II. TINJAUAN PUSTAKA
2.1. Pendidikan Politeknik
Pendidikan Politeknik merupakan jalur pendidikan profesional yang membekali lulusannya dengan keterampilan, pengetahuan teori dan sikap disiplin yang tinggi. Politeknik membekali mahasiswanya disamping kemampuan
Hardskill juga kemampuan Sofskill. Sehingga diharapkan alumni Politeknik
menjadi tenaga profesional yang siap pakai dan kompetensi di bidangnya. Pada prosesnya belajar di politeknik, mahasiswa memperoleh 40% praktek dan 60% teori. Kondisi demikian membutuhkan suatu adaptasi dan motivasi yang sangat tinggi dari mahasiswa agar dapat bertahan di tiap semesternya sehingga mereka berhasil menyelesaikan pendidikan di Politeknik tepat waktu.
Salah satu yang menjadi tolak ukur keberhasilan studi mahasiswa adalah nilai indeks prestasi (IP), begitu juga di Politeknik Negeri Bandung (POLBAN). Nilai IP tiap semester menjadi salah satu faktor yang menentukan apakah mahasiswa tersebut dapat melanjutkan ke semester berikutnya atau tidak (drop
out). Dalam aturan di POLBAN, derajat keberhasilan studi mahasiswa POLBAN
dinyatakan dengan Indeks Prestasi Kumulatif (IPK). Seorang mahasiswa POLBAN dinyatakan lulus penuh pada suatu semester bila mempunyai nilai IP ≥ 2.00 dan jumlah mata kuliah dengan nilai D maksimum 7 SKS dan tanpa nilai E. Mahasiswa dinyatakan lulus percobaan pada suatu semester jika dipenuhi : nilai IP≥ 2.00 dan nilai D>7 SKS, tanpa nilai E atau 1.70 ≤ IP ≤ 2.00 dan nilai D ≤ 7 SKS tanpa nilai E. Mahasiswa akan dikeluarkan dari Politeknik (DO) dengan alasan akademik bila dua semester berturut-turut lulus percobaan sampai dengan semester IV, mempunyai nilai 1.70≤ IP<2.00 dan jumlah SKS nilai D>7 SKS, nilai IP di bawah 1.70, mempunyai nilai E pada semester I, II, III dan IV, melewati batas studi yang telah ditetapkan yakni sekurang-kurangnya 6 semester dan selama-lamanya 10 semester, termasuk cuti dan mengulang, dan mempunyai status ketidakhadiran yang tidak diizinkan, yakni tidak hadir tanpa ijin selama 38
jam, dan tidak memenuhi syarat kelulusan pada semester VI setelah diberi kesempatan mengulang.
2.2. Faktor-faktor yang Berpengaruh Terhadap Keberhasilan Mahasiswa
Secara garis besar faktor-faktor yang mempengaruhi keberhasilan studi mahasiswa di perguruan tinggi dibagi menjadi 2 faktor yakni faktor intelektual dan faktor non-intelektual (Munthe 1995 diacu Hidayati 2002). Faktor intelektual adalah kemampuan seseorang yang diperlihatkan melalui kecerdasan dan kepandaiannya dalam berfikir dan berbuat yang meliputi : bakat, kapasitas belajar, kecerdasan dan hasil belajar yang telah dicapai. Faktor non-intelektual adalah segala kondisi dari dalam dan dari luar dirinya atau lingkungan sekitar yang terkait dengan diri seseorang dalam mempengaruhi kemampuan berfikir dan bertindak. Menurut Suryabrata (1989), hal-hal yang mempengaruhi proses belajar mengajar meliputi pengaruh dari dalam yaitu keadaan fsikologis (kesehatan, kondisi panca indra, dan gizi yang cukup) dan keadaan fisiologis (minat, kecerdasan, motivasi dan kemampuan kognitif). Selanjutnya pengaruh dari luar meliputi input lingkungan dan input instrumental.
2.3. Regresi Logistik
Analisis Regresi Logistik digunakan untuk memeriksa hubungan antara peubah respon yang berupa peubah kualitatif, yaitu peubah berskala nominal atau ordinal dengan peubah-peubah penjelas (predictor) yang bisa terdiri dari peubah kualitatif maupun kuantitatif. Peubah respon dalam regresi logistik dapat berupa peubah dikhotom (biner) maupun politom (ordinal atau nominal).
Misalkan data hasil pengamatan mempunyai n peubah penjelas yang dinyatakan oleh vektor x’ = (X1,X2,...,Xn) yang berpasangan dengan peubah respon
Y yang bernilai 1 dan 0. Nilai peubah y=1 menyatakan bahwa respon memiliki kriteria yang diharapkan dan y=0 tidak memiliki kriteria yang diharapkan, maka peubah respon Y memiliki sebaran Bernoulli dengan parameter π (x) dan fungsi sebaran peluangnya adalah :
i i y i y i i x x y f( )=π( ) (1−π( ))1− (1)
Model Regresi Logistik antara π(x) dengan x adalah : )) ( exp( 1 )) ( exp( ) ( x g x g x + = π (2)
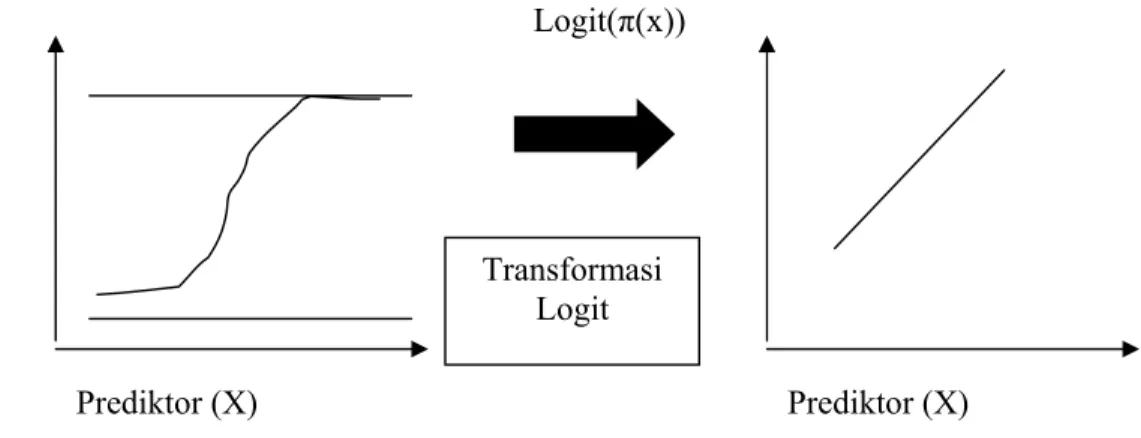
Fungsi regresi di atas berbentuk curvilinear. Dengan transformasi logit maka curvilinear tersebut akan menjadi fungsi linear. (Agresti 1996).
Ilustrasi pada Gambar 1 akan memperjelas transformasi logit.
Gambar 1 Transformasi Logit curvilinear ke Linear
Model Logit mentransformasi masalah prediksi peluang dengan range (0,1) menjadi masalah prediksi log odds. Transformasi Logit dinyatakan dalam persamaan berikut : logit ( ) ) ( 1 ) ( ln )) ( ( g x x x x ⎥ = ⎦ ⎤ ⎢ ⎣ ⎡ − = π π π (3) dimana n nX X X x g( )= β0+β1 1+β2 2+...+β (4)
merupakan logit (Hosmer & Lemeshow 2000). Pembuktian : ) ( ) ( 1 ) ( ln g x x x = ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ −π π dimana )) ( exp( 1 )) ( exp( ) ( x g x g x + = π π(x) Prediktor (X) Transformasi Logit Logit(π(x)) Prediktor (X)
maka ln
[
exp( ( )]
( ) )) ( exp( 1 )) ( exp( ) ( exp( 1 ) ( exp( 1 )) ( exp( 1 )) ( exp( ln g x g x x g x g x g x g x g x g = = ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ + − + + + (5)Jadi terbukti bahwa logit ( )
) ( 1 ) ( ln )) ( ( g x x x x ⎥= ⎦ ⎤ ⎢ ⎣ ⎡ − = π π π
Bentuk (4) dapat juga ditulis sebagai
∑
= = + + + = n j j j n nx x x x g 0 1 1 0 ... ) ( β β β β (6)Sehingga persamaan (2) dapat dinotasikan menjadi
(8) ) exp( 1 1 (x) -1 dan (7) ) exp( 1 ) exp( ) ( n 0 j j 0 0
∑
∑
∑
= = = + = + = j n j j j n j j j x x x x β π β β πSelanjutnya karena ada n pengamatan (xi,yi) yang diasumsikan bebas, maka untuk
menduga parameter (β0, β1, ..., βn) dilakukan dengan metode kemungkinan
maksimum sebagai berikut
i i y n i n i i y i i n f y x x y y y f l − = =
∏
=∏
− = = 1 1 1 2 1, ,..., ) ( ) ( ) (1 ( )) ( ) (β π π (9) (12) ) 1 ln( ) 1 ln( ) ( (11) ) 1 ln( ) 1 (( ln ) ( ) ( (10) ) ( 1 ( ) ( ln )) ( ln( ) ( 1 1 1 1 1 1∑
∑
∑
∑
∏
= = = = − = − + − = − − + = = ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ − = = n i n i i i i i n i n i i i i i i i y i n i y i y y L y y y L x x x l L i i π π β π β π π π π β β Fungsi L(β) tersebut diturunkan terhadap parameter β0, β1, ..., βn , sehinggaiterasi. Setelah diperoleh nilai dugaan β0, β1, ..., βn,, maka dapat diperoleh
penduga dari π(x) dengan persamaan :
)) ( exp( 1 )) ( exp( ) ( ^ ^ ^ x g x g x + = π (13) dimana g x x nXn ^ 1 1 ^ ^ 0 ^ ... ) ( =β +β + +β
merupakan penduga Logit yakni fungsi linear dari peubah penjelas (Hosmer & Lemeshow 2000).
2.3.1. Pengujian Kesesuaian Model
Pengujian kesesuaian model dilakukan dengan memeriksa peranan peubah-peubah penjelas dalam model. Pengujian dilakukan terhadap parameter model (β). Pengujian secara simultan (melibatkan seluruh peubah penjelas) dilakukan dengan menggunakan uji nisbah kemungkinan (likelihood ratio test) atau uji-G. Uji-G digunakan untuk pengujian parameter βi dengan hipotesis
sebagai berikut:
H0 : β1= β2= ... = βp=0
H1 : minimal ada satu βyang tidak sama dengan nol
Statistik uji yang digunakan adalah statistik G :
⎥ ⎦ ⎤ ⎢ ⎣ ⎡ − = penjelas peubah dengan likelihood penjelas peubah tanpa likelihood ln 2 G (14)
Statistik Uji- G ini secara teoritis mengikuti sebaran χ2 dengan derajat bebas k.
Kriteria keputusan yang diambil adalah menolak H0,\ jika G hitung ≥ ( )
2
k
α
χ (Hosmer & Lemeshow 2000). Apabila pada Uji G, H0 ditolak maka lanjutkan dengan
Uji-Wald yang digunakan untuk menguji parameter βi secara parsial. Hipotesis yang
akan diuji adalah : H0 : βi = 0
H1 : βi≠ 0 i=1,2,...,k
) ( i SE i W
β
β
Λ Λ = (15)Secara teori, statistik W ini mengikuti sebaran normal baku. Dengan kriteria keputusan adalah menolak H0 jika |W| ≥ Zα/2 atau nilai p ≤ α .
2.3.2. Pereduksian Peubah Penjelas
Pereduksian peubah dalam regresi logistik dikenal sebagai analisis regresi logistik bertatar (stepwise logistic regression), dimana langkah yang dilakukan adalah menambah dan mengurangi peubah-peubah penjelas satu demi satu dari model sampai didapatkan model dengn peubah-peubah penjelas yang mempunyai pengaruh signifikan.
Analisis regresi logistik bertatar (stepwise logistic regression) terdiri dari
forward selection dan backward elimination. Dalam metode forward selection
prosedur dimulai dengan intersep, kemudian peubah penjelas dimasukkan satu persatu ke dalam model dan diuji dengan uji Khi-Kuadrat. Apabila peubah penjelas tidak signifikan pada nilai α yang ditentukan, maka peubah dikeluarkan dari model. Tetapi peubah penjelas yang signifikan akan dimasukkan ke dalam model. Sedangkan dalam metode backward elimination, prosedur dimulai dengan memasukkan semua peubah penjelas ke dalam model, kemudian peubah diuji satu persatu dengan uji Khi-Kuadrat. Peubah penjelas yang tidak signifikan pada nilai α yang ditentukan dikeluarkan dari model, tetapi peubah penjelas yang signifikan tetap berada dalam model (Gonzales 2003). Teknik pereduksian peubah penjelas ini telah tersedia dalam paket pengolahan komputer. Dalam penelitian ini metode pereduksian yang digunakan adalah backward elimination.
2.3.3. Interpretasi Koefisien
Ukuran untuk melihat seberapa besar kecenderungan pengaruh peubah penjelas terhadap respon digunakan Rasio Odds (Hosmer & Lemeshow 2000). Sedangkan interpretasi koefisien pada model regresi logistik dilakukan dengan melihat nilai rasio odds dan selang kepercayaan rasio oddsnya. Tanda positif dari
koefisien menunjukkan bahwa nilai rasio odds lebih dari satu. Begitupun sebaliknya, untuk tanda koefisien negatif, maka nilai rasio oddsnya kurang dari satu.
Koefisien model logit dapat ditulis sebagai β=g(x+1)-g(x) yang menginterpretasikan bahwa perubahan nilai logit g(x) terjadi untuk setiap perubahan satu unit peubah penjelas X yang selanjutnya disebut log odds. Secara umum dapat dikatakan bahwa log odds adalah beda antara penduga logit yang dihitung pada dua nilai sembarang, misalnya x=a dan x=b yang dinotasikan sebagai :
ln [ψ(a,b)]= g(x=a)-g(x=b)=β(a-b) (16)
Sedangkan penduga rasio odds dinyatakan sebagai ψ(a,b)=exp[β(a-b)]. Sehingga apabila dimisalkan (a-b)=1 maka diperoleh ψ(a,b)=exp(β), dapat diinterpretasikan bahwa peluang untuk y=1 pada x=1 adalah ψ kali dibandingkan dengan x=0. Untuk lebih jelasnya berikut disajikan tabel model logistik dengan satu peubah dikotomi.
Tabel 1 Nilai-nilai Model Regresi Logistik dengan Peubah Penjelas Dikotomi
Transformasi logitnya : n nx x x x x x g β β β β π π = + + + + ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ − = ... ) ( 1 ) ( ln ) ( 0 1 1 2 2 (17)
Nilai odds pada y=1 untuk x=1 adalah
) 1 ( 1 ) 1 ( π π
− dengan nilai log adalah g(1) Peubah Bebas X x=1 x=0 Y=1 Peubah Respon Y=0 Jumlah 1 1 1 0 1 1 ) 1 ( 1 π β +β + = − e 0 0 1 ) 0 ( β β π e e + = 1 0 1 0 1 ) 1 ( β β β β π + + + = e e 0 1 1 ) 0 ( 1 π β e + = −
Nilai odds pada y=1 untuk x=0 adalah ) 0 ( 1 ) 0 ( π π
− dengan nilai log adalah g(0) Maka nilai rasio odds (ψ) merupakan rasio dari odds untuk x=1 dengan x=0 yang dinotasikan sebagai : 1 ) 0 ( ) 1 ( ) 0 ( 1 ) 0 ( ) 1 ( 1 ) 1 ( β π π π π ψ = − = − − = g g (18)
Jika β1 adalah beda logit, maka exp (β1) adalah nilai rasio odds (Hosmer &
Lemeshow 2000).
Selang kepercayaan (1-α)100% untuk nilai rasio odds adalah )]
(
exp[β^i±Z1−α/2SE^ β^i (19)
2.3.4. Ketepatan dan Kesalahan Klasifikasi
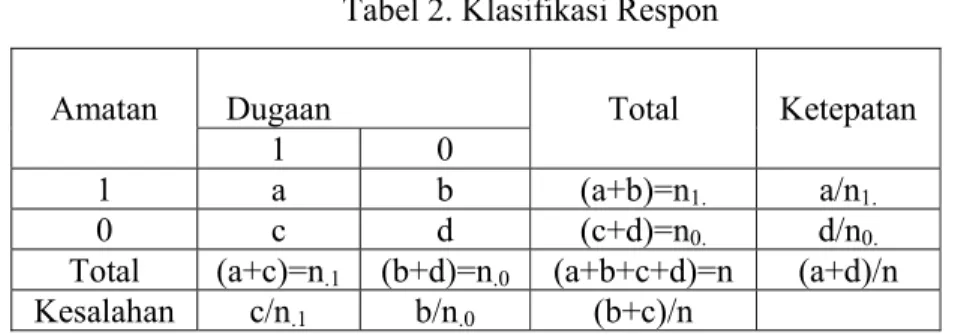
Salah satu ukuran kebaikan model dalam regresi logistik adalah jika model mempunyai peluang salah klasifikasi minimal (Hosmer & Lemeshow 2000). Ketepatan dan kesalahan klasifikasi dapat dilihat dalam tabel klasifikasi. Tabel klasifikasi untuk peubah respon dikotom terdiri atas dua kolom nilai dugaan dan dua baris nilai amatan. Dalam menentukan ketepatan klasifikasi (correct
classification) terhadap amatan harus ditentukan terlebih dahulu nilai cutpoint (c).
Nilai c yang biasa digunakan adalah 0.5. Jika peluang dugaan π(x) ≥ c, maka nilai dugaan termasuk pada respon y=1 dan sebaliknya adalah y=0. Tabel 2 memperlihatkan tabel klasifikasi secara umum.
Tabel 2. Klasifikasi Respon
Amatan Dugaan Total Ketepatan
1 0
1 a b (a+b)=n1. a/n1.
0 c d (c+d)=n0. d/n0.
Total (a+c)=n.1 (b+d)=n.0 (a+b+c+d)=n (a+d)/n
Kesalahan c/n.1 b/n.0 (b+c)/n
Ketepatan klasifikasi (correct classification) terdiri atas specificity dan sensitivity. Ketepatan klasifikasi dalam menduga kejadian bahwa respon tidak memiliki
kriteria yang diharapkan (y=0), atau prosentase nilai dugaan yang sama dengan nilai amatan untuk y=0 disebut specificity. Dalam Tabel 2 nilai specificity dinyatakan dengan (d/n0.)100%. Sedangkan prosentase nilai dugaan yang sama
dengan nilai amatan untuk y=0 disebut sensitivity. Dalam Tabel 2 nilai sensitivity dinyatakan dengan (a/n1.)100%. Persentase total nilai amatan yang secara tepat
dapat diduga oleh model disebut total correct classification. Dalam Tabel 2 total
correct classification dinyatakan dengan ((a+d)/n)100%. Kesalahan klasifikasi
terdiri dari kesalahan positif dan kesalahan negatif. Persentase kesalahan dalam menduga respon memiliki kriteria yang diharapkan (y=1), padahal sebenarnya bernilai y=0 disebut kesalahan positif. Dalam Tabel 2 kesalahan positif dinyatakan dengan (b/n.0)100%. Persentase kesalahan dalam menduga respon
tidak memiliki kriteria yang diharapkan (y=0), padahal sebenarnya bernilai y=1 disebut kesalahan negatif. Dalam Tabel 2 kesalahan negatif dinyatakan dengan (c/n.1)100%. Selanjutnya persentase kesalahan klasifikasi total adalah
((b+c)/n)100% disebut total misclassification rate.
2.4. Analisis Daya Tahan
Analisis Daya Tahan (Survival Analysis) adalah suatu teknik analisis yang digunakan dalam menganalisis daya tahan dari satu individu atau beberapa individu (Lee 1992). Data daya tahan disini merupakan data tentang jangka waktu terjadinya suatu kejadian (event). Dalam analisis daya tahan ini dapat ditentukan waktu kejadian sesuatu yang sering disebut waktu kegagalan (failure), dan waktu bertahannya sesuatu yang disebut waktu ketahanan (life time).
Pada bidang biomedical, data tersensor dapat berupa waktu berkembangnya suatu penyakit, waktu kematian penderita kanker. Pada bidang industri, berkaitan dengan tingkat keterandalan suatu alat elektronik atau komponen sistem. Pada bidang sosial dapat kita temukan pada data masa / durasi suatu perkawinan pertama, waktu kejahatan (kriminal) dan lain-lain. Berdasarkan jenisnya, data atau pengamatan tersensor dibagi 3, yakni : sensor kanan (right
sensoring), sensor kiri (left censoring), dan sensor interval (interval censoring).
sensor acak. Diketahui pada sensor kanan, individu pengamatan masih hidup sampai penelitian berakhir. Pada sensor kiri, biasanya kejadian yang sudah diamati sudah terjadi sebelum individu diteliti. Untuk sensor interval, kejadian jatuh dalam suatu interval, dimana pengamatan dilakukan secara periodik. Sedangkan pada sensor kanan jenis 1, biasanya waktu penelitian ditentukan tetapi jumlah pengamatan yang tersensor random. Dan pada sensor kanan jenis 2, waktu pengamatan sifatnya random, namun jumlah pengamatan yang tersensor ditentukan. Dalam menentukan waktu daya tahan ada 3 hal yang harus diperhatikan, yaitu :
1. waktu awal harus didefinisikan dengan jelas, walaupun tidak sama satuannya
2. skala pengukuran harus ditentukan
3. pengertian kejadian (event) harus ditentukan dengan jelas
Pada penelitian ini, waktu awal ditentukan awal semester 1(satu) dan waktu akhir penelitian adalah akhir semester 4(empat). Sedangkan skala pengukuran yang digunakan adalah semester. Kejadian yang diharapkan (event) adalah mahasiswa gagal (DO). Untuk lebih jelasnya disajikan ilustrasi data survival pada Gambar 1.
Gambar 2 Ilustrasi Data Survival Event (kejadian yang diharapkan/DO) kejadian yang tidak diharapkan)
0 1 2 3 4 t A B C D E
Pada Gambar 2, diperlihatkan bahwa subjek A mengalami kegagalan / DO setelah semester 3, maka dalam hal ini subjek A dikatakan tidak tersensor. Subjek B, sampai waktu penelitian berakhir (semester 4) tidak mengalami event, maka dikatakan subjek B tersensor di kanan. Sementara subjek C, setelah melampaui satu semester mengalami kegagalan (DO), dalam hal ini subjek C dikatakan tidak tersensor. Sementara itu subjek D setelah semester 3 mengundurkan diri, maka subjek D dikatakan tersensor. Subjek E mengalami kegagalan / DO pada semester 4, maka dapat dikatakan bahwa subjek E tidak tersensor.
Dalam penelitian disini jenis data tersensor yang diamati adalah jenis data tersensor kanan jenis 1 (satu), karena sebagian mahasiswa yang diamati setelah melampaui kurun waktu penelitian (semester 4) tidak mengalami kegagalan (DO) dan jumlah yang mahasiswa yang tersensor tidak ditentukan (random).
2.4.1. Fungsi-fungsi dalam Analisis Daya Tahan
Sebaran waktu daya tahan biasanya dinyatakan dalam 3 fungsi, yakni : Fungsi daya tahan (Survival function), fungsi Hazard (Hazard function), dan fungsi kepekatan peluang (probability density function). Ketiga fungsi ini secara matematik ekuivalen. Artinya jika salah satu fungsi diketahui, maka fungsi yang lain dapat diturunkan.
a. Fungsi Daya Tahan (Survival function)
Fungsi daya tahan adalah fenomena yang menjelaskan ukuran waktu terjadinya suatu kejadian. Fungsi daya tahan didefinisikan sebagai peluang mahasiswa bertahan dalam melanjutkan studi di POLBAN selama kurun waktu t yang dinyatakan dalam bentuk
S(t) = P (suatu individu bertahan lebih dari waktu t) = P(T≥ t) =
∫
∞t f(u)du (Collet 1996) (20)
Menurut definisi Fungsi distribusi kumulatif F(t) dari T, karena S(t)=1-P(seorang mahasiswa gagal /DO sebelum waktu t)=P(T<t)
atau S(t) = 1- F(t) maka F(t)=1-S(t) sehingga diperoleh
F(t)=
∫
t f u du0 ( ) (Collet 1996) (21)
b. Fungsi Kepekatan Peluang (probability density function)
Fungsi kepekatan peluang dari waktu daya tahan T didefinisikan sebagai limit dari peluang yang gagal pada selang waktu t sampai tΛ . Dalam hal ini didefinisikan bahwa f(t) adalah fungsi kepekatan peluang dari T. Dan F(t) adalah fungsi kepekatan kumulatif dari T yang dirumuskan sebagai berikut
f(t)= t t t t P t Δ Δ + → Δ )) , ( interval dalam gagal individu ( lim 0 f(t)= (1 S(t)) S'(t) dt d − =− (Lee 1992) (22)
c. Fungsi Hazard (Hazard function)
Fungsi Hazard h(t) dari waktu daya tahan T disebut juga laju kegagalan bersyarat (Conditional failure rate), yang didefinisikan sebagai peluang terjadinya kematian individu dalam selang waktu yang pendek (t,t+Δt), apabila diketahui bahwa individu sudah bertahan hidup selama waktu t. Fungsi Hazard dinyatakan sebagai
h(t)= t t)} t (t, interval dalam gagal waktu t pada individu { lim 0 Δ Δ + → Δ P t h(t)= t t T t t T t P t Δ > Δ + < ≤ → Δ } | } ( lim 0 = ) ( ) ( t s t f (Collet 1996) (23)
Hubungan antara S(t) dan h(t) adalah jika nilai S(t) naik, maka nilai h(t) turun. Begitu juga sebaliknya, jika nilai S(t) turun, maka nilai h(t) naik. Secara matematis S(t) dan f(t) dapat dinyatakan dalam bentuk h(t).
Karena f(t) dapat ditulis sebagai –S’(t), maka h(t)=- (ln tS())
dt d
(24) sehingga diperoleh :
0h(t)dt lnS(t)
t
= −
∫
(25)
Disamping itu S(0)=1, maka S(t) =exp (-ln
∫
t du u h 0 ) ( ) (26)
Fungsi Hazard Kumulatif dinotasikan sebagai H(t)=
∫
t du u h 0 )( atau H(t)=-ln (S(t)) sehingga S(t)=exp(-H(t) (27)
Maka fungsi densitas menjadi f(t)=h(t). exp (-
∫
t du u f 0 ) ( (Lee 1992) (28)
2.4.2. Model Regresi Hazard Proporsional (Regresi Cox)
Model regresi Hazard Proporsional (Regresi Cox) mengkaitkan antara variabel respon yang berupa waktu bertahan dengan peubah penjelas. Selanjutnya peubah penjelas yang mengandung karakteristik-karakteristik ini disebut sebagai kovariat atau peubah penjelas, sedangkan peubah respon adalah waktu ketahanan mahasiswa. Tingkat Kegagalan bersyarat / tingkat hazard dapat ditulis dalam bentuk h(t)= t t T t t T t P t Δ ≥ Δ + < ≤ → Δ ] | [ lim 0 (29)
Setiap pengamatan dalam analisis daya tahan dapat dinyatakan dalam bentuk (tj, wj, XJ) dimana:
j=1,2,...,n adalah banyaknya pengamatan
tj ∈(0, ∞ ) = waktu seorang mahasiswa dapat bertahan dalam melanjutkan
studinya di POLBAN sampai mengalami kegagalan (DO) W j = indikator yang bernilai 1 jika mahasiswa mengalami kegagalan
(pengamatan tidak tersensor) dan bernilai 0 jika mahasiswa dapat bertahan (pengamatan tersensor)
X j = kovariat atau peubah penjelas ke-j dimana X j dapat ditulis dalam vektor
X j = [ X j1 , X j2 , ... , Xjp ] merupakan peubah boneka / dummy yang memiliki
Fungsi hazard yang telah disebutkan sebelumnya dapat diuraikan menjadi bentuk perkalian antara fungsi hazard dasar yang bergantung pada waktu dan fungsi yang bergantung pada kovariat, atau ditulis dalam bentuk
h(t,X)= h0(t)G(X;β) (30)
karena nilai h(t,X) dan h0(t) positif, maka nilai G(X;β) juga harus positif. Cox
(Cox & Oakes,1984) memilih G(X;β) = exp (βTX ) sehingga model (30) berubah menjadi:
h(t,X)= h0(t) exp (βTX) (31)
dimana:
t = waktu hingga suatu kejadian terjadi (waktu mahasiswa gagal) h(t,X) = resiko mahasiswa gagal pada waktu t dengan karakteristik X.
h0(t) = fungsi hazard dasar (baseline hazard function) atau fungsi hazard pada
saat t=0 dan tidak bergantung pada karakteristik. ΒT =[ β
1, β2, ... , βp] adalah vektor koefisien regresi atau vektor parameter.
Model (32) disebut juga sebagai model “hazard proporsional” karena merupakan nisbah fungsi hazard dari dua individu dengan vektor kovariat X1 dan
X2 yang bebas terhadap t.
exp( ( )) ) , ( ) , ( 2 1 2 1 X X X t h X t h = βT − (32)
Rasio dalam persamaan (32) disebut hazard relatif yang menunjukkan adanya peningkatan atau penurunan resiko mahasiswa yang mengalami kondisi tertentu atau dikenai perlakuan tertentu (Lee, 1992).
2.4.3. Pendugaan Parameter
Dalam menduga parameter (β), Cox dalam Lee (1992) menyarankan prosedur pendugaan kemungkinan maksimum ( maximum likelihood estimation) berdasar atas fungsi kemungkinan bersyarat. Misalkan ada n pengamatan dengan k pengamatan yang tidak tersensor dan (n-k) adalah pengamatan yang tersensor diurutkan menjadi t(1) < t(2) < t(3) ... < t(k) . Selanjutnya {Ri} = {R(t(i)) adalah
himpunan resiko pada waktu t(i) , terdiri atas individu-individu yang bertahan
hingga waktu t(i). Peluang bahwa individu / mahasiswa ke-i gagal (DO), jika
diketahui individu tersebut berada dalam Ri pada waktu t(i) adalah
∑
∑
∈ ∈ i l Ri l T i R l i i i i X X X t h X t h ) exp( ) exp( atau ) , ( ) . ( T β β (33)Hasil kali peluang untuk setiap pengamatan / observasi waktu yang tidak tersensor akan membentuk fungsi kemungkinan yang hanya tergantung pada β. Fungsi ini selanjutnya disebut fungsi kemungkinan bersyarat dengan notasi
∏ ∑
= ∈ = k i R l l T i T c i X X L 1 exp( ) ) exp( ) ( β β β (34)Fungsi tersebut tidak bergantung pada nilai h0(t). Sehingga untuk menduga
parameter model regresi (β) tidak perlu harus mengetahui nilai h0(t) asalkan data
berasal dari populasi yang sama.
Untuk memudahkan kita dalam mencari penduga kemungkinan maksimum Lc(β) maka digunakan konsep logaritma yaitu Ln (Lc(β)). Selanjutnya
Ln (Lc(β)) dimaksimumkan dengan menurunkannya terhadap β dan kemudian
menyamakannya dengan nol, seperti notasi berikut
( ( ))=0
∂
∂ β
β Ln Lc (35)
2.4.4. Pengujian Kontribusi Peubah
Pengujian kontribusi peubah secara bersama-sama (simultan) dalam analisis peubah ganda digunakan uji nisbah kemungkinan dengan statistik uji : χ2 =−2[lnLsbl −ln Lssd] (36) Kriteria keputusan adalah jika nilai χ2hitung dengan taraf 0.05 lebih besar dari
nilai χ2 tabel dengan derajat bebas tertentu maka peubah-peubah tersebut
memberikan pengaruh yang nyata pada taraf nyata 5% (Lee 1992 ).
Sedangkan untuk menguji hipotesis H0 : βi = 0 dan H1 : βi ≠ 0 pada
pengujian kontribusi masing-masing peubah dalam analisis tunggal digunakan uji Wald dengan statistik uji :
( 2 )⎥⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎣ ⎡ = Λ Λ
β
β
SE W (37)dimana SE(β^ ) adalah galat baku penduga parameter.
Statistik uji ini akan menyebar χ2 dengan derajat bebas 1, untuk H
0 bernilai
benar.
2.4.5. Pengujian Fungsi Daya Tahan
Untuk menduga fungsi daya tahan dalam Regresi Cox digunakan penduga Breslow. Fungsi daya tahan individu pada t dengan peubah penjelas X adalah S(t,X)= exp( )
0()]
[S t βTX (38)
Untuk menduga S(t,X) harus terlebih dahulu menduga S0(t). Menurut Breslow
dalam Anderson (1980), S0(t) dapat ditentukan dengan rumus berikut
∏ < ∑ ∈ Λ