PENGELOMPOKAN DOKUMEN WEB MELALUI PEMBANGKITAN
METAFILE
PENYUSUN STRUKTUR DIGRAF MENGGUNAKAN
ALGORITME
DOCUMENT INDEX GRAPH
BUDI
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa tesis berjudul Pengelompokan Dokumen Web Melalui Pembangkitan Metafile Penyusun Digraf Menggunakan Algoritme Document Index Graph adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
RINGKASAN
BUDI. Pengelompokan Dokumen Web Melalui Pembangkitan Metafile Penyusun Digraf Menggunakan Algoritme Document Index Graph. Dibimbing oleh SRI NURDIATI dan BIB PARUHUM SILALAHI.
Saat ini, peningkatan volume data khususnya pada dokumen teks dan implikasinya terhadap isu tentang akurasi hasil pencarian dan temu kembali informasi telah memicu berkembangnya penggunaan teknik pengelolaan dan analisis data. Teknik tersebut digunakan untuk membagi kumpulan dokumen ke dalam kelompok-kelompok yang berbeda sehingga dokumen yang terdapat pada suatu kelompok akan mengandung informasi yang sama dan terkait satu sama lain. Oleh karena itu diperlukan sebuah metode pengelompokan dokumen agar memudahkan dalam pengambilan informasi sesuai kebutuhan pengguna.
Clustering merupakan salah satu teknik yang dapat digunakan untuk menemukan keterkaitan antar dokumen. Teknik ini memisahkan sekumpulan dokumen ke dalam beberapa cluster dengan menghitung kemiripan antar dokumen. Dokumen-dokumen yang telah dikelompokkan akan membantu pengguna untuk dapat menemukan informasi yang dibutuhkan dan akan meningkatkan kecepatan akses terhadap informasi tersebut. Adapun ruang lingkup penelitian ini adalah : 1) Dokumen uji dan dokumen latih menggunakan newswire REUTERS-21578 2) Algoritme menghasilkan output berupa sebuah metafile yang akan digunakan sebagai input untuk merepresentasikan struktur digraf.
Metode penelitian yang digunakan antara lain studi literatur; praproses data; implementasi algoritme document index graph (DIG); pembangkitan metafile untuk penyusunan struktur digraf; representasi digraf; serta analisis hasil pengelompokan. Selain ketiga proses inti yakni tokenisasi, stop-word removal dan stemming, pada tahap praproses data ditekankan kepada mekanisme dimentional reduction. Mekanisme dimentional reduction dilakukan dengan penentuan nilai term frequent threshold sebelum proses pengelompokan. Hasil praproses data dilanjutkan dengan implementasi algoritme DIG. Algoritme DIG menghitung bobot kata yang sering muncul dalam dokumen yang diproses. Hasil implementasi algoritme DIG menghasilkan kelompok kata dengan frekuensi kemunculan lebih dari 20 kali. Output implementasi algoritme ditulis ke dalam sebuah metafile yang akan digunakan sebagai input untuk pembangunan struktur digraf dan representasi digraf. Analisis hasil penelitian dilakukan dengan menghitung prosentase precision, recall dan accuracy terhadap cluster yang dihasilkan. Implementasi algoritme DIG dengan mekanisme dimentional reduction dalam tahap praproses data mampu menghasilkan akurasi di atas 70%.
SUMMARY
BUDI. Web Document Clustering Through Metafile Generation for Digraph Structuring Using Document Index Graph Algorithm. Supervised by SRI NURDIATI and BIB PARUHUM SILALAHI.
Nowaday, the increased volume of data, especially on text documents and their implications for the issue of the accuracy of the search results and information retrieval has led to the development and the use of data management and analysis techniques. The technique is used to split the document into different groups so that the documents contained in a group will contain the same topic and related to each other. Therefore we need a method of grouping documents in order to facilitate the retrieval of information according to user needs.
Clustering is a technique that can be used to discover linkages between documents. This technique separates a set of documents into several groups or clusters by calculating the similarity between documents. Documents that have been clustered, will help users finding the information needed and will increase the speed of access to that information. The scope of this research consists of : 1) the test and training documents using REUTERS newswire-21578; 2) algorithm generates output in metafile form that will be used as input to represent the structure of digraphs.
Research methods perform literature studies, data preprocessing, implementation of Document Index Graph (DIG) algorithm, generating the metafile for digraphs construction, digraphs representation, and analysis of clustering result. Instead of three core processes tokenization , stop-word removal and stemming, data preprocessing stage is concerned with dimentional reduction mechanism. Dimentional reduction will determine the document frequency threshold values before clustering process. The results of data preprocessing will be followed by the implementation of the DIG algorithm. The algorithm calculates the weight of words that often appears in the document being processed. The results bring a bag of words that frequently appear more than 20 times. The output of this result is written into a metafile that will be used as input for the digraph structuring and representation. This research analyzes the results by calculating precision, recall and accuracy percentage on clustering result. DIG algorithm implementations using dimentional reduction mechanism through data preprocessing stage is able to produce an accuracy above 70 %.
© Hak Cipta Milik IPB, Tahun 2014
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains
pada
Program Studi Ilmu Komputer
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2014
BUDI
PENGELOMPOKAN DOKUMEN WEB MELALUI PEMBANGKITAN
METAFILE
PENYUSUN STRUKTUR DIGRAF MENGGUNAKAN
Judul Tesis : Pengelompokan Dokumen Web Melalui Pembangkitan Metafile Penyusun Struktur Digraf Menggunakan Algoritme Document
Index Graph Nama : Budi
NIM : G651110201
Program Studi : Ilmu Komputer
Disetujui oleh Komisi Pembimbing
Dr Ir Sri Nurdiati, MSc. Dr Ir Bib Paruhum Silalahi, MKom
Ketua Anggota
Diketahui oleh
Ketua Program Studi Dekan Sekolah Pascasarjana
Ilmu Komputer
Dr Eng Wisnu Ananta Kusuma, SSi, MT Dr Ir Dahrul Syah, MSc,Agr
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wata’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Desember 2012 ini ialah text clustering, dengan judul Pengelompokan Dokumen Web Melalui Pembangkitan Metafile Penyusun Struktur Digraf Menggunakan Algoritme Document Index Graph.
Terima kasih penulis ucapkan kepada Ibu Dr Ir Sri Nurdiati, MSc dan Bapak Dr Ir Bib Paruhum Silalahi, ST, MT selaku pembimbing yang telah banyak memberi saran. Selain itu, penghargaan penulis sampaikan kepada pimpinan Program Diploma IPB, semua dosen dan staf Departemen Ilmu Komputer IPB, dosen dan staf Program Diploma IPB yang telah membantu selama proses penelitian. Ungkapan terima kasih juga disampaikan kepada istri Sumarlina Syahara Fona, ananda Ajji Tana Arifainy dan Jiilaan Rana Hanniyah, Ayah, Ibu, serta seluruh keluarga, atas segala doa dan kasih sayangnya.
Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
Halaman
DAFTAR TABEL ix
DAFTAR GAMBAR ix
DAFTAR LAMPIRAN ix
1 PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 3
Ruang Lingkup 4
2 TINJAUAN PUSTAKA 5
Text mining 5
Text Clustering 5
The Reuters-21578 dataset 5
Text Preprocessing 6
Document Index Graph 6
Metafile Penyusun Graf 7
Precision, Recall dan Accuracy 8
3 METODE 9
Analisis Masalah dan Studi Pustaka 10
Tahap Praproses Data 10
Implementasi Algoritme Document Index Graph (DIG) 11 Pembangkitan metafile penyusun struktur digraf 13 Representasi digraf menggunakan metafile penyusun digraf 13 Analisis hasil pengelompokan berdasarkan pengujian 13
4 HASIL DAN PEMBAHASAN 15
5 SIMPULAN DAN SARAN 21
Simpulan 21
Saran 21
DAFTAR PUSTAKA 22
DAFTAR TABEL
Halaman
1 Faktor dan level penelitian 9
2 Hasil pengelompokan 20 dokumen dengan nilai document frequency
threshold 0 16
3 Hasil pengelompokan 20 dokumen dengan nilai document frequency
threshold 2 16
4 Hasil pengelompokan 25 dokumen dengan nilai document frequency
threshold 0 17
5 Hasil pengelompokan 25 dokumen dengan nilai document frequency
threshold 3 17
6 Perhitungan precision, recall dan accuracy pada 20 dokumen 19
DAFTAR GAMBAR
Halaman
1 Posisi penelitian 3
2 Representasi dokumen dengan DIG (Hammouda, 2004) 7 3 Perbedaan accuracy dan precision (Raharjo, 2011) 8 4 Rumus perhitungan precision, recall dan accuracy (Raharjo, 2011) 8
5 Metode penelitian 9
6 Ilustrasi Document Index Graph (Hammouda 2004) 12 7 Komposisi kategorisasi teks berdasarkan Lewis (1997) 12
8 Tampilan praproses data 15
9 Representasi digraf dari input metafile penyusun struktur digraf 18 10 Grafik nilai precision, recall dan accuracy pada dokumen uji 20
DAFTAR LAMPIRAN
Halaman 1. Hasil implementasi algoritme DIG pada 50 dokumen latih dengan
beberapa variasi nilai Term Frequency threshold dan minimal bobot kemunculan kata dalam dokumen atau bobot TF lebih dari 20 kali. 23 2. Hasil implementasi algoritme DIG pada 100 dokumen latih dengan
beberapa variasi nilai Term Frequency threshold dan minimal bobot kemunculan kata dalam dokumen atau bobot TF lebih dari 20 kali. 24 3. Hasil perhitungan precision, recall dan accuracy pada 25 dokumen
REUTERS 26
4. Hasil perhitungan precision, recall dan accuracy pada 50 dokumen
1
PENDAHULUAN
Latar Belakang
Dokumen web adalah salah satu sumber daya pada sebuah sistem berbasis web yang banyak ditemukan dalam bentuk tekstual misalnya dokumen teks, dokumen web, artikel dan paper dan lain sebagainya (Hammouda, et al., 2004). Peningkatan volume data khususnya pada dokumen teks saat ini memberikan implikasi terhadap isu yang berkaitan dengan akurasi temu kembali informasi dan kecepatan akses terhadap informasi yang ditelusuri. Implikasi tersebut menjadi pemicu penggunaan teknik pengelolaan dan analisis data. Teknik yang dimaksud adalah membagi kumpulan dokumen ke dalam kelompok-kelompok yang berbeda sehingga dokumen yang terdapat pada suatu kelompok akan mengandung informasi yang sama dan terkait satu sama lain. Oleh karena itu diperlukan sebuah metode pengelompokan dokumen agar memudahkan dalam pengambilan informasi sesuai kebutuhan user.
Clustering merupakan salah satu teknik yang dapat digunakan untuk menemukan keterkaitan antar dokumen. Tujuan pengelompokan adalah untuk memisahkan sekumpulan dokumen ke dalam beberapa kelompok atau cluster dengan menilai kemiripan antar dokumen dari segi isi. Pada umumnya teknik pengelompokan dilandasi oleh 4 (empat) konsep tahapan yakni: (1) Praproses data, (2) Penghitungan kemiripan (similarity measure), (3) Pemilihan metode pengelompokan (cluster method), dan (4) Algoritme pengelompokan yang digunakan. Banyak metode yang dapat dipakai dalam pengelompokan dokumen seperti dengan Suffix Tree, Single Pass Clustering maupun K-Nearest Neighbour. Kebanyakan metode pengelompokan dokumen berbasis pemodelan ruang vektor yang merepresentasikan dokumen sebagai fitur vektor dari term yang muncul pada semua dokumen (Hammouda 2004). Pengelompokan dengan metode seperti ini hanya memperhatikan analisis single term, tanpa memperhatikan analisis berbasis frasa. Idealnya proses pengelompokan sebaiknya tidak hanya memperhatikan analisis single term saja, akan tetapi perlu diperhatikan juga analisis frasa dari suatu dokumen. Dengan analisis frasa, kesamaan antar dokumen akan dihitung berdasarkan pencocokan frasa.
Penelitian Oren Zamir (1998), melakukan analisis pengelompokan dokumen berbasis analisis frasa dengan pendekatan Suffix Tree Clustering (STC). Metode
tersebut pada dasarnya melibatkan penggunaan struktur “trie” (tree sederhana) untuk merepresentasikan suffix yang digunakan bersama antar dokumen. Berdasarkan suffix dilakukan identifikasi cluster dasar dari dokumen, dan akan digabungkan ke dalam cluster akhir berdasarkan algoritme connected-component graph. Metode ini diklaim memiliki nilai kompleksitas n log(n) dan menghasilkan cluster yang baik, akan tetapi model tree yang terbentuk dapat dikatakan memiliki nilai redundansi yang tinggi pada kasus term dari suffix yang disimpan pada tree.
kata-kata dalam kalimat tersebut. DIG memungkinkan untuk mengenali pencocokan frasa antar dokumen. Ketika sebuah dokumen baru diproses, maka algoritme akan membentuk atau membangun sebuah daftar kesamaan antar dokumen tersebut dengan semua dokumen sebelumnya telah disimpan. Penelitian tersebut dapat menangkap struktur dari kalimat pada sebuah set dokumen dibanding hanya kata tunggal saja. Dokumen yang dianalisis pada penelitian adalah dokumen HTML. Hasil pemodelannya adalah bentuk XML yang terstruktur dengan baik sesuai dengan dokumen HTML yang asli namun dengan tingkat signifikansi yang ditugaskan kebagian yang berbeda di dokumen asli. Hasil penelitian menyimpulkan bahwa kualitas cluster yang terbentuk dari pemodelan DIG lebih baik hasilnya dibanding dengan pemodelan berbasis ruang vektor. Di samping itu, penelitian ini menyimpulkan bahwa ukuran kemiripan berbasis frasa memiliki tingkat akurasi yang tinggi dengan syarat telah memperhatikan pengujian terhadap faktor-faktor yang mempengaruhi derajat overlap antar dokumen.
Penelitian Ernawati (2009) yang berjudul “Klusterisasi Dokumen Berita Berbahasa Indonesia Menggunakan Document Index Graph”, menunjukkan bahwa algoritme DIG dapat diimplementasikan untuk mendeteksi kesamaan berbasis frasa dan menangani overlap clustering. Walaupun tidak selalu terjadi, kesamaan berbasis frasa dapat memperbaiki performansi cluster berdasarkan pengukuran f-measure dan entropy. Ada beberapa titik kesamaan berbasis frasa justru dapat mengurangi nilai performansi, oleh karena itu perlu dicari titik optimal similarity blend factor dan similarity threshold.
Berdasarkan perkembangan peningkatan volume data pada dokumen web saat ini dan mencermati implikasi dari perkembangan tersebut serta mempelajari hasil penelitian yang telah dilakukan sebelumnya, maka usulan pemodelan representasi dokumen pada penelitian ini adalah melakukan pengelompokan dokumen menggunakan algoritme Document Index Graph (DIG). Model ini melakukan proses indeks terhadap dokumen dengan tetap menjaga struktur kalimat dalam dokumen asli. Hal ini memungkinkan kita untuk menggunakan pencocokan frasa lebih informatif daripada pencocokan kata-kata individu. Selain itu, DIG juga menangkap berbagai tingkat
signifikansi dari kalimat asli, sehingga memungkinkan kita untuk menggunakan kalimat secara signifikan. Suffix tree adalah struktur yang paling dekat dengan model DIG, tetapi suffix tree memiliki kendala ketika terjadi redundansi yang besar (Huang 2011). Model DIG yang diusulkan bukan hanya perpanjangan atau perangkat tambahan suffix tree, tetapi DIG memiliki perspektif yang berbeda tentang bagaimana pencocokan frasa dapat
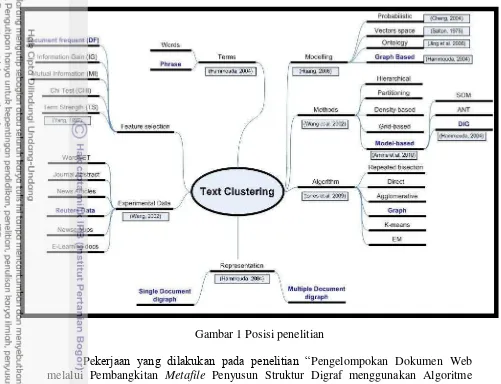
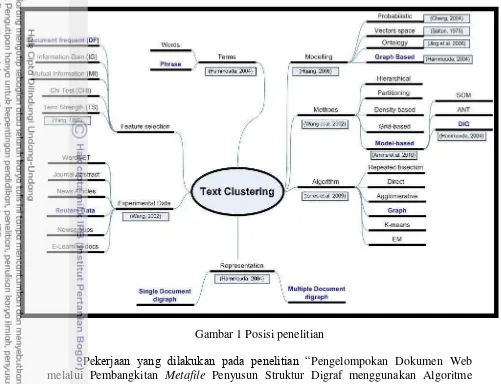
Gambar 1 Posisi penelitian
Pekerjaan yang dilakukan pada penelitian “Pengelompokan Dokumen Web melalui Pembangkitan Metafile Penyusun Struktur Digraf menggunakan Algoritme Document Index Graph (DIG)” adalah menerapkan teknik text clustering menggunakan REUTER 21578 dataset dengan menggunakan pemodelan berbasis graf dan menggunakan algoritme DIG. Untuk tahapan pekerjaan akan dilakukan kolaborasi antara perancangan pada system document clustering secara umum dengan tahapan document clustering menggunakan representasi DIG. Adapun tahapan perancangan sistem document clustering secara umum meliputi : (1) Tahap preprocessing data; (2) Analisis semantik/sintaksis; (3) Representasi dokumen; (4) Pengelompokan dokumen ; (5) Evaluasi pengelompokan. Tahapan document clustering menggunakan representasi DIG meliputi : (1) Identifikasi struktur dokumen atau tahapan praproses data; (2) Representasi dokumen menggunakan DIG; (3) Penghitungan ukuran kesamaan dokumen; (4) Proses pengelompokan dengan algoritme DIG.
Tujuan Penelitian
Ruang Lingkup
Adapun ruang lingkup penelitian ini adalah :
1 Dokumen web yang digunakan adalah dokumen SGML yang telah terstruktur dalam hal ini artikel berita REUTER-21578,
2 Implementasi praproses data dilakukan dengan melakukan perhitungan nilai Term Frequency (TF) dengan menentukan nilai intra-cluster threshold dan nilai inter-cluster threshold
3 Output algoritme berupa metafile yang akan digunakan sebagai input lanjutan untuk representasi struktur digraf
2
TINJAUAN PUSTAKA
Text mining
Text mining adalah teknik penambangan data yang berupa teks dengan sumber data biasanya didapatkan dari dokumen, dan tujuannya adalah mencari kata-kata yang dapat mewakili isi dari dokumen sehingga dapat dilakukan analisis keterhubungan antar dokumen (Langgeni 2010).
Metode pada text mining terdiri atas komponen text pre-processing, feature selection, dan komponen data mining. Komponen text pre-processing berfungsi untuk mengubah data tekstual yang tidak terstruktur seperti dokumen ke dalam data terstruktur dan disimpan ke dalam database. Feature selection akan memilih kata yang tepat dan berpengaruh pada proses klasifikasi atau proses pengelompokan. Komponen terakhir akan menjalankan teknik data mining pada output dari komponen sebelumnya.
Text Clustering
Dalam penyusunannya, penggalian teks mempunyai beberapa tahapan yaitu pemrosesan awal, penyusunan data model, clustering, proses lanjutan, visualisasi dan ontologi. Text clustering merupakan salah satu fungsi fundamental dalam penggalian teks. Text clustering didefinisikan sebagai proses untuk memecah suatu kumpulan teks dokumen ke dalam klasifikasi yang berbeda-beda, sehingga beberapa dokumen dalam satu grup kategori dapat menunjukkan kesamaan topik (Fang 2005). Text clustering sangat berpengaruh dalam penggalian teks karena menunjukkan topik yang terdapat dalam dokumen dan mengidentifikasikan kata kunci dari setiap topik.
Teknik pengelompokan (Clustering) adalah sebuah teknik pembelajaran tanpa pengawasan (unsupervised learning) yang bertujuan untuk mengelompokkan seperangkat objek abstrak atau objek fisik ke dalam kelas-kelas objek yang sama (Wang 2006). Pengelompokan pada dokumen membagi gugus dokumen ke dalam kelompok yang belum terdefinisi berdasarkan kesamaan dokumennya. Jumlah kelompok yang dihasilkan bersifat tetap atau acak tergantung dari algoritme yang digunakan. Teknik pengelompokan dokumen adalah cabang ilmu yang melibatkan temu kembali informasi, kecerdasan buatan, data mining, dan pemrosesan natural language. Secara umum, pengelompokan dokumen adalah metode pengelolaan dokumen yang efisien untuk temu kembali informasi dan data mining khususnya untuk data teks (Wang 2006).
Otomatisasi proses klasifikasi pada teks berkaitan dengan proses distribusi berdasarkan kategori atau kelas dari seperangkat dokumen-dokumen yang didasari pada karakteristik tertentu. Unsupervised classification atau clustering adalah metode yang digunakan untuk melakukan proses penemuan dan otomatisasi pengelompokan dari kelas-kelas tersembunyi dan belum teridentifikasi (Amine 2009).
The Reuters-21578 dataset
beberapa kategori oleh beberapa personel di REUTERS antara lain : Sam Dobbins, Mike Topliss, Steve Weinstein, Peggy Andersen, Monica Cellio, Phil Hayes, Laura Knecht, Irene Nirenburg.
Menurut Hotho (2009), koleksi teks Reuters-215781 terdiri atas 21.578 dokumen. Koleksi ini sangat menarik untuk evaluasi, sebagai bagian dari kehadiran klasifikasi. Koleksi berisi 135 topik. Agar lebih umum, topik merujuk kepada istilah 'kelas' di sekuel. Untuk memungkinkan evaluasi, topik dibatasi menjadi 12344 dokumen yang telah diklasifikasikan secara manual oleh Reuters. Beberapa dari dokumen tersebut tidak dapat diberikan oleh para ahli untuk salah satu kelas yang telah ditetapkan, oleh karena itu kelas tersebut dikumpulkan dalam sebuah kelas tambahan atau „defnoclass‟.
Karakteristik dataset ini adalah menggunakan bahasa markup yakni menggunakan tag SGML dan menghasilkan DTD dari bentukan SGML tersebut sehingga batasan dari bagian penting sebuah dokumen tidak ambigu atau tidak rancu. Selain itu dataset ini memiliki seperangkat kategori yang baku untuk setiap definisi dari 5 (lima) field pengendali kosakata. Karakteristik lainnya adalah dokumen-dokumen diberikan nomor ID baru berdasarkan urutan kronologis dan dikumpulkan per 1000 dokumen dalam sebuah file yang diurutkan berdasarkan ID.
Text Preprocessing
Teks yang akan dilakukan proses text mining, pada umumnya memiliki beberapa karakteristik di antaranya adalah memiliki dimensi yang tinggi, terdapat noise pada data, dan terdapat struktur teks yang tidak baik. Cara yang digunakan dalam mempelajari suatu data teks, adalah dengan terlebih dahulu menentukan fitur-fitur yang mewakili setiap kata untuk setiap fitur yang ada pada dokumen.
Sebelum menentukan fitur-fitur yang mewakili, diperlukan tahap preprocessing yang dilakukan secara umum dalam text mining pada dokumen, yaitu case folding, tokenizing, filtering, stemming, tagging dan analyzing. Case folding adalah mengubah semua huruf dalam dokumen menjadi huruf kecil. Hanya huruf „a‟ sampai dengan „z‟ yang diterima. Karakter selain huruf dihilangkan dan dianggap delimiter. Tahap tokenizing / parsing adalah tahap pemotongan string input berdasarkan tiap kata yang menyusunnya. Tahap filtering adalah tahap mengambil kata-kata penting dari hasil token. Bisa menggunakan algoritme stoplist (membuang kata yang kurang penting) atau wordlist (menyimpan kata penting). Stoplist / stopword adalah kata-kata yang tidak deskriptif yang dapat dibuang dalam pendekatan bag-of-words. Contoh stopwords adalah “yang”, “dan”, “di”, “dari” dan seterusnya. Tahap stemming adalah tahap mencari root kata dari tiap kata hasil filtering. Pada tahap ini dilakukan proses pengembalian berbagai bentukan kata ke dalam suatu representasi yang sama. Tahap ini kebanyakan dipakai untuk teks berbahasa inggris dan lebih sulit diterapkan pada teks berbahasa Indonesia. Hal ini dikarenakan bahasa Indonesia tidak memiliki rumus bentuk baku yang permanen.
Document Index Graph
kata yang mungkin berulang di antara dokumen tersebut. Jika sebuah frasa tampil lebih dari sekali maka frekuensi dari kata individual pembentuk frasa akan bertambah (Hammouda 2004).
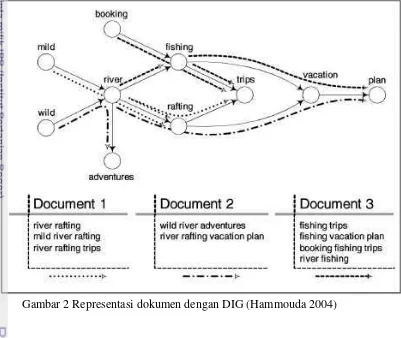
Pencocokan frasa antar dokumen bertugas untuk mencari shared-paths pada graf antar dokumen-dokumen tersebut. Hal ini dilakukan dengan membuat struktur graf dan membangun graf untuk melakukan phrase matching. Representasi graf untuk data sangat cocok mengingat setiap dokumen berisi sejumlah kalimat yang mungkin akan saling overlap dalam dokumen lain. Jika sebuah frasa tampil di lebih dari satu dokumen, maka frekuensi dari kata unik yang membangun frasa tersebut akan bertambah. Pencocokan frasa antara dokumen sama artinya dengan menemukan shared paths dalam graf di dokumen yang berbeda. Representasi dokumen menggunakan Document Index Graph ditampilkan pada Gambar 2.
Gambar 2 Representasi dokumen dengan DIG (Hammouda 2004)
Metafile Penyusun Graf
Precision, Recall dan Accuracy
Precision, recall dan accuracy digunakan pada pengukuran kinerja pada sebagian besar kajian pengenalan pola (pattern recognition) dan temu kembali informasi (information retrieval). Precision dan recall adalah dua perhitungan yang banyak digunakan untuk mengukur kinerja dari sistem/metode yang digunakan. Precision adalah tingkat ketepatan antara informasi yang diminta oleh pengguna dengan jawaban yang diberikan oleh sistem. Recall adalah tingkat keberhasilan sistem dalam menemukan kembali sebuah informasi. Accuracy didefinisikan sebagai tingkat kedekatan antara nilai prediksi dengan nilai aktual. Ilustrasi pada Gambar 3 memberikan gambaran perbedaan antara precision, recall dan accuracy.
Gambar 3 Perbedaan accuracy dan precision (Raharjo, 2011)
Pengukuran nilai precision, recall dan accuracy secara umum mengacu pada rumus pada Gambar 4 :
3
METODE
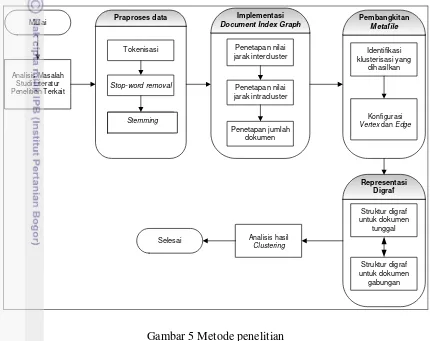
Metode penelitian metafile penyusun struktur digraf menggunakan algoritme Document Index Graph (DIG) terdiri atas beberapa tahapan yaitu tahap analisis masalah dan studi literatur dari penelitian terkait, tahap praproses data, tahap implementasi algoritme, tahap pembangkitan metafile, tahap representasi digraf dan tahap analisis output hasil pengelompokan. Metode penelitian dapat dilihat pada Gambar 5.
Mulai Analisa Masalah Studi Literatur Penelitian terkait Tokenisasi Stop-word removal Stemming Penetapan nilai jarak intercluster Penetapan nilai jarak intracluster Penetapan jumlah dokumen Konfigurasi Verteks dan Edge
Struktur digraf untuk dokumen tunggal Struktur digraf untuk dokumen gabungan Identifikasi klusterisasi yang dihasilkan Selesai
Praproses data Implementasi
Document Index Graph Pembangkitan Metafile
Representasi Digraf
Analisis hasil klusterisasi
Gambar 5 Metode penelitian
Perlakuan pada penelitian ini adalah: jumlah dokumen yang digunakan untuk dokumen latih dan dokumen uji, term frequency threshold sebagai batas frekuensi kemunculan kata yang akan digunakan untuk pengelompokan dan outputmetafile yang dihasilkan. Faktor dan level penelitian ini ditampilkan pada Tabel 1.
Tabel 1 Faktor dan level penelitian
Faktor Level
Jumlah Dokumen Pengujian algoritme dilakukan pada 20 dokumen uji dan 50-100 dokumen latih Stemming Analisis Masalah Studi Literatur Penelitian Terkait Analisis hasil Clustering Konfigurasi
Pengukuran nilai precision, recall dan accuracy dilakukan pengujian terhadap 20, 25, 50 dan 100 dokumen latih
Term Frequent Threshold Batas kemunculan kata pada dokumen minimal 20 kali
Output metafile Menggunakan format bahasa DOT untuk penyusunan struktur digraf untuk dokumen tunggal dan dokumen gabungan
Analisis Masalah dan Studi Pustaka
Pada tahap ini dilakukan analisis dan studi pustaka terhadap permasalahan yang dihadapi. Permasalahan tersebut yaitu mengenai peningkatan volume data pada dokumen web yang berkembang saat ini meskipun format dokumen yang ditemukan telah terstruktur dengan baik. Fenomena tersebut dapat diatasi dengan melakukan teknik text mining dengan melakukan proses pengelompokan terhadap dokumen-dokumen web dengan merujuk pada pola-pola dan keterkaitan isi dalam dokumen-dokumen tersebut. Pengelolaan informasi dengan text mining memberikan gambaran dari topik dalam satu set besar dokumen tanpa harus membaca isi dokumen satu per satu. Hal ini dapat dilakukan dengan pengelompokan.
Pencarian dan pembelajaran mengenai literatur yang berkaitan dengan penelitian, yang dilakukan yaitu menerapkan algoritme pengelompokan yang mudah difahami baik secara input, proses maupun output. Salah satu algoritme yang telah dikembangkan dari penelitian sebelumnya adalah algoritme Document Index Graph (DIG). Literatur tersebut dapat berupa buku, jurnal, dan media yang dapat dibuktikan kebenarannya.
Tahap Praproses Data
Tahap praproses data mengubah bentuk asli data tekstual ke dalam struktur dokumen yang siap untuk proses data mining, dan telah dapat mengidentifikasi fitur teks yang paling signifikan yang dapat menentukan perbedaan di antara kategori-kategori tertentu (Srividhya 2010). Dengan kata lain, tahap ini adalah proses penggabungan sebuah dokumen baru ke dalam sistem temu kembali informasi dan menentukan fitur-fitur yang mewakili setiap kata untuk setiap fitur yang ada pada dokumen.
atas 5 atribut yakni TOPICS, LEWISSPLIT, CGISPLIT, OLDID, NEWID. Pada kasus kategorisasi teks, data REUTERS-21578 terdiri atas 5 kategori berdasarkan isi dokumen yakni Exchange, Orgs, People, Places, Topics.
Tahapan praproses data dalam konteks text mining adalah sebagai berikut (Srividhya 2010) :
Stop-word removal. Menghilangkan kata-kata yang sering digunakan tapi tidak memuat informasi yang signifikan (the, of, and, to)
Stemming. Proses ini akan mencari kata dasar dari sebuah kata (user, used, users -> USE)
Document index. Teknik pencarian keyword yang tepat dari setiap dokumen (pemodelan graf). Salah satu metode document index adalah term weighting. Term weighting adalah pembobotan kata pada setiap kemunculannya di setiap dokumen dan menunjukkan pentingnya kata tersebut (menghitung bobot node di setiap edge). Dimentional reduction. Menentukan jumlah dokumen yang di dalamnya terdapat kata yang sering muncul dan menghilangkan kata yang jarang muncul. Jika kata yang muncul tidak melebihi n dokumen yang ditetapkan sebagai nilai threshold maka kata tersebut dapat dihilangkan.
Implementasi Algoritme Document Index Graph (DIG)
DIG merupakan algoritme pembangun digraf. Digraf yang dibangun merupakan graf berarah. Arah digraf menunjukkan struktur kalimat. Digraf yang dibangun merupakan komponen dari :
1. Node. Node berisi kata unik dari setiap kalimat dalam dokumen.
2. Edge. Merupakan penghubung antarnode. Pada edge terdapat informasi berupa nomor edge, posisi kata tersebut dalam kalimat dan dalam dokumen.
3. Path. Node pada digraf berisi informasi tentang kata unik dalam sebuah dokumen. Jalur atau path yang dibentuk oleh node dan edge merupakan representasi dari sebuah kalimat tertentu.
Algoritme Document Index Graph sebagai berikut (Hammouda 2004) : 1. Proses satu per satu kalimat pada setiap dokumen.
2. Setiap kata yang belum ada di dalam kumpulan digraf, maka akan ditambahkan sebagai node.
3. Jika kata sudah ada dalam kumpulan digraf, maka buat edge baru.
4. Untuk setiap kata yang bertetangga,hubungkan dengan edge.
5. Untuk mendapatkan matching phrase, buat daftar data dokumen-dokumen yang mempunyai edge yang serupa ke dalam sebuah tabel.
6. Jika matching phrase berikutnya mempunyai edge yang merupakan
kelanjutan dari edge sebelumnya, maka gabungkan pada matching
phrase sebelumnya.
7. Jika kata yang muncul tidak melebihi n dokumen yang ditetapkan sebagai nilai threshold maka kata tersebut dapat dihilangkan
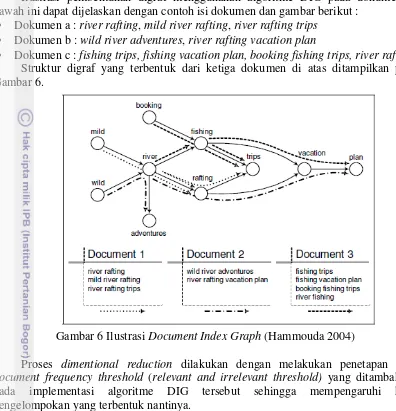
Ilustrasi pembentukan digraf menggunakan algoritme DIG pada dokumen di bawah ini dapat dijelaskan dengan contoh isi dokumen dan gambar berikut :
Dokumen a : river rafting, mild river rafting, river rafting trips Dokumen b : wild river adventures, river rafting vacation plan
Dokumen c : fishing trips, fishing vacation plan, booking fishing trips, river rafting Struktur digraf yang terbentuk dari ketiga dokumen di atas ditampilkan pada Gambar 6.
Gambar 6 Ilustrasi Document Index Graph (Hammouda 2004)
Proses dimentional reduction dilakukan dengan melakukan penetapan nilai document frequency threshold (relevant and irrelevant threshold) yang ditambahkan pada implementasi algoritme DIG tersebut sehingga mempengaruhi hasil pengelompokan yang terbentuk nantinya.
Cluster yang terbentuk dari implementasi algoritme DIG akan dicocokkan dengan hasil penelitian Lewis (1997). Pengujian pengelompokan dokumen dilakukan pada jumlah dokumen tertentu. Pengujian dilakukan dengan mencari kata-kata yang memiliki frekuensi kemunculan dokumen lebih dari 20 kali. Pengujian menghasilkan komposisi kategori yang muncul untuk selanjutnya ditentukan kelompok atau kategorinya (Lewis 1997). Komposisi kategorisasi teks ditampilkan pada Gambar 7.
Pembangkitan metafile penyusun struktur digraf
Metafile penyusun struktur digraf adalah sebuah bentukan output dari hasil implementasi algoritme DIG dengan penerapan dimentional reduction dan menghasilkan bentukan cluster dari dokumen yang diproses. Metafile berisi informasi tentang struktur node dan edge yang saling terhubung dalam sebuah path. Penentuan struktur digraf dibedakan dengan pewarnaan sesuai dengan jalur path yang terbentuk dari hasil implementasi algoritme tersebut. Adapun beberapa informasi yang terkandung di dalam metafile tersebut sebagai berikut :
digraph {
graph[fontname,fontsize,style,nodesep=3]
node [style=filled fillcolor="gray80"] "vertex =>Term Frequency" ... ;
}
Representasi digraf menggunakan metafile penyusun digraf
Representasi digraf divisualisasikan dengan menggunakan aplikasi Graphviz menggunakan lingkungan pemrograman PHP sehingga input untuk representasi digraf tersebut yakni metafile menggunakan bahasa pemrograman PHP. Output penelitian adalah bentukan digraf yang berisi hasil pengelompokan dokumen dengan batasan nilai document frequency threshold dan jumlah dokumen yang akan diuji.
Analisis hasil pengelompokan berdasarkan pengujian
Penelitian ini melakukan pengujian untuk pengelompokan hasil implementasi algoritme DIG dengan menentukan nilai-nilai batasan sebagai berikut :
1. Batasan jumlah dokumen. Jumlah dokumen yang diuji mencakup 10 dan 20 dokumen newswire REUTERS-21578 berkategori LEWISSPLIT yakni PUBLISHED-TEST.
2. Batasan nilai document frequency threshold. Membatasi kata-kata yang memiliki nilai Term Frequency (TF) yang tinggi akan tetapi tidak relevan terhadap isi dokumen.
3. Batasan nilai relevant words. Membatasi kata-kata yang memiliki nilai TF relatif kecil sehingga proses pengelompokan kata menjadi lebih sederhana.
4. Pembangkitan struktur digraf. Memberikan pilihan untuk pembangkitan struktur digraf secara keseluruhan atau masing-masing dokumen. Penentuan tersebut akan mempengaruhi kompleksnya penggambaran digraf pada aplikasi.
4
HASIL DAN PEMBAHASAN
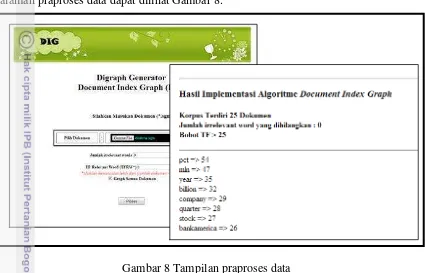
[image:31.595.91.517.173.446.2]Penelitian ini dibuat menggunakan bahasa pemrograman PHP untuk tahapan praproses data, implementasi algoritme DIG dan pembangkitan metafile penyusun struktur digraf. Representasi digraf menggunakan software Graphviz 2.30. Tampilan halaman praproses data dapat dilihat Gambar 8.
Gambar 8 Tampilan praproses data
Berdasarkan Gambar 8 untuk tahapan praproses data selain dilakukan proses tokenisasi, penghapusan kata hubung yang terdapat pada daftar stop-word dan pengambilan kata dasar (stemming), dilakukan juga proses dimentional reduction. Proses dimentional reduction akan melakukan pembacaan isi dokumen dan akan melakukan pembatasan oleh dua nilai yang menjadi threshold untuk mendapatkan hasil pengelompokan yang terbaik.
Nilai pertama adalah banyaknya kata yang memiliki nilai Term Frequency (TF) tinggi akan tetapi tidak mewakili topik dalam dokumen (document frequency threshold). Hal ini ditemukan di sebagian besar dokumen REUTERS-21578. Dalam pengujian ditemukan setidaknya 3 kata yang selalu memiliki nilai TF tinggi akan tetapi tidak relevan terhadap topik dalam dokumen. Kata tersebut adalah : pct, mln dan dlrs. Oleh karena itu untuk mendapatkan hasil pengelompokan dan representasi digraf yang lebih baik, maka beberapa kata tersebut sebaiknya dihilangkan dalam proses pengelompokan sehingga perlu ditentukan nilai document frequency threshold yang ingin dihilangkan yakni 2-3 kata berdasarkan pengujian praproses data.
Nilai kedua adalah banyaknya kata yang memiliki nilai TF tinggi dan mewakili topik dalam dokumen (relevant words), dan jumlah kemunculannya minimal lebih dari (jumlah dokumen – n) kali atau maksimal lebih dari jumlah dokumen yang diproses.
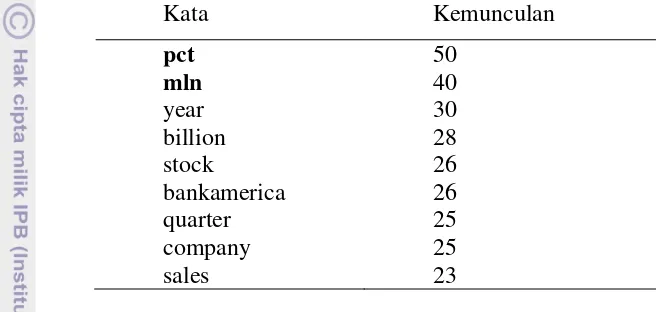
Praproses data pada 20 dokumen uji dilakukan dengan membandingkan hasil pengelompokan yang didapat dengan dan tanpa penyertaan nilai document frequency threshold dan penetapan nilai bobot Term Frequency (TF) agar hasil pengelompokan hanya akan menampilkan kemunculan kata lebih dari 20 kali. Hasil pengelompokan 20 dokumen dengan variasi nilai document frequency threshold dan nilai bobot Term Frequency = 0 ditampilkan pada Tabel 2 dan Tabel 3.
Tabel 2 Hasil pengelompokan 20 dokumen dengan document frequency threshold=0
Kata Kemunculan
pct 50
mln 40
year 30
billion 28
stock 26
bankamerica 26
quarter 25
company 25
sales 23
Tabel 3 Hasil pengelompokan 20 dokumen dengan document frequency threshold=2
Kata Kemunculan
year 30
billion 28
stock 26
bankamerica 26
quarter 25
company 25
sales 23
Berdasarkan hasil pengelompokan di atas dapat dijelaskan bahwa penetapan nilai document frequency threshold sebesar 0 (nol) akan menampilkan kata-kata yang frekuensi kemunculan dokumennya lebih dari 20 kali tanpa melakukan pembatasan kata-kata yang tidak relevan. Kata yang tidak relevan yang dimaksud adalah kata pct dan mln. Dua kata tersebut selalu ditemukan di setiap dokumen dan muncul lebih dari satu kali. Hal tersebut ditandai dengan jumlah kemunculan terbesar di antara kata-kata lain di dokumen tersebut. Berdasarkan hal itu maka mekanisme algoritme dikembangkan untuk membatasi kemunculan kata yang sering muncul tapi tidak relevan dengan menghilangkan kata yang bobot kemunculannya terbesar sebanyak nilai input document frequency threshold. Oleh karena itu ketika nilai document frequency threshold diubah menjadi 2, maka dapat diartikan bahwa algoritme akan menghilangkan dua kata dengan nilai frekuensi kemunculannya paling besar yakni kata pct dan mln.
adalah sebesar 0. Nilai tersebut dipakai agar menghasilkan minimal kemunculan yang didapat sejumlah (jumlah dokumen – n) kali.
Praproses data pada 25 dokumen latih dilakukan dengan membandingkan hasil pengelompokan yang didapat dengan dan tanpa penyertaan nilai document frequency threshold dan penetapan nilai bobot Term Frequency (TF) agar hasil pengelompokan hanya akan menampilkan kemunculan kata lebih dari 20 kali. Hasil pengelompokan 25 dokumen dengan variasi nilai document frequency threshold dan nilai bobot Term Frequency = 0 ditampilkan pada Tabel 4 dan Tabel 5.
Tabel 4 Hasil pengelompokan 25 dokumen dengan document frequency threshold=0
Kata Kemunculan
pct 54
mln 47
year 35
billion 32
company 29
quarter 28
bankamerica 26
sales 23
debt 22
Tabel 5 Hasil pengelompokan 25 dokumen dengan document frequency threshold=3
Kata Kemunculan
billion 32
company 29
quarter 28
bankamerica 26
sales 23
debt 22
Berdasarkan hasil pengelompokan di atas dapat dijelaskan bahwa penetapan nilai document frequency threshold sebesar 3 akan menampilkan kata-kata yang frekuensi kemunculan dokumennya lebih dari 20 kali dan melakukan pembatasan kata-kata yang tidak relevan sebanyak 3 kata yakni pct, mln dan year. Tiga kata tersebut selalu ditemukan di setiap dokumen dan muncul lebih dari satu kali. Hal tersebut ditandai dengan jumlah kemunculan terbesar di antara kata-kata lain di dokumen tersebut.
Penentuan nilai bobot Term Frequency (TF) pada percobaan dengan 25 dokumen didasarkan pada rumus (jumlah dokumen – n) agar dapat menampilkan hasil pengelompokan dokumen dengan kemunculan lebih dari 20 kali. Oleh karena itu nilai n=5 pada input nilai TF digunakan untuk melakukan pembatasan jumlah kata yang akan ditampilkan sebagai hasil pengelompokan berdasarkan minimal kemunculan kata di sejumlah dokumen yang diuji yakni tetap lebih dari 20 kali (Lewis 1997).
Implementasi pada 100 dokumen latih menggunakan nilai document frequency threshold=3 dan nilai bobot TF=80 menghasilkan sebanyak 95 kata dengan kemunculan lebih dari 20 kali. Hasil percobaan dapat dilihat pada Lampiran 2.
Hasil implementasi untuk 20, 25, 50 dan 100 dokumen dengan perubahan nilai document frequency threshold dan nilai bobot Term Frequency (TF) sangat penting dilakukan untuk mendapatkan hasil pengelompokan yang lebih baik dan mendapatkan representasi digraf yang lebih baik pula.
Hasil implementasi algoritme dilanjutkan dengan pembangkitan metafile yang merupakan bahasa terstruktur penyusun struktur digraf yang akan mendefinisikan komponen digraf seperti node, edge dan path. Format bahasa yang digunakan adalah DOT language dengan unsur node yakni kata-kata yang terpilih dari hasil implementasi algoritme DIG pada praproses data; unsur edge adalah keterhubungan kata-kata dalam dokumen; dan unsur path adalah pengelompokan kata berdasarkan warna pada graf. Berikut adalah format metafile penyusun digraf untuk representasi dokumen tunggal dari hasil pengelompokan 20 dokumen uji dengan nilai document frequency threshold=2 dan nilai TF=0.
digraph {
graph [fontname = "Arial", fontsize = 36, style = "bold", nodesep=3] node [style=filled fillcolor="gray80"]
"year=>30" "billion=>28" "stock=>26" "bankamerica=>26" "quarter=>25"
“bankamerica=> 26" -> "billion=>28" [color=red,penwidth=3.0]; "bankamerica=> 26" -> "stock=>26" [color=green,penwidth=3.0]; "bankamerica=> 26" -> "stock=>26" [color=orange,penwidth=3.0]; "stock=>26" -> "bankamerica=>26" -> "stock=>26"
[color=darkslateblue,penwidth=3.0];
"bankamerica=>26" -> "billion=>28" -> "year=>30" [color=darkseagreen,penwidth=3.0];
}
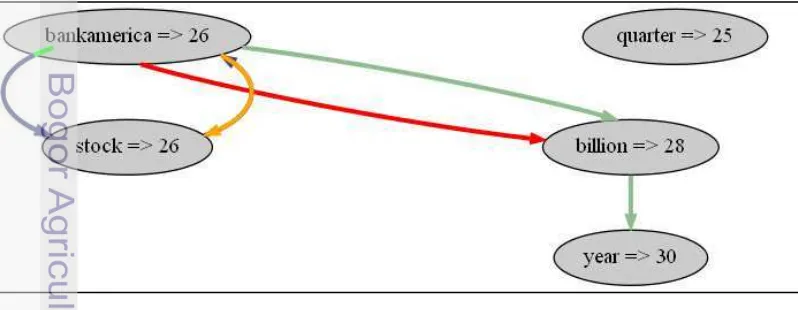
[image:34.595.87.486.545.700.2]Metafile di atas sebagai bentukan output antara dari proses pengelompokan. Output hasil pengelompokan (metafile) akan menjadi input awal penyusunan struktur digraf untuk representasi digraf pada interface aplikasi. Tampilan digraf dari input metafile dapat dilihat pada Gambar 9.
Representasi digraf yang disajikan pada Gambar 9 dapat dilihat hasil pengelompokan dokumen dengan melihat nilai Term Frequency (TF) dari kata-kata yang sering muncul pada dokumen uji. Dari implementasi 20 dokumen REUTER-21578 dengan nilai document frequency threshold = 2 dan nilai bobot TF relevant words = 0 atau sejumlah dokumen yang diproses, maka didapat 4 kata yang sering ditemukan pada pembandingan dokumen pertama dan kedua yakni : year, billion, bankamerica dan stock. Di sisi lain, kata quarter ditemukan pada pembandingan dokumen lainnya. Warna pada digraf mewakili kelompok yang terbentuk dari implementasi algoritme DIG. Jalur asiklik pada digraf menunjukkan keterkaitan kata yang sering muncul di beberapa dokumen, dan jalur siklik menunjukkan ada beberapa kata yang sama yang muncul pada sebuah dokumen.
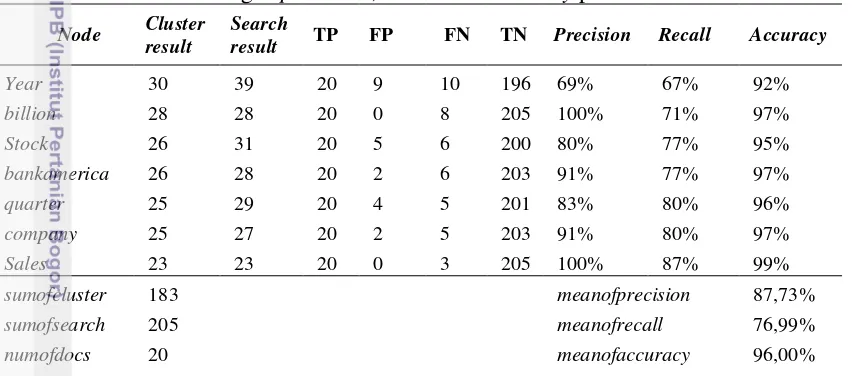
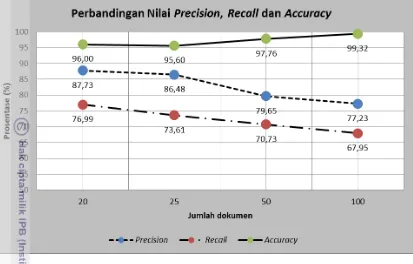
[image:35.595.90.516.304.492.2]Langkah selanjutnya adalah menganalisis tingkat akurasi dari pencarian dan temu kembali informasi dengan menghitung nilai precision, recall dan accuracy hasil pengelompokan pada 20 dokumen uji. Hasil perhitungan ditampilkan pada Tabel 6.
Tabel 6 Perhitungan precision, recall dan accuracy pada 20 dokumen
Node Cluster result
Search
result TP FP FN TN Precision Recall Accuracy
Year 30 39 20 9 10 196 69% 67% 92%
billion 28 28 20 0 8 205 100% 71% 97%
Stock 26 31 20 5 6 200 80% 77% 95%
bankamerica 26 28 20 2 6 203 91% 77% 97%
quarter 25 29 20 4 5 201 83% 80% 96%
company 25 27 20 2 5 203 91% 80% 97%
Sales 23 23 20 0 3 205 100% 87% 99%
sumofcluster 183 meanofprecision 87,73%
sumofsearch 205 meanofrecall 76,99%
numofdocs 20 meanofaccuracy 96,00%
Gambar 10 Grafik nilai precision, recall dan accuracy pada dokumen uji
[image:36.595.96.509.86.350.2]5
SIMPULAN DAN SARAN
Simpulan
Implementasi algoritme Document Index Graph (DIG) pada dokumen REUTERS telah dapat menghasilkan pengelompokan dengan nilai rataan precision sebesar 81%, rataan recall sebesar 73%, dan rataan accuracy sebesar 90%. Selain itu, penelitian ini telah menunjukkan bahwa pembangkitan metafile telah dapat merepresentasikan hasil pengelompokan berbasis digraf.
Saran
DAFTAR PUSTAKA
Salton, G. et al. 1975. A Vector Space Model for Automatic Indexing. Journal of Information Retrieval dan Language Processing.
Yang, Y. Jan O P. 1997. A Comparative Study on Feature Selection in Text Categorization.
O. Zamir and O. Etzioni. 1998. Web document clustering: A feasibility demonstration. In Proceedings of the 21st Annual International ACM SIGIR Conference, pages 46–54, Melbourne, Australia.
Wang,Y. J Hodges. 2002. Incorporating Semantic and Syntactic. Department of Computer Science & Engineering, Mississippi State University.
Hammouda K M, Mohamed S. Kamel. 2004. Efficient phrase-based document indexing for web document clustering.
P.-J. Cheng, L.-F.Chien. 1004. Effective image annotation for searches using multilevel semantics. International Journal Digital Library.4: 258–271.
Jing, L. et al. 2006. Ontology-based Distance Measure for Text Clustering.
Torres, G. J. et al. 2009. A Similarity Measure for Clustering and its Applications. International Journal of Electrical and Electronics Engineering 3:3.
Ernawati S dan Arie A, Erwin B S. 2009. Klusterisasi Dokumen Berita Berbahasa Indonesia Menggunakan Document Index Graph. Seminar Nasional Aplikasi Teknologi Informasi 2007 (SNATI 2007) Yogyakarta. 20 Juni 2012. ISSN : 1907
– 5022.
Gupta, V. 2009. A Survey of Text Mining Techniques and Applications. Journal of Emerging Technologies in Web Intelligence, 60-76.
Liu, Y. et al. 2010. Understanding of Internal Clustering Validation Measures. IEEE International Conference on Data Mining.
Amine, A. et al. 2010. Evaluation of Text Clustering Methods Using WordNet. The International Arab Journal of Information Technology, Vol. 7, No. 4.
Huang, C. J Yin. 2011. Text Clustering Using a Suffix Tree Similarity Measure. Journal of Computers. vol. 6, no. 10. Academy Publisher.
Srividhya V, R. Anitha. 2010. Evaluating Preprocessing Techniques in Text Categorization. International Journal of Computer Science and Application Issue. Rendon, E. et al. 2011. Internal Versus External Cluster Validation Indexes.
International Journal of Computers And Communications.
Gansner E. et al. 2006. Drawing Graph with dot. Dot‟s user manual. [Online]. Available: http://www.graphviz.org/Documentation/dotguide.pdf. [Accessed: 1-Nov-2013]
Lampiran 1. Hasil implementasi algoritme DIG pada 50 dokumen latih dengan beberapa variasi nilai Term Frequency threshold dan minimal bobot kemunculan kata dalam dokumen atau bobot TF lebih dari 20 kali.
Korpus terdiri atas 50 dokumen Document frequency threshold : 0 Bobot TF > 20
dlrs => 129
year => 87
mln => 84
billion => 69
company => 50
growth => 43
shares => 36
stock => 34
u.s => 32
quarter => 32
expected => 30
share => 30
debt => 30
sales => 28
dollar => 27
market => 27
interest => 27
bankamerica => 26
trade => 24
bank => 24
exchange => 24
tax => 22
west => 21
dlr => 21
group => 21
analysts => 21
Korpus terdiri atas 50 dokumen Document frequency threshold : 3 Bobot TF > 20
billion => 69
company => 50
growth => 43
shares => 36
stock => 34
u.s => 32
quarter => 32
expected => 30
share => 30
debt => 30
sales => 28
dollar => 27
market => 27
interest => 27
bankamerica => 26
trade => 24
bank => 24
exchange => 24
tax => 22
west => 21
dlr => 21
group => 21
Lampiran 2. Hasil implementasi algoritme DIG pada 100 dokumen latih dengan beberapa variasi nilai Term Frequency threshold dan minimal bobot kemunculan kata dalam dokumen atau bobot TF lebih dari 20 kali.
Korpus terdiri atas 100 dokumen Document frequency threshold : 0 Bobot TF > 20
dlrs => 210 mln => 190 year => 146
billion => 114 u.s => 89 company => 79 bank => 77 trade => 77 stock => 60 market => 58 oil => 57 shares => 56 sales => 55 foreign => 53 debt => 51 share => 49 canada => 48 growth => 48 interest => 48 banks => 44 expected => 42 tonnes => 41 told => 40 exchange => 39 quarter => 38 due => 38 tax => 35 yen => 35 prices => 34 payments => 33 economic => 33 offer => 33 price => 33
dollar => 32 rate => 32 rates => 31 made => 31 analysts => 31 export => 30 dlr => 30 cut => 30 increase => 30 japan => 30 group => 29 government => 29 reagan => 28 years => 28 february => 28 system => 27 january => 27 lower => 27 major => 27 trading => 27 officials => 27 world => 27 bankamerica => 26 agreement => 26 statement => 26 profit => 26 total => 25 wheat => 25 industry => 25 rise => 25 president => 25 west => 25 "the => 25
production => 25 current => 25 corp => 24 ecuador => 24 saudi => 24 house => 24 exports => 24 today => 24 added => 24 earnings => 24 countries => 23 month => 23 sources => 23 end => 23 time => 23 earlier => 23 week => 23 fell => 23
Korpus terdiri atas 100 dokumen Document frequency threshold : 3 Bobot TF > 20
billion => 114
u.s => 89
company => 79
bank => 77
trade => 77 stock => 60 market => 58
oil => 57
shares => 56 sales => 55 foreign => 53
debt => 51
share => 49 canada => 48 growth => 48 interest => 48 banks => 44 expected => 42 tonnes => 41
told => 40
exchange => 39 quarter => 38
due => 38
tax => 35
yen => 35
prices => 34 payments => 33 economic => 33 offer => 33 price => 33 dollar => 32
rate => 32
rates => 31
made => 31
analysts => 31 export => 30
dlr => 30
cut => 30
increase => 30 japan => 30 group => 29 government => 29 reagan => 28 years => 28 february => 28
system => 27 january => 27 lower => 27 major => 27 trading => 27 officials => 27 world => 27 bankamerica => 26 agreement => 26 statement => 26 profit => 26 total => 25 wheat => 25 industry => 25
rise => 25
president => 25
west => 25
"the => 25 production => 25 current => 25
corp => 24
ecuador => 24 saudi => 24 house => 24 exports => 24 today => 24 added => 24 earnings => 24 countries => 23 month => 23 sources => 23
end => 23
time => 23
earlier => 23
week => 23
fell => 23
committee => 22
buy => 22
french => 22
sale => 21
national => 21
half => 21
net => 21
cash => 21
london => 21
Lampiran 3. Hasil perhitungan precision, recall dan accuracy pada 25 dokumen REUTERS
Node Cluster result
Search
result TP FP FN TN Precision Recall Accuracy
Year 35 45 20 10 15 216 0,67 0,57 0,90
Billion 32 32 20 0 12 226 1,00 0,63 0,95
company 29 34 20 5 9 221 0,80 0,69 0,95
Quarter 28 32 20 4 8 222 0,83 0,71 0,95
Stock 27 32 20 5 7 221 0,80 0,74 0,95
bankamerica 26 28 20 2 6 224 0,91 0,77 0,97
Sales 23 23 20 0 3 226 1,00 0,87 0,99
Debt 22 24 20 2 2 224 0,91 0,91 0,98
sumofcluster 200 meanofprecision 86,48%
sumofsearch 226 meanofrecall 73,61%
numofdocs 25 meanofaccuracy 95,60%
Lampiran 4. Hasil perhitungan precision, recall dan accuracy pada 50 dokumen REUTERS
Node Cluster
result
Search
result TP FP FN TN Precision Recall Accuracy
analysts 21 32 20 11 1 812 0,65 0,95 0,99
Bank 24 103 20 79 4 744 0,20 0,83 0,90
bankamerica 26 28 20 2 6 821 0,91 0,77 0,99
Billion 69 69 20 0 49 823 1,00 0,29 0,95
company 50 59 20 9 30 814 0,69 0,40 0,96
Debt 30 32 20 2 10 821 0,91 0,67 0,99
Dollar 27 36 20 9 7 814 0,69 0,74 0,98
exchange 24 29 20 5 4 818 0,80 0,83 0,99
expected 30 30 20 0 10 823 1,00 0,67 0,99
Group 21 24 20 3 1 820 0,87 0,95 1,00
Growth 43 43 20 0 23 823 1,00 0,47 0,97
interest 27 33 20 6 7 817 0,77 0,74 0,98
Market 27 35 20 8 7 815 0,71 0,74 0,98
Quarter 32 38 20 6 12 817 0,77 0,63 0,98
Sales 28 28 20 0 8 823 1,00 0,71 0,99
Shares 36 36 20 0 16 823 1,00 0,56 0,98
Stock 34 45 20 11 14 812 0,65 0,59 0,97
Tax 22 27 20 5 2 818 0,80 0,91 0,99
Trade 24 29 20 5 4 818 0,80 0,83 0,99
u.s 32 43 20 11 12 812 0,65 0,63 0,97
West 21 24 20 3 1 820 0,87 0,95 1,00
sumofcluster 648 meanofprecision 79,65%
sumofsearch 823 meanofrecall 70,73%
numofdocs 50 meanofaccuracy 97,76%
Lampiran 5. Hasil perhitungan precision, recall dan accuracy pada 100 dokumen REUTERS
Node cluster result
Search
result TP FP FN TN Precision Recall Accuracy
agreement 26 31 20 5 6 3188 0,80 0,77 1,00
analysts 31 31 20 0 11 3193 1,00 0,65 1,00
bankamerica 26 28 20 2 6 3191 0,91 0,77 1,00
billion 114 114 20 0 94 3193 1,00 0,18 0,97
budget 21 21 20 0 1 3193 1,00 0,95 1,00
buy 22 34 20 12 2 3181 0,63 0,91 1,00
canada 48 60 20 12 28 3181 0,63 0,42 0,99
cash 21 23 20 2 1 3191 0,91 0,95 1,00
committee 22 26 20 4 2 3189 0,83 0,91 1,00
company 79 91 20 12 59 3181 0,63 0,25 0,98
corp 24 39 20 15 4 3178 0,57 0,83 0,99
current 25 30 20 5 5 3188 0,80 0,80 1,00
cut 30 46 20 16 10 3177 0,56 0,67 0,99
debt 51 62 20 11 31 3182 0,65 0,39 0,99
dollar 32 46 20 14 12 3179 0,59 0,63 0,99
due 38 39 20 1 18 3192 0,95 0,53 0,99
earlier 23 23 20 0 3 3193 1,00 0,87 1,00
economic 33 39 20 6 13 3187 0,77 0,61 0,99
ecuador 24 36 20 12 4 3181 0,63 0,83 1,00
exchange 39 46 20 7 19 3186 0,74 0,51 0,99
expected 42 42 20 0 22 3193 1,00 0,48 0,99
export 30 66 20 36 10 3157 0,36 0,67 0,99
february 28 29 20 1 8 3192 0,95 0,71 1,00
fell 23 23 20 0 3 3193 1,00 0,87 1,00
foreign 53 53 20 0 33 3193 1,00 0,38 0,99
french 22 22 20 0 2 3193 1,00 0,91 1,00
government 29 37 20 8 9 3185 0,71 0,69 0,99
group 29 33 20 4 9 3189 0,83 0,69 1,00
growth 48 48 20 0 28 3193 1,00 0,42 0,99
half 21 21 20 0 1 3193 1,00 0,95 1,00
house 24 34 20 10 4 3183 0,67 0,83 1,00
increase 30 52 20 22 10 3171 0,48 0,67 0,99
industry 25 31 20 6 5 3187 0,77 0,80 1,00
interest 48 62 20 14 28 3179 0,59 0,42 0,99
january 27 27 20 0 7 3193 1,00 0,74 1,00
japan 30 57 20 27 10 3166 0,43 0,67 0,99
london 21 21 20 0 1 3193 1,00 0,95 1,00
lower 27 31 20 4 7 3189 0,83 0,74 1,00
made 31 31 20 0 11 3193 1,00 0,65 1,00
major 27 30 20 3 7 3190 0,87 0,74 1,00
Node cluster result
Search
result TP FP FN TN Precision Recall Accuracy
month 23 47 20 24 3 3169 0,45 0,87 0,99
national 21 44 20 23 1 3170 0,47 0,95 0,99
net 21 33 20 12 1 3181 0,63 0,95 1,00
offer 33 52 20 19 13 3174 0,51 0,61 0,99
officials 27 29 20 2 7 3191 0,91 0,74 1,00
oil 57 60 20 3 37 3190 0,87 0,35 0,99
payments 33 34 20 1 13 3192 0,95 0,61 1,00
president 25 29 20 4 5 3189 0,83 0,80 1,00
price 33 75 20 42 13 3151 0,32 0,61 0,98
production 25 25 20 0 5 3193 1,00 0,80 1,00
profit 26 47 20 21 6 3172 0,49 0,77 0,99
quarter 38 48 20 10 18 3183 0,67 0,53 0,99
rate 32 94 20 62 12 3131 0,24 0,63 0,98
reagan 28 34 20 6 8 3187 0,77 0,71 1,00
rise 25 40 20 15 5 3178 0,57 0,80 0,99
sales 55 55 20 0 35 3193 1,00 0,36 0,99
saudi 24 28 20 4 4 3189 0,83 0,83 1,00
shares 56 56 20 0 36 3193 1,00 0,36 0,99
statement 26 26 20 0 6 3193 1,00 0,77 1,00
stock 60 76 20 16 40 3177 0,56 0,33 0,98
system 27 33 20 6 7 3187 0,77 0,74 1,00
tax 35 40 20 5 15 3188 0,80 0,57 0,99
time 23 40 20 17 3 3176 0,54 0,87 0,99
today 24 27 20 3 4 3190 0,87 0,83 1,00
told 40 40 20 0 20 3193 1,00 0,50 0,99
tonnes 41 41 20 0 21 3193 1,00 0,49 0,99
total 25 34 20 9 5 3184 0,69 0,80 1,00
trade 77 88 20 11 57 3182 0,65 0,26 0,98
trading 27 27 20 0 7 3193 1,00 0,74 1,00
united 21 22 20 1 1 3192 0,95 0,95 1,00
week 23 37 20 14 3 3179 0,59 0,87 0,99
west 25 35 20 10 5 3183 0,67 0,80 1,00
wheat 25 25 20 0 5 3193 1,00 0,80 1,00
world 27 38 20 11 7 3182 0,65 0,74 0,99
yen 35 36 20 1 15 3192 0,95 0,57 1,00
sumofcluster 2545 meanofprecision 77%
sumofsearch 3193 meanofrecall 68%
numofdocs 100 meanofaccuracy 99%
RIWAYAT HIDUP
Budi dilahirkan di Karawang, 5 Agustus 1978. Penulis merupakan anak tunggal dari pasangan Maksin Sia dan Melly Maryati. Tahun 2002, penulis lulus sarjana pada Departemen Ilmu Komputer Institut Pertanian Bogor. Penulis melanjutkan jenjang Magister pada tahun 2011 di Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor (IPB).
1
PENDAHULUAN
Latar Belakang
Dokumen web adalah salah satu sumber daya pada sebuah sistem berbasis web yang banyak ditemukan dalam bentuk tekstual misalnya dokumen teks, dokumen web, artikel dan paper dan lain sebagainya (Hammouda, et al., 2004). Peningkatan volume data khususnya pada dokumen teks saat ini memberikan implikasi terhadap isu yang berkaitan dengan akurasi temu kembali informasi dan kecepatan akses terhadap informasi yang ditelusuri. Implikasi tersebut menjadi pemicu penggunaan teknik pengelolaan dan analisis data. Teknik yang dimaksud adalah membagi kumpulan dokumen ke dalam kelompok-kelompok yang berbeda sehingga dokumen yang terdapat pada suatu kelompok akan mengandung informasi yang sama dan terkait satu sama lain. Oleh karena itu diperlukan sebuah metode pengelompokan dokumen agar memudahkan dalam pengambilan informasi sesuai kebutuhan user.
Clustering merupakan salah satu teknik yang dapat digunakan untuk menemukan keterkaitan antar dokumen. Tujuan pengelompokan adalah untuk memisahkan sekumpulan dokumen ke dalam beberapa kelompok atau cluster dengan menilai kemiripan antar dokumen dari segi isi. Pada umumnya teknik pengelompokan dilandasi oleh 4 (empat) konsep tahapan yakni: (1) Praproses data, (2) Penghitungan kemiripan (similarity measure), (3) Pemilihan metode pengelompokan (cluster method), dan (4) Algoritme pengelompokan yang digunakan. Banyak metode yang dapat dipakai dalam pengelompokan dokumen seperti dengan Suffix Tree, Single Pass Clustering maupun K-Nearest Neighbour. Kebanyakan metode pengelompokan dokumen berbasis pemodelan ruang vektor yang merepresentasikan dokumen sebagai fitur vektor dari term yang muncul pada semua dokumen (Hammouda 2004). Pengelompokan dengan metode seperti ini hanya memperhatikan analisis single term, tanpa memperhatikan analisis berbasis frasa. Idealnya proses pengelompokan sebaiknya tidak hanya memperhatikan analisis single term saja, akan tetapi perlu diperhatikan juga analisis frasa dari suatu dokumen. Dengan analisis frasa, kesamaan antar dokumen akan dihitung berdasarkan pencocokan frasa.
Penelitian Oren Zamir (1998), melakukan analisis pengelompokan dokumen berbasis analisis frasa dengan pendekatan Suffix Tree Clustering (STC). Metode
tersebut pada dasarnya melibatkan penggunaan struktur “trie” (tree sederhana) untuk merepresentasikan suffix yang digunakan bersama antar dokumen. Berdasarkan suffix dilakukan identifikasi cluster dasar dari dokumen, dan akan digabungkan ke dalam cluster akhir berdasarkan algoritme connected-component graph. Metode ini diklaim memiliki nilai kompleksitas n log(n) dan menghasilkan cluster yang baik, akan tetapi model tree yang terbentuk dapat dikatakan memiliki nilai redundansi yang tinggi pada kasus term dari suffix yang disimpan pada tree.
kata-kata dalam kalimat tersebut. DIG memungkinkan untuk mengenali pencocokan frasa antar dokumen. Ketika sebuah dokumen baru diproses, maka algoritme akan membentuk atau membangun sebuah daftar kesamaan antar dokumen tersebut dengan semua dokumen sebelumnya telah disimpan. Penelitian tersebut dapat menangkap struktur dari kalimat pada sebuah set dokumen dibanding hanya kata tunggal saja. Dokumen yang dianalisis pada penelitian adalah dokumen HTML. Hasil pemodelannya adalah bentuk XML yang terstruktur dengan baik sesuai dengan dokumen HTML yang asli namun dengan tingkat signifikansi yang ditugaskan kebagian yang berbeda di dokumen asli. Hasil penelitian menyimpulkan bahwa kualitas cluster yang terbentuk dari pemodelan DIG lebih baik hasilnya dibanding dengan pemodelan berbasis ruang vektor. Di samping itu, penelitian ini menyimpulkan bahwa ukuran kemiripan berbasis frasa memiliki tingkat akurasi yang tinggi dengan syarat telah memperhatikan pengujian terhadap faktor-faktor yang mempengaruhi derajat overlap antar dokumen.
Penelitian Ernawati (2009) yang berjudul “Klusterisasi Dokumen Berita Berbahasa Indonesia Menggunakan Document Index Graph”, menunjukkan bahwa algoritme DIG dapat diimplementasikan untuk mendeteksi kesamaan berbasis frasa dan menangani overlap clustering. Walaupun tidak selalu terjadi, kesamaan berbasis frasa dapat memperbaiki performansi cluster berdasarkan pengukuran f-measure dan entropy. Ada beberapa titik kesamaan berbasis frasa justru dapat mengurangi nilai performansi, oleh karena itu perlu dicari titik optimal similarity blend factor dan similarity threshold.
Berdasarkan perkembangan peningkatan volume data pada dokumen web saat ini dan mencermati implikasi dari perkembangan tersebut serta mempelajari hasil penelitian yang telah dilakukan sebelumnya, maka usulan pemodelan representasi dokumen pada penelitian ini adalah melakukan pengelompokan dokumen menggunakan algoritme Document Index Graph (DIG). Model ini melakukan proses indeks terhadap dokumen dengan tetap menjaga struktur kalimat dalam dokumen asli. Hal ini memungkinkan kita untuk menggunakan pencocokan frasa lebih informatif daripada pencocokan kata-kata individu. Selain itu, DIG juga menangkap berbagai tingkat
signifikansi dari kalimat asli, sehingga memungkinkan kita untuk menggunakan kalimat secara signifikan. Suffix tree adalah struktur yang paling dekat dengan model DIG, tetapi suffix tree memiliki kendala ketika terjadi redundansi yang besar (Huang 2011). Model DIG yang diusulkan bukan hanya perpanjangan atau perangkat tambahan suffix tree, tetapi DIG memiliki perspektif yang berbeda tentang bagaimana pencocokan frasa dapat