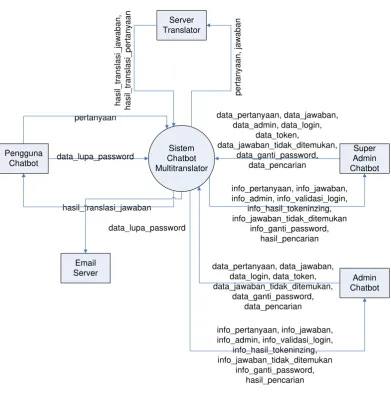
Jenis kelamin : Laki-laki
Tempat, tanggal lahir : Kediri, 19 Mei 1989
Agama : Islam
Kewarganegaraan : Indonesia
Status : Belum kawin
Anak ke : Satu dari tiga bersaudara
Alamat : Taman Candiloka Blok K3/11, Candi, Sidoarjo, Jawa Timur
Telepon : +6282131349719
Email : [email protected]
2. RIWAYAT PENDIDIKAN
NO TINGKAT NAMA PENDIDIKAN TEMPAT TAHUN LULUS
1. SD SDN. Sidoklumpuk 1 Sidoarjo 1995 - 2001 2. SLTP SLTPN 1 Candi Sidoarjo 2001 - 2004 3. SLTA SLTA 1 Porong Sidoarjo 2004 - 2007 4. S1 FTIK Unikom Bandung Bandung 2008 - 2013
Demikian riwayat hidup ini saya buat dengan sebenar-benarnya dalam keadaan sadar dan tanpa paksaan.
Bandung,
VIAN ARWANDA
10108467
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
iii
Nya yang telah dilimpahkan kepada penulis sehingga tugas akhir berjudul Sistem pakar mendiagnosis penyakit ikan lele dan cara pembudidayaan untuk meningkatkan produktifitas ikan lele berbasis mobile dapat terselesaikan dengan baik.
Tugas akhir ini juga dapat penulis selesaikan berkat kerja sama dan dukungan dari berbagai pihak. Oleh karena itu penulis ingin menyampaikan rasa hormat dan terima kasih yang sebesar-besarnya kepada:
1. Allah SWT atas karunia-Nya sehingga penulis mampu menyelesaikan tugas akhir ini.
2. Ibu dan ayah tercinta yang senantiasa memberikan dukungan dengan berbagai cara yang bisa dilakukan untuk mendukung penulis hingga saat ini.
3. Bapak Andri Heryandi, M.T. selaku dosen pembimbing yang telah memberikan banyak sekali masukan dan pengarahan dalam penulisan tugas akhir ini.
4. Bapak Irawan Afrianto, S.T., M.T. selaku dosen reviewer yang telah memberikan banyak masukan dan tambahan yang membuat tugas akhir ini menjadi lebih baik lagi.
5. Bapak Andri Heryandi, M.T. selaku dosen wali IF-9 angkatan 2008. 6. Segenap panitia skripsi 2012.
7. Dosen-dosen teknik informatika atas bimbingan dan ilmu yang telah diberikan selama ini.
8. Teman-teman IF-9 angkatan 2008.
Akhir kata penulis berharap semoga tugas akhir ini dapat bermanfaat bagi penulis pada khususnya dan pembaca pada umumnya.
iv
DAFTAR TABEL ... x
DAFTAR SIMBOL ... xiv
DAFTAR LAMPIRAN ... xvii
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Identifikasi Masalah ... 3
1.3 Maksud dan Tujuan ... 3
1.4 Batasan Masalah ... 3
1.5 Metodologi Penelitian ... 3
1.6 Sistematika Penulisan ... 5
BAB 2 TINJAUAN PUSTAKA ... 7
2.1 Landasan Teori ... 7
2.1.1 Sistem... 7
2.1.1.1 Konsep Dasar Sistem ... 7
2.1.1.2 Pengertian Sistem ... 7
2.1.1.3 Klasifikasi Sistem ... 8
2.1.1.4 Karakteristik Sistem ... 8
2.1.1.5 Komponen Sistem ... 9
2.1.2 Chatbot... 10
2.1.3 Internet ... 10
2.1.3.1 Sejarah Internet ... 11
2.1.3.2 Manfaat dan Kegunaan Internet ... 12
2.1.4 Flowmap ... 13
v
2.1.4.2 Aturan Membuat Flowmap ... 13
2.1.4.3 Jenis - Jenis Flowmap ... 14
2.1.4.4 Simbol Flowmap ... 14
2.1.5 ERD (Entity Relationship Diagram)... 16
2.1.5.1 Definisi ERD... 16
2.1.5.2 Komponen - Komponen ERD... 16
2.1.5.3 Kardinalitas ... 16
2.1.6 Text Mining ... 18
2.1.6.1 Teori Text Mining ... 18
2.1.7 Algoritma Nazief dan Adriani ... 21
2.1.8 Natural Language Processing (NLP) ... 27
2.1.8.1 Komponen Utama Bahasa Alami ... 28
2.1.8.2 Kategori Aplikasi Pengolahan Bahasa Alami ... 28
2.1.8.3 Dasar Teori ... 29
2.1.9 HTML ... 30
2.1.9.1 Definisi HTML ... 30
2.1.9.2 Tag - Tag Dasar HTML ... 31
2.1.10 PHP ... 31
2.1.10.1Definisi PHP ... 31
2.1.10.2Sejarah PHP ... 32
2.1.11 Javascript ... 33
2.1.11.1Definisi Javascript... 33
2.1.11.2Sejarah Javascript ... 33
2.1.12 Ajax ... 34
2.1.13 jQuery ... 35
2.1.13.1jQuery Selector ... 35
2.1.13.2jQuery Manipulation... 36
2.1.14 MySQL ... 36
2.1.15 Tools Yang Digunakan ... 37
BAB 3 ANALISIS DAN PERANCANGAN SISTEM ... 39
vi
3.1.5 Update Data Token ... 66
3.2 Perancangan Sistem ... 67
3.2.1 Spesifikasi Kebutuhan Perangkat Lunak (SKPL) ... 67
3.2.2 Batasan Perangkat Lunak... 67
3.2.3 ERD (Entity Relational Diagram) ... 68
3.2.4 DFD (Data Flow Diagram) ... 68
3.2.4.1 Diagram Konteks ... 69
3.2.4.2 DFD Level 1 ... 70
3.2.4.3 DFD Level 2 ... 71
3.2.4.4 DFD Level 3 ... 75
3.2.5 Spesifikasi Proses ... 76
3.2.6 Kamus Data... 85
3.2.7 Perancangan Basis Data ... 93
3.2.7.1 Skema Relasi... 93
3.2.7.2 Struktur Tabel ... 94
3.2.8 Perancangan Antarmuka ... 96
3.2.8.1 Perancangan Struktur Menu Admin Chatbot... 96
3.2.8.2 Perancangan Tampilan ... 97
BAB 4 IMPLEMENTASI DAN PENGUJIAN ... 109
4.1 Implementasi Sistem ... 109
4.1.1 Implementasi Perangkat Keras ... 109
4.1.2 Implementasi Perangkat Lunak ... 110
4.1.3 Implementasi Database ... 110
vii
4.2 Pengujian Perangkat Lunak ... 113
4.2.1 Pengujian Respon Chatbot ... 113
4.2.1.1 Skenario Pengujian Respon Chatbot ... 113
4.2.1.2 Kesimpulan Hasil Pengujian Respon Chatbot ... 120
BAB 5 KESIMPULAN DAN SARAN... 121
5.1 Kesimpulan ... 121
5.2 Saran ... 121
123
[4] Liyantanto. (2012, April) Pencarian dengan Metode Vektor Space Model (VSM). [Online]. http://liyantanto.wordpress.com/2011/06/28/pencarian-dengan-metode-vektor-space-model-vsm/
[5] Liyantanto. (2012, April) Stemming Bahasa Indonesia dengan Algoritma Nazief dan Adriani. [Online]. http://liyantanto.wordpress.com/2011/06/28/stemming-bahasa-indonesia-dengan-algoritma-nazief-dan-andriani/
[6] Novita Vitriana, "Internet dan Perpustakaan," 2011.
1
Chatbot adalah sebuah program komputer yang dirancang untuk
mensimulasikan sebuah percakapan atau komunikasi yang interaktif kepada pengguna (manusia) melalui bentuk teks, suara, dan atau visual. Percakapan yang terjadi antara komputer dengan manusia merupakan bentuk respon dari program yang telah dideklarasikan pada database program pada komputer. Kemampuan komputer dalam menyimpan banyaknya data tanpa melupakan satu pun informasi yang disimpannya digabungkan dengan kepraktisan bertanya pada sumber informasi langsung dibandingkan dengan mencari informasi sendiri serta kemampuan learning yang dimilikinya menyebabkan chatbot adalah customer service yang handal.
Respon yang dihasilkan merupakan hasil pemindaian kata kunci pada inputan pengguna dan menghasilkan respon balasan yang dianggap paling cocok, atau pola kata-kata yang dianggap paling mendekati dan pada umumnya menggunakan pendekatan Natural Language Processing (NLP). Natural
Language Processing merupakan salah satu tujuan jangka panjang dari Artficial
Intelegence (kecerdasan buatan) yaitu pembuatan program yang memiliki
kemampuan untuk memahami bahasa manusia. Pada prinsipnya bahasa alami adalah suatu bentuk representasi dari suatu pesan yang ingin dikomunikasikan antar manusia. Bentuk utama representasinya adalah berupa suara/ucapan,tetapi sering pula dinyatakan dalam bentuk tulisan.
Text Mining merupakan upaya pencarian atau penambangan data yang berupa teks dimana sumber data biasanya diperoleh dari dokumen, dengan tujuan mencari kata-kata yang dapat mewakili isi dokumen sehingga dapat dilakukan analisis keterhubungan antar dokumen. Text mining memberikan solusi pada masalah-masalah dalam memproses, mengorganisasi, dan menganalisa unstructured text dalam jumlah besar. Metode Text Mining banyak diimplementasikan untuk menyelesaikan masalah yang membutuhkan pencarian sebuah informasi atau Information Retrieval (IR). Aplikasi chatbot juga membutuhkan sebuah information retrieval untuk menentukan sebuah informasi yang terkandung dipertanyaan pengguna Chatbot tersebut. Umumnya chatbot menggunakan metode Natural Language Processing (NLP) untuk melakukan kegiatan chatting, dan fungsi dari Text Mining sebagai information retrieval diharapkan dapat diimplementasikan pada chatbot dalam melakukan kegiatan chatting.
Berdasarkan permasalahan diatas, diharapkan dapat diselesaikannya sebuah aplikasi chatbot yang menggunakan metode Text Mining untuk dibandingkan kecocokan apakah Information Retrieval pada Text Mining sudah cocok untuk diimplementasikan pada aplikasi chatbot, sehingga diharapkan aplikasi chatbot dengan menggunakan text mining dapat meminimalisir kerancuan dalam melakukan proses penalaran / relevansi pertanyaan dengan basis pengetahuan yang dimiliki chatbot tersebut.
dalam bentuk bahasa sehari-hari dengan mengangkat topik yang berjudul
“Penerapan Metode Text Mining Pada Aplikasi Chatbot”.
1.2 Identifikasi Masalah
Berdasarkan latar belakang yang telah dijelaskan, maka dapat diambil suatu rumusan masalah sebagai berikut :
1. Bagaimana mengimplementasikan metode Text Mining pada aplikasi Chatbot?
1.3 Maksud dan Tujuan
Berdasarkan permasalahan yang tertera di atas, maka maksud dari penulisan tugas akhir ini adalah bagaimana membangun aplikasi chatbot dengan pendekatan Text Mining.
Sedangkan tujuan yang diharapkan tercapai dalam penelitian ini adalah untuk :
1. Untuk menguji metode Text Mining dengan metode Natural Language Processing (NLP) terhadap bahasa alami atau bahasa sehari-hari.
1.4 Batasan Masalah
Dalam penelitian ini, penulis membatasi masalah sebagai berikut : 1. Bahasa dasar chatbot adalah bahasa Indonesia.
2. Pengetahuan yang dimiliki chatbot sudah didefinisikan terlebih dahulu di database oleh admin.
3. Metode yang digunakan pada chatbot ini menggunakan metode Text Mining.
1.5 Metodologi Penelitian
Metodologi yang digunakan dalam penulisan tugas akhir ini adalah sebagai berikut :
permasalahan yang diambil. 2. Tahap pembuatan perangkat lunak.
Teknik analisis data dalam pembuatan perangkat lunak menggunakan paradigma waterfall. Fase-fase dalam model waterfall menurut referensi Ian Sommerville adalah sebagai berikut :
Gambar 1.1 Metode Waterfall Yang meliputi beberapa proses diantaranya :
a. Requirements Analysis and Definition
b. System and Software Design
Merupakan tahap menganalisis hal-hal yang diperlukan dalam pelaksanaan proyek pembuatan perangkat lunak.
c. Implementation and Unit Testing
Desain program diterjemahkan ke dalam kode-kode dengan menggunakan bahasa pemrograman yang sudah ditentukan. Program yang dibangun langsung diuji secara unit.
d. Integration and System Testing
Penyatuan unit-unit program kemudian diuji secara keseluruhan (system testing).
e. Operation and System Testing
Mengoperasikan program dilingkungannya dan melakukan pemeliharaan, seperti penyesuaian atau perubahan karena adaptasi dengan situasi sebenarnya.
1.6 Sistematika Penulisan
Sistematika penulisan proposal penelitian ini disusun untuk memberikan gambaran umum tentang penelitian yang dilakukan. Sistematika penulisan tugas akhir ini adalah sebagai berikut :
BAB I. PENDAHULUAN
Menguraikan tentang latar belakang permasalahan, mencoba merumuskan inti permasalahan yang dihadapi, menentukan tujuan dan kegunaan penelitian, yang kemudian diikuti dengan pembatasan masalah, serta sistematika penulisan.
BAB II. TINJAUAN PUSTAKA
Membahas berbagai konsep dasar dan teori-teori yang berkaitan dengan topik penelitian yang dilakukan dan hal-hal yang berguna dalam proses analisis permasalahan.
BAB III. ANALISIS DAN PERANCANGAN
7
Pengembangan program chatbot multibahasa memerlukan faktor-faktor pendukung yang merupakan landasan teori yang akan digunakan dalam proses pengerjaan.
2.1.1 Sistem
2.1.1.1Konsep Dasar Sistem
Sistem sebagai suatu jaringan kerja dari prosedur-prosedur yang saling berhubungan, berkumpul bersama-sama untuk melakukan suatu kegiatan atau untuk menyelesaikan suatu sasaran tertentu. Sedangkan pendekatan sistem yang lebih menekankan pada elemen atau komponen mendefinisikan sistem sebagai kumpulan dari elemen-elemen yang berinteraksi untuk mencapi suatu tujuan tertentu. Kedua kelompok ini benar dan tidak bertentangan. Yang membedakan adalah cara pendekatannya.
2.1.1.2Pengertian Sistem
Sistem berasal dari bahasa Latin (systema) dan bahasa Yunani (sustema) adalah suatu kesatuan yang terdiri dari komponen atau elemen yang dihubungkan bersama untuk memudahkan aliran informasi, mater atau energi. Istilah ini sering dipergunakan untuk menggambarkan suatu set entitas yang saling berinteraksi, di mana suatu model matematika seringkali dibuat.
2. Sistem alamiah dan sistem buatan
Sistem alamiah adalah sistem yang terjadi melalui proses alam, tidak dibuat oleh manusia. Sedangkan sistem buatan manusia merupakan sistem yang melibatkan hubungan manusia dengan mesin.
3. Sistem deterministic dan sistem probabilistik
Sistem komputer adalah contoh dari sistem yang tingkah lakunya dapat dipastikan berdasarkan program-program komputer yang dijalankan. Sedangkan sistem yang bersifat probabilistik adalah sistem yang kondisi masa depannya tidak dapat diprediksi, karena mengandung unsur probabilitas. 4. Sistem tertutup dan sistem terbuka
Sistem tertutup merupakan sistem yang tidak berhubungan dan tidak terpengaruh oleh lingkungan luarnya. Sedangkan sistem terbuka adalah sistem yang berhubungan dan dipengaruhi oleh lingkungan luarnya, yang menerima masukan dan menghasilkan keluaran untuk sub sistem lainnya.
2.1.1.4Karakteristik Sistem
Model umum sebuah sistem terdiri dari input, proses, dan output. Hal ini merupakan konsep sebuah sistem yang sangat sederhana, mengingat sebuah sistem dapat mempunyai beberapa masukkan dan keluaran sekaligus. Adapun karakteristik yang dimaksudkan adalah sebagai berikut :
1. Komponen sistem (components)
2. Batasan sistem (boundary)
Ruang lingkup sistem merupakan daerah yang membatasi antara sistem dengan sistem lainnya atau sistem dengan lingkungan luarnya.
3. Lingkungan luar sistem (environment)
Bentuk apapun yang ada diluar ruang lingkup atau batasan sistem yang mempengaruhi operasi sistem tersebut disebut dengan lingkungan luar sistem.
4. Penghubung sistem (interface)
Keluaran suatu subsistem akan menjadi masukan untuk subsistem yang lain dengan melewati penghubung. Dengan demikian terjadi suatu integrasi sistem yang membentuk satu kesatuan.
5. Masukan sistem (input)
Energi yang dimasukan ke dalam sistem disebut masukan sistem, yang dapat berupa pemeliharan (maintenance input) dan sinyal (signal input).
6. Keluaran sistem (output)
Hasil dari energi yang diolah dan diklasifikasikan menjadi keluaran yang berguna. Keluaran ini merupakan masukan bagi subsistem yang lain.
7. Pengolahan sistem (proses)
Suatu sistem dapat mempunyai suatu proses yang akan mengubah masukan menjadi keluaran.
8. Sasaran sistem (objective)
Suatu sistem dikatakan berhasil bila mengenai sasaran atau tujuan yang telah direncanakan.
2.1.1.5Komponen Sistem
mengidentifikasi bots sebagai suatu program komputer, maka chatterbot tersebut dikategorikan sebagai kecerdasan buatan atau artificial intelligence.
2.1.3 Internet
Internet berasal dari kata interconnection-networking yang secara harfiah dapat diartikan sebagai berikut:
1. Rangkaian komputer yang terhubung di dalam beberapa rangkaian. 2. Sebuah sistem komunikasi global yang menghubungkan
komputer-komputer dan jaringan-jaringan komputer-komputer di seluruh dunia.
Internet merupakan sistem global dari seluruh jaringan komputer yang saling terhubung menggunakan standar Internet Protocol Suite (TCP/IP) untuk melayani pengguna internet di seluruh dunia. Internet menghubungkan pengguna komputer dari satu negara ke negara lain, di mana didalamnya terdapat berbagai sumber daya informasi yang bersifat statis maupun dinamis, dan interaktif.
Layanan internet meliputi komunikasi langsung (email, chat), diskusi (email, milis), sumber daya yang terdistribusi (World Wide Web), dan lalu lintas file (Telnet, FTP), dan berbagai macam layanan lainnya.
2.1.3.1Sejarah Internet
Jaringan internet pertama kali dikembangkan tahun 1969 oleh Departemen Pertahanan Amerika Serikat dengan nama ARPAnet (US Defense Advance Research Projects Agency). ARPAnet dibangun dengan sasaran untuk membuat
suatu jaringan komputer yang tersebar untuk menghindari pemusatan informasi di satu titik yang dipandang rawan untuk dihancurkan apabila terjadi peperangan. Dengan membangun ARPAnet ini diharapkan apabila satu bagian dari jaringan terputus, maka jalur yang melalui jaringan tersebut secara otomatis dipindahkan ke saluran lainnya.
Di awal 1980-an, ARPAnet terpecah menjadi dua jaringan, yaitu ARPAnet dan Milnet (sebuah jaringan militer), akan tetapi keduanya mempunyai hubungan sehingga komunikasi antarjaringan tetap dapat dilakukan. Pada mulanya jaringan interkoneksi ini disebut DARPA Internet, tapi lama-kelamaan disebut sebagai internet saja. Sesudahnya, internet mulai digunakan untuk kepentingan akademis dengan menghubungkan beberapa perguruan tinggi, diantaranya UCLA, University of California at St. Barbara, University of Utah, Stanford Research Institute, disusul dengan dibukanya layanan Usenet dan Bitnet yang memungkinkan internet diakses melalui sarana komputer pribadi (PC). Berikutnya, protokol standar TCP/IP mulai diperkenalkan pada tahun 1982, disusul dengan penggunaan sistem DNS (Domain Name Service) pada tahun 1984.
oleh Tim Berners-Lee. Namun, WWW browser yang pertama baru lahir dua tahun kemudian, tepatnya pada tahun 1992 dengan nama Viola. Viola diluncurkan oleh Pei Wei dan didistribusikan bersama CERN. Tentu saja web browser yang pertama ini masih sangat sederhana, belum secanggih browser modern seperti yang ada saat ini.
Terobosan berarti lainnya terjadi pada 1993 ketika InterNIC didirikan untuk menjalankan layanan pendaftaran domain. Bersamaan dengan itu, Gedung Putih (White House) mulai online di internet dan pemerintah Amerika Serikat meloloskan National Information Infrastructure Act. Penggunaan internet secara komersial dimulai pada 1994 dipelopori oleh perusahaan Pizza Hut, dan Internet Banking pertama kali diaplikasikan oleh First Virtual. Setahun kemudian, Compuserve, America Online, dan Prodigy mulai memberikan layanan akses ke internet bagi masyarakat umum.
2.1.3.2Manfaat dan Kegunaan Internet
Kegunaan internet dapat dikelompokkan menjadi beberapa kelompok, yaitu :
1. Internet sebagai media informasi
Dengan mempromosikan produk di internet maka suatu usaha mendapat beberapa keuntungan, yaitu dapat menjangkau pelanggan di mana pun berada tanpa batasan waktu dan wilayah.
3. Internet sebagai alat research and development 4. Internet sebagai media perukaran data
2.1.4 Flowmap
2.1.4.1Definisi Flowmap
Flowmap adalah penggambaran secara grafik dari langkah-langkah dan urutan prosedur dari suatu program. Flowmap berguna untuk membantu analisis dan programer untuk memecahkan masalah ke dalam segmen yang lebih kecil dan menolong dalam menganalisis alternatif pengoperasian.
2.1.4.2Aturan Membuat Flowmap
Untuk membuat sebuah analisis menggunakan flowmap, seorang analisis dan programer membutuhkan beberapa tahapan, diantaranya :
1. Flowmap digambarkan dari halaman atas ke bawah dan dari kiri ke kanan.
2. Aktivitas yang digambarkan harus didefiniskan dan definisi ini harus dapat dimengerti oleh pembacanya.
3. Kapan aktivitas dimulai dan berakhir harus ditentukan secara jelas. 4. Setiap langkah dari aktivitas harus diuraikan dengan menggunakan
deskripsi kata kerja.
5. Setiap langkah dari aktivitas harus berada pada urutan yang benar. 6. Lingkup dan range dari aktivitas yang sedang digambarkan harus
ditelusuri dengan hati-hati. Percabangan-percabangan yang memotong aktivitas yang sedang digambarkan tidak perlu digambarkan pada flowchart yang sama. Simbol konektor harus digunakan dan percabangannya diletakan pada halaman yang terpisah atau hilangkan seluruhnya bila percabangannya tidak berkaitan dengan sistem.
3. Flowmap skematik. 4. Flowmap program. 5. Flowmap proses.
2.1.4.4Simbol Flowmap
Tabel 2.1 Simbol Flowmap
Simbol Nama
Proses
Keputusan
Dokumen
Penyimpanan data
Data
Simbol Nama
Data sekuensial
Penyimpanan data yang dapat di akses langsung
Manual input
Tampilan
Operasi manual
Persiapan
Mode paralel
Batas perulangan (awal atau akhir)
Terminator
Konektor halaman
Penghubung
2.1.5.2Komponen - Komponen ERD
Tabel 2.2 Komponen-komponen ERD
Simbol Nama Keterangan
Entitas Menggambarkan objek yang mewakili sesuatu yang nyata dan dapat dibedakan dari sesuatu yang lain.
Relasi Menggambarkan hubungan antara sejumlah entitas yang berasal dari himpunan entitas yang berbeda.
Atribut Menggambarkan karakteristik dari entitas yang menjelaskan secara detil tentang entitas tersebut.
2.1.5.3Kardinalitas
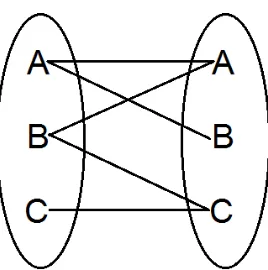
1. Satu ke satu (one to one relation)
Hubungan relasi satu ke satu yaitu setiap entitas pada himpunan entitas A berhubungan paling banyak dengan satu entitas pada himpunan entitas B (Yakub, 2008, p. 33).
Gambar 2.1 Contoh relasi satu ke satu 2. Satu ke banyak (one to many relation)
Setiap entitas pada himpunan entitas A dapat berhubungan dengan banyak entitas pada himpunan entitas B, tetapi setiap entitas pada entitas B dapat berhubungan paling banyak dengan satu entitas pada himpunan entitas A (Yakub, 2008, p. 34).
Gambar 2.2 Contoh relasi satu ke banyak 3. Banyak ke banyak (many to many relation)
Gambar 2.3 Contoh relasi banyak ke banyak 4. Banyak ke satu (many to one relation)
Setiap entitas pada himpunan entitas A dapat berhubungan dengan paling banyak dengan satu entitas pada himpunan entitas B (Yakub, 2008, p. 34).
Gambar 2.4 Contoh relasi banyak ke satu
2.1.6 Text Mining
2.1.6.1Teori Text Mining
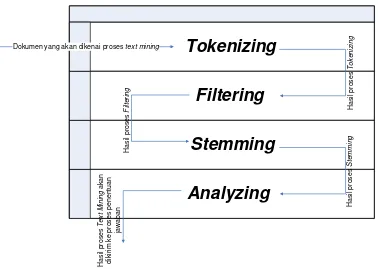
Dalam tahap Text Mining terdapat lima tahapan antara lain :
Gambar 2.5 Tahapan dalam Text Mining 1. Tahap Tokenizing
Merupakan tahap pemotongan string input berdasarkan tiap kata yang menyusunnya. Contoh dari tahap ini adalah sebagai berikut :
Gambar 2.6 Contoh tahap Tokenizing
2. Tahap Filtering
Gambar 2.7 Contoh tahap Filtering 3. Tahap Stemming
Stemming merupakan suatu proses yang terdapat dalam sistem IR (Information Retrieval) yang mentransformasi kata-kata hasil filtering ke kata-kata akarnya (rood word) dengan menggunakan aturan-aturan tertentu (Ledy Agusta, Konferensi Nasional Sistem dan Informatika 2009, KNS&I09-036, 2009, p.1).
Proses stemming pada teks berbahasa Indonesia berbeda dengan stemming pada teks berbahasa Inggris. Pada teks berbahasa Inggris, proses yang diperlukan hanya proses menghilangkan sufiks. Sedangkan pada teks berbahasa Indonesia, selain sufiks, prefiks, dan konfiks juga dihilangkan.
Contoh penggunaan stemming pada teks berbahasa Indonesia, kata bersama, kebersamaan, menyamai, jika dikenakan proses stemming ke
bentuk kata dasarnya yaitu “sama”.
4. Tahap Tagging
Tahap tagging adalah tahap mencari bentuk awal dari tiap kata lampau dari hasil stemming. Pada tahap ini dilakukan proses pengambilan berbagai bentukan kata ke dalam suatu representasi yang sama. Tahap tagging tidak digunakan dalam penelitian ini.
Gambar 2.8 Contoh tahap Tagging 5. Tahap Analyzing
Tahap penentuan seberapa jauh keterkaitan antar kata-kata pada dokumen/ inputan yang ada. Pada tahap analyzing akan digunakan rumus TF-IDF untuk mengambil sebuah informasi dari sebuah dokumen. Pada dasarnya, TF-IDF bekerja dengan menentukan frekuensi relatif dari kata-kata tertentu dalam sebuah dokumen dibandingkan dengan inverse dari seluruh dokumen. Kata-kata yang umum dalam sebuah dokumen cenderung memiliki nilai tinggi dalam perhitungan TF-IDF (Juan Ramos, Jurnal Rutgers University, p. 2). Jadi, dalam penelitian ini hanya menggunakan 4 tahap, yaitu Tokenizing, Filtering, Stemming, dan Analyzing. Tahap tagging tidak dilakukan karena pada chatbot multitranslator ini tidak memperhatikan bentuk lampau dari suatu kata.
2.1.7 Algoritma Nazief dan Adriani
imbuhan yang harus dibuang untuk mendapatkan root word (kata dasar) dari sebuah kata. Pada umumnya kata dasar pada bahasa indonesia terdiri dari kombinasi.
DP + DP + DP + Kata Dasar + DS + PP + P
Keterangan :
DP : Derivation Prefix (awalan) DS : Derivation Suffixes (akhiran)
PP : Possesive Pronouns (kepunyaan, contoh “-ku”, “-mu”) P : Particels (contoh “-lah”, “-kah”)
Mulai
Kata Yang Akan di
Stemming
Adakah kata di Kamus?
Hapus Possesive Pronouns
Adakah kata di Kamus?
Adakah kata di Kamus?
Apakah ada kombinasi awalan-akhiran yang
dilarang?
Iterasi sudah mencapai 3 kali?
Adakah kata di Kamus?
diulangi lagi untuk menghapus Possesive Pronouns (“-ku”, “-mu”, atau “
-nya”), jika ada.
3. Hapus Derivation Suffixes (“-i”, “-an”, atau “-kan”). Jika kata ditemukan di kamus, maka algoritma berhenti. Jika tidak maka ke langkah 3a.
a. Jika “-an”, telah dihapus dan huruf terakhir dari kata tersebut adalah “
-k”, maka “-k” juga ikut dihapus. Jika kata tersebut ditemukan dalam kamus kata dasar maka algoritma berhenti. Jika tidak ditemukan maka lakukan langkah 3b.
b. Akhiran yang dihapus (“-i”, “-an”, atau “-kan”) dikembalikan, lanjut ke langkah 4.
4. Hapus Derivation Prefix DP (“di-”, “ke-”, “se-”, “me-”, “be-”, “pe-”, “te
-”) dengan iterasi maksimum adalah 3 kali
a. Langkah 4 berhenti jika :
1. Terjadi kombinasi awalan dan akhiran yang terlarang seperti pada tabel 2.3.
Tabel 2.3 Kombinasi awalan-akhiran yang tidak diizinkan
Awalan Akhiran yang tidak diizinkan
be- -i
di- -an
ke- -i, -kan
me- -an
b. Tipe awalan ditentukan melalui langkah-langkah berikut :
1. Jika awalannya adalah : “di-”, “ke-”, atau “se-”, maka tipe awalannya secara berturut-turut adalah “di-”, “ke-”, atau “se-”. 2. Jika awalannya adalah “te-”, “me-”, “be-”, atau “pe-”, maka
dibutuhkan sebuah proses tambahan untuk menentukan tipe awalannya.
Tabel 2.4 Jenis awalan berdasarkan tipe awalan
Aturan Format Kata Pemenggalan
1 berV… ber-V… | be-rV…
2 berCAP… ber-CAP… dimana C != 'r' dan P != 'er' 3 berCAPerV… ber-CaerV… dimana C != 'r'
4 belajar bel-ajar
5 berC1erC2… be-C1erC2… dimana C1 != {'r'|'l'}
6 terV… ter-V… | te-rV…
7 terCerV… ter-CerV… dimana C != 'r'
8 terCP ter-CP… dimana C != 'r' dan P != 'er' 9 teC1erC2 te-C1erC2… dimana C1 !- 'r'
10 me{l|r}w}y}V… me-{l|r|w|y}V… 11 mem{b|f|v}… mem-{b|f|v}…
12 mempe{r|l}… mem-pe…
13 mem{rV|V}… me-m{rV|V}… | me-p{rV|V}… 14 men{c|d|j|z}… men-{c|d|j|z}…
15 menV… me-nV… | me-tV…
16 meng{g|h|q}… meng-{g|h|q}…
17 mengV… meng-V… | meng-kV…
18 meny… meny-sV…
19 mempV… mem-pV… dimana V != 'e'
20 pe{w|y}V… pe-{w|y}V…
21 perV… per-V… | pe-rV…
27 penV… pe-nV… | pe-tV… 28 peng{g|h|q}… peng-{g|h|q}…
29 pengV… peng-V… | peng-kV… 30 penyV... peny-sV…
31 pelV… pe-lV… kecuali "pelajar" yang menghasilkan "ajar"
32 peCerV… per-erV… dimana C != {r|w|y|l|m|n}
33 perCP…
pe-CP… dimana C != {r|w|y|l|m|n} dan P != 'er'
3. Cari kata yang telah dihilangkan awalannya ini di dalam kamus. Apabila tidak ditemukan, maka langkah 4 diulangi kembali. Apabila ditemukan, maka keseluruhan proses berhenti.
5. Melakukan recording (pada chatbot multitranslator ini, proses recording tidak dilakukan, hal ini dilakukan untuk meminimalisir kata dasar yang tidak valid).
6. Jika semua langkah telah selesai tetapi tidak juga berhasil maka kata awal diasumsikan sebagai kata dasar. Proses selesai.
Pada proses stemming menggunakan algoritma Nazief dan Adriani, kamus yang digunakan sangat mempengaruhi hasil stemming. Semakin lengkap kamus yang digunakan maka semakin akurat pula hasil stemming.
Contoh :
1. Cek kata "mempertemukannya" di dalam kamus kata dasar, kata "mempertemukannya" tidak ditemukan di dalam kamus kata dasar. 2. Hapus Inflection Suffixes ("-nya"). Sehingga kata menjadi
“mempertemukan”.
3. Hapus Derivation Suffixes ("-kan"). Cek kata "mempertemu" di dalam kamus kata dasar, kata "mempertemu" tidak ditemukan di dalam kamus kata dasar.
4. Hapus Derivation Preffixes ("me-") [iterasi 1]. Periksa tabel jenis awalan pada aturan no 13, format kata ("mem-V") sehingga kata menjadi "pertemu". Cek kata "pertemu" di dalam kamus kata dasar, kata "pertemu" tidak ditemukan di dalam kamus kata dasar.
5. Hapus Derivation Preffixes ("pe-") [iterasi 2]. Periksa tabel jenis awalan pada aturan no 21, format kata ("per-V") sehingga kata menjadi "temu". Cek kata "temu" di dalam kamus kata dasar, kata "temu" ditemukan di dalam kamus kata dasar.
6. Proses stemming berhenti dengan menghasilkan kata dasar "temu".
Jadi kata “mempertemukannya” ketika menggunakan algoritma steming Nazief dan Adriani menjadi “temu”.
2.1.8 Natural Language Processing (NLP)
Natural Language Processing atau pemrosesan bahasa alami merupakan
salah satu tujuan jangka panjang dari Artficial Intelegence (kecerdasan buatan) yaitu pembuatan program yang memiliki kemampuan untuk memahami bahasa manusia. Pada prinsipnya bahasa alami adalah suatu bentuk representasi dari suatu pesan yang ingin dikomunikasikan antar manusia. Bentuk utama representasinya adalah berupa suara/ucapan (spoken language), tetapi seringpula dinyatakan dalam bentuk tulisan.
a. Parser
Suatu sistem yang mengambil kalimat input bahasa alami dan menguraikannya ke dalam beberapa bagian gramatikal (kata benda, kata kerja, kata sifat, dan lain-lain).
b. Sistem Representasi Pengetahuan
Suatu sistem yang menganalisis output parser untuk menentukan maknanya. c. Output Translator
Suatu terjemahan yang merepresentasikan sistem pengetahuan dan melakukan langkah- langkah yang bisa berupa jawaban atas bahasa alami atau output khusus yang sesuai dengan program komputer lainnya.
2.1.8.2Kategori Aplikasi Pengolahan Bahasa Alami
Teknologi Natural Language Processing (NLP) atau pemrosesan bahasa alami adalah teknologi yang memungkinkan untuk melakukan berbagai macam pemrosesan terhadap bahasa alami yang biasa digunakan oleh manusia. Sistem ini biasanya mempunyai masukan dan keluaram berupa bahasa tulisan (teks). Natural Language Processing (NLP) mempunyai aplikasi yang sangat luas. Beberapa diantara berbagai kategori aplikasi Natural Language Processing (NLP), sebagai berikut:
per kata, tetapi harus juga mentranslasikan sintaks dari bahasa asal ke bahasa tujuannya.
2. Translator bahasa alami ke bahasa buatan, yaitu translator yang mengubah perintah-perintah dalam bahasa alami menjadi bahasa buatan yang dapat dieksekusi oleh mesin atau komputer. Sebagai contoh, translator yang memungkinkan kita memberikan perintah bahasa alami kepada komputer. Dengansistem seperti ini, pengguna sistem dapat memberikan perintah dengan bahasa sehari-hari, misalnya, untuk menghapus semua file, pengguna cukup memberikan
perintah ”komputer, tolong hapus semua file !” Translator akan
mentranslasikan perintah bahasa alami tersebut menjadi perintah bahasa formal yang dipahami oleh komputer.
3. Text Summarization, yaitu suatu sistem yang dapat ”membuat
ringkasan” hal-hal yang penting dari suatu wacana yang diberikan.
Dalam dunia kecerdasan buatan pengolahan bahasa alami merupakan aplikasi terbesar setelah sistem pakar. Banyak para ahli Artificial Intelligence berpendapat bahwa bidang yang penting yang dapat dipecahkan oleh Artificial Intelligence adalah Natural Language Processing (Pengolahan Bahasa Alami).
2.1.8.3Dasar Teori
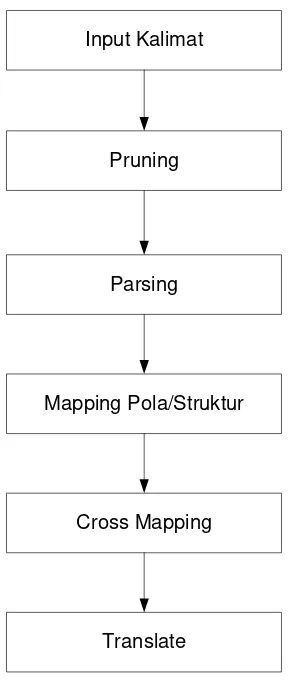
Riset ini dilaksanakan dengan tujuan untuk menerjemahkan kalimat dalam bahasa inggris ke dalam struktur kalimat berbahasa Indonesia, jadi yang ditekankan dalam riset ini lebih banyak pada struktur kalimatnya dan bukan hanya pada sintaks kalimat saja. Dalam riset ini kamu memakai beberapa referensi sebagai dasar percobaannya. Referensi tersebut memuat komponen-komponen yang digunakan dalam riset, antara lain :
Cross Mapping Mapping Pola/Struktur
Parsing Pruning
Translate
Gambar 2.10 Prosedur Natural Language Processing (NLP)
2.1.9 HTML
2.1.9.1Definsi HTML
memformatnya sehingga salah satu kata/kalimat ingin diberikan format huruf tebal (bold), miring (italic), atau Garis bawah pada teks (underline), maka hasilnya segera dapat dilihat pada dokumen tersebut. Berbeda dengan dokumen HTML, format-format yang diberikan pada suatu teks tidak bisa dilihat langsung
hasilnya, tetapi harus menggunakan program khusus, yaitu “Web Browser” atau
“Browser”.
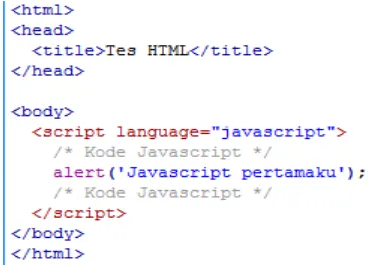
2.1.9.2Tag - Tag Dasar HTML
Gambar 2.11 Contoh tag HTML
Penjelasan kode pada bentuk umum penulisan dokumen HTML diatas : 1. Pasangan tag <html> dan </html> menandakan bahwa kode yang
terdapat didalamnya adalah kode HTML sehingga browser akan menerjemahkan sebagai dokumen HTML.
2. Bagian yang terdapat dalam <html> dan </html> umumnya terbagi atas tag <head></head> dan <body></body>.
3. Pada bagian <head> dan </head> bisa ditentukan judul dokumen HTML yang dituliskan dengan pasangan <title> dan </title>. 4. Bagian <body> dan </body> dapat dituliskan teks-teks, penyisipan
gambar, link, atau pembuatan tabel.
2.1.10 PHP
2.1.10.1 Definsi PHP
PHP adalah singkatan dari PHP : Hypertext Preprocessor, bahasa interpreter yang mempunyai kemiripan dengan bahasa pemrograman C dan Perl.
sekumpulan script yang digunakan untuk mengolah data formulir dari web.
Selanjutnya, Rasmus merilis kode sumber tersebut untuk umum dan menamakannya PHP/FI. Dengan perilisan kode sumber ini menjadi Open Source, maka banyak programer yang tertarik untuk ikut mengembangkan PHP.
Pada tahun 1997, sebuah perusahaan bernama Zend menulis ulang interpreter PHP menjadi lebih bersih, lebih baik, dan lebih cepat. Kemudian pada Juni 1998, perusahaan tersebut merilis interpreter baru untuk PHP dan meresmikan rilis tersebut sebagai PHP 3.0 dan singkatan PHP diubah menjadi akronim berulang PHP: Hypertext Preprocessing.
Pada pertengahan tahun 1999, Zend merilis interpreter PHP baru dan rilis tersebut dikenal dengan PHP 4.0. PHP 4.0 adalah versi PHP yang paling banyak dipakai pada awal abad ke-21. Versi ini banyak dipakai disebabkan kemampuannya untuk membangun aplikasi web kompleks tetapi tetap memiliki kecepatan dan stabilitas yang tinggi.
Pada Juni 2004, Zend merilis PHP 5.0. Dalam versi ini, inti dari interpreter PHP mengalami perubahan besar. Versi ini juga memasukkan model pemrograman berorientasi objek ke dalam PHP untuk menjawab perkembangan bahasa pemrograman ke arah paradigma berorientasi objek.
2.1.11 Javascript
2.1.11.1 Definsi Javascript
Javascript adalah bahasa yang berbentuk kumpulan script yang pada fungsinya berjalan pada suatu dokumen HTML. Sepanjang sejarah internet, bahasa ini adalah bahasa script pertama untuk web. Bahasa ini adalah bahasa pemrograman untuk memberikan kemampuan tambahan terhadap bahasa HTML dengan mengijinkan pengeksekusian perintah perintah di client side, yang artinya di sisi browser bukan di server side web.
Javascript bergantung kepada browser (navigator) yang memanggil halaman web yang berisi script dari javascript dan tentu saja terselip di dalam dokumen HTML. Javascript juga tidak memerlukan kompilator atau penerjemah khusus untuk menjalankannya (pada kenyataannya kompilator javascript sendiri sudah termasuk di dalam browser tersebut). Lain halnya dengan bahasa pemrograman “Java” (dengan nama javascript selalu dibanding-bandingkan) yang memerlukan kompilator khusus untuk menerjemahkannya di client side.
2.1.11.2 Sejarah Javascript
Javascript diperkenalkan pertama kali oleh Netscape pada tahun 1995. Pada awalnya bahasa ini dinamakan “LiveScript” yang berfungsi sebagai bahasa sederhana untuk browser Netscape Navigator 2. Pada masa itu bahasa ini banyak di kritik karena kurang aman, pengembangannya yang terkesan buru-buru dan tidak ada pesan kesalahan yang di tampilkan setiap kali kita membuat kesalahan pada saat menyusun suatu program. Kemudian sejalan dengan sedang giatnya kerjasama antara Netscape dan Sun (pengembang bahasa pemrograman “Java”) pada masa itu, maka Netscape memberikan nama “JavaScript” kepada bahasa tersebut pada tanggal 4 desember 1995. Pada saat yang bersamaan Microsoft
sendiri mencoba untuk mengadaptasikan teknologi ini yang mereka sebut sebagai
Gambar 2.13 Contoh penulisan javascript pada tag HTML
2.1.12 Ajax
Ajax adalah singkatan dari Asycronous Javascript and XML, pengertian lebih mudah adalah menggabungkan antara javascript dan xml untuk mengakses sumber data di server. Javascript sebagai pemrograman di sisi client bisa digunakan untuk mengakses server secara asinkron, dan XML digunakan untuk format data hasil dari server.
1. Ajax ditulis dengan javascript, memanfaatkan object javascript yang sudah ada yaitu XMLHttpRequest.
2. Ajax tergantung dengan browser, jika browser mendukung javascript, maka bisa dipastikan mendukung ajax.
3. Berdasarkan point 2, ajax merupakan teknologi browser.
4. Ajax digunakan untuk mengakses server, dan client/ pengguna menerima hasil dari server tidak secara langsung, tetapi masuk ke dalam mesin ajax terlebih dahulu baru ditampilkan kemudian.
Gambar 2.14 Mekanisme proses ajax menggunakan PHP
2.1.13 jQuery
jQuery merupakan sebuah framework atau library JavaScript yang dapat membantu kita mempermudah dan mempercepat pengolahan DOM pada halaman web. jQuery sudah mengotomatis pekerjaan-pekerjaan yang umum dan menyederhanakan code yang kompleks. jQuery merupakan salah satu library yang membuat program web di sisi klien, tidak terlihat sebagai program JavaScript biasa yang harus secara eksplisit disisipkan pada dokumen web.
Adapun kemudahan-kemudahan yang diberikan oleh jQuery antara lain: 1. jQuery menawarkan sebuah selector yang robust dan efisien untuk
mengambil bagian tertentu pada dokumen yang selanjutnya bisa dimanipulasi.
2. Dapat mengubah tampilan CSS dengan mudah.
3. Dapat menambahkan animasi ke dalam website dengan menggunakan jQuery.
4. jQuery juga mempermudah penggunaan AJAX.
2.1.13.1 jQuery Selector
Konten dari sebuah objek dapat diubah dengan dua fungsi yaitu HTML dan teks. Perbedaannya jika menggunakan teks maka semua tag-tag HTML akan dituliskan sebagai mana mestinya.
2. Insert ke dalam objek.
Terdapat dua jenis insert, yaitu append dan prepend. Append adalah menambahkan objek baru setelah value dari objek tersebut, sedangkan prepend menambahkan objek baru sebelum objek.
3. Insert ke luar objek.
Objek yang akan ditambahkan berada diluar dari masing-masing tag yang dipilih.
4. Insert di sekitar objek. 5. Mengganti objek. 6. Menghapus objek. 7. Meng-copy objek.
2.1.14 MySQL
MySQL adalah sebuah perangkat lunak sistem manajemen basis data SQL
atau DBMS yang multithread, multiuser, dengan sekitar 6 juta instalasi di seluruh dunia. MySQL AB membuat MySQL tersedia sebagai perangkat lunak gratis dibawah lisensi GNU General Public License (GPL), tetapi mereka juga menjual dibawah lisensi komersial untuk kasus-kasus dimana penggunaannya tidak cocok dengan penggunaan GPL.
dimiliki oleh penulisnya masing-masing, MySQL dimiliki dan di sponsori oleh sebuah perusahaan komersial Swedia MySQL AB, dimana memegang hak cipta hampir atas semua kode sumbernya.Kedua orang Swedia dan satu orang Finlandia yang mendirikan MySQL AB adalah: David Axmark, Allan Larsson, dan Michael "Monty" Widenius.
MySQL memiliki beberapa ke istimewaan, antara lain :
1. Portabilitas. MySQL dapat berjalan stabil pada berbagai sistem operasi. 2. Open Source. MySQL di distribusikan secara open source, dibawah lisensi
GPL sehingga dapat digunakan secara cuma-cuma.
3. Multiuser. MySQL dapat digunakan oleh beberapa pengguna dalam waktu yang bersamaan tanpa mengalami masalah atau konflik.
4. Performance tuning. MySQL memiliki kecepatan yang menakjubkan dalam menangani query sederhana, dengan kata lain dapat memproses lebih banyak SQL per satuan waktu.
5. Jenis Kolom. MySQL memiliki tipe kolom yang sangat kompleks, seperti signed/ unsigned integer, float, double, char, text, date, timestamp, dan lain-lain.
6. Perintah dan Fungsi. MySQL memiliki operator dan fungsi secara penuh yang mendukung perintah Select dan Where dalam perintah (query).
2.1.15 Tools Yang Digunakan
39
Analisis dilakukan dengan tujuan untuk mengidentifikasi dan mengevaluasi seluruh komponen yang terkait dengan sistem yang akan dibangun. Tahap analisis merupakan tahap yang kritis dan sangat penting, karena kesalahan pada tahap ini akan menyebabkan kesalahan pada tahap selanjutnya. Tahap analisis sistem dilakukan dengan cara menguraikan suatu sistem yang utuh kedalam bagian-bagian komponennya dengan maksud untuk mengidentifikasi dan mengevaluasi permasalahan-permasalahan sehingga ditemukan kelemahan dan keuntungan pada sistem tersebut.
3.1.1 Analisis Masalah
Metode Text Mining merupakan salah satu metode yang banyak diimplementasikan untuk menyelesaikan masalah yang membutuhkan pencarian sebuah informasi atau Information Retrieval (IR). Aplikasi chatbot juga membutuhkan sebuah information retrieval untuk menentukan sebuah informasi yang terkandung dipertanyaan pengguna chatbot tersebut. Kebanyakan chatbot menggunakan NLP (Natural Language Processing) untuk melakukan kegiatan chatting, fungsi dari text mining sebagai information retrieval diharapkan dapat diimplementasikan pada chatbot dalam melakukan kegiatan chatting.
Berdasarkan permasalahan di atas, diharapkan dapat diselesaikannya sebuah aplikasi chatbot yang menggunakan metode text mining untuk dibandingkan kecocokan apakah information retrieval pada metode text mining sudah cocok untuk diimplementasikan pada aplikasi chatbot.
3.1.2 Analisis Kebutuhan Non Fungsional
Analisis kebutuhan sistem non fungsional adalah sebuah langkah dimana seorang pembangun perangkat lunak menganalisis sumber daya manusia yang akan menggunakan perangkat lunak yang dibangun.
3. Analisis pengguna.
3.1.2.1Analisis Perangkat Keras
Perangkat keras yang digunakan dalam penelitian ini adalah sebagai berikut: 1. Processor
a. Nama : Intel Core i3 M 350 b. Banyak Core : 2
c. Threads per Core : 2
d. Kecepatan : 2,27 GHz per Core 2. Memory
a. Tipe : DDR 3
b. Pembuat : Hyundai Electronics c. Spesifikasi : PC3-10700
d. Kapasitas : 3072 MB e. Channels# : Single 3. Display
a. Nama : Intel Graphics Media Accelerator HD b. Pembuat : Intel Corp.
c. Tipe : Intel Graphics Media Accelerator HD (Core i3) d. Kapasitas memori : 214 MB
e. Monitor : Generic PnP Monitor (1366 768 @60Hz) 4. Audio
a. Playback Device : Speakers (4-HD Audio Device)
b. Tipe : WDM
c. Sound Cards : Intel Display Audio HD Audio Device 5. Motherboard
a. Vendor : ASUSTeK Computer Inc.
b. Model : K42F
6. Hard Disk
a. Model : Hitachi HTS545032B9A300 ATA Device b. Kapasitas : 313GB
3.1.2.2Analisis Perangkat Lunak
Spesifikasi perangkat lunak yang dibutuhkan agar aplikasi dapat berjalan adalah sebagai berikut :
1. WAMP Server sebagai Web Server 2. Adobe Dreamweaver sebagai editor PHP 3. MySQL sebagai DBMS 66
4. Tool antarmuka design Microsoft Visio 2007 5. Google Chrome sebagai web browser
3.1.2.3Analisis Pengguna
Analisis pengguna aplikasi ini memiliki karakteristik antara lain : Tabel 3.1 Tabel pengguna
Pengguna Tanggung Jawab Hak Akses
Admin Chatbot
- Mengelola
knowledge base dari chatbot.
- Menambah, mengedit, dan menghapus knowledge base chatbot.
Super Admin Chatbot
- Mengelola
knowledge base dari chatbot.
- Mengelola administrator chatbot.
- Menambah, mengedit, dan menghapus knowledge base chatbot.
- Menambah, mengedit, dan menghapus administrator chatbot.
Pengguna Chatbot
- Melakukan chatting dengan chatbot.
3.1.3 Gambaran Umum Sistem
Aplikasi chahbot yang akan dikembangkan mempunyai 2 modul utama yaitu modul proses text mining dan modul penentuan jawaban.
Pengguna
Chatbot
Penentuan Jawaban
m
b
o
b
o
ta
n
T
e
x
t Mi
n
in
g
R
e
s
p
o
n
Bo
t
Gambar 3.1 Gambaran Umum Sistem Chatbot Deskripsi :
1. Pengguna chatbot mengetikkan kalimat yang akan ditanyakan ke chatbot.
2. Pertanyaan akan dihitung tingkat similaritasnya dengan menggunakan proses text mining dengan kalimat di database.
3. Setelah proses perhitungan similaritas, akan diambil jawaban yang sesuai dengan kriteria sebagai berikut, jika hasil perhitungan text mining tidak sama dengan 0, maka akan diambil jawaban dari kalimat yang mempunyai tingkat similaritas tertinggi, jika hasil perhitungan text mining sama dengan 0 akan diambil jawaban tidak ketemu dari chatbot.
4. Hasil dari penentuan jawaban akan ditampilkan ke pengguna chatbot sebagai respon dari chatbot.
3.1.4 Analisis Metode Text Mining dalam Pencarian Similaritas Kata
Tokenizing
Filtering
Stemming
Analyzing
Dokumen yang akan dikenai proses text mining
H
Gambar 3.2 Gambaran umum proses text mining Contoh penggunaan algoritma text mining adalah sebagai berikut :
Misalkan kalimat yang akan dicari similaritasnya adalah sebagai berikut “Apa
yang diajarkan di Teknik Informatika Unikom?”
diajarkan
teknik
informatika
unikom Apa yang diajarkan
dalam Teknik Informatika UNIKOM?
Proses pemotongan kalimat ke kata (Tokenizing)
Proses
dalam bentuk array, proses ini dilakukan jika dalam kalimat hasil tokenizing ditemukan spasi.
Setelah kalimat sudah dipotong ke dalam bentuk array, langkah selanjutnya adalah melakukan proses filtering. Proses filtering merupakan tahap mengambil kata-kata penting dari hasil tekonizing. Kata-kata yang dianggap tidak penting dalam proses filtering ini disimpan di tabel tbl_stopwords, jika kata dari proses tokenizing ada yang ditemukan di tabel stopwords, maka kata tersebut akan dihilangkan atau dianggap sebagai kata tidak penting. Berikut sebagian contoh kata yang dianggap tidak penting di dalam tabel
tbl_stopwords :
ada, agar, akan, apa, dalam, entah, hingga, jadi, yaitu, yang
Setelah kalimat dihilangkan kata tidak pentingnya dengan menggunakan proses filtering, selanjutnya kata-kata yang masih dianggap penting akan dikenai proses stemming. Stemming merupakan suatu proses yang terdapat dalam sistem IR (Information Retrieval) yang mentransformasi kata yang terdapat dalam suatu dokumen ke kata-kata akarnya (rood word) dengan menggunakan aturan-aturan tertentu. Proses stemming pada aplikasi chatbot menggunakan algoritma Nazief dan Adriani. Kata dasar didefinisikan di tabel tbl_katadasar, berikut sebagian contoh kata dasar yang ada di tabel
tbl_katadasar :
ajar, acara, akal, teknik, tongkat, tidur, lubuk
Setelah proses stemming selesai, akan dilakukan proses analyzing atau perhitungan pembobotan kalimat dari pengguna dengan kalimat yang menjadi pengetahuan chatbot.
bervariasi dari satu kalimat ke kalimat yang lain bergantung pada sebuah term dalam sebuah kalimat yang diberikan.
Sedangkan IDF (Inverse Document Frequency) adalah sebuah statistik global yang mengkarakteristikkan sebuah term dalam keseluruhan korelasi kalimat. IDF merupakan sebuah perhitungan dari bagaimana term didistribusikan secara luas pada kalimat-kalimat di database.
Perhitungan bobot dari term tertentu dalam sebuah kalimat dengan menggunakan TF-IDF menunjukkan bahwa kalimat yang dianggap similaritas adalah term yang banyak muncul dalam suatu kalimat.
Kombinasi bobot dari sebuah term pada sebuah kalimat di definisikan sebagi berikut :
Dengan :
: Bobot tiap kalimat
: Term Frequency tiap kalimat
: Inverse Document Frequency tiap kalimat
Rumus mencari IDF(i) : =
Dengan :
: Banyaknya kalimat yang ada di database
: Document Frequency tiap kalimat (banyaknya term yang sama di semua kalimat di database) : Inverse Document Frequency tiap kalimat
D8 Siapa nama rektor Unikom
D9 Siapa nama ketua Program Studi di teknik informatika unikom
D10 Hai
D11 visi dari teknik informatika unikom D12 Misi dari teknik informatika Unikom D13 Alamat Unikom
D14 Singkatan dari Unikom
D15 Syarat - Syarat masuk Unikom
D16 Apa situs Teknik Informatika Unikom D17 Apa situs Unikom
D18 Situs dari perwalian Unikom
D19 Apa nama website nilai online Unikom
D20 Maksimum pengambilan SKS di Teknik Informatika Unikom
D21 Siapa wakil ketua prodi teknik Informatika Unikom D22 Ada berapa kampus di jalan Dipati Ukur
Tabel 3.3 Tabel Data Jawaban
Kode
Pertanyaan Jawaban
D1 DFD, Flowchart, Programming D2 Chatbot Text Mining
D3 14 Jurusan (Prodi)
D5 Unikom Berdiri sejak tahun 2008 D6 Jl. Dipati Ukur, Bandung
D7 3 kali D8 Bapak Edi
D9 Pa Irawan Afrianto
Kode
Pertanyaan Jawaban
D11 Visi dari teknik informatika unikom adalah untuk menjadi program studi teknik IF yang unggul dan terdepan
D12 Menyelenggarakan pendidika tinggi yang dapat menghasilkan lulusan berkualitas
D13 Jl. Dipati Ukur No. 100
D14 Universitas Komputer Indonesia D15 Lulus SMA/Sederajat
D16 http://if.unikom.ac.id D17 http://unikom.ac.id
D18 http://perwalian.unikom.ac.id D19 http://nilaionline.unikom.ac.id D20 24 SKS
D21 Ibu Dian Damayanti
D22 Ada 3 kampus Unpad, ITHB, dan Unikom
Data pertanyaan di database akan dikenai proses text mining satu-persatu untuk diketahui polanya / bag of words
1. Tokenizing
Berikut hasil dari proses tokenizing dari pertanyaan-pertanyaan di database : Tabel 3.4 Tabel Hasil Tokenizing Dari Pertanyaan di Database
Kode
Pertanyaan Hasil Tokenizing
D1 apa - yang - diajarkan - di - jurusan - teknik - informatika – unikom D2 siapa - nama – kamu
D3 ada - berapa - jurusan - di – unikom D5 kapan - unikom – berdiri
D6 dimana - lokasi - kampus – unikom
D7 berapa - kali - unikom - juara - roket - internasional D8 siapa - nama - rektor - unikom
D9 siapa - nama - ketua - program - studi - di - teknik - informatika - unikom
D10 Hai
D11 visi - dari - teknik - informatika - unikom D12 misi - dari - teknik - informatika - unikom D13 alamat - unikom
D14 singkatan - dari - unikom
Setelah proses tokenizing dilakukan dan didapat hasilnya, berikutnya pertanyaan yang telah dikenai proses tokenizing akan dikenai proses filtering. Berikut hasil filtering dari hasil tokenizing yang sebelumnya dilakukan :
Tabel 3.5 Tabel Hasil Filtering
Data Hasil Tokenizing Hasil Filtering
apa - yang - diajarkan - di - jurusan - teknik - informatika – unikom
diajarkan - jurusan- teknik - informatika - unikom
siapa - nama - kamu Nama
ada - berapa - jurusan - di - unikom jurusan - unikom kapan - unikom - berdiri unikom - berdiri
dimana - lokasi - kampus - unikom dimana - lokasi - kampus - unikom berapa - kali - unikom - juara - roket -
internasional
unikom - juara - roket - internasional
siapa - nama - rektor - unikom nama - rektor - unikom siapa - nama - ketua - program - studi - di
- teknik - informatika - unikom
nama - ketua - program - studi - teknik - informatika - unikom
hai Hai
visi - dari - teknik - informatika - unikom visi - teknik - informatika - unikom misi - dari - teknik - informatika - unikom misi - teknik - informatika - unikom
alamat - unikom alamat - unikom
singkatan - dari - unikom singkatan - unikom
syarat - - - syarat - masuk - unikom syarat - syarat - masuk - unikom apa - situs - teknik - informatika - unikom situs - teknik - informatika - unikom apa - situs - unikom situs - unikom
situs - dari - perwalian - unikom situs - perwalian - unikom apa - nama - website - nilai - online -
unikom
nama - website - nilai - online – unikom
maksimum - pengambilan - sks - di - teknik - informatika - unikom
Data Hasil Tokenizing Hasil Filtering
siapa - wakil - ketua - prodi - teknik - informatika - unikom
wakil - ketua - prodi - teknik - informatika - unikom
ada - berapa - kampus - di - jalan - dipati - ukur
kampus - jalan - dipati - ukur
3. Stemming
Setelah proses filtering dilakukan dan didapat hasilnya, berikutnya pertanyaan yang telah dikenai proses filtering akan dikenai proses stemming. Berikut hasil stemming dari hasil filtering yang sebelumnya dilakukan :
Tabel 3.6 Tabel Hasil Stemming
Data Hasil Filtering Hasil Stemming
diajarkan - teknik - informatika - unikom
ajar - jurus - teknik - informatika - unikom
nama nama
jurusan - unikom jurus - unikom
unikom - berdiri unikom - berdiri
dimana - lokasi - kampus - unikom dimana - lokasi - kampus - unikom unikom - juara - roket - internasional unikom - juara - roket - internasional nama - rektor - unikom nama - rektor - unikom
nama - ketua - program - studi - teknik - informatika - unikom
nama - ketua - program - studi - teknik - informatika - unikom
hai hai
visi - teknik - informatika - unikom visi - teknik - informatika - unikom misi - teknik - informatika - unikom misi - teknik - informatika - unikom alamat - unikom alamat – unikom
singkatan - unikom singkat - unikom
syarat - syarat - masuk - unikom syarat - syarat - masuk - unikom situs - teknik - informatika - unikom situs - teknik - informatika - unikom
situs - unikom situs - unikom teknik - informatika - unikom
maksimum - ambil - sks - teknik - informatika - unikom
wakil - ketua - prodi - teknik - informatika - unikom
wakil - ketua - prodi - teknik - informatika - unikom
D3 jurus[1] – unikom[1] D5 unikom[1] – berdiri[1]
D6 dimana[1] – lokasi[1] – kampus[1] – unikom[1] D7 unikom[1] – juara[1] – roket[1] – internasional[1] D8 nama[1] – rektor[1] – unikom[1]
D9 nama[1] – ketua[1] – program[1] – studi[1] – teknik[1] – informatika[1] – unikom[1]
D10 hai[1]
D11 visi[1] – teknik[1] – informatika[1] – unikom[1] D12 misi[1] – teknik[1] – informatika[1] – unikom[1] D13 alamat[1] – unikom[1]
D14 singkat[1] – unikom[1]
D15 syarat[2] – masuk[1] – unikom[1]
D16 situs[1] – teknik[1] – informatika[1] – unikom[1] D17 situs[1] – unikom[1]
D18 situs[1] – wali[1] – unikom[1]
D19 nama[1] – website[1] – nilai[1] – online[1] – unikom[1] D20 maksimum[1] – ambilp[1] – sks[1] – teknik[1] –
informatika[1] – unikom[1]
D21 wakil[1] – ketua[1] – prodi[1] – teknik[1] – informatika[1]
– unikom[1]
D22 kampus[1] – jalan[1] – pati[1] – ukur[1]
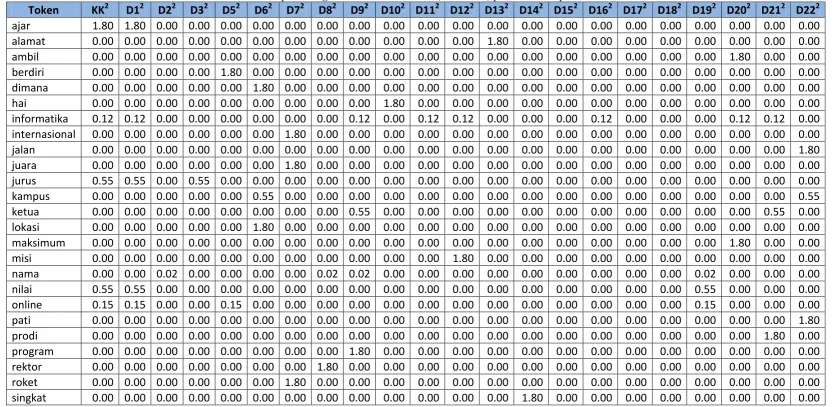
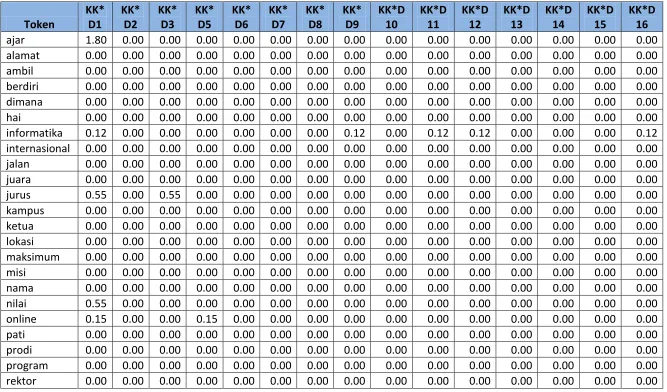
Token akan digunakan pada tabel perhitungan. Berikut contoh perhitungan pembobotan pada text mining :
1. Cari TF (Term Frequency) dari kata kunci dan tiap pertanyaan yang ada di database, berapa banyak kata di pertanyaan yang sama dengan kata yang ada pada token.
Tabel 3.8 Tabel perhitungan TF pada text mining
Token
TF Kata
Kunci D1 D2 D3 D5 D6 D7 D8 D9 D10 D11 D12 D13 D14 D15 D16 D17 D18 D19 D20 D21 D22
ajar 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
alamat 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0
ambil 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0
berdiri 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
dimana 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
hai 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0
informatika 1 1 0 0 0 0 0 0 1 0 1 1 0 0 0 1 0 0 0 1 1 0
internasional 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
jalan 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1
juara 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
jurus 1 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
kampus 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1
ketua 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0
lokasi 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
maksimum 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0
misi 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0
nama 0 0 1 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 1 0 0 0
nilai 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0
sks 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0
studi 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0
syarat 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0
teknik 1 1 0 0 0 0 0 0 1 0 1 1 0 0 0 1 0 0 0 1 1 0
ukur 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1
unikom 1 1 0 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 0
visi 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0
wakil 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0
wali 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0
2. Hitung DF (Document Frequency) dan hitung hasil pembagian antara banyak pertanyaan dengan DF dari tiap kata di token berdasarkan pertanyaan di database. Cara menghitung DF adalah dengan menjumlahkan TF dari semua pertanyaan di database tanpa TF kata kunci yang ada di tabel 3.4 di atas, misalkan DF untuk token
“ajar” adalah 1. Sedangkan untuk menghitung banyak pertanyaan dibagi dengan DF
adalah banyaknya pertanyaan di database dibagi dengan DF yang sudah dihitung sebelumnya, banyak pertanyaan di database ada 14 dokumen. Contoh perhitungannya ada di tabel 3.5 berikut :
Tabel 3.9 Tabel perhitungan DF dan pembagian banyak dokumen dengan DF
Token DF Banyak
Dokumen
Banyak Dokumen /
DF
ajar 1.34 16.39 12.21
alamat 1.34 16.39 12.21
ambil 1.34 16.39 12.21
berdiri 1.34 16.39 12.21
dimana 1.34 16.39 12.21
hai 1.34 16.39 12.21
informatika -2.43 -9.04 3.71
internasional 1.34 16.39 12.21
jalan 1.34 16.39 12.21
juara 1.34 16.39 12.21
jurus 1.48 14.86 10.03
kampus 1.48 14.86 10.03
ketua 1.48 14.86 10.03
lokasi 1.34 16.39 12.21
maksimum 1.34 16.39 12.21
misi 1.34 16.39 12.21
nama 0.55 39.77 71.89
nilai 1.48 14.86 10.03
online 1.16 18.89 16.22
pati 1.34 16.39 12.21
prodi 1.34 16.39 12.21
program 1.34 16.39 12.21
rektor 1.34 16.39 12.21
unikom -21.03 -1.05 0.05
visi 1.34 16.39 12.21
wakil 1.34 16.39 12.21
wali 1.34 16.39 12.21
website 1.34 16.39 12.21
3. Hitung IDF (Inverse Document Frequency) dari tiap token dengan rumus : IDF(i) = log (Banyak Kalimat/DF(i))
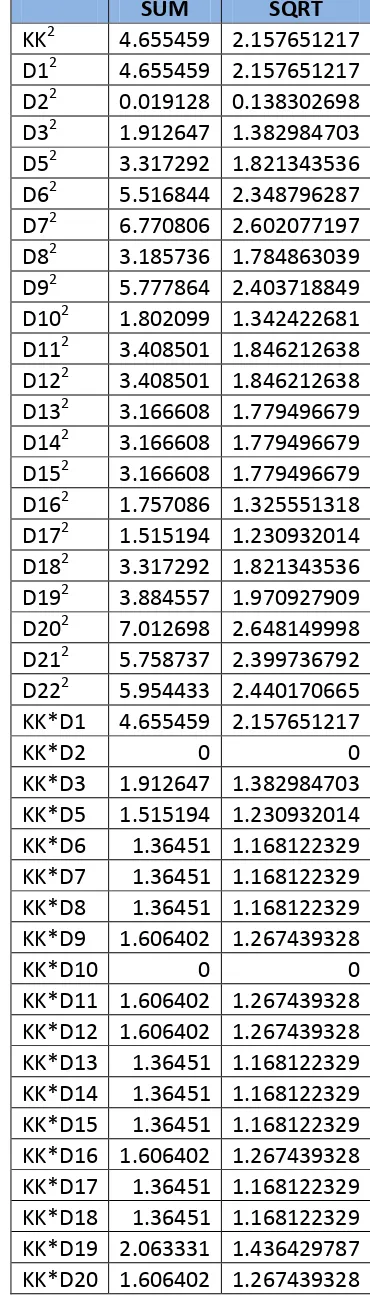
Misalkan untuk token “ajar”, perhitungan IDF adalah sebagai berikut : LOG(22) =
1.34242268082221, pembulatan 2 angka dibelakang koma menjadi 1.34. 22 adalah hasil
pembagian dari banyaknya kalimat di database (22 pertanyaan) dengan DF token “ajar”
(1).
Tabel 3.10 Tabel perhitungan IDF pada text mining
Token IDF
ajar 1.34
alamat 1.34
ambil 1.34
berdiri 1.34
dimana 1.34
hai 1.34
informatika -0.35
internasional 1.34
jalan 1.34
juara 1.34
jurus 0.74
kampus 0.74
Token IDF
lokasi 1.34
maksimum 1.34
misi 1.34
nama 0.14
nilai 0.74
online 0.39
pati 1.34
prodi 1.34
program 1.34
rektor 1.34
roket 1.34
singkat 1.34
situs 0.39
sks 1.34
studi 1.34
syarat 1.34
teknik -0.35
ukur 1.34
unikom -1.17
visi 1.34
wakil 1.34
wali 1.34
website 1.34
4. Hitung bobot ( ) dari TF dan IDF menggunakan rumus :
Perhitungan bobot ( ) untuk token kata kunci dan token pertanyaan di database. Misalkan
untuk perhitungan bobot token kata kunci “ajar” adalah sebagai berikut : token kata kunci
TF dari “ajar” adalah 1 dikali dengan IDF token “ajar” yaitu 1.342422681 sehingga bobot
Setelah bobot ( ) masing-masing tiap kalimat diketahui maka dilakukan proses perhitungan menggunakan metode vector-space model. metode vector-space model adalah model aljabar untuk dokumen teks yang mewakili sebagai vektor pengenal. Dalam Metode vector-space model ini akan menghitung nilai cosinus sudut dari dua vektor, yaitu dari tiap kalimat dan dari kata yang diketikkan pengguna chatbot. Metode vector-space model digunakan agar nilai dari similaritas semakin presisi.
Dengan :
dj : dokumen ke – j
q : kata kunci
Wij : Bobot dokumen ke – j
Wiq : Bobot kata kunci
1. Hitung kuadrat dari bobot ( ) dari masing-masing pertanyaan dan kata kunci (tabel 3.8).
2. Hitung perkalian antara bobot ( ) kata kunci dengan bobot ( ) kata ke-i dari masing-masing pertanyaan di database (tabel 3.9).
3. Setelah proses perhitungan selesai kita jumlahkan kata kunci (KK2), tiap-tiap pertanyaan di database (Di2), dan KK*Di. Setelah itu cari squere root (akar