PENANGANAN MASALAH KELAS DATA TIDAK
SEIMBANG PADA PEMODELAN RISIKO HIV
DI PAPUA
EVLINA TRISIA SALSABELLA
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2017
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa skripsi berjudul Penanganan Masalah Kelas Data Tidak Seimbang pada Pemodelan Risiko HIV di Papua adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juli 2017 Evlina Trisia Salsabella NIM G14130027
ABSTRAK
EVLINA TRISIA SALSABELLA. Penanganan Masalah Kelas Data Tidak Seimbang pada Pemodelan Risiko HIV di Papua. Dibimbing oleh BAGUS SARTONO dan AAM ALAMUDI.
Synthetics Minority Oversampling and Undersampling Technique (SMOUTE) merupakan metode perbaikan dari Synthetic Minority Oversampling Technique (SMOTE) yang digunakan untuk menangani ketidakseimbangan kelas data. Perbedaan antara SMOUTE dan SMOTE terletak pada tahap awal undersampling yang dilakukan pada kelas mayoritas. SMOUTE mengawali undersampling dengan pengelompokan kelas mayoritas melalui algoritme k-rataan. Serupa dengan SMOTE, SMOUTE akan membangkitkan amatan buatan kelas minoritas untuk dapat menyeimbangkan jumlah amatan kelas mayoritas sehingga masalah ketidakseimbangan kelas dapat diatasi. Masalah kelas data tidak seimbang akan berakibat pada ketepatan klasifikasi kelas minoritas yang dihasilkan sehingga masalah ini perlu ditangani. Data yang digunakan pada penelitian ini adalah data Surveilans Terpadu HIV – Perilaku 2006 (STHP-06) yang memiliki masalah ketidakseimbangan kelas dilihat dari jumlah responden positif HIV yang hanya sekitar 2.38% dari total seluruh responden yang berhasil diuji darahnya. Hasil klasifikasi dengan Pohon Klasifikasi C5.0 menunjukkan tidak ada satu pun amatan kelas minoritas yang berhasil diklasifikasi dengan benar. Peningkatan ketepatan klasifikasi kelas minoritas diperoleh dengan melakukan penanganan sebelum dilakukan klasifikasi dengan Pohon Klasifikasi C5.0. Hal ini disertai dengan penurunan ketepatan klasifikasi kelas mayoritas. Rataan ketepatan klasifikasi kelas minoritas terbaik diperoleh melalui penanganan SMOTE sebelum dilakukan klasifikasi.
ABSTRACT
EVLINA TRISIA SALSABELLA. Handling Imbalance Class Dataset Problem on HIV Risk Modelling in Papua. Supervised by BAGUS SARTONO and AAM ALAMUDI.
Synthetics Minority Oversampling and Undersampling Technique (SMOUTE) is a modification of Synthetic Minority Oversampling Technique (SMOTE) to overcome imbalance class – dataset problem better. The difference between SMOUTE and SMOTE lies on the way to do the undersampling step. In the SMOTE while uses simple random sampling, the SMOUTE methodology applies a stratified sampling where the strata were built by a k-means clustering. Then both SMOTE and SMOUTE will generate synthetic minority class observations to balance majority class observations. This imbalance class dataset problem has consequence on minority – class classification performance so it should be handled. This research used Surveilans Terpadu HIV – Perilaku 2006 (STHP-06) dataset that contains imbalance class dataset problem shown by number of HIV positive respondent that about 2.38% of total number of respondent. Without any pre-processing treatment on the imbalance, the C5.0 worked poorly so that none minority class observation is correctly classified. Minority – class classification performance increases when handling method is applied before classifying. The best minority – class classification performance is resulted by applying SMOTE before classifying.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Statistika
pada
Departemen Statistika
PENANGANAN MASALAH KELAS DATA TIDAK
SEIMBANG PADA PEMODELAN RISIKO HIV
DI PAPUA
EVLINA TRISIA SALSABELLA
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2017
PRAKATA
Puji syukur penulis panjatkan kepada Allah subhanahu wa ta’ala yang telah memberikan berkat dan rahmatnya sehingga karya ilmiah ini berhasil diselesaikan dengan baik. Tema yan dipilih dalam penelitian ini adalah masalah kelas data tidak seimbang, dengan judul Penanganan Masalah Kelas Data Tidak Seimbang pada Pemodelan Risiko HIV di Papua.
Penulis mengucapkan terima kasih kepada Dr Bagus Sartono dan Ir Aam Alamudi selaku dosen pembimbing yang telah memberikan bimbingan dan masukannya selama penelitian dan pembuatan karya ilmiah ini. Terima kasih juga penulis ucapkan kepada Bapak Budi Santoso yang telah memberikan bantuan dalam proses memperoleh data. Di samping itu, penulis menyampaikan terima kasih kepada Kiki, Tazkia, Nadya, Nosi, dan Nazmi selaku teman bimbingan selama ini serta teman-teman Statistika 50 IPB atas semua bantuannya. Tidak lupa penulis menyampaikan terima kasih kepada kedua orang tua, saudara, dan segenap keluarga yang senantiasa memberikan doa dan dukungan dalam menyelesaikan kaya ilmiah ini.
Semoga karya ilmiah ini bermanfaat.
Bogor, Juli 2017 Evlina Trisia Salsabella
DAFTAR ISI
DAFTAR TABEL vi DAFTAR GAMBAR vi DAFTAR LAMPIRAN vi PENDAHULUAN 1 Latar Belakang 1 Tujuan Penelitian 2 TINJAUAN PUSTAKA 2 HIV/AIDS 2Ketidakseimbangan Kelas Data 3
Synthetic Minority Oversampling Technique (SMOTE) 3 Synthetics Minority Oversampling and Undersampling Technique (SMOUTE) 4
Pohon Klasifikasi C5.0 5
Ketepatan Klasifikasi 6
METODE 7
Data 7
Metode Penelitian 8
HASIL DAN PEMBAHASAN 10
Gambaran Umum Data 10
Penanganan Kelas Data Tidak Seimbang 15
Pemilihan Metode Penanganan Terbaik 19
Peubah – peubah Penting pada Model dengan Metode Penanganan Terbaik 23
SIMPULAN 24
SARAN 24
DAFTAR PUSTAKA 25
DAFTAR TABEL
1 Confusion matrix 6
2 Daftar peubah penjelas 8
3 Persentase responden berdasarkan peubah yang digunakan 11 4 Proporsi responden positif HIV pada tiap kategori peubah penjelas 12
5 Komposisi pembagian data 15
6 Kinerja klasifikasi tanpa penanganan kelas data tidak seimbang 16
7 Komposisi data hasil SMOTE 17
8 Komposisi data hasil SMOUTE 17
9 Komposisi data hasil SMOUTE 2 tahap 18
10Perbandingan kinerja pohon klasifikasi berdasarkan akurasi terbaik 21 11Perbandingan kinerja pohon klasifikasi berdasarkan sensitivitas terbaik 21 12Perbandingan rataan kinerja klasifikasi C5.0 pada data uji 22
DAFTAR GAMBAR
1 Boxplot penghasilan per bulan (ribu) berdasarkan hasil tes HIV 14
2 Boxplot lama sekolah dan usia 15
3 Perbandingan oversampling 1 tahap dan 2 tahap 18
4 Boxplot kinerja klasifikasi berdasarkan metode penanganan 20 5 Diagram Pencar antara Akurasi dan Sensitivitas dengan Metode 21 6 Persentase Peubah yang Mengisi Urutan Tiga Besar Nilai Kepentingan
Tertinggi 24
DAFTAR LAMPIRAN
1 Pohon Klasifikasi C5.0 metode SMOUTE dengan nilai sensitivitas
PENDAHULUAN
Latar BelakangAIDS yaitu singkatan dari Acquired Immune Deficiency Syndrome merupakan penyakit menular yang disebabkan oleh infeksi Human Immunodeficiency Virus (HIV) yang menyerang sistem kekebalan tubuh (Kemkes RI 2016). Fase awal seseorang menderita AIDS adalah ketika orang tersebut dinyatakan positif HIV. Para penderita HIV/AIDS akan mengalami penurunan daya tahan tubuh sehingga menyebabkan penderita mudah terserang penyakit lain. AIDS merupakan salah satu penyakit berbahaya yang masih belum ditemukan obatnya. Namun, dari tahun ke tahun jumlah penderita HIV/AIDS di Indonesia terus meningkat. Kasus HIV/AIDS di Indonesia ditemukan pertama kali pada tahun 1987 dan hingga saat ini sudah tersebar di 77 persen kabupaten/kota di seluruh provinsi Indonesia. Data dari Kementerian Kesehatan Republik Indonesia menunjukkan bahwa jumlah penderita penyakit HIV/AIDS di Papua sudah sangat tinggi dan melampaui jumlah penderita di provinsi DKI Jakarta. Berdasarkan data dari Ditjen PP & PL Kemkes RI diketahui bahwa prevalensi kasus HIV/AIDS di Papua merupakan yang tertinggi dibandingkan provinsi lainnya. Berdasarkan data tersebut diperoleh hasil bahwa dari masing-masing seratus ribu penduduk terdapat sekitar 758 penduduk provinsi Papua dan sekitar 494 penduduk provinsi Papua Barat dinyatakan positif HIV. Kondisi buruk seperti ini harus segera mendapatkan penanganan yang tepat baik dari pemerintah, tokoh masyarakat adat atau Lembaga Swadaya Masyarakat.
Pengambilan kebijakan atau keputusan yang tepat untuk mengatasi permasalahan di Papua ini perlu diawali dengan analisis yang tepat pula. Telah disebutkan sebelumnya bahwa dari masing-masing seratus ribu penduduk terdapat sekitar 758 penduduk provinsi Papua dan sekitar 494 penduduk provinsi Papua Barat yang dinyatakan positif HIV. Hal ini menunjukkan adanya ketidakseimbangan kelas antara kelas penduduk positif HIV dan kelas penduduk negatif HIV dengan perbandingan sekitar 1:131 pada penduduk provinsi Papua dan 1:202 pada penduduk provinsi Papua Barat. Salah satu metode analisis yang dapat mengidentifikasi faktor-faktor yang berkontribusi terhadap hasil prediksi HIV seorang penduduk yaitu Pohon Keputusan, khususnya yaitu Pohon Klasifikasi karena peubah respon yang digunakan berupa data kategorik biner yaitu positif HIV atau negatif HIV. Namun, adanya permasalahan ketidakseimbangan kelas ini mengharuskan dilakukannya suatu penanganan tertentu terhadap data tidak seimbang agar hasil klasifikasi lebih akurat yaitu dengan mengklasifikasikan individu ke dalam kelas secara benar. Oleh karena itu, dilakukan penanganan ketidakseimbangan kelas melalui Synthetic Minority Oversampling Technique (SMOTE) oleh Chawla et al. (2002) dan Synthetics Minority Overampling and Undersampling Technique (SMOUTE) oleh Songwattanasiri dan Sinapiromsaran (2010) sebelum analisis klasifikasi dengan Pohon Klasifikasi C5.0 dilakukan dengan harapan dapat meningkatkan akurasi atau ketepatan klasifikasi yang diperoleh sehingga dapat diambil kebijakan atau keputusan yang tepat.
2
Tujuan Penelitian
Tujuan dari penelitian ini adalah membandingkan kinerja Pohon Klasifikasi C5.0 pada data hasil tes HIV STHP-06 tanpa dan dengan dilakukan penanganan terhadap kelas data tidak seimbang serta mengidentifikasi peubah-peubah yang paling penting dalam model klasifikasi dengan metode penanganan terbaik yang dipilih.
TINJAUAN PUSTAKA
HIV/AIDSAcquired Immune Deficiency Syndrome (AIDS) merupakan penyakit menular yang disebabkan oleh infeksi Human Immunodeficiency Virus (HIV) yang menyerang sistem kekebalan tubuh (Kemkes RI 2016). Fase awal seseorang berisiko mengidap AIDS adalah ketika orang tersebut dinyatakan positif HIV. Berdasarkan data dari Direktorat Jenderal Pencegahan dan Pengendalian Penyakit (Ditjen P2P) Kementerian Kesehatan menunjukkan bahwa jumlah penderita positif HIV cenderung membentuk tren naik dari tahun ke tahun tercatat hingga tahun 2015. Data jumlah HIV positif yang ada di masyarakat dapat diperoleh melalui tiga metode, yaitu layanan Voluntary, Counseling, and Testing (VCT), sero survey, dan Survei Terpadu Biologis dan Perilaku (STBP). Data HIV positif yang digunakan pada penelitian ini adalah data hasil Surveilans Terpadu HIV - Perilaku (STHP) pada tahun 2006 yang diselenggarakan oleh BPS bekerja sama dengan Kementerian Kesehatan. Penularan HIV dapat melalui hubungan seksual, transfusi darah, penggunaan jarum suntik bergantian (biasanya pada pengguna narkotika suntik), dan penularan dari ibu ke anak melalui air susu ibu (ASI). Penelitian ini berfokus pada faktor risiko penularan melalui hubungan seksual dengan memerhatikan faktor-faktor seperti umur saat pertama kali melakukan seks, penggunaan alat kontrasepsi dalam berhubungan seksual, perilaku seks berisiko, dan riwayat mengidap penyakit menular seksual. Pemilihan faktor risiko penularan melalui hubungan seksual sebagai fokus penelitian berdasarkan pada data Ditjen P2P yang menunjukkan bahwa lebih dari 90% penderita AIDS terlapor pada tahun 2015 tertular HIV melalui faktor hubungan seksual. Faktor lain yang akan dilihat pengaruhnya terhadap hasil tes HIV yaitu topografi wilayah tempat tinggal, jenis kelamin, suku bangsa, status perkawinan, penghasilan per bulan, pengetahuan tentang HIV, lama sekolah, dan usia. Berdasarkan Laporan Perkembangan HIV-AIDS Triwulan I Tahun 2016, prevalensi infeksi HIV terbesar di Indonesia terjadi pada dua provinsi paling timur Indonesia yaitu provinsi Papua dan Papua Barat. Diperkirakan pada masing-masing seratus ribu penduduk terdapat sekitar 758 orang positif HIV di provinsi Papua dan sekitar 494 orang dinyatakan positif HIV di provinsi Papua Barat. Oleh karena itu, penelitian ini berfokus pada kasus penyebaran HIV di provinsi Papua dan Papua Barat.
3 Ketidakseimbangan Kelas Data
Ketika suatu data terbagi menjadi dua atau lebih kelas dengan masing-masing kelas terdiri atas amatan-amatan dengan jumlah amatan yang berbeda cukup jauh antara satu kelas dengan kelas lainnya, maka data ini termasuk data kelas tidak seimbang. Terdapat kelas dengan jumlah amatan penyusun sangat banyak yang disebut kelas mayoritas, sebaliknya kelas minoritas merupakan kelas dengan jumlah amatan penyusun yang jauh lebih sedikit dibanding kelas mayoritas. Pada data dengan lebih dari dua kelas, biasanya satu kelas dengan jumlah amatan penyusun sedikit yang menjadi fokus penelitian dianggap sebagai kelas minoritas sedangkan kelas lain yang tersisa dianggap sebagai kelas mayoritas (Bunkhumpornpat et al. 2011). Kondisi ketidakseimbangan pada data ini akan menyebabkan masalah pada beberapa analisis yang mengasumsikan kondisi seimbang pada pengelompokan amatan-amatan penyusunnya. Salah satu analisis yang rentan terhadap kondisi kelas data tidak seimbang ini adalah analisis klasifikasi. Analisis klasifikasi akan menempatkan amatan ke dalam salah satu kelas berdasarkan peubah-peubah penjelas yang menyertainya. Adanya kondisi tidak seimbang pada data akan menurunkan keakuratan klasifikasi pada kelas minoritas disebabkan oleh terlalu sedikitnya amatan yang menyusun kelas tersebut. Namun kenyataannya pada banyak kasus, kelas minoritas inilah yang menjadi fokus penelitian yang dilakukan sehingga kesalahan analisis harus dihindari agar diperoleh hasil analisis yang tepat dan akurat. Upaya untuk mengatasi masalah kelas data tidak seimbang ini dapat dilakukan pada tingkat data atau pada tingkat algoritme (Han et al. 2005). Pada penelitian ini, data hasil tes HIV di provinsi Papua dan Papua Barat yang mengindikasikan adanya ketidakseimbangan kelas data akan ditangani dengan solusi tingkat data yaitu antara lain dengan metode Synthetic Minority Oversampling Technique (SMOTE) sebelum dilakukannya analisis klasifikasi dengan Pohon Klasifikasi C5.0. Dengan harapan tingkat akurasi pengklasifikasian pada kelas minoritas akan meningkat dibandingkan sebelum dilakukannya metode SMOTE ini.
Synthetic Minority Oversampling Technique (SMOTE)
Sesuai dengan namanya, SMOTE adalah salah satu teknik penambahan pengambilan amatan (oversampling) pada kelas minoritas dengan cara membangkitkan amatan buatan berdasarkan pada konsep t-tetangga terdekat untuk mengatasi masalah ketidakseimbangan kelas pada data (Chawla et al. 2002). Penentuan jarak tetangga terdekat berbeda antara data numerik dan data kategorik. Pada data dengan semua peubah numerik, jarak terdekat dihitung dengan jarak Euclidean sesuai persamaan (1) berikut ini:
( ) √( ) ( ) √∑ ( ) (1) keterangan :
( ): jarak antara amatan x dan y : nilai peubah ke-i amatan x : nilai peubah ke-i amatan y
4
SMOTE untuk data yang terdiri atas peubah numerik dan kategorik dikenal dengan SMOTE-NC (SMOTE – Nominal Continuous). Jarak terdekat dihitung dengan konsep jarak Euclidean dengan menggunakan nilai median dari simpangan baku semua peubah numerik kelas minoritas sebagai selisih nilai peubah kategorik.
Setelah menghitung jarak terdekat, berikut prosedur pembangkitan data buatan dengan SMOTE.
1. Data Numerik
i. Hitung selisih vektor amatan dari vektor t-tetangga terdekat ii. Kalikan hasil tahap 1.i dengan bilangan acak antara 0 dan 1
iii. Tambahkan hasil tahap 1.ii dengan vektor amatan sehingga diperoleh vektor amatan baru
atau dapat dituliskan dengan persamaan (2) berikut ini:
( ̂ ) (2)
keterangan :
: vektor amatan baru : vektor amatan awal
̂ : vektor t-tetangga terdekat
: bilangan acak seragam antara 0 dan 1
2. Data Kategorik
i. Tentukan kategori amatan yang paling sering muncul (modus) antara vektor amatan dengan vektor t-tetangga terdekat. Jika terjadi kesamaan nilai maka pilih secara acak
ii. Jadikan nilai tersebut sebagai amatan baru
Persentase oversampling sebesar p% berarti dari setiap amatan kelas minoritas akan dibangkitkan amatan buatan sebanyak p%. Persentase undersampling sebesar q% berarti amatan kelas mayoritas yang dipilih sebanyak q% kali dari jumlah amatan minoritas buatan yang dibangkitkan.
Synthetics Minority Oversampling and Undersampling Technique (SMOUTE) Serupa dengan SMOTE, SMOUTE merupakan salah satu teknik untuk mengatasi masalah ketidakseimbangan kelas yang terjadi pada data. SMOUTE merupakan salah satu metode perbaikan dari SMOTE yang diusulkan oleh Songwattanasiri dan Sinapiromsaran (2010). Pada SMOTE yang diusulkan oleh Chawla et al. (2002) juga diterapkan undersampling atau pengurangan pengambilan amatan pada kelas mayoritas. Undersampling pada SMOTE dilakukan dengan membuang beberapa amatan pada kelas mayoritas secara acak sampai terjadi keseimbangan antara kelas mayoritas dengan kelas minoritas. Berbeda dengan SMOTE, undersampling pada SMOUTE melalui tahap pengelompokan amatan kelas mayoritas dengan algoritme k-rataan terlebih dahulu.
Prosedur SMOUTE diawali dengan oversampling kelas minoritas sesuai SMOTE terlebih dahulu hingga diperoleh banyaknya amatan buatan yang diharapkan. Selanjutnya tahap undersampling diawali dengan pengelompokan kelas mayoritas dengan algoritme k-rataan. Undersampling dilakukan di masing-masing kelompok dengan perhitungan ukuran undersampling tiap kelompoknya sesuai persamaan (3) berikut ini:
5 keterangan :
: banyaknya amatan undersampling untuk kelompok ke-i : banyaknya amatan kelas mayoritas pada kelompok ke-i : banyaknya amatan kelas mayoritas untuk semua kelompok : banyaknya amatan undersampling yang ditentukan
Setelah diperoleh ukuran undersampling setiap kelompok, tahap selanjutnya yaitu membuang beberapa amatan kelas mayoritas seperti yang dilakukan pada SMOTE hingga mencapai ukuran undersampling yang ditentukan.
Pohon Klasifikasi C5.0
Pohon Klasifikasi C5.0 merupakan pengembangan dari Pohon Klasifikasi C4.5 yang dikembangkan oleh Quinlan Ross (Patidar dan Tiwari 2013). Keistimewaan yang membedakan Pohon Klasifikasi C5.0 dari C4.5 adalah kemampuannya untuk memisahkan populasi menjadi lebih dari dua subpopulasi di tiap tahapnya (Tufféry 2011). Selain itu, komputasi C5.0 lebih cepat dan pohon keputusan yang dihasilkan lebih kecil dibandingkan C4.5 (Pandya R dan Pandya J 2015). Sesuai dengan namanya, Pohon klasifikasi terdiri atas bagian-bagian utama seperti Simpul (node), Cabang (branch), dan Daun (leaf). Simpul terbagi menjadi beberapa jenis seperti Simpul Akar (root) yaitu simpul teratas pada susunan diagram pohon. Akar (root) ini hanya memiliki keluaran dan diisi oleh peubah penjelas yang paling berpengaruh terhadap model klasifikasi yang dilihat dari nilai information gain terbesar dibandingkan peubah penjelas lainnya. Selain Simpul Akar, terdapat pula yang dinamakan Simpul Internal yaitu simpul yang memiliki masukan dari Cabang Simpul lain dan juga memiliki keluaran. Simpul Internal ini diisi oleh peubah penjelas yang berpengaruh selanjutnya terhadap model klasifikasi. Cabang berisi hasil dari pengujian yang terjadi di Simpul yaitu berupa kategori dari peubah penjelas yang mengisi Simpul. Sedangkan Daun (leaf) merepresentasikan hasil akhir pengujian yaitu berupa kelas peubah respon. Berikut algoritme C5.0.
1. Menghitung nilai Entropy
Entropy adalah tingkat ketidakhomogenan himpunan data.
( ) ∑ ( ) (4) keterangan :
= himpunan data
= banyaknya kelas peubah respon
= proporsi banyaknya data kelas peubah respon ke-i pada himpunan data 2. Menghitung nilai information gain
Information gain adalah selisih dari nilai Entropy himpunan data awal dengan nilai rataan terboboti Entropy anak himpunan data yang dipilah peubah J. Berikut formulasi information gain sesuai persamaan (5) berikut ini:
( ) ( ) ∑ | | | | ( ) (5) keterangan:
= himpunan data = peubah penjelas
6
| | = banyaknya amatan pada himpunan data
| | = banyaknya amatan pada himpunan data S
= anak himpunan data yang berisi amatan-amatan dengan nilai peubah J =
3. Menentukan peubah penjelas dengan nilai information gain terbesar sebagai peubah pemisah yang memisahkan amatan menjadi anak himpunan data yang kemudian disebut Simpul
4. Mengulangi langkah 1 hingga 3 untuk melalukan percabangan selanjutnya 5. Percabangan dihentikan ketika setidaknya satu dari tiga kondisi di bawah ini
terjadi
a. Ketika peubah respon pada suatu Simpul telah homogen (hanya terdapat satu kelas peubah respon)
b. Ketika semua peubah penjelas homogen
c. Ketika jumlah amatan sebelum dilakukan pemisahan (split) terlalu sedikit 6. Melakukan pemangkasan (prune) untuk menghasilkan pohon yang sederhana.
C5.0 menggunakan metode Pemangkasan Berbasis Galat (Error Based Pruning) sesuai persamaan (6) berikut ini:
√ (6) keterangan:
= tingkat galat pada Daun (error rate)
= nilai kebalikan dari distribusi kumulatif normal baku dengan = 0.25 = perbandingan jumlah amatan yang salah dalam klasifikasi dengan
jumlah keseluruhan amatan pada Daun = jumlah amatan pada Daun
Peningkatan nilai ini akan mengakibatkan pembentukan pohon yang lebih besar. Pemangkasan dilakukan apabila nilai e pada Daun lebih besar dibandingkan Simpul Internal sebelum Daun (Adiangga 2015).
Ketepatan Klasifikasi
Keakuratan atau ketepatan klasifikasi diukur menggunakan confusion matrix sesuai Tabel 1 dengan menganggap kelas Positif HIV sebagai kelas positif dan kelas negatif HIV sebagai kelas negatif.
Tabel 1 Confusion matrix
Aktual Prediksi
Positif Negatif
Positif TP FN
Negatif FP TN
TP (True Positive) dan TN (True Negative) menunjukkan banyaknya amatan yang diprediksi secara tepat. FP (False Positive) menunjukkan banyaknya amatan kelas
7 negatif yang diprediksi sebagai kelas positif, hal sebaliknya disebut FN (False Negative). Ukuran keakuratan klasifikasi dapat dihitung antara lain dengan nilai akurasi, sensitivitas, dan spesifisitas sesuai persamaan (7), (8), dan (9).
(7)
(8)
(9) Akurasi (Accuracy) mengukur proporsi amatan yang diprediksikan secara tepat. Sensitivitas (Sensitivity) mengukur proporsi amatan positif HIV yang tepat diprediksikan sebagai kelas Positif HIV, sedangkan Spesifisitas (Specificity) mengukur proporsi amatan negatif HIV yang tepat diprediksikan sebagai kelas Negatif HIV.
Selain ukuran keakuratan di atas, AUC (Area Under Curve) dari ROC (Receiver Operating Characteristic) juga akan digunakan untuk mengevaluasi ketepatan klasifikasi pada data tidak seimbang. AUC ini menunjukkan performa relatif dari TP dan FP. Sumbu-x menunjukkan nilai tingkat false positive (FP/(TN+FP)) dan sumbu-y menunjukkan nilai tingkat true positive (TP/(TP+FN)). Semakin mendekati nilai satu berarti semakin baik klasifikasi yang dilakukan. Titik amatan pada kurva ROC yang menunjukkan performa relatif TP dan FP diperoleh dengan mengubah nilai Cut-Off Point (COP) atau menghitung performa klasifikasi pada beberapa nilai COP. Titik potong atau Cut-Off Point (COP) adalah nilai batas antara hasil uji positif dan hasil uji negatif.
METODE
DataPenelitian ini menggunakan data hasil Surveilans Terpadu HIV – Perilaku 2006 (STHP-06) yang dilakukan oleh Departemen Kesehatan bekerja sama dengan Badan Pusat Statistik (BPS), dengan dukungan Bank Dunia dan FHI/ASA. Survei ini mencakup sepuluh kabupaten/kota di Tanah Papua dengan mengelompokkan Tanah Papua berdasarkan topografinya menjadi tiga, yaitu sebanyak tiga kabupaten di wilayah pegunungan, empat kabupaten/kota di wilayah pesisir mudah, dan tiga kabupaten di wilayah pesisir sulit. Pengelompokan ini selanjutnya digunakan sebagai strata. Teknik penarikan contoh yang digunakan yaitu penarikan contoh tiga tahap (Three Stage Stratified Sampling). Tahap pertama untuk memilih sampel kabupaten/kota, tahap kedua memilih blok sensus pada kabupaten/kota terpilih, dan tahap ketiga untuk memilih secara sistematik responden yang memenuhi syarat yaitu sebanyak 25 responden berusia 15-49 tahun di tiap blok sensus terpilih. Daftar responden diurutkan menurut jenis kelamin dan kelompok umur (15-24, 25-39, dan 40-49 tahun). Jumlah responden yang memenuhi syarat sebanyak 6500 responden yang meliputi 260 blok sensus. Realisasi sampel responden yang berhasil dilakukan pengujian darah untuk mengetahui hasil tes HIV sebanyak 6223 responden. Namun, data
8
yang digunakan pada penelitian ini hanya terdiri atas 6217 responden. Pada data tersebut diketahui bahwa dari 6217 responden terdapat 148 responden yang hasil pengujian darahnya menunjukkan positif HIV. Dengan demikian, perbandingan antara jumlah responden positif HIV dan negatif HIV sekitar 1:41. Hal ini juga menunjukkan bahwa responden yang mengidap positif HIV hanya sekitar 2.38% dari total responden yang berhasil diuji darahnya. Oleh karena itu, data hasil STHP-06 ini termasuk data kelas tidak seimbang sehingga dapat diterapkan metode penanganan dengan harapan dapat meningkatkan ketepatan klasifikasinya. Peubah respon pada penelitian ini yaitu hasil tes HIV yang terdiri atas dua kategori yaitu 0 (negatif HIV) dan 1 (positif HIV). Sedangkan peubah penjelas yang digunakan pada penelitian ini terdiri atas peubah numerik dan peubah kategorik sesuai Tabel 2.
Tabel 2 Daftar peubah penjelas
Peubah penjelas Keterangan Kategori
X1 Umur seks pertama 0 = usia > 16 tahun
1 = usia ≤ 16 tahun X2 Penggunaan alat kontrasepsi 0 = menggunakan
1 = tidak menggunakan X3 Perilaku seks berisiko 0 = tidak; 1 = ya
X4 Penyakit Menular Seksual (PMS) 0 = tidak ada PMS 1 = ada PMS
X5 Topografi wilayah 1 = pesisir mudah
2 = pesisir sulit 3 = pegunungan
X6 Jenis kelamin 1 = laki-laki
2 = perempuan
X7 Suku bangsa 0 = non Papua;1 = Papua
X8 Status perkawinan 1 = kawin resmi
2 = belum kawin 3 = cerai
4 = hidup bersama
X9 Pengetahuan tentang HIV 0 = tahu
1 = tidak/kurang tahu X10 Penghasilan per bulan (ribu) Numerik
X11 Lama sekolah (tahun) Numerik
X12 Usia (tahun) Numerik
Metode Penelitian Berikut tahapan yang dilakukan dalam penelitian ini.
1. Melakukan eksplorasi terhadap data hasil STHP-06 untuk mengetahui gambaran umum data.
2. Membagi data secara acak menjadi dua bagian yaitu 80% sebagai data latih dan 20% sebagai data uji dengan proporsi kelas minoritas dan kelas mayoritas pada masing-masing bagian data relatif sama dengan proporsi awal.
9 3. Melakukan pengklasifikasian dengan Pohon Klasifikasi C5.0 dengan menggunakan data latih dan hitung kinerja klasifikasinya menggunakan data uji. Kinerja klasifikasi yang diukur meliputi akurasi, sensitivitas, spesifisitas, dan nilai AUC dari ROC.
4. Menerapkan penanganan kelas data tidak seimbang dengan SMOTE pada data latih.
a. Tahap Oversampling
i. Menentukan nilai t untuk t-tetangga terdekat yaitu t = 1.
ii. Menentukan besar persentase oversampling yaitu sebesar 200%. iii.Menghitung jarak antar data kelas minoritas.
iv.Menentukan 1-tetangga terdekat.
v. Melakukan perhitungan untuk membangkitkan data buatan. b. Tahap Undersampling
i. Menentukan besar persentase undersampling yaitu sebesar 150%. ii. Menyisihkan secara acak amatan kelas mayoritas sesuai jumlah pada i. iii.Menyimpan data hasil oversampling kelas minoritas dan hasil
undersampling kelas mayoritas sebagai data latih baru.
5. Menerapkan penanganan kelas data tidak seimbang dengan SMOUTE pada data latih.
a. Tahap oversampling seperti pada metode SMOTE b. Tahap Undersampling
i. Tentukan ukuran undersampling yaitu sebesar 150% dari banyaknya amatan buatan kelas minoritas.
ii. Melakukan pengelompokan kelas mayoritas dengan algoritme k-rataan menggunakan tiga peubah numerik dengan nilai k = 4. Jarak yang digunakan pada algoritme k-rataan adalah jarak Euclidean dengan dilakukan normalisasi terlebih dahulu pada data.
iii.Menyisihkan secara acak amatan kelas mayoritas di tiap kelompok dengan ukuran undersampling sesuai persamaan (3).
iv.Menyimpan data hasil oversampling kelas minoritas dan hasil undersampling kelas mayoritas sebagai data latih baru.
6. Menerapkan penanganan kelas data tidak seimbang dengan SMOUTE dua tahap pada data latih.
a. Tahap oversampling dilakukan seperti pada metode SMOTE tetapi dilakukan sebanyak dua kali. Oversampling pertama dilakukan dengan persentase 100% dan oversampling kedua dilakukan dengan persentase 50%.
b. Tahap undersampling seperti pada metode SMOUTE.
7. Melakukan pengklasifikasian kembali dengan Pohon Klasifikasi C5.0 dengan menggunakan data latih baru dan hitung kembali kinerja klasifikasinya dengan menggunakan data uji meliputi nilai akurasi, sensitivitas, spesifisitas, dan nilai AUC dari ROC.
8. Melakukan ulangan sebanyak 500 kali untuk tahap 4 hingga 7.
9. Membandingkan kinerja klasifikasi tanpa dan dengan diterapkannya penanganan kelas data tidak seimbang dan dipilih satu metode penanganan yang menghasilkan rataan kinerja klasifikasi terbaik.
10. Menentukan tiga peubah penjelas paling penting pada model klasifikasi dengan metode pananganan terbaik dan melakukan ulangan sebanyak 50 kali
10
untuk mengetahui peubah penjelas yang konsisten menjadi tiga peubah paling penting.
HASIL DAN PEMBAHASAN
Gambaran Umum DataTanah Papua terbagi menjadi dua provinsi yaitu Provinsi Papua dan Provinsi Papua Barat, serta terdiri atas 29 kabupaten/kota. Pada Surveilans Terpadu HIV – Perilaku tahun 2006 (STHP-06), Tanah Papua distratifikasikan berdasarkan topografi menjadi tiga strata, yaitu Daerah Pegunungan yang terdiri atas 6 kabupaten, Pesisir Mudah yang terdiri atas 10 kabupaten dan 2 kota, serta Pesisir Sulit yang terdiri atas 11 kabupaten. Penarikan contoh yang dilakukan menggunakan metode Three Stage Stratified. Tahap pertama penarikan contoh yaitu mengambil sepuluh kabupaten/kota yang mewakili ketiga strata tersebut sebagai sampel survei. Strata Daerah Pegunungan diwakili oleh 3 kabupaten yaitu Jayawijaya, Paniai, dan Pegunungan Bintang. Strata Pesisir Mudah diwakili oleh 4 kabupaten/kota yaitu Kota Sorong, Jayapura, Yapen, dan Kota Jayapura. Strata Pesisir Sulit diwakili oleh 3 kabupaten yaitu Teluk Bintuni, Sorong Selatan, dan Mappi. Tahap kedua penarikan contoh yaitu memilih blok sensus pada kabupaten/kota terpilih dengan komposisi sebanyak 70 blok sensus pada Daerah Pegunungan, 137 blok sensus pada Pesisir Mudah, dan 53 blok sensus pada Pesisir Sulit. Selanjutnya, tahap terakhir dari penarikan contoh yaitu memilih secara sistematik 25 penduduk berumur antara 15 hingga 49 tahun pada tiap blok sensus terpilih dengan daftar penduduk dikelompokkan berdasarkan jenis kelamin dan kelompok umur (BPS dan DepKes 2007). Berdasarkan pada penarikan contoh tersebut, target sampel yang memenuhi syarat sebanyak 6500 responden. Namun, pada realisasinya hanya terdapat 6233 responden yang berhasil diuji darahnya dan pada penelitian ini hanya akan digunakan sebanyak 6217 responden. Berdasarkan data dari 6217 responden STHP-06 dapat diringkas karakteristiknya berdasarkan peubah yang digunakan sesuai Tabel 3.
Berdasarkan Tabel 3 diketahui bahwa hanya sebesar 2.38% responden survei yang dinyatakan positif HIV. Hal inilah yang menyebabkan data hasil STHP-06 termasuk ke dalam data kelas tidak seimbang. Responden yang dinyatakan positif HIV selanjutnya dianggap sebagai kelas positif atau kelas minoritas yang menjadi pusat perhatian pada penelitian ini. Sedangkan, responden dengan hasil tes menunjukkan negatif HIV dianggap sebagai kelas negatif atau kelas mayoritas yang mana jumlahnya jauh lebih besar dibandingkan responden yang dinyatakan positif HIV.
Karakteristik lain dari responden survei STHP-06 ini antara lain sebagian besar responden yaitu sebanyak 85.46% responden melakukan seks pertama kali pada usia lebih dari 16 tahun. Artinya sekitar 15% atau sekitar 930 responden melakukan seks pertama kali saat masih di bawah umur. Selain itu, hampir seluruh responden menyatakan tidak menggunakan alat kontrasepsi dalam berhubungan seksual. Hanya sekitar 2.75% responden yang menyatakan menggunakan alat kontrasepsi dalam berhubungan seksual. Hal ini menunjukkan
11 bahwa sebagian besar masyarakat Tanah Papua tidak terbiasa menggunakan alat kontrasepsi dalam berhubungan seksual karena kurangnya akses yang ada.
Tabel 3 Persentase responden berdasarkan peubah yang digunakan
Peubah Kategori Persentase (%)
Hasil tes HIV Positif HIV 2.38
Negatif HIV 97.62
Umur seks pertama Usia ≤ 16 tahun 14.54
Usia > 16 tahun 85.46
Penggunaan alat kontrasepsi Menggunakan 2.75
Tidak menggunakan 97.25
Perilaku seks berisiko Ya 44.78
Tidak 55.22
Penyakit Menular Seksual Ada PMS 8.85
(PMS) Tidak ada PMS 91.15
Topografi wilayah Pesisir mudah 51.44
Pesisir sulit 20.59
Pegunungan 27.97
Jenis kelamin Laki-laki 50.36
Perempuan 49.64
Suku bangsa Papua 68.97
Non Papua 31.03
Status perkawinan Kawin resmi 66.45
Belum kawin 27.33
Cerai 2.70
Hidup bersama 3.52
Pengetahuan tentang HIV Tahu 30.69
Tidak/kurang tahu 69.31
Penghasilan per bulan Tidak berpendapatan 35.40
≤ Rp 100 000 8.93
Rp 101 000 – Rp 500 000 31.35 Rp 501 000 – Rp 1 500 000 18.98
> Rp 1 500 000 5.34
Lama sekolah Tidak bersekolah 21.20
SD 26.89 SMP 17.40 SMA 27.49 Perguruan tinggi 7.01 Usia 15 – 24 tahun 34.02 25 – 39 tahun 47.34 40 – 49 tahun 18.64
12
Jumlah responden yang memiliki perilaku seks berisiko tidak jauh berbeda dengan jumlah responden yang tidak memiliki perilaku seks berisiko. Berdasarkan Tabel 3 juga ditunjukkan bahwa hanya sekitar 8.85% responden menyatakan memiliki Penyakit Menular Seksual (PMS), sedangkan sisanya menyatakan tidak memiliki PMS. Ini berarti hanya sebagian kecil masyarakat Tanah Papua yang memiliki Penyakit Menular Seksual.
Berdasarkan topografi wilayahnya, perbandingan jumlah responden dari Pesisir Mudah, Pesisir Sulit, dan Daerah Pegunungan yaitu sekitar 2 : 1 : 1. Lebih dari setengah jumlah responden berasal dari Pesisir Mudah. Jumlah responden cukup seimbang antara responden laki-laki dan responden perempuan. Berdasarkan suku bangsanya, responden bersuku bangsa Papua lebih banyak dibandingkan responden non Papua yaitu sebesar 68.97% responden merupakan suku Papua asli. Selain itu, sebesar 66.45% responden menyatakan sudah menikah, 27.33% responden menyatakan belum menikah, dan sisanya menyatakan sudah bercerai atau hidup bersama. Sedangkan berdasarkan pengetahuan terhadap HIV, sebagian besar masyarakat Tanah Papua masih belum mengetahui hal-hal mengenai HIV yaitu sebesar 69.31% responden.
Hal selanjutnya yang cukup memprihatinkan yaitu sebesar 35.4% responden survei menyatakan tidak memiliki penghasilan, rata-rata penghasilan responden yaitu berkisar Rp 500 000 per bulan, dan hanya sekitar 5.34% responden yang berpenghasilan lebih dari Rp 1 500 000 tiap bulannya. Hal ini sama memprihatinkannya dengan lama masa sekolah yang dienyam responden. Terdapat sekitar 21.2% responden tidak pernah bersekolah, 26.89% responden hanya mengenyam pendidikan hingga SD, sekitar 44.89% responden mengenyam pendidikan hingga sekolah menengah, dan sisanya sekitar 7.01% responden mengenyam pendidikan hingga tingkat perguruan tinggi. Jika dilihat dari sisi usia, responden paling banyak berada pada masa dewasa awal yaitu pada rentang usia 25 hingga 39 tahun, sedangkan pada rentang usai 40 hingga 49 tahun hanya sekitar 18.64% responden.
Berikut Tabel 4 menunjukkan proporsi banyaknya responden positif HIV yang berpadanan dengan kategori peubah penjelas yang digunakan.
Tabel 4 Proporsi responden positif HIV pada tiap kategori peubah penjelas
Peubah Kategori Proporsi (%)
Umur seks pertama Usia ≤ 16 tahun 3.21
Usia > 16 tahun 2.24
Penggunaan alat kontrasepsi Menggunakan 1.75
Tidak menggunakan 2.40
Perilaku seks berisiko * Ya 3.13
Tidak 1.78
Penyakit Menular Seksual Ada PMS 3.64
(PMS) * Tidak ada PMS 2.26
*perbedaan proporsi risiko positif HIV signifikan terhadap peubah pada taraf nyata 5% dengan menggunakan uji Chi-Square
13 Tabel 4 Proporsi responden positif HIV berdasarkan peubah yang
digunakan (lanjutan)
Peubah Kategori Proporsi (%)
Topografi wilayah * Pesisir mudah 1.81
Pesisir sulit 3.13
Pegunungan 2.88
Jenis kelamin * Laki-laki 2.87
Perempuan 1.88
Suku bangsa * Papua 2.80
Non Papua 1.45
Status Perkawinan Kawin resmi 2.35
Belum kawin 2.53
Cerai 1.19
Hidup bersama 2.74
Pengetahuan tentang HIV * Tahu 1.57
Tidak/kurang tahu 2.74
*perbedaan proporsi risiko positif HIV signifikan terhadap peubah pada taraf nyata 5% dengan menggunakan uji Chi-Square
Berdasarkan Tabel 4, tanda bintang (*) pada beberapa peubah menunjukkan adanya asosiasi antara peubah tersebut dengan peubah respon yaitu berupa risiko HIV. Terdapat enam dari sembilan peubah yang dinyatakan memiliki perbedaan proporsi risiko positif HIV yang signifikan pada taraf nyata 5%. Berdasarkan tabel 4 dapat dikatakan bahwa responden yang memiliki perilaku seks berisiko atau memiliki Penyakit Menular Seksual (PMS) menghasilkan proporsi mengidap HIV positif yang lebih besar. Responden yang tinggal di daerah pesisir sulit atau di daerah pegunungan juga menunjukkan proporsi mengidap HIV positif lebih besar dibandingkan responden yang tinggal di daerah pesisir mudah. Proporsi responden laki-laki yang mengidap HIV positif juga lebih besar dibandingkan responden perempuan. Begitu pula proporsi pengidap HIV positif lebih besar merupakan responden suku Papua asli. Responden yang tidak/kurang tahu mengenai HIV pun menunjukkan proporsi mengidap HIV positif yang lebih besar. Oleh karena itu, pengetahuan mengenai HIV memang sangat penting untuk dimiliki setiap masyarakat.
Gambar 1 memperlihatkan sebaran penghasilan per bulan pada kelas responden negatif HIV dan kelas responden positif HIV. Dari gambar tersebut terlihat bahwa rata-rata penghasilan per bulan tidak jauh berbeda antara kelas responden negatif HIV dan kelas responden positif HIV yaitu berkisar Rp 400 000 per bulan. Panjang kotak boxplot untuk kedua kelas juga tidak begitu berbeda terlihat lebih jelas pada boxplot skala logaritmik sesuai Gambar 1(b) dengan mengubah penghasilan Rp 0 menjadi Rp 1 000. Hal ini menunjukkan bahwa 50% penghasilan responden yang berada di tengah sama untuk kedua kelas yaitu dengan nilai kuartil 1 adalah Rp 0 dan kuartil 3 adalah Rp 500 000.
14
Gambar 1 Boxplot penghasilan per bulan (ribu) berdasarkan hasil tes HIV Namun, perbedaan kedua boxplot Gambar 1 sangat terlihat pada banyaknya penghasilan per bulan yang dianggap sebagai pencilan. Kelas responden negatif HIV memiliki banyak sekali amatan pencilan sejalan dengan banyaknya amatan pada kelas ini yang mencapai 6069 amatan. Nilai penghasilan per bulan tertinggi pada kelas responden negatif HIV yaitu Rp 26 400 000. Sebaliknya, pada kelas responden positif HIV amatan yang dianggap pencilan tidak terlalu banyak karena jumlah amatan pada kelas ini tergolong sedikit yaitu hanya 148 amatan. Nilai penghasilan per bulan tertinggi untuk kelas responden positif HIV ini hanya sebesar Rp 5 000 000. Jadi, jika diperhatikan secara sekilas, responden dengan penghasilan lebih dari Rp 5 000 000 per bulan dapat dikatakan bahwa responden tersebut adalah responden negatif HIV.
Gambar 2(a) menunjukkan boxplot lama sekolah untuk kelas responden negatif HIV dan kelas responden positif HIV. Jika dilihat dari dua boxplot Gambar 2(a) dapat diketahui bahwa karakteristik lama sekolah untuk kedua kelas tidak jauh berbeda. Hal ini terlihat dari panjang kotak boxplot dan panjang garis whisker yang tidak berbeda jauh untuk kedua kelas. Namun, terlihat bahwa median kelas responden negatif HIV lebih besar dibandingkan median kelas responden positif HIV. Gambar 2(a) menunjukkan bahwa semakin tinggi tingkat pendidikan seseorang tidak menjamin orang tersebut terhindar dari risiko HIV.
Gambar 2(b) juga menunjukkan dua boxplot yang tidak berbeda jauh. Nilai minimum dan nilai maksimum untuk kedua boxplot sama yaitu 15 tahun dan 49 tahun sesuai dengan syarat usia responden survei yang telah ditentukan. Hal ini menunjukkan bahwa seseorang yang terinfeksi HIV tidak memandang usia, baik muda maupun tua. Median dari kedua boxplot Gambar 2(b) juga menunjukkan nilai yang sama yaitu 29 tahun. Namun, terlihat bahwa panjang kotak boxplot untuk kelas responden negatif HIV lebih sempit dibanding boxplot kelas responden positif HIV. Hal ini menunjukkan bahwa usia responden positif HIV lebih beragam dibanding usia responden negatif HIV. Artinya HIV dapat menyerang siapa saja tanpa melihat usianya.
15
Gambar 2 Boxplot lama sekolah dan usia Penanganan Kelas Data Tidak Seimbang
Ketidakseimbangan kelas pada data STHP-06 diperlihatkan dengan tidak sebandingnya persentase antara jumlah responden yang dinyatakan positif HIV dan jumlah responden yang dinyatakan negatif HIV. Pada Tabel 3 diperlihatkan bahwa terjadi ketidakseimbangan kelas data yaitu hanya sebesar 2.38% responden survei yang dinyatakan positif HIV sedangkan sisanya sebanyak 97.62% dinyatakan negatif HIV. Hal ini akan menimbulkan masalah ketika dilakukan analisis klasifikasi yaitu kecilnya nilai ketepatan klasifikasi untuk kelas responden positif HIV. Selanjutnya kelas responden positif HIV disebut kelas minoritas yang menjadi pusat perhatian dari penelitian ini, sedangkan kelas responden negatif HIV disebut kelas mayoritas. Pada penelitian ini data dibagi terlebih dahulu menjadi dua bagian yaitu 80% data latih dan 20% data uji dengan komposisi proporsi kelas yang relatif sama dengan data asli.
Tabel 5 Komposisi pembagian data
Kelas Data latih Data uji
Minoritas 118 (2.37%) 30 (2.41%) Mayoritas 4855 (97.63%) 1214 (97.59%) Total 4973 (100.00%) 1244 (100.00%)
Tahap selanjutnya yaitu melakukan pengklasifikasian data latih menggunakan Pohon Klasifikasi C5.0 untuk melihat kinerja klasifikasi pada kondisi kelas data tidak seimbang. Kinerja klasifikasi dilihat dengan membandingkan hasil prediksi pohon klasifikasi yang dihasilkan dengan data aktual pada data uji. Berikut kinerja klasifikasi Pohon Klasifikasi C5.0 sebelum dilakukan penanganan terhadap kelas data tidak seimbang.
16
Tabel 6 Kinerja klasifikasi tanpa penanganan kelas data tidak seimbang
Kinerja klasifikasi Nilai
Akurasi 0.9759
Sensitivitas 0.0000
Spesifisitas 1.0000
Tabel 6 menunjukkan kinerja klasifikasi Pohon Klasifikasi C5.0 pada data uji tanpa dilakukannya penanganan terhadap kelas data tidak seimbang. Terlihat bahwa akurasi dari Pohon Klasifikasi tersebut sangat tinggi yaitu 0.9759 artinya kesalahan klasifikasinya hanya sebesar 0.0241. Namun, jika dilihat lebih dalam yaitu pada nilai sensitivitas menunjukkan nilai yang sangat kecil yaitu 0 yang berarti tidak ada satupun amatan kelas minoritas yang berhasil diklasifikasikan secara benar. Jika diterapkan pada kasus maka tidak ada satupun responden positif HIV yang diklasifikasikan ke dalam kelas positif HIV. Hal inilah yang cukup berbahaya dalam pengambilan keputusan ke depannya. Walaupun di sisi lain spesifisitas bernilai sempurna yaitu 1 tetapi pusat perhatian pada penelitian ini adalah kelas minoritas sehingga diperlukan penanganan terhadap kelas data tidak seimbang agar kinerja klasifikasi yang dihasilkan lebih baik.
Penanganan terhadap kelas data tidak seimbang pada penelitian ini dilakukan melalui beberapa modifikasi metode Synthetic Minority Oversampling Technique (SMOTE) pada data latih dengan tujuan memperoleh model klasifikasi dengan kinerja terbaik. Metode pertama yang digunakan adalah SMOTE sesuai dengan Chawla et al. (2002). Pada metode ini akan dilakukan pembangkitan amatan kelas minoritas buatan (oversampling) dengan konsep t-tetangga terdekat dan juga akan dilakukan penarikan contoh secara acak amatan kelas mayoritas (undersampling). Penelitian ini menggunakan persentase oversampling sebesar 200% yang berarti pada setiap amatan kelas minoritas akan dibangkitkan dua amatan kelas minoritas buatan sehingga hasil akhir SMOTE ini memiliki tiga kali jumlah amatan kelas minoritas awal. Persentase oversampling sebesar 200% ini dipilih karena berdasarkan percobaan yang telah dilakukan diperoleh hasil bahwa semakin banyak amatan buatan yang dibangkitkan maka semakin kecil nilai sensitivitasnya sehingga dipilih persentase oversampling yang tidak terlalu besar. Sedangkan persentase undersampling yang digunakan adalah sebesar 150% dengan tujuan agar terjadi keseimbangan antara jumlah amatan kelas minoritas dan jumlah amatan kelas mayoritas. Semakin besar persentase undersampling akan menurunkan nilai sensitivitas yang dihasilkan pada data ini. Persentase undersampling sebesar 150% artinya amatan kelas mayoritas akan diambil secara acak sebanyak 1.5 kali dari banyaknya kelas minoritas yang dibangkitkan. Ukuran t untuk pembangkitan amatan kelas minoritas dengan konsep t-tetangga terdekat yang digunakan adalah t = 1 karena dikhawatirkan posisi amatan kelas minoritas sangat berbeda jauh satu sama lain sehingga hanya dipilih satu tetangga terdekat dalam membangkitkan amatan buatan dengan harapan amatan buatan tersebut memiliki karakteristik yang tidak berbeda jauh dari amatan acuannya.
17 Tabel 7 Komposisi data hasil SMOTE
Kelas Data latih Data hasil SMOTE Minoritas 118 (2.37%) 354 (50%) Mayoritas 4855 (97.63%) 354 (50%) Total 4973 (100.00%) 708 (100%)
Terlihat dari Tabel 7 bahwa setelah dilakukan SMOTE kondisi kelas data sudah seimbang yaitu dengan proporsi kelas minoritas 50% dan kelas mayoritas 50%.
Metode penanganan kelas data tidak seimbang yang dilakukan selanjutnya adalah metode modifikasi dari SMOTE yaitu Synthetics Minority Oversampling and Undersampling Technique (SMOUTE) yang diajukan oleh Songwattanasiri dan Sinapiromsaran (2010). Perbedaan utama metode ini adalah pada tahap awal undersampling kelas mayoritas. Undersampling pada SMOUTE diawali dengan pengelompokan kelas mayoritas terlebih dahulu melalui algoritme k-rataan. Setelah kelas mayoritas dikelompokkan ke dalam k kelompok, undersampling dilakukan secara acak di masing-masing kelompok serupa dengan undersampling pada SMOTE. Persentase oversampling dan undersampling yang digunakan pada metode ini sama dengan yang digunakan pada metode SMOTE sebelumnya yaitu masing-masing 200% dan 150%. Sedangkan nilai k untuk algoritme k-rataan yang digunakan adalah k = 4 karena berdasarkan percobaan yang telah dilakukan k = 4 cenderung menghasilkan kinerja klasifikasi yang lebih baik untuk data STHP-06 ini.
Tabel 8 Komposisi data hasil SMOUTE
Kelas Data latih Data hasil SMOUTE Minoritas 118 (2.37%) 354 (50%) Mayoritas 4855 (97.63%) 354 (50%) Total 4973 (100.00%) 708 (100%)
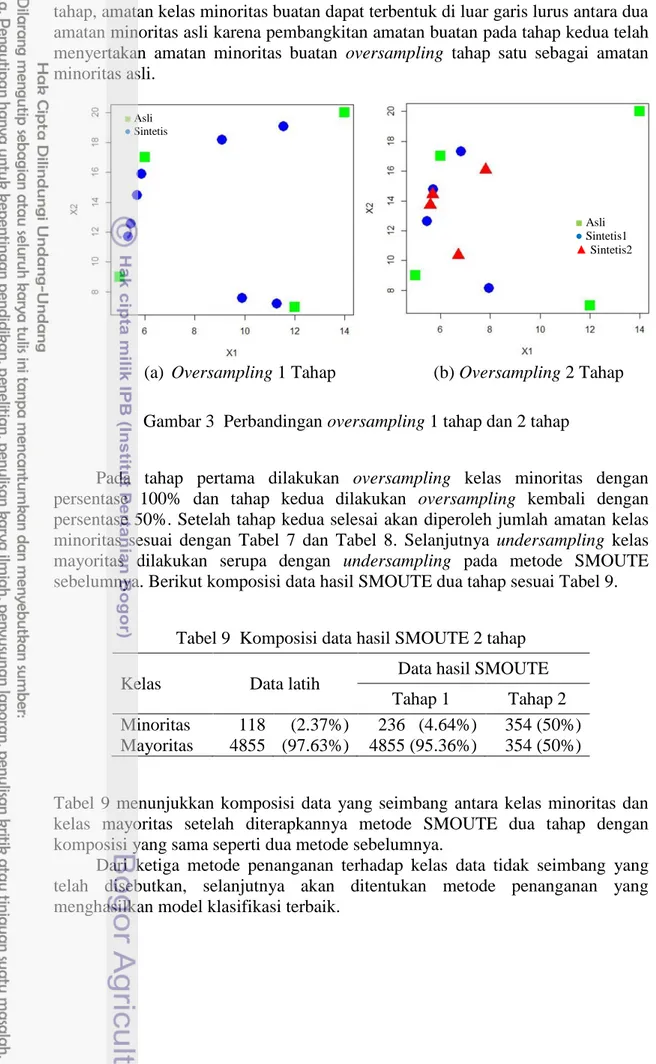
Metode SMOUTE ini kemudian dilakukan modifikasi pada bagian oversampling kelas minoritasnya. Bagian oversampling sesuai dengan oversampling yang dilakukan pada metode SMOTE tetapi oversampling ini dilakukan dalam dua tahap untuk menghasilkan komposisi akhir data yang sama dengan Tabel 7 dan Tabel 8. Ide dasar metode SMOUTE dua tahap ini adalah adanya dugaan bahwa amatan buatan yang dibangkitkan akan berbeda jika dibangkitkan dari gabungan amatan minoritas asli dan amatan minoritas buatan hasil oversampling tahap pertama dibandingkan dengan amatan buatan hasil pembangkitan oversampling satu tahap. Berikut ilustrasinya sesuai Gambar 3.
Gambar 3 menunjukkan bahwa ada perbedaan hasil amatan minoritas buatan yang dibangkitkan antara oversampling satu tahap dan oversampling dua tahap. Terlihat bahwa oversampling satu tahap dengan t = 1 untuk konsep t-tetangga terdekat akan membangkitkan amatan buatan selalu berada pada garis antara dua amatan kelas minoritas asli karena perbedaan hasil pembangkitan hanya berasal dari nilai acak yang digunakan. Sedangkan pada oversampling dua
18
tahap, amatan kelas minoritas buatan dapat terbentuk di luar garis lurus antara dua amatan minoritas asli karena pembangkitan amatan buatan pada tahap kedua telah menyertakan amatan minoritas buatan oversampling tahap satu sebagai amatan minoritas asli.
Gambar 3 Perbandingan oversampling 1 tahap dan 2 tahap
Pada tahap pertama dilakukan oversampling kelas minoritas dengan persentase 100% dan tahap kedua dilakukan oversampling kembali dengan persentase 50%. Setelah tahap kedua selesai akan diperoleh jumlah amatan kelas minoritas sesuai dengan Tabel 7 dan Tabel 8. Selanjutnya undersampling kelas mayoritas dilakukan serupa dengan undersampling pada metode SMOUTE sebelumnya. Berikut komposisi data hasil SMOUTE dua tahap sesuai Tabel 9.
Tabel 9 Komposisi data hasil SMOUTE 2 tahap
Kelas Data latih Data hasil SMOUTE
Tahap 1 Tahap 2 Minoritas 118 (2.37%) 236 (4.64%) 354 (50%) Mayoritas 4855 (97.63%) 4855 (95.36%) 354 (50%)
Tabel 9 menunjukkan komposisi data yang seimbang antara kelas minoritas dan kelas mayoritas setelah diterapkannya metode SMOUTE dua tahap dengan komposisi yang sama seperti dua metode sebelumnya.
Dari ketiga metode penanganan terhadap kelas data tidak seimbang yang telah disebutkan, selanjutnya akan ditentukan metode penanganan yang menghasilkan model klasifikasi terbaik.
(a) Oversampling 1 Tahap (b) Oversampling 2 Tahap (b) ■ Asli ● Sintetis ■ Asli ● Sintetis1 ▲ Sintetis2
19 Pemilihan Metode Penanganan Terbaik
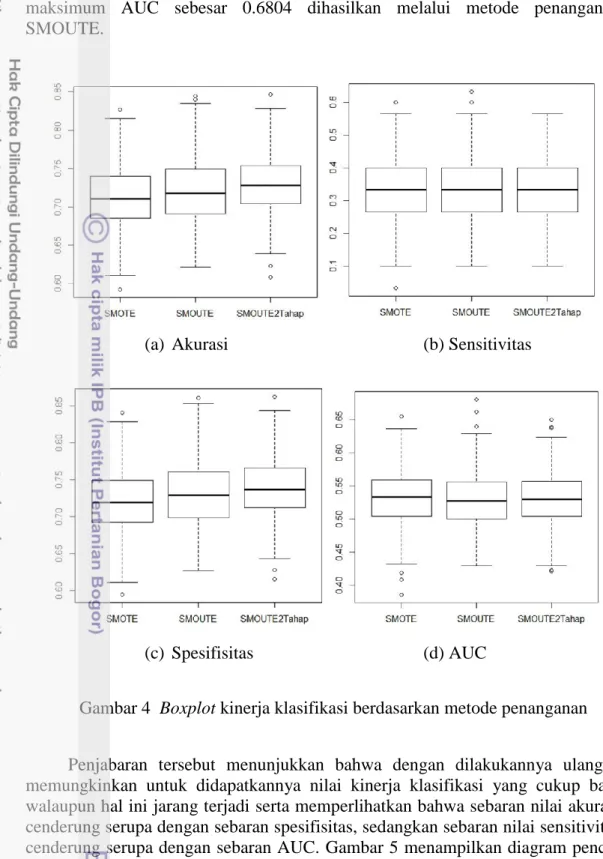
Setelah dilakukan praproses yaitu penanganan terhadap kelas data tidak seimbang dan dilakukan kembali pengklasifikasian dengan Pohon Klasifikasi C5.0, diperoleh tiga rataan kinerja klasifikasi untuk ketiga metode penanganan kelas data tidak seimbang. Kinerja klasifikasi dihitung dengan membandingkan nilai peubah respon hasil prediksi dan peubah respon aktual dari data uji. Kinerja klasifikasi yang dibandingkan yaitu meliputi akurasi, sensitivitas, spesifisitas, dan nilai AUC dari ROC. Pengklasifikasian dengan Pohon Klasifikasi C5.0 dilakukan dengan ulangan sebanyak 500 kali pada masing-masing metode penanganan kelas tidak seimbang sehingga diperoleh sebaran kinerja klasifikasi untuk ketiga metode penanganan sesuai Gambar 4.
Gambar 4(a) menunjukkan bahwa secara umum sebaran nilai akurasi untuk ketiga model klasifikasi hasil penanganan tidak berbeda jauh. Panjang kotak ketiga boxplot tersebut juga relatif sama. Namun, jika dilihat lebih detil maka diketahui bahwa posisi kotak boxplot dengan metode penanganan SMOUTE dua tahap relatif lebih tinggi dibandingkan kedua boxplot lainnya. Hal ini menunjukkan bahwa 50% nilai akurasi yang berada di bagian tengah data pada metode SMOUTE dua tahap ini cenderung lebih baik walaupun masih terjadinya tumpang tindih (overlapping) dengan kedua boxplot lainnya. Nilai mimimum akurasi terjadi pada model klasifikasi dengan metode penanganan SMOTE yaitu sebesar 0.5924 sedangkan nilai maksimum akurasi terdapat pada model klasifikasi dengan metode penanganan SMOUTE dua tahap dengan nilai sebesar 0.8465.
Boxplot pada Gambar 4(b) menunjukkan sebaran nilai sensitivitas model untuk ketiga metode penanganan. Dari Gambar 4(b) terlihat bahwa ketiga boxplot memiliki panjang kotak yang persis sama yaitu dengan nilai kuartil 1 sebesar 0.2667, kuartil 2 (median) sebesar 0.3333, dan kuartil 3 sebesar 0.4000. Hal ini berarti ketiga metode menghasilkan nilai sensitivitas yang tidak berbeda pada 50% data yang berada di bagian tengah data. Hal ini juga menunjukkan bahwa ketiga metode penanganan kelas tidak seimbang menghasilkan nilai sensitivitas yang relatif sama. Nilai sensitivitas minimum terdapat pada metode penanganan SMOTE yaitu sebesar 0.0333 sedangkan nilai tertinggi terdapat pada metode penanganan SMOUTE yaitu sebesar 0.6333.
Serupa dengan Gambar 4(a), Gambar 4(c) menunjukkan sebaran nilai spesifisitas pada ketiga metode penanganan yang tidak berbeda jauh dilihat dari tinggi kotak boxplot yang relatif sama untuk ketiga metode. Namun, pada Gambar 4(c) terlihat bahwa posisi kotak boxplot dengan metode penanganan SMOUTE dua tahap relatif lebih tinggi dibandingkan kedua boxplot lainnya walaupun masih adanya tumpang tindih nilai dengan kedua boxplot lainnya. Posisi kotak boxplot yang lebih tinggi ini menunjukkan bahwa 50% nilai spesifisitas yang berada di bagian tengah data lebih baik pada metode penanganan SMOUTE dua tahap ini. Nilai minimum spesifisitas sebesar 0.5947 terjadi pada metode penanganan SMOTE sedangkan nilai maksimum spesifisitas sebesar 0.8624 terjadi pada metode penanganan SMOUTE dua tahap.
Gambar 4(d) menunjukkan panjang kotak boxplot yang relatif sama untuk ketiga metode penanganan. Artinya sebaran 50% data AUC yang berada di bagian tengah data relatif sama untuk ketiga metode penanganan tersebut. Nilai minimum AUC sebesar 0.3855 dihasilkan oleh metode penanganan SMOTE sedangkan nilai
20
maksimum AUC sebesar 0.6804 dihasilkan melalui metode penanganan SMOUTE.
Gambar 4 Boxplot kinerja klasifikasi berdasarkan metode penanganan Penjabaran tersebut menunjukkan bahwa dengan dilakukannya ulangan memungkinkan untuk didapatkannya nilai kinerja klasifikasi yang cukup baik walaupun hal ini jarang terjadi serta memperlihatkan bahwa sebaran nilai akurasi cenderung serupa dengan sebaran spesifisitas, sedangkan sebaran nilai sensitivitas cenderung serupa dengan sebaran AUC. Gambar 5 menampilkan diagram pencar yang memperlihatkan pola kecenderungan hubungan nilai akurasi dan sensitivitas. Dari Gambar 5 tersebut terlihat bahwa akurasi dan sensitivitas memiliki pola hubungan linier negatif yang berarti semakin besar nilai akurasi maka nilai sensitivitas cenderung semakin kecil. Hal ini diperkuat dengan Tabel 10 dan Tabel 11 yang menunjukkan perbandingan kinerja klasifikasi tiap metode penanganan berdasarkan nilai akurasi tertinggi dan nilai sensitivitas tertinggi.
(a) Akurasi (b) Sensitivitas
21
Gambar 5 Diagram pencar antara akurasi dan sensitivitas dengan metode SMOUTE dua tahap
Sejalan dengan Gambar 5, Tabel 10 dan Tabel 11 menunjukkan bahwa model yang menghasilkan nilai akurasi tertinggi tidak menjamin akan menghasilkan nilai sensitivitas yang tertinggi pula, begitu juga sebaliknya.
Tabel 10 Perbandingan kinerja pohon klasifikasi berdasarkan akurasi terbaik
Kinerja
klasifikasi SMOTE SMOUTE
SMOUTE 2 tahap Akurasi 0.8272 0.8441 0.8465 * Sensitivitas 0.2667 * 0.1667 0.2000 Spesifisitas 0.8410 0.8608 0.8624 * AUC 0.5538 * 0.5137 0.5312
*Nilai tertinggi di antara ketiga metode penanganan dengan akurasi terbaik
Tabel 11 Perbandingan kinerja pohon klasifikasi berdasarkan sensitivitas terbaik
Kinerja
Klasifikasi SMOTE SMOUTE
SMOUTE 2 tahap Akurasi 0.7066 0.6897 0.7299 * Sensitivitas 0.6000 0.6333 * 0.5667 Spesifisitas 0.7092 0.6911 0.7339 * AUC 0.6546 0.6622 * 0.6503
*Nilai tertinggi di antara ketiga metode penanganan dengan sensitivitas terbaik
Tabel 10 menunjukkan bahwa pada model dengan nilai akurasi tertinggi, nilai sensitivitas cenderung bernilai rendah. Hal ini yang menunjukkan adanya
22
hubungan negatif antara akurasi dan sensitivitas. Sebaliknya, nilai akurasi dan spesifisitas cenderung berhubungan positif. Pada Tabel 10, nilai akurasi dan spesifisitas tertinggi dihasilkan oleh metode SMOUTE dua tahap, sedangkan nilai sensitivitas dan AUC tertinggi dihasilkan oleh metode SMOTE. Tabel 11 menunjukkan bahwa pada nilai sensitivitas tertinggi pada tiap metode, nilai akurasi dan spesifisitas tertinggi tetap dihasilkan oleh metode SMOUTE dua tahap. Namun, nilai sensitivitas dan AUC tertinggi dihasilkan oleh metode SMOUTE. Kesimpulan yang dapat diambil dari penjelasan ini adalah untuk menghasilkan model dengan akurasi dan spesifisitas tinggi dapat digunakan metode penanganan SMOUTE dua tahap, sedangkan untuk menghasilkan nilai sensitivitas dan AUC yang lebih baik dapat digunakan metode penanganan SMOTE atau SMOUTE.
Tabel 12 Perbandingan rataan kinerja klasifikasi C5.0 pada data uji Kinerja
klasifikasi
Tanpa penanganan
Dengan penanganan
SMOTE SMOUTE SMOUTE
2 tahap Akurasi 0.9759 0.7118 0.7205 0.7292 * Sensitivitas 0.0000 0.3431 * 0.3241 0.3201 Spesifisitas 1.0000 0.7209 0.7303 0.7393 * AUC 0.5000 0.5320 * 0.5272 0.5297
*Nilai tertinggi di antara kinerja klasifikasi model dengan penanganan
Tabel 12 menunjukkan bahwa akurasi klasifikasi cenderung mengalami penurunan dengan diterapkannya penanganan terhadap kelas data tidak seimbang. Begitu pula dengan nilai spesifisitas yang cenderung menurun dengan dilakukannya penanganan kelas data tidak seimbang ini. Lain halnya dengan nilai sensitivitas. Sensitivitas meningkat seiring dengan diterapkannya penanganan terhadap kelas data tidak seimbang. Hal ini menunjukkan bahwa penanganan kelas data tidak seimbang dengan SMOTE atau SMOUTE akan memperbaiki ketepatan klasifikasi pada kelas minoritas dengan rataan sekitar 0.3 tetapi akan menurunkan akurasi dan ketepatan klasifikasi pada kelas mayoritas dengan rataan sekitar 0.25.
Jika dibandingkan kinerja klasifikasi antar metode penanganan kelas tidak seimbang maka diketahui bahwa rataan akurasi dan spesifisitas terbesar dihasilkan pada metode SMOUTE dua tahap. Namun, jika dilihat dari nilai rataan sensitivitas maka model klasifikasi pada metode SMOTE menghasilkan nilai yang lebih baik dibandingkan metode lainnya. Seperti yang telah dijelaskan sebelumnya bahwa kelas minoritas adalah fokus perhatian pada penelitian ini yaitu model klasifikasi diharapkan mampu mengklasifikasikan seorang penderita positif HIV secara benar sehingga dapat diketahui karakteristik khusus penderita positif HIV untuk selanjutnya dibuat keputusan atau kebijakan secara tepat. Oleh karena itu, metode penanganan terbaik yang dipilih pada penelitian ini adalah penanganan terhadap kelas data tidak seimbang melalui metode SMOTE. Hal ini diperkuat dengan nilai rataan AUC pada ROC model klasifikasi dengan SMOTE yang menunjukkan nilai paling besar dibandingkan metode lainnya yaitu sebesar 0,5320. Secara umum
23 nilai kinerja klasifikasi untuk ketiga metode tidak terlalu berbeda jauh. Namun, nilai sensitivitas dari metode SMOTE menghasilkan rataan yang terbesar dibandingkan lainnya. Hal ini tidak sesuai dengan kesimpulan Songwattanasiri dan Sinapiromsaran (2010) yang menyatakan bahwa metode SMOUTE akan menghasilkan nilai sensitivitas yang lebih baik dibandingkan metode SMOTE. Hal ini mungkin disebabkan karena pengelompokan amatan kelas mayoritas hanya memperhitungkan peubah numerik saja, sedangkan peubah kategorik tidak dipertimbangkan sama sekali.
Peubah – peubah Penting pada Model dengan Metode Penanganan Terbaik Model klasifikasi terbaik yang dipilih pada penelitian ini adalah model Pohon Klasifikasi C5.0 dengan metode penanganan SMOTE. Dari model terbaik ini akan dilihat peubah-peubah yang memiliki peranan penting berdasarkan besar penggunaannya dalam model. Kepentingan peubah ini mengukur besar persentase data latih yang mengisi Simpul setelah dilakukan pemisahan (split) oleh peubah yang bersangkutan. Hal ini berarti peubah yang mengisi Simpul Akar akan memiliki nilai kepentingan sebesar 100% karena merupakan peubah yang mengalami pemisahan (split) pertama kali.
Peubah-peubah yang paling penting peranannya pada model akan memiliki nilai kepentingan yang besar. Pada penelitian ini akan ditentukan tiga peubah yang memiliki peranan paling penting pada model. Perhitungan nilai kepentingan peubah ini dilakukan sebanyak 50 kali ulangan untuk melihat peubah yang cenderung konsisten mengisi urutan tiga besar peubah yang berperan penting dalam model. Dari 50 kali ulangan yang dilakukan diperoleh hasil bahwa sekitar 90% dari ulangan menunjukkan bahwa peubah yang memiliki nilai kepentingan paling besar adalah peubah Penghasilan per bulan dengan persentase kepentingan sebesar 100%. Hal ini menunjukkan bahwa pada lebih dari 90% ulangan yang dilakukan, peubah Penghasilan per bulan selalu menjadi peubah yang mengisi Simpul Akar sehingga dapat dikatakan Penghasilan per bulan merupakan peubah yang paling mempengaruhi model. Jika dihitung seberapa sering suatu peubah mengisi urutan tiga besar peubah dengan nilai kepentingan tertinggi maka akan diperoleh persentase sesuai Gambar 6.
Gambar 6 menunjukkan bahwa Penghasilan per bulan adalah peubah yang selalu menempati urutan tiga besar nilai kepentingan tertinggi. Bahkan peubah Penghasilan per bulan ini lebih sering menempati urutan pertama dengan nilai kepentingan mencapai 100% seperti dijelaskan sebelumnya. Setelah peubah Penghasilan per bulan ini, peubah yang cukup sering muncul sebagai tiga besar urutan tertinggi selanjutnya adalah peubah Penyakit Menular Seksual (PMS) dan diikuti peubah Lama sekolah. Peubah Topografi wilayah dan Jenis kelamin bahkan tidak pernah menempati urutan tiga besar peubah dengan nilai kepentingan tertinggi. Oleh karena itu dapat ditarik kesimpulan bahwa tiga peubah yang paling penting pada model dengan metode penanganan SMOTE adalah Penghasilan per bulan, Penyakit Menular Seksual (PMS), dan Lama sekolah.
24
Gambar 6 Persentase peubah yang mengisi urutan tiga besar nilai kepentingan tertinggi
SIMPULAN
Kondisi kelas data yang tidak seimbang menyebabkan klasifikasi dengan Pohon Klasifikasi C5.0 memiliki ketepatan klasifikasi kelas minoritas yang rendah. Beberapa metode penanganan kelas tidak seimbang diterapkan sebelum dilakukannya klasifikasi dengan Pohon Klasifikasi C5.0. Hasil yang diperoleh menunjukkan bahwa terjadi peningkatan nilai ketepatan klasifikasi kelas minoritas dengan rataan sebesar 0.3 setelah dilakukan penanganan ini. Hal ini disertai dengan penurunan nilai akurasi dan ketepatan klasifikasi kelas mayoritas dengan rataan sebesar 0.25. Dari beberapa metode penanganan kelas tidak seimbang yang digunakan, metode terbaik yang dipilih adalah metode SMOTE. Metode penanganan ini dipilih karena memiliki nilai rataan ketepatan klasifikasi kelas minoritas dan nilai rataan AUC dari ROC yang paling tinggi dibandingkan metode yang lain. Dari metode terbaik yang dipilih diketahui tiga peubah yang memiliki tingkat kepentingan terbesar pada model klasifikasi yaitu peubah Penghasilan per bulan, Penyakit Menular Seksual (PMS), dan Lama sekolah.
SARAN
Nilai ketepatan klasifikasi kelas minoritas dengan penanganan SMOUTE tidak lebih baik dari SMOTE. Perbaikan metode SMOUTE mungkin dapat dilakukan pada tahapan pengelompokan kelas mayoritas sebelum dilakukannya undersampling. Pengelompokan dapat dilakukan dengan mempertimbangkan semua peubah penjelas baik numerik maupun kategorik misalnya dengan menggunakan metode Two Step Clustering. Selain itu, Pohon Klasifikasi C5.0 memiliki kelemahan yaitu tidak dapat mengatur pemilihan interaksi antar peubah sehingga pemilihan peubah pada analisis C5.0 ini harus lebih hati-hati agar tidak terjadi kesalahan interaksi antar peubah.
2% 2% 2% 6% 10% 18% 32% 44% 84% 100%
Penggunaan alat kontrasepsi Suku bangsa Usia Pengetahuan tentang HIV Perilaku seks berisiko Umur seks pertama Status perkawinan Lama sekolah Penyakit Menular Seksual (PMS) Penghasilan per bulan
25
DAFTAR PUSTAKA
Adiangga D. 2015. Perbandingan Multivariate Adaptive Regression Spline (MARS) dan Pohon Klasifikasi C5.0 pada Data Tidak Seimbang (studi kasus: pekerja anak di Jakarta) [tesis]. Bogor(ID): Institut Pertanian Bogor. [BPS dan DepKes] Badan Pusat Statistik dan Departemen Kesehatan. 2007.
Situasi Perilaku Berisiko dan Prevalensi HIV di Tanah Papua 2006. Jakarta (ID): Badan Pusat Statistik.
Bunkhumpornpat C, Sinapiromsaran K, Lursinsap C. 2012. DBSMOTE: Density-Based Synthetic Minority Over-sampling Technique. Application Intelligence. 36: 664-684.
Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP. 2002. SMOTE: Synthetic Minority Over-sampling Technique. Journal of Artificial Intelligence Research. 16: 321-357.
Han H, Wang WY, Mao BH. 2005. Borderline-SMOTE: A New Over-Sampling Method in Imbalance Data Sets Learning. Springer-Verlag Berlin Heidelberg. 878-887.
[Kemkes RI] Kementerian Kesehatan Republik Indonesia. 2016. Profil Kesehatan Indonesia Tahun 2015. Jakarta (ID): Kementerian Kesehatan Republik Indonesia.
Pandya R, Pandya J. 2015. C5.0 Algorithm to Improved Decision Tree with Feature Selection and Reduced Error Pruning. International Journal of Computer Applications. 117(16): 18-21.
Patidar P, Tiwari A. 2013. Handling Missing Value in Decision Tree Algorithm. International Journal of Computer Applications. 70(13): 31-36.
Songwattanasiri P, Sinapiromsaran K. 2010. SMOUTE: Synthetics Minority Over-sampling and Under-sampling Technique for Class Imbalanced Problem. Annual International Conference on Computer Science Education: Innovation & Technology. 78-83.
Tufféry S. 2011. Data Mining and Statistics for Decision Making. West Sussex (UK): John Wiley & Sons Ltd.