I -26 SENTRA
SIMPLE SENTIMENT ANALYSIS PADA STATUS TWEET
MENGGUNAKAN NAÏVE BAYES CLASSIFIER
Aminudin
Universitas Muhammadiyah Malang, Malang
Kontak Person : Aminudin
Jl. Raya Tlogomas 246 Malang Malang, 65144
E-mail: [email protected]
Abstrak
Analisis sentimen merupakan analisis teks yang bertujuan untuk mendukung pengambilan keputusan dengan mengekstraksi dan menganalisis berorientasi pendapat melalui teks. Analisis sintemen juga bisa digunakan untuk mengungkapkan perasaan yang di ekspresikan melalui kata-kata. Dan seiring perkembangan dunia social network maka tidak jarang kemudian seseorang mengekspresikan lewat media social network, salah satunya lewat twiter. Di dalam twiter sendiri menyediakan API (Application Programming Interface) yang bisa mempermudah developer untuk mengambil data dari twiter tersebut. Maka model program yang kami buat ini mengambil data dari API twiter kemudian diolah data tersebut sehingga menyajikan suatu hasil yang bisa mengekspresikan perasaan seseorang itu gembira atau sedih dengan menghitung probabilitasnya menggunakan algoritma Bayesian.
Kata kunci
:
API
(Application Programming Interface), Social Network, Twiter, Bayesian
Pendahuluan
Opini dan orientasi opini adalah bagian terpenting dalam pengambilan keputusan untuk suatu kebijakan. Keputusan yang tepat sangat dipengaruhi oleh analisis opini dari berbagai sumber yang terkait dengan pengambilan keputusan. Sebagai contoh pada dunia bisnis, penambahan produk oleh manajer produksi sangat memerlukan analisis dari reviewproduk barang yang ada di pasaran. Contoh lain misalnya pada dunia manajemen pelayanan pendidikan di perguruan tinggi, pengukuran tentang tingkat kepuasan layanan pembelajaran dapat diukur dari opini mahasiswa tentang proses pembelajaran. Opini muncul pada berbagai situasi, misalnya yang dengan sengaja diminta oleh suatu alat penjajagan opini melalui permintaan saran dalam aktivitas kuesener, atau muncul secara alami dari suatu forum on line yang disediakan oleh situs resmi perguruan tinggi. Volume opini on line yang berupa teks bebas ini semakin hari semakin banyak dan umumnya tidak dimanfaatkan karena bentuknya yang tidak terstruktur. Meskipun mengandung informasi berharga, opini ini juga sering menggunakan bahasa informal, misalnya : “Ir. Joko ngajarnya Jos gandoss...”, atau “AC ruang B115 parah.., tolong diperbaiki”. Di sini kata “Jos gandos...” memuat opini positif tentang dosen, sedangkan
kata “parah” memuat opini negatif tentang AC. Tentu saja menangani opini yang diungkap dengan
SENTRA I -27
Twitter merupakan jejaring sosial atau microblogging yang memberikan layanan di mana pengguna mengirim pesan (alias, tweet) ke jaringan dari berbagai perangkat. Sebuah tweet adalah posting berbasis teks dan hanya memiliki 140 karakter. Pesan pendek yang sangat mudah dan nyaman untuk kedua pengirim dan pembaca untuk berbagi hal-hal menarik dan mengkomunikasikan pikiran mereka di mana saja dan kapan saja. Twitter adalah jejaring sosial karena itu dapat menawarkan sentimen langsung.
Sentiment Analisis di artikan sebagai "studi komputasi pendapat, perasaan dan emosi yang dinyatakan dalam teks”. Ini adalah bidang penelitian baru yang menarik dengan potensi untuk sejumlah aplikasi dunia nyata di mana informasi pendapat ditemukan dapat digunakan untuk membantu orang atau perusahaan atau organisasi untuk membuat keputusan yang lebih baik. Twitter adalah sumber yang ideal untuk mencari informasi tentang ekspresi seseorang sedih atau gembira. Data di Twitter berbeda dari Data dari blog, situs review atau Halaman Web lainnya, karena ulasan cenderung lebih panjang sering mengandung kesalahan ejaan yang signifikan. Dalam kasus kali ini, kita akan fokus pada analisis sentimen tweet yang secara otomatis mengidentifikasi apakah sepotong teks dari tweets yang di tulis di twiter mengekspresikan sedih atau gembira.
Tinjauan Pustaka
NLP (Natural Language Processing)
Secara mendasar, komunikasi adalah salah satu hal paling penting yang dibutuhkan manusia sebagai makhluk sosial. Ada lebih dari trilyunan halaman berisi informasi pada Website, dimana kebanyakan diantaranya menggunakan bahasa natural. Isu yang sering muncul dalam pengolahan bahasa adalah ambiguitas, dan bahasa yang berantakan/tidak formal (tidak sesuai aturan bahasa).
Natural Language Processing (NLP) merupakan salah satu cabang ilmu AI yang berfokus pada pengolahan bahasa natural. Bahasa natural adalah bahasa yang secara umum digunakan oleh manusia dalam berkomunikasi satu sama lain. Bahasa yang diterima oleh komputer butuh untuk diproses dan dipahami terlebih dahulu supaya maksud dari user bisa dipahami dengan baik oleh komputer.
Ada berbagai terapan aplikasi dari NLP. Diantaranya adalah Chatbot (aplikasi yang membuat user bisa seolah-olah melakukan komunikasi dengan computer), Stemming atau Lemmatization (pemotongan kata dalam bahasa tertentu menjadi bentuk dasar pengenalan fungsi setiap kata dalam kalimat), Summarization (ringkasan dari bacaan), Translation Tools (menterjemahkan bahasa) dan aplikasi-aplikasi lain yang memungkinkan komputer mampu memahami instruksi bahasa yang diinputkan oleh user.
Natural Language Processing atau Pemrosesan Bahasa Alami merupakan salah satu tujuan jangka panjang dari Artficial Intelegence(kecerdasan buatan) yaitu pembuatan program yang memiliki kemampuan untuk memahami bahasa manusia. Pada prinsipnya bahasa alami adalah suatu bentuk representasi dari suatu pesan yang ingin dikomunikasikan antar manusia. Bentuk utama representasinya adalah berupa suara/ucapan (spoken language), tetapi sering pula dinyatakan dalam bentuk tulisan.
Inti dari pemrosesan bahasa alami adalah penguraian kalimat atau sering disebut dengan parser. Parser berfungsi untuk membaca kalimat, kata demi kata dan menentukan jenis kata apa saja yang boleh mengikuti kata tersebut. Dalam pemahaman suatu bahasa ada beberapa bidang yang harus disertakan yaitu morfologi, sintaksis, semantik, pragmatik, fonologi, dan pengetahuan tentang dunia sekitar.
Algoritma Naive Bayes Classifier
Klasifikasi Bayesian adalah pengklasifikasian statistik yang dapat digunakan untuk memprediksi probabilitas keanggotaan suatu class. Klasifkasi bayesian didasarkan pada teorema bayes. Dari hasil studi perbandingan algoritma klasifikasi, didapatkan bahwa hasil klasifikasi bayesian atau lebih dikenal dengan Naive Bayes Classification dari segi performa lebih baik dari algoritma decisión tree dan algoritma selected neural networks classifiers. Naive Bayesian Classifiers juga memilki kecepatan dan keakuratan yang tinggi bila di implementasikan ke dalam database yang ukurannya besar.
I -28 SENTRA
classifiers, yang memperbolelhkan representasi dari ketergantungan diantara atribut dari sebuah subset. Bayesian belief network dapat juga digunakan dalam pengklasifikasian.
Naive Bayes Classifiers (NBC) merupakan sebuah pengklasifikasi probabilitas sederhana yang mengaplikasikan Teorema Bayes dengan asumsi ketidaktergantungan (independent) yang tinggi.Keuntungan penggunaan NBC adalah bahwa metode ini hanya membutuhkan jumlah data pelatihan (training data) yang kecil untuk menentukan estimasi parameter yang diperlukan dalam proses pengklasifikasian.Karena yang diasumsikan sebagai variable independent, maka hanya varians dari statu variable dalam sebuah kelas yang dibutuhkan untuk menentukan klasifikasi, bukan keseluruhan dari matriks kovarians.
Salah satu penerapan teorema bayes adalah naive bayes. Naive bayes didasarkan pada asumsi penyederhanaan bahwa nilai atribut secara konditional saling bebas jika diberikan nilai output. Atau dengan kata lain, diberikan nilai output, probabilitas mengamati secara bersama adalah produk dari probabilitas individu atau
𝑃(𝑎1,𝑎2,𝑎3,…. ,𝑎𝑛|𝑣1) = 𝑃𝑖 (𝑎𝑖|𝑣𝑖) (1)
Persamaan ini bisa digunakan untuk mendapatkan pendekatan yang di pakai dalam klasifier Naive bayes dengan memasukan ke dalam persamaan
𝑛𝑁𝐵 = arg𝑚𝑎𝑥𝑣𝑗€𝑉 𝑃(𝑣𝑗) 𝑃𝑖 (𝑎𝑖|𝑣𝑖) (2) Dimana :
𝑛𝑁𝐵 adalah nilai output dari hasil klasifikasi Naive Bayes
𝑃(𝑎𝑖|𝑣𝑖) adalah rasio antara 𝑛𝑛𝑐
o 𝑛𝑐 adalah jumlah data training di mana 𝑣=𝑣𝑖 dan 𝑎|𝑎𝑖 o 𝑛 adalah jumlah total kemungkinan output
Kadang-kadang untuk banyak kasus, estimasi ini kurang akurat terutama jika jumlah kejadian yang diperhatikan sangat kecil. Misalnya terdapat 5 buah sample data dengan 3 buah atribut :𝑎1,𝑎2,𝑎3 dan 2 kemungkinan output ya atau tidak, pada atribut 𝑎1 5 sampel tersebut menghasilkan keputusan tidak. Maka, nilai 𝑛𝑐 untuk keputusan ya dalam atribut 𝑎1 adalah 0. Hal ini akan memunculkan dua kesulitan.
𝑛𝑐
𝑛akan menghasilkan under estimate probablitas bias.
Yang kedua, jika estimasi probabilitas ini sama dengan nol, probabilitas ini akan mendominasi klasifier bayes jika ada data baru.
Alasannya adalah nilai yang dihitung dari sample tersebut, semua term akan dikalikan dengan nol. Untuk menghindari kesulitan ini maka digunakan pendekatan Bayesian untuk estimasi probabilitas. Untuk mengestimasi probabilitas digunakan rumus, yang sering disebut m-estimate :
𝑃 𝑎𝑖|𝑣𝑖 = 𝑛𝑛+𝑐𝑚 (3)
Di mana :
𝑛 = jumlah data training di mana 𝑣=𝑣𝑗,𝑛𝑐
𝑛𝑐 = jumlah data training di mana 𝑣=𝑣𝑗 dan 𝑎=𝑎𝑗,𝑝 = prior estimate untuk 𝑃(𝑎,𝑖\𝑣𝑗)
Dan m = ukuran sample ekuivalen
Cara yang biasa digunakan untuk memilih nilai 𝑃 jika informasi lain tidak ada adalah nilai keseragaman yaitu ada 𝑘 nilai yang mungkin maka 𝑃=𝑙/𝑘. Nilai m bisa diberi nilai sembarang, tetapi konsisten untuk semua atribut. Jika n dan m keduanya tidak nol, maka fraksi yang diamati adalah 𝑛𝑛𝑐 dan probabilitas prior 𝑝 probabilitas prior pakan dikombinasikan menurut bobot m. Jadi alasan mengapa m dinamakan ukuran sample ekuivalen bahwa dalam rumus m-estimate terjadi penguatan observasi actual n dengan tambahan sample virtual.
Algoritma Naive Bayes Classifier
SENTRA I -29
random dengan distribusi probabilitas. Selanjutnya klasifikasi dokumen adalah mencari nilai maksimm dari :
Vmap = arg max P(vj | a1,a2,...an) (4) Sehingga persamaan diatas dapat ditulis sebagai berikut :
Vmap = arg max P(vj) 𝑷 𝒂𝒊 𝒗𝟏) (5) Nilai P(vj) ditentukan pada saat pelatihan, yang nilainya didekati dengan :
𝑷(𝒗𝒊 ) = |𝒅𝒐𝒄|
|𝑪𝒐𝒏𝒕𝒐𝒉| (6)
dimana docj adalah banyaknya dokumen yang memiliki kategori j dalam pelatihan, sedangkan Contoh banyaknya dokumen dalam contoh yang digunakan untuk pelatihan. Untuk nilai P(wk|vj) yaitu probabilitas, yaitu probabilitas kata wk dalam kategori j ditentukan dengan :
P(wk|vj) = 𝒏𝒊 +𝟏
𝒏+|𝒗𝒐𝒄𝒂𝒃𝒖𝒍𝒂𝒕𝒚 (7)
Dimana nk adalah frekuensi munculnya kata wk dalam dokumen yang ber kategori vj, sedangkan nilai n adalah banyaknya seluruh kata dalam dokumen berkategori vj , dan |vocabulary| adalah banyaknya kata dalam contoh pelatihan.
DESAIN SYSTEM
Perancangan Arsitektur Sistem
Perancangan system yang kami gunakan di dalam membangun aplikasi ini adalah sebagai berikut :
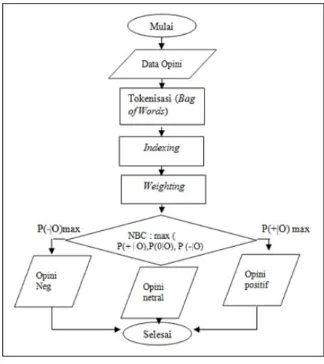
Gambar 1. Perancangan Sistem
Adapun langkah-langkah penelitian dapat disajikan seperti dalam Gambar 1. Secara ringkas dapat diuraikan langkah-langkah seperti berikut ini :
Langkah tokenisasi adalah langkah memecah string menjadi token-token dengan cara menguraikan string yang terdiri dari kalimat komentar atau saran. Pada langkah tokenisasi ini dilakukan upaya upaya pembersihan kata dari tanda-tanda baca yang tidak berguna sehingga kata menjadi unik, misalnya kata ”parah!”, atau “parah?” ataukata “parah....!?” menjadi “parah” saja. Langkah indexingadalah mencari kata unik yang dapat mewakili pengertian tertentu dari suatu opini. Langkah ini ditempuh dengan melakukan filter kata-kata yang merupakan STOP WORD seperti “dan”, “yang”,”atau”,”dari” dan lain-lain.
Langkah weighting adalah langkah memberikan bobot padamasing-masing kata unik yang ada dalam koleksi. Pembobotan dilakukan dengan menghitung frekuensi kemunculan kata pada tiap kategori opini dan mencari probabilitas P(wk|Di), yaitu probabilitas kemunculan kata ke-k (wk) dalam dokumen ke-i (Di).
Langkah klasifikasi adalah langkah mencari nilai maksimum probabilitas dari perkalian probabilitas kata-kata yang menyusun dokumen pada seluruh kategori yang ada.
Algoritma dalam penelitian ini terdari diri dua tahap, yaitu algoritma pelatihan dan klasifikasi. Adapun uraian masing-masing algoritma adalah sebagai berikut :
I -30 SENTRA
1. jumlah semua token ←jumlah semua kata yang unik dari dokumen
2. Untuk setiap kelas sentimen lakukan :
Jumlah record pada kelasj←jumlah record yang berada pada kelas j
Hitung P (sentimentj)
Untuk setiap kata wk pada daftar semua token lakukan : 3. Hitung P(katak| sentimentj)
Algoritma Klasifikasi NBC
1. Input pesan (dokumen) yang akan diketahui sentimen (klasifikasi) nya.
2. Hasilkan probabilitas untuk masing- masing kelas dengan menggunakan P(sentimentj) dan P(katak||sentimentj) yang telah diperoleh dari pelatihan.
4. Probabilitas kelas maksimum adalah kelas sentiment terpilih hasil klasifikasi.
Selanjutnya untuk mengukur kinerja algoritma digunakan rumus akurasi klasifikasi sebagai berikut :
𝐴𝑘𝑢𝑟𝑎𝑠𝑖𝐽𝑢𝑚𝑙𝑎𝑑𝑜𝑘𝑢𝑚𝑒𝑛𝑦𝑎𝑛𝑔𝑑𝑖𝑘𝑙𝑎𝑠𝑖𝑓𝑖𝑘𝑎𝑠𝑖 𝑥𝐽𝑢𝑚𝑙𝑎𝑘𝑙𝑎𝑠𝑖𝑓𝑖𝑘𝑎𝑠𝑖𝑏𝑒𝑛𝑎𝑟 100%
Berdasarkan dari gambar perancangan system diatas data tweets di ambil dari API twiter, kemudian data tersebut di kumpulkan di dalam message stream berdasarkan user yang di searching
dari system, kemudian data tersebut yang awalnya dalam bentuk kalimat di pre-processing, kalimat tersebut di potong menjadi kata-kata. Setelah proses pemotongan kata maka kata tersebut akan di klasifikasi berdasarkan sentiment analisis yang di bagi menjadi dua kelas yaitu happy dan sad.
Pengujian Sistem
Pengujian sistem ini bertujuan untuk mengevaluasi kinerja dari sistem yang telah dibuat. Pengujian ini dibagi menjadi beberapa tahapan yang akan dijelaskan pada sub-bab berikut.
Pengujian Platform Web
Table di bawah adalah hasil pengujian dari sistem, di mana untuk pengujian ini didasarkan langsung kepada account pemilik tweet dari tweeter.
Tabel 1. Hasil Pengujian
NO
Account
Hasil
1
sunupinasthika
2
aminudin2008
SENTRA I -31
Table 2 hasil dari pengujian manual dan sistem
No Tweets Class Result
Happy Sad
1. it is wonderfull grow 0.70 0.29 Happy
2. I will be sad 0.32 0.67 Sad
3. I am very sad and happy 0.13 0.86 Sad
4. I am satisfy and dispointed 0.51 0.48 Happy
5. Marie was enthusiastic about the upcoming trip.Her brother was also
passionate about her leaving-he would finally have the house for himself
0.99 0.04 Happy
6. She is seemingly very aggressive 0.53 0.46 Happy
7. very bad answer 0.40 0.59 Sad
8. it is very dispointed dan very well 0.48 0.51 Sad
9. To be or not to be? 0.62 0.377 Happy
10. He is very talented 0.40 0.59 Sad
Semakin banyak data training yang di pakai, maka hasil yang akan di tampilkan akan semakin akurat.
KESIMPULAN
Setelah melakukan perancangan, implementasi dan pengujian maka kami menyimpulkan sebagai berikut :
i. Dari 100 data training yang digunakan kami membagi dua class yaitu happy dan sad.
ii. Terdapat perbedaan hasil antara hasil dari system dan hasil sebenarnya tapi perbedaan probabilitasnya sangat tipis, karena itu di pengaruhi banyaknya data training yang sudah di masukan ke dalam database.
SARAN
Dari kesimpulan diatas kami ada beberapa saran yang bisa digunakan untuk memperbaiki aplikasi ini ke depan.
a. Data trainingnya di perbanyak kalau bisa 1000 data training, karena semakin banyak data trainingnya akan semakin akurat hasilnya.
b. Aplikasi ini juga bisa di kembangkan tidak hanya data dari twitter saja, tapi juga memanggil API facebook atau API yang lain.
c. Untuk selanjutnya bisa melakukan keterhubungan antar kata dengan menggunakan Algoritma
Cosine-Similaritiy.
Referensi
[1]. B. Liu. Handbook of Natural Language Processing, chapter Sentiment Analysis and Subjectivity. Second edition edition, 2010.
[2]. B. J. Jansen, M. Zhang, K. Sobel, and A. Chowdury. Twitter power: Tweets as electronic word of mouth. J. Am. Soc. Inf. Sci., 60(11):2169–2188, 2009.
[3]. B. Pang and L. Lee. Opinion mining and sentiment analysis. Foundations and Trends in Information Retrieval, 2(1-2):1–135, Jan. 2008.