Devi Lolita Pardosi1, Irma Damayanti Siagian2.(Klasterisasi Data Lowongan Pekerjaan Berdasarkan Fuzzy
C-Means) 27
Klasterisasi Data Lowongan Pekerjaan Berdasarkan Fuzzy
C-Means
Devi Lolita Pardosi1, Irma Damayanti Siagian2
12Faculty of Technology and Computer Science, Universitas Prima Indonesia, Indonesia, Jl. Sekip simp.
Sikambing, Medan
E-mail: decilolyta1995@gmail.com1, irma.yanti657@yahoo.com2
I. Pendahuluan
Dalam mencari informasi lowongan kerja, biasanya pelamar masih menggunakan cara konvensional, yaitu melihat informasi dari media cetak seperti koran, majalah, brosur atau informasi dari orang ke orang (Safitri, et. al., 2018). Demikian juga halnya dengan perusahaan harus mengeluarkan biaya yang cukup besar, seperti menyediakan informasi lowongan kerja melalui media cetak seperti koran ataupun menggunakan jasa pencari karyawan (Safitri, et. al., 2018). Melihat realita tingginya jumlah pencari kerja di Indonesia, masih banyak pengangguran, dan sulitnya perusahaan dalam menseleksi calon karyawan yang akan diterima, maka diperlukan perancangan sistem informasi lowongan kerja yang dapat mempermudah kedua belah pihak baik bagi pencari kerja maupun bagi perusahaan (Maiyana, 2017). Adapun sistem
INFORMASI ARTIKEL A B S T R A K
Kata Kunci:
Sistem Rekomendasi Pekerjaan, Metode Fuzzy C-Means, fuzzy, kualifikasi, lowongan pekerjaan
Proses pencarian kerja dan proses rekrutmen secara konvensional dinilai kurang efektif dan efisien dari segi biaya dan waktu. Untuk membantu pencari pekerjaan dalam memperoleh pekerjaan yang diinginkan dan membantu penyedia pekerjaan dalam memperoleh kandidat potensialnya, maka diperlukan sebuah sistem rekomendasi. Sebuah sistem rekomendasi pekerjaan yang ideal harus mampu memenuhi beberapa sasaran seperti merekomendasikan pekerjaan yang paling relevan kepada pemakai, menjamin bahwa setiap lowongan yang di-post akan memperoleh sejumlah lamaran dari kandidat yang memenuhi kualifikasi dan menjamin bahwa setiap pekerjaan yang di-posting tidak menerima terlalu banyak lamaran. Untuk menyelesaikan permasalahan tersebut, maka dapat diterapkan metode sistem rekomendasi. Salah satu metode yang dapat diterapkan adalah metode Fuzzy C-Means (FCM). FCM menggunakan model pengelompokkan fuzzy sehingga data tersebut dapat menjadi anggota dari semua klaster yang terbentuk dengan derajat atau tingkat keanggotaan yang berbeda yaitu antara 0 hingga tingkat keberadaan data dalam satu cluster ditentukan oleh derajat keanggotaanya. Hasil dari penelitian ini adalah sebuah website rekomendasi pekerjaan yang menerapkan metode Fuzzy C-Means yang mampu untuk memberikan rekomendasi lowongan pekerjaan kepada user berdasarkan kualifikasi dan jurusan dari user. Website juga menyediakan sebuah fasilitas untuk melakukan pengujian terhadap metode Fuzzy C-Means.
Keywords:
Job Recommendation System, Fuzzy C Means Method, fuzzy qualifications, job vacancies
ABSTRACT
The job search process and recruitment process are conventionally considered less effective and efficient in terms of cost and time. To assist job seekers in getting the desired job and assist job providers in finding potential candidates, a recommendation system is needed. An ideal job recommendation system should be able to meet several goals such as recommending the most relevant jobs to users, ensuring that each post posted will receive a number of applications from qualified candidates and ensuring that each job posted does not receive too many. application. To solve this problem, the recommendation system method can be applied. One method that can be applied is the Fuzzy C-Means (FCM) method. FCM uses a fuzzy grouping model so that the data can become members of all clusters formed with different degrees or levels of membership, namely between 0 and the level of data in one cluster is determined by the degree of membership. The result of this research is a job recommendation website that applies the Fuzzy C-Means method which is able to provide recommendations for job vacancies to users based on the user's qualifications and majors. The website also provides a facility to test the Fuzzy C-Means method.
Devi Lolita Pardosi1, Irma Damayanti Siagian2.(Klasterisasi Data Lowongan Pekerjaan Berdasarkan Fuzzy
C-Means) 28
informasi yang sudah ada hanya menampilkan informasi lowongan pekerjaan saja (Susilawati, 2018). Selain itu, untuk mengurangi tindakan kecurangan yang dilakukan oleh oknum tidak bertanggung jawab maka dibutuhkan sistem yang membantu para pencari kerja mendapatkan informasi yang baik dan benar (Taqwiym dan Wijaya, 2017).
Untuk membantu pencari pekerjaan dalam memperoleh pekerjaan yang diinginkan dan membantu penyedia pekerjaan dalam memperoleh kandidat potensialnya, maka dapat diterapkan metode klasterisasi (clustering). Clustering merupakan suatu proses pengelompokkan record, observasi, atau mengelompokkan kelas yang memiliki kesamaan objek (Pramesti, et. al., 2017). Sebuah cluster adalah suatu kumpulan data yang mirip dengan lainnya atau ketidakmiripan data pada kelompok lain (Muningsih dan Kiswati, 2015). Objek di dalam cluster memiliki kemiripan karakteristik antar satu sama lainnya dan berbeda dengan cluster yang lain (Simanjuntak, et. al., 2018). Tujuan utama dari metode clustering adalah pengelompokan sejumlah data atau obyek ke dalam cluster (group) sehingga dalam setiap cluster dapat berisi data yang semirip mungkin (Sulastri dan Gufroni, 2017). Terdapat banyak algoritma klastering yang telah digunakan oleh peneliti sebelumnya seperti K-Means, Improved K-Means, Fuzzy C-Means, DBSCAN, K-Medoids (PAM), CLARANS dan Fuzzy Substractive (Pramesti, et. al., 2017). Dengan menggunakan clustering ini, dapat diklasifikasikan daerah yang padat, menemukan pola-pola distribusi secara keseluruhan, dan menemukan keterkaitan yang menarik antara atribut data (Metisen dan Sari, 2015).
Fuzzy C-Means (FCM) adalah teknik pengelompokan data yang terawasi dimana keberadaan tiap-tiap titik data dalam suatu cluster ditentukan oleh derajat keanggotaan. Pada algoritma ini, jumlah cluster yang akan dibentuk perlu diketahui terlebih dahulu. Konsep dasarnya adalah menentukan pusat kelompok yang akan menandai lokasi rata-rata untuk tiap-tiap cluster (Kemala, et. al., 2019). Pada perhitungan menggunakan Fuzzy C-Means dengan menggunakan data yang sama tetapi diolah dengan jumlah cluster yang berbeda, maka hasil pengelompokannya akan sedikit berbeda, karena data tidak diolah dengan satu variabel saja tetapi dengan semua variabel. Perbedaan hasil pengelompokan itu dikarenakan data pada kelompok tertentu kemungkinan akan berpindah pada kelompok lain jika diolah dengan jumlah cluster yang berbeda, ini menunjukkan bahwa sistem aplikasi sudah berjalan dengan benar (Nurjanah, et. al, 2014).
FCM menggunakan model pengelompokkan fuzzy sehingga data tersebut dapat menjadi anggota dari semua klaster yang terbentuk dengan derajat atau tingkat keanggotaan yang berbeda yaitu antara 0 hingga tingkat keberadaan data dalam satu cluster ditentukan oleh derajat keanggotaanya (Rustiyan dan Mustakim, 2017). Beberapa penelitian telah menghasilkan kesimpulan bahwa metode Fuzzy C-Means dapat digunakan untuk mengelompokkan data berdasarkan atribut-atribut tertentu. (Muhardi dan Nisar, 2015). Algoritma Fuzzy C-Means (FCM) dipilih karena dengan metode ini, data-data serta beserta parameter-parameternya dapat dikelompokan dalam cluster-cluster sesuai dengan kecenderungannya. Selain itu, dengan metode ini dapat ditentukan jumlah cluster yang akan dibentuk. Dengan penentuan jumlah cluster diawal dapat diatur keragaman nilai akhir sesuai dengan clusternya. Kelebihan dari Algoritma Fuzzy C-Means adalah penempatan pusat cluster yang lebih tepat dibanding dengan metode clustering lainnya. Dengan cara memperbaiki pusat cluster secara berulang maka akan dapat dilihat bahwa pusat cluster bergerak menuju lokasi yang tepat. FCM juga memiliki tingkat akurasi yang tinggi dan waktu komputasi yang cepat (Agustini, 2017).
II. Metode
Metode yang digunakan untuk menyelesaikan tugas akhir ini adalah metode waterfall (Pressman, 2014). Tahapan-tahapan yang diperlukan adalah:
1. Pengumpulan Data
Pada tahapan ini, metode pengumpulan data yang digunakan mencakup:
a. Metode Observasi, dimana akan diamati proses lamaran pekerjaan di website online seperti LinkedIn.
b. Metode Studi Literatur, dimana akan dikumpulkan informasi dan bahan yang diperlukan dalam penelitian ini, yang diperoleh dari berbagai sumber baik dari buku teks, jurnal ilmiah.
2. Analisis
Pada tahapan ini, akan dianalisis proses kerja dari metode dengan menggunakan flowchart diagram. Setelah itu, akan dilakukan proses analisis kebutuhan fungsional dan non-fungsional dari sistem yang dibuat, dimana analisis kebutuhan fungsional akan menggunakan use case diagram dan analisis kebutuhan non-fungsional akan menggunakan kerangka PIECES (Performance, Information, Economics, Control, Efficiency, Service).
3. Perancangan
Setelah selesai menganalisis sistem yang akan dibuat, maka proses akan dilanjutkan dengan merancang tampilan user interface dari perangkat lunak dengan menggunakan aplikasi Balsamiq dan perancangan database menggunakan entity relationship diagram (ERD).
Devi Lolita Pardosi1, Irma Damayanti Siagian2.(Klasterisasi Data Lowongan Pekerjaan Berdasarkan Fuzzy
C-Means) 29
4. Implementasi
Coding dari perangkat lunak akan dibuat dengan menggunakan bahasa pemrograman PHP, serta proses koneksi dari PHP ke aplikasi MySQL. User yang terdapat pada sistem yang dibangun mencakup:
a. User Admin, berfungsi untuk menyetujui pendaftaran perusahaan baru dan menyetujui pembuatan lowongan pekerjaan baru.
b. User Perusahaan, berfungsi untuk menyediakan lowongan pekerjaan, meng-update status lamaran user.
c. User Pelamar, berfungsi untuk melakukan proses registrasi, mencari pekerjaan yang cocok dan memperoleh daftar rekomendasi pekerjaan.
5. Pengujian
Setelah sistem selesai dibuat, maka akan dilakukan pengujian terhadap sistem dengan menggunakan metode Root Mean Square Error (RMSE). Caranya adalah dengan membandingkan nilai prediksi jumlah pelamar dengan total jumlah pelamar sebenarnya. Proses pengujian akan dilakukan dengan mengambil data dari Kaggle sebagai data training dan data test. Selain itu, juga akan digunakan kuesioner untuk mengukur apakah perangkat lunak yang dibuat sudah user friendly dan bermanfaat bagi pemakai. Metode penilaian kuesioner yang digunakan adalah skala Likert. Skala Likert menggunakan beberapa butir pertanyaan untuk mengukur perilaku individu dengan merespon 5 titik pilihan pada setiap butir pertanyaan, yaitu sangat setuju, setuju, tidak memutuskan, tidak setuju, dan sangat tidak setuju.
III. Hasil dan Pembahasan
Proses pengujian akan dilakukan terhadap hasil prediksi yang diberikan untuk setiap harinya selama satu bulan. Proses pengujian dilakukan terhadap 100 buah pekerjaan, 100 buah perusahaan, 100 orang user, 100 buah ketertarikan dan 100 buah lamaran. Adapun proses pengujian yang dilakukan dapat dirincikan sebagai berikut:
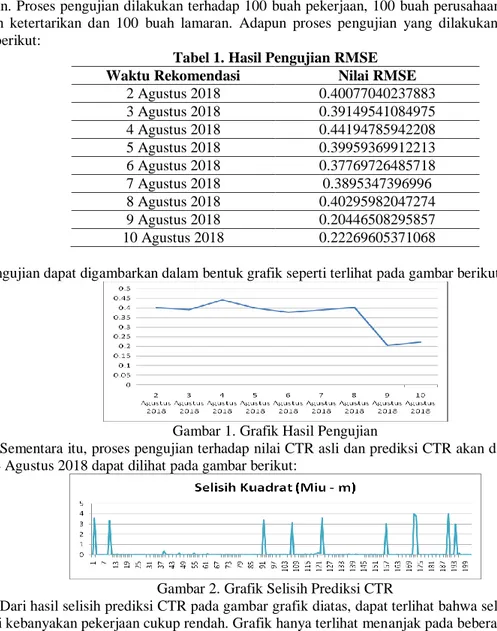
Tabel 1. Hasil Pengujian RMSE Waktu Rekomendasi Nilai RMSE
2 Agustus 2018 0.40077040237883 3 Agustus 2018 0.39149541084975 4 Agustus 2018 0.44194785942208 5 Agustus 2018 0.39959369912213 6 Agustus 2018 0.37769726485718 7 Agustus 2018 0.3895347396996 8 Agustus 2018 0.40295982047274 9 Agustus 2018 0.20446508295857 10 Agustus 2018 0.22269605371068
Hasil pengujian dapat digambarkan dalam bentuk grafik seperti terlihat pada gambar berikut:
Gambar 1. Grafik Hasil Pengujian
Sementara itu, proses pengujian terhadap nilai CTR asli dan prediksi CTR akan dilakukan terhadap tanggal 4 Agustus 2018 dapat dilihat pada gambar berikut:
Gambar 2. Grafik Selisih Prediksi CTR
Dari hasil selisih prediksi CTR pada gambar grafik diatas, dapat terlihat bahwa selisih hasil prediksi CTR dari kebanyakan pekerjaan cukup rendah. Grafik hanya terlihat menanjak pada beberapa bagian tertentu saja. Hal ini berarti bahwa hasil prediksi CTR yang diperoleh cukup akurat. Berdasarkan hasil pengujian yang dilakukan, dapat diperoleh beberapa informasi berikut:
Devi Lolita Pardosi1, Irma Damayanti Siagian2.(Klasterisasi Data Lowongan Pekerjaan Berdasarkan Fuzzy
C-Means) 30
1. Dari pengujian selisih hasil prediksi CTR diperoleh informasi bahwa selisih hasil prediksi dari kebanyakan pekerjaan cukup rendah sehingga hasil prediksi CTR yang diperoleh cukup akurat. 2. Aplikasi mampu menghasilkan rekomendasi dengan tingkat kesalahan yang rendah yaitu dengan nilai
RMSE yang dibawah 0.5.
3. Semakin banyak lamaran dan jumlah ketertarikan dari setiap pekerjaan, maka tingkat akurasi hasil rekomendasi akan semakin bagus.
IV. Kesimpulan
Dari pembahasan pada bab-bab sebelumnya, maka akhirnya penelitian pada tugas akhir ini dapat diambil beberapa kesimpulan, antara lain:
1. Metode Fuzzy C Means mampu menghasilkan rekomendasi pekerjaan secara akurat dengan tingkat kesalahan yang rendah.
2. Berdasarkan hasil pengujian, maka diperoleh informasi bahwa semakin banyak lamaran dan jumlah ketertarikan dari setiap pekerjaan, maka tingkat akurasi hasil rekomendasi akan semakin bagus.
3. Berdasarkan pengujian yang dilakukan terhadap selisih prediksi click to rate (CTR), diperoleh informasi bahwa hasil prediksi CTR dari kebanyakan pekerjaan yang diperoleh cukup akurat.
V. Daftar Pustaka
[1] M. Safitri, A. Novianti and A. Noviriandini, "SISTEM INFORMASI LOWONGAN KERJA BERBASIS WEB," Jurnal PILAR Nusa Mandiri, vol. 14, no. P-ISSN: 1978-1946 | E-ISSN: 2527-6514, 2018.
[2] R. Darmastuti, Media Relations: Konsep, Strategi & Aplikasi, Yogyakarta: CV. Andi Offset, 2012. [3] F. Borisyuk, L. Zhang and K. Kenthapadi, "LiJAR: A System for Job Application Redistribution
towards Efficient Career Marketplace," KDD 2017 Applied Data Science Paper, 2017.
[4] D. Astuti, A. Pinandito and R. K. Dewi, "Sistem Rekomendasi Lowongan Pekerjaan Untuk Fresh Graduate Menggunakan Metode Weighted Product Berbasis Android," Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, vol. 1, no. e-ISSN: 2548-964X, 2017.
[5] Firdaus, "Implementasi Simple Additive Weighting untuk Rekomendasi Pencari Kerja Terbaik Dalam Sistem Informasi Lowongan Kerja," Jurnal Edik Informatika, vol. 2.i1, no. ISSN : 2407-0491, E-ISSN : 2541-3716, pp. 53-62, 2017.
[6] A. Kusnadi, C. K. Widiarso and H. , "Rancang Bangun Sistem Rekomendasi Pemilihan Smartphone Berbasis Web," ULTIMA InfoSys, vol. VII, no. ISSN 2085-4579, 2016.
[7] L. Kristiyanti, A. Sugiharto and H. A. W, "SISTEM PENDUKUNG KEPUTUSAN PEMILIHAN PENGAJAR LES PRIVAT UNTUK SISWA LEMBAGA BIMBINGAN BELAJAR DENGAN METODE AHP (STUDI KASUS LBB SYSTEM CERDAS)," Jurnal Masyarakat Informatika, vol. 4, no. ISSN 2086 – 4930 , 2015.
[8] D. Jannach, M. Zanker, A. Felfernig and G. Friedrich, "Recommender Systems," CUP, 2010.
[9] J. Tang, X. Hu, H. Gao and H. Liu, "Exploiting Local and Global Social Context for Recommendation," In IJCAI, 2013.
[10] Yuan, "Toward a User-Oriented Recommendation System for Real Estate Websites," Information System, vol. 2, pp. 231-243, 2013.
[11] M. I. Fathurrahman, D. Nurjanah and R. Rismala, "Sistem Rekomendasi pada Buku dengan Menggunakan Metode Trust-Aware Recommendation," e-Proceeding of Engineering, vol. 4, no. ISSN: 2355-9365, 2017.
[12] D. E. Goma, "PENGARUH TUNTUTAN PEKERJAAN TERHADAP KELETIHAN KERJA DAN MOTIVASI INTRINSIK DENGAN PENGAWASAN KERJA DAN DUKUNGAN SOSIAL PEKERJAAN SEBAGAI VARIABEL KONTROL," Editor UAJY, 2013.
[13] Mulyadi, Sistem Akuntansi, Jakarta: Salemba Empat, 2016.
[14] P. Saweduling, "MOTIVASI KERJA, KOMPENSASI, PELATIHAN DAN PENGEMBANGAN, KARAKTERISTIK PEKERJAAN TERHADAP PRESTASI KERJA GURU SMP DI KABUPATEN KEPULAUAN TALAUD," Jurnal EMBA, vol. 1, no. ISSN 2303-1174, pp. 582-595, 2013.
[15] A. E. Pramadhani and T. Setiadi, "PENERAPAN DATA MINING UNTUK KLASIFIKASI PREDIKSI PENYAKIT ISPA (Infeksi Saluran Pernapasan Akut) DENGAN ALGORITMA DECISION TREE (ID3)," Jurnal Sarjana Teknik Informatika, vol. 2, no. e-ISSN: 2338-5197, 2014.
Devi Lolita Pardosi1, Irma Damayanti Siagian2.(Klasterisasi Data Lowongan Pekerjaan Berdasarkan Fuzzy
C-Means) 31
MENENTUKAN DATA NASABAH POTENSIAL MENDAPATKAN PINJAMAN," Template Artikel Seminar Prosiding SENATKOM 2015 , no. ISSN : 2460-4690.
[17] J. Han and M. Kember, Data Mining Concepts adn Techniques, San Fransisco: Morgan Kauffman, 2006.
[18] L. Rokach and O. Maimon, Data Mining with Decision Trees, Israel: World Scientific Publishing Co. Pte. Ltd., 2015.
[19] A. Nandaru, B. Sudarsono and B. D. Yuwono, "STUDI REGISTRASI POINT CLOUD PADA PEMROSESAN DATA TERRESTRIAL LASER SCANNER (TLS) (Studi Kasus : Jembatan Gading Batavia, Kelapa Gading, Jakarta Utara)," Jurnal Geodesi Undip, vol. 3, no. ISSN :2337-845X, 2014.