Gregorius Agung Purwanto Nugroho
ABSTRAK
Penelitian ini bertujuan untuk menciptakan sistem untuk mengenali emosi yang terkandung
dalam kalimat tweet. Latar belakang penelitian ini yaitu maraknya penggunaan media sosial atau
microblogging untuk mengutarakan opini tentang topik tertentu. Penelitian berkaitan opini publik dapat dijadikan sebagai dasar manajemen merk, corporate reputation, marketing, sistem
rekomendasi, dan intelijen.
Penelitian ini menggunakan metode K-Means Clustering dengan masukan berupa teks.
Penelitian mencakup tahap preprocessing, pembobotan, normalisasi, clustering, dan uji akurasi.
Peprocessing meliputi tokenizing, remove stopword, dan stemming. Pembobotan menggunakan metode term frequency-inverse document frequency (tf-idf). Normalisasi menggunakan z-score
dan min-max. Clustering menggunakan K-Means dengan penentuan centroid awal memakai
Variance Initialization dan hitung kemiripan dengan Cosine Similarity. Pengujian akurasi memakai metode Confusion Matrix.
Percobaan dilakukan pada 1000 data yang dikelompokkan menjadi lima cluster yaitu cinta,
marah, sedih, senang, dan takut. Akurasi tertinggi sebesar 76,3%. Hasil akurasi tertinggi didapat
dengan metode normalisasi min-max, batas nilai yang dinormalisasi 5, dan minimal kemunculan
kata 3.
Kata Kunci: Tweet, K-Means Clustering, Cluster, Centroid, Variance Initialization, Cosine
Gregorius Agung Purwanto Nugroho
ABSTRACT
The objective of this research is to create system to recognize emotion of a tweet. This
research is created to learn public opinion about a certain topic. The study about public opinion
can be used as the key factor to determine brand management, corporate reputation, marketing,
recommendation system, and intelligent.
The research uses the K-Means Clustering as the main algorithm and textual data as the
input. The research includes the preprocessing, the weighting, the normalization, the clustering,
and the accuration testing. The preprocessing includes the tokenizing, the stopword removal, and
the stemming. The weighting uses the term frequency - inverse document frequency (tf-idf)
method. The normalization uses the z-score and the min-max method. Clustering uses the K-Means
Clustering with the Variance Initialization method to determine the initial centroids and the Cosine
Similarity method to measure the similarities. The testing uses the Confusion Matrix.
The experiment has been applied to a data sets of 1000 tweets that divided into five clusters:
cinta (love), marah (anger), sedih (sadness), senang (happiness), and takut (fear). The experiment obtained the highest accuration of 76.3% using the min-max normalization, the min-max threshold
was 5, and the minimum word frequency was 3.
Keywords: Tweets, K-Means Clustering, Clusters, Centroids, Variance Initialization, Cosine
i ANALISIS SENTIMEN DATA TWITTER
MENGGUNAKAN K-MEANS CLUSTERING
SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer Program Studi Teknik Informatika
HALAMAN JUDUL
Oleh:
Gregorius Agung Purwanto Nugroho 115314065
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii SENTIMENT ANALYSIS OF TWITTER DATA
USING K-MEANS CLUSTERING
FINAL PROJECT
Presented as Partial Fulfillment of Requirements to Obtain Sarjana Komputer Degree in Informatics Engineering Department
TITLE PAGE
By:
Gregorius Agung Purwanto Nugroho 115314065
INFORMATICS ENGINEERING STUDY PROGRAM INFORMATICS ENGINEERING DEPARTMENT
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
v MOTTO
“Whatsoever one would understand what he hears must hasten to put into practice
viii
ABSTRAK
Penelitian ini bertujuan untuk menciptakan sistem untuk mengenali emosi
yang terkandung dalam kalimat tweet. Latar belakang penelitian ini yaitu maraknya
penggunaan media sosial atau microblogging untuk mengutarakan opini tentang
topik tertentu. Penelitian berkaitan opini publik dapat dijadikan sebagai dasar
manajemen merk, corporate reputation, marketing, sistem rekomendasi, dan
intelijen.
Penelitian ini menggunakan metode K-Means Clustering dengan masukan
berupa teks. Penelitian mencakup tahap preprocessing, pembobotan, normalisasi,
clustering, dan uji akurasi. Peprocessing meliputi tokenizing, remove stopword, dan
stemming. Pembobotan menggunakan metode term frequency-inverse document
frequency (tf-idf). Normalisasi menggunakan z-score dan min-max. Clustering
menggunakan K-Means dengan penentuan centroid awal memakai Variance
Initialization dan hitung kemiripan dengan Cosine Similarity. Pengujian akurasi
memakai metode Confusion Matrix.
Percobaan dilakukan pada 1000 data yang dikelompokkan menjadi lima
cluster yaitu cinta, marah, sedih, senang, dan takut. Akurasi tertinggi sebesar
76,3%. Hasil akurasi tertinggi didapat dengan metode normalisasi min-max, batas
nilai yang dinormalisasi 5, dan minimal kemunculan kata 3.
Kata Kunci: Tweet, K-Means Clustering, Cluster, Centroid, Variance
ix
ABSTRACT
The objective of this research is to create system to recognize emotion of a
tweet. This research is created to learn public opinion about a certain topic. The
study about public opinion can be used as the key factor to determine brand
management, corporate reputation, marketing, recommendation system, and
intelligent.
The research uses the K-Means Clustering as the main algorithm and textual
data as the input. The research includes the preprocessing, the weighting, the
normalization, the clustering, and the accuration testing. The preprocessing
includes the tokenizing, the stopword removal, and the stemming. The weighting
uses the term frequency - inverse document frequency (tf-idf) method. The
normalization uses the z-score and the min-max method. Clustering uses the
K-Means Clustering with the Variance Initialization method to determine the initial
centroids and the Cosine Similarity method to measure the similarities. The testing
uses the Confusion Matrix.
The experiment has been applied to a data sets of 1000 tweets that divided
into five clusters: cinta (love), marah (anger), sedih (sadness), senang (happiness),
and takut (fear). The experiment obtained the highest accuration of 76.3% using the
min-max normalization, the min-max threshold was 5, and the minimum word
frequency was 3.
Keywords: Tweets, K-Means Clustering, Clusters, Centroids, Variance
x KATA PENGANTAR
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Esa, sehingga penulis dapat menyelesaikan tugas akhir dengan judul “Analisis Sentimen Data
Twitter Menggunakan K-Means Clustering”. Tugas akhir ini merupakan karya
ilmiah untuk memperoleh gelar sarjana komputer program studi Teknik Informatika
Universitas Sanata Dharma Yogyakarta.
Pada kesempatan ini, penulis ingin mengucapkan terima kasih kepada
pihak-pihak yang telah membantu penulis baik selama penelitian maupun saat
mengerjakan tugas akhir ini. Ucapan terima kasih sebesar-besarnya penulis
sampaikan kepada:
1. Tuhan Yang Maha Esa, yang senantiasa memberi daya kekuatan dan
pertolongan selama menyelesaikan tugas akhir ini.
2. Orang tua, (Alm.)Romulus Purwoko dan Anastasia Sustarini, serta keluarga
yang telah memberikan dukungan spiritual dan material.
3. Dr. C. Kuntoro Adi, S.J., M.A., M.Sc. selaku dosen pembimbing tugas akhir,
atas bimbingan, waktu, dan saran yang telah diberikan kepada penulis.
4. Puspaningtyas Sanjoyo Adi, S.T., M.T. selaku dosen pembimbing akademik,
atas bimbingan, kritik dan saran yang telah diberikan kepada penulis.
5. Sri Hartati Wijono, S.Si., M.Kom. selaku dosen penguji, atas bimbingan,
kritik, dan saran yang telah diberikan kepada penulis.
6. Dr. Anastasia Rita Widiarti selaku dosen penguji dan ketua program studi
Teknik Informatika, atas bimbingan, kritik, dan saran yang telah diberikan
kepada penulis.
7. Sudi Mungkasi, Ph.D. selaku dekan Fakultas Sains dan Teknologi, atas
bimbingan, kritik, dan saran yang telah diberikan kepada penulis.
8. Seluruh dosen Teknik Informatika atas ilmu yang telah diberikan semasa
xii
PERNYATAAN KEASLIAN KARYA ... VI
LEMBAR PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK
KEPENTINGAN AKADEMIS ... VII
1.4 PEMBATASAN DAN RUANG LINGKUP PERMASALAHAN ... 3
1.5 SISTEMATIKA PENULISAN ... 3
2. BAB II... 5
2.1 ANALISIS SENTIMEN ... 5
2.1.1 Level Analisis Sentimen ... 5
2.2 EMOSI ... 6
2.2.1 Emosi Dasar ... 6
2.2.2 Kosakata Emosi ... 7
2.3 TEXT MINING ... 9
2.4 PREPROCESSING ... 9
2.4.1 Tokenization / Tokenizing ... 10
2.4.2 Stopword Removal ... 10
2.4.3 Stemming ... 11
xiii
2.5 PEMBOBOTAN TF-IDF ... 17
2.6 NORMALISASI ... 18
2.6.1 Normalisasi Z-Score ... 18
2.6.2 Normalisasi Min-Max ... 19
2.7 CLUSTERING ... 19
2.7.1 K-Means Clustering ... 20
2.7.2 Variance Initialization ... 22
2.8 COSINE SIMILARITY ... 22
3.3.1 Preprocessing ... 37
3.3.1.1 Tokenizing... 37
3.3.1.2 Stopword Removal ... 40
3.3.1.3 Stemming ... 43
3.3.1.4 Preprocessing Tambahan ... 46
3.3.2 Pembobotan ... 48
3.3.3 Normalisasi ... 56
3.3.3.1 Z-Score ... 57
3.3.3.2 Min-Max ... 59
3.3.4 K-Means Clustering ... 61
3.3.4.1 Variance Initialization ... 61
3.3.4.2 Langkah K-Means Clustering... 65
3.3.5 Hitung Akurasi ... 68
4.2.1 Preprocessing dan Pembobotan... 84
4.2.1.1 Tokenizing... 85
4.2.1.2 Stopword Removal ... 85
4.2.1.3 Stemming ... 86
4.2.1.4 Negation Handling ... 88
4.2.1.5 Pembobotan ... 89
4.2.1.6 Hasil Preprocessing dan Pembobotan... 90
4.2.2 Pengujian Sistem... 91
4.2.2.1 Normalisasi ... 92
xiv
4.2.2.1.2 Min-Max... 92
4.2.2.2 Variance Initialization ... 93
4.2.2.3 Langkah K-Means Clustering... 94
4.2.2.4 Output Centroid ... 97
4.2.2.5 Akurasi ... 98
4.2.3 Pengujian Data Baru ... 99
5. BAB V ... 101
5.1 KESIMPULAN ... 101
5.2 SARAN ... 102
DAFTAR PUSTAKA ... 103
LAMPIRAN ... 105
xv
DAFTAR TABEL
Tabel 2.1 Kosakata Emosi... 7
Tabel 2.2 Kombinasi Awalan dan Akhiran ... 14
Tabel 2.3 Cara Menentukan Tipe Awalan untuk Awalan “te-” ... 14
Tabel 2.4 Jenis Awalan Berdasarkan Tipe ... 15
Tabel 2.5 Confusion Matrix 2 kelas ... 23
Tabel 3.1 Kata Sebelum Penggabungan... 47
Tabel 3.2 Kata Setelah Penggabungan ... 47
Tabel 3.3 Hitung document frequency (df) ... 52
Tabel 3.4 Hitung inverse document frequency (idf) ... 53
Tabel 3.5 Hitung weight (w) Tweet Cinta ... 54
Tabel 3.6 Hitung weight (w) Tweet Marah... 54
Tabel 3.7 Hitung weight (w) Tweet Sedih ... 55
Tabel 3.8 Hitung weight (w) Tweet Senang ... 55
Tabel 3.9 Hitung weight (w) Tweet Takut ... 56
Tabel 3.10 Tabel Pembobotan... 56
Tabel 3.11 Tabel Mean ... 57
Tabel 3.12 Tabel Standard Deviation ... 58
Tabel 3.13 Hasil Normalisasi Z-Score ... 59
Tabel 3.14 Tabel Min-Max ... 60
Tabel 3.15 Hasil Normalisasi Min-Max ... 60
Tabel 3.16 Hitung Variance ... 61
Tabel 3.17 Pilih Kolom Data dengan Variance Terbesar ... 62
Tabel 3.18 Sort Seluruh Dokumen ... 63
Tabel 3.19 Bagi Dokumen Menjadi k Bagian (k=5) ... 64
Tabel 3.20 Pilih Median Tiap Bagian Sebagai Centroid Awal ... 64
Tabel 3.21 Centroid Awal ... 65
Tabel 3.22 K-Means Clustering ... 66
Tabel 3.23 Hasil Clustering ... 67
Tabel 3.24 Update Centroid ... 67
Tabel 3.25 Perbandingan Cluster Hasil Prediksi dan Label Aktual... 68
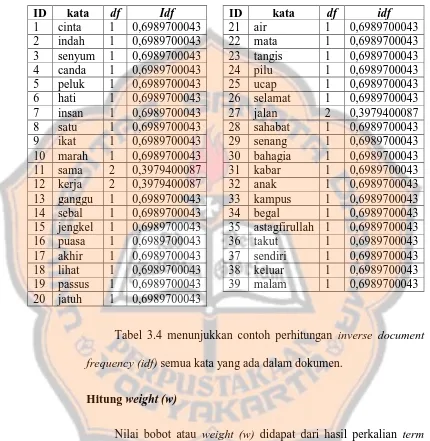
Tabel 3.26 Confusion Matrix ... 69
Tabel 3.27 Template Tabel Pengujian Tanpa Normalisasi ... 71
Tabel 3.28 Template Tabel Pengujian Menggunakan Normalisasi Z-Score ... 72
Tabel 3.29 Template Tabel Pengujian Menggunakan Normalisasi Min-Max ... 72
Tabel 4.1 Tabel Pengujian Tanpa Normalisasi ... 73
Tabel 4.2 Tabel Pengujian Menggunakan Normalisasi Z-Score ... 74
xvi
xvii
DAFTAR GAMBAR
Gambar 3.1 Tweet Cinta ... 26
Gambar 3.2 Tweet Marah ... 27
Gambar 3.3 Tweet Sedih ... 28
Gambar 3.4 Tweet Senang... 29
Gambar 3.5 Tweet Takut ... 30
Gambar 3.6 Diagram Blok ... 37
Gambar 3.7 Tokenizing Tweet Cinta ... 38
Gambar 3.8 Tokenizing Tweet Marah ... 38
Gambar 3.9 Tokenizing Tweet Sedih ... 39
Gambar 3.10 Tokenizing Tweet Senang ... 39
Gambar 3.11 Tokenizing Tweet Takut ... 40
Gambar 3.12 Stopword Removal Tweet Cinta ... 41
Gambar 3.13 Stopword Removal Tweet Marah... 41
Gambar 3.14 Stopword Removal Tweet Sedih ... 42
Gambar 3.15 Stopword Removal Tweet Senang ... 42
Gambar 3.16 Stopword Removal Tweet Takut ... 43
Gambar 3.17 Stemming Tweet Cinta ... 43
Gambar 3.18 Stemming Tweet Marah ... 44
Gambar 3.19 Stemming Tweet Sedih ... 44
Gambar 3.20 Stemming Tweet Senang ... 45
Gambar 3.21 Stemming Tweet Takut ... 45
Gambar 3.22 Penghapusan Noise Tweet ... 46
Gambar 3.23 Penanganan Kata Negasi ... 48
Gambar 3.24 Hitung term frequency (tf) Tweet Cinta... 49
Gambar 3.25 Hitung term frequency (tf) Tweet Marah ... 49
Gambar 3.26 Hitung term frequency (tf) Tweet Sedih ... 50
Gambar 3.27 Hitung term frequency (tf) Tweet Senang ... 50
Gambar 3.28 Hitung term frequency (tf) Tweet Takut ... 51
Gambar 4.1 Hasil Akurasi Tanpa Normalisasi ... 74
Gambar 4.2 Hasil Akurasi Menggunakan Normalisasi Z-Score ... 78
Gambar 4.3 Hasil Akurasi Menggunakan Normalisasi Z-Score (Threshold = 7) . 78 Gambar 4.4 Hasil Akurasi Menggunakan Normalisasi Min-Max ... 82
Gambar 4.5 Hasil Akurasi Menggunakan Normalisasi Min-Max (Threshold = 5)83 Gambar 4.6 Potongan Source Code Tokenizing ... 85
Gambar 4.7 File Stopwords.txt... 86
Gambar 4.8 Potongan Source Code Stopword Removal ... 86
xviii
Gambar 4.10 Potongan Source Code Stemming Hapus Imbuhan ... 87
Gambar 4.11 File Synonym.txt ... 88
Gambar 4.12 Potongan Source Code Stemming Sinonim Kata ... 88
Gambar 4.13 Potongan Source Code Penanganan Kata “Tidak” ... 89
Gambar 4.14 Potongan Source Code Pembobotan tf-idf ... 90
Gambar 4.15 Hasil Tahap Preprocessing dan Pembobotan... 91
Gambar 4.16 Potongan Source Code Normalisasi Z-Score ... 92
Gambar 4.17 Potongan Source Code Normalisasi Min-Max ... 93
Gambar 4.18 Potongan Source Code Variance Initialization ... 93
Gambar 4.19 Centroid Awal Berdasarkan Variance Initialization ... 94
Gambar 4.20 Potongan Source Code K-Means Clustering ... 97
Gambar 4.21 Hasil Implementasi K-Means Clustering ... 97
Gambar 4.22 Output Centroid... 98
Gambar 4.23 Potongan Source Code Confusion Matrix ... 99
Gambar 4.24 Hasil Implementasi Confusion Matrix ... 99
Gambar 4.25 Input Uji Data Baru ... 100
1
1. BAB I PENDAHULUAN
1.1 Latar Belakang
Microblogging merupakan layanan media sosial yang memungkinkan
penggunanya untuk mengirim pesan singkat berisi berita, opini, atau
komentar mengenai satu topik tertentu. Contoh layanan microblogging yaitu
Twitter, FriendFeed, Cif2.net, Plurk, Jaiku, identi.ca, dan Tumblr.
Penelitian ini menggunakan microblogging paling populer saat ini yaitu
Twitter. Twitter adalah layanan microblogging yang memungkinkan
penggunanya mengirim dan membaca tulisan singkat dengan panjang
maksimum 140 karakter. Tulisan singkat ini dikenal dengan sebutan tweet.
Tweet yang disampaikan seringkali disertai emosi penulis. Emosi dapat
diklasifikasikan menjadi emosi positif dan emosi negatif. Emosi-emosi positif
seperti rasa senang dan rasa cinta mengekspresikan sebuah evaluasi atau
perasaan menguntungkan. Emosi-emosi negatif seperti rasa marah atau rasa
sedih mengekspresikan sebaliknya. Emosi tidak dapat netral karena emosi
netral berarti nonemosional.
Pengenalan emosi pada tweet dapat dilakukan menggunakan analisis
sentimen. Analisis sentimen dapat dimanfaatkan untuk menggali opini publik
tentang suatu topik. Analisis sentimen terhadap tweet perlu dilakukan karena
dapat dijadikan sebagai dasar manajemen merk, corporate reputation,
2
Penelitian tentang analisis sentimen pernah dilakukan oleh Nur dan
Santika pada tahun 2011. Nur dan Santika membuat penelitian berjudul
“Analisis Sentimen Pada Dokumen Berbahasa Indonesia dengan Pendekatan
Support Vector Machine”. Nur dan Santika melakukan analisis sentimen
dengan data tweet berbahasa Indonesia dengan pendekatan SVM dan Naive
Bayes. Dalam penelitian, kedua penulis menambahkan fitur antara lain
feature present (FP), term frequency (TF), dan term frequency-invers
document frequency (TF-IDF). Hasil penelitian menunjukkan tingkat akurasi
mencapai sekitar 75% (Nur dan Santika, 2011).
1.2 Perumusan Masalah
Berdasarkan latar belakang di atas, rumusan masalah pada penelitian
ini adalah:
1. Bagaimana pendekatan algoritma K-Means mampu melakukan analisis
sentimen untuk mendapatkan emosi yang terkandung dalam tweet?
2. Seberapa akurat metode K-Means mampu mengekstrak dan mengenali
emosi yang terkandung dalam tweet?
1.3 Maksud dan Tujuan Tugas Akhir
Maksud dan tujuan dari penelitian ini adalah sebagai berikut:
1. Melakukan ekstraksi terhadap tweet untuk mendapatkan perbedaan
karakter tiap tweet berdasarkan emosi yang terkandung.
3
1.4 Pembatasan dan Ruang Lingkup Permasalahan
Untuk membahas topik yang lebih terarah dan terfokus pada tujuan
yang ingin dicapai, maka batasan masalahnya sebagai berikut:
1. Tweet yang dianalisis sentimen hanyalah tweet berbahasa Indonesia.
2. Analisis sentimen dilakukan menggunakan pendekatan clustering.
3. Algoritma clustering yang dipakai adalah K-Means clustering.
4. Pengelompokan tweet berdasarkan lima emosi dasar yaitu cinta, marah,
sedih, senang, dan takut.
1.5 Sistematika Penulisan
Sistematika penulisan tugas akhir ini dibagi menjadi beberapa bab
dengan susunan sebagai berikut:
BAB I: PENDAHULUAN
Bab ini berisi pendahuluan yang terdiri dari latar belakang, rumusan
masalah, tujuan, batasan masalah, dan sistematika penulisan.
BAB II: LANDASAN TEORI
Bab ini berisi teori-teori yang digunakan sebagai dasar dalam
pembuatan sistem analisis sentimen tweet berbahasa Indonesia, antara lain
teori tentang preprocessing teks, ekstraksi ciri dan algoritma K-Means
clustering yang akan dipakai untuk perancangan sistem.
BAB III: ANALISIS DAN PERANCANGAN SISTEM
Bab ini berisi analisis komponen-komponen yang akan digunakan
4
BAB IV: IMPLEMENTASI DAN ANALISA HASIL
Bab ini berisi implementasi dari perancangan yang telah dibuat
sebelumnya serta analisis dari hasil program yang telah dibuat.
BAB V: PENUTUP
Bab ini berisi kesimpulan dari penelitian dan saran-saran untuk
5
2. BAB II
LANDASAN TEORI
Bab ini berisi penjabaran teori-teori yang bersangkutan dengan penulisan
Tugas Akhir ini. Teori-teori tersebut adalah Analisis Sentimen, Emosi, Text
Preprocessing, Pembobotan tf-idf, Normalisasi, K-Means Clustering, Cosine
Similarity, dan Confusion Matrix.
2.1 Analisis Sentimen
Analisis sentimen adalah bidang studi yang menganalisis pendapat,
sentimen, evaluasi, penilaian, sikap, dan emosi seseorang terhadap sebuah
produk, organisasi, individu, masalah, peristiwa atau topik (Liu, 2012).
2.1.1 Level Analisis Sentimen
Analisis sentimen terdiri dari tiga level analisis yaitu:
1. Level Dokumen
Level dokumen menganalisis satu dokumen penuh dan
mengklasifikasikan dokumen tersebut memiliki sentimen positif atau
negatif. Level analisis ini berasumsi bahwa keseluruhan dokumen
hanya berisi opini tentang satu entitas saja. Level analisis ini tidak
cocok diterapkan pada dokumen yang membandingkan lebih dari satu
6
2. Level Kalimat
Level kalimat menganalisis satu kalimat dan menentukan tiap
kalimat bernilai sentimen positif, negatif, atau netral. Sentimen netral
berarti kalimat tersebut bukan opini (Liu, 2012).
3. Level Entitas dan Aspek
Level aspek tidak melakukan analisis pada konstruksi bahasa
(dokumen, paragraf, kalimat, klausa, atau frase) melainkan langsung
pada opini itu sendiri. Hal ini didasari bahwa opini terdiri dari sentimen
(positif atau negatif) dan target dari opini tersebut. Tujuan level analisis
ini adalah untuk menemukan sentimen entitas pada tiap aspek yang
dibahas (Liu, 2012).
2.2 Emosi
Emosi adalah suatu pikiran dan perasaan khas yang disertai perubahan
fisiologis dan biologis serta menimbulkan kecenderungan untuk melakukan
tindakan (Goleman, 2006).
2.2.1 Emosi Dasar
Emosi yang dimiliki manusia dikategorikan menjadi lima emosi
dasar yaitu cinta (love), senang (happiness), marah (anger),
khawatir/takut (anxiety/fear), dan sedih (sadness). Emosi cinta dan
senang merupakan emosi positif. Emosi marah, takut, dan sedih
7
2.2.2 Kosakata Emosi
Penelitian terhadap 124 kosakata emosi di Indonesia
menghasilkan dua kelompok besar yaitu kosakata emosi positif dan
negatif. Kelompok kosakata emosi positif terdiri dari dua emosi dasar
yaitu emosi cinta dan senang. Kelompok kosakata emosi negatif terdiri
dari tiga emosi dasar yaitu marah, takut, dan sedih (Shaver, Murdaya,
dan Fraley, 2001).
Pengelompokan terhadap 124 kosakata emosi di Indonesia
terlihat pada Tabel 2.1 berikut:
Tabel 2.1 Kosakata Emosi
Superordinat Emosi Dasar Subordinat
Positif cinta (love) ingin, kepingin, hasrat, berahi,
terangsang, gairah, demen, suka,
terbuai, terpesona, terkesiap, terpikat,
tertarik, perasaan, getar hati, setia, edan
kesmaran, kangen, rindu, kemesraan,
asmara, mesra, cinta, kasih, sayang
Positif senang
(happiness)
bangga, kagum, asik, sukacita, sukaria,
bahagia, senang, girang, gembira,
ceria, riang, damai, aman, tenteram,
lega, kepuasan, puas, berani, yakin,
ikhlas, tulus, berbesar, besar hati,
8
Superordinat Emosi Dasar Subordinat
Negatif marah
(anger)
bosan, jenuh, cemburu, curiga, histeris,
tinggi hati, iri, berdengki, dengki,
gemas, gregetan, ngambek,
tersinggung, muak, benci, dendam,
emosi, kesal, sebal, mangkel, dongkol,
jengkel, panas hati, kalap, senewen,
murka, naik darah, naik pitam, marah,
berang, geram
Negatif takut (fear) gentar, takut, berdebar, kebat-kebit,
kalut, gusar, kecemasan, cemas,
khawatir, waswas, bimbang, bingung,
galau, gundah, gelisah, risau
Negatif sedih
(sadness)
kecil hati, malu, simpati, tersentuh,
haru, keharuan, prihatin, iba, kasihan,
murung, pilu, sendu, sedih, duka,
dukacita, sakit hati, pedih hati, patah
hati, remuk hati, frustrasi, putus asa,
putus harapan, berat hati, penyesal,
9
2.3 Text Mining
Text Mining didefinisikan sebagai proses pengetahuan intensif yang
melibatkan interaksi pengguna dengan sekumpulan dokumen dari waktu ke
waktu menggunakan berbagai macam analisis. Sejalan dengan data mining,
text mining berusaha mengekstrak informasi yang berguna dari sumber data
melalui identifikasi dan eksplorasi pattern (Putri, 2013).
Text mining mencoba untuk mengekstrak informasi yang berguna dari
sumber data melalui identifikasi dan eksplorasi dari suatu pola menarik.
Sumber data berupa sekumpulan dokumen dan pola menarik yang tidak
ditemukan dalam bentuk database record, tetapi dalam data text yang tidak
terstruktur (Sujana, 2013).
2.4 Preprocessing
Pemrosesan teks merupakan proses menggali, mengolah, dan mengatur
informasi dengan cara menganalisis hubungan dan aturan yang ada pada data
tekstual semi terstruktur atau tidak terstruktur. Agar pemrosesan lebih efektif,
data tekstual diubah ke dalam format yang sesuai kebutuhan pemakai. Proses
ini disebut preprocessing. Setelah dikenai preprocessing, data tekstual semi
terstruktur atau tidak terstruktur akan menjadi lebih terstruktur. Data tersebut
dapat dijadikan sebagai sumber data yang diolah lebih lanjut (Luhulima,
2013).
10
2.4.1 Tokenization / Tokenizing
Tokenization merupakan langkah untuk memotong dokumen
menjadi potongan-potongan kecil yang disebut token dan terkadang
disertai langkah untuk membuang karakter tertentu seperti tanda baca
(Manning, Raghavan, dan Schütze, 2009).
Contoh proses tokenization:
Input: aku merasa bahagia telah temukan dirimu kekasihku
Output:
aku merasa bahagia telah temukan dirimu kekasihku
2.4.2 Stopword Removal
Kata umum yang sering digunakan memiliki nilai yang kecil
dalam membantu pemilihan dokumen yang sesuai dengan kebutuhan
pengguna. Kata umum tersebut adalah stop words.
Terdapat beberapa cara dalam menentukan stop words. Cara
pertama adalah dengan mengurutkan kata berdasarkan jumlah
kemunculan dalam dokumen kemudian mengambil kata-kata yang
sering muncul sebagai stop words. Cara kedua adalah dengan
menentukan kata-kata yang termasuk dalam stop list sesuai konteks
11
Kata-kata yang termasuk dalam daftar stop words akan
dihilangkan selama pengindeksan. Tujuan stopword removal adalah
mengurangi jumlah kata yang disimpan oleh sistem (Manning,
Raghavan, dan Schütze, 2009).
Setiap bahasa memiliki daftar stop words yang berbeda. Contoh
stop words dalam bahasa Inggris yaitu “is”, “am”, “are”, “be”, dan
“this”. Contoh stop words dalam bahasa Indonesia yaitu “aku”, “yang”,
“dan”, “ini”, dan “telah”.
Contoh proses stopword removal:
Input:
aku merasa Bahagia telah temukan dirimu kekasihku
Output:
merasa Bahagia temukan dirimu kekasihku
2.4.3 Stemming
Stemming merupakan suatu proses yang terdapat dalam sistem
information retrieval yang mentransformasi kata-kata yang terdapat
dalam suatu dokumen ke kata-kata akarnya (root word) dengan
menggunakan aturan-aturan tertentu. Sebagai contoh, kata bersama,
12
Proses stemming pada teks berbahasa Indonesia berbeda dengan
stemming pada teks berbahasa Inggris. Pada teks berbahasa Inggris,
proses yang diperlukan hanya proses menghilangkan sufiks. Sedangkan
pada teks berbahasa Indonesia, selain sufiks, prefiks, dan konfiks juga
dihilangkan (Agusta, 2009).
Algoritma Stemming yang dibuat oleh Bobby Nazief dan Mirna
Adriani memiliki tahap-tahap sebagai berikut (Agusta, 2009):
1. Pertama cari kata yang akan di-stem dalam kamus kata dasar. Jika
ditemukan maka diasumsikan kata adalah root word. Maka
algoritma berhenti.
2. Inflection Suffixes (“-lah”, “-kah”, “-ku”, “-mu”, atau “-nya”)
dibuang. Jika berupa particles (“-lah”, “-kah”, “-tah” atau “-pun”)
maka langkah ini diulangi lagi untuk menghapus Possesive
Pronouns(“-ku”, “-mu”, atau “-nya”), jika ada.
3. Hapus Derivation Suffixes (“-i”, “-an” atau “-kan”). Jika kata
ditemukan di kamus, maka algoritma berhenti. Jika tidak maka ke
langkah 3a.
a. Jika “-an” telah dihapus dan huruf terakhir dari kata
tersebut adalah “-k”,maka “-k” juga ikut dihapus. Jika kata
tersebut ditemukan dalam kamus maka algoritma berhenti.
Jika tidak ditemukan maka lakukan langkah 3b.
b. Akhiran yang dihapus (“-i”, “-an” atau “-kan”)
13
4. Hapus Derivation Prefix. Jika pada langkah 3 ada sufiks yang
dihapus maka pergi ke langkah 4a, jika tidak pergi ke langkah 4b.
a. Periksa tabel kombinasi awalan-akhiran yang tidak
diijinkan. Jika ditemukan maka algoritma berhenti, jika
tidak pergi ke langkah 4b.
b. For i = 1 to 3, tentukan tipe awalan kemudian hapus awalan.
Jika root word belum juga ditemukan lakukan langkah 5,
jika sudah maka algoritma berhenti. Catatan: jika awalan
kedua sama dengan awalan pertama algoritma berhenti.
5. Melakukan Recoding.
6. Jika semua langkah telah selesai tetapi tidak juga berhasil maka
kata awal diasumsikan sebagai root word. Proses selesai.
Tipe awalan ditentukan melalui langkah-langkah berikut:
1. Jika awalannya adalah: “di-”, “ke-”, atau “se-” maka tipe
awalannya secara berturut-turut adalah “di-”, “ke-”, atau “se-”.
2. Jika awalannya adalah “te-”, “me-”, “be-”, atau “pe-” maka
dibutuhkan sebuah proses tambahan untuk menentukan tipe
awalannya.
3. Jika dua karakter pertama bukan “di-”, “ke-”, “se-”, “te-”, “be-”,
14
4. Jika tipe awalan adalah “none” maka berhenti. Jika tipe awalan
adalah bukan “none” maka awalan dapat dilihat pada Tabel .
Hapus awalan jika ditemukan.
Tabel 2.2 Kombinasi Awalan dan Akhiran
Awalan Akhiran yang tidak diizinkan
be- -i
di- -an
ke- -i, -kan
me- -an
se- -i, -kan
Tabel 2.3 Cara Menentukan Tipe Awalan untuk Awalan “te-”
Following characters Tipe
awalan
set 1 set 2 set 3 set 4
“-r-” “-r-” - - none
“-r-” vowel - - ter- luluh
“-r-” not(vowel or “-r-”) “-er-” vowel ter
“-r-” not(vowel or “-r-”) “-er-” not vowel ter
“-r-” not(vowel or “-r-”) not “-er-” - ter
not(vowel or “-r-”) “-er-” vowel - none
15
Tabel 2.4 Jenis Awalan Berdasarkan Tipe
Tipe Awalan Awalan yang harus dihapus
di- di-
ke- ke-
se- se-
te- te-
ter- ter-
ter- luluh ter- luluh
Untuk mengatasi keterbatasan pada algoritma di atas, maka
ditambahkan aturan-aturan dibawah ini (Agusta, 2009):
1. Aturan untuk reduplikasi.
Jika kedua kata yang dihubungkan oleh kata penghubung
adalah kata yang sama maka root word adalah bentuk
tunggalnya, contoh : “buku-buku” root word-nya adalah
“buku”.
Kata lain, misalnya “bolak-balik”, “berbalas-balasan”, dan
”seolah-olah”. Untuk mendapatkan root word-nya, kedua
kata diartikan secara terpisah. Jika keduanya memiliki root
word yang sama maka diubah menjadi bentuk tunggal,
contoh: kata “berbalas-balasan”, “berbalas” dan “balasan”
16
word “berbalas-balasan” adalah “balas”. Sebaliknya, pada
kata “bolak-balik”, “bolak” dan“balik” memiliki root word
yang berbeda, maka root word-nya adalah “bolak-balik”.
2. Tambahan bentuk awalan dan akhiran serta aturannya.
Untuk tipe awalan “mem-“, kata yang diawali dengan
awalan “memp-”memiliki tipe awalan “mem-”.
Tipe awalan “meng-“, kata yang diawali dengan awalan
“mengk-”memiliki tipe awalan “meng-”.
Contoh proses stemming:
Input:
merasa bahagia temukan dirimu kekasihku
Output:
rasa bahagia temu diri kasih
2.4.4 Perbedaan Perlakuan Preprocessing
Pada klasifikasi teks berdasarkan kategori artikel, kata-kata
seperti “tidak”, “tanpa”, dan “bukan” dianggap tidak penting sehingga
dimasukkan ke dalam daftar kata yang bisa dihilangkan (stopword).
Namun, pada klasifikasi teks emosi, kata “tidak”, “tanpa”, dan “bukan”
17
Perlakuan proses sebelum klasifikasi sangat penting supaya data
yang diolah benar-benar mewakili maksud dari sebuah dokumen. Kata
“tanpa cinta” dan “tidak senang” dapat menempatkan dokumen dalam
kelas yang berbeda (Destuardi dan Sumpeno, 2009).
Sebagai contoh, dokumen yang mengandung kata “tidak senang”
akan masuk ke kelas yang berbeda dengan dokumen yang mengandung
kata ”senang”.
2.5 Pembobotan tf-idf
Pembobotan dilakukan untuk mendapatkan nilai dari kata (term) yang
telah diekstrak. Metode pembobotan yang digunakan yaitu pembobotan tf-idf.
Pada tahap ini, setiap dokumen diwujudkan sebagai sebuah vector dengan
elemen sebanyak kata (term) yang didapat dari tahap ekstraksi dokumen.
Vector tersebut beranggotakan bobot dari setiap term yang didapat dengan
perhitungan bobot tf-idf.
Metode tf-idf merupakan metode pembobotan dengan menggunakan
integrasi antara term frequency (tf) dan inverse document frequency (idf).
Metode tf-idf dirumuskan sebagai berikut:
, = , ∗ �
� = � �
18 , adalah jumlah kemunculan kata t pada dokumen d, � adalah jumlah
dokumen pada kumpulan dokumen, dan adalah jumlah dokumen yang
mengandung term t.
Fungsi metode ini untuk mencari representasi nilai dari tiap-tiap
dokumen dari kumpulan data training. Representasi nilai akan dibentuk
menjadi vector antara dokumen dengan kata (documents with terms).
Kesamaan antara dokumen dengan cluster ditentukan oleh sebuah prototype
cluster yang disebut juga dengan cluster centroid (Putri, 2013).
2.6 Normalisasi
Metode normalisasi yang digunakan pada penelitian ini adalah metode
normalisasi z-score dan metode normalisasi min-max.
2.6.1 Normalisasi Z-Score
Normalisasi z-score umumnya digunakan jika nilai minimum dan
maksimum sebuah atribut tidak diketahui. Normalisasi z-score
dirumuskan sebagai berikut:
′= − �̅ �
�
⁄ (2.2)
′ adalah nilai yang baru, adalah nilai yang lama, �̅ adalah rata-rata
dari atribut �, dan �� adalah nilai standar deviasi dari atribut �
19
2.6.2 Normalisasi Min-Max
Normalisasi min-max dirumuskan sebagai berikut:
� =�� −�
��−� (2.3)
� adalah nilai baru untuk variable �, � adalah nilai lama untuk
variabel �, � adalah nilai minimum dalam data set, dan � �� adalah
nilai maksimum dalam data set (Mustaffa dan Yusof, 2011).
2.7 Clustering
Sejumlah besar data dikumpulkan setiap hari dalam lingkup bisnis dan
sains. Data ini perlu dianalisis dengan tujuan memperoleh informasi menarik.
Salah satu metode analisis yang cukup populer adalah clustering.
Clustering merupakan salah satu alat penting dalam data mining yang
membantu peneliti mengetahui pengelompokan secara natural atribut-atribut
dalam data. Analisis cluster dipakai dalam berbagai bidang antara lain data
mining, pattern recognition, pattern classification, data compression,
machine learning, image analysis, dan bioinformatics.
Clustering adalah metode yang memungkinkan sebuah cluster
terbentuk karena kesamaan karakteristik anggota-anggota cluster tersebut.
Kriteria untuk menentukan kesamaan tergantung pada implementasi.
Algoritma clustering dapat dikelompokkan menjadi dua kelas besar yaitu
20
Algoritma Hierarchical clustering menggunakan pemisahan secara
bersarang. Teknik yang termasuk hierarchical clustering yaitu Divisive
clustering dan Agglomerative clustering. Divisive clustering menganggap
keseluruhan data merupakan sebuah cluster kemudian membagi cluster
tersebut menjadi lebih kecil. Agglomerative clustering menganggap sebuah
data merupakan sebuah cluster kemudian menggabung cluster tersebut
menjadi lebih besar.
Algoritma Partition clustering tidak menggunakan struktur cluster
seperti dendogram yang terbentuk melalui teknik hierarchical. Metode
partition diterapkan pada data sets besar untuk menghindari pemakaian
komputasi saat pembentukan dendogram. Masalah yang dijumpai pada
algoritma partition yaitu pemilihan jumlah cluster (Agha dan Ashour, 2012).
2.7.1 K-Means Clustering
K-Means clustering merupakan salah satu teknik partition
clustering yang paling banyak digunakan. K-Means diawali dengan
menginisialisasi K pusat cluster. Tiap titik data akan dimasukkan pada
cluster yang tersedia berdasarkan kedekatan dengan pusat cluster.
Langkah berikutnya adalah menghitung rata-rata setiap cluster untuk
meng-update pusat cluster. Update terjadi sebagai hasil dari perubahan
keanggotaan cluster. Proses akan berulang sampai pusat cluster tidak
21
1. Initialization: pilih K input vector data sebagai inisialisasi pusat
cluster.
2. Nearest-neighbor search: untuk setiap input vector, temukan
pusat cluster terdekat, dan masukkan input vector pada cluster
terdekat.
3. Mean update: update pusat cluster menggunakan rata-rata
(centroid) vector yang tergabung dalam setiap cluster.
4. Stopping rule: ulangi langkah 2 dan 3 sampai tidak ada perubahan
nilai rata-rata (mean).
Pemilihan pusat awal cluster sangat mempengaruhi hasil
K-Means clustering sehingga diperlukan tahap tertentu untuk memilih
pusat awal cluster yang optimal. Pemilihan dapat dilakukan secara
random atau dengan menjadikan k data pertama sebagai pusat awal
cluster, k adalah jumlah cluster. Sebagai alternatif, pemilihan dilakukan
dengan mencoba beragam kombinasi pusat awal kemudian memilih
kombinasi yang paling optimal. Namun, melakukan uji coba terhadap
kombinasi pusat awal tidak praktis terlebih untuk data sets yang besar.
Pemilihan pusat atau centroid awal dapat dilakukan dengan
algoritma tertentu. Dalam penelitian ini, algoritma yang digunakan
adalah variance initialization. Algoritma ini akan menemukan dimensi
dengan nilai variance terbesar, melakukan sort, membagi data menjadi
sejumlah bagian, mencari median pada setiap bagian, dan menjadikan
22
2.7.2 Variance Initialization
Variance initialization adalah salah satu algoritma yang
digunakan untuk menentukan centroid awal pada proses clustering.
Langkah-langkah variance initialization adalah sebagai berikut
(Al-Daoud, 2007):
1. Hitung nilai variance data pada setiap dimensi (kolom data).
2. Temukan kolom dengan nilai variance terbesar, kemudian sort
data.
3. Bagi keseluruhan data menjadi K bagian, K adalah jumlah
cluster.
4. Temukan median (nilai tengah) pada setiap bagian.
5. Gunakan vector data median setiap bagian sebagai centroid awal
cluster.
2.8 Cosine Similarity
Metode cosine similarity adalah metode untuk menghitung similaritas
antara dua dokumen. Penentuan kesesuaian dokumen dengan query
dipandang sebagai pengukuran (similarity measure) antara vector dokumen
(D) dengan vector query (Q). Perhitungan cosine similarity dirumuskan
sebagai berikut:
� �� (�, ) = ∑= � .
√(∑= �) .√(∑= )
23 � adalah dokumen uji, adalah dokumen training, dan adalah nilai
bobot setiap term pada dokumen.
Kedekatan query dengan dokumen diindikasikan dengan sudut yang
dibentuk. Nilai cosinus yang cenderung besar menunjukkan dokumen
cenderung sesuai query. Proses membandingkan satu dokumen dengan
dokumen lain menggunakan angka similaritas yang didapat dengan
perhitungan pada persamaan (Putri, 2013).
2.9 Confusion Matrix
Data pelatihan dan pengujian merupakan data yang berbeda sehingga
klasifikasi dapat diuji dengan benar. Akurasi dari klasifikasi dihitung dari
jumlah data yang dikenali sesuai dengan target kelasnya. Perhitungan akurasi
klasifikasi data dihitung menggunakan tabel yang bernama Confusion Matrix
(Tan, Steinbach, dan Kumar, 2006). Tabel 2.5 merupakan Confusion Matrix
untuk klasifikasi 2 kelas.
Tabel 2.5 Confusion Matrix 2 kelas
Hasil pengujian
1 0
Target
kelas
1 F11 F10
0 F01 F00
Fij adalah jumlah data yang dikenali sebagai kelas j dengan target kelas
i. Dari Tabel 2.1, didapat persamaan-persamaan untuk menghitung akurasi
24
1. Persamaan untuk menghitung akurasi keseluruhan klasifikasi
� � � = �ℎ � � �ℎ � �� � � � = � +� +� +�� +� (2.5)
2. Persamaan untuk menghitung error keseluruhan klasifikasi
� � � = �ℎ � � �ℎ � � � �� � � = � +� +� +�� +� (2.6)
3. Persamaan untuk menghitung akurasi klasifikasi kelas 1
� � � = �ℎ � � �ℎ � � � � � � � = � +�� (2.7)
4. Persamaan untuk menghitung error klasifikasi kelas 1
� � � = �ℎ � � �ℎ � � � � � � � � = � +�� (2.8)
5. Persamaan untuk menghitung akurasi klasifikasi kelas 0
� � � = �ℎ � � �ℎ � � � � � � � = � +�� (2.9)
6. Persamaan untuk menghitung error klasifikasi kelas 0
25
3. BAB III
METODOLOGI PENELITIAN
Bab ini berisi perancangan penelitian yang akan dibuat oleh penulis meliputi
data, deskripsi sistem, dan model analisis.
3.1 Data
Data yang digunakan pada penelitian ini adalah tweet berbahasa
Indonesia yang ditulis oleh para pengguna layanan Twitter. Tweet yang
dikumpulkan merupakan tweet yang berisi emosi cinta, sedih, senang, marah,
atau takut. Penulis mengumpulkan masing-masing 200 tweet untuk tiap
kelompok emosi sehingga total tweet yang digunakan sebagai data berjumlah
1000.
Pengumpulan data dilakukan pada tanggal 1 Januari sampai 30 Juni
2015 secara manual yaitu dengan menyalin kalimat tweet ke file teks.
Pencarian dan pengumpulan data dilakukan dengan menggunakan hashtag
#cinta, #sedih, #senang, #marah, dan #takut. Setiap tweet diletakkan pada
setiap baris pada file teks. File teks berisi tweet tersebut kemudian dijadikan
input pada sistem untuk diolah lebih lanjut.
Gambar 3.1 menunjukkan contoh tweet dengan emosi cinta. Penulis
tweet tersebut mengungkapkan kecintaan pada seseorang atau sesuatu melalui
26
@MT_lovehoney Jun 30 View translation saat hati berbunga, rindu akan
melanda,,, selmat pagi duniaaaa,,,,, #cinta
@andrisaragih6 Jun 29 View translation Rasa itu pasti ada , baik sudah
lama maupun tidak lama , dengan diri nya #Cinta
@SemuaCintaKamu Jun 29 View translation Semoga rindu ini bisa
menyatukan kita dalam satu ikatan cinta yg suci #rindu #cinta #suci
@asmi_AB Jun 29 View translation Jangan salahkan jika rindu datang,
nikmati hadirnya, hapus airmatamu dan peluk dia dengan doa. #Cinta
@ozageoradeta Jun 29 View translation Cnta itu indah.. Seindah
senyuman & candaan Cinta itu memeluk hati ke2 insan.. Menyatukan nya
dalam 1 ikatan #cinta
Gambar 3.1 Tweet Cinta
Gambar 3.2 menunjukkan contoh tweet dengan emosi marah. Penulis
tweet tersebut mengungkapkan kemarahan pada seseorang atau sesuatu
melalui kata-kata yang ditulis.
@DavidPanggi Jun 29 View translation Kampretttt...ember itu
27
@dear_darma Jun 29 Siman, East Java View translation Sadar g sih loe,
klo kata" lho udh nyakitin gw! #marah
@Lidya_christine Jun 28 View translation Hmmmm...smkn lama smkn
buat jengkel..#marah #kesel #kecewa Gini salah gitu salah...msti y apa lg
ini kudu nangis ae..
@EytikaSari Jun 27 View translation #Tamasha retweeted lisa vanestha
#Ngambek bnget #Marah thu sampai rumah depan mati lampu ,,,,, alnya
dah tidur orangnya jdi di mati'i lmpunya
@angelaflassy Jun 26 View translation Saat sedang berpuasa, jangan
buat orang lain marah dong...#marah
Gambar 3.2 Tweet Marah
Gambar 3.3 menunjukkan contoh tweet dengan emosi sedih. Penulis
tweet tersebut mengungkapkan kesedihan pada seseorang atau sesuatu
melalui kata-kata yang ditulis.
@shasiahmohd Jun 29 View translation Dengar alunan Al-Quran ni
makin rasa sedih pula. Allahu, kuatkan aku! #Sedih
@DelsaMpuspita Jun 29 View translation Malam ini banjir air mata ;(
28
@ade_noviantika Jun 29 View translation Film "Hearts Trings" oohhhh
s0 sweAt bngeett ?jdi keingat sma seseorng ? tpi kini Dia telah mnghilng
& meninggalkan Qku..#sedih rasanya?
@kuswandi_sumaga Jun 29 View translation Arti Persahabatn yg
sesungguhnya adalah,ketika sahabat meninggalkan kita.yg tersisa
kenangan & air mata.?????? #Sedih,,,??????
@NyimasPiliana_ Jun 28 View translation #sedih #sedih #sedih ni film
berhasil buat ngeluari air mata:'( #huaaaa
Gambar 3.3 Tweet Sedih
Gambar 3.4 menunjukkan contoh tweet dengan emosi senang. Penulis
tweet tersebut mengungkapkan kesenangan pada seseorang atau sesuatu
melalui kata-kata yang ditulis.
@Dino_stiel 29 Jun 2015 Alhamdulillah,terima kasih ya Allah #iphone6
#berkah #senang https://instagram.com/p/4g8kqYlObu/
@iqbalmad 28 Jun 2015 Senyum - Alhamdulillah.\^_^/ Insyaallah Besok,
29
@wady_INmadrid 26 Jun 2015 "senang bisa buat senang yang disenang"
#senang
@MarlikaD_Lilica Jun 26 View translation Alhamdulillah gua lulus ...
#Bersyukur #senang — bersyukur
@mawyow 24 Jun 2015 View translation Teman-teman, kabarnya lagu
saya masuk chart di radio @prambors #LNH20 Yeaaaayy!! dengerin yuk
sekarang sampai jam10 nanti #senang
Gambar 3.4 Tweet Senang
Gambar 3.5 menunjukkan contoh tweet dengan emosi takut. Penulis
tweet tersebut mengungkapkan ketakutan pada seseorang atau sesuatu
melalui kata-kata yang ditulis.
@rina_sugiarty Jun 30 View translation Sampe takut buat mejem #takut
yg di dapet mimpi buruk :3
@siagian_ronald Jun 27 View translation Keadaan ekonomi atau
kesusahan hidup, belum seberapa dibanding neraka #takut
@elfyesha Jun 26 View translation firasat buruk, sperti ada ssuatu yg tdk
30
@Sifni_Jumaila Jun 26 View translation .kayak lewat dilorong setan.
Sumpah serem. #takut
@shining_ning Jun 26 View translation Kok td ad suara suara horor yg
berasa ad di dpn kamar ku, huahhh apakah itu >___< #takut
Gambar 3.5 Tweet Takut
3.2 Deskripsi Sistem
Sistem ini digunakan untuk mengetahui akurasi penggolongan tweet
berdasarkan emosi dengan menggunakan metode K-Means Clustering.
Sistem dapat melakukan tahap preprocessing, pembobotan, normalisasi,
K-Means Clustering, menghitung akurasi menggunakan confusion matrix, dan
menguji data baru.
Tahap Preprocessing
Pada tahap preprocessing, sistem melakukan tahap tokenizing, remove
stopword dan stemming. Sistem juga melakukan beberapa perlakuan khusus
terhadap data yang digunakan karena tweet mengandung banyak noise.
Sistem akan menghapus link url, username, tanda retweet, dan beragam noise
lain. Sistem akan mengubah kata tidak baku atau kata yang disingkat menjadi
kata yang baku. Sistem juga akan mengambil kata yang diawali tanda pagar
(hashtag).
Langkah-langkah tokenizing :
31
2. Ambil tiap token pada kalimat tweet dengan menggunakan spasi
sebagai pemisah antara satu token dengan token lain.
3. Simpan tiap kalimat tweet yang terdiri dari token penyusun.
Langkah-langkah remove stopword :
1. Baca tiap token dan cocokkan dengan kata pada daftar
stopword.
2. Hapus token jika cocok dengan kata pada daftar stopword.
Langkah-langkah stemming :
1. Baca tiap token dan cocokkan dengan kata pada daftar kamus
kata dasar.
2. Jika token cocok dengan kata pada daftar kamus kata dasar,
berarti token adalah root word..
3. Jika token tidak cocok dengan kata pada daftar kamus kata
dasar, hapus akhiran dan awalan pada token.
4. Cocokkan hasil langkah 3 dengan kata pada daftar kamus kata
dasar, jika tidak cocok, anggap token sebelum dikenai langkah
3 sebagai root word.
Langkah-langkah hapus noise tweet :
1. Menghapus url : menghapus kalimat yang berawalan “www”,
“http” atau “https” .
2. Menghapus username : menghapus kata yang berawalan tanda
32
3. Menghapus kata berawalan angka misalnya “30hari”.
4. Memangkas huruf sama berurutan misalnya “jalannn” menjadi
“jalan”.
5. Menghapus angka, tanda baca, dan karakter selain huruf.
6. Menghapus noise lain yang ada dalam data seperti tanggal
penulisan tweet, tanda retweet, kata “view” dan “translation”,
serta penanda waktu penulisan tweet misalnya “hour”, “hours”,
“ago”.
Langkah-langkah sinonim kata :
1. Cari sinonim kata pada daftar kata sinonim.
2. Jika ditemukan, ganti kata awal dengan kata sinonim.
3. Jika tidak ditemukan, kata awal tidak diganti.
Langkah-langkah penanganan kata negasi :
1. Temukan kata tidak, bukan, atau tanpa.
2. Gabung kata tidak, bukan, atau tanpa dengan kata di belakang
misalnya “tidak” “senang” menjadi “tidaksenang”.
3. Hapus kata yang telah digabung dengan kata tidak, bukan, atau
tanpa.
Tahap Pembobotan
Pada tahap pembobotan, sistem akan merepresentasikan tweet sebagai
vector dengan nilai bobot masing-masing term. Perhitungan bobot term
33
Langkah-langkah pembobotan tf-idf :
1. Untuk setiap data tweet, lakukan langkah 2 – 4.
2. Hitung nilai tf masing-masing kata.
3. Hitung nilai idf masing-masing kata.
4. Hitung bobot tweet dengan mengalikan nilai tf dan idf.
Tahap Normalisasi
Pada tahap normalisasi, sistem akan menggunakan dua macam
normalisasi yaitu z-score dan min-max. Dua macam normalisasi digunakan
untuk mendapatkan metode yang lebih optimal pada penelitian ini. Nilai
bobot term yang dinormalkan hanya bobot term yang dominan saja. Bobot
dominan yaitu bobot yang bernilai lebih dari threshold tertentu.
Langkah-langkah normalisasi z-score :
1. Hitung nilai mean pada setiap tweet.
2. Hitung nilai standard deviation pada setiap tweet.
3. Hitung bobot baru. Bobot baru didapat dari bobot lama
dikurangi rata-rata (mean) kemudian dibagi standard deviation
Langkah-langkah normalisasi min-max:
1. Temukan nilai min dan max pada setiap kata.
2. Hitung bobot baru. Bobot baru didapat dari bobot lama
34
terbesar (max) dikurangi nilai terkecil (min). Jika nilai min sama
dengan nilai max, bobot baru akan ditentukan bernilai 0,5.
Tahap Clustering
Pada tahap clustering, sistem akan mengelompokkan tweet ke dalam
lima cluster yaitu cinta, sedih, senang, marah, dan takut. Setiap tweet akan
dikelompokkan berdasarkan kemiripan atau kedekatan dengan centroid.
Kemiripan antara tweet dengan centroid dihitung menggunakan metode
cosine similarity.
Algoritma K-Means clustering memiliki kelemahan yaitu jika pusat
(centroid) awal cluster tidak baik maka hasil akhir pengelompokan juga tidak
baik. Oleh karena itu, pada penelitian ini digunakan metode tambahan untuk
menentukan centroid awal cluster. Centroid awal ditentukan dengan metode
variance initialization.
Langkah-langkah Variance Initialization:
1. Hitung nilai variance data pada setiap dimensi (kolom data).
2. Temukan kolom dengan nilai variance terbesar, kemudian sort
data.
3. Bagi keseluruhan data menjadi K bagian, K adalah jumlah
cluster.
4. Temukan median (nilai tengah) pada setiap bagian.
5. Gunakan vector data median setiap bagian sebagai centroid
35
Langkah-langkah K-Means Clustering:
1. Initialization: pilih K input vector data sebagai inisialisasi pusat
cluster. Centroid awal cluster didapat dari tahap variance
initialization.
2. Nearest-neighbor search: untuk setiap input vector, temukan
pusat cluster terdekat, dan masukkan input vector pada cluster
terdekat. Kemiripan antara tweet dengan centroid dihitung
menggunakan metode cosine similarity.
3. Mean update: update pusat cluster menggunakan rata-rata
(centroid) vector yang tergabung dalam setiap cluster.
4. Stopping rule: ulangi langkah 2 dan 3 sampai tidak ada
perubahan nilai rata-rata (mean).
Tahap Hitung Akurasi
Pada tahap hitung akurasi, sistem akan membandingkan label cluster
hasil prediksi sistem dengan label cluster yang ditentukan penulis kemudian
merepresentasikan ke dalam sebuah confusion matrix. Kemudian sistem akan
menghitung akurasi sistem menggunakan confusion matrix.
Langkah-langkah Uji Akurasi:
1. Baca label aktual tweet berdasarkan hashtag yang diberikan
penulis tweet.
36
3. Representasikan label aktual dan prediksi ke dalam confusion
matrix.
4. Hitung akurasi dengan cara membagi jumlah tweet yang tepat
dikenali dengan jumlah seluruh data kemudian dikalikan
dengan 100 %.
Tahap Uji Data Baru
Pada tahap uji data baru, sistem akan menentukan tweet baru masuk ke
cluster cinta, sedih, senang, marah, atau takut menggunakan centroid akhir
hasil pengujian sistem.
Langkah-langkah Uji Data Baru:
1. Masukkan data tweet baru
2. Tentukan centroid akhir tahap clustering sebagai penentu data
baru termasuk cluster cinta, marah, sedih, senang, dan takut.
3. Lakukan tahap preprocessing, pembobotan dan normalisasi
sehingga didapat vector data tweet baru.
4. Hitung kemiripan data baru dengan lima centroid menggunakan
metode cosine similarity.
5. Tentukan emosi tweet berdasarkan kedekatan atau kemiripan
37
3.3 Model Analisis
Pengumpulan Data Preprocessing Pembobotan tf-idf
Normalisasi K-Means Clustering Hitung Akurasi
Gambar 3.6 Diagram Blok
3.3.1 Preprocessing
Tahap preprocessing meliputi tahap tokenizing, stopword
removal, dan stemming. Penjelasan tahap preprocessing adalah sebagai
berikut:
3.3.1.1 Tokenizing
Tokenizing bertujuan untuk memenggal kalimat tweet menjadi
tiap-tiap kata. Gambar-gambar di bawah menunjukkan contoh
perlakuan tokenizing terhadap kalimat tweet cinta, marah, sedih,
38
Gambar 3.7 Tokenizing Tweet Cinta
Gambar 3.7 menunjukkan contoh kalimat tweet yang dikenai
proses tokenizing. Kalimat tweet yang digunakan pada gambar di atas
adalah tweet yang mengandung emosi cinta.
Tokenizing tweet marah
Huuhh ... Lagi2 dibuat marah sama si dia . punya kerjaan yg
Gambar 3.8 Tokenizing Tweet Marah
Gambar 3.8 menunjukkan contoh kalimat tweet yang dikenai
proses tokenizing. Kalimat tweet yang digunakan pada gambar di atas
39
Tokenizing tweet sedih
Inilah saat terakhirku melihat passus, jatuh air mataku menangis pilu. Hanya mampu ucapkan selamat jalan passus,,, :'(
Gambar 3.9 Tokenizing Tweet Sedih
Gambar 3.9 menunjukkan contoh kalimat tweet yang dikenai
proses tokenizing. Kalimat tweet yang digunakan pada gambar di atas
adalah tweet yang mengandung emosi sedih.
Tokenizing tweet senang
Mempunyai Sahabat Seperti Dia Menyenangkan ^_^ ^_^ Bisa Bekerja Sama,Jalan Bersama,Dan Selalu Bahagia ^_^ ^_^
Gambar 3.10 Tokenizing Tweet Senang
Gambar 3.10 menunjukkan contoh kalimat tweet yang dikenai
proses tokenizing. Kalimat tweet yang digunakan pada gambar di atas
40
Gambar 3.11 Tokenizing Tweet Takut
Gambar 3.11 menunjukkan contoh kalimat tweet yang dikenai
proses tokenizing. Kalimat tweet yang digunakan pada gambar di atas
adalah tweet yang mengandung emosi takut.
3.3.1.2 Stopword Removal
Stopword removal bertujuan untuk menghilangkan kata-kata
yang memiliki nilai kecil dalam membantu pemilihan dokumen yang
sesuai dengan kebutuhan pengguna. Stopword removal dilakukan
dengan cara mencocokkan tiap kata dalam dokumen dengan sebuah
daftar stopword. Jika kata pada dokumen sama dengan kata yang ada
pada daftar stopword, kata tersebut akan dihapus. Gambar-gambar di
bawah menunjukkan contoh perlakuan stopword removal terhadap
41
Gambar 3.12 Stopword Removal Tweet Cinta
Gambar 3.12 menunjukkan contoh kalimat tweet yang dikenai
proses stopword removal. Kalimat tweet yang digunakan pada gambar
di atas adalah tweet yang mengandung emosi cinta.
Stopword removal tweet marah
Gambar 3.13 Stopword Removal Tweet Marah
Gambar 3.13 menunjukkan contoh kalimat tweet yang dikenai
proses stopword removal. Kalimat tweet yang digunakan pada gambar
42
Gambar 3.14 Stopword Removal Tweet Sedih
Gambar 3.14 menunjukkan contoh kalimat tweet yang dikenai
proses stopword removal. Kalimat tweet yang digunakan pada gambar
di atas adalah tweet yang mengandung emosi sedih.
Stopword removal tweet senang
Gambar 3.15 Stopword Removal Tweet Senang
Gambar 3.15 menunjukkan contoh kalimat tweet yang dikenai
proses stopword removal. Kalimat tweet yang digunakan pada gambar
43
Gambar 3.16 Stopword Removal Tweet Takut
Gambar 3.16 menunjukkan contoh kalimat tweet yang dikenai
proses stopword removal. Kalimat tweet yang digunakan pada gambar
di atas adalah tweet yang mengandung emosi takut.
3.3.1.3 Stemming
Stemming bertujuan untuk mengembalikan tiap kata dalam
dokumen menjadi kata dasar. Stemming dilakukan dengan
menghilangkan awalan (prefiks) dan akhiran (sufiks). Gambar-gambar
di bawah menunjukkan contoh perlakuan stemming terhadap kalimat
tweet cinta, marah, sedih, senang, dan takut.
Stemming tweet cinta
44
Gambar 3.17 menunjukkan contoh kalimat tweet yang dikenai
proses stemming. Kalimat tweet yang digunakan pada gambar di atas
adalah tweet yang mengandung emosi cinta.
Stemming tweet marah
Gambar 3.18 Stemming Tweet Marah
Gambar 3.18 menunjukkan contoh kalimat tweet yang dikenai
proses stemming. Kalimat tweet yang digunakan pada gambar di atas
adalah tweet yang mengandung emosi marah.
Stemming tweet sedih
Gambar 3.19 Stemming Tweet Sedih
Gambar 3.19 menunjukkan contoh kalimat tweet yang dikenai
proses stemming. Kalimat tweet yang digunakan pada gambar di atas
45
Gambar 3.20 Stemming Tweet Senang
Gambar 3.20 menunjukkan contoh kalimat tweet yang dikenai
proses stemming. Kalimat tweet yang digunakan pada gambar di atas
adalah tweet yang mengandung emosi senang.
Stemming tweet takut
Gambar 3.21 Stemming Tweet Takut
Gambar 3.21 menunjukkan contoh kalimat tweet yang dikenai
proses stemming. Kalimat tweet yang digunakan pada gambar di atas
46
3.3.1.4 Preprocessing Tambahan Penghapusan Noise Tweet
Selain tahap tokenizing, stopword removal, dan stemming, data
tweet memerlukan beberapa preprocessing tambahan untuk
membersihkan data dari noise. Preprocessing tambahan meliputi
menghapus link url, username, tanda retweet, dan beragam noise lain.
@riefianindita_ Tetes air mata basahi pipiku disaat kita kan berpisah
https://instagram.com/p/z1-sl9LJrF/
Tetes air mata basahi pipiku disaat kita kan berpisah
Gambar 3.22 Penghapusan Noise Tweet
Gambar 3.22 menunjukkan contoh kalimat tweet yang dikenai
proses penghapusan noise. Username dan link url yang terdapat dalam
tweet dihapus melalui tahap ini.
Penggabungan Sinonim Kata
Kata-kata yang terdapat dalam kalimat tweet berasal dari banyak
orang sehingga penulisan kata-kata tersebut sangat bervariasi. Kalimat
tweet dapat berisi kata tidak baku, kata yang disingkat, dan kata yang
dihilangkan beberapa huruf vokalnya. Oleh karena itu, proses
penggabungan kata berdasarkan kesamaan arti perlu dilakukan.
Penggabungan kata akan mengembalikan kata tidak baku atau kata