PENANGANAN MASALAH KELAS TIDAK SEIMBANG
DENGAN RUSBOOST DAN UNDERBAGGING
(STUDI KASUS: MAHASISWA DROP OUT
SPs IPB PROGRAM MAGISTER)
YULIANA PERMATASARI
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2016
Dengan ini saya menyatakan bahwa tesis berjudul Penanganan Masalah Kelas Tidak Seimbang dengan RUSBoost dan UnderBagging (Studi Kasus: Mahasiswa Drop Out SPs IPB Program Magister) adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi manapun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Februari 2016
Yuliana Permatasari
RINGKASAN
YULIANA PERMATASARI. Penanganan Masalah Kelas Tidak Seimbang dengan RUSBoost dan UnderBagging (Studi Kasus: Mahasiswa Drop Out SPs IPB Program Magister). Dibimbing oleh ASEP SAEFUDDIN dan BAGUS SARTONO.
Sekolah Pascasarjana Institut Pertanian Bogor (SPs IPB) didirikan tahun 1975 dengan tujuh program studi. Saat ini, SPs IPB memiliki 67 program studi magister dan 43 program studi doktoral. SPs IPB berusaha semaksimal mungkin untuk meningkatkan kualitas baik dari segi mutu proses penyelenggaraan pembelajaran maupun mutu lulusan. Mutu lulusan dapat dilihat dari tingkat persentase kelulusan mahasiswa yaitu persentase dari jumlah mahasiswa lulus dibagi dengan jumlah total mahasiswa pascasarjana untuk setiap angkatan. Asumsikan mahasiswa drop out mempengaruhi nilai mutu lulusan, semakin banyak mahasiswa drop out maka nilai mutu lulusan menjadi semakin buruk.
Penelitian ini bertujuan untuk membantu SPs IPB mendeteksi mahasiswa yang berisiko drop out dengan membangun sebuah model yang dibangkitkan dengan algoritme pohon klasifikasi. Pohon klasifikasi adalah gambaran pemodelan dari suatu persoalan yang terdiri dari serangkaian keputusan yang mengarah kepada solusi dengan peubah responnya kategorik.
Mahasiswa lulus jauh lebih banyak dibandingkan mahasiswa drop out, hal ini dikenal dengan kelas tidak seimbang. Kelas mahasiswa drop out dengan jumlah contoh yang jauh lebih sedikit disebut kelas minoritas atau positif, sedangkan kelas lulus disebut kelas mayoritas atau negatif. Pemodelan menggunakan pohon klasifikasi klasik akan menghasilkan model yang keputusannya condong kepada kelas mayoritas, sedangkan kelas minoritas dianggap sebagai noise. RUSBoost dan UnderBagging merupakan algoritme yang dapat digunakan untuk mengatasi masalah kelas tidak seimbang. RUSBoost merupakan kombinasi dari penarikan contoh acak undersampling dengan
ensamble boosting, sedangkan UnderBagging adalah kombinasi dari penarikan
contoh acak undersampling dengan ensamble bagging.
Dari hasil analisis, algoritme RUSBoost dan UnderBagging terbukti dapat memberikan performa yang lebih baik secara signifikan dibandingkan pohon klasifikasi klasik. RUSBoost dan UnderBagging menghasilkan pembagi yang lebih baik antara mahasiswa drop out dan mahasiswa lulus yang ditunjukkan dari
Area Under ROC yang lebih luas. RUSBoost dan UnderBagging lebih
sensitif/peka dalam memprediksi mahasiswa bersiko drop out. Sementara jika menggunakan pohon klasifikasi klasik, maka diperoleh model klasifikasi dengan nilai akurasi tinggi namun tidak sensitif terhadap objek pada kelas drop out. Hasil dari pengklasifikasian data mahasiswa SPs IPB tahun 2008-2010 menggunakan algoritme RUSBoost dan UnderBagging diperoleh bahwa faktor yang mempengaruhi status mahasiswa drop out dan mahasiswa lulus adalah beasiswa dan IPK S1.
SUMMARY
YULIANA PERMATASARI. Addressing Class Imbalance Problems Using RUSBoost and UnderBagging (Case on Drop Out Students in SPs IPB). Supervised by ASEP SAEFUDDIN and BAGUS SARTONO.
Bogor Agricultural University Graduate School (SPs IPB) was built in 1975, from only seven study programs initially to 67 magister and 43 doctoral programs. SPs IPB is required to always improve the quality of education process and graduates. Part of approximation indicators for quality of the graduates are the period of study and the percentage of graduated students. The percentage of graduated students is the number of graduated students divided by the total number of graduate students. It is assumed that the number of graduated student are related to the quality of study program. More the drop out students the worse the quality. Therefore, this indicators should be considered by the IPB Graduate School (SPs).
The aim of this study was to detect students at risk to study failure (drop out). Detection of students who are at risk to drop out can be analyzed by classification tree algorithm. Classification tree algorithm is a model containing a series of decisions to obtain an appropriate solution in which the response variable is categorical. In the application of the algorithm contains class imbalance problems which is the numbers of drop out students was much less than the number of passing student, is called class imbalance. Drop out students class with less instances was called minority or positive class, whereas passing class was called majority or negative class. Consequently, application of the classical tree classification algorithm was resulted to classification decision which were tend to the majority class while all samples of minority class were regarded as noise.
This study was using RUSBoost and UnderBagging algorithm to handle class imbalance problems. RUSBoost is a combination of random under sampling and boosting, while UnderBagging is a combination of random under sampling and bagging. Both of them are using under sampling method, which eliminates several instances on majority class so that the number of instances on majority class is relatively same to minority class. The purpose of this combination is to create a powerful model in classifying class imbalance.
Analysis results show that RUSBoost and Underbagging was proven to provide significantly better performance than using classical classification tree. RUSBoost and UnderBagging produced better separation between drop out class and passing class which is represents by higher Area Under Curve (ROC). RUSBoost and UnderBagging are more sensitive in predicting the risk of students who drop out than the classical classification tree. Whereas classical classification tree results classification model which had high accuracy performance, but was not sensitive to predict instances of drop out class. The classification of SPs IPB students in 2008-2010 using RUSBoost and UnderBagging algorithms shows that the factors which were affecting the status of drop out students and passing students were scholarship and GPA.
© Hak Cipta Milik IPB, Tahun 2016
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Dilarang mengumumkan dan memperbanyak sebagian atau seluruh karya tulis ini dalam bentuk apa pun tanpa izin IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains
pada
Program Studi Statistika Terapan
PENANGANAN MASALAH KELAS TIDAK SEIMBANG
DENGAN RUSBOOST DAN UNDERBAGGING
(STUDI KASUS: MAHASISWA DROP-OUT
SPs IPB PROGRAM MAGISTER)
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
BOGOR
2016
ii
Judul Tesis : Penanganan Masalah Kelas Tidak Seimbang dengan RUSBoost dan UnderBagging (Studi Kasus: Mahasiswa Drop Out SPs IPB Program Magister)
Nama : Yuliana Permatasari NIM : G152130151
Disetujui oleh Komisi Pembimbing
Prof Dr Ir Asep Saefuddin, MSc Ketua
Dr Bagus Sartono, MSi Anggota
iv
PRAKATA
Puji dan syukur kehadirat Allah SWT yang telah melimpahkan rahmat dan hidayah-Nya, sehingga penulis dapat menyelesaikan tesis yang berjudul “Penanganan Masalah Kelas Tidak Seimbang dengan RUSBoost dan
UnderBagging (Studi Kasus: Mahasiswa Drop Out SPs IPB Program Magister)”.
Keberhasilan penulisan tesis ini tidak lepas dari bantuan, bimbingan, dan petunjuk dari berbagai pihak.
Terima kasih penulis ucapkan kepada Bapak Prof. Dr. Ir. Asep Saefuddin, M.Sc dan Bapak Dr. Bagus Sartono, M.Si selaku pembimbing, atas kesediaan dan kesabaran untuk membimbing dan membagi ilmunya kepada penulis dalam penyusunan tesis ini. Terimakasih kepada Bapak Dr. Ir. I Made Sumertajaya, M.S selaku penguji luar komisi pembimbing atas masukan yang diberikan. Ucapan terima kasih juga penulis sampaikan sebesar-besarnya kepada seluruh Dosen Departemen Statistika IPB yang telah mengasuh dan mendidik penulis selama di bangku kuliah hingga berhasil menyelesaikan studi, serta seluruh staf Departemen Statistika IPB atas bantuan, pelayanan, dan kerjasamanya selama ini.
Ucapan terima kasih yang tulus dan penghargaan yang tak terhingga juga penulis ucapkan kepada kedua orangtuaku Bapak Mukarramah Indra dan Ibu Ria Ningsih, kakakku Eka Widyaningsih, adik-adikku tersayang Intan Rosma Indra dan Berliana Nilam Indra serta seluruh keluarga atas doa dan semangatnya.
Terakhir tak lupa penulis juga menyampaikan terima kasih kepada seluruh mahasiswa Pascasarjana Departemen Statistika atas segala bantuan dan kebersamaannya selama menghadapi masa-masa terindah maupun tersulit dalam menuntut ilmu, serta semua pihak yang telah banyak membantu dan tak sempat penulis sebutkan satu per satu.
Semoga tesis ini dapat bermanfaat bagi semua pihak yang membutuhkan. Bogor, Februari 2016
DAFTAR ISI
DAFTAR TABEL vi DAFTAR GAMBAR vi DAFTAR LAMPIRAN vi 1 PENDAHULUAN 1 Latar Belakang 1 Tujuan Penelitian 3 2 TINJAUAN PUSTAKA 3Mahasiswa drop out 3
Pohon Klasifikasi 4
Kelas Tidak Seimbang 5
Teknik Resampling 6 Metode Ensemble 6 RUSBoost 7 UnderBagging 8 Tabel Klasifikasi 9 3 METODE 11 Data 11 Metode Analisis 11
4 HASIL DAN PEMBAHASAN 13
Deskripsi Mahasiswa Sekolah Pascasarjana IPB Program Magister 13
Model Klasifikasi Mahasiswa IPB 15
Pohon Klasifikasi Klasik 15
RUSBoost (Random Under Sampling dan Boosting) 16 UnderBagging (Random Under-Sampling dan Bagging) 17
5 KESIMPULAN DAN SARAN 19
Kesimpulan 19
Saran 19
DAFTAR PUSTAKA 20
vi
DAFTAR TABEL
1 Tabel klasifikasi 9
2 Peubah penyusun model 11
3 Persentase mahasiswa drop out Sekolah Pascasarjana IPB 13 4 Tabel klasifikasi hasil prediksi pohon klasifikasi klasik pada data latih
dan uji 15
5 Kinerja klasifikasi model pohon klasifikasi klasik (%) 15 6 Kinerja model klasifikasi dari beberapa tingkat ketidakseimbangan
RUSBoost (%) 16
7 Kinerja model klasifikasi algoritme UnderBagging (%) 17
DAFTAR GAMBAR
1 Grafik persentase mahasiswa drop out SPs IPB program magister angkatan
2008-2010 3
2 Struktur pohon klasifikasi 4
3 Taksonomi metode berbasis ensemble 7
4 Ilustrasi proses UnderBagging 9
5 Kurva ROC dari beberapa tingkat ketidakseimbangan pada data latih (a)
dan data uji (b) 16
6 Kurva ROC dari model klasifikasi UnderBagging dengan pengembalian
(a) tanpa pengembalian (b) 17
DAFTAR LAMPIRAN
1 Persentase Kategori Peubah Penjelas dengan Peubah Respon 21
2 Deskripsi Peubah Kontinu 21
3 Diagram Pohon Klasifikasi Klasik 22
4 Peubah Penjelas yang berpengaruh (Variable Importance) pada
Pemodelan Menggunakan Pohon Klasifikasi Tunggal 23 5 Peubah Penjelas yang berpengaruh (Variable Importance) pada
Pemodelan Menggunakan metode RUSBoost 23
6 Peubah Penjelas yang berpengaruh (Variable Importance) pada
Pemodelan Menggunakan Metode UnderBagging 23
1 PENDAHULUAN
Latar BelakangInstitut Pertanian Bogor (IPB) merupakan salah satu universitas negeri terkemuka di Indonesia yang didirikan pada tahun 1963. IPB telah berperan aktif dalam mengembangkan ilmu pengetahuan dan teknologi khususnya pada bidang pertanian, pertenakan, dan bioscience (IPB 2015). Berbagai kerjasama telah dibangun IPB dengan berbagai institusi dari dalam dan luar negeri dalam upaya mewujudkan visi dan misi yang diembannya. Demikian pula, prestasi tingkat nasional dan tingkat internasional telah diraih IPB. Pada tahun 1975, IPB mendirikan Sekolah Pascasarjana (SPs) sebagai program pascasarjana pertama di Indonesia. Perkembangannya semakin pesat, awalnya hanya tujuh program studi, kini terdapat 67 program studi magister dan 43 program studi doktoral (IPB 2014). Sekolah Pascasarjana dituntut untuk selalu memperbaiki kualitas, mendukung percepatan kemajuan yang dicapai oleh IPB, baik dari segi mutu proses penyelenggaraan pembelajaran maupun mutu lulusan. Salah satu cerminan dari mutu lulusan adalah persentase kelulusan mahasiswa. Persentase kelulusan mahasiswa yaitu persentase dari jumlah mahasiswa lulus dibagi dengan jumlah total mahasiswa pascasarjana pada setiap angkatan.
Berdasarkan data yang diperoleh dari bagian akademik SPs IPB, terdapat mahasiswa drop out pada setiap angkatan, persentasenya semakin meningkat setiap angkatan. Hal ini dapat mempengaruhi tingkat mutu lulusan mahasiswa pascasarjana. Oleh karena itu dibutuhkan suatu model untuk mendeteksi mahasiswa yang berisiko drop out. Mendeteksi mahasiswa berisiko drop out pada saat penerimaan mahasiswa baru dapat menjadi suatu peringatan dini (early
warning) bagi SPs IPB. SPs akan lebih waspada terhadap mahasiswa berisiko drop out, sehingga jumlah mahasiswa drop out dapat diminimalisir.
Pendeteksian mahasiswa berisiko drop out dapat dibangun dengan menerapkan hasil pemodelan klasifikasi mahasiswa yang lulus maupun drop out. Klasifikasi adalah teknik data mining yang menempatkan suatu objek ke dalam satu gugus kategori berdasarkan objek atau konsep yang bersangkutan. Misalkan peubah penjelas ( , , … ) pada vektor , ruang contoh berisi vektor dan himpunan kelas peubah respon = {1,2, … . , }, menurut Breiman et al. (1984) klasifikasi adalah partisi ruang contoh menjadi kelas himpunan bagian yang saling lepas yaitu , … , dengan
j j
A
sedemikian sehingga untuk setiap ∈ diprediksi ke dalam kelas . Tujuan utama klasifikasi adalah membangun sebuah model klasifikasi untuk menentukan suatu penciri/kelas dari suatu kelompok data. Model klasifikasi dibangun dari gugus data yang disebut data latih (training set), sedangkan proses pemodelan disebut latihan (training/learning). Sebelum digunakan untuk memprediksi suatu data yang tidak diketahui kelasnya, terlebih dahulu dilakukan uji validasi terhadap model klasifikasi (classifier/learner) yang diperoleh menggunakan gugus data uji.
Ada banyak algoritme klasifikasi pada data mining, salah satunya CART (Classification and Regression Trees). CART terdiri dari dua yaitu pohon klasifikasi dan pohon regresi. Pohon klasifikasi adalah suatu gambaran pemodelan
2
dari suatu persoalan yang terdiri dari serangkaian keputusan yang mengarah kepada solusi dengan peubah responnya kategorik, sedangkan pohon regresi peubah responnya numerik (Breiman et al. 1984). Peubah respon dalam penelitian ini merupakan peubah kategorik, oleh karena itu digunakan pohon klasifikasi.
Jumlah mahasiswa drop out jauh lebih sedikit dibandingkan mahasiswa lulus, sehingga data yang digunakan pada pemodelan tidak seimbang, hal ini dikenal dengan kelas tidak seimbang (class-imbalanced). Kelas dengan jumlah contoh lebih sedikit yang menjadi perhatian dalam penelitian disebut kelas minoritas (positif), sedangkan kelas yang lainnya disebut kelas mayoritas (negatif). Kelas tidak seimbang merupakan salah satu masalah yang muncul dalam pengklasifikasian, ketika menggunakan algoritme klasifikasi klasik keputusan akan lebih condong kepada kelas mayoritas, sedangkan kelas minoritas dalam pemodelan dianggap sebagai noise (Chawla et al. 2004). Oleh karena itu, kelas tidak seimbang harus ditangani untuk membentuk klasifikasi yang relevan.
Ada banyak metode penanganan masalah kelas tidak seimbang. Galar et al. (2011) mengelompokan menjadi tiga pendekatan, yaitu level algoritme, level data, dan cost-sensitive learning. Pendekatan level algoritme dilakukan dengan membuat atau memodifikasi algoritme yang ada, untuk memperhitungkan pentingnya contoh pada kelas minoritas. Pendekatan level data menyeimbangkan kelas pada data latih dengan menambahkan/mereplikasi contoh pada kelas minoritas (oversampling) atau mengeliminasi contoh pada kelas mayoritas (undersampling). Cost-sensitive learning merupakan pendekatan yang menggabungkan level algoritme dan data.
Selain ketiga pendekatan tersebut, metode ensemble dapat digunakan untuk menangani masalah kelas tidak seimbang, dengan cara menambahkan atau mengkombinasikan metode ensemble dengan salah satu dari ketiga pendekatan metode tersebut. Ensemble adalah metode yang menggabungkan beberapa klasifikasi tunggal dengan tujuan memperoleh suatu model klasifikasi yang lebih akurat. Metode gabungan terbaik berdasarkan penelitian Galar et al. (2011) adalah algoritme RUSBoost (Random Under-Sampling dan Boosting) dan UnderBagging (Under-Sampling dan Bagging). Penelitian ini menggunakan kedua algoritme tersebut untuk menangani masalah kelas tidak seimbang pada kasus mahasiswa
drop out SPs IPB program magister.
Tujuan Penelitian
Tujuan dari penelitian ini adalah menerapkan algoritme RUSBoost dan UnderBagging untuk penanganan masalah kelas tidak seimbang pada data mahasiswa SPs IPB program magister serta membandingkan hasil ketepatan klasifikasi dari keduanya.
2 TINJAUAN PUSTAKA
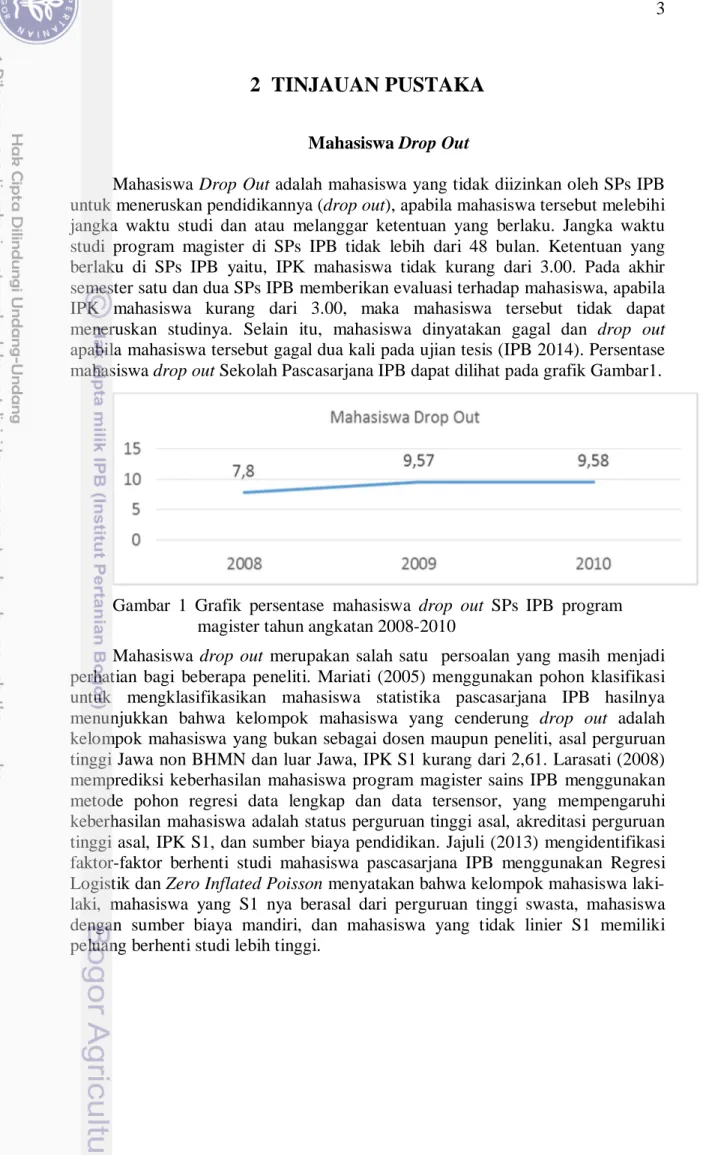
Mahasiswa Drop OutMahasiswa Drop Out adalah mahasiswa yang tidak diizinkan oleh SPs IPB untuk meneruskan pendidikannya (drop out), apabila mahasiswa tersebut melebihi jangka waktu studi dan atau melanggar ketentuan yang berlaku. Jangka waktu studi program magister di SPs IPB tidak lebih dari 48 bulan. Ketentuan yang berlaku di SPs IPB yaitu, IPK mahasiswa tidak kurang dari 3.00. Pada akhir semester satu dan dua SPs IPB memberikan evaluasi terhadap mahasiswa, apabila IPK mahasiswa kurang dari 3.00, maka mahasiswa tersebut tidak dapat meneruskan studinya. Selain itu, mahasiswa dinyatakan gagal dan drop out apabila mahasiswa tersebut gagal dua kali pada ujian tesis (IPB 2014). Persentase mahasiswa drop out Sekolah Pascasarjana IPB dapat dilihat pada grafik Gambar1.
Gambar 1 Grafik persentase mahasiswa drop out SPs IPB program magister tahun angkatan 2008-2010
Mahasiswa drop out merupakan salah satu persoalan yang masih menjadi perhatian bagi beberapa peneliti. Mariati (2005) menggunakan pohon klasifikasi untuk mengklasifikasikan mahasiswa statistika pascasarjana IPB hasilnya menunjukkan bahwa kelompok mahasiswa yang cenderung drop out adalah kelompok mahasiswa yang bukan sebagai dosen maupun peneliti, asal perguruan tinggi Jawa non BHMN dan luar Jawa, IPK S1 kurang dari 2,61. Larasati (2008) memprediksi keberhasilan mahasiswa program magister sains IPB menggunakan metode pohon regresi data lengkap dan data tersensor, yang mempengaruhi keberhasilan mahasiswa adalah status perguruan tinggi asal, akreditasi perguruan tinggi asal, IPK S1, dan sumber biaya pendidikan. Jajuli (2013) mengidentifikasi faktor-faktor berhenti studi mahasiswa pascasarjana IPB menggunakan Regresi Logistik dan Zero Inflated Poisson menyatakan bahwa kelompok mahasiswa laki-laki, mahasiswa yang S1 nya berasal dari perguruan tinggi swasta, mahasiswa dengan sumber biaya mandiri, dan mahasiswa yang tidak linier S1 memiliki peluang berhenti studi lebih tinggi.
4
Pohon Klasifikasi
Pohon klasifikasi adalah suatu gambaran pemodelan dari suatu persoalan yang terdiri dari serangkaian keputusan yang mengarah kepada solusi dengan peubah responnya kategorik (Breiman et al. 1984). Tujuan dari pohon klasifikasi adalah untuk menduga nilai Y berdasarkan nilai X yang diketahui. Struktur pohon pada metode ini diperoleh melalui suatu algoritme penyekatan rekursif terhadap ruang penjelas X.
Gambar 2 Struktur pohon klasifikasi
Pada tahap awal, seluruh gugus data berada pada akar simpul (root node) t yang kemudian disekat menjadi dua anak gugus data, simpul kiri dan kanan, tL dan
tR. Simpul dengan kelas yang masih bercampur didalamnya disekat kembali
hingga tidak dapat disekat lebih lanjut. Sekatan akhir yang dihasilkan disebut simpul akhir (terminal node), sedangkan sekatan yang masih mungkin disekat disebut simpul dalam (non-terminal node). Diagram pohon yang dihasilkan pohon klasifikasi merupakan suatu model yang akan diinterpretasikan ke dalam suatu tabel. Pembentukan pohon klasifikasi memerlukan empat komponen yaitu (Breiman et al.1984):
1. Segugus pertanyaan biner S
Pohon klasifikasi dibentuk melalui penyekatan data pada tiap simpul menjadi dua anak simpul. Penyekat s dibangkitkan dari segugus pertanyaan S yang berbentuk pernyataan biner. Pembentukan pertanyaan dilakukan dengan aturan sebagai berikut:
a. Setiap sekat tergantung pada nilai yang hanya berasal dari satu peubah penjelas.
b. Untuk peubah penjelas kontinu , banyak sekat yang diperoleh adalah ≤ , dengan = 1,2, … , − 1 dan c adalah nilai tengah antara dua nilai amatan peubah berurutan yang berbeda. Jadi jika mempunyai
n nilai yang berbeda maka akan terdapat sebanyak-banyaknya n-1
penyekatan.
c. Jika peubah penjelas kategorik, penyekatan yang terjadi berasal dari semua kemungkinan penyekatan berdasarkan terbentuknya dua anak gugus yang saling lepas (disjoint). Jika peubah merupakan peubah
kategorik nominal dengan L kategori maka terdapat 2 − 1 penyekat, sedangkan jika peubah kategorik ordinal maka terdapat − 1 penyekat.
2. Kriteria kebaikan sekat (goodness of split)
Kriteria kebaikan sekat merupakan alat evaluasi untuk melihat kebaikan sekat-s pada simpul t. Jika sekat s pada simpul t menyekat data dengan proporsi ke dalam simpul bagian kanan dan dengan proporsi ke dalam simpul bagian kiri , maka kebaikan sekat didefinisikan sebagai penurunan nilai
impurity:
∆ ( , ) = ( ) − ( ) − ( ).
Keheterogenan data (impurity) pada setiap simpul diukur dengan formula berikut:
( ) = − ( | ) log ( | )
dengan ( ) merupakan fungsi keheterogenan yang melibatkan ( | ) proporsi kelas j pada simpul t. Nilai ( ) berkisar antara nol dan satu, ( ) bernilai maksimum ketika kelas dalam simpul masih bercampur, sebaliknya akan bernilai minimum ketika kelas dalam simpul telah homogen.
3. Aturan penghentian penyekatan (stop-spliting rule) akan menentukan saat suatu simpul tidak dapat disekat lebih lanjut. Misalkan threshold > 0 , simpul t dikatakan simpul akhir apabila max ∈ ∆ ( , ) < .
4. Aturan penetapan tanda kelas pada setiap simpul akhir.
Misalkan pohon klasifikasi dibangun dan memiliki simpul akhir , aturan penetapan kelas ∗( ) pada simpul akhir adalah jika ( | ) = max ( | ) , maka ∗( ) = . Jika nilai maksimum terdapat pada dua atau lebih kelas yang berbeda, maka ∗( ) salahsatu dari yang memaksimumkan kelas.
Kelas Tidak Seimbang
Kelas tidak seimbang terjadi ketika jumlah contoh suatu kelas secara ekstrim jauh lebih banyak dari kelas yang lain. Kelas dengan jumlah contoh yang lebih banyak disebut kelas mayoritas sedangkan kelas yang lain disebut kelas minoritas. Dalam aplikasi, rasio kelas minoritas dengan mayoritas dapat sebesar 1:100, 1:1000, 1:10000 atau bahkan lebih. Masalah kelas tidak seimbang sering terjadi pada kehidupan seperti; kesalahan diagnosis/pemantauan medis, manajemen risiko, pelanggan fraud, credit scoring, dan banyak kasus lainnya (Chawla et al. 2004).
Melakukan klasifikasi pada data dengan kelas tidak seimbang akan menghasilkan klasifikasi yang bias, contoh pada kelas minoritas dianggap sebagai
noise sehingga hasil akhir klasifikasi cenderung pada kelas yang memiliki
komposisi data yang lebih besar. Pada kasus mahasiswa SPs IPB program magister tingkat persentase mahasiswa lulus 90.87%, algoritme klasifikasi klasik yang meminimalkan tingkat kesalahan akan mengklasifikasikan semua mahasiswa sebagai kelas mayoritas (mahasiswa lulus) untuk mencapai tingkat kesalahan rendah 9.03%. Namun, semua contoh pada kelas minoritas (mahasiswa drop out) akan diklasifikasikan ke dalam kelas mayoritas. Sebelumnya telah dijelaskan
6
beberapa pendekatan untuk menangani masalah kelas tidak seimbang, yaitu pendekatan level algoritme (internal), pendekatan level data (eksternal), dan pendekaatan cost-sensitive learning.
1. Pendekatan level algoritme dilakukan dengan membuat atau memodifikasi algoritme yang ada, untuk memperhitungkan pentingnya contoh mayoritas. 2. Pendekatan level data yaitu dengan menambahkan langkah penarikan contoh
resampling pada tahap pre-processing. Resampling menyeimbangkan
distribusi data untuk mengurangi efek dari distribusi kelas tak seimbang dalam proses pemodelan dengan melakukan beberapa metode resampling seperti; oversampling, undersampling, atau gabungan dari kedua metode. 3. Metode cost-sensitive merupakan pendekatan yang menggabungkan
algoritme dan data tingkat untuk memasukkan kesalahan biaya klasifikasi masing-masing kelas pada tahap latihan.
Selain ketiga pendekatan tersebut, ensemble juga dapat digunakan untuk menangani masalah kelas tidak seimbang dengan cara mengkombinasi ensemble dengan salah satu pendekatan tersebut.
Tenik Resampling
Teknik resampling adalah proses manipulasi sebaran contoh pada data dalam upaya meningkatkan kinerja pengklasifikasian. Proses resampling dilakukan pada tahap pre-processing, sebelum proses pemodelan. Tujuan dari
resampling adalah untuk menyeimbangkan gugus data yang tidak setimbang
dengan oversampling pada kelas minoritas atau dengan undersampling pada kelas mayoritas.
Oversampling meningkatkan ukuran kelas minoritas pada gugus data latih
dengan mereplikasi contoh pada kelas minoritas hingga diperoleh ukuran contoh yang diinginkan. Mereplikasi contoh pada kelas minoritas memungkinkan terjadinya overfitting. Undersampling merupakan metode resampling yang lebih efisien bila dibandingkan dengan oversampling, dengan menghilangkan beberapa contoh pada kelas mayor, gugus data menjadi lebih seimbang dan proses klasifikasi lebih cepat. Namun, undersampling memiliki kelemahan yaitu kehilangan beberapa informasi yang berguna pada contoh yang terbuang.
Metode Ensemble
Pengklasifikasian berbasis ensemble didesain untuk meningkatkan keakuratan pada klasifikasi tunggal dengan menginduksi dan menggabungkan beberapa klasifikasi tunggal. Secara umum, ensemble membangun model dengan dua tahap yaitu memodelkan beberapa klasifikasi dari data latih dan kemudian hasil prediksi tersebut dikombinasi untuk menentukan kelas dari data yang belum diketahui kelas sebelumnya. Metode ensemble yang populer digunakan adalah
Bagging dan Boosting (Zhou 2012).
Bagging adalah metode ensemble yang dikenalkan oleh Breiman pada tahun 1996 yang merupakan akronim dari bootstrap dan aggregrating. Metode ini
membangun m gugus data baru dari gugus data menggunakan teknik resampling
booostrap, kemudian dari masing-masing gugus data dilakukan proses klasifikasi.
Hasil dari klasifikasi tersebut di-voting untuk memperoleh prediksi akhir. Menggunakan Bagging ditujukan untuk mereduksi ragam dari peubah penjelas.
Boosting secara umum berfokus untuk membuat deret klasifikasi, setiap pengklasifikasi pada Boosting menggunakan data yang sama tetapi memiliki sebaran bobot yang berbeda pada setiap iterasi, tergantung pada klasifikasi sebelumnya. Penggunaan bobot juga dilakukan pada saat proses penggabungan dugaan akhir dari banyak pohon yang dihasilkan (Sartono & Syafitri 2010).
Belakangan ini, klasifikasi ensemble muncul sebagai salah satu solusi dalam penanganan masalah kelas tidak seimbang dengan cara mengkombinasikan
ensemble dengan salah satu pendekatan. Berikut taksonomi ensemble untuk
menangani masalah kelas tidak seimbang:
Gambar 3 Taksonomi metode berbasis ensemble
RUSBoost
RUSBoost, metode baru yang mulai ramai diperbincangkan merupakan
gabungan dari random under-sampling (RUS) dengan metode ensemble yaitu
boosting. Boosting adalah metode yang meningkatkan akurasi model klasifikasi
dengan mengkombinasikan beberapa model klasifikasi tunggal. Model klasifikasi dilatih berulang kali menggunakan data latih yang sama tetapi memiliki sebaran bobot yang berbeda pada setiap iterasi. Setelah proses iterasi selesai, model klasifikasi yang diperoleh digabungkan. Algoritme RUSBoost menambahkan teknik resampling yaitu random undersampling pada algoritme boosting. Pada setiap iterasi, learner dilatih dengan data yang dibangkitkan dengan penarikan contoh acak undersampling setelah penambahan bobot. Oleh karena itu, pada algoritme RUSBoost contoh pada kelas mayoritas dihilangkan terlebih dahulu kemudian mengikuti tahap per tahap proses boosting pada data yang tersisa. Proses penarikan contoh dan boosting diulang berkali-kali.
Seieffert (2010) memaparkan algoritme RUSBoost sebagai berikut: Andaikan gugus data yang kita miliki terdiri atas m pengamatan, dengan y sebagai
Ensemble pada Kelas Tidak Seimbang Cost-Sensitive Boosting Data Preprocessing + Ensemble Learnig Bagging-based OverBagging UnderBagging Boosting -based SMOTEBoost MSMOTEBoos Hybrid EasyEnsemble BalanceCascade
8
peubah respon yang memiliki k kelas. Secara ringkas, tahapan algoritme tersebut dapat dituliskan sebagai berikut:
1. Penentuan awal bobot setiap pengamatan, yaitu ( ) = 1/m untuk semua = 1,2, … ,
2. Misalkan t adalah nomor iterasi, maka untuk t = 1, 2, … T lakukan proses berikut:
a. Buat gugus data dengan menggunakan random undersampling b. Bangun model klasifikasi dari gugus data dengan memperhatikan
bobot sebesar
c. Hitung tingkat kesalahan klasifikasi
= ( ) 1 − ℎ ( , ) + ℎ ( , ) . ( , );
d. Hitung sebagai =
1 −
e. Tentukan bobot yang baru untuk setiap pengamatan menjadi ( ) = ( ) ( ( , ) ( , : )
untuk pengamatan yang salah klasifikasi, sedangkan untuk pengamatan yang diduga dengan tepat maka bobotnya tetap
3. Dugaan akhir adalah kelas k yang memiliki nilai terbesar dari
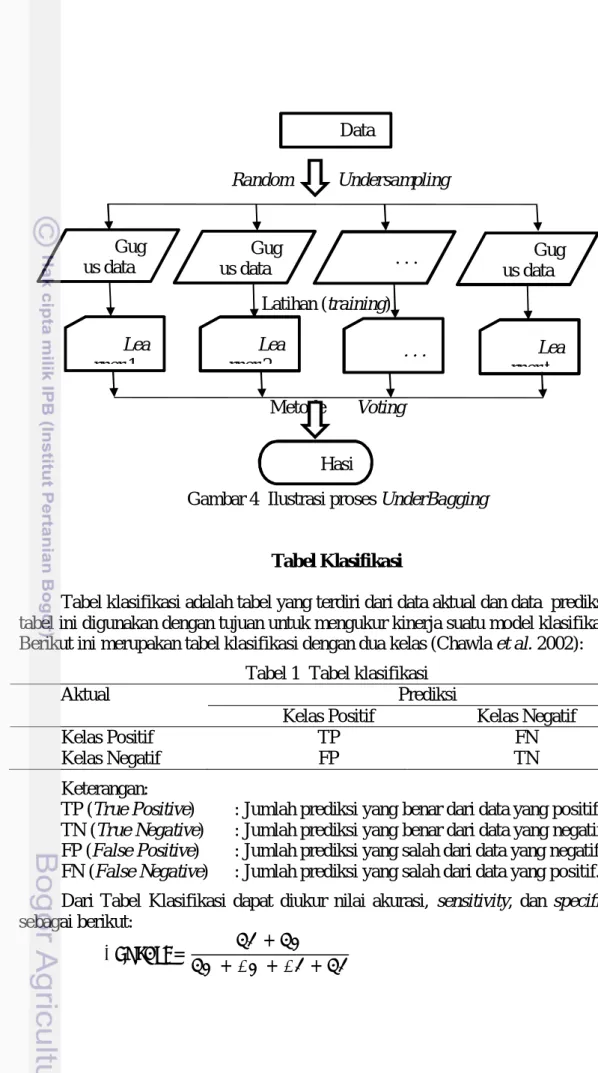
T t t t Y y y x h x H 1 1 log ) , ( max arg ) ( UnderBaggingMetode UnderBagging merupakan metode gabungan antara teknik penarikan contoh undersampling dengan bagging yang pertama kali dikenalkan oleh Barandela et al. (2003). Tujuan pembentukan metode ini adalah untuk mengatasi kesulitan pemodelan pada data dengan kelas tidak seimbang. Algoritme UnderBagging serupa dengan algoritme bagging ensamble yaitu, membangun beberapa gugus data dari data latih dan kemudian hasil masing-masing klasifikasi diagregat.
UnderBagging membangkitkan gugus data baru dari data latih sebanyak T,
yaitu rasio dari jumlah contoh pada kelas mayoritas dan kelas minoritas. Masing-masing gugus data terdiri dari semua contoh pada kelas minoritas dan dengan jumlah yang sama dipilih secara acak dengan atau tanpa pengembalian dari kelas mayoritas. Kemudian, dari masing-masing gugus data tersebut dibentuk pohon klasifikasi. Pada tahap pengujian setiap pohon klasifikasi dihitung peluang respon dari tiap observasi dan menghitung ketepatan klasifikasi dan kesalahan klasifikasi (misclassification). Klasifikasi kelas yang dihasilkan pada T gugus data tersebut di
Random Undersampling
Latihan (training)
Metode Voting
Gambar 4 Ilustrasi proses UnderBagging
Tabel Klasifikasi
Tabel klasifikasi adalah tabel yang terdiri dari data aktual dan data prediksi, tabel ini digunakan dengan tujuan untuk mengukur kinerja suatu model klasifikasi. Berikut ini merupakan tabel klasifikasi dengan dua kelas (Chawla et al. 2002):
Tabel 1 Tabel klasifikasi
Aktual Prediksi
Kelas Positif Kelas Negatif
Kelas Positif TP FN
Kelas Negatif FP TN
Keterangan:
TP (True Positive) : Jumlah prediksi yang benar dari data yang positif. TN (True Negative) : Jumlah prediksi yang benar dari data yang negatif. FP (False Positive) : Jumlah prediksi yang salah dari data yang negatif. FN (False Negative) : Jumlah prediksi yang salah dari data yang positif. Dari Tabel Klasifikasi dapat diukur nilai akurasi, sensitivity, dan specifity sebagai berikut: = + + + + Data Gug us data Gug us data Gug us data . . . Lea rner 1 Lea rner 2 . . . Lea rner t Hasi
10
= + =
+
Receiver Operating Characteristic (ROC) merupakan kurva analisis yang
juga digunakan untuk mengukur kinerja suatu model klasifikasi. Kurva ROC memplotkan true positive rate (TPR) = /( + ) pada y-axis dan peluang
false positive rate (FPR) = /( + ) pada x-axis. Dalam kurva ROC terdapat garis diagonal yang menghubungkan titik (0,0) dan (1,1). Titik yang berada di atas garis diagonal menunjukkan hasil klasifikasi yang baik, sedangkan titik yang berada di bawah garis menunjukkan hasil yang salah. Prediksi terbaik yaitu sensitivity 100% dan specifity 100%, yang berada di titik (0,1). Kurva ROC dapat diubah ke dalam bentuk skalar, salah satunya AUC. AUC adalah suatu bagian dari daerah satuan persegi yang nilainya antara 0 hingga 1. Nilai AUC semakin mendekati satu maka akurasi model klasifikasi semakin tinggi (Fawcett 2006).
3 METODE
DataPenelitian ini menggunakan data sekunder mahasiswa Sekolah Pascasarjana IPB program magister tahun angkatan 2008, 2009, dan 2010. Data diperoleh dari bagian akademik SPs IPB. Jumlah amatan sebanyak 2326 mahasiswa, dengan 2116 amatan mahasiswa lulus dan 210 amatan mahasiswa drop out. Mahasiswa
drop out yaitu mahasiswa yang memiliki IPK kurang dari 3.00 pada tahun
pertama perkuliahan dan atau mahasiswa yang tidak dapat menyelesaikan perkuliahan kurang dari 48 bulan. Persentase mahasiswa SPs IPB program magister yang di-drop out sebesar 9.03%. Peubah yang digunakan pada penelitian ini adalah:
Tabel 2 Peubah penyusun model
Peubah Nama Peubah Kategori Peubah Skala
Y Mahasiswa berhenti kuliah 0 = Lulus
1 = Drop Out Kategorik
X1 Jenis kelamin 0 = Perempuan
1 = Laki-laki Kategorik X2 Status perkawinan 0 = Belum menikah
1 = Menikah 2 = Janda/duda
Kategorik X3 Status pekerjaan 0 = Belum bekerja
1 = Bekerja Kategorik X4 Sumber biaya pendidikan 0 = Mandiri
1 = Beasiswa Kategorik X5 Status perguruan tinggi asal 0 = Negeri
1 = Swasta 2 = Kedinasan
Kategorik X6 Daerah perguruan asal 0 = Luar Jawa
1 = Jawa Kategorik
X7 Akreditasi perguruan tinggi asal 1 = A 2 = B 3 = C 4 = D
Ordinal
X8 Usia Rasio
X9 IPK S1 (skala 0-4) Rasio
Metode Analisis
Langkah-langkah analisis data yang dilakukan dalam penelitian ini adalah sebagai berikut:
12
2. Membagi gugus data menjadi dua bagian data latih dan data uji dengan proporsi kelas tetap sama, menggunakan simple random sampling sehingga diperoleh 80% untuk data latih dan selebihnya 20% untuk data uji
3. Membangun pohon klasifikasi dari data latih
a. Menggunakan Random Under Sampling Boosting (RUSBoost) untuk berbagai proporsi tingkat keseimbangan antara kelas mayoritas dengan kelas minoritas pada proses penarikan contoh acak undersampling, yaitu RB1 [50:50], RB2 [55:45] , RB3 [60:40], RB4 [65:35], dan RB5 [70:30]. b. Menggunakan UnderBagging dengan pengembalian
1) Membuat gugus data baru sebanyak p, p adalah rasio jumlah kelas mayoritas dengan kelas minoritas. Setiap gugus data berisi keseluruhan contoh kelas minoritas dan dengan jumlah yang sama contoh kelas mayoritas yang diboostrap dengan pengembalian. 2) Membuat pohon klasifikasi h(x) pada masing-masing gugus data 3) Maka pohon klasifikasi akhir H(x)
T t t Y y y x h x H 1 ) ) ( ( max arg ) ( .c. Menggunakan UnderBagging tanpa pengembalian
Proses yang sama pada langkah 3b tapi pada langkah 3a.1) dilakukan
boostrap tanpa pengembalian.
4. Melakukan uji pada gugus data uji dengan menggunakan pohon klasifikasi yang telah diperoleh dari langkah 3
5. Menghitung nilai accuracy, sensitivity, dan specifity.
6. Memilih model terbaik berdasarkan nilai AUC (Area Under Curve ROC) dan akurasi.
4 HASIL DAN PEMBAHASAN
Deskripsi Mahasiswa Sekolah Pascasarjana IPB Program Magister Mahasiswa Sekolah Pascasarjana (SPs) IPB program magister berjumlah kurang lebih 700 orang tiap angkatan. Pada setiap angkatan masih terdapat mahasiswa drop out, mahasiswa drop out di SPs IPB adalah mahasiswa ber-IPK kurang dari 3.00 pada tahun pertama perkuliahan dan mahasiswa dengan masa perkuliahan lebih dari 48 bulan. Gambaran umum tentang mahasiswa drop out SPs IPB program magiter dapat dilihat dari Tabel 3.
Tabel 3. Persentase mahasiswa drop out Sekolah Pascasarjana IPB Angk atan (tahun ) Jumlah Mahasiswa Drop Out Pers entase 2008 700 60 7.89 2009 727 77 9.57 2010 689 73 9.58 Total 2326 210 9.03
Berdasarkan Tabel 3, dapat dilihat bahwa dari 2326 mahasiswa SPs IPB program magister, sebanyak 210 (9.03%) mahasiswa yang terkena drop out. Persentase mahasiswa drop out pada setiap angkatannya terus meningkat. Pada mahasiswa angkatan 2008, 2009, dan 2010 terdapat mahasiswa drop out dengan persentase sebesar 7.89%, 9.57%, dan 9.58%.
Gambaran data mahasiswa SPs IPB program magister secara keseluruhan dapat dilihat pada Lampiran 1 dan 2. Berikut ini akan dijelaskan mahasiswa drop
out SPs IPB program magister berdasarkan karakteristiknya:
1) Peubah Jenis Kelamin. Mahasiswa berjenis kelamin perempuan lebih banyak dibandingkan dengan mahasiswa berjenis kelamin laki-laki, yaitu sebesar 53.87%. Namun mahasiswa berjenis kelamin laki-laki memiliki persentase drop out lebih besar dari mahasiswa berjenis kelamin perempuan. Hal ini dikarenakan perempuan cenderung lebih rajin dan ulet dibandingkan laki-laki, sedangkan mahasiswa laki-laki cenderung aktif pada kegiatan diluar perkuliahan seperti: olahraga, organisasi, dan lain sebagainya. Rasio odd dari mahasiswa drop out antara laki-laki dan perempuan sebesar 1.14, artinya risiko terjadinya drop out pada mahasiswa laki-laki 1.14 kali risiko terjadinya drop out pada mahasiswa perempuan.
2) Peubah Status Perkawinan. Mahasiswa belum menikah sebesar 50.56%, sedangkan mahasiswa menikah sebesar 44.56% dan sisanya 4.88% berstatus janda/duda. Persentase drop out mahasiswa berstatus menikah lebih kecil dibandingkan mahasiswa belum menikah serta mahasiswa janda/duda. Hal ini karena seseorang yang berstatus menikah memiliki tanggung-jawab dan disiplin yang tinggi pada dirinya sendiri maupun keluarga.
3) Peubah Status Pekerjaan. 70.51% dari mahasiswa SPs IPB tahun angkatan 2008-2010 berstatus bekerja. Mahasiswa berstatus bekerja memiliki persentase drop out lebih kecil dibandingkan mahasiswa berstatus tidak
14
bekerja. Hal ini dikarenakan sebahagian besar mahasiswa dengan status bekerja merupakan mahasiswa yang mendapatkan tugas belajar dari instansi terkait, sehingga memiliki tanggungjawab lebih dibandingkan mahasiswa tidak bekerja. Rasio odd dari mahasiswa drop out antara mahasiswa tidak bekerja dan bekerja sebesar 2.42, artinya risiko terjadinya drop out pada mahasiswa tidak bekerja 2.42 kali risiko terjadinya drop out pada mahasiswa berstatus bekerja.
4) Peubah Sumber Biaya Pendidikan. Persentase drop out mahasiswa biaya mandiri lebih besar dari mahasiswa beasiswa. Mahasiswa biaya mandiri memiliki peluang risiko terjadinya drop out 3.90 kali peluang risiko terjadinya drop out pada mahasiswa penerima beasiswa. Hal ini dikarenakan beasiswa mampu mendorong dan mempertahankan semangat belajar mahasiswa untuk menyelesaikan pendidikan tepat waktu, sedangkan mahasiswa biaya mandiri mempunyai beban lebih yaitu biaya kuliah
5) Peubah Status Perguruan Tinggi asal. SPs IPB didominasi oleh mahasiswa yang berasal dari perguruan tinggi negeri (83.83%), kemudian dari perguruan tinggi swasta (14.62%), dan hanya 1.55% berasal dari perguruan tinggi kedinasan. Persentase drop out mahasiswa yang berasal dari perguruan tinggi swasta lebih besar dibandingkan mahasiswa yang berasal dari perguruan tinggi negeri dan perguruan tinggi kedinasan. Hal ini dikarenakan IPB merupakan perguruan tinggi negeri sehingga terdapat perbedaan lingkungan dan sistem pengajaran bagi mahasiswa dari perguruan tinggi swasta, selain itu kualitas dan kuantitas mahasiswa antar perguruan tinggi negeri dengan swasta tentu berbeda.
6) Peubah Daerah Perguruan Tinggi asal. Mahasiswa sebahagian besar (61.32%) berasal dari perguruan tinggi di Pulau Jawa, dan sisanya (32.68%) berasal dari perguruan tinggi di luar Pulau Jawa. Persentase drop out mahasiswa asal perguruan tinggi Pulau Jawa lebih besar dari mahasiswa asal luar Pulau Jawa. Mahasiswa asal perguruan tinggi Pulau Jawa memiliki risiko drop out 1.268 kali risiko drop out mahasiswa yang berasal dari perguruan tinggi luar Pulau Jawa.
7) Peubah Akreditasi Perguruan Tinggi asal. Mahasiswa yang berasal dari perguruan tinggi berakreditasi C memiliki persentase drop out lebih besar dibandingkan mahasiswa yang berasal dari perguruan tinggi berakreditasi A dan B. Hal ini dikarenakan kualitas dan kuantitas suatu perguruan tinggi dapat ditunjukkan dari nilai akreditasi perguruan tinggi tersebut, semakin baik nilai akreditasi artinya kualitas dan kuantitas perguruan tinggi tersebut lebih baik. Oleh karena itu, lulusan perguruan tinggi dengan akreditasi yang lebih baik tentunya lebih baik dan mampu bersaing.
8) Peubah Usia. Rata-rata mahasiswa masuk pada usia 30 tahun, dengan usia paling muda 20 tahun dan paling tua 61 tahun.
9) Peubah Indeks Pretasi Kumulatif (IPK) S1. Mahasiswa memiliki rata-rata IPK S1 sebesar 3.15, nilai IPK tertinggi 4.00 dan IPK terendah 2.06. Persentase drop out pada mahasiswa ber-IPK S1 kurang dari 2.75 lebih besar dibandingkan mahasiswa ber-IPK S1 lebih dari 2.75. Risiko drop out pada mahasiswa ber-IPK S1 kurang dari 2.75 sebesar 1.56 kali risiko drop
Model Klasifikasi Mahasiswa IPB Pohon Klasifikasi Klasik
Pohon klasifikasi dibangkitkan dari data latih yang berjumlah 1860 mahasiswa dengan batas pemberhentian sekat β = 0.004. Peubah yang paling mempengaruhi pemodelan adalah peubah status sumber biaya, usia, dan status pekerjaan. Model klasifikasi yang dihasilkan berbentuk pohon dengan enam simpul yang dapat dilihat pada Lampiran 3. Pohon klasifikasi yang diperoleh dapat digunakan untuk memprediksi status mahasiswa SPs IPB program magister, masuk ke dalam kelas lulus atau kelas drop out.
Prediksi menggunakan pohon klasifikasi, mahasiswa dengan status sumber biaya mandiri, status perguruan tinggi asal swasta dan kedinasan, belum menikah, akreditasi PT asal A dan B, usia lebih dari 24 tahun, dan IPK kurang dari 3.4 diprediksi ke dalam kelas mahasiswa drop out. Hasil prediksi pada data latih dan uji dapat dilihat pada Tabel 4.
Tabel 4 Tabel klasifikasi hasil prediksi pohon klasifikasi klasik pada data latih dan uji
Aktual
Prediksi
Data Latih Data Uji
Drop Out Lulu s Drop Out Lulu s Drop Out 6 165 0 39 Lulus 1 168 8 2 425
Berdasarkan Tabel 4, sebanyak 166 dari 1860 amatan pada gugus data latih salah dalam pengklasifikasian. Pada gugus data uji, 41 dari 466 amatan salah dalam pengklasifikasian. Untuk melihat kebaikan kinerja dari hasil model klasifikasi dihitung nilai akurasi, sensitivity, dan specificity. Penerapan metode pohon klasifikasi klasik pada mahasiswa SPs IPB program magister, diperoleh kebaikan kinerja yang dapat dilihat pada Tabel 5.
Tabel 5 Kinerja klasifikasi model pohon klasifikasi klasik (%) Data Latih Data Uji
Akurasi 91.08 91.20
Sensitivity 03.59 00.00
Specificity 99.94 99.53
AUC 51.77 49.77
Berdasarkan hasil perhitungan pada Tabel 5, tingkat akurasi model klasifikasi pada data latih dan data uji sangat baik, yaitu 91.80% dan 91.20%, kesalahan klasifikasi yang diberikan kurang dari 10%. Akan tetapi nilai sensitivity dari kedua gugus data tersebut sangat kecil. Hal ini menyebabkan prediksi model akan lebih condong kepada kelas mayoritas (kategori mahasiswa lulus). Nilai
16
AUC pada data latih sebesar 51.77 dan pada data uji sebesar 49.77%, menunjukkan bahwa model tidak cukup baik.
RUSBoost (Random Under Sampling dan Boosting)
Sebelumnya telah diketahui bahwa pembangkitan model dengan pohon klasifikasi klasik memberikan model dengan kinerja yang tidak cukup baik. Masalah terjadi karena peubah respon pada gugus data yang digunakan memiliki kelas tidak seimbang, yaitu amatan pada kategori kelas lulus jumlahnya jauh lebih banyak dibandingkan amatan pada kategori kelas drop out. Random Under
Sampling Boosting merupakan salah satu metode untuk menangani masalah kelas
tidak seimbang. Model klasifikasi dibangun dari gugus data yang dibangkitkan dengan penarikan contoh acak undersampling. Gugus data akan dibangkitkan dengan lima proporsi yang berbeda antara lulus dan drop out, yaitu [0.5:0.5], [0.55:0.45], [0.6:0.4], [0.65:0.35], dan [0.7:0.3]. Peubah yang paling mempengaruhi pemodelan adalah peubah IPK S1 dan sumber biaya pendidikan, lihat Lampiran 5. Kinerja model klasifikasi yang dibangun dari gugus data dengan tingkat ketidakseimbangan yang berbeda-beda ditunjukkan oleh Tabel 6:
Tabel 6 Kinerja model klasifikasi dari beberapa tingkat ketidakseimbangan
RUSBoost (%)
Nama
Proporsi lulus dan drop
out
Data Latih Data Uji A UC Ak urasi AU C A kurasi RUSBo ost-1 RUSBo ost-2 RUSBo ost-3 RUSBo ost-4 RUSBo ost-5 0.50:0.50 0.55:0.45 0.60:0.40 0.65:0.35 0.70:0.30 7 6.88 7 6.59 7 5.38 7 1.48 7 1.26 67. 15 66. 45 74. 84 79. 78 83. 82 67.4 1 65.7 7 66.9 2 65.1 0 64.2 9 6 5.45 6 3.73 7 2.10 7 5.97 8 0.90
(a) (b)
Gambar 5 Kurva ROC dari beberapa tingkat ketidakseimbangan pada data latih (a) dan data uji (b)
Dari Tabel 6 telihat bahwa nilai AUC meningkat ketika jumlah amatan pada kelas mayoritas yang dieliminasi mendekati jumlah amatan pada kelas minoritas. Pada nilai akurasi terjadi sebaliknya, ketika jumlah amatan pada kelas mayoritas yang dieliminasi mendekati jumlah amatan pada kelas minoritas maka nilai akurasi akan semakin menurun. Kurva ROC pada Gambar 5 menunjukkan bahwa skala horizontal merupakan nilai false positive rate (1-specificity) dan skala vertikal merupakan nilai true positive rate (sensitivity). Berdasarkan kurva tersebut RUSBoost dengan proporsi [0.5:0.5], [0.55:0.45], dan [0.6:0.4] memberikan hasil yang lebih baik dibandingkan proporsi [0.65:0.35], dan [0.7:0.3].
UnderBagging (Random Under-Sampling dan Bagging)
Sebelumnya telah ditampilkan hasil dari algoritme RUSBoost, diketahui bahwa algoritme RUSBoost dapat menangani masalah kelas tidak seimbang. Selain menggunakan algoritme RUSBoost, Random UnderSampling dan Bagging juga dapat digunakan untuk menangani masalah kelas tidak seimbang. Tahap
Boostrap pada penelitian ini dilakukan dengan dan tanpa pengembalian sebanyak
11 gugus data. Dari kesebelas gugus data tersebut dibagun model klasifikasi. Membangun model klasifikasi status mahasiswa SPs IPB program magister dengan algoritme UnderBagging, peubah yang muncul sebagai peubah yang memberikan konstribusi terbesar adalah peubah sumber biaya pendidikan, 37% pada UnderBagging dengan pengembalian dan 30% pada UnderBagging tanpa pengembalian. Sebaliknya, peubah status, akreditasi, dan wilayah perguruan tinggi asal dan jenis kelamin tidak memberikan konstribusi terhadap pemodelan. Untuk mengetahui lebih jelas konstribusi dari masing-masing peubah, dapat dilihat pada Lampiran 6. Hasil kinerja dari model klasifikasi yang dibangun oleh algoritme UnderBagging ditunjukkan pada Tabel 7:
Tabel 7 Kinerja model klasifikasi algoritme UnderBagging (%) Dengan Pengembalian Tanpa Pengembalian Data
Latih
Data Uji Data Latih Data Uji Akura si 60.75 56.65 59.73 57.73 Sensiti vity 83.33 71.43 82.14 76.19 Specifi city 58.51 55.19 57.51 55.90 AUC 77.46 63.66 76.78 67.78
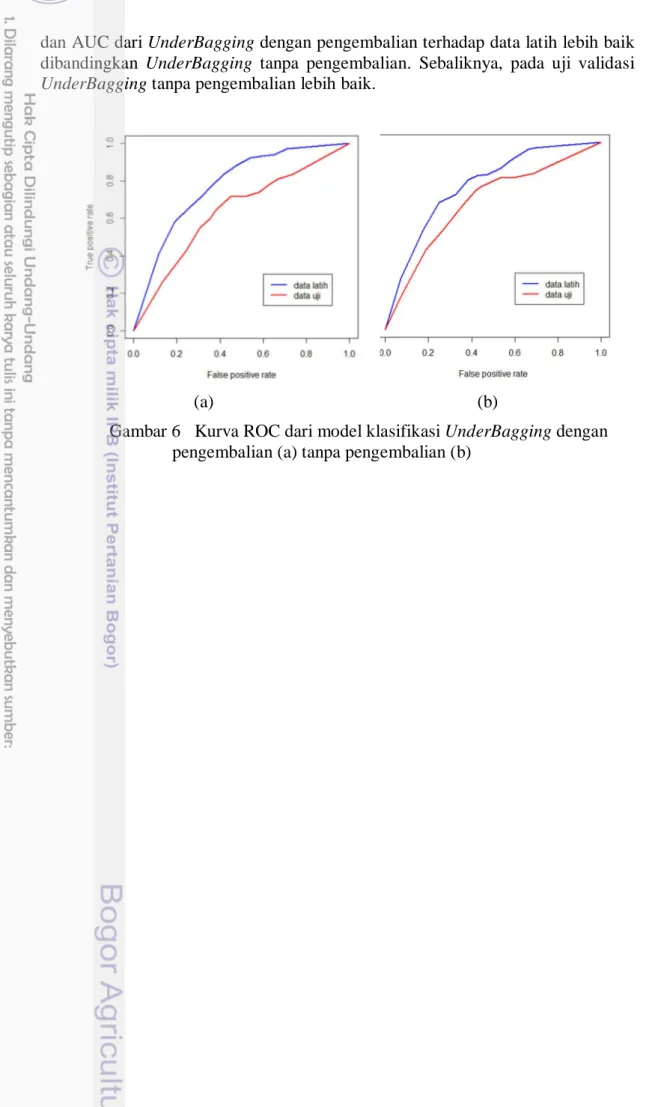
Tabel 7 menunjukkan bahwa algoritma UnderBagging juga dapat menangani masalah kelas tidak seimbang. Nilai akurasi, sensitivity, specificity,
18
dan AUC dari UnderBagging dengan pengembalian terhadap data latih lebih baik dibandingkan UnderBagging tanpa pengembalian. Sebaliknya, pada uji validasi
UnderBagging tanpa pengembalian lebih baik.
(a) (b)
Gambar 6 Kurva ROC dari model klasifikasi UnderBagging dengan pengembalian (a) tanpa pengembalian (b)
5 KESIMPULAN DAN SARAN
KesimpulanPenelitian terhadap mahasiswa SPs IPB program magister tahun angkatan 2008-2010, peubah respon dengan dua kategori yaitu mahasiswa drop out dan mahasiswa lulus. Memiliki masalah kelas tidak seimbang yaitu, 9.03% kelas drop
out dan 90.7% kelas lulus. Dari penelitian yang penulis lakukan dapat
disimpulkan:
1. Apabila membangun model dari data dengan kelas tidak seimbang menggunakan algorime pohon klasifikasi klasik, maka tidak akan efektif. Model yang dihasilkan akan memiliki nilai akurasi yang tinggi dengan kesalahan hanya sebesar 9.03%. Namun, kesalahan ini diperoleh dari kesalahan model mengklasifikasikan kelas minoritas. Secara keseluruhan amatan pada kelas minoritas dikelompokkan ke dalam kelas mayoritas. Jadi, kepekaan model klasifikasi terhadap kelas minoritas sangat buruk.
2. Algoritme RUSBoost dan UnderBagging dapat menangani masalah kelas tidak seimbang. Menggunakan salahsatu dari algoritme tersebut pada pohon klasifikasi dapat meningkatkan kepekaan model klasifikasi terhadap kelas minoritas. Dalam menangani masalah kelas tidak seimbang algoritme
RUSBoost lebih baik dibangdingkan UnderBagging. Namun pada proses
komputasi, UnderBagging lebih mudah, cepat dan ringan.
3. Peubah yang berkonstribusi lebih pada pengklasifikasian mahasiswa drop
out berdasarkan hasil pemodelan menggunakan pohon klasifikasi klasik,
RUSBoost, dan UnderBagging adalah peubah sumber biaya pendidikan dan IPK S1. Sebaliknya, peubah jenis kelamin dan status, wilayah, dan akreditasi perguruan tinggi asal tidak banyak berkonstribusi pada pemodelan.
Saran
Dari hasil penelitian ini, model dari kedua pendekatan pohon klasifikasi (RUSBoost dan UnderBagging) dapat digunakan untuk mendeteksi mahasiswa berisiko drop out. SPs IPB dapat menjadikan nilai mutu (IPK) S1 dan sumber biaya pendidikan sebagai indikator utama dalam seleksi penerimaan mahasiswa magister.
20
DAFTAR PUSTAKA
Agresti A. 2002. Categorical Data Analysis. John Willey & Sons, Inc. New York. Barandela R, Sanchez JS, Valdovinos RM. 2003. New Appllications of
Ensembles of Classifiers. Pattern Anal Applic 6: 245-256.
Breiman L, Friedman JH, Olshen RA, Stone CJ. 1984. Classification and
Regression Trees. New York: Chapman & Hall/CRC.
Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP. 2002. SMOTE: Synthetic Minority Over-sampling Technique. Journal of Artificial Intelligence Research. Vol 16:321–357.
Chawla NV, Japkowicz N, Kolcz A. 2004. Editorial: Special Issue on Learning from Imbalanced Data Sets. ACM SIGKDD Explorations. Vol. 6:1-6.
Fawcett T. 2006. An Introduction to ROC analysis. Pattern Recognition Letters. 27:861-874.
Galar M, Fernandez A, Barrenechea E, Bustince H, Herrera F. 2011. A Review on Ensembles for the Class Imbalance Problem: Bagging-, Boosting-, and Hybrid-Based Approaches. IEEE Transactions on Systems 42: 463-484.
Hutabarat IM. 2005. Pohon Klasifikasi dan Pohon Regresi Keberhasilan Mahasiswa Pascasarjana Program Studi Statistika IPB. [Thesis]. Bogor. Institut Pertanian Bogor.
[IPB] Institut Pertanian Bogor. 2014. Katalog Program Pascasarjana IPB. Bogor: Institut Pertanian Bogor.
____________. 2015. About IPB [Internet]. [diunduh 2015 Des 25]. Tersedia pada: http://ipb.ac.id/about.
Jajuli M. 2010. Identifikasi Faktor-Faktor Berhenti Studi Mahasiswa Pascasarjana IPB Menggunakan Regresi Logistik dan Zero Inflated Poisson. [Thesis]. Bogor. Institut Pertanian Bogor.
Larasati SK. 2008. Prediksi Keberhasilan Mahasiswa Program Magister Sains IPB Menggunakan Metode Pohon Regresi Data Lengkap dan Data Tersensor. [Skripsi]. Bogor. Institut Pertanian Bogor.
Liu XY, Wu J, Zhou Z. Exploratory Undersampling for Class-Imbalance Learning.
IEEE Transactions on Systems, Man and Cybernetics. Part.B: 1-14.
Sartono B dan Syafitri UD. 2010. Metode pohon gabungan: Solusi pilihan untuk mengatasi kelemahan pohon regresi dan klasifikasi tunggal. Forum Statistika
dan Komputasi. Vol 15:1-7.
Seieffert C, Khoshgoftaar TM, Hulse JV, Napollitano A. 2010. RUSBoost: A Hybrid Approach to Alleviating Class Imbalance. IEEE Transactions on Systems, Man, and Cybernetics. Part A: systems and humans: Vol.40.
Therneau TM, Atkinson EJ, Foundation M. 2015. An Introduction to Recursive Partitioning Using the RPART Routines. Tersedia pada: https://cran.r-project.org/web/packages/rpart/vignettes/longintro.pdf
Zhou, ZH. 2012. Ensemble Methods: Foundations and Algorithms. CRC Press: Florida.
Lampiran 1 Persentase Kategori Peubah Penjelas dengan Peubah Respon Peubah Kategori Peubah Jumla h Dro p out (%)
Jenis Kelamin Laki-laki
Perempua n 10 73 12 53 9.6 0 8.5 4 Status Perkawinan Belum
menikah Menikah Janda/dud a 11 76 11 36 14 11. 48 6.5 1 7.1 4
Status Pekerjaan Belum
bekerja Bekerja 68 6 16 40 14. 72 6.6 5 Sumber Biaya Pendidikan Beasiswa
Mandiri 11 67 11 59 4.0 3 14. 06 Status Perguruan Tinggi
Asal Negeri Swasta Kedinasan 19 50 34 0 36 8.5 1 12. 06 8.3 3 Wilayah Perguruan Tinggi
Asal Jawa Luar Jawa 15 66 76 0 9.6 4 7.7 6 Akreditasi Perguruan Tinggi Asal A B C 11 60 95 3 21 3 7.9 3 9.8 6 11. 27
Lampiran 2 Deskripsi Peubah Kontinu P eubah M in Q 1 M edian Q 3 M ax M ean St. Dev U sia 20 .00 2 4.73 28 .75 3 4.00 61. 00 2 9.998 6.4 57 I PK S1 02 .06 0 2.94 03 .14 0 3.37 04. 00 3. 1522 0.3 23
22
Lampiran 3 Diagram Pohon Klasifikasi Klasik
BEASISWA = tdk StatusPT = dns,sws KAWIN = blm AKREDITA = A,B USIA >= 24 IPK.S1 >= 3.4 DO lulus lulus lulus lulus lulus lulus yes no
Lampiran 4 Peubah Penjelas yang berpengaruh (Variable Importance) pada Pemodelan Menggunakan Pohon Klasifikasi Tunggal
Peubah Penjelas Importanc
e
Sumber Biaya Pendidikan 25
Usia 21
Status Perkawinan 17
Status Pekerjaan 16
IPK S1 10
Akreditasi Perguruan Tinggi Asal
7 Status Perguruan Tinggi Asal 2 Wilayah Perguruan Tinggi Asal 2
Jenis Kelamin 0
Lampiran 5 Peubah Penjelas yang berpengaruh (Variable Importance) pada Pemodelan Menggunakan metode RUSBoost
Peubah Penjelas RB -1 RB -2 RB -3 RB -4 RB -5 IPK S1 21. 35 22. 88 24. 41 29. 04 27. 50 Sumber Biaya Pendidikan 19. 58 18. 50 20. 89 18. 59 18. 10 Usia 14. 98 12. 18 17. 21 12. 32 15. 11 Status Pekerjaan 13. 89 09. 25 12. 30 12. 98 10. 45 Status Perkawinan 09. 23 06. 62 06. 25 05. 01 05. 93 Akreditasi PT Asal 08. 99 09. 95 06. 30 05. 62 08. 60 Jenis Kelamin 06. 36 07. 42 04. 91 03. 88 07. 78 Status PT Asal 04. 13 08. 11 04. 52 06. 73 03. 65 Wilayah PT Asal 01. 49 05. 08 03. 21 05. 82 02. 85
Lampiran 6 Peubah Penjelas yang berpengaruh (Variable Importance) pada Pemodelan Menggunakan Metode UnderBagging
Peubah Penjelas UnderBagging
dengan pengembalian
UnderBagging
tanpa pengembalian
24 Pendidikan Usia 17 18 Status Perkawinan 20 15 IPK S1 16 19 Status Pekerjaan 9 13 Status PT Asal 0 3 Akreditasi PT Asal 0 1 Wilayah PT Asal 0 1 Jenis Kelamin 0 0
Lampiran 7 Bobot pada pemodelan RUSBoost Iter asi ke- Bobot RUSB oost-1 RUSB oost-2 RUSB oost-3 RUSB oost-4 RUSB oost-5 1 0,335 6704 0,121 445 0,245 572 0,360 728 0,293 791 2 0,050 3004 0,095 773 0,154 217 0,157 835 0,237 333 3 0,185 6897 0,151 905 0,120 104 0,137 449 0,116 574 4 0,241 6956 0,265 293 0,129 482 0,189 145 0,113 544 5 0,003 8388 0,001 625 0,121 232 0,000 921 0,060 679 6 0,035 3574 0,025 936 0,001 342 0,025 315 0,109 974 7 0,134 2013 0,001 625 0,091 406 0,125 846 0,017 071 8 0,003 8388 0,174 911 0,094 069 0,000 921 0,000 725 9 0,003 8388 0,039 785 0,008 946 0,000 921 0,049 584 10 0,003 8388 0,121 702 0,033 631 0,000 921 0,000 725
RIWAYAT HIDUP
Penulis dilahirkan di Surabaya, Provinsi Jawa Timur pada tanggal 2 Juli 1991. Merupakan anak kedua dari empat bersaudara dari pasangan Bapak Mukarramah Indra dan Ibu Ns Ria Ningsih SKep. Pendidikan dasar penulis diselesaikan pada tahun 2002 di SD Negeri 33 Rawang Barat. Pendidikan menengah pertama ditempuh di SMP Negeri 2 Padang dan lulus pada tahun 2005. Pendidikan menengah atas ditempuh di SMA Negeri 10 Padang Program IPA dan lulus pada tahun 2008. Penulis diterima di program studi Pendidikan Matematika Universitas Andalas pada tahun yang sama, dan menyelesaikannya pada tahun 2012. Selanjutnya penulis melanjutkan program master (S2) pada program studi Statistika Terapan, Sekolah Pascasarjana IPB pada tahun 2013 dengan program Beasiswa BPPDN dari Direktorat Jendral Pendidikan Tinggi (Dikti).