ASPECT-BASED ANALYSIS PADA ULASAN PELANGGAN JARINGAN SELULER DENGAN RANDOM FORESST
SKRIPSI
WINARI ANGGANI 171402038
PROGRAM STUDI S1TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN 2022
ASPECT-BASED ANALYSIS PADA ULASAN PELANGGAN JARINGAN SELULER DENGAN RANDOM FOREST
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana Teknologi Informasi
WINARI ANGGANI 171402038
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVESITAS SUMATERA UTARA
MEDAN 2022
UCAPAN TERIMA KASIH
Puji dan syukur penulis sampaikan kepada Tuhan yang Maha Esa, karena atas berkat dan kasih-Nya penulis dapat menyelesaikan penyusunan skripsi ini sebagai syarat untuk memperoleh gelar Sarjana dari Program Studi Teknologi Informasi, Universitas Sumatera Utara.
Rasa terima kasih penulis ucapkan kepada seluruh pihak yang turut serta terlibat dalam masa perkuliahan dan masa pengerjaan skripsi ini hingga selesai. Skripsi ini ditulis dengan dukungan dan doa dari keluarga penulis, Sukirno dan Ibu Almh. Sutarni, serta saudara penulis Almh. Lisna Sahariani, S.Pd.I , Almh. Neni Triani serta Riza Wahyudi yang senantiasa memberi do’a dan dukungan penuh kepada penulis dari masa kanak-kanak hingga dapat menyelesaikan skripsi ini dengan baik pada usia sekarang.
Pihak lain yang juga terlibat, yaitu:
1. Bapak Dr. Muryanto Amin, S.Sos., M.Si., selaku Rektor Universitas Sumatera Utara.
2. Ibu Dr. Maya Silvi Lydia, M.Sc., selaku Dekan Fasilkom-TI USU.
3. Ibu Sarah Purnamawati, ST., M.Sc., selaku Ketua Program Studi S1 Teknologi Informasi Universitas Sumatera Utara dan Dosen Pembanding I yangtelah memberikan kritik dan saran untuk membantu penyempurnaan skripsi.
4. Bapak Ivan Jaya, S.Si., M.Kom , selaku Dosen Pembimbing I dan Ibu Dr. Erna Budhiarti Nababan, M.IT., selaku Dosen Pembimbing II, yang telah meluangkan banyak waktu untuk membimbing, dan memberikan saran sertamotivasi kepada penulis.
5. Ibu Umaya Ramadhani Putri Nst S.TI, M.Kom., selaku Dosen Pembanding II, yang telah memberikan kritik dan saran untuk membantu penyempurnaan skripsi.
6. Seluruh Dosen Fakultas Ilmu Komputer dan Teknologi Informasi Universitas serta staff akademik yang membantu kelancaran penulis dalam menyelesaikan studi.
7. Sahabat terbaik penulis, Fadhilah Annisa, Nurri Yusriyyah Js, dan Rima Anjalia Syuhada yang banyak memberikan dukungan semangat serta motivasi yang selalu ada baik suka ataupun duka.
8. Sahabat dan seperjuangan penulis semasa kuliah Firda Mega Tasya, Lisa Ayuning Tias, Nabila Sagita, Azmitha Azni, Arinda Bella Putri Manik, Rizki Amanda Putri, Theodora Rini Ketaren, dan Indah Ramadani yang dari awalkuliah menemani penulis dan menjadi teman baik suka dan duka, tempatbertukar pikiran dalam menjalani perkuliahan hingga menyelesaikan skripsi ini.
9. Abang-abang virtual, 9 orang di dalam satu grup bernama EXO yang telah menemani penulis saat masa-masa sulit ketika mengerjakan skripsi ini, tempat penulis berkeluh- kesah, menemani penulis dengan lagu-lagu dan karya-karyanya.
10. Teman sekaligus tempat bersandar penulis secara virtual, Mark Lee, yang telah banyak memberikan semangat kepada penulis dengan kata-kata dan tingkah lakunya yang hyper tetapi sangat menghibur penulis.
11. Semua pihak yang terlibat langsung ataupun tidak langsung yang tidak dapat penulis tuliskan satu persatu yang telah membantu menyelesaikan skripsi ini.
Semoga Tuhan Yang Maha Esa melimpahkan berkat dan anugerah-Nya kepada semua pihak yang telah terlibat baik secara langsung maupun tidak langsung memberikan bantuan, perhatian, serta dukungan kepada penulis dalam menyelesaikan skripsi ini.
Medan, 11 Januari 2022
Penulis
PERNYATAAN
ASPECT-BASED SENTIMENT ANALYSIS PADA ULASAN PELANGGAN JARINGAN SELULER DENGAN RANDOM FOREST
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 11 Januari 2022
WINARI ANGGANI 171402038
i
ABSTRAK
Internet sudah tidak asing lagi bagi masyarakat modern. Penggunaan Internet sebagai bahan utama dalam berkomunikasi jarak jauh maupun dekat membuat Internet mempunyai peranan penting di kehidupan modernisasi sekarang. Penggunaan internet dapat diakses melalui smartphone dan memerlukan operator jaringan seluler yang terdaftar di Indonesia. Untuk memilih operator jaringan seluler yang bagus pengguna harus mendapatkan informasi yang baik dan terstruktur dari ulasan-ulasan yang telah diberikan oleh pengguna yang pernah memakai operator jaringan tersebut dari media sosial. Ada banyak ulasan yang masih berbanding terbalik dengan minimnya identifikasi pengguna, oleh karen itu dibutuhkan dilakukan penelitian untuk melakukan analisis sentimen terhadap ulasan pelanggan jaringan seluler, pada penelitian ini operator jaringan seluler yang digunakan yaitu Indosat. Tujuan dari penelitian ini adalah untuk mendapatkan hasil sentimen pengguna jaringan seluler yang terstruktur sehingga memudahkan pengguna dalam mendapatkan informasi dengan menggunakan metode Random forest dan ekstraksi fitur TF-IDF yang di kelompokkan dalam opini positif, negatif dan netral dan dalam aspek yang telah ditentukan. Model terbaik pada penelitian ini mendapatkan akurasi sebesar 87,2%.
Kata Kunci : ulasan pelanggan, jaringan seluler, aspect-based analysis, random forest, TF-IDF
ASPECT-BASED SENTIMENT ANALYSIS ON CUSTOMER REVIEWS MOBILE NETWORK WITH RANDOM FOREST
ABSTRACT
Internet is no longer a stranger to modern society. The use of the Internet as the main ingredient in communicating long and near distances makes the Internet have an important role in modern life today. Internet usage can be accessed via a smartphone and requires a cellular network operator registered in Indonesia. To choose a good cellular network operator, users must get good and structured information from the reviews that have been given by users who have used the network operator from social media. There are many reviews that are still inversely proportional to the lack of user identification, therefore research is needed to conduct a sentiment analysis on customer reviews of cellular networks, in this study the cellular network operator used is Indosat. The purpose of this research is to get the results of structured cellular network user sentiments to make it easier for users to get information using the Random forest method and TF-IDF feature extraction which are grouped into positive, negative and neutral opinions and in predetermined aspects. The best model in this study obtained an accuracy of 87.2%.
Keywords: customer reviews, cellular network, aspect-based analysis, random forest, TF-IDF
3
DAFTAR ISI
ABSTRAK i
ABSTRACT ii
DAFTAR ISI iii
DAFTAR TABEL v
DAFTAR GAMBAR vi
BAB 1 PENDAHULUAN 1
1.1. Latar Belakang 1
1.2. Rumusan Masalah 3
1.3. Tujuan Penelitian 3
1.4. Batasan Masalah 3
1.5. Manfaat Penelitian 4
1.6. Metodologi Penelitian 4
1.7. Sistematika Penulisan 5
BAB 2 LANDASAN TEORI 6
2.1. Aspect Based Sentiment Analysis (ABSA) 6
2.2. Jaringan Seluler (Operator Seluler) 6
2.3. Electronic Word of Mouth (E-WOM) 7
2.4. Random Forest 7
2.5. TF-IDF 8
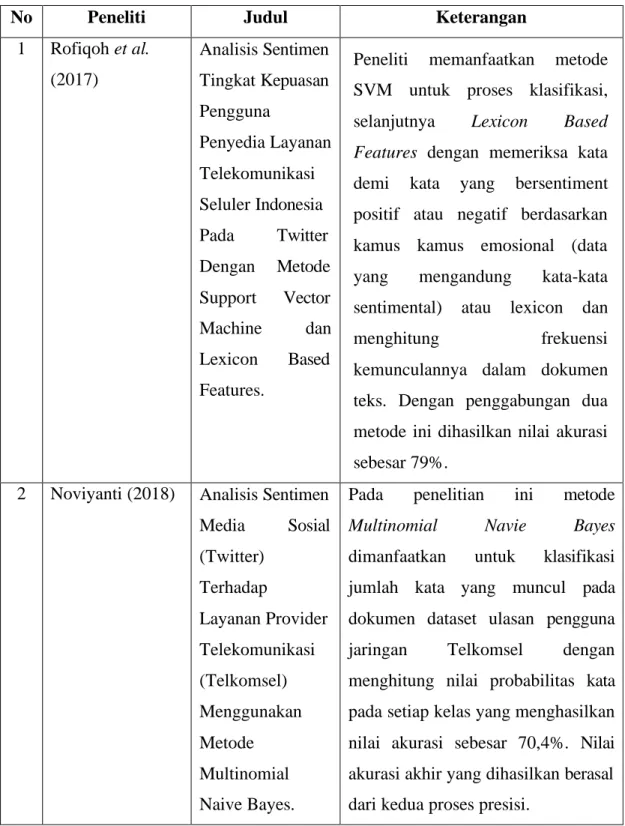
2. 6. Penelitian Terdahulu 9
BAB 3 ANALISI PERANCANGAN 14
3.1 Arsitektr Umum 14
3.2. File Dataset 15
3.3. Pre-processing 15
3.3.1. Case folding 16
3.3.2. Tokenizing 16
3.3.3. Stopword removal 16
3.3.4. Stemming 17
3.4. TF-IDF (term frequency-inverse document frequency) 18
3.5. Random Forest 19
3.6. Perancangan Sistem 19
3.6.1. Rancangan Halaman Beranda 20
3.6.2. Rancangan Halaman Training 21
3.6.3. Rancangan Halaman Testing 22
BAB 4 IMPLEMENTASI DAN PENGUJIAN 23
4.1. Implementasi Sistem 23
4.1.1. Spesifikasi Perangkat Keras dan Perangkat Lunak 23 4.1.2. Implementasi Perancangan Tampilan Antarmuka 23
4.2. Evaluasi Model 27
4.3. Pengujian Sistem 30
4.4. Evaluasi Pelanggan 35
BAB 5 KESIMPULAN DAN SARAN 37
5.1. Kesimpulan 37
5.2. Saran 37
DAFTAR PUSTAKA 38
LAMPIRAN 40
5
DAFTAR TABEL
Tabel 2.1. Penelitian Terdahulu 11
Tabel 3.1. Dataset Review Pelanggan 15
Tabel 3.2. Contoh Penerapan Case Folding 16
Tabel 3.3. Contoh Penerapan Tokenizing 16
Tabel 3.4. Contoh Penerapan Stopword Removal 17
Tabel 3.5. Contoh Penerapan Stemming 17
Tabel 3.6. Contoh Perhitungan TF-IDF 19
Tabel 4.1. Hasil Pengujian Sistem 31
DAFTAR GAMBAR
Gambar 3.1. Arsitektur Umum 14
Gambar 3.2. Halaman Home 20
Gambar 3.3. Halamam Training 21
Gambar 3.4. Halaman Testing 22
Gambar 4.1. Tampilan halaman Home 24
Gambar 4.2. Tampilan halaman Training 25
Gambar 4.3. Tampilan halaman Training (Lanjutan) 25
Gambar 4.4. Tampilan halaman Testing 26
Gambar 4.5. Tampilan classification report dan confussion matrix sinyal 26 Gambar 4.6. Tampilan classification report dan confussion matrix pelayanan 27 Gambar 4.7. Tampilan classification report dan confussion matrix harga 27
Gambar 4.6. Heatmap confussion matrix sinyal 28
Gambar 4.7. Heatmap confussion matrix pelayanan 29
Gambar 4.8. Heatmap confussion matrix harga 30
Gambar 4.9. Diagram Lingkar Aspek Sinyal 35
Gambar 4.10. Diagram Lingkar Aspek Harga 35
Gambar 4.11. Diagram Lingkar Aspek Pelayanan 35
BAB 1 PENDAHULUAN
1.1. Latar Belakang
Penggunaan Internet sangat dibutuhkan sekarang. Internet sudah menjadi bahan utama dalam berkomunikasi jarak jauh maupun dekat. Asosiasi Penyelenggara Jasa Internet Indonesia (APJII) mengatakan bahwa 196,7 juta masyarakat Indonesia atau 73,7%
dari masyarakat Indonesia menjadi pelaku penggunaan internet secara aktif pada tahun 2019-2020. Penggunaan internet dapat diakses melalui smartphone dan memerlukan operator jaringan seluler yang terdaftar di Indonesia. Salah satu operator jaringan seluler di Indonesia adalah PT. Indosat Tbk (ISAT). Bersumber dari VP Head of Strategic Communication PT. Indosat Tbk, pengguna aktif jaringan indosat pada kuartal I-III/2020 sebanyak 60,4 juta pelanggan. Tinggi nya angka pelanggan aktif jaringan seluler Indosat bukan berarti tidak ada keluhan pelanggan saat memakai provider jaringan tersebut. Diketahu melalui data Yayasan Lembaga Konsumen Indonesia (YLKI) pada tahun 2020 Indosat menjadi provider kedua yang paling banyak dikeluhkan pelanggan dengan persentase 25,5% dalam hal sistem tagihan, paket internet dan stabilisasi jaringan. Keluhan pelanggan tersebut bukan hal yang dapat dianggap ringan mengingat persaingan yang cukup ketat dalam bisnis komunikasi membuat operator jaringan seluler harus bijak dalam menerapkan strategi bisnis agar konsumen yang memakai jasa telekomunikasi jaringan seluler mereka dapat bertahan lama (Putri et al, 2017).
Melalui E-WOM (Electronic Word of Mouth) ulasan online dari konsumen dapat dibagikan. Data penting yang dapat diambil dari ulasan-ulasan tersebut adalah sentimen pengguna (Setyohari, 2020). Sentimen pengguna dapat diperoleh dengan teknologi text mining yaitu cara mengkomputasi sentimen pengguna yang dinyatakan secara positif, negatif atau netral dalam bentuk teks secara otomatis. Random Forest adalah algoritma text mining yang dapat dimanfaatkan untuk proses sentiment analysis.
Random Forest adalah sebuah algoritma yang dimanfaatkan untuk pengelompokkan atau klasifikasi dengan jumlah data yang besar. Pemisahan biner rekrusif digunakan oleh Random Forest untuk memperoleh node terakhir dalam struktur pohon berasal dari pohon klasifikasi dan regresi. Identifikasi data teks menggunakan algoritma random forest memiliki beberapa kelebihan diantaranya adalah algoritma random forest mampu memberikan hasil klasifikasi dengan rentang error yang lebih rendah, mampu menangani data training dalam jumlah yang banyak dengan tepat, serta proses yang efektif untuk memperkirakan data yang hilang (Breiman, 2001). Random Forest dapat menghasilkan target klasifikasi dengan baik karena aspect-based sentiment analysis menentukan targetnya kedalam aspek yang akan diklasifikasikan dan termasuk kedalam supervised learning.
Sebelumnya telah dilakukan penelitian mengenai analisis sentimen pada jaringan seluler, di antaranya adalah penelitian yang dilakukan oleh Rofiqoh et al.
(2017) Analisis Sentimen Tingkat Kepuasan Pengguna Penyedia Layanan Telekomunikasi Seluler Indonesia Pada Twitter Dengan Metode Support Vector Machine dan Lexicon Based Features. Peneliti memanfaatkan metode SVM untuk proses klasifikasi, selanjutnya proses untuk menguji kata yang bermakna sentimen positif atau negatif dengan cara penilaian menurut kamus lexicon yang berasal dari kamus kata-kata yang bersentimen atau sentiment dictionaries dan memperkirakan kemunculan kata-kata yang bersentimen pada dokumen teks. Dengan penggabungan dua metode ini dihasilkan nilai akurasi sebesar 79%. Selanjutnya penelitian Analisis Sentimen Media Sosial (Twitter) Terhadap Layanan Provider Telekomunikasi (Telkomsel) Menggunakan Metode Multinomial Naïve Bayes (Noviyanti, 2018). Pada penelitian ini metode Multinomial Navie Bayes dimanfaatkan untuk pengambilan jumlah kata yang muncul pada dokumen dengan menghitung nilai probabilitas kata pada setiap kelas yang menghasilkan nilai akurasi sebesar 70,4%. Penelitian lainnya yaitu Real-Time Sentiment Analysis of 2019 Election Tweets using Word2vec and Random Forest Model oleh Hitesh et al. (2019), dimana peneliti menggabungkan dua metode word2vec dengan random forest untuk mengklasifikasi tweet tentang politik di India sejak tahun 2019 dan mencapai nilai akurasi tertinggi sebesar 86,87%.
Kemudian Smart Recommendation System Based on Product Reviews using Random Forest
3
(Khanvilkar, 2019) peneliti membandingkan beberapa kinerja metode klasifikasi dan dengan random forest berhasil mencapai nilai akurasi tertinggi sebesar 95,03%.
Penelitian lain yaitu Sentiment Analysis on Youtube Social Media Using Decision Tree and Random Forest Algorithm oleh Aufar et al. (2020) peneliti memanfaatkan dua algoritma yang serupa atau memiliki tingkat kemiripan yang cukup baik untuk mengklasifikasi komentar dari saluran youtube handphone nokia dan mendapatkan nilai akurasi terbaik pada algoritma random forest sebesar 88,2%.
Berdasarkan beberapa latar belakang yang sudah dipaparkan sebelumnya, oleh karena itu penulis ingin melakukan penelitian dengan judul “Aspect-Based Sentiment Analysis Pada Ulasan Pelanggan Jaringan Seluler Dengan Random Forest”.
1.2. Rumusan Masalah
Tingginya angka keluhan pelanggan aktif jaringan seluler Indosat di berbagai platform sosial media menyebabkan data menjadi beragam sehingga sulit untuk melihat aspek mana yang paling tinggi tingkat keluhannya. Maka dari itu, dibutuhkan suatu solusi untuk dapat mengelompokkan keluhan pelanggan berdasarkan aspek yang telah ditentukan.
1.3. Tujuan Penelitian
Tujuan dari penelitian yang akan dilakukan adalah untuk mendapatkan hasil sentimen pengguna jaringan seluler menggunakan ektraksi fitur TF-IDF dan Random Forest yang di kelompokkan dalam opini positif, negatif dan netral dan dalam aspek yang telah ditentukan.
1.4. Batasan Masalah
Batasan masalah yang diberikan guna membatasi hal utama dalam masalah yang akan dikaji pada penelitian ini supaya mencapai tujuan penelitian dengan baik. Batasan masalah yang diberikan adalah sebagai berikut :
1. Operator jaringan seluler yang dibahas hanya PT. Indosat Tbk (Indosat).
2. Data diambil dari ulasan aplikasi myIM3 digoogle playstore dan ulasan tweet dari twitter @IndosatCare dan @IM3Ooredoo.
3. Berdasarkan sebaran aspek pada data maka setiap komentar atau tweet akan diklasifikasikan menjadi tiga aspek yaitu sinyal, harga, pelayanan dan kelas kalimat yang bersentimen positif, negatif dan netral.
4. Dataset hanya menggunakan Bahasa Indonesia
1.5. Manfaat Penelitian
Manfaat dari penelitian ini diharapkan dapat :
1. Memahami sentimen serta aspek yang dikaji berdasarkan ekstraksi fitur.
2. Memberikan nilai rating yang jelas berdasarkan aspek untuk provider terkait.
3. Memberikan informasi berdasarkan aspek terhadap ulasan pengguna sehingga dapat menjadi informasi tambahan bagi pengguna baru.
1.6. Metodologi Penelitian
Dibawah ini merupakan metode penelitian yang akan dilakukan : 1. Studi Literatur
Tahapan awal akan dilakukan proses pengumpulan sumber berupa artikel, buku, jurnal, dan sumber bacaan lainnya dalam menganalisis dan mengolah referensi mengenai text processing, text mining, analisis sentimen, serta metode Random Forest.
2. Analisis Permasalahan
Studi literatur yang dikumpulkan akan dilakukan analisis berdasarkan permasalahan yang dihadapi dengan metode Random Forest untuk melakukan pendekatan terhadap penyelesaian masalah tentang sentimen pengguna jaringan seluler Indosat.
3. Pengumpulan Data
Penelitian dilanjutkan dengan pengumpulan data dengan cara crawling data yang bersumber dari ulasan pengguna pada aplikasi myIM3 digoogle playstore dan ulasan tweet dari twitter @IndosatCare dan @IM3Ooredoo.
4. Perancangan dan Implementasi Sistem
Perancangan dilakukan untuk menemukan solusi berdasarkan hasil yang didapatkan dari proses menganalisis masalah. Selanjutnya rancangan tersebut akan diterapkan agar menjadi sistem yang siap untuk dipakai dalam penyelesaian problema yang ada.
5
5. Pengujian Sistem
Setelah melalui proses perancangan dan implementasi sistem, langkah berikutnya adalah pengujian performa dan evaluasi sistem pada hasil implementasi sistem tersebut dari metode yang digunakan yaitu Random Forest.
6. Pengarsipan dan Laporan
Pembuatan dokumentasi dan arsip seluruh pengerjaan serta penyusunan laporan hasil dari penelitian akan dilakukan pada tahap ini.
1.7. Sistematika Penulisan
Tahapan penulisan skripsi ini mencakup lima bagian, yaitu : Bab 1 : Pendahuluan
Bab pendahuluan yang mencakup latar belakang penentuan judul “Aspect-Based Sentimen Analysis Pada Ulasan Pelanggan Jaringan Seluler Dengan Random Forest” , rumusan masalah, tujuan penelitian, batasan masalah, manfaat penelitian, metodologi penelitian, dan sistematika penulisan.
Bab 2 : Landasan Teori
Pada bagian ini memuat konsep guna menjalankan analisis dan mengetahui masalah- masalah yang dikaji pada penelitian ini, yaitu teori mengenai Aspect Based Sentiment Analysis (ABSA), Jaringan Seluler (Operator Seluler), Electronic Word of Mouth (E- WOM), Random Forest, TF-IDF, dan penelitian terdahulu.
Bab 3 : Analisis dan Perancangan Sistem
Bagian ini merupakan bab untuk memaparkan arsitektur umum dari sistem yang dibangun, tahapan preprocessing, perhitungan bobot menggunakan TF-IDF, serta analisis dan perancangan metode Random forest.
Bab 4 : Implementasi dan Pengujian Sistem
Pada bab ini memuat paparan bermakna penerapan hasil penyusunan yang telah dilakukan pada bab 3. Pada bab ini dilakukan pengujian dan pemaparan hasil akhir serta evaluasi berdasarkan sistem yang dibuat.
Bab 5 : Kesimpulan dan Saran
Bab ini berisi pemaparan hasil dari penelitian yang sudah dikerjakan oleh penulis, dan saran-saran untuk penulis supaya dapat melakukan perbaikan dan evaluasi penelitian yang dilakukan setelahnya.
BAB 2
LANDASAN TEORI
2.1. Aspect Based Sentiment Analysis (ABSA)
Analisis sentimen adalah langkah untuk mengetahui dan mengklasifikasikan emosi (positif negatif atau netral) yang ada di sebuah teks menggunakan teknik analisis teks.
Definisi lain dari analisis sentimen adalah proses menganalisis teks online untuk menentukan nada sentimental penulis. Kemudian para ahli datang dengan jenis analisis sentimen yang lebih mendalam dari pada ulasan tertulis yang disebut Analisis Sentimen Berasis Aspek (ABSA). ABSA dapat secara otomatis mengekstrak aspek ulasan dan kemudian menentukan bagaimana perasaan aspek tersebut. Seperti saat sedang melihat ulasan pada penjualan produk secara online, pendapat yang ada tentu bukan hanya sentimen umum, namun ada aspek seperti respon penjual yang baik, produk original, pengiriman yang cepat dan lain-lain.
2.2. Jaringan Seluler (Operator Seluler)
Jaringan seluler adalah jaringan telekomunikasi yang tautan terakhirnya adalah nirkabel. Jaringan didistribusikan diatas area daratan yang disebut “sel” yang masing- masing dilayani oleh setidaknya satu transceiver lokasi tetap, tetapi lebih normal.
Jaringan seluler merupakan teknologi jaringan yang berkembang dan memungkinkan data dikirim dan diterima dalam bentuk paket data terkait teks, foto atau video. Saat ini perkembangan jaringan seluler sudah mencapai 5 Generasi (5G). Namun di Indonesia masih sampai pada 4 Generation (4G). Menurut statistik Asosiasi GSM sekitar 80% ponsel di dunia menggunakan jaringan GSM. GSM sendiri adalah kependekan dari Global System for Mobile Communication. GSM dapat diterjemahkan sebagai teknologi komunikasi seluler digital. Teknologi ini memanfaatkan gelombang mikro dan sinyal siaran yang dipisah berdasarkan waktu untuk memastikan bahwa sinyal yang dikirimkan sampai ke tujuan.
7
GSM kemudian digunakan sebagai sistem standar dikebanyakan jaringan telepon yang ada di dunia. Cara kerja yang memakai penyiar atau jaringan seluler berdasarkan teknologi satelit yang dihubungkan ke sinyal dari orbit sebagai elemen dari jaringan sistem. Seluler yang memanfaatkan jenis jaringan ini dilengkapi dengan kartu Subscriber Identification Module (SIM).
2.3. Electronic Word of Mouth (E-WOM)
Word of Mouth atau komunikasi dari mulut ke mulut sudah menjadi hal umum didalam dunia pemasaran secara online. Teknik periklanan ini telah dikenal selama ratusan tahun sebelum ilmu pemasaran berkembang hingga saat ini. Ketika pelanggan senang membeli/menggunakan produk atau jasa di satu tempat, mereka cenderung berbagi pengalaman dengan orang lain. Metode ini sangat menguntungkan bagi perusahaan, karena tidak mengeluarkan biaya untuk pengiklanan. Rekomendasi atau referensi dari pelanggan yang puas dengan produk/jasa mudah dikomunikasikan oleh konsumen lain. Ada beberapa penelitian yang menyelidiki E-WOM di platform SNS (Social Network Service) seperti Facebook, Twitter, dan Instagram. Itu terjadi karena E-WOM ditperkirakan sebagai alasan utama yang sering dipakai konsumen dalam keputusan pembelian konsumen. Kualitas E-WOM berstandar pada makna utama komentar yang ada didalam fakta pada sentimen.
2.4. Random Forest
Random Forest termasuk kedalam metode ensemble. Konsep ensemble sendiri adalah model untuk memperbesar peluang dari ketepatan metode klasifikasi atau pengelompokkan yang dapat dilakukan dengan menggabungkan beberapa metode klasifikasi (Han, 2012). Random Forest dimulai memakai cara penambangan data awalan, pohon keputusan. Di pohon keputusan, input dimasukkan disisi atas (root) dan lalu disisi bawah (daun) agar membatasi kelas tempat data tersebut berada.
Random Forest ialah proses pengelompokkan sejumlah bagian-bagian klasifikasi pohon yang sistematis dimana bagian-bagian pohon mengambil voting bagi kelas paling banyak mendapatkan suara yang input oleh x (Breiman, 2001). Artinya, Random Forest termasuk bagian dari himpunan pohon keputusan (decision tree) yang menggunakan decision tree untuk mengklasifikasikan data ke dalam kelas-kelas.
Random Forest ialah sistemasi yang bekerja secara supervisied. Sesuai dengan namanya, cara ini membuat forest dengan banyak tree. Biasanya, banyaknya jumlah pohon yang ada di hutan mempengarahui kuat atau tidaknya tampilan hutan tersebut.
Dalam kasus yang sama, semakin banyak pohon yang Anda miliki, semakin akurat yang akan Anda dapatkan. (Polamuri, 2017). Pohon keputusan menggunakan perolehan informasi dan indeks keuntungan dalam perhitungan saat menentukan simpul akar dan aturan. Hal ini juga berlaku untuk Random Forest yang menggunakan perolehan informasi dan indeks keuntungan untuk perhitungan tree. (Han, 2012), Random Forest cukup membuat kumpulan data dengan keunikan yang diperoleh menurut data sembarang yang berasal dari data training. Maksudnya, tiap-tiap pohon yang bersangkutan pada nilai vektor sampel data tetap dengan penyebaran yang sama di setiap tree. (Han, 2012). Pada tiap tahapan pengelompokkan, setiap pohon memilih kelas yang paling populer.
2.5. TF-IDF
Term Frequency – Inverse Document Frequency atau TF-IDF adalah Sebuah metode yang membantu membagi ukuran pada tiap-tiap kata yang sering dipakai. Metode ini membantu nilai Term Frequency (TF) dan Reverse Document Frequency (IDF) untuk bagian-bagian penggalan kata dalam korpus. Sederhananya, gunakan metode TF-IDF untuk mengetahui seberapa banyak satu kata ada di dalam sebuah dokumen.
1. Document Frequency
Dokumen frekuensi (Df) adalah banyak nya salinan document yang berisi istilah tertentu. Frekuensi dokumen adalah cara termudah untuk memilih fitur yang memiliki sedikit waktu komputasi.
2. Term Frequency
Term Frequency (Tf) adalah konsep untuk memperkirakan bobot setiap term di sebuah teks. Prosedur tersebut mengasumsikan bahwa nilai kepentingan untuk setiap istilah sebanding dengan berapa kali istilah tersebut muncul dalam teks.
9
3. Inverse Document Frequency (IDF)
Inverse Document Frequency (IDF) Cara menghitung kehadiran istilah di semua kumpulan teks. Dalam hal ini, istilah yang jarang muncul di seluruh kumpulan istilah dianggap lebih berharga. Makna setiap istilah diyakini berbeda dengan banyak nya teks yang berisi istilah tersebut.
4. Term Frequency Inverse Document Frequency (TF-IDF)
Term Frequency Inverse Document Frequency (TFIDF) adalah pembobotan yang dilakukan setelah dataset diekstraksi. Cara dari konsep TF-IDF ialah memperkirakan isi bobot memakai penggabungan frekuensi term (tf) dan frekuensi dokumen terbalik (idf). Tahapan di TF-IDF adalah mencari banyak nya kata (tf) yang kita kenal atau paham setelah dikalikan dengan jumlah record di mana kata (idf) muncul.
2. 6. Penelitian Terdahulu
Sebelumnya telah dilakukan beberapa penelitian mengenai aspect based sentiment analysis diantaranya adalah Analisis Sentimen Tingkat Kepuasan Pengguna Penyedia Layanan Telekomunikasi Seluler Indonesia Pada Twitter Dengan Metode Support Vector Machine dan Lexicon Based Features oleh Rofiqoh et al. (2017). Peneliti memanfaatkan metode SVM untuk proses klasifikasi, selanjutnya Lexicon Based Features dengan memeriksa kata demi kata yang bersentiment positif atau negatif berdasarkan kamus kamus emosional (data yang mengandung kata-kata sentimental) atau lexicon dan menghitung frekuensi kemunculannya dalam dokumen teks. Dengan penggabungan dua metode ini dihasilkan nilai akurasi sebesar 79%.
Penelitian lainnya yaitu Analisis Sentimen Media Sosial (Twitter) Terhadap Layanan Provider Telekomunikasi (Telkomsel) Menggunakan Metode Multinomial Naïve Bayes (Noviyanti, 2018). Pada penelitian ini metode Multinomial Navie Bayes dimanfaatkan untuk klasifikasi jumlah kata yang muncul pada dokumen dataset ulasan pengguna jaringan Telkomsel dengan menghitung nilai probabilitas kata pada setiap kelas yang menghasilkan nilai akurasi sebesar 70,4%. Nilai akurasi akhir yang dihasilkan berasal dari kedua proses presisi.
Hitesh et al. (2019) melakukan penelitian Real-Time Sentiment Analysis of 2019 Election Tweets using Word2vec and Random Forest Model. Pada penelitian ini memanfaatkan dataset yang dihimpun melalui API twitter dan memakai hashtags yang berhubungan dengan politik India sejak tahun 2019. Dataset yang dikumpulkan sebanyak 18.685 tweets kemudian peneliti menggabungkan dua metode word2vec dengan random forest untuk proses klasifikasi dan mencapai nilai akurasi tertinggi sebesar 86,87%.
Penelitian lain, Smart Recommendation System Based on Product Reviews using Random Forest (Khanvilkar, 2019). Penelitian ini memanfaatkan dataset situs amazon yang berasal dari kaggle.com dengan jumlah lebih dari 400.000 ulasan tentang ponsel dengan atribut nama produk, nama brand, harga, rating, ulasan pengguna.
Perbandingan beberapa algoritma untuk klasifikasi seperti Support Vector Machine, Multinomial Naïve Bayes, Logistic Regression dan Random Forest menghasilkan nilai akurasi yang berbeda-beda namun pada penelitian ini nilai ketepatan atau akurasi terbesar didapatkan dengan algoritma Random Forest sebesar 95,03%.
Penelitian lainnya oleh Aufar et al. (2020) Sentiment Analysis on Youtube Social Media Using Decision Tree and Random Forest Algorithm. Peneliti memanfaatkan ulasan pengguna Youtube dari channel Nokia sebanyak 2000 ulasan.
Semua ulasan yang beragam tersebut kemudian diterjemahkan ke dalam bahasa inggris agar mudah untuk diolah. Penggunaan dua algoritma yang serupa atau memiliki tingkat kemiripan yang cukup baik yaitu algoritma Decision Tree dan Random Forest untuk mengklasifikasi ulasan pengguna dapat mencapai nilai ketepatan atau akurasi tertinggi pada algoritma random forest sebesar 88,2%.
11
Tabel 2.1. Penelitian Terdahulu 1
No Peneliti Judul Keterangan
1 Rofiqoh et al.
(2017)
Analisis Sentimen Tingkat Kepuasan Pengguna
Penyedia Layanan Telekomunikasi Seluler Indonesia Pada Twitter Dengan Metode Support Vector Machine dan Lexicon Based Features.
Peneliti memanfaatkan metode SVM untuk proses klasifikasi, selanjutnya Lexicon Based Features dengan memeriksa kata demi kata yang bersentiment positif atau negatif berdasarkan kamus kamus emosional (data yang mengandung kata-kata sentimental) atau lexicon dan
menghitung frekuensi
kemunculannya dalam dokumen teks. Dengan penggabungan dua metode ini dihasilkan nilai akurasi sebesar 79%.
2 Noviyanti (2018) Analisis Sentimen Media Sosial (Twitter)
Terhadap
Layanan Provider Telekomunikasi (Telkomsel) Menggunakan Metode Multinomial Naive Bayes.
Pada penelitian ini metode Multinomial Navie Bayes dimanfaatkan untuk klasifikasi jumlah kata yang muncul pada dokumen dataset ulasan pengguna jaringan Telkomsel dengan menghitung nilai probabilitas kata pada setiap kelas yang menghasilkan nilai akurasi sebesar 70,4%. Nilai akurasi akhir yang dihasilkan berasal dari kedua proses presisi.
Tabel 2.1. Penelitian Terdahulu (Lanjutan) No Peneliti Judul Penelitian Keterangan
1 Hitesh et al.
(2019)
Real-Time Sentiment Analysis of 2019 Election Tweets using Word2vec and Random Forest Model.
Penelitian ini memanfaatkan dataset yang dirangkum melalui API twitter dengan hashtags yang berhubungan dengan politik India sejak tahun 2019. Dataset yang dikumpulkan sebanyak 18.685 tweets. Kemudian Peneliti menggabungkan dua metode word2vec dengan random forest untuk proses klasifikasi dan mencapai nilai akurasi tertinggi sebesar 86,87%.
2 Khanvilkar (2019)
Smart
Recommendation System based on Product Reviews using Random Forest.
Penelitian ini memanfaatkan dataset situs amazon yang berasal dari kaggle.com dengan jumlah lebih dari 400.000 ulasan tentang ponsel dengan atribut nama produk, nama brand, harga, rating, ulasan pengguna. Perbandingan beberapa algoritma untuk klasifikasi seperti Support Vector Machine, Multinomial Naïve Bayes menghasilkan nilai akurasi yang berbeda namun pada penelitian ini nilai akurasi terbesar yang didapatkan dengan algoritma Random Forest adalah 95,03%.
13
Tabel 2.1. Penelitian Terdahulu (Lanjutan) No Peneliti Judul Penelitian Keterangan
1 Aufar et al.
(2020)
Sentiment
Analysis on Youtube Social Media Using Decision Tree and Random Forest Algorithm: A Case Study .
Peneliti memanfaatkan ulasan pengguna Youtube dari channel Nokia sebanyak 2000 ulasan. Semua ulasan yang beragam tersebut kemudian diterjemahkan ke dalam bahasa inggris agar mudah untuk diolah. Penggunaan dua algoritma yang serupa atau memiliki tingkat kemiripan yang cukup baik yaitu algoritma Decision Tree dan Random Forest untuk mengklasifikasi ulasan pengguna dapat mencapai nilai ketepatan terbesar yang dihasilkan pada algoritma random forest sebesar 88,2%.
BAB 3
ANALISI PERANCANGAN
3.1 Arsitektr Umum
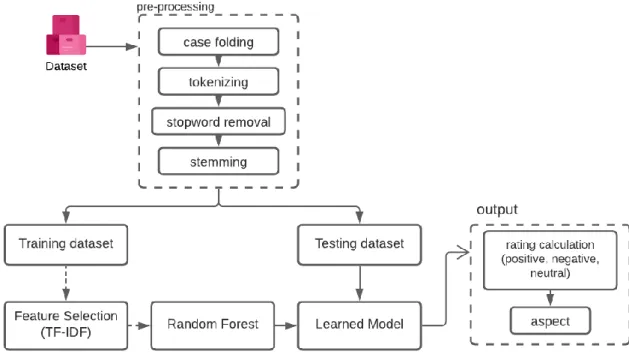
Pada penelitian ini terdapat langkah-langkah bertahap yang akan dilakukan. Tahapan tersebut yaitu penghimpunan data-data dalam format .csv . Selanjutnya data tersebut melewati langkah atau proses pre-processing yang terdiri dari case folding, tokenizing, stopword removal, dan stemming. Langkah berikutnya data tersebut di terapkan pada proses training. Data tersebut akan melalui proses feature selection TF-IDF dan penerapan algoritma random forest. Kemudian data hasil training tersebut digunakan pada proses testing. Gambaran sistem yang dibangun dapat dilihat pada gambar 3.1.
Gambar 3.1. Arsitektur Umum
15
3.2. File Dataset
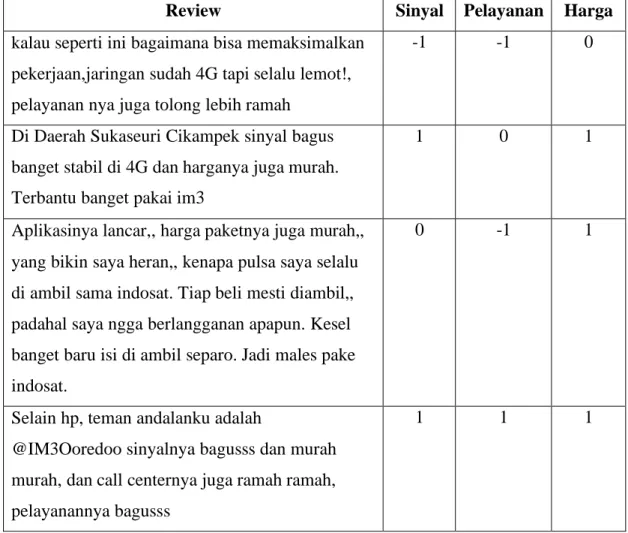
Memanfaatkan file dataset yang bersumber dari ulasan pengguna jaringan seluler Indosat di Google Playstore dan tweet ulasan pengguna jaringan seluler Indosat dari twitter @IndosatCare. Jumlah ulasan yang ditargetkan sebanyak 1500 ulasan yang digabungkan melalui dua platform tersebut. Dataset nanti nya akan dibagi menjadi dua bagian, yaitu data training sebanyak 1247 data dan data testing sebanyak 313 data. Di dalam dataset tersebut terdapat kolom review, sinyal, pelayanan, dan harga.
Review yang dinyatakan positif diberi label 1, negatif diberi label -1, dan netral diberi label 0. Contoh kalimat review diuraikan pada tabel 3.1. berikut :
Tabel 3.1. Dataset Review Pelanggan
Review Sinyal Pelayanan Harga
kalau seperti ini bagaimana bisa memaksimalkan pekerjaan,jaringan sudah 4G tapi selalu lemot!, pelayanan nya juga tolong lebih ramah
-1 -1 0
Di Daerah Sukaseuri Cikampek sinyal bagus banget stabil di 4G dan harganya juga murah.
Terbantu banget pakai im3
1 0 1
Aplikasinya lancar,, harga paketnya juga murah,, yang bikin saya heran,, kenapa pulsa saya selalu di ambil sama indosat. Tiap beli mesti diambil,, padahal saya ngga berlangganan apapun. Kesel banget baru isi di ambil separo. Jadi males pake indosat.
0 -1 1
Selain hp, teman andalanku adalah
@IM3Ooredoo sinyalnya bagusss dan murah murah, dan call centernya juga ramah ramah, pelayanannya bagusss
1 1 1
3.3. Pre-processing
Di tahap ini dataset akan di pre-processing dalam berbagai tahapan yaitu case folding, tokenizing, stopword removal, dan stemming.
3.3.1. Case folding
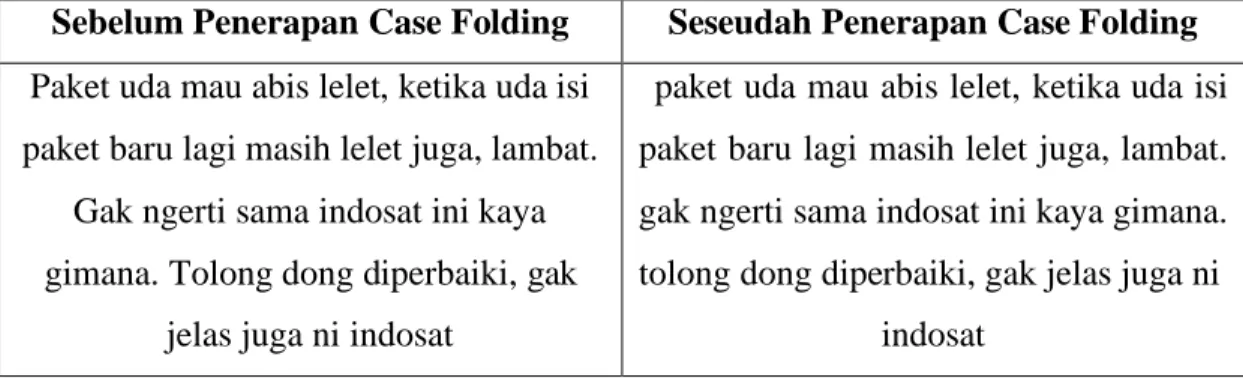
Case folding ialah metode yang ditujukan untuk merubah keseluruhan kata menjadi huruf kecil (lowercase) dan menghilangkan karakter lain yang tidak dibutuhkan pada proses selanjutnya. Contoh penerapan case folding diberikan pada Tabel 3.2.
Tabel 3.2. Contoh Penerapan Case Folding
Sebelum Penerapan Case Folding Seseudah Penerapan Case Folding Paket uda mau abis lelet, ketika uda isi
paket baru lagi masih lelet juga, lambat.
Gak ngerti sama indosat ini kaya gimana. Tolong dong diperbaiki, gak
jelas juga ni indosat
paket uda mau abis lelet, ketika uda isi paket baru lagi masih lelet juga, lambat.
gak ngerti sama indosat ini kaya gimana.
tolong dong diperbaiki, gak jelas juga ni indosat
Sesudah melalui proses case folding pada tabel di atas bisa dilihat seluruh huruf dalam data menjadi huruf kecil termasuk huruf yang berada di awal kalimat.
3.3.2. Tokenizing
Tokenizing adalah proses untuk membagi teks menjadi beberapa penggalan-penggalan terpilih (menjadi satu kata). Pada proses ini dikerjakan penghilangan tanda baca dan angka dari setiap kalimat. Contoh penerapan tokenizing diberikan pada Tabel 3.3.
Tabel 3.3. Contoh Penerapan Tokenizing
Sebelum Penerapan Tokenizing Sesudah Penerapan Tokenizing harganya makin tak terjangkau dan
jaringan saat ujan ga stabil
“harganya”, “makin”, “tak”,
“terjangkau”, “dan”, “jaringan”, “saat”,
“ujan”, “ga”, “stabil”
3.3.3. Stopword removal
Stopword removal atau penghilangan stopword ialah proses untuk penghapusan kata- kata awam atau umum yang tidak terlalu mempunyai arti penting. Kata yang umunya dihapus adalah kata preposisi, kata hubung dan kata sebagainya yang banyak tampak dan apabila dihapus maka tidak merubah arti sebenarnya dari suatu kalimat.
17
Adapun contoh kata yang akan dihapus yaitu “sangat”, “juga”, dan “dll”. Proses ini dilakukan untuk menyederhanakan kalimat sebelum di proses. Berikut ilustrasi kerja dari stopword removal diberikan pada Tabel 3.4. berikut :
Tabel 3.4. Contoh Penerapan Stopword Removal Sebelum Penerapan Stopword
Removal
Sesudah Penerapan Stopword Removal
aplikasinya sangat mudah dimengerti dan digunakan untuk cek kuota dan
pembelian kuota. Gamenya juga menyenangkan, menemani saat gabut
sepi dll. Tingkatkan terus.
aplikasinya mudah dimengerti digunakan untuk cek kuota
pembelian kuota gamenya menyenangkan menemani saat gabut
sepi tingkatkan terus
3.3.4. Stemming
Stemming adalah cara untuk mendapatkan kata dasar dari kalimat. Proses ini berufungsi untuk menghapus bagian-bagian morfologi yang terdapat disatu kata menggunakan step yaitu menghapus awalan pada kata yang dimaksud sehingga didapatkan kata yang serupa dengan susunan Indonesian morphology languange yang benar. Ilustrasi penerapan stemming diberikan pada Tabel 3.5. berikut :
Tabel 3.5. Contoh Penerapan Stemming 1
Sebelum Penerapan Stemming Sesudah Penerapan Stemming patut diberi gelar jaringan paling stabil
dan termurah
patut beri gelar jaringan paling stabil dan murah
3.4. TF-IDF (term frequency-inverse document frequency)
TF-IDF adalah cara penghitung bobot sebuah kata dalam statistik numerik yang ditujukan guna mengetahui seberapa pentingnya kata tersebut. Metode pada TF-IDF yaitu term frequency dan inverse document frequency. TF ialah banyak nya suatu kata hadir di dalam sebuah dokumen, semakin besar nilai TF maka bobotnya menjadi lebih besar, IDF menunjukkan distribusi kemuncukan kata pada dokumen secara keseluruhan.
Pada perhitungan IDF, total dokumen dibagi dengam jumlah dokumen yang memiliki kata yang dicari di dalamnya. Berikut rumus untuk mencari TF-IDF :
𝑇𝐹 (𝑖, 𝑗) = Frekuensi kemunculan kata (i)𝑑𝑎𝑙𝑎𝑚 𝑑𝑜𝑘𝑢𝑚𝑒𝑛 (𝑗) Jumlah kata dalam dokumen
𝑇𝑜𝑡𝑎𝑙 𝑑𝑜𝑘𝑢𝑚𝑒𝑛 (𝑁) 𝐼𝐷𝐹 (𝑖, 𝑁) = log (
Dokumen yang memiliki kata (i)𝑦𝑎𝑛𝑔 𝑑𝑖𝑐𝑎𝑟𝑖 )
TF-IDF = TF × IDF
Misalkan ada beberapa dokumen seperti berikut : d1 : [‘suka’, ‘jaringan’, ‘kencang’]
d2 : [‘mahal’, ‘kencang’]
d3 : [‘suka’, ‘mahal’]
d4 : [‘jaringan’, ‘kencang’]
Metode TF- IDF pada dokumen- dokumen pada tabel 3.6.
19
Tabel 3.6. Contoh Perhitungan TF-IDF
Suka Jaringan Mahal Kencang
TF ̶ d1 1 1 0 1
TF ̶ d2 0 0 1 1
TF ̶ d3 1 0 1 0
TF ̶ d4 0 1 0 1
df 2 2 2 3
N/df 2 2 2 1.3
IDF 0.3 0.3 0.3 0.1
TF-IDF ̶ d1 0.3 0.3 0 0.1
TF-IDF ̶ d2 0 0 0.3 0.1
TF-IDF ̶ d3 0.3 0 0.3 0
TF-IDF ̶ d4 0 0.3 0 0.1
3.5. Random Forest
Pada tahap ini data yang telah melalui preprocessing dan perhitungan bobot dengan TF-IDF, selanjutnya dilakukan proses training dengan penerapan algoritma Random Forest. Proses pengelompokan di random forest dimulai saat memisah data sampel yang sudah dikumpulkan menuju ke decision tree dengan tidak berurutan. Kemudian, setelah tree tampak bentuknya, selanjutnya dibuat pemilihan suara terbanyak untuk masing-masing kelas dari data contoh. Lalu, mencampurkan poling atau pemungutan suara terbanyak dari setiap kelas dan didapatkan hasil dengan suara terbanyak.
Random Forest dimanfaatkan untuk proses klasifikasi data dan akan menghasilkan jumlah suara terbanyak dan yang paling terbaik
3.6. Perancangan Sistem
Bagian perancangan sistem dipaparkan suatu cara untuk melihat menu serta alur sistem dan interface application. Perancangan antarmuka sistem ini dibuat untuk meringankan user dalam memakai aplikasi.
3.6.3. Rancangan Halaman Home
Halaman beranda ialah halaman pertama pada sistem saat dibuka. Pada halaman beranda ditunjukkan informasi tentang identitas penulis, judul penelitian, dan button yang menghubungkan ke page selanjutnya. Rancangan halaman beranda ditunjukkan pada Gambar 3.2.
Gambar 3.2. Halaman Home
Keterangan :
1. Button ini digunakan untuk mengarah kembali ke halaman home 2. Button ini digunakan untuk mengarah ke halaman training 3. Button ini digunakan untuk mengarah ke halaman testing 4. Button ini digunakan untuk mengarah ke halaman training 5. Button ini digunakan untuk mengarah kembali ke halaman home
21
3.6.4. Rancangan Halaman Training
Pada halaman training ditujukan untuk memuat hal – hal yang diperlukan untuk melakukan proses training. Proses ini dimulai dengan memilih file yang akan dilakukan proses training, setelah proses training selesai makan akan ditampilkan review, review yang telah melalui proses preprocess dan label yang didapat. Sketsa pada halaman training ditunjukkan pada Gambar 3.3.
Gambar 3.3. Halamam Training Keterangan :
1. Button ini digunakan untuk mengarah ke halaman home
2. Button ini digunakan untuk mengarah kembali ke halaman training 3. Button ini digunakan untuk mengarah ke halaman testing
4. Button ini digunakan untuk memilih file data training
5. Button ini digunakan untuk menghapus data training yang telah dipilih 6. Button ini digunakan untuk menemukan kata yang ingin dicari
7. Button ini digunakan untuk mengarah ke halaman home
3.6.5. Rancangan Halaman Testing
Pada halaman testing dimulai dengan memilih file yang akan dilakukan proses testing, yaitu file yang telah melalui proses training, setelah proses testing selesai maka akan ditampilkan review, review yang telah melalui proses preprocess, label yang didapat, classification report dan confussion matrix. Sketsa untuk tampilan testing ditunjukkan pada Gambar 3.4.
Gambar 3.4. Halaman Testing Keterangan :
1. Button ini digunakan untuk mengarah ke halaman home 2. Button ini digunakan untuk mengarah ke halaman training
3. Button ini digunakan untuk mengarah kembali ke halaman testing 4. Button ini digunakan untuk memilih file data testing
5. Button ini digunakan untuk menghapus data testing yang telah dipilih 6. Button ini digunakan untuk menemukan kata yang ingin dicari
7. Button ini digunakan untuk mengarah ke halaman home
BAB 4
IMPLEMENTASI DAN PENGUJIAN
4.1. Implementasi Sistem
Dalam pembuatan sistem aspect-based sentiment analysis pada ulasan jaringan seluler dengan metode random forest dipakai hardware serta software sebagai pendukung, antara lain :
4.1.1. Spesifikasi Perangkat Keras dan Perangkat Lunak
Perincian hardware yang dipakai untuk merancang dan membangun sistem adalah sebagai berikut.
1. Processor Intel Core i7-7700HQ 2.8 GHz with TurboBoost 3.8 GHz 2. Memori (RAM) dengan kapasitas 8 GB.
Perincian software yang dipakai untuk membuat sistem ialah sebagai berikut.
1. Sistem Operasi Windows 10 Pro 2. Microsoft Visual Studio Code
3. Phyton versi 3.6.8 dengan library Flask versi 1.1.2, matplotlib versi 3.3.1, nltk versi 3.6.2, numpy versi 1.19.5, pandas versi 1.1.5, Sastrawi versi 1.0.1, scikit-learn versi 0.24.2, seaborn versi 0.10.1
4.1.2. Implementasi Perancangan Tampilan Antarmuka
Berikut penerapan dari sketsa tampilan interface yang selesai dibuat di bab sebelumnya.
1. Tampilan Home
Home merupakan tampilan awal sistem ketika dijalankan. Terdapat penjelasan tentang judul penelitian dan penulis yang menyambungkan ke bagian selanjutnya, yaitu bagian training dan testing. Tampilan beranda ditunjukkan pada Gambar 4.
Gambar 4.1. Tampilan halaman Home
2. Tampilan Training
Pada halaman ini, hanya perlu memilih file yang akan di trainig, maka training akan dimulai. Kemudian akan ditampilkan hasil preprocesssing. Pengguna dapat mengatur berapa baris dalam satu halaman untuk ditampilkan. Proses setelah training ditunjukkan pada Gambar 4.2. dan Gambar 4.3.
25
Gambar 4.2. Tampilan halaman Training
Gambar 4.3. Tampilan halaman Training (Lanjutan)
3. Tampilan Testing
Pada halaman testing, sama halnya dengan halaman training, pengguna perlu memilih file yang telah melalui proses training. Pada halaman ini ditampilkan hasil testing dan hasil prediksi sistem. Proses setelah testing ditunjukkan pada Gambar 4.4.
Gambar 4.4. Tampilan halaman Testing
Lalu ditampilkan hasil testing, selanjutnya yaitu ditampilkan classification report dan confussion matrix dari aspek sinyal, pelayanan, dan harga. Classsification report dan confussion matrix terlihat pada Gambar 4.5., Gambar 4.6., dan Gambar 4.7.
Gambar 4.5. Tampilan classification report dan confussion matrix sinyal Dari hasil confussion matrix pada aspek sinyal, menunjukkan bahwa data actual yang bernilai negatif (-1) dan data prediction yang bernilai negatif (-1) sistem mampu mengklasifikasi sebanyak 125 sentimen. Kemudian data actual dan data prediction yang berniali netral (0), sistem mampu mengklasifikasi sebanyak 127 sentimen. Lalu untuk data actual dan data prediction dengan nilai positif (1), sistem mampu mengklasifikasi sebanyak 20 sentimen.
27
Gambar 4.6. Tampilan classification report dan confussion matrix pelayanan Dari hasil confusssion matrix dengan aspek pelayanan, menunjukkan bahwa data actual dan data prediction dengan nilai negatif (-1), sistem dapat mengklasifikasi sebanyak 92 sentimen. Kemudian untuk data actual dan data prediction dengan nilai netral (0), sistem dapat mengklasifikasi sebanyak 123 sentimen. Lalu yang terakhir data actual dan data prediction dengan nilai positif (1), sistem dapat mengklasifikasi sebanyak 43 sentimen.
Gambar 4.7. Tampilan classification report dan confussion matrix harga
Dari hasil confussion matrix dengan aspek harga, menunjukkan bahwa data actual dan data prediction dengan nilai negatif (-1), sistem mampu mengklasifikasi sebanyak 42 sentimen. Kemudian data actual dan data prediction dengan nilai netral (0), sistem mampu mengklasifikasi 127 sentimen, dan yang terakhir untuk nilai positif (1), sistem mampu mengklasifikasi 101 sentimen.
Hasil akhir yang menunjukkan bahwa rata-rata akurasi yang didapatkan adalah 80- 87%. Analisis terkait error yang menyebabkan nilai akurasi tidak lebih tinggi dari yang dihasilkan antara lain contoh penyebab nya adalah sebagai berikut :
1. Ada kesalahan stemming kata “lemot” distemming menjadi “lot”, proses stemming salah dikarenakan sistem mengidentifikasi bahwa kata lemot memiliki sisipan “em”, padahal kata lemot bukan kata yang memiliki imbuhan.
2. Tidak seimbang data dari pada bagian aspek sinyal, jumlah sentimen positif pada aspek sinyal jauh lebih sedikit dari pada sentimen negatif pada aspek sinyal, menyebabkan beberapa kalimat sentimen positif pada aspek sinyal tidak teridentifikasi.
4.2. Evaluasi Model
Kinerja suatu model klasifikasi dapat dinilai dengan banyak cara perhitungan seperti akurasi, precision, recall, dan F1-score. Pada evaluasi sistem yang dikerjakan pada penelitian ini memanfaatkan confusion matrix yang menggunakan perhitungan akurasi, precision, recaall, dan F1-score. Akurasi adalah rasio yang sesuai dengan aktual baik yang kelasnya positif atau negatif. Precision adalah perbandingan perkiraan nilai positif dari seluruh hasil yang diperkirakan positif. Recall ialah perbandingan benar positif dibandingkan dengan seluruh data aktual positif. F1-Score adalah :
29
Pertengahan dari perhitungan precision dan recall. Berikut ini adalah persamaan yang digunakan untuk melakukan evaluasi :
𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = True Positive + True Negative
Total Data × 100 %
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = True Positive
𝑇𝑟𝑢𝑒 𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑒 + 𝐹𝑎𝑙𝑠𝑒 𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑒 × 100 % 𝑅𝑒𝑐𝑎𝑙𝑙 = True Positive
𝑇𝑟𝑢𝑒 𝑃𝑜𝑠𝑖𝑡𝑖𝑣𝑒 + 𝐹𝑎𝑙𝑠𝑒 𝑁𝑒𝑔𝑎𝑡𝑖𝑣𝑒 × 100 %
F1 − 𝑠𝑐𝑜𝑟𝑒 = 2 × Precision × Recall Precision + Recall
Metode evaluasi menggunakan confussion matrix inii diterapkan pada aspek sinyal, pelayan, dan harga. Gambar heatmap aspek ditujukan pada Gambar 4.6.
Gambar 4.6. Heatmap confussion matrix sinyal
Berdasarkan gambar hetamap aspek sinyal diatas, didapatkan evaluasi akurasi 87%.
Sentimen negatif (-1) mendapat presisi 86%, recall 91%, dan fi-score 89%. Sementara itu sentimen netral (0) mendapat presisi 87%, recall 96 %, dan fi-score 92%.
Selanjutnya sentimen positif (1) mendapatakan presisi 87%, recall 44%, dan fi-score 58%. Gambar heatmap aspek pelayanan ditampilkan pada gambar 4.7.
Gambar 4.7. Heatmap confussion matrix pelayanan
Dari heatmap diastas dapat diketahui bahwa evaluasi pelayanan memiliki akurasi 82%.
Sentimen negatif (-1) mendapat presisi 82%, recall 86%, dan fi-score 84%. Sementara itu sentimen netral (0) mendapat presisi 81%, recall 87%, dan fi-score 84%. Selanjutnya sentimen positif (1) mendapatakan presisi 86%, recall 79%, dan fi-score 74%.
Selanjutnya heatmap aspek harga ditampilkan pada gambar 4.8.
31
Gambar 4.8. Heatmap confussion matrix harga
Berdasarkan gambar hetamap aspek harga diatas, didapatkan evaluasi akurasi 86%.
Sentimen negatif (-1) mendapat presisi 85%, recall 65%, dan fi-score 74%.
Sementara itu sentimen netral (0) mendapat presisi 92%, recall 91%, dan fi-score 92%.
Selanjutnya sentimen positif (1) mendapatakan presisi 80%, recall 92%, dan fi-score 86%.
4.3. Pengujian Sistem
Pada penelitian ini digunakan dataset review jaringan seluler, dimana review tersebut diberi label berdasarkan isi kalimat dan aspek yang sudah ditentukan. Model yang sudah terlatih ditahap training kemudian dicoba ke tahapan testing. Hasil dari pengujian data aktual dan prediksi dari sistem diberikan pada Tabel 4.1.
Tabel 4.1. Hasil Pengujian Sistem
Review Preprocess Sinyal Sinyal
Prediksi
Pelayanan Pelayanan Prediksi
Harga Harga Prediksi 1.Sinyal lancar
meski kuota minim 2.Kuota tidak boros (bagi saya yang aktif disosmed)
3.jaringan stabil (tidak tiba2 hilang) 4.ada warning jika kuota sudah minim Sejauh ini saya masih nyaman pake m3.sukses selalu m3.
sinyal lancar kuota minim kuota tidak boros aktif media sosial jaring stabil tidak hilang warning kuota minim nyaman pakai sukses
1 -1 0 0 0 0
4G gak stabil, payah gak semua temapat ada jaringan, pelayanannya b aja malah sering tidak membantu udah habisin uang untuk beli kuota hadeehhhh
tidak stabil payah tidak temapat jaring layan tidak bantu habis duit beli kuota hadeehhhh
-1 -1 -1 -1 -1 0
6 tahun lalu pake indosat skarang coba pake lagi ternyata jaringannya sama aja buruk tidak ada perubahan sama sekali,, rugi beli kuota mahal² dapet zonk.. Mending balik provider
lama!! Coba
diperhatikan keluhan customer!!
pakai indosat coba pakai jaring buruk tidak ubah rugi beli kuota mahal zonk mending sedia coba perhati keluh customer
-1 -1 0 0 0 -1
@IM3Ooredoo adalah andalan untuk mempererat tali silaturahmi keluargaku krn sinyalnya bagus dan OK 24 jam on truz.
Untuk menyambung persaudaraan. Yang paling saya seneng dari IM3Ooredoo ini adalah bonus kuota pas beli pulsa. Udah harga kuotanya murah terus dapat bonus lagi.
Senengnya jadi dobel2! Bonusnya jg bukan kaleng2.
Mantap bener
andal erat tali silaturahmi keluarga sinyal bagus oke jam
on terus
sambung saudara senang bonus kuota pas beli pulsa harga kuota murah bonus senang dobel bonus bukan kaleng mantap
1 0 0 0 1 1
33
Tabel 4.1. Hasil Pengujian Sistem (Lanjutan)
Review Preprocess Sinyal Prediksi Sinyal
Pelayanan Prediksi Pelayana
Harga Prediksi Harga
@IM3Ooredoo baru di isi pulsa 100 rb , pas di cek kenapa kurang dari 100 rb, padahal sebelum di isi saya matikan datanya dulu, bagaimana saya bisa beli kuota yg 100 rb kalau begini , saya sebagai pengguna / pelanggan sangat kecewa dengan hal
ini. mohon
pelayanannya jangan buruk seperti ini lagi.
isi pulsa ribu pas cek ribu isi mati data beli kuota
ribu guna
langgan kecewa mohon layan jangan buruk
0 0 -1 -1 0 0
... ... ... ... ... ... ... ...
Verifikasi SMS lelet, kode verifikasi masuk auto tapi
gagal hmmm
percuma promonya murah kalau gk bisa di pakai
verifikasi sms lelet kode verifikasi masuk auto gagal promo murah tidak pakai
0 0 -1 -1 1 1
Waduh makin ancur aja nih aplikasi, gimana nih, saya masih punya sisa pulsa sekitar 15k, lalu kuota malam saya abis dan kuota utama masih nyisa, tapi kok pulsa saya malah ke sedot ya?
Kan masih ada kuota utama, hadeh gimana sih ini sistem nya, tolong lah di benerin jangan nyolong² pulsa mulu
hancur aplikasi sisa pulsa kuota malam habis kuota utama sisa pulsa sedot kuota utama sistem tolong benar jangan curi pulsa mulu
-1 0 -1 -1 0 0
Walaupun ada kelebihan pasti tetep ada kekurangan.
Setiap beli kuota yg sedikit pasti cepet abis. Kya aku beli 5GB, 4hari udh abis pdahal aku cuma akses Whatsapp dan IG. Sedangkan klo pake provider yg lain 5GB bisa sampe 2 mingguan.
Makanya IM3 ngasih harga murah dikuota besar supaya org pada beli
lebih kurang beli kuota cepat habis beli gb habis akses whatsapp instagram pakai sedia gb minggu harga murah kuota orang beli
0 0 0 -1 1 1
Tabel 4.1. Hasil Pengujian Sistem (Lanjutan)
Review Preprocess Sinyal Prediksi Sinyal
Pelayanan Prediksi Pelayanan
Harga Prediksi Harga Walaupun ada
kelebihan pasti tetep ada kekurangan.
Setiap beli kuota yg sedikit pasti cepet abis. Kya aku beli 5GB, 4hari udh abis pdahal aku cuma akses Whatsapp dan IG. Sedangkan klo pake provider yg lain 5GB bisa sampe 2 mingguan.
Makanya IM3 ngasih harga murah dikuota besar supaya org pada beli y..
lebih kurang beli kuota cepat habis beli gb habis akses whatsapp instagram pakai sedia gb minggu harga murah kuota orang beli iya
0 0 0 -1 1 1
Wonderfull bangett, milih provider im3 dari Pertama kali pegang hape nokia jadul, dari dulu gamau berpaling karna kek udah sehati aja apalagi harga paketnya murah. Makin kesini sesuai
perkembangan jaman, makin cocok sm paket paket yg disediain. Apalagi kalo flashsale, duh seneng banget.
Bismillah
mudah2an ulasan aku menang aamiiin. Pelayanan terbaik dari im3
wonderfull banget pilih sedia kali pegang handphone nokia jadul tidak paling sehat harga paket murah kesini sesuai kembang zaman cocok paket paket sedia flashsale senang banget bismillah mudah an ulas menang aamiiin layan baik
0 0 1 1 1 1
35
4.4. Evaluasi Pelanggan
Evaluasi yang diuji oleh pelanggan, baik pelanggan lama, pelanggan baru atau pelanggan yang hanya memakai jaringan Indosat untuk beberapa waktu saja (pelanggan sementara) dilakukan dengan membagikan kuisioner secara online dengan 26 responden. Hasil dari jawaban responden akan di lampirkan dalam bentuk persentase diagram lingkar agar dapat dilihat dengan jelas aspek mana saja yang paling banyak dikeluhkan dan aspek mana saja yang paling banyak memiliki sentimen yang positif. Kuisioner yang diberikan berisi tentang penilaian dimana memakai beberapa rating seperti :
SS : Sangat Setuju S : Setuju TS : Tidak Setuju
STS : Sangat Tidak Setuju
Pertanyaan 1 :
Apakah saat kamu memakai jaringan Indosat sinyal stabil?
Gambar 4.9. Diagram Lingkar Aspek Sinyal
Hasil yang didapatkan 73,1% responden menilai bahwa stabilisasi jaringan Indosat saat mereka pakai tidak baik. 19,2% responden menilai stabilisasi jaringan Indosat sangat baik dan 7,7% responden menilai stabilisasi jaringan Indosat baik.
36
Pertanyaan 2 :
Apakah harga pake internet jaringan Indosat murah?
Gambar 4.10. Diagram Lingkar Aspek Harga
Hasil yang didapatkan 65,4% responden menilai bahwa harga paket internet dari jaringan Indosat sangat murah. Selanjutnya, 26,9% responden menilai bahwa harga paket internet dari jaringan Indosat murah dan 7,7% responden menilai paket internet jaringan Indosat mahal.
Pertanyaan 3 :
Apakah pelayanan jaringan Indosat bagus? (cth : saat menghubungi customer service)
Gambar 4.11. Diagram Lingkar Aspek Pelayanan
Hasil yang didapatkan, 53,8% responden menilai pelayanan jaringan Indosat baik, 30,8% responden menilai tidak baik dan 15,4% responden menilai pelayanan jaringan Indosat sangat baik.
37
BAB 5
KESIMPULAN DAN SARAN
5.1. Kesimpulan
Bersumber dari penelitian yang sudah dikerjakan sesuai dengan rancangan dan implementasi, maka dapat diperoleh kesimpulan yaitu:
1. Hasil kerja algoritma TF-IDF dan Random forest dalam klasifikasi ulasan pelanggan jaringan seluler menghasilkan akurasi tertinggi sebesar 87,2%.
2. Di dapatkan hasil tertinggi sentimen negatif pada aspek sinyal sebanyak 127 sentimen.
3. Di dapatkan hasil tertinggi sentimen netral pada aspek pelayanan sebanyak 123 sentimen.
4. Di dapatkan hasil tertinggi sentimen positif pada aspek harga sebanyak 101 sentimen.
5. Hasil analisis pengujian terhadap pelanggan 73,1% responden menilai aspek sinyal negatif.
6. Hasil analisis pengujian terhadap pelanggan 65,4% responden menilai aspek harga positif.
7. Hasil analisis pengujuan terhadap pelanggan 53,8% responden menilai aspek pelayanan netral.
5.2. Saran
Penelitian sudah dilakukan sesuai dengan rancangan yang diberikan namun, kekurangan dan pengembangan perlu diperhatikan untuk penelitian selanjutnya, sebagai berikut :
1. Melakukan labeling secara otomatis.
2. Menggunakan kamus normalization yang lebih lengkap agar proses training dan testing dapat dilakukan dengan waktu yang lebih efisien.