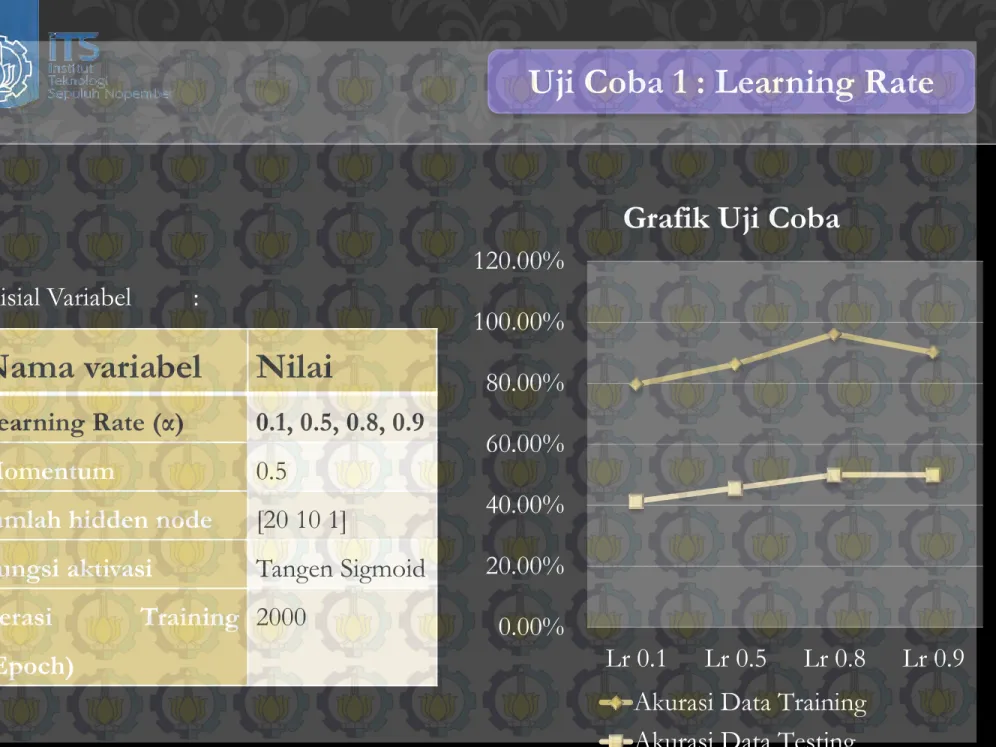
Uji Coba 1 : Learning Rate
Inisial Variabel
:
Nama variabel
Nilai
Learning Rate (α)
0.1, 0.5, 0.8, 0.9
Momentum
0.5
Jumlah hidden node
[20 10 1]
Fungsi aktivasi
Tangen Sigmoid
Iterasi
Training
(Epoch)
2000
0.00%
20.00%
40.00%
60.00%
80.00%
100.00%
120.00%
Lr 0.1
Lr 0.5
Lr 0.8
Lr 0.9
Grafik Uji Coba
Akurasi Data Training
Akurasi Data Testing
Evaluasi : Uji Coba 1
Learnin
g Rate
Akurasi
dataset
training
Akurasi
dataset
testing
Waktu
(Detik)
MSE
0.1
79,67% 41,30%
28
0.0442
0.5
86,26% 45,65%
36
0.0243
0.8
96,15%
50%
30
0.0124
0.9
90%
50%
29
0.0245
Semakin besar learning rate maka rentang untuk menentukan perubahan bobot
dalam neural network semakin besar dan berpengaruh dengan kedekatan fitur
kepada kelas yang lain. Saat learning rate kecil maka perubahan bobot semakin
kecil dan kedekatan pola ke kelas lain dari inisial target juga semakin jauh.
Lihat Penjelasan
Learning Rate
Inisial Variabel
:
Nama variabel
Nilai
Learning Rate (α)
0.8
Momentum (μ)
0.1, 0.5 , 0.9
Jumlah hidden node
[20 10 1]
Fungsi aktivasi
Tangen Sigmoid
Iterasi
Training
(Epoch)
2000
10.00%
0.00%
20.00%
30.00%
40.00%
50.00%
60.00%
70.00%
80.00%
90.00%
100.00%
μ 0.1
μ 0.5
μ 0.9
Grafik Uji Coba
Akurasi Data Training
Akurasi Data Testing
Evaluasi : Uji Coba 2
Moment
um
Akurasi
dataset
training
Akurasi
dataset
testing
Waktu
(Detik)
0.1
93,9%
43,47%
27
0.5
97.8%
54,3%
25
0.9
100%
78,26% 28
Berdasarkan tabel diatas, dapat dilihat bahwa semakin besar nilai
konstanta momentum, proses pelatihan semakin cepat. Dengan
momentum selain untuk mempercepat proses training juga
digunakan untuk mencapai akurasi yang optimum namun dengan
melihat keseimbangan nilai learning rate dan momentum.
Lihat Penjelasan
Momentum
Inisial Variabel
:
Nama variabel
Nilai
Learning Rate (α)
0.8
Momentum
0.9
Jumlah hidden node
[160 80 1]
[80 10 1]
[20 10 1]
Fungsi aktivasi
Tangen Sigmoid
Iterasi Training (Epoch)
2000
0.00%
20.00%
40.00%
60.00%
80.00%
100.00%
120.00%
[160 80 1]
[80 10 1]
[20 10 1]
Grafik Uji Coba
Akurasi Data Training
Akurasi Data Testing
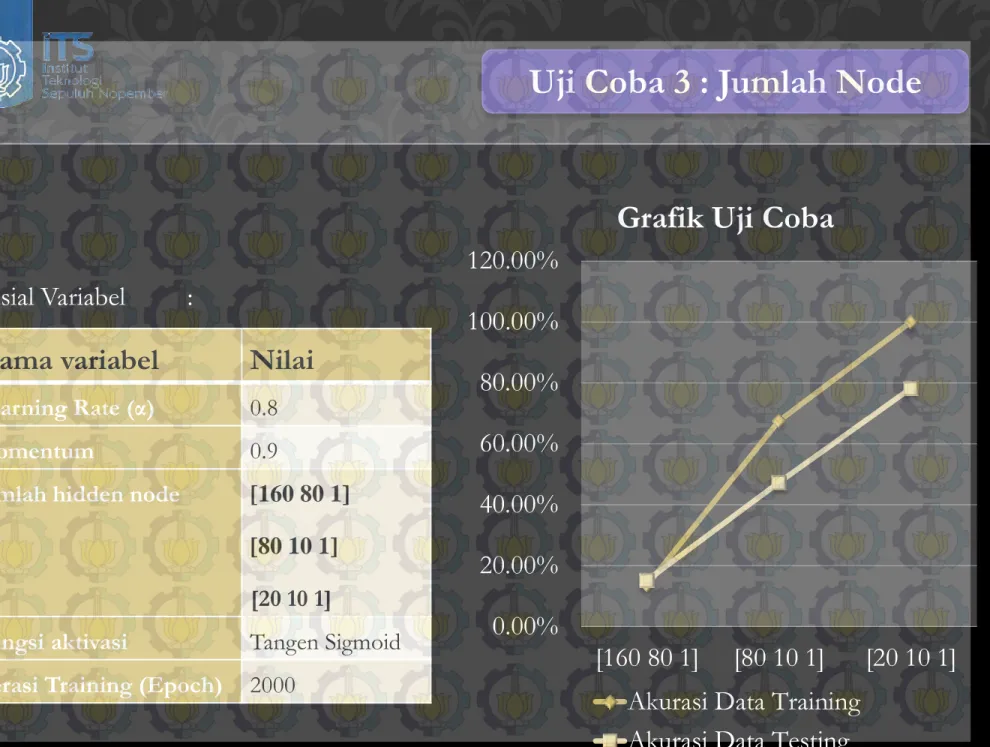
Evaluasi : Uji Coba 3
Jumlah Node Akurasi
dataset
training
Akurasi
dataset
testing
Waktu
(Detik)
[160 80 1]
13,7%
15,2%
72
[80 10 1]
67,58%
47,3 %
32
[20 10 1]
100%
78,26%
28
Tidak ada kepastian tentang berapa banyak jumlah node yang paling
optimal. Dalam neural network jumlah node bergantung pada
Inisial Variabel
:
Nama variabel
Nilai
Learning Rate (α)
0.8
Momentum
0.9
Jumlah hidden node
[20 10 1]
Fungsi aktivasi
Tangen Sigmoid
Iterasi Training (Epoch)
2000
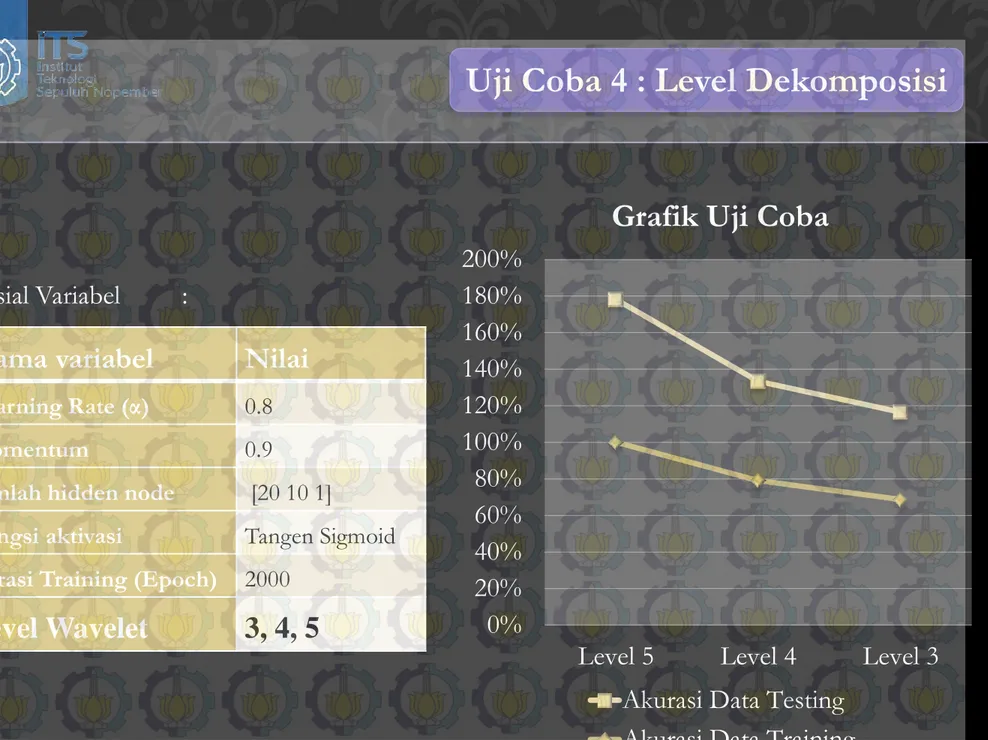
Level Wavelet
3, 4, 5
0%
20%
40%
60%
80%
100%
120%
140%
160%
180%
200%
Level 5
Level 4
Level 3
Grafik Uji Coba
Akurasi Data Testing
Akurasi Data Training
Evaluasi : Uji Coba 4
Level
Wavelet
Akurasi
dataset
training
Akurasi
dataset
testing
Waktu
(Detik)
Level 3
68,7%
47,8%
23
Level 4
79,12%
54,34%
26
Level 5
100%
78,26%
28
• Level 5 lebih optimal, meskipun lebih lama.
• Dalam setiap level nilai fitur mempresentasikan nilai skala yang berbeda,
semakin besar level semakin baik tapi penghitungan akan memakan waktu lebih
lama
• Hasil ini membuktikan bahwa kesimpulan dari penelitian Manesh Kokare, P.K.
Biswas, B.N. Chatterji [3] benar dan dapat diaplikasikan pada pengenalan motif
batik.
KESIMPULAN
Penggunaan transformasi Rotated Wavelet Filter dalam ekstraksi fitur
pengenalan batik cukup efektif untuk menghasilkan citra dekomposisi
khususnya dalam representasi citra detail diagonal.
Penggunaan Neural Network varian Multi Layer Perceptron untuk
mengklasifikasi fitur motif batik yang dikombinasikan dengan
transformasi wavelet memberikan hasil yang cukup akurat.
Representasi vektor fitur dengan dekomposisi level 5 lebih efektif
daripada dekomposisi pada level dibawahnya.
Dari hasil uji coba bisa disimpulkan bahwa akurasi tertinggi yaitu
100% untuk data testing sama dengan data training dan dicapai
78,26% untuk data testing yang berbeda dengan data training. Kedua
akurasi didapat pada nilai learning rate 0.8, menggunakan momentum
0.9, pada jumlah komposisi node hidden layer [40 10 1] di level
dekomposisi ke-5.
SARAN
Penggunaan data citra batik yang lengkap dari dinas kebudayaan
dan pariwisata nasional.
Adanya proses seleksi untuk motif batik yang memiliki unsur
modern atau pola khusus.
Pengembangan aplikasi ke sistem pengenalan isen-isen dalam
batik yang juga mempengaruhi definisi dari setiap motif.
Penilitian lebih lanjut untuk menggunakan algoritma training
neural network yang lain seperti algoritma Lavenberg Marquard
(TRAINLM) dan Gradient Descent with Adaptive learning rate
backpropagation (TRAINGDA).
Motif Geometri
Nama Motif Deskripsi Contoh Batik
Parang Pola ini terdiri atas satu atau lebih ragam hias yang tersusun membentuk garis-garis sejajar dengan sudut miring 45o. Terdapat ragam hias berbentuk belah ketupat sejajar dengan deretan ragam hias utama pola parang, disebut mlinjon.
Ceplok Motif batik yang didalamnya terdapat gambar-gambar segi empat, lingkaran dan segala variasinya dalam membuat sebuah pola yang teratur.
Lereng Pada dasarnya sama dengan pola parang tetapi memiliki perbedaan pada tidak adanya hias mlinjon dan hias gareng.
Motif Non-Geometri
Semen Ragam hias utama yang merupakan ciri pola semen adalah meru. Hakikat meru adalah lambang gunung atau tempat tumbuhan bertunas atau bersemi sehingga motif ini disebut dengan semen, yang diambil dari kata dasar semi.
Lung-Lungan Sebagian besar motif lung-lungan mempunyai ragam hias utama serupa dengan motif semen. Berbeda dengan pola semen, ragam hias utama lung-lungan tidak selalu mengandung ragam hias meru.
Buketan Pola buketan mudah dikenali melalui rangkaian bunga atau kelopak bunga dengan kupu-kupu, burung, atau berbagai satwa kecil mengelilinginya
Proses Multi Layer Perceptron
1. Inisialisasi semua bobot dengan bilangan acak kecil.
2. Jika kondisi penghentian belum dipenuhi, lakukan langkah 3-9.
3. Untuk setiap pasang data pembelajaran, lakukan langkah 4-9.
4. Tiap unit masukan menerima sinyal dan meneruskannya ke unit tersembunyi.
5. Hitung semua keluaran di unit tersembunyi z
j(j = 1, 2,..., p).
𝑍_𝑁𝑒𝑡
𝑗= 𝑉
𝑗0+
𝑛𝑖=1𝑋
𝑖𝑉
𝑗𝑖……….(2.5)
𝑍
𝑗= 𝑓 𝑍_𝑁𝑒𝑡
𝑗=
1−𝑒−2𝑧_𝑛𝑒𝑡𝑗1+𝑒−2𝑧_𝑛𝑒𝑡𝑗
………...(2.6)
6. Hitung semua keluaran jaringan di unit keluaran y
k(k = 1, 2,...,m).
𝑌_𝑁𝑒𝑡
𝑘= 𝑊
𝑘0+
𝑝𝑗=1𝑍
𝑗𝑊
𝑘𝑗……….(2.7)
𝑌
𝑘= 𝑓 𝑌_𝑁𝑒𝑡
𝑘=
1−𝑒1+𝑒−2𝑧_𝑛𝑒𝑡𝑘−2𝑧_𝑛𝑒𝑡𝑘………(2.8)
7. Hitung faktor δ unit keluaran berdasarkan kesalahan di unit keluaran yk (k = 1, 2,..., m).
𝛿
𝑘= 𝑡
𝑘− 𝑦
𝑘𝑓
′𝑌_𝑁𝑒𝑡
𝑘= 𝑡
𝑘− 𝑦
𝑘𝑦
𝑘(1 − 𝑦
𝑘), 𝑡
𝑘= 𝑡𝑎𝑟𝑔𝑒𝑡
…………..(2.9)
Hitung perubahan bobot wkj dengan laju pemahaman α
Proses Multi Layer Perceptron
8. Hitung faktor δ unit tersembunyi berdasarkan kesalahan di setiap unit
tersembunyi zj (j = 1,
𝛿_𝑛𝑒𝑡
𝑗
=
𝑚
𝑘=1
𝛿
𝑘
𝑤
𝑘𝑗
………(2.11)
Faktor δ pada unit tersembunyi.
𝛿
𝑗
= 𝛿
𝑁𝑒𝑡𝑗
𝑓
′
𝑍
𝑁𝑒𝑡𝑗
= 𝛿
𝑁𝑒𝑡𝑗
𝑍
𝑗
(1 − 𝑧𝑗)
…………(2.12)
Hitung suku perubahan bobot vji.
∆𝑉
𝑗𝑖
= 𝛼𝛿
𝑗
𝑋
𝑖
,
………....(2.13)
𝐷𝑖𝑚𝑎𝑛𝑎 𝑗 = 1,2, … , 𝑝; 𝑖 = 1,2, … . , 𝑛
9. Hitung semua perubahan bobot.
Perubahan bobot garis yang menuju ke unit keluaran, yaitu:
𝑊
𝑘𝑗𝑏𝑎𝑟𝑢 = 𝑊
𝑘𝑗𝑙𝑎𝑚𝑎 + ∆𝑊
𝑘𝑗, 𝑘 = 1,2, … , 𝑚; 𝑗 = 0,1, … , 𝑝
Perubahan bobot garis yang menuju ke unit tersembunyi, yaitu:
Proses Multi Layer Perceptron
Sedangkan algoritma untuk testing dalam MLP adalah sebagai berikut :
1. Inisialisasi bobot (dari algoritma pelatihan).
2. Untuk setiap unit masukan, lakukan langkah 3-5.
3. Untuk i = 1,...,n, atur aktivasi unit masukan x
i.
4. Untuk j = 1,...,p :
𝑍_𝑁𝑒𝑡
𝑗
= 𝑉
𝑗0
+
𝑛
𝑖=1
𝑋
𝑖
𝑉
𝑗𝑖
………..(2.16)
𝑍
𝑗
= 𝑓 𝑍_𝑁𝑒𝑡
𝑗
=
1−𝑒
−2𝑧_𝑛𝑒𝑡𝑗1+𝑒
−2𝑧_𝑛𝑒𝑡𝑗………..…(2.17)
5. Untuk k = 1,...,m :
𝑌_𝑁𝑒𝑡
𝑘
= 𝑊
𝑘0
+
𝑝
𝑗=1
𝑍
𝑗
𝑊
𝑘𝑗
………(2.18)
𝑌
𝑘
= 𝑓 𝑌_𝑁𝑒𝑡
𝑘
=
1−𝑒
1+𝑒
−2𝑧_𝑛𝑒𝑡𝑘−2𝑧_𝑛𝑒𝑡𝑘………...(2.19)
Back
MSE
Pada tugas akhir ini, untuk menghitung error dengan menggunakan
Nilai tengah kesalahan kuadrat / mean squared error (MSE) :
MSE =
𝑛
𝑖=1
𝑒
𝑛
2
𝑖
Dimana e adalah
e = |𝑦 − 𝑡|
Keterangan :
n = banyak target
e = error
y = Nilai simulasi
t = Nilai target
Learning Rate (α)
Perubahan Bobot untuk Nilai
Learning Rate Besar
Perubahan Bobot untuk Nilai
Learning Rate Kecil
Learning rate menentukan seberapa besar perubahan bobot-bobot w pada tiap langkah,
jika learning rate terlalu kecil algoritma akan memakan waktu lama menuju konvergen.
Sebaliknya jika learning rate terlalu besar maka algoritma menjadi divergen.
∆𝑊
𝑘𝑗
= 𝛼𝛿
𝑘
𝑍
𝑗
Momentum (μ)
Teknik yang bisa menolong jaringan keluar dari lokal minima adalah dengan
menggunakan momentum. Dengan momentum m, bobot diperbaharui pada
setiap waktu iterasi.
𝑊
𝑘𝑗
𝑏𝑎𝑟𝑢 = 𝑊
𝑘𝑗
𝑙𝑎𝑚𝑎 + μ∆𝑉
𝑘𝑗
Momentum ini menambahkan sebuah perkalian dengan bobot sebelumnya
pada bobot saat ini. Pada saat gradient tidak terlalu banyak bergerak, ini akan
meningkatkan ukuran langkah yang diambil menuju nilai minimum.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
function
[ELL,SLL,ELH,SLH,EHL,SHL,EHH,SHH] =
Energy_SDeviasi(LL,LH,HL,HH)
%mengambil ukuran setiap bidang
[M N]= size(LL);
%menghitung nilai energi dan
standart deviasi dari subbidang 1
ELL = energy(LL,M,N);
SLL = SDeviasi(LL,M,N);
%menghitung nilai energi dan
standart deviasi dari subbidang 2
ELH = energy(LH,M,N);
SLH = SDeviasi(LH,M,N);
%menghitung nilai energi
dan standart deviasi dari subbidang 3
EHL = energy(HL,M,N);
SHL = SDeviasi(HL,M,N);
%menghitung nilai energi
dan standart deviasi dari subbidang 4
EHH = energy(HH,M,N);
SHH = SDeviasi(HH,M,N);
end
Code : Energy & Standart Deviasi
1
2
3
4
5
6
7
8
9
10
[ELL1,SLL1,ELH1,SLH1,EHL1,SHL1,EHH1,SHH1] =
Energy_SDeviasi(LL1,LH1,HL1,HH1);
[ELL2,SLL2,ELH2,SLH2,EHL2,SHL2,EHH2,SHH2] =
Energy_SDeviasi(LL2,LH2,HL2,HH2);
[ELL3,SLL3,ELH3,SLH3,EHL3,SHL3,EHH3,SHH3] =
Energy_SDeviasi(LL3,LH3,HL3,HH3);
[ELL4,SLL4,ELH4,SLH4,EHL4,SHL4,EHH4,SHH4] =
Energy_SDeviasi(LL4,LH4,HL4,HH4);
[ELL5,SLL5,ELH5,SLH5,EHL5,SHL5,EHH5,SHH5] =
Energy_SDeviasi(LL5,LH5,HL5,HH5);
1
2
3
4
5
6
7
8
9
10
11
12
function
energy = energy(X,M,N)
% penghitungan energi
energy=sum(abs(X(:)))/(M*N);
end
function
SDeviasi = SDeviasi(X,M,N)
% penghitungan standart deviasi
meanX = mean2(X);
selX = (X-meanX).^2;
SDeviasi=sqrt(sum(selX(:)/(M*N)));
end
Fungsi Per
Level
Fungsi Per
Bidang
Fungsi
Energy+Stn
dart Deviasi
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
function NN_Training(dataset,lr,mc)%mengambil input data ekstrasi fitur beserta target training
data_training = xlsread(dataset,1); kelas_train = xlsread(dataset,2); data_train = data_training';
kelas_train = kelas_train';
%normalisasi data train menjadi rentang antara -1 dan 1
[pn,Minp,Maxp,tn,mint,maxt]=premnmx(data_train,kelas_ train);
%membuat (inisialisasi) neural network net=newff(minmax(pn),[40 20
1],{'tansig','tansig','tansig'},'traingdm');
%menentukan nilai epoch(iterasi),momentum dan learning rate
net.trainParam.epochs=1000; net.trainParam.lr=lr;
net.trainParam.mc=mc;
%melakukan training terhadap model neural network net=train(net,pn,tn);
%network hasil dari training disimpan beserta nilai dari Minp dan Maxp
assignin('base', 'net', net); assignin('base','minp',Minp); assignin('base','maxp',Maxp); 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 function t= NN_Testing(dataset,kelas_test) %inisialisasi data_test = dataset; Nkelas=size(data_test,1); data_test = data_test';
%Normalisasi data testing dengan rentang -1 sampai 1 [m n] = size(data_test);
minp = evalin('base', 'minp'); maxp = evalin('base', 'maxp'); minimp = zeros(m,n); maximp = zeros(m,n); for i=1:n minimp(:,i) = minp; maximp(:,i) = maxp; end an = 2.*(data_test-minimp)./(maximp-minimp) - 1; %melakukan simulasi testing
net = evalin('base', 'net'); y=sim(net,an);
%denormalisasi kelas testing dengan output maks 6 dan min 1
t = 0.5*(y+1)*(6-1) + 1; prediksi = round(t);
Code : Training & Testing MLP
Training
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 function [LL,LH,HL,HH] = Daub4(X,HLL,HLH,HHL,HHH)
%dekomposisi untuk representasi Image Approximation / Subbidang 1
LL = conv2(X,HLL,'same');
LL = downsample(LL,2,1);LL = LL'; LL = downsample(LL,2,1);LL = LL';
%dekomposisi untuk representasi Image Horizontal Detail / Subbidang 2
LH = conv2(X,HLH,'same');
LH = downsample(LH,2,1);LH = LH'; LH = downsample(LH,2,1);LH = LH';
%dekomposisi untuk representasi Image Vertical Detail/ Subbidang 3
HL = conv2(X,HHL,'same');
HL = downsample(HL,2,1);HL = HL'; HL = downsample(HL,2,1);HL = HL';
%dekomposisi untuk representasi Image Diagonal Detail/ Subbidang 4 HH = conv2(X,HHH,'same'); HH = downsample(HH,2,1);HH = HH'; HH = downsample(HH,2,1);HH = HH'; end 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 FunctionEF_daub4_rwf(Image)
%mengambil filter bank RWF berisiLL1,HLL,HLH,HHL,HHH dari DWT yang dirotasi
load filter_asli.mat; %dekomposisi level 1 [LL1,LH1,HL1,HH1] = Daub4(Image,HLL_R,HLH_R,HHL_R,HHH_R); %dekomposisi level 2 [LL2,LH2,HL2,HH2] = Daub4(LL1,HLL_R,HLH_R,HHL_R,HHH_R); %dekomposisi level 3 [LL3,LH3,HL3,HH3] = Daub4(LL2,HLL_R,HLH_R,HHL_R,HHH_R); %dekomposisi level 4 [LL4,LH4,HL4,HH4] = Daub4(LL3,HLL_R,HLH_R,HHL_R,HHH_R); %dekomposisi level 5 [LL5,LH5,HL5,HH5] = Daub4(LL4,HLL_R,HLH_R,HHL_R,HHH_R);