1
Abstract: Kayu jati terkenal sebagai kayu komersial bermutu tinggi,termasuk dalam family Verbenaceae. Penyebaran alami meliputi negara Birma, India, Kamboja, Thailand, Malaysia dan Indonesia. Di Indonesia jati terdapat di beberapa daerah seperti Jawa, Muna, Buton, Maluku dan Nusa Tenggara. Penyebaran terluas kayu jati di negara Indonesia terdapat di pulau Jawa yang dikelola oleh Perum Perhutani. Tempat Penimbunan Kayu (TPK) adalah sebuah kantor khusus dibidang pengumpulan kayu jati yang telah ditebang milik Perum Perhutani, dimana kayu jati hasil tebang dilakukan proses pendataan dan disimpan dalam kantor tersebut. Didalam pendataan kayu jati TPK Perum Perhutani masih menggunakan data dari Microsoft Excel yang disimpan kedalam file harian dan dimasukan ke folder bulanan. Hal tersebut menyebabkan masalah bagi pegawai TPK Perhutani untuk mengetahui dan mencari informasi data kayu pada saat diperlukan. Penelitian ini bertujuan untuk membuat sebuah sistem pengelompokan kayu jati dengan menggunakan ilmu data mining metode Klasifikasi Naive bayes agar kayu dapat dikelompokan menjadi 3 kelompok kayu jati berlabel A1, A2, dan A3 berdasarkan diameter yang telah ditentukan oleh Perum Perhutani. Sistem dibuat menggunakan bahasa pemprograman PHP dan MySQL sebagai database. Dari penelitian ini didapatkan hasil pengujian kinerja sistem dengan nilai akurasi 94,44%, dengan nilai recall 95,36%, dan nilai presisi 94,44% dari 120 data training kayu jati.
Keywords: data mining, klasifikasi kayu jati, normalisasi, naive bayes.
I. PENDAHULUAN1
Kayu jati (Tectona Grandis L.F. ) terkenal sebagai kayu komersial bermutu tinggi,termasuk dalam family Verbenaceae. Penyebaran alami meliputi negara-negara Birma, India, Kamboja, Thailand, Malaysia dan Indonesia. Di Indonesia jati terdapat di beberapa daerah seperti Jawa, Muna, Buton, Maluku dan Nusa Tenggara. Kayu jati banyak digunakan untuk bantalan rel kereta api, tiang jembatan, mebel, balok dan membuat rumah. Penyebaran pohon jati dapat dijumpai hampir di seluruh kepulauan Indonesia dan penyebaran yang paling besar di Indonesia adalah di kepulauan Jawa [1]. Saat ini sebagian besar lahan hutan jati di pulau Jawa di kelola oleh sebuah perusahaan umum milik negara di bidang kehutanan yang bernama Perum Perhutani, tercatat luas lahan hutan perhutani pada tahun 2003 hingga sekarang mencapai hampir
seperempat luas pulau Jawa yaitu sekitar 1,5 juta ha [2].
Tempat Penimbunan Kayu (TPK) Perhutani adalah sebuah tempat yang digunakan untuk mengumpulkan kayu yang sudah ditebang dan digunakan untuk pendataan kayu-kayu hasil penebangan [2]. Data-data kayu jati tersebut akan dibedakan menjadi 3 kelompok kayu berdasarkan ukuran dan diameternya menurut ketentuan yang sudah dibuat oleh Perum Perhutani. Ketentuan ini digunakan untuk membedakan besar kecilnya kayu yang telah ditebang menjadi tiga golongan kayu yaitu A1 sebagai kayu dengan ukuran diameter paling kecil yang biasanya dijual dan digunakan sebagai kayu bakar dan miniatur pahat, selanjutnya kayu golongan A2 sebagai kayu dengan ukuran sedang yang biasanya digunakan untuk membuat perabotan rumah, bantalan rel kereta api, dan sebagai bahan pembuatan rumah, selanjutnya kayu golongan A3 dengan ukuran besar yang dapat digunakan untuk bahan membangun rumah, pembangunan jembatan, dan
IMPLEMENTASI METODE KLASIFIKASI DATA MINING DENGAN
ALGORITMA NAIVE BAYES UNTUK PENGELOMPOKAN KAYU
JATI BERDASARKAN UKURAN DIAMETER KAYU PADA TEMPAT
PENIMBUNAN KAYU (TPK) PERUM PERHUTANI
Irawan Adi Kusuma1, Khafiizh Hastuti2
Fakultas Ilmu Komputer, Teknik Informatika, Universitas Dian Nuswantoro1,2 Email : [email protected]1,[email protected]2
rupa yang diukir atau dipahat.
Penebangan kayu jati oleh Perum Perhutani dilakukan pada musim kemarau dan penebangan dapat dilakukan sebanyak dua kali atau lebih per bulannya tergantung pada jumlah kayu jati yang siap ditebang. Dalam proses penebangan, kayu jati yang sudah ditebang akan diukur dan dipotong menjadi beberapa bagian menurut ketentuan dari Perum Perhutani. Semua potongan kayu jati akan dibawa ke Tempat Penimbunan Kayu (TPK) Perhutani untuk dilakukannya proses pendataan kayu per potongnya. Dengan bertambahnya jumlah kayu jati yang masuk ke TPK yang perharinya bisa mencapai 100 potong kayu jati atau bahkan lebih akan membuat susahnya pegawai TPK untuk melakukan pendataan dan pengelompokan kayu jati berdasarkan ukuran dan diameternya. Sehingga data kayu jati masih belum dikelompokkan menurut ketentuan dan data-data kayu tersebut masih berupa Microsoft Excel yang disimpan dalam file harian selanjutnya dimasukkan kedalam folder bulanan. Sehingga pegawai TPK Perum Perhutani susah untuk mengetahui dan melakukan pencarian informasi kayu jati dari banyaknya file data kayu tersebut.
Naive Bayes Clasifier merupakan salah satu metode klasifikasi penyederhanaan teorema Bayes yang menggunakan pendekatan statistik probabilitas bersyarat pada persoalan klasifikasi [7]. Dengan algoritma Naive Bayes data dapat diklasifikasikan, dimana data yang memiliki nilai data yang mirip dengan ketentuan akan dikelompokkan ke dalam golongan yang sama. Alasan menggunakan algoritma Naive bayes diantaranya ialah algoritma ini memerlukan data dalam jumlah kecil untuk mengestimasi parameter seperti rata-rata dan variasi dari variabel yang dibutuhkan untuk mengklasifikasikan data yang besar [8]. Dari banyaknya data kayu jati yang didapatkan selanjutnya akan diproses menggunakan algoritma Naive Bayes untuk mengelompokkan data kayu jati ke dalam 3 golongan kayu. Dari 3 golongan kayu jati dibedakan berdasarkan ukuran diameter kayu yang sudah ditentukan dalam bentuk tabel.
Metode Klasifikasi Naive Bayes digunakan untuk klasifikasi otomatis ukuran diameter kayu jati. Sedangkan normalisasi digunakan untuk menghapus atribut tabel pada data kayu jati yang tidak digunakan.
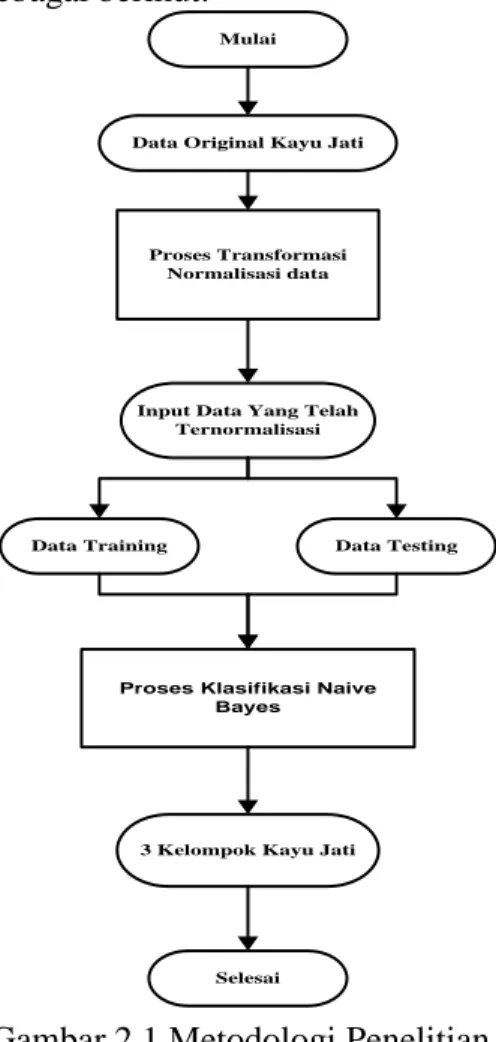
Model penelitian yang dilakukan oleh peneliti pada penelitian ini yaitu dengan menerapkan beberapa metode yang diusulkan untuk menyelesaikan masalah yang ada dalam penelitian. Prosedur penyelesaian yang dilakuakn adalah sebagai berikut:
.
Data Original Kayu Jati Mulai
Proses Transformasi Normalisasi data
Input Data Yang Telah Ternormalisasi
Proses Klasifikasi Naive Bayes
3 Kelompok Kayu Jati
Selesai
Data Training Data Testing
Gambar 2.1 Metodologi Penelitian Keterangan :
1. Data original kayu jati adalah data yang didapat dari TPK Perum Perhutani, data yang yang telah didapat berupa data dari Microsoft Excell.
2. Proses Transformasi Normalisasi data adalah proses penghapusan kolom atau atribut yang tidak dipakai dalam proses pengelompokan kayu jati dengan menggunakan metode Naive Bayes.
3
3. Input data yang telah ternormalisasi adalah data yang telah melalui proses penghapusan atribut yang tidak terpakai. Ada dua data yang digunakan atau diinputkan dalam proses ini yaitu sebagai berikut :
a) Data Training adalah data yang diinputkan sebagai sampel pengujian metode Naive Bayes.
b) Data Testing adalah data yang digunakan untuk proises pengujian data dengan menggunakan metode Naive Bayes.
4. Proses klasifikasi Naive Bayes adalah proses yang dilakukan oleh sistem untuk mengelompokkan data kayu jati setelah menginputkan data yang akan diuji.
5. Hasil yang akan didapat adalah 3 kelompok kayu jati.
Metode yang diusulkan dalam penelitian ini ada 2 macam. Metode yang pernama adalah metode Normalisasi, dalam metode ini data kayu jati original akan dinormalisasi untuk membuat atribut yang tidak digunakan dalam proses selanjutnya.
Metode yang kedua adalah metode Klasifikasi dengan algoritma Naive Bayes. Tujuan dari metode ini adalah untuk mengelompokan data kayu jati yang sudah mempunyai ketentuan diameter dan ukurannya ke dalam 3 kelompok berdasarkan diameternya. Dalam perhitungan metode Naive Bayes terdapat tahap-tahap yang harus dilakukan. Berikut tahapan dalam Naive Bayes :
1. Tahap pertama adalah menentukan prior probabilitas P(Ci) setiap class dengan cara jumlah data tiap class dari jumlah data training dibagi banyaknya data yang digunakan. Rumus mencari P(Ci) yaitu :
P(Ci ) = 𝐽𝑢𝑚𝑙𝑎 ℎ 𝑑𝑎𝑡𝑎 𝑝𝑒𝑟 𝑐𝑙𝑎𝑠𝑠 𝐽𝑢𝑚𝑙𝑎 ℎ 𝑑𝑎𝑡𝑎 𝑘𝑒𝑠𝑒𝑙𝑢𝑟𝑢 ℎ𝑎𝑛 2. Tahap kedua adalah perhitungan gausian
dengan mencari nilai mean (𝜇) dan standar deviasi (𝜎) setiap atribut berdasarkan class.dengan cara sebagai berikut : 𝜇 = 𝑋 𝑛 𝑖=1 𝑛 (1) σ = (𝑋−𝜇 ) 2 𝑛 𝑖=1 𝑛 −1 (2) X = nilai data dari atribut yang
digunakan.
n = nilai dari total data per-class. 3. Tahap ketiga adalah tahap perhitungan
gausian yang selanjutnya dengan mencari posterior probabilitas tiap class, dengan cara :
P(Xk| Ci) = 1 𝜎 2𝜋𝑒
− 𝑥 −𝜇 2 2(𝜎 2)
𝜋 adalah nilai konstanta 3,14 𝑒 adalah nilai konstanta dari
bilangan euler yaitu 2,718282. 4. Tahap keempat adalah mencari
probabilitas hipotesis Ci berdasarkan kondisi X. Dengan cara :
P(Ci|X) = ((P(Xk|Ci)1) x (P(Xk|Ci)2) x (P(Xk|Ci)3) x P(Ci))
5. Tahap kelima adalah menghitung nilai tertinggi dari hasil perhitungan P(Ci|X) tiap class. Hasil yang mempunyai nilai tertinggi akan menjadi penentu prediksi class dari data yang akan diuji dalam pengelompokan kayu jati menjadi 3 kelompok kayu A1, A2, dan A3, dengan cara :
Max (P(kelompok=”A1”|X), P(kelompok=”A2”|X), P(kelompok=”A3”|X)) III. IMPLEMENTASI
Untuk membuktikan hasil penelitian, peneliti melakukan eksperimen dan pengujian terhadap metode yang diusulkan. Data yang digunakan dalam pengujian ini didapatkan langsung dari Tempat Penimbunan Kayu (TPK) Perum Perhutani Randublatung. Data yang digunakan berjumlah 120 data kayu jati, dimana data yang didapatkan masih berbentuk file Microsoft Excel yang belum dikelompokkan berdasarkan diameter
tersebut akan dibagi menjadi 3 kelompok data, dimana masing-masing kelompok kayu jati mempunyai 40 data untuk kelompok kayu A1, 40 data untuk kelompok kayu A2, dan 40 data untuk kelompok kayu A3. Dan juga digunakan 9 data data kayu jati untuk digunakan sebagai data testing didalam sistem.
Sedangkan pada tahap pengujian metode, peneliti membuat sebuah media webside menggunakan bahasa pemprograman PHP dengan membuat tabel library yang digunakan untuk pengelompokan kayu jati. pengujian dilakukan dengan menginputkan 120 data kayu jati yang sudah di normalisasi dan dilakukan pengelompokan menjadi 3 kelompok data kayu jati. Dalam pengelompokan kayu jati setiap kelompok kayu A1, A2, A3 sudah memiliki ukuran diameter yang ditentukan, maka jika suatu data diinputkan dengan ukuran diameter yang sudah diketahui dan mendekati diameter yang ditentukan data kayu akan langsung masuk kedalam kelompok kayu jati tersebut.
IV. HASIL&PEMBAHASAN A. Persiapan Data
Dalam penelitian ini, diperlukan data kayu jati yang di dapatkan dari TPK Perum Perhutani Randublatung. Data yang digunakan dalam penelitian ini berjumlah 120 data kayu jati. Pada data tersebut sebelumnya dilakukan proses normalisasi untuk menghilangkan atribut data tabel yang tidak terpakai untuk memudahkan proses pelabelan data kayu jati, sehingga dapat dikelompokkan menjadi kelas A1, A2, dan A3 dengan metode yang diusulkan.
Dari 120 data kayu jati yang digunakan dalam penelitian ini akan dibagi menjadi tiga kelompok kayu jati sebagai data training seperti berikut 40 data kayu kelompok A1, 40 data kayu kelompok A2, dan 40 data kayu kelompok A3.
B. Pengujian Model
Proses pengujian metode merupakan fokus dari penelitian dari pengklasifikasian data kayu jati. sebelumnya peneliti telah melakukan tahapan-tahapan mulai dari normalisasi tabel, penginputan data training, dan pengklasifikasian
jati.
Proses selanjutnya dari penelitian ini adalah melakukan pengujian dari hasil pengelompokan yang sudah dulakukan oleh sistem. Pengujian ini dilakukan untuk mengetahui perhitungan Naive Bayes, presisi, recall, dan akurasi metode yang digunakan dalam metode ini.
Dari 120 data kayu jati yang telah dikelompokan menjadi 40 data kayu jati kualitas A1, 40 data kayu jati kualitas A2, dan 40 data kayu jati kualitas A3 yang dilakukan oleh sistem,akan diuji menggunakan perhitungan metode Naive Bayes dan mencari besar nilai presisi, recall, akurasinya.
C. Hasil Pengujian
Gambar 4.1 Hasil pengklasifikasian oleh sistem. Dari hasil pengelompokan data kayu jati dengan menggunakan metode Naive Bayes tersebut, didapatkan hasil kecocokan dari data uji dengan data training yang sudah diinputkan sebelumnya.
D. Pengukuran Kinerja
Untuk mengukur kinerja dari metode yang diusulkan penelini menggunakan metode pengukuran akurasi, presisi, dan recall sebagai berikut [19] [20]: 1. Mengukur akurasi Ak = 𝑇𝑃+𝑇𝑁 𝑇𝑃+𝑇𝑁+𝐹𝑃+𝐹𝑁 (1) 2. Mengukur recall Rc = 𝑇𝑃 𝑇𝑃+𝐹𝑁 (2)
5
3. Mengukur Presisi Pi = 𝑇𝑃
𝑇𝑃+𝐹𝑃 (3) Dalam hal ini dijelaskan bahwa [10]:
Ak = akurasi suatu data yang akan dicari. Rc = recall suatu data yang akan dicari. Pi = presisi suatu data yang akan dicari TP = jumlah dari data yang terklasifikasi di
kelas yang benar.
TN = jumlah dari data yang terklasifikasi di kelas yang salah.
FP = jumlah data yang dianggap berada di kelas yang benar oleh sistem tapi data tersebut berada di kelas yang salah. FN = jumlah data yang dianggap berada di
kelas yang salah oleh sistem tapi data tersebut berada di kelas yang benar. E. Hasil Eksperimen
Dari percobaan yang telah dilakukan dengan 120 data kayu jati menggunakan metode naive bayes diperoleh akurasi sebesar 94,44% dengan nilai recall sebesar 95,36% dan nilai presisi sebesar 94,44 %. Hal tersebut menunjukan bahwa metode naive bayes mempunyai akurasi bagus untuk mengklasifikasikan data kayu jati.
V. PENUTUP
Dari hasil pengujian pengelompokan terhadap 120 data kayu jati oleh sistem dengan class A1, A2, A3 didapatkan nilai akurasi 0.9444 atau 94.44%, nilai rata-rata recall semua class adalah 95,36%, dan nilai rata-rata presisi dari semua class adalah 94,44%.
Besarnya diameter kayu dari data kayu jati sangat mempengaruhi hasil pengelompokan kayu jati. Hal ini menyebabkan perbedaan kelompok kayu jati dengan class A1, A2, dan A3.
Dari hasil pengujian terhadap penelitian yang sudah dilakukan, maka metode yang diusulkan dapat mengelompokan kay jati secara otomatis oleh sistem. Sehingga peneliti dapat mengetahui dan membuktikan bahwa data kayu jati dapat di kelompokan ke 3 class berdasarkan diameternya.
Penelitian ini hanya untuk mengetahui class dari data kayu jati yang diinputkan oleh peneliti. Oleh sebab itu dibutuhkan data training untuk pengelompokan data yang akan diuji.
The conclusion after conducting the research are as follows:
1. From the test results to the data grouping is done on the system 105 test image data coconut timber with label A, B, and C obtained value f-measure or accuracy of 0.93, or 93%.
2. From the results of research and testing has been done, the method proposed in this study can be used to classify the coconut wood 2D image into 3 groups automatically. So as to facilitate a grouping graders in coconut wood image into 3 groups where each - each group representing the quality grade of coconut wood.
3. The dark color and pattern density bundle of wood 2D image greatly influence the outcome of coconut wood grouping. This is what causes the differences in the groups of test images of coconut wood with label B and C.
VI. DAFTARPUSTAKA
[1] Rina Yuliana Siagian “ Klasifikasi Parket Kayu Jati Menggunakan Metode Support Vector Machines (SVM) “, Paper, Jurusan Teknik Informatika, Fakultas Teknologi Industri, Universitas Gunadarma, 2011. [2] Achmad Fahrurozi “ Klasifikasi Kayu
Dengan Menggunakan Naive Bayes-Classifier “, Paper, Universitas Gunagarma, 2014.
[3] Ramadhana Sanja Arif, Kenneth Setiawan Sarashadi, Apiladosi Priambodo, Andro Zulfikar Al, Gusnia Syukriyawati “ Klasifikasi Otomatis Dokumen Berita Kejadian Berbahasa Indonesia Menggunakan Metode Naive Bayes ”, Paper, Fakultas Ilmu Komputer, Universitas Brawijaya, 2011.
[4] Lutfi Adhi Wijaya dan Noor Ageng Setiyanto, M.Kom, “ Perhitungan Perkiraan Jumlah Hasil Kayu Jati Balok Dengan Menggunakan Algoritma Genetika Di UD. Wahyu Jaya “, Paper, Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Dian Nuswantoro Semarang.
[5] M. Miqdad “Penentuan Kualitas Kayu Kelapa Menggunakan Algoritma Naive
Paper, Jurusan Teknik Informatika, Fakultas Ilmu Komputer, Universitas Dian Nuswantoro Semarang.
[6] Amir Hamzah “ Klasifikasi Teks Dengan Naive Bayes Classifier (NBC) Untuk Pengelompokan Teks Berita Dan Abstract Akademis “, Paper, Jurusan Teknik Informatika, Fakultas Teknologi Industri, Institut Sains Dan Teknologi AKPRIND, Yogyakarta, November 2012.
[7] Bustomi “ Penerapan Algoritma Naive Bayes Untuk Mengklasifikasi Data Nasabah Asuransi “, Paper, Dosen Teknik Informatika, Universitas Malikussaleh. [8] Alfa Saleh “ Penerapan Data Mining
Dengan Metode Klasifikasi Naive Bayes Untuk Memprediksi Kelulusan Mahasiswa Dalam Mengikuti English Proficiency Test “, Paper, Jurusan Teknik Informatika, Universitas Potensi Utama Medan.
[9] Angga Nova Indrawan “ Clustering Data Eksport Rotan Plastik Sintetis PT. Mazuvo Indo Dengan Algoritma Jaringan Kohonen “, Paper, Jurusan Teknik Informatika, Universitas Dian Nuswantoro Semarang, 2014.
[10] Indra Purnama, Ragil Saputra, Adi Wibowo “ Implementasi Data Mining Menggunakan CRISP-DM Pada Sistem Informasi Eksekutif Dinas Kelauatan Dan Perikanan Provinsi Jawa Tengah “, Paper, Universitas Diponegoro Semarang.
[11] Ririn Marlisa “ Sistem Pakar Mendiagnosa Keguguran Pada Ibu Hamil Berdasarkan Jenis Makanan Dengan menggunakan Metode Teorema Bayes “, Paper, Jurusan Teknik Informatika, Universitas STMIK Budi Darma Medan, 2014.
[12] Kustini and E. T. Luthfi, Algoritma Data Mining. Yogyakarta, Indonesia: Andi, 2006. [13] Y. Yang and G. I. Webb, “On Why Discretization Works Fors Naive-Bayes Classifier,” 2003.
[14] E. R. Anandita, “Klasifikasi Tebu Dengan Menggunakan Algoritma Naive Bayes Classification pda Dinas Kehutanan Dan Perkebunan Pati,” 2014.
[15] E. Prasetyo, Data Mining-Mengolah Data Menjadi Informasi Menggunakan Matlab,
Andi, 2014
[16] Selvie Lorena Br. Ginting dan Reggy Pasya Trinanda “ Teknik Data Mining Menggunakan Metode Bayes Classifier Untuk Optimalisasi Pencarian Pada Aplikasi Perpustakaan “, Paper, Universitas Pasundan Bandung.
[17] Prasetyo, D. D. (2004). Solusi
Pemrograman Berbasis WEB
Menggunakan PHP5, ElexMedia komputindo, Jakarta.
[18] Fikri Arfiana “ Klasifikasi Kendaraan Roda Empat Menggunakan Metode Naive Bayes “, Paper, Jurusan Teknik Informatika, Universitas Widyatama Bandung, 2014. [19] J. Han, M. Kamber, and J. Pei, Data Mining
Concepts and Techniques, 3rd ed. Waltham, United States of America: Morgan Kaufmann, 2012.
[20] D. M. W. Powers, “Evaluation : From Precision, Recall And F-Measure To Roc,Informedness, Markedness & Correlation“, Februari 2012.