BAB II
TINJAUAN PUSTAKA
2.1. Landasan Teori 2.1.1. Analisis sentimen
Opinion Mining atau bisa juga disebut Analisis Sentimen, adalah metode memproses dan memahami data teks untuk mendapatkan informasi emosi atau sentimen dalam kalimat pernyataan atau opini [4]. Menurut pendapat lain, analisis sentimen melakukan proses pengelompokan teks dalam sebuah dokumen, kalimat, atau opini untuk menghasilkan suatu nilai yang menandakan apakah suatu kalimat, dokumen, dan opini tersebut termasuk negatif atau positif [7].
2.1.2. Preprocessing
Preprocessing adalah kegiatan yang dilakukan setelah data dikumpulkan.
Kegiatan ini dimulai sebelum proses klasifikasi, tujuannya adalah untuk menghilangkan data yang tidak lengkap, berisik, dan tidak konsisten [8].
Tahap preprocessing yang dilakukan yaitu : a. Case folding
Bertujuan untuk mengubah seluruh kalimat menjadi lowercase atau huruf kecil, atau uppercase atau huruf besar
b. Cleansing
Bertujuan untuk menghilangkan karakter-karakter yang tidak dibutuhkan di dalam Tweet
c. Tokenization
Bertujuan untuk memotong kalimat menjadi kata atau token d. Normalisasi kata
Untuk mengubah kata informal atau tidak baku menjadi formal baku e. Stopword removal
Tujuannya adalah untuk menghilangkan kata yang dianggap tidak dan kurang penting dari Tweet
f. Stemming
Bertujuan untuk mengganti kata menjadi kata dasar tanpa imbuhan 2.1.3. Klasifikasi
Menurut KBBI, klasifikasi adalah pengelompokan golongan atau kelompok menurut standar atau kaidah yang telah ditetapkan [9]. Klasifikasi adalah kegiatan memberikan sebuah nilai kepada sebuah data dan menempatkannya ke sebuah kelas tertentu dari berbagai macam kelas yang tersedia. Klasifikasi merupakan analisis data yang mengambil model-model yang mendeskripsikan kelas-kelas yang penting dari data. Model yang disebut Classifier ini akan memprediksi label kelas kategorikal (diskrit, tidak berurutan) [10].
Beberapa metode klasifikasi yang sering digunakan contohnya adalah Support Vector Machine, Decission Tree, Naïve Bayes, Fuzzy, Neural Network, Maximum Entropy, KNN, Winnow dan Adaboost [11]. Klasifikasi termasuk dalam metode pembelajaran terawasi atau supervised learning karena prosesnya melalui pembelajaran dari data masa lalu. Tujuan klasifikasi adalah untuk membangun model yang menggambarkan dan membedakan kelas untuk prakiraan masa depan [12].
2.1.4. Naïve Bayes Classifier
Klasifikasi Naïve Bayes adalah teknik prakiraan atau prediksi berdasarkan penerapan teorema Bayes (atau aturan Bayes) dengan asumsi independensi yang kuat (naif) [13]. Naïve Bayes Classifier merupakan model yang populer dan sering digunakan karena kesederhanaan dan efisiensi komputasinya [14]. Bentuk umum Naïve Bayes Classifier adalah :
P(H|E) =
𝑃(𝐸
|𝐻
)𝑃(𝐻)𝑃(𝐸)
(2.1)
Dimana :
P(H | E) = Kemungkinan bersyarat bahwa hipotesis H terjadi jika ada bukti bahwa E terjadi
P(E | H) = Kemungkinan bahwa bukti E akan mempengaruhi hipotesis H P(H) = Kemungkinan awal (priori) bahwa hipotesis H terjadi terlepas dari bukti apa pun
P(E) = Kemungkinan awal (priori) bahwa bukti E terjadi terlepas dari hipotesis/bukti lain [13].
Laplace Correction adalah metode yang digunakan ketika menemukan suatu data yang memiliki nilai probabilitas nol [15]. Caranya adalah dengan menambahkan satu data pada setiap perhitungan dan hal ini tidak akan membuat perbedaan berarti dari sekian banyak data set yang akan digunakan.
Persamaannya adalah :
(2.2) Dimana :
ρi = kemungkinan atribut mi
mi = jumlah sampel dalam kelas atribut mi
k = jumlah kelas dari atribut mi
n = jumlah sampel
2.1.5. Gain Ratio
Gain Ratio adalah salah satu metode seleksi fitur. Gain Ratio meningkatkan performa Information Gain karena menormalkan kontribusi semua fitur untuk keputusan klasifikasi akhir untuk sebuah dokumen. Gain Ratio diperkenalkan dalam algoritma decision tree dan digunakan sebagai pengukur disparitas, dan skor GR yang tinggi menunjukkan bahwa fitur yang dipilih berguna untuk klasifikasi [11]. Proses perhitungan Gain Ratio adalah sebagai berikut :
a. Penghitungan Entropy
(2.3) Dimana :
C = Jumlah nilai pada fitur target
Pi = rasio antara jumlah sampel pada kelas i terhadap semua sampel pada himpunan data
b. Menghitung Nilai Information Gain
Information Gain adalah standar efektivitas fitur dalam mengklasifikasikan data. Hasil perhitungan Information Gain dan Entropy menjadi input untuk menghitung Gain Ratio.
(2.4) Dimana :
A = fitur
V = menyatakan nilai yang dapat membentuk A Valus(A) = kemungkinan himpunan untuk fitur A
|Sv| = Jumlah sampel untuk nilai v
|S| = Jumlah seluruh sampel data
Entropy(Sv) = entropy untuk sampel yang memiliki nilai v
c. Menghitung Nilai Gain Ratio
Sebelum dapat menghitung nilai Gain Ratio, perlu dicari terlebih dahulu nilai Split Information dengan persamaan :
(2.5) Dan untuk menghitung Gain Ratio menggunakan persamaan (2.5).
(2.6) 2.1.6. Pembobotan TF-IDF
Salah satu pembobotan kata yang digunakan dalam penelitian ini adalah Term Frequency-Reverse Document Frequency atau TF-IDF. Metode TF-IDF merupakan gabungan dari metode TF dan IDF. TF atau term frequency adalah frekuensi kemunculan sebuah kata dalam setiap dokumen untuk menunjukkan seberapa signifikan kata tersebut dalam setiap dokumen. DF atau document frequency adalah frekuensi dokumen yang mengandung kata tersebut, untuk
menunjukan seberapa umum kata tersebut dalam sebuah dokumen. IDF adalah kebalikan dari nilai DF. Hasil yang diperoleh dengan menggabungkan kedua metode tersebut adalah TF-IDF, dimana bobot kata lebih tinggi jika sebuah kata muncul banyak di dalam sebuah dokumen, dan lebih rendah jika muncul di banyak dokumen.
2.1.7. K-fold cross validation
Ketika menggunakan validasi silang k-fold, data awal secara acak dibagi menjadi k subset yang saling eksklusif atau fold, D1 sampai Dk, dimana setiap foldnya memiliki ukuran yang sama. Proses latihan dan pengujian akan dilakukan sebanyak k kali. Pada perulangan i, bagian Di dipisahkan dan dijadikan sebagai set pengujian dan bagian yang tersisa digunakan secara kolektif untuk melatih model. Artinya, pada perulangan pertama, subset D2, …, Dk bekerja secara kolektif sebagai data latih untuk mendapatkan model, D1 digunakan sebagai data pengujian; perulangan kedua dari data latih di subset D1, D3, …, Dk dan D2 digunakan sebagai data pengujian; dan seterusnya. K-fold yang digunakan dalam penelitian ini adalah validasi silang 10-fold karena bias dan variansnya yang rendah [10].
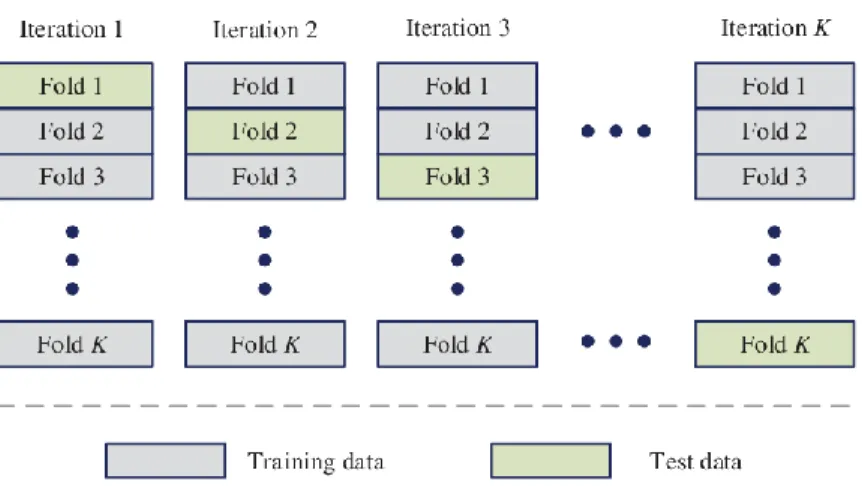
Berikut ini ilustrasi dari K-fold cross validation pada Gambar 2.1
Gambar 2. 1 Ilustrasi k-fold cross validation
Maksud dari ilustrasi di atas adalah, misalnya data D ingin melakukan validasi silang 5 kali lipat. Artinya data D akan dibagi menjadi 5 subset data yang akan diberi nama D1, D2, D3, D4, D5. D1 memiliki lipatan: fold2, fold3, fold4 dan fold5 sebagai data latihan dan fold1 sebagai data uji. D2 memiliki lipatan: fold1,fold3,fold4,fold5 sebagai data latihan dan fold2 sebagai data uji.
Begitu seterusnya hingga D5, sehingga setiap lipatan pernah digunakan sebagai data uji sebanyak satu kali.
2.1.8. Confusion Matrix
Confusion matrix merupakan metode yang berguna untuk mengevaluasi seberapa baik algoritma klasifikasi yang digunakan dapat mengklasifikasikan data dari berbagai kelas. TP dan TN menunjukkan klasifikasi yang benar, sedangkan FP dan FN menunjukkan klasifikasi yang salah [10].
Gambar 2. 2 Confusion Matrix
Confusion Matrix dapat digunakan untuk menghitung nilai :
• Accuracy : Menjelaskan seberapa akurat model dalam mengklasifikasikan dengan benar. Rumusnya dapat dilihat pada persamaan 2.7.
(TP+TN) / (TP+FP+FN+TN) (2.7)
• Precision : Menjelaskan seberapa akurat data yang diminta dengan hasil prediksi yang diberikan oleh model. Rumusnya dapat dilihat pada persamaan 2.8.
(TP) / (TP + FP) (2.8)
• Recall : menggambarkan keberhasilan model dalam mencari kembali informasi. Rumusnya dapat dilihat dalam persamaan 2.9.
TP / (TP + FN) (2.9)
• F-1 Score : menggambarkan perbandingan rata-rata recall dan precision yang dibobotkan. Rumusnya ada di persamaan 3.0.
(2 * Recall * Precision) / (Recall + Precision) (3.0) Keterangan :
TP = Data positif yang diprediksi secara benar (positif)
TN = Data negatif yang diprediksi secara benar (negatif) FP = Data negatif yang diprediksi secara salah (positif) FN = Data positif yang diprediksi secara salah (negatif)
2.2. Tinjauan Studi
Berikut ini penelitian terkait yang dijadikan sebagai referensi untuk mencari metode yang akan digunakan dalam penelitian ini :
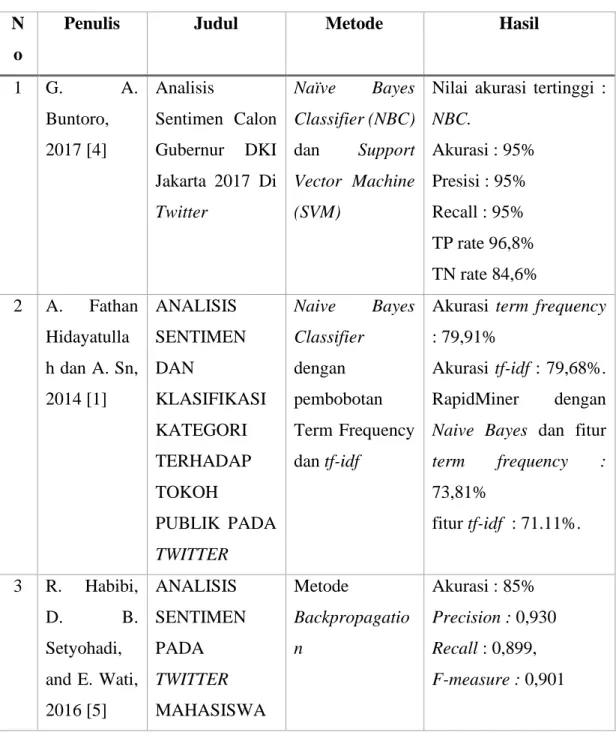
Tabel II. 1 Penelitian Terkait N
o
Penulis Judul Metode Hasil
1 G. A.
Buntoro, 2017 [4]
Analisis
Sentimen Calon Gubernur DKI Jakarta 2017 Di Twitter
Naïve Bayes Classifier (NBC) dan Support Vector Machine (SVM)
Nilai akurasi tertinggi : NBC.
Akurasi : 95%
Presisi : 95%
Recall : 95%
TP rate 96,8%
TN rate 84,6%
2 A. Fathan Hidayatulla h dan A. Sn, 2014 [1]
ANALISIS SENTIMEN DAN
KLASIFIKASI KATEGORI TERHADAP TOKOH
PUBLIK PADA TWITTER
Naive Bayes Classifier dengan pembobotan Term Frequency dan tf-idf
Akurasi term frequency : 79,91%
Akurasi tf-idf : 79,68%.
RapidMiner dengan Naive Bayes dan fitur term frequency : 73,81%
fitur tf-idf : 71.11%.
3 R. Habibi,
D. B.
Setyohadi, and E. Wati, 2016 [5]
ANALISIS SENTIMEN PADA TWITTER MAHASISWA
Metode
Backpropagatio n
Akurasi : 85%
Precision : 0,930 Recall : 0,899, F-measure : 0,901
MENGGUNAK AN METODE BACKPROPAG ATION
4 A. Sari, F.
V., dan Wibowo, 2019 [6]
ANALISIS SENTIMEN PELANGGAN TOKO ONLINE JD.ID
MENGGUNAK AN METODE NAÏVE BAYES CLASSIFIER BERBASIS KONVERSI IKON EMOSI
Naïve Bayes Classifier (NBC) dengan
pembobotan tf- idf disertai penambahan fitur konversi ikon emosi (emoticon)
Akurasi NBC tanpa pembobotan tf-idf dan konversi ikon emosi : 96,44%
Akurasi NBC dengan pembobotan tf-idf dan konversi ikon emosi : 98%,
Peningkatan akurasi sebesar 1,56%.
5 J. A.
Septian , T.
M.
Fahrudin, dan A.
Nugroho, 2019 [16]
Analisis Sentimen Pengguna Twitter Terhadap Polemik
Persepakbolaan Indonesia Menggunakan Pembobotan tf- idf dan K- Nearest
Neighbor
KNN dengan pembobotan tf- idf
Akurasi optimal pada k=23 dengan akurasi sebesar 79,99% dan error rate sebesar 20,01%.
6 A. P.
Giovani, A.
Ardiansyah,
ANALISIS SENTIMEN APLIKASI
Naive Bayes (NB), Support Vector Machine
Optimasi terbaik : PSO berbasis SVM
akurasi : 78,55%
T. Haryanti, L.
Kurniawati, and W. Gata, 2020 [17]
RUANG GURU DI TWITTER MENGGUNAK AN
ALGORITMA KLASIFIKASI
(SVM), K-
Nearest
Neighbour (K- NN), dan feature selection dengan algoritma
Particle Swarm Optimization (PSO)
AUC : 0,853.
7 E. Fitri, 2020 [7]
Analisis Sentimen Terhadap Aplikasi Ruangguru Menggunakan Algoritma Naive Bayes, Random Forest Dan Support Vector Machine
Naïve Bayes, Random Forest
dan SVM
dengan Cross Validation
Random Forest Akurasi : 97,16% & AUC : 0,996
SVM Akurasi : 96,01%
dan AUC : 0,543
NB Akurasi : 94,16%
dan AUC : 0,999
8 A. V.
Sudiantoro and E.
Zuliarso, 2018 [18]
ANALISIS SENTIMEN TWITTER MENGGUNAK
AN TEXT
MINING DENGAN ALGORITMA NAÏVE BAYES CLASSIFIER
Text Mining dan Naïve Bayes Classifier
Akurasi NBC : 84%
Data Positif : 32 Data Negatif : 68
9 Anuj
Sharma dan
A Comparative Study of Feature
NB, SVM,
MaxEnt, DT,
Seleksi fitur terbaik : Gain Ratio
Shubhamoy Dey, 2012 [11]
Selection and Machine
Learning
Techniques for Sentiment Analysis
KNN, Winnow, Adaboost
dengan seleksi fitur DF, IG,
GR, CHI,
Relief-F
Metode Klasifikasi terbaik jika fitur banyak : SVM
Metode klasifikai terbaik jika fitur sedikit : NB
Penelitian tentang analisis sentimen di Twitter telah dilakukan secara luas di Indonesia dalam beberapa tahun terakhir. Metode yang digunakan juga beragam, antara lain yang menggunakan Naïve Bayes, Backpropagation, Fine-grained, Random Forest, KNN, dan SVM. Kemudian bobot yang digunakan juga bervariasi, misalnya penelitian [1] yang menggunakan pembobotan TF dan tf-idf. Kemudian ada pembobotan PSO yang digunakan di penelitian [17].
Berdasarkan data dari penelitian terkait diatas, penulis memilih untuk menggunakan metode Klasifikasi Naïve Bayes untuk penelitian “Evaluasi Klasifikasi Naïve Bayes (Studi Kasus : Data Twitter “Sekolah Online Berbahasa Indonesia”)”.
Penulis memilih menggunakan metode tersebut karena dari data diatas dapat dilihat bahwa metode ini memiliki tingkat keakurasian yang lebih besar dibandingkan dengan metode lainnya. Kemudian, untuk membuat penelitian ini berbeda dengan penelitian lainnya, penulis memilih untuk menerapkan pembobotan kata, yakni pembobotan kata tf-idf dari penelitian [1], [6], [16] dan pembobtan kata Gain Ratio dari penelitian [11].
Hal ini dikarenakan penulis ingin membandingkan tingkat akurasi Naïve Bayes dengan pembobotan TF-IDF yang sudah sering digunakan dengan Naïve Bayes dan pembobotan Gain Ratio.