IMPLEMENTASI ALGORITME FONETIK UNTUK KOREKSI
EJAAN BAHASA INDONESIA
FAHMILU KURNIAWAN
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
IMPLEMENTASI ALGORITME FONETIK UNTUK KOREKSI
EJAAN BAHASA INDONESIA
FAHMILU KURNIAWAN
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar
Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRACT
FAHMILU KURNIAWAN. Implementation of Phonetic Algorithm for Spelling Correction in Bahasa Indonesia. Under the supervision of Ahmad Ridha.
A technique to obtain documents containing information in accordance with a user’s requirements is necessary for an information retrieval system. This research compared the performance of four phonetic algorithms: Soundex, Phonix, Metaphone, and Caverphone. This research used a database derived from KBBI 2005. The accuracy of Soundex, Phonix, Metaphone, and Caverphone is 92%, 78%, 77%, and 75%, respectively. However, Soundex and Phonix suggested twice as many words as
Metaphone and Caverphone.
Judul : Implementasi Algoritme Fonetik untuk Koreksi Ejaan Bahasa Indonesia Nama : Fahmilu Kurniawan
NRP : G64053002
Menyetujui:
Dosen Pembimbing,
Ahmad Ridha, S.Kom, M.S. NIP: 19800507 200501 1 001
Dr. Ir. Sri Nurdiati, M.Sc. NIP: 19601126 198601 2 001
Tanggal lulus:
PRAKATA
Alhamdulillahi rabbil ‘alamin, puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’alaatas segala curahan rahmat dan karunia-Nya sehingga penulis dapat menyelesaikan tugas akhir sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer di Fakultas Matematika dan IPA, Institut Pertanian Bogor.
Pada kesempatan ini, penulis mengucapkan terima kasih yang sebesar-besarnya kepada semua pihak yang telah membantu terutama kepada:
1 Ibunda tercinta yang telah banyak berkorban dan berjuang untuk membesarkan serta menye-kolahkan penulis sampai jenjang sarjana.
2 Ayahanda Alm. Drs. Pudji Mulyono atas segala kesempatan dan dorongan serta doa.
3 Kepada Bapak Ahmad Ridha, S.Kom, M.S selaku pembimbing atas segala bimbingan, dukungan, dan perhatiannya kepada penulis selama penelitian berlangsung.
4 Kepada Bapak Ir. Julio Adisantoso, M.Kom dan Bapak Sony Hartono Wijaya, S.Kom, M.Kom selaku penguji tugas akhir ini yang telah banyak memberikan masukan demi kesempurnaan tugas akhir ini.
5 Kepada kedua kakak saya Nur Hidayati, S.Hut dan Nurul Rachmawati, S.Pd yang telah mem-berikan banyak motivasi dan pengalaman hidup.
6 Eka Nani P. atas doa, kasih sayang, bantuan, dan dukungan serta semangat dan kebersamaan selama ini.
7 Indra Juniawan, Andi Sasmita, M. Saad Nurul Islah, Damas Widyatmoko, dan Fakhri Mahathir. sahabatku sebimbingan, atas doa, semangat, bantuan, dan kebersamaan selama ini.
8 Ust. Dani atas segala arahan, perhatian, dan semangat.
9 Jarot, Saiful, Mas Dekri, Mas Dede, Fathoni, dan Wikhdal atas bantuan, semangat, dan keber-samaan selama ini.
10 Mas A. Fuadi atas semangat man jadda wa jada dan pelajaran tentang keikhlasan.
11 Syariful Mizan, Fathoni Arif Musyaffa, Hermawan Tri Rosanja, Hengky Hariady, Haryanto, Desca Marwantoni, serta Furqon Hensan Mutaqien atas kebersamaan selama ini.
12 Teman-teman Ilkomerz 42 atas bantuan dan dukungannya.
13 Seluruh staf pengajar dan staf karyawan di Departemen Ilmu Komputer atas bantuannya.
Segala kesempurnaan hanya milik Allah subhanahu wa ta’ala dan penulis berharap semoga karya ilmiah ini bermanfaat, amin.
Bogor, Januari 2010
RIWAYAT HIDUP
Penulis dilahirkan di Madiun, Jawa Timur pada tanggal 14 Juli 1987 yang merupakan anak ketiga dari tiga bersaudara dengan ayah bernama Pudji Mulyono dan ibu Siti Maisaroh.
iv DAFTAR ISI
Halaman
DAFTAR TABEL ... v
DAFTAR GAMBAR ... v
DAFTAR LAMPIRAN ... v
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan ... 1
Ruang Lingkup ... 1
Manfaat Penelitian ... 1
TINJAUAN PUSTAKA ... 1
Metode Pemeriksaan Ejaan ... 2
Fonetik ... 2
Klasifikasi Konsonan ... 2
Algoritme Soundex ... 2
Algoritme Phonix ... 3
Algoritme Metaphone ... 3
Algoritme Caverphone ... 3
Damerau Lavenstein Metric ... 4
METODOLOGI PENELITIAN ... 5
Pengumpulan Data ... 5
Pembuatan Aplikasi ... 5
Pengujian Aplikasi ... 6
Percobaan ... 6
Analisis Data dan Kesimpulan ... 6
Akurasi ... 6
Lingkungan Pengembangan ... 7
HASIL DAN PEMBAHASAN... 7
Peringkat ... 7
Kata Usulan ... 7
Akurasi pada Kesalahan Penyisipan ... 8
Akurasi pada Kesalahan Penghapusan ... 9
Akurasi pada Kesalahan Penggantian ... 10
Akurasi pada Kesalahan Penukaran ... 10
Waktu Koreksi ... 11
Kelebihan dan Kekurangan ... 11
KESIMPULAN DAN SARAN... 11
Kesimpulan ... 11
Saran ... 11
DAFTAR PUSTAKA ... 12
v DAFTAR TABEL
Halaman
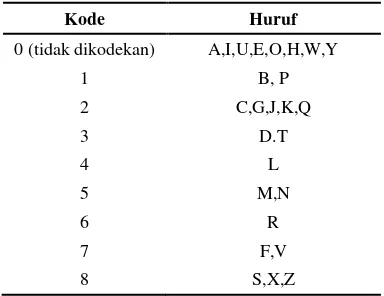
1 Kode numerik algoritme Soundex (Russel 1918)... 3
2 Kode numerik algoritme Phonix (Gadd 1990 dalam Pfeifer et al. 1994) ... 3
3 Aturan kode fonetik algoritme Metaphone (Phillips 1990) ... 4
4 Data statistik kata usulan ... 8
5 Banyak kata berdasarkan letak kesalahan penyisipan ... 8
6 Akurasi algoritme fonetik untuk letak kesalahan penyisipan di tengah kata ... 8
7 Akurasi algoritme fonetik untuk letak kesalahan penyisipan di belakang kata ... 8
8 Banyak kata berdasarkan letak kesalahan penggantian ... 9
9 Akurasi algoritme fonetik untuk letak kesalahan penggantian huruf pertama ... 9
10 Banyak kata berdasarkan letak kesalahan penukaran ... 10
11 Rata-rata waktu koreksi ... 11
DAFTAR GAMBAR Halaman 1 Metodologi penelitian ... 5
2 Proses pengodean kamus ... 5
3 Diagram alir aplikasi koreksi ejaan ... 6
4 Grafik hasil klasifikasi peringkat tiap algoritme ... 7
5 Grafik akurasi untuk kesalahan penghapusan. ... 9
6 Grafik akurasi untuk kesalahan penggantian di tengah kata ... 9
7 Grafik akurasi untuk kesalahan penggantian di belakang kata ... 10
8 Grafik akurasi untuk kesalahan penukaran... 10
9 Grafik akurasi keseluruhan ... 10
DAFTAR LAMPIRAN Halaman 1 Aturan algoritme Caverphone ... 14
2 Contoh kamus kode ... 15
3 Antarmuka aplikasi koreksi ejaan ... 16
4 Klasifikasi jenis kesalahan ... 18
5 Contoh data hasil percobaan ... 19
1 PENDAHULUAN
Latar Belakang
Penggunaan mesin pencarian di dunia maya saat ini telah menjadi salah satu kebutuhan yang tidak bisa digantikan. Pencarian informasi yang tepat dan sesuai kebutuhan menjadi sangat penting. Oleh karena itu, teknik untuk memperoleh dokumen yang memuat informasi sesuai dengan kebutuhan begitu diperlukan. Hal tersebut menuntut adanya ejaan yang benar dalam pencarian kata, sehingga adanya suatu metode yang bisa digunakan untuk koreksi ejaan diharapkan akan memberikan dampak positif terhadap perkembangan sistem temu kembali informasi.
Sekarang telah banyak dijumpai aplikasi yang mempuyai fungsi untuk melakukan koreksi ejaan. Program aplikasi pengoreksi ejaan pertama kali direalisasikan pada tahun 1971, yaitu program SPELL pada DEC-10 yang ditulis oleh Ralph Gorin di Stanford (Peterson 1980). Pengembangan program dan revisinya telah disebarkan. Aplikasi yang sekarang sedang banyak dikembangkan adalah proyek Aspell yang telah merilis aplikasi terbarunya pada April 2008. Bahkan kini hampir semua aplikasi pengolahan kata telah menyertakan program pengoreksi ejaan.
Koreksi ejaan bisa dilakukan dengan algoritme non-fonetik dan fonetik. Sutisna (2009) telah menggunakan algoritme non-fonetik untuk koreksi ejaan Bahasa Indonesia karena kesalahan pengetikan dengan menggunakan Damerau Levenstein Metric. Hasil dari penelitiannya menunjukkan bahwa metode yang digunakan dapat meningkatkan kinerja sistem temu kembali informasi.
Algoritme fonetik telah banyak dikembangkan dan digunakan untuk pencarian nama. Struktur yang menghasilkan kode-kode dari kata membuat algoritme fonetik mudah untuk diimplementasikan. Namun karena struktur bahasa yang beragam, banyak kendala yang ditemukan pada saat digunakan untuk ejaan khususnya Bahasa Indonesia. Contoh penggunaan algoritme fonetik adalah pada jasa Customer Service (CS). Ketika ada pelanggan menyebutkan nama, CS dapat mengetikkan nama tanpa harus mengetahui ejaan spesifik nama tersebut.
Penelitian tentang penggunaan algoritme fonetik pernah dilakukan oleh Primasari (1997) untuk pencarian dan temu kembali informasi nama dalam ejaan Indonesia serta oleh Syaroni (2005) untuk pencocokan string dalam Bahasa
Inggris dengan menggunakan beberapa algoritme fonetik. Algoritme yang digunakan dalam penelitian tersebut adalah: Soundex, Metaphone, dan Caverphone. Syaroni (2005) menyimpulkan bahwa algoritme Soundex paling efektif untuk pencocokan kata.
Tujuan
Tujuan dari penelitian ini adalah:
1 Menerapkan algoritme fonetik untuk koreksi ejaan Bahasa Indonesia.
2 Mengukur keefektifan beberapa algoritme fonetik (Soundex, Phonix, Metaphone, dan Caverphone) dan membandingkan dengan Damerau Levenstein Metric untuk koreksi ejaan Bahasa Indonesia. Tingkat keefektifan dilihat dari beberapa komponen, yaitu: peringkat, banyak kata usulan, akurasi dalam pengoreksian ejaan, serta waktu koreksi.
Ruang Lingkup
Beberapa lingkup penelitian ini meliputi:
1 Penelitian ini difokuskan kepada Phonix, implementasi algoritme Soundex,
Metaphone, dan Caverphone dengan melihat banyak
akurasi, kata usulan, dan waktu proses dalam pengoreksian ejaan Bahasa Indonesia.
2 Data yang digunakan diperoleh dari Kamus Besar Bahasa Indonesia (KBBI) tahun 2005 yang berisi lebih dari 50 ribu kata dasar dan kata berimbuhan selain berimbuhan di-. 3 Hasil yang diperoleh hanya sebatas
memberikan kata-kata usulan yang memiliki kesamaan kode fonetik. Di dalam kata-kata yang diusulkan terdapat kata yang benar dan yang diinginkan.
Manfaat Penelitian
Dari penelitian ini diharapkan dapat diketahui algoritme fonetik yang paling efektif untuk koreksi ejaan Bahasa Indonesia terutama untuk jenis kesalahan pengetikan, serta rata-rata kinerja algoritme fonetik untuk koreksi ejaan Bahasa Indonesia. Selain itu, dari penelitian ini diharapkan dapat diketahui perbandingan kinerja antara algoritme fonetik dengan Damerau Levenstein Metric, sehingga dapat digunakan untuk membuat sistem koreksi ejaan yang efektif.
TINJAUAN PUSTAKA
2 hal, yaitu: penggantian satu huruf, penyisipan
satu huruf, penghilangan satu huruf, dan penukaran dua huruf berdekatan.
Sedangkan Peterson (1980), berpendapat bahwa kesalahan ejaan dapat terjadi karena beberapa hal, diantaranya:
1 Ketidaktahuan penulisan. Kesalahan ini biasanya konsisten dan kemungkinan berhubungan dengan bunyi kata serta penulisan yang seharusnya.
2 Kesalahan dalam pengetikan yang lebih tidak konsisten tapi mungkin berhubungan erat dengan posisi tombol papan ketik dan pergerakan jari.
3 Kesalahan transmisi dan penyimpanan yang berhubungan dengan pengodean pada jalur mekanisme transmisi data. Kesalahan lebih pada perangkat keras.
Metode Pemeriksaan Ejaan
Salah satu metode pemeriksaan ejaan adalah metode Look-up Table yang dikenalkan oleh Peterson (1980). Dalam metode ini kata yang dimasukkan akan dibandingkan dengan kamus yang telah disediakan. Jika kata yang dimaksud tidak ada dalam kamus maka kata tersebut dianggap salah.
Fonetik
Malmberg (1963) dalam Syaroni (2005) mendefinisikan fonetik sebagai ilmu yang menyelidiki bunyi bahasa tanpa melihat fungsi bunyi itu sebagai pembeda makna dalam suatu bahasa. Kata sifat fonetik adalah fonetis.
Bagian terpenting dari fonetik adalah klasifikasi konsonan. Klasifikasi konsonan berpengaruh pada proses pengodean yang dilakukan oleh algoritme fonetik.
Klasifikasi Konsonan
Menurut Jones (1972) dalam Syaroni (2005) klasifikasi konsonan berdasarkan alat bicara yang menghasilkannya dapat dibagi menjadi tujuh bagian, yaitu:
1 Labial atau bunyi bibir, yang dapat dibedakan lagi menjadi dua golongan yaitu:
a) Bilabial, bunyi diartikulasi oleh dua bibir, contoh bunyi p, b, m, dan w. b) Labio-dental, bunyi diartikulasi oleh
bibir bawah dan gigi atas, contoh bunyi f dan v.
2 Dental, bunyi diartikulasi oleh gigi atas dengan ujung lidah, contoh bunyi th (dalam kata thin).
3 Alveolar, bunyi diartikulasi oleh ujung lidah dengan punggung gigi (teeth-ridge), contoh bunyi d, t, n, l, r, s, dan z.
4 Palato-alveolar, bunyi yang memiliki artikulasi alveolar diikuti dengan naiknya lidah sampai pada langit-langit mulut secara simultan, contoh bunyi c, j, dan sh (dalam kata show).
5 Palatal, bunyi diartikulasi oleh bagian depan lidah dengan langit-langit keras (hard palate), contoh bunyi y.
6 Velar, bunyi diartikulasi oleh bagian belakang lidah dengan langit-langit lunak (soft palate), contoh bunyi k dan g.
7 Glottal, bunyi diartikulasi oleh glottis atau celah suara, contoh bunyi h.
Algoritme Soundex
Algoritme Soundex merupakan algoritme fonetik tertua dan pertama kali dipatenkan oleh Robert C. Russel pada tahun 1918. Soundex memisahkan huruf ke dalam tujuh kelas yang berbeda. Diasumsikan huruf yang berada pada kelas yang sama memiliki kesamaan bunyi. Setiap kelas memiliki keunikan tersendiri di mana kelas ditentukan oleh bentuk kesamaan dari konsonannya, kecuali pada bagian yang mengkodekan semua huruf vokal serta huruf h,w, dan y dengan 0 (tidak dikodekan). Hal ini dikarenakan huruf-huruf tersebut dianggap sama dan tidak perlu dikodekan. Aturan pengodean dengan algoritme Soundex dapat dijelaskan seperti langkah berikut:
1 Buang semua huruf vokal, tanda baca yang pengganti yang sesuai dengan kode numerik yang ditunjukkan pada Tabel 1.
3 Ambil empat kode terdepan dan selanjutnya kode tersebut menjadi kode Soundex.
3 Tabel 1 Kode numerik algoritme Soundex
(Russel 1918)
Kode Huruf
0 (tidak dikodekan) A,I,U,E,O,H,W,Y
1 B,F,P,V
Algoritme Phonix merupakan pengem-bangan dari algoritme Soundex. Namun Phonix jauh lebih rumit bila dibandingkan dengan Soundex. Jika Soundex membagi huruf dengan tujuh kelas berbeda, maka Phonix membagi huruf dengan sembilan kelas berbeda. Pada prinsipnya cara kerja Phonix adalah sebagai berikut (Gadd 1990 dalam Pfeifer et al. 1994): 1. Jika huruf pertama adalah huruf hidup
(vokal) dan konsonan Y, maka ganti huruf pertama tersebut dengan V.
2. Buang bunyi akhir (ending sound) dari kata. Bunyi akhir adalah bagian sesudah huruf dimaksudkan dengan mengganti semua huruf yang tersisa dengan nilai numerik seperti pada Tabel 2 kecuali huruf awal. Panjang maksimum kode fonetik yang dihasilkan oleh algoritme Phonix adalah delapan karakter.
Dalam Primasari (1997) algoritme yang paling efektif dalam proses temu kembali informasi adalah Phonix4. Algoritme Phonix4 secara garis besar sama dengan algoritme Phonix. Namun panjang maksimal kode fonetiknya adalah empat karakter. Dalam penelitian ini akan digunakan algoritme Phonix4 yang selanjutnya akan disebut dengan algoritme Phonix.
Algoritme Metaphone
Algoritme Metaphone pertama dikenalkan oleh Phillips (1990). Tujuan dari algoritme ini
adalah mencari kata-kata yang memiliki persamaan bunyi. Setiap kata akan memiliki kode tertentu jika melalui algoritme Metaphone, sehingga algoritme Metaphone tidak mencari kata dasar. Kata-kata yang bunyinya sama akan memiliki kode yang sama pula.
Tabel 2 Kode numerik algoritme Phonix (Gadd 1990 dalam Pfeifer et al. 1994)
Kode Huruf
0 (tidak dikodekan) A,I,U,E,O,H,W,Y
1 B, P
Pengodean dalam Metaphone adalah dengan cara menghilangkan huruf vokal kecuali huruf vokal yang berada di awal kata. Metaphone akan mereduksi alfabet menjadi enam belas suara konsonan yaitu:
B, X, S, K, J, T, F, H, L, M, N, P, R, 0, W, dan Y.
Suara ‘sh’ direpresentasikan dengan ‘X’ dan nol (‘0’) merepresentasikan suara ‘th’.
Aturan pemberian kode fonetik oleh Metaphone untuk Bahasa Inggris dapat dilihat pada Tabel 3. Contoh: kata BAGUS akan dikodekan menjadi
’BKS’.
Algoritme Caverphone
Algoritme Caverphone dikembangkan oleh David Hood dalam proyek Caversham, Universitas Otago, New Zealand. Pertama kali, algoritme Caverphone diperkenalkan pada tahun 2002 dan ditujukan untuk pencocokan nama orang saja, tetapi kemudian dikembangkan lagi sehingga muncul algoritme 5 Caverphone versi 2.0 pada tahun 2004 yang lebih umum untuk pencocokan kata dalam Bahasa Inggris. Seperti algoritme Metaphone, algoritme Caverphone juga mengelompokkan huruf-huruf yang cenderung menimbulkan kesalahan pengucapan (satu kelompok dalam klasifikasi konsonan) dalam satu kelompok.
Langkah umum dari algoritme Caverphone untuk pencocokan nama yang pertama kali dipublikasikan oleh Hood (2002) adalah:
4 2 Diubah semua ke huruf kecil. Algoritme ini
bersifat case-sensitive.
3 Hapus semua yang bukan huruf A-Z. Misalkan: bu:kan bukan.
4 Lalu di kodekan sesuai dengan ketentuan yang sesuai. Ketentuan pengodean pada algoritme Caverphone dapat dilihat pada Lampiran 1.
Perbedaan yang tampak antara algoritme Caverphone dengan algoritme Metaphone, jika diperhatikan penjelasan algoritme-algoritme tersebut dari segi fonetik adalah (Syaroni 2005):
1 Algoritme Caverphone mempunyai langkah-langkah yang panjang dan rinci. Caverphone tidak menangani khusus untuk huruf-huruf tertentu dalam satu kelompok langkah, tetapi sudah digabung untuk beberapa huruf.
2 Algoritme Caverphone dirancang agar peka terhadap letak huruf-huruf dalam kata.
Damerau Levenstein Metric
Pfeifer et al. (1994) mendefinisikan Damerau Levenstein Metric sebagai suatu metode yang menggambarkan perbandingan kata-kata dengan memperhatikan empat macam kesalahan pengetikan (diberikan dengan contoh kata DAMERAU) seperti yang didefinisikan oleh Damerau (1964), yaitu:
1. Penyisipan huruf tambahan (insertion), misalnya DAMMERAU.
2. Penghapusan huruf dalam kata (deletion), misalnya DAMERU.
3. Penggantian sebuah huruf dengan huruf yang lain (substitution), misalnya PAMERAU.
4. Penukaran tempat dua huruf berurutan, misalnya DAMERUA.
Misalkan didefinisikan dua kata a dan b, Damerau Levenstein Metric akan dapat menghitung jumlah minimal kesalahan dari dua kata tersebut dengan persamaan:
f(0,0) = 0 HURUF KODE KETERANGAN
B B
Kecuali di akhir kata setelah 'M'
Dihapus Jika dalam SCI-', SCE-',
'-SCY-' K
D J
Jika dalam '-DGE-', '-DGY-', 'DGI'
Dihapus Jika dalam GNED', GN',
'-DGE-', '-DGI-' '-DGY-'
Dihapus Jika sesudah vokal dan tidak
diikuti vokal
H
Jika sebelum sebuah vokal dan tidak sesudah 'C', 'G',
Dihapus jika sebelum 'H'
5 Variabel i dan j menunjukkan posisi
huruf-huruf yang dibandingkan pada suatu kata, sedangkan fungsi d adalah fungsi jarak untuk huruf yang bersifat sederhana dan non-identity.
Persamaan f(i,j) menghitung jumlah kesalahan yang terkecil dengan membedakan huruf ke-i pada kata a dan huruf ke-j pada kata b.
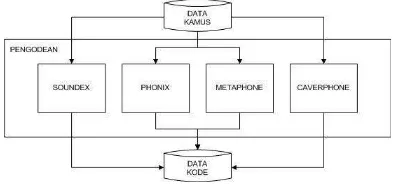
METODOLOGI PENELITIAN Pelaksanaan penelitian ini dibagi dalam beberapa tahap yang dapat dilihat pada Gambar 1. Secara garis besar tahapannya adalah (1) Pengumpulan data, (2) Pembuatan Aplikasi, (3) Pengujian Aplikasi, (4) Percobaan, dan (5) Analisis data dan Kesimpulan.
Gambar 1 Metodologi penelitian.
Pengumpulan Data
Dalam penelitian ini digunakan data dari KBBI 2005 yang berisi kata dasar dan kata berimbuhan kecuali kata yang memiliki imbuhan di-. Data tersebut digunakan sebagai
data kamus referensi yang digunakan dalam proses koreksi ejaan. Selain data kamus, dalam penelitian ini juga terdapat data kode yang berisi kode-kode fonetik yang diperoleh dari pengodean kata-kata dalam data kamus referensi sesuai dengan algoritme yang digunakan. Jadi terdapat data kode untuk Soundex, Phonix, Metaphone, dan Caverphone.
Untuk percobaan dalam penelitian ini digunakan 1000 kata yang dipilih secara acak dari basis data kamus referensi. Kemudian kata-kata tersebut dibuat salah pengejaan sesuai dengan beberapa kesalahan yang didefinisikan oleh Damerau (1964), yaitu penyisipan (insertion), penghapusan (deletion), penukaran (transposition), dan penggantian (substitution), sehingga setiap kesalahan akan ada 250 kata.
Pembuatan Aplikasi
Sebelum dirancang suatu aplikasi yang akan digunakan dalam penelitian ini, terlebih dahulu dilakukan pengodean data kamus dengan algoritme yang digunakan. Gambar 2 menunjukkan proses pengodean data kamus dengan menggunakan algoritme-algoritme fonetik.
Gambar 2 Proses pengodean kamus.
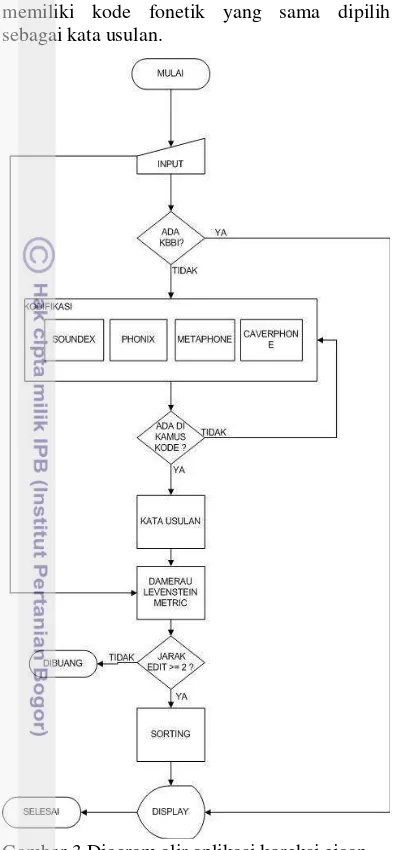
6 memiliki kode fonetik yang sama dipilih
sebagai kata usulan.
Gambar 3 Diagram alir aplikasi koreksi ejaan.
Setelah mendapatkan kata usulan dilakukan penghitungan jarak edit dengan menggunakan Damerau Levenstein Metric. Hal ini dilakukan karena kata usulan sangat banyak dan tidak berurutan, sehingga akan mengalami kesulitan untuk mencari kata yang benar di dalam kata usulan. Selanjutnya kata usulan diurutkan (sorting) sesuai dengan jarak edit. Kata usulan dengan jarak edit ≤ 2 yang diambil dan ditampilkan. Tampilan dari aplikasi koreksi ejaan yang telah dibuat dapat dilihat pada Lampiran 3.
Pengujian Aplikasi
Pada tahap ini aplikasi yang telah dibuat diuji menggunakan beberapa data contoh sebelum melakukan percobaan dengan data yang sebenarnya. Hal ini berguna untuk menyempurnakan aplikasi yang telah dibuat.
Percobaan
Percobaan dilakukan dengan cara memasukkan data kata salah ejaan ke dalam aplikasi koreksi ejaan dimana data salah eja sebelumnya telah dimasukkan dalam suatu basis data. Selanjutnya data kata salah eja tersebut dikoreksi dengan aplikasi yang telah dibuat, dengan mencoba untuk seluruh algoritme fonetik yang digunakan. Percobaan dilakukan sebanyak tiga kali perulangan. Hal ini dimaksudkan untuk melihat rata-rata waktu yang digunakan algoritme dalam proses koreksi ejaan sampai keluar hasil yang diinginkan.
Analisis data dan Kesimpulan
Pada tahap ini dilakukan analisis terhadap data hasil yang diperoleh. Analisis akan dilakukan sesuai dengan komponen dari data hasil percobaan. Dalam data hasil percobaan
banyak terdapat komponen: peringkat, kata usulan, akurasi, dan waktu yang digunakan setiap koreksi per kata.
Peringkat ditentukan dengan melihat letak kata yang benar dalam kata usulan terletak pada kelas atau bagian berapa. Dalam hal ini peringkat bukan ditentukan oleh besarnya jarak edit, tetapi pada kasus penggunaan Damerau
Metric
Levenstein dalam proses koreksi ejaan ada kemungkinan peringkat sesuai dengan besarnya jarak edit. Hal ini dikarenakan
Metric
Damerau Levenstein yang melakukan pemeriksaan seluruh data yang ada dalam kamus. Dikarenakan peringkat terendah dalam percobaan ini adalah 2, maka untuk data yang kata usulannya tidak memiliki kata yang benar tidak memiliki peringkat.
Sebagai contoh, untuk suatu kata salah eja diberikan empat kata usulan W1,W2,W3, dan W4 dengan jarak edit masing-masing adalah 1, 2, 2, dan 2. Jika kata yang benar adalah W1 maka peringkatnya adalah 1. Jika kata yang benar adalah W2,W3, dan W4 maka peringkatnya adalah 2. Jika kata yang benar tidak ada dalam kata usulan maka tidak memiliki peringkat.
Dalam analisis komponen waktu, percobaan dilakukan selama tiga kali perulangan. Hal ini dilakukan untuk melihat rata-rata waktu yang dihasilkan oleh program dalam melakukan proses koreksi ejaan pada setiap algoritme fonetik.
Akurasi
Untuk menghitung tingkat akurasi dari data hasil percobaan dilakukan penghitungan
jumlah persentase dari perbandingan antara kata
jumlah
7 digunakan dalam percobaan, seperti ditunjukkan
pada persamaan berikut:
Pencarian akurasi digunakan untuk mengetahui tingkat keefektifan dari algoritme fonetik yang digunakan, sehingga diketahui algoritme yang paling efektif dan kelemahan-kelemahan algoritme fonetik dalam koreksi ejaan yang diakibatkan oleh kesalahan pengetikan. Untuk mengetahui secara rinci keefektifan dari algoritme fonetik, analisis akurasi dilakukan dengan menganalisis setiap jenis kesalahan, yaitu penyisipan, penghapusan, penukaran, dan penggantian. Setiap jenis kesalahan dibagi lagi sesuai letak kesalahan. Kesalahan dilakukan secara acak sehingga terdapat perbedaan jumlah kata yang memiliki letak kesalahan yang sama. Kode A untuk letak kesalahan di huruf pertama, B di tengah kata, dan C untuk letak kesalahan di huruf terakhir. Aturan lengkap ditunjukkan pada Lampiran 4.
Lingkungan Pengembangan
Lingkungan pengembangan yang digunakan adalah sebagai berikut:
Perangkat lunak:
Windows XP Professional Service Pack 3
Notepad++ v5.3.1
XAMPP 1.7.1
Microsoft Office 2007
Perangkat keras:
Processor Intel Dual Core T2390 (1.86 GHz) 3072 Mbyte RAM.
HASIL DAN PEMBAHASAN Dari percobaan yang, diperoleh data hasil percobaan seperti yang dicontohkan pada Lampiran 5. Data hasil percobaan selanjutnya dibagi-bagi sesuai komponen data yang akan dianalisa.
Peringkat
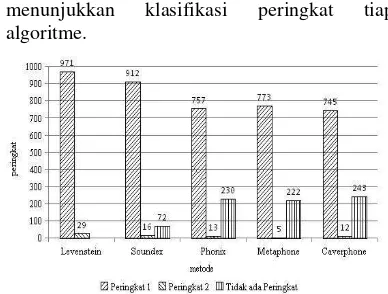
Dari data hasil percobaan dapat dilakukan proses penentuan peringkat terhadap kata yang benar diusulkan pada kata yang diusulkan. Sesuai dengan aturan yang telah dijelaskan pada metodologi penelitian, maka dapat diklasifikasikan banyaknya kata sesuai dengan peringkat dari kata tersebut. Gambar 4
menunjukkan klasifikasi peringkat tiap algoritme.
Gambar 4 Grafik hasil klasifikasi peringkat tiap algoritme.
Dari Gambar 4 dapat dilihat bahwa Damerau Metric
Levenstein memiliki jumlah kata yang memiliki peringkat 1 terbanyak dan tidak memiliki kata yang tidak memiliki peringkat. Metric Hal ini disebabkan Damerau Levenstein berhasil melakukan koreksi ejaan untuk semua kata dalam percobaan. Kemungkinan besar Metric peringkat dalam Damerau Levenstein diperoleh sesuai dengan jarak edit kata yang didapat, sehingga dapat dilihat juga Damerau
Metric
Levenstein memiliki peringkat 2 terbanyak dibanding algoritme yang lain.
Dalam klasifikasi peringkat, algoritme Caverphone memiliki kata yang tidak memiliki peringkat terbanyak. Walaupun algoritme Phonix dan Metaphone tidak terlalu berbeda jauh. Hal ini menunjukkan bahwa kata yang
Komponen data selanjutnya adalah jumlah kata yang diusulkan oleh algoritme fonetik untuk setiap kata yang salah eja. Tabel 4 menunjukkan rata-rata, simpangan baku, serta nilai maksimal dari banyaknya kata usulan untuk setiap algoritme fonetik yang digunakan. Nilai minimal untuk semua algoritme adalah 0. Grafik kata usulan untuk setiap algoritme dapat dilihat pada Lampiran 6.
8 pada algoritme Phonix hampir merata diangka
200. Algoritme Metaphone dan Caverphone yang memiliki langkah pengodean lebih rinci dan panjang memiliki rata-rata kata usulan hampir setengah dari algoritme Soundex dan Phonix.
Tabel 4 Data statistik kata usulan
Metode
Rata-Akurasi pada Kesalahan Penyisipan
Untuk melihat akurasi yang dihasilkan pada hasil percobaan terutama untuk kesalahan penyisipan, sebelumnya data kata salah eja dibagi sesuai dengan letak kesalahan seperti yang didefinisikan pada Lampiran 4. Tabel 5 menunjukkan banyak kata berdasarkan letak kesalahan penyisipan.
Seluruh akurasi untuk penyisipan satu huruf di depan kata memiliki akurasi 100%, hal ini disebabkan karena jumlah kata hanya dua sehingga akurasi tidak terlalu signifikan. Hasil akan signifikan terlihat pada algoritme Soundex dan Phonix jika kata lebih banyak. Karena kedua algoritme ini tidak mengubah huruf awal dari kata yang akan dikodekan, kecuali penyisipan huruf vokal di depan kata pada Phonix (algoritme Phonix merubah semua huruf hidup yang berada diawal kata dengan huruf V).
Tabel 5 Banyak kata berdasarkan letak kesala-han penyisipan
Subjenis Kesalahan Banyak Kata
AK 2
Tingkat akurasi untuk penyisipan huruf di tengah kata seperti yang ditunjukkan pada Tabel 6 cukup tinggi. Hal ini dikarenakan sebagian besar huruf konsonan yang disisipkan di bagian tengah adalah yang sama dengan huruf sebelumnya, sehingga terjadi perulangan huruf (misalkan: kata ‘jemang’ menjadi ‘jemmang’) dimana algoritme fonetik akan menghapusnya
atau menjadikan satu huruf. Namun penyisipan konsonan dengan huruf yang lain sangat berpengaruh terhadap kata yang akan diusulkan.
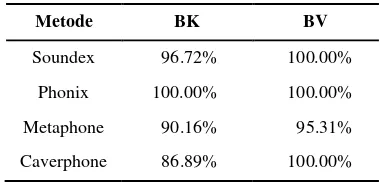
Tabel 6 Akurasi algoritme fonetik untuk letak kesalahan penyisipan di tengah kata
Metode BK BV
Soundex 96.72% 100.00%
Phonix 100.00% 100.00%
Metaphone 90.16% 95.31%
Caverphone 86.89% 100.00%
Untuk algoritme Soundex dan Phonix yang sangat peka dengan letak konsonan dalam kata, menyebabkan kata salah eja memiliki kode fonetik yang berbeda dengan kode fonetik kata yang benar, sehingga kata yang diusulkan tidak sesuai. Penyisipan huruf vokal di tengah kata tidak terlalu berpengaruh, karena sebagian besar algoritme fonetik akan menghapus huruf vokal yang ada dalam kata. Hal ini berbeda dengan Metaphone yang memiliki aturan pengodean dimana jika ada huruf konsonan yang diikuti oleh huruf vokal yang berbeda maka kodenya akan berbeda.
Tabel 7 menunjukkan akurasi dengan kesalahan penyisipan huruf di belakang kata. Sebagian besar algoritme mulai mengalami penurunan kecuali algoritme Soundex. Akurasi algoritme Soundex pada kesalahan penyisipan huruf konsonan di belakang kata mencapai 96,91%. Hal ini disebabkan karena kode fonetik yang dihasilkan oleh algoritme Soundex adalah empat karakter, sehingga kemungkinan besar huruf yang disisipkan tidak ikut dikodekan, demikian juga untuk penyisipan vokal di belakang kata karena algoritme Soundex akan menghapus semua huruf vokal kecuali huruf pertama.
Tabel 7 Akurasi algoritme fonetik untuk letak kesalahan penyisipan di belakang kata
Metode CK CV
Soundex 96.91% 100.00%
Phonix 90.72% 69.23%
Metaphone 83.51% 80.77%
Caverphone 89.69% 84.62%
9 pengodean algoritme Phonix menghapus ending
sound, kecuali jika ada huruf vokal yang disisipkan di belakang huruf, ending sound tidak akan dibuang (contoh kata BUANG menjadi BUA tetapi BUANGA tetap menjadi BUANGA).
Akurasi pada Kesalahan Penghapusan Data kata salah eja untuk kesalahan penghapusan semuanya masuk dalam kategori penghapusan vokal di tengah kata. Gambar 5 menunjukkan akurasi untuk koreksi ejaan dengan kesalahan penghapusan.
Algoritme Soundex yang menghapus semua huruf vokal selain huruf pertama memiliki akurasi terbesar mencapai 100%, sedangkan algoritme Caverphone dan Phonix memiliki akurasi terkecil. Pada algoritme Caverphone penghapusan huruf vokal di tengah kata akan berpengaruh karena adanya aturan tersendiri pada algoritme Caverphone, sedangkan pada algoritme Phonix penghapusan huruf vokal sebagian besar akan mengubah ending sound sehingga konsonan yang seharusnya dikodekan jadi terhapus (contoh: BAPAK menjadi BAPA, jika huruf A kedua dihapus maka BAPK menjadi BA).
Gambar 5 Grafik akurasi untuk kesalahan peng-hapusan.
Akurasi pada Kesalahan Penggantian Sebelum menghitung akurasi dari setiap bagian kesalahan karena penggantian sesuai letak huruf yang diganti dihitung jumlah kata untuk setiap kesalahan. Tabel 8 menunjukkan banyak kata berdasarkan letak kesalahan penggantian.
Dari Tabel 9 dapat diketahui bahwa penggantian konsonan di huruf pertama sangat berpengaruh pada hasil yang diperoleh oleh Soundex dan Phonix, karena kedua algoritme menggunakan huruf pertama sebagai identitas dari kode. Jadi jika konsonannya berubah maka kode fonetiknya juga berubah. Demikian juga pada penggantian huruf depan dengan vokal. Namun untuk algoritme Phonix penggantian vokal tidak menjadi masalah karena semua
huruf hidup yang terletak di awal kata akan diubah menjadi V, sedangkan untuk algoritme Caverphone dan Metaphone akan disesuaikan dengan aturan dari kedua algoritme tersebut.
Tabel 8 Banyak kata berdasarkan letak kesalahan penggantian
Jenis Kesalahan Banyak Kata
KAK 17 kesalahan penggantian huruf pertama
Metode KAK VAV
Soundex 0.00% 0.00%
Phonix 0.00% 100.00%
Metaphone 41.18% 100.00%
Caverphone 70.59% 100.00%
Akurasi akibat kesalahan penggantian yang lain divisualisasikan pada Gambar 6 untuk kesalahan penggantian di tengah kata dan Gambar 7 untuk kesalahan penggantian huruf belakang.
Gambar 6 Grafik akurasi untuk kesalahan peng-gantian di tengah kata.
10 algoritme fonetik kebanyakan tidak
memperhatikan huruf vokal. Untuk kesalahan penggantian konsonan dengan konsonan di tengah kata algoritme Soundex memiliki akurasi terbesar. Hal ini disebabkan karena huruf konsonan pengganti dengan konsonan yang diganti berada pada kelas yang sama, sedangkan pada algoritme Phonix ada yang berada di kelas yang sama dan ada yang berbeda, karena kelas konsonan yang dibentuk oleh algoritme Phonix merupakan pembagian dari Soundex.
Gambar 7 Grafik akurasi untuk kesalahan peng-gantian di belakang kata.
Pembuangan ending sound menguntungkan bagi algoritme Phonix pada kasus penggantian konsonan di belakang kata. Hal ini dikarenakan tidak akan berpengaruh pada kode fonetik yang akan dibentuk. Untuk penggantian konsonan dengan vokal hasilnya tidak terlalu signifikan karena kecilnya data (pada Tabel 8 KCV hanya 2 kata).
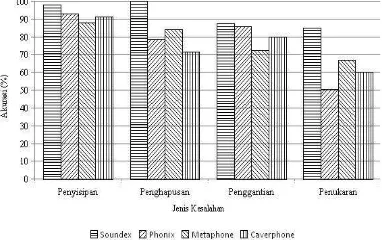
Akurasi pada Kesalahan Penukaran
Tingkat akurasi algoritme fonetik dalam koreksi ejaan dengan kesalahan penukaran dapat diketahui dengan mencari jumlah kata untuk tiap kategori kesalahan penukaran berdasarkan letak kesalahannya. Tabel 10 menunjukkan banyak kata berdasarkan letak kesalahan penukaran.
Tabel 10 Banyak kata berdasarkan letak kesalahan penukaran
Jenis Kesalahan Banyak Kata
KAK 1
Hasil penghitungan akurasi koreksi ejaan untuk data kesalahan penukaran secara keseluruhan dapat dilihat pada Gambar 8.
Gambar 8 Grafik akurasi untuk kesalahan penu-karan.
Dari Gambar 8 dapat diketahui bahwa data untuk kesalahan penukaran konsonan dengan konsonan di awal kata (KAK) tidak dimasukkan karena datanya yang sedikit. Sama halnya pada kesalahan akibat penggantian, penukaran konsonan dengan konsonan memiliki tingkat akurasi terendah. Hal ini disebabkan oleh proses pengodean yang bergantung pada letak konsonannya, sehingga jika konsonan ditukar maka kode fonetiknya akan berbeda pula.
Pada kesalahan penukaran konsonan dengan vokal (KBV) Soundex memiliki akurasi tertinggi. Walaupun langkah pengodean Phonix hampir menyerupai Soundex namun untuk kasus KBV tingkat akurasinya rendah. Seperti pada kesalahan akibat penghapusan, kasus KBV dapat mengakibatkan perubahan ending sound, sehingga konsonan yang seharusnya dikodekan, dihapus.
Gambar 9 Grafik akurasi keseluruhan.
11 Waktu Koreksi
Rata-rata waktu yang digunakan oleh Damerau Levenstein Metric dan algoritme fonetik untuk pengoreksian ejaan dalam tiga kali perulangan dapat dilihat pada Tabel 11.
Tabel 11 menunjukkan Damerau Levenstein memiliki waktu koreksi terlama, yaitu rata-rata mencapai 12 detik, sedangkan algoritme fonetik hanya memerlukan waktu rata-rata 0,3 detik untuk melakukan sekali proses koreksi ejaan. Hal ini disebabkan karena Damerau Lavenstein melakukan pemeriksaan jarak edit antara kata salah eja dengan semua kata yang ada dalam kamus referensi.
Tabel 11 Rata-rata waktu koreksi
Metode
Perulangan
1 2 3
Damerau Levenstein 12.292 12.530 12.094
Soundex 0.341 0.341 0.336
Phonix 0.346 0.346 0.344
Caverphone 0.337 0.332 0.333
Metaphone 0.328 0.328 0.329
Kelebihan dan Kekurangan
Dari percobaan yang telah dilakukan, dapat dijelaskan beberapa kelebihan dan kekurangan algoritme fonetik dibandingkan dengan Damerau Levenstein Metric dari penelitian Sutisna (2009).
Kelebihan:
Algoritme fonetik mudah melakukan koreksi pada kata yang memiliki bunyi yang sama. Waktu yang digunakan untuk koreksi ejaan relatif lebih singkat dibanding dengan Damerau Levenstein Metric.
Kekurangan:
Algoritme fonetik kurang peka terhadap penggantian dan penukaran terhadap konsonan dalam kata.
Algoritme fonetik belum memuaskan untuk koreksi ejaan dalam Bahasa Indonesia, sehingga untuk mendapatkan hasil yang memuaskan algoritme harus disesuaikan dengan aturan bahasa yang ada.
KESIMPULAN DAN SARAN Kesimpulan
Algoritme fonetik merupakan suatu algoritme yang digunakan untuk pencarian string berdasarkan kesamaan bunyi. Algoritme
fonetik telah banyak dikembangkan untuk proses koreksi ejaan dalam berbagai bahasa di dunia.
Dalam penelitian ini digunakan algoritme fonetik diantaranya: Soundex, Phonix, Metaphone, dan Caverphone untuk koreksi ejaan Bahasa Indonesia. Dari hasil penelitian dapat diketahui bahwa sebagian besar kesalahan ejaan akibat salah pengetikan seperti yang didefinisikan Damerau Levenstein dapat dikoreksi oleh algoritme fonetik tersebut. Algoritme Soundex memiliki tingkat akurasi tertinggi yang mencapai 92,80%, sedangkan algoritme Phonix, Caverphone dan Metaphone rata-rata memiliki akurasi yang hampir seragam yaitu sekitar 75%. Walaupun Phonix memiliki langkah dan pengodean yang hampir sama dengan Soundex, namun penghilangan ending sound mengakibatkan beberapa kata salah eja tidak dapat dikoreksi dengan benar.
Selain mengukur akurasi penelitian ini juga mengukur jumlah kata yang diusulkan untuk setiap kata salah eja. Soundex menghasilkan kata usulan terbanyak untuk setiap kata salah ejaan, sehingga membingungkan pengguna, sedangkan Metaphone yang tingkat akurasinya di bawah Soundex memiliki kata usulan yang lebih sedikit.
Jika dibandingkan dengan Damerau Levenstein Metric akurasi algoritme fonetik lebih unggul dibandingkan dengan algoritme fonetik. Akan tetapi, algoritme fonetik memerlukan waktu yang lebih singkat untuk koreksi. Hal ini dikarenakan pendekatan Damerau Levenstein Metric akan menghitung jarak edit dengan seluruh data yang ada dalam kamus, sedangkan algoritme fonetik hanya menghitung jarak edit dari kata masukan dengan kata-kata yang memilki kesamaan kode fonetik.
Saran
Beberapa hal dapat dilakukan untuk pengembangan lebih lanjut adalah sebagai berikut:
1 Penyesuaian algoritme fonetik yang ada disesuaikan dengan aturan Bahasa Indonesia, khususnya algoritme Metaphone, agar dapat meningkatkan akurasi koreksi ejaannya.
2 Penggabungan algoritme fonetik dengan pendekatan Damerau Levenstein Metric. 3 Pengujian data percobaan yang akan
12 4 Pengujian pengaruh koreksi ejaan dengan
menggunakan algoritme fonetik terhadap kinerja temu kembali informasi.
5 Penggunaan metode lain untuk koreksi ejaan dalam Bahasa Indonesia baik dengan algoritme fonetik yang lain seperti DoubleMetaphone, NYSIIS, atau algoritme non-fonetik seperti algoritme Knuth-Morris-Pratt, Bayer-Moore.
DAFTAR PUSTAKA
Damerau FJ. 1964. Technique for Computer Detection and Correction of Spelling Errors. Communications of the ACM 7(3):171.
Gadd T. 1990. PHONIX: The Algorithm. Program 24:363-366.
Hood D. 2002. Phonetic Matching Algorithm. Caversham Project Occasional Tech-nical Paper. CTP060902.
Jones D. 1972. The Pronouncation of English. Ed. ke-4. Cambridge: University Press.
Malmberg B. 1963. Phonetics. New York: Dover Publications.
Peterson JL. 1980. Computer Program for Detecting and Correcting in Scientific and Scholarly Text. Communications of the ACM 23(12):677-679.
Pfeifer U, Poersch T, Furh N. 1994. Searching Proper Names in Databases. University of Dortmund.
Phillips P. 1990. Hanging on the Metaphone. Computer Language 7(12):39-43. Primasari D. 1997. Metode Pencarian dan Temu
Kembali Nama Berdasarkan Kesamaan Fonetik [skripsi]. Bogor: Departemen Ilmu Komputer, Fakultas MIPA, Institut Pertanian Bogor.
Russel RC. Penemu; United States Patent Office. 2 April 1918. Spesification of Letters. US Pattent 198,458.
Sutisna U. 2009. Koreksi Ejaan Query Bahasa Indonesia Menggunakan Algoritme Damerau Levenshtein [skripsi]. Bogor: Departemen Ilmu Komputer, Fakultas MIPA, Institut Pertanian Bogor.
14
Lampiran 1 Aturan algoritme Caverphone (Hood 2002)
Algoritme:
1 Baca masukan berupa kata.
2 Ubah semua ke huruf kecil.
3 Hilangkan segala sesuatu selain A-Z.
4 Jika kata dimulai dengan rough diubah
27 Ganti dan huruf vokal diawal dengan A
28 Ganti huruf vokal yang lain dengan 3. Untuk sementara huruf vokal diganti dengan 3
29 Ganti 3gh3 dengan 3kh3
30 Ganti gh dengan 22
31 Ganti g dengan k
32 Ganti kelompok huruf s dengan S . Huruf s selanjutnya diganti dengan S
33 Ganti kelompok huruf t dengan T
34 Ganti kelompok huruf p dengan P
35 Ganti kelompok huruf k dengan K
36 Ganti kelompok huruf f dengan F
37 Ganti kelompok huruf m dengan M
38 Ganti kelompok huruf n dengan N
39 Ganti w3 dengan W3
40 Ganti wy dengan Wy
41 Ganti wh3 dengan Wh3
42 Ganti why dengan Why
43 Ganti w dengan 2
44 Ganti huruf awal h dengan A
45 Ganti huruf h yang lain dengan 2
46 Ganti r3 dengan R3
56 Hapus semua angka 3
57 Tambahkan angka 1 sebanyak 6 dibelakang kode
15 Lampiran 2 Contoh kamus kode
ID Kata Sifat Metaphone Soundex Caverphone Phonix4
1 A n A A000 A11111 V000
2 ab n APB A100 AP1111 V100
3 aba n AB A100 AP1111 V100
4 aba-aba n ABB A100 APP111 V110
5 abad n ABT A130 APT111 V130
6 berabad-abad v BRBT B613 PRPTPT B613
7 abadi a ABT A130 APT111 V130
8 mengabadi v MNKB M213 MNKPT1 M521
9 mengabadikan v MNKB M213 MNKPTK M521
10 pengabadian n PNKB P521 PNKPTN P521
11 keabadian n KBTN K135 KPTN11 K135
12 abadiah ar n ABT A130 APT111 V130
13 abadiat ABTT A130 APTT11 V130
14 abah n AB A100 AP1111 V100
15 mengabahkan v MNKB M212 MNKPKN M521
16 abah-abah n ABB A100 APP111 V110
17 abai a AB A100 AP1111 V100
18 mengabaikan v MNKB M212 MNKPKN M521
19 terabai v TRB T610 TRP111 T610
20 terabaikan v TRBK T612 TRPKN1 T612
21 abaian n ABN A150 APN111 V150
22 pengabai n PNKB P521 PNKP11 P521
23 pengabaian n PNKB P521 PNKPN1 P521
24 abaimana ark n ABMN A150 APMN11 V155
25 abaka n ABK A120 APK111 V120
26 abaktinal a bio ABKT A123 APKTN1 V123
27 abakus n ABKS A120 APKS11 V120
28 aban n ant ABN A150 APN111 V100
29 abang n ABNK A152 APNK11 V100
18 Lampiran 4 Klasifikasi jenis kesalahan
Jenis Kesalahan Subjenis
kesalahan keterangan
Penyisipan
AK Penyisipan konsonan di depan kata
AV Penyisipan vokal di depan kata
BK Penyisipan konsonan di tengah kata
BV Penyisipan vokal di tengah kata
CK Penyisipan konsonan di belakang kata
CV Penyisipan vokal di belakang kata
Penghapusan
AK Penghapusan konsonan di depan kata
AV Penghapusan vokal di depan kata
BK Penghapusan konsonan di tengah kata
BV Penghapusan vokal di tengah kata
CK Penghapusan konsonan di belakang kata
CV Penghapusan vokal di belakang kata
Penggantian
KAK Penggantian konsonan dengan konsonan di bagian depan kata
KAV Penggantian konsonan dengan vokal di bagian depan kata
VAK Penggantian vokal dengan konsonan di bagian depan kata
VAV Penggantian vokal dengan vokal di bagian depan kata
KBK Penggantian konsonan dengan konsonan di bagian tengah kata
KBV Penggantian konsonan dengan vokal di bagian tengah kata
VBK Penggantian vokal dengan konsonan di bagian tengah kata
VBV Penggantian vokal dengan vokal di bagian tengah kata
KCK Penggantian konsonan dengan konsonan di bagian belakang kata
KCV Penggantian konsonan dengan vokal di bagian belakang kata
VCK Penggantian vokal dengan konsonan di bagian belakang kata
VCV Penggantian vokal dengan vokal di bagian belakang kata
Penukaran
KAK Penukaran konsonan dengan konsonan di bagian depan kata
KAV Penukaran konsonan dengan vokal di bagian depan kata
VAV Penukaran vokal dengan vokal di bagian depan kata
KBK Penukaran konsonan dengan konsonan di bagian tengah kata
KBV Penukaran konsonan dengan vokal di bagian tengah kata
VBV Penukaran vokal dengan vokal di bagian tengah kata
KCK Penukaran konsonan dengan konsonan di bagian belakang kata
KCV Penukaran konsonan dengan vokal di bagian belakang kata
KCK Penukaran vokal dengan vokal di bagian depan kata
19 Lampiran 5 Contoh data hasil percobaan
Data Caverphone
1 aberasi aberrasi insertion aberasi,abrasi,operasi,abras,obras 1,2,3,3,4 0.331141 1 8
2 abid abd deletion abid,abdi,abdu,ibid,abad 1,1,1,2,2 0.318317 1 35 3 ablasi abalsi transposition abas,aborsi,abis,abese,apas 2,2,3,3,3 0.334895 - 25 4 abnus ebnus substitution abnus,hipnose,apanase,hibernasi 1,5,5,6 0.318216 1 4 5 agak agaak insertion agak,acak,aguk,akak,akuk 1,2,2,2,3 0.316947 1 15
6 agrafia agrfia deletion akuifer 5 0.332479 - 1
7 ahkam akham transposition ahkam,akmal,agam,hakam,agami 1,2,2,2,3 0.31526 1 16
Data Soundex
1 aberasi aberrasi insertion aberasi,abrasi,aborsi,aversi,abreaksi 1,2,3,3,3 0.332406 1 21 2 abid abd deletion abdu,abid,abdi,abad ,abet 1,1,1,2,2 0.338949 1 13 3 ablasi abalsi transposition ablasi,abolisi,apalagi,aplasia,aplus 1,2,3,3,4 0.328323 1 15 4 abnus ebnus substitution ebang,epinasti,evangelis,evangeli 3,5,6,6,7 0.34394 - 7 5 agak agaak insertion agak,agas,akak,asak,ajak 1,2,2,2,2 0.343796 1 75
6 agrafia agrfia deletion agrafia,agripnia,akrofobia,akrobat 1,3,4,4,4 0.332899 1 12 7 ahkam akham transposition ahkam,akan,agam,akuan,akhwan 1,2,2,2,3 0.339575 1 53
Data Phonix
1 aberasi aberrasi insertion aberasi,abrasi,operasi,vibrasi,aborsi 1,2,3,3,3 0.351606 1 19 2 abid abd deletion abdu,abdi,abdas,abad ,abadi 1,1,2,2,2 0.336055 - 39 3 ablasi abalsi transposition ablasi,oblasi,abolisi,aplasia,oplosan 1,2,2,3,5 0.356064 1 8
4 abnus ebnus substitution abnus,ibnu,ebonit,ibni,apnea 1,2,3,3,4 0.348398 1 14 5 agak agaak insertion agak,agan,agal,agar,agah 1,2,2,2,2 0.354367 1 227
6 agrafia agrfia deletion agrafia 1 0.347027 1 4
7 ahkam akham transposition ahkam,akar,akwal,akhir,akas 1,2,2,2,2 0.351731 1 227
Data Metaphone
1 aberasi aberrasi insertion aberasi,abrasi,abras,aborsi,obras 1,2,3,3,4 0.330108 1 7 2 abid abd deletion abdu,abdi,abid,ibid,abet 1,1,1,2,2 0.338027 1 14
3 ablasi abalsi transposition ablasi,abolisi,oblasi,iblis,obelisk 1,2,2,3,4 0.336585 1 5
4 abnus ebnus substitution abnus 1 0.329989 1 1
5 agak agaak insertion agak,akak,aguk,akuk,akik 1,2,2,3,3 0.340101 1 13
6 agrafia agrfia deletion agrafia 1 0.341266 1 4