Fakultas Ilmu Komputer
Universitas Brawijaya
1867
Query Expansion Pada Line Today Menggunakan Algoritme Ide-Dec-Hi
dan Ide-Regular
Nana Nofiana1, Indriati2, Rizal Setya Perdana3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
LINE TODAY adalah situs berita online yang menyediakan artikel berita up to date serta berasal dari sumber berita yang terpercaya. Untuk mempermudah dalam menemukan berita maka dibutuhkan mesin pencarian sehingga berita cepat untuk didapat. Namun pada proses pencarian terkadang query yang diinputkan tidak sesuai dengan hasil artikel berita yang didapatkan. Sehingga perlu dilakukan query expansion untuk membantu dalam mendapatkan artikel berita yang lebih spesifik, query expansion akan melakukan perluasan query yang sebelumnya ambigu menjadi lebih terstruktur. Query expansion diawali dengan tahapan preprocessing, dilanjutkan pembobotan TF.IDF serta cosine similarity hingga perhitungan metode ide-dec-hi dan ide-regular. Berdasarkan implementasi dan pengujian yang dilakukan pada penelitian Query Expansion Pada LINE TODAY Menggunakan Algoritme Ide-Dec-Hi Dan Ide-Regular dengan memanfaatkan 200 data latih serta 25 query yang sesuai dengan dokumen, maka didapatkan hasil untuk metode ide-dec-hi yaitu precision bernilai 0.6622, recall bernilai 0.2314, f-measure bernilai 0.2987, serta akurasi bernilai 0.9506. Sedangkan untuk metode ide-regular didapatkan hasil yaitu precision bernillai 0.6635, recall bernilai 0.0146, f-measure bernilai 0.0279, serta akurasi bernilai 0.9488. Nilai akurasi yang dihasilkan dengan memanfaatkan metode ide-dec-hi cenderung meningkat hingga 0.18% dibandingkan menggunakan metode ide-regular.
Kata kunci: LINE TODAY, Query Expansion, Ide-DecHi, Ide-Regular
Abstract
LINE TODAY is an online news site that provides up to date news articles and comes from trusted news sources. To make it easier to find news, a search engine is needed so news is quick to get. But in the search process, sometimes the queries entered are not in accordance with the results of news articles obtained. So it is necessary to do query expansion to help get more specific news articles, query expansion will expand previously ambiguous queries to be more structured. Query expansion begins with preprocessing stages, followed by weighting TF.IDF, as well as cosine similarity to the calculation of the idea-dec-hi and ide-regular method. Based on the implementation and testing carried out on the Query Expansion research on LINE TODAY, Using Ide-Dec-Hi and ide-regular Algorithm by utilizing 200 training data and 25 queries that are in accordance with the document, then the results for idea-dec-hi method that is the precision value is 0.6622, recall is 0.2314, f-measure is 0.2987, and the accuracy is 0.9506. Where as for ide-regular method results in precision values of 0.6635, recall of 0.0146, f-measure of 0.0279, and accuracy of 0.9488. Accuracy values generated using the ide-dec-hi method increase up to 0.18% compared to the ide-regular method.
Keywords: LINE TODAY, Query Expansion, Ide-Dec-Hi, Ide-Regular
1. PENDAHULUAN
Informasi merupakan salah satu kebutuhan penting bagi masyarakat pada era globalisasi saat ini. Informasi dapat membantu masyarakat dalam menambah pengetahuan, membantu mengambil keputusan, serta dapat mengetahui
segala sesuatu yang terjadi saat ini. Era globalisasi menuntut informasi yang didapat harus cepat, efektif, serta mudah didapatkan, karena itu informasi telah memanfaatkan teknologi informasi berbasis internet yang dapat menunjang kebutuhan tersebut. Informasi yang didapatkan melalui media internet biasanya
beupa artikel berita yang dapat diakses melalui situs website berita, salah satu contohnya LINE TODAY. LINE TODAY menyediakan informasi berita up to date serta berasal dari sumber yang terpercaya.
Pada penelitian ini data yang digunakan berupa artikel berita yang tersedia pada LINE TODAY. Dalam mengakses suatu artikel berita online biasanya terdapat beberapa permasalahan, salah satu nya saat kita ingin melakukan pencarian berita, query yang diinputkan tidak sesuai dengan hasil artikel berita yang didapatkan. Dari permasalahan tersebut, pemanfaatan query expansion sangat membantu dalam mendapatkan artikel berita yang lebih spesifik. Query expansion akan melakukan perluasan query sehingga query yang awalnya ambigu akan disempurnakan sehingga menjadi lebih terstruktur. Pada penelitian lain yang dilakukan Pamungkas et al (2015), penelitian pada query expansion memberikan query tambahan kata sehingga hasil pencarian menjadi lebih spesifik dan relevan.
Penelitian terdahulu yang dilakukan oleh Adisantoso et al (2006), penelitian mengenai metode ide-dec-hi dan ide-regular memberikan hasil bahwa relevance feedback meningkatkan kinerja cukup tinggi serta cocok untuk melakukan perluasan query.
Berdasarkan uraian-uraian diatas, penelitian ini membahas tentang Query Expansion pada LINE TODAY Menggunakan Algoritme Ide-Dec-Hi dan Ide-Regular. Algoritme tersebut memberikan hasil yang cukup bagus jika dipakai dalam query expansion, dikarenakan hasil pencarian yang berasal dari query asli yang telah dikombinasikan dengan query tambahan memberikan hasil dokumen yang relevan semakin sedikit, hal ini dikarenakan query yang digunakan semakin spesifik.
2. DASAR TEORI 2.1 Information Retrieval
Information retrieval adalah suatu sistem yang menerima sebuah query dari pengguna, lalu dilakukan perankingan pada dokumen berdasarkan kesesuaiannya terhadap query, hasil dari perankingan adalah dokumen relevan menurut sistem akan tetapi tingkat relevansi tergantung dari pengguna (Pamungkas, 2015).
2.2 Text Preprocessing
Text preprocessing berguna untuk mengubah data yang mulanya berstruktur sembarang menjadi data yang lebih terstruktur sesuai dengan kebutuhan untuk melakukan sebuah proses pada text mining (Imbar et al, 2014). Ada beberapa langkah proses dalam preprocessing yaitu cleansing, case folding, tokenisasi, filtering, serta stemming (Kurniawan et al, 2017).
1. Cleansing dan Case Folding
Cleansing adalah penghapusan komponen-komponen yang tidak digunakan, misalnya tag URL serta komponen-komponen lain. Sedangkan case folding merupakan proses pengubahan semua huruf pada dokumen menjadi huruf kecil semua.
2. Tokenisasi
Tokenisasi merupakan proses pemecahan teks yang semula berupa kalimat mejadi kata-kata.
3. Filtering
Filtering merupakan proses pengambilan kata-kata yang penting setelah dilakukan tokenisasi menggunakan algoritme stopword removal. Apabila ada kata-kata yang sama dengan list pada stopword akan dihapus.
4. Stemming
Stemming dilakukan untuk mencari kata dasar dari suatu dokumen dengan mengacu pada aturan-aturan tertentu. Pada penelitian ini menggunakan algoritme stemming Nazief & Adriani. Berikut merupakan tahapan-tahapan yang dilakukan (Wahyudi et al, 2017):
1. Pengecekan kata yang belum dilakukan proses stemming dalam kamus, apabila terdapat kata dalam kamus maka kata tersebut adalah kata dasar lalu algoritme akan dihentikan.
2. Menghilangkan inflectional suffixes(“-lah”, “-kah”, “-tah”, dan “-pun”), kemudian dilakukan penghilangan inflectional possessive(“-ku”, “-mu”, serta “-nya”). Lalu cek apakah terdapat pada kamus kata dasar, jika ada maka proses berhenti, jika tidak ditemukan maka lanjut ke tahap berikutnya.
3. Menghilangkan derivational suffix(“-an” serta “-i”). Cek apakah terdapat pada kamus kata dasar, jika ada maka proses berhenti, akan tetapi jika tidak ditemukan maka proses berlanjut ke tahap berikutnya:
a. Apabila “-an” sudah hilang lalu huruf terakhir dari sebuah kata yaitu “-k”,
maka “-k” akan dihapus. Jika setelah dilakukan proses tadi kata ada pada kamus kata dasar, maka proses berhenti, tapi jika sebaliknya maka proses berlanjut ke tahapan berikutnya. b. Sebuah akhiran yang sebelumnya dihapus(“-i”, “-an”, dan “-kan”) akan dikembalikan, dan lanjut ke tahapan selanjutnya.
4. Derivational prefix dihapus (“be-”, “ke-“, “di-“, “pe-“, “me-“, “se-“, serta “te-“), kemudian cari apakah kata terdapat dalam kata dasar, apabila kata tersebut ditemukan maka proses berhenti, tetapi jika tidak maka lakukan recording. Terdapat beberapa kondisi yang menyebabkan tahapan akan berhenti diantaranya:
a. Jika ditemukan awalan serta akhiran tidak sesuai ijin
b. Terdapat awalan sama dengan awalan setelah dihapus sebeumnya.
c. Ada tiga awalan yang sudah dihilangkan
5. Apabila seluruh tahapan sudah dilakukan tetapi kata dasar masih belum, kemudian kata akan dikembalikan ke kata asal sebelum dilakukan tahapan stemming.
2.3 Pembobotan Kata (Term Weighting)
Pembobotan (weighting) merupakan proses mengubah term menjadi kata berbentuk numerik sehingga dapat diproses oleh komputer. Metode yang sering digunakan untuk melakukan pembobotan yaitu TF-IDF (Wirawan et al, 2018).
Term Weighting (TF) adalah banyaknya kata yang muncul dalam dokumen. Rumus dari TF dapat dilihat pada Persamaan (1) berikut (Nurjanah et al, 2017):
𝑊𝑡𝑓= {
1 + 𝑙𝑜𝑔10 𝑡𝑓𝑡,𝑑, 𝑖𝑓 𝑡𝑓𝑡,𝑑> 0
0, 𝑙𝑎𝑖𝑛𝑛𝑦𝑎 (1)
Inverse document frequency (IDF) adalah kemunculan term pada semua dokumen (Wirawan et al, 2018). Berikut merupakan rumus IDF dapat dilihat pada Persamaan (2) berikut (Okfalisa & Harahap, 2016):
𝑖𝑑𝑓𝑡= 𝑙𝑜𝑔 ( 𝑁
𝑑𝑓𝑡) (2)
Term frequency-Invers document frequency (TF-IDF) adalah hasil perkalian antara TF dengan IDF. Rumus yang digunakan untuk menghitung TF-IDF dapat dilihat pada
Persamaan (3) berikut (Okfalisa & Harahap, 2016):
𝑊𝑡,𝑑= 𝑊𝑡𝑓× 𝑖𝑑𝑓𝑡 (3)
Keterangan:
𝑡𝑓𝑡,𝑑 : jumlah munculnya term pada dokumen N : banyak dokumen
𝑑𝑓𝑡 : banyak dokumen yang mengandung term t 2.4 Cosine Similarity
Cosine similarity dilakukan untuk menghitung kemirpan dokumen. Sebelum melakukan perhitungan cosine similarity terlebih dahulu dokumen akan dilakukan perhitungan normalisasi, dengan rumus untuk menghitung Cosine Similarity dapat dilihat pada Persamaan (4) berikut (Nurjanah et al, 2017): 𝑊𝑡,𝑑=
𝑊𝑡,𝑑
√∑𝑛𝑡=1𝑊𝑡,𝑑2
(4) Setelah nilai normalisasi didapatkan lanjut ke perhitungan cosine similarity dengan menggunakan rumus dapat dilihat pada Persamaan (5) berikut (Nurjanah et al, 2017): 𝐶𝑜𝑠𝑆𝑖𝑚(𝑞, 𝑑𝑗) = ∑𝑡𝑡=1(𝑊𝑖𝑗. 𝑊𝑖𝑞) (5)
Keterangan: t : jumlah dokumen d : dokumen
q : query (kata kunci)
𝑊𝑖𝑗: bobot pada term ke-i di dokumen data latih j
𝑊𝑖𝑞: bobot pada term ke-i di dokumen data uji q 2.5 Query Expansion
Query expansion merupakan sebuah proses untuk me-reformulasikan ulang query awal dengan menambahkan beberapa kata atau term sehingga dapat menambah performa untuk melakukan proses information retrieval (Nugroho, 2009).
2.6 Relevamce Feedback
Relevance feedback merupakan teknik yang ditemukan Rocchio yang digunakan untuk merapatkan query ke rataan dokumen relevan dan sebaliknya menjauhkan query dari rataan dokumen tidak relevan (Yugianus, 2013).
Pada perhitungan Rocchio dilakukan modifikasi oleh Ruthven dan Lalmas (2003) yang diberi nama Ide-Dec-Hi, dimana hanya menggunakan dokumen tidak relevan pertama yang dihitung. Berikut merupakan rumus
Ide-Dec-Hi dapat dilihat pada Persamaan (6) berikut (Ruthven & Lalmas, 2003):
𝑄1= 𝑄0+ ∑ 𝑟𝑖 𝑛𝑟
𝑖 − 𝑠𝑖 (6)
Muncul versi terbaru yang diberi nama Ide-Regular, pada perhitungan ini menggunakan seluruh dokumen baik relevan maupun tidak relevan. Rumus Ide-Regular dapat dilihat pada Persamaan (7) berikut (Ruthven & Lalmas, 2003): 𝑄1= 𝑄0+ ∑ 𝑟𝑖 𝑛𝑟 𝑖 − ∑ 𝑠𝑖 𝑛𝑟 𝑖 (7) Keterangan: 𝑄0 = query awal 𝑄1 = query baru
𝑛𝑟 = jumlah dokumen relevan 𝑟𝑖 = dokumen relevan ke-i 𝑠𝑖 = dokumen tidak relevan ke-i 2.7 Evaluasi
Evaluasi dilakukan untuk mengukur keefektifan dari suatu sistem klasifikasi teks dengan menggunakan matriks confusion, dimana berisi informasi tentang hasil klasifikasi sebenarnya serta hasil predikasi klasifikasi dari suatu sistem (Kiftiyani et al, 2014). Secara umum untuk mengukur kualitas data retrieval dengan menggunakan kombinasi precision dan recall (Kiftiyani et al, 2014). Berikut Tabel 1 menunjukkan Tabel Confusion Matrix.
Tabel 1 Confusion Matrix Actual Class (Expectation) + - Predicted Class (Observation) + TP FP - FN TN
Precision adalah tingkat ketepatan sebuah informasi yang diminta oleh user/pengguna dengan hasil jawaban informasi yang didapat dari sistem (Pamungkas et al, 2015). Untuk rumus precision dapat dilihat pada Persamaan (8) berikut:
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = 𝑇𝑃
𝑇𝑃+𝐹𝑃 (8)
Recall merupakan kesusaian antara informasi yang didapat dari hasil percobaan berdasarkan pada sudut pandang kelas yang digunakan (Pamungkas et al, 2015). Untuk rumus recall dapat dilihat pada Persamaan (9) berikut:
𝑅𝑒𝑐𝑎𝑙𝑙 = 𝑇𝑃
𝑇𝑃+𝐹𝑁 (9)
Semakin tinggi tingkat nilai akurasi maka kesesuaian nilai hasil prediksi pengujian dengan hasil aktual (ground truth) yang dibandingkan (Pamungkas et al, 2015). Untuk rumus akurasi dapat dilihat pada Persamaan (10) berikut: 𝐴𝑘𝑢𝑟𝑎𝑠𝑖 = 𝑇𝑃+𝑇𝑁
𝑇𝑃+𝐹𝑃+𝑇𝑁+𝐹𝑁 (10)
F1 measure merupakan bobot harmonic mean pada precisison dan recall (Pamungkas et al, 2015). Untuk rumus F1 Measure dapat dilihat pada Persamaan (11) berikut:
𝐹1 𝑚𝑒𝑎𝑠𝑢𝑟𝑒 = 2 ×𝑟𝑒𝑐𝑎𝑙𝑙×𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛
𝑟𝑒𝑐𝑎𝑙𝑙+𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 (11)
Keterangan:
TP = True Positive, hasil perankingan sistem, dimana dokumen sesuai dengan query
FP = False Positive, dokumen yang masuk dalam hasil perankingan sistem tetapi tidak sesuai dengan query
FN = False Negative, dokumen yang masuk dalam hasil perankingan sistem tetapi sesuai dengan query
TN = True Negative, dokumen tidak masuk dalam hasil perankingan sistem dan memang tidak sesuai dengan query
3. METODOLOGI PENELITIAN
Pada metodologi penelitian ini membahas proses dan teknik yang diakukan pada penelitian
Query Expansion Pada Line Today
Menggunakan Algoritme Dec-Hi Dan Ide-Regular.
3.1 Rancangan Penelitian
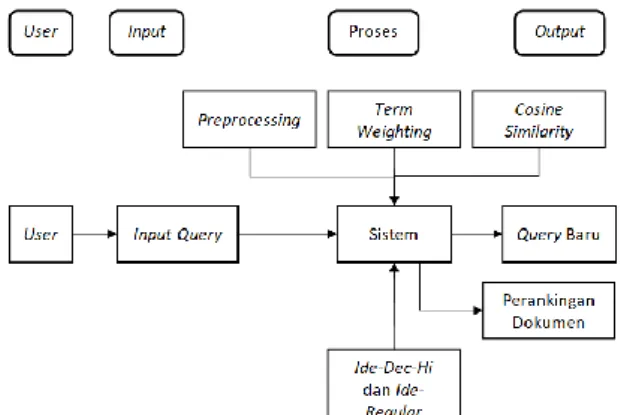
Pada bagian ini dilakukan untuk memberikan gambaran umum terkait jalannya sistem dari mulai tahap input, proses, sampai output. Berikut Gambar 1 merupakan perancangan sistemnya.
3.2 Partisipan Penelitian
Partisipan yang terlibat pada penelitian ini yaitu 3 orang mahasiswa yang berperan menilai dokumen masuk kedalam dokumen relevan atau tidak relevan sesuai dengan query yang dimasukkan.
3.3 Teknik Pengumpulan Data
Data yang digunakan pada ini menggunakan data yang diambil dari situs berita online LINE TODAY, data yang digunakan sebanyak 200 data latih berupa berita dengan 25 data uji berupa query.
4. PERANCANGAN 4.1 Diagam Alir Sistem
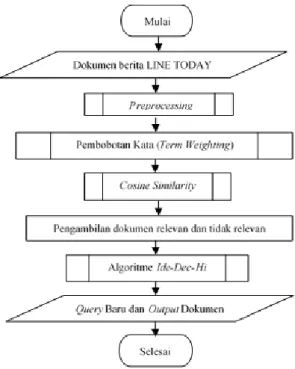
Pada diagram alir ini menunjukkan proses sistem yang dilakukan, diantaranya preprocessing, term wighting, normalisasi dan cosine similarity, serta metode ide-dec-hi dan ide-regular. Berikut merupakan diagram alir sistem ide-dec-hi ditunjukkan pada Gambar 2.
Gambar 2 Diagram Alir Sistem Ide-Dec-Hi Sedangkan untuk diagram alir sistem ide-regular ditunjukkan pada Gambar 3.
Gambar 3 Diagram Alir Sistem Ide-Regular
5. PENGUJIAN DAN ANALISIS
Pengujian pada sistem ini dibagi menjadi beberapa pengujian diantara pengujian query asli dengan query expansion, pengujian tambahan 1 kata dan 2 kata, pengujian Precision@K, serta pengujian perbandingan metode ide-dec-hi dengan ide-regular.
5.1 Pengujian Query Asli dengan Query
Expansion
Pengujian ini membandingkan hasil kenaikan precision, recall, dan f-measure antara query asli dan setelah dilakukan penambahan 1 kata tambahan menggunakan metode Ide-dec-hi dan Ide-regular. Nilai kenaikan didapat dengan mengukur berapa besar perubahan nilai yang terjadi. Kemudian, kenaikan dihitung rata-ratanya di tiap indikator pengujiannya. Berikut ini merupakan rata-rata kenaikan menggunakan metode ide-dec-hi ditunjukkan pada Tabel 2.
Tabel 2 Rata-rata Kenaikan Ide-Dec-Hi
Indikator Kenaikan
Precision -0,2691
Recall 0,055
Sedangkan rata-rata kenaikan menggunakan metode ide-regular ditunjukkan pada Tabel 3.
Tabel 3 Rata-rata Kenaikan Ide-Regular
Indikator Kenaikan
Precision -0,2934
Recall -0,7103
F-Measure -0,5657
5.2 Pengujian Tambahan 1 Kata dan 2 Kata
Pengujian ini membandingkan hasil precision, recall, f-measure dan akurasi dari query tambahan 1 kata dengan query tambahan 2 kata menggunakan metode dec-hi dan Ide-regular. Pengujian tambahan 1 dan 2 kata menggunakan metode Ide-dec-hi ditunjukkan pada Tabel 4.
Tabel 4 Pengujian Tambahan 1 Kata dan 2 Kata Metode Ide-Dec-Hi
Jumlah
Kata Precision Recall F-Measure Akurasi 1 Kata 0,6622 0,2314 0,2987 0,9506 2 Kata 0,4508 0,3127 0,3172366 0,9462 Sedangkan untuk pengujian tambahan 1 dan 2 kata menggunakan metode ide-regular ditunjukkan pada Tabel 5.
Tabel 5 Pengujian Tambahan 1 Kata dan 2 Kata Metode Ide-Regular
Jumlah
Kata Precision Recall F-Measure Akurasi 1 Kata 0,6635 0,0146 0,0279 0,9488 2 Kata 0,4519 0,2527 0,2901 0,9482
5.3 Pengujian Precision@K
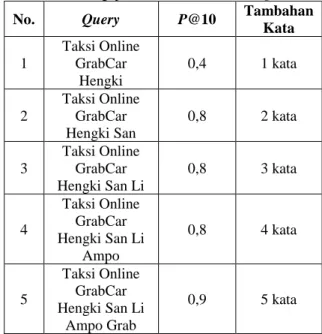
Pengujian Precision@K dilakukan untuk mengukur threshold pada peringkat K. Dokumen yang dihitung adalah dokumen relevan tertinggi sebanyak K serta mengabaikan dokumen yang berada dibawah K. Berikut ini merupakan Pengujian Precision@K menggunakan metode ide-dec-hi ditunjukkan pada Tabel 6 dengan tambahan hingga 5 kata.
Tabel 6 Pengujian P@K metode Ide-dec-hi
No. Query P@10 Tambahan
Kata 1 Taksi Online
GrabCar Hengki 0,4 1 kata
2 Taksi Online GrabCar Hengki Ampo 0,7 2 kata 3 Taksi Online GrabCar Hengki Ampo San 0,7 3 kata 4 Taksi Online GrabCar Hengki Ampo San Sopir
0,8 4 kata
5
Taksi Online GrabCar Hengki Ampo San Sopir
Penumpang
0,9 5 kata
Sedangkan untuk pengujian Precision@K menggunakan metode ide-regular ditunjukkan pada Tabel 7
Tabel 7 Pengujian P@K metode Ide-regular
No. Query P@10 Tambahan
Kata 1 Taksi Online GrabCar Hengki 0,4 1 kata 2 Taksi Online GrabCar Hengki San 0,8 2 kata 3 Taksi Online GrabCar Hengki San Li 0,8 3 kata 4 Taksi Online GrabCar Hengki San Li Ampo 0,8 4 kata 5 Taksi Online GrabCar Hengki San Li Ampo Grab 0,9 5 kata
5.4 Pengujian Perbandingan Metode
Pengujian ini dilakukan perbandingan metode antara ide-dec-hi dan ide-regular, dimana pengujian ini dilakukan pada nilai . precision, recall, f-measure dan akurasi. Perbandingan metode ditunjukkan pada Tabel 8.
Tabel 8 Pengujian Perbandingan Metode Metode Precision Recall F-Measure Akurasi
Ide-Dec-Hi 0,6622 0,2314 0,2987 0,9506 Ide
Regular 0,6635 0,0146 0,0279 0,9488
5.5 Analisis
Pada skenario pengujian 1 untuk metode ide-dec-hi terjadi penurunan nilai rata-rata precision, hal ini terjadi dikarenakan kenaikan pada nilai FP. Akan tetapi terjadi kenaikan pada nilai rata-rata recall, hal ini terjadi dikarenakan
pada nilai FN terjadi penurunan. Sedangkan metode ide-regular terjadi penurunan pada nilai rata-rata precision dan recall.
Pada skenario pengujian 2 metode ide-dec-hi dan ide-regular merupakan pengujian penambahan 1 kata menjadi 2 kata. Pada pengujian ini untuk terjadi penurunan nilai rata-rata precision yang diakibatkan penambahan kata sehingga banyak dokumen yang tidak relevan muncul dalam perankingan. Sedangkan untuk nilai rata-rata recall terjadi kenaikan dikarenakan sedikitnya dokumen relevan yang tidak muncul dalam perankingan. Nilai rata-rata akurasi terjadi penurunan yang diakibatkan semakin banyaknya query yang diinputkan sehingga dokumen yang ada pada perankingan akan semakin banyak. Hal ini berakibat dokumen relevan yang ada pada perankingan semakin sedikit sedangkan yang tidak relevan semakin banyak.
Pada skenario pengujian 3 merupakan pengujian P@K yaitu pengujian threshold nilai perankingan K=10. Pada pengujian ini menunjukkan tambahan kata cenderung meningkatkan nilai precisionnya.
Pada skenario pengujian 4 merupakan perbandingan metode antara dec-hi dan ide-regular, dimana pada metode ide-dec-hi cenderung memiliki nilai yang lebih tinggi yaitu sebesar 0,18% dibanding ide-regular.
6. KESIMPULAN
Metode ide-dec-hi dan ide-regular dapat diaplikasikan untuk melakukan pencarian dokumen di situs berita online line today. Untuk melakukan pencarian, dokumen terlebih dahulu akan melalui beberapa tahapan diantaranya preprocessing, setelah itu perhitungan term weighting serta cosine similarity. Selanjunya menentukan dokumen yang relevan dan tidak relevan, kemudian dilakukan perhitungan ide-dec-hi dan ide-regular, hingga didapatkan query tambahan yang nantinya akan digunakan untuk pencarian. Semakin banyak query yang ditambahkan dalam pencarian maka hasil pencarian akan menjadi lebih spesifik sehingga dokumen yang relavan cenderung berkurang atau sedikit sedangkan dokumen yang tidak relevan semakin banyak atau meningkat.
Pengujian query expansion menggunakan metode ide-dec-hi pada penambahan 1 kata memiliki nilai rata-rata akurasi untuk penambahan 1 kata bernilai 0,9506 dan 0,9462 untuk penambahan 2 kata. Sedangkan pengujian
query expansion menggunakan metode ide-regular didapatkan nilai rata-rata akurasi untuk penembahan 1 kata sebesar 0,9488 dan 0,9482 untuk tambahan 2 kata. Banyaknya jumlah kata yang ditambahkan pada query expansion sehingga mempengaruhi hasil dari nilai precision, recall, serta akurasi yang dihasilkan.
Penerapan metode dec-hi dan regular pada penelitian ini terbukti bahwa ide-dec-hi lebih baik daripada ide-regular dengan kenaikan hingga 0,18%.
7. DAFTAR PUSTAKA
Imbar, R. V., Adelia, Ayub, M., & Rehatta, A. (2014). Implementasi Cosine Similarity dan Algoritma Smith-Waterman untuk Mendeteksi Kemiripan Teks. Jurnal Informatika, 31-42.
Kiftiyani, U., Suprapto, & Yudistira, N. (2014). Perbandingan Algoritma Naïve Bayes Dan K Nearest Neighbour Untuk Perangkingan Dokumen Berbahasa Arab. Jurnal Teknologi Informasi dan Ilmu Komputer.
Kurniawan, B., Fauzi, M. A., & Widodo, A. W. (2017). Klasifikasi Berita Twitter Menggunakan Metode Improved Naïve Bayes. Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, 1193-1200.
Nugroho, S. A. (2009). Query Expasion Dengan Menggabungkan Metode Ruang Vektor Dan Wordnet Pada Sistem Information Retrieval. Jurnal Informatika, 1-5. Nurjanah, W. E., Perdana, R. S., & Fauzi, M. A.
(2017). Analisis Sentimen Terhadap Tayangan Televisi Berdasarkan Opini Masyarakat pada Media Sosial Twitter menggunakan Metode K-Nearest Neighbor dan Pembobotan Jumlah Retweet. Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, 1750-1757.
Okfalisa, & Harahap, A. H. (2016). Implementasi Metode Terms Frequency-Inverse Document Frequency (TF-IDF) dan Maximum Marginal Relevance Monitoring Diskusi Online. Jurnal Sains, Teknologi dan Industri, 151-159.
Pamungkas, Z. Y., Indriati, & Ridok, A. (2015). Query Expansion pada Sistem Temu
Kembali Informasi Dokumen Berbahasa Indonesia Menggunakan Pseudo Relevance Feedback Studi kasus: Perpustakaan Universitas Brawijaya. Ruthven, I., & Lalmas, M. (2003). A Survey on
the Use of Relevance Feedback for Information Access Systems. The Knowledge Engineering Review, 95-145. Wahyudi, D., Susyanto, T., & Nugroho, D.
(2017). Implementasi Dan Analisis Algoritma Stemming Nazief & Adriani Dan Porter Pada Dokumen Berbahasa Indonesia. Jurnal Ilmiah SINUS, 49-56. Wirawan, N. C., Indriati, & Adikara, P. P.
(2018). Analisis Sentimen Dengan Query Expansion Pada Review Aplikasi M-Banking Menggunakan Metode Fuzzy K-Nearest Neighbor (Fuzzy k-NN). Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, 362-368.
Yugianus, P., Dachlan, H. S., & Hasanah, R. N. (2013). Pengembangan Sistem Penelusuran Katalog Perpustakaan Dengan Metode Rocchio Relevance Feedback. Jurnal EECCIS, 47-51.