ABSTRAK
Berdasarkan data hasil pertanian buah di Dinas Pertanian Provinsi Daerah Istimewa Yogyakarta menampilkan beberapa daerah dengan hasil panen buah yang bervariasi jumlahnya. Untuk itu diperlukan pengelompokan daerah potensial penghasil buah untuk mengetahuni daerah mana saja yang menghasilkan buah dengan jumlah banyak ataupun sedikit. Pembagian hasil produksi biasanya dilakukan berdasarkan nama kabupaten penghasil buah. Oleh karena itu, dibutuhkan metode untuk memudahkan dalam pengelompokan daerah penghasil buah.
Dengan pendekatan pengklasteran K-Means, pembagian kelompok daerah dapat dilakukan berdasarkan luas panen (Ha), produksi(ton) dan tahun panen. Pada penelitian ini dilakukan pengklasteran daerah potensial penghasil buah menggunakan algoritma K-Means.
Dengan menggunakan K-Means bertujuan dalam memudahkan pengelompokan suatu daerah dengan hasil produksi buah banyak, sedang dan rendah. Hasilnya adalah sebuah gambaran yang menunjukan pengelompokan daerah berdasarkan hasil pertanian buah.
ABSTRACT
The data of fruit agriculture in Agriculture Department of Yogyakarta Province presents that some region has lots of fruit variation. Based on the data, it is necessary to classify the fruits based on the quantity of the fruits. The classification is usually done based on the regions which produce the fruits. Hence, a method is needed to make a classification easier.
The writer proposed K-Means cluster method. Using K-Means cluster method. The region classification can be done based on the area (Ha), the amount of production (ton) and the harvest time (year).This research was done with K-Means algorithm.
It is aimed to make the classification easier in a region with lot, medium and less production. The result of research is a picture that show the region classification based on the fruit agriculture.
i
PENERAPAN METODE K-MEANS CLUSTERING
UNTUK MENGELOMPOKAN POTENSI PRODUKSI BUAH – BUAHAN
DI PROVINSI DAERAH ISTIMEWA YOGYAKARTA
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh :
MIKAEL ADITYA WAHYU KRISNA MURTI
125314047
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
THE IMPLEMENTATION OF K-MEANS CLUSTERING METHODS
TO CLASSIFY THE FRUIT PRODUCTION POTENTIALITY
IN SPECIAL REGION OF YOGYAKARTA PROVINCE
A THESIS
Presented as Partial Fullfillment of Requirements To Obtain the Sarjana Komputer Degree In Informatics Engineering Study Program
By :
MIKAEL ADITYA WAHYU KRISNA MURTI
125314047
INFORMATICS ENGINEERING STUDY PROGRAM
INFORMATICS ENGINEERING DEPARTMENT
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
iii
HALAMAN PERSETUJUAN
SKRIPSI
PENERAPAN METODE K-MEANS CLUSTERING UNTUK
MENGELOMPOKAN POTENSI PRODUKSI BUAH
–
BUAHAN DI PROVINSI DAERAH ISTIMEWA
YOGYAKARTA
Oleh :
MIKAEL ADITYA WAHYU KRISNA MURTI
125314047
Telah disetujui oleh :
Dosen Pembimbing Proposal TA
iv
HALAMAN PENGESAHAN
SKRIPSI
PENERAPAN METODE K-MEANS CLUSTERING UNTUK
MENGELOMPOKAN POTENSI PRODUKSI BUAH
–
BUAHAN DI PROVINSI DAERAH ISTIMEWA
YOGYAKARTA
Dipersiapkan dan ditulis oleh :
MIKAEL ADITYA WAHYU KRISNA MURTI
125314047
Telah dipertahankan di depan Panitia Penguji Pada tanggal 2 Februari 2017
Dan dinyatakan telah memenuhi syarat
Susunan Panitia Penguji Nama Lengkap
Ketua : Paulina Heruningsih Prima Rosa M.Sc. Sekretaris : JB. Budi Darmawan S.T., M.Sc.
Anggota : Dr. Cyprianus Kuntoro Adi, S.J. M.A.,M.Sc.
v
MOTTO
“Warisan cita-cita, takdir waktu, dan impian manusia adalah hal yang tidak akan pernah berakhir. Selama manusia terus mencari arti kebebasannya, hal ini tidak
akan pernah bisa dicegah!” – Gold D Roger
“Orang lemah tidak bisa memilih cara mereka untuk mati!” – Trafalgar D.Watel Law
vi
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnya bahwa skripsi yang saya tulis
ini tidak memuat karya atau bagian karya orang lain, kecuali yang
telah disebutkan dalam kutipan dan daftar pustaka, sebagaimana
layaknya karya ilmiah.
Yogyakarta, Penulis
vii
LEMBAR PERSETUJUAN PUBLIKASI KARYA ILMIAH
UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma : Nama : Mikael Aditya Wahyu Krisna Murti
NIM : 125314047
Demi mengembangkan ilmu pengetahunan, saya memberikan kepada Perpusatakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul :
PENERAPAN METODE K-MEANS CLUSTERING UNTUK
MENGELOMPOKAN POTENSI PRODUKSI BUAH – BUAHAN DI
PROVINSI DAERAH ISTIMEWA YOGYAKARTA
Beserta perangkat yang diperlukan (bila ada). Dengan demikian, saya memberikan kepada Universitas Sanata Dharma hak untuk menyimpan, mengalihkan ke dalam bentuk media lain, mengelolanya dalam bentuk pangkalan data, mendistribusikannya secara terbatas dan mempublikasikannya di Internet atau media lain untuk kepentingan akademis tanpa perlu izin dari saya maupun memberi royalti kepada saya selama tetap mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya.
Yang menyatakan,
viii
ABSTRAK
Berdasarkan data hasil pertanian buah di Dinas Pertanian Provinsi Daerah Istimewa Yogyakarta menampilkan beberapa daerah dengan hasil panen buah yang bervariasi jumlahnya. Untuk itu diperlukan pengelompokan daerah potensial penghasil buah untuk mengetahuni daerah mana saja yang menghasilkan buah dengan jumlah banyak ataupun sedikit. Pembagian hasil produksi biasanya dilakukan berdasarkan nama kabupaten penghasil buah. Oleh karena itu, dibutuhkan metode untuk memudahkan dalam pengelompokan daerah penghasil buah.
Dengan pendekatan pengklasteran K-Means, pembagian kelompok daerah dapat dilakukan berdasarkan luas panen (Ha), produksi(ton) dan tahun panen. Pada penelitian ini dilakukan pengklasteran daerah potensial penghasil buah menggunakan algoritma K-Means.
Dengan menggunakan K-Means bertujuan dalam memudahkan pengelompokan suatu daerah dengan hasil produksi buah banyak, sedang dan rendah. Hasilnya adalah sebuah gambaran yang menunjukan pengelompokan daerah berdasarkan hasil pertanian buah.
ix
ABSTRACT
The data of fruit agriculture in Agriculture Department of Yogyakarta Province presents that some region has lots of fruit variation. Based on the data, it is necessary to classify the fruits based on the quantity of the fruits. The classification is usually done based on the regions which produce the fruits. Hence, a method is needed to make a classification easier.
The writer proposed K-Means cluster method. Using K-Means cluster method. The region classification can be done based on the area (Ha), the amount of production (ton) and the harvest time (year).This research was done with K-Means algorithm.
It is aimed to make the classification easier in a region with lot, medium and less production. The result of research is a picture that show the region classification based on the fruit agriculture.
x
KATA PENGANTAR
Puji dan syukur kepada Tuhan Yang Maha Esa atas segala berkat dan karunia-Nya, sehingga penulis dapat menyelesaikan tugas akhir yang berjudul " Penerapan Metode K-Means Clustering Untuk Memetakan Potensi Produksi Buah - buahan di Provinsi Daerah Istimewa Yogyakarta ". Tugas akhir ini merupakan salah satu mata kuliah wajib dan sebagai syarat akademik untuk memperoleh gelar sarjana komputer Program Studi Teknik Informatika Universitas Sanata Dharma Yogyakarta.
Penulis menyadari bahwa selama proses penelitian dan penyusunan laporan tugas akhir ini, banyak pihak yang telah membantu penulis, sehingga pada kesempatan ini penulis ingin mengucapkan terima kasih antara lain kepada :
1. Tuhan Yang Maha Esa, yang telah memberikan pertolongan dan kekuatan dalam proses pembuatan tugas akhir.
2. Bapak Dr. Cyprianus Kuntoro Adi, S.J. M.A.,M.Sc. selaku dosen pembimbing tugas akhir, atas kesabarannya dan nasehat dalam membimbing penulis, meluangkan waktunya, memberi dukungan, motivasi, serta saran yang sangat membantu penulis.
3. Sudi Mungkasi, S.Si., M.Math.Sc., Ph.D. selaku Dekan Fakultas Sains dan Teknologi, atas bimbingan, kritik dan saran yang telah diberikan kepada penulis.
4. Dr. Anastasia Rita Widiarti, M.Kom. selaku Ketua Program Studi Teknik Informatika atas bimbingan, kritik, dan saran yang telah diberikan kepada penulis.
5. Iwan Binanto M.Cs.selaku dosen pembimbing akademik.
6. Keluarga tercinta, kedua orang tua Modestus Adi Sulistyana dan Anastasia Endang Murtiasih, serta kakak saya Vitalista Epifani Tyas Murtiasih dan adik saya Elisabeth Dhian Novitasari.
xi
8. Warga ITIL Alvin, Bayu, Dion, Haris, Henry, Hugo, Kevin, Anjar, Dio, Seto, Cahyo, Daniel, Alex, Tobi, Willy, Wisnu, Xave, dan Yosua yang selalu memberikan semangat.
9. Anaknya Mo Kun Wiga, Desa Nada, Bondan, Echo, Nita, April, Okta, Riyadlah, dan Agustin yang selalu memberikan dukungan.
10. Teman Anime Young, Ari, Eca, dan Theo.
11. Teman PES 2016 Rudi, Blasius, Parta, Ari Ori, Theo, Dika Gd, Ahok, Dika Kc, dan Aldy.
12. Semua teman-teman Basis Data 2012 yang selalu kompak sampai akhir. 13. Teman – teman Teknik Informatika semua angkatan dan khususnya TI
angkatan 2012 yang selalu memberikan motivasi dan bantuan hingga penulis menyelesaikan tugas akhir ini.
14. Reza Oktovian , The Jooomers , PokoPow, MiawAug, Erix Soekamti, Tara Arts Game Indonesia, Bagoes Kresnawan, dan Picky Picks yang selalu memberikan tontonan yang menarik.
Penulis menyadari bahwa masih banyak kekurangan dalam penyusunan tugas akhir ini. Saran dan kritik sangat diharapkan untuk perbaikan yang akan datang.
Penulis
xii
DAFTAR ISI
HALAMAN PERSETUJUAN... iii
HALAMAN PENGESAHAN ... iv
MOTTO ... v
PERNYATAAN KEASLIAN KARYA ... vi
LEMBAR PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS ... vii
1.7 Sistematika Penulisan ... 4
BAB II ... 5
LANDASAN TEORI ... 5
2.1 Data mining ... 5
2.1.1 Pengertian Data mining Dalam Berbagai Disiplin Ilmu ... 5
2.1.2 Posisi Data mining Dalam Berbagai Disiplin Ilmu ... 7
2.1.3 Data, Informasi, dan Pengetahunan (Knowledge) ... 7
2.1.5 Clustering ... 10
xiii
2.2.1 Clustering K-Means ... 11
2.2.2 Tujuan Clustering K-Means ... 12
2.2.3 Langkah Clustering K-Means ... 15
2.2.4 Jenis Data Dalam Set Data ... 15
BAB III ... 17
METODE PENELITIAN ... 17
3.1 Tahap Penelitian ... 17
3.1.1 Gambaran Penelitian ... 18
3.2 Data... 18
3.3 Jenis Data... 19
3.4 Analisa Data ... 19
3.4.1 Transformasi Data ... 19
3.4.2 Pengolahan Data... 20
3.5 Desain User Interface ... 27
3.6 Spesifikasi Alat ... 28
BAB IV ... 29
IMPLEMENTASI SISTEM DAN ANALISISA HASIL ... 29
4.1 Implemantasi ... 29
4.2 K-Means Clustering... 29
4.3 User Interface ... 30
4.4 Input Data ... 31
4.5 Proses K-Means Clustering ... 31
4.6 Analisa Hasil ... 32
Lampiran 1. Tabel Data Produksi Buah ... 44
xiv
DAFTAR TABEL
Tabel 3. 1 Inisialisasi nama buah ... 19
Tabel 3. 2 Inisialisasi nama Kabupaten... 20
Tabel 3. 3 Contoh data Jumlah Pohon dan Produksi Buah – buahan ... 21
Tabel 3. 4 Contoh data Jumlah Pohon dan Produksi Buah – buahan ... 21
Tabel 3. 5 Tabel Hasil Perhitungan Jarak Pusat Cluster ... 22
Tabel 3. 6 Tabel Pengelompokan Group... 23
Tabel 3. 7 Tabel Hasil Perhitungan Jarak Pusat Cluster ... 25
Tabel 3. 8 Tabel Pengelompokan Group... 26
xv
DAFTAR GAMBAR
Gambar 2. 1 Tahap penemuan Knowledge pada Data mining (KDD) Han, Jiawei
(2011) ... 6
Gambar 3. 1 Block Diagram ... 18
Gambar 3. 2 User Interface ... 27
Gambar 4. 1 Implementasi – K-Means clustering dengan tiga cluster ... 29
Gambar 4. 2 Tampilan keseluruhan sistem ... 30
Gambar 4. 3 Input dokumen... 31
1
BAB I
PENDAHULUAN
1.1Latar Belakang
Pangan adalah kebutuhan manusia yang paling mendasar. Menurut UU RI nomor 7 tahun 1996 tentang pangan menyebutkan bahwa pangan merupakan hak asasi bagi setiap individu di Indonesia. Buah adalah bahan makanan yang kaya akan vitamin, mineral, lemak, protein dan serat. Setiap jenis buah mempunyai keunikan dan daya tarik tersendiri, seperti rasa yang lezat dan beraroma yang khas dalam buah itu sendiri. Buah – buahan saat ini semakin mendapat perhatian dari masyarakat, baik sebagai menu makanan maupun sebagai komoditas ekonomi yang bernilai tinggi (Widodo, 1996).
Sektor pertanian merupakan sektor yang mendapatkan perhatian cukup besar dari pemerintah dikarenakan peranannya yang sangat penting dalam rangka pembangunan ekonomi jangka panjang maupun dalam rangka pemulihan ekonomi bangsa. Peranan sektor pertanian adalah sebagai sumber penghasil bahan kebutuhan pokok, sandang dan papan, menyediakan lapangan kerja bagi sebagian besar penduduk, memberikan sumbangan terhadap pendapatan nasional yang tinggi, memberikan devisa bagi negara dan mempunyai efek pengganda ekonomi yang tinggi dengan rendahnya ketergantungan terhadap impor (multiplier effect), yaitu keterkaitan input-output antar industri, konsumsi dan investasi. Dampak pengganda tersebut relatif besar, sehingga sektor pertanian layak dijadikan sebagai sektor andalan dalam pembangunan ekonomi nasional. Sektor pertanian juga dapat menjadi basis dalam mengembangkan kegiatan ekonomi perdesaan melalui pengembangan usaha berbasis pertanian yaitu agribisnis dan agroindustri. Dengan pertumbuhan yang terus positif secara konsisten, sektor pertanian berperan besar dalam menjaga laju pertumbuhan ekonomi nasional (Antara,2009).
Di sisi lain, keragaman karakteristik lahan, agroklimat serta sebaran wilayah yang luas memungkinkan wilayah Indonesia digunakan untuk pengembangan hortikultura tropis dan sub tropis.
Indonesia merupakan salah satu negara penghasil buah tropis yang memiliki keanekaragaman dan keunggulan cita rasa yang cukup baik bila dibandingkan dengan buah-buahan dari negara-negara penghasil buah tropis lainnya. Produksi buah dalam negeri diharapkan dapat memenuhi semua kebutuhan masyarakat. Karena dengan berhasilnya produksi buah berarti pemerintah tidak memerlukan tindakan untuk menimpor buah dari negara lain. Akan tetapi dalam kenyataannya, Indonesia dalam pemenuhan kebutuhan akan buah masih tergantung pada impor dari Negara lain. Produksi buah dari tahun ke tahun mengalami penurunan.
Penurunan produksi buah tersebut antara lain disebabkan karena menipisnya stok di beberapa daerah karena belum memasuki masa panen atau juga dikarenakan impor buah yag dilakukan oleh pemerintah untuk memenuhi kebutuhan belum teralisasi.
Produksi buah di Indonesia dari tahun ke tahun mengalami penurunan. Untuk itu dalam rangka memenuhi kebutuhan buah, peran dinas pertanian untuk mengelompokan daerah yang menghasilkan produksi buah di daerah Indonesia khususnya Provinsi Daerah Istimewa Yogyakarta agar dapat mengoptimalkan produksi buah, tidak semata mengutamakan keuntungan pribadi tetapi mendukung peningkatan nilai tambah produk dan peningkatan pendapatan petani.
Pengelompokan tersebut dapat menggunakan metode pengelompokan dengan
algoritma Means. Dengan data yang sudah dikelompokkan menggunakan algoritma K-Means diharapkan dapat mempermudah dinas pertanian dalam menghitung hasil pertanian di
tiap daerahnya agar mengetahuni daerah mana yang menghasilkan buah terbanyak, sedang, dan sedikit.
1.2Rumusan Masalah
1.3Tujuan Penelitian
Tujuan dari penelitian ini adalah mengetahui daerah potensial penghasil buah dan dapat mengetahui daerah tersebut cocok untuk tanaman padi. Pengelompokan tersebut dapat menggunakan metode pengelompokan dengan algoritma K-Means.
1.4Manfaat Penelitian
Berdasarkan tujuan penelitian diatas, manfaat yang dapat diberikan adalah diharapkan dapat membantu pihak Dinas Pertanian dalam memudahkan mengelompokan daerah potensial untuk produksi buah di Provinsi Daerah Istimewa Yogyakarta.
1.5Batasan Masalah
Dalam batasan masalah ini, penulis membatasi permasalah yang perlu yaitu :
1. Data yang akan digunakan adalah data produksi buah - buahan dan jumlah pohon selama lima tahun dari tahun 2005 sampai 2009.
2. Data yang digunakan dalam proses pengelompokan adalah data data produksi buah - buahan dan jumlah pohon menurut Kabupaten di Provinsi Daerah Istimewa
Yogyakarta.
3. Data produksi buah meliputi alpokat, mangga, rambutan, duku, jeruk, sirsak, sukun, belimbing, durian, jambu biji, manggis, sawo, pepaya, pisang, nenas, salak, nangka, dan semangka.
1.6Metode Penelitian
Metode penelitian pada penyusunan penulisan ini, adalah : 1. Studi literatur dengan tujuan :
a. Mempelajari dan memahami K-Means clustering dalam data mining. b. Mengetahui data produksi buah beberapa kabupaten.
2. Pengumpulan data melalui Dinas Pertanian Provinsi Daerah Istimewa Yogyakarta. 3. Implementasi algoritma ke dalam sistem.
1.7Sistematika Penulisan
Bab I. Pendahuluan
Dalam bab ini tentang latar belakang masalah, rumusan masalah, tujuan penelitian, batasan masalah, dan sistematika penulisan.
Bab II. Landasan Teori
Dalam bab ini berisi tentang teori yang dapat menunjang peneitian, yaitu berupa pengertian data mining, proses data mining, dan algoritma K-Means.
Bab III. Analisa dan Perancangan Sistem
Dalam bab ini berisi tentang cara penerapan konsep dasar yang telah diuraikan pada Bab II untuk menganalisis dan merancang tentang system sesuai tahap – tahap penyelesaian masalah tersebut dengan menggunakan algoritma K-Means.
Bab IV. Implementasi dan Analisa Sistem
Dalam bab ini berisi tentang implementasi ke program computer beradasarkan hasil perancangan yang dibuat, analisis perangkat lunak yang telah dibuat.
Bab V. Penutup
5
BAB II
LANDASAN TEORI
Pada Bab II ini akan dipaparkan mengenai landasan teori yang medukung penelitian yang dilakukan oleh penulis. Dalam Bab ini akan dijelaskan pengertian dan metode yang akan
digunakan oleh penulis.
2.1Data mining
2.1.1 Pengertian Data mining Dalam Berbagai Disiplin Ilmu
Data mining adalah sebuah proses percarian secara otomatis informasi yang
berguna dalam tempat penyimpanan data berukuran besar. Istilah lain yang sering digunakan diantaranya knowledge discovery (mining) in databases (KDD), knowledge extraction, data atau pattern analysis, data archeology, data dredging, information
harvesting, dan business intelligence. Teknik data mining digunakan untuk memeriksa
basis data berukuran besar sebagai cara untuk menemukan pola yang baru dan berguna. Tidak semua pekerjaan pencarian informasi dinyatakan sebagai data mining. Sebagai contoh, pencarian record individual menggunakan database management system atau pencarian halaman we tertentu melalui kueri ke semua search engine adalah pekerjaan pencarian informasi yang erat kaitannya dengan information retrieval. Teknik-teknik data mining dapat digunakan untuk meningkatkan kemampuan sistem-sistem
information retrieval.
Data mining adalah adalah bagian integral dari knowledge discovery in databases
Database
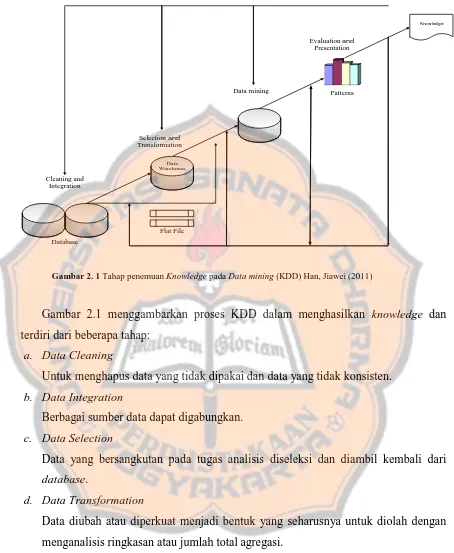
Gambar 2. 1 Tahap penemuan Knowledge pada Data mining (KDD) Han, Jiawei (2011)
Gambar 2.1 menggambarkan proses KDD dalam menghasilkan knowledge dan terdiri dari beberapa tahap:
a. Data Cleaning
Untuk menghapus data yang tidak dipakai dan data yang tidak konsisten. b. Data Integration
Berbagai sumber data dapat digabungkan. c. Data Selection
Data yang bersangkutan pada tugas analisis diseleksi dan diambil kembali dari database.
d. Data Transformation
Data diubah atau diperkuat menjadi bentuk yang seharusnya untuk diolah dengan menganalisis ringkasan atau jumlah total agregasi.
e. Data mining
f. Pattern Evaluation
Untuk mengidentifikasi pola-pola menarik yang menjelaskan mengenai ukuran dasar pengetahunan yang ada.
g. Knowledge Presentation
Visualisasi dan teknik representasi knowledge digunakan untuk menyajikan knowledge yang telah diolah untuk pengguna.
2.1.2 Posisi Data mining Dalam Berbagai Disiplin Ilmu
Para ahli berusaha menetukan posisi bidang data mining di antara bidang-bidang yang lain. Hal dikarenakan ada kesamaan antara sebagian bahasan data mining dengan bahasan di bidang lain. Memang tidak seratus persen sama, tetapi ada sejumlah kesamaan karakteristik dalam beberapa hal. Kesamaan bidang data mining dalam bidang statistik adalah penyampelan, estimasi, dan pengujian hipotesis.
2.1.3 Data, Informasi, dan Pengetahunan (Knowledge)
Data adalah segala fakta, angka, atau teks yang dapat diproses oleh komputer. Saat ini, akumulasi pertumbuhan jumlah data berjalan dengan cepat dalam format dan basis data yang berbeda. Data-data tersebut antara lain, adalah :
a. Data operasional atau transaksional. Contoh : penjualan, inventaris, penggajian, akuntansi, dll.
b. Data non operasional. Contoh : Indusri penjualan, inventaris, permalan, dan data ekonomi makro.
c. Meta data adalah mengenai data itu sendiri, seperti desain logikabasis data.\
2.1.4 Pengelompokan Data mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat
dilakukan, yaitu (Larose, 2005) : a. Deskripsi (Description)
atau fakta bahwa siapa yang tidak cukup profesional akan sedikit didukung dalam pemilihan presiden. Deskripsi dari pola dan kecenderungan sering memberikan kemungkinan penjelasan untuk suatu pola atau kecenderungan.
b. Estimasi (Estimation)
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi lebih ke arah numerik daripada ke arah kategori. Model dibangun menggunakan record lengkap yang menyediakan nilai dari variabel target sebagai nilai prediksi. Selanjutnya, pada peninjauan berikutnya estimasi nilai dari variabel target dibuat berdasarkan nilai variabel prediksi. Sebagai contoh, akan dilakukan estimasi tekanan darah sistolik pada pasien rumah sakit berdasarkan umur pasien, jenis kelamin, indeks berat badan, dan level sodium darah. Hubungan antara tekanan darah sistolik dan nilai variabel prediksi dalam proses pembelajaran akan menghasilan model estimasi. Model estimasi yang dihasilkan dapat digunakan untuk kasus baru lainnya.
c. Prediksi (Prediction)
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada di masa datang. Contoh prediksi dalam bisnis dan penelitian adalah prediksi harga beras dalam tiga bulan yang akan datang, prediksi persentase kenaikan kecelakaan lalu lintas tahun depan jika batas bawah kecepatan dinaikkan. Beberapa metode dan teknik yang digunakan dalam klasifikasi dan estimasi dapat pula digunakan untuk prediksi.
d. Klasifikasi (Classification)
Dalam klasifikasi, terdapat target variabel kategori. Sebagai contoh, penggolongan pendapatan dapat dipisahkan dalam tiga kategori, yaitu pendapatan tinggi,
pendapatan sedang dan pendapatan rendah.
atau buruk, dan mendiagnosis penyakit seorang pasien untuk mendapatkan kategori penyakit apa.
e. Pengklusteran (Clustering)
Pengklusteran merupakan pengelompokan record , pengamatan atau memperhatikan dan membentuk kelas objek – objek yang memiliki kemiripan. Cluster adalah kumpulan record yang memiliki kemiripan satu dengan yang
lainnya dan memiliki ketidakmiripan dengan record – record dalam cluster lain. Pengklusteran berbeda dengan klasifikasi yaitu tidak adanya variabel target dalam Pengklusteran. Pengklusteran tidak mencoba untuk melakukan klasifikasi, mengestimasi, atau memprediksi nilai dari variabel target. Akan tetapi, algoritma Pengklusteran mencoba untuk melakukan pembagian terhadap keseluruhan data menjadi kelompok-kelompok yang memiliki kemiripan (homogen), yang mana kemiripan record dalam satu kelompok akan bernilai maksimal, sedangkan kemiripan dengan record dalam kelompok lain akan bernilai minimal. Contoh Pengklusteran dalam bisnis dan penelitian adalah melakukan Pengklusteran terhadap ekspresi dari gen, untuk mendapatkan kemiripan perilaku dari gen dalam jumlah besar. Mendapatkan kelompok – kelompok konsumen untuk target pemasaran dari suatu produk bagi perusahaan yang tidak memiliki dana pemasaran yang besar, dan untuk tujuan audit akuntansi, yaitu melakukan pemisahan terhadap perilaku finansial dalam keadaan baik atau mencurigakan.
f. Asosiasi (Assosiation)
2.1.5 Clustering
Clustering data dapat dibedakan menjadi dua tujuan (Tan et al,2006), yaitu
clustering untuk pemahaman dan clustering untuk penggunaan. Jika tujuan untuk
pemahaman maka cluster yang terbentuk harus menangkap struktur alami data. Biasanya proses clustering dalam tujuan ini hanya sebagai proses awal untuk kemudian dilanjutkan dengan pekerjaan ini seperti summarization (rata-rata, standar deviasi), pelabelan kelas pada setiap kelompok untuk kemudian digunakan sebagai data latih klasifikasi, dan sebagainya. Sementara jika tujuannya untuk penggunaan, biasanya tujuan utama untuk mencari prototype cluster yang paling representative terhadap data dan memberikan abstraksi dan setiap objek data dalam cluster di mana sebuah data terletak didalamnya.
Banyak metode clustering yang sudah dikembangkan oleh para ahli. Masing – masing metode mempunyai karakter, kelebihan, dan kekurangan. Clustering dapat dibedakan menurut stuktur cluster, keanggotaan data dalam cluster dan kekompakan data dalam cluster.
Metode clustering menurut strukturnya dibagi menjadi dua yaitu pengelompokan hirarki dan partitioning. Pengelompokan hirarki memiliki aturan satu data tunggal bisa dianggap sebagai sebuah kelompok, dua atau lebih kelompok kecil dapat bergabung menjadi satu kelompok besar dan begitu seterusnya hingga semua data dapat bergabung menjadi satu kelompok. Metode clustering hirarki merupakan satu-satunya metode yang masuk ke dalam kategori pengelompokan hirarki. Metode clustering partitioning membagi set data ke dalam sejumlah kelompok yang tidak tumpang tindih (overlap) antara satu kelompok dengan kelompok yang lain artinya setiap data hanya menjadi anggota satu kelompok. Metode seperti K-Means dan DBSCAN masuk dalam kategori pengelompokan partitioning.
membolehkan sebuah data menjadi anggota di lebih dari satu kelompok, misalnya Fuzzy C-Means.
Metode clustering menurut kategori kekompakan terbagi menjadi dua yaitu komplet dan parsial. Semua data bisa dikatakan kompak menjadi satu kelompok jika semua data bisa bergabung menjadi satu (dalam konteks penyekatan) namun jika ada sedikit data yang tidak ikut bergabung dalam kelompok mayoritas data tersebut dikatakan mempunyai perilaku menyimpang. Data yang menyimpang ini dikenal dengan sebutan noise. Metode yang tangguh untuk mendeteksi noise ini adalah DBSCAN (Eko Prasetyo, 2014).
2.2Teorema K-Means
2.2.1 Clustering K-Means
Algoritma K-Means merupakan algoritma pengelompokan iterative yang melakukan partisi set data ke dalam sejumlah K cluster yang sudah ditetapkan di awal. Algoritma K-Means sederhana untuk diimplemtasikan dan dijalankan, relative cepat, mudah beradaptasi, umum penggunaannya dalam praktek. Secara historis, K-Means menjadi salah satu algoritma yang paling penting dalam bidang data mining (Wu dan Kumar, 2009).
K-Means merupakan salah satu metode data clustering non hirarki yang berusaha
mempartisi data yang ada ke dalam bentuk satu atau lebih cluster atau kelompok. Metode ini mempartisi ke dalam cluster atau kelompok sehingga data yang memiliki karakteristik yang sama (High intra class similarity) dikelompokkan ke dalam satu cluster yang sama dan yang memiliki karakteristik yang berbeda (Law inter class
similarity) dikelompokkan pada kelompok yang lain. Proses clustering dimulai dengan
mengidentifikasi data yang akan dicluster , Xij (i=1,...,n; j=1,...,m) dengan n adalah
jumlah data yang akan dicluster dan m adalah jumlah variabel. Pada awal iterasi, pusat setiap cluster ditetapkan secara bebas (sembarang), Ckj (k=1,...,k; j=1,...,m). Kemudian
dihitung jarak antara setiap data dengan setiap pusat cluster. Untuk melakukan penghitungan jarak data ke-i (xi) pada pusat cluster ke-k (ck), diberi nama (dik), dapat
√∑ ( ) (1)
Suatu data akan menjadi anggota dari cluster ke-k apabila jarak data tersebut ke pusat cluster ke-k bernilai paling kecil jika dibandingkan dengan jarak ke pusat cluster lainnya. Hal ini dapat dihitung dengan menggunakan persamaan (2) Selanjutnya, kelompokkan data-data yang menjadi anggota pada setiap cluster.
∑ √∑ (2)
Nilai pusat cluster yang baru dapat dihitung dengan cara mencari nilai rata-rata dari data-data yang menjadi anggota pada cluster tersebut, dengan menggunakan rumus pada persamaan (3):
∑ (3)
Dimana xij∈ cluster ke – k
p = banyaknya anggota cluster ke k
2.2.2 Tujuan Clustering K-Means
Tujuan pekerjaan pengelompokan (clustering) data dapat dibedakan menajadi dua, yaitu pengelompokan untuk pemahaman dan pengelompokan untuk penggunaan. Jika tujuannya untuk pemahaman, kelompok yang terbentuk harus menangkap struktur alami data, bisanya proses pengelompokan dalam tujuan ini hanya sebagai proses awal untuk kemudian dilanjutkan dengan pekerjaan inti seperti peringkasan atau summarization (rata – rata, standart deviasi), pelabelan kelas pada setiap kelompok untuk kemudian digunakan sebagai data latih klasifikasi, dan sebagainya. Sementara jika penggunaan, tujuan utama pengelompokan biasanya adalah mencari prototype kelompok yang paling respresentatif terhadap data, memberikan abstraksi dari setiap objek data dalam kelompok dimana sebuah data terletak di dalamnya. Contoh – contoh tujuan pengelompokan untuk pemahaman adalah sebagai berikut :
a. Biologi
kerajaan, sedangkan level terendah adalah spesies. Satu jenis hewan mempunyai nama spesies sendiri. Dua hewan dengan spesies berbeda dapat mempunyai genus yang sama. Sejumlah hewan dengan genus berbeda dapat mempunyai suku yang sama. Begitu juga dengan ordo, kelas, filum, dan kerajaan. Semua hewan berada dalam kelompok yang sama (satu kelompok) di level kerajaan, yaitu hewan. Contoh teknik pengelompkan dalam bidang biologi yang lain adalah pengelompokan gen – gen yang fungsinya sama.
b. Information retrieval
Situs web di internet berjumlah miliaran. Ketika di-query, mesin pencari akan memberikan hasil ribuan halaman. Teknik pengelompokan dapat digunakan untuk mengelompokkan hasil halaman yang diberikan mesin pencari ke dalam kelompok yang lebih kecil di mana setiap kelompok berisi halaman yang berkarakteristik sama atau mirip. Misalnya, dengan kata kunci query “movie” dapat diberikan hasil
halaman yang dibedakan dalam kategori seperti “genre”, “star”,”theaters”, dan sebagainya. Setiap kategori dapat dipecah kembali menjadi subkategori yang membentuk hierarki sehingga membatu pengguna mengekspolarsi hasil query.
c. Klimatologi
Pemahaman cuaca di bumi memerlukan pencarian pola atmosfer dan lautan.analisis kelompok dapat diterapkan untuk menemukan pola tekanan udara di wilayah kutub dan lautan yang berpengaruh besar pada cuaca di daratan.
d. Bisnis
Contoh – contoh tujuan pengelompokan untuk penggunaan adalah sebagai berikut : a. Peringkasan (Summarization)
Ada banyak teknik analisis data, seperti regresi atau PCA, yang membutuhkan waktu dan atau kompleksitas komputasi O(m2) atau lebih (m adalah jumlah data). Dengan semakin banyak data, biaya untuk melakukan peringkasan menjadi mahal (berat dan kompleks). Teknik pengelompokan data dapat diterapkan untuk membuat sebuah prototype yang dapat mewakili kondisi seluruh data, misalnya dengan mengambil nilai rata – rata untuk semua data dari setiap kelompok sehingga sejumlah data yang bergabung dalam sebuah kelompok akan diwakili oleh sebuah data. Dengan cara ini, waktu dan kompleksitas komputasi data dikurangi secara signifikan.
b. Kompresi
Data – data yang bergabung dalam setiap kelompok dapat dianggap berkarakter sama atau mirip sehingga data – data dalam kelompok yang sama dapat dikompresi dengan diwakili oleh indeks prototype dari setiap kelompok. Setiap objek diresprentasikan dengan indeks prototype yang dikaitkan dengan sebuah kelompok. Teknik kompresi ini dikenal dengan kuatisasi vektor (vector quatization).
c. Pencarian Tetangga Terdekat Secara Efisien
2.2.3 Langkah Clustering K-Means
Proses clustering dengan menggunakan algoritma K-Means memiliki langkah-langkah sebagai berikut :
a. Inisialisasi : tentukan K sebagai jumlah cluster yang diinginkan dan metrik ketidakmiripan (jarak) yang diinginkan. Jika perlu, tetapkan ambang batas perubahan fungsi objektif dan ambang batas perubahan centroid.
b. Pilih K data baru set data X sebagai centroid.
c. Alokasikan semua data ke centroid terdekat dengan metrik jarak yang sudah ditetapkan (memperbaharui ID setiap data).
d. Hitung kembali centroid C berdasarkan data yang mengikuti cluster masing-masing.
e. Ulangi langkah tiga dan empat hingga kondisi konvergen tercapai, yaitu (a) perubahan fungsi objektif sudah dibawah ambang batas yang diinginkan; atau (b) tidak ada data yang berpindah cluster ; atau (c) perubahan posisi centroid sudah dibawah ambang batas yang ditetapkan.
2.2.4 Jenis Data Dalam Set Data
Sebuah data set dapat dipandang sebagai sebuah koleksi dari objek- objek data. Nama lain dari sebuah objek data adalah record, titik, vektor, pola, event , case, sample, observasi atau entitas. Objek-objek data dijelaskan oleh sejumlah atribut yang menangkap karakteristik dasar dari sebuah objek, seperti massa dari sebuah objek fisik atau waktu pada saat sebuah kejadian terjadi. Nama-nama lain untuk atribut adalah variabel, karekteristik, field , fitur atau dimensi.
Atribut adalah sifat atau property atau karakteristik objek data yang nilainya dapat bermacam – macam dari dari suatu objek ke objek yang lain, dari satu waktu ke waktu yang lain. Misalnya, warna kulit seseorang bisa berbeda dengan warna kulit orang lain, berat badan seseorang juga bisa berubah dari waktu ke waktu. Warna kulit bisa mempunyai nilai simbolik (hitam, putih, kuning, langsat, cokelat, sawo matang), sedangkan berat badan bisa berupa nilai angka numerik.
17
BAB III
METODE PENELITIAN
Berdasarkan pada landasan teori yang berada pada Bab II yang telah disampaikan oleh penulis. Pada bab ini menjelaskan cara kerja algoritma yang digunakan dan proses yang akan dibangun untuk melakukan pengelompokan.
3.1Tahap Penelitian
Dalam sub bab ini akan membahas tentang metode perancangan yang akan digunakan dan langkah-langkah dalam penelitian ini, adapun sebagai berikut :
1. Tahap pencarian, pada tahap ini akan dilakukan pencarian data langsung melalui Dinas Pertanian Provinsi Daerah Istimewa Yogyakarta. Pencarian data di lakukan dengan proses wawancara terhadap Kepala Dinas Pertanian Provinsi Daerah Istimewa Yogyakarta.
2. Pencarian informasi mengenai segala sesuatu yang berhubungan dengan penelitian ini.
3. Pengumpulan data.
4. Menganalisa data yang sudah didapatkan, dan membuat perancangan sistemnya. 5. Mengimplementasikan perancangan yang sudah dilakukan ke dalam perangkat lunak. 6. Melakukan pengujian terhadap sistem dengan memasukan data .
3.1Model Analisis
Pada bagian model analisis berisi diagram block yang teridi dari preprocessing data, K-Means clustering. Berikut ini penjelasannya :
3.1.1 Gambaran Penelitian
Di bawah ini merupakan proses system menggunakan diagram block :
]\
Gambar 3. 1 Block Diagram
Pada gambar 3.1 proses clustering di mulai dari input data mentah yang berupa data produksi buah – buahan yang berektensi .xlsx akan mengalami representasi dari data. Tahap kedua yaitu tahap data pembersihan (cleaning) untuk membuang data yang tidak konsisten. Apabila sudah selesai maka didapatkan data yang sudah diproses atau data matang siap untuk ke tahap selanjutnya. Tahap ke tiga yaitu tranformasi data, data yang berjenis alfabet seperti nama buah dan kabupaten harus dilakukan proses inisialisasi data terlebih dahulu ke dalam bentuk angka/numerikal. Tahap ke empat yaitu K-Means clutering disini tahap K-Means clustering adalah menggelompokan data yang
sudah ada ke dalam tiga kelompok yaitu banyak, sedang, dan rendah.
3.2Data
3.3Jenis Data
Jenis data yang diambil adalah dari dokumen jumlah pohon dan produksi
buah – buahan Provinsi Daerah Istimewa Yogyakarta tahun 2005 sampai dengan tahun 2009 yang berupa format pdf kemudian yang kemudian diubah ke dalam bentuk dokumen yang berekstensi .xlsx.
3.4Analisa Data
Secara umum, system yang akan dibangun dalam penelitian ini adalah sebuah system dengan fungsi utama untuk melakukan pengelompokan produksi buah.
Data yang digunakan untuk penelitian merupakan data yang diperoleh dari arsip Dinas Pertanian Provinsi Daerah Istimewa Yogyakarta. Data yang digunakan merupakan data jumlah pohon dan produksi. Sehingga nantinya dinas terkait dapat mengambil tindakan untuk memetakan tempat produksi. Berikut ini adalah contoh data yang akan digunakan untuk perhitungan dengan K-Means clustering :
3.4.1 Transformasi Data
Agar data di atas dapat diolah dengan menggunakan metode K-Means clustering, maka data yang berjenis data nominal seperti nama buah dan
kabupaten harus diinisialisasikan terlebih dahulu dalam bentuk angka. Tabel 3. 1 Inisialisasi nama buah
Sukun 7
Belimbing 8
Durian 9
Jambu Biji 10
Manggis 11
Sawo 12
Pepaya 13
Pisang 14
Nanas 15
Salak 16
Nangka 17
Semangka 18
Tabel 3. 2 Inisialisasi nama Kabupaten
Kabupaten Inisalisasi
Kabupaten Bantul 1
Kabupaten Gunungkidul 2
Kota Yogyakarta 3
Kabupaten Kulonprogo 4
Kabupaten Sleman 5
3.4.2 Pengolahan Data
Setelah semua data nama buah dan kabupaten pada tahun 2005 sampai 2009 ditransformasi ke dalam bentuk angka, maka data-data tersebut telah dapat dikelompokan dengan menggunakan algoritma K-Means Clustering.Untuk dapat melakukan pengelompokan data-data tersebut
a. Tentukan jumlah cluster yang diinginkan. Dalam penelitian ini data – data yang ada akan dikelompokan menjadi tiga cluster .
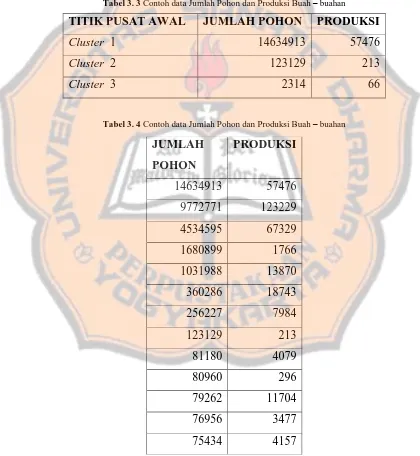
b. Tentukan titik pusat awal dari setiap cluster . Dalam penelitian ini titik pusat awal ditentukan secara random dan didapat titik pusat dari setiap cluster dapat dilihat pada tabel 3.3 dan contoh data sample yang
digunakan dapat dilihat pada tabel 3.4.
Tabel 3. 3 Contoh data Jumlah Pohon dan Produksi Buah – buahan
TITIK PUSAT AWAL JUMLAH POHON PRODUKSI
Cluster 1 14634913 57476
Cluster 2 123129 213
Cluster 3 2314 66
Tabel 3. 4 Contoh data Jumlah Pohon dan Produksi Buah – buahan
Setelah diketahui nilai k dan pusat cluster awal selanjutnya mengukur jarak antara pusat cluster menggunakan euclidian distance, kemudian akan didapatkan matriks jarak yaitu C1, C2 dan C3 sebagai berikut:
Rumus euclidian distance:
Perhitungan jarak data pertama dengan pusat cluster pertama adalah :
√
Perhitungan jarak data pertama dengan pusat cluster kedua adalah :
√
Perhitungan jarak data pertama dengan pusat cluster ketiga adalah :
√
Tabel 3. 5 Tabel Hasil Perhitungan Jarak Pusat Cluster
JUMLAH
POHON
PRODUKSI C1 C2 C3 Jarak
Terpendek
14634913 57476 0.00 14511896.98 14632711.62 0.00
9772771 123229 4862586.58 9650426.09 9771233.24 4862586.58 4534595 67329 10100322.81 4411976.52 4532780.09 4411976.52 1381584 21811 13253376.99 1258640.32 1379441.40 1258640.32 1031988 13870 13602994.89 908961.60 1029766.53 908961.60 360286 18743 14274679.55 237879.81 358458.90 237879.81 256227 7984 14378771.18 133324.66 254036.43 133324.66
123129 213 14511896.98 0.00 120815.09 0.00
81180 4079 14553830.96 42126.77 78968.03 42126.77
80960 296 14554065.32 42169.08 78646.34 42169.08
79262 11704 14555722.97 45347.07 77823.12 45347.07 76956 3477 14558057.15 46288.22 74719.90 46288.22 75434 4157 14559576.63 47857.79 73234.35 47857.79 73069 10337 14561920.30 51073.47 71496.60 51073.47
2314 66 14632711.62 120815.09 0.00 0.00
Jarak hasil perhitungan akan dilakukan perbandingan dan dipilih jarak terdekat antara data dengan pusat cluster, jarak ini menunjukkan bahwa data tersebut berada dalam satu kelompok dengan pusat cluster terdekat. Dengan cara membandingkah hasil cluster dan diambil yang paling kecil.
Berikut ini akan ditampilkan data matriks pengelompokan group, nilai 1 berarti data tersebut berada dalam group (kelompok data).
Tabel 3. 6 Tabel Pengelompokan Group
1
1
1
Setelah diketahui anggota tiap-tiap cluster kemudian pusat cluster baru dihitung berdasarkan data anggota tiap-tiap cluster sesuai dengan rumus pusat anggota cluster .
Dengan perhitungan sebagai berikut : Cluster baru yang keempat
Jumlah Pohon :
Cluster baru yang kelima
Jumlah Pohon :
Cluster baru yang keenam
Jumlah Pohon :
Hasil Produksi :
Pusat cluster keempat dengan jumlah pohon sebesar 12203842.00 dan hasil produksi sebesar 90352.50, pusat cluster kelima jumlah pohon sebesar
679555.83 dan hasil produksi sebesar 13666.67, pusat cluster keenam jumlah
pohon sebesar 2314 dan hasil produksi sebesar 66.
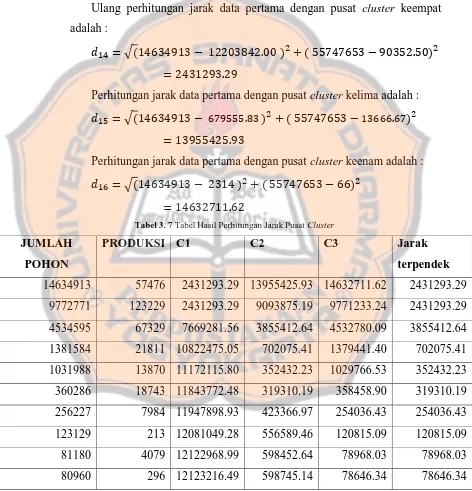
Ulang perhitungan jarak data pertama dengan pusat cluster keempat adalah :
√
Perhitungan jarak data pertama dengan pusat cluster kelima adalah :
√
Perhitungan jarak data pertama dengan pusat cluster keenam adalah :
√
Tabel 3. 7 Tabel Hasil Perhitungan Jarak Pusat Cluster
JUMLAH
POHON
PRODUKSI C1 C2 C3 Jarak
terpendek
79262 11704 12124835.08 600297.04 77823.12 77823.12 76956 3477 12127197.18 602685.98 74719.90 74719.90 75434 4157 12128714.29 604196.68 73234.35 73234.35 73069 10337 12131036.89 606495.97 71496.60 71496.60
2314 66 12201862.04 677378.39 0.00 0.00
Langkah selanjutnya hasil perhitungan akan dilakukan perbandingan dan dipilih jarak terdekat antara data dengan pusat cluster , jarak ini menunjukkan bahwa data tersebut berada dalam satu kelompok dengan pusat cluster terdekat.
Tabel 3. 8 Tabel Pengelompokan Group
Pada perhitungan ini iterasi berhenti pada iterasi ke-9 karena kelompok data 3 sama dengan kelompok data 2 dari hasil clustering, dan telah mencapai stabil dan konvergen.
3.5Desain User Interface
Gambar 3. 2 User Interface
User interface penerapan metode K-Means Cluster ing untuk memetakan potensi produksi buah – buahan di Provinsi Daerah Istimewa Yogyakarta. Dalam user interface terdapat button “cari data” untuk memasukan data yang akan
3.6 Spesifikasi Alat
Sistem ini mempunyai kebutuhan perangkat keras dan lunak untuk mendapatkan hasil yang maksimal.
1. Kebutuhan perangkat lunak : a. Microsoft Windows 10 b. Microsoft Excel 10 c. Matlab 2012
2. Kebutuhan perangkat keras :
a. Processor : AMD A8-6410 Quad Core 2.0Ghz up to 2.4Ghz b. Memory : 4GB DDR3
29
BAB IV
IMPLEMENTASI SISTEM DAN ANALISISA HASIL
Bab ini berisikan tentang implementasi dan analisis keluaran dari system dengan algoritma yang telah digunakan serta perancangan antarmuka.
4.1Implemantasi
Landasan teori dan metodologi yang telah disampaikan berkurang manfaatnya jika disertai dengan implementasi. Implementasi dibagi kedalam dua bagian, yaitu berkaitan dengan pengolahaan data dan user interface system.
4.2K-Means Clustering
Gambar 4. 1 Implementasi – K-Means clustering dengan tiga cluster
Tabel 4. 1 Jumlah data masing – masing cluster
Cluster Jumlah
1 142 2 176 3 127
4.3User Interface
Dalam membuta system implementasi K-Means clustering untuk pengelompokan capaian belajar ini penulisan menggunakan Matlab R2012b. User Interface system telah dipaparkan dalam bab sebelumnya diimplementasikan dan digunkan untuk melakukan proses pengelompokan dengan K-Means clustering. Sistem menampilkan hasil cluster . Gambar 4.2 Contoh User Interface dari keseluruhan system yang telah terbentuk.
Gambar 4. 2 Tampilan keseluruhan sistem
4.4Input Data
Data sistem dijalankan, langkah pertama yang harus dilakukan user adalah memasukan. Tombol cari file digunakan untuk meng-input-kan data yang berkestensi *.xlsx. Setelah di-inputkan, sistem akan menampilkan pada tabel hasil. Selanjutnya yang harus dilakukan user adalah dengan menekan button proses. Gambar 4.3 Contoh adalah proses input dokumen.
Gambar 4. 3 Input dokumen
4.5Proses K-Means Clustering
User interface dari implementasi hasil proses K-Means clustering dapat
dilihat pada gambar 4.4
Ketika tombol “proses” seperti pada gambar 4.4 di klik maka akan muncul hasil proses clustering metode K-Means.
4.6Analisa Hasil
Implementasi yang telah dijelaskan di bab 4 membantu analisis terhadap pengelompokan untuk memetakan potensi produksi buah – buahan di Provinsi Daerah Istimewa Yogyakarta. Analisis dilakukan terhadap 450 data dalam lima tahun.
Dalam pengelompokan ini, yang menjadi atribut adalah jumlah pohon dan jumlah produksi. Data tersebut diolah dengan menggunakan K-Means clustering. Hasil Penelitian menggunakan data produksi buah di Provinsi Yogyakarata.
1. Produksi Alpokat
2. Mangga
Untuk produksi mangga Kabupaten Bantul, termasuk dalam kelompok produksi sedang pada tahun 2005, 2006, dan 2009. Itu diketahui karena terdapat pada cluster ke 2. Untuk produksi mangga tahun 2007 dan 2008 Kabupaten Bantul termasuk dalam kelompok produksi sedikit. Untuk produksi mangga Kabupaten Gunung Kidul, termasuk dalam kelompok produksi sedang pada tahun 2005, 2006, 2008 ,dan 2009. Itu diketahui karena terdapat pada cluster ke 2. Untuk produksi mangga tahun 2007 Kabupaten Gunung Kidul termasuk dalam kelompok produksi banyak terdapat pada cluster ke 3. Kota Yogyakarta termasuk dalam kelompok produksi sedikit pada tahun 2005 sampai 2009 banyak terdapat pada cluster ke 1. Kulonprogo termasuk dalam kelompok produksi sedikit
pada tahun 2005 banyak terdapat pada cluster ke 1, pada tahun 2006 sampai 9 Kulonprogo termasuk dalam kelompok produksi sedang terdapat pada cluster ke 2. Kabupaten Sleman termasuk dalam kelompok produksi sedang terdapat pada cluster ke 2 pada tahun 2005 sampai 2009.
3. Rambutan
kelompok produksi yang sedang pada tahun 2005 sampai dengan tahun 2009. Itu diketahui karena terdapat pada cluster ke 2.
4. Duku
Untuk produksi duku Kabupaten Bantul, Kabupaten Gunung Kidul, Kota Yogyakarta, termasuk dalam kelompok produksi sedang pada tahun 2005 sampai dengan tahun 2009. Itu diketahui karena terdapat pada dan Kabupaten Sleman termasuk dalam kelompok produksi yang sedikit pada tahun 2006 sampai dengan tahun 2009. Itu diketahui karena terdapat pada cluster ke 3.
5. Jeruk
Untuk produksi jeruk Kabupaten Bantul, Kabupaten Gunung Kidul, Kota Yogyakarta, termasuk dalam kelompok produksi sedang pada tahun 2005 sampai dengan tahun 2009. Itu diketahui karena terdapat pada cluster ke 2. Kulonprogo, termasuk dalam kelompok produksi yang
6. Sirsak
Untuk produksi sirsak Kabupaten Bantul termasuk dalam kelompok produksi yang sedikit pada tahun 2005, 2006, 2007 dan 2008, itu diketahui karena terdapat pada cluster ke 3. Sedangkan tahun 2009 termasuk dalam kelompok produksi yang banyak karena terdapat pada cluster ke 1. Kabupaten Gunung Kidul tahun 2005 termasuk dalam
kelompok produksi yang sedikit karena terdapat pada cluster ke 3. Sedangkan tahun 2006 sampai 2009 termasuk dalam kelompok produksi yang sedang karena terdapat pada cluster ke 2, Kota Yogyakarta tahun 2005 sampai 2009 termasuk dalam kelompok produksi yang banyak karena terdapat pada cluster ke 1, Kulonprogo tahun 2005, 2006, 2008, dan 2009 termasuk dalam kelompok produksi yang banyak karena terdapat pada cluster ke 1, pada tahun 2007 termasuk kelompok produksi yang sedikit karena terdapat pada cluster ke 3 dan Kabupaten Sleman termasuk dalam kelompok produksi yang sedikit pada tahun 2005 sampai dengan tahun 2009. Itu diketahui karena terdapat pada cluster ke 3.
7. Sukun
Untuk produksi suku Kabupaten Bantul dan Kota Yogyakarta termasuk kelompok produksi yang sedikit karena terdapat pada cluster terdapat pada cluster ke 3 pada tahun 2005 dan 2006, tahun 2008, tahun 2007 termasuk kelompok produksi yang sedang karena terdapat pada cluster ke 2, dan tahun 2009 termasuk kelompok produksi yang banyak
2006, 2008, dan 2009 termasuk dalam kelompok produksi yang banyak karena terdapat pada cluster ke 1, pada tahun 2007 termasuk kelompok produksi yang sedikit karena terdapat pada cluster ke 3.
8. Belimbing
Untuk produksi belimbing Kabupaten Bantul tahun 2005 dan 2006 termasuk kelompok produksi yang sedang karena terdapat pada cluster ke 2, pada tahun 2007 termasuk kelompok produksi yang sedikit karena terdapat pada cluster ke 3, pada tahun 2008 dan 2009 termasuk kelompok produksi yang banyak karena terdapat pada cluster ke 1. Kabupaten Gunung Kidul, Kulonprogo dan Kabupaten Sleman tahun 2005, 2006, 2008, dan 2009 termasuk dalam kelompok produksi yang sedang karena terdapat pada cluster ke 2, pada tahun 2007 termasuk kelompok produksi yang sedikit karena terdapat pada cluster ke 3, Kota Yogyakarta termasuk kelompok produksi yang banyak karena terdapat pada cluster ke 1 pada tahun 2005 sampai dengan tahun 2009.
9. Durian
10. Jambu Biji
Untuk produksi jambu biji Kabupaten Bantul pada tahun 2005 dan 2007 termasuk kelompok produksi yang sedang karena terdapat pada cluster ke 2, dan termasuk kelompok produksi yang banyak karena
terdapat pada cluster ke 1 pada tahun 2006, 2008 dan 2009. Kabupaten Gunung Kidul pada tahun 2005, 2006 dan 2007 termasuk kelompok produksi yang sedang karena terdapat pada cluster ke 2, dan termasuk kelompok produksi yang banyak karena terdapat pada cluster ke 1 pada tahun 2008 dan 2009. Kota Yogyakarta termasuk kelompok produksi yang banyak karena terdapat pada cluster ke 1 pada tahun 2005 sampai 2009, Kulonprogo pada tahun 2005, 2008 dan 2009 termasuk kelompok produksi yang sedang karena terdapat pada cluster ke 2, termasuk kelompok produksi yang banyak karena terdapat pada cluster ke 1 pada tahun 2006, dan termasuk kelompok produksi yang sedikit karena terdapat pada cluster ke 3 pada tahun 2005 dan Kabupaten Sleman tahun 2005, 2006, 2008, dan 2009 termasuk dalam kelompok produksi yang sedang karena terdapat pada cluster ke 2, pada tahun 2007 termasuk kelompok produksi yang sedikit karena terdapat pada cluster ke 3.
11. Manggis
12. Sawo
Untuk produksi sawo Kabupaten Bantul, Kabupaten Gunung Kidul Kulonprogo, dan Kabupaten Sleman tahun 2005, 2006, 2008, dan 2009 termasuk dalam kelompok produksi yang banyak karena terdapat pada cluster ke 1, tahun 2007 termasuk dalam kelompok produksi yang
sedang karena terdapat pada cluster ke 2. Kota Yogyakarta termasuk dalam kelompok produksi yang sedikit pada tahun 2005 sampai dengan tahun 2009. Itu diketahui karena terdapat pada cluster ke 3.
13. Pepaya
Untuk produksi pepaya Kabupaten Bantul tahun 2005, 2006, 2008, dan 2009 termasuk dalam kelompok produksi yang sedikit karena terdapat pada cluster ke 3, tahun 2006 termasuk dalam kelompok produksi yang banyak karena terdapat pada cluster ke 1, Kabupaten Gunung Kidul tahun 2005, 2006, 2008, dan 2009 termasuk dalam kelompok produksi yang sedikit karena terdapat pada cluster ke 3, tahun 2007 termasuk dalam kelompok produksi yang sedang karena terdapat pada cluster ke 2. Kota Yogyakarta, dan Kulonprogo, termasuk dalam kelompok produksi yang sedikit pada tahun 2005 sampai dengan tahun 2009. Itu diketahui karena terdapat pada cluster ke 3. Kabupaten Sleman tahun 2005, 2006, 2008, dan 2009 termasuk dalam kelompok produksi yang sedikit karena terdapat pada cluster ke 3, tahun 2007 termasuk dalam kelompok produksi yang banyak karena terdapat pada cluster ke 1.
14. Pisang
termasuk dalam kelompok produksi yang sedang karena terdapat pada cluster ke 2, tahun 2007 termasuk dalam kelompok produksi yang
banyak karena terdapat pada cluster ke 1. Kota Yogyakarta, termasuk dalam kelompok produksi yang sedikit pada tahun 2005 sampai dengan tahun 2009. Itu diketahui karena terdapat pada cluster ke 3.
15. Nanas
Untuk produksi nanas Kabupaten Bantul dan Kota Yogyakarta termasuk dalam kelompok produksi yang sedang pada tahun 2005 sampai dengan tahun 2009. Itu diketahui karena terdapat pada cluster ke 2. Kabupaten Gunung Kidul tahun 2005, 2006, 2008, dan 2009 termasuk dalam kelompok produksi yang sedang karena terdapat pada cluster ke 2, tahun 2007 termasuk dalam kelompok produksi yang banyak karena terdapat pada cluster ke 1. Kulonprogo, dan Kabupaten Sleman tahun 2005, 2006, 2008, dan 2009 termasuk dalam kelompok produksi yang banyak karena terdapat pada cluster ke 1, tahun 2007 termasuk dalam kelompok produksi yang sedikit karena terdapat pada cluster ke 3.
16. Salak
17. Nangka
Untuk produksi nangka Kabupaten Bantul tahun 2005 dan 2007 termasuk dalam kelompok produksi yang banyak karena terdapat pada cluster ke 1, tahun 2006, 2008, dan termasuk dalam kelompok produksi
yang sedikit karena terdapat pada cluster ke 3. Kabupaten Gunung Kidul dan Kabupaten Sleman tahun 2005, 2006, 2008, dan 2009 termasuk dalam kelompok produksi yang banyak karena terdapat pada cluster ke 1, tahun 2007 termasuk dalam kelompok produksi yang sedang karena terdapat pada cluster ke 2. Kota Yogyakarta termasuk dalam kelompok produksi yang sedikit pada tahun 2005 sampai dengan tahun 2009. Itu diketahui karena terdapat pada cluster ke 3. Kabupaten Kulonprogo termasuk dalam kelompok produksi yang banyak pada tahun 2005 sampai dengan tahun 2009. Itu diketahui karena terdapat pada cluster ke 1.
18. Semangka
41
BAB V
PENUTUP
Bab terakhir pada penulisan ini menjelaskan mengenai kesimpulan dari penelitian terkait dengan terhadap pengelompokan untuk memetakan potensi produksi buah – buahan di Provinsi Yogyakarta. Pada bab ini dijelaskan saran yang diberikan pada system yang sudah dibuat.
5.1Analisa Hasil
Dari permasalahan tentang data produksi buah – buahan di Provinsi Daerah Istimewa Yogyakarta dapat diselesaikan dengan Algoritma K-Means dapat melakukan pengelompokan dokumen dalam jumlah yang banyak akan tetapi belum efisien dalam mengelompokan dokumen secara tepat. Untuk mengelompokan daerah potensial buah – buahan di Provinsi Daerah Istimewa Yogyakarta. Penentuan centroid (titik pusat) pada tahap awal algoritma K-Means sangat berpengaruh pada hasil cluster seperti pada hasil pengujian yang dilakukan dengan centroid yang berbeda menghasilkan hasil cluster yang berbeda juga.
5.2Saran
Saran yang diperlukan untuk pengembangan system lebih lanjut sebagai berikut :
43
DAFTAR PUSTAKA
Gorunescu, Florin (2011). Data mining: Concepts, Models, and Techniques. Verlag Berlin Heidelberg: Springer
Han, Jiawei & Micheline Kamber. 2006. Second Edition. Data mining : Concepts and Techniques. New York : Morgan Kaufman
Han, Jiawei & Micheline Kamber. 2012. Third Edition. Data mining : Concepts and Techniques. New York : Morgan Kaufman
Kusrini, dan Luthfi, Emha. Taufiq. (2009). Algoritma Data mining. Yogyakarta: Andi Publishing.
Larose, Daniel. T. (2005).Discovering Knowledge in Data. New Jersey: John Willey & Sons, Inc.
Lee, Finn. S. dan Santana, Juan (2010). Data mining : Meramalkan Bisnis Perusahaan. Jakarta: Elex Media Komputindo
Liao. (2007). Recent Advances in Data mining of Enterprise Data: Algorithms and Application. Singapore: World Scientific Publishing
44
LAMPIRAN
Lampiran 1. Tabel Data Produksi Buah
JENIS BUAH DAERAH JUMLAH POHON PRODUKSI TAHUN
Alpokat Kabupaten Bantul 7405 553 2005
Alpokat Kabupaten
Alpokat Kabupaten Sleman 79262 11704 2005
Alpokat Kabupaten Bantul 1522 348 2006
Alpokat Kabupaten
Alpokat Kabupaten Sleman 21740 3944 2006
Alpokat Kabupaten Bantul 1660 108 2007
Alpokat Kabupaten
Alpokat Kabupaten Sleman 54731 3302 2007
Alpokat Kabupaten Bantul 1550 66 2008
Alpokat Kabupaten
Gunungkidul
45
Alpokat Kota Yogyakarta 343 49 2008
Alpokat Kabupaten
Kulonprogo
7597 370 2008
Alpokat Kabupaten Sleman 38166 3613 2008
Alpokat Kabupaten Bantul 597 83 2009
Alpokat Kabupaten Sleman 37775 3900 2009
Mangga Kabupaten Bantul 113591 6361 2005
Mangga Kabupaten
Mangga Kabupaten Sleman 131779 9881 2005
Mangga Kabupaten Bantul 96279 5559 2006
Mangga Kabupaten
Mangga Kabupaten Sleman 153471 11115 2006
Mangga Kabupaten Bantul 72682 1885 2007
Mangga Kabupaten
Gunungkidul
46
Mangga Kota Yogyakarta 8994 292 2007
Mangga Kabupaten
Kulonprogo
167815 5779 2007
Mangga Kabupaten Sleman 148929 10125 2007
Mangga Kabupaten Bantul 69118 7638 2008
Mangga Kabupaten
Mangga Kabupaten Sleman 166999 13131 2008
Mangga Kabupaten Bantul 100667 4531 2009
Mangga Kabupaten
Mangga Kabupaten Sleman 169635 14298 2009
Rambutan Kabupaten Bantul 27383 946 2005
Rambutan Kabupaten
Rambutan Kabupaten Sleman 132426 13685 2005
Rambutan Kabupaten Bantul 26561 1139 2006
Rambutan Kabupaten Gunungkidul
47
Rambutan Kota Yogyakarta 2689 152 2006
Rambutan Kabupaten Kulonprogo
36914 2510 2006
Rambutan Kabupaten Sleman 187168 16721 2006
Rambutan Kabupaten Bantul 25070 546 2007
Rambutan Kabupaten
Rambutan Kabupaten Sleman 186543 15167 2007
Rambutan Kabupaten Bantul 24815 1234 2008
Rambutan Kabupaten Gunungkidul
16801 396 2008
Rambutan Kota Yogyakarta 3526 102 2008
Rambutan Kabupaten Kulonprogo
51448 3873 2008
Rambutan Kabupaten Sleman 191286 21850 2008
Rambutan Kabupaten Bantul 30532 1888 2009
Rambutan Kabupaten Gunungkidul
31931 479 2009
Rambutan Kota Yogyakarta 5767 119 2009
Rambutan Kabupaten Kulonprogo
26025 2236 2009
Rambutan Kabupaten Sleman 197496 20201 2009
Duku Kabupaten Bantul 301 9 2005
Duku Kabupaten
Gunungkidul
50
Sirsak Kabupaten Bantul 16983 246 2007
Sirsak Kabupaten
Gunungkidul
51
Sirsak Kota Yogyakarta 489 5 2007
Sirsak Kabupaten
Kulonprogo
6963 100 2007
Sirsak Kabupaten Sleman 15588 284 2007
Sirsak Kabupaten Bantul 7304 133 2008
Sukun Kabupaten Sleman 12055 1935 2005
Sukun Kabupaten Bantul 8866 474 2006
Sukun Kabupaten
Gunungkidul
52
Sukun Kota Yogyakarta 276 27 2006
Sukun Kabupaten
Kulonprogo
27514 2107 2006
Sukun Kabupaten Sleman 10561 1869 2006
Sukun Kabupaten Bantul 8416 226 2007
Sukun Kabupaten Sleman 30545 1830 2007
Sukun Kabupaten Bantul 7368 488 2008
Sukun Kabupaten Sleman 10723 1693 2008
Sukun Kabupaten Bantul 6129 362 2009
Sukun Kabupaten Sleman 11778 1694 2009
Belimbing Kabupaten Bantul 4119 229 2005
Belimbing Kabupaten Gunungkidul
53
Belimbing Kota Yogyakarta 311 24 2005
Belimbing Kabupaten Kulonprogo
4451 144 2005
Belimbing Kabupaten Sleman 4807 370 2005
Belimbing Kabupaten Bantul 4150 184 2006
Belimbing Kabupaten
Belimbing Kabupaten Sleman 4971 186 2006
Belimbing Kabupaten Bantul 7236 103 2007
Belimbing Kabupaten Gunungkidul
8599 119 2007
Belimbing Kota Yogyakarta 1725 26 2007
Belimbing Kabupaten Kulonprogo
7729 152 2007
Belimbing Kabupaten Sleman 12187 223 2007
Belimbing Kabupaten Bantul 1980 87 2008
Belimbing Kabupaten
Belimbing Kabupaten Sleman 4682 254 2008
Belimbing Kabupaten Bantul 1619 85 2009
Belimbing Kabupaten Gunungkidul
54
Belimbing Kota Yogyakarta 502 32 2009
Belimbing Kabupaten Kulonprogo
5550 219 2009
Belimbing Kabupaten Sleman 4545 252 2009
Durian Kabupaten Bantul 1463 75 2005
Durian Kabupaten Sleman 38973 3008 2005
Durian Kabupaten Bantul 1655 67 2006
Durian Kabupaten Sleman 34402 3683 2006
Durian Kabupaten Bantul 1191 44 2007
Durian Kabupaten Sleman 35143 3014 2007
Durian Kabupaten Bantul 1719 163 2008
Durian Kabupaten
Gunungkidul
55
Durian Kota Yogyakarta 28 3 2008
Durian Kabupaten
Kulonprogo
33726 2708 2008
Durian Kabupaten Sleman 35462 3388 2008
Durian Kabupaten Bantul 1508 83 2009
Durian Kabupaten Sleman 45114 5688 2009
Jambu Biji Kabupaten Bantul 26131 1516 2005
Jambu Biji Kabupaten
Jambu Biji Kabupaten Sleman 44635 3071 2005
Jambu Biji Kabupaten Bantul 18091 1279 2006
Jambu Biji Kabupaten
Jambu Biji Kabupaten Sleman 37987 1197 2006
Jambu Biji Kabupaten Bantul 46089 567 2007
Jambu Biji Kabupaten Gunungkidul