i
ANALISIS SENTIMEN PADA TWITTER MENGGUNAKAN PENDEKATAN AGGLOMERATIVE HIERARCHICAL CLUSTERING
SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer Program Studi Teknik Informatika
Oleh: Yenni Tresnawati
135314018
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
SENTIMENT ANALYSIS OF TWITTER
USING AGGLOMERATIVE HIERARCHICAL CLUSTERING
A THESIS
Presented as Partial Fulfillment of Requirements to Obtain Sarjana Komputer Degree in Informatics Engineering Department
By :
Yenni Tresnawati 135314018
INFORMATICS ENGINEERING STUDY PROGRAM INFORMATICS ENGINEERING DEPARTMENT
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
v
HALAMAN PERSEMBAHAN
“Serahkaan segala kekhawatiran mu kepada-Nya, sebab Ia
yang memelihara kamu”
-
1 Petrus 5 : 7 -
“Dan segala sesuatu yang kamu lakukan dengan perkatan atau
perbuatan, lakukan semuanya itu dalam nama Tuhan Yesus,
sambil mengucap syukur oleh Dia k
epada Allah, Bapa kita”
- Kolose 3:17 -
Skripsi ini saya persembahkan untuk :
Tuhan Yesus Kristus,
Bunda Maria,
Keluarga tercinta, dosen dan teman - teman terkasih,
viii INTISARI
Twitter merupakan salah satu situs microblogging memungkinkan penggunanya untuk menulis tentang berbagai opini, komentar, dan berita yang membahas isu-isu yang tejadi pada saat ini. Banyak pengguna yang melakukan posting pendapat mereka akan sebuah produk atau layanan yang mereka gunakan. Hal tersebut dapat digunakan sebagai sumber data untuk menilai sentimen pada Twitter. Cara pengelompokkan emosi secara otomatis dapat digunakan, salah satunya menggunakan Agglomerative Hierarchical Clustering. Tujuan dari penelitian ini adalah membangun sistem yang secara otomatis mampu mengelompokkan emosi setiap tweet, dan mengetahui tingkat akurasi pengelompokkan.
Tahapan proses dimulai dari preprocessing, terdapat beberapa proses yaitu tokenizing, stopword, stemming, pembobotan kata, serta normalisasi, selanjutnya dapat diolah menggunakan Agglomerative Hierarchical Clustering. Proses clustering terdiri dari, menghitung matriks jarak antar data, mencari jarak terdekat, menggabungkan menjadi satu cluster, memperbaharui matriks hingga semua data menjadi satu cluster. Setelah itu melakukan perhitungan akurasi menggunakan confusion matrix. Selanjutnya untuk melihat kesesuaian sistem yang dibuat, maka dimasukkan data baru yang diproses dengan sistem, lalu dapat menentukan data tergolong salah satu jenis emosi.
Dari penelitian yang telah dilakukan, didapatkan total data tweet sebanyak 500 data serta jumlah cluster terbagi menjadi lima yaitu cinta, marah, sedih, senang, dan takut. Hasil penelitian analisis sentimen pada twitter dapat berjalan dengan baik dengan akurasi 81,6% untuk jumlah frekuensi kata unik maksimal 85 dan kata unik minimal 2 dengan melakukan normalisasi menggunakan Z-Score, perhitungan jarak menggunakan Cosine Similarity serta metode AHC Average Linkage.
ix ABSTRACT
Twitter is one of the site microblogging that allows users to write about various opinion, comments, and news that discussing issues that are happening at this time. Many users post their opinions on a product or service they use. It can be used as a data source to assess sentiment on Twitter. Automatic grouping of emotions can be
used, one of them is using agglomerative hierarchical clustering. The purpose of this research is to build a system that automatically able to group the emotions of every
tweet, and know the level of accuracy of grouping.
Stages of the process starts from preprocessing, there are several processes
that are tokenizing, stopword, stemming, word weighting, and normalization, then can
be processed using Agglomerative Hierarchical Clustering. The clustering process
consists of, calculating the distance matrix between data, finding the closest distance,
merging into one cluster, updating the matrix until all the data into one cluster. After that perform the calculation of accuracy using confusion matrix. Next to see the
suitability of the system created, then inserted new data processed with the system, and
then can determine the data belong to one type of emotion.
From the research that has been done, got the total data tweet as much as 500
data and the number of cluster is divided into five clusters that is love, angry, sad,
happy, and afraid. The results of sentimental analysis on twitter can run well with an
accuracy of 81.6% for the maximum number of unique word of 85 and minimum
number of unique word of at least 2 by normalizing using Z-Score, Cosine Similarity
distance and AHC Average Linkage method.
x
KATA PENGANTAR
Puji dan syukur penulis panjatkan kepada Tuhan Yesus Kristus atas berkat yang diberikan dalam penyusunan Skripsi ini sehingga semuanya dapat berjalan dengan baik dan lancar.
Skripsi ini merupakan salah satu syarat mahasiswa untuk mendapatkan gelar S-1 pada Prodi Teknik Informatika, Fakultas Sains dan Teknologi, Universitas Sanata Dharma Yogyakarta.
Berkat bimbingan dan dukungan dari berbagai pihak, Skripsi ini dapat terselesaikan. Pada kesempatan ini dengan segenap kerendahan hati penulis menyampaikan rasa terima kasih kepada :
1. Sudi Mungkasi, S.Si., M.Math.Sc., Ph.D selaku Dekan Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta.
2. Dr. C. Kuntoro Adi, S.J., M.A.,M.Sc., selaku Dosen Pembimbing Skripsi, yang dengan sabar memberi arahan, bimbingan, serta waktunya kepada penulis dalam pembuatan Skripsi.
3. Heri Bertus S.Pd.,M.Si, Asna Nuraini,S.Ag, Millavenia Pusparini, Krisna Wahyu Tri Anugrah selaku keluarga penulis yang senantiasa mendoakan, memberikan motivasi dan pengorbanannya baik dari segi moril, materi kepada penulis sehingga penulis dapat menyelesaikan Skripsi ini.
4. Ian Arisaputra yang selalu mendukung, memberikan semangat serta menjadi pendengar setiap cerita suka-duka yang penulis rasakan dalam proses pembuatan skripsi hingga dapat menyelesaikan skripsi ini.
xi
xii DAFTAR ISI
ANALISIS SENTIMEN PADA TWITTER MENGGUNAKAN PENDEKATAN
AGGLOMERATIVE HIERARCHICAL CLUSTERING ... i
SENTIMENT ANALYSIS OF TWITTER ... ii
USING AGGLOMERATIVE HIERARCHICAL CLUSTERING ... ii
HALAMAN PERSETUJUAN PEMBIMBING ... Error! Bookmark not defined. ANALISIS SENTIMEN PADA TWITTER MENGGUNAKAN PENDEKATAN AGGLOMERATIVE HIERARCHICAL CLUSTERING ... Error! Bookmark not defined. HALAMAN PENGESAHAN ... Error! Bookmark not defined. ANALISIS SENTIMEN PADA TWITTER MENGGUNAKAN PENDEKATAN AGGLOMERATIVE HIERARCHICAL CLUSTERING ... Error! Bookmark not defined. HALAMAN PERSEMBAHAN ... v
PERNYATAAN KEASLIAN KARYA ... Error! Bookmark not defined. LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS ... Error! Bookmark not defined. INTISARI ... viii
ABSTRACT ... ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR TABEL ... xv
DAFTAR GAMBAR ... xvii
xiii
1.7 Sistematika Penulisan ... 4
BAB II ... 6
LANDASAN TEORI ... 6
2.1 Analisis Sentimen ... 6
2.2 Emosi ... 7
2.3 Information Retrieval ... 9
2.4 Euclidean Distance ... 20
2.5 Cosine Similarity ... 20
2.6 Agglomerative Hierarchical Clustering ... 21
2.7 Confusion Matriks ... 33
BAB III ... 34
METODE PENELITIAN ... 34
3.1 Data ... 34
3.2 Kebutuhan Sistem ... 36
3.3 Tahapan Penelitian ... 37
3.4 Desain Interface ... 38
xiv
3.5.1 Gambaran Umum Sistem ... 39
3.6 Desain Pengujian ... 70
BAB IV ... 71
HASIL DAN ANALISIS HASIL ... 71
4.1 Implementasi ... 71
4.2 Hasil & Analisis Hasil ... 81
4.3 User Interface ... 91
BAB V ... 92
PENUTUP ... 92
5.1 Kesimpulan ... 92
5.2 Saran ... 93
xv
DAFTAR TABEL
Tabel 2. 1 Kosa Kata Emosi ... 8
Tabel 2. 2 Tabel awalan-akhiran ... 13
Tabel 2. 3 Aturan peluruhan kata dasar ... 13
Tabel 2. 4 Contoh Data ... 23
Tabel 2. 5 Similarity Matriks ... 24
Tabel 2. 6 Matriks Jarak ... 24
Tabel 2. 7 Matriks Jarak pertama Single Linkage... 25
Tabel 2. 8 Matriks Jarak kedua Single Linkage ... 25
Tabel 2. 9 Matriks jarak pertama Complete Linkage ... 26
Tabel 2. 10 Matriks Jarak kedua Complete Linkage... 27
Tabel 2. 11 Matriks Jarak pertama Average Linkage ... 28
Tabel 2. 12 Matriks Jarak kedua Average Linkage... 29
Tabel 2. 13 Tabel Confusion Matriks ... 33
Tabel 3. 1 Tabel menghitung df ... 50
Tabel 3. 8 Tabel contoh data belum mengalami proses penggabungan ... 54
Tabel 3. 9 Tabel contoh data setelah penggabungan... 55
Tabel 3. 10 Tabel Contoh data pembobotan ... 55
Tabel 3. 11 Tabel Min-max ... 56
Tabel 3. 12 Tabel data hasil normalisasi min - max ... 56
Tabel 3. 13 Tabel Rata - Rata... 58
xvi
Tabel 3. 15 Hasil Normalisasi Zscore ... 59
Tabel 3. 16 Tabel hasil matriks jarak dari normalisasi min - max ... 60
Tabel 3. 17 Hasil matriks jarak normalisasi Z-Score ... 62
Tabel 3. 18 Hasil max cluster 5 single linkage- Z-Score ... 67
Tabel 3. 19 Hasil max cluster 5 complete linkage- Z-Score ... 67
Tabel 3. 20 Hasil max cluster 5 average linkage- Z-Score ... 67
Tabel 3. 21 Hasil max cluster 5 single linkage- Min - Max ... 67
Tabel 3. 22 Hasil max cluster 5 complete linkage- Min - Max... 68
Tabel 3. 23 Hasil max cluster 5 average linkage- Min - Max ... 68
Tabel 3. 24 Tabel perbandingan cluster hasil prediksi dan label aktual ... 69
Tabel 3. 25 Tabel Confusion matriks ... 69
Tabel 4. 1 Tabel Percobaan tanpa normalisasi dengan batas atas = 85 dan batas bawah =2 ... 83
Tabel 4. 2 Confusion matrix data tanpa normalisasi average linkage... 84
Tabel 4. 3 Tabel Percobaan normalisasi min - max dengan batas atas = 85 dan batas bawah =2 ... 85
Tabel 4. 4 Confusion matrix data normalisasi min – max average linkage ... 87
Tabel 4. 5 Tabel Percobaan normalisasi z-score dengan batas atas = 85 dan batas bawah =2 ... 88
xvii
DAFTAR GAMBAR
Gambar 2. 1 Dendrogram ... 22
Gambar 2. 2 Dendrogram Single linkage ... 26
Gambar 2. 3 Dendrogram Complete Linkage ... 27
Gambar 2. 4 Dendrogram average linkage ... 29
Gambar 2. 5 Flowchart AHC ... 32
Gambar 3. 1 Tweet Cinta ... 34
Gambar 3. 2Tweet Senang ... 35
Gambar 3. 3 Tweet Marah ... 35
Gambar 3. 4 Tweet Takut... 36
Gambar 3. 5 Tweet Sedih ... 36
Gambar 3. 6 Desain Interface... 38
Gambar 3. 7 Block Diagram ... 39
Gambar 3. 8 Tokenizing tweet cinta ... 41
Gambar 3. 9 Tokenizing tweet senang ... 41
Gambar 3. 10 Tokenizing tweet marah ... 42
Gambar 3. 11 Tokenizing tweet takut ... 42
Gambar 3. 12 Tokenizing tweet sedih ... 43
Gambar 3. 13 Stopword tweet cinta ... 44
Gambar 3. 14 Stopword tweet senang... 44
Gambar 3. 15 Stopword tweet marah ... 45
Gambar 3. 16 Stopword tweet sedih ... 45
Gambar 3. 17 Stopword tweet takut ... 45
Gambar 3. 18 Stemming tweet cinta ... 46
Gambar 3. 19 Stemming tweet senang ... 47
Gambar 3. 20 Stemming tweet marah ... 47
xviii
Gambar 3. 22 Stemming tweet takut ... 48
Gambar 3. 23 TF tweet cinta ... 48
Gambar 3. 32 Data Z-Score Single linkage ... 65
Gambar 3. 33 Data Z-Score Complete linkage ... 65
Gambar 3. 34 Data Z-Score Average linkage ... 66
Gambar 3. 35 Source code AHC Z-Score ... 66
Gambar 4. 1 Kumpulan Data ... 71
Gambar 4. 2 Contoh Data... 72
Gambar 4. 3 Source code Tokenizing ... 72
Gambar 4. 4 Source code Stopword ... 73
Gambar 4. 5 Source code Stemming ... 73
Gambar 4. 6 Kamus Kata Sinonim ... 74
Gambar 4. 7 Source code Penanganan Sinonim ... 74
Gambar 4. 8 Source code Pembobotan ... 75
Gambar 4. 9 Source code Normalisasi Min – Max ... 76
Gambar 4. 10 Source code Normalisasi Z-Score ... 76
Gambar 4. 11 Source code Hitung Jarak Euclidean ... 77
Gambar 4. 12 Source code Hitung Jarak Cosine... 77
Gambar 4. 13 Source code AHC ... 79
Gambar 4. 14 Gambar Output Hasil ... 79
xix
Gambar 4. 16 Hasil Implementasi Confusion Matrix ... 80
Gambar 4. 17 Contoh Tweet Uji ... 81
Gambar 4. 18 Hasil Tweet Uji ... 81
Gambar 4. 19 Grafik percobaan tanpa normalisasi ... 83
Gambar 4. 20 Dendrogram data tanpa normalisasi average linkage ... 84
Gambar 4. 21 Grafik percobaan normalisasi min – max ... 86
Gambar 4. 22 Dendrogram data normalisasi min – max average linkage ... 87
Gambar 4. 23 Grafik percobaan normalisasi z-score ... 88
Gambar 4. 24 Dendrogram data normalisasi z-score average linkage ... 89
Gambar 4. 25 Grafik percobaan menggunakan batas atas=85 dan batas bawah =2 ... 90
1 BAB I PENDAHULUAN 1.1 Latar Belakang
Pada saat ini situs microblogging telah menjadi alat komunikasi yang sangat populer di kalangan pengguna internet. Microblogging merupakan suatu layanan media social yang memungkinkan pengguna mem-publish pesan pendek berupa opini, komentar, berita dalam karakter terbatas (kurang dari 200 karakter). Contoh layanan microblogging yaitu Twitter, Plurk, Jaiku, Posterous, Pownce, Kronologger, Koprol, Moofmill, dan Tumblr.
Menurut data yang dirilis Twitter, pada tahun 2012 Indonesia menjadi negara dengan pengguna Twitter terbesar kelima di dunia (Tempo,2012). Twitter memungkinkan pengguna untuk berbagi pesan menggunakan teks pendek disebut Tweet.
Twitter seringkali digunakan untuk mengungkapkan emosi mengenai sesuatu hal, baik memuji ataupun mencela. Emosi dapat dikelompokkan menjadi emosi positif dan emosi negatif. Emosi manusia dapat dikategorikan menjadi lima emosi dasar yaitu cinta, senang, sedih, marah, dan takut. Emosi cinta dan senang merupakan emosi positif. Emosi sedih, marah, dan takut merupakan emosi negatif (Shaver & Fraley , 2001)
penjualan antara 73% sampai dengan 87%, pelanggan bersedia membayar lebih sebesar 20% sampai 99% terhadap review di internet yang mendapatkan bintang 5 daripada bintang 4 (Pang & Lee,2008). Pengaruh dan manfaat dari sentimen sedemikian besar sehingga penelitian ataupun aplikasi mengenai analisis sentimen berkembang sangat pesat. Terdapat kurang lebih 20-30 perusahaan di Amerika yang fokus pada layanan analisis sentiment (Liu, 2012). Faktor keuntungan tersebut mendorong perlunya dilakukan penelitian analisis sentimen terhadap tweet berbahasa Indonesia.
Dengan cara manual, analisa sentimen bisa saja dilakukan. Misalnya memonitor berita-berita di media massa. Akan tetapi untuk data tweet, cara manual tidak mungkin bisa dilakukan karena jumlah datanya yang sangat besar dan terus mengalir. Disinilah peranan text mining, yang secara otomatis dapat mengolah kata. Pada text mining terdapat beberapa proses yaitu tokenizing, stopword, stemming, dan pembobotan kata(Liu, 2010). Setelah melakukan text mining, diperlukan normalisasi. Setelah melakukan normalisasi, dilakukan penggolongan atau clustering pada setiap tweet, salah satunya menggunakan metode Agglomeartive Hierarchical Clustering.
Contoh kasus yang telah diselesaikan menggunakan metode Agglomerative Hierarchical Clustering adalah aplikasi automated text integration, dimana pada penelitian ini menghasilkan cluster yang baik. Dari hasil survei terhadap 100 orang responden, sebanyak 78% responden mengatakan bahwa integrasi dokumen yang dihasilkan telah benar(Budhi,Rahardjo,Taufik, 2008). Sehingga dengan melakukan penelitian menggunakan metode Agglomerative Hierarchical Clustering dapat mengetahui tingkat akurasi serta efisien untuk menyelesaikan masalah clustering data twitter berdasarkan emosi.
Salah satu faktor yang mempengaruhi agar fitur klasifikasi memberikan hasil yang maksimal adalah pada tahap preprocessing data tweet dilakukan filtering dengan menghapus kata-kata yang tidak ada di KBBI dan dilakukan proses stemming, sehingga hanya berupa kumpulan kata dasar(Nur & Santika, 2011).
Berdasarkan penelitian yang telah ada sebelumnya, penelitan ini mencoba melakukan analisis sentimen dengan mengklasifikasi data twitter berbahasa Indonesia. Data tersebut akan diproses dengan text mining untuk menghindari data yang kurang sempurna kemudian mengelompokkan data tweet berdasarkan emosi ke dalam lima cluster yaitu senang, takut, sedih, marah, cinta. Pengelompokkan ini menggunakan algoritma Agglomerative Hierarchical Clustering.
1.2 Rumusan Masalah
Berdasarkan Latar Belakang yang telah dikemukakan diatas, maka permasalahan yang akan dibahas dalam penelitian ini, yaitu :
1. Bagaimana pendekatan Agglomerative Hierarchical Clustering mampu mengelompokkan emosi setiap tweet dengan baik ?
2. Berapakah tingkat akurasi analisis sentimen twitter menggunakan pendekatan Agglomerative Hierarchical Clustering?
1.3 Tujuan Penelitian
1.4 Manfaat
Manfaat yang diberikan pada penelitian ini, yaitu :
1. Dapat membantu menganalisis sentimen pada twitter dengan metode Agglomerative Hierarchical Clustering.
2. Menjadi referensi bagi penelitian – penelitian berikutnya yang relevan dengan kasus analisis sentimen twitter.
1.5 Luaran
Luaran yang diharapkan pada penelitian ini berupa suatu sistem yang secara otomatis mampu mengelompokkan emosi setiap tweet.
1.6 Batasan Masalah
Pada pengerjaan penelitian ini diberikan batasan-batasan masalah untuk permasalahan yang ada antara lain:
1. Tweet yang dianalisis sentimen hanya tweet berbahasa Indonesia.
2. Pengelompokkan tweet berdasarkan lima emosi yaitu cinta, marah, senang, sedih, dan takut
3. Tweet yang digunakan hanya tweet yang berupa text, tidak mengandung gambar.
1.7 Sistematika Penulisan
Sistematika penulisan proposal tugas akhir ini dibagi menjadi beberapa bab dengan susunan sebagai berikut:
BAB I : Pendahuluan
BAB II : Landasan Teori
Berisi mengenai penjelasan dan uraian teori-teori yang berkaitan dengan topik analisis sentimen twitter, antara lain teori tentang analisis sentimen, emosi, preprocessing teks( Information Retrieval ), pembobotan kata, normalisasi min-max, normalisasi z-score, algoritma Agglomerative Hierarchical Clustering, Cosine Similarity, Euclidean Distance, dan Confusion Matriks
BAB III : Metodologi Penelitian
Berisi analisa dan design yang merupakan detail teknis sistem yang akan dibangun.
BAB IV : Implementasi dan Analisis Hasil
Bab ini berisi implementasi dari perancangan yang telah dibuat sebelumnya serta analisis dari hasil program yang telah dibuat
BAB V : Penutup
6 BAB II
LANDASAN TEORI
Bab ini berisi penjabaran teori-teori yang bersangkutan dengan penulisan Tugas Akhir ini. Teori-teori tersebut mencakup Analisis Sentimen, Emosi, Information Retrieval, Agglomerative Hierarchical Clustering, Euclidean Distance, dan Confusion Matriks.
2.1 Analisis Sentimen
Analisis sentimen adalah bidang studi yang menganalisi pendapat, sentimen, evaluasi, penilaian, sikap, dan emosi seseorang terhadap sebuah produk, organisasi, individu, masalah, peristiwa atau topik (Liu, 2012). Analisis sentimen dilakukan untuk melihat pendapat terhadap sebuah masalah, atau dapat juga digunakan untuk identifikasi kecenderungan hal yang sedang menjadi topik pembicaran. Analisis sentimen dalam penelitian ini adalah proses pengelompokkan tweet ke dalam lima emosi yaitu emosi senang, emosi cinta, emosi sedih, emosi marah dan emosi takut.
Pengaruh dan manfaat dari analisis setimen, menyebabkan penelitian mengenai analisis sentimen berkembang pesat. Di Amerika kurang lebih 20-30 perusahaan yang memfokuskan pada layanan analisis sentimen (Liu,2012). Manfaat Analisis sentimen dalam dunia usaha antara lain untuk melakukan pemantauan terhadap suatu produk. Secara cepat dapat digunakan sebagai alat bantu untuk melihat respon masyarakat terhadap produk tersebut, sehingga dapat segera diambil langkah- langkah strategis berikutnya.
2.1.1 Level Analisis Sentimen
Analisis sentimen terdiri dari tiga level analisis yaitu : 1. Level Dokumen
Level dokumen menganalisis satu dokumen penuh dan mengklasifikasikan dokumen tersebut memiliki sentimen positif atau Negatif. Level analisis ini berasumsi bahwa keseluruhan dokumen hanya berisi opini tentang satu entitas saja. Level analisis ini tidak cocok diterapkan pada dokumen yang membandingkan lebih dari satu entitas (Liu, 2012).
2. Level Kalimat
Level kalimat menganalisis satu kalimat dan menentukan tiap kalimat bernilai sentimen positif, netral, atau Negatif. Sentimen netral berarti kalimat tersebut bukan opini (Liu, 2012).
3. Level Entitas dan Aspek
Level aspek tidak melakukan analisis pada konstruksi bahasa (dokumen, paragraph, kalimat, klausa, atau frase) melainkan langsung pada opini itu sendiri. Hal ini didasari bahwa opini terdiri dari sentimen (positif dan negatif) dan target dari opini tersebut. Tujuan level analisis ini adalah untuk menemukan sentimen entitas pada tiap aspek yang dibahas (Liu,2012).
2.2 Emosi
Emosi adalah suatu pikiran dan perasaan khas yang disertai perubahan fisiologis dan biologis serta menimbulkan kecendrungan untuk melakukan tindakan (Goleman, 2006).
menggunakan analisis sentimen. Analisis sentimen dapat dimanfaatkan untuk menggali opini publik tentang suatu topik.
2.2.1 Emosi Dasar
Emosi yang dimiliki manusia dikategorikan menjadi lima emosi dasar yaitu cinta, senang, marah, khawatir/takut, dan sedih. Emosi cinta dan senang merupakan emosi positif. Emosi marah, takut, dan sedih merupakabb emosi Negatif (Shaver, Murdaya, dan Fralet, 2001).
2.2.2 Kosakata Emosi
Penelitian terhadap 124 kosakata emosi di Indonesia menghasilkan dua kelompok besar yaitu kosakata emosi positif dan Negatif. Kelompokan kosakata emosi positif terdiri dari dua emosi dasar yaitu emosi cinta dan senang. Kelompokan kosakata emosi Negatif terdiri dari tiga emosi dasar yaitu marah, takut, dan sedih (Shaver, Murdaya, dan Fraley, 2001).
Pengelompokkan terhadap 124 kosakata emosi di Indonesia terlihat pada Tabel 2.1 berikut:
Tabel 2. 1 Kosa Kata Emosi Superordinat Emosi
Dasar
Subordinat
Positif Cinta Ingin, kepingin, hasrat, berahi, terangsang, gairah, demen, suka, terbuai, terpesona, terkesiap, terpikat, tertarik, perasaan, getar hati, setia, edan kesmaran, kangen, rindu, kemesraan, asmara, mesra, cinta, kasih, sayang, hati.
kepuasan, puas, berani, yakin, ikhlas, tulus, berbesar, besar hati, rendah hati, sabar, tabah
Negatif Marah Bosan, jenuh, cemburu, curiga, histeris, tinggi hati, iri, dengki, gemas, gregetan, ngambek, tersinggung, muak, benci, emosi, kesal, sebal, mangkel, jengkel, dendam, dongkol, panas hati, kalap, murka, naik darah, naik pitam, marah, berang, geram
Negatif Takut Gentar, takut, berdebar, kebat – kebit, kalut, gusar, cemas, khawatir, waswas, bimbang, bingung, galau, gundah, gelisah, risau
Negatif Sedih Patah hati,kecil hati, malu, simpati, tersentuh, haru, prihatin, iba, kasihan, murung,pilu, sendu, sedih , duka, dukacita, sakit hati, pedih hati, patah hati, remuk hati, frustasi, putus asa, putus harapan, menyesal, penyesalan, sesal, berat hati.
2.3 Information Retrieval
Penelitian ini mencoba menganalisis emosi yang terkandung dalam sebuah tweet berbahasa Indonesia.
Dengan cara manual, analisis emosi atau analisis sentimen bisa saja dilakukan. Misalnya memonitor berita-berita di media massa. Akan tetapi untuk data tweet, cara manual tidak mungkin bisa dilakukan karena jumlah datanya yang sangat besar dan terus mengalir. Disinilah peranan Information Retrieval, yang secara otomatis dapat mengolah kata.
2.3.1 Proses Information Retrieval 2.3.1.1 Text Operation
Text Mining merupakan penambangan data yang berupa teks dimana sumber data biasanya didapatkan dari dokumen, dan tujuannya adalah mencari kata-kata yang dapat mewakili isi dari dokumen sehingga dapat dilakukan analisa keterhubungan antar dokumen (Harlian, 2006).
a. Tokenizing
Tokenizing merupakan langkah untuk memotong dokumen menjadi potongan-potongan kecil yang disebut token dan terkadang disertai langkah untuk membuang karakter tertentu seperti tanda baca (Manning,Raghavan,dan Schutze, 2009).
Contoh proses tokenizing : Kalimat asal :
Disaat sedih jangan lupakan kamu juga pernah bahagia, sedih itu membuatMu dewasa Hasil dari tokenizing :
Disaat Juga MembuatMu
Sedih Pernah Dewasa
Jangan Bahagia
Lupakan Sedih Kamu itu
b. Stopwords Removal
kata – kata tersebut akan dihapus dari deskripsi sehingga kata – kata yang tersisa di dalam deskripsi dianggap sebagai kata-kata yang mencirikan isi dari suatu dokumen. Daftar stoplist dipenelitian ini bersumber dari Tala (2003).
Contoh proses stopword : Hasil dari tokenizing :
Disaat Juga MembuatMu
Sedih Pernah Dewasa Jangan
Bahagia Lupakan Sedih Kamu itu
Hasil dari Stopword Disaat Membuat
Sedih Pernah Dewasa
Jangan Bahagia Lupakan Sedih
c. Stemming
Stemming merupakan tahap mencari kata dasar (root) dari tiap kata hasil stopword.
Contoh Proses Stemming : Hasil dari Stopwords : Disaat Membuat
Sedih Pernah Dewasa
Lupakan Sedih Hasil dari Stemming :
Saat Buat Dewasa
Sedih Pernah Jangan Bahagia Lupa Sedih
1) Rule Stemming
Algoritma Stemming untuk menghilangkan kata berimbuhan memiliki tahap – tahap sebagai berikut (Nazief dan Adriani, 2007) :
1. Pertama cari kata yang akan distem dalam kamus kata dasar. Jika ditemukan maka diasumsikan kata adalah root word. Maka algoritma berhenti. Jika tidak ditemukan maka lakukan langkah 2.
2. Hilangkan Inflection Suffixes bila ada. Dimulai dari Inflectional Particle(“-lah”,
“-kah”, “-ku”, “-mu”, atau “-nya”) ,kemudian Possesive Pronouns (“-ku”, “-mu”,
atau “-nya”). Cari kata pada kamus kata dasar jika ditemukan maka algoritma berhenti, jika tidak ditemukan maka lakukan langkah 3.
3. Hapus Derivation Suffixes (“-i”, “-an”, atau “-kan”).
Jika kata ditemukan di kamus, maka algoritma berhenti. Jika tidak maka ke langkah 3a
a. Jika “-an” telah dihapus dan huruf terakhir dari kata tersebut adalah “-k”, maka
“-k” juga ikut dihapus. Jika tidak ditemukan maka lakukan langkah 3b.
b. Akhiran yang dihapus (“-i”, “-an”, atau “-kan”) dikembalikan, lanjut ke langkah 4.
1. Ditemukannya kombinasi akhiran yang tidak diizinkan berdasarkan awalan Tabel 2. 2 Tabel awalan-akhiran
Awalan Akhiran yang tidak diizinkan
be- -i
3. Tiga awalan telah dihilangkan
b. Identifikasi tipe awalan dan hilangkan. Awalan terdiri dari dua tipe : 1. Standar(“di-”, “ke-”, “se-”) yang dapat langsung dihilangkan dari kata 2. Kompleks (“me-”, “be”, “pe”, “te”) adalah tipe awalan yang dapat berubah
sesuai kata dasar yang mengikutinya. Oleh karena itu dibutuhkan aturan pada tabel berikut untuk mendapakan hasil pemenggalan yang tepat. Tabel 2. 3 Aturan peluruhan kata dasar
Aturan Bentuk awalan Peluruhan
10 Mem{rV|V}… Me-m{rV|V}…| Me
-p{rV|V}…
11 Men{c|d|j|z}…. Men-{c|d|j|z}…. 12 menV…. Me-nV…|me-tV…. 13 Meng{g|h|q|k}….. Meng-{g|h|q|k}….. 14 mengV….. Meng-V…|meng-kV
Pada tabel 2.3 dapat dilihat aturan – aturan peluruhan kata dasar yang apabila
dilekati oleh awalan “me-”, “be-”, “te-”, “pe-”. Dimana pada kolom kedua dari tabel tersebut menjelaskan bentuk – bentuk kata dasar yang dilekati awalan “me-”, “be-”,
karakter pada kata dasar yang mungkin terjadi apabila algoritma telah menghilangkan
awalan yang telah melekati kata dasar tersebut. Huruf “V” pada tabel tersebut menunjukkan huruf hidup atau huruf vocal, huruf “C” menunjukkan huruf mati atau
konsonan, dan huruf “P” menunjukkan pecahan “er”. Sebagai contoh, jika algoritma menerima kata “menyusun”, maka proses Stemming pada kata tersebut mengikuti aturan ke-16 yaitu “menyV..” dan perubahannya menjadi “me-ny” atau “meny-sV..”. Berdasarkan aturan tersebut maka algoritma akan menghilangkan awalan “me-” maka
akan didapatkan kata “nyusun”, selanjutnya kata “nyusun” akan diperiksa ke dalam database kata dasar karena kata “nyusun” bukan kata dasar maja tahap selanjutnya
algoritma akan menghilangkan kata “meny-” dan kemudian algoritma akan
menambahkan huruf “s” diddepan huruf “u”, maka akan didapatkan kata “susun”, selanjutnya kata “susun” akan diperiksa kedalam database kata dasar. Karena kata “susun” merupakan kata dasar maka kata tersebut akan diidentifikasikan sebagai kata dasar.
c. Cari kata yang telah dihilangkan awalannya. Apabila tidak ditemukan maka langkah diulang kembali. Jika ditemukan maka algoritma berhenti.
5. Apabila setelah langkah 4 kata dasar masih belum ditemukan, maka proses recording dilakukan dengan mengacu pada aturan tabel 2.3. Recording dilakukan dengan menambahkan karakter recording di awal kata yang dipenggal. Pada tabel 2.3 , karakter recording adalah huruf kecil setelah
tanda hubung (‘-‘) dan terkadang berada sebelum tanda kurung. Sebagai contoh,
kata “menangkap” (aturan 15) pada tabel 2.3 , setelah dipenggal menjadi “nangkap”. Karena tidak valid, maka recording dilakukan dan menghasilkan
kata “tangkap”.
Untuk mengatasi keterbatasan pada algoritma di atas, maka ditambahkan aturan
– aturan dibawah ini (Agusta, 2009) : 1. Aturan untuk reduplikasi
➢ Jika kedua kata yang dihubungkan oleh kata penghubung adalah kata yang sama maka root word adalah bentuk tunggalnya, contoh : “buku - buku” root wordnya
adalah “buku”.
➢ Kata lain, misalnya “bolak-balik”, “berbalas-balasan”, dan “seolah-olah”. Untuk mendapatkan root wordnya, kedua kata diartikan secara terpisah. Jika keduanya memiliki root word yang sama maka diubah menjad bentuk tunggal, contoh :
kata “berbalas-balasan”, “berbalas” dan “balasan” memiliki root word yang
sama yaitu “balas”. Maka root word “berbalas-balasan” adalah “balas”.
Sebaliknya, pada kata “bolak-balik”, “bolak ” dan “balik” memiliki root word yang berbeda, maka root wordnya adalah “bolak- balik”.
2. Tambahan bentuk awalan dan akhiran serta aturannya
➢ Untuk tipe awalan “mem-”, kata yang diawali dengan awalan “memp” memiliki
tipe awalan “mem-”.
➢ Tipe awalan “meng-”, kata yang diawali dengan awalan “mengk-” memiliki tipe
awalan “meng-”
d. Penggabungan Kata Berdasarkan Sinonim
Menurut Kamus Besar Bahasa Indonesia (KBBI) sinonim adalah bentuk bahasa yang maknanya mirip atau sama dengan bahasa lain. Proses sinonim akan dilakukan ketika ada kata berbeda namun memiliki makna yang sama, untuk me-minimal-kan jumlah kata yang terdapat pada sistem, tanpa menghilangkan jumlah frekuensi.
e. Pembobotan Kata
nilai kesusaian semakin besar pula. Pembobotan kata dipengaruhi oleh hal – hal berikut ini (Mandala dan Setiawan, 2004) :
1. Term Frequency (TF) faktor , yaitu faktor yang menentukan bobot term pada suatu dokumen berdasarkan jumlah kemunculan dalam dokumen tersebut. Nilai jumlah kemunculan suatu kata (term frequency) diperhitungkan dalam pemberian bobot terhadap suatu kata. Semakin besar jumlah kemunculan suautu term (TF tinggi) dalam dokumen, semakin besar pula bobotnya dalam dokumen atau akan memberikan nilai kesesuaian yang semakin besar.
2. Inverse Document Frequency (idf) faktor, yaitu pengurangan dominansi term yang sering muncul di bagian dokumen. Hal ini diperlukan karena term yang banyak muncul di berbagai dokumen, dapat dianggap sebagai term umum (common term) sehingga tidak penting nilainya. Sebaliknya faktor kejarangmunculan kata (term scarcity) dalam koleksi dokumen harus diperhatikan dalam pemberian bobot. Kata yang muncul pada sedikit dokumen harus dipandang sebagai kata yang lebih penting (uncommon term) daripada kata yang muncul pada banyak dokumen. Pembobotan akan memperhitungkan faktor kebalikan frekuensi dokumen yang mengandung suatu kata (Inverse Document Frequency).
Pada metode ini, perhitungan bobot term t dalam dokumen dilakukan dengan mengalikan nilai Term Frequency dengan Inverse Document Frequency.
Pada Term Frequency (TF) terdapat beberapa perhitungan yang dapat digunakan yaitu (Mandala dan Setiawan, 2004) :
1. TF biner , hanya memperhatikan apakah suatu kata ada atau tidak dalam dokumen, jika ada berikan nilai satu, jika tidak berikan nilai nol.
3. TF logaritmik, metode ini digunakan untuk menghindari dominansi dokumen yang mengandung sedikit kata dalam query, namun mempunyai frekuensi yang tinggi.
� = + log � (2.1)
4. TF normalisasi, metode ini menggunakan perbandingan antara frekuensi sebuah kata dengan jumlah keseluruhan kata pada dokumen.
� = . + . [max ���� ] (2.2)
Pada Inverse Document Frequency (idf) perhitungannya adalah :
� � = log �/ � (2.3)
Keterangan :
D : Jumlah semua dokumen dalam koleksi df : Jumlah dokumen yang mengandung term t
Jenis formula yang akan digunakan untuk perhitungan term frequency (TF) yaitu TF murni (raw TF). Oleh karena itu untuk rumus yang digunakan untuk TF-IDF adalah nilai raw TF dikalikan dengan nilai Inverse Document Frequency Persamaan(2.3) :
= � � �
= � log �/ � (2.4)
Keterangan :
: bobot term terhadap dokumen
� : jumlah kemunculan term dalam dokumen
� : jumlah semua dokumen yang ada dalam database
Berdasarkan persamaan (2.4) berapapun besar nilai � , jika D = �, didapatkan hasil 0 untuk perhitungan � �. Maka dapat ditambahkan nilai 1 pada sisi
� �, sehingga perhitungan bobot menjadi sebagai berikut :
= � log �/ � + (2.5)
f. Normalisasi 1. Z-Score
Normalisasi Z-Score umumnya digunakan jika nilai minimum dan maksimum sebuah atribut tidak diketahui (Mustaffa dan Yusof,2011). Normalisasi Z-Score dirumuskan sebagai berikut :
�′= �− ̅
� (2.6)
Keterangan
�′ : nilai yang baru � : nilai yang lama
̅ : rata - rata dari atribut A
� : nilai standar deviasi dari Atribut A
2. Min-max
Normalisasi min – max dirumuskan sebagai berikut (Mustaffa dan Yusof, 2011) :
= �0− � �
� ��−� � (2.7)
Keterangan :
: nilai lama untuk variable X : nilai minimum dalam data set : nilai maksimum dalam data set
2.4 Euclidean Distance
Euclidean Distance digunakan untuk menghitung nilai kedekatan antara dua dokumen. Perhitungan Euclidean Distance dirumuskan sebagai berikut (Prasetyo, 2014) :
, = √| − | + | − | + … … . + | − | (2.8)
Atau
, = √∑= − (2.9)
Keterangan :
� : Jumlah atribut
− : Data
2.5 Cosine Similarity
Menurut Prasetyo pada buku Data Mining: Pengelolahan Data menjadi infromasi menggunakan matlab (2014), ukuran kemiripan yang sering digunakan untuk mengukur kemiripan dua dokumen x dan y adalah Cosine Similarity. Kemiripan yang diberikan adalah 1 jika dua vektor x dan y sama , dan bernilai 0 jika kedua vektor berbeda. Nilai jarak 1 menyatakan sudut yang dibentuk oleh vektor x day y adalah 0º, yang artinya vektor x dan y adalah sama (dalam hal jarak).
,
= cos ,
=
|| |||| || ∙ (2.8)Tanda titik (
∙
) melambangkan inner-product,∙ = ∑
�=(2.9)
Tanda
|| ||
adalah panjang dari vektor
x, dimana :|| || = √∑
�=
= √ ∙
(2.10)
2.6 Agglomerative Hierarchical Clustering
Agglomerative Hierarchical Clustering merupakan metode pengelompokkan berbasis hierarki dengan pendekatan bottom up, yaitu proses penggelompokkan dimulai dari masing-masing data sebagai satu cluster, kemudian secara rekursif mencari cluster terdekat sebagai pasangan untuk bergabung sebagai satu cluster yang lebih besar (Prasetyo,2014). Proses tersebut diulang terus sehingga tampak bergerak ke atas membentuk hierarki.
Kunci operasi metode Agglomerative Hierarchical Clustering adalah penggunaan ukuran kedekatan diantara dua cluster (Hartini,2012). Ada tiga teknik yang dapat digunakan untuk menghitung kedekatan diantara dua cluster dalam metode Agglomerative Hierarchical Clustering yaitu Single linkage, Complete Linkage, dan Average Linkage.
Pada metode Single linkage kedekatan di antara dua cluster ditentukan dari jarak terdekat (terkecil) di antara pasangan diantara dua data dari dua cluster berbeda (satu dari cluster pertama satu dari cluster yang lain) . Dengan menggunakan single linkage jarak antara dua cluster didefinisikan sebagai berikut :
, = ��� ∈ , ∈ {� , } (2.10)
Keterangan :
Pada Complete Linkage kedekatan diantara dua cluster ditentukan dari jarak terjauh (terbesar) diantara pasangan diantara dua data dari dua cluster berbeda (satu dari cluster pertama satu dari cluster yang lain). Dengan menggunakan metode complete lingkage jarak antara dua cluster didefinisikan sebagai berikut :
, = � ∈ , ∈ {� , } (2.11)
Keterangan :
{� , } : jarak antara data x dan y dari masing – masing Cluster A dan B.
Pada Average Linkage kedekatan diantara dua cluster ditentukan dari jarak rata-rata diantara pasangan diantara dua data dari dua cluster berbeda (satu dari cluster pertama satu dari cluster yang lain). Dengan menggunakan metode average lingkage jarak antara dua cluster didefinisikan sebagai berikut :
, = ∑ ∈ ∑ ∈ �{ , } (2.12)
Keterangan :
� : banyaknya data dalam cluster A
� : banyaknya data dalam cluster B
Dengan menggunakan rumus perhitungan-perhitungan diatas akan diketahui jarak antar cluster. Masing – masing perhitungan dapat menghasilkan dendrogram.
Dari penjelasan yang telah dipaparkan diatas, maka secara singkat AHC dapat dimengerti sebagai metode yang dimulai dengan setiap n cluster yang membentuk cluster masing-masing. Kemudian dua cluster dengan jarak terdekat bergabung. Selanjutnya cluster yang lama akan bergabung dengan cluster yang sudah ada dan membentuk cluster baru. Hal ini tetap memperhitungkan jarak kedekatan antar cluster. Proses akan berulang hingga akhirnya membentuk satu cluster yang memuat keseluruhan cluster.
Sebagai contoh, diketahui data seperti pada tabel dibawah ini Tabel 2. 4 Contoh Data
Dengan menggunakan rumus Euclidean Distance setiap obyek data tersebut dihitung similaritasnya sebagai berikut :
, = √ | − | + | − | =
Tabel 2. 5 Similarity Matriks
A b C d
A 0 1 3.16 2.236
B 1 0 2.82 3
C 3.16 2.82 0 2.236 D 2.236 3 2.236 0
Karena similarity matriks bersifat simetris maka dapat ditulis seperti dibawah ini dan menjadi matriks jarak:
Tabel 2. 6 Matriks Jarak
A B C D
A 0 1 3.16 2.236
B 0 2.82 3
C 0 2.236
D 0
1. Single linkage
Dari tabel 2.6 dapat dilihat bahwa jarak obyek yang paling dekat yaitu a dan b,berjarak 1. Kedua obyek data ini menjadi satu cluster pertama. Kemudian untuk menemukan cluster berikutnya dicari jarak antar obyek data dari sisa yang ada (c,d) dan berada paling dekat dengan cluster(ab). Untuk pencarian jarak ini pertama digunakan Single linkage.
= min{ , } = min{ . , . } = .
Kemudian baris – baris dan kolom – kolom matriks jarak yang bersesuaian dengan cluster a dan b dihapus dan ditambahkan baris dan kolom untuk cluster ab, sehingga matriks jarak menjadi seperti berikut :
Tabel 2. 7 Matriks Jarak pertama Single Linkage
Ab C d
Ab 0 2.82 2.236
C 0 2.236
D 0
Berdasarkan pada matriks jarak pertama, dipilih kembali jarak terdekat antar cluster. Ditemukan dua nilai terdekat yaitu abd dan cd dengan nilai 2.236. Maka dapat dipilih salah satu dari kedua nilai tersebut. Dalam contoh ini cluster yang dipilih yaitu cd. Kemudian hitung jarak cluster cd dengan cluster ab.
= min{ , , , } = min{ . , . , . , } = .
Kemudian baris – baris dan kolom – kolom matriks jarak yang bersesuaian dengan cluster c dan d dihapus dan ditambahkan baris dan kolom untuk cluster cd, sehingga matriks jarak menjadi seperti berikut :
Tabel 2. 8 Matriks Jarak kedua Single Linkage ab cd
ab 0 2.236
cd 0
Gambar 2. 2 Dendrogram Single linkage 2. Complete Linkage
Perhitungan jarak dengan Complete Linkage akan dicari jarak antar cluster dengan yang paling jauh. Dengan tetap menggunakan tabel matriks jarak (tabel 2.7),perhitungan Complete Linkage ini dilakukan. Pada awal perhitungan, cluster ab tetap digunakan sebagai cluster pertama karena jarak antar obyek yang paling dekat yaitu 1. Berikut akan dilakukan perhitungan jarak antar cluster ab dengan c dan d.
= max{ , } = max{ . , . } = . = max{ , } = max{ . , } =
Kemudian baris-baris dan kolom-kolom matriks jarak yang bersesuaian dengan cluster a dan b dihapus dan ditambahkan baris dan kolom untuk cluster ab, sehingga matriks jarak seperti berikut :
Tabel 2. 9 Matriks jarak pertama Complete Linkage
ab c d
ab 0 3.16 3
c 0 2.236
Berdasarkan tabel diatas dipilih kembali jarak terdekat antar cluster. Ditemukan cluster cd yang paling dekat yaitu 2.236. Kemudian dihitung jarak dengan cluster ab.
= max{ , , , } = max{ . , . , . , } = .
Kemudian baris – baris dan kolom – kolom matriks jarak yang bersesuaian dengan cluster c dan d dihapus dan ditambahkan baris dan kolom untuk cluster cd, sehingga matriks jarak menjadi seperti berikut :
Tabel 2. 10 Matriks Jarak kedua Complete Linkage ab cd
ab 0 3.16
cd 0
Dengan demikian proses iterasi perhitungan jarak untuk pembentukan cluster sudah selesai karena cluster sudah tersisa satu. Jadi cluster ab dan cd digabung menjadi satu cluster yaitu abcd dengan jarak terdekat 3.16. Berikut ini hasil dendrogram AHC dengan Complete Linkage:
3. Average Linkage
Menggunakan Average Linkage akan dicari jarak antara cluster dengan menghitung nilai rata-rata pasangan setiap cluster. Dengan tetap menggunakan tabel matriks jarak (tabel 2.7), perhitungan Average Linkage ini dilakukan. Pada awal perhitungan, cluster ab teta digunakan sebagai cluster pertama karena jarak antar obyek yang paling dekat. Berikut ini akan dilakukan perhitungan jarak antara cluster ab dengan c dan d.
= average{ , } = average{ . , . } = . + . = .
= average{ , } = average{ . , } = . + = .
Kemudian baris-baris dan kolom-kolom matriks jarak yang bersesuaian dengan cluster a dan b dihapus dan ditambahkan baris dan kolom untuk cluster ab, sehingga matriks jarak menjadi seperti berikut :
Tabel 2. 11 Matriks Jarak pertama Average Linkage
ab c d
ab 0 2.99 2.618
c 0 2.236
d 0
Berdasarkan pada matriks jarak pertama, dipilih kembali jarak terdekat antar cluster. Ditemukan cluster cd paling dekat, yaitu bernilai 2.236. Kemudian dihitung jarak dengan cluster ab.
= average{ , , , } = average{ . , . , . , } = . + . + . +
= .
Tabel 2. 12 Matriks Jarak kedua Average Linkage ab cd
ab 0 2.804
cd 0
Dengan demikian proses iterasi perhitungan jarak untuk pembentukan cluster sudah selesai karena cluster sudah tersisa satu. Jadi cluster ab dan cd digabung menjadi satu cluster yaitu abcd dengan jarak terdekat 2.804. Berikut ini hasil dendrogram AHC dengan Average Linkage:
Gambar 2. 4 Dendrogram average linkage
2.5.1 Langkah Algoritma Agglomerative Hierarchical Clustering
Algoritma Agglomerative Hierarchical Clustering untuk mengelompokkan n obyek adalah sebagai berikut ( Tan, Steinbach dan Kumar,2006 ) :
1. Hitung matriks kedekatan berdasarkan jenis jarak yang digunakan. 2. Ulangi langkat 3 sampai 4, hingga hanya satu kelompok yang tersisa
3. Gabungkan dua cluster terdekat berdasarkan parameter kedekatan yang ditentukan. 4. Perbarui matriks kedekatan untuk merepresentasikan kedekatan diantara kelompok
2.5.2 Flowchart Agglomerative Hierarchical Clustering 1. Single Linkage
2. Complete Linkage
3. Average Linkage
2.7 Confusion Matriks
Confusion Matriks merupakan metode external evaluasi yang berisi informasi yang actual dan dapat diprediksi (Kohavi dan Provost, 1998), dimana kinerja sistem dapat di evaluasi menggunakan perbandingan hasil luaran sistem dengan label data.
Tabel dibawah ini menunjukkan Confusion Matriks untuk dua class (Kohavi dan Provost, 1998):
Tabel 2. 13 Tabel Confusion Matriks Predicted
Negatif Positif
Actual Negatif a b
Positif c d
Keterangan :
a : jumlah prediksi yang salah bahwa contoh bersifat negatif b : jumlah prediksi yang benar bahwa contoh bersifat negatif c : jumlah prediksi yang salah bahwa contoh bersifat positif d : jumlah prediksi yang benar bahwa contoh bersifat positif
Perhitungan akurasi dirumuskan sebagai berikut :
34 BAB III
METODE PENELITIAN
Bab ini berisi perancangan penelitian yang akan dibuat oleh penulis meliputi data, kebutuhan system, tahapan penelitian, desain interface, skenario sistem, dan desain pengujian.
3.1 Data
Data yang digunakan pada penelitian ini adalah tweet berbahasa Indonesia yang ditulis oleh para pengguna Twitter. Tweet yang dikumpulkan berupa tweet-tweet yang mengandung emosi cinta, senang, marah, takut, dan sedih. Dari masing- masing emosi, diambil 100 data per emosi sehingga total tweet yang digunakan sebagai data berjumlah 500 .
Pencarian data dilakukan dengan menggunakan hashtag #cinta, #senang, #takut, dan #sedih pada website www.netlytic.org. Pemilihan data secara manual yaitu memilih kalimat-kalimat tweet yang berbahasa Indonesia dan tidak mengandung gambar. Tweet yang telah dipilih kemudian di simpan ke file teks. Setiap tweet diletakkan pada setiap baris pada file teks. File teks berisi tweet tersebut kemudian dijadikan input pada sistem untuk diolah lebih lanjut.
Berikut contoh tweet dengan emosi cinta. Penulis tweet mengungkapkan perasaan cintanya pada seseorang atau sesuatu melalui kata-kata yang ditulis.
Berikut contoh tweet dengan emosi senang. Penulis tweet mengungkapkan perasaan senangnya pada seseorang atau sesuatu melalui kata-kata yang ditulis.
Gambar 3. 2Tweet Senang
Berikut contoh tweet dengan emosi marah. Penulis tweet mengungkapkan perasaan marahnya pada seseorang atau sesuatu melalui kata-kata yang ditulis.
Gambar 3. 3 Tweet Marah
Gambar 3. 4 Tweet Takut
Berikut contoh tweet dengan emosi sedih. Penulis tweet mengungkapkan perasaan sedihnya pada seseorang melalui kata-kata yang ditulis.
Gambar 3. 5 Tweet Sedih
3.2 Kebutuhan Sistem
Untuk proses membuat sistem digunakan software dan hardware sebagai berikut :
1. Software
a) Sistem Operasi : Windows 8 64-bit b) Bahasa Pemograman : Matlab R2010A 2. Hardware
a) Processor : Intel (R) Core(TM) i3-3217U CPU @ 1.8GHz b) Memory : 2 Gb
3.3 Tahapan Penelitian 3.3.1 Studi Pustaka
Pada Studi Pustaka ini penulis mencantumkan dan menggunakan teori – teori yang terkait dengan penelitian yang dilakukan,seperti teori Analisis sentimen, emosi, Preprocessing text( Information Retrieval), Pembobotan kata, Normalisasi, Agglomerative Hierarchical Clustering, Euclidean Distance, dan Confusion matriks.
3.3.2 Pengumpulan Data
Data yang digunakan pada penelitian ini adalah tweet berbahasa Indonesia yang ditulis oleh para pengguna Twitter. Tweet yang dikumpulkan berupa tweet yang berisi emosi cinta, marah, senang, sedih, dan takut.
3.3.3 Pembuatan Alat Uji
Pada tahap ini, akan dirancang suatu alat uji yang dimulai dengan perancangan interface dan pembuatan alat uji untuk menguji Agglomerative Hierarchical Clustering untuk mengelompokkan tweet serta mendapatkan akurasi dari sistem yang telah dibangun.
3.3.4 Pengujian
3.4 Desain Interface
Gambar 3. 6 Desain Interface
3.5 Perancangan Struktur Data
Struktur data digunakan untuk mengelola penyimpanan data agar data dapat diakses sewaktu – waktu jika sedang diperlukan. Pada penelitian ini konsep struktur data yang digunakan ialah :
a. ArrayList
ArrayList digunakan untuk menampung data tweet. Sebagai contoh dapat dilihat pada ilustrasi berikut :
[ � � � � � ]
Obyek Atribut
Data 1 Cinta tak kan menuntut kesempurnaan. Cinta kan menerima, memahami, rela berkorban. Karena seharusnya cinta
membuat mu bahagia
Data 2 Dalam hidup ini berbagi kepada sesama memberi jiwa rasa damai. Berbagi dengan tulus tanpa pamrih memberikan perasaan sukacita..
Data 3 Aku patah hati, mas! Sakit sesakit-sakitnya. Data 4 Resah dan gelisah tanpa arah.
Data 5 Baru ditinggal berapa jam rasanya khawatir.
3.6 Skenario Sistem
3.5.1 Gambaran Umum Sistem
Gambar 3. 7 Block Diagram
(sinonim), jika ditemukan kata yang berbeda namun memiliki makna yang sama maka gabungkan menjadi satu kata. Setelah mendapatkan bobot, maka hasil pembobotan di normalisasi. Pada tahap normalisasi ini peneliti menggunakan normalisasi Min-Max dan Z-Score, dilakukan dua macam normalisasi agar mendapatkan metode yang lebih optimal pada penelitian ini. Tahap selanjutnya yaitu menentukan kedekatan data emosi (cinta, senang, sedih, marah,dan takut) dengan metode Agglomerative Hierarchical Clustering menggunakan Euclidean Distance. Tahap terakhir adalah proses perhitungan akurasi menggunakan Confusion matriks.
Setelah menemukan hasil akurasi serta pengelompokkan selanjutnya sistem melakukan proses input data baru, yang berfungsi untuk mengetahui data baru termasuk dalam cluster emosi yang mana. Maka data baru dapat dikategorikan termasuk salah satu dari emosi yang ada.
3.5.1.1 Tahap Preprocessing
Tahap preprocessing meliputi tahap Tokenizing, stopword removal, dan stemming. Sistem akan menghapus link url, username, dan tanda retweet. Sistem akan mengubah kata tidak baku atau kata yang disingkat menjadi kata yang baku. Sistem juga akan mengambil kata yang diawali tanda pagar (hashtag).
Penjelasan tahap preprocessing adalah sebagai berikut:
a. Tokenizing
Pada tahap ini sistem akan memotong dokumen menjadi potongan-potongan kecil yang disebut token dan terkadang disertai langkah untuk membuang karakter tertentu seperti tanda baca (Manning,Raghavan,dan Schutze, 2009). Langkah-Langkah Tokenizing :
1. Baca tiap baris pada file text sebagai satu tweet
2. Ambil tiap token pada kalimat tweet dengan menggunakan spasi sebagai pemisah antara satu token dengan token lain.
Berikut contoh Tokenizing terhadap kalimat tweet cinta, senang, marah, sedih, dan takut :
- Tokenizing tweet cinta
-Gambar 3. 8 Tokenizing tweet cinta
Gambar 3.8 merupakan contoh tweet yang mengalami proses Tokenizing, tweet yang digunakan pada gambar diatas adalah contoh tweet yang mengandung emosi cinta
- Tokenizing tweet senang
Gambar 3. 9 Tokenizing tweet senang
- Tokenizing tweet marah
Gambar 3. 10 Tokenizing tweet marah
Gambar 3.10 merupakan contoh tweet yang mengalami proses Tokenizing, tweet yang digunakan pada gambar diatas adalah contoh tweet yang mengandung emosi marah.
- Tokenizing tweet takut
Gambar 3. 11 Tokenizing tweet takut
- Tokenizing tweet sedih
Gambar 3. 12 Tokenizing tweet sedih
Gambar 3.12 merupakan contoh tweet yang mengalami proses tokenizing, tweet yang digunakan pada gambar diatas adalah contoh tweet yang mengandung emosi sedih.
b. Stopword
Setelah mengalami proses tokenizing , kemudian data tweet diolah melalui proses stopword. Dalam proses stopword, kata-kata yang penting akan disaring sehingga kata yang tidak relevan dapat dibuang.
Langkah – langkah stopword : 1. Baca data hasil tokenizing
2. Cek setiap kata hasil tokenizing dengan sebuah daftar stopword
3.Jika kata pada hasil tokenizing sama dengan kata pada daftar stopword, maka kata tersebut dihapus.
4.Jika tidak maka kata akan disimpan.
Gambar 3. 13 Stopword tweet cinta
Gambar 3.13 merupakan contoh kalimat tweet yang mengalami proses stopword. Kalimat tweet yang digunakan pada diatas adalah tweet yang mengandung emosi cinta.
Gambar 3. 14 Stopword tweet senang
Gambar 3. 15 Stopword tweet marah
Gambar 3.15 merupakan contoh kalimat tweet yang mengalami proses stopword. Kalimat tweet yang digunakan pada diatas adalah tweet yang mengandung emosi marah.
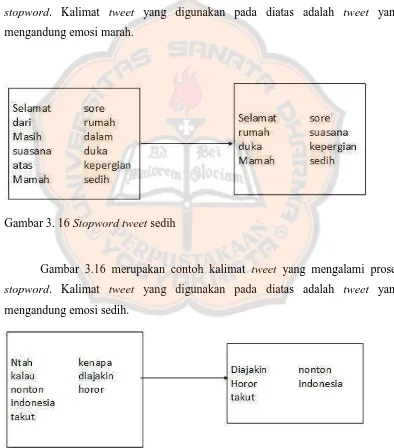
Gambar 3. 16 Stopword tweet sedih
Gambar 3.16 merupakan contoh kalimat tweet yang mengalami proses stopword. Kalimat tweet yang digunakan pada diatas adalah tweet yang mengandung emosi sedih.
Gambar 3.17 merupakan contoh kalimat tweet yang mengalami proses stopword. Kalimat tweet yang digunakan pada diatas adalah tweet yang mengandung emosi takut.
c. Stemming
Setelah mengalami proses stopword, proses selanjutnya ialah proses stemming dimana mencari kata dasar(root word) dari data tweet. Stemming dilakukan dengan menghilangkan awalan (prefiks) dan akhiran (surfiks). Berikut langkah – langkah stemming :
1. Baca tiap kata(token) dan cocokan dengan kata pada kamus kata dasar. 2. Jika token cocok dengan kata pada daftar kamus kata dasar, maka token
adalah kata dasar (root word).
3. Jika token tidak cocok dengan kata pada daftar kamus kata dasar, hapus akhiran dan awalan pada token.
4. Cocokkan hasil langkah ke 3 dengan kata pada daftar kamus kata dasar, jika tidak cocok, anggap token sebelum dikenai langkah 3 sebagai kata dasar. Dibawah ini merupakan contoh data tweet yang mengalami proses stemming:
Gambar 3. 18 Stemming tweet cinta
Gambar 3. 19 Stemming tweet senang
Gambar 3.19 merupakan contoh kalimat tweet yang mengalami proses stemming. Kalimat tweet yang digunakan pada diatas adalah tweet yang mengandung emosi senang.
Gambar 3. 20 Stemming tweet marah
Gambar 3.20 merupakan contoh kalimat tweet yang mengalami proses stemming. Kalimat tweet yang digunakan pada diatas adalah tweet yang mengandung emosi marah.
Gambar 3. 21 Stemming tweet sedih
Gambar 3. 22 Stemming tweet takut
Gambar 3.22 merupakan contoh kalimat tweet yang mengalami proses stemming. Kalimat tweet yang digunakan pada diatas adalah tweet yang mengandung emosi takut.
3.5.1.2 Tahap Pembobotan dan Penggabungan Sinonim Kata
Setelah data melewati proses preprocessing, langkah selanjutnya ialah tahap pembobotan. Tahap pembobotan ini bertujuan untuk memberi nilai frekuensi suatu kata sebagai bobot yang nantinya dapat di proses pada Agglomerative Hierarchical Clustering. Langkah pertama ialah menghitung nilai term frequency tiap kata. Langkah kedua yaitu menghitung nilai document frequency tiap kata. Langkah ketiga yaitu menghitung inverse document frequency. Langkah terakhir yaitu menghitung bobot atau weight dari hasil perkalian term frequency dengan inverse document frequency. Berikut contoh proses pembobotan kata :
a. Menghitung term frequency
Gambar 3.23 merupakan contoh kalimat tweet yang mengalami proses penghitungan term frequency. Kalimat tweet yang digunakan pada diatas adalah tweet yang mengandung emosi cinta.
Gambar 3. 24 TF tweet senang
Gambar 3.24 merupakan contoh kalimat tweet yang mengalami proses penghitungan term frequency. Kalimat tweet yang digunakan pada diatas adalah tweet yang mengandung emosi senang.
Gambar 3. 25 TF tweet marah
Gambar 3.25 merupakan contoh kalimat tweet yang mengalami proses penghitungan term frequency. Kalimat tweet yang digunakan pada diatas adalah tweet yang mengandung emosi marah.
Gambar 3.26 merupakan contoh kalimat tweet yang mengalami proses penghitungan term frequency. Kalimat tweet yang digunakan pada diatas adalah tweet yang mengandung emosi sedih.
Gambar 3. 27 TF tweet takut
Gambar 3.27 merupakan contoh kalimat tweet yang mengalami proses penghitungan term frequency. Kalimat tweet yang digunakan pada diatas adalah tweet yang mengandung emosi takut.
b. Menghitung document frequency Tabel 3. 1 Tabel menghitung df
14. Sedih 1
Pada tabel 3.1 merupakan contoh perhitungan document frequency, document frequency merupakan banyaknya bobot yang terkandung dalam seluruh data tweet.
18. Indonesia 1 0.698970004
19. Takut 1 0.698970004
Pada tabel 3.2 merupakan contoh perhitungan inverse document frequency.
d. Menghitung bobot atau weight
Setelah menghitung idf, langkah selanjutnya ialah menghitung bobot (Wij) yang terdapat pada masing – masing emosi. Dimana bobot ialah hasil perkalian antara term frequency dengan inverse document frequency. Dibawah ini merupakan contoh data tweet yang melakukan proses perhitungan bobot.
Hitung bobot (Wij) tweet cinta Tabel 3. 3 Hitung Wij Tweet Cinta
Kata tf idf Wij
Cinta 2 0.397940009 0.795880018
Sayang 3 0.22184875 0.66554625
Total 1.461426268
Pada tabel 3.3 menunjukkan conntoh perhitungan bobot yang terkandung dalam tweet. Tweet yang digunakan pada gambar diatas adalah tweet yang mengandung emosi cinta.
Hitung bobot (Wij) tweet senang Tabel 3. 4 Hitung Wij Tweet Senang
Kata TF Idf Wij
Ikhlas 1 0.698970004 0.698970004
Enak 1 0.698970004 0.698970004
Pada tabel 3.4 menunjukkan conntoh perhitungan bobot yang terkandung dalam tweet. Tweet yang digunakan pada gambar diatas adalah tweet yang mengandung emosi senang.
Hitung bobot (Wij) tweet marah Tabel 3. 5 Hitung Wij Tweet Marah
Kata TF Idf Wij
Muak 1 0.698970004 0.698970004
Sifat 1 0.698970004 0.698970004
Total 1.397940008
Pada tabel 3.5 menunjukkan conntoh perhitungan bobot yang terkandung dalam tweet. Tweet yang digunakan pada gambar diatas adalah tweet yang mengandung emosi marah.
Hitung bobot (Wij) tweet sedih Tabel 3. 6 Hitung Wij Tweet Sedih
Kata TF Idf Wij
Selamat 1 0.698970004 0.698970004
Sore 1 0.698970004 0.698970004
Rumah 1 0.698970004 0.698970004
Suasana 1 0.698970004 0.698970004
Duka 1 0.698970004 0.698970004
Pergi 1 0.698970004 0.698970004
Mamah 1 0.698970004 0.698970004
Sedih 1 0.698970004 0.698970004
Pada tabel 3.6 menunjukkan conntoh perhitungan bobot yang terkandung dalam tweet. Tweet yang digunakan pada gambar diatas adalah tweet yang mengandung emosi sedih.
Hitung bobot (Wij) tweet takut Tabel 3. 7 Hitung Wij tweet takut
Kata TF Idf Wij
Ajak 1 0.698970004 0.698970004
Nonton 1 0.698970004 0.698970004
Horror 1 0.698970004 0.698970004
Indonesia 1 0.698970004 0.698970004
Takut 1 0.698970004 0.698970004
Total 3.49485002
Pada tabel 3.7 menunjukkan conntoh perhitungan bobot yang terkandung dalam tweet. Tweet yang digunakan pada gambar diatas adalah tweet yang mengandung emosi takut.
e. Penggabungan Kata (Sinonim)
Menurut Kamus Besar Bahasa Indonesia (KBBI) sinonim adlah bentuk bahasa yang maknanya mirip, maka pada proses penggabungan kata dapat dilakukan ketika terdapat kata berbeda namun memiliki makna yang sama, dapat digabungkan menjadi satu kata, tanpa mengubah nilai frekuensi.
Berikut contoh kata yang mengalami proses penggabungan kata : Tabel 3. 8 Tabel contoh data belum mengalami proses penggabungan
Kata TF
Riang 1
Gembira 1
Senank 1
Umpat 1
Kesel 1
Kesal 1
Tabel 3. 9 Tabel contoh data setelah penggabungan
Kata TF
Gembira 3
Kesal 3
3.5.1.3 Tahap Normalisasi
Setelah data diproses melalui tahap preprocessing, data selanjutnya di normalisasi. Normalisasi pada penelitian ini menggunakan normalisasi min-max dan normalisasi Z-Score.
a) Normalisasi Min-max
Pada tabel 3.10 terdapat bobot yang dominan dibandingkan bobot-bobot lain. Pada contoh diatas, bobot yang dianggap dominan adalah bobot yang paling banyak muncul. Bobot dominan diitunjukkan dengan warna biru.
Langkah – Langkah Normalisasi Min-max :
1. Cari masing – masing nilai terkecil (min) dan nilai terbesar (max) pada setiap kata.
Tabel 3. 11 Tabel Min-max
cinta Senang kesal takut Sedih
Min 0 0 0 0 0
Max
1.397940 2.096910 1.397940 1.397940 1.39794
Tabel 3.11 menunjukkan nilai terkecil dan nilai terbesar pada data. Nilai terkecil dan terbesar digunakan pada normalisasi min-max.
2. Hitung nilai bobot baru :
= �0− � �
� ��−� � (3.1)
Tabel 3.12 menunjukkan hasil hitung bobot baru menggunakan normalisasi min-max. Bobot baru ditunjukkan dengan warna biru.
b) Normalisasi Z-Score
Normalisasi Z-Score digunakan supaya kata hasil pembobotan data dapat dibandingkan. Dibawah ini merupakan langkah – langkah untuk mendapatkan hasil normalisasi Z-Score.
1. Hasil pembobotan setelah proses preprocessing Tabel 3.10 Tabel contoh data pembobotan
2. Mencari nilai rata-rata dari masing – masing data tweet.
Tabel 3.13 menunjukkan hasil perhitungan rata-rata setiap kalimat tweet. Kemudian dicari total rata-rata tweet untuk dapat diproses pada tahap normalisasi
3. Mencari nilai standar deviasi dari masing – masing tweet. Tabel 3. 14 Tabel Standar Deviasi
Standar Deviasi Standar
deviasi
0,564853063
4. Hasil Normalisasi
Perhitungan rumus yang telah dipaparkan pada bab sebelumnya pada persamaan 2.6.
Tabel 3. 15 Hasil Normalisasi Zscore
Kata
Tabel 3.15 Menunjukkan hasil normalisasi menggunakan Z-Score. Bobot baru ditunjukkan dengan warna biru.
3.5.1.4 Agglomerative Hierarchical Clustering
Setelah data dinormalisasi, data kemudian masuk pada tahap clustering. Pengelompokkan pada penelitian ini menggunakan Agglomerative Hierarchical Clustering (AHC). Matriks jarak dihitung dengan menggunakan Cosine Similarity. Masing-masing data akan dikelompokkan berdasarkan karakteristik kedekatannya. Proses pengelompokkan ini akan menggunakan tiga metode yaitu, single linkage, complete linkage, dan average linkage. Berikut langkah – langkah pengelompokkan menggunakan AHC.