PENGEMBANGAN ALGORITMA LATENT
SEMANTIC ANALYSIS PADA PENILAI
ESAI OTOMATIS DALAM BAHASA
INGGRIS
Martin Sendra, Josep Harianata, Rudy Sutrisno, Derwin
Suhartono
Universitas Bina Nusantara
Jl. K H. Syahdan No. 9 Kemanggisan – Palmerah Jakarta Barat 11480 +62.21 534 5830 / +62.21 530 0244
[email protected], [email protected], [email protected], [email protected]
ABSTRACT
The research objective is to build an algorithm which is able to provide the closest correlation value to human grader in assessing an essay. Hence, the essay quality measurement will be more consistent. In this study, we develop an automated essay scoring system which is used in English essays. An enhanced version of Latent Semantic Analysis (LSA) which is combined with term similarity feature is developed. The term similarity is to provide tolerance value of typo words. The tolerance will be given when typo word has a suggested word, and its frequency is less than the correct words in the essay. The research tested on 119 student’s essay. LSA which is combined with term similarity indicates the correlation level of 0.242 to human judgment, while original LSA algorithm indicates the correlation level of 0.244 to human judgment. The experiment results indicate that LSA with term similarity has a better correlation value compared with the correlation value of original LSA.
ABSTRAK
Penelitian ini bertujuan untuk membangun pengembangan algoritma yang mampu
memberikan penilaian yang lebih mirip dengan penilai manusia dalam menilai esai,
agar para penilai esai memiliki kualitas penilaian yang konsisten. Pada penelitian ini,
sistem penilai otomatis yang dikembangkan adalah penilaian otomatis pada esai
(Automated Essay Grading) dalam Bahasa Inggris dengan menggunakan metode
Latent Semantic Analysis (LSA) dengan penambahan fitur term similarity. Term
similarity berfungsi untuk memberikan nilai toleransi pada kata yang salah ketik.
Nilai akan diberikan apabila terdapat kata yang salah ketik, dan terdapat kata yang
disarankan, dan memiliki kata tersebut memiliki frekuensi yang lebih sedikit
dibandingkan kata yang benar pada esai. Pada penelitian ini sistem
diimplementasikan menggunakan PHP untuk tampilan dan bahasa pemrograman
Python untuk proses penerapan LSA dengan term similarity. Esai yang diuji pada
penelitian ini berjumlah 119 esai. LSA dengan term similarity menunjukkan rata-rata
selisih nilai sebesar 0,237 dengan penilaian manusia. Kesimpulan yang didapat dari
penelitian ini adalah metode LSA dengan term similarity memiliki tingkat kemiripan
penilaian yang lebih menjanjikan dibandingkan LSA.
Kata Kunci : Automated Essay Grading, Latent Semantic Analysis, Term Similarity.
PENDAHULUAN
Menurut konteks barat, proses edukasi cenderung ke arah memperkuat kemampuan analisa, mempertanyakan, mengevaluasi pengetahuan, mendorong pelajar untuk mengkritisi dan mengkombinasikan pengetahuan untuk mengkritisi kearifan tradisional dan membentuk sudut pandang tersendiri (Hyland, 2009:38). Menurut Hyland (2014:3) menulis merupakan salah satu metode untuk membagikan pemahaman seseorang terhadap suatu topik pengetahuan.
Namun pemahaman tiap individu terhadap suatu topik dapat berbeda satu sama lain, oleh karena itu diperlukan pengujian pemahaman agar makna suatu pengetahuan terjaga sesuai makna aslinya. Menurut Wild, Stahl, Stermsek, dan Neumann (2005:2), esai lebih menilai kualitas pemahaman pengetahuan para pelajar dibandingkan ujian pilihan ganda karena untuk menulis esai.
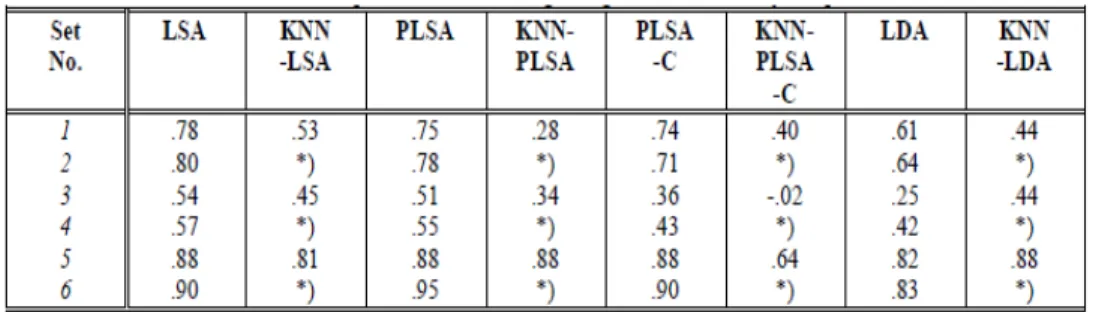
Memberikan respon pada suatu esai dinilai penting untuk meningkatkan kualitas penulisan esai. Namun kadang kala para pengajar, dapat merasa terbebani ketika terdapat banyak esai yang harus dinilai (Dikli, 2006). Oleh karena itu, penelitian ini dilakukan untuk membantu para pengajar menilai esai melalui sistem penilai esai otomatis. Dalam perkembangannya, terdapat beberapa algoritma untuk menilai esai, seperti Latent Semantic Analysis (LSA), Probabilistic Latent Semantic Analysis (PLSA), Latent Dirichlet Allocation (LDA), dan Generalized Latent Semantic Analysis (GLSA). Berdasarkan penelitian Kakkonen, Myller, Sutinen, dan Timonen (2008) terhadap uji akurasi algoritma LSA, PLSA, LDA, dan KNN, didapatkan hasil pengujian dapat dilihat pada tabel berikut :
Tabel Perbandingan Hasil LSA, PLSA, LDA, dan KNN (Kakkonen, Myller, Sutinen, dan Timonen, 2008)
Berdasarkan tabel tersebut, dapat dilihat bahwa LSA memiliki akurasi yang lebih tinggi dengan nilai manusia dibandingkan metode lainnya, sehingga pada penelitian ini, pengembangan algoritma dilakukan pada algoritma LSA.
Tujuan yang ingin dicapai dari penelitian ini adalah :
1. Membangun algoritma Latent Semantic Analysis dengan term similarity yang memiliki rata-rata selisih nilai yang lebih tinggi dalam menilai esai dibandingkan dengan algoritma Latent Semantic Analysis.
2. Memberikan perbandingan selisih nilai beberapa algoritma penilai esai otomatis.
Manfaat yang ingin dicapai dari penelitian ini adalah :
1. Membantu institusi atau tenaga pengajar dalam menilai esai dengan lebih akurat. 2. Penilai esai dapat menilai esai dengan lebih akurat dalam waktu yang lebih singkat.
METODE
Metode Penelitian yang digunakan dalam penelitian ini terbagi menjadi 3 tahapan, yaitu pengumpulan data dan analisis dengan studi literatur, wawancara narasumber, analisa aplikasi sejenis, dan kuesioner untuk membangun algoritma yang tepat guna, dilanjutkan dengan metode perancangan dengan mengkombinasikan algoritma LSA dengan term similarity, kemudian algoritma tersebut akan dievaluasi secara objektif dengan menguji selisih nilai dengan membandingkan nilai yang dihasilkan oleh sistem dengan nilai manusia.
Berikut langkah-langkah proses penilai esai otomatis yang dikembangkan : 1. Esai referensi dan esai mahasiswa diinput ke dalam sistem.
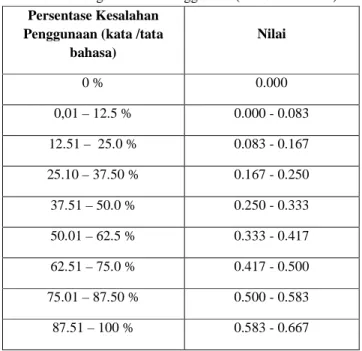
2. Lingual checking akan dilakukan pada esai mahasiswa untuk diuji dan dinilai berdasarkan total kesalahan kata, tata bahasa, dan kesesuaian total kata pada esai dengan kriteria penguji manusia. Pengujian dilakukan dengan Microsoft Word yang dikomputasi dengan Python. Penilaian tata bahasa dan kata dihitung secara terpisah, namun memiliki rumus dan rentang penilaian yang sama. Penilaian kata dan tata bahasa dirumuskan sebagai berikut :
= Persentase (kata /tata bahasa) error / salah = Total (kata /tata bahasa) error / salah
= Total (kata /tata bahasa) pada esai
Untuk menentukan nilai yang didapatkan dari perhitungan penilaian penggunaan kata pada esai, ditentukan dengan rumus :
= Nilai (kata /tata bahasa) error / salah = Persentase (kata /tata bahasa) error / salah
Nilai 0.667 didapatkan dari total nilai maksimum yang dapat diberikan untuk penggunaan (kata /tata bahasa) pada esai. Rentang penilaian penggunaan (kata /tata bahasa) dapat dilihat pada tabel berikut :
Tabel Rentang Penilaian Penggunaan (kata /tata bahasa) Persentase Kesalahan
Penggunaan (kata /tata bahasa) Nilai 0 % 0.000 0,01 – 12.5 % 0.000 - 0.083 12.51 – 25.0 % 0.083 - 0.167 25.10 – 37.50 % 0.167 - 0.250 37.51 – 50.0 % 0.250 - 0.333 50.01 – 62.5 % 0.333 - 0.417 62.51 – 75.0 % 0.417 - 0.500 75.01 – 87.50 % 0.500 - 0.583 87.51 – 100 % 0.583 - 0.667
Sementara untuk penilaian kesesuaian total kata pada esai dengan kriteria penguji manusia dirumuskan sebagai berikut :
Tabel Persentase Rentang Penilaian Total kata Persentase Total Kata Nilai
0 – 20,32 % 0.000 20,33 – 30,32 % 0.083 30,33 – 40,32 % 0.167 40,33 – 50,32 % 0.250 50,33 – 60,32 % 0.333 60,33 – 70,32 % 0.417 70,33 – 80,32 % 0.500 80,33 – 90,32 % 0.583 90,33 - 100 % 0.667
3. Text preprocessing dilakukan pada esai referensi dan esai mahasiswa dengan menghilangkan stopwords, tokenization, dan stemming untuk mengubah kata menjadi kata dasar.
4. Esai mahasiswa akan diproses dengan metode term similarity. Proses rinci term similarity digambarkan dengan flowchart berikut :
Apabila terdapat term yang salah ketik, maka dilanjutkan dengan pemeriksaan ketersediaan kata yang disarankan, apabila ada, maka diperiksa jumlah kata yang error dan kata yang disarankan, bila jumlah kata yang error lebih kecil dibandingkan jumlah kata yang disarankan, maka dilakukan perhitungan sebagai berikut :
TS = term similarity = total huruf yang sama
= total huruf pada kata terpanjang = kata yang salah
Dalam perhitungan tersebut, kata terpanjang terpilih berdasarkan hasil perbandingan total huruf kata yang salah ketik dengan kata yang disarankan. Setelah dihitung, maka dilakukan pengecekan ketersediaan term, apabila masih tersedia term¸maka akan dilakukan proses term similarity, bila tidak, maka proses term similarity berakhir.
5. Term yang dihasilkan oleh text preprocessing dan term similarity akan diubah menjadi term-document matrix yang menggambarkan bobot tiap term berdasarkan frekuensi kemunculan term pada setiap document.
6. Term-document matrix akan diproses dalam SVD
untuk mengurangi noise/ term yang tidak dibutuhkan. SVD akan mereduksi matriks menjadi 3 matriks yang nantinya akan disatukan kembali membentuk matriks yang baru.
7. Hasil dari proses SVD akan membentuk vektor yang akan dihitung tingkat kemiripannya dengan cosine similarity.
8. Hasil penilai esai otomatis didapatkan dari
penjumlahan proses cosine similarity dengan hasil dari proses lingual checking.
9. Nilai yang diberikan penilai esai otomatis diuji tingkat
korelasinya dengan membandingkan dengan nilai yang diberikan manusia.
HASIL DAN PEMBAHASAN
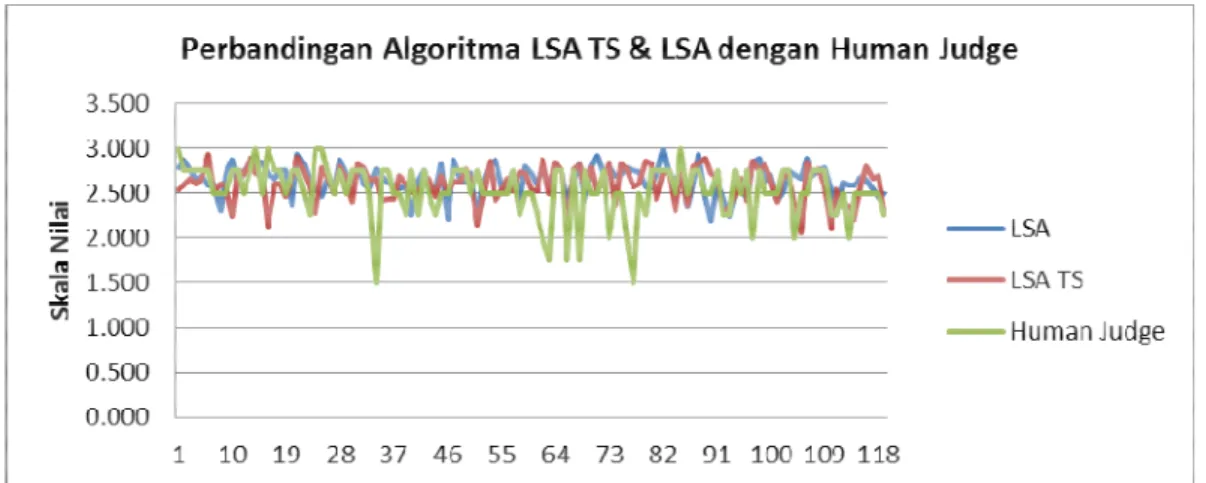
Evaluasi Objektif dilakukan dengan membandingkan hasil penilaian algoritma yang dikembangkan dalam penilai esai otomatis menggunakan Bahasa Inggris dengan algoritma yang pernah dikembangkan sebelumnya. Algoritma yang digunakan sebagai pembanding yaitu algoritma LSA. Berikut hasil perbandingannya :
Gambar Perbandingan Algoritma LSA & LSA TS dengan Human Judge
Dari Gambar di atas, dapat disimpulkan bahwa dalam algoritma LSA, algoritma yang menunjukkan selisih nilai dengan penilaian manusia adalah algoritma LSA dengan term similarity. LSA dengan term similarity memiliki nilai rata-rata selisih sebesar 0.237 , dibandingkan LSA dengan nilai rata-rata selisih sebesar 0,239.
Pengujian berikutnya dilakukan untuk membandingkan algoritma LSA dengan term similarity dengan algoritma GLSA dalam menilai esai, hasil pengujian dapat dilihat pada Gambar berikut
Gambar Perbandingan Algoritma LSA TS & GLSA dengan Human Judge
Berdasarkan Gambar di atas, dapat disimpulkan bahwa algoritma GLSA memiliki nilai rata-rata selisih sebesar 0,236 dengan penilaian manusia, lebih unggul dibandingkan algoritma LSA dengan term similarity (LSA TS) yang memiliki nilai rata-rata selisih sebesar 0,237. Dalam pengujian yang dilakukan, berikut Tabel perbandingan algoritma LSA TS dengan GLSA.
Tabel Hasil Perbandingan Algoritma LSA TS dengan GLSA
LSA TS GLSA Draw
9 9 101
0.237 0.236 0.241
Dari Tabel di atas, dapat dilihat hasil perbandingan algoritma LSA TS dengan GLSA dalam menilai 119 esai, GLSA dan LSA TS seimbang sebanyak 9 esai. Namun dalam tingkat rata-rata selisih nilai yang dihasilkan, GLSA lebih unggul dengan nilai rata-rata selisih sebesar 0.236, sementara algoritma LSA dengan term similarity memiliki nilai rata-rata selisih sebesar 0.237.
SIMPULAN DAN SARAN
Setelah melakukan penelitian terkait pengembangan algoritma Latent Semantic Analysis dengan term similarity pada penilai esai otomatis dalam bahasa inggris, diperoleh kesimpulan sebagai berikut :
1. Algoritma LSA dengan term similarity menunjukkan performa yang lebih tinggi dibandingkan algoritma LSA. LSA dengan term similarity unggul dengan total sebanyak 31 esai dengan rata-rata selisih nilai sebesar 0.237 , dibandingkan algoritma LSA yang unggul sebanyak 26 esai dengan rata-rata selisih nilai sebesar 0.239.
2. Dalam perbandingan algoritma LSA dengan term similarity dan GLSA, meskipun menghasilkan penilaian yang sama-sama unggul pada 9 esai, namun algoritma LSA dengan term similarity hanya memiliki rata-rata selisih nilai sebesar 0.237, sementara algoritma GLSA memiliki rata-rata selisih nilai sebesar 0.236. Hal ini menunjukkan GLSA masih lebih unggul dibandingkan algoritma LSA dengan term similarity.
3. Berdasarkan hasil wawancara dengan 3 dosen Bahasa Inggris Universitas Bina Nusantara, diperoleh hasil bahwa sistem penilai esai otomatis yang dikembangkan dapat membantu para penilai esai.
Saran untuk pengembangan lebih lanjut :
1. Training data dalam jumlah yang lebih besar agar algoritma dapat memberikan nilai yang lebih dekat dengan penilaian manusia.
2. Mencoba mengembangkan term similarity dalam algoritma penilai esai otomatis selain LSA seperti PLSA, LDA, dan GLSA.
3. Penambahan fitur pada aplikasi penilai esai otomatis seperti forum / chat sebagai sarana dosen dan mahasiswa berdiskusi untuk meningkatkan kualitas penulisan esai.
4. Penambahan fitur pada aplikasi penilai esai otomatis seperti penanda kesalahan mahasiswa dalam menulis esai agar mahasiswa dapat mengetahui letak kesalahan penulisan yang dilakukan.
REFERENSI
Dikli, S. (2006). Automated Essay Scoring. Turkish Online Journal of Distance Education - TOJDE, 7, 5.
Dikli, S. (2006). An Overview of Automated Scoring of Essays. Journal of Technology, Learning, and Assessment, 5(1). Retrieved [date] from http://www.jtla.org.
Hyland, K. (2009). Second Language Writing. New York: Cambridge University Press.
Hyland, K. (2014). Disciplinary discourses: social interactions in academic writing. Michigan: The University of Michigan Press.
Kakkonen, T., Myller, N., Sutinen, E., & Timonen, J. (2008). Comparison of Dimension Reduction Methods for Automated Essay Grading. Educational Technologi & Society, 275-288. Wild, F., Stahl, C.,Stermsek, G., & Neumann, G. (2005). Parameters driving effectiveness of
automated essay scoring with LSA. IN: Proceedings of the 9th CAA Conference, Loughborough: Loughborough University
RIWAYAT PENULIS
1.PERSONAL INFORMATION
Binusian ID 1501151426
Full Name MARTIN SENDRA
E-mail [email protected]
Address JL. TSS RAYA nomor 53, RT 003 RW 004, Kecamatan Tambora, Kelurahan Duri Selatan, DKI Jakarta, Indonesia
Phone Numbers Mobile : 62 - 857 - 73731118 Home : 62 - 21 - 63868377
Gender Male
Birth Place / Date JAKARTA / 16 September 1993
Nationality Indonesia
Marital Status Single
Religion Christian
FORMAL EDUCATION
Sep 2011 – present Bina Nusantara University, Jakarta, Indonesia Bachelor (S1), Computer Science GPA: 3.53 Jul 2008 - Jul 2011 SMA Damai, Jakarta, Indonesia
Senior High School
2.
PERSONAL INFORMATION
Binusian ID 1501154535
Full Name JOSEP HARIANATA
E-mail [email protected]
Address Ambar Bogor Regency 3 blok F2 no. 18
RT/04 RW/08 kel. Nagrak, kec. Sukaraja, kab. Bogor Bogor 16710
Jawa Barat, Indonesia Phone Numbers Mobile : 62 – 87- 872310474
Home : -
Gender Male
Birth Place / Date JAKARTA/26 Dec 1993
Nationality Indonesia
Marital Status Single
Religion Christian
FORMAL EDUCATION
Sep 2011 – present Bina Nusantara University, Jakarta, Indonesia Bachelor (S1), Computer Science GPA: 3.37 Jul 2008 - Jul 2011 Mardi Yuana, Sukabumi, Indonesia
Senior High
Jul 2005 - Jul 2008 Yuwati Bhakti, Sukabumi, Indonesia Junior High
3.
PERSONAL INFORMATION
Binusian ID 1501169013
Full Name RUDY SUTRISNO
E-mail [email protected]
TANGERANG
15122, Banten, Indonesia Phone Numbers Mobile : 62-0898-9207-406
Home : -
Gender Male
Birth Place / Date MEDAN / 17 March1993
Nationality Indonesia
Marital Status Single
Religion Buddha
FORMAL EDUCATION
Sep 2011 – present Bina Nusantara, Jakarta, Indonesia
Bachelor (S1), Computer Science GPA: 3.52 Jul 2008 - Jul 2011 SMAN 57, Jakarta, Indonesia
Senior High
Jul 2005 - Jul 2008 SMP PROVIDENTIA, Jakarta, Indonesia Junior High