IMPROVEMENT OF SENTENCES SCORING BASED NEWS
FEATURE FOR NEWS SUMMARY ON SOCIAL MEDIA ISSUES
Nur Hayatin*1, Gita I. Marthasari2
1,2Informatic Engineering Departement, Engineering Departement
Universitas Muhammadiyah Malang, Indonesia
Kontak Person : Nur Hayatin
e-mail : [email protected]
Abstrak
Salah satu fase penting yang ada dalam sistem peringkasan berita otomatis khususnya secara ekstraktif adalah fase pembobotan kalimat (sentence scoring). Penelitian ini bertujuan untuk memperbaiki pembobotan pada sistem peringkasan berita terhadap isu media sosial, yaitu dengan menambahkan fitur penting yang ada pada dokumen (News Feature) terhadap trending issue. Metode pembobotan News Feature (NF) mengkombinasikan 4 fitur penting pada berita : Word Frequency(WF), TFIDF, posisi kalimat, dan kemiripan kalimat terhadap judul berita. Terdapat Empat tahapan proses yang dilakukan dalam penelitian ini, yaitu : seleksi berita berdasarkan hasil ekstraksi trending issue media sosial, ekstraksi fitur berita, penghitungan bobot kalimat, dan pembangkitan ringkasan berita. Hasil pengujian dengan menggunakan ROUGE-N menunjukkan bahwa peringkasan dengan pembobotan NF lebih unggul sebesar 73% dari pembobotan Word Frequency (WF). Hal ini membuktikan bahwa pembobotan News Feature (NF) pada peringkasan multi dokumen berita mampu menghasilkan kualitas ringkasan yang lebih baik.
Kata kunci:news feature, pembobotan kalimat, peringkasan berita, trending issue
1. Pendahuluan
Peringkasan berita secara otomatis adalah salah satu solusi untuk menjawab kebutuhan dalam
mengakses informasi khususnya situs berita online secara praktis. Menurut Karel, peringkasan
dokumen didefinisikan sebagai sebuah penyulingan informasi yang paling penting dari dokumen sumber untuk menghasilkan sebuah versi singkat untuk tugas maupun pengguna tertentu [1]. Sedangkan ringkasan berita dapat diartikan sebagai sebuah teks yang dihasilkan dari satu atau lebih kalimat yang mampu menyampaikan informasi penting dari sebuah berita. Sistem peringkasan berita
dapat melibatkan satu (single) atau lebih dari satu artikel berita (multi) sebagai input.
Salah satu fase penting yang ada dalam sistem peringkasan berita secara otomatis khususnya
secara ekstraktif adalah fase pembobotan kalimat (sentence scoring) [2]. Metode pembobotan kalimat
yang biasa digunakan adalah : centroid, posisi, dan kemiripan kalimat terhadap kalimat pertama [3];
word frequency (WF) dan TF-IDF [4]. Selain itu, metode pembobotan kalimat berbasistrending issue
juga digunakan terutama untuk peringkasan dari beberapa dokumen berita [5][6]. Pembobotan trending issue mempertimbangkan isu yang berkembang di media sosial sehingga harapannya ringkasan yang dihasilkan lebih koheren.
Kim Daeyong telah membangun sebuah sistem peringkasan berita dengan mempertimbangkan
isu media sosial berdasarkan data Twitter. Namun untuk fitur pada berita sendiri, penelitian ini hanya
mempertimbangkan pembobotan berbasisWord Frequency[5]. Padahal, menurut Ferreira pembobotan
kalimat pada dokumen yang memiliki karakter teks pendek dan terstruktur seperti berita, maka teknik
pembobotan kalimat terbaik adalah dengan menggunakan kombinasi empat fitur yaitu : Word
Frequency(WF), TFIDF, posisi kalimat, dan kemiripan kalimat terhadap judul berita [7].
Penelitian ini bertujuan untuk memperbaiki pembobotan kalimat pada peringkasan multi dokumen
berita dengan menambahkan fitur penting yang ada pada dokumen terhadaptrending issue. Adapun
metode pembobotan yang digunakan adalah dengan mengkombinasikan 4 fitur penting pada berita berdasarkan penelitian Ferreira yang telah disebutkan sebelumnya. Dimana ke-empat fitur penting
tersebut disebut dengan News Feature(NF). Selanjutnya dari hasil ringkasan yang didapatkan akan
pembobotan fitur berita diharapkan dapat menyeleksi kalimat penting dari berita secara lebih tepat sehingga dihasilkan kualitas ringkasan yang lebih baik.
2. Metode Penelitian
Sistem peringkasan berita terhadap isu media sosial yang dikerjakan dalam penelitian ini
mempertimbangkan fitur trending issue media sosial,News Feature(NF), dan juga redundansi kalimat.
Pembobotan kalimat berbasis NF mempertimbangkan 4 fitur penting berita, yaitu: Word Frequency
(WF), TFIDF, posisi kalimat, dan kemiripan kalimat terhadap judul berita. Secara garis besar ada empat proses yang dilakukan pada penelitian ini. Empat tahapan proses tersebut adalah seleksi berita
berdasarkan hasil ekstraksi trending issue media sosial, ekstraksi fitur berita, penghitungan bobot
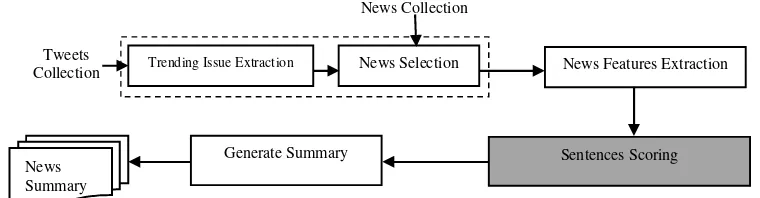
kalimat, dan pembangkitan ringkasan berita (gambar 1).
Gambar 1Tahapan proses sistem peringkasan berita berbasis isu media sosial dengan pembobotan
News Feature (NF)
Data yang digunakan dalam penelitian ini terdiri dari kumpulan tweets dan artikel berita dari
beberapa topik. Dimana dataset dan beberapa proses yang dibutuhkan dalam penelitian ini seperti
ekstraksitrending issue, seleksi berita, dan ekstraksi fitur berita, mengacu pada penelitian sebelumnya
[8]. Jumlah topik koleksi berita terdiri dari 11 topik, dengan rata-rata banyak kalimat dalam 1 artikel
berita adalah 160 kalimat. Topik tweets mengikuti topik berita dengan jumlah tweet untuk tiap topik
kurang lebih 100tweets.
Tahap pertama adalah melakukan seleksi berita berdasarkan Trending Issue (TI). Hasil dari
proses seleksi adalah didapatkan sejumlah n berita yang relevan terhadap TI. Selain itu dilakukan
seleksi fitur redundansi kalimat (Rd). Fitur redundansi kalimat digunakan untuk meminimalisir adanya redundansi pada hasil akhir ringkasan. Selanjutnya dilakukan ekstraksi fitur berita untuk mendapatkan
bobot dari 4 fitur berita yang digunakan (NF_score). Setiap kalimatsjyang ada pada dokumen berita akan
dihitung bobotWeight( )dengan menggunakan persamaan 1. Sedangkan pembobotanNews Feature
( ) diformulasikan pada persamaan 2.
Weight(sj) = + (sj) - (sj) (1)
= ( ) + , + + ( ) (2)
Total fitur yang akan diekstraksi dalam penelitian ini ada 6, yaituResemblance to the Trending
Issue, Word Frequency (WF), Term Frequency Inverse Document Frequency (TF-IDF), posisi kalimat,
Resemblance to the Title, dan nilai redundansi kalimat (Rd). Nilai bobot dari fitur trending issue ( (sj))
didapatkan dari nilai kemiripan antara kalimat terhadap Trending Issue ( ( , )). Metode
pengukuran kemiripan kalimat terhadap TI menggunakan cosine similarity, dimana kalimat yang
memiliki skor kemiripan tinggi terhadap TI akan dianggap sebagai kalimat penting. Nilai bobot
redundansi kalimat (Rd) diidentifikasi dari kemiripan kalimat sj terhadap kalimat yang lainsi dengan
mengadopsi konsep MMR[9]. Nilai bobotWF(sj)merupakan nilai kemiripan kalimatsiterhadapWFList
menggunakan cosine similarity, dimana S={ s1,..., sm }, sehingga WF adalah ( , ).
Pembobotan TFIDF merupakan hasil penjumlahan dari seluruh bobotterm iyang muncul pada kalimat
sj, dimanaj sebanyak jumlah kalimat yang ada pada dokumen (D). Nilai bobot posisi kalimat dihitung
dengan mengadopsi penelitian Mei & Chen, dimana bobot dari posisi kalimatsjadalah
( )
, dengan
asumsi kalimat yang posisinya berada diawal dokumen memiliki skor lebih besar dibanding kalimat yang posisinya diakhir[10]. Nilai bobot berikutnya adalah kemiripan kalimat terhadap judul berita (Rt) yang mengadopsi dari penelitian Ferreira dkk. yaitu dengan menghitung kesamaan term yang muncul pada
judul dan kalimatj, selanjutnya dibagi dengan jumlah term pada judul [2].
Tahapan proses berikutnya adalah pembangkitan ringkasan. Setiap kalimat berita pada akhirnya
akan memiliki bobot (Weight(sj)), selanjutnya seluruh kalimat akan diurutkan berdasarkan bobot
tersebut. Ringkasan dokumen diambil darinkalimat dengan bobot tertinggi. Dengan asumsi semakin
besar total bobot yang dimiliki oleh sebuah kalimat maka kalimat tersebut adalah kalimat penting.
3. Hasil Penelitian dan Pembahasan
Penelitian ini telah mampu menghasilkan ringkasan berita dengan menggunakan metode
pembobotan berbasis News Feature dan Trending Issue. Berikut adalah contoh ringkasan yang
dihasilkan dari topik “ebola” dengan panjang ringkasan 10 kalimat:
“Program Pangan Dunia (WFP) PBB menyatakan akan memberikan bantuan pangan kepada satu juta orang di tiga negara Afrika barat yang kesulitan menghadapi wabah Ebola terbaru. Wabah itu sudah membunuh 467 orang di Guinea, Liberia, dan Sierra Leone. WHO mengatakan pekan ini, penolakan masyarakat di Sierra Leone menghalangi usaha untuk mengidentifikasi dan menghubungi mereka yang mungkin telah tertular virus Ebola. Presiden organisasi internasional Dokter Tanpa Tapal Batas mengatakan wabah Ebola berada dalam tahapan yang berbeda di tiga negara. Seorang pejabat tinggi badan kesehatan PBB (WHO) mengatakan wabah ebola di Afrika Barat dapat berlangsung beberapa bulan. Penyebaran Ebola telah melambat di negara tetangganya, Guinea, dan berhenti di Liberia, setelah para pejabat kesehatan mengisolasi pasien dan memperingatkan masyarakat untuk menghindari kontak langsung dengan korban Ebola, termasuk yang sudah meninggal dunia. Pemerintah mengatakan, Ebola kini telah merenggut 16 nyawa di Sierra Leone. Sekitar 70 persen penderita telah meninggal dalam wabah saat ini. Para pakar mengatakan wabah Ebola di Afrika Barat sudah tidak terkendali.”
Untuk mengetahui pengaruh dari pembobotan yang diusulkan terhadap kualitas ringkasan yang dihasilkan maka perlu dilakukan pengujian. Dalam hal ini, pengujian dilakukan dengan cara membandingkan hasil ringkasan yang diusulkan (NF) dengan hasil ringkasan yang hanya
mempertimbangkan bobot dari Word Frequency (WF). Adapun metode yang digunakan untuk
mengukur kualitas ringkasan menggunakan metode pengukuran N [11]. Pengukuran
ROUGE-N didasarkan pada kemunculan secara statistik dari n-gram (N-gram Co-Occurrence Statistics).
Penelitian ini menggunakan 3groundtruthsebagai pembanding hasil ringkasan sistem. Nilai ROUGE
akan diambil dari nilai maksimal ROUGE-N (ROUGE-Nmulti) dari tiap pasangan ringkasan yang
dihasilkan oleh sistemsterhadap ringkasangroundtruth ri. Persamaan 3 digunakan untuk mendapatkan
nilai maksimal ROUGE-N. Sedangkan nilai ROUGE-N sendiri dapat dihitung dengan menggunakan
persamaan 4, dimananmerepresentasikan panjang darin-gram. Sedangkancountmatchadalah jumlah
n-gram yang sama antara n-gram dari ringkasan oleh sistem dengan n-gram yang ada pada
groundtruth. Dengan penyebut dari persamaan tersebut merupakan jumlah totaln-gramyang ada pada ringkasan referensi.
diketahui kualitasnya dengan menghitung nilai ROUGE-Nmulti. Tabel 1 berisi hasil perhitungan nilai
ROUGE-Nmultiuntuk ringkasan yang dihasilkan pada tiap topik berita.
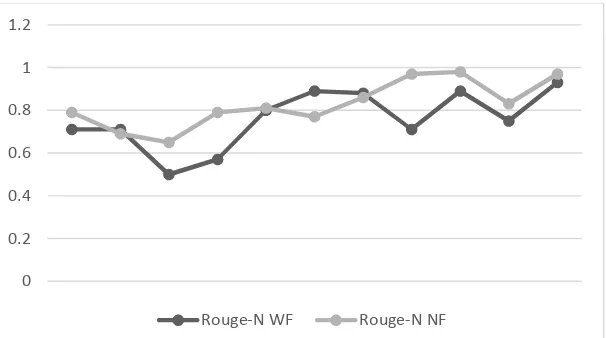
Tabel 1Hasil ROUGE-Nmultipada tiap topik untuk panjang ringkasan 30 kalimat
No Topik Total Kalimat Rouge-Nmulti
WF NF
1 Air asia 78 0.71 0.79
2 banjarnegara 186 0.71 0.69
3 bbm 161 0.50 0.65
4 bpjs 244 0.57 0.79
5 dolly 151 0.80 0.81
6 ebola 75 0.89 0.77
7 kurikulum 2013 319 0.88 0.86
8 Palestina 177 0.71 0.97
9 Pilpres 201 0.89 0.98
10 Sinabung 73 0.75 0.83
11 u19 105 0.93 0.97
Semakin tinggi nilai ROUGE maka dapat disimpulkan semakin banyak kalimat yang sama antara
kalimat yang ada pada hasil ringkasan oleh sistem dengan ringkasan groundtruth. Dengan kata lain
semakin tinggi nilai ROUGE sebuah ringkasan maka semakin tinggi kualitas dari ringkasan tersebut.
Dari tabel 1 dapat dilihat hasil nilai ROUGE-Nmultiuntuk tiap topik berita. Dimana pada pembobotan NF
didapatkan Nilai ROUGE tertinggi adalah 0.97 yaitu pada berita dengan topik “U19”. Sedangkan pada pembobotan WF nilai ROUGE tertinggi adalah 0.93 dengan topik yang sama. Sedangkan nilai ROUGE terendah untuk pembobotan NF adalah 0.65 dan untuk pembobotan WF adalah 0.50. Keduanya ada di topik yang sama yaitu “bbm”.
Dari hasil keseluruhan topik, didapatkan 8 topik dengan pembobotan NF memiliki nilai ROUGE
lebih tinggi dibanding dengan hasil dari pembobotan WF (lihat Gambar 2). Hasil dari pengujian
menunjukkan bahwa peringkasan dengan pembobotan NF lebih unggul sebesar 73% dari pembobotan WF. Dimana fitur yang digunakan pada pembobotan NF terdiri dari 4 fitur, yaitu : WF, TFIDF, posisi kalimat, dan kemiripan kalimat terhadap judul berita. Hal ini membuktikan bahwa peringkasan berita
dengan menggunakan pembobotan News Feature (NF) menghasilkan kualitas ringkasan yang lebih
baik dibanding dengan ringkasan yang dihasilkan dengan hanya menggunakan pembobotan Word
Frequency(WF). Terutama pada penerapan sistem peringkasan berita dengan mempertimbangkan isu media sosial.
Gambar 2Grafik perbandingan nilai ROUGE-N dari pembobotan WF dan NF
0 0.2 0.4 0.6 0.8 1 1.2
4. Kesimpulan
Penelitian ini telah mampu menghasilkan ringkasan berita dengan menggunakan metode
pembobotan berbasisNews FeaturedanTrending Issue. Berdasarkan pengujian dengan menggunakan
metode ROUGE diketahui bahwa peringkasan dengan pembobotan NF lebih unggul sebesar 73% dari pembobotan WF. Dimana fitur yang digunakan pada pembobotan NF terdiri dari 4 fitur, yaitu : WF, TFIDF, posisi kalimat, dan kemiripan kalimat terhadap judul berita. Hal ini membuktikan bahwa
peringkasan berita dengan menggunakan pembobotan News Feature (NF) menghasilkan kualitas
ringkasan yang lebih baik dibanding dengan ringkasan yang dihasilkan dengan hanya menggunakan
pembobotan Word Frequency (WF). Terutama pada penerapan sistem peringkasan berita dengan
mempertimbangkan isu media sosial.
Referensi
[1] K. Jezek and J. Steinberger, “Automatic Text Summarization (The state of the art 2007 and new
challenges),” pp. 1–12, 2008.
[2] R. Ferreira et al., “Assessing sentence scoring techniques for extractive text summarization,”
Expert Syst. Appl., vol. 40, no. 14, pp. 5755–5764, 2013.
[3] D. R. Radev, H. Jing, M. Styś, and D. Tam, “Centroid-based summarization of multiple documents,”
Inf. Process. Manag., vol. 40, no. 6, pp. 919–938, 2004.
[4] M. Fachrurrozi, N. Yusliani, and R. U. Yoanita, “Frequent Term based Text Summarization for
Bahasa Indonesia,”Int. Conf. Innov. Eng. Technol., pp. 30–32, 2013.
[5] D. Kim, D. Kim, S. Kim, M. Jo, and E. Hwang, “SNS-based issue detection and related news
summarization scheme,” Proc. 8th Int. Conf. Ubiquitous Inf. Manag. Commun. - ICUIMC ’14, pp.
1–7, 2014.
[6] T.-Y. Kim, J. Kim, J. Lee, and J.-H. Lee, “A tweet summarization method based on a keyword
graph,”Proc. 8th Int. Conf. Ubiquitous Inf. Manag. Commun. - ICUIMC ’14, pp. 1–8, 2014.
[7] R. Ferreiraet al., “A Context Based Text Summarization System,”2014 11th IAPR Int. Work. Doc.
Anal. Syst., pp. 66–70, 2014.
[8] N. Hayatin, C. Fatichah, and D. Purwitasari, “PEMBOBOTAN KALIMAT BERDASARKAN FITUR
BERITA DAN TRENDING ISSUE UNTUK PERINGKASAN MULTI DOKUMEN BERITA,” vol. 13, no. 1, pp. 38–44, 2015.
[9] J. Carbonell and J. Goldstein, “The use of MMR, diversity-based reranking for reordering
documents and producing summaries,”Proc. 21st Annu. Int. ACM SIGIR Conf. Res. Dev. Inf. Retr.
- SIGIR ’98, pp. 335–336, 1998.
[10] J. P. Mei and L. Chen, “SumCR: A new subtopic-based extractive approach for text
summarization,”Knowl. Inf. Syst., vol. 31, no. 3, pp. 527–545, 2012.
[11] C. Y. Lin, “Rouge: A package for automatic evaluation of summaries,” Proc. Work. text Summ.
![KJI.Il. ]'r,lrиlIсв al](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)