計江RS甦.ItiミJttjAヽ
SKRIPSI
PEヽ
ERAPAN卜 IETODEご
′ヽ:ゞ∬MBLE tlNTtiK MENINGKATKAN
「ゝRUR蛭滋AB00R∬
ヽlAlklJttlFIK竃 頸DttOS妙ヽrIREごC4応じ亀A■llMENDlAGNOSA PIEヽ YAKIT Dl_tBETES■lEl』TllS
pada tangga1 16:れ ゝL2018
tclall
Dosen Pembilnbing II
ilttsan Rollllii SiSi.,M、 Sc. NII)N:0413058603 Yang disusun oleh
PENGESAHAN
S彊願lIPSiPENERAPAN MEI「
ODE ENSEMBLE■
iNTUK PIENIIA GKATKAN…
…
爾 磁
5…
1■量皿
ND独
IGNOSA PEN■「AttT DRttETttS聖雪塁LITUS Yallg disustul olcllANNISA httULANA
Ⅳ饉JID
311410198
緩all dip戦 4all嶽機 di d彎籠 Dttall P鐵画 i
睾
Putri Allttgun Sari.S.Pl..ⅣI,Si.NIDN:0424088403 NIDN:042011 NIE卜Tヾ30401066695 N*ma Penguii
趙
鰺/・
Kettta SA′I Pettit農 懲象建gsa ltensetalrui
PERNYATAAN KEASLIAN PENELITIAN
Saya yang bcrlarldatangan diba、vah i通 1■cFlyataklan bah、va,skripsi illi mcrupakall k.nr)la saya scndiri(ノヽSLI), dan iSi dalalla skripsi ini tidak tcrdapat karya yallg
pcl‐lltt dittukan OICh orang iain urltuk mclllpcFOleh gc]ar akadcmis di suatu institusi pcndidikan tinggi lllanaplln,dall scpall」 ang pellgctallllan saya illga tidak
tcrdapat kiatta atau pcndapat yang pcFrtah ditulis dan/atau diterbitkan oich orang
lain, kccuali yallg sccara tcrttllis diacll dalalll naskall ini dan discbutkan dalalll dattar ptlstaka.
Scsala scsllatu yang terkait dcngall naskah dan karya yang telah dibuat adal象11
menjadi tanggungjawab saya pribadi.
Bchas:ぅ 15]uli 20 18
卜II卜1:311410198 ■llatllana Mttid
iv
KATA PENGANTAR
Puji syukur atas kehadirat Allah SWT Yang Maha Pengasih lagi Maha Penyayang, karena berkat rahmat dan hidayah-Nya, penulis dapat menyelesaikan Skripsi dengan judul “Penerapan Metode Ensemble Untuk Meningkatkan Akurasi Algoritma Klasifikasi Decision Tree C4. 5 Dalam Mendiagnosa Penyakit Diabetes Melitus”. Laporan Skripsi ini merupakan salah satu persyaratan dalam rangka menempuh ujian akhir untuk memperoleh gelar Sarjana Komputer (S.Kom.) pada Program Studi Teknik Informatika di Sekolah Tinggi Teknologi (STT) Pelita Bangsa.
Penulis menyadari bahwa dalam menyelesaikan Skripsi tidak lepas dari bimbingan, bantuan, arahan, dukungan, dan kerjasama dengan pihak lain. Berkenaan dengan hal tersebut, maka penulis menyampaikan ucapan terima kasih kepada yang terhormat :
1. Bapak Dr. Ir. Supriyanto, M.P., selaku Ketua STT Pelita Bangsa.
2. Bapak Aswan S. Sunge, M.Kom., selaku Ketua Program Studi Teknik Informatika STT Pelita Bangsa.
3. Bapak Agung Nugroho, S.Kom., M.Kom., selaku Dosen Pembimbing utama yang telah banyak memberikan arahan dan bimbingan kepada penulis dalam penyusunan Skripsi ini.
4. Bapak Ikhsan Romli, S.Si., M.Sc., selaku Dosen Pembimbing kedua yang juga telah banyak memberikan arahan dan bimbingan dalam penyusunan Skripsi ini.
v
6. Rekan-rekan yang ikut mendukung dan mendoakan serta memberi motivasi. 7. Semua pihak yang secara langsung maupun tidak langsung turut membantu
dalam penyusunan Skripsi ini.
Dengan ini penulis mohon maaf kepada pihak yang terlibat apabila ada kesalahan dan kekurangan baik disengaja atau tidak disengaja. Semoga segala bantuan yang diberikan segala pihak menjadi amalan yang bermanfaat dan mendapat balasan dari Allah SWT. Demikian laporan Skripsi ini penulis susun, penulis berharap semoga dapat bermanfaat bagi pembaca khususnya di lingkungan STT Pelita Bangsa dan Indonesia pada umumnya.
Bekasi, Juli 2018 Penulis
vi
DAFTAR ISI
PERSETUJUAN ... i
PENGESAHAN ...ii
PERNYATAAN KEASLIAN PENELITIAN ... iii
KATA PENGANTAR ... iv DAFTAR ISI ... vi DAFTAR TABEL ... ix DAFTAR GAMBAR ...x ABSTRACT ... xii ABSTRAK ... xiii BAB I PENDAHULUAN ... 1 1.1 Latar Belakang ... 1 1.2 Identifikasi Masalah ... 3 1.3 Rumusan Masalah ... 4 1.4 Batasan Masalah ... 4
1.5 Tujuan dan Manfaat Penelitian ... 4
1.5.1 Tujuan Penelitian ... 4
1.5.2 Manfaat Penelitian ...5
1.6 Sistematika Penulisan ... 5
BAB II TINJAUAN PUSTAKA ... 7
2.1 Kajian Pustaka ... 7
2.2 Dasar Teori ... 11
vii
2.2.2 Pengertian Data Mining ... 13
2.2.3 Tahapan Data Mining ... 14
2.2.4 Pengelompokan Data Mining ... 16
2.2.5 Pengertian Decision Tree ... 21
2.2.6 Kelebihan Decision Tree ... 22
2.2.7 Kekurangan Decision Tree ... 23
2.2.8 Pengertian Algoritma C4.5 ... 24
2.2.9 Keuntungan Algoritma C4.5 ... 24
2.2.10 Kerugian Algoritma C4.5 ... 25
2.2.11 Tahap Membangun Algoritma C4.5 ... 25
2.2.12 Metode Ensemble ... 27
2.2.13 AdaBoost ... 30
2.3 Kerangka Berpikir ... 33
BAB III METODE PENELITIAN ... 35
3.1 Objek Penelitian ... 35
3.2 Pengumpulan Data ... 35
3.3 Peralatan ... 37
3.4 Waktu Penelitian ... 38
3.5 Tahap Analisa Data ... 39
3.6 Model yang diusulkan ... 44
BAB IV HASIL DAN PEMBAHASAN ... 49
4.1 Hasil Penelitian ... 49
viii
4.1.2 Pengujian 2 ...59
4.2 Pembahasan ... 67
4.3 Hasil Uji Validasi dan Uji Klasifikasi Data Testing Decision Tree C4.5 dan Decision Tree C4.5 Menggunakan Adaboost ... 71
BAB V KESIMPULAN DAN SARAN ... 77
5.1 Kesimpulan ... 77
5.2 Saran ... 77
ix
DAFTAR TABEL
Tabel 3.1 Dataset Diabetes Melitus ... 36
Tabel 3.2 Kegiatan Penelitian ... 38
Tabel 3.3 Atribut-atribut Bernilai 0 ... 40
Tabel 3.4 Jumlah Missing Value ... 41
Tabel 3.5 Atribut Dataset ... 42
Tabel 3.6 Atribut yang digunakan ... 43
Tabel 3.7 Confusion Table ... 47
Tabel 4.1 Hasil Penelitian ... 68
x
DAFTAR GAMBAR
Gambar 2.1 Diagram Hasil Akurasi Penelitian Terdahulu ... 10
Gambar 2.2 Hasil Riskesdas 2007-2013 ... 12
Gambar 2.3 Tahap-Tahap Data Mining ... 14
Gambar 2.4 Data Mining Berdasarkan Fungsionalitas ... 18
Gambar 2.5 Contoh Decision Tree ... 22
Gambar 2.6 Gambaran Ensemble Classification ... 29
Gambar 2.7 Kerangka Berfikir ... 33
Gambar 3.1 Alur Model Penelitian ... 44
Gambar 3.2 Representasi 10 Folds Cross Validation ... 46
Gambar 4.1 Model Pengujian 1 dengan Decision Tree C4.5 ... 49
Gambar 4.2 Hasil Import Dataset ... 50
Gambar 4.3 Setting Filter Examples ... 51
Gambar 4.4 Setting Select Attributes ... 52
Gambar 4.5 Hasil Data Preprocessing ... 52
Gambar 4.6 Model Cross Validation dengan Decision Tree C4.5... 53
Gambar 4.7 Permodelan Decision Tree C4.5... 54
Gambar 4.8 Deskripsi Permodelan Decision Tree C4.5... 55
Gambar 4.9 Hasil Accuracy Decision Tree C4.5... 57
Gambar 4.10 Hasil Recall Decision Tree C4.5... 58
Gambar 4.11 Hasil Precision Decision Tree C4.5... 58
Gambar 4.12 Hasil AUC Decision Tree C4.5... 59
xi
Gambar 4.14 Model Cross Validation dengan Adaboost... 60
Gambar 4.15 Model Adaboost ... 61
Gambar 4.16 Permodelan dengan Adaboost ... 62
Gambar 4.17 Deskripsi Permodelan Adaboost ... 63
Gambar 4.18 Hasil Accuracy Dengan Adaboost ... 65
Gambar 4.19 Hasil Recall Dengan Adaboost ... 66
Gambar 4.20 Hasil Precision Dengan Adaboost... 66
Gambar 4.21 Hasil AUC Dengan Adaboost ... 67
Gambar 4.22 Grafik Peningkatan Nilai Accuracy ... 68
Gambar 4.23 Grafik Peningkatan Nilai Recall ... 69
Gambar 4.24 Grafik Peningkatan Nilai Precision ... 69
Gambar 4.25 Grafik Peningkatan Nilai AUC ... 70
Gambar 4.26 Model Klasifikasi Decision Tree C4.5 ... 71
Gambar 4.27 Hasil Accuracy Klasifikasi Decision Tree C4.5 ... 72
Gambar 4.28 Hasil Recall Klasifikasi Decision Tree C4.5... 72
Gambar 4.29 Hasil Precision Klasifikasi Decision Tree C4.5... 72
Gambar 4.30 Hasil AUC Klasifikasi Decision Tree C4.5... 73
Gambar 4.31 Model Klasifikasi Decision Tree C4.5 + Adaboost ... 73
Gambar 4.32 Model Klasifikasi Menggunakan Adaboost ... 74
Gambar 4.33 Hasil Accuracy Klasifikasi Decision Tree C4.5 + Adaboost ... 74
Gambar 4.34 Hasil Recall Klasifikasi Decision Tree C4.5 + Adaboost ... 74
Gambar 4.35 Hasil Precision Klasifikasi Decision Tree C4.5 + Adaboost ... 75
xii ABSTRACT
Data mining has developed in various fields, including in the field of health, one of which predict diabetes mellitus. Delay in diagnosis results in patients’ not getting quick and proper treatment. Mortality caused by diabetes mellitus can be reduced if there is an accurate diagnosis early on. Previous research in predicting diabetes mellitus with accuracy has been done but resulted in a small accuracy in the Decision Tree C4.5 algorithm. It is necessary to increase the accuracy to produce accurate information. The ensemble technique is a method to improve the accuracy of the classification algorithm. This research uses data of Pima Indian Diabetes Dataset, Decision Tree C4.5 classification algorithm by applying ensemble technique that is adaboost. Tools used are Rapidminer 8.2.1 applications. The results obtained in the test using the single Decision Tree C4.5 algorithm is 73.99%, and combined testing of the Decision Tree C4.5 algorithm with Adaboost yields an accuracy of 84.19%. These results indicate an increase in the Decision Tree C4.5 classification algorithm by using the ensemble technique, Adaboost.
Keywords: Data Mining, Diabetes Mellitus, Decision Tre C4.5, Engineering Ensemble, Adaboost.
xiii
ABSTRAK
Data mining sudah berkembang dalam berbagai bidang, termasuk dalam bidang kesehatan, salah satunya prediksi suatu penyakit yaitu diabetes melitus. Keterlambatan dalam diagnosa mengakibatkan pasien tidak mendapatkan penanganan cepat dan tepat. Angka kematian yang disebabkan oleh diabetes melitus dapat dikurangi jika ada diagnosa yang akurat sejak dini. Penelitian sebelumnya dalam memprediksi penyakit diabetes melitus dengan tingkat akurasi telah dilakukan namun menghasilkan akurasi yang kecil pada algoritma Decision Tree C4.5. Untuk itu diperlukan adanya peningkatan akurasi agar menghasilkan keakuratan informasi. Teknik ensemble merupakan metode untuk meningkatkan akurasi dari algortima klasifikasi. Penelitian ini menggunakan data Pima Indian Diabetes Dataset, algoritma klasifikasi Decision Tree C4.5 dengan menerapkan teknik ensemble yaitu Adaboost. Tools yang digunakan yaitu aplikasi Rapidminer 8.2.1. Hasil yang didapat dalam pengujian menggunakan algoritma tunggal Decision Tree C4.5 yaitu 73,99% dan pengujian gabungan algoritma Decision Tree C4.5 dengan Adaboost menghasilkan akurasi 84,19%. Hasil ini menunjukkan adanya peningkatan algoritma klasifikasi Decision Tree C4.5 dengan menggunakan teknik ensemble, yaitu Adaboost.
Kata Kunci : Data Mining , Diabetes Melitus, Decision Tre C4.5, Teknik Ensemble, Adaboost.
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Teknologi informasi semakin berkembang mengakibatkan tingkat kebutuhan akan informasi semakin meningkat. Begitu pula dengan keakuratan sebuah informasi sangat dibutuhkan dalam berbagai bidang baik perusahaan, pendidikan, maupun bidang kesehatan. Keakuratan informasi dalam sebuah keputusan sangat dibutuhkan untuk mendapatkan hasil terbaik. Untuk mendapatkan sebuah informasi dapat dilakukan dengan penggalian data dalam jumlah besar supaya mendapatkan pengetahuan baru yang disebut data mining.
Dalam bidang kesehatan data mining dapat digunakan untuk memprediksi suatu penyakit, salah satunya adalah diabetes melitus. Diabetes melitus merupakan penyakit mematikan dengan jumlah pasien yang bertambah tiap tahunnya berdasarkan hasil Riset Kesehatan Dasar (Rikesdas) 2007-2013. Beberapa orang yang terkena diabates melitus tidak tahu bahwa dirinya terkena atau berpotensi diabetes melitus. Banyak kasus seperti terlambatnya diagnosa penyakit diabetes sering terjadi oleh tenaga medis, sehingga pasien tidak mendapatkan penanganan lebih awal. Peningkatan jumlah kematian akibat diabetes melitus dapat dikurangi jika ada diagnosa yang lebih akurat sejak dini mengenai diabetes melitus.
Penelitian telah dilakukan dengan berbagai algoritma dalam mendiagnosa diabetes melitus diantaranya, Decision Tree, Naive Bayes, Support Vector Machine (SVM), k-Nearest Neighbor (KNN), Radial Basis Function (RBF) Network,
2 Artificial Neural Network (ANN), dan lain-lain. Hasil penelitian-penelitian tersebut menunjukkan bahwa Decision Tree menghasilkan tingkat akurasi lebih kecil dari algoritma lain dengan perbedaan yang tidak signifikan. Kelemahan algortima C4.5 adalah salah satunya overfitting akibat terjadi misklasifikasi karena noisy data, dan ketidakseimbangan data menyebabkan tingkat akurasi rendah, untuk itu diperlukan adanya peningkatan akurasi pada algoritma Decision Tree. Peningkatan akurasi dapat menggunakan metode Ensemble.
Metode Ensemble classifier adalah metode yang digunakan dengan menggabungkan base classifier dengan klasifikasi untuk menghasilkan tingkat akurasi prediksi yang tinggi, (Fitriansyah & Saparudin, 2016). Pada metode Ensemble ada dua algoritma yang paling populer, yaitu Boosting dan Bagging, (Bee Wah Yap, Khatijahhusna Abd Rani & Simon Fong, Zuraida Khairudin, 2014). Menurut Mirqotussa’adah dkk (2017), prediksi menggunakan Decision Tree C4.5 menghasilkan akurasi 68,61%. Eksperimen kedua dengan menambahkan teknik Bagging pada algoritma C4.5 menghasilkan akurasi 69,79%, pada klasifikasi dataset diabetes, dari hasil tersebut diperlukan adanya peningkatan akurasi untuk menghasilkan tingkat akurasi terbaik.
Adaptive Boosting adalah kepanjangan dari Adaboost yang dikemukakan oleh Yoav Freund dan Robert Schapire merupakan algoritma Ensemble. Keunggulan Boosting yaitu algoritma yang fokus dalam hal misclasssified tuples dan lebih tinggi tingkat akurasinya dari pada menggunakan Bagging. Dalam penelitian ini akan menggunakan teknik Adaboost sebagai metode Ensemble untuk
3 meningkatkan akurasi dari algoritma Decision Tree C4.5 pada dataset Pima Indian Diabetes dalam mendiagnosa penyakit diabetes melitus.
1.2 Identifikasi Masalah
Berdasarkan latar belakang masalah maka, identifikasi masalah antara lain, yaitu :
1. Terjadi keterlambatan diagnosa pada penyakit diabetes melitus karena belum ada informasi secara akurat dalam mengambil keputusan diagnosa. 2. Tingkat kematian pasien diabetes melitus bertambah tiap tahunnya karena
tidak ada keputusan dini mengenai penyakit diabetes melitus.
3. Tahun 2007 hingga 2013 pasien diabetes yang tidak terdiagnosa meningkat dengan persentase 4,1%.
4. Hasil penelitian lain menunjukkan perbandingan akurasi Decision Tree lebih kecil dibandingkan dengan algoritma lain.
5. Perlu dilakukan penelitian untuk meningkatkan akurasi untuk menghasilkan informasi yang akurat dalam mendiagnosa penyakit diabetes melitus.
6. Sudah dilakukan penelitian dalam mendiagnosa penyakit diabetes melitus menggunakan algoritma C4.5 dengan menambahkan teknik Bagging dengan tingkat akurasi 69,79%.
7. Algoritma C4.5 memiliki kelemahan yaitu overfitting akibat misklasifikasi yang terjadi karena noisy data ketidakseimbangan data menyebabkan akurasi C4.5 buruk dalam pengklasifikasian data.
4 8. Antara Bagging dan Boosting, Boosting lebih dipilih karena berfokus pada
misclassified tuples.
1.3 Rumusan Masalah
Berdasarkan identifikasi masalah, maka dirumuskan permasalahan, bagaimana meningkatkan akurasi dengan menggunakan metode Ensemble pada algoritma klasifikasi Decision Tree C4.5 dalam mendiagnosa penyakit diabetes melitus?
1.4 Batasan Masalah
Berdasarkan rumusan masalah diatas maka dibatasi permasalahan dalam penelitian, yaitu peningkatan akurasi pada prediksi penyakit diabetes melitus menggunakan metode Ensemble dengan teknik Adaboost pada algoritma Decision Tree C4.5 dan menggunakan aplikasi RapidMiner untuk menghitung tingkat akurasi.
1.5 Tujuan dan Manfaat Penelitian
1.5.1 Tujuan Penelitian
Berdasarkan rumusan masalah yang telah diuraikan, maka tujuan dari penelitian ini adalah untuk meningkatkan akurasi dengan menggunakan metode Ensemble pada algoritma klasifikasi Decision Tree C4.5 dalam mendiagnosa penyakit diabetes melitus.
5
1.5.2 Manfaat Penelitian 1.5.2.1 Bagi Mahasiswa
Sebagai sarana untuk menerapkan ilmu pada bidang Teknik Informatika dengan kajian data mining serta sebagai salah satu syarat kelulusan gelar Sarjana S1 program studi Teknik Informatika di STT Pelita Bangsa.
1.5.2.2 Bagi Program Studi Teknik Informatika STT Pelita Bangsa
Menambah sumber kajian atau literatur di perpustakaan STT Pelita Bangsa serta dapat menjadi tolak ukur tentang pemahaman serta penguasaan materi kuliah yang diberikan kepada mahasiswa dalam masa perkuliahan di STT Pelita Bangsa.
1.5.2.3 Bagi Tenaga Medis
Dapat digunakan untuk pengambilan keputusan secara dini dengan akurasi terbaik dalam mendiagnosa penyakit diabetes melitus.
1.6 Sistematika Penulisan
Untuk mempermudah dalam memahami laporan Tugas Akhir ini, maka laporan Tugas Akhir dikelompokan ke dalam beberapa sub bab pembahasan dan menggunakan sistematika. Berikut sub bab pembahasan laporan antara lain, yaitu:
BAB I PENDAHULUAN
Bab ini menjelaskan tentang informasi umum yaitu latar belakang, identifikasi masalah, batasan masalah, rumusan masalah, tujuan dan manfaat penelitian, serta sistematika penulisan.
6
BAB II TINJAUAN PUSTAKA
Bab ini berisikan dasar-dasar teori yang diambil dari beberapa kutipan buku, jurnal, dan studi pustaka lainnya yang berupa pengertian yang berkaitan dengan penelitian yang dibahas.
BAB III METODE PENELITIAN
Bab ini menjelaskan metode yang digunakan untuk menyelesaikan permasalahan dalam penelitian.
BAB IV HASIL DAN PEMBAHASAN
Pada bab ini menjelaskan hasil dari penelitian dan pembahasan yang telah dilakukan.
BAB V PENUTUP
Bab ini menjelaskan tentang kesimpulan dan saran yang dapat digunakan untuk penelitian selanjutnya.
7
BAB II
TINJAUAN PUSTAKA
2.1 Kajian Pustaka
Tinjauan pustaka berisi landasan teori serta referensi yang berkaitan dengan penelitian. Dalam penelitian ini penulis mengkaji beberapa referensi atau penelitian terdahulu yang sudah pernah dilakukan. Penelitian pertama oleh Thirumal P. C dan Nagarajan N. dengan judul “Utilization Of Data Mining Techniques For Diagnosis Of Diabetes Mellitus A Case Study” pada tahun 2015. Mereka menggunakan algoritma Naive Bayes, Decision Tree C4.5, SVM, dan KNN yang dilakukan pada dataset Pima Indian Diabetes pada UCI Machine Learning Repository. Tools yang digunakan adalah aplikasi WEKA. Data preprocessing yang dilakukan adalah dengan menggunakan discretize untuk menormalisasikan data. Hasil dari penelitian menunjukkan bahwa algoritma Decision Tree C4.5 memiliki tingkat akurasi lebih tinggi dibandingkan algortima lain, yaitu sebesar 78,25%, Naive Bayes sebesar 77,86%, KNN sebesar 77,73%, dan SVM sebesar 77,47%.
Penelitian kedua oleh Iyer dan kawan-kawan dengan judul “Diagnosis Of Diabetes Using Classification Mining Techniques”. Dalam penelitiannya menggunakan algoritma Decision Tree J48 dan Naive Bayes, aplikasi WEKA, dan dataset Pima Indians Diabetes Database dari National Institute of Diabetes dan Digestive and Kidney Diseases dataset. Pada penelitian ini menerapkan data preprocessing dengan replace value data yang bernilai 0 dengan mengubah menjadi nilai rata-rata, menormalisasikan data dengan discretize, dan pemilihan atribut yang
8 dipakai dengan menggunakan algoritma CfsSubsetEval. Hasil yang ditunjukkan adalah algoritma Naive Bayes memiliki tingkat akurasi lebih tinggi dengan nilai 79,56% dan nilai akurasi sebesar 76,95% pada algoritma Decision Tree J48.
Penelitian ketiga berjudul “Comparison Of Data Mining Algorithms In The Diagnosis Of Type II Diabetes” oleh Sa’di dan kawan-kawan. Metode dalam penelitian ini menggunakan algoritma Naive Bayes, RBF Network, dan Decision Tree J48, diimplementasikan menggunakan aplikasi WEKA dan menggunakan Pima Indians Diabetes sebagai dataset. Hasil yang diperoleh adalah algoritma Naive Bayes menghasilkan akurasi sebesar 76,95%, Decision Tree J48 sebesar 76,52%, dan RBF Network sebesar 74,34%.
Penelitian kelima tahun 2016 oleh Harleen dan Bhambri yang berjudul “A Prediction Technique in Data Mining for Diabetes Mellitus”. Metode dalam penelitian menggunakan algoritma Decision Tree J48 dan Naive Bayes. Dataset dan tools yang digunakan adalah Pima Indians Diabetes Dataset dan aplikasi WEKA. Penelitian ini menggunakan teknik preprocessing dengan penghapusan data pada set yang kosong dalam atribut serta menghapus redudansi. Hasil penelitian yaitu algortima Naive Bayes sebesar 76,3% dan Decision Tree sebesar 73,82%.
Tahun 2017 Mirqotussa’adah dan kawan-kawan melakukan penelitian berjudul “Penerapan Discretization dan Teknik Bagging Untuk Meningkatkan Akurasi Klasifikasi Berbasis Ensemble pada Algortima C4.5 dalam mendiagnosa Diabetes”. Mereka menggunakan metode algortima Decision Tree C4.5 dan metode Ensemble dengan teknik Bagging dan discretization. Aplikasi yang digunakan untuk implementasi adalah aplikasi RapidMiner. Dataset yang digunakan adalah
9 Pima Indian Diabetes Dataset pada UCI Machine Learning Repository. Penelitian ini menggunakan discretize dan replace missing value dalam tahap preprocessing. Hasil yang diperoleh Mirqotussa’adah dkk yaitu algoritma Decision Tree C4.5 menghasilkan akurasi 68,61% dan Decision Tree C4.5 yang dikombinasikan teknik Bagging sebesar 69,79%.
Mazini, dkk, tahun 2018 melakukan penelitian dengan judul “Anomaly Network-Based Intrusion Detection System Using a Reliable Hybrid Artificial Bee Colony And Adaboost Algorithms”. Metode yang digunakan adalah teknik
Adaboost dengan hasil akurasi sebesar 98,9%. Tahap preprocessing mengonversi
dataset fitur non-numerik menjadi jumlah numerik, kemudian, normalisasi data.
Penulis menggunakan penelitian-penelitian tersebut sebagai referensi untuk menghasilkan tingkat akurasi dalam mendiagnosa penyakit diabetes melitus. Hasil yang ditunjukkan dalam penelitian-penelitian sebelumnya, algoritma Decision Tree memiliki tingkat akurasi rendah dari pada algoritma lain, seperti Naive Bayes. Perbedaan penelitian ini yaitu menerapkan metode Ensemble dengan teknik Adaboost yang dikombinasikan dengan algoritma Decision Tree C4.5 dalam hal meningkatkan akurasi. Metode Ensemble dipilih karena merupakan salah satu metode yang populer untuk meningkatkan akurasi klasifikasi, tools yang digunakan penulis adalah dengan aplikasi RapidMiner dan Pima Indians Diabetes Database sebagai dataset.
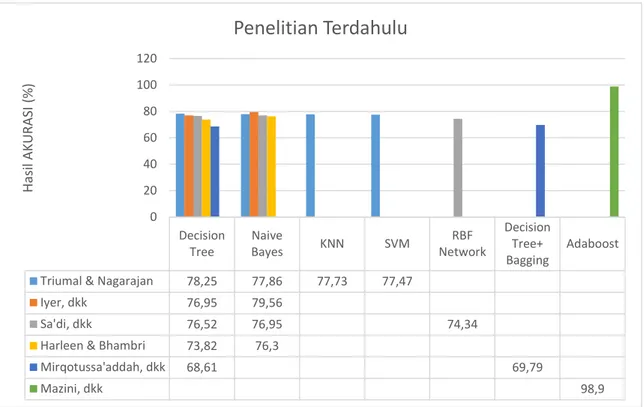
10 Berikut adalah gambar 2.1 menunjukkan gambar diagram hasil akurasi dari 6 penelitian terdahulu :
Gambar 2.1 Diagram Hasil Akurasi Penelitian Terdahulu Sumber : (Penulis, 2018)
Berdasarkan gambar diagram 2.1, Decision Tree memiliki tingkat akurasi yang tidak stabil, namun terjadi peningkatan akurasi pada penelitian Mirqotussa’addah, dkk, yaitu sebesar 1,18 % dengan menambahkan teknik Bagging pada algoritma Decision Tree. Pada penelitian dengan menggunakan teknik Adaboost diketahui memiliki tingkat akurasi mencapai 98,9 % dan menunjukkan hasil terbaik. Decision Tree Naive Bayes KNN SVM RBF Network Decision Tree+ Bagging Adaboost
Triumal & Nagarajan 78,25 77,86 77,73 77,47
Iyer, dkk 76,95 79,56
Sa'di, dkk 76,52 76,95 74,34
Harleen & Bhambri 73,82 76,3
Mirqotussa'addah, dkk 68,61 69,79 Mazini, dkk 98,9 0 20 40 60 80 100 120 H asi l AKU RASI (% )
Penelitian Terdahulu
11
2.2 Dasar Teori
Dasar teori berisi landasan-landasan yang terkait dalam penelitian yang dilakukan. Pengertian-pengertian serta teori yang akan dijabarkan yaitu mengenai penyakit diabetes melitus, pengertian data mining, tahapan data mining, pengelompokkan data mining, Decision Tree, kelebihan serta kekurangan Decision Tree, pengertian algoritma C.45, kelebihan, dan kekurangan algoritma C4.5, tahap membangun algoritma C4.5, metode Ensemble, dan teknik Adaboost.
2.2.1 Diabetes Melitus
Penyakit diabetes melitus jenis diabetes tipe 2 merupakan penyakit yang disebabkan oleh prankeas yang tidak menghasilkan insulin dalam jumlah normal sesuai kebutuhan tubuh, (Durairaj & Kalaiselvi, 2015).
Diabetes melitus ditandai adanya tingkat glukosa tinggi. Penyakit ini dibagi menjadi dua bagian, yaitu diabetes melitus tipe 1, diabetes yang terjadi karena prankeas yang menghasilkan sel-sel yang rusak sehingga kurang optimal dalam menurunkan glukosa dalam tubuh dan diabetes melitus tipe 2, yaitu penyakit diabetes yang terjadi karena resistensi insulin dan gangguan sekresi insulin yang tidak bekerja dengan baik, diabetes tipe ini bisa disebut diabetes non-insulin, (Wu, Yang, Huang, He, & Wang, 2018).
Penyakit diabetes merupakan penyakit yang menyebabkan tingkat kematian bertambah tiap tahun. Gambar 2.2 menggambarkan hasil Riset Kesehatan Dasar (Riskesdas) dari tahun 2007 sampai dengan tahun 2013.
12
Gambar 2.2 Hasil Riskesdas 2007-2013 Sumber : (Kemenkes RI, 2014)
Berdasarkan pada gambar 2.2 hasil riset menunjukkan bahwa pada tahun 2007 sebesar 93,1% tidak mengalami diabetes sedangkan sebesar 6,9% pasien mengalami diabetes dengan persentase 30,4% pasien telah terdiagnosis diabetes, dan sisanya 69,6% tidak terdiagnosis.
Pada tahun 2013 hasil riset menyatakan bahwa sebesar 94,3% orang tidak mengalami diabetes dan sebesar 5,7% mengalami diabetes, hal ini menunjukkan bahwa tingkat pasien diabetes mulai menurun. Namun dari persentase sebesar 5,7 % tersebut jumlah pasien yang terdiagnosis hanya sebesar 26,3% saja sedangkan pasien yang tak terdiagnosis sebesar 73,7%, hal ini menyebabkan tingkat kematian pasien diabetes meningkat karena tidak terdeteksi diabetes sejak awal, sehingga mengalami keterlambatan dalam penanganan pasien diabetes.
Dalam data dari World Economic Forum april 2015 menyatakan bahwa negara Indonesia dapat mengalami kerugian dalam jumlah besar yaitu 4,47 triliun, hal itu disebabkan karena Penyakit Tidak Menular (PTM) berkisar periode tahun
13 2015-2030, salah satunya diakibatkan oleh penderita penyakit diabetes berdasarkan klaim BPJS sampai tahun 2015, (Depkes RI, 2018).
2.2.2 Pengertian Data Mining
Data mining merupakan proses yang dilakukan dengan menggali suatu nilai yaitu informasi dengan cara mengekstraksi dan menemukan pola penting atau menarik dari suatu basis data yang sebelumnya tidak diketahui jika dilakukan secara manual, (Vulandari, 2017).
Data mining yaitu analisis yang dilakukan di dalam basis data untuk menemukan pengetahuan dalam bentuk pola atau relasi data valid yang disebut Knowledge Discovery in Databases (KDD), (Suyanto, 2017).
Data mining menjadi bagian dari berbagai bidang ilmu seperti kecerdasan buatan (Artificial Intelligent), machine leraning, statistik, dan databases, (D. A. C, Baskoro, Ambarwati, & Wicaksana, 2013).
Pengekstraksian data yang tidak diketahui sebelumnya untuk menghasilkan informasi yang bermanfaat dan secara otomatis menyaring database untuk menemukan pola kuat yang dapat digunakan dalam prediksi akurat pada masa yang akan datang, (Ahmed & Jesmin, 2014).
Dapat disimpulkan bahwa data mining merupakan proses analisis dengan menggali informasi dalam basis data dengan mengekstraksi untuk menemukan suatu pola pengetahuan baru yang tidak diketahui sebelumnya dan akan bermanfaat pada masa depan.
14
2.2.3 Tahapan Data Mining
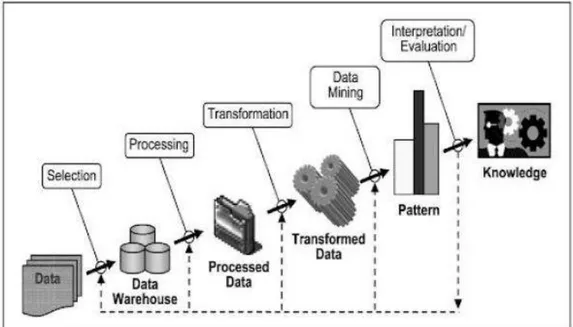
Data mining atau biasa disebut Knowledge Discovery in Database (KDD) memiliki tahapan-tahapan dalam pemrosesannya. Gambar 2.3 menggambarkan tahapan-tahapan pada data mining.
Gambar 2.3 Tahap-Tahap Data Mining Sumber : (Nofriansyah, 2014)
Berikut adalah tahap-tahap data mining atau Knowledge Discovery in Database (KDD), (Nofriansyah, 2014):
1. Data Selection
Kumpulan database operasional yang dipilih atau diseleksi berdasarkan kebutuhan atau kepentingan sebelum melakukan proses data mining, kemudian disimpan dalam sebuah berkas atau tempat penyimpanan yang berbeda dengan
15 database operasional sebelumnya agar mempermudah penggunaan data selanjutnya.
2. Pre-proccesing (Data Cleaning)
Pembersihan data dari ketidaksempurnaan isi yang telah diperoleh dari database seperti, hilangnya data, data tidak valid, baik disebabkan karena kesalahan dalam pengetikan, serta adanya atribut-atribut yang tidak relevan agar tidak mengurangi nilai mutu atau akurasi yang akan dihasilkan dari data tersebut, tahap pembersihan bisa disebut garbage in barbage out. Dalam tahap ini performasi akan berpengaruh sebab data yang dihasilkan dapat berkurang jumlah dan kompleksitasnya.
3. Transformation
Teknik yang dilakukan untuk mengubah bentuk format data agar sesuai sebelum dilakukan proses data mining. Teknik analisis asosiasi dan klastering sebagai contoh hanya dapat menerima input kategorikal dan memerlukan pembagian beberapa interval pada data angka, disebut binning. Kualitas data mining akan ditentukan pada proses ini karena beberapa dari karakerstik metode yang dipakai bergantung pada proses transformation.
4. Data Mining
Data mining adalah suatu proses yang dilakukan untuk menemukan model pola atau informasi menarik dari data yang telah di seleksi dan dilakukan dengan menggunakan teknik, metode, atau algoritma yang tepat sehingga sesuai dengan tujuan secara kesuruhan.
16
5. Interpretation (Evaluation)
Interprestation atau bisa disebut dengan evaluation merupakan tahap menampilkan pola informasi hasil dari data mining ke dalam bentuk sederhana sehingga mudah dipahami pihak yang berkepentingan kemudian memeriksa kesesuian pola informasi tersebut dengan fakta atau hipotesis yang telah ada.
2.2.4 Pengelompokan Data Mining
Data mining dapat dikelompokan menjadi tiga kelompok yang berbeda. Pengelompokan tersebut didasarkan pada arti secara luas, pengelompokan berdasarkan kegunaan secara umum, dan berdasarkan fungsionalitasnya. Berikut penjelasan dari tiga pengelompokan pada data mining antara lain, yaitu :
1. Berdasarkan arti secara luas
Pengelompokan data mining berdasarkan arti secara luas data mining dibagi menjadi dua kelompok, antara lain yaitu :
a) Supervised
Supervised merupakan metode data mining yang dilakukan dengan adanya pelatihan dan pengujian sebagai pendekatan untuk menemukan suatu fungsi, (Ridwan, Suyono, & Sarosa, 2013).
Pengarahan atau pengawasan terhadap data mining dan menemukan fungsi atau hubungan pada data latih berlabel, selanjutnya fungsi tersebut akan digunakan untuk data baru yang tidak berlabel, (Kotu & Deshpande, 2015). Supervised diperlukan adanya data latih berlabel yang akan diterapkan fungsinya pada data tidak berlabel.
17
b) Unsupervised
Data mining diambil dari data yang tidak berlabel, data tersebut merupakan data yang tidak mempunyai atribut khusus didalamnya, hal ini disebut sebagai unsupervised, (Bramer, 2013).
Data mining dilakukan dengan cara association untuk menemukan suatu pola data yang tidak diketahui sebelumnya, namun dengan menggunakan data training yang tidak memiliki label, (Kavakiotis et al., 2017).
2. Berdasarkan kegunaan
Pengelompokan data mining secara umum berdasarkan kegunaannya meliputi:
a) Deskriptif
Secara deskriptif, data mining yang digunakan untuk menemukan pola-pola yang akan memudahkan manusia yang berkepentingan dalam mengartikan karakterstik suatu data, (Suyanto, 2017). Menemukan suatu pola yang tersembunyi dalam suatu data, (Ridwan et al., 2013).
b) Prediktif
Menurut Kamagi dan Hansun (2014), data mining dilakukan dengan prediksi dengan tujuan untuk membuat model prediksi dari suatu nilai atribut yang memiliki ciri-ciri khusus, proses pengelolaan disebut sebagai prediktif, (Kamagi & Hansun, 2014). Prediktif merupakan data mining yang dikelola untuk membentuk suatu pola atau model pengetahuan baru yang akan digunakan untuk prediksi, (Suyanto, 2017).
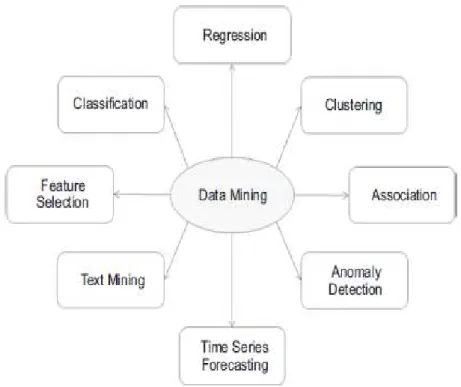
18 3. Berdasarkan fungsionalitas
Berdasarkan fungsionalitasnya data mining dibagi menjadi delapan kelompok. Gambar 2.4 menunjukkan gambaran data mining berdasarkan fungsionalitas.
Gambar 2.4 Data Mining Berdasarkan Fungsionalitas Sumber : (Kotu dan Deshpande, 2014)
Berikut data mining berdasarkan fungsionalitasnya menurut (Kotu & Deshpande, 2015) dibagi menjadi delapan antara lain, yaitu :
a) Classification
Tugas dari klasifikasi adalah memprediksi variabel output, yang bersifat kategoris atau polimonial (misalnya, keputusan ya atau tidak untuk
19 menyetujui a pinjaman). Algoritma yang dipakai dalam klasifikasi yaitu Decision Tree, Naive bayes, KNN, dan SVM.
Data mining dalam proses klasifikasi dapat dipengaruhi oleh empat komponen menurut, (Raharja, 2014), antara lain yaitu :
Class Label
Class Label, yaitu variable yang bertipe kategorikal yang mempresentasikan label yang terdapat pada suatu data.
Predictor
Variable Independent yang direpresentasikan oleh karakteristik atau atribut-atribut data.
Data Training
Data pelatihan dari set data yang berisi nilai dari kedua komponen class label dan predictor yang digunakan untuk menentukan kelas yang cocok berdasarkan predictor atau menentukan label pada data yang tidak berlabel.
Data Testing
Berisi data baru yang akan diklasifikasikan oleh model yang sudah dibuat dari data training dan kemudian dievaluasi.
b) Regresion
Dalam tugas-tugas regresi, variabel output merupakan bentuk numerik (misalnya, suku bunga hipotek atas pinjaman).
20
c) Clustering
Clustering adalah proses mengidentifikasi pengelompokan alami dalam dataset. Karena proses clustering ini tidak diawasi atau termasuk unsupervised maka penambangan data dilakukan terserah kepada pengguna akhir untuk menyelidiki mengapa gugus ini terbentuk dalam data dan generalisasi keunikan masing-masing cluster. Algoritma yang dipakai dalam tahap ini, yaitu : K-means, K-Medoids, dan Self-Organizing Map.
d) Association
Metode data mining yang dilakukan dengan cara mengidentifikasi data pelatihan secara spesifik dan teknik dilakukan dengan mengumpulkan data. Algoritma yang dipakai dalam tahap ini, salah satu nya adalah algortima A-priori.
e) Anomaly Detection
Proses deteksi dengan mengidentifikasi dan menemukan suatu titik yang berbeda secara signifikan dari titik data lain. Contoh kasus yang dinilai produktif yaitu penipuan dalam transaksi kartu kredit.
f) Time Series Forecasting
Proses data mining dimana akan membentuk model untuk memprediksi nilai suatu masa depan dengan melihat atau menganalisa model di masa yang lalu.
21
g) Text Mining
Proses mengubah file teks menjadi vektor dokumen yang berarti kata unik akan menjadi atribut dalam data mining yang berupa data teks untuk mempemudah proses penambangan data teks. File teks yang telah diubah, selanjutnya akan diberi tugas baik klasifikasi, regresi, dan lain sebagainya.
h) Feature Selection
Proses pengurangan atribut dalam data untuk memilih atribut-atribut yang dianggap unik atau penting.
2.2.5 Pengertian Decision Tree
Decision Tree atau pohon keputusan adalah suatu persoalan yang membentuk model berupa pohon (tree) yang berisi sekumpulan keputusan yang akan mengarah pada keputusan akhir sebagai pemecahan masalah, (D. A. C et al., 2013). Decision Tree adalah bagian dari metode classification yang populer karena kemudahan dalam menginterpretasi, (Vulandari, 2017).
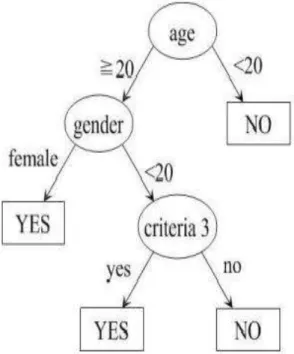
Decision Tree dibagi menjadi tiga node menurut (Sathyadevan & Nair, 2015), diantaranya yaitu sebagai berikut :
1. Root Node, yaitu sebagai node utama atau node akar yang akan membentuk
cabang dan node-node internal.
2. Internal node, yaitu node yang menjadi perwakilan sebagai atribut test.
Cabang-cabang dari node sebagai perwakilan dari hasil test.
22 Data yang tidak berlabel dapat diidentifikasi dengan cara menyusuri jalur cabang dari akar (root node) hingga sampai ke leaf node yang terdapat label kelas.
Gambar 2.5 Contoh Decision Tree Sumber : (Dai & Ji, 2014)
2.2.6 Kelebihan Decision Tree
Decision Tree selain mudah untuk diinterpretasikan oleh manusia untuk kebutuhan klasifikasi mempunyai beberapa kelebihan lain. Menurut Vulandari (2017), Decision Tree memiliki 4 kelebihan antara lain, yaitu :
1. Membuat serangkaian cara dalam membuat keputusan yang sebelumnya mempunyai ruang lingkup luas dan kompleks menjadi lebih spesifik, ringkas dan sederhana.
23 2. Penggunaan metode Decision Tree hanya menguji data sample berdasarkan kriteria atau kelas tertentu dan mengeliminasi perhitungan-perhitungan yang tidak digunakan, untuk memudahkan proses pengambilan keputusan. 3. Dapat digunakan secara fleksibel karena dapat memilih internal node sesuai
dengan kriteria yang dimiliki data sample, untuk meningkatkan kualitas dari keputusan yang akan dihasilkan dari pohon keputusan.
4. Decision Tree dapat menggunakan kriteria yang jumlahnya sedikit pada
internal node tanpa perlu melakukan estimasi dari segi distribusi dimensi tinggi dan parameter tertentu dengan jumlah kelas atau kriteria yang banyak, hal ini tidak mempengaruhi tingkat kualitas dari hasil keputusan.
2.2.7 Kekurangan Decision Tree
Berikut kekurangan Decision Tree menurut Vulandari (2017), yaitu: 1. Jika kriteria mencapai jumlah yang sangat besar menyebabkan overlap yang
dapat memperlambat dalam proses pengambilan keputusan serta membutuhkan jumlah memori yang besar.
2. Setiap tingkat pada kriteria dalam Decision Tree terjadi akumulasi jumlah eror sehingga dapat menyebabkan jumlah eror yang besar.
3. Kesulitan membuat desain untuk Decision Tree yang menghasilkan keputusan secara optimal.
4. Desain Decision Tree akan mempengaruhi kualitas dari keputusan yang diambil.
24
2.2.8 Pengertian Algoritma C4.5
Algoritma C4.5 merupakan pengembangan dari algoritma ID3 yang digunakan untuk mengambil keputusan dengan membentuk pohon keputusan yang memiliki simpul cabang secara optimal sampai menghasilkan cabang akhir, (Rahmayuni, 2014).
Algoritma C4.5 bila diimplemetasikan dalam aplikasi WEKA disebut juga algoritma J48, (Chauhan & Chauhan, 2013). Decision Tree pada algoritma ID3 mengalami perbaikan dan diubah menjadi algoritma C4.5, salah satu perbaikan dari algoritma tersebut adalah dalam hal pemangkasan (prunning), (Nurzahputra & Muslim, 2017).
Dapat disimpulkan bahwa algoritma C4.5 merupakan algoritma pembaruan dari algoritma ID3 yang menghasilkan algoritma yang lebih baik.
2.2.9 Keuntungan Algoritma C4.5
Algoritma C4.5 memiliki tiga keuntungan, (Singh & Gupta, 2014). Berikut keuntungan algoritma C4.5 diantaranya, yaitu :
1. Dapat menangani atribut bertipe diskrit dan kontinyu.
2. Jika terdapat nilai atribut yang hilang maka dapat di ubah menjadi tanda “?”, nilai tersebut tidak akan digunakan dalam perhitungan gain dan entropy. 3. Dapat dilakukan pemangkasan terhadap cabang pohon yang tidak
25
2.2.10 Kerugian Algoritma C4.5
Selain keuntungan algoritma C4.5 memiliki beberapa kerugian (Singh & Gupta, 2014). Berikut kerugian dari algoritma C4.5 menurut Sigh dan Gupta (2014) antara lain, yaitu :
1. Algoritma C4.5 dapat membangun cabang kosong yang nilainya tidak berkontribusi untuk menghasilkan aturan.
2. Terjadi overfitting akibat dari noise data.
3. Kebisingan (noise data) yang rentan terjadi pada C4.5.
2.2.11 Tahap Membangun Algoritma C4.5
Algoritma C4.5 memiliki tahap-tahap dalam pengimplementasiannya, berikut tahap-tahap untuk membangun algoritma C4.5 menurut (Raharja, 2014) dan (Rohman, 2016) diantaraya, yaitu :
1. Tahap awal dengan mempersiapkan data training, yaitu data latih yang menjadi histori atau data yang sebelumnya sudah ada kelompokan menjadi beberapa atribut atau kelas-kelas khusus.
2. Menghitung entropy, information gain, split information, dan gain ratio dari setiap atribut–atribut yang ada pada data training. Berikut rumus entropy, information gain, split information, dan gain ratio :
a. Entropy, yaitu konsep yang menyatakan tingkat impurity dari
kumpulan objek atau suatu himpunan (dataset). Rumus:
𝐸𝑛𝑡𝑟𝑜𝑝𝑦 (𝑆) = ∑ − 𝑛
𝑗=1
26
b. Information Gain, yaitu kriteria yang digunakan untuk memilih
suatu atribut yang populer, dapat dihitung dengan cara pengelompokan berdasarkan masing-masing atribut dalam suatu data. Notasi information gain adalah Gain (S,A) yang berarti dalam data atribut A relatif terhadap output S. Rumus nya sebagai berikut:
c. Split Information, yaitu nilai split pada tiap atribut atau term baru
sebelum menentukan gain ratio. Berikut rumus split info:
d. Gain Ratio, yaitu nilai yang dipilih untuk menjadi root node atau
akar pohon. Rumus :
Keterangan :
S = himpunan dataset kasus atau ruang sample n = banyaknya partisi S 𝐺𝑎𝑖𝑛 (𝑆, 𝐴) = 𝐸𝑛𝑡𝑟𝑜𝑝𝑦 (𝑆) − ∑|𝑆𝑖| |𝑆| ∗ 𝐸𝑛𝑡𝑟𝑜𝑝𝑦(𝑆𝑖) 𝑛 𝑖=1 𝑆𝑝𝑙𝑖𝑡 𝐼𝑛𝑓𝑜𝑟𝑚𝑎𝑡𝑖𝑜𝑛 (𝑆, 𝐴) = − ∑𝑆𝑖 𝑆 ∗ 𝑙𝑜𝑔2∗ 𝑆𝑖 𝑆 𝑛 𝑖=1 𝐺𝑎𝑖𝑛 𝑅𝑎𝑡𝑖𝑜 (𝑆, 𝐴) = 𝐺𝑎𝑖𝑛 (𝑆, 𝐴) 𝑆𝑝𝑙𝑖𝑡 𝐼𝑛𝑓𝑜𝑟𝑚𝑎𝑡𝑖𝑜𝑛 (𝑆, 𝐴)
27 A = Atribut
Pj = Probabilitas dari atribut kelas dibagi jumlah total kasus (j) Si = jumlah kasus pada atribut A yang memiliki partisi (i) 3. Menentukan root node atau akar pohon dari atribut dengan nilai gain ratio
yang tertinggi.
4. Setelah memilih akar, hitung kembali entropy, information gain, split information, dan gain ratio namun hilangkan atribut yang telah dipilih. 5. Membuat cabang atau internal node dengan menghitung entropy,
information gain, split information, dan gain ratio kembali, lalu tentukan gain ratio tertinggi.
6. Ulangi langkah nomor 5 sampai semua atribut sudah terbentuk menjadi pohon. Apabila ada cabang yang tidak diperlukan maka dapat dihilangkan dengan cara pemangkasan.
7. Proses akan berhenti apabila, semua tupel dalam node memiliki kelas, tidak ada atribut dalam tupel yang dapat dijadikan node kembali, dan tidak ada tupel didalam cabang yang memiliki nilai kosong. Tupel merupakan kumpulan atribut dalam satu baris.
2.2.12 Metode Ensemble
Metode Ensemble classification merupakan pembelajaran dengan menggabungkan hasil prediksi dari satu set klasifikasi tidak hanya menggunakan satu metode klasifikasi. Metode Ensemble classification disebut juga dengan metode Ensemble learning, (Bramer, 2013).
28 Metode Ensemble classification merupakan bagian dari kategori supervised karena menggunakan data latih yang berlabel, Ensemble classification menggabungkan beberapa teknik pembelajaran lemah dan menggabungkan hasil prediksi pembelajaran tersebut menjadi pembelajaran kuat untuk meningkatkan hasil akurasi, (Kulkarni, 2014).
Ensemble classification, mengoptimalkan hasil hipotesa untuk
meningkatkan akurasi dengan menggunakan beberapa model prediksi kemudian menggabungkan beberapa model tersebut untuk membentuk satu hipotesa, (Kotu & Deshpande, 2015).
Metode Ensemble merupakan metode yang dilakukan untuk menghasilkan tingkat akurasi yang lebih baik dari pada menggunakan algoritma klasifikasi tunggal, (Abdelaal, Elmahdy, Halawa, & Youness, 2018).
Dapat disimpulkan bahwa metode Ensemble merupakan teknik penggabungan hasil prediksi dari beberapa klassifikasi menjadi satu untuk meningkatkan hasil akurasi. Metode Ensemble menggabungkan beberapa algoritma klasifikasi lemah menjadi kuat dan menghasilkan akurasi lebih baik daripada menggunakan satu algoritma klasifikasi.
29
Gambar 2.6 Gambaran Ensemble Classification Sumber : (Bramer, 2013)
Dalam membangun metode Ensemble classification memiliki 4 teknik untuk diimplementasikan menurut, (Kotu & Deshpande, 2015). Berikut penjelasan 4 teknik dalam metode Ensemble classification diantaranya, yaitu :
1. Voting
Teknik Ensemble dengan menggabungkan beberapa algoritma klasifikasi, baik Decision Tree, Naive Bayes, KNN dalam operator vote, kemudian memilih salah satu algoritma yang mempunyai jumlah suara terbanyak untuk dijadikan model Ensemble.
2. Bootstrap Aggregating atau Bagging
Teknik Ensemble untuk meningkatkan stabilitas dari algoritma klasifikasi dengan mengubah data latih karena menggabungkan beberapa hipotesis data yang sama, untuk menetralkan variasi data pelatihan. Bagging berbeda dengan teknik voting karena hanya dapat memiliki satu algoritma klasifikasi didalam operatornya.
30 Metode Ensemble dengan teknik bagging dapat menyelesaikan permasalahan, diantaranya dalam menangani masalah varians dan overfitting pada data, (Kotu & Deshpande, 2015).
3. Boosting
Teknik peningkatan dilakukan secara berulang dan berurutan satu persatu pada data latih dan menentukan semua bobot data latih. Peningkatan konsentrasi dilakukan pada data latih yang sulit diklasifikasikan. Teknik boosting yang populer dan sering diimplementasikan adalah teknik Adaboost, (Nurzahputra & Muslim, 2017).
4. Random Forest
Teknik yang mengganggap subset acak dari setiap atribut pada data latih. Algortima dalam teknik ini dibagi menjadi dua level untuk mengurangi tingkat kesalahan generalisasi, yaitu pemilihan data latih (training) dan pemilihan atribut dalam masing-masing algortima.
2.2.13 Adaboost
Adaboost merupakan kepanjangan dari Adaptive Boosting, Adaboost adalah teknik pemberian bobot terhadap klasifikasi lemah dan mengumpulkannya menjadi klasifikasi kuat, (Cheng, Liu, Shi, Jun, & Li, 2015).
Algoritma Adaboost dari Freund dan Schapire (1995) merupakan algoritma penguat praktis pertama, dan tetap menjadi salah satu yang paling banyak digunakan dan dipelajari, dengan aplikasi di berbagai bidang, (Nurzahputra & Muslim, 2017).
31 Kelebihan dari Adaboost sehingga sukses diterapkan yaitu teori yang ada dalam teknik Adaboost kuat, prediksi yang dihasilkan akurat, dan diimplementasikan dengan sederhana, (Listiana & Muslim, 2017) .
Langkah-langkah dalam teknik Adaboost adalah sebagai berikut, (Kotu & Deshpande, 2015) :
1. Memberikan bobot pada data training dengan 𝑤𝑖 = 1/n, w merupakan data data training.
2. Mengambil sample dari data training dan membangun basis pertama bk (x) 3. Tingkat error dapat dihitung dengan rumus :
Persamaan I(x) = {0. 𝑗𝑖𝑘𝑎 𝑝𝑟𝑒𝑑𝑖𝑘𝑠𝑖 𝑠𝑎𝑙𝑎ℎ 1, 𝑗𝑖𝑘𝑎 𝑝𝑟𝑒𝑑𝑖𝑘𝑠𝑖 𝑏𝑒𝑛𝑎𝑟
4. Menghitung berat algoritma klasifikasi dengan rumus :
Apabila tingkat kesalahan rendah maka bobot klasifikasi yang dihasilkan tinggi, namun jika tingkat kesalahan tinggi maka akan menghasilkan bobot klasifikasi yang rendah.
5. Memperbarui bobot data training dengan persamaan rumus : 𝑒𝑘 = ∑ 𝑤𝑖∗ I (𝑏𝑘(𝑥𝑖) ≠ 𝑦𝑖) 𝑛 𝑘=1 𝛼𝑘 = ln(1 − 𝑒𝑘) 𝑒𝑘
𝑤
𝑘+1(i + 1) = 𝑤
𝑘(i) ∗ 𝑒
(𝛼𝑘F(bk(xi)≠𝑦𝑖32 Persamaan F(x) = {−1, 𝑗𝑖𝑘𝑎 𝑝𝑟𝑒𝑑𝑖𝑘𝑠𝑖 𝑏𝑒𝑟𝑛𝑖𝑙𝑎𝑖 𝑏𝑒𝑛𝑎𝑟1. 𝑗𝑖𝑘𝑎 𝑝𝑟𝑒𝑑𝑖𝑘𝑠𝑖 𝑏𝑒𝑟𝑛𝑖𝑙𝑎𝑖 𝑠𝑎𝑙𝑎ℎ
Keterangan :
w(i,k) = bobot pada data training (i,k) αk = model dasar
ek = Tingkat error
n = jumlah data training dinyatakan ((x1,y1), (x2,y2), ..., (xn,yn)) bk = data training baris pertama pada classifier
33 Metode Ensemble Boosting
Classification
2.3 Kerangka Berfikir
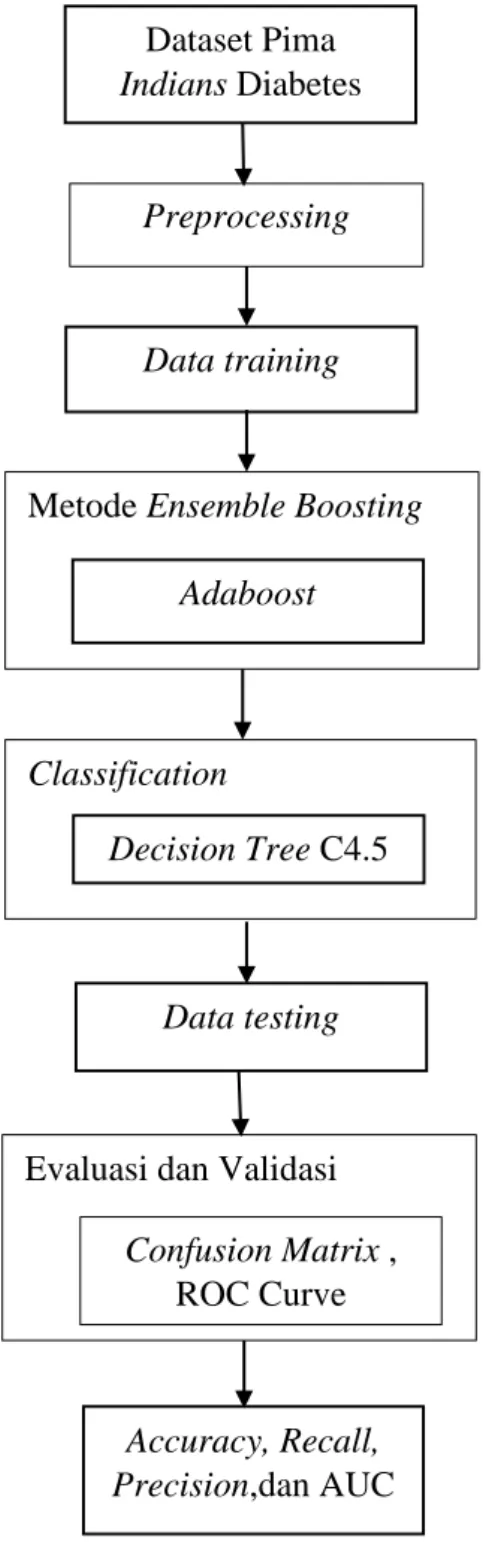
Gambar 2.7 Kerangka Berfikir Sumber : (Penulis, 2018) Dataset Pima Indians Diabetes Data training Data testing Decision Tree C4.5 Adaboost Accuracy, Recall, Precision,dan AUC Preprocessing
Evaluasi dan Validasi Confusion Matrix ,
34 Kerangka berfikir dalam penelitian ini dimulai dari pengambilan dataset. Dataset yang dipilih yaitu dataset Pima Indian Diabetes pada GitHub. Setelah didapatkan dataset kemudian dilakukan pengolahan data yaitu preprocessing. Data yang telah melalui tahap preprocessing akan dijadikan data training. Lanjut proses menggunakan metode Ensemble dengan teknik Adaboost yang dikombinasikan dengan algoritma klasifikasi Decision Tree C4.5 dan melakukan testing data. Hasil akhir sebagai evaluasi dan validasi berupa confussion matrix yang akan menghasilkan accuracy, recall, dan precision serta Receiver Operating Characteristic (ROC) kurva yang menghasilkan nilai Area Under Curve (AUC).
35
BAB III
METODE PENELITIAN
3.1 Objek Penelitian
Pada penelitian ini yang menjadi objek penelitian adalah penderita penyakit diabetes melitus. Data yang diambil berupa dataset diabetes dengan 9 atribut, yaitu sebagai berikut :
1. Number of times pregnant (jumlah kehamilan)
2. Plasma glucose concentration (konsentrasi glukosa plasma)
3. Diastolic blood pressure (tekanan darah diastolik)
4. Triceps skin fold thickness (ketebalan lipatan kulit trisep)
5. 2-Hour serum insulin (insulin serum 2 jam)
6. Body mass index (indeks massa tubuh)
7. Diabetes pedigree function (fungsi silsilah diabetes)
8. Age (usia)
9. Class (kelas)
3.2 Pengumpulan Data
Pengumpulan data dalam penelitian ini menggunakan metode pengumpulan data sekunder. Data sekunder adalah data yang diperoleh tidak secara langsung pada sumbernya. Sumber data yang digunakan penelitian ini berasal dari data publik yaitu dataset Pima Indians Diabestes dari GitHub
36 dengan jumlah data sebanyak 768 data. Berikut tabel 3.1 menunjukkan tabel sebagian dari dataset diabetes melitus :
Tabel 3.1 Dataset Diabetes Melitus
Number of times preg Plasma glucose concen Diastolic blood pressure Triceps skin fold thickness 2-Hour serum insulin Body mass index Diabetes pedigree function Age Class 6 148 72 35 0 33.6 0.627 50 positive 1 85 66 29 0 26.6 0.351 31 negative 8 183 64 0 0 23.3 0.672 32 positive 1 89 66 23 94 28.1 0.167 21 negative 0 137 40 35 168 43.1 2.288 33 positive 5 116 74 0 0 25.6 0.201 30 negative 3 78 50 32 88 31.0 0.248 26 positive 10 115 0 0 0 35.3 0.134 29 negative 2 197 70 45 543 30.5 0.158 53 positive 8 125 96 0 0 0.0 0.232 54 positive 4 110 92 0 0 37.6 0.191 30 negative 10 168 74 0 0 38.0 0.537 34 positive 10 139 80 0 0 27.1 1.441 57 negative 1 189 60 23 846 30.1 0.398 59 positive 5 166 72 19 175 25.8 0.587 51 positive 7 100 0 0 0 30.0 0.484 32 positive 0 118 84 47 230 45.8 0.551 31 positive 7 107 74 0 0 29.6 0.254 31 positive 1 103 30 38 83 43.3 0.183 33 negative 1 115 70 30 96 34.6 0.529 32 positive 3 126 88 41 235 39.3 0.704 27 negative 8 99 84 0 0 35.4 0.388 50 negative 7 196 90 0 0 39.8 0.451 41 positive 9 119 80 35 0 29.0 0.263 29 positive 11 143 94 33 146 36.6 0.254 51 positive 10 125 70 26 115 31.1 0.205 41 positive 7 147 76 0 0 39.4 0.257 43 positive 1 97 66 15 140 23.2 0.487 22 negative 13 145 82 19 110 22.2 0.245 57 negative ... ... ... ... ... ... ... ... ...
37
3.3 Peralatan
Penelitian yang dilakukan memerlukan peralatan untuk mendukung pelaksanaan penelitian. Peralatan-peralatan tersebut berupa kebutuhan software (perangkat lunak) dan hardware (perangkat keras). Berikut kebutuhan yang diperlukan antara lain, yaitu :
1. Kebutuhan software
Berikut adalah kebutuhan software yang diperlukan dalam penelitian antara lain, yaitu :
a. Sistem Operasi Windows 7 versi 64 bit
Penelitian dilakukan dengan menggunakan sistem operasi Windows 7 versi 64 bit untuk sebagai platform untuk menjalankan program data mining tools.
b. RapidMiner versi 8.2.1
RapidMiner versi 8.2.1 digunakan sebagai data mining tools untuk menjalankan tahap-tahap data mining, implemetasi algoritma, implementasi metode Ensemble, serta menghitung hasil akurasi. 2. Kebutuhan Hardware
Berikut hardware yang digunakan dalam penelitian ini, yaitu : a. Laptop Intel Pentium
b. RAM 6 GB
c. Hardisk 300 GB
38
3.4 Waktu Penelitian
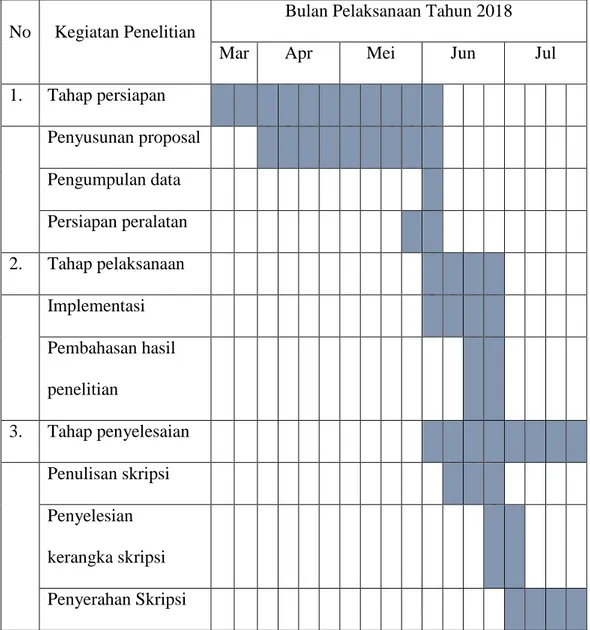
Tahap-tahap dalam kegiatan penelitian ini meliputi, tahap persiapan, tahap pelaksanaan, dan tahap penyelesaian. Adapun waktu penelitian dimulai pada bulan maret sampai dengan Juli 2018. Berikut adalah tabel perincian tahap-tahap penelitian :
Tabel 3.2 Kegiatan Penelitian
No Kegiatan Penelitian
Bulan Pelaksanaan Tahun 2018
Mar Apr Mei Jun Jul
1. Tahap persiapan Penyusunan proposal Pengumpulan data Persiapan peralatan 2. Tahap pelaksanaan Implementasi Pembahasan hasil penelitian 3. Tahap penyelesaian Penulisan skripsi Penyelesian kerangka skripsi Penyerahan Skripsi
39
3.5 Tahap Analisa Data
Dataset Pima Indians Diabetes yang berasal dari GitHub mempunyai jumlah data sebanyak 768 data terdiri dari 8 atribut dan 1 atribut sebagai class. Atribut class mempunyai dua nilai yaitu positif dan negatif. Jumlah nilai positif ada 268 data sedangkan nilai negatif ada 500 data.
Dalam membuat sebuah keputusan atau menentukan akurasi perlu adanya data yang berkualitas untuk itu dilakukan tahap data preprocessing. Data preprocessing digunakan untuk membersihkan data dari missing value, ketidak konsistenan, data tidak lengkap, dan noise data. Berikut tahap-tahap data preprocessing antara lain, yaitu :
1. Data Cleaning
Data Cleaning (pembersihan data) merupakan penyaringan data atau pembersihan data yang tidak dibutuhkan karena adanya kesalahan data untuk menghasilkan data yang berkualitas.
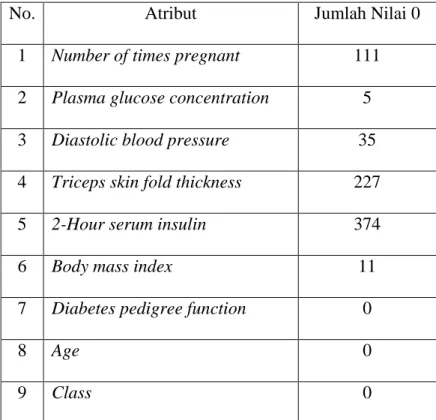
Menurut (Srivastava, 2014), pembersihan data dilakukan jika ada kesalahan yakni, missing data, yaitu data yang hilang, penanganan data yang hilang dapat dilakukan dengan mengabaikan tuple atau baris data yang memiliki nilai hilang, mengisi nilai secara manual, menggunakan mean/median, mengganti dengan nilai terbanyak atau dengan menerapkan nilai prediksi. Pada dataset Pima Indians Diabetes tidak ada atribut dengan nilai yang hilang atau missing value namun terdapat 6 atribut yang memiliki nilai 0.
40 Berikut tabel 3.3 yang menunjukkan atribut yang bernilai 0 beserta jumlah nilai 0 pada dataset :
Tabel 3.3 Atribut-atribut Bernilai 0
No. Atribut Jumlah Nilai 0
1 Number of times pregnant 111
2 Plasma glucose concentration 5
3 Diastolic blood pressure 35
4 Triceps skin fold thickness 227
5 2-Hour serum insulin 374
6 Body mass index 11
7 Diabetes pedigree function 0
8 Age 0
9 Class 0
Berdasarkan tabel dapat dilihat bahwa ada 6 atribut yang terdapat nilai 0. Pada atribut number of times pregnant merupakan nilai sebenarnya karena menyatakan berapa jumlah dari kehamilan, apabila bernilai 0 maka dapat diartikan bahwa belum pernah hamil namun untuk atribut konsentrasi glukosa plasma, tekanan darah diastolik, ketebalan lipatan kulit trisep, insulin serum 2-jam, dan indeks massa tubuh, nilai 0 pada data tidak dapat terjadi untuk itu atribut-atribut tersebut merupakan missing value. Perlu dilakukan pembersihan data dari missing
41 value menggunakan teknik penghapusan tuple atau record data yang bernilai 0 yaitu menggunakan fitur filter examples pada aplikasi RapidMiner.
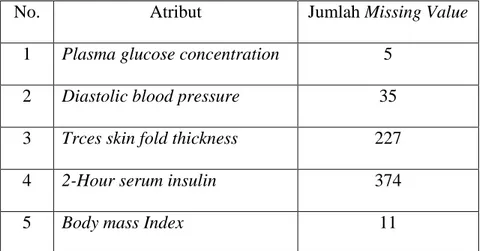
Berikut tabel 3.4 merupakan lima atribut yang akan ditangani pada tahap data cleaning dengan mengurangi tuple atau record bernilai 0 :
Tabel 3.4 Jumlah Missing Value
No. Atribut Jumlah Missing Value
1 Plasma glucose concentration 5
2 Diastolic blood pressure 35
3 Trces skin fold thickness 227
4 2-Hour serum insulin 374
5 Body mass Index 11
2. Data Reduction
Data reduction merupakan tahap data preprocessing dengan mengurangi jumlah data yang dihasilkan dari data asli, pengurangan tersebut dapat dilakukan dengan cara pengurangan jumlah atribut, namun tetap memilih atribut yang penting yang akan digunakan dalam data mining, (Alasadi & Bhaya, n.d.). Berkurangnya atribut tidak akan mempengaruhi hasil representasi akhir karena akan menunjukkan hasil yang sama.
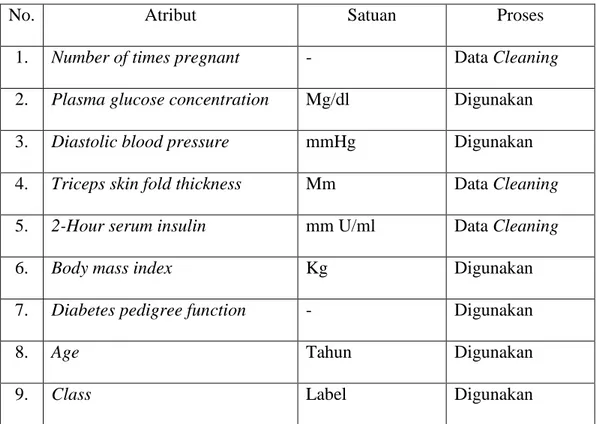
42 Berikut tabel 3.5 merupakan tabel atribut data penelitian dari dataset diabetes yang akan dikurangi :
Tabel 3.5 Atribut Dataset
No. Atribut Satuan Proses
1. Number of times pregnant - Data Cleaning
2. Plasma glucose concentration Mg/dl Digunakan
3. Diastolic blood pressure mmHg Digunakan
4. Triceps skin fold thickness Mm Data Cleaning
5. 2-Hour serum insulin mm U/ml Data Cleaning
6. Body mass index Kg Digunakan
7. Diabetes pedigree function - Digunakan
8. Age Tahun Digunakan
9. Class Label Digunakan
Dataset yang terdiri dari 9 atribut dilakukan proses data preprocessing dengan tahap reduction untuk mengurangi atribut. Berdasarkan penelitian dari (Fatimah, 2015), faktor yang menyebabkan terjadinya penyakit diabetes melitus antara lain, obesitas, glukosa darah, hipertensi, riwayat keluarga diabetes melitus, dan umur, maka dari 9 atribut yang ada dalam dataset akan dikurangi menjadi 6 atribut. Pengurangan dilakukan untuk mempermudah dalam proses data mining dengan tidak mengubah hasil representasi akhir. Pengurangan dilakukan dengan menggunakan fitur select attributes pada aplikasi RapidMiner.
43 Berikut tabel 3.6 merupakan tabel atribut yang digunakan dalam proses mining :
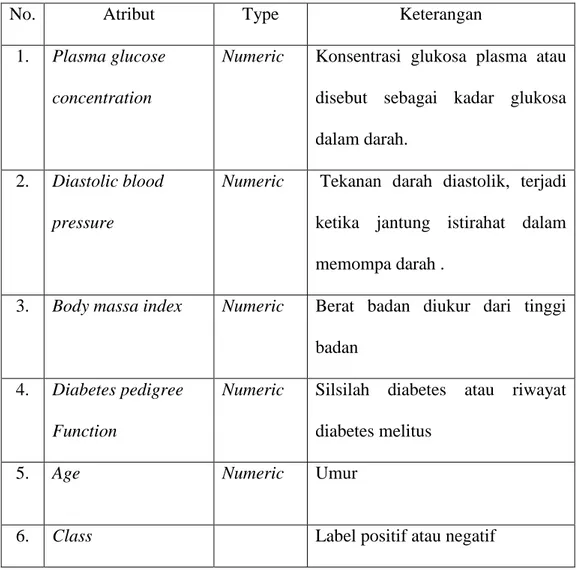
Tabel 3.6 Atribut yang digunakan
No. Atribut Type Keterangan
1. Plasma glucose
concentration
Numeric Konsentrasi glukosa plasma atau
disebut sebagai kadar glukosa dalam darah.
2. Diastolic blood
pressure
Numeric Tekanan darah diastolik, terjadi
ketika jantung istirahat dalam memompa darah .
3. Body massa index Numeric Berat badan diukur dari tinggi
badan
4. Diabetes pedigree
Function
Numeric Silsilah diabetes atau riwayat
diabetes melitus
5. Age Numeric Umur
44
3.6 Model yang diusulkan
Model yang diusulkan menggunakan algoritma Decision Tree C4.5 dengan menambahkan metode Ensemble yaitu Adaboost. Berikut gambar 3.1 alur model yang diusulkan :
Gambar 3.1 Alur Model Penelitian Sumber (Penulis, 2018)
45 Berdasarkan gambar 3.1 maka dapat diketahui bahwa langkah awal dimulai dari pengumpulan dataset sebanyak 768 data, kemudian dilakukan proses preprocessing yang digunakan untuk memperbaiki data sehingga akan menghasilkan data yang berkualitas. Penelitian ini dilakukan proses preprocessing dengan 2 tahap, yaitu data cleaning dan data reduction. Setelah dilakukan data preprocessing maka akan menghasilkan dataset baru. Dataset baru tersebut akan dibagi menjadi data training dan data testing dalam proses validasi.
Pada penelitian ini menggunakan k-folds cross validation sebagai metode untuk validasi dengan nilai k=10. Validasi dilakukan untuk menguji model algoritma yang digunakan. K-folds cross validation merupakan metode untuk mengetahui tingkat keberhasilan pada model algoritma dengan cara melakukan pengujian ulang atribut input yang acak, dalam metode ini data dibagi menjadi k subset secara acak, satu subset digunakan untuk data testing dan sisanya untuk data training, (Banjarsari, Budiman, & Farmadi, 2016).
10 Fold Cross Validation merupakan salah satu metode pengujian yang digunakan untuk pembelajaran terlatih (supervised learning). Setiap fold dibagi menjadi beberapa subset dengan ukuran sama pada tiap subset-nya. Kemudian akan dilakukan training sebanyak 10 kali dengan menggunakan 9 fold untuk training set dan 1 fold digunakan sebagai test set, (Defiyanti & Kom, 2013).
Nilai k yang digunakan yaitu 5 atau 10, biasa disebut 10 folds cross validation, yaitu data dibagi menjadi 10 bagian , 90% untuk training dan 10% lainnya digunakan sebagai testing. Proses dilakukan berulang sampai dengan 10
46 kali atau 10 iterasi sampai semua record data mendapatkan bagian sebagai data testing, (Indrayanti, Sugianti, & Karomi, 2017).
Berikut gambar 3.2 representasi dari 10 fold cross validation.
Gambar 3.2 Representasi 10 Folds Cross Validation Sumber (Indrayanti et al., 2017)
Cara kerja k-folds cross validation, yaitu total data dibagi menjadi n bagian, iterasi atau fold ke 1, yaitu bagian ke 1 menjadi testing, bagian sisanya menjadi data training, kemudian hitung akurasi menggunakan persamaan berikut :
Keterangan : Jumlah klasifikasi benar : jumlah prediksi klasifikasi yang tepat Jumlah data uji : jumlah dataset yang digunakan untuk testing
47 Pada fold ke 2, dimana bagian ke 2 yang menjadi testing, sisanya menjadi training, kemudian hitung akurasinya, proses tersebut berulang sampai mencapai fold ke -k. Hitung rata-rata dari semua nilai k, hasil akurasi tersebut merupakan hasil akurasi akhir.
Pada proses validasi dilakukan pembuatan model, dalam penelitian ini menggunakan metode Ensemble dengan teknik Boosting, yaitu Adaboost dan menggunakan Decision Tree C4.5 pada data training. Setelah itu dilanjutkan proses evaluasi dengan confusion table dan ROC curve. Hasil confusion table digunakan untuk menyajikan accuracy, recall, dan precision dalam algortima klasifikasi. Accuracy merupakan persentase antara nilai prediksi dengan nilai sebenarnya yang ada. Recall merupakan persentase nilai kinerja keberhasilan algoritma yang dipakai. Precision merupakan nilai akurasi dengan class yang telah diprediksi, (T. P. C & N, 2015). Berikut merupakan tabel confusion dapat dilihat pada tabel 3.7 :
Tabel 3.7 Confusion Table
Confusion matrix Nilai Prediksi Positive Negative Nilai Sebenarnya Positive TP FP Negative FN TN Rumus Accuracy : Rumus Recall : Accuracy = (𝑇𝑃+𝐹𝑃+𝑇𝑁+𝐹𝑁)𝑇𝑃+𝑇𝑁 Recall = (𝑇𝑃+𝐹𝑁)𝑇𝑃
48 Rumus Precision :
Keterangan : TP : True Positive FP : False Positive TN : True Negative FN : False Negative
Receiver Operating Characteristic (ROC) digunakan untuk evaluasi hasil akurasi dalam bentuk grafik. ROC merupakan kurva yang akan menghasilkan nilai Area Under Curve (AUC). AUC merupakan nilai akurasi area dibawah kurva yang dihasilkan oleh ROC, (Saifudin & Wahono, 2015). Menurut (Silalahi, Murfi, & Satria, 2017), keakurasian nilai AUC dapat diklasifikasi menjadi 5 kelompok antara lain, yaitu : 1. 0.90 – 1.00 = Exellent Classification 2. 0.80 – 0.90 = Good Classification 3. 0.70 – 0.80 = Fair Classification 4. 0.60 – 0.70 = Poor Classification 5. 0.50 – 0.60 = Failure Precision = (𝑇𝑃+𝐹𝑃)𝑇𝑃