Optimalisasi Katalog Bintang Untuk Navigasi Sikap Satelit Menggunakan Metode Clustering Berbasis Densitas
Teks penuh
Gambar


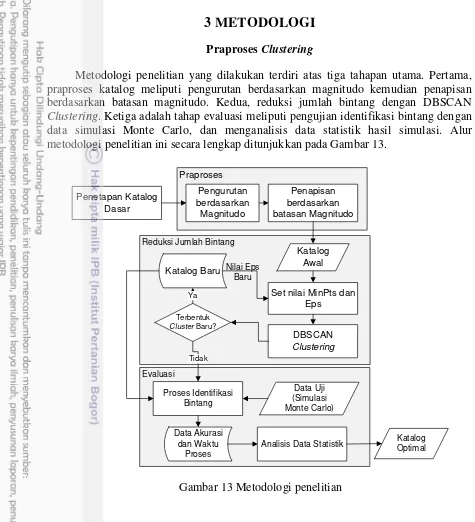


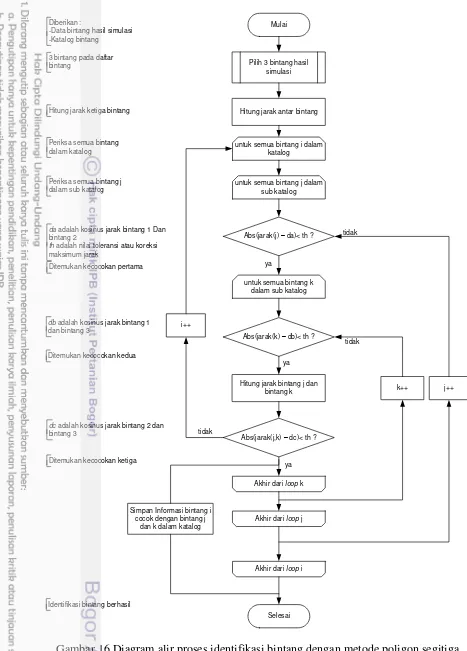
Dokumen terkait
Maka dapat disimpulkan bahwa nisbah merupakan jumlah yang didapat sebagai kelebihan modal dengan ketentuan pembagian keuntungan tidak boleh ditetapkan dengan jumlah
dalam penelitian ini penulis mengeksplorasi 150 data nasabah salah satu bank (nama bank tidak disebutkan dalam penelitian ini) mencakup total saldo, agama,
Berdasarkan permasalahan diatas, peneliti ingin mengetahui hubungan antara lifestyle (aktivitas fisik, kebiasaan merokok, konsumsi kafein konsumsi garam dan stres)
Smoking have a significant relationship with periodontal tissues health, smoking were four more likely to have periodontal disesases (unhealthy periodontal tissues) as compared
Analisis titik impas umumnya berhubungan dengan proses penentuan tingkat produksi untuk menjamin agar kegiatan usaha yang dilakukan dapat membiayai sendiri (self financing).
Therefore, an information space such as system have information tied to each other, but in different sub-systems can be built mutually bound: Google search engine and Yahoo
Sehingga menjadi suatu hal yang sangat penting untuk melakukan penelitian mengenai pengelolaan obat terutama penyimpanan obat di puskesmas untuk mengetahui seberapa
Low Mental Conflict ”, Di dalam makalah yang telah diteliti mencoba untuk mengidentifikasi, untuk memberikan pilihan dan menyediakan struktur ekuitas merek kepada
