DAFTAR RIWAYAT HIDUP
Data Pribadi
Nama : Silvia Manela
Tempat/TanggalLahir : Bandung, 29 Maret 1993
Umur : 23 Tahun
JenisKelamin : Perempuan
Alamat : Jl. Abdul Halim No.89 RT.01 RW.07 Kel.Cigugur
Tengah Kec.Cimahi Tengah Kota Cimahi
No. Telepon : 085659003676
Riwayat Pendidikan
1999 - 2005 Lulus SD Negeri Pasir Kaliki 9 Kota Bandung
2005 - 2008 Lulus SMP Negeri 47 Kota Bandung
2008 - 2011 Lulus SMK Pasundan 2 Kota Bandung
2011 – 2016 Universitas Komputer Indonesia
PENERAPAN
DATA MINING
UNTUK PENYUSUNAN
LAYOUT
PRODUK DI SUMMIT THE BOUTIQUE OUTLET
MENGGUNAKAN METODE
ASSOCIATION
RULE
SKRIPSI
Diajukan untuk Menempuh Tugas Akhir Sarjana
SILVIA MANELA 10111595
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
UNIVERSITAS KOMPUTER INDONESIA
KATA PENGANTAR
Alhamdulillahi Rabbil ‘Alamiin, Puji syukur Alhamdulillah penulis panjatkan kepada Allah SWT yang telah melimpahkan rahmat, hidayah dan
karunia-Nya, sehingga penulis dapat menyelesaikan skripsi yang berjudul
“PENERAPAN DATA MINING UNTUK PENYUSUNAN LAYOUT PRODUK
DI SUMMIT THE BOUTIQUE OUTLET MENGGUNAKAN METODE
ASSOCIATION RULE.” untuk memenuhi salah satu syarat dalam menyelesaikan
studi jenjang starata satu (S1) di Program Studi Teknik Informatika, Fakultas
Teknik dan Ilmu Komputer, Universitas Komputer Indonesia.
Dengan keterbatasan ilmu dan pengetahuan yang dimiliki oleh penulis,
penyusunan skripsi ini tidak akan terwujud tanpa mendapat dukungan, bantuan
dan masukan dari berbagai pihak. Oleh karena itu melalui kata pengantar ini,
penulis ingin menyampaikan terima kasih yang sebesar-besarnya kepada:
1. Allah SWT atas segala nikmat yang telah diberikan sehingga penulis
dapat menyelesaikan skripsi ini.
2. Junjungan besar, Nabi Muhammad SAW yang telah menujukkan
kepada kita jalan yang lurus berupa ajaram agama islam yang
sempurna dan menjadi anugerah serta rahmat bagi seluruh alam
semesta.
3. Kedua orang tua yang sangat penulis sayangi, Bapak Sudirman dan
Ibu Elita yang selama ini telah memberikan dukungan baik secara
moril maupun materil serta kasih sayang dan juga pengorbanan kepada
penulis yang tidak terbalaskan.
4. Ibu Dian Dharmayanti, S.T., M.Kom selaku Sekertaris Program Studi
iv
6. Ibu Ednawati Rainarli, M.SI. selaku Dosen Wali IF-13/2011.
7. Kepada Ibu Paula selaku store manager dan juga Bapak Ilham selaku
Supervisor di Summit Boutique Outlet yang telah memberikan ijin
kepada penulis untuk melakukan penelitian di Summit The Boutique
Outlet.
8. Adik-adik penulis, Ritno Andrian dan Putri Amelia yang telah
memberikan semangat serta dukungan kepada penulis dalam
menyelesaikan tugas akhir ini.
9. Nirwan Saeful Ahmad yang selalu setia menemani dan bersedia
meluangkan waktunya untuk membantu segala keperluan selama
menyelesaikan tugas akhir ini.
10.Lizuardi Danar, Dienurra, dan Deden yang selalu menyempatkan
waktunya untuk membantu, memotivasi, dan bertukar pikiran dalam
penyelesaian skripsi ini.
11.Teman – teman sehidup seskripsi, Martono, Wita, Rizal, Lukman, Eza,
kak Mukti, dan Kiki yang sering menjadi teman begadang dalam
mengerjakan revisi skripsi juga saling menyemangati disaat merasa
lelah karena revision yang rasanya gak beres – beres.
12.Teman-Teman “Minion” Fitri, Adisty, Yayah, dan Evi yang selalu
memberikan dukungan, motivasi, dan juga semangat kepada penulis.
13.Sahabatku tersayang Selvi Ramanda, Friska Suprianti, dan Winda
Puspita, maaf sering nolak diajak main dan piknik tapi tetap tak
hentinya memberikan semangat dan doa agar skripsi ini cepat selesai.
14.Kepada teman-teman satu bimbingan Ibu Dian Dharmayanti, S.T.,
M.Kom yang selalu datang paling awal dan pulang paling akhir
diantara mahasiswa skripsi lain dan bersama – sama menjadi “kuncen”
terakhir di lorong sekjur IF.
15.Bapak dan Ibu dosen serta seluruh staf pegawai Program Studi Teknik
Informatika Universitas Komputer Indonesia yang telah membantu
16.
Serta seluruh pihak yang tidak dapat penulis sebutkan satu persatu,terima kasih atas segala bentuk dukungan untuk menyelesaikan skripsi
ini.
Di dalam pembuatan skripsi ini, penulis telah berusaha semaksimal
mungkin walaupun demikian penulis menyadari bahwa skripsi ini jauh dari
sempurna. Untuk itu penulis akan selalu menerima segala masukan yang ditujukan
untuk menyempurnakan skripsi ini. Akhir kata, penulis berharap semoga skripsi
ini dapat bermanfaat bagi penulis pada khususnya dan pembaca pada umumnya.
Wassalamu’alaikum Wr. Wb.
Bandung, Agustus 2016
vi
1.5 Metodologi Penelitian ... 3
1.5.1 Metode Pengumpulan Data ... 4
1.5.2 Metode Pembangunan Data Mining ... 4
1.5.3 Metode Pembangunan Perangkat Lunak ... 6
1.6 Sistematika Penulisan ... 8
BAB 2 TINJAUAN PUSTAKA ... 9
2.1 Tentang Perusahaan ... 9
2.1.1 Struktur Organisasi Perusahaan ... 9
2.1.2 Deskripsi Kerja ... 10
2.2 Landasan Teori ... 10
2.2.1 Data ... 10
2.2.2 Basis Data ... 11
2.2.3 Database Management System ... 16
2.2.4 Data Mining ... 16
2.2.5 Association Rule ... 19
2.2.6 Algoritma CT-Pro ... 21
2.2.7 Unifief Modelling Language (UML) ... 29
3.1 Analisis Sistem ... 33
3.1.1 Analisis Masalah ... 33
3.1.2 Analisis Non Fungsional dan Kebutuhan Non Fungsional ... 75
3.1.3 Analisis Kebutuhan Fungsional ... 76
3.2 Perancangan Sistem ... 103
3.2.1 Perancangan Kelas ... 103
3.2.2 Peracangan Data ... 106
3.2.3 Perancangan Struktur Menu ... 108
3.2.4 Perancangan Antar Muka ... 109
3.2.5 Perancangan Pesan ... 112
3.2.6 Jaringan Sematik ... 112
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM ... 113
4.1 Implementasi Sistem ... 113
4.1.1 Perangkat keras yang digunakan ... 113
4.1.2 Perangkat Lunak yang Digunanakan ... 114
4.1.3 Implementasi Basis Data ... 114
4.1.4 Implemetasi antar muka ... 115
4.2 Pengujian Sistem ... 116
4.2.1 Skenario Pengujian ... 117
4.2.2 Pengujian Fungsional ... 117
4.2.3 Kesimpulan Pengujian Fungsional ... 119
4.2.4 Hasil Wawancara ... 119
4.2.5 Kesimpulan Pengujian Betha ... 120
4.2.6 Pengujian Hasil ... 120
4.2.7 Kesimpulan Pengujian Hasil ... 124
BAB 5 KESIMPULAN DAN SARAN ... 125
5.1 Kesimpulan ... 125
127
DAFTAR PUSTAKA
[1] Sugiyono, “Metode Penelitian Kuantitatif dan R&D”, Bandung: Alfabeta,
2010.
[2] Brigida Arie, "Data Mining dalam Kerangka Kerja CRM", 2012. [Online].
Available: http://Data MiningData Mining_Informatika.html. [Diakses 4
Oktober 2015].
[3] I. Sommerville, “Software Engineering”, Edisi 6, Jakarta: Erlangga, 2003.
[4] F. Buku Teks Komputer: “Basis Data”, 5th ed., Bandung: Informatika,
2004.
[5] W. Sistem Basis Data, “Analisis dan Pemodelan Data”, 1st ed., Yogyakarta:
Graha Ilmu, 2003.
[6] Fathansyah, “Basis Data”, Bandung: Informatika 2012.
[7] B. Santoso, Data Mining: “Teknik Pemanfaatan Data Untuk Keperluan
Bisnis”, Yogyakarta: Graha Ilmu, 2007.
[8] Kusrini, Taufiq Luthfi Emha, “Algoritma Data Mining”, Yogyakarta, Andi,
2009.
[9] J. Han and M. Kamber, Data Mining: Concepts and Techniques, 2nd ed.,
San Francisco: Morgan Kaufmann Publishers, 2006.
[10] K. and E. T. Luthfi, Algoritma Data Mining, Andi, 2009
[11] D. T. Larose, Discovering Knowledge In Data: “An Introduction To Data
Mining”, New Jersey: Wiley Interscience, 2005.
[12] Rohmania Putri Nurlaili, Sari Widya Sihwi dan Meiyanto Eko Sulistyo,
“Implementasi Algoritma CT-Pro untuk menemukan pola pada data siswa
SMA”, Sesindo, 2014.
[13] Y.G Sucahyo and R. P. Gopalan, “ CT-PRO: A Bpttom Up Non Recursive
Sructure”. In proc Paper presented at the IEEE ICDM Workshop on
Frequent Itemset Mning Implementation (FIMI), Brighton UK, 2004.
[14] Prabowo P. Widodo dan Herlawati. “Menggunakan UML”. Informatika
1
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Summit Boutique Outlet adalah sebuah tempat perbelanjaan yang
menyediakan banyak jenis barang antara lain pakaian, aksesoris, juga oleh – oleh.
Dari barang - barang yang tersedia, barang tersebut dibedakan menjadi beberapa
jenis art. Setiap beberapa bulan sekali Summit memperbarui tata letak barangnya,
ini dikarenakan beberapa jenis art yang jarang dibeli oleh konsumen sehingga
butuh penempatan yang baru, diharapkan layout baru ini dapat membuat jenis art
lebih mudah diperhatikan oleh pelanggan dan layout baru juga dimaksudkan agar
toko terlihat rapi dan juga suasana baru untuk toko.
Format tampilan letak jenis art di Summit ini masih berdasarkan
pandangan dari Supervisor dan tidak ada aturan khusus dari atasan toko dalam
penyusunannya, yang pasti Supervisor ditugaskan untuk menentukan letak jenis
art agar barang terlihat rapi dan menarik yang nantinya Supervisor akan
memerintahkan Pramuniaga untuk menyusun jenis art tersebut berdasarkan letak
terbaik menurutnya. Jenis art di Summit yang banyak dan barang baru dengan
berbagai jenis art yang datang sering kali membuat bingung Supervisor untuk
memutuskan tempat mana yang paling baik untuk meletakkan jenis art tersebut
sehingga kerap kali Supervisor meletakkan barang tersebut di tempat yang kurang
bagus sehingga malah membuat jenis art tersebut tidak diperhatikan oleh
pelanggan, belum lagi kadang terdapat jenis art yang jarang dibeli oleh pelanggan
dan butuh layout baru.
Konsumen yang datang ke Summit kebanyakan merupakan rombongan
yang sering kali membeli beberapa barang secara bersama sehingga sering kali
ditemukan satu transaksi penjualan dengan lebih dari satu jenis art. Banyaknya
data penjualan yang ada di Summit hanya disimpan sebagai arsip semata dan tidak
dimanfaatkan guna kepentingan Summit itu sendiri. Pemanfaatan data penjualan
2
akan menghasilkan pola pembelian rata – rata konsumen yang terjadi setiap hari.
Pola pembelian konsumen setiap hari dapat digunakan untuk mengatasi salah satu
masalah yang terjadi di Summit yaitu dalam penempatan layout barang. Oleh
karena itu penulis ingin mencoba mengatasi masalah tersebut dengan mencoba
memberikan rekomendasi terhadap penempatan tata letak jenis art kepada
karyawan toko dengan merapkan data mining pada data penjualan di Summit The
Boutique Outlet menggunakan metode Association Rule untuk melihat hubungan
asosiasi antara sejumlah atribut penjualan guna mendapatkan pola pembelian dari
konsumen tentang jenis art apa saja yang konsisten dibeli secara bersamaan
sehingga nantinya dapat menjawab permasalah penyusunan tata letak jenis art
yang baik guna memudahkan karyawan toko untuk menyusun barang juga
memudahkan calon konsumen dalam memilih barang yang diinginkan.
Data mining adalah serangkaian proses untuk menggali nilai tambah dari
suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara
manual (Pramudiono, 2007). Dalam bidang keilmuan data mining, terdapat suatu
metode yang dinamakan Association Rule. Metode ini sering disebut dengan
market basket analysis karena awal mulanya yang berasal dari studi tentang
database transaksi penjualan (Santoso, 2007). Association Rule bertujuan untuk
menunjukan nilai asosiatif antara kategori produk yang sering dibeli bersamaan
dalam satu transaksi penjualan. Dengan mengetahui kategori apa saja yang sering
dibeli bersamaan maka dapat menghasilkan sebuah rekomendasi penempatan
layout barang yang lebih baik dalam mengambil keputusan dalam penempatan
barang.
1.2 Rumusan Masalah
Dari latar belakang yang telah dipaparkan di atas, maka dapat disimpulkan
bagaimana cara menerapkan data mining pada data penjualan yang ada pada
Summit The Boutique Outlet dengan menggunakan metode Association rule
3
1.3 Maksud dan Tujuan
Maksud dari skripsi ini adalah untuk menerapkan data mining pada data
penjualan dengan menggunakan metode association rule untuk penyusunan layout
produk di Summit The Boutique Outlet menggunakan algoritma CT- PRO.
Adapun tujuan yang ingin dicapai pada penelitian ini adalah :
1. Membantu Summit the Boutique Outlet mengetahui informasi tentang
pola pembelian konsumen.
2. Memberikan rekomendasi kepada Supervisor tentang penempatan
setiap jenis art di Summit the Boutique Outlet
1.4 Batasan Masalah
Agar penelitian terfokus pada tujuan yang ingin dicapai maka dibuatlah
suatu batasan masalah mengenasi penilitian ini. Di bawah ini merupakan batasan
masalah, yaitu:
1. Data yang akan dianalisis adalah data transaksi penjualan yang ada
pada Summit the Boutique Outlet pada bulan januari 2014 dengan
banyak data penjualan yang digunakan sebanya 353 record.
2. Metode yang digunakan adalah metode association rule dengan
menggunakan algoritma CT-PRO.
3. Hasil analisis adalah pengetahuan mengenai pola pembelian
konsumen terhadap produk yang tersedia di Summit the Boutique
Outlet.
4. Metode analisis yang digunakanan dalam pembangunan perangkat
lunak ini menggunakan pendekatan analisis Pemrograman
Berorientasi Objek.
5. Aplikasi yang dibangun berbasis desktop dengan bahasa pemrograman
C# dan menggunakan databaseMYSQL.
1.5 Metodologi Penelitian
Metodologi penelitian yang digunakan adalah metode penelitian deskriptif,
yaitu metode penelitian yang bertujuan untuk memberikan gambaran atau
4
dibagi menjadi 2 tahap, yaitu metode pengumpulan data dan metode
pembangunan perangkat lunak. Adapun metode pengumpulan data, penelitian
data mining dan pembangunan perangkat lunak sebagai berikut :
1.5.1 Metode Pengumpulan Data
Metode pengumpulan data yang digunakan pada penelitian ini adalah
sebagai berikut:
1. Studi Literatur
Teknik pengumpulan data dengan cara mengumpulkan literatur,
jurnal, paper, dan buku yang berkaitan dengan penelitian yang
dilakukan.
2. Wawancara
Teknik pengumpulan data dengan cara berinteraksi atau
berkomunikasi secara langsung kepada responden dengan mengajukan
pertanyaan yang sesuai dengan topik yang diambil.
1.5.2 Metode Pembangunan Data Mining
Dalam penelitian ini mengikuti standar dari Cross-Industry Standard for
Data Mining (CRISP-DM) merupakan suatu standar yang telah dikembangkan
pada tahun 1996 yang ditunjukkan untuk melakukan proses analisis dari suatu
industri sebagai strategi pemecahan masalah dari bisnis satu unit penelitian [2].
Untuk data yang dapat diproses dengan CRISP-DM ini, tidak ada ketentuan atau
karakteristik tertentu, karena data tersebut akan diproses kembali pada fase-fase
5
Gambar 1. 1 Cross-Industry Standard for Data Mining (CRISP-DM) [2]
Berikut ini adalah tahapan-tahapan yang akan dilakukan dalam penelitian
ini sesuai dengan CRISP-DM:
a. Business Understanding
Penerapan data mining pada penelitian ini adalah untuk memberikan
informasi tentang rekomendasi penyusunan layout jenis art di Summit
the Boutique Outlet.
b. Data Understanding
Pada tahap pemahaman data ini terlebih dahulu akan mengumpulkan
semua data yang diperlukan dari hasil data-data transaksi di Summit
the Boutique Outlet.
c. Data Preparation
Pada tahapan ini akan dilakukan proses pemilihan dan pengolahan
data yang nantinya akan diperlukan dalam tahap pemodelan sehingga
pemodelan yang dilakukan dapat memberikan hasil yang maksimal
sesuai dengan target yang diinginkan, data yang akan dipilih adalah
data transaksi di Summit the Boutique Outlet adalah data penjualan
pada bulan Januari 2014 sebanyak 353 record.
d. Modeling
Dalam tahapan pemodelan ini akan menggunakan teknik metode data
6
aturan asosiatif atau pola kombinasi barang berdasarkan hasil data
transaksi, sehingga dapat diketahui barang apa saja yang sering dibeli
secara bersamaan oleh konsumen.
e. Evaluation
Pada tahap evaluasi ini akan dibandingkan hasil CT-Pro dilakukan
oleh sistem dengan perhitungan manual, dengan mengambil beberapa
sampel acak. Evaluasi ini ditujukan untuk mengukur apakah
pemodelan yang dilakukan sesuai dengan tujuan pengimplementasian
data mining pada sistem ini.
f. Deployment
Setiap tahap evaluasi dimana menilai secara detail hasil dari
pemodelan, maka akan dilakukan pengimplementasian dari
keseluruhan model yang telah dirancang. Selain itu juga dilakukan
penyesuaian dari model dengan sistem yang akan dibangun sehingga
dapat menghasilkan suatu hasil yang sesuai dengan target pemahaman
bisnis
1.5.3 Metode Pembangunan Perangkat Lunak
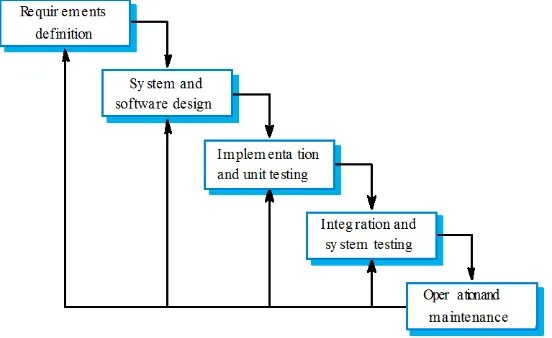
Dalam pembangunan aplikasi ini menggunakan model waterfall sebagai
tahapan pengembangan perangkat lunak ini. Waterfall adalah model klasik yang
bersifat sistematis, berurutan dalam membangun software [3]. Adapun tahapan
7
1. Requirements analysis and definition
Tahap requirements analysis and definition adalah tahap
pengumpulan data terhadap kebutuhan sistem, batasan dan tujuan
dibuatnya perangkat lunak. Tahap pengumpulan data haruslah sedetail
mungkin, karena nantinya akan digunakan sebagai spesifikasi sistem
yang akan dibangun.
2. System and software design
Tahap system and software design adalah tahap mendesain perangkat
lunak yang dikerjakan setelah kebutuhan selesai dikumpulkan secara
lengkap.
3. Implementation and unit testing
Tahap implementation and unit testing merupakan hasil dari tahap
desain yang dibentuk kedalam baris kode-kode program berdasarkan
bahawa pemrograman yang telah di tentukan sebelumnya. Program
yang telah di buat kemudian diuji bersarkan unitnya.
4. Integration and system testing
Tahap integration and system testing adalah tahap penyatuan unit-unit
program menjadi sebuah kesatuan sistem yang kemudian diuji secara
keseluruhan.
5. Operation and maintenance
Tahap operation and maintenance adalah tahap pengoprasian program
di lingkungannya dan melakukan pemeliharaan, seperti koreksi error
yang sebelumnya tidak diketahui pada tahapan sistem testing, selain
daripada itu tahapan ini juga digunakan untuk mengadaptasi terhadap
8
1.6 Sistematika Penulisan
Sistematika penulisan laporan akhir penelitian ini disusun untuk
mendeskripsikan secara umum tentang penelitian yang dilakukan. Sistematika
penulisan tugas akhir ini adalah sebagai berikut :
BAB 1 PENDAHULUAN
Menjelaskan tentang latar belakang permasalahan, merumuskan
inti permasalahan, menentukan maksud dan tujuan penelitian,
batasan masalah, yang kemudian diikuti dengan metodologi
penelitian, serta sistematika penulisan.
BAB 2 LANDASAN TEORI
Membahas berbagai konsep dasar dan teori-teori yang berkaitan
dengan topik penelitian yang dilakukan dan hal-hal yang berguna
dalam proses analisis permasalahan serta tinjauan terhadap
penelitian.
BAB 3 ANALISIS DAN PERANCANGAN
Menganalisis masalah dari data hasil penelitian, kemudian
dilakukan pula proses perancangan sistem yang akan dibangun
sesuai dengan analisa yang telah dilakukan.
BAB 4 IMPLEMENTASI DAN PENGUJIAN
Membahas tentang mplementasi dari tahapan-tahapan penting yang
telah dilakukan sebelumnya kemudian dilakukan pengujian
terhadap sistem sesuai dengan tahapan yang telah dijalani untuk
memperlihatkan sejauh mana sistem yang dibangun layak
digunakan.
BAB 5 KESIMPULAN DAN SARAN
Berisi kesimpulan dan saran yang diharapkan dapat menjadi
BAB 2
TINJAUAN PUSTAKA
2.1 Tentang Perusahaan
Summit The Boutique Outlet adalah sebuah tempat perbelanjaan yang
berada di Jl. R.E. Marthadinata Bandung yang berdiri sejak tahun 2001 dan salah
satu bidang usaha yang dikelola oleh PT. The Big Price Cut Group yang berada di
Jl. Cipaganti Kota Bandung. Ada banyak jenis barang yang dijual di Summit
antara lain fashion, aksesoris, juga oleh – oleh khas Bandung. Dari barang yang
tersedia, jenis barang tersebut dibedakan menjadi beberapa kategori barang untuk
membedakan jenis barang tersebut.
2.1.1 Struktur Organisasi Perusahaan
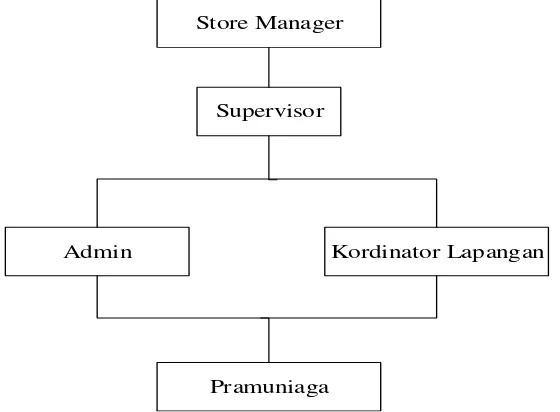
Struktur organisasi perusahaan adalah gambar suatu bagan yang
menerangkan posisi atau jabatan dan struktur kerja pegawai dalam suatu
perusahaan. Berikut ini adalah struktur organisasi di Summit The Boutique Outlet:
Store Manager
Supervisor
10
2.1.2 Deskripsi Kerja
Setiap perusahaan tentu memiliki karyawan – karyawan yang
diperkerjakan untuk membuat perusahaan maju dan keryawan – karywan
memiliki tugasnya masing – masing. Berikut deskripsi kerja dari masing – masing
karyawan yang bekerja di Summit the boutique outlet :
1. Store Manager
Store Maneger bertugas untuk mengawasi kerja para karyawan,
pengambil keputusan dan penanggung jawab semua aktifitas yang
berada di Summit.
2. Supervisor
Supervisor bertugas untuk Mengawasi semua aktifitas dan membatu
aktifitas di Summit.
3. Admin
Admin bertugas untuk mengelola semua data yang ada di Summit
seperti data penjualan, data gudang, data barang dan lain – lain.
4. Kordinator Lapangan
Mengevaluasi absensi karyawan kepada Store manager.
5. Pramuniaga
Bertugas untuk melayani customer yang akan membeli barang di
Summit, merapihkan barang, juga menyimpan letak barang untuk
dipajang.
2.2 Landasan Teori
Landasan teori adalah membahas tentang materi atau teori apa saja yang
digunakan sebagai bahan acuan dalam membuat tugas akhir ini. Landasan teori
yang digunakan merupakan hasil studi literature baik dari buku atau situs internet.
2.2.1 Data
Data adalah sesuatu yang belum mempunyai arti bagi penerimanya dan
masih memerlukan adanya suatu pengolahan. Data bisa berujut suatu keadaan,
yang bisa kita gunakan sebagai bahan untuk melihat lingkungan, obyek, kejadian
ataupun suatu konsep [4]. Dalam pendekatan basis data tidak hanya berisi basis
data itu sendiri tetapi juga termasuk definisi atau deskripsi dari data yang
disimpan. Definisi data disimpan dalam sistem katalog, yang berisi informasi
tentang struktur tiap berkas, tipe dan format penyimpanan tiap item data, dan
berbagai konstrin dari data. Semua informasi yang disimpan dalam katalog ini
biasa disebut meta-data [5].
2.2.2 Basis Data
Basis data adalah mekanisme yang digunakan untuk menyimpan informasi
atau data. Informasi adalah sesuatu yang kita gunakan sehari-hari untuk berbagai
alasan. Dengan basis data, pengguna dapat menyimpan data secara terorganisasi.
Setelah data disimpan, informasi harus mudah diambil. Kriteria dapat digunakan
untuk mengambil informasi. Cara data disimpan dalam basis data menentukan
seberapa mudah mencari informasi berdasarkan banyak kriteria. Data pun harus
mudah ditambahkan ke dalam basis data, dimodifikasi, dan dihapus [6].
basis data sendiri dapat didefinisikan dalam sejumlah sudut pandang
seperti:
1. Himpunan kelompok data (arsip) yang saling berhubungan yang
diorganisasi sedemikian rupa agar kelak dapat dimanfaatkan kembali
dengan cepat dan mudah.
2. Kumpulan data yang saling berhubungan yang disimpan secara
bersama sedemikian rupa dan tanpa pengulangan (redudansi) yang
tidak perlu, untuk memenuhi berbagai kebutuhan.
3. Kumpulan file/ tabel/ arsip yang saling berhubungan yang disimpan
12
2.2.2.1Operasi Dasar Basis Data
Didalam sebuah disk, basis data dapat diciptakan dan dapat pula
ditiadakan. Didalam sebuah disk, kita dapat pula menempatkan beberapa (lebih
dari satu) basisdata. Sementara dalam sebuah basis data, kita dapat menempatkan
satu atau lebih file/tabel. Pada file/tabel inilah sesungguhnya data
disimpan/ditempatkan. Setiap basis data umumnya dibuat untuk mewakili sebuah
semesta data yang spesifik. Misalnya, ada basis data kepegawaian, basis data
akademik, basis data inventori (pergudangan), dan sebagainya. Sementara dalam
basis data akademik, misalnya, kita dapat menempatkan file mahasiswa, file
mata_kuliah, file dosen, file jadwal, file kehadiran, file nilai, dan seterusnya.
Karena itu, operasi-operasi dasar yang dapat kita lakukan berkenaan dengan basis
data dapat meliputi [6]:
1. Pembuatan basis data baru (create database), yang identik dengan
pembuatan lemari arsip yang baru.
2. Penghapusan basis data (drop database), yang identik dengan
perusakan lemari arsip (sekaligus beserta isinya, jika ada).
3. Pembuatan file/tabel dari suatu basis data (create table), yang identik
dengan penambahan map arsip baru ke sebuah lemari sarsip yang
telah ada.
4. Penghapusan file/tabel dari suatu basis data (drop table), yang identik
dengan perusakan map arsip lama yang ada disebuah lemari arsip.
5. Penambahan/pengisian data baru ke sebuah file/tabel disebuah basis
data (insert), yang identik dengan penambahan ke lemari arsip ke
sebuah map arsip.
6. Pengambilan data dari sebuah file/tabel (retrieve/search) yang identik
dengan pencarian lembaran arsip dari sebuah map arsip.
7. Pengubahan data dari sebuah file/tabel (update), yang identik dengan
perbaikanisi lembaran arsip yang ada di sebuah map arsip.
8. Penghapusan data dari sebuah file/tabel (delete), yang identik dengan
Operasi yang berkenaan dengan pembuatan objek (basis data dan tabel)
merupakan operasi awal yang hanya dilakukan sekali dan berlaku seterusnya.
Sedang operasi-operasi yang berkaitan dengan isi tabel (data) merupakan operasi
rutin yang akan berlangsung berulang-ulang dan karena itu operasi-operasi inilah
yang lebih tepat mewakili aktivitas pengelolaan (management) dan pengolahan
(processing) data dalam basis data [6].
2.2.2.2Objektif Basis Data
Telah disebutkan diawal bahwa tujuan awal dan utama dalam pengelolaan
data dalam sebuah basis data adalah agar kita dapat memperoleh/menemukan
kembali data (yang kita cari) dengan mudah dan cepat. Di samping itu,
pemanfaatan basis data untuk pengelolaan data, juga memiliki tujuan-tujuan lain
[6]. Secara lebih lengkap, pemanfaatan basis data dilakukan untuk memenuhi
sejumlah tujuan (objektif) seperti buku ini [6]:
1. Kecepatan dan Kemudahan (Speed)
Pemanfaatan basis data memungkinkan kita untuk dapat menyimpan
data atau melakukan perubahan/manipulasi terhadap data atau
menampilkan kembali data tersebut dengan lebih cepat dan mudah,
daripada jika kita menyimpan data secara manual (non elektronis) atau
secara elektronis (tetapi tidak dalam bentuk penerapan basis data,
misalnya dalam bentuk spread sheet atau dokumen teks biasa).
2. Efisiensi Ruang Penyimpanan (Space)
Karena keterkaitan yang erat antar kelompok data dalam sebuah basis
data, maka redundansi (pengulangan) data pasti akan selalu ada.
Banyaknya redundansi ini tentu akan memperbesar ruang
penyimpanan (baik di memori utama maupun memori sekunder) yang
14
3. Keakuratan (Accuracy)
Pemanfaatan pengkodean atau pembentukan relasi antar data bersama
dengan penerapan aturan/batasan (constraint) tipe data, domain data,
keunikan data, dan sebagainya, yang seara ketat dapat diterapkan
dalam sebuah basis data, sangat berguna untuk menekan
ketidakakuratan pemasukan/penyimpanan data.
4. Ketersediaan (Availability)
Pertumbuhan data (baik dari sisi jumlah maupun jenisnya) sejalan
dengan waktu akan semakin membutuhkan ruang penyimpanan yang
besar. Padahal tidak semua data itu selalu kita gunakan/butuhkan.
Karena itu kita dapat memilah adanya data utama/master/referensi,
data transaksi, data histori hingga data kadaluarsa. Data yang sudah
jarang atau bahkan tidak pernah lagi kita gunakan, dapat kita atur
untuk dilepaskan dari sistem basis data yang sedang aktif (menjadi
off-line) baik dengan cara penghapusan atau dengan memindahkannya ke
media penyimpanan off-line (seperti removable disk atau tape). Di sisi
lain, karena kepentingan pemakaian data, sebuah basis data dapat
memiliki data yang disebar di banyak lokasi geografis. Data nasabah
sebuah bank, misalnya, dipisah-pisah dan disimpan dilokasi yang
sesuai dengan keberadaan nasabah. Dengan pemanfaatan teknologi
jaringan komputer, data yang berada di suatu lokasi/cabang, dapat
juga diakses (menjadi tersedia/available) bagi lokasi/cabang lain.
5. Kelengkapan (Completenes)
Lengkap/tidaknya data yang kita kelola dalam sebuah basis data
bersifat relatif (baik terhadap kebutuhan pemakai maupun terhadap
waktu). Bila seorang pemakai sudah menganggap bahwa data yang
dipelihara sudah lengkap, maka pemakai yang lain belum tentu
berpendapat sama. Atau, yang sekarang dianggap sudah lengkap,
belum tentu di masa yang akan datang juga demikian. Dalam sebuah
basis data, di samping data kita juga harus menyimpan struktur (baik
dari tiap objek, seperti struktur file/tabel atau indeks). Untuk
mengakomodasi kebutuhan kelengkapan data yang semakin
berkembang, maka kita tidak hanya dapat menambah record-record
data, tetapi juga dapat melakukan perubahan struktur dalam basis data,
baik dalam bentuk penambahan objek baru (tabel) atau dengan
penambahan field-field baru pada suatu tabel.
6. Keamanan (Security)
Memang ada sejumlah (aplikasi) pengelola basis data yang tidak
menerapkan aspek keamanan dalam penggunaan basis data. Tetapi
untuk sistem yang besar dan serius, aspek keamanan juga dapat
diterapkan dengan ketat. Dengan begitu kita dapat menentukan
siapa-siapa (pemakai) yang boleh menggunakan basis data beserta
objek-objek di dalamnya dan menentukan jenis-jenis operasi apa saja yang
boleh dilakukannya.
7. Kebersamaan Pemakaian (Sharability)
Pemakai basis data seringkali tidak terbatas pada satu pemakai saja,
atau di satu lokasi saja atau oleh satu sistem/aplikasi saja. Data
pegawai dalam basis data kepegawaian, misalnya, dapat digunakan
oleh banyak pemakai, dari sejumlah departemen dalam perusahaan
atau oleh banyak sistem (sistem penggajian, sistem akuntansi, sistem
inventori, dan sebagainya). Basis data yang dikelola oleh sistem
(aplikasi) yang mendukung lingkungan multiuser, akan dapat
memenuhi kebutuhan ini, tetapi tetap dengan menjaga/menghindari
(karena data yang sama diubah oleh banyak pemakai pada saat yang
bersamaan) atau kondisi deadlock (karena ada banyak pemakai yang
16
2.2.3 Database Management System
Kumpulan atau gabungan database dengan perangkat lunak aplikasi yang
berbasis database tersebut dinamakan Database Management System (DBMS).
DBMS merupakan koleksi terpadu dari database dan program–program komputer
(utilitas) yang digunakan untuk mengakses dan memelihara database.
Program-program tersebut menyediakan berbagai fasilitas operasi untuk memasukan,
melacak, dan memodifikasi data kedalam database, mendefinisikan data baru,
serta mengolah data menjadi informasi yang dibutuhkan (DBMS = Database +
Program Utilitas) [4]. Perangkat lunak yang termasuk DBMS seperti dBase,
FoxBase, Rbase, Microsoft-Access (sering juga disingkat Ms-Access) dan Borland
Pradox (untuk DBMS yang sederhana) atau Borland-Interbase, MS-Sql, Sever,
Oracle Database, IBM, DB2, Informix, Sybase, MySql, PostgreSQL (untuk
DBMS yang lebih kompleks dan lengkap) [6].
2.2.4 Data Mining
Data mining, sering juga disebut knowledge discovery in database (KDD),
adalah kegiatan yang meliputi pengumpulan, pemakaian data historis untuk
menemukan keteraturan, pola atau hubungan dalam set data berukuran besar.
Keluaran dari data mining ini bisa dipakai untuk memperbaiki pengambilan
keputusan di masa depan. Sehingga istilah pattern recognition sekarang jarang
digunakan karena ia termasuk bagian dari data mining [7]. Data Mining adalah
suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan didalam
database. Data Mining adalah proses yang menggunakan teknik statistik,
matematika, kecerdasan buatan, dan machine learning untuk mengektrasi dan
mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari
berbagai database besar (Turban, dkk. 2005) [8].
2.2.4.1Tahapan Data Mining
Berikut adalah tahapan dalam data mining :
Seleksi data dari sekumpulan data operasional perlu dilakukan
sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil
seleksi yang akan digunakan untuk proses data mining, disimpan
dalam suatu berkas, terpisah dari baris data operasional.
2. Pre-Processing/cleaning
Sebelum proses data mining dapat dilakukan, perlu dilakukan dahulu
proses cleaning pada data yang menjadi fokus KDD, Knowledge
Discovery Databases. Proses cleaning mencakup antara lain
membuang duplikasi data, memeriksa data yang inkonsisten, dan
memeperbaiki kesalahan pada data. Juga dilakukan proses enrichment,
yaitu proses “meperkaya” data yang sudah ada dengan data atau
informasi lain yang relevan dan diperlukan untuk KDD.
Pre-processing data adalah hal yang harus dilakukan dalam proses data
mining karena tidak semua data atau atribut data dalam data
digunakan dalam proses data mining. Proses ini dilakukan agar data
yang akan digunakan sesuai dengan kebutuhan. Adapun
langkah-langkah pre-processing adalah sebagai berikut :
a. Pemilihan atribut (atribut selection)
Pemilihan atribut adalah proses pemilihan atribut data yang akan
digunakan sehingga dapat kita olah untuk proses mining.
b. Pembersihan data (data cleaning)
Proses menghilangkan noise dan menghilangkan data yang tidak
relevan.
3. Transformation
Coding adalah proses transformasi pada ata yang telah dipilih,
sehingga data tersebut sesuai untuk proses data mining. Proses coding
18
Teknik, metode, atau algortima yang tepat sangat bergantung pada
tujuan dan proses KDD secara keseluruhan.
5. Interpretation/evaluate on
Pola informasi yang dihasilkan dari proses data mining perlu
ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang
berkepentingan. Tahap ini merupakan bagian dari proses KDD yang
disebut interpretation. Tahap ini mencakup pemeriksaan apakah pola
atau informasi yang disebut bertentangan dengan fakta atau hipotesis
yang ada sebelumnya.
2.2.4.2Metode Data Mining
Secara garis besar, Han dalam bukunya menjelaskan bahwa metode data
mining dapat dilihat dari dua sudut pandang pendekatan yang berbeda, yaitu
pendekatan deskriptif dan pendekatan prediktif [9].
Pendekatan deskriptif adalah pendekatan dengan cara mendeskripsikan
data inputan. Metode yang termasuk kedalam pendekatan ini adalah :
1. Metode deskripsi konsep/kelas, yaitu data dapat diasosiasikan dengan
kelas atau konsep. Ada tiga macam pendeskripsian yaitu (1)
karakteristik data, dengan membuat summary karakter umum atau
fitur data suatu kelas target, (2) diskriminasi data, dengan
membandingkan class target dengan satu atau sekelompok kelas
pembanding, (3) gabungkan antara karakterisasi dan diskriminasi.
2. Metode association rule, yaitu menemukan aturan asosiatif atau pola
kombinasi dari suatu item yang sering terjadi dalam sebuah data.
Pendekatan kedua adalah pendekatan prediktif, yaitu pendekatan yang
dapat digunakan untuk memprediksi, dengan hasil berupa kelas atau cluster.
Metode yang termasuk dalam pendekatan ini adalah :
1. Metode klasifikasi dan prediksi, yaitu metode analisis data yang
digunakan untuk membentuk model yang mendeskripsikan kelas data
yang penting, atau model yang memprediksikan trend data. Klasifikasi
sedangkan prediksi untuk memodelkan fungsi yang mempunyai nilai
kontinu.
2. Metode clustering, mengelompokan data untuk membentuk
kelas-kelas baru atau sering disebut cluster. Metode clustering bertujuan
untuk memaksimalkan persamaan dalam satu cluster dan
meminimalkan perbedaan antar cluster.
2.2.5 Association Rule
Association Rule atau Aturan Asosiasi adalah teknik Data Mining untuk
menemukan aturan asosiatif atau pola kombinasi dari suatu item. Bila kita
mengambil contoh aturan asosiatif dalam suatu transaksi pembelian barang di
suatu minimarket adalah kita dapat mengetahui berapa besar kemungkinan
seorang konsumen membeli suatu item bersamaan dengan item lainnya (membeli
roti bersama dengan selai). Karena awalnya berasal dari studi tentang database
transaksi pelanggan untuk menentukan kebiasaan suatu produk dibeli bersama
apa, maka association rule sering juga dinamakan market basket analysis [7].
Association Rule adalah bentuk jika “kejadian sebelumnya” kemudian “konsekuensinya” (If antecedent, then consequent), yang diikuti dengan perhitungan aturan support dan confidence. Bentuk umum dari association rule
adalah Antecedent -> Consequent. Bila kita ambil contoh dalam sebuah transaksi
pembelian barang di sebuah minimarket didapat bentuk association rule roti ->
selai, artinya bahwa pelanggan yang membeli roti ada kemungkinan pelanggan
tersebut juga akan membeli selai, dimana tidak ada batasan dalam jumlah
item-item pada bagian antecedent ataupun consequent dalam sebuah rule.
Association rule memiliki dua tahap pengerjaan, yaitu [10]:
1. Mencari kombinasi yang paling sering terjadi dari suatu itemset.
20
1. Support : suatu ukuran yang menunjukkan seberapa besar tingkat dominasi
suatu item/itemset dari keseluruhan transaksi. Ukuran ini menentukan
apakah suatu item/itemset layak untuk dicari confidence-nya (misal, dari
keseluruhan transaksi yang ada, seberapa besar tingkat dominasi suatu item
yang menunjukkan bahwa item A dan item B dibeli bersamaan).
2. Confidence : suatu ukuran yang menunjukkan hubungan antara 2 item
secara conditional (misal, menghitung kemungkinan seberapa sering item B
dibeli oleh pelanggan jika pelanggan tersebut membeli sebuah item A).
Kedua ukuran ini nantinya berguna dalam menentukan kekuatan suatu pola
dengan membandingkan pola tersebut dengan nilai minimum kedua parameter
tersebut yang ditentukan oleh pengguna. Bila suatu pola memenuhi kedua nilai
minimum parameter yang sudah ditentukan sebelumnya, maka pola tersebut dapat
disebut sebagai interesting rule atau strong rule.
2.2.5.1Metodologi Dasar Analisis Asosiasi
Metodologi dasar Association Rule terbagi menjadi dua tahap, yaitu [10]:
a. Analisa pola frekuensi tinggi
Tahap ini mencari pola item yang memenuhi syarat minimum dari nilai
support dalam database. Menurut Larose, kita bebas menentukan nilai
minimum support (minsup) dan minimum confidence (mincof) sesuai
kebutuhan [11]. Sebagai contoh, bila ingin menemukan data-data yang
memiliki hubungan asosiasi yang kuat, minsup dan mincof-nya bisa diberi
nilai yang tinggi. Sebaliknya, bila ingin melihat banyaknya variasi data
tanpa terlalu mempedulikan kuat atau tidaknya hubungan asosiasi antara
item-nya, nilai minsup dan mincofnya dapat diisi rendah. Untuk
rekomendasi dalam menentukan minimum support dapat diambil dari
perhitungan rata-rata 1 jenis produk pada data yang digunakan, seperti
rumus berikut :
Persamaan 1 menjelaskan bahwa nilai support didapat dengan cara
membagi jumlah transaksi yang mengandung item A (satu item) dengan
jumlah total seluruh transaksi. Sedangkan untuk mencari nilai support dari
2 item menggunakan rumus berikut :
Support(A,B) = P(A ∩ B) = (Persamaan 2-2)
Persamaan 2 menjelaskan bahwa nilai support 2-itemsets didapat
dengan cara membagi jumlah transaksi yang mengandung item A dan item
B (item pertama bersamaan dengan item yang lain) dengan jumlah total
seluruh transaksi.
1. Pembentukan Aturan Assosiatif
Setelah semua pola frekuensi tinggi ditemukan, kemudian mencari
aturan asosiatif yang memenuhi syarat minimum untuk confidence dengan
menghitung confidence aturan assosiatif A -> B dari support pola
frekuensi tinggi A dan B, menggunakan rumus :
Confidence = (A -> B) = (Persamaan 2-3)
Persamaan 3 menjelaskan bahwa nilai confidence diperoleh dengan
cara membagi jumlah transaksi yang mengandung item A dan item B (item
pertama bersamaan dengan item yang lain) dengan jumlah transaksi yang
mengandung item A (item Pertama atau item yang ada disebelah kiri).
2.2.6 Algoritma CT-Pro
22
baik pembentukan tree maupun frequent itemset mining yang dilakukan menjadi
lebih cepat[12].
Langkah-langkah algoritma CT-PRO adalah sebagai berikut [13]:
1. Mencari Frequent Item, pada tahap ini terjadi proses-proses sebagai
berikut:
Data-data yang telah dikumpulkan, diseleksi dan pilih data yang
relevan (data yang lengkap).Data-data yang ada, kemudian dilakukan
transformasi data. Kemudian masing masing data diseleksi berdasarkan
minimum support yang telah ditentukan, kemudian didapat item yang
frekuen .Masing-masing item dihitung frekuensi kemunculannya sehingga
dihasilkan GlobalitemTable.
2. Membangun CFP-Tree , pada tahap ini terjadi proses-proses sebagai
berikut:
1. Frequent item yang telah didapatkan, diurutkan berdasarkan
Global Item tabel yang ada secara menurun (diurutkan mulai dari
item berfrekuensi terbesar hingga terkecil).
2. Dengan frequentitem yang telah terurut ini dibentuk Global
CFP-Tree , aturan pembentukan Global CFP-Tree sebagai berikut:
a. CFP-Tree terdiri dari tree yang memiliki root yang mewakili
indeks dari item dengan tingkat kemunculan tertinggi dan
kumpulan subtree sebagai anak dari root.
b. Jika I = {i1,i2, …, ik} adalah kumpulan dari frequent item
pada node tersebut, dan level yang menunjukkan struktur data
tree pada node tersebut dimulai dari item yang terdapat pada
24
Dalam pencarian itemfrequent dan membangun CFP tree digunakan Algoritma
sebagai berikut :
input Database D, Support Threshold σ output CFP-Tree 1 begin
12 Sort GlobalItemTable in frequency descending order
13 Assign an index for each frequent item in the GlobalItemTable 14 // Step 2: Construct CFP-Tree
15 Construct the left most branch of the tree 16 for each transaction t ∈ D
17 Initialize mappedTrans 18 for each frequent item i ∈ t
19 mappedTrans = mappedTrans ∪ GetIndex(i) 20 end for
21 Sort mappedTrans in ascending order of item ids 22 InsertToCFPTree(mappedTrans)
23 end for 24 end
25 Procedure InsertToCFPTree(mappedTrans) 26 firstItem := mappedTrans[1]
27 currNode := root of subtree pointed by ItemTable[firstItem] 28 for each subsequent item i ∈ mappedTrans
29 if currNode has child represent i
Gambar 2. 3 Algorithm 1 CT-PRO Algorithm: Step 1 and Step 2[13]
3. Melakukan penggalian frequent patterns, pada tahap ini terjadi
proses-proses sebagai berikut :
a. Pada tahap mining ini, algoritma CT-Pro bekerja dengan
melakukan bottom-up mining sehingga Global Item tabel
diurutkan mulai dari item berfrekuensi terkecil hingga
terbesar.
b. Untuk setiap item yang terdaftar pada Global Item tabel yang
telah diurutkan, dilakukan pencarian node yang berkaitan
dengan item tersebut pada Global CFP-Tree . Dari semua
node yang ditemukan untuk setiap item inilah yang disebut
dengan Local Frequent item dan digunakan untuk membuat
Local Item Tabel.
c. Pada pembuatan Local item tabel ini juga dilakukan
berdasarkan jumlah minimum support yang telah ditentukan.
d. Setelah itu, dibuat Local CFP-Tree berdasarkan Local Item
Tabel yang terbentuk. Aturan pembentukan Local CFP-Tree
sama dengan pembentukan Global CFP-Tree , yang
membedakan adalah pada Global CFP-Tree yang digunakan
dalam pembentukan tree-nya adalah Global Item tabel yang
terbentuk dari Global Item tabel data sedangkan pada Local
CFP-Tree yang digunakan dalam pembentukan tree-nya
adalah Local Item tabel yang terbentuk dari Local Frequent
item.
e. Dari Local CFP-Tree dibentuk frequent pattern sesuai
dengan item yang di-mining.
26
Berikut merupakan algoritma dalam penggalian frequent Patterns:
Gambar 2. 4 Algoritma 1 CT-PRO Penggalian Frequent Patterns[13]
Berikut ini merupakan contoh kasus penerapan metode association rule
menggunakan CFP-Tree:
Misalkan terdapat itemset seperti gambar di bawah dan ingin kita dapatkan
frequentPattern-nya. Min_support untuk itemset di bawah ini adalah 2 (20%). input CFP-Tree output Frequent Itemsets FP
1 Procedure Mining
2 for each frequent item i ∈ GlobalItemTable from the least to the most frequent 3 Initialize LocalFrequentPatternTree with i as the root
10 Traverse the LocalFrequentPatternTree to print the frequent itemsets
25 for each occurrence of node i in the CFP-Tree 26 Initialize mappedTrans
27 for each frequent item j ∈ LocalItemTable in the path to the root
28 mappedTrans = mappedTrans ∪ GetIndex(j) 29 end for
30 Sort mappedTrans in ascending order of item ids
Tabel 2. 1 Sampel Transaksi
tid item
1 C D E F G H
2 A C D E M
3 A B D E G K
4 A C D H
5 A C D J
Dari itemset di atas kita hitung jumlah kemunculan masing-masing item dan
buang yang tidak memenuhi min support dan buat tabel baru dengan nama header
Table secara menurun sehingga didapatkan Frequent item.berikut Hasil pencarian
item frequent item.
Tabel 2. 2 Item yang Frequent
tid item
1 C D E F G H
2 A C D E
3 A B D E G
4 A C D H
5 A C D
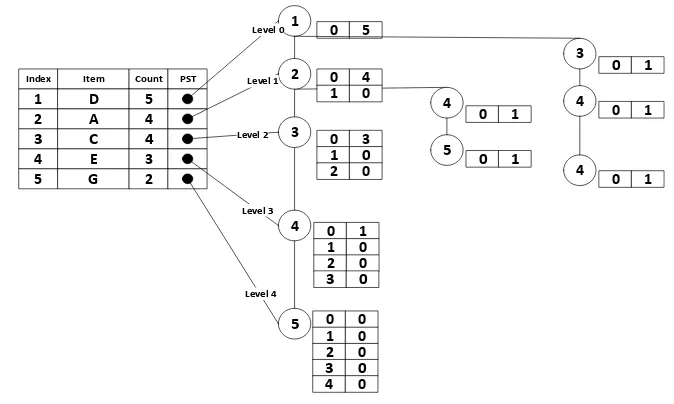
Didapat dari transaksi di atas item A(4),C(4),D(5),E(3),G(2) Setelah kita dapatkan
item dengan jumlah count setiap item lakukan mapping pada transaksi dengan
Index pertama yang memiliki count terbesar.Berikut merupakan Hasil Mapping
Node data :
Tabel 2. 3 Mapping Transaksi
tid item
28
Setelah dilakukan mapping data selanjutnya adalah membangun Global CFP-Tree
dengan menggunakan data transaksi pada Table 2.1 berikut hasil dari
Gambar 2. 5 Hasil Global CFP-Tree
Setelah membuat Global CFP-Tree selanjutnya adalah membuat mencari
frequent Pattern dari Global- CFP - tree dengan memilih item dengan support
count terkecil atau memilih node terkahir sebagai contoh pada Global CFP –Tree
pada gambar 2.3 Index node 5 merupakan node terakhir kemudian lakukan
penulusuran pada node tersebut dengan menghitung setiap count dari item.Dari
hasil di atas item yang memenuhi minimum support count adalah item D(2) dan
E(2) selanjutnya berikan Index ide baru pada local item Table, lalu lakukan
pembangunan Local CFP-Tree sebagai berikut :
Index Item Count
count yang telah di tentukan berati item tersebut memnuhi frequent berikut hasil
projek id 5:
1
D
5
2
E
4
5
G
4
1
D
5
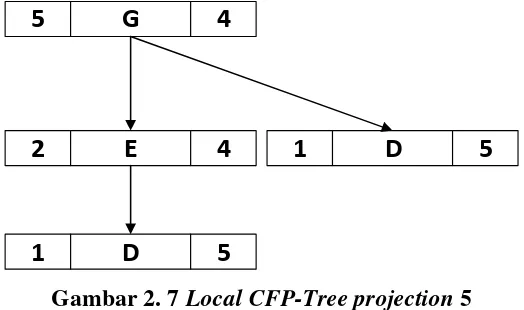
Gambar 2. 7 Local CFP-Tree projection 5
Dari Local CFP-Tree projection maka didapatkan itemfrequent untuk Index 5
dengan item G adalah sebagai berikut: (5,2,1:6)
2.2.7 Unifief Modelling Language (UML)
UML singkatan dari Unified Modeling Languages yang berarti bahasa
pemodelan standar. Ketika kita membuat model menggunakan konsep UML ada
aturan-aturan yang harus diikuti. Bagaimana elemen pada model-model yang kita
buat berhubungan satu dengan yang lainnya harus mengikuti standar yang ada.
UML bukan hanya sekedar diagram tetapi juga menceritakan konteksnya[14].
Berikut adalah beberapa model yang digunakan dalam perancangan aplikasi Data
Mining untuk menentuan rekomendasi layout barang di Summit the Boutique
Outlet untuk menggambarkan sistem dalam UML:
1. Diagram Use Case
2. Diagram Activity
3. Diagram Sequence
30
komponen, kejadian atau kelas[14]. Komponen pembentuk Use Case Diagram
adalah sebagai berikut :
1. Actor
Pada dasarnya actor bukanlah bagian dari use case diagram, namun
untuk dapat terciptanya suatu use case diagram diperlukan beberapa actor.
Actor tersebut mempresentasikan seseorang atau sesuatu (seperti
perangkat, sistem lain) yang berinteraksi dengan sistem. Sebuah actor
mungkin hanya memberikan informasi inputan pada sistem, hanya
menerima informasi dari sistem atau keduanya menerima, dan memberi
informasi pada sistem. Actor hanya berinteraksi dengan use case, tetapi
tidak memiliki kontrol atas use case. Actor digambarkan dengan stick man.
Actor dapat digambarkan secara secara umum atau spesifik, dimana untuk
membedakannya kita dapat menggunakan relationship.
2. Use Case
Use case adalah gambaran fungsionalitas dari suatu sistem, sehingga
customer atau pengguna sistem paham dan mengerti mengenai kegunaan
sistem yang akan dibangun.
Catatan : Use case diagram adalah penggambaran sistem dari sudut
pandang pengguna sistem tersebut (user), sehingga pembuatan use case
lebih dititikberatkan pada fungsionalitas yang ada pada sistem, bukan
berdasarkan alur atau urutan kejadian.
Cara menentukan Use Case dalam suatu sistem:
1. Pola perilaku perangkat lunak aplikasi.
2. Gambaran tugas dari sebuah actor.
3. Sistem atau “benda” yang memberikan sesuatu yang bernilai
kepada actor.
4. Apa yang dikerjakan oleh suatu perangkat lunak (*bukan
bagaimana cara mengerjakannya).
Ada beberapa relasi yang terdapat pada use case diagram:
2. Generalization, disebut juga inheritance (pewarisan), sebuah
elemen dapat merupakan spesialisasi dari elemen lainnya.
3. Dependency, sebuah elemen bergantung dalam beberapa cara ke
elemen lainnya.
4. Aggregation, bentuk association dimana sebuah elemen berisi
elemen lainnya.
Tipe relasi/ stereotype yang mungkin terjadi pada use case diagram:
1. <<include>> , yaitu kelakuan yang harus terpenuhi agar sebuah
event dapat terjadi, dimana pada kondisi ini sebuah use case
adalah bagian dari use case lainnya.
2. <<extends>>, kelakuan yang hanya berjalan di bawah kondisi
tertentu seperti menggerakkan alarm.
3. <<communicates>>, mungkin ditambahkan untuk asosiasi yang
menunjukkan asosiasinya adalah communicates association. Ini
merupakan pilihan selama asosiasi hanya tipe relationship yang
dibolehkan antara actor dan use case.
2.2.7.2Activity Diagram
Activity diagram memiliki pengertian yaitu lebih fokus kepada
menggambarkan proses bisnis dan urutan aktivitas dalam sebuah proses. Dipakai
pada business modeling untuk memperlihatkan urutan aktifitas proses bisnis.
Memiliki struktur diagram yang mirip flowchart atau data flow diagram pada
perancangan terstruktur. Memiliki pula manfaat yaitu apabila kita membuat
diagram ini terlebih dahulu dalam memodelkan sebuah proses untuk membantu
memahami proses secara keseluruhan dan activity dibuat berdasarkan sebuah atau
32
diketahui objek-objek yang terlibat dalam sebuah use case beserta metode-metode
sekuen juga di butuhkan untuk melihat skenario yang ada pada use case[14].
Sequence diagram biasa digunakan untuk menggambarkan skenario atau
rangkaian langkah-langkah yang dilakukan sebagai respons dari sebuah event
untuk menghasilkan output tertentu. Diawali dari apa yang men-trigger aktivitas
tersebut, proses dan perubahan apa saja yang terjadi secara internal dan output apa
yang dihasilkan. Masing-masing objek, termasuk aktor, memiliki lifeline vertikal.
Message digambarkan sebagai garis berpanah dari satu objek ke objek lainnya.
2.2.7.4Class Diagram
Diagram kelas atau class diagram menggambarkan struktur sistem dari
segi pendefinisian kelas-kelas yang akan di buat untuk membangun sistem. Kelas
memiliki apa yang disebut atribut dan metode atau operasi.
1. Atribut merupakan variabel-variabel yang di miliki oleh suatu kelas
2. Operasi atau metode adalah fungsi-fungsi yang dimiliki oleh suatu
kelas
Diagram kelas dibuat agar pembuat program atau programmer membuat
kelas-kelas sesuai rancangan di dalam diagram kelas agar antara dokumentasi
perancangan dan perangkat lunak sinkron. banyak berbagai kasus, perancangan
kelas yang dibuat tidak sesuai dengan kelas-kelas yang dibuat pada perangkat
lunak, sehingga tidaklah ada gunanya lagi sebuah perancangan karena apa yang
BAB 5
KESIMPULAN DAN SARAN
Pada bab ini akan disimulkan hasil penelitian yang telah dilakukan serta
saran untuk pengembangan penelitian lebih lanjut.
5.1 Kesimpulan
Berdasarkan hasil Implementasi dan Pengujian yang telah dilakukan pada
sistem Data Mining yang telah dibagun dengan menggunakan Metode Association
Rule dan Algoritma CT-Pro, maka dapat diambil kesimpulan sebagai berikut :
1. Aplikasi yang dibangun dapat menghasilkan informasi berupa jenis art apa
saja yang saling berkaitan dan sering dibeli secara bersama sebagai dasar
keputusan dalam menentukan rekomendasi layout.
2. Aplikasi yang dibangun dapat membantu Supervisor memberikan informasi
rekomendasi layout produk kepada pramuniaga pada saat penempatan produk
dilakukan.
5.2Saran
Saran untuk pengembangan lebih lanjut, yaitu sebagai berikut :
1. Pengembangan dalam memberikan rekomendasi layout produk dengan
output yang lebih dinamis lagi sehingga memudahkan dan menyenangkan
Supervisor dalam menggunakan aplikasi.
2. Pengembangan dengan Menggunakan database yang tersedia di Summit
Boutique Outlet sebagai pengganti import data yang pada penelitian ini
menggunakan format .xlxs dalam mengeksekusi data penjualannya
sehinggal aplikasi dapat digunakan dengan memilih berdasarkan data
![Gambar 1. 1 Cross-Industry Standard for Data Mining (CRISP-DM) [2]](https://thumb-ap.123doks.com/thumbv2/123dok/1213863.779131/17.595.210.414.109.299/gambar-cross-industry-standard-data-mining-crisp-dm.webp)
![Gambar 2. 4 Algoritma 1 CT-PRO Penggalian Frequent Patterns[13]](https://thumb-ap.123doks.com/thumbv2/123dok/1213863.779131/39.595.110.542.141.512/gambar-algoritma-ct-pro-penggalian-frequent-patterns.webp)