HASIL DAN PEMBAHASAN
Praproses Data
Tahap pertama yang dilakukan adalah menyeleksi seluruh data pada kedua dataset dengan memperhatikan keberadaan setiap record data pada keduanya. Jika terdapat record tertentu pada salah satu dataset namun record tersebut tidak terdapat pada dataset yang lain, maka record yang dimaksud akan dihapus karena record tersebut dinilai tidak konsisten. Pada Tabel 5 dan Tabel 6 di bawah ini berisi contoh ketidak-konsistenan data pada dataset mahasiswa dan dataset IPK.
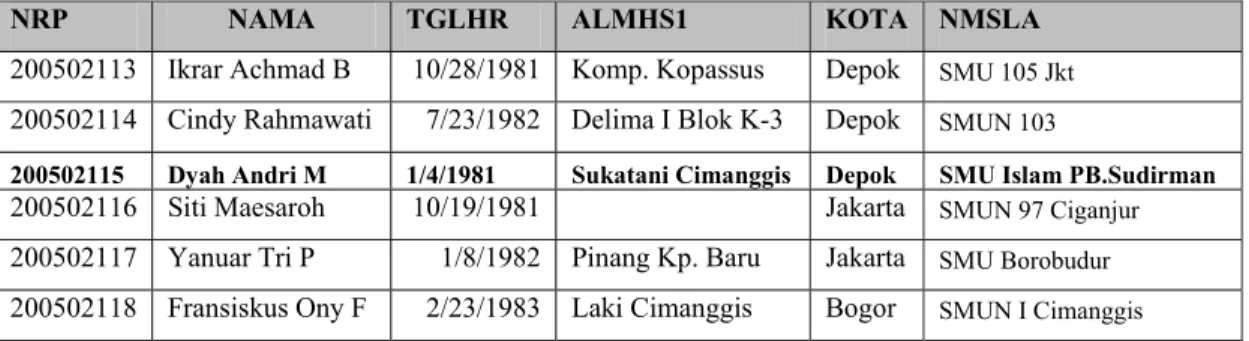
Tabel 5. Contoh data pada dataset mahasiswa
NRP NAMA TGLHR ALMHS1 KOTA NMSLA
200502113 Ikrar Achmad B 10/28/1981 Komp. Kopassus Depok SMU 105 Jkt 200502114 Cindy Rahmawati 7/23/1982 Delima I Blok K-3 Depok SMUN 103
200502115 Dyah Andri M 1/4/1981 Sukatani Cimanggis Depok SMU Islam PB.Sudirman 200502116 Siti Maesaroh 10/19/1981 Jakarta SMUN 97 Ciganjur 200502117 Yanuar Tri P 1/8/1982 Pinang Kp. Baru Jakarta SMU Borobudur 200502118 Fransiskus Ony F 2/23/1983 Laki Cimanggis Bogor SMUN I Cimanggis
Tabel 6. Contoh data pada dataset IPK
I_NRP I_THAK I_SMT I_IPS I_JSKSS I_IPK I_JSKSK 200502113 0001 1 1.90 20 1.90 20 200502114 0001 1 2.00 16 2.00 16 200502116 0001 1 2.50 20 2.50 20 200502117 0001 1 2.00 14 2.00 14 200502118 0001 1 2.10 20 2.10 20 200502119 0001 1 1.70 20 1.70 20
Record dengan NRP=200502115 yang terdapat pada dataset mahasiswa tidak terdapat pada dataset IPK, maka record tersebut dihapus karena dinilai tidak konsisten keberadaan informasinya.
Yang dilakukan selanjutnya adalah seleksi terhadap atribut dataset, dimana diketahui sebanyak 64 atribut terdapat pada dataset mahasiswa dan 7 atribut pada dataset IPK. Seleksi ini dilakukan untuk mendapatkan atribut-atribut
dengan nilai yang relevan terhadap status keaktifan studi mahasiswa sehingga untuk selanjutnya atribut-atribut yang dinilai berisi nilai yang tidak relevan tidak lagi disertakan dalam dataset. Di bawah ini disajikan contoh instances dengan beberapa atribut pada dataset mahasiswa seperti tampak pada Tabel 7.
Tabel 7. Contoh instances dengan beberapa atribut pada dataset mahasiswa NoForm NoUjiGel NoUji NRP Nama PilJur1 PilJur2 TglDft TryOut 0049 30076 WIDYA SIST 311 511 3/30/2001 FALSE 0067 50013 M.ARYA NUG 511 512 4/3/2001 TRUE 0070 50016 ANDRI SUHA 512 502 4/3/2001 FALSE 0082 50005 BONDAN AND 511 414 4/4/2001 FALSE 0088 50026 SITI KOMAL 512 502 4/5/2001 FALSE 0097 30038 ASNIDA RAT 311 511 4/6/2001 TRUE 0120 5 ACHMAD DJO 502 4/10/2001
0122 5 EDO TIAS R 511 4/10/2001
0131 50039 IKA MARYAN 512 4/10/2001 FALSE 0147 50062 ANGELA RUS 512 112 4/12/2001 FALSE
NoForm, NoUjiGel, NoUji, NRP, Nama adalah atribut-atribut yang tidak digunakan dalam penelitian karena menjadi tidak relevan jika seorang mahasiswa berpotensi tidak aktif pada waktu yang akan datang ditentukan oleh atribut-atribut tersebut. PilJur1, PilJur2, TglDft dan TryOut dapat dipilih sebagai atribut dalam penelitian, namun tidak terdapat keterangan atau penjelasan yang berkaitan dengan atribut-atribut tersebut baik berupa nilai hasil ujian masuk, lama waktu yang disediakan untuk mendaftar pada setiap gelombang daftar, dan lembaga yang melaksanakan tryout serta kapan dilaksanakannya, maka atribut-atribut yang tertera pada tabel di atas tidak dipilih untuk digunakan dalam penelitian. Pada Tabel 8 di bawah ini, disajikan contoh instances dengan atribut pada dataset IPK.
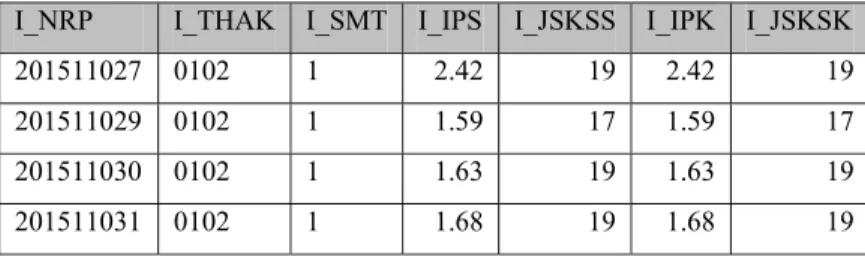
Tabel 8. Contoh instances dengan atribut pada dataset IPK I_NRP I_THAK I_SMT I_IPS I_JSKSS I_IPK I_JSKSK 201511027 0102 1 2.42 19 2.42 19 201511029 0102 1 1.59 17 1.59 17 201511030 0102 1 1.63 19 1.63 19 201511031 0102 1 1.68 19 1.68 19
I_NRP I_THAK I_SMT I_IPS I_JSKSS I_IPK I_JSKSK 201511048 0102 1 2.58 19 2.58 19 201511001 0102 2 2.62 21 2.75 40 201511003 0102 2 2.48 21 2.50 40 201511004 0102 2 2.71 21 2.85 40 201511005 0102 2 3.28 25 3.41 44 201511007 0102 2 2.83 23 2.90 42
Contoh dataset di atas digunakan untuk melihat prestasi akademik yang diperoleh oleh setiap mahasiswa pada tiap semester yang diambil. Atribut I_IPK adalah satu-satunya atribut yang dipilih karena dinilai sudah mewakili informasi prestasi akademik mahasiswa hingga saat masa akhir studi yang ditempuh. Pada sistem yang berjalan, masa studi yang telah ditempuh oleh setiap mahasiswa dapat dilihat pada atribut I_THAK, I_SMT dan I_JSKSK. Jika mahasiswa dengan NRP tertentu tidak muncul pada tahun akademik selanjutnya baik pada semester ganjil maupun genap maka mahasiswa tersebut dianggap tidak menyelesaikan masa studi yang harus ditempuh. Misal masa studi D3 adalah 7 semester dengan total sks 115 sks, namun mahasiswa yang dimaksud tidak melakukan registrasi pada tahun akademik dan semester yang sedang berjalan dan pada semester selanjutnya hingga masa studi yang berlaku dan total sks yang telah diambil lebih kecil atau sama dengan separuh dari total sks yang berlaku .
Tahap seleksi atribut tidak hanya dilakukan untuk mendapatkan konsistensi dan relevansi isi dari atribut yang dimiliki namun juga dilakukan seleksi terhadap atribut yang mengandung missing value atau nilai yang hilang atau kosong, serta atribut yang mengandung data yang redudancy atau data yang duplikat. Jika ditemukan dalam kedua dataset terdapat atribut dengan nilai kosong atau missing value ataupun atribut dengan data yang redudancy, maka data tersebut dihapus, demikian halnya seperti seleksi yang dilakukan sebelumnya terhadap atribut-atribut dalam dataset. Hal ini dilakukan karena atribut yang missing value tidak memberikan informasi apapun jika dipertahankan keberadaannya, demikian pula dengan atribut yang redundancy, maka cukup dipilih salah satunya saja dari data yang redundant karena data tersebut berisi informasi yang sama. Tahap seleksi ini disebut juga dengan tahap pembersihan data atau data cleaning yang bertujuan mendapatkan data yang bersih, sehingga
data tersebut dapat digunakan untuk tahap selanjutnya yaitu transformasi data.
Pada Gambar 2 telah diperlihatkan bahwa proses data cleaning adalah proses awal yang dikerjakan sebelum melakukan tahap mining.
Dari tahap seleksi atribut yang telah dilakukan di atas diperoleh beberapa atribut sementara yang akan digunakan dalam penelitian, yaitu : NRP, Tgllhr, Alamat, Pekerjaan Orangtua, JenisSLA, WilSMU, Anakke, dan Dari yang berasal dari dataset mahasiswa dan atribut IPK dari dataset IPK. Dan jumlah data akhir yang diperoleh adalah sebanyak 1.175 record data dari total data sebelumnya adalah 3.203 record data.
Selanjutnya adalah menghapus atribut NRP , dimana pada tahap sebelumnya atribut ini digunakan untuk melihat kemunculannya pada tiap semester dan tahun akademik pada dataset IPK, setelah diperoleh informasi yang dicari maka atribut ini sudah tidak lagi diperlukan. Sehingga atribut-atribut yang digunakan hanya tinggal atribut Tgllhr, JenisSLA, PkOrtu, Anakke dan Dari.
Tahap berikutnya adalah merubah tipe data dari beberapa atribut tadi, diantaranya adalah atribut Tgllhr, JenisSLA, PkOrtu, Anakke dan atribut Dari. Hal ini dilakukan dengan tujuan agar isi pada setiap atribut lebih mudah dipahami oleh pengguna data maupun pengguna informasi. Pada Tabel 9 di bawah ini ditampilkan contoh instances dengan atribut-atribut yang disebutkan tadi.
Tabel 9. Contoh instances dengan atribut yang akan dirubah tipe datanya TGLLAHIR PK_ORTU JNSSLA AKKE DARI
3/4/1983 1 1 1 2 8/3/1982 1 1 1 3 9/23/1981 3 1 2 4 9/24/1979 4 1 5 7 11/19/1981 4 1 1 2 1/11/1983 4 1 2 2 2/1/1981 2 1 3 3 9/7/1982 4 1 1 3 7/13/1982 4 1 4 4 4/1/1983 4 1 1 1 7/11/1980 2 1 3 3 5/28/1981 3 1 3 3
TGLLAHIR PK_ORTU JNSSLA AKKE DARI 10/25/1981 2 1 2 2
3/23/1981 4 1 2 4
Tipe data atribut TglLhr yang semula adalah date diubah menjadi atribut Usia dengan tipe data numeric, sehingga tidak lagi berisi tanggal lahir mahasiswa melainkan berisi usia mahasiswa pada saat awal kuliah pada semester satu. Tipe data JenisSLA, PkOrtu, Anakke dan Dari diubah menjadi bertipe data string, sehingga dapat lebih mudah dipahami isi atribut yang dikandung dan tipe data ini dan sesuai dengan tipe data yang digunakan dalam algoritma decision tree.
Atribut Anakke dan atribut Dari dijadikan dalam satu atribut baru bernama Anakke yang berisi informasi kategori urutan anak dalam keluarga.
Beberapa atribut pada tabel di atas masih berisi data dalam bentuk kode angka, seperti nampak pada atribut PkOrtu dan JenisSLA. Berikut ini pada Tabel 10 disajikan keterangan kode pada kedua atribut tersebut.
Tabel 10. Keterangan kode pada atribut PkOrtu dan JenisSLA Atribut Kode Keterangan
PkOrtu 1 TNI
2 PNS
3 Swasta
4 Purnawirawan
JenisSLA 1 SMU
2 SMK
3 MA/MAN
Setelah perubahan tipe data dan pemberian nama baru dilakukan kepada beberapa atribut maka isi dari atribut yang bersangkutanpun berubah. Berikut ini tampak pada Tabel 11 adalah contoh instances dengan tipe data dan nama atribut yang baru.
Tabel 11. Contoh instances dengan tipe data dan nama atribut yang baru USIA PKORTU JNSSLA Anakke
17 TNI smu sulung 18 TNI smu sulung 19 SWASTA smu tengah
USIA PKORTU JNSSLA Anakke 21 PURNAWIRAWAN smu tengah 19 PURNAWIRAWAN smu sulung 17 PURNAWIRAWAN smu bungsu 19 PNS smu bungsu 18 PURNAWIRAWAN smu sulung 18 PURNAWIRAWAN smu bungsu 17 PURNAWIRAWAN smu tunggal 20 PNS smu bungsu 19 SWASTA smu bungsu 19 PNS smu tengah 19 PURNAWIRAWAN smu tengah
Beberapa tahapan yang telah dilakukan sebelumnya telah memberikan hasil berupa dataset dengan atribut-atribut terpilih yang akan digunakan selanjutnya pada tahap transformasi data. Selengkapnya atribut terpilih tersebut beserta contoh datanya dapat dilihat pada Tabel 12 di bawah ini.
Tabel 12. Contoh instances dengan atribut terpilih
USIA ALAMAT PKORTU JNSSLA WILSMU Anakke IPK 17 JAKARTA TNI smu jakarta sulung 2.41 18 JAKARTA TNI smu jakarta sulung 2.64 19 TANGERANG SWASTA smu tangerang tengah 2.62 21 JAKARTA PURNAWIRAWAN smu jakarta tengah 1.64 19 JAKARTA PURNAWIRAWAN smu jakarta sulung 2.15 17 JAKARTA PURNAWIRAWAN smu jakarta bungsu 3.3 19 DEPOK PNS smu lainnya bungsu 2.19 18 LAINNYA PURNAWIRAWAN smu lainnya sulung 2.49 18 JAKARTA PURNAWIRAWAN smu jakarta bungsu 3.07 17 JAKARTA PURNAWIRAWAN smu jakarta tunggal 3.61 20 DEPOK PNS smu jakarta bungsu 3.24 19 JAKARTA SWASTA smu jakarta bungsu 2.71 19 JAKARTA PNS smu jakarta bungsu 2.95 19 JAKARTA PNS smu jakarta bungsu 2.19
Berikut ini disajikan beberapa keterangan yang berkaitan dengan atribut- atribut pada tabel di atas, yaitu :
a. Usia
Merupakan atribut yang berisi usia mahasiswa pada saat masuk kuliah semester satu. Atribut ini adalah atribut pengganti dari atribut sebelumnya yaitu Tgllhr.
b. Alamat
Merupakan atribut yang berisi alamat tinggal mahasiswa pada saat melakukan registrasi ulang. Untuk selanjutnya atribut ini dikelompokkan dalam enam kategori kota wilayah tinggal yaitu Jakarta, Bogor, Depok, Tangerang, Bekasi, dan Lainnya. Kategori kota lainnya memberikan arti bahwa kota yang dimaksud adalah kota wilayah selain dari lima kota wilayah yang sudah disebutkan tadi.
c. PkOrtu
Merupakan atribut yang menjelaskan jenis pekerjaan orang tua dari mahasiswa, yang kemudian dikelompokkan dalam empat kategori yaitu Purnawirawan, Swasta, TNI (yang maksud adalah anggota Tentara Nasional Indonesia), dan PNS (Pegawai Negeri Sipil). Pengelompokkan ini didasarkan kepada data sumber tentang jenis pekerjaan orang tua yang dimiliki oleh FIK-UPNVJ.
d. JenisSLA
Merupakan atribut yang menjelaskan kelompok sekolah lanjutan asal mahasiswa yang dikelompokkan ke dalam jenis sekolah kejuruan (SMK), sekolah menengah umum (SMU), dan sekolah lanjutan atas keagamaan (MA/Madrasah Aliyah).
e. WilSMU
Berisi alamat wilayah kota sekolah lanjutan asal mahasiswa. Kategori yang dibuat untuk atribut ini adalah sama dengan kategori yang ada pada atribut sebelumnya yaitu alamat, yaitu Jakarta, Bogor, Depok, Tangerang, Bekasi, dan Lainnya.
f. Anakke
Merupakan atribut yang menjelaskan urutan anak dalam keluarga. Kategori yang dibuat berdasarkan kepada informasi yang ada pada atribut Anakke
dan Dari, dengan menganalisa isi terhadap keduanya sehingga atribut yang dihasilkan terbagi ke dalam empat kategori yaitu sulung, tengah, bungsu, dan tunggal.
g. IPK
Merupakan atribut yang berisi nilai prestasi kumulatif mulai dari semester satu hingga akhir semester yang di tempuh oleh mahasiswa. Terdapat lima kategori IPK yang diberlakukan pada FIK-UPNVJ yaitu IPK < 1.50, 1.50 – 1.99, 2.00 – 2.49, 2.50 – 2.99, dan >= 3.00.
Hasil yang di peroleh dari tahap seleksi atribut di atas telah menghasilkan sejumlah 7 atribut baru dan 1.175 record data dengan isi data yang tidak lagi redundant, tidak missing value dan data yang digunakan adalah data yang konsisten. Untuk selanjutnya dataset tersebut disebut dengan nama dataset akademik. Tahapan yang akan dikerjakan kemudian adalah transformasi data, yang akan dijelaskan pada sub bahasan selanjutnya.
Data Mining
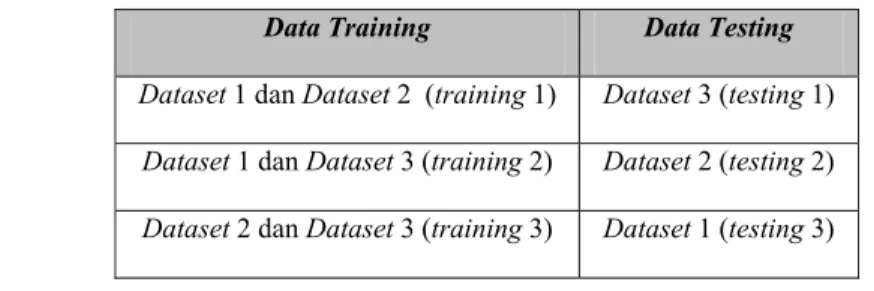
Dengan menggunakan metode 3-fold cross validation maka dataset akademik secara acak dibagi ke dalam tiga bagian, yaitu dua bagian sebagai data training dan satu bagian sebagai data testing. Pada Tabel 13 berikut ini disajikan kombinasi dari tiga bagian dataset akademik tersebut.
Tabel 13. Kombinasi dataset hasil pemisahan dengan metode 3-fold cross validation
Data Training Data Testing
Dataset 1 dan Dataset 2 (training 1) Dataset 3 (testing 1) Dataset 1 dan Dataset 3 (training 2) Dataset 2 (testing 2) Dataset 2 dan Dataset 3 (training 3) Dataset 1 (testing 3)
Kemudian dataset di atas digunakan untuk mengkonstruksi pohon keputusan (decision tree) yang dimulai dengan pembentukan bagian akar, kemudian data terbagi berdasarkan atribut-atribut yang sesuai untuk dijadikan leaf
node. Tahap ini dimulai dengan melakukan seleksi atribut menggunakan formula information gain yang terdapat pada algoritma C5.0 seperti tampak pada halaman 11 Formula 2.1, Formula 2.2 dan Formula 2.3, sehingga diperoleh nilai gain untuk masing-masing atribut, yang mana atribut dengan nilai gain tertinggi akan menjadi parent bagi node-node selanjutnya. Node-node tersebut berasal dari atribut-atribut yang memiliki nilai gain yang lebih kecil dari nilai gain atribut parent. Maka untuk mendapatkan nilai gain dari dua kelas output yang berbeda yaitu ’aktif’ dan ’tidak aktif’ pada dataset akademik adalah dengan menghitung tingkat impurity kedua kelas tersebut. Berikut ini pada Tabel 14 disajikan contoh data kelas mahasiswa aktif dan tidak aktif berdasarkan atribut JnsSLA.
Tabel 14. Contoh data dengan kelas mahasiswa aktif dan tidak aktif berdasarkan atribut JnsSLA
JnsSLA Aktif Tidak Aktif SMU 801 219 SMK 104 23
MA 20 8
Selanjutnya dengan menggunakan data pada Tabel 14 di atas dicari nilai information gainnya yaitu,
( )
1175 log 250 1175
250 1175 log 925 1175 250 925
,
925 =− 2 − 2
I
=0,739
Jika dalam satu set hanya terdiri dari satu kelas maka entropinya = 0. Jika perbandingan dua kelas rasionya sama maka nilai entropinya=1. Dengan menggunakan formula yang sama dilakukan pemilihan atribut, dimana akan dihitung rasio nilai kelas aktif dan tidak aktif dari seluruh atribut. Salah satu contoh penerapan formula tersebut untuk pemilihan atribut (atribut JnsSLA) adalah sebagai berikut,
• JnsSLA = SMU,
( )
0,751020 log 219 1020
219 1020 log 801 1020 219 801
,
801 =− 2 − 2 =
I
• JnsSLA = SMK,
( )
0,682127 log 23 127
23 127 log 104 127 23 104
,
104 =− 2 − 2 =
I
• JnsSLA = MA,
( )
0.86228 log 8 28
8 28 log 20 28 8 20 ,
20 =− 2 − 2 =
I
• Maka total entropi atribut JnsSLA :
( ) ( ) ( ) (
0,862)
0,7451175 682 28
, 1175 0 75 127 , 1175 0
1020 + + =
= JnsSLA E
• Maka nilai Gain atribut JnsSLA :
(
JnsSLA)
=0,739−0,745=−0,006 GHasil diatas diperoleh dengan menggunakan data 100% yang berjumlah 1175 dengan keadaan data tidak terbagi ke dalam 3-fold cross validation. Bila diterapkan pada data yang sudah terbagi ke dalam 3-fold cross validation akan memberikan hasil yang berbeda pada setiap kelompok datanya.
Untuk tahap selanjutnya hal yang sama yaitu penerapan formula information gain dilakukan terhadap atribut-atribut yang lainnya dalam dataset akademik, sehingga diperoleh atribut dengan nilai gain tertinggi yang kemudian dipilih sebagai simpul pertama pada decision tree yang dikenal dengan nama root/akar. Pada simpul selanjutnya secara berurutan diisi oleh atribut-atribut yang bernilai gain lebih rendah, dan akan berhenti pada simpul akhir yang berisi kelas output dari setiap cabangnya yang dikenal dengan nama leaf/daun. Tabel 15 di bawah ini menyajikan nilai gain dari seluruh atribut pada kelompok data training dan data testing yang mana nilai gain atribut Alamat, PkOrtu, JnsSLA, WilSMU, Anakke, dan IPK yang terdapat dalam tabel adalah hasil pembulatan terhadap nilai aslinya.
Tabel 15. Nilai gain seluruh atribut pada kelompok data training dan data testing
Dataset Instances Gain
Usia Alamat PkOrtu JnsSLA WilSMU Anakke IPK
training 1 784 0 0.024 0.002 0.005 0.013 0.002 0.242
Dataset Instances Gain
Usia Alamat PkOrtu JnsSLA WilSMU Anakke IPK
training 2 783 0 0.018 0.002 0.002 0.009 0.002 0.249
training 3 783 0 0.023 0.004 0.002 0.011 0.003 0.204
rata-rata 0 0.022 0.003 0.003 0.011 0.002 0.232
Pada Tabel 15 diatas tampak bahwa atribut IPK memiliki nilai Gain tertinggi, sehingga atribut ini menjadi atribut root pada decision tree, kemudian dilanjutkan dengan atribut Alamat dan WilSMU yang berfungsi sebagai child node, dan diakhiri oleh label kelas aktif dan tidak aktif yang berfungsi sebagai leaf. Maka dapat dikatakan bahwa parameter penentu pertama seorang mahasiswa berpotensi untuk aktif atau tidak aktif pada waktu yang akan datang dilihat dari IPK yang diperoleh mahasiswa yang bersangkutan, kemudia Alamat tinggal dan WilSMU mahasiswa tersebut. Atribut Usia, PkOrtu, JnsSLA dan Anakke rata-rata nilai gain yang diperoleh sangat kecil jika dibandingkan dengan atribut Alamat, WilSMU dan IPK, sehingga dapat disimpulkan bahwa dukungan informasi yang terkandung dalam atribut tersebut terhadap output yang dicapai sangat kecil. Maka atribut akhir yang terpilih hanya terdiri dari atribut IPK, Alamat, dan WilSMU.
Dengan menggunakan tiga atribut terakhir tadi maka diperoleh dengan jelas karakteristik mahasiswa aktif dan tidak aktif beserta aturan yang mengklasifikasikan data tersebut.
Pada Gambar 6 berikut ini disajikan hasil klasifikasi pada data testing 3 dengan menggunakan tiga atribut terakhir tadi.
Gambar 6. Gambar hasil klasifikasi data testing 3 menggunakan weka classifier Salah satu hasil klasifikasi decision tree seperti pada Gambar 6 diatas menggunakan beberapa parameter yang tersedia pada weka classifier untuk klasifikasi menggunakan algoritma C5.0 ( atau J48 pada weka ) yaitu :
- binary splits= false, jika bernilai true maka setiap level hanya terdiri dari dua cabang (pada setiap atribut hanya terdiri dari dua kategori, kategori lain dianggap sebagai kategori pada atibut lain)
- confidencefactor = 0.25, atribut dengan nilai gain sama dengan 0.25 atau lebih tinggi maka terpilih sebagai atribut untuk decision tree, sedangkan atribut dengan nilai lebih kecil dari 0.25 akan dipangkas (pruned) dan tidak terpilih sebagai atribut untuk decision tree.
- debug = false, jika bernilai true maka classifier akan memberikan informasi yang akan ditampilkan pada layar console.
- minnumObj = 2, jumlah minimum instances per leaf.
- numfolds=3, data yang akan diklasifikasi dibagi menjadi 3 bagian yaitu 1 bagian data digunakan untuk proses pruning sedangkan 2 bagian data yang lainnya digunakan untuk membentuk decision tree berdasarkan hasil dari bagian data sebelumnya .
- reducederrorpruning = false,tidak dilakukan prosedur pruning yang lain - save instance data = false, tidak dilakukan penyimpanan data training untuk
visualisasi
- seed = 1, digunakan untuk mengacak data saat reduksi error pruning dilakukan - subtreeraising = true, memeriksa posisi subtree pada saat proses pruning
dilakukan
- unpruned = false, jika bernilai true maka proses pruning tidak dikerjakan.
- uselaplace = false,dengan menggunakan metode Laplace akan dihitung jumlah true classified dan missclassified.
Pada Gambar 6 diatas terlihat bahwa weka classifier hanya memilih atribut IPK sebagai atribut dalam decision tree, sedangkan atribut lainnya terpangkas dari decision tree. Maka dapat disimpulkan bahwa dengan jumlah dan jenis data yang ada pada testing 3 hanya dibutuhkan atribut IPK untuk mendapatkan kelas output dari dataset tersebut. Hasil klasifikasi pada data testing 3 diatas tampak pula struktur if -then yang menunjukkan susunan aturan-aturan yang diperoleh, berikut pada Gambar 7 ditampilkan kembali bentuk aturan yang dimaksud :
Gambar 7. Aturan-aturan klasifikasi hasil data testing 3 Adapun struktur if-then untuk aturan diatas adalah sebagai berikut : If IPK <= 1.77 then Status = Tidak Aktif
Else
If IPK > 1.77 then Status = Aktif
Dan bentuk Gambar 7 diatas dapat pula dilihat dalam bentuk decision tree yang dihasilkan, seperti pada Gambar 8 berikut ini :
Gambar 8. Hasil klasifikasi dengan algoritma C5.0 menggunakan weka classifier dalam bentuk struktur pohon keputusan
Klasifikasi dengan decision tree (algoritma C5.0) telah menghasilkan beberapa aturan, baik dalam bentuk struktur pohon keputusan maupun dalam bentuk aturan if – then. Kegiatan selanjutnya adalah melakukan klasifikasi dengan menggunakan metode K-Nearest Neighbor (KNN) yang mana dalam weka classifier diberi nama IBk. Pada dasarnya tahapan yang dilakukan kali ini menggunakan beberapa parameter yang berisi nilai yang sudah default pada weka classifier, hanya saja untuk parameter KNN akan diisi dengan nilai ganjil mulai dari 1, 3 dan 5. Karena jumlah data/tetangga pada KNN ditentukan oleh user dan untuk mendapatkan hasil yang reasonable maka k berisi data dalam bilangan ganjil, maka dipilihlah jumlah tetangga dengan angka-angka tersebut, dengan asumsi bahwa jumlah tetangga data yang diambil adalah sebanyak 1, 3 dan 5 tetangga data. Parameter-parameter yang dimaksud yaitu :
- KNN=1,banyaknya jumlah tetangga data yang diambil.
- crossValidate = false, digunakan untuk menentukan k yang terbaik.
- debug = false, jika bernilai true maka classifier akan memberikan informasi yang akan ditampilkan pada layar console.
- distanceWeighting =no distance weighting, setiap data tetangga yang dipilih tidak diberi bobot.
- meanSquared = false,akan lebih baik bila digunakan untuk data-data regresi.
- nearestNeighborSearchAlgorithm=LinearNNSearch, adalah algoritma standar yang digunakan untuk mencari tetangga data pada weka.
- windowsize = 0, jumlah maksimum data yang diklasifikasi tidak terbatas.
Hasil yang diperoleh menunjukkan kecenderungan yang lebih baik dalam mengklasifikasikan data, baik dengan jumlah tetangga data=1, 3 atau 5. Setiap data yang diuji diperhatikan tingkat ketepatan dan ketidaktepatan dalam mengklasifikasikan data tersebut dan lama waktu yang dibutuhkan untuk membangun model. Hasil klasifikasi dengan tingkat ketepatan klasifikasi data yang tertinggi dan lama waktu terendah dalam membangun model akan dijadikan sebagai model terbaik. Karena k adalah satu-satunya hyper-paramater dalam KNN yang mana nilainya harus ditentukan dengan coba-coba, maka k yang diambil adalah k=1, k=3 dan k=5. Angka-angka tersebut diambil bertujuan untuk mendapatkan hasil yang reasonable yaitu hasil yang diperoleh memiliki waktu yang singkat dalam membangun model , data terklasifikasi dengan baik.
Seperti halnya pada algoritma C5.0, penggunaan algoritme ini dalam data training dan data testing memberikan hasil yang berbeda-beda, dan berikut ini pada Gambar 9 ditampilkan hasil klasifikasi dengan KNN=1 atau jumlah data tetangga yang diambil adalah sebanyak 1 pada data testing 3.
Gambar 9. Hasil klasifikasi dengan KNN=1 pada data testing 3 menggunakan weka classifier
Pada Gambar 9 di atas sebanyak 82 record data diklasifikasikan sebagai mahasiswa tidak aktif, 309 record data mahasiswa aktif dan 9 record data diklasifikasikan tidak sesuai dengan kelasnya yaitu terdiri dari 3 record data diduga sebagai mahasiswa tidak aktif ternyata adalah mahasiswa aktif serta 6 data diduga sebagai mahasiswa aktif ternyata adalah mahasiswa tidak aktif. Selebihnya hasil uji coba klasifikasi dengan KNN dapat dilihat pada bab lampiran yang terdapat pada tesis ini. Pengujian data dengan KNN relatif lebih singkat untuk dilakukan dibandingkan dengan C5.0.
Pada bahasan berikutnya akan dilakukan analisis dengan menggunakan beberapa alat ukur evaluasi seperti yang sudah dijelaskan pada bahasan sebelumnya, terhadap hasil yang diperoleh dengan menggunakan algoritma C5.0 dan KNN.
Evaluasi
Seperti yang sudah dijelaskan pada bahasan sebelumnya, pada tahap ini akan dilakukan evaluasi terhadap kedua algoritma yang dipakai pada dataset akademik dengan memperhatikan beberapa parameter evaluasi yaitu correctly classified, incorrectly classified, yang mana kedua parameter ini diwakili oleh parameter overall success rate yang terdapat pada confusion matrix. Persentase klasifikasi sesuai dengan kelasnya dan klasifikasi yang tidak sesuai dengan kelasnya diukur menggunakan lift chart dan recall precision sehingga diperoleh
informasi yang tersembunyi di dalamnya. Untuk lebih mempermudah pemahaman dalam menganalisa hasil klasifikasi yang disajikan, dilampirkan pula beberapa visualisasi hasil tersebut dalam bentuk grafik yang akan disajikan setelah tabel persentase hasil klasifikasi.
Berikut ini pada Tabel 16 disajikan persentase hasil klasifikasi data sesuai dengan kelasnya berdasarkan alat ukur evaluasi berupa confusion matrix yang terdiri dari overall success rate, lift chart, dan recall precision pada C5.0 dan KNN terhadap data training dan data testing.
Tabel 16. Persentase hasil klasifikasi berdasarkan alat ukur evaluasi confusion matrix (overall success rate, lift chart, dan recall precision)
Overall success rate Lift chart Recall precision Dataset
C5.0 K=1 K=3 K=5 C5.0 K=1 K=3 K=5 C5.0 K=1 K=3 K=5
Training 87.91 94.21 88.64 86.94 38 41 38 37 81 90 85 84
Testing 86.98 95.83 88.17 89.03 39 42 38 37 80 90 85 85
Pada Tabel 16 diatas dapat dilihat bahwa kecenderungan hasil terbaik diperoleh pada saat uji coba data menggunakan KNN dengan k=1. Baik pada saat uji coba dengan data training yang jumlah datanya dua kali lebih banyak dari data testing, hasil yang diperoleh tetap menunjukkan nilai tertinggi hingga mencapai lebih dari 95%.
Berikut ini pada Gambar 10, Gambar 11, Gambar 12, disajikan grafik yang menunjukkan perbandingan terhadap dua metode diatas ke dalam masing-masing alat ukur evaluasi yang digunakan seperti disebutkan sebelumnya.
0 10 20 30 40 50 60 70 80 90 100
C5.0 knn=1 knn=3 knn=5
Overall success rate
nilai (%)
Training Testing
Gambar 10. Grafik Overall Success Rate pada dataset akademik menggunakan metode decision tree (C5.0) dan KNN
Pada grafik di atas terlihat bahwa keberhasilan klasifikasi yang mencapai nilai hampir 100% menunjukkan bahwa KNN dengan k=1 menjadi lebih baik dibandingkan C5.0, namun keberhasilan tersebut tidak terulang pada saat jumlah k diberikan nilai yang lebih besar. Maka dapat disimpulkan bahwa klasifikasi metode KNN dengan k=1 adalah model terbaik.
0 10 20 30 40 50 60 70 80 90 100
c5.0 knn=1 knn=2 knn=3
lift chart
nilai (%)
training testing
Gambar 11. Grafik Lift Chart pada dataset akademik menggunakan metode decision tree (5.0) dan KNN
Pada Gambar 11 di atas, kecenderungan hasil yang sama yaitu jumlah kelas positif pada kedua algoritma terjadi pada saat klasifikasi dilakukan dengan
menggunakan data training dan testing. Rata-rata jumlah data yang terklasifikasi ke dalam kelas positif mencapai 40% dari seluruh data yang diklasifikasi.
0 10 20 30 40 50 60 70 80 90 100
C5.0 knn=1 knn=3 knn=5
recall precision
nilai (%)
Training Testing
Gambar 12. Grafik Recall Precision pada dataset akademik menggunakan metode decision tree (5.0) dan KNN
Pada grafik di atas data yang di klasifikasi dan sesuai dengan kelasnya rata-rata mencapai nilai hingga 80% lebih, yang menyatakan bahwa seluruh data yang di klasifikasi dapat dikenali dengan sangat baik oleh kedua algoritma. Hal ini dapat disebabkan oleh karena dilakukannya tahap seleksi data dan atribut sebelum dilakukan kegiatan klasifikasi, sehingga seluruh data yang diolah hanyalah data yang bersih dari missing value dan redudancy. Sementara itu sejumlah data yang diklasifikasi namun tidak sesuai dengan kelasnya (missclassified) sebanyak 5%, dan berikut ini pada Gambar 13 disajikan grafik persentase klasifikasi sesuai dengan kelasnya (true classified) dan klasifikasi tidak sesuai dengan kelasnya (missclassified).
ketepatan klasifikasi
0 10 20 30 40 50 60 70 80 90 100
C5.0 knn=1 knn=3 knn=5
nilai (%) true classified
missclassified
Gambar 13. Grafik persentase true classified dan missclassified
Hasil yang diperoleh dalam penelitian ini dengan menggunakan algoritma C5.0 dan KNN menunjukkan bahwa decision tree dengan algoritma C5.0 tetap dinilai lebih baik ini dibandingkan dengan KNN, karena decision tree memberikan output berupa karakteristik data yang terklasifikasi, baik untuk kelas aktif maupun kelas tidak aktif. Sedangkan knn tidak dapat memberikan karakteristik tersebut sehingga tidak diperoleh informasi karakteristik data yang dibutuhkan, melainkan hanya memberikan informasi jumlah data yang dapat terklasifikasi dan tidak terklasifikasi saja.