5
BAB 2
LANDASAN TEORI
2.1. Pengertian Algoritma
Algoritma adalah prosedur komputasi yang didefinisikan dengan baik yang
mengambil beberapa nilai yaitu seperangkat nilai sebagai input dan output yang
menghasilkan nilai (Sedgewick & Wayne, 2011). Pengertian Algoritma adalah logika,
metode, dan tahapan (urutan) sistematis yang digunakan untuk memecahkan suatu
permasalahan. Algoritma dapat juga diartikan sebagai urutan langkah secara
sistematis dan logis. Dalam perkembangannya, algoritma banyak dipakai di bidang
komputer.
Menurut Rinaldi Munir, algoritma adalah urutan langkah-langkah logis penyelesaian
masalah yang disusun secara sistematis.
Tidak semua urutan langkah penyelesaian masalah yang logis dapat disebut sebagai
algoritma.
Menurut Donald E. Knuth, algoritma harus mempunyai lima ciri penting yang
meliputi:
1. Input
Suatu algoritma harus memiliki 0(nol) atau lebih masukan (input). Artinya, suatu
algoritma itu dimungkinkan tidak memiliki masukan secara langsung dari
pengguna tetapi dapat juga memiliki beberapa masukan. Algoritma yang tidak
memiliki masukan secara langsung dari pengguna, maka semua data dapat
diinisialisaikan atau dibangkitkan dalam algoritma.
2. Output
Suatu algoritma harus memiliki satu atau lebih algoritma. Suatu algoritma yang
tidak memiliki keluaran (output) adalah suatu algoritma yang sia sia, yang tidak
perlu dilakukan. Algoritma dibuat untuk tujuan menghasilkan sesuatu yang
diinginkan, yaitu berupa hasil keluaran.
3. Finiteness
Setiap pekerjaan yang dikerjakan pasti berhenti. Demikian juga algoritma harus
6
4. Definiteness
Algoritma tersebut tidak menimbulkan makna ganda (ambiguous). Setiap baris
aksi/pernyataan dalam suatu algoritma harus pasti, artinya tidak menimbulkan
penafsiran lain bagi setiap pembaca algoritma, sehingga memberikan output yang
sesuai dengan yang diharapkan oleh pengguna.
5. Effectiveness
Setiap langkah algoritma harus sederhana sehingga dikerjakan dalam waktu yang
wajar.
Sifat algoritma adalah:
1. Tidak menggunakan simbol atau sintaks dari suatu bahasa pemrograman
tertentu.
2. Tidak tergantung pada bahasa pemrograman tertentu.
3. Notasi-notasinya dapat digunakan untuk seluruh bahasa manapun.
4. Algoritma dapat digunakan utuk mempresentasikan suatu urutan kejadian
secara logis dan dapat diterapkan disemua kejadian sehari-hari.
2.2. Algoritma Pengurutan ( Sorting )
Algoritma pengurutan adalah proses menyusun kembali rentetan objek-objek untuk
meletakkan objek dari suatu kumpulan data ke dalam urutan yang logis (Cormen et al,
2009).
Pada dasarnya, pengurutan (sorting) membandingkan antar data atau elemen
berdasarkan kriteria dan kondisi tertentu (Indrayana & Ihsan, 2005).
Pengurutan dapat dilakukan dari nilai terkecil ke nilai terbesar (ascending) atau
sebaliknya (descending).
Ada dua kategori pengurutan (Suarga, 2012):
1. Pengurutan internal
Pengurutan internal adalah pengurutan yang dilaksanankan hanya dengan
menggunakan memori komputer, pada umumnya digunakan bila jumlah elemen
7
2. Pengurutan eksternal
Pengurutan eksternal adalah pengurutan yang dilaksanakan dengan bantuan
memori virtual atau harddisk karena jumlah elemen yang akan diurutkan terlalu
banyak.
2.3. Klasifikasi Algoritma Pengurutan
Klasifikasi algoritma-algoritma pengurutan dibedakan berdasarkan (Erzandi, 2009):
1. Kompleksitas perbandingan antar elemen terkait dengan kasus terbaik,
rata-rata dan terburuk
2. Kompleksitas pertukaran elemen, terkait dengan cara yang digunakan elemen
setelah dibandingkan
3. Penggunaan memori
4. Rekursif atau tidak rekursif
5. Proses pengurutannya (metode penggunaannya)
Klasifikasi algoritma pengurutan berdasarkan proses pengurutannya sebagai berikut
(Putranto, 2007):
1. Exchange Sort
Dalam prosesnya, algoritma-algoritma pengurutan yang diklasifikasikan sebagai
exchange sort melakukan pembandingan antar data, dan melakukan pertukaran
apabila urutan yang didapat belum sesuai. Contohnya: bubble sort, cocktail sort,
comb sort, gnome sort, quick sort.
2. Selection Sort
Prinsip utama algoritma dalam klasifikasi ini adalah mencari elemen yang tepat
untuk diletakkan di posisi yang telah diketahui, dan meletakkannya di posisi
tersebut setelah data tersebut ditemukan. Contohnya: selection sort, heap sort,
smooth sort, strand sort.
3. Insertion Sort
Algoritma pengurutan yang diklasifikasikan ke dalam kategori ini mencari tempat
yang tepat untuk suatu elemen data yang telah diketahui ke dalam subkumpulan
data yang telah terurut, kemudian melakukan penyisipan (insertion) data di tempat
yang tepat tersebut. Contohnya: insertion sort, shell sort, tree sort, library sort,
8
4. Merge Sort
Dalam algoritma ini kumpulan data dibagi menjadi subkumpulan-subkumpulan
yang kemudian sub kumpulan tersebut diurutkan secara terpisah, dan kemudian
digabungkan kembali dengan metode merging.
Dalam kenyataannya algoritma ini melakukan metode pengurutan merge sort juga
untuk mengurutkan subkumpulan data tersebut, atau dengan kata lain, pengurutan
dilakukan secara rekursif. Contohnya: Merge sort.
5. Non-Comparison Sort
Sesuai namanya dalam proses pengurutan data yang dilakukan algoritma ini tidak
terdapat pembandingan antardata, data diurutkan sesuai dengan pigeon hole
principle. Dalam kenyataanya seringkali algoritma non-comparison sort yang
digunakan tidak murni tanpa pembandingan, yang dilakukan dengan
menggunakan algoritma-algoritma pengurutan cepat lainnya untuk mengurutkan
sub kumpulan - sub kumpulan datanya. Contohnya: Radix sort, Bucket sort,
Counting sort, Tally sort.
Berdasarkan klasifikasi algoritma pengurutan yang sudah dijelaskan maka akan
dianalisis pada penelitian ini adalah algoritma strand sort, sievesort, dan gnome sort.
2.4. Algoritma Strand Sort
Strand Sort adalah algoritma pengurutan yang mencari elemen yang tepat untuk
diletakkan di posisi yang telah diketahui, dan meletakkannya di posisi tersebut setelah
data tersebut ditemukan. Strand Sort melakukan pengurutan yang mencari nilai data
terbesar atau terkecil dan kemudian menempatkannya pada posisi yang sebenarnya,
dimulai dari data diposisi 0 hingga data diposisi N-1 dengan tahapan indeks yang
dimulai dari 0. (Triono Puji, 2010).
Proses pengurutan dengan menggunakan algoritma Strand Sort dilakukan dengan cara
mencari data yang terkecil dari data pertama sampai terakhir. Kemudian data tersebut
dipertukarkan dari data pertama.
Dengan demikian, data pertama mempunyai nilai paling kecil dibanding dengan data
lain. Setelah itu data terkecil mulai dicari lagi dari data ke-i (dimana i dimulai dari
data ke-2 sampai dengan data terakhir).
Jika ditemukan data yang lebih kecil maka data tersebut ditempatkankan kedepan
9
Proses algoritma Strand Sort bertujuan untuk menjadikan bagian sisi kiri array
terurutkan sampai dengan seluruh array berhasil diurutkan.
Metode ini mengurutkan bilangan-bilangan yang telah dibaca dan berikutnya secara
berulang akan menempatkan bilangan-bilangan dalam array yang telah terbaca kesisi
kiri array yang telah terurut.
Kelebihan dan kekurangan Strand Sort :
Kelebihan:
1. Stabil dan sederhana dalam penerapannya.
2. Proses pengurutan lebih cepat dalam data yang sebagian sudah terurut dan
lebih cepat dalam data yang kecil.
3. Jika list sudah terurut atau sebagian terurut maka algoritma Strand Sort akan
lebih cepat daripada Quick Sort.
4. Lebih cepat dibandingkan Bubble Sort karena dapat mengurangi jumlah
perbandingan.
5. Loop (Perulangan) pada Strand Sort sangat cepat, sehingga termasuk menjadi
salah satu algoritma pengurutan tercepat dalam jumlah elemen yang sedikit.
Kekurangan:
1. Banyaknya operasi yang diperlukan dalam mencari posisi yang tepat untuk
elemen List.
2. Untuk List yang jumlahnya besar algoritma Strand Sort tidak praktis.
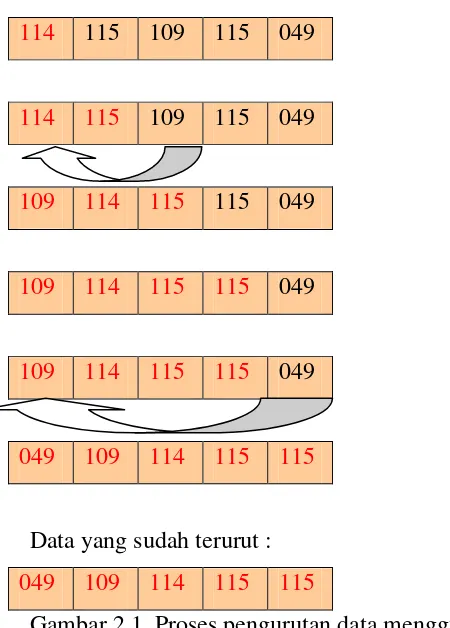
Contoh Proses pengurutan data menggunakan Strand Sort dapat dilihat pada gambar
2.1.
Data yang ingin diurutkan :
String yang diinputkan berdasarkan kode ASCII
String : ruth
stephany
marsaulina
siahaan
141421092
r = 114, s = 115, m = 109, 1 = 49
10
114 115 109 115 049
114 115 109 115 049
109 114 115 115 049
109 114 115 115 049
109 114 115 115 049
049 109 114 115 115
Data yang sudah terurut :
049 109 114 115 115
Gambar 2.1. Proses pengurutan data menggunakan strand sort
Ket: data yang berwarna merah merupan bagian yang terurut. Proses Strand Sort
dilakukan dengan menempatkan elemen-elemen dari sebelah kanan ketempatnya yang
sesuai dibagian terurut (kiri).
2.4.1 Pseudocode Algoritma Strand Sort
Public static Strand Sort;
For (i=1 to (array.length-1))
j=i-1; index;
while (arr[i]<arr[j]{
index=j;
j--;
if (j<0)
break;
}
11
2.5. Algoritma Sieve Sort
Sieve Sort adalah algoritma sorting seperti sebuah proses Penyaringan, data tersebut
disaring kemudian ditata kembali sesuai dengan jumlah data yang ada sebelumnya
dengan cara yang tepat.
Dalam algoritma Sieve Sort adanya elemen-elemen dalam list yang kemudian akan
disaring dan ditata kembali. Kasus terburuk dan kasus terbaik akan berjalan berulang
kali selama proses penyaringan data tersebut yakni O(n2) and O(n), dimana n
merupakan jumlah record dalam list yang akan diurutkan. Pada kompleksitas waktu
O(n2) algoritma Sieve Sort ini bekerja dalam wort case (Kasus terburuk) sehingga
algoritm Sieve Sort ini dikatakan lebih baik dari algoritma Quick Sort. Sedangkan
pada kompleksitas waktu O(n) ini elemen pada list tersebut akan dibagi dan
didistribusikan ke subsequence lain.
Contoh Proses pengurutan data menggunakan Sieve Sort dapat dilihat pada gambar
2.2.
Data yang ingin diurutkan :
String yang diinputkan berdasarkan kode ASCII
String : ruth
stephany
marsaulina
siahaan
141421092
r = 114, s = 115, m = 109, 1 = 49
114 115 109 115 049
Dimulai dengan melakukan pengecekan pada data yang belum disortir. Angka
pertama pada list tersebut dijadikan sebagai pivot
114 115 109 115 049
pivot
Kemudian angka yang menjadi pivot tersebut dibandingkan dengan angka selanjutnya. Jika angka selanjutnya itu lebih besar nilainya atau sama
dibanding dengan pivot tersebut maka pivotnya akan berpindah selanjutnya ke
angka yang lebih besar tersebut dan begitu seterusnya sampai di angka terakhir
12
114 115 109 115 049
pivot pivot pivot
asc [1] = [ 114, 115, 115]
non_asc = [109, 049]
Selanjutnya angka pada elemen list yang non_asc tersebut akan kembali
disortir dengan cara yang sama seperti diatas.
109 049
pivot
asc[2] = [109]
non_asc = [049]
109
pivot
asc[3] = [049]
non_asc = [ ]
Setelah selesai disortir sampai pada elemen terakhir pada list, selanjutkan dilakukan merge pada asc[1] dan asc[2], nilai pada asc[1] dibandingkan
dengan nilai pada asc[2] dan hasilnya dimasukkan pada sebuah list baru.
asc [1] = [ 114, 115, 115]
asc[2] = [109]
Result = [109. 114, 115, 115]
Kemudian akan dilakukan merge kembali dengan membandingkan nilai pada
list Result dengan nilai pada list asc[3], dan hasilnya dimasukkan pada sebuah
list baru.
Result = [109. 114, 115, 115]
asc[3] = 049
Result = [049, 109, 114, 115, 115]
Data yang sudah terurut :
049 109 114 115 115
13
2.5.1 Pseudocode Algoritma Sieve Sort
def sieve(list):
pivot = list[0]
asc = [pivot]
non_asc = []
for i in range(1, len(list)):
if list[i] >= pivot:
pivot = list[i]
asc.append(pivot)
else:
non_asc.append(list[i])
return asc,non_asc
def merge(left,right):
merged = []
while (true):
if left == []:
return merged + right
if right == []:
return merged + left
if left[0] < right[0]:
merged.append(left.pop(0))
else:
merged.append
return merged
def sievesort(list):
result = []
while list != []:
asc,non_asc = sieve(list)
result = merge(result,asc)
list = non_asc
14
2.6. Algoritma Gnome Sort
Gnome sort adalah algoritma sorting seperti mengurutkan Penyisipan, tetapi
perpindahan sebuah element ke tempat yang tepat dilakukan dengan serangkaian
swap, seperti di Bubble Sort.
Data yang sudah masuk secara acak akan dibandingkan jika pengurutannya adalah
berdasarkan nilai terkecil ke nilai yang terbesar atau pengurutan ascending.
Data akan diambil dan dibandingkan dengan data yang disamping kirinya. Jika data
yang disamping kirinya nilainya lebih besar maka akan ditukar (swap) dan jika
sebaliknya maka tidak ditukar. Kemudian tetap pada nilai itu akan dibandingkan lagi
dengan nilai yang kecil dari belakang, begitu seterusnya sampai nilai terkecil berada
pada urutan yang paling depan, kemudian akan dibandingkan lagi dari belakang jika
masih ada nilai yang kecil pada posisi belakang akan di bandingkan dengan nilai yang
ada didepannya.
Keuntungan Gnome Sort:
1. Dapat dijalankan dengan cukup cepat dan efisien untuk mengurutkan list yang
urutannya sudah hampir benar.
2. Algoritma ini biasanya digunakan untuk mengenalkan konsep dari sorting
algoritma pada pendidikan komputer karena idenya yang cukup sederhana.
Kelemahan Gnome Sort:
1. Ukuran kode relatif kecil.
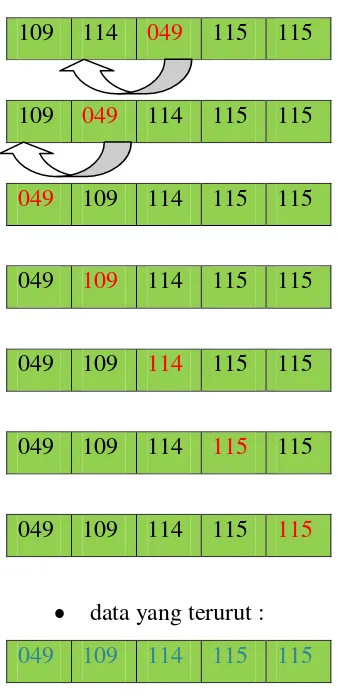
Contoh Proses pengurutan data menggunakan Gnome Sort dapat dilihat pada gambar
2.3.
Data yang ingin diurutkan :
String yang diinputkan berdasarkan kode ASCII
15
114 115 109 115 049
Data yang berwarna merah merupakan data yang telah diambil dan
dibandingkan dengan data yang disamping krirnya.
114 115 109 115 049
Jika data yang disamping kirinya nilainya lebih besar maka akan ditukar
(swap).
114 115 109 115 049
swap
Kemudian tetap pada nilai itu akan dibandingkan lagi dengan nilai yang kecil
dari belakang, jika masih ada nilai yang kecil pada posisi belakang akan di
bandingkan dengan nilai yang ada didepannya, begitu seterusnya sampai nilai
terkecil berada pada urutan yang paling depan.
swap
Jika nilai di posisi kiri lebih kecil daripada nilai di posisi kanan maka tidak
akan dipertukarkan (swap) dan dilanjutkan dengan membandingkan pada data
yang selanjutnya.
swap
Swap
114 109 115 115 049
109 114 115 115 049
109 114 115 115 049
109 114 115 115 049
109 114 115 115 049
109 114 115 115 049
16
data yang terurut :
Gambar 2.3. Proses pengurutan data menggunakan gnome sort
2.6.1 Pseudocode Algoritma Gnome Sort
procedure gnomeSort(a[]):
i := 0
while i < length(a):
if (i == 0 or a[i] >= a[i-1]):
i := i + 1
else:
swap a[i] and a[i-1]
if (i > 1)
i := i-1
end if
end if
end while
end procedure
109 114 049 115 115
109 049 114 115 115
049 109 114 115 115
049 109 114 115 115
049 109 114 115 115
049 109 114 115 115
049 109 114 115 115
17
2.7. Kompleksitas Algoritma
Kompleksitas dari suatu algoritma merupakan ukuran seberapa banyak komputasi
yang dibutuhkan algoritma tersebut untuk menyelesaikan masalah. Kompleksitas
algoritma terdiri dari dua macam yaitu kompleksitas ruang dan kompleksitas waktu.
Dalam penelitian ini yang dibahas hanya kompleksitas waktu.
Dalam aplikasinya, setiap algoritma memiliki dua buah ciri khas yang dapat
digunakan sebagai parameter pembanding, yaitu jumlah proses yang dilakukan dan
jumlah memori yang digunakan untuk melakukan proses. Jumlah proses ini dikenal
sebagai kompleksitas waktu yang disimbolkan dengan T(n), sedangkan jumlah
memori ini dikenal sebagai kompleksitas ruang yang disimbolkan dengan S(n).
2.7.1. Kompleksitas waktu
Kompleksitas waktu yang disimbolkan dengan T(n), diukur dari jumlah tahapan
komputasi yang dibutuhkan untuk menjalankan algoritma sebagai fungsi dari ukuran
masukan n, dimana ukuran masukan n merupakan jumlah data yang diproses oleh
sebuah algoritma.
Dengan menggunakan kompleksitas waktu dapat ditentukan laju peningkatan waktu
yang diperlukan algoritma, seiring dengan meningkatnya ukuran masukan n.
2.7.2. Kompleksitas waktu asimptotik
Kompleksitas waktu asimptotik adalah analisis efisiensi asimptotik dari suatu
algoritma untuk menentukan kompleksitas waktu yang sesuai. Analisis dilakukan
untuk nilai n cukup besar dan bahkan tidak terbatas.
Notasi asimptotik adalah notasi yang diguakan untuk menentukan kompleksitas waktu
asimptotik dengan melihat waktu tempuh (running time) algoritma.
Kompleksitas waktu asimptotik dibagi menjadi tiga, yaitu:
1. Kondisi terbaik (Best case)dinotasikan dengan Ω (Big-Omega).
2. Keadaan rata-rata (Average case) dinotasikan dengan Θ (Big-Theta).
3. Keadaan terburuk (Worst case)dinotasikan dengan Ο (Big- Οh).
Notasi asimptotik dapat dituliskan dengan beberapa simbol, yaitu :
1. Notasi “O” disebut notasi “O-Besar” (Big-O) yang merupakan notasi
kompleksitas waktu asimptotik. Kompleksitas waktu asimptotik merupakan
18
2. Pada umumnya, algoritma menghasilkan laju waktu yang semakin lama bila
nilai n semakin besar. Berikut pengelompokan algoritma berdasarkan notasi
O-Besar dapat dilihat pada Tabel 2.1.
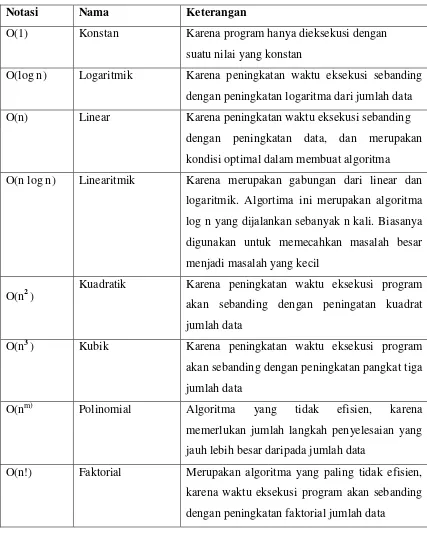
Tabel 2.1 Pengelompokkan algoritma berdasarkan notasi O-Besar
Notasi Nama Keterangan
O(1) Konstan Karena program hanya dieksekusi dengan
suatu nilai yang konstan
O(log n) Logaritmik Karena peningkatan waktu eksekusi sebanding
dengan peningkatan logaritma dari jumlah data
O(n) Linear Karena peningkatan waktu eksekusi sebanding
dengan peningkatan data, dan merupakan
kondisi optimal dalam membuat algoritma
O(n log n) Linearitmik Karena merupakan gabungan dari linear dan
logaritmik. Algortima ini merupakan algoritma
log n yang dijalankan sebanyak n kali. Biasanya
digunakan untuk memecahkan masalah besar
menjadi masalah yang kecil
O(n2)
Kuadratik Karena peningkatan waktu eksekusi program
akan sebanding dengan peningatan kuadrat
jumlah data
O(n3) Kubik Karena peningkatan waktu eksekusi program
akan sebanding dengan peningkatan pangkat tiga
jumlah data
O(nm) Polinomial Algoritma yang tidak efisien, karena
memerlukan jumlah langkah penyelesaian yang
jauh lebih besar daripada jumlah data
O(n!) Faktorial Merupakan algoritma yang paling tidak efisien,
karena waktu eksekusi program akan sebanding
19
3. Notasi Little o, yaitu notasi asimptotik sebuah fungsi algoritma untuk batas
atas namun tidak secara ketat terikat (not asymptotically tight).
4. Notasi Theta (θ), yaitu notasi asimptotik sebuah fungsi algoritma untuk batas
atas dan bawah.
5. Notasi Omega (Ω), yaitu notasi asimptotik sebuah fungsi algoritma untuk
batas bawah, notasi ini berlawanan dengan notasi little-o.
2.7.2.1. Big-oh
Notasi big-oh pertama kali diperkenalkan oleh seorang teoritis bilangan bernama Paul
Bachmann pada tahun 1894, didalam buku keduanya yang berjudul Analytische
Zahlentheorie(“analytic number teory”).
Dalam teori kompleksitas komputasi, notasi big-oh sering digunakan untuk
menjelaskan bagaimana ukuran data masukan mempengaruhi sebuah kegunaan
algoritma dari sumber daya komputasi (biasanya running time atau memori). Definisi
pertama dalam pengukuran kompleksitas suatu masalah adalah big-oh (Weiss dan
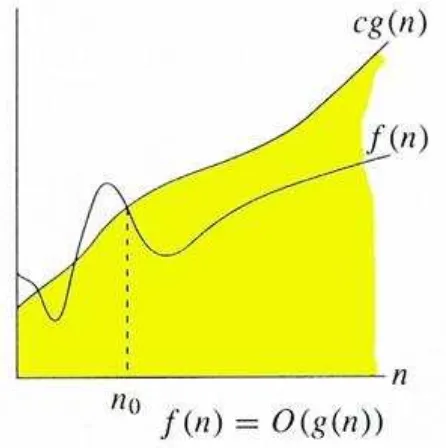
Mark Allen, 1996). Grafik fungsi big-oh dapat dilihat pada gambar 2.4.
Gambar 2.4. Grafik fungsi big-oh
Untuk fungsi g(n), kita definisikan O(g(n)) sebagai big-oh dari n, sebagai himpunan:
O(g(n)) = {f(n) : ada konstanta positif c dan n0, sedemikian rupa untuk semua n≥ n0,
20
f(n) secara intuitif merupakan himpunan seluruh fungsi yang rateofgrowth-nya adalah
sama atau lebih kecil dari g(n).
g(n) adalah asymptotic upper bound untuk f(n).
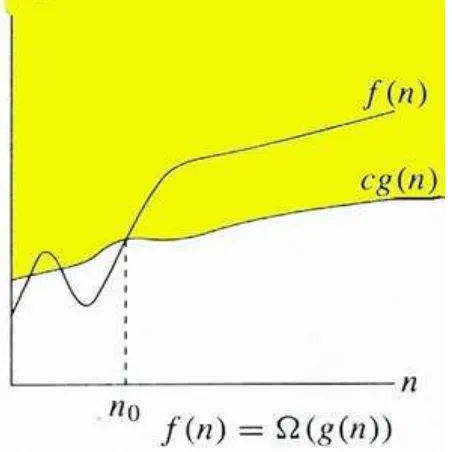
2.7.2.2. Big-omega (Ω)
Defenisi kedua dalam pengukuran kompleksitas suatu masalah adalah big omega.
(Weiss dan Mark Allen, 1996). Grafik fungsi big-oh dapat dilihat pada gambar 2.5.
Gambar 2.5. Grafik fungsi big-omega
Untuk fungsi g(n), kita definisikan Ω(g(n)) sebagai big-omega dari n, sebagai
himpunan:
Ω(g(n)) = {f(n) : ada konstanta positif c dan n0, sedemikian rupa untuk semua n≥ n0,
sehingga 0 ≤ cg(n)≤ f(n) }.
f(n) secara intuitif merupakan himpunan seluruh fungsi yang rateofgrowth-nya adalah
sama atau lebih tinggi dari g(n).
21
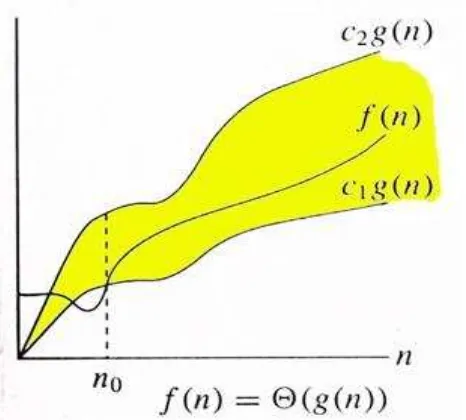
2.7.2.3. Big-theta (θ)
Definisi ketiga dalam pengukuran kompleksitas suatu masalah adalah big theta.
(Weiss dan Mark Allen, 1996). Grafik fungsi big-oh dapat dilihat pada gambar 2.6.
Gambar 2.6. Grafik fungsi big-theta
Untuk fungsi g(n), kita definisikan Θ(g(n)) sebagai big-theta dari n, sebagai himpunan:
Θ(g(n)) = {f(n) : ada konstanta positif c1, c2 dan n0, sedemikian rupa untuk semua n≥
n0, sehingga 0 ≤c1g(n) ≤f(n)≤ c1g(n)}.
f(n) merupakan Θ(g(n)) pada nilai antara c1 sampe c2. g(n) adalah asymptoticallytight bound untuk f(n).
Secara intuitif merupakan himpunan seluruh fungsi yang rateofgrowth-nya adalah
sama dengan g(n).
2.8. Running Time
Running time adalah waktu yang digunakan oleh sebuah algoritma untuk
menyelesaikan masalah pada sebuah komputer paralel dihitung mulai dari saat
algoritma mulai hingga saat algoritma berhenti. Jika prosesor-prosesornya tidak mulai
dan selesai pada saat yang bersamaan, maka running time dihitung mulai saat
komputasi pada prosesor pertama dimulai hingga pada saat komputasi pada prosesor
22
2.9. Struktur Data
Struktur data adalah sebuah skema organisasi, seperti variabel dan array,dll, yang
diterapkan pada data sehingga data dapat diinterpretasikan dan sehingga operasi
operasi spesifik dapat dilaksanakan pada data tersebut. Pemakaian struktur data yang
tepat didalam proses pemrograman akan menghasilkan algoritma yang lebih jelas dan
tepat, sehingga menjadikan program secara keseluruhan lebih efisien dan sederhana.
Data adalah representasi dari fakta dunia nyata. Setiap data memiliki tipe data. Tipe
data adalah pengelompokkan data berdasarkan isi dan sifatnya.
Secara garis besar tipe data dapat dikategorikan menjadi :
1. Tipe data sederhana/dasar
a. Tipe data sederhana tunggal
Integer Real Boolean Karakter
b. Tipe data sederhana majemuk misalnya string
2. Struktur data, meliputi :
a. Struktur data sederhana
Array Record
b. Struktur data majemuk, yang terdiri dari:
Linier : Stack, Queue, List dan Multilist No Linier : Pohon Biner (tree) dan Graph
Pemakaian struktur data yang tepat didalam proses pemrograman akan menghasilkan
algoritma yang lebih jelas dan tepat, sehingga menjadikan program secara keseluruhan
lebih efesien dan sederhana. Struktur data yang ′′standar′′ yang biasanya digunakan
dibidang informatika adalah List, Multilist, Stack (Tumpukan), Queue (Antrian), Tree
( Pohon ), Graph ( Graf ). Adapun perbedaan array dan list secara umum dapat dilihat
23
Tabel 2.2 Perbedaan Array dan List
Array List
1.Pengaksesan bersifat Statis
2.volumenya selalu tetap tidak tergantung
pada jumlah data
3.alokasi memori dilakukan pada saat array
didefinisikan.
4.pembebasan memori dilakukan pada saat
program berhenti.
5.Cara akses bersifat random dengan
menggunakan nomor index.
1.Pengaksesan bersifat Dinamis
2.ukurannya berubah-ubah disesuaikan
dengan kebutuhan.
3.alokasi memori ditentukan pada saat
data baru dibuat.
4.pembebasan memori dilakukan setiap
ada penghapusan data.
5.Cara akses ke masing-masing class
data dilakukan secara linier (selalu