PE
FA
EMILIHAN
AKULTAS
N
PASSAG
UNTUK D
DEPA
S MATEM
INST
GES
DALA
DOKUMEN
SUCI AR
ARTEMEN
MATIKA D
TITUT PE
B
AM
QUEST
N BERBAH
RMELIA S
N ILMU K
DAN ILMU
ERTANIAN
BOGOR
2011
TION ANS
HASA IND
SANUR
KOMPUTE
U PENGE
N BOGOR
WERING S
DONESIA
ER
ETAHUAN
R
SYSTEM
PEMILIHAN
PASSAGES
DALAM
QUESTION ANSWERING SYSTEM
UNTUK DOKUMEN BERBAHASA INDONESIA
SUCI ARMELIA SANUR
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
SUCI ARMELIA SANUR. Passages Selection in Question Answering System for Indonesian Language Documents. Supervised by JULIO ADISANTOSO.
The first step on Question Answering System was the user enter question query. The used question query is limited to question type: WHO, WHERE, WHEN, and HOW MANY or HOW MUCH. The question word on query is used to obtain an answer candidate, while other words beside the question word are used to analyze the question. Question analysis process is started by parsing into keyword become tokens. The question sentence that has parsed is used to retrieve document and top passage. Top passage is obtained of question from passages that has highest point. Passages was done by three scoring method : rule-based, heuristic, and combination of rule-based with heuristic. The answer extraction is conducted by calculating the nearest distance between each answer candidate in top passage and each word in keyword. Answer correction is evaluated by using these criteria: right, unsupported, wrong, and null.
The evaluation of the research was seen on the set of question and document, also the accuracy for each answer. The result of rule-based scoring used 10 top documents was 77.5 % for criteria right, 2.5 % for criteria unsupported, 17.5 % for criteria wrong, and 2.5 % for criteria null. The result of heuristic scoring was 75 % for criteria right, 2.5 % for criteria unsupported, 20 % for criteria wrong, and 2.5 % for criteria null. The result of rule-based and heuristic scoring was 72.5 % for criteria right, 2.5 % for criteria unsupported, 22.5 % for criteria wrong, and 2.5 % for criteria null. The result of heuristic scoring used 2 top documents was 75 % for criteria right, 22.5 % for criteria wrong, and 2.5 % for criteria null. The result of rule-based scoring was 60 % for criteria right, 37.5 % for criteria wrong, and 2.5 % for criteria null. The result of rule-based and heuristic scoring was 75 % for criteria right, 22.5 % for criteria wrong, and 2.5 % for criteria null.
Judul : Pemilihan Passages dalam Question Answering System untuk Dokumen Berbahasa Indonesia
Nama : Suci Armelia Sanur NRP : G64086011
Menyetujui:
Pembimbing
Ir. Julio Adisantoso, M.Kom NIP 196207141986011002
Mengetahui: Ketua Departemen
Dr. Ir. Sri Nurdiati, M.Sc NIP 196011261986012001
PRAKATA
Alhamdulilahirobbil’alamin, segala puji syukur penulis panjatkan kehadirat Allah SWT atas segala karunia-Nya sehingga tugas akhir ini berhasil diselesaikan. Topik tugas akhir yang dipilih dalam penelitian adalah Pemilihan Passages dalam Question Answering System untuk Dokumen Berbahasa Indonesia.
Penulis sadar bahwa tugas akhir ini tidak akan terwujud tanpa bantuan dari berbagai pihak. Pada kesempatan ini penulis ingin mengucapkan terima kasih kepada :
1. Orang tua tercinta, adikku tersayang Dwi Lestari, serta segenap keluarga besar, terima kasih atas doa dan dukungan yang tiada henti.
2. Bapak Ir. Julio Adisantoso, M.Kom selaku dosen pembimbing tugas akhir. Terima kasih atas kesabaran dan dukungan dalam penyelesaian tugas akhir ini.
3. Bapak Sony Hartono Wijaya, S. Kom, M.Kom dan Ibu Dr. Yeni Herdiyeni, S.Si, M.Kom selaku dosen penguji, Dr. Sri Nurdiati, MSc selaku Kepala Departemen Ilmu Komputer serta seluruh dosen dan staf Departemen Ilmu Komputer FMIPA IPB.
4. Sahabat-sahabatku Mamet, Kak Wanda, Utie, Vira dan seluruh teman-teman Ilkomerz angkatan 3. Terima kasih atas semangat dan kebersamaannya selama penyelesaian tugas akhir ini.
5. Seluruh pihak yang turut membantu baik secara langsung maupun tidak langsung dalam pelaksanaan tugas akhir.
Penulis menyadari bahwa dalam penulisan tugas akhir ini masih terdapat banyak kekurangan dan kelemahan dalam berbagai hal karena keterbatasan kemampuan penulis. Penulis berharap adanya masukan berupa saran atau kritik yang bersifat membangun dari pembaca demi kesempurnaan tugas akhir ini. Semoga tugas akhir ini bermanfaat.
Bogor, Maret 2011
RIWAYAT HIDUP
Penulis dilahirkan di Kepala Hilalang Sumatera Barat pada tanggal 04 Mei 1988 dari ayah Sayadi dan ibu Nurlela. Penulis merupakan putri pertama dari dua bersaudara.
DAFTAR ISI
Halaman
DAFTAR TABEL... ... v
DAFTAR LAMPIRAN... ... v
PENDAHULUAN Latar Belakang. ... 1
Tujuan.. ... 1
Ruang Lingkup.. ... 1
TINJAUAN PUSTAKA Question Answering (QA) .. ... 1
Pembobotan.. ... 1
Ekstraksi Jawaban .. ... 2
Pembobotan heuristic.. ... 2
Pembobotan rule-based .. ... 3
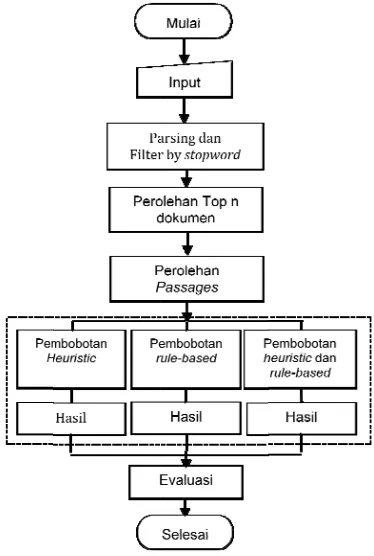
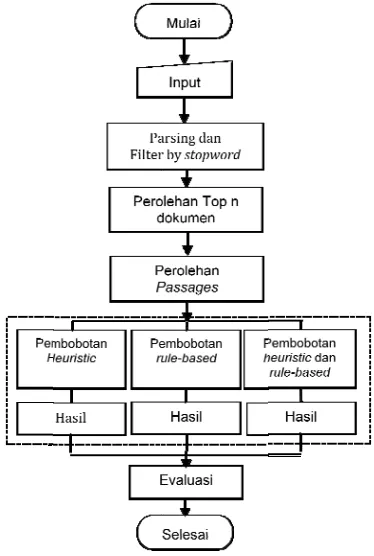
METODE PENELITIAN Pemrosesan Offline .. ... 4
Pemrosesan Online .. ... 4
Evaluasi Hasil Percobaan.. ... 5
Lingkungan Pengembangan .. ... 5
HASIL DAN PEMBAHASAN Koleksi Dokumen Pengujian .. ... 5
Pemrosesan Dokumen.. ... 6
Perhitungan tf-idf.. ... 6
Pembentukan Passages .. ... 6
Pemrosesan Kueri .. ... 6
Perolehan dokumen teratas.. ... 7
Perolehan Top Passages .. ... 7
Pembobotan Heuristic .. ... 7
Pembobotan Heuristic dan Rule-Based .. ... 8
Ekstraksi Jawaban.. ... 8
Hasil Percobaan.. ... 9
KESIMPULAN DAN SARAN Kesimpulan.. ... 13
Saran .. ... 13
DAFTAR PUSTAKA .. ... 13
DAFTAR GAMBAR
Halaman
1 Ilustrasi matriks inverted index ... 2
2 Kedekatan dokumen dalam ruang vektor (Manning 2008). ... 2
3 Alur pemrosesan offline ... 4
4 Diagram alur pemrosesan online ... 4
5 Struktur dokumen pengujian. ... 5
6 Ilustrasi bagian dokumen yang digunakan untuk pemrosesan. ... 5
7 Contoh hasil tagging dokumen. ... 6
8 Grafik hasil percobaan keseluruhan kata tanya menggunakan 10 dokumen teratas. ... 12
9 Grafik hasil percobaan keseluruhan kata tanya menggunakan 2 dokumen teratas. ... 12
DAFTAR TABEL Halaman 1 Daftar pasangan kata tanya dan named entity ... 7
2 Persentase perolehan jawaban oleh Cidhy (2009) dan penulis ... 9
DAFTAR LAMPIRAN Halaman 1 Antarmuka implementasi ... 15
2 Contoh dokumen XML dalam koleksi pengujian ... 16
3 Contoh pemberian entitasdokumen text dalam koleksi pengujian ... 17
4 Tabel hasil kata tanya ‘Siapa’ ... 18
5 Tabel hasil kata tanya ‘Kapan’ ... 19
6 Tabel hasil kata tanya ‘Dimana’ ... 20
PENDAHULUAN Latar Belakang
Sistem temu kembali informasi memiliki kaitan erat dengan sistem pencarian (search engine). Untuk menemukembalikan suatu informasi, sistem pencarian membutuhkan masukan yang dikenal dengan query. Salah satu sistem pencarian yang sudah dikembangkan adalah sistem pencarian yang memiliki fitur
query berupa pertanyaan. Sistem ini dikenal dengan Question Answering System (QAS) misalnya www.ask.com. Dengan adanya fitur pertanyaan sebagai query, diharapkan informasi yang diperoleh lebih relevan dan spesifik sesuai kebutuhan pengguna.
Penelitian tentang Question Answering System dalam perkembangannya sudah diimplementasikan oleh Ballesteros dan Xiaoyan-Li (2007) berupa Question Answering
yang digunakan untuk bahasa Inggris dan Mandarin. Dalam penelitian tersebut digunakan pembobotan heuristic dan syntactic untuk mengidentifikasi kandidat kalimat yang relevan. Cidhy (2009) mengimplementasikan penggunaan pembobotan heuristic yang dilakukan Ballesteros dan Xiaoyan-Li (2007) ke dalam dokumen berbahasa Indonesia. Berbeda dengan penelitian yang dilakukan oleh Cidhy (2009), Sianturi (2008) menyempurnakan penelitian Ikhsani (2006) untuk membangun sistem temu kembali jawaban tidak hanya menggunakan satu dokumen bacaan dan bahasa baku, tetapi membangun sistem temu kembali jawaban atas query pertanyaan terhadap banyak dokumen yang tidak baku. Penelitian Ikhsani (2006) dan Sianturi (2008) mengacu pada penelitian Riloff dan Thelen (2000) yang menggunakan konsep rule-based untuk mendapatkan kalimat jawaban.
Mengacu pada penelitian yang dikembangkan Sianturi (2008) proses pengembalian jawaban masih terbatas pada menemukembalikan kalimat jawaban sedangkan Cidhy (2009) sudah mengembalikan jawaban berupa entitas tetapi masih memiliki persentase jawaban benar yang rendah. Hal ini karena pemilihan passages yang kurang tepat. Penelitian ini akan mencoba membuat sistem dengan pembobotan rule-based yang dapat mengembalikan jawaban berupa entitas dan menggabungkan metode Rule-Based (Sianturi 2008) dan pembobotan heuristic (Cidhy 2009) sehingga dapat diperoleh passages yang tepat untuk mengembalikan jawaban yang benar.
Tujuan
Penelitian ini bertujuan memperoleh pembobotan passages yang tepat dalam
Question Answering System yang dapat mengembalikan jawaban yang benar.
Ruang Lingkup
Ruang lingkup penelitian ini adalah:
1. Korpus terdiri atas beberapa dokumen berbahasa Indonesia
2. Menggunakan kata tanya yaitu siapa, dimana, kapan, dan berapa.
3. Kueri pertanyaan yang dimasukkan dibatasi pada tipe factoid question, yaitu pertanyaan yang memiliki jawaban tunggal.
4. Hasil dari penelitian dievaluasi menggunakan persepsi manusia.
TINJAUAN PUSTAKA Question Answering (QA)
Question Answering System (QAS) merupakan kombinasi antara Information Retrieval (IR) dengan Natural Language Processing (NLP). QA memiliki tujuan menampilkan jawaban berdasarkan kueridalam bentuk pertanyaan yang diajukan oleh pengguna (Lin 2004). Perbedaan yang mendasar antara QA dengan IR terletak pada masukan (kueri) dan keluaran yang dihasilkan. Pada IR kueri yang dimasukkan berupa kata atau kalimat pertanyaan dan keluaran yang dihasilkan adalah dokumen yang dianggap relevan oleh sistem. Sedangkan pada QA, kueri berupa kalimat tanya dan keluarannya berupa jawaban (entitas) yang dianggap sesuai oleh sistem sehingga memungkinkan sistem tidak mengembalikan jawaban apapun.
Pembobotan
Information Retrieval pada dasarnya adalah membandingkan kata yang ada pada kueri dengan kata yang ada dalam dokumen. Untuk memperoleh kata tertentu dalam dokumen yang mengandung informasi yang berkaitan dengan
query tertentu juga, dilakukan dengan cara menghitung kesamaan antara vektor dokumen dan vektor kueri. Informasi yang diperlukan yaitu term frequency (tf), document frequency (df), dan invers document frequency(idf).
Nilai tf menggambarkan frekuensi kemunculan suatu kata t dalam dokumen d, yang dilambangkan dengan tft,d. Nilai df menggambarkan banyaknya dokumen di dalam koleksi yang mengandung kata tertentu. Nilai
dokumen yang ada dalam koleksi menghasilkan nilai idf untuk setiap kata sebagai berikut :
log
dengan N merupakan notasi untuk jumlah dokumen yang ada dalam koleksi. Melalui idf
dapat diketahui kata-kata tertentu yang merupakan penciri suatu dokumen. Dengan demikian, dapat diperoleh bobot untuk masing-masing kata dalam dokumen, yaitu wt,d yang merupakan hasil perkalian antara tft,d dan idft.
Gambar 1 menunjukkan ilustrasi matriks
inverted index, yang berisi bobot setiap kata t
dalam suatu dokumen d
d1 d2 … d3
t1 wt1d1 wt1d2 … wt1dn
t2 wt2d1 wt2d2 … wt2dn
… … … … … t3 wtkd1 wtkd2 … wtkdn
Gambar 1 Ilustrasi matriks inverted index
Ide untuk mengukur kesamaan dokumen dengan menggunakan kesamaan cosine adalah dokumen yang saling berdekatan dalam ruang vektor memiliki kecenderungan berisi informasi yang sama. Gambar 2 mengilustrasikan vektor dokumen yang terdapat dalam ruang vektor, yang diberi nilai oleh bobot kata.
Gambar 2 Kedekatan dokumen dalam ruang vektor (Manning 2008).
Formula untuk memperoleh kesamaan
cosine untuk dj dan dk adalah:
, d .d d |d |
Berdasarkan formula kesamaan cosine, dj
dan dk adalah dokumen yang terdapat dalam
ruang vektor M kata. Dalam implementasi perolehan n dokumen teratas, hal serupa dilakukan untuk mengukur kesamaan antara vektor kueri dengan dokumen. Dokumen diurutkan berdasarkan perolehan nilai cosine
dengan kueri, kemudian dipilih n dokumen teratas dengan nilai cosine tertinggi.
Ekstraksi Jawaban
Setelah diperoleh n dokumen teratas, tahap selanjutnya adalah ekstraksi jawaban. Setiap n dokumen teratas yang terambil dianalisis kembali untuk mengidentifikasi kandidat jawaban dengan cara sebagai berikut (Ballesteros & Xiaoyan-Li 2007):
1. Dilakukan identifikasi named entity yang terdiri atas orang, organisasi, lokasi, ekspresi waktu, tanggal, ekspresi numerik, uang, dan persen.
2. Dokumen dibagi menjadi passage. Passage
terdiri atas dua kalimat yang berdampingan. Setiap passage memiliki satu kalimat yang
overlap.
3. Dilakukan pembobotan pada setiap passage. 4. Dilakukan pengurutan terhadap seluruh
passage dari setiap n dokumen teratas.
Pengurutan dilakukan berdasarkan bobot yang dimiliki oleh setiap passage.
5. Ekstraksi kandidat jawaban dari passage
peringkat teratas. Jarak antara kandidat jawaban dan posisi dari setiap query yang cocok dalam passage dihitung. Kandidat jawaban yang memiliki total jarak terkecil terpilih sebagai jawaban akhir.
Pembobotan heuristic
Pembobotan heuristic merupakan metode pembobotan passages yang dikembangkan oleh Ballesteros dan Xiaoyan-Li (2007). Pertama didefinisikan count_query adalah jumlah kata yang terdapat pada query (kalimat tanya),
count_match adalah jumlah hasil pencocokan antara kata yang terdapat pada query dan
passage (wordmatch), score adalah bobot dari
passage dan wordmatch_words adalah hasil
wordmatch. Yang diperhitungkan dalam pembobotan heuristic diantaranya count_match, nilai count_match yang terdapat dalam passage
yang sama, ukuran dari passage tertentu, dan jarak antara sebuah kandidat jawaban dengan
wordmatch_words. Proses pembobotan adalah sebagai berikut:
1. Jika tidak ada named entity yang ditampilkan, passage menerima nilai 0. Jika
named entity ditampilkan pada passage
namun tidak memiliki tipe yang sama dengan pertanyaan, named entity diabaikan. 2. Dilakukan pencocokan kata-kata pada query
dengan kata-kata pada passage (proses t1
dj
query
θ
dk
0 t2
wordmatch). Jika nilai count_match kurang dari threshold (t), score = 0. Selain itu score = count_match. Nilai threshold (t), didefinisikan dengan cara sebagai berikut: a. Jika count_query kurang dari 4,
t=count_query.
b. Jika count_query antara 4 dan 8,
t=count_query/2.0+1.0
c. Jika lebih besar dari 8,
t=count_query/3.0+2.0
Nilai threshold digunakan untuk mengambil kata yang penting pada passages. Dengan kata lain, paragraf apapun yang tidak mengandung kata-kata yang terdapat pada
query tidak diperhitungkan.
3. Kata yang berdekatan memiliki hubungan keterkaitan informasi yang lebih tinggi. Jika seluruh kata yang cocok dengan query
terdapat pada satu passagesSm=1, selain itu
Sm=0. Maka, score = score + (Sm*0.5). 4. Seperti yang diketahui urutan kata dapat
mempengaruhi arti. Oleh karena itu, diberikan bobot yang lebih tinggi (Ord=1) terhadap passage jika kata-kata yang cocok dengan query memiliki urutan yang sama seperti pada pertanyaan asli. Selain itu
Ord=0. Dengan demikian, score = score +
(Ord*0.5).
5. Score = score + (count_match/W), dimana
W adalah jumlah kata dari passage dengan bobot tertinggi.
Pembobotan terakhir yaitu menghitung total perolehan nilai yang disimpan dalam variabel
heuristic_score yaitu count_match + 0.5*Sm + 0.5*Ord + count_match/W.
Pembobotan rule-based
Metode rule-based adalah metode yang dikembangkan oleh Riloff & Thelen (2000).
Cara kerja metode rule-based adalah menghitung nilai dari masing-masing passages
pada dokumen dengan kueri yang diberikan. Nilai yang diberikan berdasarkan pada jumlah nilai hasil perbandingan kata yang sama antara kueri dengan kata yang ada pada
passages dan nilai pada masing-masing rule
berdasarkan tipe pertanyaan. Suatu rule dapat memberikan empat kemungkinan nilai, yaitu:
clue (+3), good_clue (+4), confident (+6), dan
slam_dunk (+20). Menurut Riloff dan Thelen (2000), nilai yang digunakan hanya berdasarkan intuisi yang bertujuan untuk memperkirakan seberapa pentingnya rule yang digunakan dalam
menemukembalikan jawaban berdasarkan tipe pertanyaan kueri. Jawaban atas queri yang diberikan adalah passages yang memiliki nilai tertinggi.
Algoritme rule telah dimodifikasi oleh Ikhsani (2006) dari rule yang dibuat oleh Riloff dan Thelen (2000) karena melakukan penyesuaian terhadap kaidah bahasa Indonesia. Adapun rule yang dibuat Sianturi (2008) sebagai berikut:
1. “KAPAN”
Score(S) += WordMatch(Q,S)
If contains(S, WAKTU) and contains (S,{saat, ketika, kala, semenjak,sejak, waktu, setelah, sebelum})then
Score(S) += slam_dunk
If contains(S, WAKTU) then
Score(S) += good_clue
If contains(S,{saat, ketika, kala, semenjak, sejak, waktu, setelah, sebelum}) then
Score(S) +=clue
2. “DIMANA”
Score(S) += WordMatch(Q,S)
If contains(S,TEMPAT) and contains (S,{dalam,dari, pada}) then
Score(S) += slam_dunk
If contains(S,{dalam, dari, pada}) then
Score(S) += clue
If contains(S, TEMPAT) then
Score(S) += good_clue
3. “SIAPA”
Score(S) += WordMatch(Q,S)
If ~contains(Q,ORANG) and contains (Q,ORANG) then
score(S) += slam_dunk
4. “APA”
Score(S) += WordMatch(Q,S)
If contains(Q,{tujuan,manfaat}) and contains (S,{untuk,guna}) then
Score(S) += confident
Elseif contains(Q,{maksud}) and contains (S,{adalah,ialah}) then
Score(S) += slam_dunk
P yaitu dan Pem P prep emb dilak pass onli 1. P Pad peng doku stop Kem IPB 2. I Pros men inde doku 3. P T pass kali dilak dahu pada entit mem (200 Citr ORG NUM MET Penelitian ini u pemrosesan evaluasi hasil mrosesan Offli
Pemrosesan proses dokum bentukan pa
kukan untuk
sage yang akan
ine.
Gambar 3 Preproses Dok a tahap ini d ghilangan st
umen uji. Kol
pwords diamb mbali Informas
.
Indexing Doku ses indexing
nggunakan p
exing berupa n umen. Pembentukan P
Tahap selanj
sages yang m mat yang sal kukan pemb ulu dilakukan a koleksi dok tas atau ta
manfaatkan ha 09). Entitas ya raningputra
GANIZATION, MBER, dan CUR
ODE PENEL dilakukan da n offline, pem percobaan (Ga
ine
offline terdir men, indexing
assages. Pe mendapatkan n digunakan p
3 Alur pemrose kumen dilakukan pros
topwords terh leksi dokumen bil dari Lab si Departemen
umen
dokumen p embobotan t nilai idf dan
tf-Passages
utnya adalah masing-masing
ling berdampi entukan pass
n penamaan e kumen penguj
agging dilak asil penelitian ang dihasilkan
(2009) y
DATE TIME RRENCY.
ITIAN lam tiga tahap mrosesan onlin
ambar 3 dan 4)
ri atas taha dokumen, da mrosesan in
nilai tf-idf da ada pemrosesa
esan offline
ses parsing da rhadap kolek n uji dan daft botarium Tem
Ilmu Komput
pada tahap in tf-idf. Has -idf dari seluru
h pembentuka terdiri atas du ingan. Sebelum
sages, terlebi entitas (entita jian. Penamaa kukan denga n Citraningputr pada penelitia yaitu NAME
E, LOCATION p, ne, ). ap an ni an an an ksi ar mu er ni sil uh an ua m ih as) an an ra an E, N, Pemro Pem prepros peroleh dan ek Ga 1. Pre Ku dimasu penghi kata ta tanya). pada k
BERAP 2. Per Sist dokum cosine 3. Per Kan yang te 4. Pem Pem dengan dan gab yang
osesan Online
mrosesan onl
ses kueri, pero han top passag
straksi jawaban
ambar 4 Diagra eproses Kueri
eri berupa k ukkan penggun ilangan stopw
anya dan keyw
. Kata tanya kata : SIAPA, PA.
rolehan 10 Dok tem akan men teratas y
teratas. rolehan Passag
ndidat passag
erletak pada se mbobotan Pas
mbobotan terh n tiga metode y bungan heurist
mendapatkan
line terdiri olehan 10doku
ges, pembobot n.
am alur pemro
kalimat perta na, dilakukan
words untuk m
word (kata-kata yang diguna
, KAPAN, DIM
kumen Teratas mengembalik yang memilik
ge
ge diperoleh d puluh dokume
ssage
hadap passag
yaitu heuristi tic dan rule-ba
n nilai tert
atas tahap umen teratas, tan passages,
sesan online
anyaan yang
parsing dan mendapatkan a selain kata akan dibatasi
MANA, DAN
an sepuluh ki kesamaan
dari passages
en teratas.
ge dilakukan
c,rule-based ased. Passage
dikembalikan sebagai top passage dari kueri pertanyaan yang diberikan.
5. Ekstraksi Jawaban
Top passages yang diperoleh dilakukan perhitungan terhadap jarak kata. Entitas yang memiliki jarak terpendek dengan kata kunci pada kalimat tanya (kueri) akan menjadi entitas jawaban.
Evaluasi Hasil Percobaan
Tahap evaluasi dilakukan secara objektif dari segi:
1. Pasangan jawaban dan dokumen (Responsiveness)
2. Ketepatan untuk setiap jawaban.
Pemberian nilai dilakukan berdasarkan empat kriteria, yaitu:
1. Wrong (W): jawaban tidak benar.
2. Unsupported (U): jawaban benar tapi dokumen tidak mendukung.
3. Inexact (X): jawaban dan dokumen benar tapi terlalu panjang.
4. Right (R): jawaban dan dokumen benar
Lingkungan Pengembangan
Perangkat lunak yang digunakan untuk penelitian yaitu :
1. Windows 7 sebagai sistem operasi,
2. Apache Xampp-win32-1.7.1 sebagai web
server,
3. Notepad ++ sebagai editor program.
Perangkat keras yang digunakan untuk penelitian yaitu :
1. Processor Intel Centrino 2.3 GHz, 2. RAM 4 GB,
3. Harddisk kapasitas 250 GB.
HASIL DAN PEMBAHASAN Koleksi Dokumen Pengujian
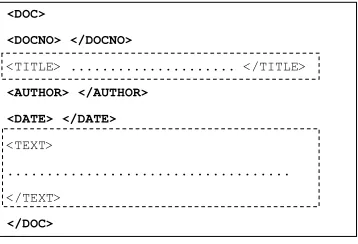
Dokumen uji yang digunakan adalah dokumen berbahasa Indonesia yang sudah tersedia di Laboratorium Temu Kembali Informasi Departemen Ilmu Komputer IPB. Sumber koleksi dokumen diambil dari media koran, majalah, dan jurnal penelitian. Dokumen ini disimpan dalam satu direktori. Secara umum, nama dokumen diberi nama berdasarkan sumber data dan tanggal data diterbitkan, misalnya suaramerdeka040104.txt yang berarti data berasal dari majalah Suara Merdeka dan diterbitkan oleh Suara Merdeka pada tanggal 04 bulan Januari tahun 2004. Dokumen memiliki ukuran terkecil 1 KB dan terbesar 53 KB. Masing-masing dokumen uji berekstensi teks (*.txt) dan struktur XML di dalamnya. Gambar 5 menunjukkan contoh format strukur dokumen yang digunakan.
<DOC>
<DOCNO> suaramerdeka040104 </DOCNO> <TITLE> Ribuan Bibit untuk Lahan Kritis </TITLE>
<AUTHOR> </AUTHOR>
<DATE> Minggu, 4 Januari 2004 </DATE> <TEXT>
NGALIYAN- Kecamatan Ngaliyan telah mendistribusikan sekitar 30 ribu bibit berbagai jenis tanaman. Sebelumnya, wilayah itu telah menerima bantuan 140.250 bibit tanaman dari Departemen Pertanian. Bibit tanaman yang diberikan adalah petai, durian, rambutan, mangga, sukun, dan jati.
</TEXT> </DOC>
Gambar 5 Struktur dokumen pengujian. Pemrosesan dokumen pada tahap indexing, hanya diambil bagian dokumen yang diapit oleh
tag <TITLE> dan <TEXT>, sedangkan untuk pembentukan passages, hanya digunakan bagian dokumen yang diapit oleh tag <TEXT>. Gambar 6 menunjukkan ilustrasi bagian dokumen yang diproses.
<DOC>
<DOCNO> </DOCNO>
<TITLE> ... </TITLE>
<AUTHOR> </AUTHOR> <DATE> </DATE> <TEXT>
...
</TEXT>
</DOC>
Pemrosesan Dokumen
Langkah pertama pada pemrosesan dokumen adalah penamaan entitas (named entity) yang disebut tagging pada dokumen dengan menggunakan hasil penelitian dari Citrainingputra (2009). Penamaan entitas dilakukan untuk proses perolehan kandidat jawaban sesuai dengan jenis pertanyaannya. Adapun named entity yang digunakan terdiri dari NAME, ORGANIZATION, NUMBER, PERCENT, CURRENCY, DATE, TIME, dan LOCATION. Pada tahap ini dilakukan dengan memasukkan satu per satu setiap bagian dokumen yang diapit tag <TEXT> ke dalam sistem name entity tagging (Citraningputra 2009). Gambar 7 menunjukkan hasil tagging
untuk dokumen suaramerdeka040104.txt. Selanjutnya semua dokumen hasil tagging
kemudian disimpan dalam korpus.
NGALIYAN- <LOCATION> Kecamatan Ngaliyan </LOCATION> telah mendistribusikan sekitar <NUMBER>30</NUMBER> ribu bibit berbagai jenis tanaman. Sebelumnya, wilayah itu
telah menerima bantuan <NUMBER>140.250</NUMBER> bibit tanaman dari <ORGANIZATION> Departemen Pertanian </ORGANIZATION>. Bibit tanaman yang diberikan adalah petai, durian, rambutan, mangga, sukun, dan jati.
Gambar 7 Contoh hasil tagging dokumen. Langkah kedua adalah pembacaan terhadap isi file dari korpus. Pembacaan hanya berlaku pada isi file yang berada pada tag <TITLE> dan <TEXT>. Kemudian pada isi file tersebut dilakukan parsing dengan pemisah kata yang tersimpan dalam variabel pemisahKata
yang terdiri atas tanda baca
[+\/%,.\"\];()\':=`?\[!@]. Tidak
semua hasil parsing disimpan, karena hasil
parsing diseleksi kembali oleh stopwords yang merupakan kata buangan atau daftar kata umum yang mempunyai fungsi tapi tidak mempunyai arti. File ini tersimpan dalam file stopwords.txt yang terdiri atas 733 kata yang dipisahkan dengan karakter enter, contoh kata tersebut antara lain acapkali, dalam, dan,
dapat, sesaat, dari, dan lain-lain.
Perhitungan tf-idf
Langkah pertama melakukan perhitungan tf-idf adalah mendapatkan informasi term frequency, dengan memanfaatkan hasil pada tahap pemrosesan dokumen. Term frequency
diperoleh dari pasangan dokumen dan hasil
parsing (token-token) dari masing-masing file
disimpan dalam suatu array pada variabel tf.
Variabel ini digunakan untuk menghitung nilai df, idf, dan tf-idf setiap kata.
Langkah selanjutnya adalah mendapatkan
document frequency (df). Document frequency
adalah jumlah dokumen yang mengadung kata tertentu. Kemudian dari hasil tersebut dapat dihitung nilai invers document frequency (idf). Tujuan dari idf adalah untuk menentukan kata-kata (term) yang merupakan penciri dari suatu dokumen, oleh karena itu dalam penelitian ini hanya kata dengan nilai idf lebih besar sama dengan 0.3 yang disimpan. Hal ini bertujuan untuk menghapus kata-kata yang tidak termasuk dalam stopwords namun bukan penciri dari sebuah dokumen. Hasil idf disimpan dalam
fileGenerate/idf.txt dengan
menggunakan tanda “>>” sebagai pemisah. Melalui idf dapat diperoleh informasi untuk menghitung nilai tf-idf yang merupakan perkalian antara nilai tf dan idf. Selanjutnya hasil tf-idf kata juga disimpan dalam satu file
fileGenerate/tfidf.txt dengan
menggunakan tanda “>>” sebagai pemisah. Pembentukan Passages
Tahap awal pembentukan passages adalah dilakukan pembentukan kalimat untuk setiap dokumen dengan menggunakan tanda pemisah antar kalimat yaitu [.?!]. Setiap passage
dibentuk dari dua kalimat yang berurutan sehingga passage yang posisinya berdekatan saling overlap. Hasil pembentukan passages ini
disimpan dalam satu file .
./fileGenerate/passages.txt. Nilai yang
disimpan adalah id passage, nama dokumen, dan passage. Masing-masing variabel dipisahkan dengan tanda “>>”.
Pemrosesan Kueri
Kueri berupa kalimat Tanya yang diawali dengan kata tanya dan diakhiri dengan tanda tanya (?). Kata tanya yang digunakan pada penelitian ini adalah SIAPA, KAPAN, DIMANA, dan BERAPA.
Langkah pertama yang dilakukan pada pemrosesan kueri adalah parsing terhadap kalimat tanya dengan pemisah kata yang tersimpan dalam variabel pemisahKata
yang terdiri atas tanda baca
[+\/%,.\"\];()\':=`?\[!@].
Kueri di-parsing terlebih dahulu, kemudian dilakukan proses case folding yaitu pengubahan semua huruf menjadi huruf kecil. Selanjutnya dilakukan tokenisasi untuk mendapatkan kata-kata penyusun kueri berupa kata-kata tanya dan
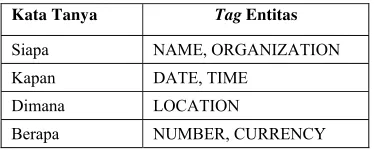
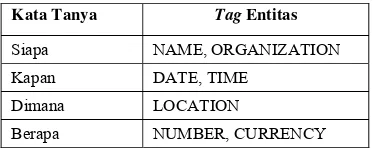
identifikasi dan menyimpan kata tanya dari kueri pertanyaan berupa array dengan index ke-0 atau query[0]. Tujuannya adalah menentukan tipe jawaban yang akan dikembalikan oleh sistem. Tipe jawaban dicirikan dengan tagnamed entity yang terdapat pada dokumen. Tabel 1 menunjukkan daftar pasangan jenis kata tanya dan named entity
yang menjadi acuan dari jawaban yang akan dikembalikan.
Tabel 1 Daftar pasangan kata tanya dan named entity
Kata Tanya Tag Entitas
Siapa NAME, ORGANIZATION
Kapan DATE, TIME
Dimana LOCATION
Berapa NUMBER, CURRENCY
Perolehan dokumen teratas
Dokumen yang digunakan untuk proses perolehan jawaban adalah 10 dokumen dengan bobot kesamaan cosine tertinggi. Dengan memanfaatkan nilai idf dan tf-idf dapat dilakukan perolehan norm dari kueri dan dokumen. Kueri dimasukkan secara manual kemudian dilakukan perhitungan terhadap norm query, tf-idf query, dan norm untuk setiap dokumen. Langkah selanjutnya adalah memasangkan nilai norm query dengan query
setiap dokumen untuk menghasilkan nilai
dotproduct dan cosine. Setelah diperoleh nilai
cosine, dilakukan pengurutan nilai cosine. Dokumen yang diambil untuk memasuki langkah selanjutnya adalah 2 dan 10 dokumen dengan nilai cosine tertinggi.
Selanjutnya dilakukan pemilihan passages pada kamus passage yang termasuk dalam 10 dokumen di atas. Hasil pemilihan passages ini disimpan dalam variabel $passagesDocTop
untuk digunakan pada tahap perolehan top passages.
Perolehan Top Passages
Passages yang akan digunakan dalam proses pembobotan adalah passages yang mengandung
tag named entity yang dibutuhkan, yang dalam pembahasan kali ini disebut arrayTag. arrayTag merupakan hasil dari identifikasi kata tanya. Misalnya ‘Siapa’ yang mengacu pada PERSON- ORGANIZATION, dan Kapan yang mengacu pada DATE-TIME.
Selanjutnya passage yang disimpan variabel
$passagesDocTop kemudian disaring untuk
diambil passages yang memiliki TAG sesuai
kata tanya kueri pertanyaan. Selanjutnya dilakukan pembobotan passages menggunakan pembobotan heuristic dan pembobotan menggunakan metode rule-based.
Pembobotan Heuristic
Sesuai dengan tahapan yang terdapat dalam jurnal Ballesteros dan Xiaoyan-Li (2007) serta penelitian Cidhy (2009) yang digunakan sebagai acuan dalam penelitian ini, pembobotan
passages terdiri atas :
1. Pembobotan passages berdasarkan hasil dari proses wordmatch sesuai threshold. Hasilnya disimpan dalam variabel
count_match.
2. Pembobotan passages berdasarkan urutan nilai dari arrayWordQuestion (kata-kata selain kata tanya pada kueri) dalam
passages. Hasilnya bernilai Boolean, disimpan dalam variabel Ord.
3. Pembobotan passages berdasarkan nilai dari
arrayWordQuestion dalam passages.
Hasilnya bernilai Boolean, disimpan dalam variabel Sm.
4. Pembobotan berdasarkan hasil dari proses
wordmatch sesuai threshold berbanding ukuran passage (jumlah kata dalam satu
passage).
Setelah diperoleh nilai dari ke-empat variabel di atas kemudian dihitung skor
heuristic setiap passage yaitu:
heuristic_score = count_match + count_match/W + Sm*0.5 + Ord*0.5.
Pembobotan Rule-based
Mengacu pada rule yang terdapat dalam Riloff dan Thelen (2000) serta penelitian Sianturi (2008), yang digunakan sebagai acuan dalam penelitian ini pembobotan passages
terdiri atas:
1. Fungsi WordMatch.WordMatch adalah nilai perbandingan antara kalimat kueri dengan kalimat pada dokumen. Algoritme
WordMatch dilakukan dengan cara membandingkan token-token pada setiap
passages dengan token-token pada kalimat kueri. Setiap token yang sama akan menambahkan nilai pada passages tersebut. Hasilnya disimpan dalam variabel WordMatch.
digunakan sebagai acuan dalam penelitian ini:
1. “SIAPA”
Score(S) +=WordMatch (Q,S)
If contains(Q,HUMAN) && (S,Human) then
Score(S) += slam_dunk
Algoritme rule untuk kueri pertanyaan dengan kata tanya “SIAPA” pada sistem yang dibangun pada penelitian ini berbeda dengan algoritme rule yang telah diimplementasikan oleh Sianturi (2008). Perbedaannya terletak pada penambahan
rule dan pemberian nilai score.
2. “KAPAN”
Score(S) +=WordMatch (Q,S)
If contains(S, {saat, ketika, kala,
semenjak, sejak, waktu, setelah,
sebelum}) and contains(S,TIME)
then
Score(S) += slam_dunk
If contains(S,TIME) and contains(Q,TIME) then
Score(S) += confident
If contains(S, {saat, ketika, kala,
semenjak, sejak, waktu, setelah,
sebelum}) or contains(S,TIME)
then
Score(S) += good_clue
Algoritme rule untuk kueri pertanyaan dengan kata tanya “KAPAN” yang dibangun pada penelitian ini dengan algoritme rule
yang telah diimplementasikan oleh Sianturi (2008) hanya berbeda pada pemberian nilai
score.
3. “DIMANA”
Score(S) +=WordMatch (Q,S)
If contains(S, {dalam, dari,
pada}) and contains(S,LOCATION) then
Score(S) += slam_dunk
If contains(S,LOCATION) then Score(S) += good_clue
If contains(S, {dalam, dari, pada }) then
Score(S) += clue
Algoritme rule yang digunakan sama dengan rule yang telah diimplementasikan oleh Sianturi (2008).
4. “BERAPA”
Score(S) +=WordMatch (Q,S)
If contains(Q,NUMBER) and
contains(S,NUMBER) then Score(S) += slam_dunk
If contains(S,NUMBER) then Score(S) += confident
Algoritme rule yang digunakan dibuat sendiri oleh penulis.
Fungsi dan notasi yang digunakan dalam
rules tersebut adalah sebagai berikut : 1. Notasi S = sentence (kalimat dokumen). 2. Notasi Q = query (kalimat kueri).
3. Fungsi contains adalah fungsi untuk memeriksa kalimat dokumen dan kalimat kueri pertanyaan, apakah mengandung kata yang telah ditentukan.
4. Fungsi WordMatch adalah fungsi untuk memeriksa kesamaan kata.
5. Fungsi score adalah fungsi pemberian nilai pada kalimat dokumen.
Setelah diperoleh nilai dari Wordmatch dan
rule dihitung skor setiap passage. Pembobotan Heuristic dan Rule-Based
Pembobotan passages gabungan heuristic
dan rule-based dilakukan berdasarkan nilai hasil dari proses pembobotan heuristic yang diperoleh dari pencocokan kata kueri dengan
passages dan nilai pembobotan rule-based
diperoleh dari rule yang digunakan. Formula untuk penggabungan kedua metode:
$scoreTotal =
α*$heuristic+(1-α)* $rule-based
dengan α=0.5.
Ekstraksi Jawaban
Tahap berikutnya adalah ekstraksi jawaban dari toppassages yang diperoleh. Passage yang memiliki nilai tertinggi pada pembobotan
passages menjadi top passage. Kata yang menjadi kandidat jawaban adalah kata yang memiliki entitas sesuai dengan kata tanya pada kueri pertanyaan. Yang perlu diperhatikan dalam perolehan entitas jawaban adalah top passage dapat terdiri atas satu atau lebih
passage dan setiap passage dapat memiliki satu atau lebih kandidat jawaban. Jawaban akhir setiap passage diperoleh dengan cara menghitung jarak antara setiap kandidat jawaban pada setiap passage dengan masing-masing kata pada $arrayWordMatch.
$arrayWordMatch merupakan array yang
terpendek dianggap sebagai jawaban yang paling tepat.
Contoh hasil percobaan menggunakan kueri
“Siapa Muwardi P. Simatupang?”,
diperoleh 19 passages pada satu dokumen teratas. Setelah diambil passage yang mengandung tag <NAME> atau <ORGANIZATION> diperoleh 12 passage dari 19 passage. TopPassage yang diperoleh dengan
heuristic, rule-based serta gabungan heuristic dan rule-based adalah sama. Nilai pembobotan untuk rule-based 5,078 ,heuristic 10 dan gabungan kedua metode adalah 7,53. Top passages yang diperoleh:
Ini mungkin karena pendekatan pembangunan pertanian masih bersifat subsisten kata <ORGANIZATION> Ketua Umum Dewan Pimpinan Pusat Himpunan Alumni Institut Pertanian Bogor
</ORGANIZATION> <NAME> Muwardi P
Simatupang </NAME> pada acara
diskusi 'Membangun Pertanian <LOCATION> Indonesia </LOCATION> Untuk Meningkatkan Pendapatan Petani dan Negara' di <LOCATION> Jakarta </LOCATION> <DATE> Kamis(22/4) </DATE> <NAME>
Muwardi</NAME> mengatakan
pendekatan subsisten merupakan pendekatan yang menitikberatkan pada peningkatan produksi
Kandidat jawaban yang diperoleh hanya ada satu yaitu kata Ketua Umum Dewan Pimpinan Pusat Himpunan Alumni Institut Pertanian Bogor sehingga kata tersebut menjadi jawaban akhir.
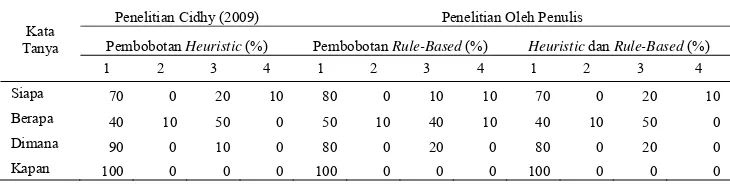
Hasil Percobaan
Hasil percobaan dilakukan dengan membandingkan hasil penelitian yang dilakukan oleh penulis dengan hasil penelitian Cidhy (2009). Perbandingan dilakukan dengan melihat perolehan toppassage, ketepatan jawaban dan
dokumen yang ditemukembalikan dengan menggunakan tiga pembobotan passages yaitu
heuristic (Cidhy 2009), rule-based serta gabungan heuristic dan rule-based dengan menggunakan 10 dokumen teratas.
Jumlah koleksi dokumen yang digunakan sebanyak 106 dokumen dan sebanyak 40 kueri. Kueri tersebut diambil dari penelitian Cidhy (2009). Proses dokumentasi evaluasi kueri dicatat dalam bentuk tabel yang terdiri atas sumber dokumen, pertanyaan (kueri), perolehan
passages, ketepatan dokumen, ketepatan jawaban, dan koreksi. Kemudian dilakukan pencocokan antara hasil pencarian yang diperoleh terhadap pasangan dokumen dan kueri pertanyaan yang seharusnya. Berdasarkan kesesuaian pasangan jawaban dan dokumen, penilaian dibedakan menjadi 4 jenis yaitu :
right, wrong, unsupported,dan null. Persentase evaluasi hasil percobaan yang dilakukan oleh Cidhy dan penulis dapat dilihat pada Tabel 2. Berikut pembahasan untuk masing-masing percobaan :
1. Perbandingan Hasil Percobaan Untuk Kata Tanya SIAPA
Berdasarkan 10 kueri pertanyaan yang diuji, diambil contoh kueri pertanyaan Siapa
Bungaran Saringgih ?. Hasil penelitian
Cidhy (2009) dan penulis mengembalikan 10 dokumen teratas yang sama, namun mengembalikan top passage dan jawaban yang berbeda. Top passage yang diperoleh pada penelitian Cidhy (2009) :
Tabel 2 Persentase perolehan jawaban oleh Cidhy (2009) dan penulis menggunakan 10 dokumen teratas
Kata Tanya
Penelitian Cidhy (2009) Penelitian Oleh Penulis
Pembobotan Heuristic (%) Pembobotan Rule-Based (%) Heuristic dan Rule-Based (%) 1 2 3 4 1 2 3 4 1 2 3 4
Siapa 70 0 20 10 80 0 10 10 70 0 20 10
Berapa 40 10 50 0 50 10 40 10 40 10 50 0
Dimana 90 0 10 0 80 0 20 0 80 0 20 0
Kapan 100 0 0 0 100 0 0 0 100 0 0 0
Menurut <NAME> Bungaran Saragih </NAME>, hal tersebut wajar dengan keadaan setiap penyalur pupuk, dimana mereka memerlukan waktu dalam proses pengepakan kembali. Mengenai kelangkaan pupuk di <LOCATION> Cirebon </LOCATION> yang hanya terjadi di beberapa kecamatan, <NAME> Bungaran Saragih </NAME> menegaskan bahwa produsen pupuk setempat telah menutupi kelangkaan tersebut dengan pengiriman pupuk dari luar wilayah <LOCATION> Cirebon </LOCATION>.
Toppassage di atas diperoleh dari dokumen
indosiar260504.txt. Berdasarkan hasil top
passage, tidak diperoleh kandidat jawaban sehingga jawaban yang dikembalikan null.
Dengan menggunakan kueri pertanyaan yang sama, penelitian yang dilakukan menggunakan rule-based menghasilkan kriteria
right yaitu Menteri Pertanian. Jawaban ini diperoleh setelah sistem mengembalikan top passage sebagai berikut :
Dalam acara yang dihadiri <ORGANIZATION> Menteri Pertanian </ORGANIZATION> <NAME>Bungaran Saragih</NAME>, <ORGANIZATION> Menteri Kelautan dan Perikanan </ORGANIZATION> <NAME> Rokhmin Dahuri </NAME>, serta Menakertrans <NAME> Jacob Nuwa Wea </NAME>, <NAME> Presiden Megawati </NAME> menyampaikan rasa terima kasihnya kepada masyarakat <LOCATION> Gorontalo </LOCATION> yang telah bekerja keras menanam dan memproduksi jagung. Dalam pidato tanpa teks, <NAME>Mega</NAME> mengatakan, ''Saya melihat potensi menanam jagung di <LOCATION> Gorontalo</LOCATION> memang bisa digerakkan, bahkan bisa menjadi satu potensi yang sangat luar biasa.
Toppassage di atas diperoleh dari dokumen
indosiar260504.txt.
Masih menggunakan kueri pertanyaan yang sama, penelitian yang dilakukan menggunakan gabungan heuristic dan rule-based juga menghasilkan kriteria null yaitu tidak mengembalikan jawaban. Hal ini disebabkan
top passage yang dihasilkan sama dengan top passage pada penelitian Cidhy (2009).
Jawaban yang diperoleh dengan rule-based
lebih tepat dibanding metode yang lain. Hal ini disebabkan oleh top passage yang dihasilkan
rule-based lebih relevan dibanding metode yang lain.
Persentase ketepatan jawaban untuk kata tanya SIAPA pada penelitian Cidhy (2009) menghasilkan persentase kriteria right sebesar 70%, wrong 20% dan null 10%, sedangkan hasil penelitian penulis menghasilkan persentase kriteria right sebesar 80%, wrong
10% dan null 10% untuk rule-based dan kriteria
right sebesar 70%, wrong 20% dan null 10% untuk gabungan heuristic dan rule-based. Daftar kueri pertanyaan dan evaluasi untuk kata tanya SIAPA dapat dilihat pada Lampiran 4. 2. Perbandingan Hasil Percobaan Untuk
Kata Tanya KAPAN
Berdasarkan 10 kueri pertanyaan yang diuji, diambil contoh kueri pertanyaan Kapan dilakukan penelitian di rumah kaca
Balitro?. Hasil penelitian Cidhy (2009) dan
penulis mengembalikan 10 dokumen teratas, top passage dan jawaban yang dihasilkan pada ketiga percobaan adalah sama. Jawaban yang diperoleh adalah 1998/1999. Berikut top passage yang bersumber dari dokumen balaipenelitian000000-009.txt:
Penelitian ini bertujuan untuk menguji potensi agensi hayati dalam menekan perkembangan penyakit layu bakteri jahe. Untuk itu telah dilakukan penelitian di <LOCATION>rumah kaca Balittro Bogor
</LOCATION> pada tahun <DATE>1997/1998 </DATE> dan di lanjutkan penelitian di lapang di <LOCATION> IP Sukamulya (Sukabumi)</LOCATION> pada tahun <DATE>1998/1999</DATE>.
Persentase ketepatan jawaban untuk kata tanya KAPAN merupakan yang paling tinggi dibanding kata tanya yang lain. Baik penelitian Cidhy maupun yang dilakukan penulis, menghasilkan persentase kriteria right sebesar 100%. Hal ini disebabkan kedua penelitian menghasilkan top passage yang sama dengan tepat sehingga diperoleh jawaban yang sama. Daftar kueri pertanyaan dan evaluasi untuk kata tanya KAPAN dapat dilihat pada Lampiran 5. 3. Perbandingan Hasil Percobaan Untuk
Kata Tanya DIMANA
Berdasarkan 10 kueri pertanyaan yang diuji, diambil contoh kueri pertanyaan Dimana terjadi kekeringan dengan jumlah
terbanyak?. Hasil penelitian Cidhy (2009)
dan penulis mengembalikan 10 dokumen teratas yang sama, namun mengembalikan toppassage
pada dokumen mediaindonesia270308.txt. Adapun top passages yang dihasilkan:
Mereka yang terkena dampak kekeringan khususnya pada kebutuhan rumah tangga itu terdapat di
wilayah <LOCATION> Kabupaten
Gunungkidul</LOCATION>, <LOCATION> Sleman, dan Kulonprogo </LOCATION>. Jumlah yang terkena kekeringan terbanyak di wilayah
<LOCATION> Kabupaten
Gunungkidul</LOCATION> yang mencapai lebih dari <NUMBER> 100
ribu jiwa </NUMBER>.
Berdasarkan hasil top passage, diperoleh kriteria right dengan kandidat jawaban
Sleman, dan Kulonprogo.
Dengan menggunakan kueri pertanyaan yang sama, penelitian yang dilakukan menggunakan rule-based menghasilkan kriteria
wrong yaitu Kabupaten Rembang. Jawaban ini diperoleh setelah sistem mengembalikan top passage yang kurang tepat sebagai berikut :
Provinsi <LOCATION> Jateng </LOCATION> menghadapi kekeringan tahun ini telah memprioritaskan pembuatan embung-embung air agar dapat mengairi lahan pertanian yang dilanda kekeringan. "Kita tengah mempercepat pembuatan embung di <LOCATION>Kabupaten
Rembang</LOCATION> pada tahun <DATE>2005</DATE>, agar lahan pertanian di <LOCATION>Kabupaten Rembang</LOCATION> yang sering dilanda kekeringan dapat terairi," katanya.
Masih menggunakan kueri pertanyaan yang sama, penelitian yang dilakukan menggunakan gabungan heuristic dan rule-based juga menghasilkan kriteria wrong yaitu Kabupaten
Rembang. Hal ini disebabkan toppassage yang
dihasilkan sama dengan toppassage pada rule-based.
Persentase ketepatan jawaban untuk kata tanya DIMANA pada penelitian Cidhy (2009) lebih baik dari metode yang lain, karena menghasilkan persentase kriteria right sebesar 90% dan wrong 10%, sedangkan hasil penelitian penulis dengan rule-based dan untuk gabungan heuristic dan rule-based
menghasilkan persentase yang sama dengan kriteria right sebesar 80% dan wrong 20%. Daftar kueri pertanyaan dan evaluasi untuk kata tanya DIMANA dapat dilihat pada Lampiran 6
.
4. Perbandingan Hasil Percobaan Untuk Kata Tanya BERAPA
Berdasarkan 10 kueri pertanyaan yang diuji, diambil contoh kueri pertanyaan Berapa luas wilayah yang ditanami tanaman padi
di Kalimantan Timur?. Hasil penelitian
Cidhy (2009) dan penulis mengembalikan 10 dokumen teratas yang sama, namun mengembalikan top passage dan jawaban yang berbeda. Top passage yang diperoleh pada penelitian Cidhy (2009) maupun gabungan
heuristic dan rule-based mengembalikan kriteria wrong dengan jawaban 6 kecamatan.
Adapun top passage yang diperoleh dari
dokumen indosiar031203.txt, yaitu :
Dari catatan <ORGANIZATION>Dinas Pertanian dan Tanaman Pangan Provinsi Jambi</ORGANIZATION>, rusaknya tanaman pertanian akibat banjir yang terjadi pada tanaman padi, cabe, kacang tanah, dan jeruk. Hal itu terjadi di <NUMBER>6 kecamatan</NUMBER> yang ada di <LOCATION>Kabupaten
Kerinci</LOCATION>, seperti tanaman
padi seluas <NUMBER>11,87
hektar</NUMBER> tergenang air, dan
sebanyak <NUMBER>148
hektar</NUMBER> mengalami puso.
Pada kueri pertanyaan yang sama, penelitian yang dilakukan menggunakan rule-based
mengembalikan jawaban yang benar yaitu 11,5 juta dengan toppassage sebagai berikut :
Semua pelaku usaha perbenihan
masih mengonsentrasikan pemasarannya di <LOCATION> Pulau
Jawa </LOCATION> yang dinilai sudah maju dalam usaha tanaman pangan, sedangkan di luar <LOCATION> Pulau Jawa </LOCATION> belum banyak disentuh atau dimanfaatkan produsen benih sehingga produktivitas padi yang dihasilkannya pun masih rendah. <NAME> Susena </NAME> mengatakan, peluang pemasaran benih padi unggul saat ini masih terbuka lebar karena dari areal tanaman padi sekira <NUMBER>11,5 juta</NUMBER> ha, hanya sekira <NUMBER> 4 juta </NUMBER> ha yang menggunakan benih padi unggul.
Jawaban yang diperoleh dengan rule-based lebih tepat dibanding metode yang lain. Hal ini disebabkan oleh top passage yang dihasilkan
Persentase ketepatan jawaban untuk kata tanya BERAPA merupakan yang paling rendah dibanding kata tanya yang lain. Dengan metode
rule-based menghasilkan persentase kriteria
right sebesar 50%, unsupported 10%, dan
wrong 40%, sedangkan penelitian Cidhy (2009) maupun metode gabungan menghasilkan persentase kriteria right sebesar 40%,
unsupported 10%, dan wrong 50%. Hal ini disebabkan pada panamaan entitas ( Name-Entity-Tagger) untuk Kata Tanya BERAPA masih dalam ruang lingkup yang kecil, yaitu hanya menggunakan tangging <NUMBER>, <CURRENCY>, dan <PERCENT> sedangkan penulisan teks dan informasi untuk jawaban BERAPA seringkali disajikan dengan cara lebih variatif. Seperti adanya penulisan dalam bentuk rincian untuk jumlah, luas dan lain-lain.
Daftar kueri pertanyaan dan evaluasi untuk kata tanya BERAPA dapat dilihat pada Lampiran 7.
5. Perbandingan Hasil Percobaan untuk keseluruhan Kata Tanya
Percobaan dilakukan dengan membandingkan ketepatan passage dan jawaban yang ditemukembalikan pada keseluruhan Kata Tanya menggunakan tiga metode pembobotan passages.
Perbandingan Hasil Percobaan menggunakan 10 Dokumen Teratas
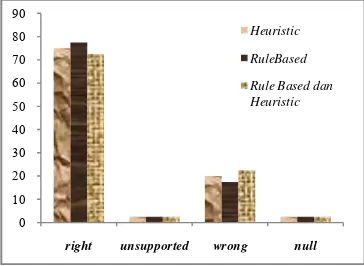
Persentase ketepatan jawaban yang ditemukembalikan dari hasil percobaan dapat dilihat pada Gambar 8.
Gambar 8 Grafik hasil percobaa keseluruhan kata tanya menggunakan 10 dokumen teratas.
Berdasarkan Gambar 8 dapat dilihat bahwa metode pembobotan rule-based menghasilkan persentase kriteria right yang tinggi dibanding metode yang lain. Persentase untuk kriteria
right untuk rule-based sebesar 77,5%, heuristic
persentasenya lebih rendah daripada rule-based
sebesar 75%, dan untuk penggabungan kedua metode hasil persentasenya lebih kecil dari masing-masing metode sebesar persentase 72,5%.
Perbandingan Hasil Percobaan menggunakan 2 Dokumen Teratas
Persentase ketepatan jawaban yang ditemukembalikan dari hasil percobaan dapat dilihat pada Gambar 9.
Gambar 9 Grafik hasil percobaan keseluruhan kata tanya menggunakan 2 dokumen teratas.
Berdasarkan Gambar 9 dapat dilihat bahwa metode pembobotan heuristic serta gabungan
heuristic dan rule-based menghasilkan persentase kriteria right yang tinggi dibanding metode rule-based. Persentase heuristic dan penggabungan kedua metode hasil persentasenya sebesar 75% sedangkan persentase untuk kriteria right untuk rule-based
sebesar 60%.
Dengan menggunakan keseluruhan Kata Tanya yang diambil dari 10 dokumen teratas, metode rule-based lebih banyak mengembalikan top passages dan jawaban yang tepat. Diambil dari 2 dokumen teratas, metode
heuristic serta gabungan heuristic dan rule-based yang lebih banyak mengembalikan top passages dan jawaban yang tepat. Dengan demikian, dilihat untuk masing-masing pembobotan dapat mengembalikan jawaban yang tepat namun tergantung pada banyaknya dokumen yang digunakan. Untuk pembobotan dengan metode rule-based berpengaruh pada banyaknya dokumen namun tergantung pada
rule yang digunakan dalam menemukembalikan jawaban berdasarkan tipe pertanyaan kueri, sedangkan pembobotan heuristic berpengaruh pada banyaknya dokumen dan keterkaitan informasi dan urutan susunan kata pada kueri dengan passages.
0 10 20 30 40 50 60 70 80 90
right unsupported wrong null Heuristic RuleBased Rule Based dan Heuristic
0 10 20 30 40 50 60 70 80
right unsupported wrong null Heuristic
RuleBased
Untuk penggabungan metode rule-based
dan heuristic ternyata metode ini belum dapat mengembalikan top passages yang lebih tepat, Hal ini disebabkan karena ada kemungkinan beberapa top passage yang ditemukembalikan pada metode rule-based memiliki satu atau lebih top passages dengan nilai yang sama, sehingga nilai gabungan kedua metode cenderung mengikuti nilai top passages pada nilai yang diperoleh pada pembobotan heuristic. Ada beberapa top-passages yang tepat, baik menggunakan heuristic, rule-based dan gabungan kedua metode, namun memperoleh nilai wrong. Hal ini disebabkan perolehan entitas jawaban yang kurang tepat. Contoh dengan menggunakan kueri “Berapa luas
areal sagu dunia ?” dapat di peroleh
passage yang tepat berikut dengan bobot tertinggi:
<ORGANIZATION>Indonesia</ORGANIZA TION> adalah pemilik areal sagu terbesar, dengan luas areal sekitar <NUMBER>1 128 juta ha</NUMBER> atau <PERCENT> 51.3% <.PERCENT> dari <NUMBER>2 201 juta ha</NUMBER> areal sagu dunia, disusul oleh <ORGANIZATION> Papua New Guinea </ORGANIZATION> <PERCENT> 43.3% </PERCENT>. Namun dari segi
pe-manfaatannya, <ORGANIZATION> Indonesia</ORGANIZATION> masih jauh
tertinggal dibandingkan dengan
<ORGANIZATION> Malaysia </ORGANIZATION> dan <ORGANIZATION>
Thailand </ORGANIZATION> yang masing-masing hanya memiliki areal seluas <PERCENT>1.5%</PERCENT> dan <PERCENT>0.2%</PERCENT>.
Jawaban yang tepat harusnya 2 201 juta ha, namun karena perolehan entitas jawaban berdasarkan pada rataan kedekatan jarak antara kandidat jawaban dengan kata hasil wordmatch, maka jawaban yang dikembalikan 1 128 juta ha.
Pada kriteria null atau tidak mengembalikan jawaban apapun dikarenakan tidak ditemukan entitas yang sesuai pada top passage. Dengan demikian, tidak ditemukan jawaban dari top passage tersebut.
Hasil ketiga metode menunjukkan ketepatan top passage yang diperoleh sangat mempengaruhi jawaban yang dihasilkan. Oleh karena itu, semakin baik metode untuk melakukan pembobotan passage maka semakin tepat jawaban yang diperoleh.
KESIMPULAN DAN SARAN Kesimpulan
Hasil penelitian menunjukkan pembobotan
passages menggunakan metode rule-based
tidak berpengaruh pada banyaknya dokumen namun tergantung pada rule yang digunakan dalam menemukembalikan jawaban berdasarkan tipe pertanyaan kueri, sedangkan pembobotan heuristic berpengaruh pada banyaknya dokumen dan keterkaitan informasi dan urutan susunan kata pada kueri dengan
passages. Saran
1. Perlu dilakukan perbaikan metode perolehan entitas jawaban secara semantik dengan POS-Tagging pada penelitian-penelitian selanjutnya.
2. Perlu dilakukan penambahan Name-Entity-Tagger untuk Kata Tanya BERAPA.
DAFTAR PUSTAKA
Ballesteros, L. A dan Xiaoyan-Li. 2007.
Heuristic and Syntactic for Cross-language Question Answering. Di dalam: Proceedings of NTCIR-6 Workshop Meeting. Tokyo, 15-18 Mei 2007. hlm 230-233.
Cidhy D A T K. 2009. Implementasi Question Answering System dengan Pembobotan
Heuristic [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Citraningputra P. 2009. Entitas Tagging untuk Dokumen Berbahasa Indonesia Menggunakan Metode Berbasis Aturan [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Manning C D, Raghavan P, Schütze H. 2008.
Introduction to Information Retrieval. Cambridge: Cambridge University Press. Riloff E, Thelen M. 2000. A Rule-based
Question Answering System for Reading Comprehension Tests. ANLP/NAACL-2000 Workshop on Reading Comprehension Tests as Evaluation for Computer-Based Language Understanding System.
Lampiran 2 Contoh dokumen XML dalam koleksi pengujian
<DOC>
<DOCNO>republika311002-001</DOCNO>
<TITLE>Meski Surplus, Produktivitas Pertanian Padi Sulsel Masih Rendah </TITLE>
<AUTHOR> Ant/Rambe </AUTHOR>
<DATE> 31-10-2002 </DATE>
<TEXT>
Makassar -RoL-- Meskipun provinsi Sulawesi Selatan (Sulsel) setiap tahun sudah surplus beras 1,3 juta ton, namun produktivitas pertanamannya masih sangat rendah, kata Asisten II Sekwilprov Sulsel, H. Abbas Sabbi di Makassar, hari Kamis.
Rendahnya produktivitas pertanaman itu disebabkan dari keseluruhan bibit yang digunakan oleh petani, hanya terdapat 15 persen bibit yang ditanam berlabel. Berarti, ucap Abbas Sabbi, produksi lahan pertanian Sulsel yang luasnya 700 ribu hektare itu, masih dapat ditingkatkan apabila petani sepenuhnya menanam bibit berlabel.
Menurutnya, kebutuhan bibit di Sulsel setiap musim tanam sebanyak 24.000 ton, tetapi diantaranya petani hanya menggunakan 15 persen atau sekitar 3.600 ton bibit berlabel. Melalui penggunaan bibit berlabel, produksi beras Sulsel dapat ditingkatkan 4,5 juta ton per tahun untuk dua kali musim tanam.
Abbas Sabbi mengimbau agar pihak terkait lebih mengintensifkan pembinaan kepada petani agar seluruh areal tanam menggunakan bibit berlabel, karena sangat erat dengan upaya peningkatan produksi, dan pendapatan petani. Dalam 2 - 3 tahun ke depan, sekitar 30 persen lahan pertanian di Sulsel akan dikembangkan dengan beras "aromatik".
Program beras aromatik ini sangat terkait dengan penggunaan bibit berlabel, sehingga petani sudah saatnya mulai dibiasakan menggunakan bibit berlabel.
</TEXT>
Lampiran 3 Contoh pemberian entitasdokumen text dalam koleksi pengujian
Lampiran 4 Tabel hasil kata tanya ‘Siapa’
Keterangan R: Right U: Unsupported W: Wrong N: Null
No Query
Heuristic Rule-based Heuristic dan
Rule-based
Jawaban Ket Jawaban Ket Jawaban Ket
1 Siapa Asisten Sekretaris Daerah (Assekda) Bidang Kesejahteraan Rakyat Provinsi DIY?
Bambang
Purnomo R
Bambang
Purnomo R
Bambang
Purnomo R
2 Siapa Bambang Purnomo?
Asisten Sekretaris Daerah Assekda Bidang Kesejahteraan Rakyat
R
Asisten Sekretaris Daerah Assekda Bidang
Kesejahteraan Rakyat
R
Asisten Sekretaris Daerah Assekda Bidang Kesejahteraa n Rakyat
R
3 Siapa Juru Bicara Departemen Luar Negeri Republik Indonesia?
Marty
Natalegawa R
Marty
Natalegawa R
Marty
Natalegawa R
4 Siapa Marty Natalegawa?
Departemen Luar Negeri Republik Indonesia
R
Departemen Luar Negeri Republik Indonesia
R
Departemen Luar Negeri Republik Indonesia
R
5 Siapa menteri pertanian?
Bungaran
Saragih R
Bungaran
Saragih R
Bungaran
Saragih R
6 Siapa yang bekerja sama dengan Unibraw untuk menangani pasca panen ikan?
Lembaga Kimia Nasional R
Lembaga Kimia Nasional R
Lembaga Kimia Nasional
R
7 Siapa Ketua Umum Dewan Pimpinan Pusat Himpunan Alumni Institut Pertanian Bogor?
Muwardi P
Simatupang R
Muwardi P
Simatupang R
Muwardi P Simatupang R
8 Siapa Prof. Dr Ir Naik Sinukaban MSc
Null - Null - Null -
9 Siapa Bungaran
Saragih? Null -
Menteri
Pertanian R Kompas W
1 0
Siapa menghasilkan penelitian tentang budi daya pisang dengan kultur jaringan?
Lampiran 5 Tabel hasil kata tanya ‘Kapan’
No
Query
Heuristic Rule-based Heuristic dan
Rule-based
Jawaban Ket Jawaban Ket Jawaban Ket
1 Kapan dilakukan penelitian di rumah kaca Balitro?
1997/1998 R 1997/1998 R 1997/1998 R
2 Kapan Malaysia menyatakan akan menindak tegas para pekerja asing?
Senin 12/7 R Senin 12/7 R Senin 12/7 R
3 Kapan Bungaran Saragih menyatakan kelangkaan pupuk diakibatkan adanya penyebaran yang terjadi secara sporadic?
Rabu
26/05/2004 R
Rabu
26/05/2004 R
Rabu
26/05/2004 R
4 Kapan diadakan semiloka pengelolaan ekosistem pesisir?
31 Juli 2002 R 31 Juli 2002 R 31 Juli 2002 R
5 Kapan dilakukan Penelitian secara on-farm adaptif pada dua lokasi di desa Nepo Kecamatan Mallusetasi, kabupaten Barru?
Agustus sampai Nopember 2000
R Agustus sampai
Nopember 2000 R
Agustus sampai Nopember 2000
R
6 Kapan pengaruh isu pertanian, kenaikan harga pangan, mempengaruhi sejarah Indonesia?
1965 R 1965 R 1965 R
7 Kapan perkenalan Warno dengan cacing?
1998 R 1998 R 1998 R
8 Kapan WTO RIO DE JANERIO 20 negara dilaksanakan?
10-14 September 2003
R 10-14
September 2003 R
10-14 September 2003
R
9 Kapan diadakan semiloka Pengembangan Kawasan Pantai sebagai alternative akselerator pembangunan daerah?
31 Juli 2002 R 31 Juli 2002 R 31 Juli 2002 R
10 Kapan dilaksanakan Konpernas Ekonomi Pertanian XIV dan Kongres XIII?
Lampiran 6 Tabel hasil kata tanya ‘Dimana’
No Query
Heuristic Rule-based Heuristic dan
Rule-based
Jawaban Ket Jawaban Ket Jawaban Ket
1 Dimana terjadi
kekeringan dengan jumlah terbanyak?
Kabupaten Gunung Kidul R
Kabupaten Rembang W
Kabupaten Rembang W
2 Dimana dilakukan pengembangan tanaman jahe gajah secara besar-besaran?
Kabupaten Rejang Lebong R
Kabupaten Rejang Lebong R
Kabupaten Rejang Lebong
R
3 Dimana dilakukan peresmian Pencanangan Gerakan Tambahan Dua Juta Ton Jagung (Gentataton)?
DunggalanTiba wa Gorontalo R
DunggalanTibaw a Gorontalo R
DunggalanTib awa Gorontalo
R
4 Dimana Bureau of Animal and Plant Health Inspection and Quarantine (BAPHIQ)?
Taiwan R Taiwan R Taiwan R
5 Dimana Peter Allgeire
menjadi deputi perwakilan dagang?
AS R AS R AS R
6 Dimana kegiatan bongkar muat beras import dilakukan?
Pelabuhan Tanjung Perak
Surabaya
R
Pelabuhan Tanjung Perak
Surabaya
R
Pelabuhan Tanjung
Perak Surabaya
R
7 Dimana pengolahan sagu
skala industry berkembang?
Maluku dan Irian Jaya R
Maluku dan Irian Jaya R
Maluku dan Irian Jaya R
8 Dimana unsure N diyakini sebagai kunci utama peningkatan produksi padi?
Sulawesi
Selatan R
Sulawesi
Selatan R
Sulawesi Selatan R
9 Dimana terjadi masalah sempitnya lahan pertanian,
inefisiensi,
produktivitas rendah, dan fluktuasi harga produk pertanian?
Indonesia R Indonesia R Indonesia R
10 Dimana terjadi
penurunan produksi tanaman tembakau?
Indonesia W Indonesia W Indonesia W
Lampiran 7 Tabel hasil kata tanya ‘Berapa’
No
Query
Heuristic Rule-based Heuristic dan
Rule-based
Jawaban Ket Jawaban Ket Jawaban Ket
1 Berapa harga jual untuk sapi dengan berat 250 kg?
Rp 3 juta-Rp 4 juta R
Rp 3 juta-Rp 4 juta R
Rp 3 juta-Rp 4 juta R
2 Berapa harga
pemesanan kursi Rafles?
Rp 275
ribu/unit R
Rp 275
ribu/unit R
Rp 275
ribu/unit R
3 Berapa luas
Kalimantan Timur?
24,5 juta hektar R
24,5 juta hektar R
24,5 juta hektar R
4 Berapa luas areal
sagu Malaysia? 51,5% W 51,5% W 51,5% W
5 Berapa usia panen pertama kali lengkeng?
2-3 kali|2 tahun W
2-3 kali|2 tahun W
2-3 kali|2 tahun W
6 Berapa luas areal sagu dunia?
51.3%|1 128 juta ha|2 201
juta ha
W
51.3%|1 128 juta ha|2 201
juta ha
W
51.3%|1 128 juta ha|2 201 juta ha
W
7 Berapa harga
beras dalam negri antara bulan Juni-Juli?
Rp 4000 U Rp 4000 U Rp 4000 U
8 Berapa luas areal sagu Indonesia?
1 128 juta
ha, R 1 128 juta ha, R
1 128 juta
ha, R
9 Berapa jumlah
penduduk China? 70 centimeter W 70 centimeter W
70
centimeter W
10 Berapa luas
wilayah yang ditanami tanaman
padi di Kalimantan Timur?
6 kecamatan W 11,5 juta ha R 6 kecamatan W
ABSTRACT
SUCI ARMELIA SANUR. Passages Selection in Question Answering System for Indonesian Language Documents. Supervised by JULIO ADISANTOSO.
The first step on Question Answering System was the user enter question query. The used question query is limited to question type: WHO, WHERE, WHEN, and HOW MANY or HOW MUCH. The question word on query is used to obtain an answer candidate, while other words beside the question word are used to analyze the question. Question analysis process is started by parsing into keyword become tokens. The question sentence that has parsed is used to retrieve document and top passage. Top passage is obtained of question from passages that has highest point. Passages was done by three scoring method : rule-based, heuristic, and combination of rule-based with heuristic. The answer extraction is conducted by calculating the nearest distance between each answer candidate in top passage and each word in keyword. Answer correction is evaluated by using these criteria: right, unsupported, wrong, and null.
The evaluation of the research was seen on the set of question and document, also the accuracy for each answer. The result of rule-based scoring used 10 top documents was 77.5 % for criteria right, 2.5 % for criteria unsupported, 17.5 % for criteria wrong, and 2.5 % for criteria null. The result of heuristic scoring was 75 % for criteria right, 2.5 % for criteria unsupported, 20 % for criteria wrong, and 2.5 % for criteria null. The result of rule-based and heuristic scoring was 72.5 % for criteria right, 2.5 % for criteria unsupported, 22.5 % for criteria wrong, and 2.5 % for criteria null. The result of heuristic scoring used 2 top documents was 75 % for criteria right, 22.5 % for criteria wrong, and 2.5 % for criteria null. The result of rule-based scoring was 60 % for criteria right, 37.5 % for criteria wrong, and 2.5 % for criteria null. The result of rule-based and heuristic scoring was 75 % for criteria right, 22.5 % for criteria wrong, and 2.5 % for criteria null.
Gambar

Dokumen terkait
Oleh karena itu, penelitian ini diperlukan untuk menguji efektivitas daya bunuh dari produk pembersih lantai yang digunakan oleh masyarakat Indonesia terhadap bakteri
APAC INTI CORPORA Bawen, Semarang berdasarkan SNI 7231:2009 tentang Metode Pengukuran Intensitas Kebisingan di Tempat Kerja dan hubungannya pada perubahan nilai ambang
Dalam penelitian dapat dirumuskan pemasalahan sebagai berikut : (1) Bagaimana pola pembinaan cabang olahraga pelajar (13 cabang olahraga) melalui Dinas Pendidikan
Dari uraian di atas dapat kita simpulkan pertama kemahiran memilih kata hanya dimungkinkan bila seseorang menguasai kemahiran kosa kata yang cukup luas, kedua diksi atau
Program Farmakomatic diran- cang untuk mengolah data konsen- trasi obat yang diperoleh dari sampel darah menjadi parameter farma- kokinetik secara otomatis pada rute pemberian
Pengaruh non monotonic, menunjukkan arah yang sesuai dengan hipotesis yang diajukan, yaitu semakin besar komitmen organisasi akan menyebabkan semakin menurunnya
Penelitian yang berkaitan dengan ang- garan yang berbasis kinerja telah banyak dilakukan antara lain Ritongan (2008) hasil- nya menunjukkan bahwa budaya paterna- listik
(7) Bentuk dan isi slip setoran sebagaimana dimaksud pada ayat (5) tercantum dalam Lampiran XII yang merupakan bagian yang tidak terpisahkan dari
