Implementasi Data Mining untuk Prediksi Mahasiswa Pengambil Mata Kuliah dengan Algoritme Naive Bayes
Bebas
113
0
0
Teks penuh
(2) PENGESAHAN IMPLEMENTASI DATA MINING UNTUK PREDIKSI MAHASISWA PENGAMBIL MATA KULIAH DENGAN ALGORITME NAIVE BAYES SKRIPSI Diajukan untuk memenuhi sebagian persyaratan memperoleh gelar Sarjana Komputer Disusun Oleh : Indra Kurniawan Syahputra NIM: 145150401111030. Skripsi ini telah diuji dan dinyatakan lulus pada 25 Juli 2018 Telah diperiksa dan disetujui oleh:. Dosen Pembimbing I. Dosen Pembimbing II. Dr.Eng., Fitra A. Bachtiar, S.T., M.Eng. Satrio Agung Wicaksono, S.Kom., M.Kom. NIK: 201201 840628 1 001 NIP: 19860521 201212 1 001. Mengetahui Ketua Jurusan Sistem Informasi. Dr. Eng., Herman Tolle, S.T., M.T. NIP: 19740823 200012 1 001. ii.
(3) DAFTAR PENGUJI Ketua Majelis (Penguji I). Pembimbing I. Himawat Aryadita, S.T, M.Sc. Dr.Eng, Fitra A. Bachtiar, S.T, M.Eng.. Penguji II. Pembimbing II. Issa Arwani, S.Kom, M.Sc. Satrio Agung Wicaksono, S.Kom, M.Kom. iii.
(4) PERNYATAAN ORISINALITAS Saya menyatakan dengan sebenar-benarnya bahwa sepanjang pengetahuan saya, di dalam naskah skripsi ini tidak terdapat karya ilmiah yang pernah diajukan oleh orang lain untuk memperoleh gelar akademik di suatu perguruan tinggi, dan tidak terdapat karya atau pendapat yang pernah ditulis atau diterbitkan oleh orang lain, kecuali yang secara tertulis disitasi dalam naskah ini dan disebutkan dalam daftar pustaka. Apabila ternyata didalam naskah skripsi ini dapat dibuktikan terdapat unsurunsur plagiasi, saya bersedia skripsi ini digugurkan dan gelar akademik yang telah saya peroleh (sarjana) dibatalkan, serta diproses sesuai dengan peraturan perundang-undangan yang berlaku (UU No. 20 Tahun 2003, Pasal 25 ayat 2 dan Pasal 70). Malang, 25 Juli 2018. Indra Kurniawan Syahputra NIM: 145150401111030. iv.
(5) DAFTAR RIWAYAT HIDUP Data Pribadi Nama. : Indra Kurniawan Syahputra. Tempat, Tanggal Lahir. : Trenggalek, 1 April 1996. Agama. : Islam. Alamat Rumah. : Jl. Joyolengkoro No. 9, Ploso, Jombang. Nomor Telephone. : 082333197447. Email. : [email protected]. Riwayat Pendidikan 2014 sampai dengan 2018. : Universitas Brawijaya Malang. 2011 sampai dengan 2014. : SMAN Ploso, Jombang. 2008 sampai dengan 2011. : SMPN 3 Bukit Batu, Bengkalis. 2002 sampai dengan 2008. : SDN 20 Kelas Jauh Sukajadi, Bukit Batu. Keahlian Web Development, Database Programming, Photoshop Pengalaman . Ketua Panitia SMANIS Campus Fair-5 , SMAN Ploso Jombang 2016 Staff Ahli bidang Legislasi Badan Perwakilan Mahasiswa Sistem Informasi Universitas Brawijaya Periode 2016/2017 Anggota Divisi Dekorasi dan Dokumentasi Acara Pemilihan Wakil Mahasiswa Sistem Informasi Universitas Brawijaya 2016/2017 Tim dalam mengerjakan Projek Sistem Monitoring Pembenahan Jaringan (BENJAR) di Telkom Surabaya tahun 2017. v.
(6) KATA PENGANTAR Puji syukur kehadirat Allah SWT yang telah melimpahkan segala rahmatnya, Sang Maha berkehendak sehingga Penulis dapat menyelesaikan skripsi ini. Shalawat serta salam semoga dicurahkan kepada junjungan dan suri tauladan kita, Nabi Muhammad SAW yang telah memberikan tuntunan dan petunjuk kepada umat manusia. Penulis menyadari bahwa skripsi ini masih jauh dari kata sempurna. Namun, penulis berharap skripsi ini dapat memnuhi persyaratan untuk memperoleh gelar sarjana (S1) dala program studi Sistem Informasi pada Fakultas Ilmu Komputer Universitas Brawijaya. Skripsi yang berjudul “Implementasi Data Mining untuk Prediksi Mahasiswa Pengambil Mata Kuliah dengan Algoritme Naive Bayes”, akhirnya dapat diselesaikan sesuai harapan Penulis. Selama penyusunan skripsi ini tentunya penulis menemukan banyak kesulitan dan hambatan dalam proses pengumpulan data dan lain sebagainya. Namun berkat ketulusan hati dan bantuan dari berbagai pihak, segala kesulitan dan hambatan dapat diatasi dengan baik oleh penulis. Sebagai bentuk penghargaan yang tak terlukiskan, izinkan Penulis menuangkan bentuk ucapan terima kasih sebesar-besarnya kepada : 1. Dr.Eng, Fitra A. Bachtiar, S.T, M.Eng. selaku dosen pembimbing I yang telah memberikan waktu, bimbingan, ilmu, arahan, nasihat, dan masukan untuk penyelesaian skripsi ini. 2. Satrio Agung Wicaksono, S.Kom., M.Kom. selaku dosen pembimbing II yang telah memberikan waktu, bimbingan, ilmu, arahan, nasihat, dan masukan untuk penyelesaian skripsi ini. 3. Wayan Firdaus Mahmudy, S.Si., M.T., Ph.D selaku Dekan Fakultas Ilmu Komputer Universitas Brawijaya. 4. Dr. Eng., Herman Tolle, S.T., M.T. selaku Ketua Jurusan Sistem Informasi Fakultas Ilmu Komputer Universitas Brawijaya. 5. Suprapto, S.T., M.T. selaku Ketua Program Studi Sistem Informasi Fakultas Ilmu Komputer Universitas Brawijaya. 6. M. Tanzil Furqon, S.Kom, M.CompSc dan Ismiarta Aknuranda, S.T, M.Sc, Ph.D selaku sekretaris jurusan atas bantuan dan masukan yang telah diberikan selama penulis melakukan penelitian. 7. Bapak Aditya Rachmadi, S.ST., M.TI selaku Dosen PA penulis yang telah memberikan bimbingan selama kuliah. 8. Kedua Orang Tua penulis, Bapak Irwan Yudiarto, S.H, Ibu Nurfadilla yang selalu memberikan do’a, kasih sayang, motivasi serta dukungan moril dan materil.. vi.
(7) 9. Tante dan Om, Titik Rofidah, S.Pd dan Toni Wijarno, SE yang juga menjadi orang tua penulis sejak SMA dan terus memberikan do’a, motivasi serta dukungan moril dan materil. 10. Mas Yohanes selaku staff akademik yang memberikan bantuan pengumpulan data dan masukan kepada penulis untuk dapat mengerjakan skripsi. 11. Sepupu penulis Mas Wisnu yang terus memberikan motivasi dan masukan kepada penulis dalam mengerjakan skripsi. 12. Para sahabat penulis, Diago Ariesandika, Eki Yusandhi Iskandar, Savira Fahrunnisa, dan Aziza Zuhroh Sya’bandiyah yang memberikan motivasi dan membantu penulis selama perkuliahan dan pengerjaan skripsi. 13. Teman-teman seperjuangan penulis, keluarga Sistem Informasi 2014 yang memberikan motivasi dan bantuan selama kuliah. 14. Seluruh pihak yang telah membantu secara langsung maupun tidak langsung kepada penulis sehingga penulis dapat menyelesaikan skripsi ini. Malang, 25 Juli 2018 Penulis [email protected]. vii.
(8) ABSTRAK Indra Kurniawan Syahputra, Implementasi Data Mining untuk Prediksi Mahasiswa Pengambil Mata Kuliah dengan Algoritme Naive Bayes Pembimbing : Dr.Eng., Fitra A. Bachtiar, S.T., M.Eng dan Satrio Agung Wicaksono, S.Kom., M.Kom. Bagian akademik Fakultas Ilmu Komputer Universitas Brawijaya setiap semester memiliki tugas dalam melakukan penjadwalan dan penentuan mata kuliah yang harus dibuka untuk mahasiswa. Akan tetapi proses tersebut memiliki permasalahan seperti contohnya kelas yang dibuka terlalu banyak dibanding jumlah siswa yang berminat atau kelas yang dibuka sedikit sementara jumlah peminat untuk mata kuliah tersebut sangat tinggi. Sehingga dibutuhkan suatu sistem yang dapat memprediksi apakah suatu mahasiswa akan mengambil mata kuliah atau tidak. Salah satu solusinya menggunakan pendekatan klasifikasi data mining. Berdasarkan atribut dari data mahasiswa yaitu Nilai, IP, IP Kumulatif, SKS, SKS Kumulatif dan Semester akan dilakukan proses klasifikasi sehingga menghasilkan prediksi apakah mahasiswa tersebut mengambil mata kuliah tertentu atau tidak. Hasil klasifikasi dibagi menjadi 2 kelas yaitu kelas ‘Ya’ untuk mahasiswa yang diprediksi mengambil dan ‘Tidak’ untuk mahasiswa yang diprediksi tidak mengambil. Proses klasifikasi dilakukan dengan menggunakan algoritme Naive Bayes Classification (NBC). Dataset yang digunakan untuk training adalah data dari tahun 2014 semester ganjil sampai tahun 2015 semester genap. Sementara dataset yang digunakan untuk testing adalah data dari tahun 2016 semester ganjil. Dari hasil prediksi menggunakan 2 mata kuliah sebagai sampel, diperoleh hasil nilai Accuracy untuk mata kuliah Manajemen Hubungan Pelanggan adalah sebesar 85,88% sementara untuk mata kuliah Jaringan Nirkabel adalah sebesar 44,92%. Luaran dari penelitian ini adalah dashboard berbasis web yang menampilkan grafik perbandingan nilai actual dan prediksi dari setiap mata kuliah pada tahun dan semester tertentu. Kata kunci: data mining, naive bayes, klasifikasi, akademik, mahasiswa. viii.
(9) ABSTRACT Indra Kurniawan Syahputra, Data Mining Implementation for Prediction of Student Taking Course using Naive Bayes Algorithm Supervisors : Dr.Eng., Fitra A. Bachtiar, S.T., M.Eng and Satrio Agung Wicaksono, S.Kom., M.Kom. Faculty of Computer Science of Brawijaya University’s academic division has tasks for scheduling and determining courses every semester offered for students. However, the scheduling process has some problems such as, many of classes are offered while the students who are interests in that course are very low. Otherwise, only a few classes are opened while plenty of students are interests to the course. Therefore, a system is needed that can predict students will take a course or not. One of the solutions is using data mining classification approach. Based on student’s attributes values, grade points, grade point average, semester credit units, cumulative semester credit units, and the semester is used to classify whether the student will take certain courses or not. Result of the classification divided into two classes that are ‘Yes’ class for student who take the class and ‘No’ class for student who put off the class. Classification process is performed using Naive Bayes Classification (NBC) algorithm. The process using data from the odd semester in 2014 to even semester in 2015 for training. Also, it is using dataset from odd semester in 2016 for testing. Prediction result using two courses as sample, the result of accuracy score for Customer Relationship Management course is 85,88%, while for Wireless Network course is 44,92%. The output of this research is a web-based dashboard that displays a comparison of actual dan predict values of each course in certain year and semester. Keywords: data mining, naive bayes, classification, academic, student. ix.
(10) DAFTAR ISI PENGESAHAN .................................................................................................. ii PERNYATAAN ORISINALITAS ........................................................................... iv KATA PENGANTAR .......................................................................................... vi ABSTRAK ...................................................................................................... viii ABSTRACT ...................................................................................................... ix DAFTAR ISI....................................................................................................... x DAFTAR TABEL .............................................................................................. xiii DAFTAR GAMBAR ......................................................................................... xiv DAFTAR LAMPIRAN ....................................................................................... xv BAB 1 PENDAHULUAN ..................................................................................... 1 1.1 Latar belakang........................................................................................ 1 1.2 Rumusan masalah .................................................................................. 3 1.3 Tujuan .................................................................................................... 3 1.4 Manfaat.................................................................................................. 3 1.5 Batasan masalah .................................................................................... 3 1.6 Sistematika penulisan ............................................................................ 4 BAB 2 LANDASAN KEPUSTAKAAN .................................................................... 6 2.1 Kajian Pustaka ........................................................................................ 6 2.2 Profil Fakultas Ilmu Komputer ............................................................... 7 2.3 Landasan Teori ....................................................................................... 8 2.3.1 Data Mining .................................................................................. 8 2.3.2 Naive Bayes Classifier (NBC) ....................................................... 10 2.3.3 Laplacian Correction / Laplace Estimator ................................... 12 2.3.4 Pengukuran Kinerja Klasifikasi .................................................... 13 2.3.5 Basis Data (Database) ................................................................. 15 2.3.6 System Usability Scale (SUS) ....................................................... 17 BAB 3 METODOLOGI ...................................................................................... 19 3.1 Identifikasi Masalah ............................................................................. 20 3.2 Studi Literatur ...................................................................................... 20 3.3 Pengumpulan Data .............................................................................. 20 3.4 Perancangan Sistem............................................................................. 21 x.
(11) 3.5 Implementasi Teknik Data Mining....................................................... 21 3.6 Implementasi Dashboard..................................................................... 22 3.7 Pengujian dan Hasil Analisis................................................................. 22 3.8 Kesimpulan dan Saran ......................................................................... 22 BAB 4 ANALISIS DAN PERANCANGAN ............................................................. 23 4.1. 4.2. Analisis Kebutuhan .......................................................................... 23 4.1.1. Deskripsi Umum Sistem ........................................................... 23. 4.1.2. Kebutuhan Data ....................................................................... 23. 4.1.3. Identifikasi Aktor ...................................................................... 24. 4.1.4. Daftar Kebutuhan .................................................................... 24. 4.1.5. Use Case Diagram.................................................................... 26. Perancangan Sistem ........................................................................ 26 4.2.1. Arsitektur Sistem ..................................................................... 26. 4.2.2. Pemodelan Sistem ................................................................... 27. 4.2.3. Perancangan Basis Data ........................................................... 34. 4.2.4. Pre-Processing Data ................................................................. 39. 4.3.5 Perancangan Algoritme ............................................................ 40 4.3.6 Perhitungan Manual ................................................................. 47 4.3.7 Perancangan Antarmuka .......................................................... 52 BAB 5 IMPLEMENTASI .................................................................................... 56 5.1. Spesifikasi Software dan Hardware ................................................ 56 5.1.1. Spesifikasi Software ................................................................. 56. 5.1.2. Spesifikasi Hardware................................................................ 56. 5.2. Batasan-batasan Implementasi....................................................... 57. 5.3. Pre Processing Data ......................................................................... 57. 5.4. 5.5. 5.3.1. Integrasi Data ........................................................................... 57. 5.3.2. Transformasi Data.................................................................... 58. Implementasi Algoritme Naive Bayes Classifier.............................. 59 5.4.1. Perhitungan nilai prior ............................................................. 59. 5.4.2. Perhitungan untuk tahap training data ................................... 60. 5.4.3. Perhitungan untuk tahap testing data..................................... 66. Implementasi Antarmuka ............................................................... 68 xi.
(12) BAB 6 PENGUJIAN DAN ANALISIS HASIL PENGUJIAN....................................... 71 6.1. Klasifikasi dengan Naive Bayes Classification (NBC) ....................... 71 6.1.1 Proses Training Data ................................................................... 71 6.1.2 Proses Testing Data ..................................................................... 74. 6.2 Pengujian Hasil Klasifikasi Naive Bayes ............................................... 74 6.2.1 Confusion Matrix ......................................................................... 74 6.2.2 Precision, Recall, Accuracy .......................................................... 75 6.2.3 F-Measure ................................................................................... 76 6.2.4 Akurasi Global ............................................................................. 77 6.3 Pengujian Usability Dashboard ............................................................ 78 6.4. Analisis Hasil Klasifikasi Naive Bayes............................................... 79 6.4.1 Confusion Matrix ......................................................................... 79 6.4.2 Precision, Recall, Accuracy .......................................................... 80 6.4.3 F-Measure ................................................................................... 81 6.4.4 Akurasi Global ............................................................................. 81. 6.5. Analisis Usability Dashboard ........................................................... 82. BAB 7 PENUTUP ............................................................................................. 83 7.1. Kesimpulan ...................................................................................... 83. 7.2. Saran................................................................................................ 84. DAFTAR PUSTAKA .......................................................................................... 85 LAMPIRAN A LAPORAN HASIL WAWANCARA ................................................. 87 LAMPIRAN B HASIL KUESIONER SYSTEM USABILITY SCALE ............................. 92 LAMPIRAN C POTONGAN DATA PRIMER ........................................................ 95 LAMPIRAN D POTONGAN DATA TRAINING ..................................................... 97 LAMPIRAN E POTONGAN DATA TESTING ........................................................ 98. xii.
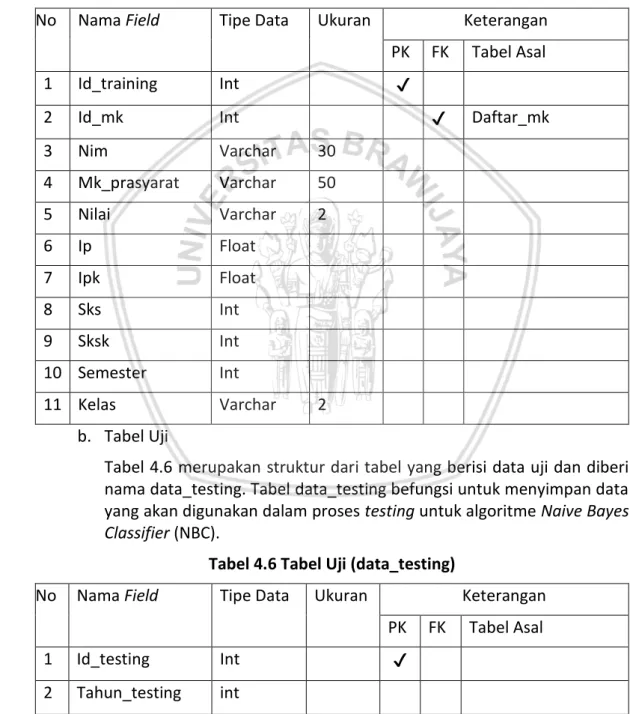
(13) DAFTAR TABEL Tabel 2.1 Confusion Matrix ................................................................................... 13 Tabel 2.2 Instrumen Pengujian System Usability Scale ........................................ 17 Tabel 4.1 Fitur-fitur data yang digunakan............................................................. 23 Tabel 4.2 Identifikasi aktor sistem ........................................................................ 24 Tabel 4.3 Kebutuhan Fungsional Administrator ................................................... 25 Tabel 4.5 Kebutuhan Fungsional User .................................................................. 25 Tabel 4.6 Tabel Latih (data_training) .................................................................... 34 Tabel 4.7 Tabel Uji (data_testing) ......................................................................... 34 Tabel 4.8 Tabel Mata Kuliah (daftar_mk) ............................................................. 35 Tabel 4.9 Tabel Program Studi (program_studi) ................................................... 35 Tabel 4.10 Tabel Data Mata Kuliah (data_mk) ..................................................... 36 Tabel 4.11 Tabel Model Probabilitas .................................................................... 36 Tabel 4.12 Tabel ipk .............................................................................................. 37 Tabel 4.13 Tabel khs .............................................................................................. 37 Tabel 4.14 Tabel rekap khs.................................................................................... 38 Tabel 4.15 Nilai ...................................................................................................... 40 Tabel 4.16 Kelas .................................................................................................... 40 Tabel 4.17 Contoh Data Training Sistem .............................................................. 47 Tabel 4.18 Data Uji Sistem .................................................................................... 48 Tabel 4.19 Perhitungan rata-rata .......................................................................... 51 Tabel 4.20 Perhitungan standar deviasi ................................................................ 52 Tabel 5.1 Spesifikasi Software ............................................................................... 56 Tabel 5.2 Spesifikasi Hardware ............................................................................. 56 Tabel 5.3 Kode sumber proses integrasi data ....................................................... 57 Tabel 5.4 Kode sumber proses transformasi data ................................................ 58 Tabel 5.5 Kode sumber perhitungan prior untuk setiap kelas .............................. 59 Tabel 5.6 Tabel kode sumber proses training data .............................................. 60 Tabel 5.7 Tabel kode sumber perhitungan data diskrit ........................................ 62 Tabel 5.8 Tabel kode sumber perhitungan data non diskrit ................................. 64 Tabel 5.9 Tabel kode sumber perhitungan untuk tahap testing data .................. 66 Tabel 6.1 Komposisi Data Training........................................................................ 71 Tabel 6.2 Tabel Probabilitas Mata Kuliah Manajemen Hubungan Pelanggan ...... 72 Tabel 6.3 Tabel Probabilitas Mata Kuliah Jaringan Nirkabel................................. 73 Tabel 6.4 Hasil Klasifikasi Data Testing ................................................................. 74 Tabel 6.5 Nilai Confusion Matrix Mata Kuliah Manajemen Hubungan Pelanggan 75 Tabel 6.6 Nilai Confusion Matrix Mata Kuliah Jaringan Nirkabel.......................... 75 Tabel 6.7 Perbandingan Hasil Klasifikasi Mata Kuliah ........................................... 77 Tabel 6.8 Rekapitulasi hasil kuesioner System Usability Scale ............................. 78. xiii.
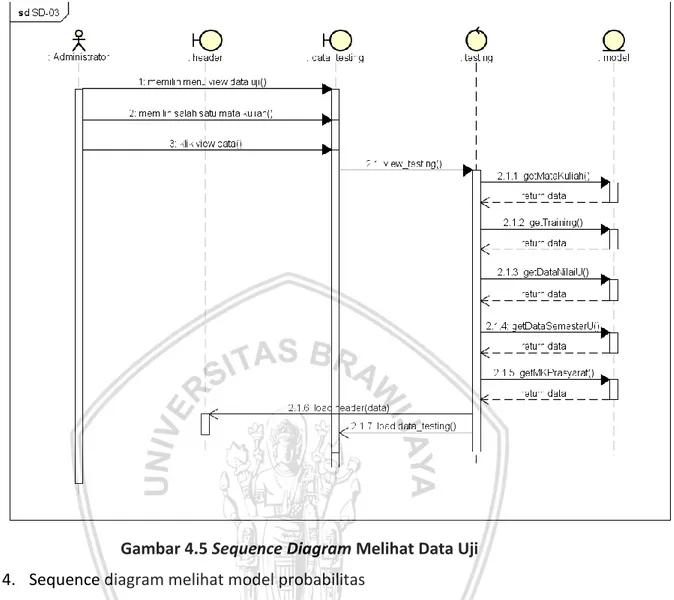
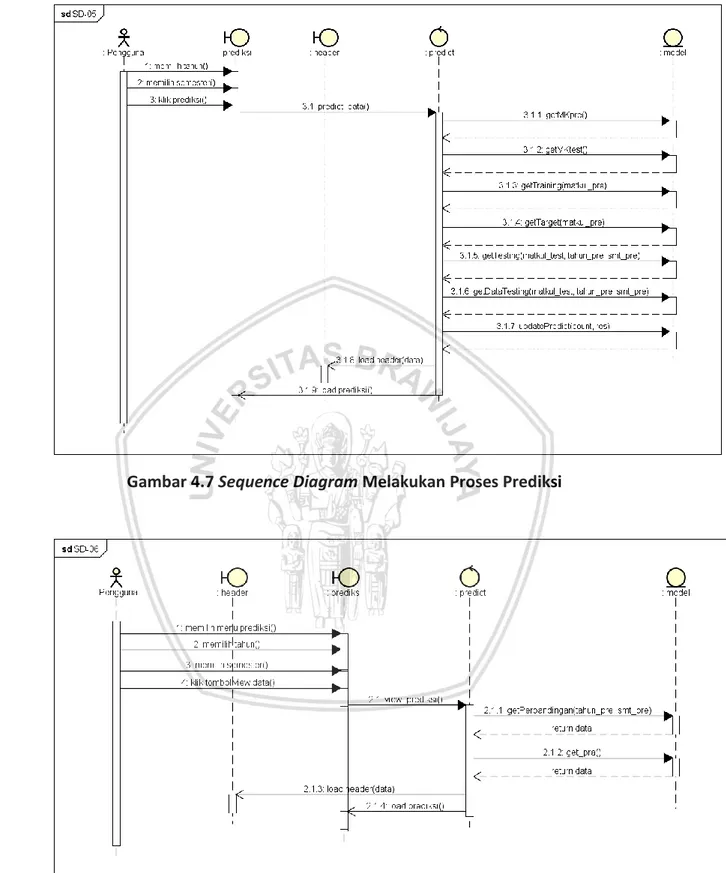
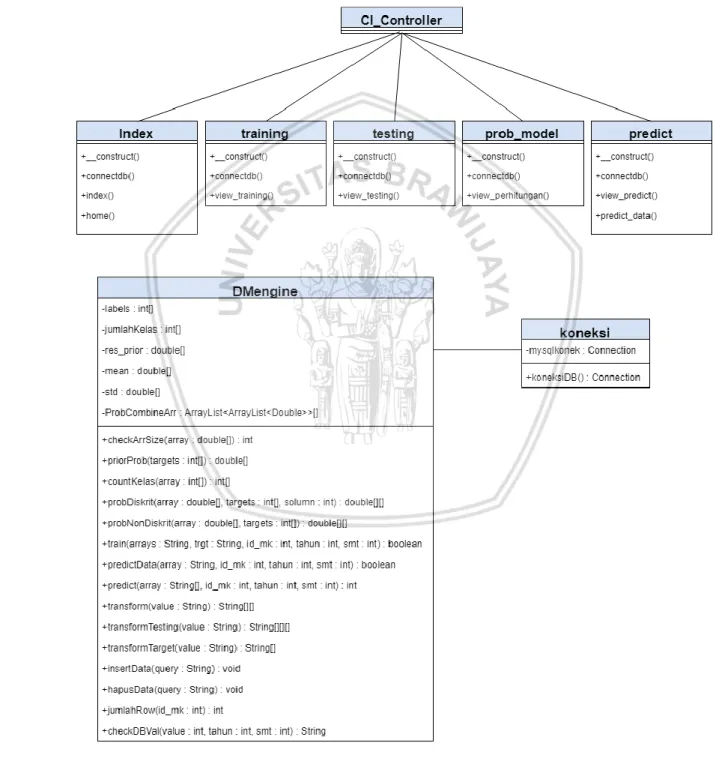
(14) DAFTAR GAMBAR Gambar 2.1 Tahap-tahap data mining .................................................................... 9 Gambar 3.1 Alur metodologi penelitian ............................................................... 19 Gambar 4.1 Use Case Diagram Sistem.................................................................. 26 Gambar 4.2 Arsitektur Sistem ............................................................................... 27 Gambar 4.3 Sequence Diagram Login ................................................................... 28 Gambar 4.4 Sequence Diagram Melihat Data Latih.............................................. 29 Gambar 4.5 Sequence Diagram Melihat Data Uji ................................................. 30 Gambar 4.6 Sequence Diagram Melihat Model Probabilitas ............................... 31 Gambar 4.7 Sequence Diagram Melakukan Proses Prediksi ................................ 32 Gambar 4.8 Sequence Diagram Melihat Hasil Prediksi ........................................ 32 Gambar 4.9 Class Diagram Sistem ........................................................................ 33 Gambar 4.10 Desain database dm_db .................................................................. 39 Gambar 4.11 Flowchart alur kerja sistem ............................................................. 42 Gambar 4.12 Flowchart alur Naive Bayes ............................................................. 44 Gambar 4.13 Flowchart perhitungan likelihood data continue ............................ 45 Gambar 4.14 Flowchart perhitungan data diskrit ................................................. 46 Gambar 4.15 Rancangan antarmuka halaman View DataLatih ............................ 53 Gambar 4.16 Rancangan antarmuka halaman View Data Uji............................... 54 Gambar 4.17 Rancangan antarmuka halaman View Data Perhitungan ............... 54 Gambar 4.18 Rancangan antarmuka halaman View Hasil Prediksi ...................... 55 Gambar 5.1 Implementasi Antarmuka Halaman View Data Latih ........................ 68 Gambar 5.2 Implementasi Antarmuka Halaman View Data Uji ........................... 69 Gambar 5.3 Implementasi Antarmuka Halaman View Perhitungan..................... 69 Gambar 5.4 Implementasi Antarmuka Halaman Prediksi..................................... 70 Gambar 6.1 Grafik Perbandingan Nilai Precision, Recall, Accuracy untuk Mata Kuliah Manajemen Hubungan Pelanggan ............................................................. 76 Gambar 6.2 Grafik Perbandingan Nilai Precision, Recall, Accuracy untuk Mata Kuliah Jaringan Nirkabel ........................................................................................ 76. xiv.
(15) DAFTAR LAMPIRAN. LAMPIRAN A LAPORAN HASIL WAWANCARA ....................................................... 87 A.1 Hasil Wawancara ke-I .......................................................................... 87 A.2 Hasil Wawancara ke-II ......................................................................... 90 LAMPIRAN B HASIL KUESIONER SYSTEM USABILITY SCALE .................................. 92 B.1 Hasil Kuesioner I .................................................................................. 92 B.2 Hasil Kuesioner II ................................................................................. 93 B.3 Hasil Kuesioner III ................................................................................ 94 LAMPIRAN C POTONGAN DATA PRIMER .............................................................. 95 C.1 Data IPK ............................................................................................... 95 C.2 Data KHS .............................................................................................. 96 LAMPIRAN D POTONGAN DATA TRAINING........................................................... 97 LAMPIRAN E POTONGAN DATA TESTING ............................................................. 98. xv.
(16) BAB 1 PENDAHULUAN 1.1 Latar belakang Perguruan tinggi merupakan institusi pendidikan sebagai penyelenggara kegiatan akademik bagi mahasiswa. Menurut undang-undang Republik Indonesia nomor 20 tahun 2003 tentang sistem pendidikan nasional, perguruan tinggi dapat berbentuk akademi, politeknik, sekolah tinggi, institute, atau universitas. Perguruan tinggi diharapkan dapat memberikan pelayanan dan menyelenggarakan pendidikan yang berkualitas bagi mahasiswa, sehingga dapat menghasilkan sumber data manusia yang berkualitas dan kompeten dibidangnya. Untuk itu, perguruan tinggi perlu menjalankan proses bisnis dalam institusinya secara efektif dan efisien. Salah satu bagian dalam perguruan tinggi yang memiliki pengaruh terhadap proses didalam perguruan tinggi tersebut adalah bagian akademik. Bagian akademik memiliki beberapa tugas diantaranya adalah membantu dan melaksanakan serta melayani kegiatan yang berkaitan dengan pendaftaran mahasiswa baru, heregistrasi mahasiswa, pemrograman mata kuliah, pencetakkan absensi kuliah mahasiswa, pembagian KHS dan pengecekan nilai hasil ujian bila ada keluhan dari mahasiswa. (Biro Administrasi Akademik dan Kemahasiswaan UIN Malang). Salah satu proses atau tugas yang membutuhkan usaha ekstra bagian akademik dalam perguruan tinggi adalah saat masa pengisian Kartu Rencana Studi (KRS) mahasiswa. Pada masa ini, bagian akademik tiap fakultas memiliki kewajiban untuk merancang jadwal mata kuliah sedemikian rupa sebelum dapat diambil oleh mahasiswa. Universitas Brawijaya khususnya Fakultas Ilmu Komputer merupakan salah satu pendidikan tinggi yang juga memiliki proses bisnis yang tidak jauh berbeda dengan perguruan tinggi lainnya, termasuk memiliki kewajiban dalam merancang jadwal mata kuliah dan menentukan jumlah kelas setiap mata kuliah untuk mahasiswanya. Berdasarkan hasil wawancara yang dilakukan kepada sekretaris jurusan Teknik Informatika dan Sistem Informasi yang dapat dilihat pada Lampiran A, proses penjadwalan mata kuliah dan penentuan jumlah kelas yang dibuka dalam satu semester merupakan suatu proses yang rumit, terutama dalam menentukan mata kuliah yang berada pada semester 5 atau lebih (mata kuliah pilihan). Karena untuk menentukan berapa kelas mata kuliah yang akan dibuka pada suatu semester perlu mempertimbangkan beberapa faktor, termasuk trend tahun sebelumnya. Hal tersebut berdampak pada saat masa pengisian KRS (Kartu Rencana Studi) yang menimbulkan beberapa permasalan diantaranya kelas yang tersedia tidak dapat memenuhi jumlah mahasiswa yang berminat dan kelas yang tersedia cukup banyak namun sepi peminat. Akibatnya, pihak akademik harus menambah waktu pengisian KRS untuk mengakomodir mahasiswa yang kehabisan kelas sedangkan jadwal pengisian KRS seharusnya sudah berakhir. Padahal, masa pengisian KRS merupakan salah satu saat yang penting bagi mahasiswa sebagaimana disebutkan dalam buku pedoman Fakultas Ilmu Komputer Universitas Brawijaya pasal 13 ayat 1 yang berbunyi : “Setiap mahasiswa yang 1.
(17) terdaftar diwajibkan mengisi Kartu Rencana Studi Semester dengan bimbingan dan persetujuan Penasehat Akademik”. Pencegahan permasalahan tersebut sebenarnya sudah dilakukan oleh pihak akademik Fakultas Ilmu Komputer, seperti penyebaran kuisioner sebelum masa pengisian KRS yang melibatkan Advokesma setiap jurusan untuk memberi acuan jumlah mahasiswa yang berencana untuk mengambil suatu mata kuliah. Atau dengan cara hanya membuka sebagian dari kelas yang tersedia terlebih dahulu sebelum melakukan penambahan kelas yang dibuka untuk mata kuliah pada semester tersebut. Namun, menurut sekretaris jurusan cara tersebut tidak efektif karena dalam keadaan sebenarnya data yang dihimpun dari kuisioner dengan jumlah mahasiswa yang sebenarnya berminat untuk mengambil suatu mata kuliah tidak sesuai dan seharusnya penanganan permasalahan tersebut dapat ditangani lebih awal lagi. Untuk itu diperlukan suatu prediksi mahasiwa yang berminat untuk mengambil suatu mata kuliah dalam suatu semester. Dan dalam penelitian kali ini, akan menggunakan teknik data mining untuk prediksi. Data Mining merupakan sebuah teknik yang bertujuan untuk mendapatkan pengetahuan yang masih tersembunyi dari bongkahan data. (Susanto, 2010). Pemanfaatan data mining untuk prediksi telah digunakan pada berbagai macam kasus, seperti penggunaan data mining untuk prediksi pada data akademik berupa peningkatan kinerja mahasiswa pascasarjana menggunakan klasifikasi (Bunker, et.al., 2012), mengevaluasi kinerja akdemik mahasiswa dengan menggunakan Naive Bayes dan C4.5 (Ridwan, et.al.,2013), mencari perkiraan waktu studi mahasiswa (Jananto, 2013), prediksi jumlah mahasiswa yang mengambil suatu mata kuliah dengan mengimplementasikan algoritme Decision Tree C4.5 (Manullang, 2011), dan algoritme Genetika (Hazaki,et.al.,2011) atau penerapan dalam bidang lainnya seperti memodelkan prediksi curah hujan menggunakan pendekatan Bayesian (Nikam, 2013), atau untuk memprediksi lama pasien menginap pada bidang kesehatan (Liu, et.al., 2006). Algoritme Naive Bayes merupakan salah satu teknik data mining yang melakukan pengklasifikasian probabilitas sederhana dan merupakan penerapan dari Teorema Bayes. Ide dari Teorema Bayes adalah menangani masalah yang bersifat hipotesis yakni mendesain suatu klasifikasi untuk memisahkan objek. (Santosa, 2007). Dalam beberapa penelitian Naive Bayes menunjukkan hasil yang lebih baik dibandingkan dengan metode klasifikasi lainnya, seperti memiliki akurasi yang lebih tinggi dibandingkan dengan metode Jaringan Syaraf Tiruan dalam mendeteksi seseorang terkena penyakit stroke (Rohmana, 2014). Naive Bayes juga memiliki nilai Accuracy, Precission, dan F-measure yang lebih baik jika dibandingkan dengan dengan Decission Tree dalam proses training halaman web. (Xhemali, 2009). Berdasarkan permasalahan yang telah dijelaskan sebelumnya, penelitian akan menggunakan algortime Naive Bayes untuk melakukan prediksi terhadap mahasiswa pengambil mata kuliah pada Fakultas Ilmu Komputer Universitas Brawijaya. Hasil dari prediksi akan ditampilkan kedalam suatu dashboard berbasiskan web dengan penerapan algoritme Naive Bayes dan web service. 2.
(18) Dashboard yang terbentuk diharapkan dapat membantu sekretaris jurusan dalam menentukan jumlah kelas yang harus dibuka dalam suatu semester berdasarkan hasil prediksi. Oleh karena itu, penelitian ini mengangkat judul “Implementasi Data Mining untuk Prediksi Mahasiswa Pengambil Mata Kuliah dengan Algoritme Naive Bayes”.. 1.2 Rumusan masalah 1. Bagaimana hasil penerapan algoritme Naive Bayes untuk prediksi mahasiswa yang mengambil mata kuliah? 2. Bagaimana hasil pengujian dari prediksi mahasiswa yang mengambil mata kuliah menggunakan algoritme Naive Bayes? 3. Bagaimana hasil rancangan dashboard untuk prediksi mahasiswa yang mengambil mata kuliah?. 1.3 Tujuan Tujuan dalam penelitian skripsi ini terbagi menjadi 2 yaitu tujuan umum dan tujuan khusus. Tujuan umum dari penelitian ini adalah membuat implementasi Naive Bayes dalam melakukan prediksi untuk menunjukkan mahasiswa yang mengambil suatu mata kuliah tertentu. Sedangkan tujuan khusus dari penelitian ini dapat dijabarkan dalam poin-poin sebagai berikut : 1. Mengetahui hasil penerapan algoritme Naive Bayes untuk prediksi mahasiswa yang mengambil mata kuliah. 2. Mengetahuai hasil pengujian dari prediksi mahasiswa yang mengambil mata kuliah menggunakan algoritme Naive Bayes. 3. Mengetahui hasil rancangan dashboard untuk prediksi mahasiswa yang mengambil mata kuliah.. 1.4 Manfaat Manfaat yang ingin didapat dari penelitian ini adalah sebagai berikut : 1. Mengimplementasikan algoritme Naive Bayes untuk membuat aplikasi prediksi jumlah mahasiswa yang mengambil suatu mata kuliah tertentu. 2. Membantu bagian akademik Fakultas Ilmu Komputer Universitas Brawijaya dalam menentukan jumlah kelas yang harus dibuka pada suatu semester.. 1.5 Batasan masalah Adapun batasan masalah dari permasalahan yang dijabarkan pada sub bab sebelumnya adalah sebagai berikut : 1. Data yang digunakan sebagai data latih dan data uji untuk penelitian skripsi ini adalah data yang berasal dari akademik Fakultas Ilmu Komputer Universitas Brawijaya. 2. Studi kasus yang digunakan adalah Fakultas Ilmu Komputer Universitas Brawijaya. 3.
(19) 3. Algoritme yang digunakan adalah Naive Bayes Classifier (NBC). 4. Mengabaikan aturan peralihan kurikulum dalam proses penentuan mata kuliah yang digunakan. 5. Dataset yang digunakan untuk proses training adalah data akademik tahun 2014 semester ganjil sampai tahun 2015 semester genap. 6. Dataset yang digunakan untuk proses testing adalah data akademik tahun 2016 semester ganjil. 7. Mata kuliah yang diprediksi adalah mata kuliah pilihan berdasarkan mata kuliah prasyaratnya. 8. Mata kuliah yang digunakan adalah mata kuliah Manajemen Hubungan Pelanggan, Basis Data Terdistribusi, Sistem Pendukung Keputusan, Sistem Pakar, Logika Fuzzy, Arsitektur Jaringan Terkini dan Jaringan Nirkabel. 9. Fitur data yang digunakan dalam penelitian ini adalah dari segi akademik, yaitu Nilai, IP, IP Kumulatif, SKS, SKS Kumulatif dan Semester.. 1.6 Sistematika penulisan Sistematika penulisan yang dibutuhkan untuk mencapai tujuan yang diharapkan dari penelitian skripsi ini adalah sebagai berikut : BAB I. Pendahuluan. Bab ini membahas mengenai masalah umum seperti latar belakang, rumusan masalah, tujuan, manfaat, batasan masalah, dan sistematika penulisan. BAB II. Landasan Pustaka. Bab ini membahas tentang teori-teori yang berkaitan dengan proses penelitian skrispi yang berkaitan dengan penggunaan algoritme yang sama atau algoritme yang berbeda tetapi digunakan untuk permasalahan yang mirip. Bab ini juga membahas tentang penelitian terdahulu dan perbedaannya dengan penelitian ini. BAB III. Metodologi Penelitian. Bab ini membahas tentang metode yang digunakan dan langkah kerja yang dilakukan dalam proses penelitian. Metodologi penelitian terdiri dari studi literatur, identifikasi masalah, pengumpulan data, analisis dan perancangan sistem, implementasi teknik data mining, pengujian dan hasil analisis, dan kesimpulan. BAB IV. Analisis dan Perancangan. Bab ini membahas tentang analisis mengenai kebutuhan sistem dan data. Selain itu juga membahas mengenai perancangan dari sistem yang dibangun, dan perancangan algoritme yang diterapkan didalam sistem.. 4.
(20) BAB V. Implementasi. Bab ini membahas tentang penerapan sistem berdasarkan hasil analisis dan perancangan yang telah dibahas pada bab sebelumnya. Penerapan yang terdapat pada bab in meliputi penerapan algoritme Naive Bayes Classifier (NBC) ke dalam sistem dan pembuatan antarmuka untuk pengguna. BAB VI. Pengujian dan Analisis. Bab ini membahas tentang pengujian menggunakan algoritme Naive Bayes Classifier (NBC) terhadap data yang telah disediakan dan analisis hasil klasifikasi dengan Naive Bayes Classifier (NBC) untuk mengetahui akurasi dari model yang terbentuk. BAB VII. Penutup. Bab ini membahas segala hal terkait kesimpulan yang didapatkan dari hasil penelitian yang telah dilakukan, juga pemberian saran untuk perbaikan penelitian di masa yang akan datang.. 5.
(21) BAB 2 LANDASAN KEPUSTAKAAN Pada bab kedua landasan kepustakaan terdiri dari kajian pustaka dan dasar teori. Landasan pustaka membahas tentang penelitian-penelitian terdahulu yang berkaitan dengan penelitian ini. Sedangkan dasar teori membahas teori yang menunjang dan diperlukan untuk menyusun penelitian. Pada penelitian ini dasar teori yang diperlukan berdasarkan latar belakang dan rumusan masalah adalah data mining, Naive Bayes Classifier (NBC), pengukuran kinerja klasifikasi dan basis data.. 2.1 Kajian Pustaka Penelitian sebelumnya yang berkaitan dengan penelitian yang akan dilakukan pertama adalah penelitian tentang implementasi decision tree untuk prediksi jumlah mahasiswa pengambil mata kuliah yang dilakukan oleh (Romauli Manullang, 2011). Permasalahan yang diangkat dalam penelitian ini adalah bagaimana menggunakan teknik data mining decision tree C4.5 dalam memprediksi jumlah mahasiswa yang mengambil mata kuliah. Dalam penelitiannya peneliti melakukan uji coba dengan 3 skenario yang berbeda berdasarkan atribut yang dipilih sebagai model dalam pembentukan tree, ditambah sebuah kondisi ketika tree dipruning. Atribut yang digunakan dalam uji coba adalah nilai, jenis kelamin, tahun lahir, IP Kumulatif, angkatan, semester, umur, selisih tahun prediksi, dan IP Semester. Hasilnya adalah uji coba dengan scenario pertama yaitu kombinasi atribut nilai, jenis kelamin, tahun lahir, IPK, angkatan dan semester yang menghasilkan nilai error rata-rata paling kecil yaitu sebesar 58,33%. Kemudian dibawahnya adalah scenario kedua dengan atribut nilai, selisih tahun prediksi, hasil, IPS, angkatan dan umur yang menghasilkan nilai error rata-rata sebesar 61,45%. Dilanjutkan dengan kondisi setelah tree dipruning yang menghasilkan nilai error rata-rata sebesar 63,5% dan terakhir dengan nilai error rata-rata paling besar yaitu scenario 3 yang memiliki atribut nilai, selisih, angkatan, IPS dan umur dengan nilai sebesar 112,5%. Meskipun menggunakan decision tree C4.5 namun dalam proses implementasinya pembuatan decision tree dilakukan secara semi-manual karena terdapat missing value. Penelitian yang kedua adalah penelitian yang memiliki permasalahan dan studi kasus yang sama dengan penelitian pertama akan tetapi menggunakan algoritme yang berbeda. Penelitian ini dilakukan oleh (Hazaki, 2011). Permasalahan yang diangkat dalam penelitian ini adalah bagaimana menggunakan metode Algoritme Genetika dalam memprediksi jumlah mahasiswa pengambil mata kuliah. Algoritme genetika digunakan untuk mengolah inputan, kemudian dicari kombinasi-kombinasi dari gen-gen yang ada selanjutnya dicari yang terbaik dari gen-gen tersebut. Langkah awal yang menentukan hasil penelitian yaitu pada pencarian nilai fitness dalam data yang dipilih. Dimana dalam penelitian ini diketahui bahwa penyesuaian nilai fitness dengan regresi data kemudian dicari rata-rata nilai fitness-nya memiliki kakuratan yang lebih tinggi daripada tanpa adanya regresi data terlebih dahulu. Adapun atribut yang digunakan adalah nilai 6.
(22) sebelumnya, selisih tahun prediksi dengan tahun terkahir pengambilan mata kuliah, umur, penghasilan orang tua dan IPS. Penelitian ini juga melakukan uji coba model sebanyak 2 kali, dimana model kedua memiliki nilai selisih yang lebih kecil dengan nilai 37% daripada model pertama yang memiliki nilai sebesar 70,6%. Penelitan ketiga adalah penelitian yang berkaitan dengan penerapan algoritme Naive Bayes untuk evaluasi kinerja mahasiswa yang dilakukan oleh (Mujib Ridwan). Pada penelitian ini evaluasi dilakukan hanya pada tahun pertama dan atau tahun kedua saja, data mahasiswa yang telah lulus dijadikan sebagai data latih sedangkan data mahasiswa tahun kedua yang diasumsikan belum lulus dijadikan sebagai data target. Dalam tahap pengujian, dilakukan sebanyak 5 kali percobaan yang menghasilkan nilai presisi, recall dan akurasi yang bervariasi. Hasilnya, pengujian pada data mahasiswa angkatan 2005-2009 yang menghasilkan nilai presisi, recall, dan akurasi yang paling tinggi yakni sebesar 83%, 50% dan 70%. Dari hasil penelitian ini juga dapat diambil kesimpulan bahwa penentuan data training sangat mempengaruhi hasil pengujian yang juga berdampak pada hasil prediksi. Perbedaan penelitian yang akan dilakukan dengan penelitian ketiga ini adalah dari implementasi algoritme Naive Bayes. Dalam penelitian ketiga ini, Naive Bayes digunakan untuk mengevaluasi kinerja akademik mahasiswa sedangkan penelitian yang akan dilakukan mengambil kasus/implementasi yang berbeda yaitu pada prediksi jumlah mahasiswa yang mengambil suatu mata kuliah. Sama seperti beberapa penelitian tersebut, dalam penelitian kali ini juga akan menggunakan pendekatan data mining untuk penggalian informasi dalam database akademik dan melakukan prediksi terhadap mahasiswa yang akan mengambil suatu mata kuliah. Akan tetapi, yang membedakan penelitian ini dengan penelitian terdahulu yakni metode data mining yang digunakan untuk menyelesaikan permasalahan. Dimana pada penelitian kali ini akan menggunakan algoritme Naive Bayes untuk melakukan prediksi mahasiswa pengambil mata kuliah berdasarkan data mahasiswa dan data mata kuliah dengan atribut yaitu Nilai, IP, IP Kumulatif, SKS, SKS Kumulatif, dan Semester.. 2.2 Profil Fakultas Ilmu Komputer Fakultas Ilmu Komputer Universitas Brawijaya merupakan salah satu fakultas yang terdapat di Univesitas Brawijaya. Fakultas Ilmu Komputer berdiri pada tahun 2011 dengan nama PTIIK (Program Teknologi Informasi dan Ilmu Komputer) dan kemudian diresmikan dengan nama Fakultas Ilmu Komputer (FILKOM) pada tahun 2015. Fakultas Ilmu Komputer mengelola 2 jurusan yaitu Teknik Informatika dan Sistem Infromasi, dan terdapat 3 program studi pada setiap jurusan. Pada jurusan Teknik Informatika terdapat program studi S1 Teknik Informatika, program studi S1 Teknik Komputer dan program studi S2 Magister Ilmu Komputer. Sedangkan pada jurusan Sistem Informasi terdapat program studi S1 Sistem Informasi, program studi S1 Pendidikan Teknologi Informasi dan program studi S1 Teknologi Informasi. 7.
(23) Dalam proses penjadwalan mata kuliah pada Fakultas Ilmu Komputer terdapat KJFD (Kelompok Jabatan Fungsional Dosen) yang berada dibawah jurusan. KJFD memiliki wewenang untuk menentukan anggota team teaching suatu mata kuliah. Sementara itu Kaprodi (Kepala Program Studi) memberikan usul mengenai mata kuliah yang ditawarkan dan berapa jumlah kelasnya permata kuliah berdasarkan data dari KJFD. Untuk jurusan Teknik Informatika maka berdasarkan keminatan, sementara jurusan Informasi berdasarkan kelompok mata kuliah. Dari data-data tersebut kemudian Sekjur (Sekretaris Jurusan) akan mengalokasikan dosen beserta mata kuliahnya.. 2.3 Landasan Teori 2.3.1 Data Mining Data Mining adalah proses menemukan pola yang menarik dan pengetahuan dari sejumlah besar data. Sumber data dapat mencakup database, gudang data (data warehouse), web, repositori informasi lainnya, atau data yang dialirkan ke dalam sistem dinamis. (Han, 2012). Banyak orang mengartikan data mining sebagai sinonim untuk sebuah istilah populer, yaitu Knowledge Discovery from Data (KDD), sementara yang lainnya melihat data mining sebagai langkah penting untuk mendapatkan pengetahuan. Sebagai sebuah rangkaian proses, proses pencarian pengetahuan secara iteratif pada data mining dapat dibagi dalam beberapa tahap, sebagaimana diilustrasikan pada Gambar 2.1. Tahap-tahap tersebut bersifat interaktif, pengguna terlibat langsung atau dengan perantaraan knowledge base. Adapun tahap-tahap data mining adalah sebagai berikut : 1. Pembersihan data (data cleaning) Pembersihan data merupakan proses menghilangkan noise dari data dan data yang tidak konsisten atau data tidak relevan. 2. Integrasi data (data integration) Integrasi data merupakan proses penggabungan data dari berbagai database ke dalam sebuah database baru. 3. Seleksi data (data selection) Seleksi data dibutuhkan karena data yang terdapat pada database seringkali tidak semuanya dapat dipakai, oleh karena itu hanya data yang sesuai untuk dianalisis yang akan diambil dari database. 4. Transformasi data (data transformation) Proses dimana data diubah atau digabung ke dalam format yang sesuai sebelum diproses dalam data mining.. 8.
(24) 5. Proses mining Proses mining merupakan proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari data yang ada. 6. Evaluasi pola (pattern evaluation) Evaluasi pola digunakan untuk mengidentifikasi pola-pola menarik ke dalam knowledge based yang ditemukan. 7. Presentasi pengatahuan (knowledge presentation) Presentasi pengetahuan merupakan visualisasi dan penyajian pengetahuan mengenai metode yang digunakan untuk memperoleh pengetahuan dari pengguna.. Gambar 2.1 Tahap-tahap data mining (Sumber : Han. 2012) Ada beberapa teknik yang dimiliki data mining berdasarkan tugas yang bisa dilakukan, yaitu : 1. Deskripsi Biasanya akan mencoba untuk menemukan cara dalam mendeskripsikan pola dan trend yang tersembunyi dalam data. 9.
(25) 2. Estimasi Estimasi mirip dengan klasifikasi, kecuali variabel tujuan pada estimasi yang lebih kearah numerik daripada kategori. 3. Prediksi Prediksi memiliki kemiripan dengan estimasi dan klasifikasi. Hanya saja, prediksi hasilnya menunjukkan sesuatu yang belum terjadi (mungkin terjadi di masa depan). 4. Klasifikasi Dalam klasifikasi variabel, tujuan bersifat kategorik. Misalnya, kita akan mengklasifikasikan pendapatan dalam tiga kelas, yaitu pendapatan tinggi, pendapatan sedang, dan pendapatan rendah. 5. Clustering Clustering merupakan suatu metode pengelompokan data yang dimulai dengan mengelompokkan dua atau lebih objek yang memiliki kesamaan diantaranya, biasanya diukur dengan ukuran kedekatan antara satu objek dengan objek lainnya. 6. Asosiasi Dalam asosiasi perlu dibuat dependency rules (aturan ketergantungan) yang akan memprediksikan kemunculan suatu item berdasarkan kemunculan item yang lain.. 2.3.2 Naive Bayes Classifier (NBC) Naive Bayes Classifier (NBC) termasuk kedalam Classifier Statistic yaitu menyelesaikan prediksi probabilitas dan memprediksi peluang keanggotaan suatu kelas. Naive Bayes memiliki performa tinggi dalam akurasi dan kecepatan, dan merupakan generative learning algorithm, yaitu algoritme yang menghitung probabilitas pada suatu kelas sampai menemukan sebuah cluster. Naive Bayes menggunakan rumus yang didasarkan pada teorema Bayes. Teorema keputusan bayes merupakan pendekatan statistik yang fundamental dalam pengenalan pola (pattern recognition). Naive Bayes didasarkan pada asumsi penyederhanaan bahwa nilai atribut secara kondisional saling bebas jika diberikan nilai output. (Ridwan, 2011). Naive Bayes Classifier (NBC) dapat digunakan untuk memproses data baik data diskrit atau data kontinu. Naive Bayes merupakan asumsi independen bersyarat, termasuk dalam melakukan perhitungan peluang dalam setiap kombinasi X, dan hanya perlu mengestimasikan peluang bersyarat untuk setiap X yang diberikan Y. Untuk mengklasifikasi data uji, Naive Bayes Classifier (NBC) menggunakan nilai posterior untuk setiap kelas Y : 𝑃(𝑌|𝑋) =. 𝑃(𝑌) ∏𝑑𝑖=1 𝑃(𝑋𝑖 | 𝑌). (2.1). 𝑃(𝑋). 10.
(26) Dimana : - P (Y|X) adalah probabilitas data dengan vektor X pada kelas Y. - P (Y) adalah nilai probabilitas awal kelas Y. - P (Xi | Y) adalah probabilitas independen kelas Y dari semua fitur dalam vektor X. Naive Bayes mudah digunakan untuk menghitung fitur dengan data kategoris seperti pada kasus fitur “jenis kelamin” dengan nilai {pria, wanita} namun untuk fitur numerik terdapat pendekatan yang dilakukan sebelum dimasukkan kedalam Naive Bayes. (Wasiati, 2014). Caranya adalah sebagai berikut : 1. Melakukan diskretisasi pada setiap fitur untuk data kontinu dan mengganti nilai pada fitur tersebut dengan nilai interval diskrit. Pendekatan ini dilakukan dengan melakukan transformasi fitur untuk data kontinu ke dalam bentuk fitur dengan nilai ordinal. 2. Melakukan asumsi dengan bentuk tertentu dari distribusi probabilitas untuk fitur kontinu dan memperkirakan parameter distribusi dengan menggunakan data latih. 1. Perhitungan Probabilitas Pada Data Kontinu Distribusi Gaussian sering digunakan untuk merepresentasikan peluang bersyarat untuk atribut dengan data kontinu. Pada Gaussian, distribusi dikarakterisasi dengan menggunakan nilai rerata/mean (µ) dan varian (𝜎2 ) atau standar deviasi (𝜎). Persamaan yang digunakan untuk menghitung nilai rerata/mean (µ) : 𝜇=. ∑𝑛 𝑖=0 𝑛𝑖. (2.2). 𝑛. (Sumber : Saleh, 2015) Keterangan : . 𝜇 = rata-rata. . 𝑛 = jumlah datapada kelas dan fitur tertentu. . 𝑛𝑖 = nilai data pada data ke-i. Persamaan yang digunakan untuk menghitung varian (σ2) atau standar deviasi (σ) adalah sebagai berikut : 2 ∑𝑛 𝑖=0(𝑛𝑖 −𝜇). 𝜎= √. (2.3). 𝑛−1. (Sumber : Saleh, 2015) Keterangan : . n = jumlah data pada kelas dan fitur tertentu.. . 𝜇 = rata-rata pada kelas dan fitur tertentu.. . 𝑛𝑖 = nilai data pada data ke-i.. 11.
(27) Untuk setiap kelas yi , peluang kelas bersyarat untuk atribut Xi dihitung dengan persamaan berikut : P(Xi = xi | Yi = yi) =. 1. 𝑒𝑥𝑝. (𝑥𝑖 − µ𝑖𝑗 )2 2 𝜎2 𝑖𝑗. √2 𝜋 𝜎𝑖𝑗 (Sumber : Saleh, 2015). (2.4). Dimana : - Parameter µ𝑖𝑗 diestimasi berdasarkan sampel mean xi pada seluruh data uji yang memiliki kelas yj. - Parameter 𝜎𝑖𝑗2 dapat diestimasi menggunakan sampel varian (s2) pada seluruh data uji dengan kelas yj. 2. Perhitungan Probabilitas Pada Data Diskrit Sedangkan untuk melakukan perhitungan Naive Bayes dengan data diskrit, maka nilai posterior dihitung menggunakan persamaan teorema bayes sebagaimana ditunjukkan dalam persamaan 2.3 untuk mendapatkan nilai posteriornya, sebagai berikut : 𝑃 (𝑋|𝐻) 𝑃(𝐻) P (H|X) = (2.5) 𝑃(𝑋) (Sumber : Saleh, 2015) Dimana : - X merupakan data dengan kelas yang belum diketahui - C merupakan hipotesis data yang merupakan suatu kelas spesifik - P (C|X) merupakan probabilitas hipotesis dengan syarat X (posterior probability) - P (C) merupakan probabilitas hipotesis (prior probability) - P (X|C) merupakan probabilitas berdasarkan kondisi pada hipotesis. 2.3.3 Laplacian Correction / Laplace Estimator Untuk menyiasati supaya probabilitas pada perhitungan dengan Naive Bayes Classifier (NBC) tidak menghasilkan nilai 0 dikarenakan tidak adanya data untuk suatu kategori tertentu dalam suatu kelas, maka dapat digunakan teknik estimasi yang disebut dengan Laplacian Correction atau Laplace Estimator. (Han, 2012). Dalam teknik ini dilakukan penambahan nilai 1 pada data untuk setiap kategori ketika terdapat kategori dengan nilai probabilitas 0 (nol) sehingga untuk sebanyak k kategori dimana j = 1,2,...k dan N = ∑𝑘𝑗=1 𝑛𝑗 jika masing-masing kategori dalam kelasnya bernilai ni , sehingga dapat ditunjukkan dalam persamaan 2.6 berikut : 𝑛𝑖 +1 𝑃 (𝑋 = 𝑖) = 𝑁+𝑏𝑎𝑛𝑦𝑎𝑘 (2.6) 𝑘𝑎𝑡𝑒𝑔𝑜𝑟𝑖 Dimana : - ni menunjukkan jumlah data pada ketegori ke-i - N menunjukkan jumlah data pada kelas tertentu pada suatu kategori. 12.
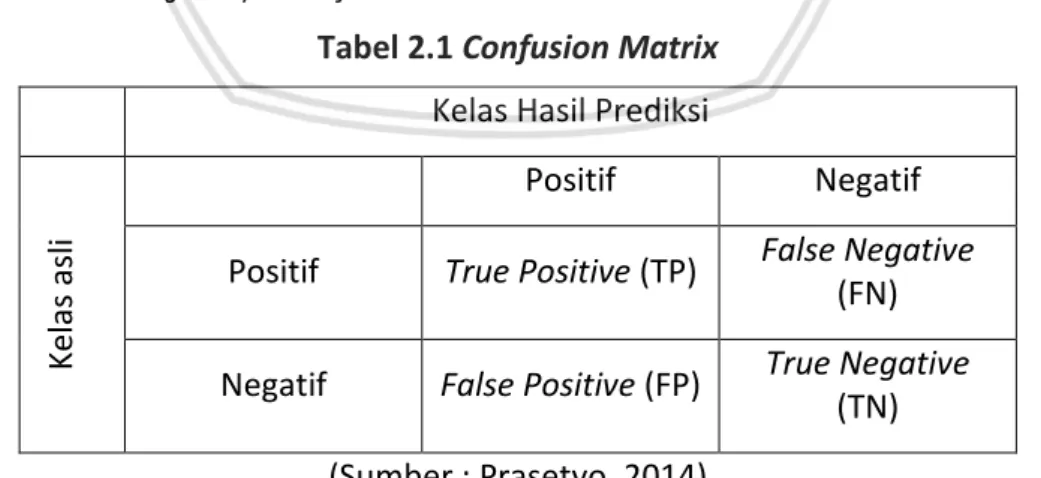
(28) Sebagai contoh, diasumsikan terdapat kelas buy = yes pada suatu data uji dan memiliki 1000 sampel. Terdapat sebanyak 0 (nol) sampel dengan income = low, 990 sampel dengan income = medium, dan 10 sampel dengan income = high. Sehingga apabila dihitung probabilitasnya tanpa Laplacian Correction, maka nilainya berturut-turut adalah 0, 0.990 (dari 990/1000), 0.0010 (dari 10/1000). Dengan menggunakan Laplacian Correction dari ketiga sampel tersebut, diasumsikan terdapat 1 sampel lagi untuk masing-masing nilai income. Dengan cara ini, didapatkanlah probabilitas sebagai berikut (dibulatkan menjadi 3 angka dibelakang koma) : 1 991 1 = 0.001, = 0.988 dan = 0.011 1003 1003 1003 Probabilitas yang “dibenarkan” nilainya tidak berbeda jauh dengan hasil probabilitas sebelumnya sehingga nilai probabilitas 0 (nol) dapat dihindari.. 2.3.4 Pengukuran Kinerja Klasifikasi Confusion Matrix Sebuah sistem klasifikasi diharapkan agar dapat melakukan klasifikasi pada seluruh dataset dengan benar. Akan tetapi tidak semua proses klasfikasi menghasilkan nilai klasifikasi benar 100%. Sehingga, diperlukan suatu teknik pengukuran kinerja untuk mengetahui seberapa besar kinerja dari sistem klasifikasi yang dibangun. Pada umumnya, teknik yang digunakan untuk mengukur kinerja klasifikasi adalah dengan menggunakan matrik konfusi (confusion matrix). Confusion Matrix menampilkan jumlah prediksi tepat dan tidak tepat yang dibuat oleh model dibandingkan dengan hasil klasifikasi sebenarnya pada data uji. (Oprea, 2014). Confusion Matrix untuk sebuah classifier dengan 2 kelas yaitu benar (true) dan salah (false) ditunjukkan oleh Tabel 2.1 berikut : Tabel 2.1 Confusion Matrix. Kelas asli. Kelas Hasil Prediksi Positif. Negatif. Positif. True Positive (TP). False Negative (FN). Negatif. False Positive (FP). True Negative (TN). (Sumber : Prasetyo, 2014) True Positive (TP) menunjukkan nilai sampel positif yang diklasifikasikan dengan tepat, sementara True Negative (TN) menunjukkan nilai sampel negatif yang diklasifikasikan dengan tepat. False Positive (FP) adalah nilai sampel negatif yang diklasifikasikan dengan tidak tepat (misalkan nilai sampel dari kelas 13.
(29) buys_computer = no dan classifier memprediksi buys_computer = yes). Sebaliknya, False Negative (FN) adalah nilai sampel positif yang diklasfikasikan dengan tidak tepat (misalkan nilai sampel dari kelas buys_computer = yes dan classifier memprediksi buys_computer = no). -. True Positive Rate (TP Rate) adalah kelas dengan nilai positif yang diprediksi sebagai positif dan setara dengan nilai Recall. False Positive Rate (FP Rate) adalah kelas dengan nilai negatif yang diklasifikasikan sebagai positif. True Negative Rate (FN Rate) adalah kelas dengan nilai negatif yang diklasifikasikan dengan tepat sebagai negatif. False Negative Rate (TN Rate) adalah kelas dengan nilai positif yang diklasifikasikan dengan tidak tepat sebagai negatif.. Terdapat beberapa pengukuran yang dapat dilakukan berdasarkan nilai dari Confusion Matrix, diantaranya adalah : 1. Accuracy (Akurasi) Akurasi merupakan proporsi dari jumlah nilai yang diklasifikasikan dengan tepat dan dihitung sebagai rasio antara jumlah kasus yang diklasifikasikan dengan tepat dengan jumlah kasus keseluruhan. Nilai akurasi adalah persentase tuple set uji yang benar diklasifikasikan oleh classifier. Dalam pengenalan pola, disebut juga sebagai tingkat pengenalan keseluruhan dari classifier, yaitu mencerminkan seberapa baik classifier mengenali tuple dari berbagai kelas. (Han, 2012). Akurasi dapat dihitung dengan menggunakan persamaan 2.7 berikut : Accuracy =. 𝑇𝑁+𝑇𝑃. (2.7). 𝑇𝑁+𝐹𝑁+𝐹𝑃+𝑇𝑃. (Sumber : Xhemali, 2009) Kuantitas dari suatu Confusion Matrix yaitu berupa nilai akurasi. Dengan mengetahui berapa banyak jumlah data yang telah diklasifikasikan dengan tepat, maka dapat diketahui akurasi hasil klasifikasi yang telah dilakukan. 2. Precision Precision merupakan tingkat ketepatan antara informasi yang diminta oleh pengguna terhadap hasil jawaban yang diberikan oleh sistem. Dalam bidang pencarian informasi, precision (disebut juga positive prediction value) merupakan metrik untuk mengukur kinerja sistem dalam mendapatkan data yang relevan. (Prasetyo, 2014). Nilai precision dapat dihitung menggunakan persamaan 2.8. 𝑇𝑃. Precision = 𝑇𝑃+𝐹𝑃. (2.8) Sumber : Prasetyo, 2014. 3. Recall 14.
(30) Recall merupakan tingkat keberhasilan sistem dalam menemukan kembali informasi yang relevan. Recall (disebut juga sensitivitas) merupakan metrik untuk mengukur kinerja sistem dalam mendapatkan data relevan yang terbaca (dalam bidang pencarian infomasi). (Prasetyo, 2014). Nilai recall dapat dihitung menggunakan persamaan 2.9 berikut : 𝑇𝑃. Recall = 𝑇𝑃+𝐹𝑁. (2.9) (Sumber : Prasetyo, 2014). 4. F-measure F-measure adalah sebuah ukuran yang mengkombinasikan tingkat presisi (precision) dan sensitifitas (recall) sebagai rerata harmoni dari 2 buah parameter. F-measure menunjukkan ukuran timbal balik antara recall dan precision, dimana rentang nilai F-measure adalah dari 0 sampai 1. Nilai Fmeasure yang bagus adalah mendekati atau sama dengan 1 sementara yang jelek adalah mendekati atau sama dengan 0. F-measure dapat dihitung dengan persamaan 2.10 berikut : F=2𝑥. 𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 𝑥 𝑟𝑒𝑐𝑎𝑙𝑙. (2.10). 𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑖𝑛+ 𝑟𝑒𝑐𝑎𝑙𝑙. (Sumber : Prasetyo, 2014). 2.3.5 Basis Data (Database) Basis Data adalah suatu susunan atau kumpulan data operasional lengkap dari suatu organisasi atau perusahaan yang diorganisir atau dikelola dan disimpan secara terintegrasi dengan menggunakan metode tertentu menggunakan komputer sehingga mampu menyediakan informasi optimal yang diperlukan pemakainya. (Marlinda, 2004). Database adalah kumpulan data yang saling berkaitan, berhubungan yang disimpan sedemikian rupa tanpa pengulangan yang tidak perlu, untuk memnuhi kebutuhan. Data-data yang disimpan tersebut harus mengandung semua informasi untuk mendukung kebutuhan sistem. Proses atau fungsi dasar yang dimiliki oleh database ada empat, yaitu : 1. 2. 3. 4.. Membuat data baru (create) Menambah data (insert) Mengubah data (update) Menghapus data (delete). Elmasri (2011) mengatakan bahwa sebuah basis data memiliki sifat implisit sebagai berikut.. 15.
(31) . Basis data mewakili beberapa aspek dunia nyata, yang terkadang disebut sebagai miniworld or the universe of discourse (UoD). Perubahan ke dunia yang kecil tercermin dalam database. Basis data adalah kumpulan data logis yang koheren dengan beberapa makna yang melekat. Sebuah data acak yang random tidak bisa disebut sebagai basis data. Basis data dirancang, dibangung dan diisi dengan data untuk tujuan tertentu. Didalamnya terdapat kelompok dengan maksud yang berbeda dan beberapa aplikasi yang telah terbentuk dimana pengguna tersebut memiliki ketertarikan terhadapnya.. Basis data merupakan salah satu komponen yang penting dalam pembentukan suatu sistem informasi, karena menjadi dasar dalam menyediakan informasi kepada para pengguna sistem informasi tersebut. Basis data (database) menjadi penting disebabkan karena munculnya beberapa masalah apabila tidak menggunakan data yang terpusat, misalnya akan terjadi duplikasi data, hubungan antar data yang tidak jelas, melakukan pengelolaan dan update data menjadi rumit. Jadi tujuan dari pengelolaan data menggunaan basis data adalah : 1. Menyediakan penyimpanan data untuk dapat digunakan organisasi pada saat ini dan seterusnya. 2. Cara memasukkan atau menambahkan data sehingga memudahkan tugas operator dan berkaitan dengan waktu yang diperlukan oleh pengguna untuk mendapatkan data serta hak-hak yang dimilikinya terhadap data tersebut. 3. Pengendalian data untuk setiap siklus agar data selalu up-to-date dan dapat mencerminkan perubahan spesifik yang terjadi pada setiap sistem. 4. Pengamanan data terhadap kemungkinan penambahan, modifikasi, pencurian dan gangguan-gangguan lain. Dalam basis data sistem informasi digambarkan sebagai model entity relationship (ER). Bahasa yang digunakan dalam basis data yaitu : . DDL (Data Definition Language) DDL merupakan bahasa pendefinisian data yang digunakan untuk membuat dan mengelola objek database seperti database, tabel dan view. DML (Data Manipulation Language) Merupakan bahasa manipulasi data yang digunakan untuk memanipulasi data pada objek database seperti tabel. DCL (Data Control Language) Merupakan bahasa yang digunakan untuk mengendalikan pengaksesan data.. Pentusunan basis data meliputi proses memasukkan data kedalam media penyimpanan data dan diatur dengan menggunakan perangkat Sistem Manajemen Basis Data (Database Management System / DBMS).. 16.
(32) 2.3.6 System Usability Scale (SUS) System Usability Scale (SUS) pertama kali dikembangkan oleh John Brooke pada tahun 1986 (Brooke. J, 2013) tujuannya adalah memberikan skor referensi tunggal untuk partisipan dalam melihat usability suatu produk. System Usability Scale merupakan suatu skala sederhana terdiri 10 item kuesioner yang memberikan pandangan menyeluruh terkait penilaian yang subyektif dari usability sebuah sistem. SUS menggunakan skala likert, yang terdiri dari 5 poin skala mulai dari sangat setuju sampai sangat tidak setuju. Instrumen Pengujian SUS Tabel 2.2 Instrumen Pengujian System Usability Scale No 1. Pernyataan I think that I would like to use this system.. Skala 1 s/d 5. (Saya berpikir akan menggunakan sistem ini lagi.) 2. I found the system unnecessarily complex.. 1 s/d 5. (Saya merasa sistem ini rumit untuk digunakan.) 3. I thought the system was easy to use.. 1 s/d 5. (Saya merasa sistem ini mudah untuk digunakan.) 4. I think that I would need the support of a technical person to be 1 s/d 5 able to use this system. (Saya membutuhkan bantuan dari orang lain atau teknisi dalam menggunakan sistem ini.). 5. I found the various functions in the system were well integrated. 1 s/d 5 (Saya merasa fitur-fitur sistem ini berjalan dengan semestinya.). 6. I thought there was too much inconsistency in this system.. 1 s/d 5. (Saya merasa ada banyak hal yang tidak konsisten (tidak serasi) pada sistem ini.) 7. I would imagine that most people would learn to use this 1 s/d 5 system very quickly. (Saya merasa orang lain akan memahami cara menggunakan sistem ini dengan cepat.). 8. I found the system very cumbersome to use.. 1 s/d 5. (Saya merasa sistem ini membingungkan.) 9. I felt very confident using the system. (Saya merasa tidak ada hambatan dalam menggunakan sistem ini.) 17. 1 s/d 5.
(33) Tabel 2.2 Instrumen Pengujian System Usability Scale (lanjutan) 10 I needed to learn a lot of things before I could get going with this 1 s/d 5 system. (Saya perlu membiasakan diri terlebih dahulu sebelum menggunakan sistem ini.) (Sumber : Sharfina, 2016) Perhitungan Hasil System Usability Scale Nilai SUS dapat dihitung dari hasil kuesioner yang didapat. Untuk melakuka perhitungan nilai SUS dilakukan dengan cara memberikan bobot untuk setiap item dengan skor 0 sampai 4. Aturan perhitungan bobot adalah sebagai berikut : 1. Untuk item no 1,3,5,7, dan 9 nilai yang didapat adalah posisi skala dikurangi 1. 2. Untuk item no 2,4,6,8, dan 10 nilai yang didapat adalah 5 dikurangi posisi skala. Skor SUS memiliki rentang nilai 0-100, akan tetapi angka tersebut bukan persentase. Sebuah produk dipertimbangkan memiliki usability yang baik apabila memiliki skor SUS sama dengan atau diatas 68. (Sauro, 2011). Nilai SUS dapat dihitung menggunakan rata-rata dari total responden yang diperoleh, menggunakan persamaan 2.11 sebagai berikut : 𝑥. 𝑁𝑖𝑙𝑎𝑖 𝑟𝑎𝑡𝑎 − 𝑟𝑎𝑡𝑎 = ∑𝑛𝑖=1 𝑁𝑖. (2.11). (Sumber : Pudjoatmodjo, 2016) Dimana : -. x : nilai score responden. -. N : jumlah responden. Berdasarkan hasil rata-rata, skor SUS dapat dikelompokkan menjadi 3 kategori yang berbeda yaitu : 1. Not Acceptable. : 0-50.. 2. Marginal. : 50-70.. 3. Acceptable. : 70-100.. 18.
(34) BAB 3 METODOLOGI Pada bab ini akan dibahas metode-metode yang akan digunakan dalam penelitian ini, yang dimulai dari proses identifikasi masalah sampai pada kesimpulan hasil penelitian. Alur metodologi penelitian ini secara umum dapat dilihat pada Gambar 3.1.. Mulai. Identifikasi Masalah. Studi Literatur. Pengumpulan Data. Analisis dan Perancangan Sistem. Implementasi Teknik Data Mining. Implementasi Dashboard. Pengujian dan Hasil Analisis. Kesimpulan dan Saran Gambar 3.1 Alur metodologi penelitian. 19.
(35) 3.1 Identifikasi Masalah Identifikasi masalah merupakan proses menggali permasalahan dalam organisasi hingga mendapatkan masalah yang dapat diselesaikan melalui teknik Data Mining. Identifikasi masalah juga berguna untuk memahami tujuan dan kebutuhan bisnis organisasi. Proses identifikasi masalah dilakukan dengan melakukan observasi dan wawancara pada bagian akademik dan sekretaris jurusan Teknik Informatika dan Sistem Informasi Fakultas Ilmu Komputer Universitas Brawijaya.. 3.2 Studi Literatur Studi literatur diperlukan sebagai dasar teori yang digunakan untuk membantu penulisan penelitian skripsi dan berkaitan dengan metode yang digunakan dalam penelitian tentang prediksi dengan algoritme Naive Bayes. Sumber yang biasa digunakan untuk mendapatkan keterangan serta penjelasan mengenai teori-teori yang relevan dengan penelitian yang dilakukan antara lain mengenai Data Mining, Naive Bayes, database, pengukuran hasil klasifikasi, dan pengujian Usability. Dari pengumpulan literatur, didapatkan beberapa literatur yang mendukung penelitian ini, antara lain : 1. Paper penelitian yang berasal dari jurnal-jurnal yang berkaitan dengan penelitian yang akan dilakukan. Paper yang dijadikan sebagai referensi adalah yang berkaitan tentang proses data mining menggunakan algoritme Naive Bayes dan proses mining dengan studi kasus yang hampir serupa dengan peneltian yang akan dilakukan. 2. E-book yang membahas tentang basis data dan data mining. 3. Skripsi dan tesis yang berkaitan dengan metode yang digunakan dan studi kasus yang serupa.. 3.3 Pengumpulan Data Pada skripsi ini data primer yang didapatkan berasal dari bagian akademik Fakultas Ilmu Komputer Universitas Brawijaya. Dalam tahap ini selain pengumpulan data juga akan dilakukan proses pemahaman data untuk mendapatkan pemahaman yang mendalam tentang data. Data yang diambil berupa data mengenai aktifitas akademik mahasiswa yaitu data Kartu Hasil Studi (KHS) dan nilai mahasiswa dari semester ganjil tahun 2014 sampai semester genap tahun 2016 sebanyak 162.734 records. Setelah data terkumpul maka akan dilakukan proses pre-processing data dengan melakukan integrasi data sehingga menjadi dataset berdasarkan prasyarat mata kuliah yang akan diprediksi. Proses pre-processing akan dilakukan melalui stored procedure pada database. Pre-processing juga digunakan untuk mengambil atribut-atribut data yang diperlukan untuk proses mining. Adapun atribut yang digunakan adalah Nilai, IP, IP Kumulatif, SKS, SKS Kumulatif, dan Semester 20.
(36) mahasiswa. Dataset yang terbentuk kemudian akan dibagi menjadi 2, yaitu dataset untuk training adalah data semester ganjil tahun 2014 sampai semester genap tahun 2015 dan dataset untuk testing adalah data semester ganjil tahun 2016.. 3.4 Perancangan Sistem Dalam membangun sebuah sistem maka diperlukan tahap analisis dan perancangan sistem yang akan dibangun. Tahap analisis dilakukan dengan mengidentifikasi aktor beserta kebutuhannya. Selain itu juga dilakukan proses identifikasi kebutuhan data terkait dengan atribut-atribut yang akan digunakan dalam proses Data Mining. Rancangan sistem yang dibangun adalah berasal dari proses identifikasi masalah dan studi literatur untuk menyesuaikan sistem yang akan dibangun dengan kebutuhan pengguna/proses Data Mining. Rancangan sistem termasuk didalamnya adalah membuat arsitektur sistem, memodelkan sistem, merancang basis data, merancang proses pre-processing data, merancang algoritme yang akan digunakan dalam sistem, melakukan perhitungan manual dan merancang antarmuka sistem.. 3.5 Implementasi Teknik Data Mining Pada tahap ini proses pengolahan data dengan teknik Data Mining dilakukan untuk melakukan prediksi jumlah mahasiswa yang mengambil mata kuliah tertentu. Implementasi dilakukan berdasarkan rancangan dari tahapan sebelumnya. Tujuan dari tahap ini adalah untuk menerapkan hasil rancangan yang telah dilakukan pada tahap sebelumnya sehingga dihasilkan sistem yang mampu melakukan klasifikasi menggunakan algoritme Naive Bayes. Adapun proses implementasi yang dilakukan adalah Pre Processing Data, dan implementasi algoritme Naive Bayes Classifier (NBC). Pre-processing Data dilakukan melalui stored procedure database. Pre-processing data dilakukan untuk mengintegrasikan data khs dan ipk mahasiswa sehingga menjadi sebuah dataset yang memiliki atribut-atribut yang dibutuhkan dalam proses Data Mining dalam proses training dan testing yaitu Nilai, IP, IP Kumulatif, SKS, SKS Kumultif dan Semester. Selain itu akan dilakukan proses transformasi data untuk mengubah nilai dari atribut Nilai dan Semester menjadi kategori berupa numerik. Sedangkan implementasi dari algoritme Naive Bayes dilakukan menggunakan web service Java yang menyediakan fungsi-fungsi dalam melakukan klasifikasi menggunakan algoritme Naive Bayes Classifier (NBC) yaitu proses training dan testing. Proses training akan menghasilkan nilai model probabilitas berdasarkan dataset training yang langsung dinputkan ke dalam database. Sementara proses testing akan mengembalikan nilai hasil klasifikasi yaitu nilai 0 jika diklasifikasikan tidak mengambil dan 1 jika diklasifikasikan mengambil. 21.
(37) 3.6 Implementasi Dashboard Pada tahap ini akan mengimplementasikan sebuah dashboard berbasis web untuk memberikan informasi mengenai hasil prediksi mata kuliah berdasarkan hasil rancangan sebelumnya. Implementasi dashboard dilakukan menggunakan PHP Codeigniter. Tujuannya pembuatan dashboard adalah sebagai antarmuka dari sistem sehingga pengguna dapat berinterkasi dengan sistem yang telah dibangun. Dashboard yang dibuat menampilkan hasil prediksi mata kuliah untuk setiap tahun dan semester mata kuliah termasuk didalamnya dataset yang digunakan untuk training dan testing, hasil dari proses training yaitu tabel probabilitas dan testing yaitu hasil prediksi mata kuliah yang terdapat pada semester dan tahun prediksi. Selain itu akan ditampilkan juga hasil pengujian implementasi Naive Bayes untuk mengetahui unjuk kerja dari algoritme tersebut dalam melakukan klasifikasi data untuk setiap mata kuliah.. 3.7 Pengujian dan Hasil Analisis Pengujian diperlukan untuk mengetahui unjuk kerja algoritme Naive Bayes dalam mengklasifikasikan data pada kelas tertentu sebagai hasil prediksi. Oleh karena itu sebelum benar-benar digunakan untuk melakukan prediksi maka diperlukan pengujian dengan data latih (training set) untuk membentuk tabel probabilitas dimana akan digunakan data dari tahun 2014 semester ganjil sampai 2015 semester genap. Tabel probabilitas yang terbentuk akan menjadi acuan dalam proses testing menggunakan data uji. Selain itu juga akan dilakukan analisis usability terhadap dashboard menggunakan System Usability Scale (SUS). Analisis akan dilakukan terhadap hasil klasifikasi yang dihasilkan menggunakan Confusion Matrix untuk mengetahui nilai accuracy, precision, recall dan F-measurenya. Nilai akurasi digunakan untuk mengetahui persentase data yang dengan tepat diklasifikasikan oleh sistem. Nilai precision digunakan untuk mengetahui ketepatan antara kelas dari data uji dengan hasil klasifikasi yang dilakukan oleh sistem. Nilai recall digunakan untuk mengetahui sensitifitas hasil klasifikasi atau kinerja sistem dalam mendapatkan data relevan yang dilakukan oleh sistem. Sedangkan nilai F-measure digunakan untuk mengetahui kinerja sistem dengan mengkombinasikan tingkat presisi dan sensitifitas.. 3.8 Kesimpulan dan Saran Tahap terakhir dari penelitian skripsi ini adalah pengambilan kesimpulan dan saran. Kesimpulan diambil setelah semua tahap-tahap mulai dari perancangan sistem dan database, implementasi Data Mining dengan Naive Bayes, dan sampai pada pengujian sistem dan dashboard telah selesai dilakukan. Saran berguna untuk memperbaiki kesalahan dan diharapkan dapat menyempurnakan penulisan serta untuk memberikan pertimbangan untuk penelitian selanjutnya. 22.
(38) BAB 4 ANALISIS DAN PERANCANGAN. 4.1 Analisis Kebutuhan Sub bab ini membahas mengenai analisis kebutuhan pengguna terhadap sistem. Tahapan ini digunakan untuk memodelkan informasi yang akan digunakan dalam tahap perancangan sistem. Dalam sub bab ini juga dijelaskan mengenai deskripsi sistem, kebutuhan data, aktor yang berinteraksi dengan sistem, daftar kebutuhan dan diagram use case yang digunakan untuk memodelkan sistem.. 4.1.1 Deskripsi Umum Sistem Dalam penelitian ini, secara umum sistem yang dibangun dapat menampilkan hasil prediksi dengan Naive Bayes Classifier (NBC) dan menampilkan grafik perbandingan hasil prediksi dengan hasil sebenarnya. Selain itu sistem juga dapat menampilkan seberapa akurat prediksi yang dihasilkan berdasarkan pengujian. Proses data mining untuk prediksi dengan Naive Bayes dilakukan dengan menggunakan data latih dan data uji yang terdapat dalam database, kemudian data tersebut akan diklasifikasikan untuk kemudian hasil klasifikasi dengan kelas yang sama akan dijumlahkan dan menghasilkan nilai prediksi berupa jumlah mahasiswa yang mengambil suatu mata kuliah tertentu.. 4.1.2 Kebutuhan Data Data yang digunakan dalam penelitian diambil dari bagian Akademik Fakultas Ilmu Komputer Universitas Brawijaya. Sebelum proses pengumpulan data, dilakukan proses identifikasi permasalahan dan penggalian informasi fitur-fitur data yang berpengaruh dalam proses prediksi menggunakan teknik wawancara. Wawancara dilakukan kepada Sekretaris Jurusan Informatika dan Sistem Informasi. Kemudian hasil wawancara tersebut akan digunakan sebagai bahan pertimbangan dalam penentuan fitur-fitur apa saja yang akan digunakan dan halhal apa saja yang dapat menjadi pertimbangan atau berpengaruh dalam proses data mining. Dari hasil wawancara dengan Sekretaris Jurusan Informatika didapatkan hasil bahwa fitur yang dapat berpengaruh dalam proses data mining adalah nilai, selain itu juga didapat informasi bahwa kuisioner yang dilakukan setiap semester dapat menjadi bahan pertimbangan dalam penentuan jumlah kelas yang dibuka setiap semesternya, sebagaimana ditunjukkan pada Lampiran A . Adapun fitur-fitur yang digunakan ditunjukkan dalam Tabel 4.1 berikut. Tabel 4.1 Fitur-fitur data yang digunakan No. Fitur. Keterangan. 1. X1. Nilai Mata Kuliah Prasyarat. 2. X2. IP Semester. 23.
(39) Tabel 4.1 Fitur-fitur data yang digunakan (lanjutan) 3. X3. IP Kumulatif. 4. X4. SKS. 5. X5. SKS Kumulatif. 6. X6. Semester. 4.1.3 Identifikasi Aktor Daftar aktor sebagaimana diperlihatkan pada Tabel 4.2 adalah pihak-pihak yang akan berinterkasi dengan sistem yang dibuat. Adapun aktor yang teridentifikasi terbagi menjadi 2, yaitu Administrator dan User. Dalam hal ini Administrator merupakan pihak akademik Fakultas Ilmu Komputer Unversitas Brawijaya. Sedangkan sebagai User adalah pihak-pihak yang terlibat dalam pembuatan keputusan pembukaan jumlah kelas pada masa pengisian KRS atau yang terlibat dalam penjadwalan yang dalam hal ini adalah sekretaris jurusan. Tabel 4.2 Identifikasi aktor sistem Aktor. Deskripsi Aktor. Keterangan. Administrator. Administrator merupakan aktor Orang yang memiliki hak yang memiliki kendali penuh dalam mengakses dan terhadap sistem. mengelola data akademik mahasiswa.. User. User merupakan aktor yang Orang yang memiliki menggunakan sistem ini untuk peran dalam fitur utamanya yaitu prediksi. pengambilan keputusan jumlah kelas mata kuliah yang dibuka dalam satu semester.. 4.1.4 Daftar Kebutuhan Daftar kebutuhan menjelaskan kebutuhan apa saja yang harus disediakan oleh sistem, dan juga menyebutkan nama proses yang akan menunjukkan fungsionalitas masing-masing kebutuhan sistem tersebut. Adapun daftar kebutuhan fungsional sistem ditunjukkan pada Tabel 4.3.. 24.
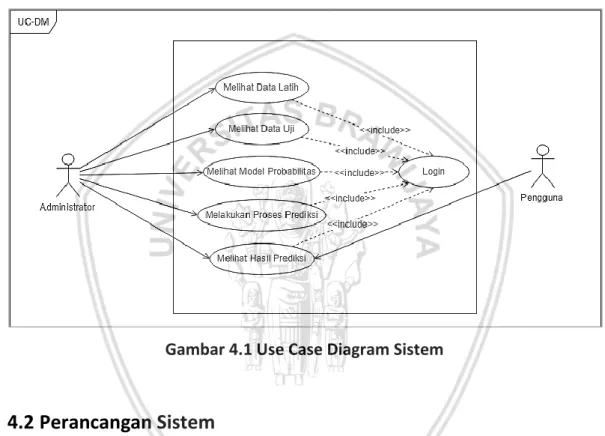
Gambar

+7

Garis besar
Dokumen terkait
Fungsi prediksi dengan memanfaatkan teknik data mining menggunakan algoritma naive bayes telah dapat dibuat dan digunakan untuk memprediksi (menentukan kelas) dari masa
Hasil dari penelitian ini adalah aplikasi data mining yang dibangun menggunakan algoritma Naive Bayes Classifier yang dapat memberikan informasi penting berupa
Tahapan evaluasi yang dilakukan dalam penelitian ini adalah untuk memberikan penilaian dari hasil penggunaan algoritma naive bayes saja dan naive bayes yang disertai
Permasalahan pada penelitian ini adalah belum diketahui akurasi dari metode klasifikasi data mining untuk prediksi penyakit hepatitis.. Oleh sebab itu metode yang
Berdasarkan data akademik siswa yang diperoleh, proses Data Mining membantu dalam penerapan metode Naive Bayes dalam mendapatkan informasi dari hasil
Journal of Local News Classification Radar Malang Using Naive Bayes Method With N-Gram Features The steps of the Naive Bayes Classifier method in this journal are as follows: 1 Mining
Data latih merupakan data yang akan digunakan pada proses mining untuk menghasilkan rule dengan menggunakan data mahasiswa angkatan 2014-2016.. Sedangkan data uji adalah data yang akan
Pada penelitian terdahulu, banyak metode data mining yang telah digunakan untuk mendiagnosis penyakit Peningkatan performa algoritma naive bayes dengan gain ratio untuk klasifikasi
