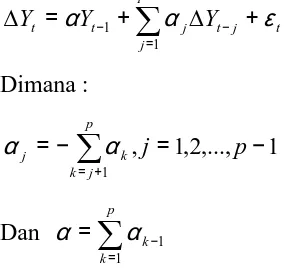ANALISIS HUBUNGAN ANTARA PENDAPATAN DAN
INVESTASI DI PTPN IV GUNUNG BAYU DENGAN
MENGGUNAKAN REGRESI BERGANDA
SKRIPSI
NURBAITY GINTING
040803051
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
ANALISIS HUBUNGAN ANTARA PENDAPATAN DAN
INVESTASI DI PTPN IV GUNUNG BAYU DENGAN
MENGGUNAKAN REGRESI BERGANDA
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar sarjana sains
NURBAITY GINTING
040803051
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : ANALISIS HUBUNGAN ANTARA PENDAPATAN
DAN INVESTASI DI PTPN IV GUNUNG BAYU DENGAN MENGGUNAKAN REGRESI
BERGANDA
Kategori : SKRIPSI
Nama : NURBAITY GINTING
Nomor Induk Mahasiswa : 040803051
Program Studi : SARJANA (S1) MATEMATIKA
Departemen : MATEMATIKA
Fakultas : MATEMATIKA DAN ILMU PENGETAHUAN
ALAM (FMIPA) UNIVERSITAS SUMATERA UTARA
Diluluskan di Medan, Juli 2010
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Dra.Rahmawati Pane, M.Si Drs. Agus Salim Harahap, M.Si
NIP.19560219 1985032002 NIP.1954082819 81031004
Diketahui oleh
Departemen Matematika FMIPA USU Ketua,
PERNYATAAN
ANALISIS HUBUNGAN ANTARA PENDAPATAN DAN INVESTASI DI PTPN IV GUNUNG BAYU DENGAN MENGGUNAKAN
REGRESI BERGANDA
(Studi Kasus di PTPN IV Gunung Bayu)
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Juli 2010
PENGHARGAAN
Dengan mengucapkan puji dan syukur kehadirat Allah SWT yang telah memberikan limpahan karunia-Nya sehingga kertas kajian ini berhasil di selesaikan dalam waktu yang telah ditetapkan. Skripsi ini merupakan salah satu syarat untuk menyelesaikan perkuliahan di Departemen Matematika FMIPA USU.
Penulis mengucapkan terima kasih kepada Drs. Agus Salim Harahap, M.Si dan Dra. Rahmawati Pane, M.Si sebagai dosen pembimbing yang telah membimbing dan mengarahkan penulis serta kebaikannya untuk meluangkan waktu, tenaga dan bantuannya sehingga skripsi ini dapat selesai tepat waktu. Ucapan terima kasih juga penulis sampaikan kepada ketua dan sekretaris Departemen Matematika, Dr. Saib Suwilo, M.Sc dan Drs. Henry Rani Sitepu, M.Si, Dekan dan Pembantu Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Sumatera Utara, semua dosen pada Departemen Matematika FMIPA USU, serta para pegawai di FMIPA USU. Saya juga mengucapkan terima kasih kepada rekan-rekan mahasiswa Matematika stambuk 2004, sahabat-sahabatku Uci, Hemmi, Nova, Ija, Rini, Nanda, Eva, dan Masna yang telah memberikan motivasi dan bantuannya, adik-adikku Kiki dan Herry juga abangku Hendrik. Akhirnya terima kasihku kepada ayahanda dan ibunda tercinta atas semua doanya, motivasi dan bantuan baik moril maupun materil yang selama ini diberikan kepada penulis.
Medan, Juli 2010 Penulis,
ABSTRAK
Vector Auto Regression (VAR) merupakan alat atau metode analisis statistik yang
ABSTRACT
DAFTAR ISI
Halaman
Persetujuan ii
Pernyataan iii
Penghargaan iv
Abstrak v
Abstrack vi
Daftar Isi viii
Daftar Tabel ix
Daftar Gambar x
Bab 1 Pendahuluan 1
1.1Latar Belakang Masalah 1
1.2Perumusan Masalah 2
1.3Batasan Masalah 3
1.4Tujuan Peenelitian 3
1.5Kontribusi Penelitian 3
1.6Kajian Pustaka 3
1.7Metodologi Penelitian 6
Bab 2 Landasan Teori 8
2.1 Variabel 8
2.2 Data 8
2.2.1 Data Menurut Sifatnya 9
2.2.2 Data Menurut Sumbernya 9
2.2.3 Data Menurut Cara Memperolehnya 10
2.2.4 Data Menurut Waktu Pengumpulannya 10
2.3 Pendapatan 11
2.4 Investasi 11
2.5 Analisis Regresi 12
2.6 Model Regresi Linier 12
2.7 Uji Akar Unit (Unit Root Test) 13
2.8 Likelihood Ratio Test 15
2.9 Granger Causality Test 18
2.10 The Impulse Responses 19
2.11 The Cholesky Decomposition 20
2.12 Pengujian Hipotesis 21
Bab 3 Pembahasan 23
3.1 Gambaran Umum 23
3.2 Pengolahan Data 24
3.2.1 Uji Akar Unit (Unit Root Test) 25
3.2.2 Likelihood Ratio Test 27
3.2.3 Granger Causality Test 28
3.2.5 The Cholesky Decomposition 36
3.2.6 Analisis Data 37
Bab 4 Kesimpulan dan Saran 48
4.1 Kesimpulan 48
4.2 Saran 49
Daftar Pustaka 50
DAFTAR TABEL
Halaman
Tabel 3.1 Tabel Data Pendapatan dan Investasi PTPN IV Gunung Bayu 24
Tabel 3.2 Tabel Uji Akar Unit untuk PDB 25
Tabel 3.3 Tabel Uji Akar Unit untuk RP 26
Tabel 3.4 Tabel uji 4 Lag 27
Tabel 3.5 Tabel uji 10 Lag 27
Tabel 3.6 Tabel Hasil Vector Auto Regresi 29
Tabel 3.7 Tabel Granger Causality Test 30
Tabel 3.8 Tabel The Impulse Response 32
DAFTAR GAMBAR
Halaman
ABSTRAK
Vector Auto Regression (VAR) merupakan alat atau metode analisis statistik yang
ABSTRACT
BAB 1
PENDAHULUAN
1.1 Latar Belakang Masalah
Dalam sistem perekonomian suatu perusahaan, tingkat pertumbuhan ekonomi sangat mempengaruhi kemajuan perusahaan pada masa yang akan datang. Pendapatan dan investasi merupakan faktor pendukung dalam meningkatkan pertumbuhan ekonomi tersebut. PTPN IV Gunung Bayu merupakan Badan Usaha Milik Negara (BUMN) yang bergerak di bidang perkebunan. PTPN IV Gunung Bayu ini adalah salah satu perusahaan penghasil minyak mentah kelapa sawit (CPO) di Indonesia. Dalam proses produksi, perusahaan ini harus mempunyai anggaran yang cukup untuk pembiayaan pada tahun berikutnya. Untuk itu setiap tahunnya, perusahaan ini harus mampu mencapai kestabilitasan tersebut guna kelangsungan perusahaan. Agar tetap menjaga kestabilan perekonomian tersebut, banyak usaha yang dilakukan antara lain adalah meminimalisasikan pengeluaran perusahaan dan mengoptimalkan hasil produksi yang akan menambah anggaran pendapatan.
Dari asumsi itulah diperkirakan hasil pendapatan dan investasi sangat berpengaruh terhadap tingkat pertumbuhan ekonomi perusahaan. Seperti yang dikemukakan (Hadi, 2003) “Semakin tinggi pertumbuhan ekonomi suatu perusahaan, berarti semakin besar bagian dari pendapatan yang bisa ditabung, sehingga investasi yang tercipta akan semakin besar pula dan di lain pihak, semakin besar investasi suatu perusahaan, akan semakin besar pula tingkat pertumbuhan ekonomi yang bisa dicapai”. Kebijakan dari adanya hubungan timbal balik antara tingkat investasi dan tingkat pendapatan tersebut adalah pada pembuatan proyeksi atau perkiraan kebutuhan investasi setiap tahun dengan pencapaian target perekonomian di PTPN IV Gunung Bayu. Dengan memegang asumsi bahwa hubungan timbal balik tersebut akan terlaksana, sehingga dalam membuat proyeksi investasi harus memperhitungkan variabel pertumbuhan ekonomi, dan sebaliknya dalam memproyeksikan angka pertumbuhan ekonomi, variabel investasi harus dijadikan salah satu faktor penentu.
Berdasarkan hubungan timbal balik (interrelationship) tersebut penulis mencoba memproyeksikan sistem variabel-variabel deret waktu di PTPN IV Gunung Bayu untuk menganalisis dampak dinamis dari faktor gangguan yang terdapat dalam sistem untuk dengan menggunakan metode analisis Vector Auto Regression (VAR), agar proyeksi terhadap besarnya investasi dapat semaksimal mungkin. Sehingga pada akhirnya penulis memilih judul “Analisis Hubungan antara Pendapatan dan Investasi di PTPN IV Gunung Bayu dengan Menggunakan Regresi Berganda”.
1.2 Perumusan Masalah
1.3 Batasan Masalah
Ada beberapa batasan-batasan masalah dalam penyusunan tulisan, agar penelitian menjadi jelas yaitu :
Data yang akan dianalisis adalah data yang stasioner. Data yang diambil dibatasi antara tahun 2000 s/d 2007
1.4 Tujuan Penelitian
Adapun tujuan dari penelitian yang ingin dicapai penulis adalah :
Mengetahui ada atau tidaknya hubungan timbal balik (interrelationship) antara pendapatan dengan investasi di PTPN IV Gunung Bayu.
1.5 Kontribusi Penelitian
Berdasarkan tujuan penulisan manfaatnya yang akan diperoleh adalah :
a Mengetahui dampak dinamis dari faktor gangguan yang terdapat dalam sistem variabel.
b Akan diketahui hubungan timbal balik (interrelationship) antara pendapatan dan investasi sehingga perusahaan mampu memproyeksikan besarnya investasi di masa yang datang.
1.6 Kajian Pustaka
Berikut ini kajian pustaka tentang analisis Vektor Auto Regression (VAR) dalam perekonomian :
1. Vector Auto Regression (VAR) :
Vector Auto Regression (VAR) merupakan alat analisis atau metode
terdapat dalam sistem variabel tersebut. Selain itu, VAR Analysis juga merupakan alat analisis yang sangat berguna, baik di dalam memahami adanya hubungan timbal balik (interrelationship) antara variabel-variabel ekonomi, maupun di dalam pembentukan model ekonomi berstruktur (Hadi, 2003). Untuk lebih memahami analisis VAR, diberikan sistem dua variabel sederhana ( the simple
bivariate system) berikut :
yt t t
t t
t a a Y a Y a Z a Z e
Y = 10 + 11 −1+ 12 −2 + 13 −1+ 14 −2 +
zt t t
t t
t a a Y a Y a Z a Z e
Z = 20 + 21 −1+ 22 −2 + 23 −1+ 24 −2 +
dengan: t
Y = Pendaptan pada tahun t
t
Z = investasi pada tahun t
n t
Y− = Pendapatan pada tahun t-n n
t
Z− = investasi pada tahun t-n j
j a
a1 , 2 = konstanta ; j = 0,1,2,3,4
eyt, ezt = faktor gangguan
Persamaan VAR secara umum menurut Thomas (1999) sebagai berikut:
∑
= −
+
= k
i
t t i
t AY
Y
1
1 ε
dengan: t
Y = Vektor kolom dari pengamatan pada waktu t semua variabel dalam model t
A = matrik parameter
k = Ordo dari model VAR
2. Teori mengenai cakupan VAR a Uji akar unit
(Verbeek, 2002) sehingga terlebih dahulu dilakukan uji Augmented
Dickey-Fuller (ADF).
b (Gujarati, 1997) menjelaskan bahwa penaksiran model lag yang terbaik adalah jika koefisien regresi dari variabel lag mulai menjadi tidak signifikan secara statistik atau koefisien dari variabel berubah tanda dari positif ke negatif atau sebaliknya.
c Granger Causality Test
Pengujian hubungan kausalitas dikembangakan oleh Granger (1969). Test ini menguji apakah suatu variabel bebas (independent variable) meningkatkan kinerja forecasting dari variabel tidak bebas (dependent variable).
d The Cholesky Decomposition dan The Impulse Responses
( Hadi, 2003) menjelaskan bahwa The Impulse Responses digunakan untuk melihat efek gejolak (shock) suatu standar deviasi dari variabel baru terhadap nilai sekarang (current time values) dan nilai yang akan datang (future values) dari variabel model yang diamati dan The Cholesky Decomposition atau biasa disebut juga dengan The Variance Decomposition memberikan informasi mengenai variabel inovasi untuk menyusun perkiraan error variance suatu variabel.
3. Teori investasi dan teori pertumbuhan :
Salah satu teori ekonomi terkenal yang menganalisa hubungan antara tingkat investasi dan tingkat pertumbuhan adalah Teori Harrod-Domar. Kedua ekonom ini menyimpulkan adanya hubungan ekonomi langsung antara besarnya stok modal keseluruhan, K, dengan GNP, Y, yang mereka formulasikan sebagai rasio modal /output (capital/output ratio, COR). Semakin tinggi peningkatan stok modal, semakin tinggi pula output yang dapat dihasilkan. Secara sederhana, Teori
Harrod-Domar dapat diformulasikan sebagai berikut:
k s Y Y/ = /
∆ (1)
di mana :
Y Y /
∆ = tingkat perubahan atau tingkat pertumbuhan GNP (yaitu persentase perubahan GNP).
s = rasio tabungan nasional
Persamaan di atas menyatakan bahwa tingkat pertumbuhan GNP (∆Y /Y) ditentukan bersama-sama oleh rasio tabungan nasional, s, dan rasio modal/output nasional, k. Seacara khusus, persamaan tersebut menyatakan bahwa tingkat pertumbuhan pendapatan nasional akan secara langsung atau secara "positif" bertalian erat dengan rasio tabungan (yakni, lebih banyak bagian GNP yang ditabung, dan diinvestasikan, maka akan lebih besar lagi pertumbuhan GNP tersebut) dan sebaliknya atau secara "negatif" terhadap nisbah modal output suatu perekonomian (yakni, lebih besar, k, lebih kecil lagi pertumbuhan GNP).
1.7 Metodologi Penelitian
Penelitian ini merupakan penelitian tentang studi kasus dari VAR terhadap korelasi timbal balik (interrelationship) antara pendapatan dan investasi perusahaan PTPN IV Gunung Bayu. Untuk mengetahui korelasi dalam menganalisis permasalahan maka langkah-langkah yang digunakan adalah sebagai berikut :
1. Pengumpulan Data
Data yang akan diproses adalah data skunder tentang investasi dan pendapatan pada tahun 2000 s/d 2007 di PTPN IV Gunung Bayu.
2. Pengolahan Data
Setelah data diterima, peneliti akan mulai mengolah data dengan menggunakan analisis Vector Auto Regression (VAR) sebagai berikut:
Analisis data
Metode analisis yang digunakan adalah Vector Auto Regression dengan menggunakan bantuan program Eviews. Tahapan yang dilakukan adalah sebagai berikut :
Uji akar unit ini digunakan untuk melihat apakah data yang diamati stationer atau tidak. Dengan menggunakan Augmented Dickey Fuller diperoleh nilai t. Dengan membandingkan nilai t Augmented Dickey Fuller dan MacKinnon.
c. Menguji hipotesis
Pengujian hipotesis dilakukan dengan tahapan sebagai berikut:
1. Likelihood Ratio Test digunakan untuk menguji hipotesis mengenai
berapakah jumlah lag yang sesuai untuk model yang diamati. Uji hipotesis yang dilakukan adalah :
H0 : Model tanpa pembatasan adalah model terbaik H1 : Model dengan pembatasan adalah model terbaik
2. Granger Causality Test menguji apakah suatu variabel bebas
(independent variable) meningkatkan kinerja forecasting dari variabel tidak bebas (dependent variable). Hipotesis dilakukan untuk menguji apakah X mempengaruhi Y atau sebaliknya.
H0 : β = 0 H1 : β > 0
d. Menghitung variabel baru
Pada dasarnya test ini digunakan untuk menguji struktur dinamis dari sistem variabel dalam model yang diamati, yang dicerminkan oleh variabel baru (innovation variable). Dengan kata lain, test ini merupakan test terhadap variabel baru (innovation variable). Test ini terdiri dari: 1. The Impulse Responses berguna untuk melihat efek gejolak (shock)
suatu standar deviasi dari variabel baru terhadap nilai sekarang (current
time values) dan nilai yang akan datang (future values) dari variabel
model yang diamati.
2. The Cholesky Decomposition atau biasa disebut juga dengan The Variance Decomposition digunakan untuk menyusun perkiraan error
variance suatu variabel, yaitu seberapa besar perbedaan antara
variance sebelum dan sesudah shock, baik shock yang berasal dari diri
BAB 2
LANDASAN TEORI
2.1 Variabel
Variabel adalah karakter yang akan di observasi dari unit amatan. Variabel dalam penelitian merupakan suatu atribut dari sekelompok objek yang diteliti dan memiliki variasi antara satu objek dengan objek yang lain dalam kelompok tersebut, misalnya tinggi badan dan berat badan merupakan atribut seseorang yang merupakan objek penelitian.
Menurut hubungan antara suatu variabel dengan variabel lainnya, variabel terbagi atas beberapa bagian yaitu :
a Dependent variable atau variabel terikat, yaitu variabel yang nilainya di
pengaruhi oleh variabel bebasnya.
b Independent variable atau variabel bebas, yaitu variabel yang menjadi sebab
terjadinya variabel terikat.
c Variabel moderator yaitu variabel yang memperkuat atau memperlemah hubungan antara suatu variabel dependen dengan variabel independen.
d Variabel intervening, seperti variabel moderator tetapi nilainya tidak dapat di ukur seperti, kecewa, gembira, sakit hati dan sebagainya.
e Variabel kontrol adalah variabel yang dapat di kendalikan oleh peneliti.
2.2 Data
data di lakukan untuk mendapatkan gambaran mengenai suatu keadaan sehingga dapat memecahkan persoalan. Untuk memperoleh itu semua terlebih dahulu harus di ketahui jenis elemen atau objek yang akan di teliti. Elemen adalah unit terkecil dari objek penelitian. Elemen atau unit terkecil dapat berupa orang, angka dan sebagainya. Disini elemen yang akan digunakan sebagai penelitian berupa angka yaitu nilai investasi dan pendapatan perusahaan di PTPN IV Gunung Bayu.
Adapun tujuan pengumpulan data adalah untuk mengetahui karakteristik dari elemen tersebut. Karakteristik adalah sifat-sifat atau ciri-ciri yang dimiliki yang elemen sehingga seluruh keterangan tentang elemen dapat di ketahui dengan jelas. Untuk itu diperlukan data-data mengenai pendapatan dan investasi di PTPN IV Gunung Bayu sehingga dapat di teliti faktor-faktor yang mempengaruhi hubungan timbal balik dari elemen-elemen tersebut.
2.2.1 Data Menurut Sifatnya
Menurut sifatnya data di bagi menjadi dua bagian yaitu : a Data Kuantitatif
Data kuantitatif adalah serangkaian observasi atau pengukuran yang dapat di nyatakan dalam angka-angka (numerik). Misalnya, produksi sawit meningkat 30 persen, harga daging sapi per kilogram Rp. 30.000, dan lain-lain.
b Data Kualitatif
Data kulitatif adalah serangkaian observasi dimana tiap observasi yang terdapat dalam sampel atau populasi tergolong dalam salah satu kelas-kelas yang saling lepas dan yang kemungkinannya tidak di nyatakan dalam angka-angka. Misalnya produksi padi meningkat, harga pupuk melonjak naik dan sebagainya.
2.2.2 Data Menurut Sumbernya
a Data Internal
Data internal adalah data yang di butuhkan seorang pemimpin perusahaan yang berguna sebagai landasan pengambilan keputusan dimana data tersebut di peroleh dari catatan-catatan intrn perusahaan tersebut. Misalnya data penjualan, pendapatan perusahaan dan investasi.
b Data Eksternal
Data eksternal adalah data yang hanya dapat di peroleh dari sumber-sumber yang ada di luar perusahaan atau instansi. Misalnya perusahaan mencari data mengenai daya beli konsumen dari kantor pusat statistik setempat.
2.2.3 Data Menurut Cara Memperolehnya
Menurut cara memperolehnya data dibagi atas dua bagian yaitu : a. Data Primer
Data Primer adalah data yang dikumpulkan dan diolah sendiri oleh organisasi yang menerbitkannya atau perorangan langsung dari orangnya.
b. Data Sekunder
Data sekunder adalah data yang diterbitkan oleh organisasi yang bukan merupakan pengolahan atau data yang diperoleh dalam bentuk jadi dan telah diolah oleh pihak lain, yang biasanya dalam bentuk publikasi.
2.2.4 Data Menurut Waktu Pengumpulannya
Menurut pengumpulannya data dibagi atas dua bagian yaitu : a. Data cross section
b. Data berkala (time series)
Data berkala (time series) adalah data yang dikumpulkan dari waktu ke waktu. Tujuannya adalah untuk menggambarkan perkembangan suatu kegiatan dari waktu ke waktu. Misalnya, perkembangan produksi padi selama lima tahun terakhir. Data ini disebut juga data historis.
2.3 Pendapatan
Pendapatan perusahaan merupakan dana yang memberikan penghasilan bagi perusahaan yang berasal dari dividen atas investasi atau penyertaan berupa kepemilikan saham perusahaan lain, dan bunga yang di terima oleh perusahaan dari investasi perusahaan pada obligasi perusahaan lain atau dari simpanan uang perusahaan pada suatu instansi seperti Bank.
2.4 Investasi
Investasi adalah suatu aktiva yang di gunakan perusahaan untuk pertumbuhan kekayaan melalui distribusi hasil investasi seperti, bunga, royalti, dividen, uang sewa untuk apresiasi nilai investasi atau untuk manfaat lain bagi perusahaan yang berinvestasi. Aktiva yang di gunakan dalam penelitian ini adalah aktiva bergerak seperti berikut :
1. Kas dan bank 2. Deposito berjangka 3. Tagihan
4. Porsi piutang jangka panjang 5. Uang muka pembelian impor 6. Pinjaman pegawai/karyawan 7. Pinjaman lain-lain
11.Persediaan produksi dan hasil jadi
Hal ini dilakukan karena aktiva bergerak mempunyai nilai yang berubah setiap tahun sehingga selalu berpengaruh pada pandapatannya. Contohnya manfaat yang di peroleh dari hubungan perdagangan. Investasi biasanya merupakan bentuk penanaman dana perusahaan ke dalam perusahaan lain dalam jangka panjang dalam bentuk saham, obligasi atau surat berharga lainnya.
2.5 Analisis Regresi
Analisis regresi adalah teknik statistika yang berguna untuk memeriksa dan memodelkan hubungan di antara varibel-variabel. Analisis regresi dapat di gunakan untuk dua hal pokok yaitu :
a Untuk memperoleh suatu persamaan dan garis yang menunjukkan persamaan hubungan antara dua variabel. Persamaan dan garis yang terdapat disebut persamaan regresi yang dapat berbentuk linier maupun nonlinier.
b Untuk menaksir satu variabel yang disebut variabel terikat dengan variabel lain yang disebut variabel bebas berdasarkan hubungan yang di tunjukan persamaan regresi tersebut.
2.6 Model Regresi Linear
Suatu model regresi dari suatu populasi di mana terdapat satu variabel yang dependen (dependent variable) misalnya Y dan sebanyak k-1 variabel-variabel bebas (independent variables) misalnya X1,X2, ,Xk yang merupakan variabel-variabel yang menentukan nilai Y dapat diyatakan sebagai berikut :
i ki k i
i
i X X X e
Y =β1+β2 2 +β3 3 + +β + (2.1)
i = 1, 2, ... , N
di mana : 1
2
β samapi βk = koefisien-koefisien regresi
e = sthocastic disturbance term
i = jumlah observasi
N = besar populasi
Persamaan (2.1) dapat dipecah dalam bentuk suatu rangkaian persamaan-persamaan simultan sebanyak N, yaitu sebagai berikut :
N kN k N N N k k k k e X X X Y e X X X Y e X X X Y + + + + + = + + + + + = + + + + + = β β β β β β β β β β β β 3 3 2 2 1 2 2 32 3 22 2 1 2 1 1 31 3 21 2 1 1 (2.2)
Persamaan (2.2) dapat juga di nyatakan dalam bentuk matrik sebagai berikut :
+ = N k kN N N k k e e e X X X X X X X X X Y Y Y N 2 1 2 1 3 2 2 32 22 1 31 21 2 1 1 1 1 β β β (2.3)
Atau Y = Xβ +e
Di mana :
Y = matriks observasi sebanyak N yang terdiri dari sebanyak k-1 variabel bebas yaitu
k X X
X2, 3, ,
β= vektor kolom berdimensi k x 1 yang terdiri dari parameter β1,β2, ,βk
e = vektor kolom berdimensi Nx1 yang terdiri dari disturbance terms.
2.7 Uji Akar Unit (Unit Root Test)
seperti kebanyakan data ekonomi, maka hasil regresi yang berkaitan dengan data
time-series ini akan mengandung R yang relatif tinggi dan Durbin-Watson statistics yang 2
rendah seperti yang di kemukakan oleh Granger dan Newbold (1974, 1977). Dengan kata lain akan timbul masalah yang disebut spurious regression (Philips, 1986).
Kestabilan suatu model time-series bermakna terkandung sifat stationary dalam model berikut :
t t t
t Y u
Y =β −1+µ ; ~ NID(0, σ2) (2.4)
t = 1,...,n
NID(0, σ2) menyatakan adanya normal distribution dengan nilai rata-rata = 0, varian tetap = σ2 dan kovarian = 0. Kondisi stationary dalam model (2.4) mengandung pengertian bahwa β <1. Dalam hal ini perlu di lakukan pengujian null-hypothesis
1
=
β terhadap alternatif hypothesis β <1. Pengujian null-hypothesis tentang akar
unit ini diselesaikan dengan menggunakan prosedur Fuller(1976) dan Dickey dan Fuller (1979). Misalkan data time-series berbentuk:
(1) Yt =b1Yt−1+e1t (2.5) (2) Yt =a2 +b2Yt−1 +e2t (2.6) (3) Yt =a3 +b3Yt−1 +c3t+e3t (2.7)
Apabila nilai absolut β <1 dalam model (2.4) maka nilai bi dari setiap model regresi dari model (2.5) sampai (2.7) di perkirakan bersifat normal dan distribusi t-statistics menjadi ti =(bi −β)/se(bi) yang akan mendekati tn−k dimana k bernilai 1, 2 atau 3 tergantung model regresi yang digunakan. Apabila β =1 dan model (2.4) merupakan model yang sebenarnya, maka distribusi empirikal t-statistics adalah ti dan bukan tn−k.
Dickey-Fuller yaitu masing-masing untuk model regresi tanpa intercept, untuk model regresi dengan intercept dan untuk model regresi dengan intercept dan trend waktu. Masing-masing t-statistic ini dinyatakan dengan symbol-simbol
∧ ∧
µ
τ
τ, dan ττ
∧
dalam tabel Dickey-Fuller. Melalui tabel Dickey-Fuller kita akan menolak null-hypothesis yang menyatakan adanya sifat stationary apabila nilai t-statistics yang di peroleh berkaitan dengan koefisien regresi model ini lebih kecil daripada nilai t-statistics pada tingkat signifikan 1 %, 5% dan 10%.
Prosedur pengujian Dickey dan Fuller tidak berubah apabila kita ingin menguji model regresi yang mengandung higher order autoregressive processes. Misalnya, kita ingin menguji unit root model regresi yang berikut:
∑
− = − − + ∆ + = ∆ 1 1 1 p j t j t j tt Y Y
Y α α ε
Dimana :
∑
+ = − = − = p j k kj j p
1 1 ,..., 2 , 1 , α α
Dan
∑
= − = p k k 1 1 α α
Distribusi t-statistics berkaitan dengan Yt−1 adalah sama dengan yang tertera dalam table Dickey-Fuller untuk model regresi yang mengandung AR(1). Pengujian dalam model ini disebut pengujian Fuller yang diperluas (Augmented
Dickey-Fuller Test).
2.8 Likelihood Ratio Test
Likelihood ratio test digunakan untuk menguji apakah suatu model regresi yang di
taksir dengan menggunakan metode maximum likelihood memenuhi persyaratan yang telah di tetapkan mengenai parameter-parameter model regresi yang di taksir.
Likelihood ratio test di dasarkan atas pemikiran bahwa apabila persyaratan yang di
adanya persyaratan atau pembatasan tidak akan banyak berbeda dari nilai log
likelihood function yang di maximumkan dari model regrsi tanpa adanya pembatasan.
Log likelihood ratio di hitung dengan menggunakan formula sebagai berikut : LR = -2(L0 - L1) ~
2 m
χ (2.8)
di mana: L0 = nilai log likelihood function dalam model regresi tanpa pembatasan L1 = nilai log likelihood function dalam model regresi dengan pembatasan m = jumlah pembatasan.
Fungsi likelihood yang biasa dinyatakan dalam bentuk log sehingga di sebut fungsi log likelihood (L) yang akan di maximumkan berdasarkan nilai-nilai yang cocok untuk α, β, σ2adalah :
L =
∑
= n i i Y f 1 ) (
log (2.9)
di mana :
2 2 1 2 2 1 exp ) 2 ( ) ( − − − = − σ β α
πσ i i
i
X Y
Y
f (2.10)
yang merupakan fungsi normal density. Oleh sebab itu, fungsi log likelihood dapat di nyatakan sebagai berikut :
L =
∑
= − − − − − n i i i X Y n n 1 2 2 2 ) ( 2 1 log 2 ) 2 log(
2 π σ σ α β (2.11)
Diferensialkan (2.11) dalam hubungannya dengan α, β, σ2 dan samakan derivatif dengan nol, maka di peroleh :
0 ) ˆ ˆ ( ˆ 2 1 1
2
∑
− − ==
n
i
i
i X
Y α β
σ (2.12) 0 ) ˆ ˆ ( ˆ 2 1 1
2
∑
− − ==
n
i
i i
i Y X
X α β
σ (2.13)
0 ) ˆ ˆ ( ˆ 2 1 ˆ 2 1 2 4
2 + − − =
−
∑
= n i i i X Yn α β
σ
σ (2.14)
, ˆ , ˆ β
α dan σ2 adalah simbol-simbol untuk hasil penaksiran berdasarkan metode
maximum likelihood. Dari (2.12) dan (2.13) di peroleh :
∑
∑
Yi =αˆn+βˆ Xi (2.15)∑
∑
∑
= + ˆ 2ˆ i i
i
iY X X
Persamaan (2.15) dan (2.16) adalah persamaan-persamaan normal. Hasil penaksiran berdasarkan metode maximum likelihood di nyatakan dengan formula sebagai berikut :
n e n X Y n i i n i i i
∑
∑
= − = − − = 1 2 1 2 2 ) ˆ ˆ ( α β σ (2.17)Dengan demikian untuk kasus-kasus model regresi dengan k-variabel fungsi log
likelihood adalah sebagai berikut :
L = ( ) ( )
2 1 log 2 2 log 2 ' 2
2 β β
σ σ
π n y X y X
n − − − −
−
(2.18)
Dengan mendeferensial parsial dan menyamakan derivatif sama dengan nol di peroleh:
(
2 ' 2 ' ˆ 0)
ˆ 2
1
2 − + =
− β
σ X y X X
(
ˆ)(
' ˆ)
0ˆ 2 1 ˆ 2 1 4
2 + − − =
− β β
σ
σ y X y X
Sehingga pemecahannya menghasilkan
n e e y X X X ' ' ) ' ( ˆ 2 1 = = − σ β
Likelihood ratio test digunakan untuk melihat berapakah jumlah lag yang paling
sesuai dalam untuk suatu model. Setelah diketahui berapa lag yang akan di gunakan dalam suatu model maka akan ditentukan lag mana yang paling relevan di pakai dalam model dengan menggunakan Final Prediction Error (FPE). Penentuan lag yang optimal untuk y sebagai variabel bebas dan lag operator untuk x tidak ada, didasarkan atas ukuran Final Prediction Error (FPE) yang minimum yang telah diformulasikan oleh Akaike (1969) yang dalam hal ini adalah sebagai berikut:
FPEy =
− × − − + +
∑
= ∧ T t t t T y y S T S T 1 2 ) ( 1 1FPE = Final Prediction Error
T = jumlah observasi
S = jumlah lag dalam model
∧
t
y adalah nilai y yang diramalkan berdasarkan hasil regresi (predicted value of y).
2.9 Granger Causality Test
Dalam realitas ekonomi, model regresi linier di mana variabel dependen di regresikan atas variabel-variabel bebas tidak dapat di pastikan mengandung pengertian bahwa variabel dependen secara kausal betul-betul di tentukan oleh variabel-variabel secara sepihak. Ada kemungkinan dalam suatu model persamaan tunggal, variabel dependen ditentukan oleh variabel bebas, tetapi sebaliknya variabel bebas juga ditentukan oleh variabel dependen sehingga dalam hal ini terdapat kausalitas dua arah.
Dua perangkat data time-series yang linier berkaitan dengan variabel X dan Y di formulasikan dalam dua bentuk model regresi yang berikut :
∑
∑
= − + = − + = n i t n j j t j i t it a X bY u
X
1 1`
(2.19)
∑
∑
= − + = − + = r i t s j j t j i t it cY d X v
Y
1 1`
(2.20) Dengan u ,t vt adalah error terms yang di asumsikan tidak mengandung korelasi serial dan m = n = r = s. Hasil-hasil regresi linear ini akan menghasilkan empat kemungkinan mengenai nilai koefisien-koefisien regresi masing-masing yaitu :
(1) Jika
∑
= ≠ n j j b 1
0 dan
∑
= = s j j d 1
0 maka terdapat kausalitas satu arah dari Y ke X.
(2) Jika
∑
= = n j j b 1
0 dan
∑
= ≠ s j j d 1
0 maka terdapat kausalitas satu arah dari X ke Y
(3) Jika
∑
= = n j j b 1
0 dan
∑
= = s j j d 1
(4) Jika
∑
= ≠ n j j b 10 dan
∑
= ≠ s j j d 1
0 maka terdapat kausalitas dua arah antara Y dan X Untuk memperkuat indikasi keberadaan berbagai bentuk kausalitas yang tersebut di atas, maka di lakukan F-test unutk masing-masing model regresi.
Cara lain untuk menjelaskan metode pengujian kausalitas Granger adalah dengan menggunakan regresi tanpa pembatasan (unrestricted regression) dan regresi dengan pembatasan (restricted regression). Misalnya, kita ingin menguji hipotesis bahwa X tidak mempengaruhi Y. Untuk itu mula-mula menghitung regresi-regresi yang berikut:
∑
∑
= − = − + + = m i t m i i t i i tiY X
Y
1 1
ε β
α (2.21)
∑
= − + = m i t i t iY Y 1 ε α (2.22)Persamaan (2.21) disebut persamaan tanpa pembatasan dan Persamaan (2.22) disebut persamaan dengan pembatasan.
Selanjutnya berdasarkan nilai-nilai sum square of residual yangdiperoleh dari masing-masing persamaan diatas, dengan menghitung F-statistic dan melakukan pengujian apakah keseluruhan nilai-nilai β, yaitu parameter-parameter yang berkaitan dengan x secara signifikan tidak sama dengan nol. Seandainya keseluruhan nilai-nilai ini positif secara signifikan, maka kita dapat menolak null hypothesis yang menyatakan bahwa X tidak mempengaruhi Y. Prosedur pengujian yang sama dapat dilakukan untuk menguji null hypothesis yang lain bahwa Y tidak mempengaruhi X.
2.10 The Impulse Responses
∑
= − − − Φ = Φ = + + + = α 0 1 1 ) ( i i t i t t p t p t t U U B U Y A Y A Y (2.23)I = (I − A1 B – A2 B − · · · − Ap Bp) Φ (B) (2.24)
Dengan, cov(Ut) =
∑
, Φiadalah pengukur the impulse response terhadap koefisien MA. Selanjutnya Φjk ,i mewakili respon dari j variabel ke impulse unit dalam k-variabel ke i-th periode yang lampau. Impulse response function digunakan untuk mengevaluasi efektivitas suatu perubahan shock dari satu variabel terhadap variabel lainnya. Apabila∑
non-diagonal, maka tidak mungkin terjadi shock dari satu variabel terhadap variabel lain yang sudah ditentukan.Keterangan :
1. Untuk K-dimensi VAR(p) stabil jika
i jk ,
Φ = 0 untuk j ≠ k, i = 1,2,…
Atau
i jk ,
Φ = 0 untuk i = 1,…,p(K-1)
Dengan kata lain, jika pK-p respon yang pertama terhadap j variabel ke impulse k variabel adalah nol, maka semua response adalah nol. (Lutkepohl
Proposition 2.4)
2. Variabel k tidak menyebabkan variabel j jika dan hanya jika Φjk ,i= 0, i = 1,2,…
2.11 The Cholesky Decomposition
The Cholesky Decomposition atau The Variance Decomposition digunakan untuk
di lakukan. Misalkan P matriks segitiga bawah sehingga persamaan (2.23) menjadi ∑
− Θ −
= α
0
i t i w i
Yt (2.25)
Dengan :
( )
ww IE
U P w
P
t t
t t
i i
= =
Φ = Θ
−
' 1
Misalkan D merupakan diagonal matriks yang sama dengan P dan W= PD-1, Λ=DD’
setelah dimanipulasi diperoleh:
Yt = B0 Yt + B1 Yt-1 + · · · + Bp Yt-p + Vt (2.26)
Dengan, B0 = Ik – W-1, W = PD-1, Bi = W-1 Ai.
B0 adalah matriks segitiga bawah dengan diagonal 0. Dengan kata lain, cholesky
decomposition menentukan struktur hubungan kausal dari variabel atas ke variabel bawah, tapi tidak berlaku sebaliknya.
2.12 Pengujian Hipotesis
Pengujian hipotesis dilakukan untuk mengetahui signifikan atau tidak analisis regresi yang di analisis. Adapun langkah-langkah untuk menguji hipotesis adlah sebagai berikut:
1. Uji secara gabungan
Uji secara gabungan dilakukan dengan menggunakan uji F dengan langkah sebagai berikut :
a. Menghitung F penelitian.
b. Menghitung F tabel dengan ketentuan sebagai berikut:
Taraf signifikansi 0,05 dan derajat kebebasan dengan ketentuan numerator = k-1 dan denumerator = N - k
c. Menentukan uji kriteria hipotesis Kriteria pengujian :
e. Membandingkan angka taraf signifikansi
- Jika nilai probabilitas 0,05 lebih kecil atau sama dengan nilai probabilitas maka H0 diterima dan H1 ditolak, artinya ada hubungan linier antar variabel secara gabungan.
- Jika nilai probabilitas 0,05 lebih besar daripada probabilitas maka H0 ditolak dan H1 diterima, artinya tidak ada hubungan linier antar variabel secara gabungan.
2. Uji Keselarasan
Uji secara keselarasan menggunakan uji chi-square dengan langkah sebagai berikut :
a. Menentukan hipotesis Hipotesis :
H0 : kedua faktor selaras. H1 : kedua faktor tidak selaras. b. Menghitung besarnya χ2 penelitian
c. Menghitung basarnya χ2 tabel dengan ketentuan sebagai berikut : Taraf signifikansi dan derajat kebebasan = n-1.
d. Menentukan Kriteria :
Kriteria uji hipotesis sebagai berikut :
BAB 3
PEMBAHASAN
3.1 Gambaran Umum
Pendapatan adalah dana yang memberikan penghasilan bagi perusahaan yang berasal dari dividen atas investasi atau penyertaan berupa kepemilikan saham perusahaan lain, dan bunga yang di terima oleh perusahaan dari investasi perusahaan pada obligasi perusahaan lain atau dari simpanan uang perusahaan pada suatu instansi seperti Bank.
Sedangkan investasi adalah suatu aktiva yang di gunakan perusahaan untuk pertumbuhan kekayaan melalui distribusi hasil investasi seperti, bunga, royalti, dividen, uang sewa untuk apresiasi nilai investasi atau untuk manfaat lain bagi perusahaan yang berinvestasi. Contohnya manfaat yang di peroleh dari hubungan perdagangan. Investasi biasanya merupakan bentuk penanaman dana perusahaan ke dalam perusahaan lain dalam jangka panjang dalam bentuk saham, obligasi atau surat berharga lainnya. Disini investasi yang di gunakan adalah investasi bergerak atau aktiva.
Di dalam tulisan ini penulis mencoba untuk melihat seberapa besar hubungan timbal balik (interrelationship) yang terjadi antara pendapatan dan investasi di perkebunan PTPN IV Gunung Bayu.
3.2 Pengolahan Data
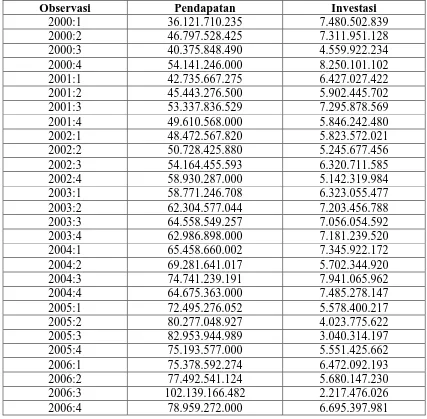
[image:37.595.105.532.354.773.2]Data yang di gunakan dalam penelitian ini adalah data skunder yang berasal dari perkebunan PTPN IV Gunung Bayu. Adapun data yang di gunakan tersebut adalah sebagai berikut :
Tabel 3.1 Tabel Data Pendapatan dan Investasi PTPN IV Gunung Bayu 2000 s/d 2007
Observasi Pendapatan Investasi
2000:1 36.121.710.235 7.480.502.839
2000:2 46.797.528.425 7.311.951.128
2000:3 40.375.848.490 4.559.922.234
2000:4 54.141.246.000 8.250.101.102
2001:1 42.735.667.275 6.427.027.422
2001:2 45.443.276.500 5.902.445.702
2001:3 53.337.836.529 7.295.878.569
2001:4 49.610.568.000 5.846.242.480
2002:1 48.472.567.820 5.823.572.021
2002:2 50.728.425.880 5.245.677.456
2002:3 54.164.455.593 6.320.711.585
2002:4 58.930.287.000 5.142.319.984
2003:1 58.771.246.708 6.323.055.477
2003:2 62.304.577.044 7.203.456.788
2003:3 64.558.549.257 7.056.054.592
2003:4 62.986.898.000 7.181.239.520
2004:1 65.458.660.002 7.345.922.172
2004:2 69.281.641.017 5.702.344.920
2004:3 74.741.239.191 7.941.065.962
2004:4 64.675.363.000 7.485.278.147
2005:1 72.495.276.052 5.578.400.217
2005:2 80.277.048.927 4.023.775.622
2005:3 82.953.944.989 3.040.314.197
2005:4 75.193.577.000 5.551.425.662
2006:1 75.378.592.274 6.472.092.193
2006:2 77.492.541.124 5.680.147.230
2006:3 102.139.166.482 2.217.476.026
2007:1 68.036.868.927 5.522.309.854
2007:2 83.563.077.000 4.719.490.318
2007:3 90.132.802.875 21.994.681.312
2007:4 111.708.392.000 6.173.278.435
Sumber : PTPN IV Gunung Bayu
3.2.1 Uji Akar Unit ( Unit Root Test )
Sesuai dengan teknis analisis data deret waktu ( time series ), untuk data deret waktu memerlukan pengujian kestasioneran terlebih dahulu. Data yang langsung di analisis akan menimbulkan kelancungan ( spurious ). Setelah uji akar di peroleh, kemudian bandingkan antara nilai statistik dengan nilai kritis ( critical value ) 95 % dan 99%. Hipotesis nol akan ditolak apabila nilai t-statistik yang di peroleh berkaitan dengan koefisien regresi model ini lebih kecil daripada t-statistik dalam tabel pada tingkat signifikan 5%.
[image:38.595.107.532.84.146.2]Berdasarkan data di atas maka uji akar unit (unit root test ) yang di peroleh adalah sebagai berikut:
Tabel 3.2 Tabel Uji Akar Unit untuk Pendapatan
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -7.559786 0.0000
Test critical values: 1% level -4.339330
5% level -3.587527
10% level -3.229230
Pengujian hipotesis :
1. Menentukan Hipotesis
H0 = pendapatan mengandung akar unit H1 = pendapatan tidak mengandung akar unit
2. Membandingkan nilai t-statistik Augmented Dickey Fuller dengan t-statistik MacKinnon pada level 1%,5%, dan 10%. Apabila nilai t-statistik Augmented
3. Pengambilan keputusan
Dari hasil perhitungan diperoleh bahwa nilai t-statistik Augmented Dickey
Fuller (-7,559786) lebih kecil dari nilai t-statistik MacKinnon pada level
[image:39.595.132.480.291.360.2]1%,5%, dan 10%. Nilai probabilitas 0,0000 lebih kecil dari nilai kritik sebesar 5% (0,0000 < 0,05) sehingga dapat disimpulkan H0 ditolak dan H1 diterima. Ini berarti hipotesis nol atau hipotesis adanya akar unit dalam pendapatan di PTPN IV Gunung Bayu ini dapat ditolak. Dari hasil pengujian data baru stasioner pada differensiasi tahap pertama (1st difference).
Tabel 3.3 Tabel Uji Akar Unit untuk Rupiah
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -4.604380 0.0071
Test critical values: 1% level -4.440739
5% level -3.632896
10% level -3.254671
Pengujian hipotesis :
1. Menentukan Hipotesis
H0 = rupiah mengandung akar unit H1 = rupiah tidak mengandung akar unit
2. Membandingkan nilai t-statistik Augmented Dickey Fuller dengan t-statistik MacKinnon pada level 1%,5%, dan 10%. Apabila nilai t-statistik Augmented
Dickey Fuller lebih kecil dari nilai t-statistik MacKinnon maka H0 ditolak. 3. Pengambilan keputusan
Dari hasil perhitungan diperoleh bahwa nilai t-statistik Augmented Dickey
Fuller sebesar -4,604380 lebih kecil dari nilai t-statistik MacKinnon pada level
1%,5%, dan 10%. Nilai probabilitas 0,0071 juga lebih kecil dari nilai kritik sebesar 5% (0,0071 < 0,05) sehingga dapat disimpulkan H0 ditolak dan H1 diterima. Ini berarti hipotesis nol atau hipotesis adanya akar unit dalam rupiah di PTPN IV Gunung Bayu ini dapat ditolak. Dari hasil pengujian data baru. Dari hasil pengujian data sudah stasioner pada data dasarnya (level) atau stasioner pada order 0.
Akan tetapi dalam penelitian ini tingkat signifikan yang digunakan adalah 5% karena data yang digunakan kurang dari 100 data.
3.2.2 The likelihood Ratio Test
[image:40.595.112.543.328.407.2]Setelah dilakukan perhitungan, maka jumlah lag yang memenuhi untuk digunakan ke dalam model adalah hanya lag range hingga 9. Dari hasil perhitungan lag order selection criteria diperoleh :
Tabel 3.4 Tabel uji 3 lag Included observations: 28
Lag LogL LR FPE AIC SC HQ
0 -1335.790 NA 1.08E+39 95.55640 95.65156 95.58549 1 -1331.275 8.061221 1.05E+39 95.51967 95.80514 95.60694 2 -1324.853 10.55102 8.85E+38 95.34664 95.82243 95.49209 3 -1311.952 19.35088* 4.75E+38* 94.71089* 95.37699* 94.91452* * indicates lag order selected by the criterion
Tabel 3.5 Tabel uji 7 Lag Included observations: 24
Lag LogL LR FPE AIC SC HQ
0 -1147.285 NA 1.35E+39 95.77375 95.87192 95.79979 1 -1142.774 7.893607 1.29E+39 95.73120 96.02571 95.80933 2 -1136.071 10.61416 1.04E+39 95.50589 95.99674 95.63611 3 -1121.369 20.82670* 4.37E+38* 94.61412* 95.30132* 94.79644* 4 -1118.854 3.144613 5.16E+38 94.73782 95.62136 94.97222 5 -1116.845 2.176041 6.54E+38 94.90376 95.98364 95.19025 6 -1112.387 4.086821 7.04E+38 94.86556 96.14179 95.20415 7 -1106.375 4.509024 7.08E+38 94.69790 96.17046 95.08857 * indicates lag order selected by the criterion
[image:40.595.108.543.472.613.2]Pengujian hipotesis untuk membandingkan lag yang paling sesuai untuk model dari permasalahan diatas adalah :
1. Menentukan Hipotesis
H0 = model dengan lag 7 adalah model terbaik H1 = model dengan lag 3 adalah model terbaik
2. Menghitung nilai likelihood ratio test (LR) dimana nilainya asymtotik dengan nilai distribusi chi-square (χ2) yaitu :
The likelihood ratio test dengan rumus : LR = -2 ( I3 – I7 )
= -2(-1320,007 –(-1129,915)) = 380,184
3. Menghitung nilai χ2 tabel dengan ketentuan sebagai berikut :
Taraf signifikan 0,05 dan derajat kebebasan N-1= 32-1=31. Sehingga diperoleh 2
%) 5 , 31 (
χ = 55,7585
4. Menentukan kriteria uji hipotesis: Kriteria pengujian:
Jika LR >χ2 table maka tolak H0 dan terima H1 Jika LR ≤χ2 table maka terima H0 dan tolak H1 5. Pengambilan keputusan
Dari hasil perhitungan diperoleh LR sebesar 380,184 > χ2 sebesar 55,7585 sehingga H0 ditolak dan H1 diterima. Ini berarti bahwa model dengan lag 3 adalah model terbaik dapat diterima dan menolak model dengan lag 7.
3.2.3 The Granger Causality Test
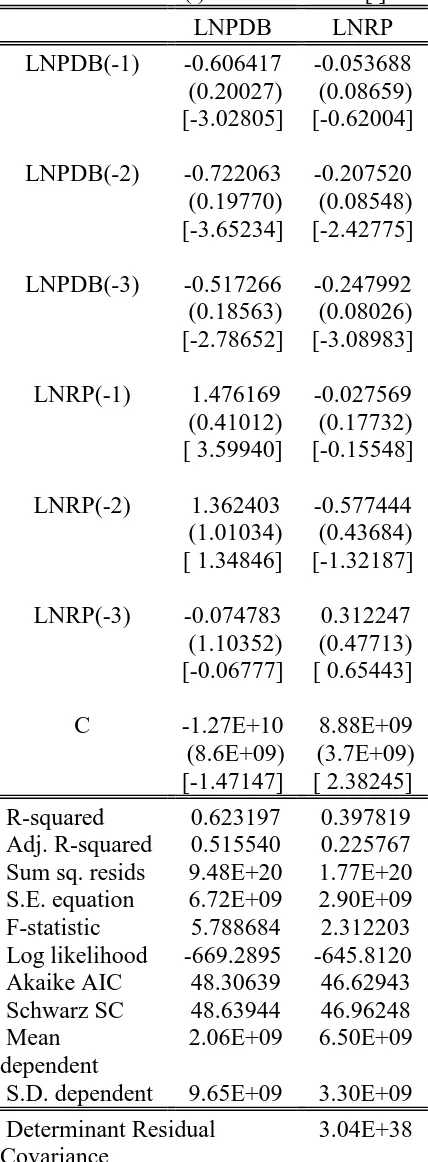
Tabel 3.6 Tabel Hasil Vector Auto Regresi Vector Autoregression Estimates
Date: 07/01/10 Time: 22:54 Sample(adjusted): 2001:1 2007:4
Included observations: 28 after adjusting Endpoints
Standard errors in ( ) & t-statistics in [ ]
LNPDB LNRP
LNPDB(-1) -0.606417 -0.053688 (0.20027) (0.08659) [-3.02805] [-0.62004] LNPDB(-2) -0.722063 -0.207520 (0.19770) (0.08548) [-3.65234] [-2.42775] LNPDB(-3) -0.517266 -0.247992 (0.18563) (0.08026) [-2.78652] [-3.08983] LNRP(-1) 1.476169 -0.027569 (0.41012) (0.17732) [ 3.59940] [-0.15548] LNRP(-2) 1.362403 -0.577444 (1.01034) (0.43684) [ 1.34846] [-1.32187] LNRP(-3) -0.074783 0.312247 (1.10352) (0.47713) [-0.06777] [ 0.65443] C -1.27E+10 8.88E+09 (8.6E+09) (3.7E+09) [-1.47147] [ 2.38245] R-squared 0.623197 0.397819 Adj. R-squared 0.515540 0.225767 Sum sq. resids 9.48E+20 1.77E+20 S.E. equation 6.72E+09 2.90E+09 F-statistic 5.788684 2.312203 Log likelihood -669.2895 -645.8120 Akaike AIC 48.30639 46.62943 Schwarz SC 48.63944 46.96248 Mean
dependent
2.06E+09 6.50E+09 S.D. dependent 9.65E+09 3.30E+09 Determinant Residual
Covariance
Log Likelihood (d.f. adjusted)
-1320.007 Akaike Information Criteria 95.28625 Schwarz Criteria 95.95235
Untuk menentukan variabel yang mana yang lebih berpengaruh maka akan dilihat dari hubungan kausal dari setiap variabel, dengan hasil sebagai berikut:
Tabel 3.7 Tabel Granger Causality Test Pairwise Granger Causality Tests
Date: 07/01/10 Time: 23:03 Sample: 2000:1 2007:4 Lags: 3
Null Hypothesis: Obs F-Statistic Probability LNRP does not Granger Cause LNPDB 28 4.94587 0.00942 LNPDB does not Granger Cause LNRP 4.30412 0.01626
Pengujian hipotesis I:
1. Menentukan Hipotesis
H0 = Rupiah tidak Granger menyebabkan pendapatan H1 = Rupiah Granger menyebabkan Pendapatan 2. Menghitung nilai F penelitian
F penelitian dari eviews adalah sebesar 4,94587
3. Menghitung nilai F tabel dengan ketentuan sebagai berikut :
Taraf signifikan 0,05 dan derajat kebebasan dengan numerator 2-1= 1 dan dumerator 32-2 = 30. Dari ketentuan tersebut diperoleh F table = 4,17
4. Menentukan kriteria uji hipotesis: Kriteria pengujian:
Jika F statistik > F table maka tolak H0 dan terima H1 Jika F statistik ≤ F table maka terima H0 dan tolak H1 5. Pengambilan keputusan
dimasukkan ke dalam komponen variabel untuk memprediksi nilai Pendapatan, secara statistik hasilnya signifikan.
Pengujian hipotesis II:
1. Menentukan Hipotesis
H0 = Pendapatan tidak Granger menyebabkan Investasi H1 = Pendapatan Granger menyebabkan Investasi 2. Menghitung nilai F penelitian
F penelitian dari eviews adalah sebesar 4,30412
3. Menghitung nilai F tabel dengan ketentuan sebagai berikut :
Taraf signifikan 0,05 dan derajat kebebasan dengan numerator 2-1= 1 dan dumerator 32-2 = 30. Dari ketentuan tersebut diperoleh = 4,17
4. Menentukan kriteria uji hipotesis: Kriteria pengujian:
Jika F statistik > F table maka tolak H0 dan terima H1 Jika F statistik ≤ F table maka terima H0 dan tolak H1 5. Pengambilan keputusan
Dari hasil perhitungan diperoleh bahwa nilai F statistik sebesar 4,30412 lebih besar dari nilai F tabel sebesar 4,17 dan nilai probabilitas 0,01626 lebih kecil dari nilai kritik 0,05 (0,01626 < 0,05) sehingga dapat disimpulkan bahwa H0 ditolak dan H1 diterima. Hal ini menunjukkan bahwa Pendapatan Granger menyebabkan investasi. Ini berarti bahwa apabila variabel Pendapatan dimasukkan ke dalam komponen variabel untuk memprediksi nilai Rupiah, secara statistik hasilnya signifikan.
Dengan demikian model yang digunakan adalah sebagai berikut : 17 6 16 5 15 4 14 3 13 2 12 1
11Y c Y c Y c Z c Z c Z c
c
Yt = t− + t− + t− + t− + t− + t− +
27 6 26 5 25 4 24 3 23 2 22 1
21Z c Z c Z c Y c Y c Y c
c
Zt = t− + t− + t− + t− + t− + t− +
Dan persamaan strukturalnya menjadi :
.74 8877106909 0.247992 0.207520 0.053688 0.312247 0.577444 0.027569 6 5 4 3 2 1 + − − − + − − = − − − − − − t t t t t t t Y Y Y Z Z Z Z
3.2.4 The Impulse Response Test
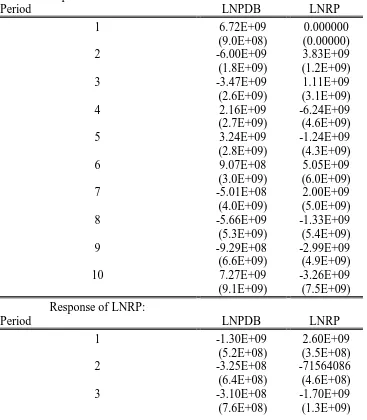
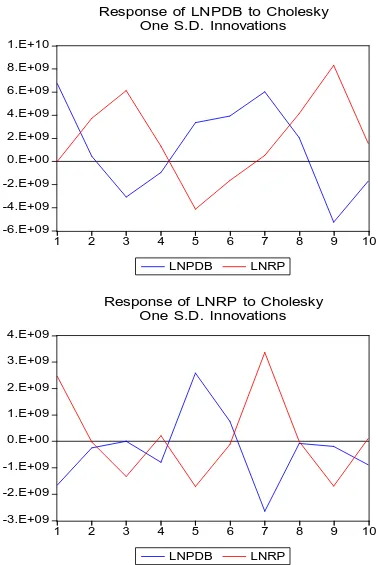
The Impulse Response test dilakukan 2 tahap. Tahap pertama, melihat pengaruh dari variabel Pendapatan terhadap variabel investasi. Tahap kedua, untuk melihat pengaruh dari variabel investasi terhadap variabel Pendapatan. Dari hasil uji the impulse
[image:45.595.114.481.347.767.2]response melalui Eviews diperoleh hasil sebagai berikut :
Tabel 3.8 Tabel The Impulse Response of PDB and Rupiah Response of LNPDB:
Period LNPDB LNRP
1 6.72E+09 0.000000
(9.0E+08) (0.00000)
2 -6.00E+09 3.83E+09
(1.8E+09) (1.2E+09)
3 -3.47E+09 1.11E+09
(2.6E+09) (3.1E+09)
4 2.16E+09 -6.24E+09
(2.7E+09) (4.6E+09)
5 3.24E+09 -1.24E+09
(2.8E+09) (4.3E+09)
6 9.07E+08 5.05E+09
(3.0E+09) (6.0E+09)
7 -5.01E+08 2.00E+09
(4.0E+09) (5.0E+09)
8 -5.66E+09 -1.33E+09
(5.3E+09) (5.4E+09)
9 -9.29E+08 -2.99E+09
(6.6E+09) (4.9E+09)
10 7.27E+09 -3.26E+09
(9.1E+09) (7.5E+09) Response of LNRP:
Period LNPDB LNRP
1 -1.30E+09 2.60E+09
(5.2E+08) (3.5E+08)
2 -3.25E+08 -71564086
(6.4E+08) (4.6E+08)
3 -3.10E+08 -1.70E+09
4 -4.46E+08 44170074 (7.9E+08) (1.3E+09)
5 2.18E+09 1.15E+08
(8.3E+08) (1.5E+09)
6 3.39E+08 5.28E+08
(8.3E+08) (1.5E+09)
7 -2.66E+09 1.47E+09
(1.8E+09) (1.4E+09)
8 -4.07E+08 -1.16E+09
(1.6E+09) (1.5E+09)
9 1.84E+09 -2.25E+09
(2.7E+09) (2.6E+09)
10 7.01E+08 1.13E+09
(2.4E+09) (3.1E+09) Cholesky Ordering: D(LNPDB) LNRP
Standard Errors: Analytic
Dari uji mengenai The Impulse Response diatas diperoleh bahwa satu standar deviasi dari PDB sebesar 0,67241 tidak membawa efek apapun terhadap variabel Rupiah ( standar deviasinya sama dengan nol ). Setelah satu periode, standar deviasi dari PDB menurun dan membawa pengaruh terhadap kenaikan standar deviasi dari variabel Rupiah sebesar 0,3817 di atas rata-rata. Periode ketiga standard deviasi dari PDB masih menurun tetapi 0,1107 membawa pengaruh terhadap kenaikan terhadap variabel Rupiah sebesar 0,107. Hingga pada periode kelima standar deviasi dari PDB sebesar 0,3243 membawa penurunan terhadap variabel Rupiah sebesar 0,1245. Dan pada akhirnya pada periode 10, standar deviasi dari variabel PDB sebesar 0,7272 membawa pengaruh negatif terhadap variabel Rupiah 0,3257.
akhirnya pada periode kesepuluh, standar deviasi dari variabel Rupiah sebesar -0,1129 membawa pengaruh kenaikan terhadap variabel PDB sebesar 0,0701.
Gambar 3.1 Grafik The Impulse Response -6.E+09
-4.E+09 -2.E+09 0.E+00 2.E+09 4.E+09 6.E+09 8.E+09 1.E+10
1 2 3 4 5 6 7 8 9 10
LNPDB LNRP
Response of LNPDB to Cholesky One S.D. Innovations
-3.E+09 -2.E+09 -1.E+09 0.E+00 1.E+09 2.E+09 3.E+09 4.E+09
1 2 3 4 5 6 7 8 9 10
LNPDB LNRP
3.2.5 The Cholenski Decomposition
[image:49.595.109.518.208.548.2]Dari hasil The Cholenski Decomposition melalui eviews diperoleh hasil sebagai berikut:
Tabel 3.9 Tabel The Cholenski Decomposition Variance Decomposition of
LNPDB:
Period S.E. LNPDB LNRP
1 6724117210.62 100,0000000000 0,0000000000
2 7713353429.29 76.3589422008 23.6410577992
3 10323467156.5 51.5113485147 48.4886514853
4 10449906521.2 51.1172704872 48.8827295128
5 11734461002.2 48.7883667832 51.2116332168
6 12479938351 52.9965702419 47.0034297581
7 13871323329.2 61.81146913 38.18853087
8 14621247721.1 57.5765046426 42.4234953574
9 17625627123 48.5036154994 51.4963845006
10 17775956667.3 48.6014484095 51.3985515905
Variance Decomposition of LNRP:
Period S.E. LNPDB LNRP
1 2965950402.44 31.0008258006 68.9991741994
2 2976556461.93 31.4859084119 68.5140915881
3 3260298242.1 26.2446450542 73.7553549458
4 3363248285.15 30.2587579236 69.7412420764
5 4568115015.94 48.2583925191 51.7416074809
6 4631874654.64 49.6024816119 50.3975183881
7 6305191327.8 44.4129598058 55.5870401942
8 6305671090.25 44.4211402649 55.5788597351
9 6532983057.68 41.4672079702 58.5327920298
10 6593603039.58 42.515657528 57.484342472
Cholesky Ordering: LNPDB LNRP
Selanjutnya, dari tabel the variance decomposition untuk variabel Rupiah diperoleh bahwa pada step 1, variabel PDB sudah memiliki pengaruh terhadap error varians dari Rupiah sebesar 20,1%. Selanjutnya pada step 2, pengaruhnya sedikit meningkat menjadi 21,1%. Pada step 3, pengaruh variabel PDB tetap memberikan pengaruhnya sebesar 16,5% dan terus meningkat hingga step 7 sebesar 53,7%. Hingga akhirnya pada step 10 terus memberikan pengaruhnya sebesar 47,8%.
3.2.6 Analisis Data
Menganalisis Data Dengan Menggunakan Program Eviews
Data dianalisis dengan menggunakan Program Eviews. Adapaun tahapan dalam penganalisisan data adalah sebagai berikut :
1. Uji akar unit ( unit root test )
Adapun langkah-langkah untuk mencari Uji akar unit ( unit root test ) nya adalah sebagai berikut :
Untuk variabel PDB :
a. Buka lembar pendapatan b. Klik view
c. Pilih unit root test d. Klik OK
Untuk variabel Rupiah a. Buka lembar investasi b. Klik view
c. Pilih unit root test d. Klik OK
2. The Likelihood Ratio Test
Adapun langkah-langkah untuk mencari The Likelihood Ratio Test nya adalah sebagai berikut :
c. Klik view
d. Pilih lag structure e. Pilih lag length criteria
3. The Granger Causality Test
Adapun langkah-langkah untuk mencari The Granger Causality Testnya adalah sebagai berikut :
a. Buka lembar data pendapatan dan investasi sebagai group b. Klik view
c. Granger causality
d. Masukkan nilai lag yang terpilih e. Klik OK
4. The Impulse Response
Adapun langkah-langkah mencari The Impulse Responsenya adalah sebagai berikut :
a. Buka lembar data pendapatan dan investasi sebagai VAR b. Klik OK
c. Klik view
d. Pilih Impulse Response e. Pilih tampilan table f. OK
5. The cholenski Decomposition
Adapun langkah-langkah mencari The cholenski Decomposition nya adalah sebagai berikut :
a. Buka lembar data pendapatan dan investasi sebagai VAR b. Klik OK
c. Klik view
d. Pilih cholenski Decomposition e. Pilih tampilan table
Hasil Analisis Data
a. Uji akar unit ( unit root test )
Null Hypothesis: D(LNPDB) has a unit root Exogenous: Constant
Lag Length: 3 (Automatic based on SIC, MAXLAG=9)
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -7.837654 0.0000
Test critical values: 1% level -3.699871
5% level -2.976263
10% level -2.627420
*MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(LNPDB,2) Method: Least Squares
Date: 05/03/10 Time: 06:56 Sample(adjusted): 2001:2 2007:4
Included observations: 27 after adjusting endpoints
Variable Coefficient Std. Error t-Statistic Prob.
D(LNPDB(-1)) -5.816255 0.742091 -7.837654 0.0000
D(LNPDB(-1),2) 3.681131 0.581570 6.329649 0.0000
D(LNPDB(-2),2) 2.301523 0.397165 5.794884 0.0000
D(LNPDB(-3),2) 0.944400 0.194826 4.847401 0.0001
C 8.84E+09 1.49E+09 5.929240 0.0000
R-squared 0.850734 Mean dependent var 1.22E+09
Adjusted R-squared 0.823595 S.D. dependent var 1.40E+10
S.E. of regression 5.90E+09 Akaike info criterion 47.99984
Sum squared resid 7.66E+20 Schwarz criterion 48.23981
Log likelihood -642.9978 F-statistic 31.34701
Durbin-Watson stat 1.979567 Prob(F-statistic) 0.000000
Null Hypothesis: LNRP has a unit root Exogenous: Constant
Lag Length: 9 (Automatic based on SIC, MAXLAG=9)
t-Statistic Prob.*
Augmented Dickey-Fuller test statistic -3.950575 0.0067
Test critical values: 1% level -3.769597
5% level -3.004861
10% level -2.642242
*MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(LNRP)
Method: Least Squares Date: 05/03/10 Time: 06:57 Sample(adjusted): 2002:3 2007:4
Included observations: 22 after adjusting endpoints
Variable Coefficient Std. Error t-Statistic Prob.
D(LNRP(-1)) 5.140462 1.500828 3.425083 0.0057
D(LNRP(-2)) 4.147163 1.354950 3.060750 0.0108
D(LNRP(-3)) 4.746575 1.124661 4.220448 0.0014
D(LNRP(-4)) 3.903053 1.246334 3.131627 0.0095
D(LNRP(-5)) 3.853429 1.186100 3.248824 0.0078
D(LNRP(-6)) 4.124223 0.988515 4.172142 0.0016
D(LNRP(-7)) 4.049953 1.103042 3.671622 0.0037
D(LNRP(-8)) 2.436729 1.001791 2.432372 0.0333
D(LNRP(-9)) 1.121179 0.657566 1.705044 0.1162
C 4.18E+10 1.05E+10 3.985143 0.0021
R-squared 0.903362 Mean dependent var 42163681
Adjusted R-squared 0.815510 S.D. dependent var 5.39E+09 S.E. of regression 2.32E+09 Akaike info criterion 46.27048
Sum squared resid 5.90E+19 Schwarz criterion 46.81600
Log likelihood -497.9753 F-statistic 10.28274
Durbin-Watson stat 1.917435 Prob(F-statistic) 0.000306
b. The Likelihood Ratio Test
VAR Lag Order Selection Criteria
Endogenous variables: D(LNPDB) LNRP Exogenous variables: C
Date: 07/01/10 Time: 22:55 Sample: 2000:1 2007:4 Included observations: 30
Lag LogL LR FPE AIC SC HQ
0 -1430.742 NA* 1.04E+39 95.51613 95.60954* 95.54601*
1 -1426.378 7.855921 1.02E+39* 95.49184* 95.77208 95.58149
* indicates lag order selected by the criterion
LR: sequential modified LR test statistic (each test at 5% level) FPE: Final prediction error
AIC: Akaike information criterion SC: Schwarz information criterion HQ: Hannan-Quinn information criterion
VAR Lag Order Selection Criteria
Endogenous variables: D(LNPDB) LNRP Exogenous variables: C
Date: 07/01/10 Time: 22:56 Sample: 2000:1 2007:4 Included observations: 29
Lag LogL LR FPE AIC SC HQ
0 -1383.412 NA 1.07E+39 95.54567 95.63997* 95.57520
1 -1379.101 7.731055 1.05E+39 95.52418 95.80707 95.61278
2 -1373.353 9.514065* 9.36E+38* 95.40363* 95.87511 95.55129*
* indicates lag order selected by the criterion
LR: sequential modified LR test statistic (each test at 5% level) FPE: Final prediction error
AIC: Akaike information criterion SC: Schwarz information criterion HQ: Hannan-Quinn information criterion
VAR Lag Order Selection Criteria
Date: 07/01/10 Time: 22:57 Sample: 2000:1 2007:4 Included observations: 28
Lag LogL LR FPE AIC SC HQ
0 -1335.790 NA 1.08E+39 95.55640 95.65156 95.58549
1 -1331.275 8.061221 1.05E+39 95.51967 95.80514 95.60694
2 -1324.853 10.55102 8.85E+38 95.34664 95.82243 95.49209
3 -1311.952 19.35088* 4.75E+38* 94.71089* 95.37699* 94.91452*
* indicates lag order selected by the criterion
LR: sequential modified LR test statistic (each test at 5% level) FPE: Final prediction error
AIC: Akaike information criterion SC: Schwarz information criterion HQ: Hannan-Quinn information criterion
VAR Lag Order Selection Criteria
Endogenous variables: D(LNPDB) LNRP Exogenous variables: C
Date: 07/01/10 Time: 22:57 Sample: 2000:1 2007:4 Included observations: 27
Lag LogL LR FPE AIC SC HQ
0 -1288.008 NA 1.08E+39 95.55614 95.65212 95.58468
1 -1283.266 8.430169 1.03E+39 95.50118 95.78914 95.58680
2 -1275.902 12.00093 8.06E+38 95.25197 95.73191 95.39469
3 -1264.741 16.53364* 4.82E+38 94.72159 95.39350 94.92138
4 -1258.019 8.963716 4.05E+38* 94.51990* 95.38379* 94.77678*
* indicates lag order selected by the criterion
LR: sequential modified LR test statistic (each test at 5% level) FPE: Final prediction error
AIC: Akaike information criterion SC: Schwarz information criterion HQ: Hannan-Quinn information criterion
VAR Lag Order Selection Criteria
Endogenous variables: D(LNPDB) LNRP Exogenous variables: C
Date: 07/01/10 Time: 22:58 Sample: 2000:1 2007:4 Included observations: 26
Lag LogL LR FPE AIC SC HQ
0 -1241.269 NA 1.17E+39 95.63606 95.73283 95.66392
1 -1236.661 8.152997 1.12E+39 95.58927 95.87960 95.67287
2 -1229.139 12.15003 8.62E+38 95.31839 95.80227 95.45773
3 -1218.590 15.41724* 5.30E+38 94.81465 95.49209* 95.00973
4 -1212.306 8.217748 4.59E+38* 94.63894* 95.50993 94.88976*
5 -1210.180 2.453583 5.60E+38 94.78306 95.84761