international food-trade multi network
S Torreggiani1, G Mangioni2, M J Puma3‡ and G Fagiolo4 1 SOAS University of London, U.K., and Istituto di Economia, Scuola Superiore Sant’Anna, Pisa, Italy.
2 Dipartimento di Ingegneria Elettrica, Elettronica e Informatica, University of Catania, Catania, Italy
3 Center for Climate Systems Research and Center for Climate and Life, Columbia University; NASA Goddard Institute for Space Studies, New York, USA
4 Istituto di Economia, Scuola Superiore Sant’Anna, Pisa, Italy.
Abstract. Achieving international food security requires improved understand-ing of how international trade networks connect countries around the world through the import-export flows of food commodities. The properties of food trade net-works are still poorly documented, especially from a multi-network perspective. In particular, nothing is known about the community structure of food networks, which is key to understanding how major disruptions or “shocks” would impact the global food system. Here we find that the individual layers of this network have densely connected trading groups, a consistent characteristic over the period 2001 to 2011. We also fit econometric models to identify social, economic and geographic factors explaining the probability that any two countries are co-present in the same community. Our estimates indicate that the probability of country pairs belonging to the same food trade community depends more on geopolitical and economic fac-tors – such as geographical proximity and trade agreements co-membership – than on country economic size and/or income. This is in sharp contrast with what we know about bilateral-trade determinants and suggests that food country commu-nities behave in ways that can be very different from their non-food counterparts.
Keywords: Food security, international trade, complex networks,
community-structure detection, multi-layer networks
Submitted to: Environ. Res. Lett.
‡ Corresponding author. NASA Goddard Institute for Space Studies, 2880 Broadway, New York, NY 10025 USA. Email: [email protected]
1. Introduction
Achieving international food security [1] is undoubtedly one of the major challenges of the forthcoming decades and a globally recognized
priority [2]. However, understanding how
and why the availability of and access
to food commodities change across time
and space is a dauntingly difficult task, due to its inherent multidimensional nature [3]. International food security may indeed depend on many intertwined phenomena [4], including population growth [5]; agricultural productivity and (over) exploitation of natural resources [6, 7, 8]; climate change [9, 10, 11]; regional conflicts and epidemics [12]; and the evolution of consumption habits [13, 14, 15].
The resulting impact of these interacting factors may generate unexpected volatility and substantial shocks in the supply and availability of food commodities, possibly leading to global crises [16]. International trade, in this respect, may act both as a dampening force and as an amplifying device
to regional shocks [17]. On the one hand,
international trade may provide new channels to meet increasing food demand through the transfer of food commodities and resources to food-scarce regions. Empirical evidence indeed shows that the amount of traded food has more than doubled in the last 30 years, and it now accounts for 23% of global production [3]. Furthermore, whereas in the past insufficient domestic production generally implied scarcity in food supplies, production shortfalls in more recent years have been increasingly dealt with by increasing food imports [1, 18].
On the other hand, import-export linkages
across countries can boost shock diffusion: increased connectivity in the international
trade network (ITN, cf. [19]) can lead
to a growing fragility [20, 21, 18]. This
parallels what happened during the 2007-2008 global financial crisis (GFC henceforth), when seemingly minor shocks spread quickly in a complex, networked world, with disastrous effects [22].
To better understand how shocks can spread beyond a regional scope, it is therefore important to shed light on the structure of the networks connecting countries through
import-export flows of food commodities. Despite
advances in understanding the ITN at the aggregate level [23] and for a set of highly-traded commodities (not necessarily food related) [24, 25], the properties of food trade networks are still poorly documented [26, 27, 28, 29, 18], especially from a multi-network perspective [30, 31, 32]. In particular, nothing is known about the community structure (CS) of food networks [33], that is the organization of network nodes in clusters, where nodes within a cluster are comparatively more intensively connected than they are with nodes belonging to different clusters. Documenting the CS of the international food trade multi-network (IFTMN) may help us better understand how food crises propagate. Indeed, if trade across countries is organized into well-defined clusters, shocks originating within a cluster would likely spread more readily within that group than across groups.
for the period 1992-2011. We document the evolution of CSs in the IFTMN both across layers (i.e., when the IFTMN is analyzed as a collection of separate layers, each one representing bilateral trade for a specific
food commodity, e.g. wheat) and in the
multi-layer graph (i.e., when the IFTMN is conceived as a single multi-layer network where countries are connected by multiple import-export relationships, e.g. for maize, wheat, rice, etc.).
We then fit econometric models to
identify social, economic and geographic
factors explaining the probability that any two country are co-present in the same community. Results reveal that countries in the IFMN tend to organize into densely connected trading groups that remain sufficiently stable over time. Overall, our estimates indicate that the probability for country pairs to belong to the same food trade community depends more on geopolitical and economic factors —such as geographical proximity and trade agreements co-membership— than country economic sizes
and/or incomes. This is in sharp contrast
with what we know about bilateral-trade determinants and suggest that food country communities behave in ways that can be very different from their non-food counterparts.
2. Materials and Methods
2.1. Data and Definitions
We use FAOSTAT data on international trade flows, which contain bilateral export-import yearly figures for food and agricultural products in the period 1986-2013§
We select the 16 most-traded commodities
in 2013, ranked according to the total
kilocalories (kcal henceforth) embodied, so as
§ Data are available atfao.org/faostat.
to account for about 90% of the total kcal trade for food-related goodsk.
Table 1 lists the top 16 commodities according to kcal embodied (in 2013) and their trade value (in current USD). As expected,
the two rankings are not correlated. For
example, there are traded commodities with an extremely high economic value that contribute much less in terms of kcal (e.g., meat and
animal products). Notice also that the
distribution of kcal is extremely skewed: more than 55% of total kcal are accounted for by wheat, soybean, maize and rice (which together form just 23% of total value in USD). Selecting commodities according to a mass-to-kcal conversion —rather than value or volume— allows us to better address the role of trade in the nutritional security of countries¶. Furthermore, the 16 commodities selected also have a substantial environmental footprint, as they typically use the most cropland and strongly influence irrigation water consumption [38].
In order not to bias our analysis with issues related to the collapse of the USSR and of the former Yugoslavia, we do not include the years 1986-1991. We also remove the two most recent years (2012-2013) from the sample, as bilateral updated data are still not available
for some products and/or countries+. We
eventually end up withN = 178 countries (see table A1 in Appendix A for a complete list)∗,
k To compute total kcal embodied we explicitly consider caloric values of secondary and derivative products, see table B1 in Appendix B for details. Primary and secondary products are aggregated after converting them to kcal.
¶ Other factors such as water [34, 35, 36, 27] or nutritional [37] content of the food may be included in future studies.
+ Note that our selected commodities are still the
top-16 most-traded agricultural products in terms of kcal also in 2011.
Table 1. Top world 16 import commodities in 2013 according to kcal embodied.
Code Commodity kcala
USD % kcal
1 Wheat 6.45×1014
9.71×1010
21.11 2 Soybeans 5.93×1014 1.07×1011 19.43
3 Maize 4.44×1014 4.22×1010 14.54
4 Sugar 2.25×1014 3.31×1010 7.38
5 Rice 1.36×1014 2.61×1010 4.47
6 Barley 1.32×1014
2.74×1010
4.33 7 Oil, Palm 9.74×1013 4.20×1010 3.18
8 Oil, Sunflower 7.22×1013
1.01×1010
2.37 9 Milk 6.81×1013 8.23×1010 2.21
10 Cassava 5.33×1013 4.07×109 1.75
11 Pulses 4.64×1013 1.02×1010 1.49
12 Cocoa 4.51×1013 4.22×1010 1.46
13 Pig Meat 4.47×1013
4.21×1010
1.43 14 Poultry Meat 2.82×1013 3.45×1010 0.92
15 Nuts 2.61×1013
2.03×1010
0.86 16 Sorghum 2.40×1013 2.01×109 0.78
Source: Our computation on FAOSTAT data (seefao.org/faostat).
whose bilateral trade flows for the 16 selected commodities are observed from 1992 to 2011 (T = 20).
We define the IFTMN as the sequence of T multi-layer networks, where each layer
represents bilateral trade among our N
countries for a specific commodityc= 1, . . . , C
(C = 16) in a given year. More formally,
in each year t = 1992, . . . ,2011, let Xt be
the 3-dimensional weight matrix whose generic entryxt
ij,c ≥0 represents exports (in kcal) from
countryito country j for commodity cin year
t. As usual, we posit that xt
ii,c = 0 for all i,
c and t. We define the IFTMN as the time
sequence of multi-layer networks characterized by the time sequence of weighted-directed matrices {Xt, t = 1, . . . , T}. In other words,
each snapshot (year) of the IFTMN is a multi-layer network, where the nodes are the 178 countries connected by multiple directed links, each of which represents an exporter-importer
in a positive bilateral flow for at least one year or one commodity.
flow for a particular commodity, weighted by its correspondent intensity in terms of
kcal traded. A directed link (i → j)t
c is
therefore present for a given commodity-year combination (c, t) if i exports to j a non-zero volume for commodity c in year t. All zero off-diagonal entries therefore represent either a missing value or a sheer zero-trade flow.♯
2.2. Network Structure
Prior to performing community detection, we explore the properties of the time sequence of multi-networks Xt using a principal compo-nent analysis in the space of network statistics computed over each single layer. More pre-cisely, given link weightsxt
ij,c of layer (c, t), let
♯ In the IFTMN, links between any two commodity layers c1 and c2, c1 6= c2 are present only between
copies of the same country, i.e. any country i is
connected to herself in all the layers. Two different countries are not linked across different layers. In this respect, the IFTMN can be defined as a multiplex or
Wt
c be the associated log-transformed weight
matrix†† and At
c the correspondent adjacency
matrix. In each year t, we compute a number of network statistics over Wt
c and Atc to fully
characterize the weighted and binary topolog-ical properties of the layer (see Appendix F for details). We include measures of binary and weighted connectivity (e.g., network den-sity, size of largest connected component, av-erage and standard deviation of link weights), assortativity, node clustering and network cen-trality, in order to provide a full topological characterization of each layer. After removing the statistics that turn out to be redundant (i.e., too highly correlated with the most basic statistics like density), we perform a principal-component analysis to reduce the dimension-ality of the space of remaining statistics, and we then interpret the results. This allows us both to identify network measures that better characterize the topological structure IFTMN in each year and to explore similarities and dif-ferences among commodity networks.
2.3. Community Structure Detection
Identifying communities in a network is damental for gaining insights about its fun-damental structure, its robustness, and the ways in which shocks percolate through it [39]. Essentially, communities are clusters of ver-tices characterized by a higher “within” con-nectivity, but a much sparser connectivity “be-tween” nodes belonging to different clusters. Community detection is a very difficult task and a host of different techniques and defini-tions have been recently proposed in the lit-erature for the case of simple or multi-graphs [33, 40, 41].
††As it is customary in this literature [19], positive trade levels are log-transformed in order to reduce the skewness of their distribution.
Here, we tackle the problem of community detection in the IFTMN using two complemen-tary approaches.
First, in any givent, we treat the IFTMN
as a collection of C different
commodity-specific weighted-directed simple graphs, and we analyze the CS of each layer separately. To identify communities, we employ the modularity optimization approach originally introduced by [42] and subsequently extended to the case of weighted directed graphs by [43]. In this case, the modularity function to be maximized is: δ is a Kronecker delta function equal to 1 if nodesi and j are in the same community and 0 otherwise. Eis the expected value of the link weight xt
ij,c, which following [43] reads:
E[xtij,c] = s
out-strength of nodei and in-strength of node
j [44]. To optimize Qtc, we employ the
modularity-clustering heuristic developed by [45], which extends and improves the well-known “Louvain” algorithm pionereed by [46]
(see Appendix C for more details). This
procedure ends up, for any given year t and commodity-layerc, with a univocal assignment of countries into clusters, the number of which is not fixed ex-ante, in such a way that each country belongs to a single cluster (i.e.,
communities are not overlapping). Clusters
can also contain a single country, e.g., if that country is an isolated node in the network.
C layers making up a time snapshot of the IFTMN as being connected through weighted, non-directed links that join the same node across all the layers. The weight of such links (θ) is homogeneous across time, nodes and layers, and is treated as a system parameter. In such a multi-layer perspective, communities are formed by country-commodity pairs. So, for example, the same country can end up in different clusters in association with different commodities; or different countries can belong to the same cluster in association with the same commodity. Here, we perform a multilayer community-detection analysis as in [47], who extend modularity to multi-layer graphs on the base of generalized null models obtained by considering a Laplacian dynamics on the multi-layer. More specifically, we use the implementation of the algorithm in [47] available in MuxViz [49], which is based on a generalization of the “Louvain” algorithm [46] (see Appendix C for further details).
2.4. Econometric Models
As mentioned, identifying communities in the IFTMN treated as a collection of C separate layers, results in a univocal assignment of countries to clusters for any given choice of t
and c. Clusters are multilateral entities, as they emerge whenever a group of countries trades comparatively more among them than they do with countries outside the cluster. But what are the factors underlying the emergence of such clusters? Here, we address this issue fitting probit and logit models [50] that explain the probability that any two countries belong to the same cluster (for a given (c, t) slice of the IFTMN) as a function of economic, socio-political and geographical, bilateral relationships. More precisely, we perform two sets of exercises.
First, for allc= 1, . . . ,16 and two selected years (t0 = 2001 and t1 = 2011)†, we fit to
the data the following probit model using a maximum-likelihood procedure:
P rob{γij,ct = 1}= Φ(α+βZtij), (3)
where γij,ct is a binary indicator for the event
that countries i and j belong to the same
community for product cand year t∈ {t0, t1},
Φ is the cumulative distribution function for the standard normal variate‡, α is a constant,
β is a vector of slopes and Zt
ij is a set of
bilateral covariates (more on that below). Second, we run a panel-data estimation
of the probit model in Eq. (3) on the
pooled dataset containing all the years in our sample, for some selected commodities
(i.e., wheat, maize and rice). We choose
wheat, maize, and rice (and their associated commodities) as they are among the most important internationally traded grains and are fundamental to staple food supplies around the world. Panel estimations feature the same covariates of the cross-section setup, but they now become time-varying. Furthermore, as it is customary in this approach [51], we control for unobserved heterogeneity and common trend effects including in panel regressions time-invariant country fixed-effects and time dummies.
To choose the covariates, we rely on the literature on the empirical trade-gravity model [52], see Appendix E and Table E1 for de-tails. We employ five classes of covariates: economic variables (i.e., combined measures of economic country size and income); trade pol-icy variables (e.g., whether the two countries
† These two years have been chosen in order to focus on two time periods sufficiently far from the GFC.
belong to the same preferential trade agree-ments); geographical variables (e.g., distance between countries and whether they share a border); historical/political variables (e.g., for-mer colonial relationships); and cultural vari-ables (i.e., whether countries share the same language).
Despite the fact that our probit specifica-tion has an obvious gravity flavor, it departs from traditional trade-gravity models in the way we treat directionality of relationships. In-deed, since the co-presence relations are sym-metric by definition, the binary response model in Eq. 3 does not distinguish between importer and exporter, as, on the contrary, gravity mod-els with trade flows as dependent variable often do. Therefore, sign and intensity of the impact of covariates cannot differ between origin and destination markets.
3. Results
We now turn to a description of our main
results. First, we describe some basic
network properties of the IFTMN, both across
commodity-layers and time. Second, we
discuss the CS of ITMN considered as a
collection of C separate layers. Third, we
explain co-presence in clusters using probit models. Finally, we check what happens when CS detection is performed over the IFTMN described as a multi-layer network.
3.1. Overview of network properties
The IFTMN is characterized by low variability over the time interval under observation but substantial heterogeneity across layers in each
year. A comparison of results in Tables
F1-F2 in Appendix F, which report network statistics in 2001 and 2011, suggests that network structure did not go through dramatic
changes before and after the GFC.
However, our analysis indicates consid-erable variation in the topological properties
across commodity layers. For example, the
IFTMN is composed of small-density layers (as compared to the aggregate ITN), whose link probabilities range from 0.01 to 0.16. Substan-tial variation is also detected in the size of the largest connected component (LCC) – from 87 to 171 – and many other statistics. Therefore, a principal component (PC) analysis can help in summarizing the most important dimen-sions of variability. Results for year 2011 are reported in Figure 1. We use a bi-plot to repre-sent both the units (commodities) in the space of the first two PCs (which together explain 83% of total variance) and network statistics as vectors (whose direction and length indicate how each variable contributes to the two prin-cipal components in the plot). The first PC is positively correlated with connectivity mea-sures (density and size of LCC), network sym-metry and centralization, and negatively corre-lated with binary assortativity (i.e., the larger the x-axis coordinate, the smaller the assorta-tivity coefficient). The second PC is instead positively correlated with average and stan-dard deviation of link weights (in addition to assortativity). This means that, overall, com-modity layers tend to display a higher density and size of LCC, and to be more centralized and symmetric, but less assortative. Moreover, more intense bilateral connections are gained, on average, at the expense of a larger standard deviation thereof.
Zooming inside commodities, the position of layers in the bi-plot suggests the existence
of two paradigmatic cases. The first one
is represented by layers such as wheat, cocoa and barley, which are characterized by a relatively high connectivity, centralization
-0.6 -0.4 -0.2 0 0.2 0.4 0.6
Size of LCC
Centralization Binary Assortativity
Ave of Weights Std of Weights
Sorghum
Figure 1. The IFTMN in year 2011. Principal component (PC) analysis in the space of network statistics. First two PCs explain 83% of total variance.
assortativity, and a lower intensity and
variability of import-export relationships. To the second one belong layers such as sorghum and cassava, who are much less connected and symmetric, and they are structured over more intense and less variable trade relationships. Other important layers like maize, rice and soybeans play instead an intermediate role, being less internally connected than wheat but displaying stronger and more variable bilateral connections.
Network statistics in Tables F1-F2 and their correlations (see Figure F1) reveal two important additional facts. First, the layers of the IFTMN are mostly assortative: more-intensively connected countries tend to im-port and exim-port to countries which are
them-selves more connected. This conflicts with
widespread evidence observed both in the ag-gregate ITN and across commodity-specific trade layers, not necessarily related to food, representing import-export relationships for specific product classes at a two-digit break-down (e.g., cereals, pharmaceutical products,
iron and steel, etc.), see Ref. [19, 24].
Second, the weighted version of statis-tics such as asymmetry, clustering and as-sortativity are almost linearly correlated with their binary counterpart, suggesting that in the IFTMN, unlike in the aggregate ITN, the creation of new trade channels are more im-portant than increases in trade flows of already existing connections (i.e., in economics jargon, extensive trade margins are more important than intensive ones).
−1
Pig meat Pulses Sugar Nuts Oil, sunflo
w
er
Rice Oil, palm Sorghum Cassa
va
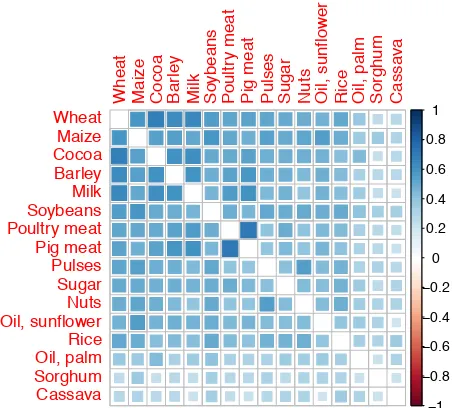
Figure 2. Correlation between logged link weights of commodity layers. Year=2011. Commodities have been ordered using a (Ward) hierarchical clustering.
We now explore across-layer correlation in (logs of) link-weight distributions wt
ij,c =
log(xt
ij,c), cf. Figure 2 for year 2011 and Figure
F3 in Appendix F for year 2001. We notice that almost all commodities are traded as complements (i.e., all correlations are positive and significant). The only exceptions are palm oil, sorghum and cassava, which are traded in an almost uncorrelated way with all the
others. This may probably be due to the
(i.e., palm oil) or extremely agglomerated geographically (i.e., cassava and sorghum).
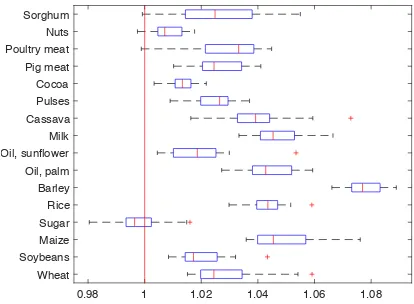
Finally, we investigate the extent to which export per outward link is associated with imports per inward link, across years
and layers. Figure 3 depicts time-series
distributions for the ratio between layer-average import intensity vs. layer-average export intensity (i.e., the import/export intensity
ratio). Import (resp. export) intensity is
defined as total country import (resp. export) per importing (resp. exporting) partner, that is, in network jargon, the ratio between node
in (resp. out) strength and node in (resp.
out) degree. Note how almost all layers have been characterized by ratios always larger than
one across the years. This means that, on
average, countries tend to have, irrespective of the commodity traded and its share on the world market, more intensive import relations than export ones. This result is consistent with the evidence shown by Ref. [24] for a more aggregated set of commodity-specific – not necessarily food-related – networks (and it is, in particular, true for coarse cereals). This evidence could be a symptom of the high dependency of several countries on few relevant import channels for their staple-food supply.
3.2. Layer-by-layer community structure
We now discuss community-detection findings when the IFTMN is treated, in each year, as a collection of independent food-staple trade layers. We begin with results related to two temporal cross sections – for the individual years 2001 and 2011 – across all layers. Then, for three selected commodities (wheat, maize and rice), we document the evidence on community-detection for the 2001-2011 panel. As Table H1 shows, the first general observation is that the IFTMN exhibits a
0.98 1 1.02 1.04 1.06 1.08
Figure 3. Time-series distributions for the average import/export intensity ratio. The central red mark of each box is the median, the edges of the box are the 25th and 75th percentiles, the whiskers extend to the most extreme not-outlier observations, and the outliers are plotted individually (red plus).
very high level of (maximum) modularity in almost all layers and years. This suggests that the IFTMN is characterized throughout by a strong community structure, with countries that organize into densely linked groups. Indeed, maximum modularity levels typically fall in the range [0.2,0.5], which, as suggested in Ref. [42], is strong evidence for the existence of well-defined clusters. The only exception to this general rule is cassava, which displays an almost negligible level of modularity. In each layer, we identify on average 6 clusters (or communities) with number ranging from 3 (for poultry meat in 2011, the least dispersed layer on average) to 10 (for sorghum in 2001, the most dispersed layer on average).
!!!!!!!!!!!!!!!!!!!!
1. Wheat 2. Soybeans
3. Maize 4. Sugar !
!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!5. Rice 6. Barley
!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!7. Palm Oil 8. Sunflower Oil
! !
9. Cocoa 10. Poultry Meat
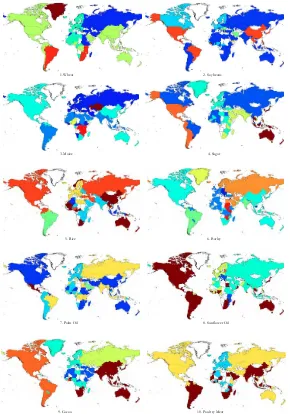
Figure 4. Community detection in year 2011. Choropleth maps display country membership to communities for selected commodities. In white, countries not belonging to any community or for which no data are available.
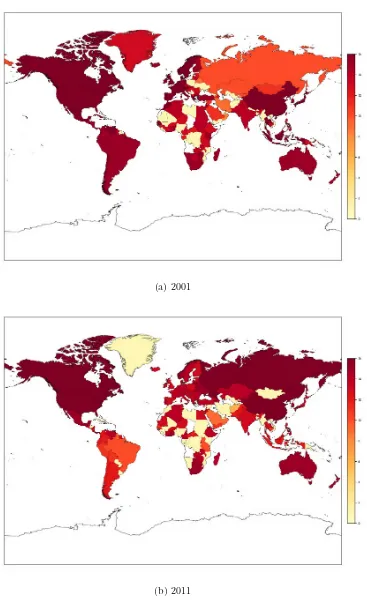
Choropleth maps for year 2011 reveal interesting across-layer regularities. First, there often exists a North American cluster (with the US and Canada often linked to Central and Latin America countries), whereas relevant breadbaskets such as Brazil and Argentina often set up alternative communities independently. Second, Russia generally forms a cluster together with Central, Caucasian and East- European (non EU-members) states, often absorbing some MENA region countries (especially Egypt). A unified European cluster
often emerges, sometimes linked with the Russian cluster and rarely linked with the US, confirming that Europe is not such an open market for many agricultural products. Furthermore, a consolidated and independent Asian cluster seems to exist only in the case the region is a net importer for that commodity (i.e., wheat, milk and diary
products, and cocoa). East Asian (e.g.,
communities, orbiting around other clusters such as the North American and South American ones. Finally, Africa and the Middle East are often divided – independently of the commodity examined – and only in a few cases we can observe a small independent Eastern Sub-Saharan cluster.
Apart from these macro regularities, sev-eral cross-sectional differences also emerge among commodity-specific community struc-tures†, the most striking of which concerns concentration in their size distributions (see Figure H2 in Appendix H for the case of year 2011). The most concentrated commu-nity structures are those of soybeans, palm oil, poultry meat and nuts, whereas rice exhibits the most homogeneous size distribution.‡
Similarities and differences among com-munity structures can be better appreciated computing the normalized mutual informa-tion (NMI) index between pairs of community structures (see Figure 5 and Appendix D for
details). The NMI index ranges between 0
and 1 and increases the more the two com-munity structures are similar. Three groups of commodities can be identified (outlined by the three squares in the figure). The first one comprises the most similar structures, i.e. coarse grains (barley, maize, wheat), pig meat and milk. The other two consist of commodi-ties that exhibit quite different trading blocs, and differ from the other groups. These are (i) nuts, pulses, sugar and rice; (ii) soybeans, poultry meat, oil, cocoa and sorghum. Note that pig and poultry meat are very similar in terms of their community structures but
be-† In Appendix G we discuss in details economic factors that can explain the pattern of each commodity-specific community structure in 2011
‡ This result is confirmed when one computes the Herfindahl concentration index (see description that follows).
long to different groups.
0.12
Oil, palm Poultr
y meat
Oil, sunflo
w
er
Cocoa Sorghum Bar
le
y
Maiz
e
Pig meat Wheat Milk Nuts Pulses Sugar Rice
Soybeans
Figure 5. Normalized mutual information (NMI) index in year=2011. Higher values of the index suggest that the two community structures are similar. Commodities have been ordered using a (Ward) hierarchical clustering. Squares identify clusters.
We now explore whether community structures have changed from 2001 to 2011. Figure H1 in Appendix H shows, for a few commodities, country community membership
in 2001. A qualitative comparison with
Figure 4 shows that in 2011 the European trading bloc became larger, possibly due the Eastern enlargement of the Union (from 15 to
27 members). This evidence is particularly
strong in the case of wheat, maize, sugar, rice, palm oil and cocoa, whereas holds to a lesser extent for barley, milk, pulses and poultry meat. Overall, this may be interpret as a first evidence of the effectiveness of the Common Agricultural Policy (CAP) of the
European Union. Furthermore, comparing
2001 and 2011 maps reveals an increasing influence of Brazil, Russia, India and China (i.e., the BRIC countries) in the African
explained by the increasing hegemony of Russia and India in Eastern Africa, which has gradually undermined that of Australia in wheat and rice trade. Similarly, maps seem to be coherent with the increasing importance that Brazil gained as maize supplier in African and Middle Eastern countries, at the expense of the Northern American and the European clusters.
More generally, community structures in 2001 differ from those in 2011 because the size distributions of the latter are typically more concentrated. Figure H3 in Appendix H plots the normalized Herfindahl concentration index computed in 2001 and 2011 for all commodity networks (expect cassava) and shows that the lion’s share of layers lie
above the main diagonal. Rice, soybeans,
poultry meat and sunflower oil display the
largest increase in concentration. A more
concentrated community structure implies that a larger share of countries belong to existing trading groups. Therefore, increases in H index can be interpreted as a tendency to a more globalized trade network. Notice that increasing concentration levels are not necessary associated with a decrease in the number of detected communities (cf Table
H1). This suggests that, when detected,
increasing concentration levels in community size distributions are attained through country switching among clusters and not due to a reduction in the number of trading blocs.
To delve further into the time dynamics of community structures, we focus on three selected commodities, i.e. wheat, maize and rice. We document how community structure for these three products evolve across the
whole time sample (1992-2011). Figure H4
plot the time series of community number (left) and maximum modularity (right). Note that in general modularity has been increasing
over time, suggesting that the IFTMN, at least in the three layers considered in the figure, has exhibited a stronger and stronger tendency to clusterize into well-defined trading
blocs. Furthermore, the three commodities
considered have followed quite distinct time patterns as far as the number of detected
communities is concerned. Maize trade
network has been organizing itself into an increasing number of clusters, whereas the number of trading blocs in the wheat network has decreased and stabilized around four. Finally, the rice network has experiencing a lot of turbulence, oscillating between 6 and 9 trading groups over time.
3.3. Econometric models
As visual inspection of Figures H1 and 4 shows, community structures in the IFTMN exhibits evident geopolitical and socioeconomic regu-larities. In order to quantitatively explore this issue, we run a set of probit-regression exer-cises where we explain the probability that any two countries belong to the same trade bloc as a function of a host of covariates (see Sec-tion 3.3 and Table E1), capturing country-pair (dis)similarity along geographical, economic, social, and political dimensions.
Covariates employed in the analysis are borrowed from the trade-gravity literature [52], which suggests that bilateral trade flows typically increase in the importer and exporter market size and income (proxied by country total and per-capita GDP) and decrease the
stronger trade frictions. The latter are
whether they belong to the same geographical macro-area.
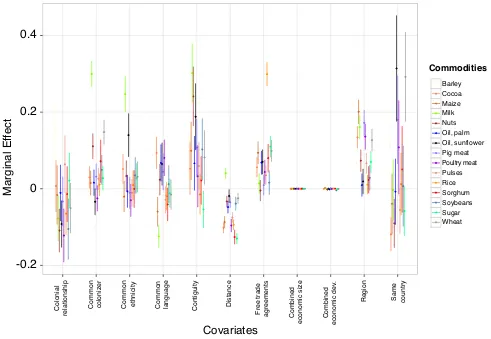
We begin by fitting Eq. (3)
cross-sectionally to year 2001 and year 2011, for all commodity layers. Results for year 2011 are visually presented in Figure 6, where point estimates of marginal effects of covariates are plotted together with their 95% confidence intervals for all commodities (see Figure H5 in Appendix H for year 2001)§.
Our findings indicate that distance has a negative and statistically significant impact on the probability that two countries belong to the same trade community, for all products considered (but milk). Other geographically-related covariates such as contiguity and regional membership have a product-specific effect, both in terms of significance and sign, notwithstanding they generally boost the co-presence of country pairs in the same trade
bloc. Furthermore, free-trade agreements
almost always promote co-presence, and their importance has become higher in 2011 as compared to 2001. The role of past colonial relationships and common language is instead less relevant in explaining joint membership. Most importantly, regressions suggest that economic indicators, i.e. absolute and per-capita GDP, are not significant either in statistical and in economic terms, because of too high standard errors and too small marginal effects.
These results are confirmed by panel-data exercises run for the cases of wheat, rice and maize. We regress co-presence probabilities against the same set of covariates used in the cross-section setup, but now employing the entire time sample in a dynamic fashion, and controlling for common trends and
country-§ All models turn out to be nicely specified according to standard goodness-of-fit tests, e.g., the Akaike information criterion (AIC).
specific unobserved heterogeneity with an appropriate use of dummy variables. Again, as Figure H6 shows, distance and free trade agreementsk are two important determinants of the co-presence of country pairs in the same trade community, whereas economic factors are almost not significant —and their impact is very weak if they are.
Overall, our econometric estimates are in line with the trade-gravity literature, as they show that distance, trade frictions and trade agreements are important determinants of country co-presence in trade communities as they are for bilateral trade flows. However, they strongly depart from traditional gravity exercises as they indicate a very weak impact of country economic size and income in shaping food-trade blocs, whereas it is well known that these two covariates explain to a great extent the intensive margins of aggregate trade [52]¶. We suggest that such a mismatch with trade gravity results may partly depend on the fundamental difference existing between the dependent variable in gravity exercises and in those explaining country co-membership in
trade communities. Whereas in the former
the dependent variable mostly concerns a bi-lateral relationship, in the latter the depen-dent variable refers to co-presence in a group
k More precisely, the EU27 trade agreement and NAFTA seem to strongly affect co-presence probabili-ties, as well as AFTA for maize and EFTA for wheat.
Covariates
Colonial
relationship
Common colonizer Common ethnicity Common language Contiguity Distance
Free trade agreements Combined
economic size Combined economic dev.
Region Same country
-0.2
Marginal Effect 0
0.2
Commodities
Barley Cocoa Maize Milk Nuts Oil, palm Oil, sunflower Pig meat Poultry meat Pulses Rice Sorghum Soybeans Sugar Wheat
0.4
Figure 6. Probit estimation for year 2011. Marginal effects obtained fitting Eq. (3) to each commodity layer separately using maximum-likelihood. X-axis: covariates used in the model. Y-axis: marginal effect of the covariate on the probability that two countries belong to the same community. Dots represent the point estimate of marginal effects and bars are 95% confidence intervals.
of countries, and therefore is mostly about a multi-lateral relationship. Therefore, regional and trade-policy variables that describe bilat-eral relationship in a multi-latbilat-eral setup (e.g. regional trade agreements or geographic po-sitioning) may better explain co-presence of countries in trading blocs. At the same time, the differences between our exercises and tradi-tional gravity models suggest that community detection techniques are really able to statis-tically elicit multi-lateral relationship among countries, even they start from fundamentally bilateral trade relationships among pairs of countries.
3.4. Multi-layer community detection
In the last subsection, we have performed a community-detection analysis assuming that the IFTMN consists of independent layers
in each time period. Here, we ask what
communities look like if they can span across
layers. More precisely, we suppose that
each country is coupled with itself across
commodity slices. Therefore, in each year,
many times: the same country (respectively, commodity) may belong to different clusters as it can appear coupled with different commodities (respectively, countries).
A first question that naturally arises is whether projecting communities into the space of commodities results in country clusters that are similar to those obtained assuming that the IFTMN consists of independent layers. Of course, communities now span over commodity layers. Therefore, this exercise must be just intended as a robustness check as it entails loosing a lot of information. Figure Appendix H in Appendix H shows NMI values when comparing community structures in the multi-layer and in the independent-multi-layer cases, for year 2001 and year 2011. NMI values appear to be quite high, especially in year 2011, where for most products communities in the multi-layer become more similar to the independent-layer case. The fact that results previously obtained in the independent-layer case are in general robust to a multi-layer representation can be visually appreciated looking at choropleth maps of projections of multi-layer communities into the space of commodities, see Figure H8 for the cases of wheat, rice and maize (and the correspondent maps in Figure 4 and Figure H1).
A second interesting issue concerns ex-ploring the shape of clusters in the multi net-work. To do so, we begin by studying the dis-tribution of the number of different communi-ties a country belongs to, which we interpret as a rough measure of country diversification in the IFTMN. The intuition is that a country belonging to a small number of different com-munities tends to be mostly connected with in-stances of “itself” in different commodity lay-ers and therefore depends on the same group of other country-commodity pairs for all possi-ble staple-food products it trades. Conversely,
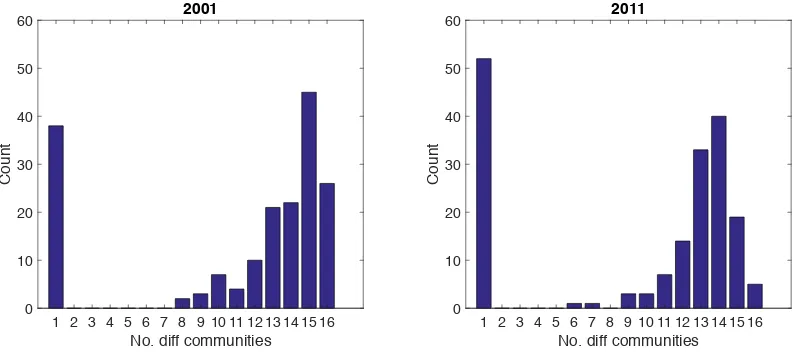
if a country appears in a large number of dif-ferent communities in the multi-network (and thus is never isolated) then it relies on several different clusters of country-product pairs de-pending on the specific product it trades. As we show in Figure 7, the frequency distribution of this statistics are markedly bi-modal, with a peak at 1 and another peak around 14-15. This suggests that community structures in the multi-layer are polarized into two groups. The first one consists of countries that irrespective of the commodity traded always belong to the same community in the multilayer. These are countries that are poorly diversified and are the least networked in the food-trade system. Countries in the second group belong instead to several different communities depending on the commodity traded and therefore are highly diversified in the multilayer. This finding is relevant for food-security issues as it suggests that countries belonging to the first group may be more vulnerable than those in the second group to shocks that put at risk the supply of one or more food commodities.
The geographical distribution of the two groups of countries is depicted in Figure 8 in Appendix H. Notice how the first group is mostly located in Africa, but also features countries in the Middle and Far East.
4. Discussion and Conclusions
The topology of the international food trade multi-network – particularly its community structure – is key to understanding how major disruptions or “shocks” will impact the global
food system. We find that the individual
layers of this network have densely connected trading groups, a consistent characteristic over
the period 1994 to 2011. This community
2001
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
No. diff communities
0 10 20 30 40 50 60
Count
2011
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
No. diff communities
0 10 20 30 40 50 60
Count
Figure 7. Multilayer community detection. Distribution of the number of different communities a country belongs to in the multi-layer. Years 2001 and 2011.
the global food system. If, for example, the epicenter of a shock is within a community, we would expect that countries in this community would face a two-fold challenge: 1) reduced supply from domestic production and/or from their usual import partners and 2) high international prices. To the extent possible, governments and companies within these countries would adjust their procurement strategies to find new sources from members of the other trading communities. Outside of the epicenter community, network characteristics like inter-community connectivity and other global dynamics like trade interventions would be critically important.
One straightforward application of the knowledge generated from understanding com-modity specific community structures is that we can improve our understanding of potential vulnerabilities to various disruption scenarios. First let us consider a major disruption to rice production. In a scenario where China experi-ences a major negative production shock, how would the community structure of the rice net-work modulate global impacts? China would look to the international markets to make up for any shortfall that its food reserve system
could not handle. Four of the top five exporters – Thailand, Vietnam, India and Pakistan – are co-located in Asia, where Thailand is in the same community as China, Vietnam is part of a predominantly Southeast Asian community, and India and Pakistan are both in another community. Therefore, the burden of making up for the Chinese production shortfall would fall primarily on Asian countries, with perhaps the US also contributing (considering that it is the fifth largest rice exporters). Countries like those in western Africa (e.g., Ghana and Ivory Coast) would be highly vulnerable, as they are part of the same community as China (Figure 4) and would face the task of competing with China on the global rice markets. International rice prices would increase, assuming that rice production does not increase substantially else-where, there is no major release of rice reserves to the international markets (e.g., as Japan did in 2008), and that there major changes to the other global grain markets. In this situation, low- and lower-middle-income countries that are dependent on imports for their staple food supply will be at a severe disadvantage.
(a) 2001
(b) 2011
the rice network (Figure 5), so we might expect
a priori that there are differences in shock vulnerability. The soybean network reveals one of the most concentrated community structure, composed by only three large clusters without a clear regional scheme (Figure 4). The most important bloc – in terms of trade volume – includes the US and Brazil from the producing and exporting side, which together account for over 70% of global soybean exports, and China from the importing side, which alone accounts for 56% of global soybeans imports. If one of these main producers experiences a sharp decline in production, the global implications of the shock will largely depend on the capacity of few other major producing countries to make up for the production shortfall.
The global wheat market has a commu-nity structure that falls in-between the struc-tures found in the rice and soybean markets. Major producers are grouped together in three separate communities: 1) the US, Canada, and Australia, 2) Argentina and Brazil, 3) Russia and Ukraine. Interestingly, Europe belongs to yet another separate cluster, in which France is the notable producer and exporter. One might hypothesize that this geographic diversity is advantageous for dealing with a disruption, particularly if it has as spatial component (e.g., crop disease spreading over an area, a regional conflict, or regional-scale extreme weather). Of course, community structure alone is not suffi-cient for understanding the impacts of shocks on these global markets.
Knowledge of community structure can be linked to the latest efforts to understand non-equilibrium conditions in the global food sys-tem. For example, recent models of food shock propagation [18, 53, 54] would benefit from these community-structure insights. Improved disruption scenarios can be generated to ana-lyze potential responses and identify
vulnera-bilities of the food system, at scales ranging from the individual country to the global sys-tem.
Food reserves are increasingly seen as an essential variable that influences how shock would propagate through a trade network [54]. Additionally, a recent analysis showed that a simply supply-demand model with food-reserve dynamics and trade policies can explain most of the observed variations in global cereal prices over the last 40 years solely, including the most recent price peaks in 2007/08 and 2010/11 [55]. The importance of food reserves and trade policies – particularly changes in policies when markets are out-of-equilibrium – is connected to community structures in the markets. A natural extension is to explore the interplay among communities,
food reserves, and trade policies. Market
dynamics including panic buying, hoarding, and large-scale governmental intervention are poorly understood, but we should expect that community structures would play a significant role. Likewise, we might expect that country-level policy decisions on the balance between self sufficiency and import dependency in food production would be influenced by how one’s country is connected to others.
More generally, the role of food price shocks in shaping the community structure of global food-trade system should be better understood [56, 57]. Food price shocks can alter global trade patterns as they typically encourage countries both to rise export barriers and to lower import tariffs, which
may in turn exacerbate price spikes. Such
they may have pervasive consequences on less developed countries, generally extremely dependent on imports, thus altering the way in which they locally form their trade networks.
Along similar lines, one may investigate more deeply the importance of other determi-nants of bilateral import-export flows in ex-plaining the formation of clusters in the inter-national web of food trade. For example, ex-change rate volatility has grown significantly after the GFC. This can correlate with trade growth, as typically the more a country un-dergoes currency devaluation, the slower the growth in its trade [58]. Other determinants to be explored include climate-related shocks, which are especially relevant because of crop sensitivity to weather extremes [11, 10], re-gional conflicts, epidemics, agro-terrorism and crop pests [12].
From a more methodological perspec-tive, this study could be improved by ad-ditional tests aimed at checking the robust-ness of the main results against alterna-tive parameterizations of (and assumptions about) the community-detection algorithms
employed. For example, the well-known
resolution-limit bias affecting many existing methods may be explored using the multiple-resolution community detection strategy by in-troduced in Ref. [59]. Furthermore, despite the fact that the foregoing analysis was fo-cused on the identification of non-overlapping communities, this work can be extended using community-detection algorithms that look for clusters that may partly overlap [60, 61]. This is important, as knowing the degree of over-lap among communities may shed more light on the way in which food crises may spread across clusters. Finally, when analyzing the IFTMN as a multi-layer network, we have im-plicitly assumed that any pair of layers are linked by fictional edges connecting the same
country in the two layers, and that the weights of this edge are homogeneous across countries and equal to one. Such a system parameter, however, may affect the emerging community structure [47]. Therefore, experimenting with different values of such a parameter can give interesting insights on the emergence of clus-ters in the product-country space.
Acknowledgments
Giorgio Fagiolo gratefully acknowledges sup-port by the European Union’s Horizon 2020 research and innovation program under grant
agreement No. 649186 - ISIGrowth. M.J.
Puma gratefully acknowledges fellowship sup-port from the Columbia University Center for Climate and Life.
References
[1] Porkka M, Kummu M, Siebert S and Varis O 2013
PLOS ONE 8 1–12 URL https://doi.org/
10.1371/journal.pone.0082714
[2] United Nations 2015 Transforming our world: the 2030 agenda for sustainable development Tech. Rep. A/RES/70/1 UN General Assembly
URL https://sustainabledevelopment.un.
org/resourcelibrary
[3] D’Odorico P, Carr J A, Laio F, Ridolfi L and Vandoni S 2014 Earth’s Future 2 458–469 ISSN 2328-4277 2014EF000250 URL http:// dx.doi.org/10.1002/2014EF000250
[4] Godfray H C J, Beddington J R, Crute I R, Haddad L, Lawrence D, Muir J F, Pretty J, Robinson S, Thomas S M and Toulmin C
2010 Science 327 812–818 ISSN 0036-8075
(Preprint http://science.sciencemag.
org/content/327/5967/812.full.pdf) URL
http://science.sciencemag.org/content/ 327/5967/812
[6] Hazell P and Wood S 2008 Philos Trans R Soc
Lond B Biol Sci 363 495–515 ISSN 0962-8436
rstb20072166[PII] URL http://www.ncbi. nlm.nih.gov/pmc/articles/PMC2610166/
[7] Hanjra M A and Qureshi M E 2010 Food
Policy 35 365 – 377 ISSN 0306-9192 URL
http://www.sciencedirect.com/science/ article/pii/S030691921000059X
[8] Woods J, Williams A, Hughes J K, Black M and Murphy R 2010 Philosophical Transactions of the Royal Society of London B: Biological
Sci-ences 3652991–3006 ISSN 0962-8436 (Preprint
http://rstb.royalsocietypublishing.org/
content/365/1554/2991.full.pdf) URL
http://rstb.royalsocietypublishing.org/ content/365/1554/2991
[9] Coumou D and Rahmstorf S 2012 Nature Clim.
Change 2491–496 ISSN 1758-678X URLhttp:
//dx.doi.org/10.1038/nclimate1452
[10] Battisti D S and Naylor R L 2009 Sci-ence 323 240–244 ISSN 0036-8075
(Preprint http://science.sciencemag.
org/content/323/5911/240.full.pdf) URL
http://science.sciencemag.org/content/ 323/5911/240
[11] Gornall J, Betts R, Burke E, Clark R, Camp J, Willett K and Wiltshire A 2010
Philo-sophical Transactions of the Royal
So-ciety of London B: Biological Sciences
365 2973–2989 ISSN 0962-8436 (Preprint
http://rstb.royalsocietypublishing.org/
content/365/1554/2973.full.pdf) URL
http://rstb.royalsocietypublishing.org/ content/365/1554/2973
[12] McCloskey B, Dar O, Zumla A and Heymann D L 2014 The Lancet Infectious Diseases 14
1001–1010 ISSN 1473-3099 URL http://dx. doi.org/10.1016/S1473-3099(14)70846-1
[13] Nonhebel S and Kastner T 2011 Livestock
Science 139 3 – 10 ISSN 1871-1413 special
Issue: Assessment for Sustainable Develop-ment of Animal Production Systems URL
http://www.sciencedirect.com/science/ article/pii/S1871141311001041
[14] Tilman D, Balzer C, Hill J and Befort B L 2011
Proceedings of the National Academy of
Sci-ences 10820260–20264 (Preprint http://www.
pnas.org/content/108/50/20260.full.pdf)
URL http://www.pnas.org/content/108/
50/20260.abstract
[15] Cassidy E S, West P C, Gerber J S and Foley J A
2013Environmental Research Letters 8034015
URL http://stacks.iop.org/1748-9326/8/
i=3/a=034015
[16] Clapp J and Cohen M J 2009 The global food crisis: Governance challenges and opportunities
(Wilfrid Laurier Univ. Press)
[17] Clapp J 2015 Food security and trade: Un-packing disputed narratives Tech. rep. Food and Agriculture Organization of the United Nations,Rome URL http://www.fao.org/3/ a-i5160e.pdf
[18] Puma M J, Bose S, Chon S Y and Cook B I 2015 Environmental Research Letters
10 024007 URL http://stacks.iop.org/ 1748-9326/10/i=2/a=024007
[19] Fagiolo G, Schiavo S and Reyes J 2009 Physical
Review E 79036115
[20] Lee K M, Yang J S, Kim G, Lee J, Goh K I and Kim I m 2011 PLoS ONE 6
e18443 URL http://dx.doi.org/10.1371% 2Fjournal.pone.0018443
[21] d’Amour C B, Wenz L, Kalkuhl M, Steckel J C and Creutzig F 2016 Environmental Research
Letters 11 035007 URL http://stacks.iop.
org/1748-9326/11/i=3/a=035007
[22] Haldane A G and May R M 2011Nature469351– 355
[23] Fagiolo G The International Trade Network:
Empirics and Modeling chap 28
[24] Barigozzi M, Fagiolo G and Garlaschelli D
2010 Phys. Rev. E 81(4) 046104 URL
https://link.aps.org/doi/10.1103/ PhysRevE.81.046104
[25] Barigozzi M, Fagiolo G and Mangioni G 2011
Physica A: Statistical Mechanics and its
Ap-plications 390 2051 – 2066 ISSN
0378-4371 URL http://www.sciencedirect.com/ science/article/pii/S0378437111001129
[26] Brooks D H, Ferrarini B and Go E C 2013
Journal of International Commerce,
Eco-nomics and Policy 04 1350015 (Preprint
http://www.worldscientific.com/doi/
pdf/10.1142/S1793993313500154) URL
http://www.worldscientific.com/doi/abs/ 10.1142/S1793993313500154
[27] Fracasso A, Sartori M and Schiavo S 2016
Science of The Total Environment 543,
Part B 1054 – 1062 ISSN 0048-9697 special Issue on Climate Change, Water and Security in the Mediterranean URL
article/pii/S0048969715002028
[28] Gephart J A and Pace M L 2015
Environ-mental Research Letters 10 125014 URL
http://stacks.iop.org/1748-9326/10/i= 12/a=125014
[29] Wu F and Guclu H 2013Risk Analysis 332168– 2178 ISSN 1539-6924 URL http://dx.doi. org/10.1111/risa.12064
[30] Battiston F, Nicosia V and Latora V 2014 Phys.
Rev. E 89(3) 032804 URLhttps://link.aps.
org/doi/10.1103/PhysRevE.89.032804
[31] Kivel¨a M, Arenas A, Barthelemy M, Glee-son J P, Moreno Y and Porter M A
2014 Journal of Complex Networks 2
203 (Preprint /oup/backfile/content_
public/journal/comnet/2/3/10.1093_
comnet_cnu016/2/cnu016.pdf) URL +http:
//dx.doi.org/10.1093/comnet/cnu016
[32] Boccaletti S, Bianconi G, Criado R, del Genio C, Gomez-Gardenes J, Romance M, Sendina-Nadal I, Wang Z and Zanin M 2014 Physics
Reports 544 1 – 122 ISSN 0370-1573 the
structure and dynamics of multilayer net-works URL http://www.sciencedirect.com/ science/article/pii/S0370157314002105
[33] Fortunato S 2010 Physics Reports 486
75 – 174 ISSN 0370-1573 URL http: //www.sciencedirect.com/science/
article/pii/S0370157309002841
[34] Konar M, Dalin C, Suweis S, Hanasaki N, Rinaldo A and Rodriguez-Iturbe I 2011 Water
Resources Research 47 n/a–n/a ISSN
1944-7973 w05520 URL http://dx.doi.org/10. 1029/2010WR010307
[35] Sartori M and Schiavo S 2014 Virtual water trade and country vulnerability: A network perspective Tech. Rep. 77 URLhttps://ssrn. com/abstract=2518934
[36] Tamea S, Carr J A, Laio F and Ridolfi L
2014Water Resources Research 5017–28 ISSN
1944-7973 URLhttp://dx.doi.org/10.1002/ 2013WR014707
[37] Billen G, Lassaletta L and Garnier J 2014Global
Food Security 3209–219
[38] MacDonald G K, Brauman K A, Sun S, Carlson K M, Cassidy E S, Gerber J S and West P C 2015 BioScience 65
275 (Preprint /oup/backfile/content_
public/journal/bioscience/65/3/10.1093_
biosci_biu225/1/biu225.pdf) URL +http:
//dx.doi.org/10.1093/biosci/biu225
[39] Porter M A, Onnela J P and Mucha P J 2009
ArXiv e-prints (Preprint 0902.3788)
[40] Malliaros F D and Vazirgiannis M 2013
Physics Reports 533 95 – 142 ISSN
0370-1573 clustering and Community Detec-tion in Directed Networks: A Survey URL
http://www.sciencedirect.com/science/ article/pii/S0370157313002822
[41] Kim J and Lee J G 2015 SIGMOD Rec. 44 37– 48 ISSN 0163-5808 URLhttp://doi.acm.org/ 10.1145/2854006.2854013
[42] Newman M E J and Girvan M 2004 Phys. Rev. E69026113 URLhttp://link.aps.org/doi/ 10.1103/PhysRevE.69.026113
[43] Arenas A, Duch J, Fernandez A and G´omez S 2007 CoRR abs/physics/0702015 URL
http://dblp.uni-trier.de/db/journals/ corr/corr0702.html#abs-physics-0702015
[44] Barrat A, Barth´elemy M, Pastor-Satorras R and Vespignani A 2004 Proceedings of the National Academy of Sciences of the United
States of America 101 3747–3752 (Preprint
http://www.pnas.org/content/101/11/
3747.full.pdf) URL http://www.pnas.org/
content/101/11/3747.abstract
[45] Rotta R and Noack A 2011 J. Exp. Algorithmics
162.3:2.1–2.3:2.27 ISSN 1084-6654 URLhttp: //doi.acm.org/10.1145/1963190.1970376
[46] Blondel V D, Guillaume J L, Lambiotte R and Lefebvre E 2008 Journal of
Statis-tical Mechanics: Theory and Experiment
2008 P10008 URL http://stacks.iop.org/ 1742-5468/2008/i=10/a=P10008
[47] Mucha P J, Richardson T, Macon K, Porter M A and Onnela J P 2010
Science 328 876–878 ISSN 0036-8075
(Preprint http://science.sciencemag.
org/content/328/5980/876.full.pdf) URL
http://science.sciencemag.org/content/ 328/5980/876
[48] Carchiolo V, Longheu A, Malgeri M and Man-gioni G 2011 Communities Unfolding in
Mul-tislice Networks (Berlin, Heidelberg: Springer
Berlin Heidelberg) pp 187–195 ISBN 978-3-642-25501-4 URLhttps://doi.org/10.1007/ 978-3-642-25501-4_19
[49] De Domenico M, Porter M A and Arenas A 2015 Journal of Complex Networks 3
159 (Preprint /oup/backfile/content_
public/journal/comnet/3/2/10.1093/
//dx.doi.org/10.1093/comnet/cnu038
[50] R W 2008 Econometric analysis of count data
(Springer, New York)
[51] Baldwin R and Taglioni D 2006 Gravity for dummies and dummies for gravity equations Working Paper 12516 National Bureau of Economic Research URL http://www.nber. org/papers/w12516
[52] Anderson J E 2011Annual Review of Economics
3133–160
[53] Gephart J A, Rovenskaya E, Dieckmann U, Pace M L and Br¨annstr¨om ˚A 2016 Environmental
Research Letters 11035008
[54] Marchand P, Carr J A, Dell?Angelo J, Fader M, Gephart J A, Kummu M, Magliocca N R, Porkka M, Puma M J, Ratajczak Z et al.2016
Environmental Research Letters 11 095009
[55] Schewe J, Otto C and Frieler K 2017
Environmen-tal Research Letters 12054005
[56] Headey D 2011 Food Policy 36 136 – 146 ISSN 0306-9192 URL http://www. sciencedirect.com/science/article/pii/ S0306919210001065
[57] Anderson K and Nelgen S 2012
Ox-ford Review of Economic Policy 28
235 (Preprint /oup/backfile/content_
public/journal/oxrep/28/2/10.1093/
oxrep/grs001/2/grs001.pdf) URL
+http://dx.doi.org/10.1093/oxrep/grs001
[58] Kang J W 2016 International trade and exchange rate Working Paper 498 Asian Development Bank URL
https://www.adb.org/sites/default/ files/publication/202841/ewp-498.pdf
[59] Arenas A, Fernandez A and Gomez S 2008
New Journal of Physics 10 053039 URL
http://stacks.iop.org/1367-2630/10/i=5/ a=053039
[60] Nicosia V, Mangioni G, Carchiolo V and Malgeri M 2009 Journal of Statistical Mechanics:
Theory and Experiment 2009 P03024 URL
http://stacks.iop.org/1742-5468/2009/i= 03/a=P03024
[61] Xie J, Kelley S and Szymanski B K 2013 ACM
Comput. Surv. 45 43:1–43:35 ISSN
0360-0300 URL http://doi.acm.org/10.1145/
2501654.2501657
[62] Danon L, Diaz-Guilera A, Duch J and Arenas A 2005 Journal of Statistical Mechanics:
Theory and Experiment 2005 P09008 URL
http://stacks.iop.org/1742-5468/2005/i=
09/a=P09008
[63] de Sousa J and Lochard J 2011The Scandinavian
Journal of Economics113553–578 ISSN 1467–
9442 URL http://dx.doi.org/10.1111/j. 1467-9442.2011.01656.x
[64] Fagiolo G 2006Economics Bulletin 31–12 [65] Freeman L C 1978 Social Networks
1 215 – 239 ISSN 0378-8733 URL
http://www.sciencedirect.com/science/ article/pii/0378873378900217
Supplemental Materials
Appendix A. List of Countries
Table A1 lists the countries used in our analysis with their ISO3 Code.
Appendix B. Primary and secondary products employed in the analysis
Table B1 contains a list of the 16 commodi-ties employed in the analysis together with sec-ondary products considered when aggregating the kcal content (with FAOSTAT code).
Appendix C. Community Detection: Methods and Algorithms
The IFTMN as a collection of separate layers.
In this analysis, we employ a new heuristic for modularity clustering, inspired to the fast modularity optimization algorithm originally introduced by [46]. The well-known Louvain algorithm is a multi-level coarsening procedure by iterated vertex moving based on a local optimization of Newman-Girvan modularity
in the neighborhood of each node. More
specifically, it follows a two-stage procedure that is iterated, until the gain in modularity
is below a given threshold. The first step
is represented by community reassignments.
We define a network with N nodes, each
of which is initially assigned to a separate
community, thus obtaining N single-vertex
clusters. For each node i we consider its
neighboring nodesj and we evaluate the gain, in terms of increased modularity, which would be obtained by removingifrom his community
and assigning it to that of j. Node i at
this point is moved to the communities to which this gain is maximum. If no increase in modularity is possible, the node is not
moved. This process is applied repetitively and sequentially for all nodes, until modularity falls below a given tolerance threshold. The second step follows a coarse-graining scheme. We use the clusters discovered at the end of the community reassignment stage previously mentioned, in order to define a new,
coarse-grained network. The formerly identified
communities constitute the nodes of this second-stage graph. The edge weight between the nodes representing two communities is solely the sum of the edge weights between the lower-level nodes of each community. The links within each community generate self-loops in the new, coarse-grained network. It is now possible to apply again the first step, using as input the network obtained at the end of the second phase and to repeat the method. The algorithm stops when results impossible to get any further improvement in terms of modularity.
In this work, the optimization of Q
is performed by using an extension of the
Louvain algorithm described above. More
clus-Table A1. List of countries used in the analysis.
Country ISO3 Country ISO3
Afghanistan AFG Lebanon LBN
Albania ALB Libya LBY
Algeria DZA Lithuania LTU
Antigua and Barbuda ATG Luxembourg LUX
Argentina ARG Macao MAC
Armenia ARM Macedonia MKD
Aruba ABW Madagascar MDG
Australia AUS Malawi MWI
Austria AUT Malaysia MYS
Azerbaijan AZE Maldives MDV
Bahamas BHS Mali MLI
Bahrain BHR Malta MLT
Bangladesh BGD Mauritania MRT
Barbados BRB Mauritius MUS
Belarus BLR Mexico MEX
Belgium BEL Moldova MDA
Belize BLZ Mongolia MNG
Benin BEN Montenegro MNE
Bermuda BMU Morocco MAR
Bhutan BTN Mozambique MOZ
Bolivia BOL Myanmar MMR
Bosnia Herzegovina BIH Namibia NAM
Botswana BWA Nepal NPL
Brazil BRA Netherland Antilles ANT
Brunei BRN Netherlands NLD
Bulgaria BGR New Caledonia NCL
Burkina-Faso BFA New Zealand NZL
Burundi BDI Nicaragua NIC
Cape Verde CPV Niger NER
Cambodia KHM Nigeria NGA
Cameroon CMR Norway NOR
Canada CAN Oman OMN
Central African Republic CAF Pakistan PAK
Chile CHL Panama PAN
China CHN Papua New Guinea PNG
Colombia COL Paraguay PRY
Congo COG Peru PER
Cook Islands COK Philippines PHL
Costa Rica CRI Poland POL
Cote d’Ivoire CIV Portugal PRT
Croatia HRV Qatar QAT
Cuba CUB Republic of Korea KOR
Cyprus CYP Romania ROU
Table A1. (cont’d)List of countries used in the analysis.
Country ISO3 Country ISO3
Democratic Republic of Congo COD Rwanda RWA
Denmark DNK Saint Kitts and Nevis KNA
Djibouti DJI Saint Lucia LCA
Dominica DMA Saint Vincent VCT
Dominican Republic DOM Sao Tome STP
Ecuador ECU Saudi Arabia SAU
Egypt EGY Senegal SEN
El Salvador SLV Serbia SRB
Estonia EST Seychelles SYC
Ethiopia ETH Sierra Leone SLE
Faroe Islands FRO Singapore SGP
Fiji FJI Slovakia SVK
Finland FIN Slovenia SVN
France FRA Solomon Islands SLB
French Polynesia PYF South Africa ZAF
Gabon GAB Spain ESP
Gambia GMB Sri Lanka LKA
Georgia GEO Sudan SDN
Germany DEU Suriname SUR
Ghana GHA Swaziland SWZ
Greece GRC Sweden SWE
Greenland GRL Switzerland CHE
Grenada GRD Syria SYR
Guatemala GTM Taiwan TWN
Guinea GIN Tanzania TZA
Guyana GUY Thailand THA
Honduras HND Togo TGO
Hong Kong HKG Tonga TON
Hungary HUN Trinidad and Tobago TTO
Iceland ISL Tunisia TUN
India IND Turkey TUR
Indonesia IDN Tuvalu TUV
Iran IRN Uganda UGA
Ireland IRL Ukraine UKR
Israel ISR United Arab Emirates ARE
Italy ITA United Kingdom GBR
Jamaica JAM Uruguay URY
Japan JPN United States of America USA
Jordan JOR Uzbekistan UZB
Kazakhstan KAZ Vanuatu VUT
Kenya KEN Venezuela VEN
Kiribati KIR Vietnam VNM
Kuwait KWT Yemen YEM
Kyrgyzstan KGZ Zambia ZMB
Table B1. List of primary and secondary products used in the analysis (with FAOSTAT code).
Primary Code Secondary Code
Wheat
Wheat 15
Bran 17
Flour 16
Macaroni 18
Bread 20
Bulgur 21
Pastry 22
Breakfast Cereals 41
Rice
Rice, Total 30
Rice, Paddy 27
Rice, Husked 28
Milled Rice from Imported Husked
Rice 29
Milled Paddy Rice 31
Rice, Broken 32
Flour 38
Bran Oil 36
Maize
Maize 56
Flour 58
Germ 57
Bran 59
Oil 60
Cake 61
Maize, Green 446
Soybeans
Soybeans 236
Cake 238
Oil 237
Soya Sauce 239
Barley
Barley 44
Pot Barley 45
Barley Pearled 46
Bran 47
Flour 48
Malt 49
Malt Extract 50
Beer 51
Sorghum
Sorghum 83
Bran 85
Table B1. (cont’d)List of primary and secondary products used in the analysis (with FAOSTAT code).
Primary Code Secondary Code
Cassava 1953
Cassava 125
Starch 129
Cassava, Dried 128
Flour 126
Tapioca 127
Sugar 1955
Cane Sugar, Raw, Centrifugal 158 Beet Sugar, Raw Centrifugal 159
Sugar Raw, Centrifugal 162
Sugar Refined 164
Sugar Confectionery 168
Sugar Flavoured 171
Pigmeat 2073
Pig Meat 1035
Pork 1038
Bacon and Ham 1039
Sausages of Pig Meat 1041
Prep. of Pig Meat 1042
Poultry Meat 2074
Chicken Meat 1058
Foie Gras 1060
Meat of Chicken Cannes 1061
Duck Meat 1069
Goose and Guinea Fowl Meat 1073
Turkey Meat 1080
Milk 2030
Milk, Whole Fresh Cow 882
Cream Fresh 885
Butter, Cow Milk 886
Milk, Skimmed Cow 888
Milk, Whole Condensed 889
Whey, Condensed 890
Yoghurt, Concentrated or Not 892 Buttermilk, Curdled, Acidified Milk 893
Milk, Whole Evaporated 894
Milk, Whole Dried 897
Milk, Skimmed Dried 898
Whey, Dry 900
Cheese, Whole Cow Milk 901
Cheese, Processed 907
Milk, Products of Natural Constituents Nes. 909
Ghee, of Buffalo Milk 953
Milk, Whole Fresh Sheep 982