TUGAS AKHIR
PENGENALAN UCAPAN ANGKA DALAM BAHASA INDONESIA MENGGUNAKAN EKSTRAKSI CIRI MFCC DAN JARINGAN
SYARAF TIRUAN BACKPROPAGATION
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Teknik
Program Studi Teknik Elektro
Oleh :
MEISY FARADHIA NIM : 165114054
PROGRAM STUDI TEKNIK ELEKTRO FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
2020
FINAL PROJECT
INDONESIAN NUMBERS SPEECH RECOGNITION USING MFCC FEATURE EXTRACTION AND BACKPROPAGATION ARTIFICIAL
NEURAL NETWORK
Presented as Partial Fulfilment of the Requirements To Obtain the Sarjana Teknik Degree
In Electrical Engineering Study Program
MEISY FARADHIA NIM : 165114054
ELECTRICAL ENGINEERING STUDY PROGRAM DEPARTMENT OF ELECTRICAL ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
YOGYAKARTA 2020
vi
HALAMAN PERSEMBAHAN
MOTTO :
“Segala perkara dapat kutanggung didalam Dia yang memberi kekuatan kepadaku.”
Filipi 4:13
Persembahan Tugas Akhir ini kupersembahkan kepada Tuhan Yesus Kristus yang selalu memimpin setiap langkahku Kedua orang tua dan keluarga yang selalu mendoakan yang terbaik Dan selalu mendukung dalam segala hal
viii
INTISARI
Ucapan manusia merupakan salah satu gelombang yang sangat unik. Jenis gelombang ucapan manusia beraneka ragam. Berbagai penelitian menemukan inovasi terhadap komputer yang mampu mengenali ucapan manusia. Hal inilah yang memberikan daya tarik penulis untuk membuat sistem pengenalan ucapan. Penulis berfokus kepada pengenalan ucapan angka 0-9 dalam bahasa Indonesia.
Penelitian ini memproses ucapan manusia yang telah terekam. Perekaman dilakukan menggunakan mikrofon. Data perekaman yang sudah dibuat dalam format .wav akan dibagi menjadi 2 yaitu untuk data training dan data testing. Pada data training maupun data testing memiliki jumlah ucapan yang sama sebanyak 200 data. Data tersebut terdiri atas 20 kali perekaman. Masing-masing pengucapan dilakukan sebanyak 10 kali untuk setiap angka 0 hingga 9 dari 2 orang yang berbeda. Proses yang dilakukan untuk sistem pengenalan ucapan angka meliputi pre-processing, ekstraksi ciri MFCC, klasifikasi jaringan syaraf tiruan backpropagation dan penentuan hasil ucapan pengenalan. Jaringan syaraf tiruan backpropagation dilatih dengan algoritma pelatihan gradient descent.
Percobaan dilakukan dengan memvariasi nilai terhadap beberapa parameter jaringan syaraf tiruan diantaranya learning rate, jumlah neuron hidden layer, dan epoch. Hasil pengujian tidak langsung terletak pada variasi learning rate 0,07 dengan jumlah neuron hidden layer 10 dan epoch 500. Hasil pengujian secara real time mendapat rata-rata tingkat pengenalan sebesar 86%.
Kata kunci : Pengenalan Ucapan, Mel Frequency Cepstral Coefficients (MFCC), Jaringan Syaraf Tiruan Backpropagation.
ix
ABSTRACT
Human speech is a very unique wave. Types of human speech waves are various. Many studies have found innovations in computers that are able to recognize human speech. This is what attracts the writer to create a speech recognition system. The author focuses on the recognition of the numbers 0-9 in Indonesian.
This research processes recorded human speech. Recording is done using a microphone. The recording data that has been made in the .wav format will be divided into 2, for training data and testing data. The training data and testing data have the same amount with the speech amount, which are 200 data. The data consists of 20 recordings. Each pronunciation is done 10 times for each number 0 to 9 from 2 different people. The process carried out for the speech recognition system includes pre-processing, MFCC feature extraction, backpropagation neural network classification and determination of speech recognition results. The backpropagation neural network is trained with a gradient descent training algorithm.
Experiments were carried out by varying the values for several parameters of the artificial neural network including learning rate, number of hidden layer neurons, and epoch. The indirect test results lie in the variation of the learning rate 0,07 with the number of hidden layer neurons 10 and epoch 500. The real time test results get an average recognition rate of 86%.
Keywords: Speech Recognition, Mel Frequency Cepstral Coefficients (MFCC), Backpropagation Neural Network.
xii
DAFTAR ISI
LEMBAR PERSETUJUAN ... iii
HALAMAN PENGESAHAN ... iv
LEMBAR PERNYATAAN KEASLIAN KARYA ... v
HALAMAN PERSEMBAHAN ... vi
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS ... vii
INTISARI ... viii
ABSTRACT ... ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR GAMBAR ... xv
DAFTAR TABEL ... xvii
BAB I ... 1
1.1 Latar Belakang ... 1
1.2 Tujuan dan Manfaat Penelitian ... 2
1.3 Batasan Masalah ... 2
1.4 Metodologi Penelitian ... 3
BAB II ... 5
2.1 Ucapan ... 5
2.2 Mikrofon ... 5
2.3 USB Sound Card ... 6
2.4 Sampling ... 7
2.5 Pre-processing ... 8
2.5.1 Pre-emphasis ... 8
xiii
2.5.2 Frame Blocking ... 9
2.5.3 Windowing ... 10
2.5.4 FFT (Fast Fourier Transform) ... 11
2.6 Mel Frequency Cepstral Coefficients (MFCC)... 11
2.7 Jaringan Syaraf Tiruan ... 13
2.7.1 Arsitektur Jaringan Syaraf Tiruan ... 14
2.7.2 Backpropagation ... 14
2.7.3 Fungsi Aktivasi ... 15
2.7.4 Proses Pelatihan Backpropagation ... 16
BAB III ... 19
3.1 Sistem Pengenalan Ucapan ... 19
3.1.1 Proses Pengenalan Ucapan ... 19
3.1.2 Proses Pelatihan ... 20
3.1.3 Proses Pembuatan Data ... 20
3.2 Ucapan Uji ... 22
3.3 Perancangan Perangkat Lunak ... 23
3.3.1 Perancangan Antarmuka Program ... 23
3.3.2 Perancangan Diagram Alir Program... 24
3.3.3 Perancangan Diagram Alir Sub-rutin Perekaman ... 27
3.3.4 Perancangan Diagram Alir Sub-rutin Pre-processing ... 28
3.3.5 Perancangan Diagram Alir Sub-rutin Ekstraksi Ciri MFCC ... 31
3.4 Jaringan Syaraf Tiruan ... 32
BAB IV ... 35
4.1 Pengujian Secara Real Time... 35
4.1.1 Implementasi GUI Sistem Pengenalan Ucapan ... 35
4.1.2 Hasil Pengenalan Ucapan ... 36
4.2 Evaluasi Secara Non Real Time ... 37
xiv
4.3 Tambahan Proses untuk Perbaikan Kinerja ... 40
4.4 Catatan Dalam Metode Penelitian ... 41
BAB V ... 42
5.1 Kesimpulan ... 42
5.2 Saran ... 42
DAFTAR PUSTAKA ... 43 LAMPIRAN 1 ... L-1 LAMPIRAN 2 ... L-2 LAMPIRAN 3 ... L-3
xv
DAFTAR GAMBAR
Gambar 2.1 Microphone Taffware BM-800... 6
Gambar 2.2 Usb sound card ... 6
Gambar 2.3 Sinyal Masukkan ... 7
Gambar 2.4 Sinyal Hasil Pre-emphasis ... 8
Gambar 2.5 Contoh overlapping ... 9
Gambar 2.6 Sinyal Hasil Frame Blocking ... 10
Gambar 2.7 Sinyal Hasil Windowing ... 10
Gambar 2.8 Triangular filterbank dengan mel scale [7] ... 12
Gambar 2.9 Urutan Zig zag Scanning [15] ... 13
Gambar 2.10 Jaringan Lapisan Jamak [6] ... 14
Gambar 2.11 Arsitektur Jaringan Backpropagation [6] ... 15
Gambar 3.1 Blok Sistem Pengenalan Ucapan ... 19
Gambar 3.2 Blok Diagram Pengenalan Ucapan ... 20
Gambar 3.3 Blok Diagram Proses Pelatihan ... 20
Gambar 3.4 Blok Diagram Proses Pembuatan Data ... 20
Gambar 3.5 Blok Diagram Subproses Pre-processing ... 21
Gambar 3.6 Blok Diagram Ekstraksi Ciri MFCC [13] ... 22
Gambar 3.7 Tampilan GUI Sistem Pengenalan Ucapan ... 24
Gambar 3.8 Diagram Alir Training ... 25
Gambar 3.9 Diagram Alir Pengujian Langsung ... 26
Gambar 3.10 Diagram Alir Pengujian Tidak Langsung ... 27
Gambar 3.11 Diagram Alir Sub-rutin Perekaman ... 28
Gambar 3.12 Diagram Alir Sub-rutin Pre-processing ... 28
Gambar 3.13 Diagram Alir Sub-rutin Pre-emphasis ... 29
Gambar 3.14 Diagram Alir Sub-rutin Frame Blocking ... 30
Gambar 3.15 Diagram Alir Sub-rutin Windowing... 30
Gambar 3.16 Diagram Alir Sub-rutin FFT ... 31
Gambar 3.17 Diagram Alir Sub-rutin Ekstraksi Ciri MFCC... 32
Gambar 3.18 Arsitektur JST 1 Hidden Layer ... 33
Gambar 4.1 Hasil Keluaran Pengenalan Ucapan Angka Dua ... 36
xvi
Gambar 4.2 Variasi Learning Rate 0,05 ... 38 Gambar 4.3 Variasi Learning Rate 0,06 ... 39 Gambar 4.4 Variasi Learning Rate 0,07 ... 39
xvii
DAFTAR TABEL
Tabel 2.1 Spesifikasi Microphone Taffware BM-800 ... 6
Tabel 3.1 Data Training... 22
Tabel 3.1 (Lanjutan) Data Training ... 23
Tabel 3.2 Data Testing... 23
Tabel 3.4 Keterangan Tampilan GUI Sistem Pengenalan Ucapan ... 24
Tabel 4.1 Tingkat Pengenalan Rata-Rata Pengujian Real Time ... 36
Tabel 4.1 (Lanjutan) Tingkat Pengenalan Rata-Rata Pengujian Real Time ... 37
Tabel 4.2 Hasil Tingkat Pengenalan Dengan Learning Rate 0,05 Tanpa Normalisasi ... 41
Tabel 4.3 Hasil Tingkat Pengenalan Dengan Learning Rate 0,06 Tanpa Normalisasi ... 41
Tabel 4.4 Hasil Tingkat Pengenalan Dengan Learning Rate 0,07 Tanpa Normalisasi ... 41
1
1 BAB I
PENDAHULUAN
1.1 Latar Belakang
Setiap manusia mempunyai ucapan yang berbeda-beda, ada yang bernada tinggi, rendah, lembut dan serak. Bentuk dan ukuran tebal tipisnya pita suara yang dimiliki setiap orang dapat membedakan suara seseorang terdengar tinggi, rendah lembut dan serak. Ucapan manusia dapat dikatakan unik karena setiap orang memliki ucapan yang berbeda-beda maka ada beberapa hal yang harus diperhatikan dalam mengimplementasikan pengenalan ucapan yaitu seperti derau atau noise, frekuensi ucapan yang berubah-ubah, pola kata yang diucapkan, serta mengklarifikasi kata-kata yang diucapkan tersebut. Tidak semua manusia dapat mendengar ucapan dengan baik maka diperlukan adanya inovasi teknologi yang memungkinkan para penyandang cacat fisik dapat mengenali setiap ucapan manusia.
Penelitian ini mengidentifikasi suatu sistem yang dapat mengenali ucapan manusia berupa tulisan.
Metode yang dibuat ini merupakan salah satu aplikasi pengenalan ucapan (speech recognition), yaitu sebuah pengembangan sistem yang memungkinkan komputer untuk dapat menerima masukan berupa kata yang diucapkan. Teknologi pengenalan ucapan saat ini telah mengalami perkembangan cukup pesat. Pengenalan ucapan merupakan suatu pengembangan teknik dan sistem yang memungkinkan komputer untuk menerima masukkan berupa kata yang diucapkan. Teknologi ini memungkinkan suatu perangkat untuk mengenali ucapan dengan cara digitalisasi kata dan menyelarasan sinyal digital tersebut dengan pola tertentu yang tersimpan dalam suatu perangkat [3].
Sebelumnya telah dilakukan penelitian tentang pengenalan ucapan menggunakan ekstraksi ciri FFT dan fungsi similaritas [1] dan sistem pengenalan suara untuk menganali perintah suara menggunakan jaringan syaraf tiruan backpropagation [16]. Proses identifikasi ucapan sangat diperlukan untuk mengetahui keakuratan ucapan berdasarkan ciri yang dimiliki, karena beberapa manusia memiliki kemiripan dalam berucap. Adapun metode ekstraksi ciri yang digunakan adalah Mel Frequency Cepstral Coefficients (MFCC) dan proses identifikasi atau proses pembelajaran menggunakan jaringan syaraf tiruan backpropagation.
1.2 Tujuan dan Manfaat Penelitian
Tujuan dari penelitian tugas akhir ini adalah membuat sistem pengenalan ucapan angka dengan menggunakan ekstraksi ciri MFCC dan jaringan syaraf tiruan backpropagation. Manfaat dari penelitian ini adalah sebagai refrensi pengembangan alat bantu pendengaran manusia yang kurang sempurna, sehingga dapat diganti dengan membaca hasil identifikasi suara.
1.3 Batasan Masalah
Sistem pengenalan ucapan terdiri dari perangkat keras (hardware) dan perangkat lunak (software). Hardware yang digunakan berupa microphone dan usb sound card yang tersedia dipasaran, sedangkan software yang digunakan adalah octave.
Pada pengerjaan tugas akhir ini penulis fokus pada sistem pembuatan perangkat lunak komputer untuk memproses pengenalan ucapan manusia. Agar pengerjaan tugas akhir ini lebih terfokus pada tujuan yang telah ditetapkan maka perlu adanya batasan masalah.
Batasan-batasan masalah tersebut yaitu sebagai berikut:
a. Sinyal masukan berupa ucapan angka.
b. Ucapan angka yang dikenali nol, satu, dua, tiga, empat, lima, enam, tujuh, delapan, dan sembilan dalam bahasa Indonesia, pengucapan selain angka tersebut akan tetap dikenali nol, satu, dua, tiga, empat, lima, enam, tujuh, delapan, atau sembilan.
c. Ucapan yang dikenali dari 2 orang.
d. Menggunakan perangkat lunak komputasi (Octave) dalam pembuatan program.
e. Menggunakan MFCC sebagai ekstraksi ciri.
f. Menggunakan jaringan syaraf tiruan backpropagation sebagai proses identifikasi atau proses pembelajaran ucapan.
g. Variasi jumlah hidden layer yang digunakan satu hidden layer.
h. Hasil pengenalan tidak mengakomodasi error.
i. Memakai jenis microphone taffware BM 800 dengan jarak pengucapan kurang lebih 5cm dari bibir pembicara.
j. Keluaran berupa teks di layar monitor.
1.4 Metodologi Penelitian
Langkah-langkah dalam pengerjaan tugas akhir:
a. Studi literatur
Pengumpulan bahan-bahan refrensi berupa buku-buku dan jurnal-jurnal ilmiah mengenai pengolahan ucapan, pemrograman matlab maupun octave, metode jaringan syaraf tiruan backpropagation dan ekstraksi ciri MFCC (Mell Frequency Cepstral Coefficient). Studi literatur dilakukan untuk mempelajari lebih dalam metode yang digunakan yaitu ekstraksi ciri Mell Frequency Cepstral Coefficient dan proses pembelajaran jaringan syaraf tiruan backpropagation.
b. Perancangan software
Perancangan dilakukan pada software octave. Melalui tahap ini penulis merancang tampilan GUI beserta rangkaian-rangkaian pendukung untuk setiap proses pengenalan ucapan. Hal ini dilakukan untuk mengetahui terlebih dahulu garis besar proses pengenalan ucapan.
c. Pembuatan software
Pembuatan software dilakukan untuk mengimplementasikan perancangan yang telah dilakukan pada tahap sebelumnya. Sistem akan bekerja apabila user memberikan interupsi melalui komputer dengan media push button yang sudah disediakan dalam perangkat lunak. Sistem akan mengolah interupsi yang diterima dan memulai proses perekaman sampai user memberikan interupsi kembali untuk menghentikan proses perekaman. Setelah itu user memberikan interupsi untuk memulai proses pengenalan ucapan. Komputer akan mengolah ucapan dan ditampilkan berupa teks pada layar monitor.
d. Pengambilan data
Proses pengambilan data ucapan manusia yang digunakan untuk proses pelatihan (training) maupun proses pengujian (testing). Pengucapan dilakukan oleh 2 orang, salah satunya adalah penulis sendiri.
e. Analisa dan kesimpulan
Analisa dilakukan untuk mengetahui potensi keberhasilan penelitian mengenali beberapa ucapan angka dalam bahasa Indonesia. Analisa dilakukan dengan pendataan dari hasil akurasi terhadap setiap kondisi variasi nilai dan variable data yang ditentukan seperti hidden layer, epoch dan learning rate. Analisa dan
pembahasan dilakukan dengan mengamati persentase error dari percobaan pengenalan ucapan berdasarkan pengaruh variasi nilai-nilai variabel datanya.
5
2 BAB II DASAR TEORI
2.1 Ucapan
Manusia memiliki beragam jenis nada ucapan. Frekuensi uacapan yang dapat didengar oleh manusia antara 20 sampai 20.000 Hz. Range ini berbeda-beda secara individu dan umumnya tergantung usia [2]. Sistem pengenalan ucapan ini merupakan pengenalan ucapan manusia sebagai input yang kemudian diproses melalui komputer. Ucapan yang terekam akan disimpan dalam bentuk .wav sebelum dilanjutkan ke tahap selanjutnya.
Proses terbentuknya ucapan pada manusia dapat terjadi ketika udara yang dikeluarkan oleh paru-paru menggerakkan pita suara. Gerakan membuka dan menutup pita suara dapat menyebabkan udara di sekitar pita suara tersebut bergetar. Perubahan bentuk saluran suara yang terdiri atas rongga faring, rongga mulut, dan rongga hidung menghasilkan bunyi atau nada yang berbeda-beda. Sinyal ucapan terdiri dari serangkaian suara yang masing-masing menyimpan sepotong informasi [5].
Pada penelitian ini ucapan yang akan dikenali dari 2 orang salah satunya penulis sendiri. Ucapan yang akan dikenali adalah ucapan angka yaitu nol, satu, dua, tiga, empat, lima, enam, tujuh, delapan, dan sembilan. Selain ucapan angka yang telah ditentukan, akan tetap dikenali sebagai nol, satu, dua, tiga, empat, lima, enam, tujuh, delapan, atau sembilan.
2.2 Mikrofon
Pada penelitian ini, peneliti menggunaka mikrofon taffware BM-800 yang merupakan jenis mikrofon kondenser berstandart professional yang dapat membantu menghasilkan rekaman suara yang jernih. Mikrofon ini bertujuan untuk menangkap ucapan yang diucapkan kemudian diteruskan ke proses selanjutnya. Gambar 2.1 menujukkan jenis mikrofon yang digunakan dan tabel 2.1 menunjukkan spesifikasi dari microphone taffware BM-800.
Gambar 2.1 Microphone Taffware BM-800 Tabel 2.1 Spesifikasi Microphone Taffware BM-800
Connection XLR-to-Jack 3.5mm
Frequency Response 20Hz-20kHz
Dimension
Microphone Length: 15.15cm Microphone Diameter: 4cm
Cable Length: 250cm
2.3 USB Sound Card
Usb sound card adalah alat penghubung komputer dengan microphone yang berfungsi mengubah sinyal analog menjadi sinyal digital kemudian diolah untuk proses pengenalan pada octave. Usb sound card yang digunakan adalah jenis sound card USB virtual 7.1 channel dengan chipset China. Gambar 2.2 menunjukkan model usb sound card yang digunakan oleh penulis.
Gambar 2.2 Usb sound card
2.4 Sampling
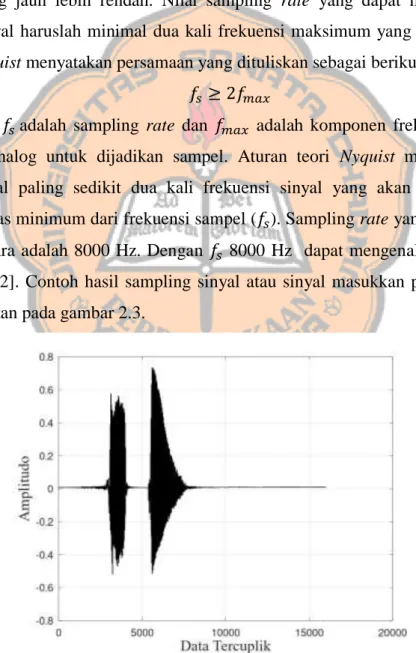
Sampling adalah proses pencuplikan gelombang suara yang akan menghasilkan gelombang diskret. Proses sampling ada yang disebut dengan laju pencuplikan (sampling rate). Pada saat proses sampling, nilai frekuensi sampling harus diperhatikan. Frekuensi sampling merupakan laju pengambilan yang menandakan banyak pengambilan sinyal analog dalam satu detik. Sampling rate menandakan banyaknya jumlah sampel dalam satuan Hertz (Hz) yang diambil dalam satuan waktu (detik). Sampling rate menandakan banyaknya pencuplikan gelombang analog dalam 1 detik [10].
Sinyal ucapan yang hanya berisi ucapan manusia (speech signal) dapat di sampling pada nilai yang jauh lebih rendah. Nilai sampling rate yang dapat menangkap semua komponen sinyal haruslah minimal dua kali frekuensi maksimum yang ada dalam sinyal.
Pada teori Nyquist menyatakan persamaan yang dituliskan sebagai berikut:
𝑓𝑠 ≥ 2𝑓𝑚𝑎𝑥 (2.1)
dengan 𝑓𝑠 adalah sampling rate dan 𝑓𝑚𝑎𝑥 adalah komponen frekuensi maksimum sinyal suara analog untuk dijadikan sampel. Aturan teori Nyquist menyatakan bahwa frekuensi sinyal paling sedikit dua kali frekuensi sinyal yang akan di sampling dan merupakan batas minimum dari frekuensi sampel (𝑓𝑠). Sampling rate yang digunakan pada pengenalan suara adalah 8000 Hz. Dengan 𝑓𝑠 8000 Hz dapat mengenali ucapan manusia dengan baik [12]. Contoh hasil sampling sinyal atau sinyal masukkan pengucapan angka satu diperlihatkan pada gambar 2.3.
Gambar 2.3 Sinyal Masukkan
2.5 Pre-processing
Pre-processing adalah proses-proses awal yang dilakukan sebelum proses ekstraksi ciri. Tujuan dari pre-processing ini adalah untuk menyetarakan sinyal ucapan masukkan agar lebih mudah diproses untuk pencocokan pengenalan angka. Pre-processing terdiri dari beberapa proses yaitu pre-emphasis, frame blocking, hamming window, dan FFT.
2.5.1 Pre-emphasis
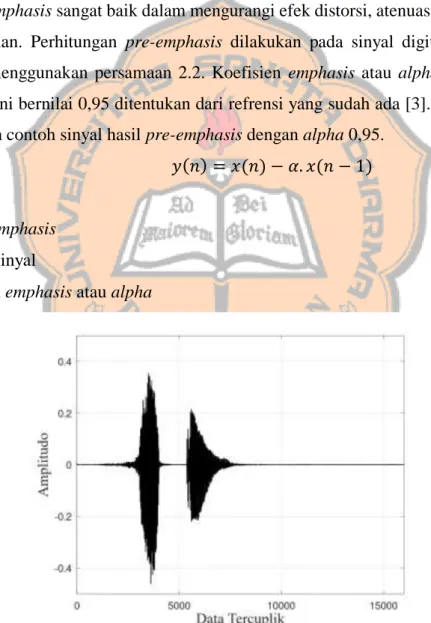
Pre-emphasis merupakan salah satu jenis filter yang sering digunakan sebelum sebuah signal diproses lebih lanjut [4]. Pre-emphasis bertujuan untuk memberikan penekanan pada frekuensi tinggi dan menghilangkan frekuensi rendah yang lemah [11].
Proses pre-emphasis sangat baik dalam mengurangi efek distorsi, atenuasi, dan saturasi dari media rekaman. Perhitungan pre-emphasis dilakukan pada sinyal digital dalam domain waktu dan menggunakan persamaan 2.2. Koefisien emphasis atau alpha yang digunakan pada proses ini bernilai 0,95 ditentukan dari refrensi yang sudah ada [3]. Pada Gambar 2.4 menunjukkan contoh sinyal hasil pre-emphasis dengan alpha 0,95.
𝑦(𝑛) = 𝑥(𝑛) − 𝛼. 𝑥(𝑛 − 1) (2.2)
Keterangan:
𝑦(𝑛) = pre-emphasis 𝑥(𝑛) = data sinyal
𝛼 = koefisien emphasis atau alpha
Gambar 2.4 Sinyal Hasil Pre-emphasis
2.5.2 Frame Blocking
Pada tahap ini sinyal suara yang telah ter-emphasis dibagi menjadi beberapa frame dengan panjang sekitar 10-30 ms. Panjang frame yang digunakan sangat mempengaruhi keberhasilan dalam analisa spektral. Pada satu sisi ukuran dari frame harus sepanjang mungkin untuk dapat menunjukkan resolusi frekuensi yang baik, tetapi di sisi yang lain ukuran frame juga harus cukup pendek untuk menunjukkan resolusi waktu yang baik.
Proses frame blocking dilakukan terus menerus sampai seluruh sinyal dapat terproses. Pada umumnya proses ini dilakukan secara overlapping untuk setiap frame dan panjang daerah overlap yang digunakan adalah kurang lebih 30% hingga 50% dari panjang frame.
Overlapping dilakukan untuk menghindari hilangnya ciri atau karakteristik suara pada perbatasan perpotongan setiap frame [7].
Pada proses frame blocking setiap sampel rekaman suara yang terbentuk pasti mengandung daerah silence. Daerah silence pada suara biasanya terletak pada awal dan akhir rekaman suara serta tidak mengandung kalimat yang diucapkan pembicara. Untuk mengidentifikasi silence pada frame dilakukan dengan membatasi maksimal amplitudo.
Sehingga frame yang nilai amplitudonya kurang dari yang telah ditetapkan akan dipotong.
Gambar 2.5 Contoh overlapping
Gambar 2.6 Sinyal Hasil Frame Blocking
2.5.3 Windowing
Windowing digunakan untuk menghilangkan diskontinuitas yang diakibatkan oleh proses frame blocking. Windowing yang dipakai dalam proses ini menggunakan Hamming window, hal ini dikarenakan Hamming window menghasilkan side lobe yang paling kecil dan main lobe yang paling besar sehingga windowing akan lebih halus dalam menghilangkan efek diskontinuitas. Window dinyatakan dalam w(n), 0< n , N-1, dengan N adalah jumlah sampel dari masing-masing frame [8]. Berikut ini merupakan persamaan Hamming window:
𝑤(𝑛) = 0,54 − 0,46 cos(2𝜋𝑛
𝑁−1) ; n = 0, … , N-1 (2.3) Keterangan :
𝑤(𝑛) = windowing n = waktu diskrit
N = jumlah data dari sinyal
Gambar 2.7 Sinyal Hasil Windowing
2.5.4 FFT (Fast Fourier Transform)
Tahap ini bertujuan untuk mengubah setiap frame dari domain waktu ke domain frekuensi. FFT (fast fourier transform) dilakukan tehadap setiap frame dari sinyal yang sudah di windowing. FFT merupakan algoritma yang mengimplementasikan DFT (discrete fouries transform) [11]. Persamaan FFT sebagai algoritma yang mengimplementasikan DFT ditunjukkan pada persamaan 2.4 sebagai berikut:
𝑓(𝑛) = ∑ 𝑦𝑘
𝑁−1
𝐾=0
𝑒−2𝜋𝑗𝑘𝑛𝑁 𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑𝑑(2.4) Keterangan :
N = Jumlah sampel n = 0,1,2,3….,N-1
𝑦= Sinyal hasil windowing 𝑘 =0,1,2,3….,N-1
2.6 Mel Frequency Cepstral Coefficients (MFCC)
Mel Frequency Cepstral Coefficients (MFCC) merupakan metode yang cukup popular digunakan dalam melakukan ekstraksi ciri bidang pengenalan ucapan, baik pengenalan nada musik maupun nada ucapan. Tujuan ekstraksi ciri ini adalah mengubah vektor ucapan yang dihasilkan dari digitalisasi yang memiliki vektor yang besar menjadi vektor ciri tanpa menghilangkan karakteristik ucapan tersebut [4].
a) Mel Filterbanks Processing
Mel-filterbanks sebenarnya merupakan triangular filterbank biasa, hanya saja range frekuensi linier yang didapat dari FFT dikonversi ke dalam skala mel-frequency untuk mendapat batas-batas filterbank berdasarkan skala mel-frequency. Metode MFCC menggunakan dua tipe filter yaitu filter linier dibawah 1000 Hz dan filter logaritmik diatas 1000 Hz [11]. Skala mel-frequency dapat diperoleh dengan persamaan 2.5. Gambar 2.8 menunjukkan triangular filterbank dengan mel scale.
𝑚𝑒𝑙(𝑓) = 1125 × ln(1 + 𝑓
700) 𝑔𝑔𝑔𝑔𝑔𝑔𝑔𝑔𝑔𝑔𝑔𝑔𝑔𝑔𝑔𝑔 (2.5) Keterangan :
𝑚𝑒𝑙(𝑓) = Skala mel-frequency f = frekuensi linier (Hz)
Sebelum menghitung skala mel-filterbanks diperlukan penentuan batas atas dan batas bawah dari filter yang artinya nilai yang berada diluar batas yang sudah ditentukan tidak akan masuk kedalam filter. Batas tersebut dikonversi kedalam skala mel, kemudian kedua batas dibagi sesuai jumlah filter yang ingin dibuat maka akan diketahui batas atas dan batas bawah dari setiap filterbank dalam skala mel. Kemudian semua batas tersebut dikonversi kembali kedalam skala frekuensi linier, karena range yang ada tidak dapat mempresentasikan di bin FFT. Setelah itu dibuatlah filter triangular berdasarkan batas-batas tersebut. Hasil dari FFT pada tahap sebelumnya kemudian dikalikan dengan mel-filterbanks [11].
Gambar 2.8 Triangular filterbank dengan mel scale [7]
b) Log dan Discrete Cosine Transform (DCT)
Tahap berikutnya adalah mengkonversi hasil perkalian dari mel-filterbanks yang masih berada pada domain frekuensi ke domain waktu karena untuk menentukan ciri mengacu pada urutan waktu. Tahap mengkonversi spectrum log mel menjadi domain waktu menggunakan Discrete Cosine Transform (DCT). Tahap ini merupakan tahap akhir dari proses utama ekstraksi ciri MFCC. Hasil dari konversi ini disebut Mel Frequency Cepstrum Coefficient. Berikut adalah rumus yang digunakan untuk menghitung DCT: [11]
𝐶𝑠(𝑛; 𝑚) = ∑ 𝛼𝑘
𝑁−1
𝑘=0
× log(𝑓𝑚𝑒𝑙𝑘) cos (𝜋(2𝑛 + 1)𝑘
2𝑁 )𝑤𝑤𝑤𝑤𝑤𝑤 𝑤 (2.6) Keterangan :
n = 0,1,2,3, …N-1 N = Jumlah sampel 𝑓𝑚𝑒𝑙 = mel-frequency c) Zig zag scanning
Zig zag scanning berfungsi untuk merepresentasikan Matriks 2-D dari koefisien DCT terkuantisasi dalam bentuk vektor satu dimensi. Setelah kuantisasi, sebagian besar koefisien frekuensi tinggi (pojok kanan bawah) adalah nol. Dalam memanfaatkan jumlah nol maka
digunakan scan zig zag dari matriks. Zig zag scan memungkinkan semua koefisien DC dan AC dengan nilai yang terendah akan diproses terlebih dahulu [14]. Gambar 2.9 menunjukan urutan zig zag scanning.
Gambar 2.9 Urutan Zig zag Scanning [15]
2.7 Jaringan Syaraf Tiruan
Jaringan syaraf tiruan adalah sistem pemrosesan informasi yang dibentuk sebagai generalisasi model matematika dan memiliki karakteristik mirip dengan jaringan syaraf tiruan biologi dengan asumsi bahwa [6]:
a) Pemrosesan informasi terjadi pada banyak elemen sederhana (neuron).
b) Sinyal dikirimkan diantara neuron-neuron melalui penghubung-penghubung.
c) Penghubung antar neuron memiliki bobot yang akan memperkuat sinyal atau memperlemah sinyal.
d) Untuk menentukan output, setiap neuron menggunakan fungsi aktivasi (biasanya bukan fungsi linier) yang dikenakan pada jumlahan input yang diterima. Besarnya output ini selanjutnya dibandingkan dengan batas ambang.
Jaringan syaraf tiruan ditentukan oleh 3 hal :
1. Pola hubungan antar neuron (disebut arsitektur jaringan) 2. Metode untuk menentukan bobot penghubung disebut metode.
3. Fungsi aktivasi.
2.7.1 Arsitektur Jaringan Syaraf Tiruan
Pada umumnya neuron-neuron yang terletak pada lapisan yang sama akan memiliki keadaan yang sama. Faktor terpenting dalam menentukan kelakuan suatu neuron adalah fungsi aktivasi dan pola bobotnya [9]. Ada beberapa arsitektur jaringan syaraf tiruan, salah satunya adalah jaringan layar jamak (multi layer network). Pada arsitektur jaringan layar jamak (multi layer network) memiliki lapisan input yang dilewatkan pada beberapa layar tersembunyi (Hidden Layer). Jaringan ini dapat menyelesaikan masalah yang lebih sulit atau kompleks dibandingkan dengan lapisan layar tunggal. Proses pelatihan pada jaringan ini memang lebih kompleks dan lama. Gambar 2.10 menunjukan arsitektur jaringan layar jamak dengan n unit masukkan (X1, X2, …. Xn) dan m buah unit keluaran (Y1, Y2, …. Ym), sebuah lapis tersembunyi yang terdiri dari p buah unit (Z1,…,Zp) [6].
Gambar 2.10 Jaringan Lapisan Jamak [6]
2.7.2 Backpropagation
Jaringan syaraf tiruan backpropagation membandingkan perhitungan keluaran dengan target keluaran yang telah ditentukan dan menghitung nilai error untuk setiap unit jaringan. Backpropagation merupakan salah satu model yang menggunakan pelatihan dengan terawasi (supervised learning) dan termasuk jaringan layar jamak (multi layer network). Pada jaringan ini, setiap unit yang berada di lapisan input berhubungan dengan setiap unit yang ada di lapisan tersembunyi. Sedangkan setiap unit di lapisan tersembunyi terhubung dengan setiap unit di lapisan output.
Pola pelatihan pada jaringan ini akan diberi input-an yang akan diteruskan kedalam layar tersembunyi dan menuju hingga output. Ketika hasil keluaran ternyata tidak sesuai dengan harapan maka keluaran akan kembali disebarkan secara mundur (backward) pada lapisan tersembunyi hingga menuju lapisan input. Tahap selanjutnya adalah dengan melakukan perubahan bobot. Iterasi akan terus dilakukan hingga ditemukan penyelesaian yang optimal.
Gambar 2.11 menunjukan arsitektur jaringan syaraf tiruan backpropagation dengan n unit masukkan (𝑥1, 𝑥𝑖, … , 𝑥𝑛) yang ditambah sebuah bias, sebuah layar tersembunyi (Hidden Layer) yang terdiri dari p unit yang ditambah sebuah bias, serta m buah unit keluaran (𝑦1, 𝑦𝑗, … , 𝑦𝑚). 𝑣𝑗𝑖 merupakan bobot garis dari unit masukan 𝑥𝑖 ke unit layar tersembunyi 𝑧𝑗 yang terhubung dengan bias 𝑣𝑗0. 𝑤𝑘𝑗 merupakan bobot dari unit layar tersembunyi 𝑧𝑗 ke unit keluaran 𝑦𝑘 yang terhubung dengan bias 𝑤𝑘0.
Gambar 2.11 Arsitektur Jaringan Backpropagation [6]
2.7.3 Fungsi Aktivasi
Dalam jaringan syaraf tiruan backpropagation, fungsi aktivasi yang dipakai harus memenuhi beberapa syarat yaitu: kontinu, terdiferensial dengan mudah dan merupakan fungsi yang tidak turun. Salah satu fungsi yang memenuhi ketiga syarat tersebut sehingga sering dipakai adalah fungsi sigmoid biner yang memiliki range (0,1).
𝑓(𝑥) = 1
1+𝑒−𝑥 dengan turunan 𝑓′(𝑥) = 𝑓(𝑥)(1 − 𝑓(𝑥)) (2.7)
Selain fungsi sigmoid biner ada juga fungsi lain yang sering dipakai yaitu fungsi sigmoid bipolar yang memiliki range (-1,1).
𝑓(𝑥) = 2
1+𝑒−𝑥− 1 dengan turunan 𝑓′(𝑥) =(1+𝑓(𝑥))(1−𝑓(𝑥))
2 (2.8)
Fungsi sigmoid memiliki nilai maksimum = 1. Maka untuk pola yang targetnya > 1, pola masukan dan keluaran harus terlebih dahulu ditransformasikan sehingga semua polanya memiliki range yang sama seperti fungsi sigmoid yang dipakai. Alternatif lain adalah menggunakan fungsi aktivasi sigmoid hanya pada layar yang bukan layar keluaran. Pada layar keluaran, fungsi aktivasi yang dipakai adalah fungsi identitas: 𝑓(𝑥) = 𝑥.
Pelatihan fungsi aktivasi tergantung pada kebutuhan nilai keluaran jaringan yang diharapkan. Bila keluaran jaringan yang diharapkan ada yang bernilai negatif, maka yang digunakan adalah fungsi sigmoid bipolar. Sebaliknya bila nilai keluaran jaringan yang diharapkan bernilai positif atau sama dengan nol, maka yang digunakan adalah fungsi sigmoid biner. [6]
2.7.4 Proses Pelatihan Backpropagation
Pelatihan backpropagation terdiri dari 3 proses, yaitu proses propagasi maju, propagasi mundur, dan perubahan bobot. Ketiga proses pelatihan tersebut dilakukan secara berulang sampai kondisi penghentian terpenuhi. Penghentian yang dipakai pada umumnya adalah iterasi dan error. Iterasi akan berhenti ketika iterasi melebihi iterasi yang ditentukan atau ketika nilai error sudah lebih kecil dari yang ditentukan.
1. Proses Propagasi Maju
Selama propagasi maju, sinyal masukkan (= 𝑥𝑖) dipropagasikan ke lapis tersembunyi menggunakan fungsi aktivasi yang ditentukan. Keluaran dari setiap unit lapis tersembunyi (= 𝑧𝑗) tersebut selanjutnya diprpagasikan maju lagi ke lapis tersembunyi diatasnya. Demikian seterusnya hingga mendapat luaran jaringan (= 𝑦𝑘).
Berikutnya, keluaran jaringan (= 𝑦𝑘) dibandingkan dengan target yang harus dicapai (= 𝑡𝑘). Selisih 𝑡𝑘− 𝑦𝑘 adalah error yang terjadi. Jika nilai error ini lebih kecil dari batas toleransi yang ditentukan, maka iterasi dihentikan. Akan tetapi apabila nilai error masih lebih besar dari batas toleransinya, maka bobot setiap garis dalam jaringan akan dimodifikasi untuk mengurangi error yang terjadi.
2. Proses Propagasi Mundur
Berdasarkan error 𝑡𝑘− 𝑦𝑘, dihitung faktor 𝛿𝑘 (k=1,2,…,m) yang dipakai untuk mendistribusikan error di unit 𝑦𝑘 ke semua unit tersembunyi yang terhubung langsung dengan 𝑦𝑘. 𝛿𝑘 juga dipakai untuk mengubah bobot garis yang berhubungan langsung dengan unit keluaran.
Dengan cara yang sama, dihitung faktor 𝛿𝑗 di setiap unit di layar tersembunyi sebagai dasar perubahan bobot semua garis yang berasal dari unit tersembunyi dibawahnya.
Demikian seterusnya hingga semua faktor 𝛿 di unit tersembunyi yang berhubungan langsung dengan unit masukkan dihitung.
3. Perubahan Bobot
Setelah semua faktor 𝛿 dihitung, bobot semua garis dimodifikasi beramaan.
Perubahan bobot suatu garis didasarkan atas faktor 𝛿 neuron di lapis atasnya.
Algoritma pelatihan jaringan syaraf tiruan backpropagation untuk jaringan dengan satu layar tersembunyi (dengan fungsi aktivasi sigmoid biner) adalah sebagai berikut [6]:
Langkah 0 : Inisialisasi bobot (umumnya menggunakan nilai random) dan set learning rate α.
Langkah 1 : Selama kondisi penghentian belum terpenuhi, lakukan langkah 2-9.
Langkah 2 : Untuk setiap pasang data pelatihan, lakukan langkah 3-8.
Proses I : Propagasi maju
Langkah 3 : Setiap unit masukan menerima sinyal dan meneruskannya ke seluruh unit layar tersembunyi diatasnya.
Langkah 4 : hitung semua keluaran di setiap unit tersembunyi 𝑧𝑗 ( j = 1, 2, …, p)
𝑧_𝑛𝑒𝑡𝑗 = 𝑣𝑗𝑜+ ∑ 𝑥𝑖𝑣𝑗𝑖
𝑛
𝑖=1
(2.9)
kemudian menghitung sinyal keluaran dengan fungsi aktivasi sebagai berikut:
𝑧𝑗 = 𝑓(𝑧_𝑛𝑒𝑡𝑗) = 1
1 + 𝑒−𝑧_𝑛𝑒𝑡𝑗 (2.10) Langkah 5 : Menghitung total sinyal masukan terbobot untuk setiap unit output 𝑦𝑘 (k = 1,
…, m)
𝑦_𝑛𝑒𝑡𝑘 = 𝑤𝑘𝑜+ ∑ 𝑧𝑗𝑤𝑘𝑗
𝑝
𝑗=1
(2.11)
Kemudian menghitung sinyal keluaran dengan fungsi aktivasi sebagai berikut:
𝑦𝑘 = 𝑓(𝑦_𝑛𝑒𝑡𝑘) = 1
1 + 𝑒−𝑦_𝑛𝑒𝑡𝑘 (2.12) Proses II : Propagasi mundur
Langkah 6 : hitung faktor 𝛿𝑘 unit keluaran berdasarkan error di setiap unit keluaran 𝑦𝑘 (k = 1, …, m)
𝛿𝑘 = (𝑡𝑘− 𝑦𝑘)𝑓′(𝑦𝑛𝑒𝑡𝑘) = (𝑡𝑘− 𝑦𝑘)𝑦𝑘(1 − 𝑦𝑘) (2.13) Kemudian hitung suku perubahan bobot 𝑤𝑘𝑗 dengan laju percepatan α yang telah ditentukan diawal
∆𝑤𝑘𝑗 = 𝛼𝛿𝑘𝑧𝑗= 𝛼𝛿𝑧𝑗 ; (k =1,2, … ,m) (j =0,1, … ,p) (2.14) Langkah 7 : Hitung faktor 𝛿 unit keluran berdasarkan kesalahan di setiap unit tersembunyi 𝑧𝑗 (j =1,2, … ,p)
𝛿_𝑛𝑒𝑡𝑗 = ∑ 𝛿𝑘𝑤𝑘𝑗
𝑚
𝑘=1
(2.15) kemudian menghitung error dengan turunan fungsi aktivasi
𝛿𝑗 = 𝛿𝑛𝑒𝑡𝑗𝑓′(𝑧𝑛𝑒𝑡𝑗) = 𝛿𝑛𝑒𝑡𝑗𝑧𝑗(1 − 𝑧𝑗) (2.16) selanjutnya, menghitung perubahan bobot untuk mengubah 𝑣𝑗𝑖 yang akan dipakai nanti
∆𝑣𝑗𝑖= 𝛼𝛿𝑗𝑥𝑖 ; (j =0,1, … ,p); (i = 0,1, …, n) (2.17) Proses III : Perubahan bobot
Langkah 8 : hitung semua perubahan bobot (update bobot dan bias). Perubahan bobot yang menuju ke unit keluaran
𝑤𝑘𝑗(𝑏𝑎𝑟𝑢) = 𝑤𝑘𝑗(𝑙𝑎𝑚𝑎) + ∆𝑤𝑘𝑗 ; (k = 1,2, …,m) ; (j = 0,1, …, p) (2.18) Perubahan bobot yang menuju ke unit tersembunyi
𝑣𝑗𝑖(𝑏𝑎𝑟𝑢) = 𝑣𝑗𝑖(𝑙𝑎𝑚𝑎) + ∆𝑣𝑗𝑖 ; (j = 1,2, …,p) ; (i = 0,1, …, n) (2.19) Langkah 9 : bandingkan kondisi penghentian
Tujuan utama backpropagation adalah mendapatkan keseimbangan antara pengenalan pola pelatihan secara benar dan respon yang baik untuk pola lain yang sejenis (disebut data pengujian). Jaringan dapat dilatih terus menerus hingga pola pelatihan dikenali dengan benar. Akan tetapi hal tersebut tidak menjamin jaringan akan mampu mengenali pola pengujian dengan tepat. Jadi tidaklah bermanfaat untuk meneruskan iterasi hingga semua kesalahan pola pelatihan=0 [6].
19
3 BAB III
RANCANGAN PENELITIAN
3.1 Sistem Pengenalan Ucapan
Sistem pengenalan ucapan (speech recognition) merupakan proses atau metode dalam menterjemahkan signal suara menjadi tulisan dengan menggunakan alat berupa komputer.
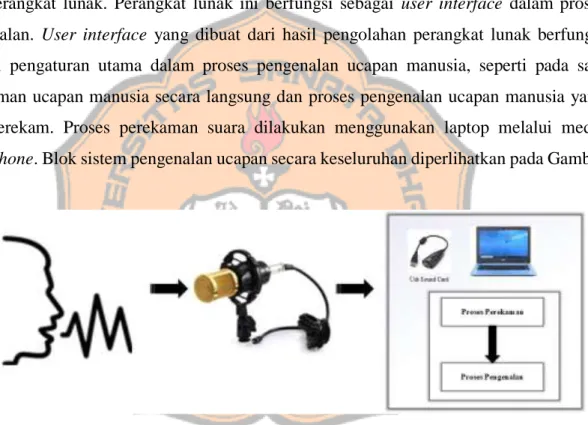
Pengenalan ucapan bertujuan untuk mengidentifikasi atau mengenali ucapan yang diolah oleh perangkat lunak. Perangkat lunak ini berfungsi sebagai user interface dalam proses pengenalan. User interface yang dibuat dari hasil pengolahan perangkat lunak berfungsi sebagai pengaturan utama dalam proses pengenalan ucapan manusia, seperti pada saat perekaman ucapan manusia secara langsung dan proses pengenalan ucapan manusia yang telah terekam. Proses perekaman suara dilakukan menggunakan laptop melalui media microphone. Blok sistem pengenalan ucapan secara keseluruhan diperlihatkan pada Gambar 3.1.
Gambar 3.1 Blok Sistem Pengenalan Ucapan
3.1.1 Proses Pengenalan Ucapan
Proses pengenalan ucapan terdiri dari sampling, pre-processing, ekstraksi ciri MFCC, jaringan syaraf tiruan backpropagation dan hasil pengenalan. Blok diagram pengenalan ucapan secara langsung dapat dilihat pada Gambar 3.2. Blok diagram subproses pada pre-processing dapat dilihat pada Gambar 3.5 dan blok diagram subproses pada ekstraksi ciri dapat dilihat pada Gambar 3.6.
Gambar 3.2 Blok Diagram Pengenalan Ucapan
3.1.2 Proses Pelatihan
Proses pelatihan dilakukan dengan memberi nilai parameter kemudian di ekstraksi ciri. Hasil ekstraksi ciri dijadikan sebagai masukkan kemudian dilakukan perhitungan jaringan syraf tiruan backpropagation dan hasil keluarannya adalah update bobot dan bias.
Gambar 3.3 menunjukkan blok diagram proses pelatihan.
Gambar 3.3 Blok Diagram Proses Pelatihan
3.1.3 Proses Pembuatan Data
Proses pembuatan data terdiri dari sampling, pre-processing, ekstraksi ciri MFCC.
Data dilakukan dengan pengambilan ucapan angka 0-9 dalam bentuk .wav yang kemudian diproses pre-processing dan ekstraksi ciri. Hasil ekstraksi ciri ditampilkan dan disimpan dalam bentuk mat. Blok diagram proses pembuatan data ucapan dapat dilihat pada Gambar 3.4. Blok diagram subproses pada pre-processing dapat dilihat pada Gambar 3.5.
Gambar 3.4 Blok Diagram Proses Pembuatan Data A. Masukkan
Masukkan pada sistem ini adalah file ucapan yang tersimpan maupun perekaman secara langsung disimpan dalam format .wav.
B. Pre-processing
Pada proses pre-processing terdapat subproses yaitu pre-emphasis, frame blocking, windowing, dan FFT. Blok diagram pre-processing dapat dilihat pada Gambar 3.5.
Gambar 3.5 Blok Diagram Subproses Pre-processing a) Pre-emphasis
Pre-emphasis merupakan salah satu jenis filter yang sering digunakan sebelum sebuah signal diproses lebih lanjut. Filter ini mempertahankan frekuensi-frekuensi tinggi pada sebuah spektrum. Proses pre-emphasis sangat baik dalam mengurangi efek distorsi, atenuasi, dan saturasi dari media rekaman.
b) Frame Blocking
Proses frame blocking bertujuan untuk membagi sampel sinyal ucapan pada beberapa frame tertentu dan akan memilih data dari ucapan terekam.
Frame blocking pada sistem ini terjadi secara overlap.
c) Windowing
Fungsi dari windowing adalah untuk mengurangi efek diskontinuitas dari sinyal digital hasil perekaman. Pada penelitian ini menggunakan Hamming window.
d) FFT (Fast Fourier Transform)
Proses FFT (Fast Fourier Transform) bertujuan untuk memperoleh parameter tertentu yang kemudian dilanjutkan ke tahap MFCC.
C. Ekstraksi Ciri
Proses ekstraksi ciri memakai Mel Frequency Cepstral Coefficients (MFCC) yang merupakan metode cukup popular digunakan dalam melakukan ekstraksi ciri dari data suara. Blok diagram ekstraksi ciri MFCC dapat dilihat pada Gambar 3.6.
Gambar 3.6 Blok Diagram Ekstraksi Ciri MFCC [13]
D. Jaringan Syaraf Tiruan Backpropagation
Proses ini merupakan proses klasifikasi. Hasil dari proses ini adalah model jaringan dengan akurasi terbaik yang akan digunakan dalam proses klasifikasi.
E. Penentuan Keluaran
Penentuan keluaran merupakan subproses terakhir dari proses pengenalan ucapan. Pada proses ini, hasil pengenalan ucapan ditentukan berdasarkan nilai target yang diperoleh setelah proses jaringan syaraf tiruan backpropagation.
F. Keluaran
Penentuan keluaran ucapan yang telah diproses berupa teks.
3.2 Ucapan Uji
Ucapan uji merupakan ucapan yang terekam untuk menjalankan fungsi program secara offline atau non real time. Penulis memiliki 2 data yaitu data training dan data testing. Data training digunakan untuk melatih jaringan syaraf tiruannya dan data testing digunakan untuk menguji secara real time maupun non real time.
Tabel 3.1 Data Training
Sampel_1 [satuA, satuB, satuC, satuD, satuE, satuF, satuG, satuH, satuI, satuJ]
Sampel_2 [duaA, duaB, duaC, duaD, duaE, duaF, duaG, duaH, duaI, duaJ]
Sampel_3 [tigaA, tigaB, tigaC, tigaD, tigaE, tigaF, tigaG, tigaH, tigaI, tigaJ]
Sampel_4 [empatA, empatB, empatC, empatD, empatE, empatF, empatG, empatH, empatI, empatJ]
Sampel_5 [limaA, limaB, limaC, limaD, limaE, limaF, limaG, limaH, limaI, limaJ]
Sampel_6 [enamA, enamB, enamC, enamD, enamE, enamF, enamG, enamH, enamI, enamJ]
Sampel_7 [tujuhA, tujuhB, tujuhC, tujuhD, tujuhE, tujuhF, tujuhG, tujuhH, tujuhI, tujuhJ]
Sampel_8 [delapanA, delapanB, delapanC, delapanD, delapanE, delapanF, delapanG, delapanH, delapanI, delapanJ]
Sampel_9 [sembilanA, sembilanB, sembilanC, sembilanD, sembilanE, sembilanF, sembilanG, sembilanH, sembilanI, sembilanJ]
Tabel 3.2 (Lanjutan) Data Training
Sampel_0 [nolA, nolB, nolC, nolD, nolE, nolF, nolG, nolH, nolI, nolJ]
Tabel 3.3 Data Testing
Sampel_1 [satuAA, satuBB, satuCC, satuDD, satuEE, satuFF, satuGG, satuHH, satuII, satuJJ]
Sampel_2 [duaAA, duaBB, duaCC, duaDD, duaEE, duaFF, duaGG, duaHH, duaII, duaJJ]
Sampel_3 [tigaAA, tigaBB, tigaCC, tigaDD, tigaEE, tigaFF, tigaGG, tigaHH, tigaII, tigaJJ]
Sampel_4 [empatAA, empatBB, empatCC, empatDD, empatEE, empatFF, empatGG, empatHH, empatII, empatJJ]
Sampel_5 [limaAA, limaBB, limaCC, limaDD, limaEE, limaFF, limaGG, limaHH, limaII, limaJJ]
Sampel_6 [enamAA, enamBB, enamCC, enamDD, enamEE, enamFF, enamGG, enamHH, enamII, enamJJ]
Sampel_7 [tujuhAA, tujuhBB, tujuhCC, tujuhDD, tujuhEE, tujuhFF, tujuhGG, tujuhHH, tujuhII, tujuhJJ]
Sampel_8 [delapanAA, delapanBB, delapanCC, delapanDD, delapanEE, delapanFF, delapanGG, delapanHH, delapanII, delapanJJ]
Sampel_9 [sembilanAA, sembilanBB, sembilanCC, sembilanDD, sembilanEE, sembilanFF, sembilanGG, sembilanHH, sembilanII, sembilanJJ]
Sampel_0 [nolAA, nolBB, nolCC, nolDD, nolEE, nolFF, nolGG, nolHH, nolII, nolJJ]
3.3 Perancangan Perangkat Lunak 3.3.1 Perancangan Antarmuka Program
Tampilan program GUI yang akan dibuat pada software octave dapat dilihat pada Gambar 3.7 dan keterangan dari tampilan utama sistem dapat dilihat pada tabel 3.4.
Gambar 3.7 Tampilan GUI Sistem Pengenalan Ucapan Tabel 3.4 Keterangan Tampilan GUI Sistem Pengenalan Ucapan
NO. NAMA BAGIAN KETERANGAN
1. PLOT PEREKAMAN Tampilan grafik untuk suara hasil perekaman 2. PLOT HASIL MFCC Tampilan grafik hasil eksraksi ciri MFCC
3. KELUARAN JST Tampilan nilai keluaran dari JST backpropagation 4. HASIL PENGENALAN Menunjukkan hasil pengenalan ucapan
5. REKAM Tombol tekan untuk memulai perekaman
6. RESET Tombol tekan untuk mengulangi proses
7. KELUAR Tombol tekan untuk mengakhiri aplikasi
3.3.2 Perancangan Diagram Alir Program
Ketika pengguna akan memulai program pengenalan ucapan angka, pengguna akan dihadapkan tampilan GUI sistem pengenalan ucapan pada perangkat lunak komputasi octave. Kurang lebih gambar yang akan ditampilkan dapat dilihat pada Gambar 3.7. Terdapat 3 push button yang digunakan untuk tombol tekan yaitu rekam, reset dan keluar. Ada 2 tampilan grafik yaitu grafik perekaman, dan grafik hasil MFCC. Ada teks statis untuk keluaran jaringan syaraf tiruan dan hasil pengenalan.
3.3.2.1 Perancangan Diagram Alir Training
Gambar 3.8 memperlihatkan diagram alir training jaringan syaraf tiruan backpropagation. Proses untuk setiap data dimulai dari memberi nilai parameter seperti hidden layer, maksimal epoch dan learning rate. Kemudian dilakukan penginisialisai nilai bias dan bobot awal menggunakan nilai random yang sudah disimpan sebelumnya. Data input hasil ekstraksi ciri akan diproses perhitungan dan memperbaiki (update) bobot dan bias tiap layer sampai target epoch terpenuhi. Keluaran pada proses pelatihan (training) ini adalah hasil update bobot dan bias.
Gambar 3.8 Diagram Alir Training
3.3.2.2 Perancangan Diagram Alir Pengujian Langsung
Perancangan diagram alir pengujian langsung dapat dilihat pada Gambar 3.9.
Masukkan dari tahap ini adalah pengucapan angka yang dilakukan secara langsung melalui proses rekam. Setelah proses perekaman dilakukan, akan dilakukan proses pre-processing yang kemudian di ekstraksi ciri MFCC. Selanjutnya dilakukan proses perhitungan backpropagation dan penentuan hasil pengenalan. Keluaran pada pengujian langsung ini adalah teks hasil pengenalan angka.
Gambar 3.9 Diagram Alir Pengujian Langsung
3.3.2.3 Perancangan Diagram Alir Pengujian Tidak Langsung
Pada pengujian tidak langsung masukkan berupa hasil dari ekstraksi ciri MFCC yang disimpan dalam bentuk mat. Selanjutnya dilakukan proses perhitungan backpropagation.
Keluaran pada proses pengujian tidak langsung ini tingkat pengenalan. Gambar 3.10 menunjukkan digram alir pengujian tidak langsung.
Gambar 3.10 Diagram Alir Pengujian Tidak Langsung
3.3.3 Perancangan Diagram Alir Sub-rutin Perekaman
Proses perekaman merupakan proses pengambilan ucapan manusia, dan masuknya data ucapan terekam berupa sinyal digital. Saat proses perekaman berlangsung sinyal analog dikonversi menjadi sinyal digital dengan frekuensi sampling. Panjang durasi perekaman 2 detik dan frekuensi sampling sebesar 8000 Hz. Penulis memilih nilai frekuensi sampling tersebut berdasarkan refrensi [12]. Pada refrensi tersebut disampaikan bahwa dengan 𝑓𝑠 8000 Hz dapat mengenali ucapan manusia dengan baik. Penentuan panjang durasi perekaman disesuaikan dengan perkiraan pengucapan kata untuk setiap angka. Data ucapan yang telah terekam disimpan dengan format .wav dan diberi nama sesuai urutan yang diinginkan.
Diagram alir sub-rutin perekaman dapat dilihat pada Gambar 3.11.
Gambar 3.11 Diagram Alir Sub-rutin Perekaman
3.3.4 Perancangan Diagram Alir Sub-rutin Pre-processing
Diagram alir sub-rutin pada pre-processing terdiri dari beberapa proses. Proses- proses pada pre-processing terdiri dari pre-emphasis, frame blocking, windowing, dan FFT.
Diagram alir sub-rutin pre-procesing dapat dilihat pada Gambar 3.12.
Gambar 3.12 Diagram Alir Sub-rutin Pre-processing
3.3.4.1 Perancangan Diagram Alir Sub-rutin Pre-emphasis
Pre-emphasis merupakan proses filtering yang bertujuan memproses pengiriman sinyal melalui filter. Masukkan pada tahap ini adalah hasil dari perekaman secara langsung maupun tidak langsung yang kemudian dilakukan proses konvolusi antara input dengan sistem. Keluaran pada proses ini adalah hasil pre-emphasis atau y(n) sesuai dengan persamaan 2.2. Koefisien emphasis atau alpha yang digunakan pada proses ini bernilai 0,95 ditentukan dari refrensi yang sudah ada [3]. Gambar 3.13 menujukkan diagram alir sub-rutin pre-emphasis.
Gambar 3.13 Diagram Alir Sub-rutin Pre-emphasis
3.3.4.2 Perancangan Diagram Alir Sub-rutin Frame Blocking
Pada tahap ini hasil dari pre-emphasis akan diambil data sepanjang nilai frame, sehingga menghasilkan jumlah frame yang banyak atau overlapping. Gambar 3.14 menunjukkan diagram alir sub-rutin frame blocking.
Gambar 3.14 Diagram Alir Sub-rutin Frame Blocking
3.3.4.3 Perancangan Diagram Alir Sub-rutin Windowing
Setelah mendapat hasil dari frame blocking tahap selanjutnya adalah windowing.
Windowing yang dipakai dalam proses ini menggunakan Hamming window. Rumus Hamming window dapat dilihat pada persamaan 2.3. Masukkan dari proses Hamming window ini adalah hasil proses frame blocking. Sinyal hasil windowing didapat dari perkalian elemen antara data Hamming window dengan data sinyal hasil frame blocking. Banyaknya elemen yang didapat hasil dari frame blocking sama dengan banyaknya elemen pada Hamming window. Diagram alir sub-rutin windowing dapat dilihat pada Gambar 3.15.
Gambar 3.15 Diagram Alir Sub-rutin Windowing
3.3.4.4 Perancangan Diagram Alir Sub-rutin FFT (Fast Fourier Transform)
FFT (fast fourier transform) bertujuan untuk untuk mengubah setiap frame dari domain waktu ke domain frekuensi, artinya proses perekaman ucapan disimpan dalam bentuk digital berupa gelombang spectrum ucapan berbasis frekuensi. Rumus FFT dapat dilihat pada persamaan 2.4. FFT dilakukan tehadap setiap frame dari sinyal yang sudah di windowing. Proses FFT akan memperoleh parameter tertentu yang kemudian dilanjutkan ke tahap MFCC. Gambar 3.16 menunjukkan diagram alir sub-rutin FFT.
Gambar 3.16 Diagram Alir Sub-rutin FFT
3.3.5
Perancangan Diagram Alir Sub-rutin Ekstraksi Ciri MFCCPerancangan diagram alir sub-rutin ekstraksi ciri MFCC dapat dilihat pada Gambar 3.17. Masukkan dari ekstraksi ciri MFCC adalah hasil dari FFT. Range frekuensi linier yang didapat dari FFT dikonversi ke dalam skala mel-frequency untuk mendapat batas-batas filterbank berdasarkan skala mel-frequency. Untuk menghitung mel-filterbanks dapat dilihat pada persamaan 2.5. Hasil dari mel-filterbanks masih berada pada domain frekuensi yang kemudian perlu dikonversi ke domain waktu. Mengkonversi spectrum log mel menjadi domain waktu menggunakan DCT (Discrete Cosine Transform). Untuk rumus DCT dapat dilihat pada persamaan 2.6. Setelah itu mengambil koefisien DCT secara zig zag, untuk urutan zig zag scanning dapat dilihat pada Gambar 2.9. Proses ekstraksi ciri MFCC akan
menghasilkan 13 output. Setelah itu data feature yang telah didapat akan dijadikan sebagai input pada jaringan syaraf tiruan.
Gambar 3.17 Diagram Alir Sub-rutin Ekstraksi Ciri MFCC
3.4 Jaringan Syaraf Tiruan
Jaringan syaraf tiruan yang digunakan dalam penelitian ini adalah jaringan syaraf tiruan backpropagation. Proses pelatihan jaringan dan klasifikasi data dalam pengujian menggunakan metode jaringan syaraf tiruan backpropagation. Jenis arsitektur jaringan syaraf tiruan yang digunakan untuk proses pelatihan dan pengujian, yaitu arsitektur dengan satu hidden layer. Gambar 3.18 menunjukkan arsitektur jaringan syaraf tiruan dengan 1
hidden layer. Diambil contoh dengan jumlah data input sebanyak 13 data, kemudian menggunakan 1 hidden layer dengan jumlah neuron sebanyak n dan jumlah neuron pada output sebanyak 10.
Gambar 3.18 Arsitektur JST 1 Hidden Layer
Jenis arsitektur jaringan syaraf tiruan yang digunakan untuk proses pelatihan dan pengujian adalah arsitektur dengan satu hidden layer. Dalam pengujian arsitektur jaringan syaraf tiruan akan dilakukan beberapa kali percobaan untuk mendapatkan model terbaik berdasarkan akurasi hasil yang tertinggi. Percobaan dilakukan dengan mengambil input-an hasil dari ekstraksi ciri sebanyak 13 data, kemudian dilakukan percobaan untuk satu hidden layer dengan variasi jumlah neuron. Jumlah neuron pada hidden layer akan divariasi mulai dari 10 dengan penambahan jumlah kelipatan 10, misalnya 10, 20, 30, 40, hingga 50.
Learning rate yang akan dipakai sebesar 0,05; 0,06; dan 0,07. Nilai learning rate ditentukan berdasarkan penelitian yang sudah pernah dilakukan [17]. Variasi nilai epoch mulai dari 500 dengan penambahan jumlah kelipatan 500, misalnya 500, 1000, 1500, 2000, hingga 2500.
Dari semua percobaan tersebut akan memperoleh model jaringan terbaik berdasarkan akurasi tertinggi. Jumlah luaran yang dihasilkan sebanyak 10 neuron, sesuai dengan jumlah pengenalan angka dari 0 sampai 9. Neuron pada lapisan output merupakan target keluaran jaringan yang didapat dari hasil nilai maksimal dan untuk pengenalan angka selain 0 sampai 9 akan tetap dikenali sebagai salah satu angka.
35
4 BAB IV
HASIL DAN PEMBAHASAN
Bab ini akan membahas uraian implementasi perancangan sistem berupa hasil penelitian dalam melakukan pengujian pendataan dari hasil akurasi terhadap setiap kondisi variasi nilai dan variabel data yang ditentukan seperti neuron hidden layer, epoch dan learning rate. Serta uraian mengenai analisa hasil output terkait dengan keberhasilan pemilihan variasi nilai dan akurasinya.
4.1 Pengujian Secara Real Time
Pengujian secara real time dilakukan dengan menggunakan masukan ucapan secara langsung dari penulis. Ketika penulis merekam ucapan angka yang ingin dikenali saat itu juga hasil keluaran dari pengenalan ucapan angka tampil. Hasil keluaran pengenalan ucapan telah melalui proses pre-processing, ekstraksi ciri dan jaringan syaraf tiruan backpropagation. Keluaran hasil JST akan menampilkan 10 nilai dari 10 neuron output.
Hasil pengenalan dilakukan dengan mencari nilai maksimum dari hasil keluaran JST.
Klasifikasi pada pengujian real time menggunakan parameter hasil pengenalan terbaik dari sistem jaringan yang sudah dilatih dan disimpan dalam bentuk .mat. File .mat berisi bobot dan bias yang telah diperoleh pada hasil pelatihan.
4.1.1 Implementasi GUI Sistem Pengenalan Ucapan
Implementasi GUI sistem pengenalan ucapan berhasil menampilkan keluaran sesuai dengan perancangan yang telah dibuat pada bab III. Hasil keluaran dari pengucapan angka dua pada GUI dapat dilihat pada Gambar 4.1. Dari Gambar 4.1 terlihat 2 gambar sinyal yaitu sinyal hasil perekaman ucapan angka dan sinyal hasil ekstraksi ciri MFCC. Terdapat 10 nilai keluaran jaringan syaraf tiruan yang nilai maksimumnya berada pada neuron 2 dan kolom hasil pengenalan berupa tulisan “DUA”. Dari hasil tersebut terlihat bahwa program sudah dapat berjalan dengan baik ketika dilakukan pengujian pada antarmuka program.
Gambar 4.1 Hasil Keluaran Pengenalan Ucapan Angka Dua
Pengujian secara real time dilakukan dengan mengambil salah satu hasil terbaik dari pengujian non real time. Hasil pengujian non real time dengan tingkat pengenalan tertinggi diantara variasi nilai lain dipakai untuk klasifikasi pada pengujian real time. Grafik dengan tingkat pengenalan tertinggi berada pada neuron hidden layer 10 dengan epoch 500 dan learning rate 0,07. Rincian hasil pengujian dapat dilihat pada Lampiran 3 tabel L3-L5.
4.1.2 Hasil Pengenalan Ucapan
Hasil pengenalan ucapan angka secara real time mencapai 85%, dapat dilihat pada Lampiran 3 tabel L1. Tingkat pengenalan dapat dihitung dengan membagi jumlah data yang dikenali dengan jumlah data uji. Hasil pengenalan ucapan angka secara real time oleh subjek lainnya sebesar 87%, dapat dilihat pada Lampiran 3 tabel L2. Berdasarkan Tabel 4.1 menunjukan tingkat pengenalan rata-rata pada pengujian real time.
Tabel 4.1 Tingkat Pengenalan Rata-Rata Pengujian Real Time Masukan (Ucapan) Tingkat Pengenalan (%)
Satu 100
Dua 65
Tiga 90
Empat 75
Lima 100
Enam 65
Tujuh 85
Delapan 95
Tabel 4.2 (Lanjutan) Tingkat Pengenalan Rata-Rata Pengujian Real Time
Sembilan 100
Nol 85
Ketidakmampuan pengenalan ucapan angka untuk mengenali 100% dikarenakan adanya pengucapan pada penekanan suku kata dan tempo pengucapan yang berbeda baik dari data training maupun data testing. Pada data training mapupun data testing penekanan pengucapan angka satu berada di depan yaitu bagian “sa” dengan diikuti suku kata berikutnya yaitu “tu” dengan nada rendah. Begitu juga untuk pengucapan angka dua, tiga, empat, lima, enam, tujuh, delapan, sembilan, dan nol penekanan berada di depan atau suku kata pertama.
Untuk menghitung perbedaan nilai keluaran dengan nilai target dapat dilakukan dengan menggunakan salah satu rumus yaitu (Mean Squared Error) MSE yang ada [18].
Berdasarkan hasil pengujian pengucapan angka satu secara real time mendapat nilai (Mean Squared Error) MSE 0,0096 dengan menggunakan data testing yang optimal. Sedangkan pengujian real time pengucapan angka satu dengan menggunakan data testing yang tidak optimal mendapat nilai MSE 0,9. Nilai MSE didapat dari keluaran JST. Rincian hasil pengujian dapat dilihat pada Lampiran 3 tabel L6 dan L7. Jaringan syaraf tiruan backpropagation dengan nilai MSE yang rendah menghasilkan nilai keluaran JST yang semakin mendekat dengan target.
4.2 Evaluasi Secara Non Real Time
Evaluasi secara non real time menggunakan rekaman ucapan angka dari data perekaman yang sudah dibuat. Hasil perekaman ucapan harus disimpan dengan nama yang berbeda. Data perekaman yang sudah dibuat dalam format .wav akan dibagi menjadi 2 yaitu untuk data training dan data testing. Pada data training maupun data testing memiliki jumlah ucapan yang sama yaitu, sebanyak 200 yang terdiri atas 20 kali perekaman untuk setiap angka 0 hingga 9 dari 2 orang yang berbeda masing-masing 10 kali pengucapan. Data training dan data testing diproses pre-processing dan diproses ekstraksi ciri MFCC terlebih dahulu. Hasil dari data training dan data testing disimpan dalam bentuk .mat. Data training dan data testing menghasilkan ekstraksi ciri sebanyak 13 koefisien pada masing-masing data.
Data masukan untuk evaluasi non real time menggunakan rekaman ucapan angka dari data training dan data testing yang telah disimpan dalam format .mat. Hasil dari data training yang sudah disimpan dalam format .mat digunakan sebagai masukan jaringan syaraf tiruan backpropagation. Proses training dilakukan dengan mengubah nilai parameter untuk mendapat akurasi tingkat pengenalan yang baik. Evaluasi dilakukan dengan mengubah parameter variasi nilai pada variabel data. Variasi nilai dari variabel data yang digunakan meliputi nilai learning rate 0,05; 0,06; 0,07; nilai epoch mulai dari 500, 1000, 1500, 2000 hingga 2500 dan nilai jumlah neuron hidden layer mulai dari 10, 20, 30, 40 hingga 50.
Gambar 4.2 Variasi Learning Rate 0,05
Berdasarkan grafik pada Gambar 4.2 untuk mendapatkan tingkat pengenalan tertinggi dengan learning rate 0,05 berada pada neuron hidden layer 10 dengan epoch 1000 sebesar 92%. Pada neuron hidden layer 30 kemampuan pengenalan berkurang cukup drastis dibandingkan variasi neuron hidden layer lainnya.
NHL = 10 NHL = 20 NHL = 30 NHL = 40 NHL = 50
Epoch=500 91 90,5 10 10 19,5
Epoch=1000 92 92 10 10 19,5
Epoch=1500 91 91,5 10 10 19,5
Epoch=2000 90,5 91 10 10 19,5
Epoch=2500 90,5 91 10 10 19,5
91 90,5
10 10
19,5 92
92
10 10 19,5
91
91,5
10 10
19,5 90,5
91
10 10 19,5
90,5
91
10 10
19,5
0 10 20 30 40 50 60 70 80 90 100
Tingkat Pengenalan (%)
VARIASI LEARNING RATE 0,05




![Gambar 2.9 Urutan Zig zag Scanning [15]](https://thumb-ap.123doks.com/thumbv2/123dok/3754909.3929549/24.893.231.657.221.841/gambar-urutan-zig-zag-scanning.webp)
![Gambar 2.10 Jaringan Lapisan Jamak [6]](https://thumb-ap.123doks.com/thumbv2/123dok/3754909.3929549/25.893.231.705.404.844/gambar-jaringan-lapisan-jamak.webp)