PERINGKAS DOKUMEN BERBAHASA INDONESIA
BERBASIS KATA BENDA DENGAN BM25
RENDY RIVALDI PINANDHITA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
RENDY RIVALDI PINANDHITA. Indonesian Document Summarization Based on Nouns with BM25. Under supervision of AHMAD RIDHA.
This research develops summarization of Indonesian documents based on nouns. The problem in this study is that high number of digital documents makes it difficult for the reader to find the desired information. We use cosine similarity, content overlap, and Okapi BM25 in the summarization. This research used newspaper articles from previous research. In the process of summarization, before calculating the similarities, the documents were preprocessed using stoplist, stemming, and selection of nouns. Then, the documents were ranked using PageRank. We used kappa measure to evaluate the level of agreement among evaluators in assessing the relevance of the summaries. Dice coefficient was used to compare automatic summarization to manual ones. Based on the observations, we find that Okapi BM25 is better than cosine similarity and content overlap.
PERINGKAS DOKUMEN BERBAHASA INDONESIA
BERBASIS KATA BENDA DENGAN BM25
RENDY RIVALDI PINANDHITA
Skripsi
sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul Skripsi : Peringkas Dokumen Berbahasa Indonesia Berbasis Kata Benda dengan BM25 Nama : Rendy Rivaldi Pinandhita
NIM : G64061408
Menyetujui:
Pembimbing,
Ahmad Ridha, S.Kom., M.S. NIP 19800507 200501 1 001
Mengetahui:
Ketua Departemen,
Dr. Ir. Agus Buono, M.Si., M.Kom. NIP 19660702 199302 1 001
Dosen Penguji:
RIWAYAT HIDUP
Penulis dilahirkan di Tangerang, tanggal 7 Oktober 1988. Penulis merupakan anak kedua dari tiga bersaudara dari pasangan Supriadi dan Cici Kusmayati. Penulis lulus dari SMA Negeri 6 Tangerang, Banten pada tahun 2006 dan melanjutkan studi di Departemen Ilmu Komputer IPB melalui jalur USMI. Pada tahun 2007, penulis diterima di Departemen Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam.
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah Subhanahu wata’ala atas segala nikmat dan karunia-Nya sehingga penulis dapat menyelesaikan penelitian ini. Tulisan ini merupakan hasil penelitian penulis dalam bidang kajian temu kembali informasi yang berjudul Peringkas Dokumen Berbahasa Indonesia Berbasis Kata Benda dengan BM25. Penulisan hasil penelitian ini ditujukan sebagai salah satu syarat untuk meraih gelar Sarjana Komputer.
Tidaklah mudah bagi penulis untuk menyelesaikan penelitian ini jika tanpa bantuan dan bimbingan dari berbagai pihak. Oleh karena itu, penulis mengucapkan terima kasih kepada:
1 Bapak Ahmad Ridha, S.Kom., M.S. selaku dosen pembimbing yang telah sabar membimbing, memotivasi, dan berbagi ilmu yang baru bagi penulis.
2 Orang tua penulis, Supriadi dan Cici Kusmayati, dan juga saudara penulis, Fani dan Rayhan
serta keluarga besar penulis atas semua kasih sayang, motivasi, kepercayaan, dan do‟a yang
tidak pernah berhenti dipanjatkan.
3 Guru-guru dan teman-teman di Tangerang yang telah bersedia menjadi pembaca dan penilai terhadap hasil penelitian penulis sehinggga berkat penilaian-penilaian tersebut, penulis dapat menyelesaikan tulisan ini.
4 Teman-teman Ilkomerz 43 atas dukungan dan pengalaman-pengalaman yang berharga.
Penulis berharap semoga semua bantuan yang telah diberikan mendapat balasan yang lebih baik dari Allah Subhanahu wata’ala. Juga, semoga apa yang telah dikerjakan dapat bermanfaat bagi semua pihak.
Bogor, Februari 2013
vi
DAFTAR ISI
Halaman
DAFTAR TABEL ... vii
DAFTAR GAMBAR ... vii
PENDAHULUAN Latar Belakang ... 1
Tujuan ... 2
Ruang Lingkup ... 2
METODE PENELITIAN Pengumpulan Data ... 2
Perancangan dan Pengembangan Sistem ... 3
Evaluasi Sistem ... 5
Lingkungan Pengembangan Sistem ... 6
HASIL DAN PEMBAHASAN Koleksi Dokumen ... 6
Peringkasan Dokumen ... 6
Waktu Uji ... 6
Hasil Evaluasi Kumpulan Dokumen Pertama (Tiga Puluh Satu Dokumen) ... 7
Hasil Evaluasi Kumpulan Dokumen Kedua (Seratus Dokumen) ... 8
KESIMPULAN DAN SARAN Kesimpulan ... 9
Saran ... 9
DAFTAR PUSTAKA ... 9
vii
DAFTAR TABEL
Halaman
1 Hasil kappa measure percobaan 1, 2, dan 3 ... 7
2 Hasil kappa measure percobaan 4, 5, dan 6 ... 8
3 Koefisiendice menggunakan PageRank atau tanpa judul... 8
4 Koefisiendice menggunakan judul ... 8
DAFTAR GAMBAR
Halaman 1 Diagram proses peringkasan teks ... 32 Format dokumen. ... 6
3Perbandingan jumlah kata benda dan waktu proses. ... 7
DAFTAR LAMPIRAN
Halaman 1 Diagram proses pemilihan kata benda ... 111
PENDAHULUAN
Latar BelakangTeknologi internet telah menjadi basis penting dalam pemanfaatan media digital. Namun, timbul masalah ketika banyaknya informasi yang masuk setiap harinya membuat banjirnya informasi yang belum tentu sesuai dengan yang diinginkan. Oleh sebab itu, dibutuhkan sebuah sistem yang dapat mempermudah pencarian informasi yang sesuai dengan kebutuhan pengguna.
Peningkatan jumlah informasi pada media digital memunculkan ide untuk membuat ringkasan teks digital. Ringkasan merupakan ekspresi yang ketat dari isi utama suatu bacaan untuk menginformasikan pembaca tentang isi asli mengenai suatu pikiran utama atau ide sentral dari bacaan tersebut. Pembaca akan lebih tertarik membaca sesuatu baik itu artikel, dokumentasi, dan sebagainya jika terdapat ringkasan dari bacaan tersebut. Pembaca dapat menghemat waktu dalam memperoleh intisari tulisan dengan bentuk yang lebih pendek. Ringkasan teks umumnya mempunyai dua bentuk, yaitu ekstraktif dan abstraktif. Ringkasan ekstraktif merupakan ringkasan teks yang berupa kumpulan dari bagian-bagian penting tulisan, sedangkan ringkasan abstraktif adalah ringkasan teks berupa kalimat-kalimat baru yang merepresentasikan teks sumber dalam bentuk lain. Akan tetapi, sekarang ini masih banyak dokumen digitalyang belum memiliki abstrak atau ringkasan. Pembuatan abstrak atau ringkasan secara manual akan memakan banyak waktu dan biaya sehingga perlu dikembangkan sistem pembuatan ringkasan secara otomatis oleh komputer.
Peringkas teks otomatis merupakan pemanfaatan suatu aplikasi dalam proses pembuatan ringkasan yang lebih pendek dari sumber bacaan dan berisi kumpulan informasi utama bacaan tersebut. Miptahudin (2010) membuat peringkas teks otomatis berdasarkan kata benda dari dokumen berbahasa Indonesia. Kata benda atau nomina adalah jenis kata dalam bahasa Indonesia yang dapat diterangkan menggunakan jenis kata-kata lain, misalnya kata sifat dan kata sandang. Contoh penggunaannya ialah “mobil mewah”. Kata
„mobil‟ termasuk dalam jenis kata benda, sedangkan kata „mewah‟ termasuk dalam jenis
kata sifat. Dalam contoh tersebut, kata sifat
„mewah‟ menerangkan kata benda „mobil‟.
Hasil penelitian Miptahudin (2010) memberikan tingkat relevansi penilaian ahli
sebesar 100%, sedangkan penilaian pembaca umum adalah 87.09%.
Ukuran kesamaan yang digunakan Miptahudin (2010) dalam perhitungannya ialah cosine similarity dan content overlap. Sebelum melakukan perhitungan similarity terlebih dahulu dilakukan preprocessing seperti segmentasi, tokenizing, stemming, dan pemilihan kata benda. Cosine similarity atau ukuran kesamaan kosinus adalah ukuran kesamaan antara dua vektor dengan mengukur kosinus sudut antara mereka (Manning et al. 2009). Vektor merepresentasikan tiap kalimat dan berisi bobot dari tiap term. Nilai bobot dihitung menggunakan pembobotan tf.idf terhadap setiap kalimat bukan dokumen pada umumnya.
Ukuran kesamaan Content overlap antara dua kalimat didefinisikan sebagai jumlah kata yang sama antara keduanya. Sim (Si, Sj) adalah nilai kesamaan antar-kalimat Si dan Sj yang akan dihitung untuk setiap pasangan kalimat. Formula ini menghitung jumlah kata yang sama (word overlap) antar-pasangan kalimat dan dinormalisasi dengan membagi jumlah word overlap dengan panjang tiap kalimat. Banyaknya kata yang sama dalam satu kalimat tidak memengaruhi perhitungan.
Misalnya, jumlah kata „makan‟ dalam kalimat
Si adalah 3 maka content overlap tetap dihitung sebagai 1 word overlap.
Selain cosine similarity dan content overlap, masih banyak lagi ukuran kesamaan yang dapat digunakan, seperti Okapi BM25. Okapi BM25 adalah pembobotan dokumen yang mengurutkan set dokumen berdasarkan term kueri yang muncul pada setiap dokumen koleksi. Hubungan antara term kueri dan dokumen dipengaruhi oleh parameter k1 dan b.
2
informasi yang diambil dari struktur graf tersebut. Penelitian ini mengimplementasikan algoritme pada weighted directed graph (graf yang berarah yang terboboti). Setiap edge pada graf dianggap sebagai dua edge yang saling berlawanan dengan memiliki nilai atau bobot yang sama pada tiap arah. Ilustrasinya sebagai berikut:
AB
dengan edge antara verteks A dan verteks B. Edge tersebut dianggap memiliki dua arah yang berlawanan pada implementasi algoritme, yaitu link verteks A ke verteks B dan link verteks B ke verteks A. Setelah algoritme ini dijalankan, dihasilkan sebuah nilai yang merepresentasikan tingkat kepentingan verteks di dalam graf. Nilai-nilai tersebut nantinya diurutkan dari nilai terbesar sampai terkecil. Berdasarkan tingkat kompresi yang telah ditentukan dihasilkan sejumlah verteks teratas sebagai keluaran peringkas otomatis.
Pengujian yang dilakukan Miptahudin (2010) menggunakan kappa measure. Kappa measure bertujuan mengukur tingkat kesepakatan (agreement) dalam menilai suatu klasifikasi data antara beberapa ahli (Manning et al. 2009). Kappa measure menggunakan penilaian ahli (human judgement) dalam menentukan tingkat keberhasilan sistem. Penilaian para ahli kemudian diukur tingkat kesepakatannya.
Aristoteles (2011) membuat sistem pembobotan fitur pada peringkasan teks bahasa Indonesia menggunakan algoritme genetika. Sistem ini bertujuan melakukan optimasi peringkasan teks dengan menggunakan algoritme genetika dan menganalisis penambahan ekstraksi fitur teks kalimat semantik menggunakan teknik singular value decomposition. Hasil ringkasan menggunakan tiga tingkat pemampatan atau compression rate sebesar 10%, 20%, dan 30%. Hasil terbaik pengujian dicapai pada tingkat pemampatan 30% dengan tingkat akurasi sebesar 41%. Tingkat akurasi Aristoteles dihitung menggunakan F-Measure. F-Measure secara fungsi dan rumus mirip dengan koefisien dice. Menurut Kim dan Choi (1999), ukuran kesamaan istilah antara x dan y selain cosine similarity dapat menggunakan koefisiendice.
Tujuan
Tujuan penelitian ini adalah:
Mengembangkan sistem peringkas teks berbahasa Indonesia dengan berdasarkan kata benda.
Menganalisis kinerja sistem dengan beberapa ukuran kesamaan.
Membandingkan penelitian terhadap penelitian Miptahudin (2010) dan Aristoteles (2011).
Ruang Lingkup
Penelitian yang dilakukan dibatasi pada pemrosesan peringkasan teks berdasarkan kata benda. Ukuran kesamaan yang digunakan meliputi cosine similarity, Okapi BM25, content overlap dan koefisien dice serta menggunakan algoritme PageRank dengan mempertimbangkan pemakaian kalimat judul atau tidak. Metode evaluasi yang digunakan untuk menilai klasifikasi data antara beberapa ahli dalam menentukan tingkat keberhasilan sistem, yaitu kappa measure. Koefisien dice digunakan untuk membandingkan peringkasan teks sistem dengan manual. Dokumen penelitian diperoleh dari penelitian Miptahudin (2010) dan Aristoteles (2011).
METODE PENELITIAN
Tahapan yang dilakukan pada penelitian ini meliputi:
Pengumpulan data.
Perancangan dan pengembangan sistem. Pengujian sistem.
Pengumpulan Data
Penelitian ini menggunakan dua kumpulan dokumen. Kumpulan dokumen pertama terdiri atas tiga puluh satu dokumen artikel koran dengan topik di luar pertanian. Dokumen-dokumen tersebut dikumpulkan dan dievaluasi dengan cara yang sama dengan yang dilakukan oleh Miptahudin (2010). Dokumen-dokumen tersebut tidak memiliki ringkasan manual. Kumpulan dokumen kedua terdiri atas seratus dokumen dari penelitian Aristoteles (2011) pada pemampatan sebesar 30%. Dokumen-dokumen Aristoteles tersebut memiliki ringkasan manual.
3
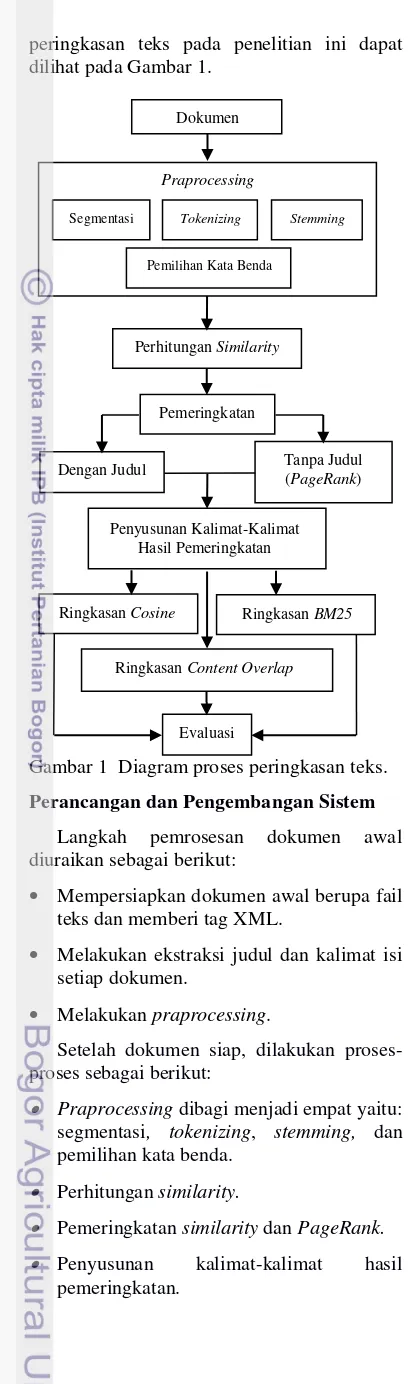
peringkasan teks pada penelitian ini dapat dilihat pada Gambar 1.
Gambar 1 Diagram proses peringkasan teks.
Perancangan dan Pengembangan Sistem
Langkah pemrosesan dokumen awal diuraikan sebagai berikut:
Mempersiapkan dokumen awal berupa fail teks dan memberi tag XML.
Melakukan ekstraksi judul dan kalimat isi setiap dokumen.
Melakukan praprocessing.
Setelah dokumen siap, dilakukan proses-proses sebagai berikut:
Praprocessing dibagi menjadi empat yaitu: segmentasi, tokenizing, stemming, dan pemilihan kata benda.
Perhitungan similarity.
Pemeringkatan similarity dan PageRank.
Penyusunan kalimat-kalimat hasil pemeringkatan.
1 Praprocessing
Pada praprocessing ini terdapat tiga proses yang dilakukan yaitu segmentasi, tokenizing, dan pemilihan kata benda.
Segmentasi
Segmentasi pada dokumen dilakukan dengan memecah dokumen menjadi kalimat-kalimat terpisah yang kemudian dikumpulkan dalam suatu koleksi. Pemecahan dokumen dilakukan dengan menggunakan separator titik (”.”), tanda kalimat yang dihasilkan dilakukan proses tokenizing. Proses ini dilakukan dengan cara memeriksa setiap karakter pada dokumen dan memecah string kalimat menjadi token yang merupakan kata unik. Pada proses ini juga dilakukan pembersihan terhadap kata buang (stoplist) untuk mendapatkan token atau term yang diinginkan.
Stemming dan Pemilihan kata benda
Setelah melalui proses tokenizing maka dilakukan proses stemming dan pemilihan kata benda terhadap term yang dihasilkan. Pemakaian imbuhan baik prefiks dan sufiks pada bahasa Indonesia menjadikan proses stemming penting dalam temu kembali informasi, walaupun tidak memengaruhi kinerja secara signifikan.
Pemilihan kata benda dilakukan menggunakan Kamus Besar Bahasa Indonesia (KBBI) edisi ke-3 yang tersimpan dalam berkas KBBI dan daftar kata benda KBBI yang tersimpan dalam berkas noun. Langkah-langkah pemilihan kata benda Miptahudin (2010) dapat dilihat pada Lampiran 1.
2 Perhitungan Similarity
Metode kesamaan yang diterapkan dalam sistem terdiri atas empat metode, yaitu Okapi BM25, cosine similarity, content overlap, dan koefisien dice. Metode kesamaan yang pertama ialah cosine similarity. Rumus yang digunakan sebagai berikut:
cos(θ) = || || || || = ∑
√∑ √∑
Ringkasan Cosine
Ringkasan Content Overlap
4
Kesamaan ini menggunakan pembobotan
tf.idf untuk memboboti setiap term. Perhitungan idf menggunakan . Setelah pembobotan, perhitungan cosine similarity
dilakukan.
Metode kesamaan yang kedua ialah Okapi BM25. Kesamaan ini mirip dengan cosine similarity yaitu menggunakan pembobotan tf dan idf untuk memboboti setiap term. Bedanya selain tf dan idf, juga ditambahkan parameter bebas k1 dan b. Nilai yang optimal untuk parameter k1 dan b adalah k1 = 1.2 dan b = 0.75 (Manning et al. 2009). Kemudian, diperhitungkan pula pemakaian panjang kalimat dan panjang seluruh koleksi kalimat. Rumus yang digunakan sebagai berikut:
RSVd = ∑
tf dan panjang dokumen.
tftd = frekuensi term t pada kalimat d.
Ld dan Lave = panjang kalimat d dan rata-rata dari panjang seluruh koleksi kalimat.
Metode kesamaan selanjutnya ialah content overlap. Content overlap antara dua kalimat didefinisikan sebagai jumlah kata yang sama (word overlap) antara keduanya dan dinormalisasi dengan membagi jumlah word overlap dengan panjang tiap kalimat. Pembobotan tidak dilakukan karena nilai kesamaan antar-kalimat langsung dihitung berdasarkan banyaknya kata yang sama antar-kalimat. Rumus perhitungannya adalah sebagai berikut: kalimat tidak memengaruhi perhitungan. Misalnya jumlah kata ‘mobil‟ dalam kalimat Si adalah tiga, perhitungan content overlap tetap menganggapnya sebagai satu word overlap.
Yang terakhir ialah metode koefisiendice. Sebelum dilakukan perhitungan koefisien dice, hasil pemeringkatan manual dan sistem disiapkan. Pemeringkatan secara sistem menggunakan aplikasi dengan melibatkan cosine similarity, Okapi BM25, dan content overlap serta penggunakan judul dan tanpa judul atau menggunakan PageRank. Pemeringkatan manual didapat dengan cara memeringkat hasil peringkasan sistem Aristoteles (2011) secara manual. Kemudian, hasil sistem tersebut dibandingkan dengan hasil pemeringkatan manual, dengan asumsi hasil pemeringkatan Aristoteles (2011) adalah benar. Rumus perhitungannya sebagai berikut:
S2(x, y) = | | manual dan hasil perhitungan sistem.
= jumlah irisan x dan y.
= jumlah x. = jumlah y.
3 Pemeringkatan Similarity dan PageRank
Untuk tiga puluh satu dokumen di luar topik pertanian, nilai yang dihasilkan oleh perhitungan similarity diurutkan dari yang terbesar hingga terkecil dan merupakan 25% dari dokumen karena Miptahudin (2010) menyatakan bahwa 25% hasil ekstrak dari teks sumber memiliki tingkat informasi yang sama besar dengan teks itu sendiri.
5
tersebut yang disusun sesuai dengan posisi keterurutan kalimat pada dokumen.
Sistem menerapkan beberapa percobaan berdasarkan judul, tanpa judul, dan koefisien dice. Pada percobaan tanpa menggunakan judul, kalimat judul tidak diikutsertakan dalam pemrosesan sehingga pemeringkatan hasil peringkasan dilakukan memakai algoritme PageRank. Pada percobaan menggunakan judul, kalimat judul dianggap sebagai kueri. Adapun pengelompokannya menurut kategori dokumen yang digunakan adalah sebagai berikut:
Percobaan dengan kategori dokumen pertama (tiga puluh satu dokumen)
- Penerapan algoritme PageRank dengan cosine similarity (percobaan 1).
- Penerapan algoritme PageRank dengan ukuran kesamaan Okapi BM25 (percobaan 2).
- Penerapan algoritme PageRank dengan ukuran kesamaan content overlap (percobaan 3).
- Penerapan cosine similarity tanpa penggunaan algoritme PageRank (percobaan 4).
- Penerapan ukuran kesamaan Okapi BM25 tanpa penggunaan algoritme PageRank (percobaan 5).
- Penerapan ukuran kesamaan content overlap tanpa penggunaan algoritme PageRank (percobaan 6).
Percobaan dengan kategori dokumen kedua (seratus dokumen)
Percobaan ini membandingkan hasil perhitungan manual dengan hasil perhitungan sistem. Perhitungan manual menggunakan hasil ringkasan Aristoteles (2011), sedangkan perhitungan sistem melibatkan cosine similarity, Okapi BM25 dan content overlap pada peringkasan dokumen serta memperhitungkan pemakaian judul dan tanpa judul (dengan PageRank) (percobaan 7).
Percobaan 1 hingga 6 menggunakan 31 dokumen di luar pertanian dan percobaan 7 menggunakan dokumen Aristoteles (2011). Setelah perhitungan similarity selanjutnya adalah proses pembentukan graf untuk menghitung nilai PageRank pada percobaan tanpa menggunakan judul. Rumus untuk
menghitung nilai PageRank pada penelitian ini adalah sebagai berikut:
PRw(vi) = (1 - d) + d * ∑ ∑
dengan d adalah damping factor bernilai antara 0 dan 1. Nilai d yang biasa dipakai adalah 0.85 (Rogers 2002). Edge antar-verteks dinilai dengan bobot (weight) wij.
4 Penyusunan Kalimat-Kalimat Hasil Pemeringkatan
Setelah semua perhitungan dilakukan, kalimat-kalimat tersebut diperingkat dengan diurutkan berdasar pada nilai perhitungan tertinggi hingga terendah. Nilai kesamaan teratas menjadi bagian dari ringkasan dengan menggunakan tingkat kompresi dokumen sebesar 25% pada percobaan 1 hingga percobaan 6, dan 30% pada percobaan 7. Tingkat kompresi tersebut berdasarkan penelitian Miptahudin (2010) dan Aristoteles (2011). Pada percobaan dengan menggunakan judul, ekstraksi kalimat dilakukan setelah pemeringkatan nilai kesamaan. Pada percobaan PageRank, ekstraksi kalimat dilakukan setelah pemeringkatan nilai PageRank.
Evaluasi Sistem
Parameter yang digunakan dalam evaluasi dokumen kategori pertama adalah kappa measure. Kappa measure digunakan untuk mengukur tingkat kesepakatan beberapa ahli dalam menilai suatu klasifikasi data. Rumusnya sebagai berikut: kemungkinan bernilai berbeda dalam penilaian.
Pengujian yang dilakukan pada percobaan satu hingga enam melibatkan tiga ahli dan tiga pembaca umum yang menilai tingkat relevansi hasil ringkasan sistem dengan isi dokumen. Para ahli berasal dari Jurusan Sastra Indonesia dan memiliki latar belakang profesi sebagai guru bahasa Indonesia di sekolah yang berbeda, sedangkan para pembaca umum yaitu mahasiswa yang berbeda jurusan dan Universitas.
6
membandingkan dokumen asli dengan hasil ringkasan, kemudian tiap dokumen diberikan nilai relevan atau tidak. Hasil tersebut kemudian dikumpulkan untuk dilakukan perhitungan kappa measure.
Tingkat relevansi hasil ringkasan dapat dikategorikan menjadi beberapa bagian yaitu relevan, agak relevan, kurang relevan dan tidak relevan. Namun, penelitian ini hanya berdasarkan dua kategori, yaitu relevan dan tidak relevan. Nilai kappa measure dihitung untuk setiap pasangan penguji yaitu antara ahli dengan ahli dan umum dengan umum.
Parameter yang digunakan dalam evaluasi dokumen kategori kedua atau pada dokumen Aristoteles (2011) adalah koefisien dice. Untuk perhitungan sistem digunakan dokumen berupa artikel koran. Untuk perhitungan manual digunakan hasil ringkasan dari artikel tersebut.
Lingkungan Pengembangan Sistem
Penelitian ini dilakukan dalam lingkungan pengembangan sebagai berikut:
Perangkat lunak: Microsoft Windows XP Professional SP3, Microsoft Visual Basic 2008 dan Microsoft SQL Server 2005 Express.
Perangkat keras: Intel Pentium 4 2.80 GHz, 2 GB RAM.
HASIL DAN PEMBAHASAN
Koleksi DokumenPenelitian ini, baik dokumen kategori pertama maupun kedua, menggunakan
dokumen berbahasa Indonesia yang disimpan dalam fail teks (*.txt) dan diberi tag XML. Tag yang berpengaruh dalam peringkasan yaitu tag title dan text. Tag title digunakan untuk ekstraksi judul dan text untuk ekstraksi isi bacaan. Ekstraksi judul digunakan sebagai kueri dalam perhitungan similarity pada percobaan menggunakan judul.
Pada dokumen kategori pertama ukuran dokumen minimal 3 KB dan maksimal 10 KB. Rata-rata jumlah kalimat teks sumber adalah 47 kalimat. Rata-rata banyaknya kata benda dokumen dapat dilihat pada Gambar 2.
Gambar 2 Format dokumen.
Gambar 3 Perbandingan jumlah kata benda dan waktu proses. 0 ...Yang perlu dilakukan sekarang, segera menghentikan semua penggunaan anggaran nonbudgeter,... ... </TEXT>
7
Peringkasan Dokumen
Dalam proses peringkasan, sistem hanya akan mengenali dokumen masukan dengan format XML, selainnya tidak dikenali dan tidak bisa dijadikan dokumen masukan. Saat diproses, terlebih dahulu dilakukan praprocessing untuk mendapatkan term-term yang diinginkan. Kemudian, term-term tersebut digunakan untuk menghitung similarity dan diperingkat secara terpisah sesuai dengan percobaan yang dilakukan.
Waktu Uji
Waktu yang dibutuhkan dalam proses peringkasan rata-rata 1.178 detik dengan minimal 0.535 detik dengan 107 kata benda dan maksimal 2.241 dengan 601 kata benda. Dari Gambar 3 dapat disimpulkan bahwa secara umum semakin banyak kata benda yang diproses, semakin panjang waktu proses yang dibutuhkan. Fluktuasi yang terjadi pada kata benda dengan jumlah kata benda yang hampir sama terjadi karena faktor internal kinerja sistem pada komputer yang digunakan.
Hasil Evaluasi Kumpulan Dokumen Pertama (Tiga Puluh Satu Dokumen)
Persentase tingkat relevansi hasil ringkasan terhadap isi dokumen untuk keseluruhan percobaan oleh ketiga penilai ahli sangat tinggi yaitu di atas 96%. Untuk percobaan 1 dan 3 persentase tingkat relevansi hasil ringkasan rata-rata sebesar 96.77% sedangkan untuk percobaan 2, 4, 5, dan 6 sebesar 100%. Pada percobaan Miptahudin (2010), semua penilai ahli memberikan persentase tingkat relevansi sebesar 100%, kecuali pada percobaan 2 dan 5, karena Miptahudin (2010) tidak melakukan percobaan menggunakan Okapi BM25.
Hasil ini memperlihatkan bahwa peranan kata benda pada suatu dokumen memang sangat penting dan berpengaruh besar dalam menghasilkan suatu ringkasan. Dari nilai relevansiyang didapat, dapat dikatakan bahwa para penilai ahli secara umum memiliki pandangan yang sama terhadap hasil ringkasan.
Persentase tingkat relevansi hasil ringkasan terhadap isi dokumen oleh penilai umum rata-rata sebesar 76.34%, 84.95%, dan 74.19% untuk percobaan 1, 2, dan 3. Pada percobaan 4, 5, dan 6 para pembaca menilai 91.39%, 77.42%, dan 91.39%. Percobaan Miptahudin (2010) memberikan hasil rata-rata masing-masing percobaan 1, 3, 4, dan 6
sebesar 69.89%, 65.59%, 82.79%, dan 79.57%.
Hasil tersebut memperlihatkan bahwa nilai ringkasan yang didapat bervariasi, bergantung kepada penilai. Dapat disimpulkan pula bahwa percobaan menggunakan judul oleh penilai umum dinilai dapat memberikan hasil ringkasan yang lebih baik.
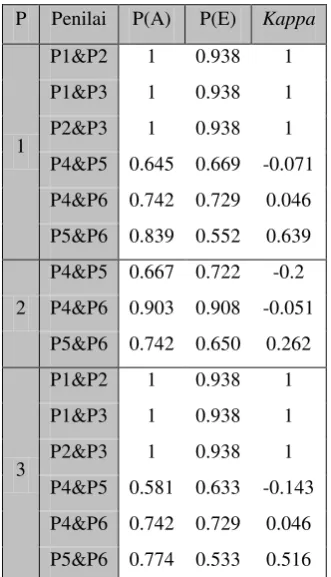
Tabel 1 menunjukkan nilai kappameasure pada percobaan 1, 2, dan 3 yaitu percobaan dengan menggunakan cosine similarity, Okapi BM25 dan content overlap menggunakan algoritme PageRank untuk pemeringkatannya. P1, P2, dan P3 adalah penilai ahli dan P4, P5, dan P6 adalah penilai umum serta P melambangkan percobaan.
Tabel 1 Hasil kappameasure percobaan 1, 2, dan 3 rata mempunyai tingkat kesepakatan yang tinggi dalam menilai hasil ringkasan. Nilai kappa measure dari percobaan 1 hingga 3 bernilai 1 dengan nilai P(E) pada percobaan 1 dan 3 sebesar 0.938 yang diakibatkan oleh persentase penilaian P1, P2, dan P3 pada percobaan 1 dan 3 sebesar 96.78%. Pada percobaan 2 seluruh penilai umum menghasilkan 100% nilai kesepakatan sehingga tidak dimunculkan dalam tabel.
8
kesepakatan yang rendah dalam menilai hasil ringkasan. Hal ini mungkin disebabkan oleh latar belakang pendidikan penilai yang berbeda sehingga menghasilkan nilai di bawah 0.800 hingga minus. Menurut Manning et al. (2009), nilai kappameasure yang baik berada di atas 0.800. Jika nilai berada di antara 0.670 dan 0.800, tingkat kesepakatan dikatakan cukup. Jika kappa measure berada di bawah 0.670, berarti tingkat kesepakatan rendah.
Tabel 2 Hasil kappameasure percobaan 4, 5, dan 6 menunjukkan bahwa seluruh penilai mempunyai tingkat kesepakatan 100%. Dapat disimpulkan bahwa semua penilai ahli memiliki pandangan yang hampir sama terhadap hasil ringkasan. Sedangkan hasil uji kappa measure P4, P5, dan P6 mempunyai tingkat kesepakatan yang rendah yaitu di bawah 0.670.
Secara umum, hasil uji kappa measure pada penilai pembaca umum untuk setiap percobaan menunjukkan tingkat kesepakatan yang rendah. Nilai kappa measure tertinggi pada penilai umum adalah 0.639 pada percobaan 1.
Hasil Evaluasi Kumpulan Dokumen Kedua (Seratus Dokumen)
Percobaan ini meliputi perhitungan koefisien dice antara hasil ringkasan manual dan hasil ringkasan sistem yang menggunakan cosine similarity, Okapi BM25, dan content overlap. Berikut hasil perhitungan koefisien dice pada percobaan 7. Cos merupakan perhitungan cosine similarity, BM25 merupakan perhitungan Okapi BM25, dan Con merupakan perhitungan content overlap.
Tabel 3 Koefisiendice menggunakan PageRank atau tanpa judul
Cos BM25 Con
Min 0 0 0
Max 0.800 0.833 0.750
Rata-rata 0.363 0.442 0.396
Tabel 4 Koefisiendice menggunakan judul
Cos BM25 Con
Min 0 0 0
Max 0.750 0.750 0.750
Rata-rata 0.327 0.327 0.310
Dari Tabel 3 dan 4 dapat dilihat bahwa nilai rata-rata hasil perhitungan koefisiendice dengan menggunakan PageRank lebih baik dari percobaan dengan menggunakan judul. Itu terbukti dari rentang nilai rata-rata PageRank berkisar antara minimum 36% dan maksimum 44%, sedangkan pada percobaan dengan menggunakan judul berkisar antara minimum 31% sampai maksimum 32%.
Perhitungan Okapi BM25 pada Tabel 3 dan Tabel 4 memiliki nilai rata-rata lebih besar dari cosine similarity dan content overlap. Sedangkan, jika nilai Okapi BM25 pada Tabel 3 dan Tabel 4 dibandingkan, maka dapat disimpulkan bahwa nilai terbesar yang dihasilkan, yaitu pada percobaan tanpa menggunakan judul (PageRank).
Hasil rata-rata seluruh koefisien dice tiap dokumen yang didapatkan sebesar 0.361 dengan rata-rata minimal sebesar 0.143 dan maksimal 0.708. Pada percobaan 7 nilai koefisien dice yang dihasilkan sebesar 36%, sedangkan nilai akurasi yang didapatkan dari data dan compression rate sebesar 30% pada penelitian Aristoteles (2011) yaitu berada di atas 41%. Hasil perhitungan koefisien dice dapat dilihat pada Lampiran 2.
KESIMPULAN DAN SARAN
Kesimpulan
Berdasarkan hasil penelitian ini, dapat ditarik kesimpulan sebagai berikut:
9
content overlap. Hasil terbaik dihasilkan oleh Okapi BM25 pada percobaan tanpa menggunakan judul (PageRank).
Penilaian pakar cenderung bersifat
homogen daripada penilaian penilai umum. Perbedaan penilaian antara pakar dan penilai umum mungkin disebabkan oleh latar belakang pendidikan dan bidang kajian ilmu masing-masing.
Evaluasi dengan penilai memiliki subjektifitas yang tinggi untuk penilai umum sehingga sulit untuk mendapatkan kesepakatan yang tinggi.
Penilaian dengan menggunakan koefisien
dice lebih efektif karena dilakukan secara objektif dengan asumsi terdapat hasil ringkasan manual.
Saran
Penilaian relevansi dapat dilakukan oleh manusia secara per kalimat untuk melihat tingkat homogenitas penilaian pakar dan penilai umum.
DAFTAR PUSTAKA
Aristoteles. 2011. Pembobotan fitur pada rangkaian teks bahasa Indonesia menggunakan algoritme genetika [tesis].
Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Kim M, Choi K. 1999. A comparison of collocation-based similarity measures in query expansion. Information Processing and Management. 35(1):19-30.
Manning C, Raghavan P, Schutze H. 2009. An Introduction to Information Retrieval. Cambridge: University Press.
Mihalcea R. 2005. Language independent extractive summarization. Proceedings of the Association for Computational Linguistics Interactive Poster and Demonstration Sessions; Stroudsburg, US,
Juni 2005. hlm 49-52.
doi:10.3115/1225753.1225766.
Miptahudin D. 2010. Peringkasan dokumen berbahasa Indonesia berbasis kata benda [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
11
Lampiran 1 Diagram proses pemilihan kata benda
Token
Ada di berkas KBBI Ada di
berkas noun
Ya
Awal kapital
Tidak
Terdapat imbuhan ke-, pe-, ke-an, pe-an
Tidak
Terdapat akhiran -an, -in, -at, -wan, -wati, -isme,
-isasi, -logi, -tas, -nya, -ku, -mu, -kau
Tidak
Kata ulang
Tidak
Terdapat akhiran -nya, -ku, -mu, -kau
Ya
Potong akhiran. Kata dasar ada di
berkas noun
Kata dasar ada di berkas noun
Ya
Tidak
Return token Returnnull
Ya
Tidak
Ya Tidak
Ya Tidak
Tidak Ya
12
Lampiran 2 Hasil perhitungan koefisiendice antara sistem dan manual pada percobaan 7
No Dokumen
KoefisienDice Rata-rata
Seluruh Dice
CosTJ BmTJ ConTJ CosJ BmJ ConJ
1 0.625 0.250 0.375 0.500 0.375 0.375 0.416
2 0.000 0.417 0.250 0.267 0.267 0.267 0.244
3 0.250 0.250 0.250 0.286 0.286 0.286 0.267
4 0.714 0.429 0.714 0.545 0.545 0.545 0.582
5 0.600 0.400 0.600 0.200 0.200 0.000 0.333
6 0.294 0.529 0.294 0.174 0.174 0.174 0.273
7 0.286 0.500 0.286 0.357 0.357 0.357 0.357
8 0.750 0.750 0.750 0.750 0.500 0.750 0.708
9 0.286 0.571 0.571 0.286 0.143 0.143 0.333
10 0.500 0.333 0.667 0.000 0.333 0.167 0.333
11 0.200 0.400 0.400 0.600 0.600 0.600 0.466
12 0.333 0.167 0.333 0.167 0.333 0.333 0.277
13 0.333 0.500 0.500 0.167 0.333 0.167 0.333
14 0.250 0.750 0.250 0.250 0.500 0.250 0.375
15 0.300 0.500 0.400 0.300 0.300 0.300 0.350
16 0.286 0.286 0.286 0.333 0.333 0.333 0.309
17 0.444 0.556 0.444 0.444 0.444 0.333 0.444
18 0.444 0.333 0.333 0.222 0.333 0.222 0.314
19 0.429 0.429 0.429 0.286 0.286 0.143 0.333
20 0.625 0.375 0.500 0.625 0.500 0.500 0.520
21 0.071 0.429 0.500 0.273 0.273 0.273 0.303
22 0.400 0.600 0.400 0.400 0.200 0.400 0.400
23 0.250 0.250 0.375 0.250 0.375 0.375 0.312
24 0.250 0.333 0.500 0.417 0.500 0.417 0.402
25 0.250 0.250 0.250 0.500 0.500 0.500 0.375
26 0.400 0.467 0.200 0.111 0.111 0.111 0.233
27 0.375 0.250 0.500 0.167 0.167 0.167 0.270
28 0.188 0.250 0.188 0.291 0.291 0.291 0.249
29 0.467 0.267 0.467 0.286 0.286 0.286 0.342
30 0.318 0.318 0.318 0.273 0.227 0.273 0.287
31 0.333 0.333 0.500 0.333 0.333 0.333 0.361
32 0.667 0.333 0.667 0.667 0.667 0.500 0.583
33 0.400 0.200 0.400 0.200 0.200 0.200 0.266
34 0.250 0.500 0.500 0.500 0.500 0.750 0.500
35 0.200 0.400 0.200 0.200 0.200 0.200 0.233
36 0.333 0.333 0.400 0.261 0.261 0.261 0.308
37 0.556 0.333 0.556 0.167 0.167 0.167 0.324
38 0.667 0.667 0.167 0.333 0.333 0.333 0.416
39 0.200 0.200 0.200 0.400 0.400 0.400 0.300
40 0.364 0.455 0.545 0.545 0.545 0.455 0.484
41 0.333 0.500 0.333 0.167 0.167 0.167 0.277
42 0.389 0.389 0.389 0.375 0.375 0.375 0.381
43 0.333 0.444 0.222 0.222 0.222 0.333 0.296
44 0.074 0.444 0.074 0.129 0.129 0.129 0.163
45 0.286 0.571 0.429 0.400 0.400 0.400 0.414
46 0.500 0.667 0.667 0.333 0.333 0.333 0.472
47 0.429 0.571 0.571 0.154 0.154 0.154 0.338
13
Lampiran 2 Lanjutan
No Dokumen
KoefisienDice Rata-rata
Seluruh Dice
CosTJ BmTJ ConTJ CosJ BmJ ConJ
49 0.500 0.500 0.750 0.250 0.500 0.500 0.500
50 0.222 0.556 0.444 0.444 0.444 0.222 0.388
51 0.250 0.500 0.250 0.500 0.500 0.500 0.416
52 0.375 0.250 0.500 0.250 0.250 0.250 0.312
53 0.000 0.500 0.000 0.250 0.250 0.000 0.166
54 0.444 0.556 0.444 0.333 0.000 0.333 0.351
55 0.400 0.267 0.333 0.160 0.167 0.160 0.247
56 0.600 0.600 0.533 0.200 0.200 0.267 0.400
57 0.800 0.400 0.200 0.400 0.400 0.200 0.400
58 0.357 0.500 0.214 0.357 0.357 0.357 0.357
59 0.556 0.556 0.556 0.333 0.222 0.222 0.407
60 0.571 0.571 0.571 0.286 0.143 0.429 0.428
61 0.000 0.667 0.333 0.667 0.667 0.333 0.444
62 0.333 0.500 0.500 0.222 0.222 0.222 0.333
63 0.286 0.286 0.286 0.143 0.571 0.143 0.285
64 0.000 0.500 0.750 0.500 0.500 0.500 0.458
65 0.500 0.000 0.500 0.500 0.500 0.500 0.416
66 0.143 0.429 0.143 0.286 0.286 0.286 0.261
67 0.500 0.357 0.500 0.429 0.429 0.429 0.440
68 0.600 0.600 0.600 0.400 0.400 0.400 0.500
69 0.500 0.500 0.500 0.167 0.167 0.167 0.333
70 0.333 0.333 0.000 0.667 0.333 0.333 0.333
71 0.500 0.375 0.375 0.250 0.125 0.250 0.312
72 0.500 0.375 0.500 0.125 0.125 0.250 0.312
73 0.500 0.167 0.333 0.333 0.333 0.333 0.333
74 0.429 0.714 0.714 0.143 0.143 0.286 0.404
75 0.500 0.833 0.500 0.333 0.333 0.333 0.472
76 0.500 0.667 0.333 0.500 0.500 0.333 0.472
77 0.167 0.333 0.333 0.167 0.500 0.333 0.305
78 0.667 0.333 0.667 0.000 0.000 0.000 0.277
79 0.273 0.455 0.273 0.200 0.200 0.200 0.266
80 0.400 0.600 0.600 0.600 0.600 0.600 0.566
81 0.500 0.333 0.167 0.111 0.111 0.111 0.222
82 0.125 0.625 0.625 0.500 0.375 0.375 0.437
83 0.500 0.500 0.625 0.375 0.375 0.250 0.437
84 0.333 0.667 0.667 0.500 0.500 0.500 0.527
85 0.143 0.571 0.143 0.286 0.286 0.286 0.285
86 0.250 0.750 0.250 0.750 0.750 0.750 0.583
87 0.333 0.583 0.250 0.167 0.167 0.167 0.277
88 0.000 0.500 0.000 0.500 0.500 0.250 0.291
89 0.100 0.600 0.300 0.600 0.500 0.500 0.433
90 0.429 0.143 0.286 0.000 0.000 0.000 0.142
91 0.400 0.800 0.400 0.400 0.400 0.400 0.466
92 0.167 0.333 0.333 0.182 0.182 0.182 0.229
93 0.429 0.714 0.429 0.333 0.333 0.333 0.428
94 0.143 0.286 0.286 0.143 0.143 0.143 0.190
95 0.250 0.250 0.250 0.250 0.250 0.000 0.208
14
Lampiran 2 Lanjutan
No Dokumen
KoefisienDice Rata-rata
Seluruh Dice
CosTJ BmTJ ConTJ CosJ BmJ ConJ
97 0.500 0.333 0.500 0.667 0.500 0.667 0.527
98 0.600 0.200 0.600 0.200 0.200 0.200 0.333
99 0.444 0.444 0.444 0.333 0.333 0.444 0.407
100 0.100 0.400 0.100 0.300 0.500 0.400 0.300
Min 0.000 0.000 0.000 0.000 0.000 0.000 0.143
Max 0.800 0.833 0.750 0.750 0.750 0.750 0.708
Rata-Rata 0.363 0.442 0.396 0.327 0.327 0.310 0.361
Keterangan: