RINGKASAN
KAMELIA. Penyusunan Paket R untuk Pengembangan Pakar (Paket Analisis Regresi). Dibimbing oleh AGUS MOHAMAD SOLEH dan UTAMI DYAH SYAFITRI.
R merupakan perangkat lunak statistika berbasis open source dan berbasis pemrograman, sehingga tidak semua orang terbiasa untuk menggunakannya. Sejak tahun 2009, Departemen Statistika Institut Pertanian Bogor melakukan pengembangan paket dalam R dengan ant armuka user friendly untuk memudahkan penggunaan R sebagai alat analisis statistika. Analisis statistika yang sudah dikembangkan dalam paket tersebut diantaranya analisis regresi, analisis peubah ganda, analisis deret waktu, dan analisis perancangan percob aan. Namun paket yang telah dikembangkan masih memiliki beberapa kekurangan, sehingga penelitian ini dilakukan untuk menyempurnakan beberapa kekurangan tersebut.
Paket yang disusun dalam penelitian ini merupakan pe ngembangan dari Pakar (Paket Analisis Regresi) yang telah disusun sebelumnya oleh Melisa (2009). Paket ini diberi nama Pakar 2.0. Komponen analisis regresi yang ditambahkan dalam Pakar 2.0 meliputi analisis regresi komponen utama, analisis regresi gulud, analisis regresi logistik biner, analisis r egresi logistik ordinal, analisis regresi logistik multinomial, dan analisis regresi kuadrat terkecil parsial. Untuk menjalankan fungsi-fungsinya, Pakar 2.0 membutuhkan paket lain yaitu tcltk, tkrplot, RODBC, R2HTML, car, nortest, tseries, stats, foreign, MASS, nnet, dan pls. Menu utama pada Pakar 2.0 meliputi menu File, menu Edit, menu Data, menu Statistika, dan menu Bantuan. Hasil pengujian Pakar 2.0 dengan membandingkan keluaran dari perangkat lunak statistika lain secara umum sudah menunjukkan hasil yan g relatif sama, kecuali pada beberapa kasus uji. Perbedaan pada beberapa kasus uji tersebut disebabkan adanya perbedaan kategori acuan pada regresi logistik dan perbedaan nilai desimal hasil iterasi.
1
PENDAHULUAN
Latar BelakangR merupakan perangkat lunak statistika berbasis open source dan berbasis pemrograman, sehingga tidak semua orang terbiasa untuk menggunakannya. Sejak tahun 2009, Departemen Statistika Institut Pertanian Bogor melakukan pengembangan paket dal am R dengan antarmuka user friendly untuk memudahkan penggunaan R sebagai alat analisis statistika. Analisis statistika yang sudah dikembangkan dalam paket tersebut diantaranya analisis regresi, analisis peubah ganda, analisis deret waktu, dan analisis perancangan percobaan. Namun paket yang telah dikembangkan masih memiliki beberapa kekurangan, sehingga penelitian ini dilakukan untuk menyempurnakan beberapa kekurangan tersebut.
Paket analisis regresi (Pakar) merupakan bagian dari paket R yang telah dikemba ngkan. Pakar meliputi perhitungan statistika dasar, plot pengepasan garis, analisis regresi linier, dan analisis regresi bertatar (Melisa 2009). Komponen analisis regresi dan sistem manajemen data pada Pakar masih terbatas. Batasan tersebut yaitu hanya sa tu dataset yang dapat digunakan dalam sistem, impor dan ekspor data masih terbatas pada file Excel dengan ekstensi .csv dan .xls, serta keterbatasan menu untuk memodifikasi data. Penelitian ini dilakukan untuk mengembangkan Pakar dengan menambahkan beberapa analisis regresi dan menyempurnakan sistem manajemen data. Paket hasil pengembangan Pakar akan diberi nama Pakar 2.0.
Tujuan
Tujuan dari penelitian ini adalah menyusun paket R untuk mengembangkan paket analisis regresi (Pakar) dengan menambahkan analisis regresi komponen utama, analisis regresi gulud, analisis regresi logistik biner, analisis regresi logistik ordinal, analisis regresi logistik multinomial, dan analisis regresi kuadrat terkecil parsial dengan antarmuka user friendly serta mengatasi batasan-batasan yang ada pada Pakar.
TINJAUAN PUSTAKA
Pakar 2.0 merupakan suatu sistem dengan antarmuka user friendly pada lingkungan R. Menurut Hornik (2010), R merupakanimplementasi sebuah lingkungan komputasi dan pemrograman bahasa statistika. R disusun dari bahasa S dan bahasa Scheme oleh Ross Ihaka dan Robert Gentleman. Paket R merupakan sebuah ekstensi dari sistem dasar R yang terdiri atas kode, data, dan dokumentasi. Paket R dapat diunduh secara bebas pada http://CRAN.R-Project.org. Untuk membuat paket R pada lingkungan Windows dibutuhkan Rtools, LaTeX, dan HTML Help Workshop sebagai perangkat lunak tambahan.
Komponen analisis regresi yang ditambahkan dalam Pakar 2.0 antara lain regresi komponen utama, regresi gulud, regresi logistik, dan regresi kuadrat terkecil parsial.
Regresi Komponen Utama (RKU) Regresi Komponen Utama (RKU) merupakan implementasi dari Analisis Komponen Utama (AKU). RKU digunakan untuk mengatasi masalah multikolinier antar peubah bebas. Prinsip dari RKU adalah mentransformasi peubah -peubah bebas menjadi peubah-peubah baru yang saling ortogonal. Kemudian peubah -peubah baru tersebut diregresikan dengan peubah bebas. Transformasi peubah bebas menjadi peubah baru tersebut adalah dengan AKU.
Komponen utama yang dibentuk berdasarkan matriks ragam -peragam adalah sebagai berikut. Misalkan Σ merupakan matriks ragam-peragam dari vektor x1,x2,…,xp dengan pasangan akar ciri dan vektor ciri yang saling ortonormal (λ1,e1), (λ2,e2), …, (λp,ep) dengan λ1≥λ2≥ … ≥ λp≥0, maka komponen utama ke-i didefinisikan sebagai berikut (Jollife 2002):
λ1 merupakan akar ciri terbesar yang memaksimumkan ragam KU1 dan e1
merupakan vektor ciri yang berpadanan dengan λ1. Urutan KU1, KU2, …, KUpharus
memenuhi persyaratan λ1 ≥ λ2 ≥ … ≥ λp. Sementara itu, kontribusi keragaman dari setiap komponen utama ke -k terhadap keragaman total adalah:
λ λ
λ λ … λ
Matriks Σ dapat berupa matriks ragam -peragam atau matriks korelasi.
1
PENDAHULUAN
Latar BelakangR merupakan perangkat lunak statistika berbasis open source dan berbasis pemrograman, sehingga tidak semua orang terbiasa untuk menggunakannya. Sejak tahun 2009, Departemen Statistika Institut Pertanian Bogor melakukan pengembangan paket dal am R dengan antarmuka user friendly untuk memudahkan penggunaan R sebagai alat analisis statistika. Analisis statistika yang sudah dikembangkan dalam paket tersebut diantaranya analisis regresi, analisis peubah ganda, analisis deret waktu, dan analisis perancangan percobaan. Namun paket yang telah dikembangkan masih memiliki beberapa kekurangan, sehingga penelitian ini dilakukan untuk menyempurnakan beberapa kekurangan tersebut.
Paket analisis regresi (Pakar) merupakan bagian dari paket R yang telah dikemba ngkan. Pakar meliputi perhitungan statistika dasar, plot pengepasan garis, analisis regresi linier, dan analisis regresi bertatar (Melisa 2009). Komponen analisis regresi dan sistem manajemen data pada Pakar masih terbatas. Batasan tersebut yaitu hanya sa tu dataset yang dapat digunakan dalam sistem, impor dan ekspor data masih terbatas pada file Excel dengan ekstensi .csv dan .xls, serta keterbatasan menu untuk memodifikasi data. Penelitian ini dilakukan untuk mengembangkan Pakar dengan menambahkan beberapa analisis regresi dan menyempurnakan sistem manajemen data. Paket hasil pengembangan Pakar akan diberi nama Pakar 2.0.
Tujuan
Tujuan dari penelitian ini adalah menyusun paket R untuk mengembangkan paket analisis regresi (Pakar) dengan menambahkan analisis regresi komponen utama, analisis regresi gulud, analisis regresi logistik biner, analisis regresi logistik ordinal, analisis regresi logistik multinomial, dan analisis regresi kuadrat terkecil parsial dengan antarmuka user friendly serta mengatasi batasan-batasan yang ada pada Pakar.
TINJAUAN PUSTAKA
Pakar 2.0 merupakan suatu sistem dengan antarmuka user friendly pada lingkungan R. Menurut Hornik (2010), R merupakanimplementasi sebuah lingkungan komputasi dan pemrograman bahasa statistika. R disusun dari bahasa S dan bahasa Scheme oleh Ross Ihaka dan Robert Gentleman. Paket R merupakan sebuah ekstensi dari sistem dasar R yang terdiri atas kode, data, dan dokumentasi. Paket R dapat diunduh secara bebas pada http://CRAN.R-Project.org. Untuk membuat paket R pada lingkungan Windows dibutuhkan Rtools, LaTeX, dan HTML Help Workshop sebagai perangkat lunak tambahan.
Komponen analisis regresi yang ditambahkan dalam Pakar 2.0 antara lain regresi komponen utama, regresi gulud, regresi logistik, dan regresi kuadrat terkecil parsial.
Regresi Komponen Utama (RKU) Regresi Komponen Utama (RKU) merupakan implementasi dari Analisis Komponen Utama (AKU). RKU digunakan untuk mengatasi masalah multikolinier antar peubah bebas. Prinsip dari RKU adalah mentransformasi peubah -peubah bebas menjadi peubah-peubah baru yang saling ortogonal. Kemudian peubah -peubah baru tersebut diregresikan dengan peubah bebas. Transformasi peubah bebas menjadi peubah baru tersebut adalah dengan AKU.
Komponen utama yang dibentuk berdasarkan matriks ragam -peragam adalah sebagai berikut. Misalkan Σ merupakan matriks ragam-peragam dari vektor x1,x2,…,xp dengan pasangan akar ciri dan vektor ciri yang saling ortonormal (λ1,e1), (λ2,e2), …, (λp,ep) dengan λ1≥λ2≥ … ≥ λp≥0, maka komponen utama ke-i didefinisikan sebagai berikut (Jollife 2002):
λ1 merupakan akar ciri terbesar yang memaksimumkan ragam KU1 dan e1
merupakan vektor ciri yang berpadanan dengan λ1. Urutan KU1, KU2, …, KUpharus
memenuhi persyaratan λ1 ≥ λ2 ≥ … ≥ λp. Sementara itu, kontribusi keragaman dari setiap komponen utama ke -k terhadap keragaman total adalah:
λ λ
λ λ … λ
Matriks Σ dapat berupa matriks ragam -peragam atau matriks korelasi.
2
dengan adalah vektor peubah respons, adalah vektor koefisien regresi kom -ponen utama dari m buah kom-ponen utama, adalah matriks berukuran (n x m) yang kolomnya merupakan skor komponen utama, serta adalah komponen error model (Jollife 2002).
Regresi Gulud
Regresi gulud juga digunakan untuk mengatasi masalah multikolinieritas antar peubah bebas. Multikolinieritas ini mengakibatkan nilai dugaan parameter model menjadi tidak stabil. Regresi gulud didasarkan pada konsep bahwa penduga berbias namun memiliki ragam yang lebih kecil akan lebih disukai.
Menurut Myers (1990), prosedur regresi gulud adalah dengan menambahkan sebuah konstantakyang berada dalam selang [0,1] ke dalam matriks (X’X) pada pendugaan parameter regresi sehingga diperoleh:
adalah penduga berbias bagi namun memiliki ragam yang lebih kecil daripada . Ada beberapa cara untuk menentukan nilai k yang optimum. Salah satunya adalah dengan menggunakan metode ridge trace. Metode ini merupakan penelusuran nilai kyang optimum dengan mencoba berbagai macam nilai kdan melihat pengaruhnya pada nilai yang didapatkan. Plot antara dengan berbagai nilai k dapat digunakan untuk melihat metode tersebut secara eksploratif.
Regresi Logistik
Menurut Hosmer dan Lemeshow (2000) regresi logistik adalah metode analisis statistika yang mendeskripsikan hubungan antara peubah respons yang memiliki dua kategori atau lebih dengan satu atau lebih peubah bebas berskala kategori atau kontinu. Pendugaan parameter yang digunakan dalam regresi logistik adalah metode kemungkinan maksimum (maximum likelihood). Model regresi logistik terdiri atas regresi logistik dengan respons biner, ordinal, dan multinomial.
Regresi Logistik Biner
Model regresi logistik biner merupak an model matematika yang dapat digunakan untuk memodelkan hubungan antara peubah bebas X dengan peubah respons Y yang bersifat biner. Peubah respons Y mengikuti sebaran Bernoulli dengan y = 0 atau 1 dan
adalah peluang terjadinya y = 1. Model regresi logistik dengan E( Y= 1|x) sebagai
π( x)adalah:
exp
1 exp
Fungsi hubung yang sesuai untuk model regresi logistik biner adalah fungsi logit. Transformasi logit sebagai fungsi dari π( x)
adalah (Hosmer dan Lemeshow 2000):
ln 1
Regresi Logistik Ordinal
Model regresi logistik ordinal digunakan untuk menganalisis peubah respons berskala ordinal dengan lebih dari dua kategori. Menurut Hosmer dan Lemeshow (2000), salah satu cara yang dapat digunakan untuk membentuk model dengan respons kategorik yang berskala ordinal adalah dengan membentuk fungsi logit dari peluang kumulatif :
|
dengan k bernilai 0, 1, 2, …, K-1. K adalah banyaknya nilai respons yang mungkin terjadi, dan adalah peluang kumulatif kategori k. Fungsi logit dari peluang kumulatif adalah sebagai berikut (Hosmer dan Lemeshow 2000):
| |
Regresi Logistik Multinomial
Model regresi logistik multinomial digunakan untuk menganalisis peubah respons berskala nominal dengan lebih dari dua kategori. Misalkan πj( x) = P( Y= j|x) dimana
j=0,1,2,…,K-1 adalah peubah nominal yang digunakan dalam model. Berikut adalah persamaan umum yang digunakan untuk menyatakan peluang bersyarat bagi setiap kategori (Hosmer dan Lemeshow 2000):
| exp ∑ exp
3
| 0|
Pengujian Parameter Regresi Logistik Pengujian peranan peubah bebas dalam model secara bersama-sama adalah dengan uji rasio kemungkinan (likelihood ratio test) menggunakan statistik uji -G. Rumus umum untuk statistik uji-G adalah:
2
dimana L0adalah fungsi kemungkinan tanpa peubah bebas dan L1 adalah fungsi kemungkinan dengan peubah bebas. Hipotesis yang digunakan adalah sebagai berikut:
H0: β1= β2= … = βp= 0 H1: minimal ada satu βj≠ 0
dimana j = 1,2,...,p. Statistik uji-G mengikuti sebaran χ2dengan derajat bebas p. Hipotesis nol ditolakjika G > χ2p(α).
Pengujian peubah bebas secara parsial dilakukan menggunakan statistik uji Wald dengan rumus umum:
Hipotesis yang digunakan dalam uji Wald: H0: βj= 0
H1:βj≠ 0 dimanaj = 1,2,...,p.
Statistik uji Wald mengikuti sebaran normal baku. H0ditolak jika |W| > Zα/2(Hosmer dan
Lemeshow 2000).
Rasio Odds
Dalam kajian hubungan antar peubah kategorik dikenal adanya ukuran asosiasi atau ukuran keeratan hubungan antara peubah kategorik. Rasio odds merupakan salah satu ukuran asosiasi yang dapat diperoleh melalui analisis regresi logistik. Odds sendiri diartika n sebagai rasio peluang kejadian sukses dengan kejadian tidak sukses dari peubah respons. Rasio odds didefinisikan sebagai exp β
dengan selang kepercayaan (Hosmer dan Lemeshow 2000):
Akaike Information Criterion(AIC)
Ravishanker dan Dey (2002) menyatakan bahwa salah cara untuk melihat kebaikan model regresi logistik adalah menggunakan statistikAkaike Information Criterion(AIC):
2 2
Selain untuk melihat kebaikan model, statistik AIC juga digunakan untuk pemilihan peubah bebas (stepwise, forward,danbackward) yang berbasis pada fungsi kemungkinan. Nilai AIC yang semakin kecil menandakan model yang semakin baik.
Sisaan
Dalam regresi linier, sisaan didefinisikan sebagai beda antara respons dan dugaan respons . Dalam regresi logistik, terdapat beberapa cara untuk menghitung sisaan, diantaranya (Hosmer dan Lemeshow 2000):
1. Sisaan Pearson
Sisaan Pearson didefini sikan sebagai:
,
1
dimana adalah peluang kejadian sukses. 2. SisaanDeviance
Sisaandeviancedidefinisikan sebagai:
, 2 1 1
1
dimana tanda + atau –digunakan untuk memastikan bahwa sisaan deviance memiliki tanda yang sama dengan
.
Regresi Kuadrat Terkecil Parsial Metode regresi kuadrat terkecil parsial (RKTP) adalah suatu metode untuk melakukan pendugaan model ketika banyak terdapat peubah bebas dalam model dan peubah-peubah tersebut saling berkorelasi. Untuk meregresikan sekumpulan peubah Y dengan peubah X1, X2, …, Xp, metode PLSR melibatkan peubah bebas baru yang berperan seperti X. Peubah ini disebut peubah laten dimana setiap komponennya merupakan kombinasi linier dari X1, X2, .., Xp. Peubah laten ini kemudian dinotasikan sebagai T.
Metode RKTP menggambarkan hubungan eksternal dan hubungan internal antar peubah X dan peubah Y. Hubungan eksternal tersebut ditulis dengan persamaan berikut (Naes et al. 2002):
∑
∑
4
sisaan. MatriksT dihitung sebagai kombinasi linier dariXdengan Wyang saling ortogonal sehingga diperoleh:
dimana W adalah matriks dengan kolom -kolom yang berupa vektor pembobot.
Validasi Silang
Validasi silang digunakan untuk menentukan jumlah komponen optimum pada analisis regresi komponen utama dan analisis regresi kuadrat terkecil parsial. Pemilihan jumlah komponen yang optimum ini diperlukan untuk mengatasi masa lah overfitting. Overfitting disebabkan oleh jumlah peubah bebas yang lebih banyak daripada amatan atau karena peubah bebas yang saling berkorelasi. Akibat dari overfitting ini adalah model yang dihasilkan sudah sesuai menggambarkan keadaan data contoh namun kurang baik untuk memprediksi data baru.
Menurut Draper dan Smith (1992) terdapat dua pendekatan validasi silang, diantaranya buang satu amatan dan buang sekelompok amatan. Validasi silang ini menghasilkan statistik-statistik untuk melihat kemampuan model dalam memprediksi diantaranya (Myers 1990):
1. PRESS (Prediction Sum of Square)
∑ ,
dengan , adalah nilai dugaan respons tanpa amatan yang dibuang. Model yang baik adalah model dengan nilai PRESS yan relatif kecil.
2. (R2Prediction)
1 ∑
merefleksikan kemampuan model dalam memprediksi amatan baru. Nilai yang besar menggambarkan bahwa model tersebut mampu melakukan prediksi dengan baik.
3. RMSECV (Root Mean Square Error of Cross Validation)
RMSECV adalah kuadrat tengah sisaan berdasarkan hasil validasi silang. Semakin kecil nilai RMSECV maka model tersebut akan semakin baik.
∑ ,
METODOLOGI
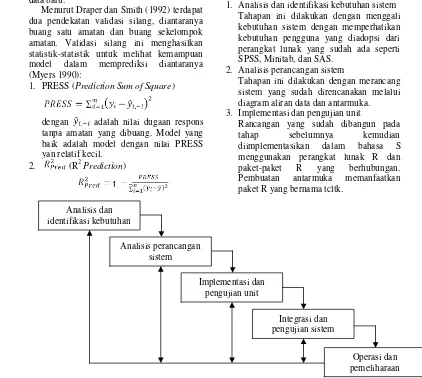
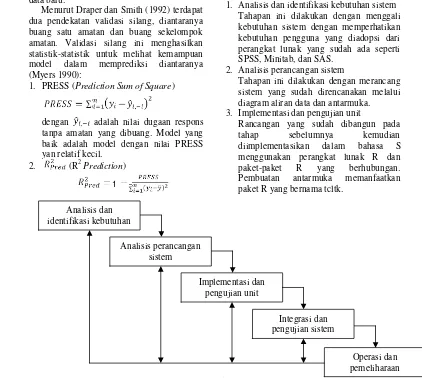
Pembuatan paket R ini mengikuti kaidah rekayasa perangkat lunak dengan model air terjun, berikut tahapannya:
1. Analisis dan identifikasi kebutuhan sistem Tahapan ini dilakukan dengan menggali kebutuhan sistem dengan memperhatikan kebutuhan pengguna yang diadopsi dari perangkat lunak yang sudah ada seperti SPSS, Minitab, dan SAS.
2. Analisis perancangan sistem
Tahapan ini dilakukan dengan merancang sistem yang sudah direncanakan melalui diagram aliran data dan antarmuka. 3. Implementasi dan pengujian unit
Rancangan yang sudah dibangun pada tahap sebelumnya kemudian diimplementasikan dalam bahasa S menggunakan perangkat lunak R dan paket-paket R yang berhubungan. Pembuatan antarmuka memanfaatkan paket R yang bernama tcltk.
4
sisaan. MatriksT dihitung sebagai kombinasi linier dariXdengan Wyang saling ortogonal sehingga diperoleh:
dimana W adalah matriks dengan kolom -kolom yang berupa vektor pembobot.
Validasi Silang
Validasi silang digunakan untuk menentukan jumlah komponen optimum pada analisis regresi komponen utama dan analisis regresi kuadrat terkecil parsial. Pemilihan jumlah komponen yang optimum ini diperlukan untuk mengatasi masa lah overfitting. Overfitting disebabkan oleh jumlah peubah bebas yang lebih banyak daripada amatan atau karena peubah bebas yang saling berkorelasi. Akibat dari overfitting ini adalah model yang dihasilkan sudah sesuai menggambarkan keadaan data contoh namun kurang baik untuk memprediksi data baru.
Menurut Draper dan Smith (1992) terdapat dua pendekatan validasi silang, diantaranya buang satu amatan dan buang sekelompok amatan. Validasi silang ini menghasilkan statistik-statistik untuk melihat kemampuan model dalam memprediksi diantaranya (Myers 1990):
1. PRESS (Prediction Sum of Square)
∑ ,
dengan , adalah nilai dugaan respons tanpa amatan yang dibuang. Model yang baik adalah model dengan nilai PRESS yan relatif kecil.
2. (R2Prediction)
1 ∑
merefleksikan kemampuan model dalam memprediksi amatan baru. Nilai yang besar menggambarkan bahwa model tersebut mampu melakukan prediksi dengan baik.
3. RMSECV (Root Mean Square Error of Cross Validation)
RMSECV adalah kuadrat tengah sisaan berdasarkan hasil validasi silang. Semakin kecil nilai RMSECV maka model tersebut akan semakin baik.
∑ ,
METODOLOGI
Pembuatan paket R ini mengikuti kaidah rekayasa perangkat lunak dengan model air terjun, berikut tahapannya:
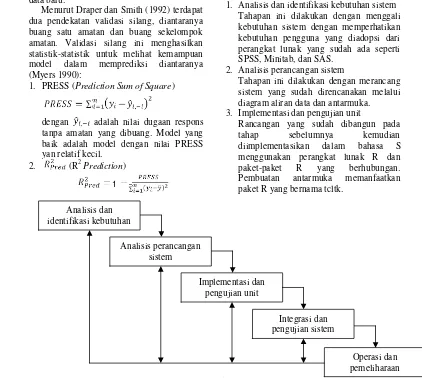
1. Analisis dan identifikasi kebutuhan sistem Tahapan ini dilakukan dengan menggali kebutuhan sistem dengan memperhatikan kebutuhan pengguna yang diadopsi dari perangkat lunak yang sudah ada seperti SPSS, Minitab, dan SAS.
2. Analisis perancangan sistem
Tahapan ini dilakukan dengan merancang sistem yang sudah direncanakan melalui diagram aliran data dan antarmuka. 3. Implementasi dan pengujian unit
Rancangan yang sudah dibangun pada tahap sebelumnya kemudian diimplementasikan dalam bahasa S menggunakan perangkat lunak R dan paket-paket R yang berhubungan. Pembuatan antarmuka memanfaatkan paket R yang bernama tcltk.
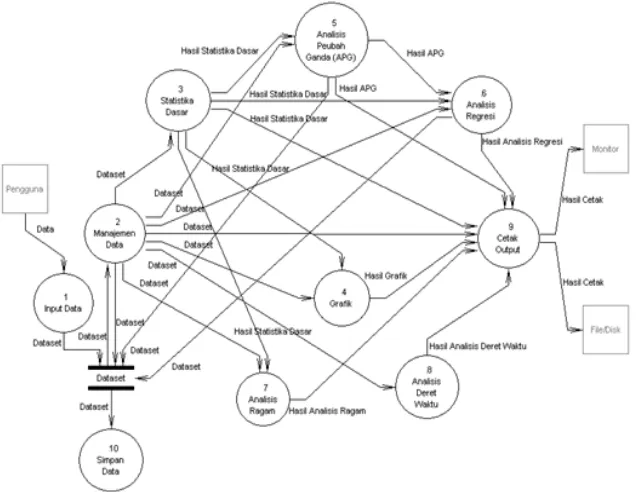
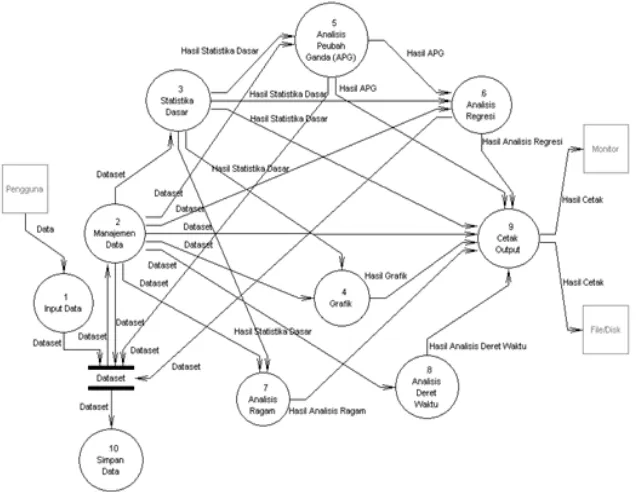
menjadi input untuk pro dapat didekomposisi men Pilih Dataset Aktif, P Dataset Aktif, Proses Proses 2.4 Bangkitkan Bila Proses 2.5 Pilih Peubah. Se memilih peubah, maka d digunakan untuk an manajemen data ini dita Lampiran 2. Data yang te sistem kemudian dapat d dua proses, yaitu Prose Dataset dan Proses 10.2 (Lampiran 3).
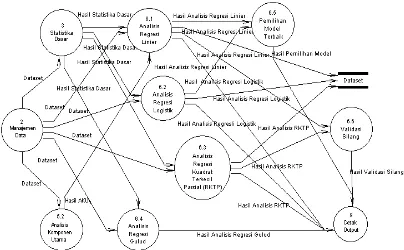
Aliran data pada Pro Regresi dijelaskan oleh G 6.2 Analisis Reg didekomposisi lagi menj Regresi Logistik Bine Regresi Logistik Ordin 6.2.3 Regresi Logisti (Lampiran 4). Kemudian Proses 6.2.2 akan masuk Fungsi Penghubung. P didekomposisi kembali fungsi penghubung, ya dan complementary disajikan dalam Lamp menentukan fungsi pe yang masuk dapat lan baik melalui prosedur p regresi terbaik (stepwis
Gambar 3 Diagram aliran data level 1.
roses 2. Proses 2 enjadi Proses 2.1 Proses 2.2 Edit s 2.3 Kalkulator, Bilangan Acak, dan . Setelah pengguna dataset telah siap analisis. Proses ditampilkan pada telah diolah dalam t disimpan melalui oses 10.1 Ekspor .2 Simpan Dataset
roses 5 Analisis
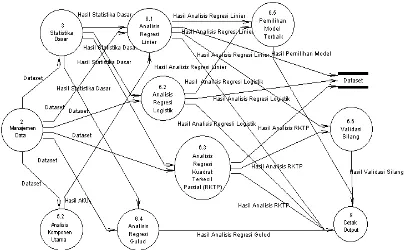
h Gambar 4. Proses egresi Logistik enjadi Proses 6.2.1 iner, Proses 6.2.2 dinal, dan Proses istik Multinomial ian Proses 6.2.1 dan uk ke Proses 6.2.4 Proses 6.2.4 ini ali menjadi tiga yaitu logit, probit log-log yang piran 5. Setelah penghubung, data langsung dianalisis r pe milihan model ise, forward, dan
backward) ataupun tidak (L Nilai sisaan, nilai peluang r nilai dugaan kategori res analisis regresi logistik disimpan dalam dataset. Analisis Regresi Kuadrat Ter didekomposisi kembali empat algoritma yang biasa yaitu algoritma kernel, w SIMPLS dan orthogonal s biasa dikenal dengan NIPALS. dijelaskan pada Lampiran regresi komponen utama keluaran dari analisis komp yang merupakan bagian analisis peubah ganda. Nilai a vektor ciri yang dihasilkan komponen utama akan digun analisis regresi linier untuk analisis regresi kompone Selanjutnya pengguna dapa mencetak hasil analisis regr terkecil parsial dan hasil ana komponen utama atau melak 6.6 Validasi Silang. Ada validasi silang yang digun buang satu amatan dan buan satu amatan (Lampiran 8). N respons, sisaan, skor X dan analisis regresi komponen analisis regresi kuadrat terk tersimpan dalam dataset.
6
Gam
Implementasi Si Implementasi sistem program R.2.11.1 dan tambahan lainnya untuk men fungsi pada Pakar 2.0. Tabe paket-paket yang dipe menjalankan Pakar 2.0. Pake paket yang sudah tersedia da Sedangkan paket tambahan a harus diunduh melalui Project.org.
Tabel 1. Paket-paket yang d menjalankan Pakar 2
No. Paket standar P
1. tcltk tk
2. stats R
3. foreign R
4. MASS ca
5. nnet n
6. ts
7. p
Pakar 2.0 tersusun oleh bagian atas dan jendela hasil menu untuk menampilkan ke terdiri atas lima menu utama Menu Edit, Menu Data, Men Menu Bantuan. Lingkungan u menu Pakar 2.0 disajikan pad
ambar 4 Diagram aliran data level 2 proses 1.
i Sistem
menggunakan beberapa paket enjalankan fungsi -bel 1 menunjukkan iperlukan untuk aket standar adalah dalam program R. adalah paket yang i
http://CRAN.R-.
dibutuhkan untuk r 2.0 Paket tambahan tkrplot RODBC R2HTML car nortest tseries pls
h pilihan menu di sil di bagian bawah keluaran. Pakar 2.0 a yaitu Menu File, enu Statistika, dan n utama dan skema ada Lampiran 9.
Menu File
Menu File terdiri atas delapa yaitu:
1. Buat Dataset Baru
Submenu ini digunaka memasukkan data ke dalam s langsung. Sebelum membuat d pengguna harus memberi n dataset tersebut.
2. Memuat Dataset
Submenu ini digunakan untu dataset yang telah disimpan d dengan ekstensi .rda atau .rd fungsi ini tidak dapat digun memuat dataset yang tersimpan R tambahan.
3. Impor Dataset
Submenu ini terdiri atas lima “SPSS”, “.csv (,)”, “.csv (;)”, dan “Ms. Access”. Fungsi-fun memungkinkan pengguna mengimpor dataset darifileSP .por), Ms. Excel (.xls, .xlsx, da Ms. Access (.mdb dan .accdb) dengan ekstensi .csv dapat untuk mengimpor file denga “,” dan “;”. Sebelum meng pengguna harus memberi n dataset yang akan diimpor data
7
.
lapan submenu
kan untuk sistem secara t dataset baru, i nama untuk
ntuk memuat dalam file R .rdata. Namun unakan untuk pan pada paket
a fungsi yaitu ”, “Ms. Excel” fungsi tersebut na untuk SPSS (.sav dan dan .csv), dan b). Impor data at digunakan gan pembatas ngimpor data, i nama untuk
8
4. Ekspor Dataset
Submenu ini terdiri atas empat fungsi yaitu “SPSS”, “.csv (,)”, “.csv (;)”, dan “Ms. Excel 2003”. Fungsi-fungsi tersebut memungkinkan pengguna untuk mengekspor dataset aktif ke file SPSS (.sps) dan Ms. Excel 2003 (.xls dan .csv). Ekspor data dengan ekstensi .csv dapat digunakan untuk mengekspor file dengan pembatas “,” dan “;”.
5. Simpan Dataset
Submenu simpan dataset digunakan untuk menyimpan dataset hasil input langsung atau dataset hasil pengolahan data dengan Pakar 2.0. Dataset tersebut akan tersimpan dengan ekstensi .rda atau .rdata.
6. Simpan Hasil
Submenu ini digunakan untuk menyimpan keluaran yang terdapat pada je ndela hasil dalam bentuk teks dengan ekstensi .txt. Selain itu hasil juga dapat disimpan dengan ekstensi .doc.
7. Hasil HTML
Submenu ini digunakan untuk menampilkan keluaran yang dicetak ke jendela hasil dalam format HTML. Fungsi ini aktif jika tombol cek “Tampilkan Output HTML” dan direktori folder terisi. Jika fungsi ini aktif maka setiap pengguna mencetak keluaran ke jendela hasil, keluaran tersebut juga akan ditampilkan olehbrowseryang terdapat pada komputer pengguna.
8. Keluar
Submenu ini digunakan untuk keluar dari Pakar 2.0.
Menu Edit
Menu edit terdiri atas tujuh submenu untuk melakukan edit pada jendela hasil. Ketujuh submenu tersebut antara lain :
1. Cut
Submenu ini digunakan untuk mengirimkan objek yang terpilih pada jendela hasil keclipboardsistem komputer dan menghapus objek yang terpilih pada jendela hasil.
2. Salin
Submenu ini digunakan untuk mengirimkan objek yang terpilih pada jendela hasil ke clipboard sistem komputer. Fungsi ini biasanya digunakan untuk menyalin objek yang terpilih. 3. Paste
Submenu ini digunakan untuk menampilkan objek yang ada pada clipboard sistem komputer ke jendela
hasil. Fungsi ini biasanya digunakan untuk menampilkan objek yang sudah disalin. 4. Hapus
Submenu ini digunakan untuk menghapus objek yang terpilih pada jendela hasil. 5. Undo
Submenu ini digunakan untuk mengembalikan tampilan jendela hasil ke tampilan sebelum tampilan terakhir. 6. Pilih Semua
Submenu ini digunakan untuk memilih semua objek yang ada pada jendela hasil. 7. Bersihkan Jendela
Submenu ini digunakan untuk menghapus semua objek yang ada pada jendela hasil. Untuk menggunakan fungsi pada menu edit, pengguna harus mengaktifkan kursor pada jendela hasil. Fungsi-fungsi dalam menu ini mempunyai kegunaan yang sama dengan fungsi klik kanan pada jendela hasil.
Menu Data
Menu data merupakan menu untuk memodifikasi, memilih, melihat, mengedit, dan mencetak dataset. Menu ini dapat dijalankan jika terdapat dataset aktif pada program. Submenu dalam menu data antara lain:
1. Pilih Dataset Aktif
Submenu pilih dataset aktif digunakan untuk memilih dataset mana yang akan digunakan, sehingga memungkinkan pengguna untuk memiliki lebih dari satu dataset dalam sistem.
2. Lihat Dataset Aktif
Submenu ini digunakan untuk melihat dataset aktif.
3. Edit Dataset Aktif
Submenu ini digunakan untuk mengedit data atau menambahkan data baru pada dataset aktif.
4. Kalkulator
Submenu kalkulator terdiri atas perhitungan aritmatika standar (+, -, *, /, ^), operator perbandingan (>, <, >=, <=, !=), operator logika (&, |), serta beberapa fungsi lain yang tersedia dalam program R. Submenu ini memungkinkan pengguna untuk melakukan modifikasi data.
5. Bangkitkan Bilangan Acak
Submenu ini digunakan untuk membangkitkan bilangan acak dari sebaran seragam, sebaran binomial, dan sebaran normal.
6. Cetak Dataset Aktif
9
Menu Statistika
Menu statistika adalah menu utama dalam Pakar 2.0 yang berisi fungsi -fungsi untuk melakukan analisis regresi dan perhitungan statistika dasar. Menu ini terdiri atas dua submenu, yaitu statistika dasar dan analisis regresi. Submenu statistika dasar terdiri atas perhitungan korelasi, perhit ungan kovarian, dan uji kenormalan. Submenu analisis regresi terdiri atas sembilan sub-submenu, yaitu plot pengepasan garis, analisis regresi linier, analisis regresi bertatar, analisis regresi komponen utama, analisis regresi gulud, analisis regresi logistik biner, analisis regresi logistik ordinal, analisis regresi logistik multinomial, dan analisis regresi kuadrat terkecil parsial. Sesuai dengan ruang lingkup dalam karya ilmiah ini, maka yang akan dibahas lebih lanjut adalah enam sub -submenu terakhir:
1. Regresi Komponen Utama
Sub-submenu ini merupakan fungsi untuk mengatasi masalah multikolinieritas pada regresi linier berganda menggunakan analisis komponen utama. Sub -submenu ini memanfaatkan paket pls. Pengguna harus memasukkan peubah respons dan peubah prediktor terlebih dahulu. Peubah prediktor minimal terdiri atas dua peubah. Pengguna dapat menentukan berapa jumlah komponen yang akan disertakan dalam model dengan mengetikkan jumlah komponen yang diinginkan.
Input data yang digunakan adalah matriks X dan matriks Y. Matriks X adalah matriks yang setiap kolomnya merupakan peubah prediktor dan berukuran (n x p). Sedangakan matriks Y adalah matriks peubah respons berukuran (n x 1). Hasil dari fungsi ini adalah nilai proporsi keragaman, nilai loading, nil ai skor, RMSEP, R2, MSEP, koefisien regresi, serta plot-plot regresi komponen utama. Nilai skor X dari regresi komponen utama tersimpan dalam dataset aktif. Plot yang dihasilkan dalam fungsi ini antara lain plot R2, plot RMSEP, plot MSEP, plot prediksi, plot koefisien, plot skor, plot loading, biplot skor X vs loading X, dan biplot loading X vs loading Y. Kotak dialog untuk fungsi ini disajikan pada Lampiran 10. Berikut adalah sintaks R yang digunakan untuk melakukan analisis regresi komponen utama (misalka n jumlah komponen = 1):
rku <- mvr(Y ~ X, ncomp = 1, data = Data, scale = TRUE, method = ”svdpc”)
Fungsi validasi silang digunakan untuk menentukan jumlah komponen yang optimum dalam model. Ada dua jenis validasi yang digunakan dalam analisis ini, yaitu validasi dengan membuang satu amatan dan validasi dengan membuang lebih dari satu amatan.
Buang satu amatan:
rku <- mvr(Y ~ X, ncomp = 1, data = Data, scale = TRUE, method = ”svdpc”, validation = “LOO”)
Buang lebih dari satu amatan (misalkan 10 kelompok amatan):
val <- crossval(rku, ncomp = 1, segments = 10,
segment.type= c(“random”, “consecutive”,
“interleaved”))
Validasi silang akan menghasilkan nilai PRESS, RMSECV, dan R2 prediksi
.
Fungsi plot yang digunakan dalam analisis regresi komponen utama sama d engan fungsi plot pada analisis regresi kuadrat terkecil parsial.Berikut adalah sintaks R yang digunakan untuk menampilkan plot -plot regresi komponen utama:
Plot R2:
plot(rku, estimate = “all”, “validation”, val.type = “R2”)
Plot RMSEP:
plot(rku, estimate = “all”, “validation”, val.type= “RMSEP”)
Plot MSEP:
plot(rku, estimate = “all”, “validation”, val.type = “MSEP”)
Plot prediksi:
predplot(rku, ncomp=rku$ncomp)
Plot koefisien:
plot(rku, plottype = “coefficients”, ncomp = 1:rktp$ncomp, type = “l”)
Plot skor:
plot(rku, plottype = “scores”, comps = 1: rktp$ncomp)
Plot loading:
plot(rku, plottype=“loadings”, comps = 1: rktp$ncomp)
Biplot skor X vs loading X:
biplot(rku, which = “x”)
Biplot loading X vs loading Y:
biplot(rku, which = “loadings”)
2. Regresi Gulud
10
digunakan dalam analisis ini ha rus berskala interval atau rasio. Pengguna harus memasukkan peubah respons dan peubah prediktor terlebih dahulu. Untuk melakukan ridge trace, pengguna harus mengisis tombol cek pada “jejak gulud” dan mengisi nilai k awal, k akhir dan lebar grid yang ingin digunakan.
Fungsi ini menghasilkan koefisien regresi gulud, persamaan gulud, serta plot koefisien gulud. Kotak dialog untuk fungsi regresi gulud disajikan pada Lampiran 11. Berikut adalah sintaks R yang digunakan (misalkan nilai k awal=0, k akhir=0.1 dan lebar grid=0.01):
gulud <- lm.ridge(y ~ x1 + x2, data = Data, lambda = seq(0,0.1,0.01)) select(gulud)
Plot koefisien gulud:
matplot(lambda, t(koef), lwd = 2, type = "l", xlab =
expression(lambda), ylab = expression(hat(beta)))
3. Regresi Logistik Biner
Sub-submenu ini merupakan fungsi untuk melakukan analisis regresi logistik biner berdasarkan tiga jenis fungsi penghubung (logit, probit, da n complementary log-log). Sub-submenu ini memanfaatkan paket stats. Data respons yang digunakan dalam analisis ini harus memiliki dua kategori. Pengguna harus memasukkan peubah respons dan peubah prediktor terlebih dahulu. Kemudian pengguna harus memilih f ungsi penghubung yang ingin digunakan.
Fungsi ini menghasilkan tabel analisis deviance, uji Wald, uji G, tabel klasifikasi, prosedur regresi bertatar, serta nilai rasio odds khusus untuk fungsi penghubung logit. Kotak dialog untuk fungsi ini disajikan pada Lampiran 12. Berikut adalah sintaks R yang digunakan:
logistik <- glm(y ~ x1 + x2, data = Data, family = binomial(“logit”, “probit”,“cloglog”)) summary(logistik)
anova(logistik, test = ”Chisq”)
Prosedur pemilihan model regresi terbaik menggunakan statistik AIC sebagai indikator. Berikut adalah sintaksnya:
null <- glm(y ~ 1, data=Data, family = binomial (“logit”,“probit”, “cloglog”))
atas <- glm(y ~ x1 + x2, data = Data, family =binomial
(“logit”,“probit”,“clo glog”))
untukstepwise:
step.AIC(null, scope = list(lower = null, upper = atas), direction = 'both')
untukforward:
step.AIC(null, scope = list(lower = null, upper = atas), direction = 'forward')
untukbackward:
step.AIC(atas, direction = 'backward')
Tabel klasifikasi yang dihasilkan adalah tabulasi silang antara respons dengan dugaan kategori respons. Nilai peluang respons yang melebihi atau sama dengan batas cutoff akan dikategorikan sebagai kategori tinggi. Sedangkan nilai peluang respons yang kurang dari batas cutoffakan dikategorikan seba gai kategori rendah. Kategori tinggi dan rendah dalam fungsi ini disesuaikan berdasarkan abjad atau angka dari kategori yang dimasukkan oleh pengguna. Berikut adalah fungsi untuk membuat dugaan kategori respons pada regresi logistik biner:
y <- logistik$fitted n <- length(Data[,y]) Kategori <- 1:n for (i in 1:n) {
if (y[i] >= cutoff)
{Kategori[i] <- kategori2} else if (y[i] < cutoff) {Kategori[i] <- kategori1} }
4. Regresi Logistik Ordinal
Sub-submenu ini merupakan fungsi untuk melakukan analisis regresi logistik ordinal berdasarkan tiga jenis fungsi penghubung (logistic, probit, dan complementary log-log) dengan metode kemungkinan maksimum. Sub -submenu ini memanfaatkan paket MASS. Model regresi logistik ordinal yang digunakan adalah proportional odds. Data respons yang digunakan dalam analisis ini harus berskala ordinal dengan lebih dari dua kategori. Pengguna harus memasukkan peubah respons dan peubah prediktor terlebih dahulu. Kemudian pengguna harus memilih fungsi penghubung yang ingin digunakan.
11
Berikut adalah sintaks R yang digunakan untuk melakukan analisis regresi logistik ordinal:
logistik <- polr(y ~ x1 + x2, data = Data, method = c(“logistic”, “probit”,“cloglog”))
Sintaks regresi bertatar yang digunakan sama dengan sintaks regresi bertatar pada analisis regresi logistik biner.
5. Regresi Logistik Multinomial
Sub-submenu ini merupakan fungsi untuk melakukan analisis regresi logistik multiomial berdasarkan fungsi penghubung logit. Sub -submenu ini memanfaatkan paket nnet. Data respons yang digunakan dalam analisis ini harus berskala nominal dengan lebih dari dua kategori. Pengguna harus memasukkan peubah respons dan peubah prediktor terlebih dahulu.
Fungsi ini menghasilkan uji Wald, tabel klasifikasi, prosedur regresi bertatar, serta nilai rasio odds. Kotak dialog untuk fungsi ini disajikan pada Lampiran 14. Berikut adalah sintaks R yang digunakan:
logistik <- multinom(y ~ x1 + x2, data = Data) summary(logistik, “Wald”=T)
Sintaks regresi bertatar yang digunakan sama dengan sintaks regresi bertatar pada analisis regresi logistik biner.
6. Regresi Kuadrat Terkecil Parsial
Sub-submenu ini merupakan fungsi untuk melakukan analisis regresi kuadrat terkecil parsial. Sub-submenu ini memanfaatkan paket pls. Fungsi ini digunakan ketika peubah-peubah prediktor saling berkorelasi tinggi atau ketika jumlah pengamatan lebih sedikit daripada jumlah peubah prediktor. Pengguna harus memasukkan peubah respons dan peubah prediktor terlebih dahulu. Peubah respons dapat berjumlah lebih dari satu peubah. Peubah prediktor minimal terdiri atas dua peubah. Pengguna dapat menentukan berapa jumlah komponen yang akan disertakan dalam model dengan mengetikkan jumlah komponen yang diinginkan. Selanjutnya pengguna harus memilih algoritma dan tipe validasi silang yang akan digunakan.
Input data yang digunakan adalah matriks X dan matriks Y. Matriks X adalah matriks yang setiap kolomnya merupakan peubah prediktor dan berukuran (n x p). Matriks Y adalah matriks yang setiap
kolomnya merupakan peubah respons dan berukuran (n x q). Hasil dari fungsi ini adalah nilai proporsi keragam an, nilai loading, nilai skor, RMSEP, R2, MSEP, koefisien regresi, serta plot -plot regresi kuadrat terkecil parsial. Nilai skor X dari regresi kuadrat terkecil parsial tersimpan dalam dataset aktif. Plot yang dihasilkan dalam fungsi ini antara lain plot R2, plot RMSEP, plot MSEP, plot prediksi, plot koefisien, plot skor, plot loading, biplot skor X vs loading X, biplot skor Y vs loading Y, biplot skor X vs skor Y, dan biplot loading X vs loading Y. Biplot antara skor Y vs loading Y serta skor X vs skor Y tidak dapat ditampilkan jika hanya terdapat satu komponen dalam model. Kotak dialog untuk fungsi ini disajikan pada Lampiran 15. Berikut adalah sintaks R yang digunakan (misalkan jumlah komponen = 1):
rktp <- mvr(Y ~ X, ncomp = 1, data = Data, scale = TRUE, method = c(“oscorespls”,
“simpls”, “kernelpls”, “widekernelpls”))
Fungsi validasi silang digunakan untuk menentukan jumlah komponen yang optimum dalam model. Ada dua jenis validasi yang digunakan dalam analisis ini, yaitu validasi dengan membuang satu amatan dan validasi dengan membuang lebih dari satu amatan.
Buang satu amatan:
rktp <- mvr(Y ~ X, ncomp = 1, data = Data, scale = TRUE, method = c(“oscorespls”,
“simpls”, “kernelpls”, “widekernelpls”), validation = “LOO”)
Buang lebih dari satu amatan (misalka n 10 kelompok amatan):
val <- crossval(rktp, ncomp = 1, segments = 10,
segment.type= c(“random”, “consecutive”,
“interleaved”))
Terdapat tiga cara untuk membangkitkan data yang akan dibuang dalam setiap kelompok amatan yaitu acak (random), berurutan (consecutive), dan berselang-seling (interleaved). Validasi silang akan menghasilkan nilai PRESS, RMSECV, dan R2prediksi
.
12
Plot R2:
plot(rktp, estimate = “all”, “validation”, val.type = “R2”)
Plot RMSEP:
plot(rktp, estimate = “all”, “validation”, val.type= “RMSEP”)
Plot MSEP:
plot(rktp, estimate = “all”, “validation”, val.type = “MSEP”)
Plot prediksi:
predplot(rktp, ncomp=rktp$ncomp)
Plot koefisien:
plot(rktp, plottype = “coefficients”, ncomp = 1:rktp$ncomp, type = “l”)
Plot skor:
plot(rktp, plottype = “scores”, comps = 1: rktp$ncomp)
Plot loading:
plot(rktp, plottype=“loadings”, comps = 1: rktp$ncomp)
Biplot skor X vs loading X:
biplot(rktp, which = “x”)
Biplot skor Y vs loading Y:
biplot(rktp, which = “y”)
Biplot skor X vs skor Y:
biplot(rktp, which = “scores”)
Biplot loading X vs loading Y:
biplot(rktp, which = “loadings”)
Menu Bantuan
Menu bantuan digunakan untuk memberikan informasi penggunaan Pakar 2.0. Menu ini terdiri atas dua submenu yaitu: 1. Bantuan Pakar 2.0
Submenu ini berisis dokumentasi tentang pengunaan Pakar 2.0.
2. Tentang Pakar 2.0
Submenu ini berisi informasi tentang versi Pakar 2.0 dan pengembangan Pakar 2.0.
Pengujian
Pengujian Pakar 2.0 dimulai dari implementasi fungsi-fungsi Pakar 2.0 hingga pengujian Pakar 2.0 secara menyeluruh. Ada beberapa data yang digunakan dalam pengujian ini. Data Winearoma.MTW yang berasal dari lembar kerja Minitab digunakan untuk menguji regresi kuadrat terkecil parsial dan regresi komponen utama. Data EXH_REGR.MTW digunakan untuk menguji regresi logistik biner. Data mlogit.csv digunakan untuk menguji regresi logistik multinomial dan diunduh dari http://www.ats.ucla.edu/stat/r/dae/mlogit.csv Data ologit.csv digunakan untuk menguji regresi logistik ordinal dan diunduh dari http://www.ats.ucla.edu/stat/r/dae/ologit.csv . Data longley yang berasal dari dataset R digunakan untuk menguji regresi gulud.
Tabel 2. Perbandingan keluaran Pakar 2.0 dengan Minitab, SAS, dan SPSS menggunakan metodeblackbox Fungsi dalam Pakar 2.0 Perangkat Lunak Perbandingan Keluaran Regresi Komponen Utama Minitab -SAS Berbeda* SPSS -Regresi Gulud Minitab -SAS Berbeda SPSS -Regresi Logistik Biner Minitab Sama SAS Sama SPSS Sama Regresi Logistik Ordinal Minitab Berbeda* SAS Berbeda* SPSS Sama Regresi Logistik Multinomial Minitab Sama SAS Sama SPSS Berbeda* Regresi Kuadrat Terkecil Parsial Minitab Sama SAS Berbeda* SPSS
-*) berbeda tidak signifikan akibat adanya perbedaan kategori acuan yang digunakan dan perbedaan nilai desimal hasil iterasi.
Pengujian paket dilakukan dengan membandingkan keluaran Pakar 2.0 dengan keluaran dari perangkat lunak statistika lainnya yaitu Minitab, SAS, dan SPSS. Hasil perbandingan dari keempat perangkat lun ak tersebut ditampilkan pada Tabel 2. Berikut adalah penjelasan mengenai tabel perbandingan di atas:
1. Regresi Komponen Utama
Data yang digunakan untuk analisis regresi komponen utama adalah data terbakukan. Matriks yang digunakan dalam analisis ini adalah matriks kovarian. Terdapat perbedaan nilai loading antara Pakar 2.0 dengan SAS, namun kisaran nilai loading yang dihasilkan sama. Nilai loadingdalam analisis ini adalah vektor ciri. Oleh sebab itu, perbedaan nilai loading antara kedua perangkat lunak dikarenakan nilai vektor ciri yang tidak unik. Hasil perbandingan antara Pakar 2.0 dan SAS dapat dilihat pada Lampiran 16. Berdasarkan hasil simulasi, analisis regresi komponen utama pada Pakar 2.0 mampu menganalisis hingga 5000 peubah prediktor.
2. Regresi Gulud
13
antara kedua perangkat lunak. Hasil perbandingan regresi gulud dis ajikan pada Lampiran 17. Sedangkan perbandingan plot regresi gulud antara Pakar 2.0 dan SAS ditampilkan pada Lampiran 18. 3. Regresi Logistik Biner
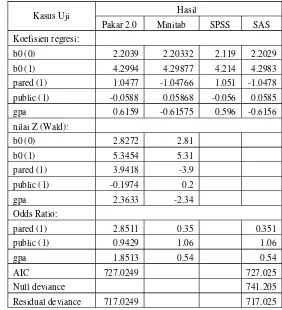
Perbandingan analisis regresi logistik biner antara Pakar 2.0, Minitab, SPSS, dan SAS menunjukkan hasil yang sama untuk beberapa kasus uji. Tabel klasifikasi keluaran dari Pakar 2.0, SPSS dan SAS menunjukkan hasil yang sama. Hasil perbandingan regresi logistik biner dengan fungsi penghubung logit ditampilkan pada Lampiran 19. Sedangkan perbandingan tabel klasifikasinya ditampilkan pada Lampiran 20.
4. Regresi Logistik Ordinal
Perbandingan nilai koefisien regresi untuk analisis regresi ordinal antara Pakar 2.0, Minitab, SPSS, dan SAS menunjukkan hasil yang berbeda. Perbedaan tersebut terjadi pada peubah prediktor yang bernilai kategorik. Peubah pared dan public merupakan peubah kategorik dengan nilai 0 dan 1. Pakar 2.0 dan SPSS menggunakan 1 sebagai kategori acuan, sedangkan Minitab dan SAS menggunakan 0 sebagai kategori acuan, oleh sebab itu tanda koefisiennya menjadi berbeda. Nilai koefisien antara Pakar 2.0, Minitab, dan SAS berbeda dengan SPSS. Hal ini disebabkan oleh proses iterasi pada metode kemungkinan maksimum yang berbeda. Nilai rasio odds hasil keluaran Pakar 2.0 berbeda dengan Minitab dan SAS disebabkan oleh perbedaan tanda pada koefisien regresi. Hasil perbandingan regresi logistik ordinal dapat dilihat pada Lampiran 21.
5. Regresi Logistik Multinomial
Perbandingan analisis regresi multinomial antara Pakar 2.0, Minitab, SPSS, dan SAS menunjukkan hasil yang sama untuk beberapa kasus uji. Namun nilai dugaan koefisien SPSS sedikit berbeda dibandingkan hasil keluaran dari perangkat lunak lainnya. Hal ini disebabkan karena SPSS menggunakan kategori acuan dan proses iterasi pada metode kemungkinan maksimum yang berbeda dengan ketiga perangkat lunak lainnya. Hasil perbandingan regresi logistik multinomial dapat dilihat pada Lampiran 22.
6. Regresi Kuadrat Terkecil Parsial
Hasil perbandingan menggunakan algoritma NIPALS menunjukkan bahwa nilai loading keluaran Pakar 2.0 dan
Minitab sama, tetapi berbeda dengan SAS. Hal ini dikarenakan proses iterasi yang berbeda pada setiap perangkat lunak. Tabel hasil perbandingan antara Pakar 2.0, Minitab dan SAS dapat dilihat pada Lampiran 23. Berdasarkan hasil simula si, analisis regresi kuadrat terkecil parsial pada Pakar 2.0 mampu menganalisis hingga 5000 peubah prediktor.
Batasan dan Pemasangan Sistem Sistem ini mempunyai batasan -batasan tertentu yaitu:
1. Analisis regresi gulud hanya menghasilkan nilai koefisien regresi gulud dan plotnya, tidak menghasilkan nilai RMSE.
2. Analisis regresi logistik belum mampu melakukan pengaturan terhadap kategori acuan yang digunakan.
3. Plot regresi komponen utama dan plot regresi kuadrat terkecil parsial yang mampu ditampilkan dalam satu jendela grafik maksimum berjumlah sembilan plot.
4. Analisis regresi komponen utama dan analisis regresi kuadrat terkecil parsial belum menghasilkan nilai prediksi. 5. Ekspor dataset aktif pada Pakar 2.0 masih
terbatas pada file SPSS dan Ms. Excel 2003.
Pemasangan Pakar 2.0 diawali dengan pemasangan program R dan paket R lain yang dibutuhkan. Setelah itu, pasang paket Pakar 2.0 melalui menu “Packages > Install package(s) from local zip file …”. Untuk memuat Pakar 2.0 ketikkan pada R console sebagai berikut:
library(Pakar2) Pakar2()
KESIMPULAN DAN SARAN
Kesimpulan13
antara kedua perangkat lunak. Hasil perbandingan regresi gulud dis ajikan pada Lampiran 17. Sedangkan perbandingan plot regresi gulud antara Pakar 2.0 dan SAS ditampilkan pada Lampiran 18. 3. Regresi Logistik Biner
Perbandingan analisis regresi logistik biner antara Pakar 2.0, Minitab, SPSS, dan SAS menunjukkan hasil yang sama untuk beberapa kasus uji. Tabel klasifikasi keluaran dari Pakar 2.0, SPSS dan SAS menunjukkan hasil yang sama. Hasil perbandingan regresi logistik biner dengan fungsi penghubung logit ditampilkan pada Lampiran 19. Sedangkan perbandingan tabel klasifikasinya ditampilkan pada Lampiran 20.
4. Regresi Logistik Ordinal
Perbandingan nilai koefisien regresi untuk analisis regresi ordinal antara Pakar 2.0, Minitab, SPSS, dan SAS menunjukkan hasil yang berbeda. Perbedaan tersebut terjadi pada peubah prediktor yang bernilai kategorik. Peubah pared dan public merupakan peubah kategorik dengan nilai 0 dan 1. Pakar 2.0 dan SPSS menggunakan 1 sebagai kategori acuan, sedangkan Minitab dan SAS menggunakan 0 sebagai kategori acuan, oleh sebab itu tanda koefisiennya menjadi berbeda. Nilai koefisien antara Pakar 2.0, Minitab, dan SAS berbeda dengan SPSS. Hal ini disebabkan oleh proses iterasi pada metode kemungkinan maksimum yang berbeda. Nilai rasio odds hasil keluaran Pakar 2.0 berbeda dengan Minitab dan SAS disebabkan oleh perbedaan tanda pada koefisien regresi. Hasil perbandingan regresi logistik ordinal dapat dilihat pada Lampiran 21.
5. Regresi Logistik Multinomial
Perbandingan analisis regresi multinomial antara Pakar 2.0, Minitab, SPSS, dan SAS menunjukkan hasil yang sama untuk beberapa kasus uji. Namun nilai dugaan koefisien SPSS sedikit berbeda dibandingkan hasil keluaran dari perangkat lunak lainnya. Hal ini disebabkan karena SPSS menggunakan kategori acuan dan proses iterasi pada metode kemungkinan maksimum yang berbeda dengan ketiga perangkat lunak lainnya. Hasil perbandingan regresi logistik multinomial dapat dilihat pada Lampiran 22.
6. Regresi Kuadrat Terkecil Parsial
Hasil perbandingan menggunakan algoritma NIPALS menunjukkan bahwa nilai loading keluaran Pakar 2.0 dan
Minitab sama, tetapi berbeda dengan SAS. Hal ini dikarenakan proses iterasi yang berbeda pada setiap perangkat lunak. Tabel hasil perbandingan antara Pakar 2.0, Minitab dan SAS dapat dilihat pada Lampiran 23. Berdasarkan hasil simula si, analisis regresi kuadrat terkecil parsial pada Pakar 2.0 mampu menganalisis hingga 5000 peubah prediktor.
Batasan dan Pemasangan Sistem Sistem ini mempunyai batasan -batasan tertentu yaitu:
1. Analisis regresi gulud hanya menghasilkan nilai koefisien regresi gulud dan plotnya, tidak menghasilkan nilai RMSE.
2. Analisis regresi logistik belum mampu melakukan pengaturan terhadap kategori acuan yang digunakan.
3. Plot regresi komponen utama dan plot regresi kuadrat terkecil parsial yang mampu ditampilkan dalam satu jendela grafik maksimum berjumlah sembilan plot.
4. Analisis regresi komponen utama dan analisis regresi kuadrat terkecil parsial belum menghasilkan nilai prediksi. 5. Ekspor dataset aktif pada Pakar 2.0 masih
terbatas pada file SPSS dan Ms. Excel 2003.
Pemasangan Pakar 2.0 diawali dengan pemasangan program R dan paket R lain yang dibutuhkan. Setelah itu, pasang paket Pakar 2.0 melalui menu “Packages > Install package(s) from local zip file …”. Untuk memuat Pakar 2.0 ketikkan pada R console sebagai berikut:
library(Pakar2) Pakar2()
KESIMPULAN DAN SARAN
Kesimpulan14
Menu Edit, Menu Data, Menu Statistika, dan Menu Bantuan. Pengujian yang dilakukan menunjukkan bahwa Pakar 2.0 sudah mampu melakukan analisis-analisis yang ditentukan dengan baik, walaupun masih terdapat beberapa perbedaan hasil dengan perangkat lunak statistika lainnya.
Saran
Untuk menyempurnakan penelitian ini, maka dibutuhkan beberapa perbaikan pada penelitian selanjutnya yaitu:
1. Ekspor dataset aktif mencakup file Ms. Excel 2007 dan Ms. Access.
2. Menampilkan nilai RMSE untuk analisis regresi gulud.
3. Membuat pengaturan kategori acuan untuk regresi logistik.
4. Jendela grafik mampu menampilkan lebih dari sembilan plot.
5. Analisis regresi komponen utama dan analisis regresi kuadrat terkecil parsial mampu menghasilkan nilai prediksi untuk amatan baru.
DAFTAR PUSTAKA
Draper N, Smith H. 1992. Analisis Regresi Terapan, Edisi Kedua. Terjemahan Bambang Sumantri. Jakarta : Gramedia. Hornik F. 2010. Frequently Asked Questions
on R. http://www.r-project.org [10 Januari 2011].
Hosmer DW, Lemeshow S. 2000. Applied Logistic Regression, Second Edition. New York: John Wiley & Sons.
Jollife IT. 2002. Principal Component Analysis, Second Edition. New York : Springer.
Melisa. 2009. Pengembangan Paket R Analisis Regresi Linier dengan Antar Muka User Friendly Bagi Praktisi. [Skripsi]. Departemen Statistika FMIPA IPB, Bogor.
Myers RH. 1989. Classical and Modern Regression with Applications, Second Edition. Boston: PWS-KENT Publishing Company.
Naes T, Isaksson T, Fear T, Davies T. 2002. A User-Friendly Guide to Multivariate Calibration and Classification. Chichester: NIR Publications.
Ravishanker N, Dey DK. 2002. A First Course in Linear Model Theory. New York: Chapman & Hall.
PENYUSUNAN PAKET R UNTUK PENGEMBANGAN PAKAR
(PAKET ANALISIS REGRESI)
KAMELIA
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Statistika
pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
14
Menu Edit, Menu Data, Menu Statistika, dan Menu Bantuan. Pengujian yang dilakukan menunjukkan bahwa Pakar 2.0 sudah mampu melakukan analisis-analisis yang ditentukan dengan baik, walaupun masih terdapat beberapa perbedaan hasil dengan perangkat lunak statistika lainnya.
Saran
Untuk menyempurnakan penelitian ini, maka dibutuhkan beberapa perbaikan pada penelitian selanjutnya yaitu:
1. Ekspor dataset aktif mencakup file Ms. Excel 2007 dan Ms. Access.
2. Menampilkan nilai RMSE untuk analisis regresi gulud.
3. Membuat pengaturan kategori acuan untuk regresi logistik.
4. Jendela grafik mampu menampilkan lebih dari sembilan plot.
5. Analisis regresi komponen utama dan analisis regresi kuadrat terkecil parsial mampu menghasilkan nilai prediksi untuk amatan baru.
DAFTAR PUSTAKA
Draper N, Smith H. 1992. Analisis Regresi Terapan, Edisi Kedua. Terjemahan Bambang Sumantri. Jakarta : Gramedia. Hornik F. 2010. Frequently Asked Questions
on R. http://www.r-project.org [10 Januari 2011].
Hosmer DW, Lemeshow S. 2000. Applied Logistic Regression, Second Edition. New York: John Wiley & Sons.
Jollife IT. 2002. Principal Component Analysis, Second Edition. New York : Springer.
Melisa. 2009. Pengembangan Paket R Analisis Regresi Linier dengan Antar Muka User Friendly Bagi Praktisi. [Skripsi]. Departemen Statistika FMIPA IPB, Bogor.
Myers RH. 1989. Classical and Modern Regression with Applications, Second Edition. Boston: PWS-KENT Publishing Company.
Naes T, Isaksson T, Fear T, Davies T. 2002. A User-Friendly Guide to Multivariate Calibration and Classification. Chichester: NIR Publications.
Ravishanker N, Dey DK. 2002. A First Course in Linear Model Theory. New York: Chapman & Hall.
PENYUSUNAN PAKET R UNTUK PENGEMBANGAN PAKAR
(PAKET ANALISIS REGRESI)
KAMELIA
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Statistika
pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
RINGKASAN
KAMELIA. Penyusunan Paket R untuk Pengembangan Pakar (Paket Analisis Regresi). Dibimbing oleh AGUS MOHAMAD SOLEH dan UTAMI DYAH SYAFITRI.
R merupakan perangkat lunak statistika berbasis open source dan berbasis pemrograman, sehingga tidak semua orang terbiasa untuk menggunakannya. Sejak tahun 2009, Departemen Statistika Institut Pertanian Bogor melakukan pengembangan paket dalam R dengan ant armuka user friendly untuk memudahkan penggunaan R sebagai alat analisis statistika. Analisis statistika yang sudah dikembangkan dalam paket tersebut diantaranya analisis regresi, analisis peubah ganda, analisis deret waktu, dan analisis perancangan percob aan. Namun paket yang telah dikembangkan masih memiliki beberapa kekurangan, sehingga penelitian ini dilakukan untuk menyempurnakan beberapa kekurangan tersebut.
Paket yang disusun dalam penelitian ini merupakan pe ngembangan dari Pakar (Paket Analisis Regresi) yang telah disusun sebelumnya oleh Melisa (2009). Paket ini diberi nama Pakar 2.0. Komponen analisis regresi yang ditambahkan dalam Pakar 2.0 meliputi analisis regresi komponen utama, analisis regresi gulud, analisis regresi logistik biner, analisis r egresi logistik ordinal, analisis regresi logistik multinomial, dan analisis regresi kuadrat terkecil parsial. Untuk menjalankan fungsi-fungsinya, Pakar 2.0 membutuhkan paket lain yaitu tcltk, tkrplot, RODBC, R2HTML, car, nortest, tseries, stats, foreign, MASS, nnet, dan pls. Menu utama pada Pakar 2.0 meliputi menu File, menu Edit, menu Data, menu Statistika, dan menu Bantuan. Hasil pengujian Pakar 2.0 dengan membandingkan keluaran dari perangkat lunak statistika lain secara umum sudah menunjukkan hasil yan g relatif sama, kecuali pada beberapa kasus uji. Perbedaan pada beberapa kasus uji tersebut disebabkan adanya perbedaan kategori acuan pada regresi logistik dan perbedaan nilai desimal hasil iterasi.
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta pada tanggal 23 November 1988 dari pasangan Zainal Mutakin dan Kamini. Penulis merupakan putri pertama dari dua bersaudara.
KATA PENGANTAR
Segala puji dan rasa syukur penulis panjatkan kehadirat Allah SWT atas segala karunia -Nya hingga penulis dapat menyelesaikan karya ilmiah dengan judul “Penyusunan Paket R untuk Penyempurnaan Pakar (Paket Analisis Regresi)“.
Terima kasih penulis ucapkan ke pada semua pihak yang telah berperan serta dalam penyusunan karya ilmiah ini terutama kepada :
1. Bapak Agus Mohamad Soleh, S.Si, MT. dan Ibu Utami Dyah Syafitri, M.Si atas bimbingan, arahan, dan perhatian kepada penulis.
2. Bapak Prof. Dr. Ir. Aunuddin selaku penguji atas semua sarannya.
3. Rekan-rekan seperjuangan, Defri Ramadhan Ismana dan M. Mufti Mubarak atas semua saran, diskusi, dan semangat yang diberikan kepada penulis selama mengerjakan karya ilmiah ini. 4. Melisa, Anton Kisworo, Tri Miranti, dan Angga Warel la untuk diskusi mengenai paket R yang
telah dikembangkan sebelumnya.
5. Rekan-rekan pembahas seminar (Septiyan Allan dan Lili Puspita Rahayu) serta rekan -rekan yang bersedia hadir pada seminar saya. Terima kasih atas semua masukan yang diberikan. 6. Mama, Papa, dan Noer Alvisachrin atas doa, kepercayaan, dan semangat yang diberikan
kepada penulis hingga saat ini.
Semoga segala budi baik yang telah diberikan kepada penulis mendapat balasan dari Allah SWT. Penulis juga berharap agar karya ilmiah ini dapat bermanf aat bagi semua pihak yang membutuhkan dan memberikan sedikit kontribusi untuk kemajuan statistika di Indonesia.
Bogor, Februari 2011
Judul : Penyusunan Paket R untuk Pen gembangan Pakar (Paket Analisis
Regresi)
Nama : Kamelia
NRP
: G14061870
Menyetujui :
Pembimbing I,
Agus Mohamad Soleh , S.Si, MT.
NIP. 197503151999031004
Pembimbing II,
Utami Dyah Syafitri, S.Si., M.Si
NIP. 197709172005012001
Mengetahui :
Ketua Departemen Statistika,
Fakultas Matematika dan Ilmu Pengetahuan Alam IPB
Dr. Ir. Hari Wijayanto, M.Si
NIP. 196504211990021001
DAFTAR ISI
Halaman DAFTAR GAMBAR ...viii
DAFTAR TABEL ...viii
DAFTAR LAMPIRAN ...viii
PENDAHULUAN ... 1
Latar Belakang ... 1 Tujuan... 1
TINJAUAN PUSTAKA ... 1
Regresi Komponen Utama ... 1 Regresi Gulud ... 2 Regresi Logistik ... 2 Regresi Logistik Biner ... 2 Regresi Logistik Ordinal ... 2 Regresi Logistik Multinomial ... 2 Pengujian Parameter Regresi Logistik ... 3 Rasio Odds ... 3 Akaike Information Criterion(AIC) ... 3 Sisaan... 3 Regresi Kuadrat Terkecil Parsial ... 3 Validasi Silang ... 4
METODOLOGI ... 4
HASIL DAN PEMBAHASAN ... 5
Kebutuhan Sistem... 5 Analisis dan Perancangan Sistem ... 5 Implementasi Sistem ... 7 Menu File ... 7 Menu Edit ... 7 Menu Data ... 7 Menu Statistika ... 9 Menu Bantuan ... 12 Pengujian ...12 Batasan dan Pemasangan Sistem ... 13
KESIMPULAN DAN SARAN ...13
Kesimpulan... 13 Saran...14
DAFTAR PUSTAKA ... 14
DAFTAR GAMBAR
Halaman 1. Tahapan penyusunan paket R dengan model air terjun. ... 4 2. Diagram aliran data level 0 ... 5 3. Diagram aliran data level 1. ... 6 4. Diagram aliran data level 2 proses 1. ... 7
DAFTAR TABEL
Halaman 1. Paket-paket yang dibutuhkan untuk menjalankan Pakar 2.0 ... 7 2. Perbandingan keluaran Pakar 2.0 dengan Minitab, SAS, dan SPSS menggunakan metode
blackbox... 12
DAFTAR LAMPIRAN
Halaman 1. Diagram aliran data level 2 proses 1 (Input Data) ... 16 2. Diagram aliran data level 2 proses 2 (Manajemen Data) ... 16 3. Diagram aliran data level 2 proses 10 (Simpan Data) ... 16 4. Diagram aliran data level 3 proses 6.2 (Regresi Logistik) ... 17 5. Diagram aliran data level 4 proses 6.2.4 (Fungsi Penghubung) ... 17 6. Diagram aliran data level 3 proses 6.5 (Pemilihan Model Regresi Terbaik) ... 17 7. Diagram aliran data level 3 proses 6.3 (Algoritma Regresi Kuadrat Terkecil Parsial) ... 18 8. Diagram aliran data level 3 proses 6.6 (Validasi Silang) ... 18 9. Lingkungan utama dan skema menu Pakar 2.0 ... 19 10. Kotak Dialog Regresi Komponen Utama ... 22 11. Kotak Dialog Regresi Gulud ... 23 12. Kotak Dialog Regresi Logistik Biner ... 24 13. Kotak Dialog Regresi Logist ik Ordinal ... 25 14. Kotak Dialog Regresi Logistik Multinomial ... 26 15. Kotak Dialog Regresi Kuadrat Terkecil Parsial ... 27 16. Tabel perbandingan keluaran regresi komponen utama antara Pakar 2.0 dengan SAS ... 28 17. Tabel perbandingan keluaran regresi gulud antara Pakar 2.0 dengan SAS ... 29 18. Perbandingan plot regresi gulud antara Pakar 2.0 dengan SAS ... 30 19. Tabel perbandingan keluaran regresi logistik biner (fungsi penghubung logit) antara
Pakar 2.0 dengan Minitab, SAS, dan SPSS ... 31 20. Perbandingan tabel klasifikasi regresi logistik biner (fungsi penghubung logit) antara
Pakar 2.0 dengan Minitab, SAS, dan SPSS ... 32 21. Tabel perbandingan keluaran regresi logistik ordinal (fungsi penghubung logit) antara
Pakar 2.0 dengan Minitab, SAS, dan SPSS ... 33 23. Tabel perbandingan keluaran regresi kuadrat terkecil parsial antara Pakar 2.0 dengan
1
PENDAHULUAN
Latar BelakangR merupakan perangkat lunak statistika berbasis open source dan berbasis pemrograman, sehingga tidak semua orang terbiasa untuk menggunakannya. Sejak tahun 2009, Departemen Statistika Institut Pertanian Bogor melakukan pengembangan paket dal am R dengan antarmuka user friendly untuk memudahkan penggunaan R sebagai alat analisis statistika. Analisis statistika yang sudah dikembangkan dalam paket tersebut diantaranya analisis regresi, analisis peubah ganda, analisis deret waktu, dan analisis perancangan percobaan. Namun paket yang telah dikembangkan masih memiliki beberapa kekurangan, sehingga penelitian ini dilakukan untuk menyempurnakan beberapa kekurangan tersebut.
Paket analisis regresi (Pakar) merupakan bagian dari paket R yang telah dikemba ngkan. Pakar meliputi perhitungan statistika dasar, plot pengepasan garis, analisis regresi linier, dan analisis regresi bertatar (Melisa 2009). Komponen analisis regresi dan sistem manajemen data pada Pakar masih terbatas. Batasan tersebut yaitu hanya sa tu dataset yang dapat digunakan dalam sistem, impor dan ekspor data masih terbatas pada file Excel dengan ekstensi .csv dan .xls, serta keterbatasan menu untuk memodifikasi data. Penelitian ini dilakukan untuk mengembangkan Pakar dengan menambahkan beberapa analisis regresi dan menyempurnakan sistem manajemen data. Paket hasil pengembangan Pakar akan diberi nama Pakar 2.0.
Tujuan
Tujuan dari penelitian ini adalah menyusun paket R untuk mengembangkan paket analisis regresi (Pakar) dengan menambahkan analisis regresi komponen utama, analisis regresi gulud, analisis regresi logistik biner, analisis regresi logistik ordinal, analisis regresi logistik multinomial, dan analisis regresi kuadrat terkecil parsial dengan antarmuka user friendly serta mengatasi batasan-batasan yang ada pada Pakar.
TINJAUAN PUSTAKA
Pakar 2.0 merupakan suatu sistem dengan antarmuka user friendly pada lingkungan R. Menurut Hornik (2010), R merupakanimplementasi sebuah lingkungan komputasi dan pemrograman bahasa statistika. R disusun dari bahasa S dan bahasa Scheme oleh Ross Ihaka dan Robert Gentleman. Paket R merupakan sebuah ekstensi dari sistem dasar R yang terdiri atas kode, data, dan dokumentasi. Paket R dapat diunduh secara bebas pada http://CRAN.R-Project.org. Untuk membuat paket R pada lingkungan Windows dibutuhkan Rtools, LaTeX, dan HTML Help Workshop sebagai perangkat lunak tambahan.
Komponen analisis regresi yang ditambahkan dalam Pakar 2.0 antara lain regresi komponen utama, regresi gulud, regresi logistik, dan regresi kuadrat terkecil parsial.
Regresi Komponen Utama (RKU) Regresi Komponen Utama (RKU) merupakan implementasi dari Analisis Komponen Utama (AKU). RKU digunakan untuk mengatasi masalah multikolinier antar peubah bebas. Prinsip dari RKU adalah mentransformasi peubah -peubah bebas menjadi peubah-peubah baru yang saling ortogonal. Kemudian peubah -peubah baru tersebut diregresikan dengan peubah bebas. Transformasi peubah bebas menjadi peubah baru tersebut adalah dengan AKU.
Komponen utama yang dibentuk berdasarkan matriks ragam -peragam adalah sebagai berikut. Misalkan Σ merupakan matriks ragam-peragam dari vektor x1,x2,…,xp dengan pasangan akar ciri dan vektor ciri yang saling ortonormal (λ1,e1), (λ2,e2), …, (λp,ep) dengan λ1≥λ2≥ … ≥ λp≥0, maka komponen utama ke-i didefinisikan sebagai berikut (Jollife 2002):
λ1 merupakan akar ciri terbesar yang memaksimumkan ragam KU1 dan e1
merupakan vektor ciri yang berpadanan dengan λ1. Urutan KU1, KU2, …, KUpharus
memenuhi persyaratan λ1 ≥ λ2 ≥ … ≥ λp. Sementara itu, kontribusi keragaman dari setiap komponen utama ke -k terhadap keragaman total adalah:
λ λ
λ λ … λ
Matriks Σ dapat berupa matriks ragam -peragam atau matriks korelasi.
2
dengan adalah vektor peubah respons, adalah vektor koefisien regresi kom -ponen utama dari m buah kom-ponen utama, adalah matriks berukuran (n x m) yang kolomnya merupakan skor komponen utama, serta adalah komponen error model (Jollife 2002).
Regresi Gulud
Regresi gulud juga digunakan untuk mengatasi masalah multikolinieritas antar peubah bebas. Multikolinieritas ini mengakibatkan nilai dugaan parameter model menjadi tidak stabil. Regresi gulud didasarkan pada konsep bahwa penduga berbias namun memiliki ragam yang lebih kecil akan lebih disukai.
Menurut Myers (1990), prosedur regresi gulud adalah dengan menambahkan sebuah konstantakyang berada dalam selang [0,1] ke dalam matriks (X’X) pada pendugaan parameter regresi sehingga diperoleh:
adalah penduga berbias bagi namun memiliki ragam yang lebih kecil daripada . Ada beberapa cara untuk menentukan nilai k yang optimum. Salah satunya adalah dengan menggunakan metode ridge trace. Metode ini merupakan penelusuran nilai kyang optimum dengan mencoba berbagai macam nilai kdan melihat pengaruhnya pada nilai yang didapatkan. Plot antara dengan berbagai nilai k dapat digunakan untuk melihat metode tersebut secara eksploratif.
Regresi Logistik
Menurut Hosmer dan Lemeshow (2000) regresi logistik adalah metode analisis statistika yang mendeskripsikan hubungan antara peubah respons yang memiliki dua kategori atau lebih dengan satu atau lebih peubah bebas berskala kategori atau kontinu. Pendugaan parameter yang digunakan dalam regresi logistik adalah metode kemungkinan maksimum (maximum likelihood). Model regresi logistik terdiri atas regresi logistik dengan respons biner, ordinal, dan multinomial.
Regresi Logistik Biner
Model regresi logistik biner merupak an model matematika yang dapat digunakan untuk memodelkan hubungan antara peubah bebas X dengan peubah respons Y yang bersifat biner. Peubah respons Y mengikuti sebaran Bernoulli dengan y = 0 atau 1 dan
adalah peluang terjadinya y = 1. Model regresi logistik dengan E( Y= 1|x) sebagai
π( x)adalah:
exp
1 exp
Fungsi hubung yang sesuai untuk model regresi logistik biner adalah fungsi logit. Transformasi logit sebagai fungsi dari π( x)
adalah (Hosmer dan Lemeshow 2000):
ln 1
Regresi Logistik Ordinal
Model regresi logistik ordinal digunakan untuk menganalisis peubah respons berskala ordinal dengan lebih dari dua kategori. Menurut Hosmer dan Lemeshow (2000), salah satu cara yang dapat digunakan untuk membentuk model dengan respons kategorik yang berskala ordinal adalah dengan membentuk fungsi logit dari peluang kumulatif :
|
dengan k bernilai 0, 1, 2, …, K-1. K adalah banyaknya nilai respons yang mungkin terjadi, dan adalah peluang kumulatif kategori k. Fungsi logit dari peluang kumulatif adalah sebagai berikut (Hosmer dan Lemeshow 2000):
| |
Regresi Logistik Multinomial
Model regresi logistik multinomial digunakan untuk menganalisis peubah respons berskala nominal d