari dimensi yang tidak berkepentingan. Ini merupakan langkah penting dalam tahap preprocessing dan salah satu cara untuk menghindari curse of dimentionality.
Forward selection dimulai tanpa variabel dan menambahkan mereka satu
persatu, pada setiap langkah ditambahkan variabel yang menurunkan error paling banyak, sampai semua error dihilangkan.
Backward selection dimulai dengan semua variabel dan membuangnya satu
persatu, pada setiap langkah membuang variabel yang membuang error paling banyak sampai semua error dihilangkan.
Untuk menghilangkan overfitting, kesalahan yang disebutkan diatas adalah kesalahan pada validasi yang berbeda dari training set.
2.4.1.1Variance of Variable Subset Selection
Menurut (Isabelle Guyon dan Andree elisseff,2003) banyak metode dari
variable subset selection sensitif terhadap gangguan kecil saat dilakukan
percobaan. Jika terdapat variable yang bersifat redundan, himpunan bagian yang berbeda dari variable dengan prediksi yang identic dapat diperoleh sesuai dengan kondisi awal dari algoritma atau tambahan dari beberapa variable atau contoh
training. Untuk sebagian aplikasi, seseorang bertujuan menghasilkan subset yang dpat disajikan pada tahap proses berikutnya tetapi terkadang masih terdapat varian yang tidak diinginkan karena varian memiliki model yang buruk yang tidak tergeneralisasi dengan baik, hasil tidak dapat diproduksi kembali, dan subset tersebut gagal untuk mengambarkan keseluruhan gambaran.
Salah satu metode untuk melakukan stabilisasi dengan menggunakan beberapa “bootstraps“. Proses variable selection dilakukan berulang dengan sub
sample dari training data. Gabungan subset yang terdiri dari beberapa variable di bootstrap yang berbagai macan diambil sebagai subset yang stabil
2.4.1.2Supervised Feature Selection
Ulasan tentang 3 pendekatan untuk memilih features dimana features harus dibedakan dari variabel karena keduanya muncul bersamaan disistem yang sama (Isabelle Guyon dan Andree elisseff,2003) :
1. Nested subset methods.
Sejumlah extract features dari learning machines sebagai bagian dari proses pembelajaran. Hal ini termasuk neural network dimana
internal nodes nya merupakan feature extractors.
2. Filters
Torkkola (2003) mengajukan metode filter untuk menbangun
features menggunakan mutual information criterion. Penulis
vektor y. Melakukan modeling pada fungsi kepadatan fitur dengan Parzen
windows memperbolehkan komputasi derivatif yang dimana bersifat transform independent.. Kemudian digabungkan dengan
transform-dependent derivatives , dibuat algoritma gradient keturunan untuk melakukan optimasi parameter w dari transform
3. Direct objective optimization
Metode kernel memiliki fitur ruang implisit yang diungkapkan
oleh : adalah feature vector yang
terbatas dimensi. Memilih fitur yang implisit dapat meningkatkan generalisasi, tetapi tidak mengubah waktu yang berjalan.Didalam kasus ini. Weston et al (2003) mengusulkan metode untuk memilih kernel
feature secara implisit dengan polynomial kernal, menggunakan kerangka
dari minimisasi L0-norm.
2.4.2Support Vector Machine
Menurut (Habib,2008) Support Vector Machines adalah sebuah metode baru yang menjanjikan untuk klasifikasi baik data linier dan nonlinier. Dalam Singkatnya, Support Vector Machine (atau SVM) adalah algoritma yang bekerja sebagai berikut. Menggunakan pemetaan nonlinier untuk mengubah training data ke dimensi yang lebih tinggi. Dalam dimensi baru ini akan dicari sebuah optimal
l m y d h d
2
m r k k n m | E y " t d b linear yang memisahkan yang sesuai dengan seb hyperplane dan margin (2.4.2.1 Su
Menu merupakan m rekan di lab kami memil kita memilik negatif (a "m menunjukan |w| |adalah j Euclidean d yang memis "margin" da terpisah, alg dengan mar bahwa semu g memisah n tuple dari ke dimensi buah hyper tersebut me (didefinisikaupport Ve
urut (Madz metode klas oratorium B liki pelatihan ki beberapa memisahkan n wx+b=0, d jarak tegak dari w. Dian sahkan ke c ari hyperpla goritma duk rgin terbesa ua data pelati hkan hyper satu kelas cukup tingg rplane.Suppo enggunakan an oleh vektoector Mac
zarov,et.al,20 sifikasi biner Bell (Vladim n titik data: hyperplane n hyperplane imana w ada lurus dari ndaikan d+( contoh posit ane yang te kungan vek r. Hal ini d ihan memen rplane (yai dari yang l gi, data dariort Vector dukungan v or dukungan
chineFor
009,pp 233 r yang dikem mir,1998) (Bu {xi, yi}, i= yang memi e"). Titik-tit alah keadaan hyperplane (d-) menjadi tif (negatif) erpisah men ktor hanya dapat dirum nuhi batasan itu, sebuah lain). Denga dua kelas s r Machine vektor ("pen n).r Pattern
3-241) Supp mbangkan o urges,1998). 1,..., l,yi={-isahkan posi tik x yang t n normal unt ke asal, da i jarak terpe terdekat. m njadi d++d-terlihat me muskan seba sebagai beri h "batas k an pemetaan selalu dapat menemuka nting" pelatiRecognit
port Vector leh Vapnik . Untuk mas 1, 1}, xi,Rd itif dari con terdapat di h tuk hyperpla an| |w| |adal endek dari h misalnya. Did -. Untuk ka emisahkan h agai berikut ikut: keputusan" n nonlinier dipisahkan an bahwa ihan tupel)tion
r Machine dan rekan-salah biner, d. Misalkan ntoh contoh hyperplane ane itu, |b|/| lah bentuk hyperplane definisikan asus linear hyperplane : dianggapH P ( w n y d = S k m m
Hal ini dapa
Perhatikan ti (1) holds (m w dan b. Ti normal dan yang setara d denganw no = d-= 1 / | | w Support Vec keadaan yan mereka. De memberikan atdigabungka itik-titik kes membutuhkan itik-titik yan jarak tegak dalam Persa rmal dan jar w | | dan mar Gam kasus ya ctor dilingka ng sama nor ngan demik n margin mak an menjadi s setaraan dala n adanya poi ng terdapat lurus dari ti amaan. (2)ho rak tegak lur rgin adalah h mbar 2.2 Lin ang terpisah ari. Perhatika rmal) dan b kian kita da ksimal deng satusetdari pe am Persamaa in a) adalah di hyperplan itik asal | 1-olds terdapat rus dari asal hanya 2 / | | w near separat .(Madzarov, an bahwa H ahwa tidak apat menem gan meminim ertidaksama an. setara denga ne H1: xi w -b | / | | w | t di H2 hyper |-1-b | / | | w w | |. ting hyperpla ,et.al,2009,p 1 dan H2 sej ada titik pe mukan sepasa malkan | |w| |2 an: an memilih s w • + b = 1 |. Demikian rplane: b w w | |. Oleh kar ane untuk pp 234) jajar (merek elatihan jatuh ang hyperpl 2. skala untuk dengan w pula, poin xi + • = -1, rena itu d + ka memiliki h di antara lanes yang
2.4.2.2 Teknik Multiclass Support Vector Machine
2.4.2.2.1One-against-all (OvA)
Menurut (Habib,2008) Untuk masalah N-kelas (N>2), N two-class SVM
Classifiers dibangun (Vladimir,1999). SVM dilatih ketika proses labeling sampel
didalam contoh kelas positif dan sisanya contoh kelas negatif .Dalam fase pengakuan, contoh uji disajikan kepada semua NSVMs dan diberi label menurut output maksimum antara pengklasifikasiN. Kerugian dari metode ini adalah kompleksitas pelatihan, jumlah pelatihan sample tergolong besar. Setiap pengklasifikasi N dilatih menggunakan semua sampel yang tersedia.
2.4.2.2.2One-against-one (OvO)
Algoritma ini membangun N (N-1) / 2 two-class classifiers, menggunakan semua pasangan- kombinasi binary pair-wise dari kelas N. Setiap classifier dilatih dengan menggunakan sampelkelas pertama sebagai contoh positif dan sampelkelas dua sebagai contoh negatif. Untuk menggabungkan penggolong, algoritma Max Wins digunakan. Ditemukan kelas yang dihasilkan dengan memilih kelas dipilih oleh mayoritas pengklasifikasi (Friedman,1997). Jumlah sample digunakan untuk pelatihan masing-masing dari pengklasifikasi 0v0 adalah lebih kecil, karena sampel hanya dari dua dari semua kelas N diambil dengan pertimbangan. Jumlah sampel yang lebih rendah menyebabkan non linieritas yang kecil, sehingga waktu pelatihan lebih singkat.Kerugian dari metode ini adalah bahwa setiap tes sampel harus disampaikan kepada sejumlah besar penggolong N
(N-1) / 2.Hal ini mengakibatkan pengujian lebih lambat, terutama ketika jumlah kelas dalam masalah besar (Xu,2003,pp 1116-1119).
2.5Confusion Matrix
Menurut (Neila et al, 2012) metode klasifikasi akan dilakukan evaluasi terutama pada bagian akurasi dari hasil klasifikasi. Akurasi sebuah klasifikasi berpengaruh terhadap performa dari suatu klasifikasi.Untuk melakukan analisa dapat digunakan confusion matrix yaitu sebuah matrik dari prediksi yang akan dibandingkan dengan kelas yang asli dari data inputan. Sebagai contoh, sebuah test (i,j) dari sebuah confusion matrix adalah persentase dari waktu dari sebuah
classifier yang melakukan identifikasi input I sebagai pattern dari kelas j. Setiap
kolom dari matriks berkorespondensi kepada classifier output dan setiap baris pada input. Akurasi sebuah klasifikasi dimana i=j menerangkan akurasi dari klasifikasi pada setiap kelas.
2.6Telemarketing
Menurut (Mehrotra, A., & Agarwal, R.,2009) telemarketing merupakan proses interaktif antara perusahaan dan pelanggannya menggunakan media sistem yang komprehensif untuk mendapatkan respon dari pelanggan. Hal tersebut merupakan seni dan ilmu dari mendapatkan penawaran yang tepat, pelanggan yang tepat diwaktu yang tepat untuk memenuhi kebutuhan pelanggan akan produk dan servis.Telemerketing banyak digunakan di banyak industri termasuk perusahaan telekomunikasi, perbankan, asuransi, dan lainnya. Telemarketing merupakan metode yang lebih dominan dari direct marketing yang digunakan oleh banyak perusahaan untuk mendapatkan pelanggan dengan cara melakukan
hubungan antar pelanggan dan sales person yang terbentuk melalui percakapan telepon.
Terdapat 2 macam tipe dari telemarketing yaitu inbound dan outbound .
Inbound marketing adalah ketika pelanggan dihubungi oleh perusahaan melalui
telepon dengan tujuan mengadukan komplain, mendapatkan informasi dan lainnya. Sedangkan outbound telemarketing adalah ketika perusahaan menghubungi pelanggan untuk menjual produk, melihat riset pasar dan lain lain.Telepon merupakan medium paling ideal untuk bangunan dan menjaga hubungan yang dekat dengan pelanggan.Telemarketing yang efektif membutuhkan kualitas data pelanggan yang bagus, kemampuan pengelompokan, dan hasil yang bisa dijelaskan untuk strategi dan melakukan percobaan. Teknologi seperti data mining banyak digunakan oleh perusahaan untuk lebih mengerti pelanggannya lebih baik dan melayani lebih baik.