BAB I
PENDAHULUAN
1.1 Latar BelakangTransportasi merupakan kebutuhan mendasar masyarakat modern sebagai sebuah sarana yang digunakan untuk berpindah ke tempat lain, seiring dengan meningkatnya pertumbuhan penduduk, kebutuhan transportasi dengan kendaraan pribadi akan meningkat pula, hal ini yang menjadikan semakin tinggi jumlah kendaraan dan semakin padatnya ruas ruang jalan terutama pada jam sibuk, sehingga membuat kemacetan akan semakin sulit untuk dikurangi. Menurut data badan statistik menunjukkan pertumbuhan kendaraan bermotor di Indonesia tahun 2013 berjumlah 104,2 juta unit dan naik secara signifikan dari tahun ke tahun [1]. Oleh karena hal tersebut dibutuhkan transportasi massal alternatif yang bisa diandalkan untuk mengurangi pemakaian kendaraan pribadi pada mobilitas perkotaan.
Bus Rapid Transit (BRT) adalah moda transportasi publik massal alternatif berbasis sistem transit yang cepat, nyaman, dan biaya murah untuk mobilitas perkotaan, pada moda transportasi ini menggunakan jaringan transit halte atau shelter khusus sebagai tempat pertemuan antara penumpang dan bus [2], dan sebagai alat pembayaran memanfaatkan Smart Card Automated Fare Collection System (SCAFCS) atau sistem tiket berbasis teknologi smart card yang mempunyai rangkaian terintegrasi dan mampu memproses serta menyimpan data, dengan popularitas teknologi smart card tersebut sebagai e-ticketing fare atau alat pembayaran elektronik transportasi publik yang menjadikan pelayanan transaksi transportasi lebih efisien, cepat dan mudah [3]. Salah satu Bus Rapid Transit di Indonesia yang menerapkan e-ticketing dengan smart card diantaranya adalah Trans Jogja yang merupakan salah satu program penerapan teknologi smart card pada Bus Rapid Transit (BRT) yang diadakan oleh Kementerian Perhubungan dan dioperasikan oleh Dinas Perhubungan Komunikasi dan Informatika Daerah Istimewa Yogyakarta (DISHUBKOMINFO DIY).
Seiring dengan pertumbuhan jumlah penduduk Yogyakarta, permintaan layanan transportasi publik Trans Jogja mengalami kenaikan dari waktu ke waktu, akan tetapi kenaikan tersebut belum ditopang dengan peningkatan layanan yang memadai, sehingga banyak penumpang yang tidak terangkut di beberapa jalur Trans Jogja, disisi lain pada halte tertentu
hanya terdapat sedikit penumpang pada jam-jam tertentu [4]. Dalam masalah tersebut pihak pengelola belum memperhatikan masalah pola perilaku temporal penumpang terhadap supply dan demand bus Trans Jogja berdasarkan waktu, sehingga masih ditemukan antrian penumpang yang padat atau hanya terdapat sedikit penumpang pada halte dan jam-jam tertentu, hal tersebut perlu diperhatikan pihak pengelola agar tidak terjadi penurunan kualitas pelayanan yang dapat mengakibatkan penurunan jumlah penumpang yang menggunakan Trans Jogja, salah satunya dengan melakukan analisis pola temporal penumpang dengan memanfaatkan pendekatan teknik data mining untuk mengeksplorasi dan mengekstraksi informasi tersembunyi dari data SCAFCS Trans Jogja, informasi yang didapat dari data mining digunakan sebagai Bussiness Intelligence untuk memahami dan mempelajari pola temporal penumpang pada peak-time sehingga dapat membantu pengelola untuk mendapatkan informasi yang mendukung pengelolaan transportasi dan strategi peningkatan layanan transportasi publik, dan hal ini juga belum pernah dilakukan pada SCAFCS Trans Jogja karena sebelumnya hanya digunakan sebagai sistem untuk revenue collection.
Menurut Bagchi dan White [5] metode pendekatan teknik data mining sangat sesuai dengan Smart Card Automated Fare Collection System (SCAFCS) karena sistem tersebut memungkinkan pengumpulan data dengan jumlah yang sangat besar, sehingga perilaku perjalanan penumpang dapat dimodelkan dengan pola yang berbeda berdasarkan dimensi waktu (temporal), dimensi ruang (spatio), struktur dan jenis data (structure), hal ini akan menyulitkan jika menggunakan metode analisis statistik standar, terutama jika dilihat dari perubahan perilaku penumpang dari waktu ke waktu. Oleh karena itu mining dan analisis data smart card pada transportasi publik dapat membantu memahami lebih dalam tentang pola perilaku penumpang transportasi publik, karena mining data smart card dengan jumlah data yang besar memberikan observasi yang lebih mendalam daripada pendekatan pengumpulan data dengan cara yang lain.
Beberapa penelitian tentang mining smart card data di bidang transportasi publik di berbagai negara telah dilakukan beberapa tahun belakangan, kebanyakan penelitian fokus pada pengelompokan perilaku dan pengkategorian penumpang, seperti penelitian [6] menggunakan teknik data mining clustering algoritme k-means untuk mengidentifikasi dan menganalisis keberagaman pola perilaku perjalanan penumpang, kemudian pada penelitian lanjutannya membahas keberagaman pola transit pengguna transportasi publik [7]. Pada penelitian [8] menggunakan metode k-means yang diperbaiki dan membandingkan dengan beberapa metode
yang lainnya, tujuan pada penelitian ini adalah untuk mengkategorikan pola perjalanan dan user origin information, akan tetapi dalam beberapa kasus tidak semua data smart card pada transportasi publik menyediakan data yang detil, khususnya data smart card BRT di Indonesia yang bersifat anonim karena tidak ada informasi mengenai pemegang kartu di dalamnya, sehingga data tersebut tidak memiliki atribut sosio-geografis pengguna, hal ini disebabkan karena pertimbangan masalah privasi pengguna, proses bisnis dan standar operasional prosedur yang berbeda, umumnya data yang tersedia pada transaksi smart card adalah tanggal, waktu dan serial number dan lokasi keberangkatan sehingga dapat menyajikan informasi kalkulasi jumlah penumpang dalam skala waktu dan detil spasial. Seperti pada penelitian [9] yang menggunakan dan membandingkan metode clustering k-means dan agglomerative hierarchical clustering (AHC) untukmengelompokan jumlah penumpang BRT Trans Jogja. Akan tetapi kuantitas jumlah data yang digunakan masih terbatas karena masih menggunakan pendekatan observasi standar dan angket survei perjalanan penumpang, sehingga tidak merepresentasikan fluktuatif jumlah penumpang dalam jumlah yang besar.
Algoritme k-means umum digunakan karena relatif mudah di implementasikan dan efektif digunakan pada dataset yang memiliki jumlah cluster dan dimensi yang kecil, akan tetapi algoritme k-means mempunyai kekurangan pada akurasi dan kemungkinan waktu proses yang lebih lama jika titik/point data yang dikelompokkan berjumlah sangat besar, hal ini disebabkan inisiasi pemilihan awal centroid bersifat random sehingga akurasi pengelompokan yang dihasilkan menjadi kurang optimal karena centroid yang berbeda mempunyai kemungkinan terpilih dalam satu cluster yang sama atau terjebak pada local optima [10]. Penelitian [11] mengusulkan k-means++, pengembangan k-means dengan non-random atau careful seeding yang secara teoritis cukup efektif untuk memecahkan masalah optimasi inisiasi cluster pada algoritme simple k-means, yaitu dengan menyebarkan inisial centroid secara merata dan tidak berdekatan dengan centroid lain, atau dengan kata lain pemilihan starting point cluster yang baik sehingga dapat lebih akurat dan lebih cepat daripada simple k-means, akan tetapi skalabilitasnya masih tidak feasible pada data dengan jumlah besar karena akan menyebabkan banyak iterasi pada multiple starting point [12], dalam hal ini data pada SCAFCS memiliki ukuran data yang besar (volume) dan kecepatan pertambahan data yang tinggi (velocity). Pada penelitian ini mengusulkan penerapan algoritme scalable k-means++ clustering dengan Hadoop Platform untuk optimasi algoritme k-means++ pada penanganan skalabilitas dataset besar. Aspek penting
lainnya yang perlu diperhatikan dalam penelitian ini selain akurasi dan toleransi algoritme pada skalabilitas data besar yang digunakan pada data mining adalah preprocessing sumber data SCAFCS, dimana akses sumber data SCAFCS menggunakan secure connection dan read-only sehingga perlu penyesuaian data preprocessing dengan menerapkan mekanisme ELT (Extract, Load, Transform) data warehouse sebagai pendekatan alternatif dimana data diekstrak dari data source, dimuat ke dalam target database, dan kemudian diubah dan diintegrasikan ke dalam format yang diinginkan. Oleh karena itu penelitian ini juga mengembangkan tools data preprocessing berbasis open-source dengan pendekatan ELT data warehouse dan temporal extraction untuk proses pre-mining pola temporal penumpang transportasi publik Trans Jogja. 1.2 Perumusan masalah
Dari latar belakang yang dikemukakan di atas, dapat dirumuskan permasalahan pada penelitian ini, yaitu :
i. Teknik data mining untuk pengelompokan data yang sering digunakan adalah algoritme k-means, akan tetapi k-means mempunyai kelemahan, yaitu sangat sensitif pada inisiasi karena pemilihan awal centroid yang bersifat acak dan dapat memberikan hasil yang berbeda sehingga menghasilkan cluster yang kurang optimal, terlebih jika yang diproses adalah dataset dengan jumlah besar yang berakibat pada tingkat akurasi dan kecepatan proses komputasi.
ii. Metode k-means++ clustering dapat diterapkan sebagai penyelesaian masalah inisiasi random pada algoritme simple k-means clustering untuk meningkatkan performa pengelompokan data, akan tetapi masih tidak feasible pada skalabilitas dataset besar karena menyebabkan banyak iterasi pada multiple starting point, dalam hal ini data SCAFCS pada transportasi publik BRT Trans Jogja memiliki jumlah data besar (volume) dan kecepatan pertambahan data yang tinggi (velocity).
1.3 Keaslian penelitian
Penelitian ini didasarkan pada beberapa hasil penelitian sebelumnya tentang mining smart card data pada transportasi publik, serta metode atau pendekatan data mining yang pernah diusulkan dalam penelitian terkait, dengan fokus pengelompokan perilaku penumpang berdasarkan waktu (temporal), lokasi keberangkatan (spatio) dan segmentasi jenis penumpang
(structure) untuk mengekstraksi informasi pola perilaku supply dan demand penumpang pada transportasi publik. Tabel 1.1 menunjukkan rangkuman penelitian terdahulu yang menjadi acuan penelitian yang dilakukan.
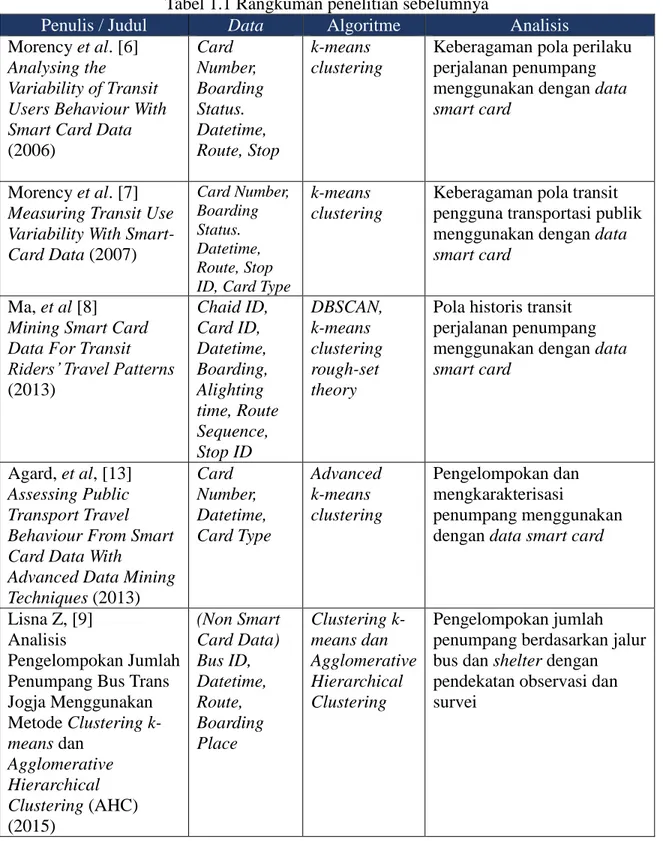
Tabel 1.1 Rangkuman penelitian sebelumnya
Penulis / Judul Data Algoritme Analisis
Morency et al. [6] Analysing the
Variability of Transit Users Behaviour With Smart Card Data (2006) Card Number, Boarding Status. Datetime, Route, Stop k-means clustering
Keberagaman pola perilaku perjalanan penumpang menggunakan dengan data smart card
Morency et al. [7] Measuring Transit Use Variability With Smart- Card Data (2007) Card Number, Boarding Status. Datetime, Route, Stop ID, Card Type
k-means clustering
Keberagaman pola transit pengguna transportasi publik menggunakan dengan data smart card
Ma, et al [8]
Mining Smart Card Data For Transit Riders’ Travel Patterns (2013) Chaid ID, Card ID, Datetime, Boarding, Alighting time, Route Sequence, Stop ID DBSCAN, k-means clustering rough-set theory
Pola historis transit perjalanan penumpang menggunakan dengan data smart card
Agard, et al, [13] Assessing Public Transport Travel Behaviour From Smart Card Data With
Advanced Data Mining Techniques (2013) Card Number, Datetime, Card Type Advanced k-means clustering Pengelompokan dan mengkarakterisasi penumpang menggunakan dengan datasmart card
Lisna Z, [9] Analisis
Pengelompokan Jumlah Penumpang Bus Trans Jogja Menggunakan Metode Clustering k-means dan Agglomerative Hierarchical Clustering (AHC) (2015) (Non Smart Card Data) Bus ID, Datetime, Route, Boarding Place Clustering k-means dan Agglomerative Hierarchical Clustering Pengelompokan jumlah penumpang berdasarkan jalur bus dan shelter dengan pendekatan observasi dan survei
Clustering merupakan teknik data mining unsupervised learning untuk mengelompokan suatu data yang memiliki karakteristik sama. Dalam bidang transportasi publik digunakan untuk mengelompokan penumpang dan mengekstraksi informasi perilaku demand penumpang. Informasi yang didapatkan pun bisa beragam tergantung struktur yang tersedia dari data capture smart card, seperti pada penelitian [8] mencoba mengekstraksi data smart card pada jaringan transportasi di Québec, Canada menggunakan teknik k-means clustering untuk mengkonstruksi cluster hari yang merepresentasikan keberagaman transit dan pola temporal penumpang yang mirip untuk mengetahui keberagaman perilaku penumpang pada jaringan transit transportasi. Pada penelitian lanjutannya [7] masih menggunakan teknik k-means clustering untuk mengukur spatial-temporal variability penumpang antara bus boarding dan bus stop pada jaringan transit transportasi berdasarkan kelas jenis pemegang kartunya. Metode simple k-means mulai dipertanyakan performanya pada skalabilitas dataset dengan jumlah yang besar, seperti pada penelitian [13] mengusulkan teknik data mining untuk pengelompokan dan mengkarakterisasi pengguna transportasi publik, dengan metode novel Advanced k-means clustering dan binary mapping untuk mengetahui similiaritas pola temporal perjalanan penumpang transportasi publik, perbaikan algoritme dalam penelitian ini fokus pada metrik euclidean distance calculation dengan mengkalkulasi urutan binary yang dipetakan dengan cartesian cordinate, hasilnya Advancedk-meansclustering yang diusulkan mampu memproses data dengan jumlah data yang masif (4,47 juta data) dengan waktu proses yang cepat. Selanjutnya penelitian [8] mulai membandingkan metode k-means dengan metode lain, memanfaatkan algoritme Density-based Spatial Clustering of Applications with Noise (DBSCAN) untuk mengidentifikasi pola perjalanan historis penumpang berdasarkan karakteristik spatio temporal dari dataset transaksi smart card pada jaringan transit transportasi di Beijing, China, dan metode k-means clustering yang digabungkan dengan rough-set theory untuk membagi pola perjalanan regular-passenger, dan membandingkan dengan beberapa metode klasifikasi Naïve Bayes Classifier, C4.5 Decision Tree, K-Nearest Neighbor (KNN) dan Three-hidden-layers Neural Network, performa dan hasil mengindikasikan bahwa algoritme k-means dengan rough-set theory lebih unggul dari algoritme yang lain dalam sisi akurasi dan efisiensi. Pada penelitian [9] juga membandingkan k-means clustering dan Agglomerative Hierarchical Clustering (AHC) untuk pengelompokan jumlah penumpang berdasarkan jalur bus dan shelter pada BRT Trans Jogja akan tetapi masih menggunakan pendekatan data observasi, dari hasil penelitian tersebut menunjukkan bahwa
metode k-means memiliki hasil pengelompokan yang lebih baik dari pada metode AHC.
Mengacu penelitian di atas mengenai analisis pola temporal penumpang transportasi publik menggunakan pendekatan teknik mining di Indonesia masih dilakukan dengan pendekatan observasi dan angket survei perjalanan penumpang dalam skala data yang relatif kecil. Pada penelitian ini mencoba memanfaatkan dataSmart Card Automatic Fare Collection System untuk mengekstraksi pola temporal penumpang dari waktu ke waktu dengan teknik data mining, adapun metode k-means adalah teknik mining yang umum digunakan untuk menangani pengelompokan data pada penelitian terdahulu, dimana metode tersebut masih mempunyai kelemahan pada tingkat akurasi dan kecepatan proses pada dataset dengan jumlah besar. Dalam hal ini datasmart card pada transportasi publik di BRT Trans Jogja memiliki jumlah data besar (volume) dan kecepatan pertambahan data yang tinggi (velocity). Penelitian ini mencoba untuk mengisi gap penerapan algoritme k-means++ dengan Hadoop Platform untuk skalabilitas penemuan pola pada structured/semi-structured data dalam jumlah besar yang dikumpulkan oleh SCAFCS dan pendekatan pre-processing untuk optimasi pre-mining. Diharapkan dapat dijadikan sebagai Bussiness Intelligence yang memberikan informasi untuk memahami pola perilaku supply dan demand penumpang terhadap transportasi publik Trans Jogja. berdasarkan pada review [14] gap penelitian big data clustering yang dapat dimanfaatkan pada penelitian ini dijelaskan pada Gambar 1.1 berikut.
Adapun keaslian penelitian dapat dijabarkan sebagai berikut:
i. Menggunakan pendekatan data mining pada dataset SCAFCS Trans Jogja sebagai ilustrasi pemanfaatan mining untuk menemukan informasi tersembunyi pada data SCAFCS yang pada awalnya hanya digunakan sebagai revenue collection.
ii. Menerapkan algoritme k-means++ clustering [11] sebagai optimasi inisiasi random centroid untuk meningkatkan performa pengelompokan simple k-means pada miningsmart card data BRT Trans Jogja.
iii. Menerapkan Hadoop Platform untuk mengatasi kekurangan k-means++ pada skalabilitas dataset besar yang menyebabkan multiple starting point/iteration dan pengembangan tools data preproccessing dengan mekanisme ELT (Extract Load, Transform) data warehouse dan temporal extraction dengan binary mapping sebagai optimasi proses pre-mining pola temporal penumpang transportasi publik pada skalabilitas dataset besar SCAFCS Trans Jogja.
1.4 Tujuan Penelitian
Tujuan yang ingin dicapai dalam penelitian ini antara lain sebagai berikut:
i. Penerapan algoritme k-means++ clustering sebagai optimasi dan penyelesaian masalah inisiasi random pada algoritme simple k-means clustering dengan non-random atau careful seeding untuk meningkatkan performa pengelompokan simple k-means.
ii. Pendekatan data preproccessing dengan data warehouse dan temporal extraction dengan binary mapping sebagai optimasi proses pre-mining pola temporal penumpang, dan penerapan Hadoop Platform untuk memperbaiki multiple starting point inisiasi cluster k-means++ pada skalabilitas dataset besar SCAFCS Trans Jogja.
iii. Pengelompokan pola temporal penumpang BRT Trans Jogja berdasarkan waktu (temporal), lokasi (spatio) dan segmentasi penumpang (structure).
1.5 Manfaat Penelitian
Hasil penelitian ini diharapkan dapat menambah kontribusi penelitian di- bidang Intelligent Transport System (ITS), dengan data warehousing dan mining data SCAFCS diharapkan dapat membantu pengelola untuk mendapatkan informasi yang dapat mendukung
pengelolaan transportasi publik dan strategi peningkatan layanan transportasi publik sebagai Bussiness Intelligence (BI) dengan memetakan pola temporal penumpang untuk mengefisienkan pengelolaan transportasi publik, sehingga tersedia layanan transportasi publik yang memadai untuk mengurangi kemacetan dengan mengurangi pemakaian kendaraan pribadi pada mobilitas perkotaan.
![Gambar 1.1 Gaps penelitian big data clustering [14].](https://thumb-ap.123doks.com/thumbv2/123dok/2283705.2185108/7.918.310.659.673.1020/gambar-gaps-penelitian-big-data-clustering.webp)
